
1. Introduction
In this lab, you will use BigQuery to train and serve a model with tabular data using a console. This offering is the favorite addition to the SQL based model serving and training. BigQuery ML enables users to create and execute machine learning models in BigQuery by using SQL queries. The goal is to democratize machine learning by enabling SQL practitioners to build models using their existing tools and to increase development speed by eliminating the need for data movement.
What you will learn
- Explore the data available in Bigquery
- Create a model using SQL in Bigquery using console
- Evaluate the results of the model created
- Predict a transaction if its fraudulent or not with the model created
2. About the data
The datasets contain transactions made by credit cards in September 2013 by european cardholders. This dataset presents transactions that occurred in two days, where we have 492 frauds out of 284,807 transactions. It is highly unbalanced, the positive class (frauds) account for 0.172% of all transactions.
It contains only numerical input variables which are the result of a PCA transformation. Unfortunately, due to confidentiality issues, we cannot provide the original features and more background information about the data.
- Features V1, V2, ... V28 are the principal components obtained with PCA, the only features which have not been transformed with PCA are ‘Time' and ‘Amount'.
- Feature ‘Time' contains the seconds elapsed between each transaction and the first transaction in the dataset.
- Feature ‘Amount' is the transaction Amount, this feature can be used for example-dependant cost-senstive learning.
- Feature ‘Class' is the response variable and it takes value 1 in case of fraud and 0 otherwise.
The dataset has been collected and analysed during a research collaboration of Worldline and the Machine Learning Group ( http://mlg.ulb.ac.be) of ULB (Université Libre de Bruxelles) on big data mining and fraud detection.
More details on current and past projects on related topics are available on https://www.researchgate.net/project/Fraud-detection-5 and the page of the DefeatFraud project
Citation:
Andrea Dal Pozzolo, Olivier Caelen, Reid A. Johnson and Gianluca Bontempi. Calibrating Probability with Undersampling for Unbalanced Classification. In Symposium on Computational Intelligence and Data Mining (CIDM), IEEE, 2015
Dal Pozzolo, Andrea; Caelen, Olivier; Le Borgne, Yann-Ael; Waterschoot, Serge; Bontempi, Gianluca. Learned lessons in credit card fraud detection from a practitioner perspective, Expert systems with applications,41,10,4915-4928,2014, Pergamon
Dal Pozzolo, Andrea; Boracchi, Giacomo; Caelen, Olivier; Alippi, Cesare; Bontempi, Gianluca. Credit card fraud detection: a realistic modeling and a novel learning strategy, IEEE transactions on neural networks and learning systems,29,8,3784-3797,2018,IEEE
Dal Pozzolo, Andrea Adaptive Machine learning for credit card fraud detection ULB MLG PhD thesis (supervised by G. Bontempi)
Carcillo, Fabrizio; Dal Pozzolo, Andrea; Le Borgne, Yann-Aël; Caelen, Olivier; Mazzer, Yannis; Bontempi, Gianluca. Scarff: a scalable framework for streaming credit card fraud detection with Spark, Information fusion,41, 182-194,2018,Elsevier
Carcillo, Fabrizio; Le Borgne, Yann-Aël; Caelen, Olivier; Bontempi, Gianluca. Streaming active learning strategies for real-life credit card fraud detection: assessment and visualization, International Journal of Data Science and Analytics, 5,4,285-300,2018,Springer International Publishing
Bertrand Lebichot, Yann-Aël Le Borgne, Liyun He, Frederic Oblé, Gianluca Bontempi Deep-Learning Domain Adaptation Techniques for Credit Cards Fraud Detection, INNSBDDL 2019: Recent Advances in Big Data and Deep Learning, pp 78-88, 2019
Fabrizio Carcillo, Yann-Aël Le Borgne, Olivier Caelen, Frederic Oblé, Gianluca Bontempi Combining Unsupervised and Supervised Learning in Credit Card Fraud Detection Information Sciences, 2019
3. Set up your environment
You'll need a Google Cloud Platform project with billing enabled to run this codelab. To create a project, follow the instructions here.
- Enable the bigquery API
Navigate to BigQuery and select Enable if it isn't already enabled. You'll need this to create your model.
