
1. مقدمة
تاريخ آخر تعديل: 2024-02-05
ما هو الذكاء الاصطناعي التوليدي؟
يشير الذكاء الاصطناعي التوليدي إلى استخدام الذكاء الاصطناعي لإنشاء محتوى جديد، مثل النصوص والصور والموسيقى والملفات الصوتية والفيديوهات.
يستند الذكاء الاصطناعي التوليدي إلى النماذج الأساسية (نماذج الذكاء الاصطناعي الكبيرة) التي يمكنها تنفيذ مهام متعددة ومهام جاهزة للاستخدام، بما في ذلك التلخيص والأسئلة والأجوبة والتصنيف وغير ذلك. بالإضافة إلى ذلك، يمكن تكييف النماذج الأساسية مع حالات الاستخدام المستهدَفة باستخدام القليل جدًا من بيانات الأمثلة، وذلك لأنّها لا تتطلّب سوى الحد الأدنى من التدريب.
كيف يعمل الذكاء الاصطناعي التوليدي؟
يعمل الذكاء الاصطناعي التوليدي من خلال استخدام نموذج تعلُّم الآلة (ML) لتعلُّم الأنماط والعلاقات في مجموعة بيانات من المحتوى الذي أنشأه الإنسان. ثم يستخدم الأنماط التي تعلّمها لإنشاء محتوى جديد.
إنّ الطريقة الأكثر شيوعًا لتدريب نموذج ذكاء اصطناعي توليدي هي استخدام التعلُّم الموجَّه، حيث يتم تزويد النموذج بمجموعة من المحتوى الذي أنشأه الإنسان والتصنيفات المقابلة. بعد ذلك، يتعلّم كيفية إنشاء محتوى مشابه للمحتوى الذي ينشئه المستخدمون ويتم تصنيفه باستخدام التصنيفات نفسها.
ما هي التطبيقات الشائعة للذكاء الاصطناعي التوليدي؟
يعالج الذكاء الاصطناعي التوليدي كميات كبيرة من المحتوى، وينشئ معلومات وإجابات من خلال النصوص والصور والتنسيقات السهلة الاستخدام. يمكن استخدام الذكاء الاصطناعي التوليدي في ما يلي:
- تحسين تفاعلات العملاء من خلال تجارب محادثة وبحث محسّنة
- استكشاف كميات هائلة من البيانات غير المنظَّمة من خلال واجهات المحادثة والملخّصات
- المساعدة في المهام المتكررة، مثل الرد على طلبات تقديم المقترحات (RFP) وتكييف المحتوى التسويقي مع الثقافة المحلية بخمس لغات والتحقّق من امتثال عقود العملاء، وغير ذلك
ما هي عروض الذكاء الاصطناعي التوليدي التي تقدّمها Google Cloud؟
باستخدام Vertex AI، يمكنك التفاعل مع النماذج الأساسية وتخصيصها وتضمينها في تطبيقاتك، بدون الحاجة إلى خبرة كبيرة في تعلُّم الآلة. يمكنك الوصول إلى النماذج الأساسية على Model Garden أو ضبط النماذج من خلال واجهة مستخدم بسيطة على Generative AI Studio أو استخدام النماذج في دفتر ملاحظات لعلوم البيانات.
توفّر Vertex AI Search and Conversation للمطوّرين أسرع طريقة لإنشاء محركات بحث وبرامج دردشة تستند إلى الذكاء الاصطناعي التوليدي.
Duet AI هو أداة تعاون مستندة إلى الذكاء الاصطناعي ومتاحة على Google Cloud وبيئات التطوير المتكاملة لمساعدتك في إنجاز المزيد من المهام بشكل أسرع.
ما هو موضوع هذا الدرس التطبيقي حول الترميز؟
يركّز هذا الدرس التطبيقي حول الترميز على النموذج اللغوي الكبير PaLM 2 (LLM) المستضاف على Google Cloud Vertex AI الذي يشمل جميع منتجات وخدمات تعلُّم الآلة.
ستستخدم Java للتفاعل مع PaLM API، بالإضافة إلى أداة تنسيق إطار عمل النماذج اللغوية الكبيرة LangChain4J. ستتعرّف على أمثلة عملية مختلفة للاستفادة من النموذج اللغوي الكبير في الإجابة عن الأسئلة، وإنشاء الأفكار، واستخراج الكيانات والمحتوى المنظَّم، وتلخيص المحتوى.
أريد المزيد من المعلومات حول إطار عمل LangChain4J.
إطار عمل LangChain4J هو مكتبة مفتوحة المصدر لدمج النماذج اللغوية الكبيرة في تطبيقات Java، وذلك من خلال تنسيق المكوّنات المختلفة، مثل النموذج اللغوي الكبير نفسه، بالإضافة إلى أدوات أخرى مثل قواعد بيانات المتجهات (لعمليات البحث الدلالي) وأدوات تحميل المستندات وتقسيمها (لتحليل المستندات والتعلم منها) وأدوات تحليل الإخراج وغير ذلك.

ما ستتعلمه
- كيفية إعداد مشروع Java لاستخدام PaLM وLangChain4J
- كيفية استخراج معلومات مفيدة من المحتوى غير المنظَّم (استخراج الكيانات أو الكلمات الرئيسية، الإخراج بتنسيق JSON)
- كيفية إنشاء محادثة مع المستخدمين
- كيفية استخدام نموذج المحادثة لطرح أسئلة حول مستنداتك
المتطلبات
- معرفة بلغة البرمجة Java
- مشروع على السحابة الإلكترونية من Google
- متصفّح، مثل Chrome أو Firefox
2. الإعداد والمتطلبات
إعداد البيئة بالسرعة التي تناسبك
- سجِّل الدخول إلى Google Cloud Console وأنشِئ مشروعًا جديدًا أو أعِد استخدام مشروع حالي. إذا لم يكن لديك حساب على Gmail أو Google Workspace، عليك إنشاء حساب.



- اسم المشروع هو الاسم المعروض للمشاركين في هذا المشروع. وهي سلسلة أحرف لا تستخدمها Google APIs. ويمكنك تعديلها في أي وقت.
