
1. Overview
TPUs are very fast. The stream of training data must keep up with their training speed. In this lab, you will learn how to load data from GCS with the tf.data.Dataset API to feed your TPU.
This lab is Part 1 of the "Keras on TPU" series. You can do them in the following order or independently.
- [THIS LAB] TPU-speed data pipelines: tf.data.Dataset and TFRecords
- Your first Keras model, with transfer learning
- Convolutional neural networks, with Keras and TPUs
- Modern convnets, squeezenet, Xception, with Keras and TPUs

What you'll learn
- To use the tf.data.Dataset API to load training data
- To use TFRecord format to load training data efficiently from GCS
Feedback
If you see something amiss in this code lab, please tell us. Feedback can be provided through GitHub issues [ feedback link].
2. Google Colaboratory quick start
This lab uses Google Collaboratory and requires no setup on your part. Colaboratory is an online notebook platform for education purposes. It offers free CPU, GPU and TPU training.

You can open this sample notebook and run through a couple of cells to familiarize yourself with Colaboratory.
Select a TPU backend
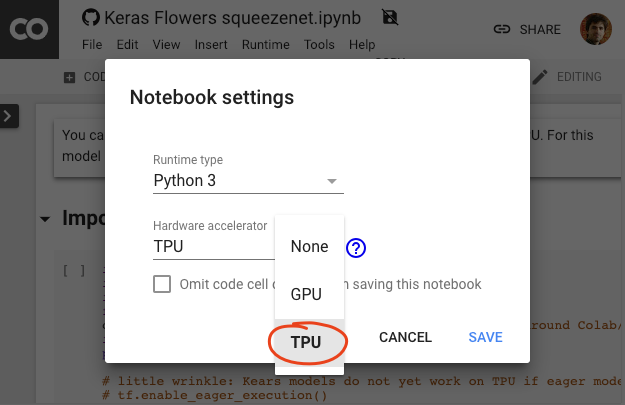
In the Colab menu, select Runtime > Change runtime type and then select TPU. In this code lab you will use a powerful TPU (Tensor Processing Unit) backed for hardware-accelerated training. Connection to the runtime will happen automatically on first execution, or you can use the "Connect" button in the upper-right corner.
Notebook execution
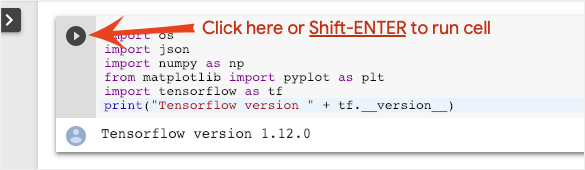
Execute cells one at a time by clicking on a cell and using Shift-ENTER. You can also run the entire notebook with Runtime > Run all
Table of contents

All notebooks have a table of contents. You can open it using the black arrow on the left.
Hidden cells

Some cells will only show their title. This is a Colab-specific notebook feature. You can double click on them to see the code inside but it is usually not very interesting. Typically support or visualization functions. You still need to run these cells for the functions inside to be defined.
Authentication
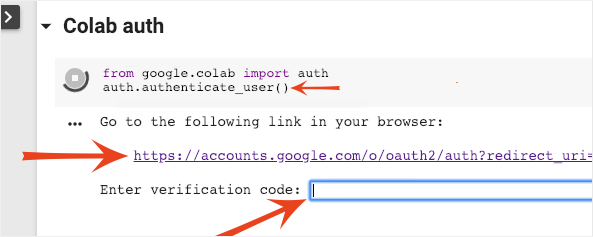
It is possible for Colab to access your private Google Cloud Storage buckets provided you authenticate with an authorized account. The code snippet above will trigger an authentication process.
3. [INFO] What are Tensor Processing Units (TPUs) ?
In a nutshell

The code for training a model on TPU in Keras (and fall back on GPU or CPU if a TPU is not available):
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
We will use TPUs today to build and optimize a flower classifier at interactive speeds (minutes per training run).
Why TPUs ?
Modern GPUs are organized around programmable "cores", a very flexible architecture that allows them to handle a variety of tasks such as 3D rendering, deep learning, physical simulations, etc.. TPUs on the other hand pair a classic vector processor with a dedicated matrix multiply unit and excel at any task where large matrix multiplications dominate, such as neural networks.

Illustration: a dense neural network layer as a matrix multiplication, with a batch of eight images processed through the neural network at once. Please run through one line x column multiplication to verify that it is indeed doing a weighted sum of all the pixels values of an image. Convolutional layers can be represented as matrix multiplications too although it's a bit more complicated ( explanation here, in section 1).
The hardware
MXU and VPU
A TPU v2 core is made of a Matrix Multiply Unit (MXU) which runs matrix multiplications and a Vector Processing Unit (VPU) for all other tasks such as activations, softmax, etc. The VPU handles float32 and int32 computations. The MXU on the other hand operates in a mixed precision 16-32 bit floating point format.