4. Explore the data
Step 1: Navigate to Bigquery
Look for Bigquery in https://cloud.google.com/console
Step 2: Explore the data using query
In the editor , type the below SQL query to review the data in the public dataset .
SELECT * FROM `bigquery-public-data.ml_datasets.ulb_fraud_detection` LIMIT 5
Step 3: Execute
Press the Run command above to execute the query

Results
Should be in the Query Results panel and look something like this. The data might vary
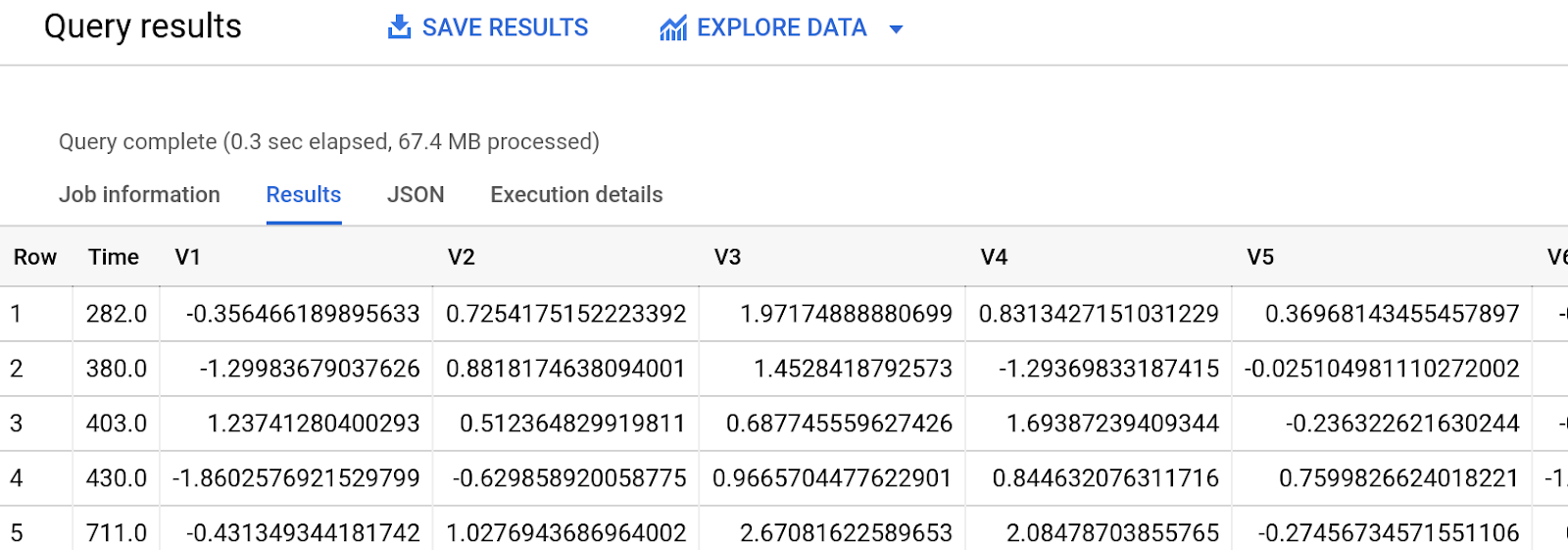
Explore the columns involved and the output.
