
১. ভূমিকা
সর্বশেষ হালনাগাদ: ২০২৪-০২-০৫
জেনারেটিভ এআই কী
জেনারেটিভ এআই বা জেনারেটিভ কৃত্রিম বুদ্ধিমত্তা বলতে কৃত্রিম বুদ্ধিমত্তার ব্যবহার করে নতুন বিষয়বস্তু, যেমন পাঠ্য, ছবি, সঙ্গীত, অডিও এবং ভিডিও তৈরি করাকে বোঝায়।
জেনারেটিভ এআই ফাউন্ডেশন মডেল (বৃহৎ এআই মডেল) দ্বারা চালিত হয়, যা মাল্টি-টাস্কিং করতে পারে এবং সারসংক্ষেপ তৈরি, প্রশ্নোত্তর, শ্রেণিবিন্যাসসহ আরও অনেক ধরনের কাজ স্বতঃস্ফূর্তভাবে সম্পাদন করতে পারে। এছাড়াও, ন্যূনতম প্রশিক্ষণের মাধ্যমে খুব অল্প উদাহরণ ডেটা ব্যবহার করে ফাউন্ডেশন মডেলগুলোকে নির্দিষ্ট ব্যবহারের জন্য অভিযোজিত করা যায়।
জেনারেটিভ এআই কীভাবে কাজ করে?
জেনারেটিভ এআই একটি এমএল (মেশিন লার্নিং) মডেল ব্যবহার করে মানুষের তৈরি কন্টেন্টের ডেটাসেটের মধ্যেকার প্যাটার্ন ও সম্পর্কগুলো শেখে। এরপর এটি সেই শেখা প্যাটার্নগুলো ব্যবহার করে নতুন কন্টেন্ট তৈরি করে।
একটি জেনারেটিভ এআই মডেলকে প্রশিক্ষণ দেওয়ার সবচেয়ে প্রচলিত উপায় হলো সুপারভাইজড লার্নিং ব্যবহার করা — এক্ষেত্রে মডেলটিকে মানুষের তৈরি এক সেট কন্টেন্ট এবং তার সাথে সম্পর্কিত লেবেল দেওয়া হয়। এরপর এটি মানুষের তৈরি কন্টেন্টের অনুরূপ এবং একই লেবেলযুক্ত কন্টেন্ট তৈরি করতে শেখে।
জেনারেটিভ এআই-এর সাধারণ প্রয়োগগুলো কী কী?
জেনারেটিভ এআই বিপুল পরিমাণ কন্টেন্ট প্রক্রিয়াজাত করে টেক্সট, ছবি এবং ব্যবহারকারী-বান্ধব ফরম্যাটের মাধ্যমে অন্তর্দৃষ্টি ও উত্তর তৈরি করে। জেনারেটিভ এআই নিম্নলিখিত ক্ষেত্রে ব্যবহার করা যেতে পারে:
- উন্নত চ্যাট এবং সার্চ অভিজ্ঞতার মাধ্যমে গ্রাহক মিথস্ক্রিয়া উন্নত করুন
- কথোপকথনমূলক ইন্টারফেস এবং সারসংক্ষেপের মাধ্যমে বিপুল পরিমাণ অসংগঠিত ডেটা অন্বেষণ করুন।
- প্রস্তাবনা অনুরোধের (RFP) উত্তর দেওয়া, পাঁচটি ভাষায় বিপণন সামগ্রী স্থানীয়করণ করা, এবং সম্মতি যাচাইয়ের মতো পুনরাবৃত্তিমূলক কাজে সহায়তা করা, এবং আরও অনেক কিছু।
গুগল ক্লাউডের কী কী জেনারেটিভ এআই পরিষেবা রয়েছে?
Vertex AI-এর সাহায্যে, আপনার অ্যাপ্লিকেশনগুলিতে ফাউন্ডেশন মডেলগুলির সাথে ইন্টারঅ্যাক্ট করুন, সেগুলিকে কাস্টমাইজ করুন এবং এম্বেড করুন — এর জন্য খুব সামান্য বা কোনো ML দক্ষতার প্রয়োজন নেই। Model Garden- এ ফাউন্ডেশন মডেলগুলি অ্যাক্সেস করুন, Generative AI Studio- এর একটি সহজ UI-এর মাধ্যমে মডেলগুলি টিউন করুন, অথবা একটি ডেটা সায়েন্স নোটবুকে মডেলগুলি ব্যবহার করুন।
ভার্টেক্স এআই সার্চ অ্যান্ড কনভারসেশন ডেভেলপারদের জন্য জেনারেটিভ এআই চালিত সার্চ ইঞ্জিন এবং চ্যাটবট তৈরির দ্রুততম উপায় প্রদান করে।
আর, ডুয়েট এআই হলো আপনার এআই-চালিত সহযোগী, যা গুগল ক্লাউড এবং আইডিই জুড়ে উপলব্ধ থেকে আপনাকে আরও বেশি কাজ দ্রুত সম্পন্ন করতে সাহায্য করে।
এই কোডল্যাবটি কীসের উপর আলোকপাত করছে?
এই কোডল্যাবটি গুগল ক্লাউড ভার্টেক্স এআই-তে হোস্ট করা PaLM 2 লার্জ ল্যাঙ্গুয়েজ মডেল (LLM)-এর উপর আলোকপাত করে, যা সমস্ত মেশিন লার্নিং পণ্য এবং পরিষেবা অন্তর্ভুক্ত করে।
আপনি LangChain4J LLM ফ্রেমওয়ার্ক অর্কেস্ট্রেটরের সাথে একত্রে PaLM API-এর সাথে ইন্টারঅ্যাক্ট করার জন্য জাভা ব্যবহার করবেন। প্রশ্নোত্তর, ধারণা তৈরি, এনটিটি ও স্ট্রাকচার্ড কন্টেন্ট এক্সট্র্যাকশন এবং সারসংক্ষেপ তৈরির জন্য LLM-এর সুবিধা নিতে আপনি বিভিন্ন বাস্তব উদাহরণের মধ্য দিয়ে যাবেন।
LangChain4J ফ্রেমওয়ার্ক সম্পর্কে আমাকে আরও বলুন!