Mixed precision floating point and bfloat16
The MXU computes matrix multiplications using bfloat16 inputs and float32 outputs. Intermediate accumulations are performed in float32 precision.
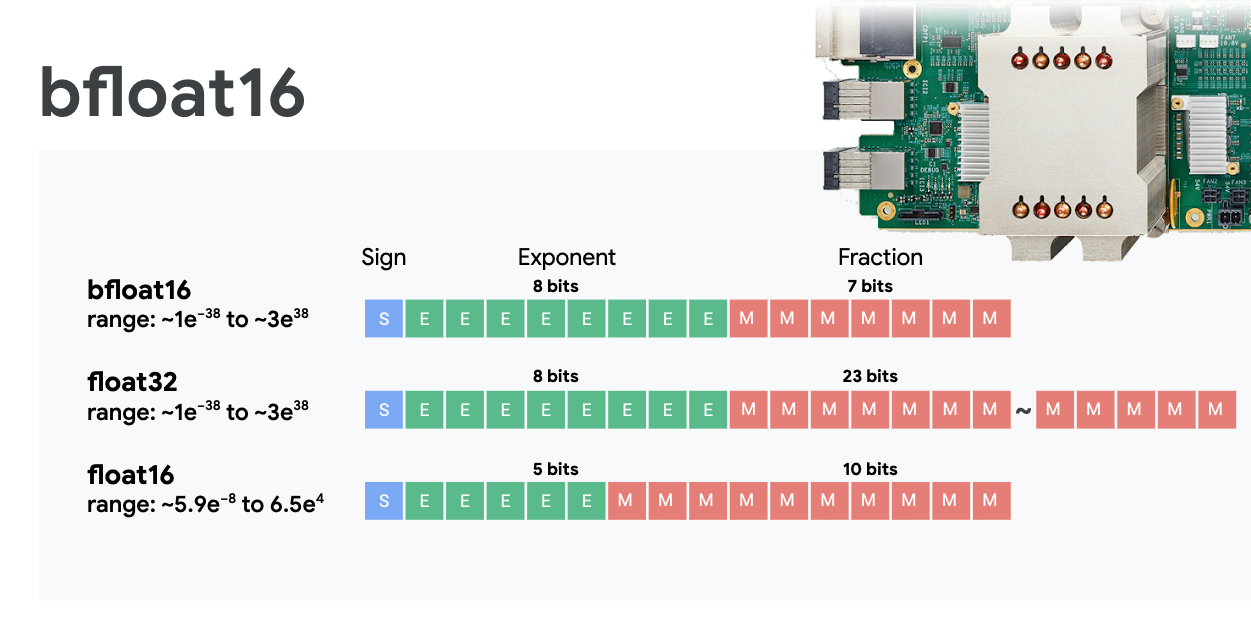
Neural network training is typically resistant to the noise introduced by a reduced floating point precision. There are cases where noise even helps the optimizer converge. 16-bit floating point precision has traditionally been used to accelerate computations but float16 and float32 formats have very different ranges. Reducing the precision from float32 to float16 usually results in over and underflows. Solutions exist but additional work is typically required to make float16 work.
That is why Google introduced the bfloat16 format in TPUs. bfloat16 is a truncated float32 with exactly the same exponent bits and range as float32. This, added to the fact that TPUs compute matrix multiplications in mixed precision with bfloat16 inputs but float32 outputs, means that, typically, no code changes are necessary to benefit from the performance gains of reduced precision.
Systolic array
The MXU implements matrix multiplications in hardware using a so-called "systolic array" architecture in which data elements flow through an array of hardware computation units. (In medicine, "systolic" refers to heart contractions and blood flow, here to the flow of data.)
The basic element of a matrix multiplication is a dot product between a line from one matrix and a column from the other matrix (see illustration at the top of this section). For a matrix multiplication Y=X*W, one element of the result would be:
Y[2,0] = X[2,0]*W[0,0] + X[2,1]*W[1,0] + X[2,2]*W[2,0] + ... + X[2,n]*W[n,0]
On a GPU, one would program this dot product into a GPU "core" and then execute it on as many "cores" as are available in parallel to try and compute every value of the resulting matrix at once. If the resulting matrix is 128x128 large, that would require 128x128=16K "cores" to be available which is typically not possible. The largest GPUs have around 4000 cores. A TPU on the other hand uses the bare minimum of hardware for the compute units in the MXU: just bfloat16 x bfloat16 => float32 multiply-accumulators, nothing else. These are so small that a TPU can implement 16K of them in a 128x128 MXU and process this matrix multiplication in one go.