- رقم تعريف المشروع هو معرّف فريد في جميع مشاريع Google Cloud ولا يمكن تغييره بعد ضبطه. تنشئ Cloud Console تلقائيًا سلسلة فريدة، ولا يهمّك عادةً ما هي. في معظم دروس البرمجة، عليك الرجوع إلى رقم تعريف مشروعك (يُشار إليه عادةً باسم
PROJECT_ID). إذا لم يعجبك رقم التعريف الذي تم إنشاؤه، يمكنك إنشاء رقم تعريف عشوائي آخر. يمكنك بدلاً من ذلك تجربة اسم مستخدم من اختيارك ومعرفة ما إذا كان متاحًا. لا يمكن تغيير هذا الخيار بعد هذه الخطوة وسيظل ساريًا طوال مدة المشروع. - للعلم، هناك قيمة ثالثة، وهي رقم المشروع، تستخدمها بعض واجهات برمجة التطبيقات. يمكنك الاطّلاع على مزيد من المعلومات عن كل هذه القيم الثلاث في المستندات.
- بعد ذلك، عليك تفعيل الفوترة في Cloud Console لاستخدام موارد/واجهات برمجة تطبيقات Cloud. لن تكلفك تجربة هذا الدرس التطبيقي حول الترميز الكثير، إن وُجدت أي تكلفة على الإطلاق. لإيقاف الموارد وتجنُّب تحمّل تكاليف تتجاوز هذا البرنامج التعليمي، يمكنك حذف الموارد التي أنشأتها أو حذف المشروع. يمكن لمستخدمي Google Cloud الجدد الاستفادة من برنامج الفترة التجريبية المجانية بقيمة 300 دولار أمريكي.
بدء Cloud Shell
على الرغم من إمكانية تشغيل Google Cloud عن بُعد من الكمبيوتر المحمول، ستستخدم في هذا الدرس العملي Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
تفعيل Cloud Shell
- من Cloud Console، انقر على تفعيل Cloud Shell
 .
.

إذا كانت هذه هي المرة الأولى التي تبدأ فيها Cloud Shell، ستظهر لك شاشة وسيطة توضّح ماهية هذه الخدمة. إذا ظهرت لك شاشة وسيطة، انقر على متابعة.

يستغرق توفير Cloud Shell والاتصال به بضع لحظات فقط.

يتم تحميل هذا الجهاز الافتراضي بجميع أدوات التطوير اللازمة. توفّر هذه الخدمة دليلًا رئيسيًا دائمًا بسعة 5 غيغابايت وتعمل في Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يمكن إنجاز معظم عملك في هذا الدرس التطبيقي حول الترميز، إن لم يكن كله، باستخدام متصفح.
بعد الاتصال بـ Cloud Shell، من المفترض أن يظهر لك أنّه تم إثبات هويتك وأنّه تم ضبط المشروع على رقم تعريف مشروعك.
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من إكمال عملية المصادقة:
gcloud auth list
ناتج الأمر
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- نفِّذ الأمر التالي في Cloud Shell للتأكّد من أنّ أمر gcloud يعرف مشروعك:
gcloud config list project
ناتج الأمر
[core] project = <PROJECT_ID>
إذا لم يكن كذلك، يمكنك تعيينه من خلال هذا الأمر:
gcloud config set project <PROJECT_ID>
ناتج الأمر
Updated property [core/project].
3- إعداد بيئة التطوير
في هذا الدرس التطبيقي حول الترميز، ستستخدم وحدة Cloud Shell الطرفية وأداة تعديل الرموز البرمجية لتطوير برامج Java.
تفعيل واجهات برمجة التطبيقات في Vertex AI
- في Google Cloud Console، تأكَّد من ظهور اسم مشروعك في أعلى Google Cloud Console. إذا لم يكن كذلك، انقر على اختيار مشروع لفتح أداة اختيار المشاريع، ثم اختَر المشروع المطلوب.
- إذا لم تكن في قسم Vertex AI في وحدة تحكّم Google Cloud، اتّبِع الخطوات التالية:
- في بحث، أدخِل Vertex AI، ثم اضغط على Return
- في نتائج البحث، انقر على Vertex AI. ستظهر لوحة بيانات Vertex AI.
- انقر على تفعيل جميع واجهات برمجة التطبيقات المقترَحة في لوحة بيانات Vertex AI.
سيؤدي ذلك إلى تفعيل العديد من واجهات برمجة التطبيقات، ولكن أهمها في هذا الدرس التطبيقي حول الترميز هو aiplatform.googleapis.com، ويمكنك أيضًا تفعيله من سطر الأوامر في نافذة Cloud Shell الطرفية عن طريق تنفيذ الأمر التالي:
$ gcloud services enable aiplatform.googleapis.com
إنشاء بنية المشروع باستخدام Gradle
لإنشاء أمثلة على رموز Java البرمجية، ستستخدم أداة الإنشاء Gradle والإصدار 17 من Java. لإعداد مشروعك باستخدام Gradle، أنشئ في وحدة Cloud Shell الطرفية دليلاً (palm-workshop هنا)، ثم نفِّذ الأمر gradle init في هذا الدليل:
$ mkdir palm-workshop $ cd palm-workshop $ gradle init Select type of project to generate: 1: basic 2: application 3: library 4: Gradle plugin Enter selection (default: basic) [1..4] 2 Select implementation language: 1: C++ 2: Groovy 3: Java 4: Kotlin 5: Scala 6: Swift Enter selection (default: Java) [1..6] 3 Split functionality across multiple subprojects?: 1: no - only one application project 2: yes - application and library projects Enter selection (default: no - only one application project) [1..2] 1 Select build script DSL: 1: Groovy 2: Kotlin Enter selection (default: Groovy) [1..2] 1 Generate build using new APIs and behavior (some features may change in the next minor release)? (default: no) [yes, no] Select test framework: 1: JUnit 4 2: TestNG 3: Spock 4: JUnit Jupiter Enter selection (default: JUnit Jupiter) [1..4] 4 Project name (default: palm-workshop): Source package (default: palm.workshop): > Task :init Get more help with your project: https://docs.gradle.org/7.4/samples/sample_building_java_applications.html BUILD SUCCESSFUL in 51s 2 actionable tasks: 2 executed
ستنشئ تطبيقًا (الخيار 2) باستخدام لغة Java (الخيار 3) بدون استخدام مشاريع فرعية (الخيار 1) باستخدام بنية Groovy لملف التصميم (الخيار 1) بدون استخدام ميزات التصميم الجديدة (الخيار no)، وإنشاء اختبارات باستخدام JUnit Jupiter (الخيار 4)، ويمكنك استخدام palm-workshop كاسم للمشروع، وبالمثل يمكنك استخدام palm.workshop لحزمة المصدر.