LangChain4J ফ্রেমওয়ার্কটি আপনার জাভা অ্যাপ্লিকেশনগুলিতে বৃহৎ ল্যাঙ্গুয়েজ মডেলগুলিকে একীভূত করার জন্য একটি ওপেন সোর্স লাইব্রেরি। এটি স্বয়ং LLM-এর মতো বিভিন্ন উপাদানকে সমন্বিত করে, এবং এর পাশাপাশি ভেক্টর ডেটাবেস (অর্থগত অনুসন্ধানের জন্য), ডকুমেন্ট লোডার ও স্প্লিটার (ডকুমেন্ট বিশ্লেষণ ও তা থেকে শেখার জন্য), আউটপুট পার্সার এবং আরও অনেক টুলের মতো অন্যান্য সরঞ্জামও ব্যবহার করে।

আপনি যা শিখবেন
- PaLM এবং LangChain4J ব্যবহার করার জন্য কীভাবে একটি জাভা প্রজেক্ট সেটআপ করবেন
- অসংগঠিত কন্টেন্ট থেকে কীভাবে দরকারি তথ্য বের করা যায় (এনটিটি বা কীওয়ার্ড নিষ্কাশন, JSON ফরম্যাটে আউটপুট)
- আপনার ব্যবহারকারীদের সাথে কীভাবে কথোপকথন তৈরি করবেন
- আপনার নিজের ডকুমেন্টেশনে প্রশ্ন জিজ্ঞাসা করতে চ্যাট মডেলটি কীভাবে ব্যবহার করবেন
আপনার যা যা লাগবে
- জাভা প্রোগ্রামিং ভাষার জ্ঞান
- একটি গুগল ক্লাউড প্রকল্প
- ক্রোম বা ফায়ারফক্সের মতো একটি ব্রাউজার
২. সেটআপ এবং প্রয়োজনীয়তা
স্ব-গতিতে পরিবেশ সেটআপ
- Google Cloud Console- এ সাইন-ইন করুন এবং একটি নতুন প্রজেক্ট তৈরি করুন অথবা বিদ্যমান কোনো প্রজেক্ট পুনরায় ব্যবহার করুন। যদি আপনার আগে থেকে Gmail বা Google Workspace অ্যাকাউন্ট না থাকে, তবে আপনাকে অবশ্যই একটি তৈরি করতে হবে।


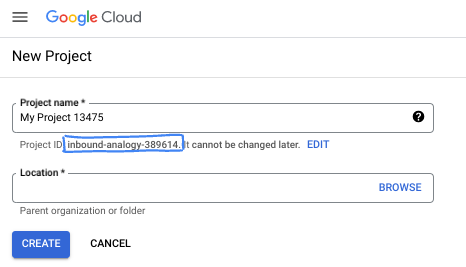
- প্রজেক্টের নামটি হলো এই প্রজেক্টের অংশগ্রহণকারীদের প্রদর্শিত নাম। এটি একটি ক্যারেক্টার স্ট্রিং যা গুগল এপিআই ব্যবহার করে না। আপনি যেকোনো সময় এটি আপডেট করতে পারেন।
- প্রজেক্ট আইডি সমস্ত গুগল ক্লাউড প্রজেক্ট জুড়ে অনন্য এবং অপরিবর্তনীয় (একবার সেট করার পর এটি পরিবর্তন করা যায় না)। ক্লাউড কনসোল স্বয়ংক্রিয়ভাবে একটি অনন্য স্ট্রিং তৈরি করে; সাধারণত এটি কী তা নিয়ে আপনার মাথা ঘামানোর দরকার নেই। বেশিরভাগ কোডল্যাবে, আপনাকে আপনার প্রজেক্ট আইডি উল্লেখ করতে হবে (যা সাধারণত
PROJECT_IDহিসাবে চিহ্নিত করা হয়)। তৈরি করা আইডিটি আপনার পছন্দ না হলে, আপনি এলোমেলোভাবে আরেকটি তৈরি করতে পারেন। বিকল্পভাবে, আপনি আপনার নিজের আইডি দিয়ে চেষ্টা করে দেখতে পারেন যে সেটি উপলব্ধ আছে কিনা। এই ধাপের পরে এটি পরিবর্তন করা যাবে না এবং প্রজেক্টের পুরো সময়কাল জুড়ে এটি অপরিবর্তিত থাকবে। - আপনার অবগতির জন্য জানাচ্ছি যে, তৃতীয় একটি ভ্যালু রয়েছে, যা হলো প্রজেক্ট নম্বর , এবং কিছু এপিআই এটি ব্যবহার করে থাকে। ডকুমেন্টেশনে এই তিনটি ভ্যালু সম্পর্কে আরও বিস্তারিত জানুন।
- এরপর, ক্লাউড রিসোর্স/এপিআই ব্যবহার করার জন্য আপনাকে ক্লাউড কনসোলে বিলিং চালু করতে হবে। এই কোডল্যাবটি সম্পন্ন করতে খুব বেশি খরচ হবে না, এমনকি আদৌ কোনো খরচ নাও হতে পারে। এই টিউটোরিয়ালের পর বিলিং এড়াতে রিসোর্সগুলো বন্ধ করার জন্য, আপনি আপনার তৈরি করা রিসোর্সগুলো অথবা প্রজেক্টটি ডিলিট করে দিতে পারেন। নতুন গুগল ক্লাউড ব্যবহারকারীরা ৩০০ মার্কিন ডলারের ফ্রি ট্রায়াল প্রোগ্রামের জন্য যোগ্য।
ক্লাউড শেল শুরু করুন
যদিও গুগল ক্লাউড আপনার ল্যাপটপ থেকে দূরবর্তীভাবে পরিচালনা করা যায়, এই কোডল্যাবে আপনি ক্লাউড শেল ব্যবহার করবেন, যা ক্লাউডে চালিত একটি কমান্ড লাইন পরিবেশ।
ক্লাউড শেল সক্রিয় করুন
- ক্লাউড কনসোল থেকে, Activate Cloud Shell-এ ক্লিক করুন।
 .
.

আপনি যদি প্রথমবারের মতো ক্লাউড শেল চালু করেন, তাহলে এটি কী তা বর্ণনা করে একটি মধ্যবর্তী স্ক্রিন আপনার সামনে আসবে। যদি একটি মধ্যবর্তী স্ক্রিন আসে, তাহলে 'চালিয়ে যান' (Continue) এ ক্লিক করুন।

ক্লাউড শেল প্রস্তুত করতে এবং এর সাথে সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগা উচিত।

এই ভার্চুয়াল মেশিনটিতে প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলস লোড করা আছে। এটি একটি স্থায়ী ৫ জিবি হোম ডিরেক্টরি প্রদান করে এবং গুগল ক্লাউডে চলে, যা নেটওয়ার্ক পারফরম্যান্স ও অথেনটিকেশনকে ব্যাপকভাবে উন্নত করে। এই কোডল্যাবে আপনার প্রায় সমস্ত কাজই একটি ব্রাউজার দিয়ে করা সম্ভব।
ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি দেখতে পাবেন যে আপনাকে প্রমাণীকৃত করা হয়েছে এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে।
- আপনি প্রমাণীকৃত কিনা তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান:
gcloud auth list
কমান্ড আউটপুট
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে জানে কিনা তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান:
gcloud config list project
কমান্ড আউটপুট
[core] project = <PROJECT_ID>
যদি তা না থাকে, তবে আপনি এই কমান্ডটি দিয়ে এটি সেট করতে পারেন:
gcloud config set project <PROJECT_ID>
কমান্ড আউটপুট
Updated property [core/project].