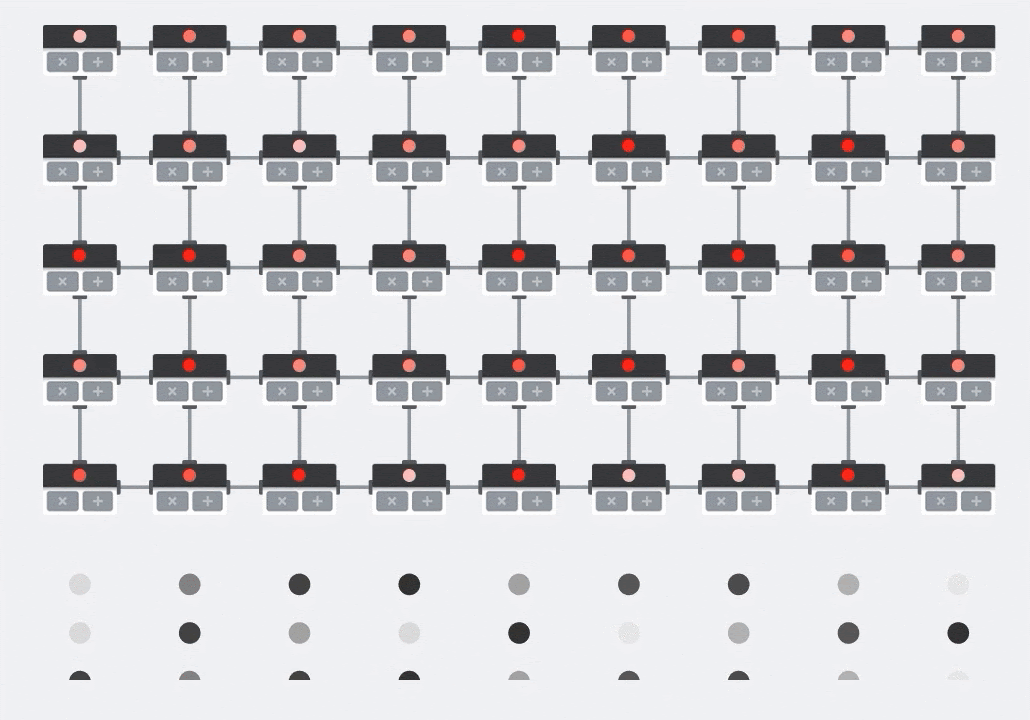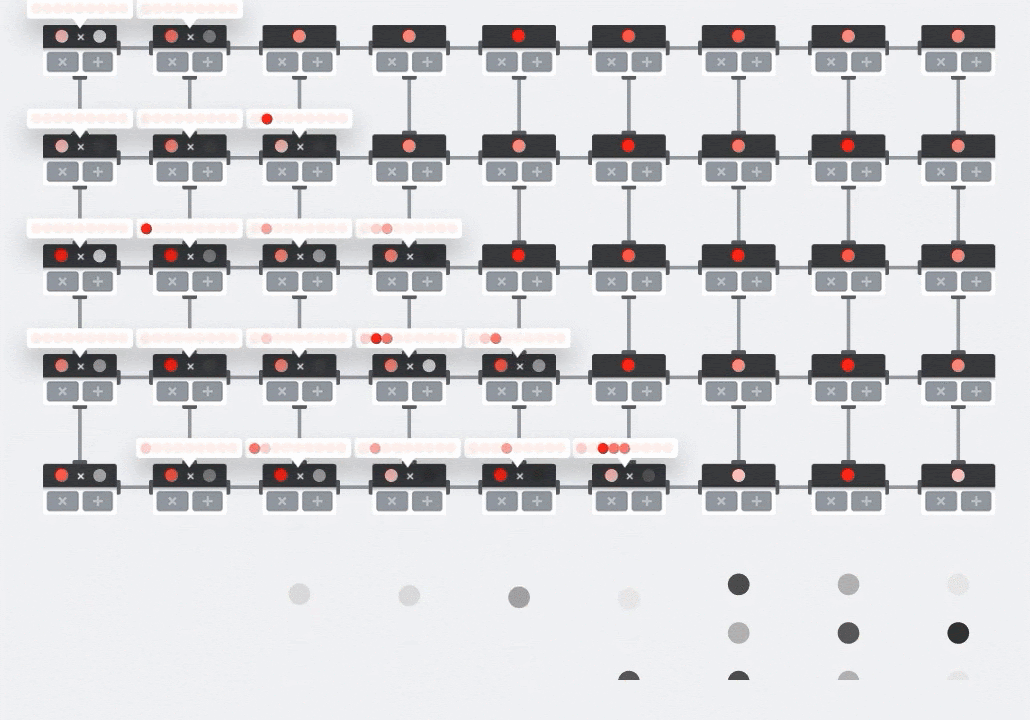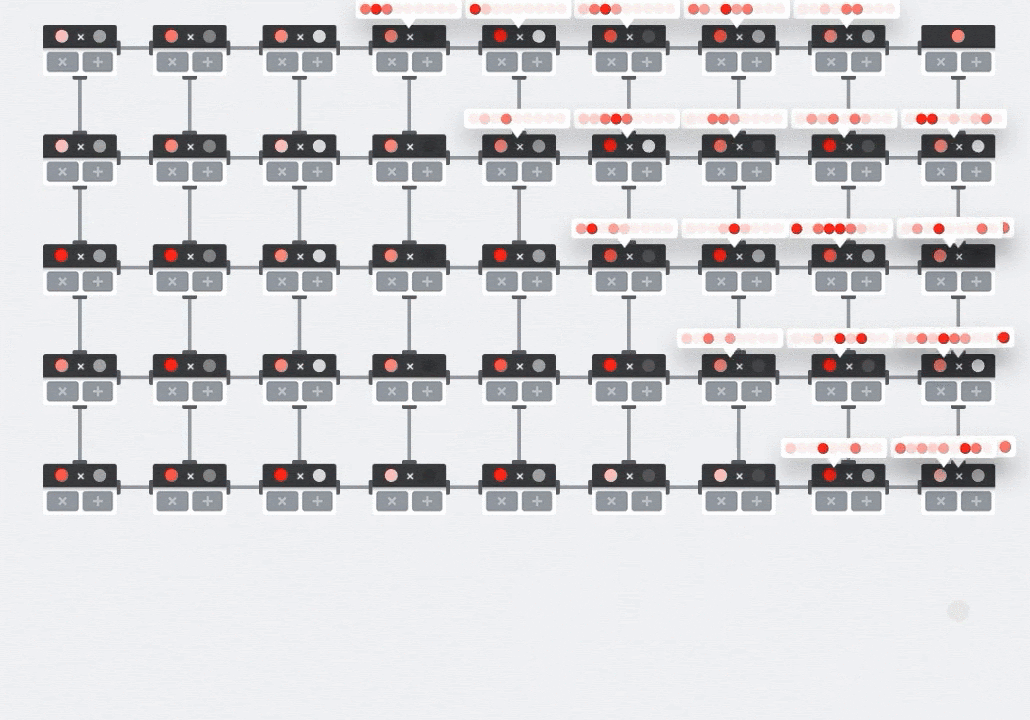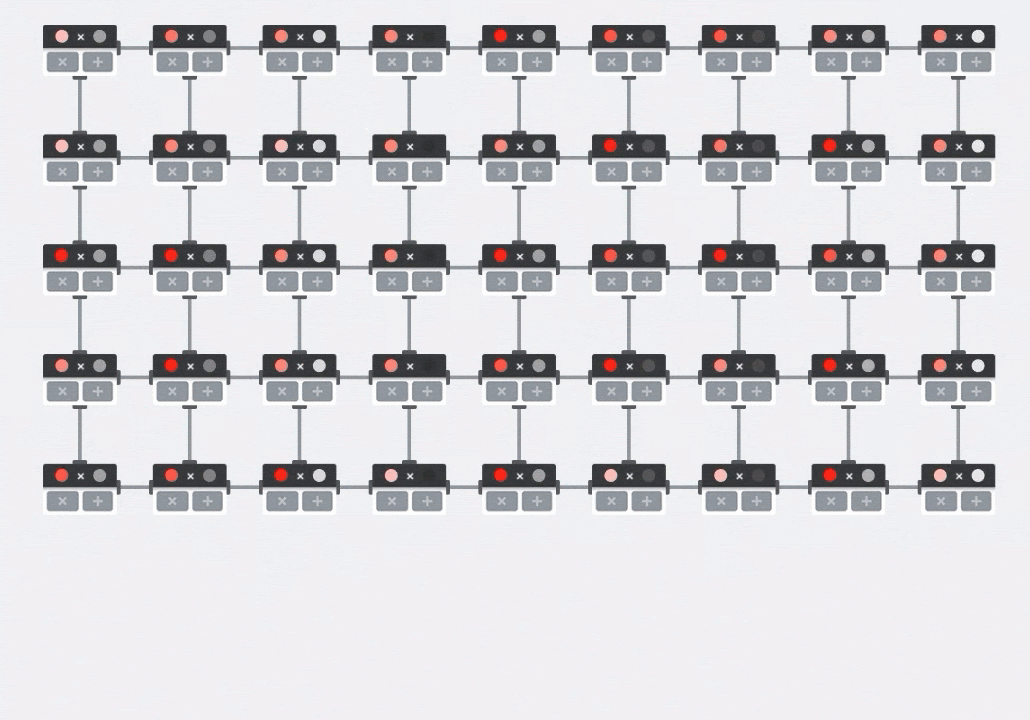
Illustration: the MXU systolic array. The compute elements are multiply-accumulators. The values of one matrix are loaded into the array (red dots). Values of the other matrix flow through the array (grey dots). Vertical lines propagate the values up. Horizontal lines propagate partial sums. It is left as an exercise to the user to verify that as the data flows through the array, you get the result of the matrix multiplication coming out of the right side.