ستبدو بنية المشروع على النحو التالي:
├── gradle
│ └── ...
├── gradlew
├── gradlew.bat
├── settings.gradle
└── app
├── build.gradle
└── src
├── main
│ └── java
│ └── palm
│ └── workshop
│ └── App.java
└── test
└── ...
لنعدّل ملف app/build.gradle لإضافة بعض التبعيات اللازمة. يمكنك إزالة الاعتمادية guava إذا كانت متوفّرة، واستبدالها بتبعيات مشروع LangChain4J ومكتبة التسجيل لتجنُّب رسائل السجلّ المفقودة المزعجة:
dependencies {
// Use JUnit Jupiter for testing.
testImplementation 'org.junit.jupiter:junit-jupiter:5.8.1'
// Logging library
implementation 'org.slf4j:slf4j-jdk14:2.0.9'
// This dependency is used by the application.
implementation 'dev.langchain4j:langchain4j-vertex-ai:0.24.0'
implementation 'dev.langchain4j:langchain4j:0.24.0'
}
هناك تبعيتان لـ LangChain4j:
- أحدهما في المشروع الأساسي،
- وواحد لوحدة Vertex AI المخصّصة.
لاستخدام Java 17 في تجميع برامجنا وتشغيلها، أضِف الكتلة التالية أسفل الكتلة plugins {}:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
يجب إجراء تغيير آخر، وهو تعديل حزمة application في app/build.gradle، للسماح للمستخدمين بتجاوز الفئة الرئيسية التي سيتم تشغيلها في سطر الأوامر عند استدعاء أداة الإنشاء:
application {
mainClass = providers.systemProperty('javaMainClass')
.orElse('palm.workshop.App')
}
للتحقّق من أنّ ملف الإنشاء جاهز لتشغيل تطبيقك، يمكنك تشغيل الفئة الرئيسية التلقائية التي تطبع رسالة Hello World! بسيطة:
$ ./gradlew run -DjavaMainClass=palm.workshop.App > Task :app:run Hello World! BUILD SUCCESSFUL in 3s 2 actionable tasks: 2 executed
أنت الآن مستعد للبرمجة باستخدام نموذج PaLM اللغوي الكبير للنصوص، وذلك من خلال استخدام مشروع LangChain4J.
للعلم، إليك الشكل الذي يجب أن يبدو عليه ملف app/build.gradle build الكامل الآن:
plugins {
// Apply the application plugin to add support for building a CLI application in Java.
id 'application'
}
java {
toolchain {
// Ensure we compile and run on Java 17
languageVersion = JavaLanguageVersion.of(17)
}
}
repositories {
// Use Maven Central for resolving dependencies.
mavenCentral()
}
dependencies {
// Use JUnit Jupiter for testing.
testImplementation 'org.junit.jupiter:junit-jupiter:5.8.1'
// This dependency is used by the application.
implementation 'dev.langchain4j:langchain4j-vertex-ai:0.24.0'
implementation 'dev.langchain4j:langchain4j:0.24.0'
implementation 'org.slf4j:slf4j-jdk14:2.0.9'
}
application {
mainClass = providers.systemProperty('javaMainClass').orElse('palm.workshop.App')
}
tasks.named('test') {
// Use JUnit Platform for unit tests.
useJUnitPlatform()
}
4. إجراء أول طلب إلى نموذج المحادثة في PaLM
بعد إعداد المشروع بشكل صحيح، حان الوقت لطلب بيانات من PaLM API.
أنشئ فئة جديدة باسم ChatPrompts.java في الدليل app/src/main/java/palm/workshop (بجانب الفئة التلقائية App.java)، واكتب المحتوى التالي:
package palm.workshop;
import dev.langchain4j.model.vertexai.VertexAiChatModel;
import dev.langchain4j.chain.ConversationalChain;
public class ChatPrompts {
public static void main(String[] args) {
VertexAiChatModel model = VertexAiChatModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("chat-bison@001")
.maxOutputTokens(400)
.maxRetries(3)
.build();
ConversationalChain chain = ConversationalChain.builder()
.chatLanguageModel(model)
.build();
String message = "What are large language models?";
String answer = chain.execute(message);
System.out.println(answer);
System.out.println("---------------------------");
message = "What can you do with them?";
answer = chain.execute(message);
System.out.println(answer);
System.out.println("---------------------------");
message = "Can you name some of them?";
answer = chain.execute(message);
System.out.println(answer);
}
}
في هذا المثال الأول، عليك استيراد الفئة VertexAiChatModel، وLangChain4J ConversationalChain لتسهيل التعامل مع جانب المحادثات المتعددة الأدوار.
بعد ذلك، في طريقة main، ستعمل على ضبط نموذج لغة المحادثة باستخدام أداة الإنشاء VertexAiChatModel لتحديد ما يلي:
- نقطة النهاية
- المشروع،
- المنطقة
- الناشر
- واسم النموذج (
chat-bison@001).
بعد أن أصبح نموذج اللغة جاهزًا، يمكنك إعداد ConversationalChain. هذا هو مستوى تجريد أعلى توفّره LangChain4J لإعداد مكوّنات مختلفة معًا للتعامل مع محادثة، مثل نموذج اللغة الخاص بالمحادثة نفسه، ولكن قد يشمل مكوّنات أخرى للتعامل مع سجلّ المحادثة، أو لتوصيل أدوات أخرى مثل أدوات الاسترجاع لجلب المعلومات من قواعد بيانات المتجهات. لا تقلق، سنتطرق إلى ذلك لاحقًا في هذا الدرس التطبيقي حول الترميز.