৩. আপনার ডেভেলপমেন্ট পরিবেশ প্রস্তুত করা
এই কোডল্যাবে, আপনারা ক্লাউড শেল টার্মিনাল এবং কোড এডিটর ব্যবহার করে আপনাদের জাভা প্রোগ্রামগুলো তৈরি করবেন।
ভার্টেক্স এআই এপিআই সক্রিয় করুন
- গুগল ক্লাউড কনসোলে, নিশ্চিত করুন যে আপনার প্রোজেক্টের নামটি কনসোলের শীর্ষে প্রদর্শিত হচ্ছে। যদি তা না হয়, তাহলে প্রোজেক্ট সিলেক্টর খোলার জন্য ‘সিলেক্ট এ প্রোজেক্ট’-এ ক্লিক করুন এবং আপনার কাঙ্ক্ষিত প্রোজেক্টটি নির্বাচন করুন।
- আপনি যদি গুগল ক্লাউড কনসোলের ভার্টেক্স এআই অংশে না থাকেন, তাহলে নিম্নলিখিতগুলি করুন:
- সার্চ- এ, Vertex AI লিখুন, তারপর ফিরে আসুন।
- অনুসন্ধানের ফলাফলে, Vertex AI-তে ক্লিক করুন। Vertex AI ড্যাশবোর্ডটি প্রদর্শিত হবে।
- Vertex AI ড্যাশবোর্ডে ‘Enable All Recommended APIs’-এ ক্লিক করুন।
এর মাধ্যমে বেশ কয়েকটি এপিআই (API) চালু করা যাবে, কিন্তু কোডল্যাবের জন্য সবচেয়ে গুরুত্বপূর্ণটি হলো aiplatform.googleapis.com , যেটি আপনি ক্লাউড শেল টার্মিনালে কমান্ড-লাইন থেকেও নিম্নলিখিত কমান্ডটি চালিয়ে চালু করতে পারেন:
$ gcloud services enable aiplatform.googleapis.com
গ্রেডল দিয়ে প্রোজেক্টের কাঠামো তৈরি করা
আপনার জাভা কোডের উদাহরণগুলো বিল্ড করার জন্য, আপনি গ্রেডল বিল্ড টুল এবং জাভার ভার্সন ১৭ ব্যবহার করবেন। গ্রেডল দিয়ে আপনার প্রজেক্ট সেট আপ করতে, ক্লাউড শেল টার্মিনালে একটি ডিরেক্টরি তৈরি করুন (এখানে, palm-workshop ), এবং সেই ডিরেক্টরিতে gradle init কমান্ডটি চালান:
$ mkdir palm-workshop $ cd palm-workshop $ gradle init Select type of project to generate: 1: basic 2: application 3: library 4: Gradle plugin Enter selection (default: basic) [1..4] 2 Select implementation language: 1: C++ 2: Groovy 3: Java 4: Kotlin 5: Scala 6: Swift Enter selection (default: Java) [1..6] 3 Split functionality across multiple subprojects?: 1: no - only one application project 2: yes - application and library projects Enter selection (default: no - only one application project) [1..2] 1 Select build script DSL: 1: Groovy 2: Kotlin Enter selection (default: Groovy) [1..2] 1 Generate build using new APIs and behavior (some features may change in the next minor release)? (default: no) [yes, no] Select test framework: 1: JUnit 4 2: TestNG 3: Spock 4: JUnit Jupiter Enter selection (default: JUnit Jupiter) [1..4] 4 Project name (default: palm-workshop): Source package (default: palm.workshop): > Task :init Get more help with your project: https://docs.gradle.org/7.4/samples/sample_building_java_applications.html BUILD SUCCESSFUL in 51s 2 actionable tasks: 2 executed
আপনি একটি অ্যাপ্লিকেশন তৈরি করবেন (বিকল্প ২), জাভা ভাষা ব্যবহার করে (বিকল্প ৩), সাবপ্রজেক্ট ব্যবহার না করে (বিকল্প ১), বিল্ড ফাইলের জন্য গ্রুভি সিনট্যাক্স ব্যবহার করে (বিকল্প ১), নতুন বিল্ড ফিচার ব্যবহার না করে (বিকল্প না), JUnit Jupiter দিয়ে টেস্ট তৈরি করে (বিকল্প ৪), এবং প্রজেক্টের নাম হিসেবে আপনি palm-workshop ব্যবহার করতে পারেন, একইভাবে সোর্স প্যাকেজের জন্য আপনি palm.workshop ব্যবহার করতে পারেন।
প্রকল্পের কাঠামোটি নিম্নরূপ হবে:
├── gradle
│ └── ...
├── gradlew
├── gradlew.bat
├── settings.gradle
└── app
├── build.gradle
└── src
├── main
│ └── java
│ └── palm
│ └── workshop
│ └── App.java
└── test
└── ...
প্রয়োজনীয় কিছু ডিপেন্ডেন্সি যোগ করার জন্য চলুন app/build.gradle ফাইলটি আপডেট করি। যদি guava ডিপেন্ডেন্সিটি থাকে, তবে আপনি সেটি সরিয়ে ফেলতে পারেন এবং এর পরিবর্তে LangChain4J প্রোজেক্টের ডিপেন্ডেন্সি ও লগিং লাইব্রেরি যোগ করতে পারেন, যাতে লগার অনুপস্থিত থাকার বিরক্তিকর বার্তা এড়ানো যায়।
dependencies {
// Use JUnit Jupiter for testing.
testImplementation 'org.junit.jupiter:junit-jupiter:5.8.1'
// Logging library
implementation 'org.slf4j:slf4j-jdk14:2.0.9'
// This dependency is used by the application.
implementation 'dev.langchain4j:langchain4j-vertex-ai:0.24.0'
implementation 'dev.langchain4j:langchain4j:0.24.0'
}
LangChain4J-এর জন্য ২টি নির্ভরতা রয়েছে:
- মূল প্রকল্পের উপর একটি,
- এবং ডেডিকেটেড ভার্টেক্স এআই মডিউলটির জন্য একটি।
আমাদের প্রোগ্রামগুলো কম্পাইল ও রান করার জন্য জাভা ১৭ ব্যবহার করতে, plugins {} ব্লকের নিচে নিম্নলিখিত ব্লকটি যোগ করুন:
java {
toolchain {
languageVersion = JavaLanguageVersion.of(17)
}
}
আরও একটি পরিবর্তন করতে হবে: app/build.gradle এর application ব্লকটি আপডেট করুন, যাতে ব্যবহারকারীরা বিল্ড টুল চালু করার সময় কমান্ড-লাইনে চালানোর জন্য মেইন ক্লাসটিকে ওভাররাইড করতে পারেন।
application {
mainClass = providers.systemProperty('javaMainClass')
.orElse('palm.workshop.App')
}
আপনার অ্যাপ্লিকেশনটি চালানোর জন্য বিল্ড ফাইলটি প্রস্তুত কিনা তা পরীক্ষা করতে, আপনি ডিফল্ট মেইন ক্লাসটি চালাতে পারেন, যা একটি সাধারণ Hello World! বার্তা প্রিন্ট করে:
$ ./gradlew run -DjavaMainClass=palm.workshop.App > Task :app:run Hello World! BUILD SUCCESSFUL in 3s 2 actionable tasks: 2 executed
এখন আপনি LangChain4J প্রজেক্টটি ব্যবহার করে PaLM বৃহৎ ভাষার টেক্সট মডেল দিয়ে প্রোগ্রামিং করার জন্য প্রস্তুত!
তথ্যসূত্র হিসেবে, সম্পূর্ণ app/build.gradle বিল্ড ফাইলটি এখন দেখতে এইরকম হওয়া উচিত:
plugins {
// Apply the application plugin to add support for building a CLI application in Java.
id 'application'
}
java {
toolchain {
// Ensure we compile and run on Java 17
languageVersion = JavaLanguageVersion.of(17)
}
}
repositories {
// Use Maven Central for resolving dependencies.
mavenCentral()
}
dependencies {
// Use JUnit Jupiter for testing.
testImplementation 'org.junit.jupiter:junit-jupiter:5.8.1'
// This dependency is used by the application.
implementation 'dev.langchain4j:langchain4j-vertex-ai:0.24.0'
implementation 'dev.langchain4j:langchain4j:0.24.0'
implementation 'org.slf4j:slf4j-jdk14:2.0.9'
}
application {
mainClass = providers.systemProperty('javaMainClass').orElse('palm.workshop.App')
}
tasks.named('test') {
// Use JUnit Platform for unit tests.
