
1. Introduzione
In questo lab utilizzerai BigQuery per addestrare e gestire un modello con dati tabulari utilizzando una console. Questa offerta è l'aggiunta preferita all'addestramento e alla pubblicazione di modelli basati su SQL. BigQuery ML consente agli utenti di creare ed eseguire modelli di machine learning in BigQuery utilizzando query SQL. L'obiettivo è democratizzare il machine learning consentendo a chi utilizza SQL di creare modelli con i propri strumenti esistenti e aumentare la velocità di sviluppo attraverso l'eliminazione della necessità di spostare i dati.
Cosa imparerai a fare
- Esplorare i dati disponibili in BigQuery
- Creare un modello utilizzando SQL in BigQuery utilizzando la console
- Valuta i risultati del modello creato
- Prevedi se una transazione è fraudolenta o meno con il modello creato
2. Informazioni sui dati
I set di dati contengono le transazioni effettuate con carte di credito a settembre 2013 dai titolari di carte europei. Questo set di dati presenta transazioni avvenute in due giorni, in cui abbiamo 492 frodi su 284.807 transazioni. È molto sbilanciato: la classe positiva (frodi) rappresenta lo 0, 172% di tutte le transazioni.
Contiene solo variabili di input numeriche che sono il risultato di una trasformazione PCA. Purtroppo, a causa di problemi di riservatezza, non possiamo fornire le funzionalità originali e ulteriori informazioni di base sui dati.
- Features V1, V2, ... V28 sono i componenti principali ottenuti con PCA. Le uniche funzionalità che non sono state trasformate con PCA sono "Time" e "Amount".
- La funzionalità "Tempo" contiene i secondi trascorsi tra ogni transazione e la prima transazione nel set di dati.
- La caratteristica "Importo" è l'importo della transazione. Questa caratteristica può essere utilizzata, ad esempio, per l'apprendimento sensibile ai costi dipendente dall'esempio.
- La funzionalità "Classe" è la variabile di risposta e assume il valore 1 in caso di frode e 0 in caso contrario.
Il set di dati è stato raccolto e analizzato durante una collaborazione di ricerca tra Worldline e il Machine Learning Group ( http://mlg.ulb.ac.be) dell'ULB (Université Libre de Bruxelles) su estrazione di big data e rilevamento di frodi.
Maggiori dettagli sui progetti attuali e passati su argomenti correlati sono disponibili su https://www.researchgate.net/project/Fraud-detection-5 e nella pagina del progetto DefeatFraud.
Citazione:
Andrea Dal Pozzolo, Olivier Caelen, Reid A. Johnson e Gianluca Bontempi. Calibrating Probability with Undersampling for Unbalanced Classification. In Symposium on Computational Intelligence and Data Mining (CIDM), IEEE, 2015
Dal Pozzolo, Andrea; Caelen, Olivier; Le Borgne, Yann-Ael; Waterschoot, Serge; Bontempi, Gianluca. Learned lessons in credit card fraud detection from a practitioner perspective, Expert systems with applications,41,10,4915-4928,2014, Pergamon
Dal Pozzolo, Andrea; Boracchi, Giacomo; Caelen, Olivier; Alippi, Cesare; Bontempi, Gianluca. Credit card fraud detection: a realistic modeling and a novel learning strategy, IEEE transactions on neural networks and learning systems,29,8,3784-3797,2018,IEEE
Dal Pozzolo, Andrea Adaptive Machine learning for credit card fraud detection ULB MLG PhD thesis (supervised by G. Bontempi)
Carcillo, Fabrizio; Dal Pozzolo, Andrea; Le Borgne, Yann-Aël; Caelen, Olivier; Mazzer, Yannis; Bontempi, Gianluca. Scarff: a scalable framework for streaming credit card fraud detection with Spark, Information fusion,41, 182-194,2018,Elsevier
Carcillo, Fabrizio; Le Borgne, Yann-Aël; Caelen, Olivier; Bontempi, Gianluca. Streaming active learning strategies for real-life credit card fraud detection: assessment and visualization,International Journal of Data Science and Analytics, 5,4,285-300,2018,Springer International Publishing
Bertrand Lebichot, Yann-Aël Le Borgne, Liyun He, Frederic Oblé, Gianluca Bontempi Deep-Learning Domain Adaptation Techniques for Credit Cards Fraud Detection, INNSBDDL 2019: Recent Advances in Big Data and Deep Learning, pp 78-88, 2019
Fabrizio Carcillo, Yann-Aël Le Borgne, Olivier Caelen, Frederic Oblé, Gianluca Bontempi Combining Unsupervised and Supervised Learning in Credit Card Fraud Detection Information Sciences, 2019
3. Configura l'ambiente
Per eseguire questo codelab, devi avere un progetto Google Cloud Platform con la fatturazione abilitata. Per creare un progetto, segui le istruzioni riportate qui.
- Abilita l'API BigQuery
Vai a BigQuery e seleziona Abilita se non è già abilitata. Ti servirà per creare il modello.
4. esplora i dati
Passaggio 1: vai a BigQuery
Cerca BigQuery all'indirizzo https://cloud.google.com/console.
Passaggio 2: esplora i dati utilizzando la query
Nell'editor , digita la seguente query SQL per esaminare i dati nel set di dati pubblico .
SELECT * FROM `bigquery-public-data.ml_datasets.ulb_fraud_detection` LIMIT 5
Passaggio 3: esecuzione
Premi il comando Esegui riportato sopra per eseguire la query.