بعد ذلك، ستجري محادثة متعدّدة الجولات مع نموذج الدردشة لطرح عدة أسئلة ذات صلة. في البداية، تتساءل عن النماذج اللغوية الكبيرة، ثم تسأل عن إمكانات استخدامها وبعض الأمثلة عليها. لاحظ كيف أنّك لست بحاجة إلى تكرار نفسك، فالنموذج اللغوي الكبير يعرف أنّ "هذه النماذج" تشير إلى النماذج اللغوية الكبيرة، في سياق تلك المحادثة.
لإجراء محادثة متعدّدة الجولات، ما عليك سوى استدعاء طريقة execute() في السلسلة، وسيتم إضافتها إلى سياق المحادثة، وسينشئ نموذج المحادثة ردًا ويضيفه إلى سجلّ المحادثات أيضًا.
لتشغيل هذه الفئة، نفِّذ الأمر التالي في وحدة Cloud Shell الطرفية:
./gradlew run -DjavaMainClass=palm.workshop.ChatPrompts
من المفترض أن تظهر لك نتيجة مشابهة لما يلي:
$ ./gradlew run -DjavaMainClass=palm.workshop.ChatPrompts Starting a Gradle Daemon, 2 incompatible and 2 stopped Daemons could not be reused, use --status for details > Task :app:run Large language models (LLMs) are artificial neural networks that are trained on massive datasets of text and code. They are designed to understand and generate human language, and they can be used for a variety of tasks, such as machine translation, question answering, and text summarization. --------------------------- LLMs can be used for a variety of tasks, such as: * Machine translation: LLMs can be used to translate text from one language to another. * Question answering: LLMs can be used to answer questions posed in natural language. * Text summarization: LLMs can be used to summarize text into a shorter, more concise form. * Code generation: LLMs can be used to generate code, such as Python or Java code. * Creative writing: LLMs can be used to generate creative text, such as poems, stories, and scripts. LLMs are still under development, but they have the potential to revolutionize a wide range of industries. For example, LLMs could be used to improve customer service, create more personalized marketing campaigns, and develop new products and services. --------------------------- Some of the most well-known LLMs include: * GPT-3: Developed by OpenAI, GPT-3 is a large language model that can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. * LaMDA: Developed by Google, LaMDA is a large language model that can chat with you in an open-ended way, answering your questions, telling stories, and providing different kinds of creative content. * PaLM 2: Developed by Google, PaLM 2 is a large language model that can perform a wide range of tasks, including machine translation, question answering, and text summarization. * T5: Developed by Google, T5 is a large language model that can be used for a variety of tasks, including text summarization, question answering, and code generation. These are just a few examples of the many LLMs that are currently being developed. As LLMs continue to improve, they are likely to play an increasingly important role in our lives. BUILD SUCCESSFUL in 25s 2 actionable tasks: 2 executed
ردّ نموذج PaLM على أسئلتك الثلاثة ذات الصلة.
تتيح لك أداة الإنشاء VertexAIChatModel تحديد مَعلمات اختيارية تتضمّن بعض القيم التلقائية التي يمكنك تجاهلها. وإليك بعض الأمثلة:
.temperature(0.2): لتحديد مستوى الإبداع المطلوب في الردّ (0 يعني مستوى إبداع منخفضًا وغالبًا ما يكون الردّ أكثر واقعية، بينما 1 يعني مستوى إبداع أعلى)-
.maxOutputTokens(50)— في المثال، تم طلب 400 رمز مميز (تعادل 3 رموز مميزة حوالي 4 كلمات)، وذلك حسب طول الإجابة التي تريد إنشاءها .topK(20): لاختيار كلمة عشوائية من بين عدد أقصى من الكلمات المحتملة لإكمال النص (من 1 إلى 40).topP(0.95): لاختيار الكلمات المحتملة التي يصل مجموع احتمالاتها إلى رقم النقطة العائمة هذا (بين 0 و1).maxRetries(3): في حال تجاوزت عدد الطلبات المسموح به في كل مرة، يمكنك أن تطلب من النموذج إعادة محاولة إجراء المكالمة 3 مرات مثلاً.
5- برنامج محادثة مفيد يتميّز بطابع شخصي
في القسم السابق، بدأت على الفور بطرح أسئلة على برنامج الدردشة الآلي المستند إلى نموذج اللغة الكبير بدون تقديم أي سياق معيّن. ولكن يمكنك تخصيص روبوت محادثة ليصبح خبيرًا في مهمة معيّنة أو موضوع معيّن.
كيف يمكن إجراء ذلك؟ تحديد السياق: من خلال شرح المهمة التي يجب أن ينفّذها النموذج اللغوي الكبير، وتوضيح السياق، وربما تقديم بعض الأمثلة على ما يجب أن يفعله، والشخصية التي يجب أن يتّبعها، والتنسيق الذي تريد تلقّي الردود به، وربما النبرة، إذا كنت تريد أن يتصرف برنامج الدردشة بطريقة معيّنة.
توضّح هذه المقالة حول صياغة الطلبات هذا الأسلوب بشكلٍ جيد باستخدام هذا الرسم:

https://medium.com/@eldatero/master-the-perfect-chatgpt-prompt-formula-c776adae8f19
لتوضيح هذه النقطة، لنستلهم بعض الأفكار من المواقع الإلكترونية prompts.chat التي تقدّم الكثير من الأفكار الرائعة والممتعة حول برامج الدردشة الآلية المخصّصة التي تتيح لها العمل على النحو التالي:
- مترجم رموز إيموجي: لترجمة رسائل المستخدمين إلى رموز إيموجي
- أداة تحسين الطلبات: لإنشاء طلبات أفضل
- مُراجع المجلات: للمساعدة في مراجعة الأوراق البحثية
- مصمّم أزياء شخصي: للحصول على اقتراحات بشأن أسلوب الملابس
إليك مثالاً على كيفية تحويل روبوت دردشة مستند إلى نموذج لغوي كبير إلى لاعب شطرنج. لننفّذ ذلك.