You can run multiple queries to understand how the data is distributed. Some examples might include
SELECT count(*) FROM `bigquery-public-data.ml_datasets.ulb_fraud_detection`
where Class=0;
SELECT count(*) FROM `bigquery-public-data.ml_datasets.ulb_fraud_detection`
where Class=1;
5. Create an output dataset
Step1: Create dataset for model creation
- In the Explorer panel - Left hand side pick the project you are currently working on , click the three dots next to it
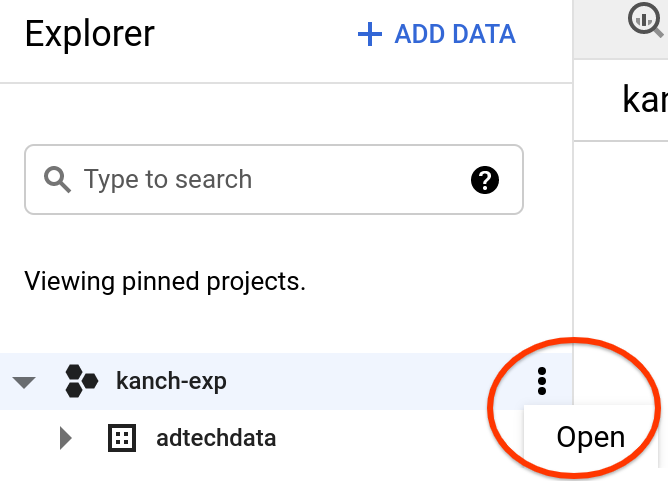
- Click Create Dataset in the top right

- Enter the details for dataset name, retention, location etc., Use these settings
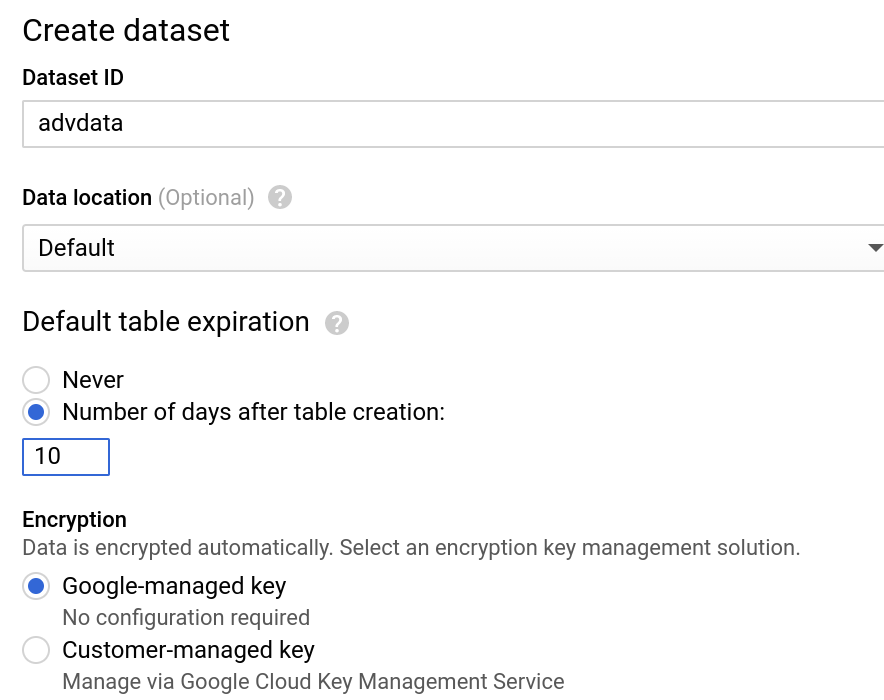
6. Create Logistic Regression Model
Step 1: Create Statement
In the Query window, type out the below query for model creation. Understand the key options with this statement. Explained in this link.