Risultati
Dovrebbe trovarsi nel riquadro Risultati query e avere un aspetto simile a questo. I dati potrebbero variare

Esplora le colonne coinvolte e l'output.
Puoi eseguire più query per capire come vengono distribuiti i dati. Alcuni esempi potrebbero includere
SELECT count(*) FROM `bigquery-public-data.ml_datasets.ulb_fraud_detection`
where Class=0;
SELECT count(*) FROM `bigquery-public-data.ml_datasets.ulb_fraud_detection`
where Class=1;
5. Crea un set di dati di output
Passaggio 1: crea il set di dati per la creazione del modello
- Nel riquadro Explorer, a sinistra, seleziona il progetto su cui stai lavorando e fai clic sui tre puntini accanto.

- Fai clic su Crea set di dati in alto a destra.

- Inserisci i dettagli per il nome, la conservazione, la posizione e così via del set di dati. Utilizza queste impostazioni

6. Crea modello di regressione logistica
Passaggio 1: crea la dichiarazione
Nella finestra Query, digita la query riportata di seguito per la creazione del modello. Comprendi le opzioni chiave con questa dichiarazione. Spiegato in questo link.
INPUT_LABEL_COLS indica l'etichetta di previsione
AUTO_CLASS_WEIGHTS vengono utilizzati per i set di dati sbilanciati
MODEL_TYPE indica l'algoritmo utilizzato, in questo caso la regressione logistica
DATA_SPLIT_METHOD indica la suddivisione tra i dati di addestramento e di test
CREATE OR REPLACE MODEL advdata.ulb_fraud_detection
TRANSFORM(
* EXCEPT(Amount),
SAFE.LOG(Amount) AS log_amount
)
OPTIONS(
INPUT_LABEL_COLS=['class'],
AUTO_CLASS_WEIGHTS = TRUE,
DATA_SPLIT_METHOD='seq',
DATA_SPLIT_COL='Time',
MODEL_TYPE='logistic_reg'
) AS
SELECT
*
FROM `bigquery-public-data.ml_datasets.ulb_fraud_detection`
Passaggio 2: esegui
Esegui l'istruzione precedente. Il completamento dell'operazione dovrebbe richiedere un paio di minuti
Notare le cose principali al termine della corsa