عدِّل فئة ChatPrompts على النحو التالي:
package palm.workshop;
import dev.langchain4j.chain.ConversationalChain;
import dev.langchain4j.data.message.SystemMessage;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.vertexai.VertexAiChatModel;
import dev.langchain4j.store.memory.chat.InMemoryChatMemoryStore;
public class ChatPrompts {
public static void main(String[] args) {
VertexAiChatModel model = VertexAiChatModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("chat-bison@001")
.maxOutputTokens(7)
.maxRetries(3)
.build();
InMemoryChatMemoryStore chatMemoryStore = new InMemoryChatMemoryStore();
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder()
.chatMemoryStore(chatMemoryStore)
.maxMessages(200)
.build();
chatMemory.add(SystemMessage.from("""
You're an expert chess player with a high ELO ranking.
Use the PGN chess notation to reply with the best next possible move.
"""
));
ConversationalChain chain = ConversationalChain.builder()
.chatLanguageModel(model)
.chatMemory(chatMemory)
.build();
String pgn = "";
String[] whiteMoves = { "Nf3", "c4", "Nc3", "e3", "Dc2", "Cd5"};
for (int i = 0; i < whiteMoves.length; i++) {
pgn += " " + (i+1) + ". " + whiteMoves[i];
System.out.println("Playing " + whiteMoves[i]);
pgn = chain.execute(pgn);
System.out.println(pgn);
}
}
}
إليك الخطوات المفصّلة:
- يجب استيراد بعض العناصر الجديدة للتعامل مع ذاكرة المحادثة.
- يمكنك إنشاء نموذج المحادثة، ولكن مع عدد صغير من الرموز المميزة القصوى (هنا 7)، لأنّنا نريد فقط إنشاء الخطوة التالية، وليس أطروحة كاملة عن الشطرنج.
- بعد ذلك، يمكنك إنشاء مساحة تخزين لبيانات المحادثات لحفظ محادثات Chat.
- يمكنك إنشاء ذاكرة محادثة فعلية بنظام النوافذ للاحتفاظ بالحركات الأخيرة.
- في ذاكرة المحادثة، يمكنك إضافة رسالة "نظام" توجّه نموذج المحادثة بشأن هوية الشخص الذي من المفترض أن يكون (أي لاعب شطرنج خبير). تضيف رسالة "النظام" بعض السياق، بينما تمثّل رسائل "المستخدم" و "الذكاء الاصطناعي" المناقشة الفعلية.
- يمكنك إنشاء سلسلة محادثات تجمع بين الذاكرة ونموذج المحادثة.
- بعد ذلك، لدينا قائمة بنقلات الأبيض، والتي تتكرر. يتم تنفيذ السلسلة مع حركة الأبيض التالية في كل مرة، ويردّ نموذج المحادثة بأفضل حركة تالية.
عند تشغيل هذه الفئة مع هذه الحركات، من المفترض أن يظهر لك الناتج التالي:
$ ./gradlew run -DjavaMainClass=palm.workshop.ChatPrompts Starting a Gradle Daemon (subsequent builds will be faster) > Task :app:run Playing Nf3 1... e5 Playing c4 2... Nc6 Playing Nc3 3... Nf6 Playing e3 4... Bb4 Playing Dc2 5... O-O Playing Cd5 6... exd5
يا للروعة! هل يعرف نموذج PaLM كيفية لعب الشطرنج؟ حسنًا، ليس بالضبط، ولكن أثناء تدريب النموذج، يجب أن يكون قد رأى بعض التعليقات على مباريات الشطرنج، أو حتى ملفات PGN (Portable Game Notation) الخاصة بالمباريات السابقة. من غير المرجّح أن يفوز هذا الروبوت الدردشة على AlphaZero (الذكاء الاصطناعي الذي يتغلّب على أفضل لاعبي Go وShogi وChess)، وقد تنحرف المحادثة أكثر في المستقبل، حيث لا يتذكّر النموذج الحالة الفعلية للعبة.
تتسم نماذج المحادثات بقدرتها العالية، ويمكنها إنشاء تفاعلات غنية مع المستخدمين، والتعامل مع مهام سياقية مختلفة. في القسم التالي، سنلقي نظرة على مهمة مفيدة: استخراج البيانات المنظَّمة من النص.
6. استخراج المعلومات من النصوص غير المنظَّمة
في القسم السابق، أنشأت محادثات بين مستخدم ونموذج لغة خاص بالمحادثات. ولكن باستخدام LangChain4J، يمكنك أيضًا استخدام نموذج محادثة لاستخراج معلومات منظَّمة من نص غير منظَّم.
لنفترض أنّك تريد استخراج اسم شخص وعمره، مع الأخذ في الاعتبار سيرة ذاتية أو وصفًا لهذا الشخص. يمكنك توجيه النموذج اللغوي الكبير لإنشاء بنى بيانات JSON من خلال طلب معدَّل بذكاء (يُعرف هذا الإجراء عادةً باسم "هندسة الطلبات").
عدِّل الصف ChatPrompts على النحو التالي:
package palm.workshop;
import dev.langchain4j.model.vertexai.VertexAiChatModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.UserMessage;
public class ChatPrompts {
static class Person {
String name;
int age;
}
interface PersonExtractor {
@UserMessage("""
Extract the name and age of the person described below.
Return a JSON document with a "name" and an "age" property, \
following this structure: {"name": "John Doe", "age": 34}
Return only JSON, without any markdown markup surrounding it.
Here is the document describing the person:
---
{{it}}
---
JSON:
""")
Person extractPerson(String text);
}
public static void main(String[] args) {
VertexAiChatModel model = VertexAiChatModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("chat-bison@001")
.maxOutputTokens(300)
.build();
PersonExtractor extractor = AiServices.create(PersonExtractor.class, model);
Person person = extractor.extractPerson("""
Anna is a 23 year old artist based in Brooklyn, New York. She was born and
raised in the suburbs of Chicago, where she developed a love for art at a
young age. She attended the School of the Art Institute of Chicago, where
she studied painting and drawing. After graduating, she moved to New York
City to pursue her art career. Anna's work is inspired by her personal
experiences and observations of the world around her. She often uses bright
colors and bold lines to create vibrant and energetic paintings. Her work
has been exhibited in galleries and museums in New York City and Chicago.