useJUnitPlatform()
}
৪. PaLM-এর চ্যাট মডেলে আপনার প্রথম কল করা
প্রজেক্টটি এখন সঠিকভাবে সেট আপ করা হয়ে গেছে, এবার PaLM API-কে কল করার পালা।
app/src/main/java/palm/workshop ডিরেক্টরিতে (ডিফল্ট App.java ক্লাসের পাশে) ChatPrompts.java নামে একটি নতুন ক্লাস তৈরি করুন এবং নিম্নলিখিত বিষয়বস্তু টাইপ করুন:
package palm.workshop;
import dev.langchain4j.model.vertexai.VertexAiChatModel;
import dev.langchain4j.chain.ConversationalChain;
public class ChatPrompts {
public static void main(String[] args) {
VertexAiChatModel model = VertexAiChatModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("chat-bison@001")
.maxOutputTokens(400)
.maxRetries(3)
.build();
ConversationalChain chain = ConversationalChain.builder()
.chatLanguageModel(model)
.build();
String message = "What are large language models?";
String answer = chain.execute(message);
System.out.println(answer);
System.out.println("---------------------------");
message = "What can you do with them?";
answer = chain.execute(message);
System.out.println(answer);
System.out.println("---------------------------");
message = "Can you name some of them?";
answer = chain.execute(message);
System.out.println(answer);
}
}
এই প্রথম উদাহরণটিতে, কথোপকথনের মাল্টিটার্ন দিকটি সহজে পরিচালনা করার জন্য আপনাকে VertexAiChatModel ক্লাস এবং LangChain4J ConversationalChain ইম্পোর্ট করতে হবে।
এরপরে, main মেথডে, আপনি VertexAiChatModel এর বিল্ডার ব্যবহার করে চ্যাট ল্যাঙ্গুয়েজ মডেলটি কনফিগার করবেন, যা নিম্নরূপে নির্দিষ্ট করতে হবে:
- শেষ বিন্দু,
- প্রকল্পটি,
- অঞ্চলটি,
- প্রকাশক,
- এবং মডেলের নাম (
chat-bison@001)।
এখন যেহেতু ল্যাঙ্গুয়েজ মডেলটি প্রস্তুত, আপনি একটি ConversationalChain ) তৈরি করতে পারেন। এটি LangChain4J দ্বারা প্রদত্ত একটি উচ্চ-স্তরের অ্যাবস্ট্রাকশন, যা একটি কথোপকথন পরিচালনা করার জন্য বিভিন্ন কম্পোনেন্টকে একসাথে কনফিগার করতে ব্যবহৃত হয়। যেমন—স্বয়ং চ্যাট ল্যাঙ্গুয়েজ মডেল, তবে এর সাথে চ্যাট কথোপকথনের ইতিহাস পরিচালনা করার জন্য অন্যান্য কম্পোনেন্টও যুক্ত করা যেতে পারে, অথবা ভেক্টর ডেটাবেস থেকে তথ্য আনার জন্য রিট্রিভারের মতো অন্যান্য টুলও প্লাগ ইন করা যায়। কিন্তু চিন্তা করবেন না, আমরা এই কোডল্যাবের পরবর্তী অংশে এ বিষয়ে আবার ফিরে আসব।
এরপর, আপনি চ্যাট মডেলটির সাথে একটি বহু-পর্যায়ের কথোপকথন শুরু করবেন, যেখানে আপনি কয়েকটি পরস্পর সম্পর্কিত প্রশ্ন জিজ্ঞাসা করবেন। প্রথমে আপনি এলএলএম (LLM) সম্পর্কে জানতে চাইবেন, তারপর জিজ্ঞাসা করবেন যে এগুলো দিয়ে কী করা যায় এবং এগুলোর কিছু উদাহরণ কী কী। লক্ষ্য করুন, আপনাকে একই কথা বারবার বলতে হচ্ছে না; এলএলএম-টি নিজেই জানে যে সেই কথোপকথনের প্রেক্ষাপটে 'সেগুলো' বলতে এলএলএম-কেই বোঝানো হচ্ছে।
ওই মাল্টিটার্ন কথোপকথনটি নিতে, আপনাকে শুধু চেইনের execute() মেথডটি কল করতে হবে; এটি সেটিকে কথোপকথনের কনটেক্সটে যুক্ত করে দেবে, চ্যাট মডেলটি একটি রিপ্লাই তৈরি করবে এবং সেটিকে চ্যাট হিস্ট্রিতেও যোগ করে দেবে।
এই ক্লাসটি চালানোর জন্য, ক্লাউড শেল টার্মিনালে নিম্নলিখিত কমান্ডটি চালান:
./gradlew run -DjavaMainClass=palm.workshop.ChatPrompts
আপনি এর মতো একটি আউটপুট দেখতে পাবেন:
$ ./gradlew run -DjavaMainClass=palm.workshop.ChatPrompts Starting a Gradle Daemon, 2 incompatible and 2 stopped Daemons could not be reused, use --status for details > Task :app:run Large language models (LLMs) are artificial neural networks that are trained on massive datasets of text and code. They are designed to understand and generate human language, and they can be used for a variety of tasks, such as machine translation, question answering, and text summarization. --------------------------- LLMs can be used for a variety of tasks, such as: * Machine translation: LLMs can be used to translate text from one language to another. * Question answering: LLMs can be used to answer questions posed in natural language. * Text summarization: LLMs can be used to summarize text into a shorter, more concise form. * Code generation: LLMs can be used to generate code, such as Python or Java code. * Creative writing: LLMs can be used to generate creative text, such as poems, stories, and scripts. LLMs are still under development, but they have the potential to revolutionize a wide range of industries. For example, LLMs could be used to improve customer service, create more personalized marketing campaigns, and develop new products and services. --------------------------- Some of the most well-known LLMs include: * GPT-3: Developed by OpenAI, GPT-3 is a large language model that can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way. * LaMDA: Developed by Google, LaMDA is a large language model that can chat with you in an open-ended way, answering your questions, telling stories, and providing different kinds of creative content. * PaLM 2: Developed by Google, PaLM 2 is a large language model that can perform a wide range of tasks, including machine translation, question answering, and text summarization. * T5: Developed by Google, T5 is a large language model that can be used for a variety of tasks, including text summarization, question answering, and code generation. These are just a few examples of the many LLMs that are currently being developed. As LLMs continue to improve, they are likely to play an increasingly important role in our lives. BUILD SUCCESSFUL in 25s 2 actionable tasks: 2 executed
PaLM আপনার তিনটি সম্পর্কিত প্রশ্নের উত্তর দিয়েছেন!
VertexAIChatModel বিল্ডার আপনাকে ঐচ্ছিক প্যারামিটার নির্ধারণ করার সুযোগ দেয়, যেগুলোর কিছু ডিফল্ট মান আগে থেকেই দেওয়া থাকে এবং আপনি সেগুলো পরিবর্তন করতে পারেন। এখানে কিছু উদাহরণ দেওয়া হলো:
-
.temperature(0.2)— প্রতিক্রিয়াটি কতটা সৃজনশীল হবে তা নির্ধারণ করতে (0 মানে কম সৃজনশীল এবং প্রায়শই তথ্যভিত্তিক, আর 1 মানে আরও সৃজনশীল আউটপুট) -
.maxOutputTokens(50)— উদাহরণে, 400টি টোকেন অনুরোধ করা হয়েছিল (3টি টোকেন প্রায় 4টি শব্দের সমান), এটি নির্ভর করে আপনি তৈরি করা উত্তরটি কতটা দীর্ঘ করতে চান তার উপর। -
.topK(20)— টেক্সট কমপ্লিশনের জন্য সর্বাধিক সংখ্যক সম্ভাব্য শব্দ (১ থেকে ৪০ এর মধ্যে) থেকে এলোমেলোভাবে একটি শব্দ নির্বাচন করতে। -
.topP(0.95)— সেই সম্ভাব্য শব্দগুলো নির্বাচন করার জন্য যাদের মোট সম্ভাবনার যোগফল ঐ ফ্লোটিং পয়েন্ট সংখ্যাটির (০ এবং ১ এর মধ্যে) সমান হয়। -
.maxRetries(3)— যদি আপনার প্রতিবার অনুরোধ পাঠানোর কোটা পূর্ণ হয়ে যায়, তাহলে আপনি মডেলটিকে উদাহরণস্বরূপ ৩ বার কলটি পুনরায় চেষ্টা করতে বলতে পারেন।
৫. ব্যক্তিত্বসম্পন্ন একটি কার্যকরী চ্যাটবট!