- Nel riquadro Esplora verrà visualizzato il modello creato.
- Il riquadro Risultati query mostrerà la durata dell'elaborazione di ML SQL in modo simile a qualsiasi istruzione SQL.
- Il riquadro Risultati query conterrà anche il link Vai al modello per consentirti di esplorarlo.
Passaggio 3: esplora
Esplora il modello creato facendo clic su Vai al modello o dal riquadro Explorer. Le schede forniscono informazioni sul modello creato, sull'addestramento, sulla valutazione e così via. Esaminare i risultati
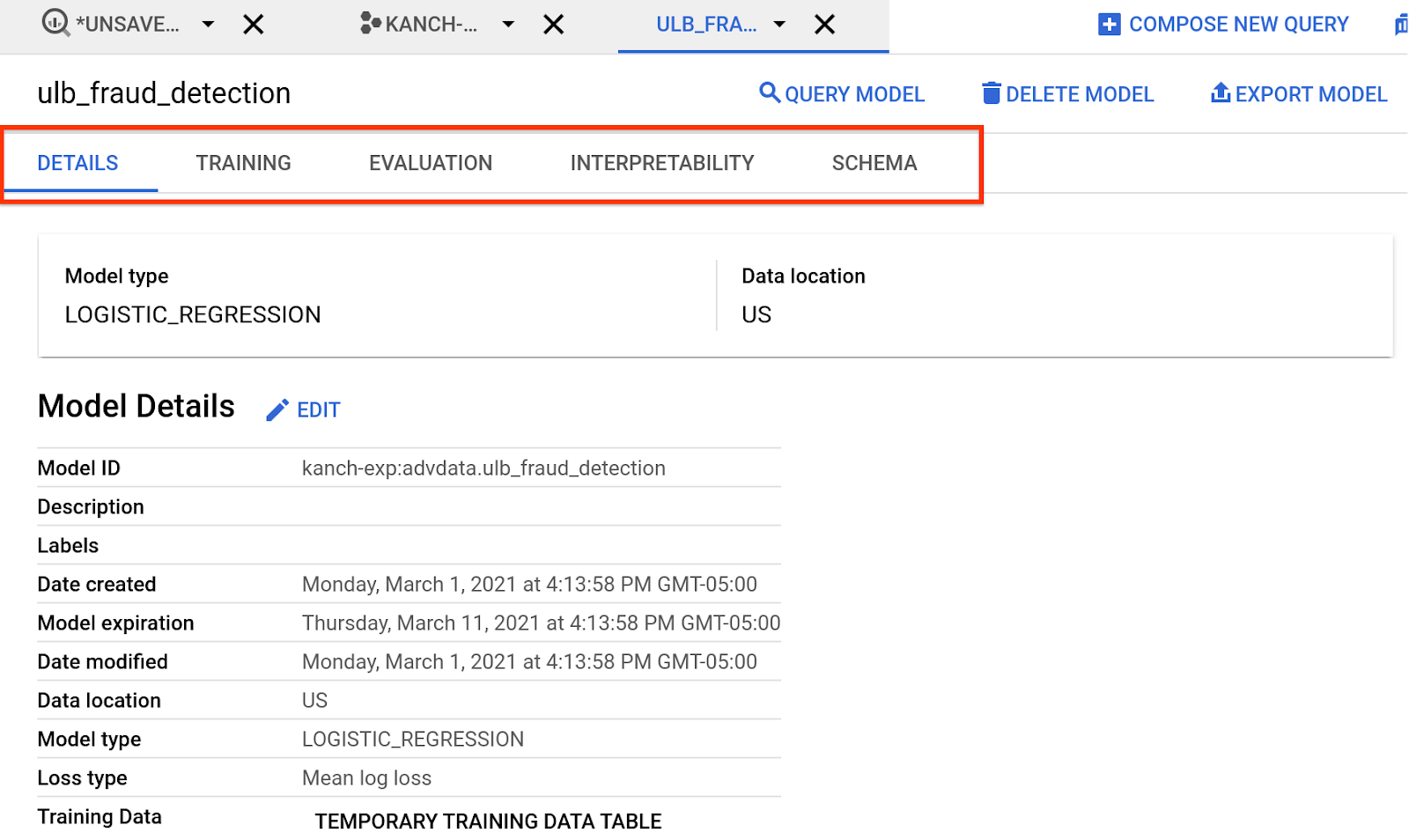
Approfondiremo questo aspetto nelle sezioni successive.
Per saperne di più sulla regressione logistica, consulta questa pagina.
7. Esplorazione delle metriche di valutazione del modello
In questo passaggio vedremo il rendimento del nostro modello.
Una volta completato il job di addestramento del modello, fai clic sul modello appena addestrato e dai un'occhiata alla scheda Valuta. Qui sono presenti molte metriche di valutazione. Ci concentreremo solo su una :roc_auc
SELECT * FROM ML.EVALUATE(MODEL advdata.ulb_fraud_detection)
I risultati saranno simili a questi. roc_auc è generalmente più importante in un set di dati non bilanciato

Per saperne di più sui risultati. Cerca la documentazione di ML.Evaluate qui.
8. Prevedi la classe per un determinato periodo di tempo
Premi Crea una nuova query ed esegui il seguente SQL. Il tempo identificato qui ha un importo fraudolento. Stiamo cercando di valutare che la previsione funzioni
SELECT Amount, predicted_class_probs, Class
FROM ML.PREDICT( MODEL advdata.ulb_fraud_detection,
(SELECT * FROM `bigquery-public-data.ml_datasets.ulb_fraud_detection` WHERE Time = 85285.0)
)
L'output dovrebbe essere simile al seguente (i numeri potrebbero variare)

In questo caso, mostriamo l'importo con la probabilità associata dell'etichetta. La colonna Classe indica i risultati effettivi.
Per saperne di più su ML.PREDICT. Guarda qui
9. Esegui la pulizia
Se vuoi ripulire le risorse create con questo lab, apri il set di dati dal riquadro Explorer sul lato sinistro.

Fai clic su Elimina set di dati nell'angolo in alto a destra.

Inserisci di nuovo il nome del set di dati per confermare i dettagli. Nel nostro caso, sarà advdata
10. Complimenti
Congratulazioni, hai creato il tuo primo modello, lo hai valutato e hai eseguito la previsione utilizzando il machine learning supervisionato.
Ora conosci i passaggi chiave necessari per creare un modello di regressione logistica.
Passaggi successivi
Scopri alcuni di questi altri modi coinvolti nella previsione
- Iniziare a utilizzare BigQuery ML
- Previsione delle serie temporali con BigQuery ML
- Modello di rilevamento delle frodi utilizzando AutoML
- Rilevamento di frodi con TensorFlow