"""
);
System.out.println(person.name);
System.out.println(person.age);
}
}
لنلقِ نظرة على الخطوات المختلفة في هذا الملف:
- يتم تحديد
Personفئة لتمثيل التفاصيل التي تصف شخصًا (اسمه وعمره). - يتم إنشاء واجهة
PersonExtractorباستخدام طريقة تعرض مثيلاً منشأً منPersonعند توفّر سلسلة نصية غير منظَّمة. - يتمّ إضافة تعليق توضيحي
@UserMessageإلىextractPerson()يربط طلبًا به. هذا هو الطلب الذي سيستخدمه النموذج لاستخراج المعلومات، وسيعرض التفاصيل في شكل مستند JSON، وسيتم تحليله لك، وإلغاء تسلسله إلى مثيلPerson.
لنلقِ الآن نظرة على محتوى الطريقة main():
- يتم إنشاء مثيل لنموذج المحادثة.
- يتم إنشاء كائن
PersonExtractorبفضل فئةAiServicesفي LangChain4J. - بعد ذلك، يمكنك ببساطة استدعاء
Person person = extractor.extractPerson(...)لاستخراج تفاصيل الشخص من النص غير المنظَّم، والحصول على مثيلPersonيتضمّن الاسم والعمر.
الآن، شغِّل هذه الفئة باستخدام الأمر التالي:
$ ./gradlew run -DjavaMainClass=palm.workshop.ChatPrompts > Task :app:run Anna 23
نعم. هذه "آنا"، عمرها 23 عامًا.
ما يهمّ بشكل خاص في طريقة AiServices هذه هو أنّك تعمل باستخدام عناصر مكتوبة بشكل صارم. أنت لا تتفاعل مباشرةً مع النموذج اللغوي الكبير الخاص بروبوت الدردشة. بدلاً من ذلك، أنت تعمل مع فئات ملموسة، مثل فئة Person لتمثيل المعلومات الشخصية المستخرَجة، ولديك فئة PersonExtractor تتضمّن طريقة extractPerson() تعرض مثيلاً من Person. يتم إخفاء مفهوم النموذج اللغوي الكبير، وبصفتك مطوّر Java، ما عليك سوى التعامل مع الفئات والكائنات العادية.
7. التوليد المعزّز بالاسترجاع: الدردشة مع مستنداتك
لنرجع إلى المحادثات. في هذه المرة، ستتمكّن من طرح أسئلة حول مستنداتك. ستنشئ برنامج دردشة آليًا قادرًا على استرداد المعلومات ذات الصلة من قاعدة بيانات تتضمّن مقتطفات من مستنداتك، وسيستخدم النموذج هذه المعلومات لإسناد إجاباته، بدلاً من محاولة إنشاء ردود مستندة إلى التدريب الذي تلقّاه. يُعرف هذا النمط باسم RAG أو التوليد المعزّز بالاسترجاع.
في عملية "الاسترجاع المعزّز للإنشاء"، هناك مرحلتان:
- مرحلة الاستيعاب: يتم تحميل المستندات وتقسيمها إلى أجزاء أصغر، ويتم تخزين تمثيل متّجهي لها ("تضمين متّجهي") في "قاعدة بيانات متّجهات" يمكنها إجراء عمليات بحث دلالية.
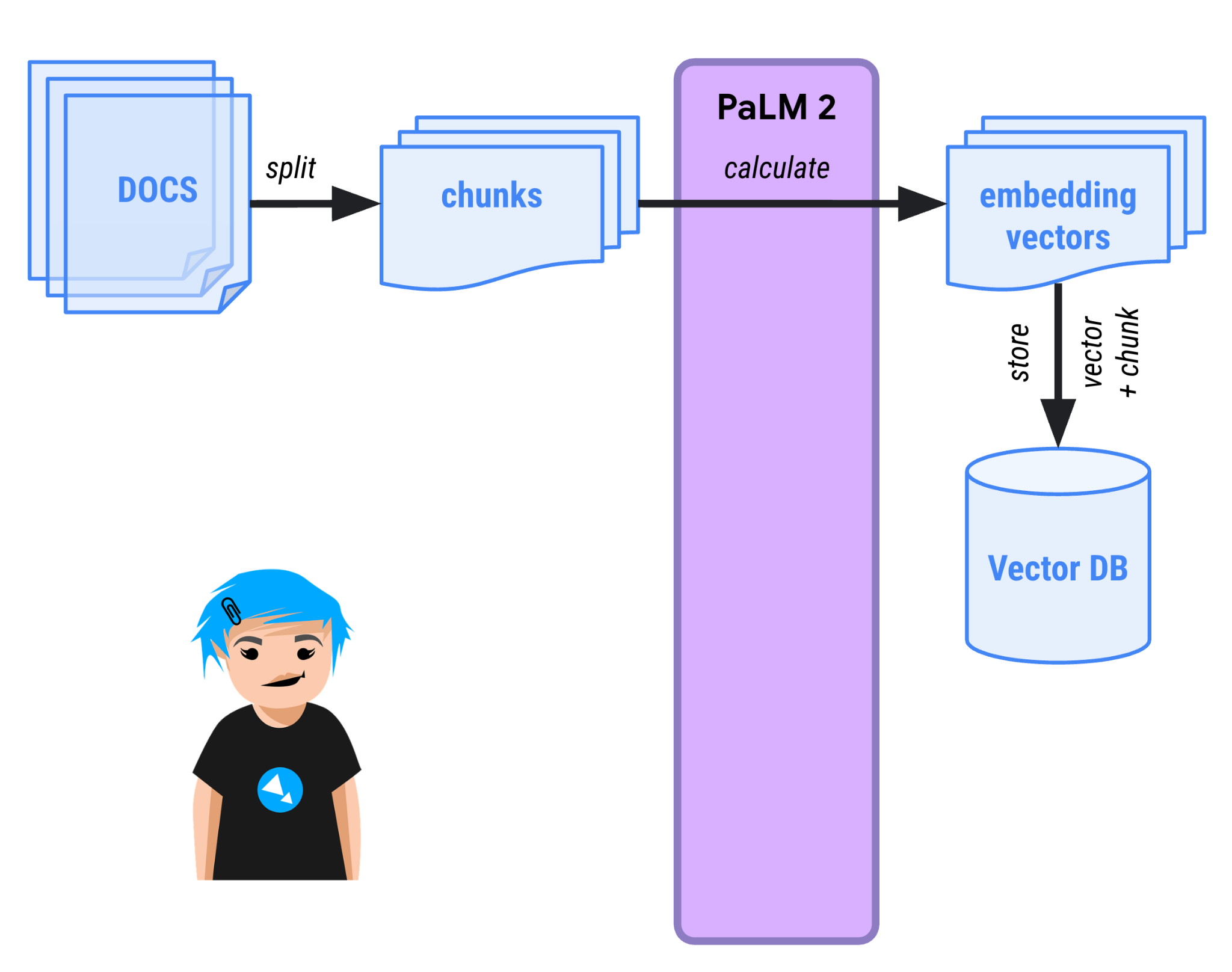
- مرحلة طلب البحث: يمكن للمستخدمين الآن طرح أسئلة على برنامج الدردشة الآلي حول المستندات. سيتم تحويل السؤال إلى متّجه أيضًا، ومقارنته بجميع المتّجهات الأخرى في قاعدة البيانات. عادةً ما تكون المتجهات الأكثر تشابهًا مرتبطة دلاليًا، وتعرضها قاعدة بيانات المتجهات. بعد ذلك، يتم تزويد النموذج اللغوي الكبير بسياق المحادثة ومقتطفات النص التي تتوافق مع المتّجهات التي تعرضها قاعدة البيانات، ويُطلب منه تحديد مصدر إجابته من خلال النظر إلى هذه المقتطفات.

إعداد مستنداتك
في هذا العرض التوضيحي الجديد، ستطرح أسئلة حول بنية الشبكة العصبية "المحوّل" التي ابتكرتها Google، وهي الطريقة التي يتم بها تنفيذ جميع النماذج اللغوية الكبيرة الحديثة في الوقت الحالي.
يمكنك استرداد ورقة البحث التي وصفت هذه البنية ("Attention is all you need") باستخدام الأمر wget لتنزيل ملف PDF من الإنترنت:
wget -O attention-is-all-you-need.pdf \
https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
تنفيذ سلسلة استرجاع حوارية