আগের অংশে, আপনি কোনো নির্দিষ্ট প্রেক্ষাপট না দিয়েই সরাসরি এলএলএম চ্যাটবটকে প্রশ্ন করা শুরু করেছিলেন। কিন্তু আপনি এই ধরনের চ্যাটবটকে কোনো নির্দিষ্ট কাজে বা কোনো বিশেষ বিষয়ে বিশেষজ্ঞ করে তুলতে পারেন।
আপনি সেটা কীভাবে করেন? প্রেক্ষাপট তৈরি করে: এলএলএম-কে হাতে থাকা কাজটি ও তার প্রেক্ষাপট ব্যাখ্যা করে, তাকে কী করতে হবে তার কয়েকটি উদাহরণ দিয়ে, তার ব্যক্তিত্ব কেমন হওয়া উচিত, আপনি কোন বিন্যাসে উত্তর পেতে চান এবং সম্ভবত তার বাচনভঙ্গিও বলে দিয়ে, যদি আপনি চান যে চ্যাটবটটি একটি নির্দিষ্ট উপায়ে আচরণ করুক।
নির্দেশনা তৈরির উপর এই নিবন্ধটি এই গ্রাফিকটির মাধ্যমে পদ্ধতিটি সুন্দরভাবে তুলে ধরেছে:

https://medium.com/@eldatero/master-the-perfect-chatgpt-prompt-formula-c776adae8f19
এই বিষয়টি ব্যাখ্যা করার জন্য, আসুন prompts.chat ওয়েবসাইটগুলো থেকে কিছু অনুপ্রেরণা নিই, যেখানে বিশেষভাবে তৈরি করা চ্যাটবটগুলোর অনেক চমৎকার ও মজার ধারণা তালিকাভুক্ত করা আছে, যেগুলোকে নিম্নলিখিত ভূমিকা পালন করতে দেওয়া যায়:
- একটি ইমোজি অনুবাদক — ব্যবহারকারীর বার্তাগুলোকে ইমোজিতে অনুবাদ করার জন্য
- একটি প্রম্পট এনহ্যান্সার — আরও ভালো প্রম্পট তৈরি করার জন্য
- জার্নাল পর্যালোচক — গবেষণা পত্র পর্যালোচনা করতে সাহায্য করার জন্য
- একজন ব্যক্তিগত স্টাইলিস্ট — পোশাকের স্টাইল সংক্রান্ত পরামর্শ পেতে
একটি এলএলএম চ্যাটবটকে দাবা খেলোয়াড়ে পরিণত করার একটি উদাহরণ রয়েছে! চলুন, সেটি বাস্তবায়ন করা যাক!
ChatPrompts ক্লাসটি নিম্নরূপভাবে আপডেট করুন:
package palm.workshop;
import dev.langchain4j.chain.ConversationalChain;
import dev.langchain4j.data.message.SystemMessage;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.model.vertexai.VertexAiChatModel;
import dev.langchain4j.store.memory.chat.InMemoryChatMemoryStore;
public class ChatPrompts {
public static void main(String[] args) {
VertexAiChatModel model = VertexAiChatModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("chat-bison@001")
.maxOutputTokens(7)
.maxRetries(3)
.build();
InMemoryChatMemoryStore chatMemoryStore = new InMemoryChatMemoryStore();
MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder()
.chatMemoryStore(chatMemoryStore)
.maxMessages(200)
.build();
chatMemory.add(SystemMessage.from("""
You're an expert chess player with a high ELO ranking.
Use the PGN chess notation to reply with the best next possible move.
"""
));
ConversationalChain chain = ConversationalChain.builder()
.chatLanguageModel(model)
.chatMemory(chatMemory)
.build();
String pgn = "";
String[] whiteMoves = { "Nf3", "c4", "Nc3", "e3", "Dc2", "Cd5"};
for (int i = 0; i < whiteMoves.length; i++) {
pgn += " " + (i+1) + ". " + whiteMoves[i];
System.out.println("Playing " + whiteMoves[i]);
pgn = chain.execute(pgn);
System.out.println(pgn);
}
}
}
চলুন বিষয়টি ধাপে ধাপে বিশ্লেষণ করা যাক:
- চ্যাটের মেমরি পরিচালনার জন্য কিছু নতুন ইম্পোর্ট প্রয়োজন।
- আপনি চ্যাট মডেলটি ইনস্ট্যানশিয়েট করবেন, কিন্তু সর্বোচ্চ টোকেনের সংখ্যা কম রেখে (এখানে ৭টি), কারণ আমরা শুধু পরবর্তী চালটি তৈরি করতে চাই, দাবা নিয়ে গোটা কোনো গবেষণাপত্র নয়!