INPUT_LABEL_COLS indicate the prediction label
AUTO_CLASS_WEIGHTS are used for imbalanced datasets
MODEL_TYPE would indicate the algorithm used in this case it is Logistic Regression
DATA_SPLIT_METHOD indicates the split between the training and testing data
CREATE OR REPLACE MODEL advdata.ulb_fraud_detection
TRANSFORM(
* EXCEPT(Amount),
SAFE.LOG(Amount) AS log_amount
)
OPTIONS(
INPUT_LABEL_COLS=['class'],
AUTO_CLASS_WEIGHTS = TRUE,
DATA_SPLIT_METHOD='seq',
DATA_SPLIT_COL='Time',
MODEL_TYPE='logistic_reg'
) AS
SELECT
*
FROM `bigquery-public-data.ml_datasets.ulb_fraud_detection`
Step 2: Execute
Run the above statement. This should take a couple of minutes to complete
Notice the key things after the run is complete
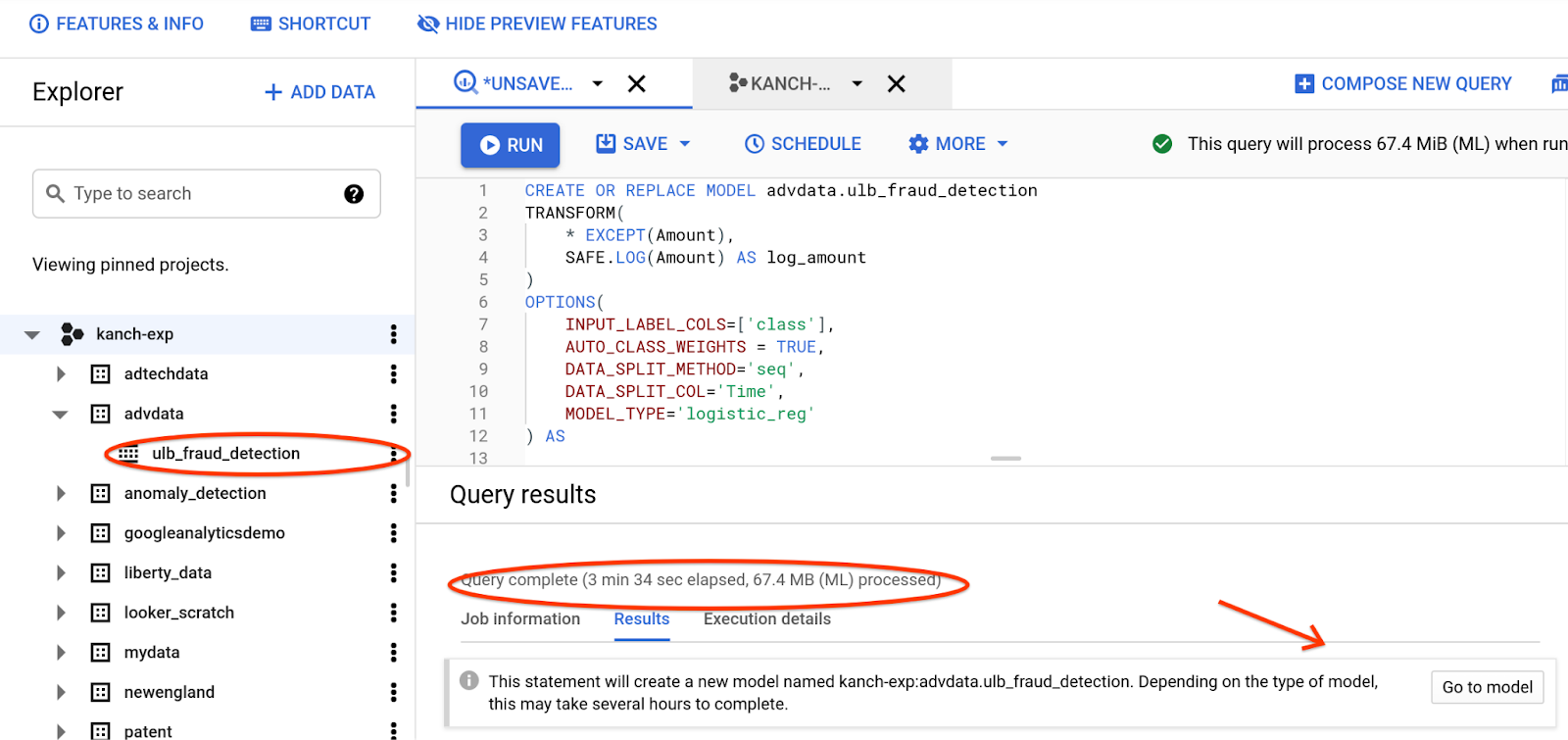
- Explorer panel will have the model created
- Query Results panel will have the duration it took to process the ML SQL similar to any SQL statement
- Query Results panel will also have the Go to Model link for you to explore
Step 3: Explore
Explore the Model created by clicking on the Go to Model or from the Explorer panel. The tabs provide information on the model created , training, evaluation etc., Review the results
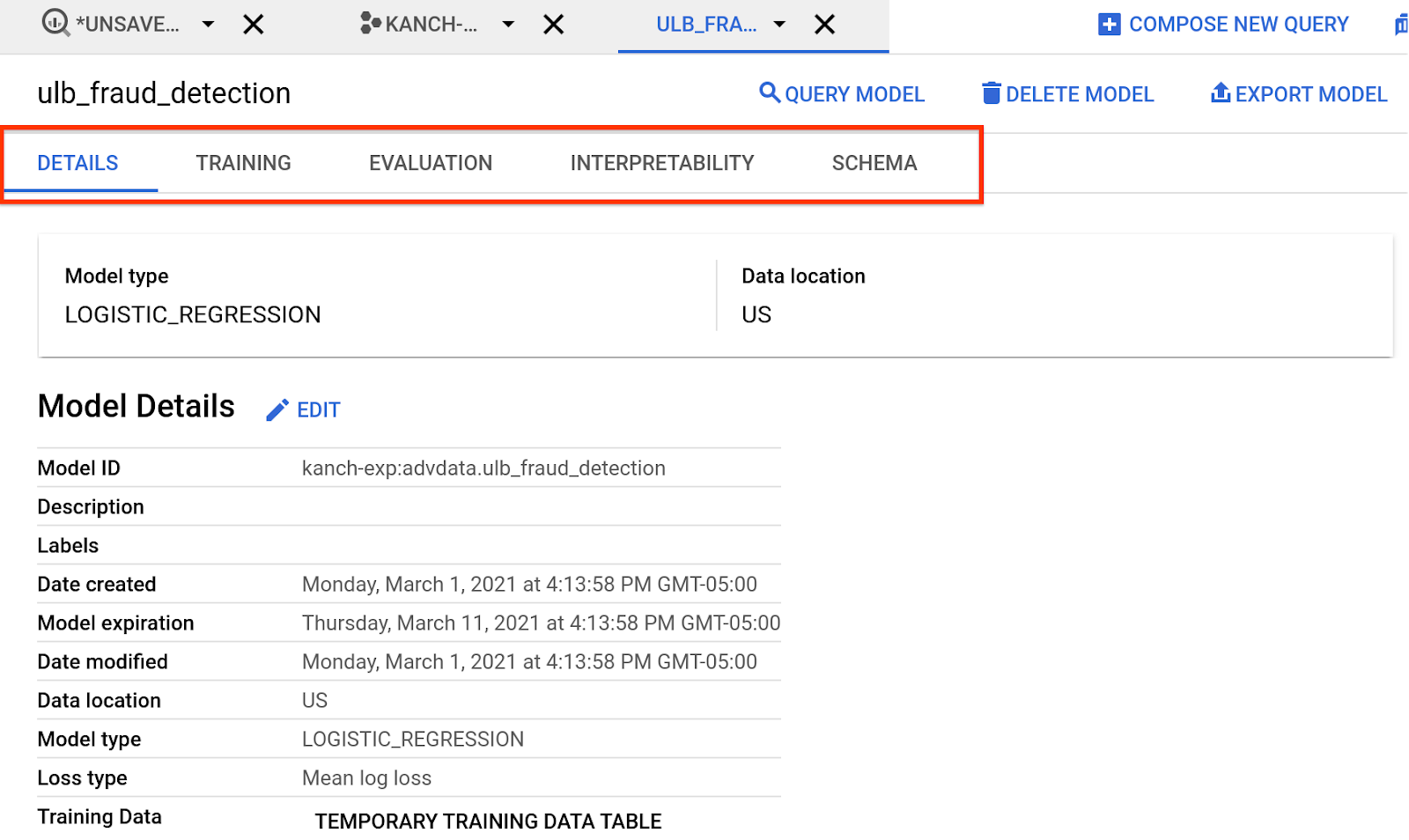
We will explore this further in the next sections
To know more about Logistic Regression look here
7. Exploring model evaluation metrics
In this step we'll see how our model performed.