لنستكشف خطوة بخطوة كيفية إنشاء الأسلوب المكوّن من مرحلتين، بدءًا من إدخال المستند، ثم وقت الاستعلام عندما يطرح المستخدمون أسئلة حول المستند.
عرض المستندات
تتمثّل الخطوة الأولى في مرحلة نقل المستند في تحديد موقع ملف PDF الذي سننزّله، وإعداد PdfParser لقراءته:
PdfDocumentParser pdfParser = new PdfDocumentParser();
Document document = pdfParser.parse(
new FileInputStream(new File("/home/YOUR_USER_NAME/palm-workshop/attention-is-all-you-need.pdf")));
بدلاً من إنشاء نموذج لغوي عادي للدردشة، عليك إنشاء مثيل لنموذج "تضمين" أولاً. هذا نموذج ونقطة نهاية محدّدان يتمثّل دورهما في إنشاء تمثيلات متجهة لأجزاء من النص (كلمات أو جمل أو حتى فقرات).
VertexAiEmbeddingModel embeddingModel = VertexAiEmbeddingModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("textembedding-gecko@001")
.maxRetries(3)
.build();
بعد ذلك، ستحتاج إلى بعض الصفوف للتعاون معًا من أجل:
- تحميل مستند PDF وتقسيمه إلى أجزاء
- أنشئ تضمينات متجهة لكل هذه الأجزاء.
InMemoryEmbeddingStore<TextSegment> embeddingStore =
new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor storeIngestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(500, 100))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
storeIngestor.ingest(document);
EmbeddingStoreRetriever retriever = EmbeddingStoreRetriever.from(embeddingStore, embeddingModel);
يتم إنشاء مثيل من InMemoryEmbeddingStore، وهي قاعدة بيانات متّجهات في الذاكرة، لتخزين تضمينات المتّجهات.
يتم تقسيم المستند إلى أجزاء بفضل الفئة DocumentSplitters. سيتم تقسيم نص ملف PDF إلى مقتطفات من 500 حرف، مع تداخل 100 حرف (مع الجزء التالي، لتجنُّب قطع الكلمات أو الجمل).
يربط "المستوعب" في المتجر أداة تقسيم المستندات ونموذج التضمين لاحتساب المتجهات وقاعدة بيانات المتجهات في الذاكرة. بعد ذلك، ستتولّى الطريقة ingest() عملية النقل.
الآن، انتهت المرحلة الأولى، وتم تحويل المستند إلى أجزاء نصية مع تضميناتها المتجهة المرتبطة، وتم تخزينها في قاعدة بيانات المتجهات.
طرح الأسئلة
حان الوقت الآن لطرح الأسئلة. يمكن إنشاء نموذج المحادثة المعتاد لبدء المحادثة:
VertexAiChatModel model = VertexAiChatModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("chat-bison@001")
.maxOutputTokens(1000)
.build();
ستحتاج أيضًا إلى فئة "مسترجِع" تربط قاعدة بيانات المتجهات (في المتغيّر embeddingStore) ونموذج التضمين. مهمة هذا النظام هي البحث في قاعدة بيانات المتّجهات من خلال احتساب تضمين متّجه لطلب المستخدم، وذلك للعثور على متّجهات مشابهة في قاعدة البيانات:
EmbeddingStoreRetriever retriever =
EmbeddingStoreRetriever.from(embeddingStore, embeddingModel);
في هذه المرحلة، يمكنك إنشاء مثيل للفئة ConversationalRetrievalChain (هذا مجرد اسم مختلف لنمط Retrieval Augmented Generation):
ConversationalRetrievalChain rag = ConversationalRetrievalChain.builder()
.chatLanguageModel(model)
.retriever(retriever)
.promptTemplate(PromptTemplate.from("""
Answer to the following query the best as you can: {{question}}
Base your answer on the information provided below:
{{information}}
"""
))
.build();
تربط هذه "السلسلة" ما يلي:
- نموذج لغة المحادثة الذي أعددته سابقًا
- يقارن المسترجِع طلب بحث عن تضمين متّجه بالمتّجهات في قاعدة البيانات.