In addition to that, while the dot products are being computed in an MXU, intermediate sums simply flow between adjacent compute units. They do not need to be stored and retrieved to/from memory or even a register file. The end result is that the TPU systolic array architecture has a significant density and power advantage, as well as a non-negligible speed advantage over a GPU, when computing matrix multiplications.
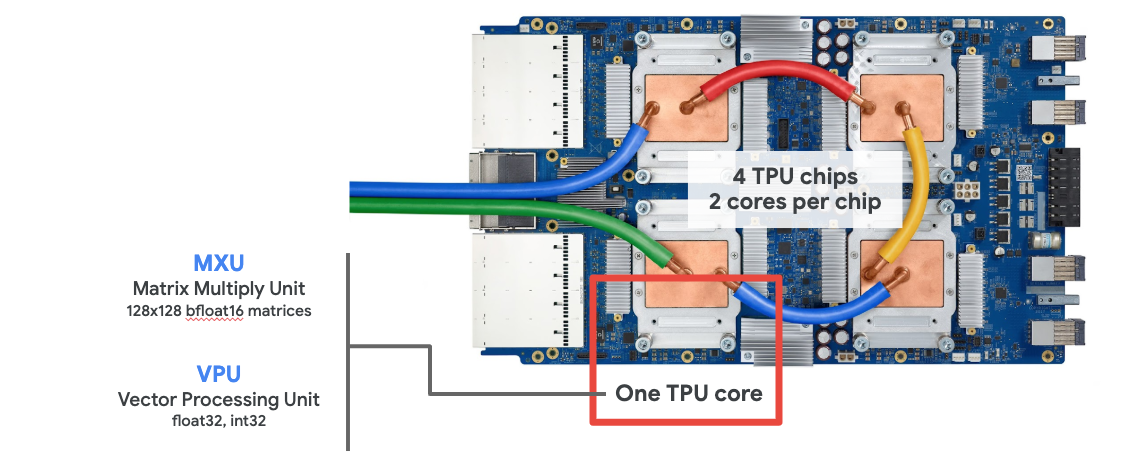
Cloud TPU
When you request one " Cloud TPU v2" on Google Cloud Platform, you get a virtual machine (VM) which has a PCI-attached TPU board. The TPU board has four dual-core TPU chips. Each TPU core features a VPU (Vector Processing Unit) and a 128x128 MXU (MatriX multiply Unit). This "Cloud TPU" is then usually connected through the network to the VM that requested it. So the full picture looks like this:
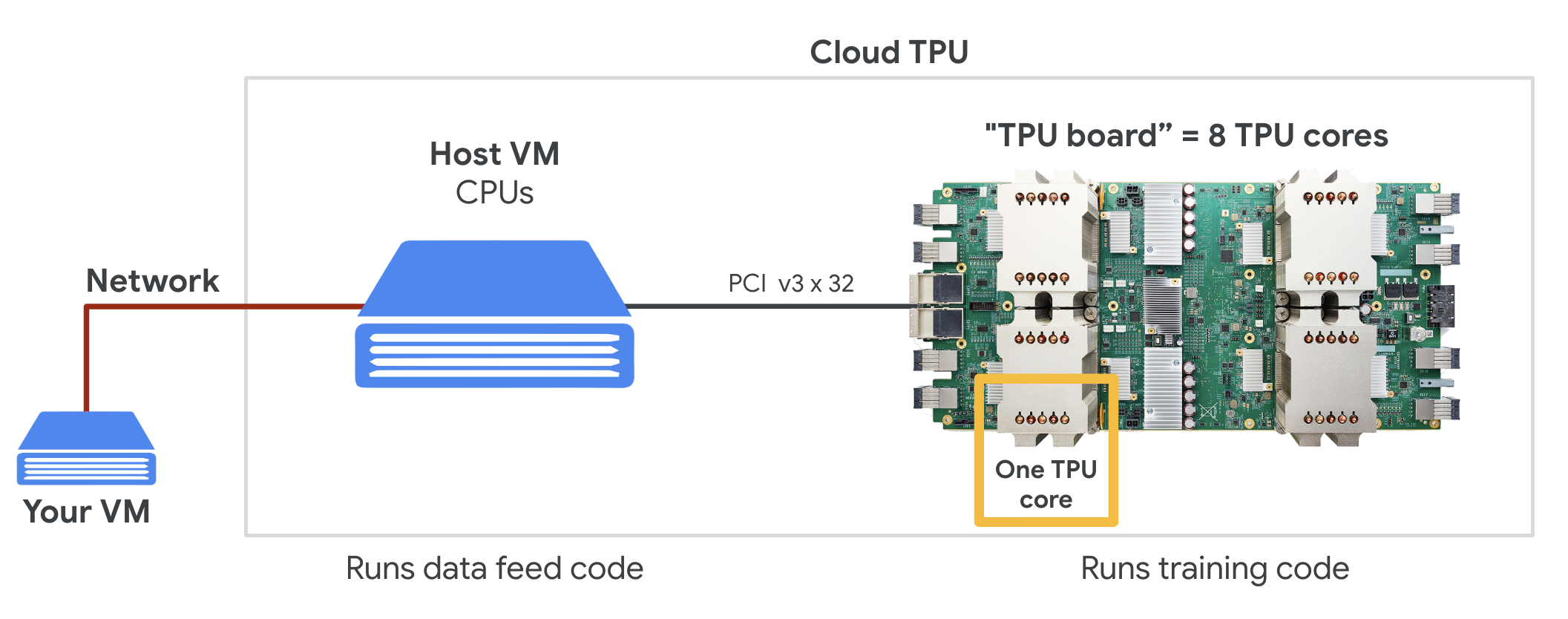
Illustration: your VM with a network-attached "Cloud TPU" accelerator. "The Cloud TPU" itself is made of a VM with a PCI-attached TPU board with four dual-core TPU chips on it.
TPU pods
In Google's data centers, TPUs are connected to a high-performance computing (HPC) interconnect which can make them appear as one very large accelerator. Google calls them pods and they can encompass up to 512 TPU v2 cores or 2048 TPU v3 cores..

Illustration: a TPU v3 pod. TPU boards and racks connected through HPC interconnect.
During training, gradients are exchanged between TPU cores using the all-reduce algorithm ( good explanation of all-reduce here). The model being trained can take advantage of the hardware by training on large batch sizes.

Illustration: synchronization of gradients during training using the all-reduce algorithm on Google TPU's 2-D toroidal mesh HPC network.
The software
Large batch size training