Once your model training job has completed, click on the model you just trained and take a look at the Evaluate tab. There are many evaluation metrics here - we'll focus on just one :roc_auc
SELECT * FROM ML.EVALUATE(MODEL advdata.ulb_fraud_detection)
The results would look something like this. roc_auc is generally more important on an imbalanced dataset

To know more about the results. Look for the ML.Evaluate docs here
8. Predict class for a certain time
Press Compose a new query and execute the below SQL. Time here identified has a fraudulent amount. We are trying to evaluate that the prediction works
SELECT Amount, predicted_class_probs, Class
FROM ML.PREDICT( MODEL advdata.ulb_fraud_detection,
(SELECT * FROM `bigquery-public-data.ml_datasets.ulb_fraud_detection` WHERE Time = 85285.0)
)
Output should look something like this (numbers might vary)
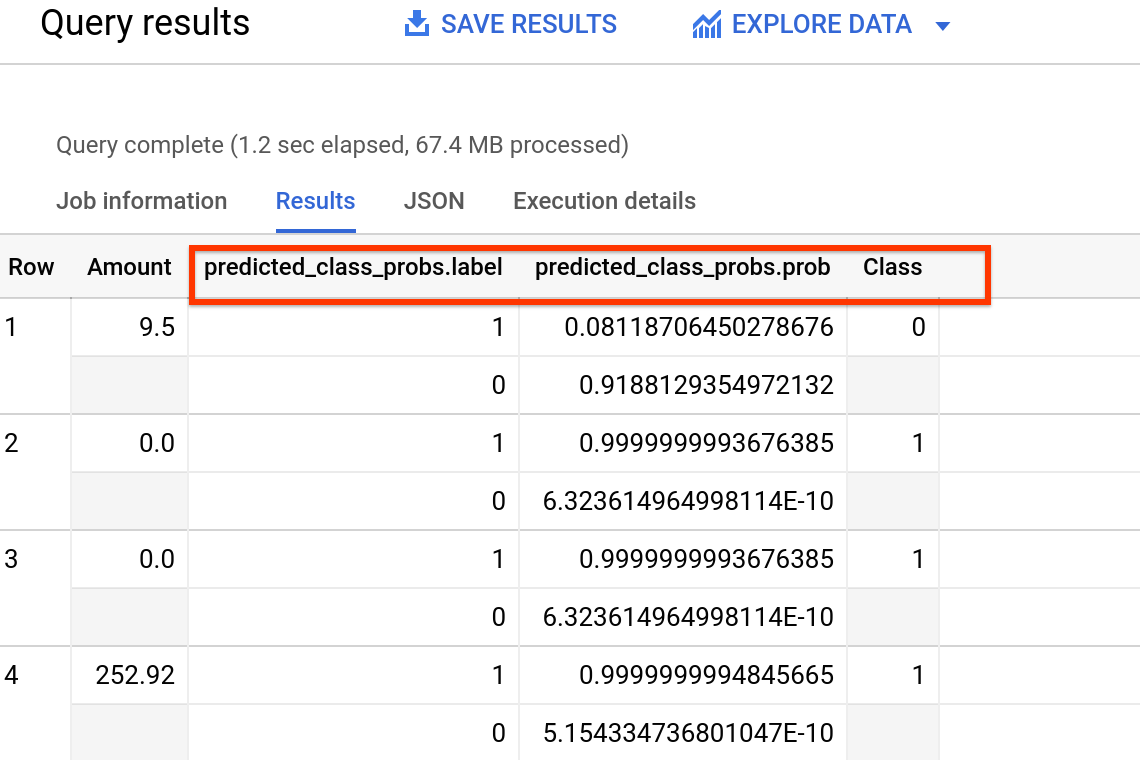
In this instance, we are displaying the amount with the associated probability of the label. The class column here indicates what the actual results were.
To know more about ML.PREDICT. Look here
9. Cleanup
If you'd like to cleanup the resources created with this lab, open the dataset from the Explorer panel in the left hand side
Click Delete Dataset in the top right corner

Enter the dataset name again to confirm the details. For our case this will be advdata
10. Congratulations
Congratulations, you've successfully created your first model, evaluated and predicted using supervised machine learning!
You now know the key steps required to create a logistic regression model.
What's next?
Check out some of these other ways involved in predicting
- Getting started with Bigquery ML
- Timeseries forecasting with Bigquery ML
- Fraud detection model using AutoML
- Fraud detection using Tensorflow