- يُشير نموذج الطلب بوضوح إلى أنّ نموذج المحادثة يجب أن يردّ استنادًا إلى المعلومات المقدَّمة (أي المقتطفات ذات الصلة من المستندات التي يكون تضمينها المتّجهي مشابهًا لمتّجه سؤال المستخدم).
أصبحتم الآن جاهزين لطرح أسئلتكم.
String result = rag.execute("What neural network architecture can be used for language models?");
System.out.println(result);
System.out.println("------------");
result = rag.execute("What are the different components of a transformer neural network?");
System.out.println(result);
System.out.println("------------");
result = rag.execute("What is attention in large language models?");
System.out.println(result);
System.out.println("------------");
result = rag.execute("What is the name of the process that transforms text into vectors?");
System.out.println(result);
شغِّل البرنامج باستخدام:
$ ./gradlew run -DjavaMainClass=palm.workshop.ChatPrompts
في الناتج، يجب أن يظهر لك الجواب عن أسئلتك:
The Transformer is a neural network architecture that can be used for language models. It is based solely on attention mechanisms, dispensing with recurrence and convolutions. The Transformer has been shown to outperform recurrent neural networks and convolutional neural networks on a variety of language modeling tasks. ------------ The Transformer is a neural network architecture that can be used for language models. It is based solely on attention mechanisms, dispensing with recurrence and convolutions. The Transformer has been shown to outperform recurrent neural networks and convolutional neural networks on a variety of language modeling tasks. The Transformer consists of an encoder and a decoder. The encoder is responsible for encoding the input sequence into a fixed-length vector representation. The decoder is responsible for decoding the output sequence from the input sequence. The decoder uses the attention mechanism to attend to different parts of the input sequence when generating the output sequence. ------------ Attention is a mechanism that allows a neural network to focus on specific parts of an input sequence. In the context of large language models, attention is used to allow the model to focus on specific words or phrases in a sentence when generating output. This allows the model to generate more relevant and informative output. ------------ The process of transforming text into vectors is called word embedding. Word embedding is a technique that represents words as vectors in a high-dimensional space. The vectors are typically learned from a large corpus of text, and they capture the semantic and syntactic relationships between words. Word embedding has been shown to be effective for a variety of natural language processing tasks, such as machine translation, question answering, and sentiment analysis.
الحلّ الكامل
لتسهيل عملية النسخ واللصق، إليك المحتوى الكامل لفئة ChatPrompts:
package palm.workshop;
import dev.langchain4j.chain.ConversationalRetrievalChain;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.parser.PdfDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.input.PromptTemplate;
import dev.langchain4j.model.vertexai.VertexAiChatModel;
import dev.langchain4j.model.vertexai.VertexAiEmbeddingModel;
import dev.langchain4j.retriever.EmbeddingStoreRetriever;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class ChatPrompts {
public static void main(String[] args) throws IOException {
PdfDocumentParser pdfParser = new PdfDocumentParser();
Document document = pdfParser.parse(new FileInputStream(new File("/ABSOLUTE_PATH/attention-is-all-you-need.pdf")));
VertexAiEmbeddingModel embeddingModel = VertexAiEmbeddingModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("textembedding-gecko@001")
.maxRetries(3)
.build();
InMemoryEmbeddingStore<TextSegment> embeddingStore =
new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor storeIngestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(500, 100))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
storeIngestor.ingest(document);
EmbeddingStoreRetriever retriever = EmbeddingStoreRetriever.from(embeddingStore, embeddingModel);
VertexAiChatModel model = VertexAiChatModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("genai-java-demos")
.location("us-central1")
.publisher("google")
.modelName("chat-bison@001")
.maxOutputTokens(1000)
.build();
ConversationalRetrievalChain rag = ConversationalRetrievalChain.builder()
.chatLanguageModel(model)
.retriever(retriever)
.promptTemplate(PromptTemplate.from("""
Answer to the following query the best as you can: {{question}}
Base your answer on the information provided below:
{{information}}
"""
))
.build();
String result = rag.execute("What neural network architecture can be used for language models?");
System.out.println(result);
System.out.println("------------");
result = rag.execute("What are the different components of a transformer neural network?");
System.out.println(result);
System.out.println("------------");
result = rag.execute("What is attention in large language models?");
System.out.println(result);
System.out.println("------------");
result = rag.execute("What is the name of the process that transforms text into vectors?");
System.out.println(result);
}
}
8. تهانينا
تهانينا، لقد أنشأت بنجاح أول تطبيق محادثة يعمل بالذكاء الاصطناعي التوليدي في Java باستخدام LangChain4J وPaLM API. لقد اكتشفت على طول الطريق أنّ نماذج الدردشة اللغوية الكبيرة فعّالة جدًا وقادرة على التعامل مع مهام مختلفة، مثل الإجابة عن الأسئلة، حتى في مستنداتك الخاصة، واستخراج البيانات، بل إنّها كانت قادرة إلى حدّ ما على لعب بعض مباريات الشطرنج.
ما هي الخطوات التالية؟
اطّلِع على بعض الدروس البرمجية التالية لتتعمّق في استخدام PaLM في Java:
Further reading
- حالات الاستخدام الشائعة للذكاء الاصطناعي التوليدي
- مصادر تدريب حول الذكاء الاصطناعي التوليدي
- التفاعل مع PaLM من خلال Generative AI Studio
- الذكاء الاصطناعي المسؤول