- এরপরে, চ্যাট কথোপকথনগুলো সংরক্ষণ করার জন্য আপনাকে একটি চ্যাট মেমরি স্টোর তৈরি করতে হবে।
- শেষ চালগুলো মনে রাখার জন্য আপনি একটি প্রকৃত উইন্ডোযুক্ত চ্যাট মেমরি তৈরি করেন।
- চ্যাট মেমরিতে, আপনি একটি "সিস্টেম" বার্তা যোগ করেন, যা চ্যাট মডেলকে নির্দেশ দেয় যে এটি কার ভূমিকা পালন করবে (যেমন, একজন বিশেষজ্ঞ দাবা খেলোয়াড়)। "সিস্টেম" বার্তাটি কিছু প্রাসঙ্গিক তথ্য যোগ করে, অন্যদিকে "ব্যবহারকারী" এবং "এআই" বার্তাগুলো হলো প্রকৃত আলোচনা।
- আপনি মেমরি এবং চ্যাট মডেলকে একত্রিত করে একটি কথোপকথন শৃঙ্খল তৈরি করেন।
- এরপর, সাদা পক্ষের চালগুলোর একটি তালিকা রয়েছে, যার ওপর আপনি পুনরাবৃত্তি করছেন। এই চালক্রমটি প্রতিবার সাদা পক্ষের পরবর্তী চাল দিয়ে কার্যকর হয় এবং চ্যাট মডেলটি তার পরের সেরা চালটি দিয়ে উত্তর দেয়।
এই মুভগুলো ব্যবহার করে ক্লাসটি রান করলে, আপনি নিম্নলিখিত আউটপুট দেখতে পাবেন:
$ ./gradlew run -DjavaMainClass=palm.workshop.ChatPrompts Starting a Gradle Daemon (subsequent builds will be faster) > Task :app:run Playing Nf3 1... e5 Playing c4 2... Nc6 Playing Nc3 3... Nf6 Playing e3 4... Bb4 Playing Dc2 5... O-O Playing Cd5 6... exd5
ওয়াও! PaLM দাবা খেলতে জানে? ঠিক তা নয়, তবে প্রশিক্ষণের সময় মডেলটি নিশ্চয়ই কিছু দাবা খেলার ধারাভাষ্য, বা এমনকি অতীতের খেলাগুলোর PGN (পোর্টেবল গেম নোটেশন) ফাইল দেখেছে। তবে এই চ্যাটবটটি সম্ভবত AlphaZero-র (যে AI সেরা গো, শোগি এবং দাবা খেলোয়াড়দের পরাজিত করে) বিরুদ্ধে জিততে পারবে না এবং পরবর্তীতে কথোপকথনটি লাইনচ্যুতও হতে পারে, কারণ মডেলটি খেলার প্রকৃত অবস্থা ঠিকমতো মনে রাখতে পারবে না।
চ্যাট মডেলগুলো খুবই শক্তিশালী এবং এগুলো আপনার ব্যবহারকারীদের সাথে গভীর মিথস্ক্রিয়া তৈরি করতে ও বিভিন্ন প্রাসঙ্গিক কাজ সামলাতে পারে। পরবর্তী অংশে, আমরা একটি দরকারি কাজ দেখব: টেক্সট থেকে কাঠামোগত ডেটা বের করা ।
৬. অসংগঠিত পাঠ্য থেকে তথ্য আহরণ
পূর্ববর্তী অংশে, আপনি একজন ব্যবহারকারী এবং একটি চ্যাট ল্যাঙ্গুয়েজ মডেলের মধ্যে কথোপকথন তৈরি করেছিলেন। কিন্তু LangChain4J-এর সাহায্যে, আপনি অসংগঠিত টেক্সট থেকে সংগঠিত তথ্য বের করার জন্য একটি চ্যাট মডেলও ব্যবহার করতে পারেন।
ধরা যাক, আপনি কোনো ব্যক্তির জীবনী বা বিবরণ থেকে তার নাম এবং বয়স বের করতে চান। এক্ষেত্রে আপনি একটি চতুরভাবে পরিবর্তিত প্রম্পটের মাধ্যমে বৃহৎ ল্যাঙ্গুয়েজ মডেলকে JSON ডেটা স্ট্রাকচার তৈরি করার নির্দেশ দিতে পারেন (এটিকে সাধারণত "প্রম্পট ইঞ্জিনিয়ারিং" বলা হয়)।
আপনাকে ChatPrompts ক্লাসটি নিম্নরূপভাবে আপডেট করতে হবে:
package palm.workshop;
import dev.langchain4j.model.vertexai.VertexAiChatModel;
import dev.langchain4j.service.AiServices;
import dev.langchain4j.service.UserMessage;
public class ChatPrompts {
static class Person {
String name;
int age;
}
interface PersonExtractor {
@UserMessage("""
Extract the name and age of the person described below.
Return a JSON document with a "name" and an "age" property, \
following this structure: {"name": "John Doe", "age": 34}
Return only JSON, without any markdown markup surrounding it.
Here is the document describing the person:
---
{{it}}
---
JSON:
""")
Person extractPerson(String text);
}
public static void main(String[] args) {
VertexAiChatModel model = VertexAiChatModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("chat-bison@001")
.maxOutputTokens(300)
.build();
PersonExtractor extractor = AiServices.create(PersonExtractor.class, model);
Person person = extractor.extractPerson("""
Anna is a 23 year old artist based in Brooklyn, New York. She was born and
raised in the suburbs of Chicago, where she developed a love for art at a
young age. She attended the School of the Art Institute of Chicago, where
she studied painting and drawing. After graduating, she moved to New York
City to pursue her art career. Anna's work is inspired by her personal
experiences and observations of the world around her. She often uses bright
colors and bold lines to create vibrant and energetic paintings. Her work
has been exhibited in galleries and museums in New York City and Chicago.
"""
);
System.out.println(person.name);
System.out.println(person.age);
}
}
চলুন এই ফাইলের বিভিন্ন ধাপগুলো দেখে নেওয়া যাক:
- কোনো ব্যক্তির বিবরণ (তার নাম এবং বয়স) উপস্থাপন করার জন্য একটি
Personক্লাস সংজ্ঞায়িত করা হয়। -
PersonExtractorইন্টারফেসটি এমন একটি মেথডসহ তৈরি করা হয়েছে, যা একটি অসংগঠিত টেক্সট স্ট্রিং পেলে একটি ইনস্ট্যানসিয়েটেডPersonইনস্ট্যান্স রিটার্ন করে। -
extractPerson()ফাংশনটি@UserMessageঅ্যানোটেশন দ্বারা যুক্ত, যা এর সাথে একটি প্রম্পটকে সংযুক্ত করে। মডেলটি এই প্রম্পটটি ব্যবহার করেই তথ্য সংগ্রহ করবে এবং একটি JSON ডকুমেন্ট আকারে বিস্তারিত তথ্য ফেরত দেবে, যা আপনার জন্য পার্স করা হবে এবং একটিPersonইনস্ট্যান্সে আনমার্শাল করা হবে।
এবার main() মেথডের বিষয়বস্তু দেখা যাক:
- চ্যাট মডেলটি ইনস্ট্যানশিয়েট করা হয়েছে।
- LangChain4J-এর
AiServicesক্লাসের মাধ্যমে একটিPersonExtractorঅবজেক্ট তৈরি করা হয়। - তারপর, আপনি অসংগঠিত টেক্সট থেকে ব্যক্তির বিবরণ বের করতে এবং নাম ও বয়স সহ একটি
Personইনস্ট্যান্স ফেরত পেতে কেবলPerson person = extractor.extractPerson(...)কল করতে পারেন।
এখন, নিম্নলিখিত কমান্ড দিয়ে এই ক্লাসটি চালান:
$ ./gradlew run -DjavaMainClass=palm.workshop.ChatPrompts > Task :app:run Anna 23
হ্যাঁ! ইনি অ্যানা, ওর বয়স ২৩!