The ideal batch size for TPUs is 128 data items per TPU core but the hardware can already show good utilization from 8 data items per TPU core. Remember that one Cloud TPU has 8 cores.
In this code lab, we will be using the Keras API. In Keras, the batch you specify is the global batch size for the entire TPU. Your batches will automatically be split in 8 and ran on the 8 cores of the TPU.

For additional performance tips see the TPU Performance Guide. For very large batch sizes, special care might be needed in some models, see LARSOptimizer for more details.
Under the hood: XLA
Tensorflow programs define computation graphs. The TPU does not directly run Python code, it runs the computation graph defined by your Tensorflow program. Under the hood, a compiler called XLA (accelerated Linear Algebra compiler) transforms the Tensorflow graph of computation nodes into TPU machine code. This compiler also performs many advanced optimizations on your code and your memory layout. The compilation happens automatically as work is sent to the TPU. You do not have to include XLA in your build chain explicitly.
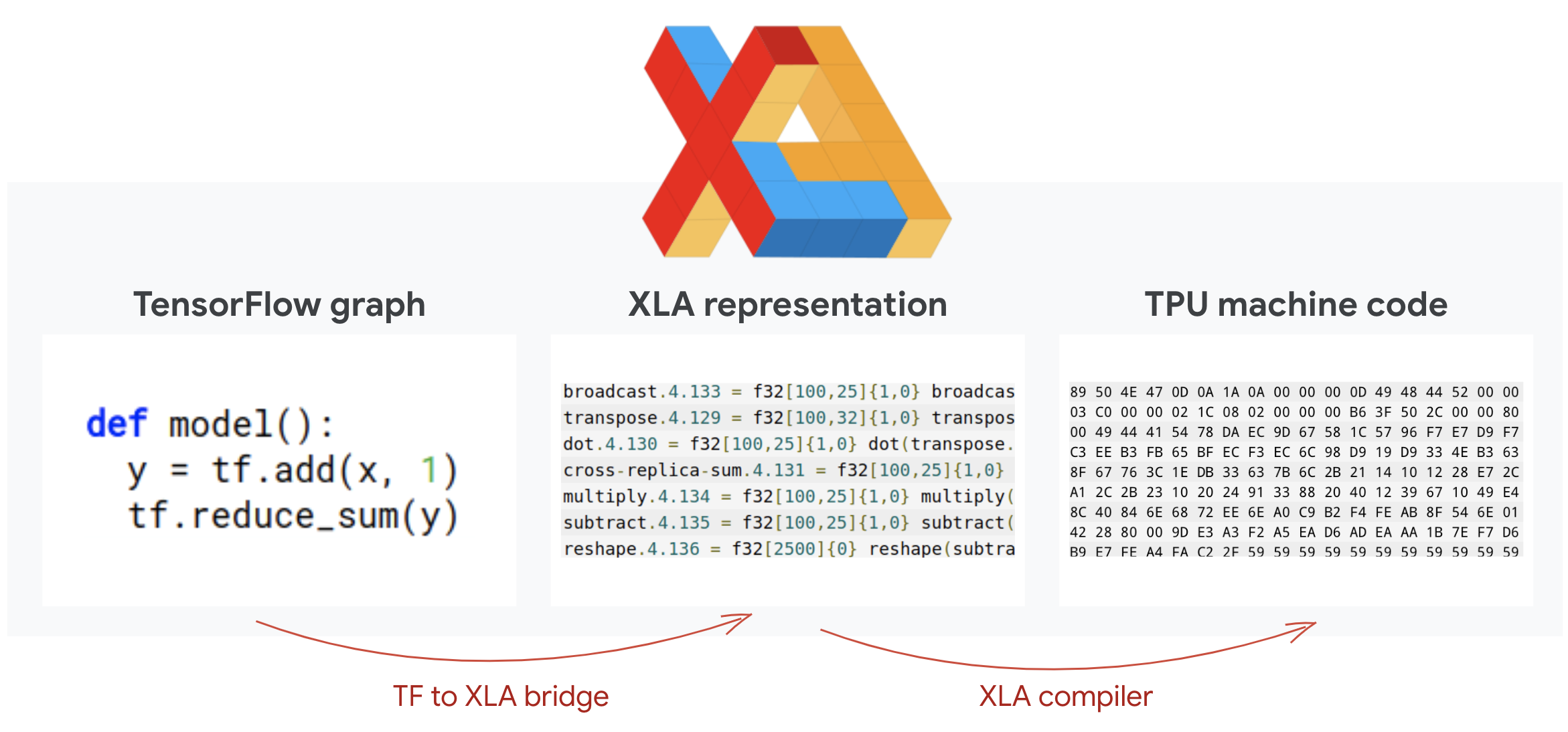
Illustration: to run on TPU, the computation graph defined by your Tensorflow program is first translated to an XLA (accelerated Linear Algebra compiler) representation, then compiled by XLA into TPU machine code.
Using TPUs in Keras
TPUs are supported through the Keras API as of Tensorflow 2.1. Keras support works on TPUs and TPU pods. Here is an example that works on TPU, GPU(s) and CPU:
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.MirroredStrategy() # for CPU/GPU or multi-GPU machines
# use TPUStrategy scope to define model
with strategy.scope():
model = tf.keras.Sequential( ... )
model.compile( ... )
# train model normally on a tf.data.Dataset
model.fit(training_dataset, epochs=EPOCHS, steps_per_epoch=...)
In this code snippet:
TPUClusterResolver().connect()finds the TPU on the network. It works without parameters on most Google Cloud systems (AI Platform jobs, Colaboratory, Kubeflow, Deep Learning VMs created through the ‘ctpu up' utility). These systems know where their TPU is thanks to a TPU_NAME environment variable. If you create a TPU by hand, either set the TPU_NAME env. var. on the VM you are using it from, or callTPUClusterResolverwith explicit parameters:TPUClusterResolver(tp_uname, zone, project)TPUStrategyis the part that implements the distribution and the "all-reduce" gradient synchronization algorithm.- The strategy is applied through a scope. The model must be defined within the strategy scope().
- The
tpu_model.fitfunction expects a tf.data.Dataset object for input for TPU training.
Common TPU porting tasks
- While there are many ways to load data in a Tensorflow model, for TPUs, the use of the
tf.data.DatasetAPI is required. - TPUs are very fast and ingesting data often becomes the bottleneck when running on them. There are tools you can use to detect data bottlenecks and other performance tips in the TPU Performance Guide.
- int8 or int16 numbers are treated as int32. The TPU does not have integer hardware operating on less than 32 bits.
- Some Tensorflow operations are not supported. The list is here. The good news is that this limitation only applies to training code i.e. the forward and backward pass through your model. You can still use all Tensorflow operations in your data input pipeline as it will be executed on CPU.
tf.py_funcis not supported on TPU.
4. Loading Data






We will be working with a dataset of flower pictures. The goal is to learn to categorize them into 5 flower types. Data loading is performed using the tf.data.Dataset API. First, let us get to know the API.
Hands-on
Please open the following notebook, execute the cells (Shift-ENTER) and follow the instructions wherever you see a "WORK REQUIRED" label.