এই AiServices পদ্ধতির বিশেষত্ব হলো, আপনি স্ট্রংলি টাইপড অবজেক্ট নিয়ে কাজ করেন। আপনি সরাসরি চ্যাট LLM-এর সাথে ইন্টারঅ্যাক্ট করছেন না। এর পরিবর্তে, আপনি কনক্রিট ক্লাস নিয়ে কাজ করছেন, যেমন সংগৃহীত ব্যক্তিগত তথ্য উপস্থাপনের জন্য Person ক্লাস, এবং আপনার একটি PersonExtractor ক্লাস আছে যার extractPerson() মেথডটি একটি Person ইনস্ট্যান্স রিটার্ন করে। LLM-এর ধারণাটি এখানে অ্যাবস্ট্রাক্ট করা থাকে, এবং একজন জাভা ডেভেলপার হিসেবে আপনি কেবল সাধারণ ক্লাস ও অবজেক্ট নিয়েই কাজ করেন।
৭. তথ্য পুনরুদ্ধারে বর্ধিত প্রজন্ম: আপনার ডাক্তারদের সাথে আলাপচারিতা
চলুন কথোপকথনের প্রসঙ্গে ফিরে আসি। এবার, আপনি আপনার ডকুমেন্টগুলো সম্পর্কে প্রশ্ন করতে পারবেন। আপনি এমন একটি চ্যাটবট তৈরি করবেন যা আপনার ডকুমেন্টের নির্বাচিত অংশের একটি ডেটাবেস থেকে প্রাসঙ্গিক তথ্য সংগ্রহ করতে সক্ষম হবে, এবং মডেলটি তার প্রশিক্ষণ থেকে প্রাপ্ত প্রতিক্রিয়া তৈরি করার চেষ্টা না করে, সেই তথ্য ব্যবহার করে তার উত্তরগুলোকে ভিত্তি দেবে । এই পদ্ধতিটিকে RAG বা Retrieval Augmented Generation বলা হয়।
রিট্রিভাল অগমেন্টেড জেনারেশন-এ, সংক্ষেপে বলতে গেলে, দুটি পর্যায় রয়েছে:
- ইনজেশন পর্যায় — ডকুমেন্টগুলো লোড করে ছোট ছোট খণ্ডে বিভক্ত করা হয় এবং সেগুলোর একটি ভেক্টরীয় উপস্থাপনা (একটি 'ভেক্টর এমবেডিং' ) একটি 'ভেক্টর ডেটাবেস'- এ সংরক্ষণ করা হয়, যা সিমান্টিক সার্চ করতে সক্ষম।

- কোয়েরি পর্যায় — ব্যবহারকারীরা এখন আপনার চ্যাটবটকে ডকুমেন্টেশন সম্পর্কে প্রশ্ন করতে পারবেন। প্রশ্নটিকেও একটি ভেক্টরে রূপান্তরিত করা হবে এবং ডাটাবেসের অন্য সব ভেক্টরের সাথে তুলনা করা হবে। সবচেয়ে সাদৃশ্যপূর্ণ ভেক্টরগুলো সাধারণত অর্থগতভাবে সম্পর্কিত হয় এবং ভেক্টর ডাটাবেস থেকে সেগুলো ফেরত দেওয়া হয়। এরপর, LLM-কে কথোপকথনের প্রেক্ষাপট, ডাটাবেস থেকে ফেরত আসা ভেক্টরগুলোর সাথে সঙ্গতিপূর্ণ টেক্সটের অংশগুলো দেওয়া হয় এবং সেই অংশগুলোর উপর ভিত্তি করে তার উত্তর তৈরি করতে বলা হয়।

আপনার নথি প্রস্তুত করা
এই নতুন ডেমোটির জন্য, আপনারা গুগলের উদ্ভাবিত 'ট্রান্সফরমার' নিউরাল নেটওয়ার্ক আর্কিটেকচার নিয়ে প্রশ্ন করবেন, যা দিয়ে আজকাল সমস্ত আধুনিক বৃহৎ ল্যাঙ্গুয়েজ মডেল বাস্তবায়ন করা হয়।
আপনি wget কমান্ড ব্যবহার করে ইন্টারনেট থেকে PDF ডাউনলোড করে এই আর্কিটেকচারটির ("Attention is all you need") গবেষণাপত্রটি সংগ্রহ করতে পারেন:
wget -O attention-is-all-you-need.pdf \
https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
কথোপকথনমূলক পুনরুদ্ধার শৃঙ্খল বাস্তবায়ন করা
চলুন, ধাপে ধাপে খতিয়ে দেখি কীভাবে এই দ্বি-পর্যায়ের পদ্ধতিটি তৈরি করা যায়: প্রথমে ডকুমেন্ট গ্রহণ এবং তারপরে কোয়েরি পর্ব, যখন ব্যবহারকারীরা ডকুমেন্টটি সম্পর্কে প্রশ্ন করেন।
নথি গ্রহণ
ডকুমেন্ট ইনজেশন পর্বের সর্বপ্রথম ধাপ হলো আমাদের ডাউনলোড করা পিডিএফ ফাইলটি খুঁজে বের করা এবং সেটি পড়ার জন্য একটি PdfParser প্রস্তুত করা:
PdfDocumentParser pdfParser = new PdfDocumentParser();
Document document = pdfParser.parse(
new FileInputStream(new File("/home/YOUR_USER_NAME/palm-workshop/attention-is-all-you-need.pdf")));
সাধারণ চ্যাট ল্যাঙ্গুয়েজ মডেল তৈরি করার পরিবর্তে, তার আগে আপনাকে একটি "এম্বেডিং" মডেলের ইনস্ট্যান্স তৈরি করতে হবে। এটি একটি বিশেষ মডেল এবং এন্ডপয়েন্ট, যার কাজ হলো টেক্সটের অংশগুলোর (শব্দ, বাক্য বা এমনকি অনুচ্ছেদ) ভেক্টর উপস্থাপনা তৈরি করা।
VertexAiEmbeddingModel embeddingModel = VertexAiEmbeddingModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("textembedding-gecko@001")
.maxRetries(3)
.build();
এরপরে, নিম্নলিখিত কাজগুলো করার জন্য আপনাদের কয়েকটি ক্লাসের একসাথে কাজ করতে হবে:
- পিডিএফ ডকুমেন্টটি লোড করুন এবং খণ্ডে খণ্ডে বিভক্ত করুন।
- এই সমস্ত চাঙ্কগুলির জন্য ভেক্টর এমবেডিং তৈরি করুন।
InMemoryEmbeddingStore<TextSegment> embeddingStore =
new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor storeIngestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(500, 100))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
storeIngestor.ingest(document);
EmbeddingStoreRetriever retriever = EmbeddingStoreRetriever.from(embeddingStore, embeddingModel);
ভেক্টর এমবেডিংগুলো সংরক্ষণ করার জন্য InMemoryEmbeddingStore নামক একটি ইন-মেমরি ভেক্টর ডেটাবেসের ইনস্ট্যান্স তৈরি করা হয়।
DocumentSplitters ক্লাসের সাহায্যে ডকুমেন্টটি বিভিন্ন খণ্ডে বিভক্ত করা হয়েছে। এটি পিডিএফ ফাইলের টেক্সটকে ৫০০ অক্ষরের ছোট ছোট অংশে ভাগ করবে, যেখানে পরবর্তী অংশের সাথে ১০০ অক্ষরের একটি ওভারল্যাপ থাকবে (যাতে শব্দ বা বাক্য খণ্ড খণ্ড হয়ে কেটে না যায়)।
"ইনজেস্টর" স্টোরটি ডকুমেন্ট স্প্লিটার, ভেক্টর গণনার জন্য এমবেডিং মডেল এবং ইন-মেমরি ভেক্টর ডেটাবেসকে সংযুক্ত করে। এরপর, ingest() মেথডটি ইনজেশনের কাজটি সম্পন্ন করে।
এখন, প্রথম পর্যায় শেষ হয়েছে, ডকুমেন্টটিকে তার সংশ্লিষ্ট ভেক্টর এমবেডিং সহ টেক্সট খণ্ডে রূপান্তরিত করে ভেক্টর ডেটাবেসে সংরক্ষণ করা হয়েছে।
প্রশ্ন জিজ্ঞাসা করা
প্রশ্ন করার জন্য প্রস্তুত হওয়ার সময় হয়েছে! কথোপকথন শুরু করার জন্য প্রচলিত চ্যাট মডেলটি তৈরি করা যেতে পারে:
VertexAiChatModel model = VertexAiChatModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("chat-bison@001")
.maxOutputTokens(1000)
.build();
আপনার একটি "retriever" ক্লাসেরও প্রয়োজন হবে যা ভেক্টর ডাটাবেস ( embeddingStore ভেরিয়েবলে) এবং এমবেডিং মডেলকে সংযুক্ত করবে। এর কাজ হলো ব্যবহারকারীর কোয়েরির জন্য একটি ভেক্টর এমবেডিং গণনা করে ভেক্টর ডাটাবেসে কোয়েরি করা, যাতে ডাটাবেসে অনুরূপ ভেক্টরগুলি খুঁজে পাওয়া যায়।
EmbeddingStoreRetriever retriever =
EmbeddingStoreRetriever.from(embeddingStore, embeddingModel);
এই পর্যায়ে, আপনি ConversationalRetrievalChain ক্লাসটি ইনস্ট্যানশিয়েট করতে পারেন (এটি Retrieval Augmented Generation প্যাটার্নেরই একটি ভিন্ন নাম):
ConversationalRetrievalChain rag = ConversationalRetrievalChain.builder()
.chatLanguageModel(model)
.retriever(retriever)
.promptTemplate(PromptTemplate.from("""
Answer to the following query the best as you can: {{question}}
Base your answer on the information provided below:
{{information}}
"""
))
.build();
এই 'শৃঙ্খল' একত্রে বেঁধে রাখে:
- যে চ্যাট ল্যাঙ্গুয়েজ মডেলটি আপনি আগে কনফিগার করেছিলেন।
- রিট্রিভারটি একটি ভেক্টর এমবেডিং কোয়েরিকে ডাটাবেসের ভেক্টরগুলোর সাথে তুলনা করে।
- একটি প্রম্পট টেমপ্লেটে স্পষ্টভাবে বলা থাকে যে, চ্যাট মডেলটি প্রদত্ত তথ্যের (অর্থাৎ ডকুমেন্টেশনের প্রাসঙ্গিক অংশ, যার ভেক্টর এমবেডিং ব্যবহারকারীর প্রশ্নের ভেক্টরের অনুরূপ) উপর ভিত্তি করে তার প্রতিক্রিয়া জানাবে।
এবং এখন আপনি অবশেষে আপনার প্রশ্নগুলো করার জন্য প্রস্তুত!
String result = rag.execute("What neural network architecture can be used for language models?");
System.out.println(result);
System.out.println("------------");
result = rag.execute("What are the different components of a transformer neural network?");
System.out.println(result);
System.out.println("------------");
result = rag.execute("What is attention in large language models?");
System.out.println(result);
System.out.println("------------");
result = rag.execute("What is the name of the process that transforms text into vectors?");
System.out.println(result);
প্রোগ্রামটি চালান এভাবে:
$ ./gradlew run -DjavaMainClass=palm.workshop.ChatPrompts
আউটপুটে আপনি আপনার প্রশ্নগুলোর উত্তর দেখতে পাবেন:
The Transformer is a neural network architecture that can be used for language models. It is based solely on attention mechanisms, dispensing with recurrence and convolutions. The Transformer has been shown to outperform recurrent neural networks and convolutional neural networks on a variety of language modeling tasks. ------------ The Transformer is a neural network architecture that can be used for language models. It is based solely on attention mechanisms, dispensing with recurrence and convolutions. The Transformer has been shown to outperform recurrent neural networks and convolutional neural networks on a variety of language modeling tasks. The Transformer consists of an encoder and a decoder. The encoder is responsible for encoding the input sequence into a fixed-length vector representation. The decoder is responsible for decoding the output sequence from the input sequence. The decoder uses the attention mechanism to attend to different parts of the input sequence when generating the output sequence. ------------ Attention is a mechanism that allows a neural network to focus on specific parts of an input sequence. In the context of large language models, attention is used to allow the model to focus on specific words or phrases in a sentence when generating output. This allows the model to generate more relevant and informative output. ------------ The process of transforming text into vectors is called word embedding. Word embedding is a technique that represents words as vectors in a high-dimensional space. The vectors are typically learned from a large corpus of text, and they capture the semantic and syntactic relationships between words. Word embedding has been shown to be effective for a variety of natural language processing tasks, such as machine translation, question answering, and sentiment analysis.
সম্পূর্ণ সমাধান
কপি ও পেস্ট করার সুবিধার জন্য, এখানে ChatPrompts ক্লাসের সম্পূর্ণ বিষয়বস্তু দেওয়া হলো:
package palm.workshop;
import dev.langchain4j.chain.ConversationalRetrievalChain;
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.parser.PdfDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.input.PromptTemplate;
import dev.langchain4j.model.vertexai.VertexAiChatModel;
import dev.langchain4j.model.vertexai.VertexAiEmbeddingModel;
import dev.langchain4j.retriever.EmbeddingStoreRetriever;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class ChatPrompts {
public static void main(String[] args) throws IOException {
PdfDocumentParser pdfParser = new PdfDocumentParser();
Document document = pdfParser.parse(new FileInputStream(new File("/ABSOLUTE_PATH/attention-is-all-you-need.pdf")));
VertexAiEmbeddingModel embeddingModel = VertexAiEmbeddingModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("YOUR_PROJECT_ID")
.location("us-central1")
.publisher("google")
.modelName("textembedding-gecko@001")
.maxRetries(3)
.build();
InMemoryEmbeddingStore<TextSegment> embeddingStore =
new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor storeIngestor = EmbeddingStoreIngestor.builder()
.documentSplitter(DocumentSplitters.recursive(500, 100))
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
storeIngestor.ingest(document);
EmbeddingStoreRetriever retriever = EmbeddingStoreRetriever.from(embeddingStore, embeddingModel);
VertexAiChatModel model = VertexAiChatModel.builder()
.endpoint("us-central1-aiplatform.googleapis.com:443")
.project("genai-java-demos")
.location("us-central1")
.publisher("google")
.modelName("chat-bison@001")
.maxOutputTokens(1000)
.build();
ConversationalRetrievalChain rag = ConversationalRetrievalChain.builder()
.chatLanguageModel(model)
.retriever(retriever)
.promptTemplate(PromptTemplate.from("""
Answer to the following query the best as you can: {{question}}
Base your answer on the information provided below:
{{information}}
"""
))
.build();
String result = rag.execute("What neural network architecture can be used for language models?");
System.out.println(result);
System.out.println("------------");
result = rag.execute("What are the different components of a transformer neural network?");
System.out.println(result);
System.out.println("------------");
result = rag.execute("What is attention in large language models?");
System.out.println(result);
System.out.println("------------");
result = rag.execute("What is the name of the process that transforms text into vectors?");
System.out.println(result);
}
}
৮. অভিনন্দন
অভিনন্দন, আপনি LangChain4J এবং PaLM API ব্যবহার করে জাভাতে আপনার প্রথম জেনারেটিভ এআই চ্যাট অ্যাপ্লিকেশনটি সফলভাবে তৈরি করেছেন! এই প্রক্রিয়ায় আপনি আবিষ্কার করেছেন যে, বৃহৎ ভাষার চ্যাট মডেলগুলো বেশ শক্তিশালী এবং প্রশ্নোত্তর পর্ব, এমনকি আপনার নিজস্ব ডকুমেন্টেশন তৈরি, ডেটা নিষ্কাশনের মতো বিভিন্ন কাজ সামলাতে সক্ষম। এমনকি কিছুটা দাবাও খেলতে পেরেছে!
এরপর কী?
জাভাতে PaLM নিয়ে আরও এগিয়ে যেতে নিচের কোডল্যাবগুলো দেখে নিন:
আরও পড়ুন
- জেনারেটিভ এআই-এর সাধারণ ব্যবহারের ক্ষেত্রসমূহ
- জেনারেটিভ এআই সম্পর্কিত প্রশিক্ষণ উপকরণ
- জেনারেটিভ এআই স্টুডিওর মাধ্যমে PaLM-এর সাথে যোগাযোগ করুন
- দায়িত্বশীল এআই