Fun with tf.data.Dataset (playground).ipynb
Additional information
About the "flowers" dataset
The dataset is organised in 5 folders. Each folder contains flowers of one kind. The folders are named sunflowers, daisy, dandelion, tulips and roses. The data is hosted in a public bucket on Google Cloud Storage. Excerpt:
gs://flowers-public/sunflowers/5139971615_434ff8ed8b_n.jpg
gs://flowers-public/daisy/8094774544_35465c1c64.jpg
gs://flowers-public/sunflowers/9309473873_9d62b9082e.jpg
gs://flowers-public/dandelion/19551343954_83bb52f310_m.jpg
gs://flowers-public/dandelion/14199664556_188b37e51e.jpg
gs://flowers-public/tulips/4290566894_c7f061583d_m.jpg
gs://flowers-public/roses/3065719996_c16ecd5551.jpg
gs://flowers-public/dandelion/8168031302_6e36f39d87.jpg
gs://flowers-public/sunflowers/9564240106_0577e919da_n.jpg
gs://flowers-public/daisy/14167543177_cd36b54ac6_n.jpg
Why tf.data.Dataset?
Keras and Tensorflow accept Datasets in all of their training and evaluation functions. Once you load data in a Dataset, the API offers all the common functionalities that are useful for neural network training data:
dataset = ... # load something (see below)
dataset = dataset.shuffle(1000) # shuffle the dataset with a buffer of 1000
dataset = dataset.cache() # cache the dataset in RAM or on disk
dataset = dataset.repeat() # repeat the dataset indefinitely
dataset = dataset.batch(128) # batch data elements together in batches of 128
AUTOTUNE = tf.data.AUTOTUNE
dataset = dataset.prefetch(AUTOTUNE) # prefetch next batch(es) while training
You can find performance tips and Dataset best practices in this article. The reference documentation is here.
tf.data.Dataset basics
Data usually comes in multiple files, here images. You can create a dataset of filenames by calling:
filenames_dataset = tf.data.Dataset.list_files('gs://flowers-public/*/*.jpg')
# The parameter is a "glob" pattern that supports the * and ? wildcards.
You then "map" a function to each filename which will typically load and decode the file into actual data in memory:
def decode_jpeg(filename):
bits = tf.io.read_file(filename)
image = tf.io.decode_jpeg(bits)
return image
image_dataset = filenames_dataset.map(decode_jpeg)
# this is now a dataset of decoded images (uint8 RGB format)
To iterate on a Dataset:
for data in my_dataset:
print(data)
Datasets of tuples
In supervised learning, a training dataset is typically made of pairs of training data and correct answers. To allow this, the decoding function can return tuples. You will then have a dataset of tuples and tuples will be returned when you iterate on it. The values returned are Tensorflow tensors ready to be consumed by your model. You can call .numpy() on them to see raw values:
def decode_jpeg_and_label(filename):
bits = tf.read_file(filename)
image = tf.io.decode_jpeg(bits)
label = ... # extract flower name from folder name
return image, label
image_dataset = filenames_dataset.map(decode_jpeg_and_label)
# this is now a dataset of (image, label) pairs
for image, label in dataset:
print(image.numpy().shape, label.numpy())
Conclusion:loading images one by one is slow !
As you iterate on this dataset, you will see that you can load something like 1-2 images per second. That is too slow! The hardware accelerators we will be using for training can sustain many times this rate. Head to the next section to see how we will achieve this.
Solution
Here is the solution notebook. You can use it if you are stuck.
Fun with tf.data.Dataset (solution).ipynb
What we've covered
- 🤔 tf.data.Dataset.list_files
- 🤔 tf.data.Dataset.map
- 🤔 Datasets of tuples
- 😀 iterating through Datasets
Please take a moment to go through this checklist in your head.
5. Loading data fast
The Tensor Processing Unit (TPU) hardware accelerators we will be using in this lab are very fast. The challenge is often to feed them data fast enough to keep them busy. Google Cloud Storage (GCS) is capable of sustaining very high throughput but as with all cloud storage systems, initiating a connection costs some network back and forth. Therefore, having our data stored as thousands of individual files is not ideal. We are going to batch them in a smaller number of files and use the power of tf.data.Dataset to read from multiple files in parallel.
Read-through
The code that loads image files, resizes them to a common size and then stores them across 16 TFRecord files is in the following notebook. Please quickly read through it. Executing it is not necessary since properly TFRecord-formatted data will be provided for the rest of the codelab.
Flower pictures to TFRecords.ipynb
Ideal data layout for optimal GCS throughput
The TFRecord file format
Tensorflow's preferred file format for storing data is the protobuf-based TFRecord format. Other serialization formats would work too but you can load a dataset from TFRecord files directly by writing:
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
For optimal performance, it is recommended to use the following more complex code to read from multiple TFRecord files at once. This code will read from N files in parallel and disregard data order in favor of reading speed.
AUTOTUNE = tf.data.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
filenames = tf.io.gfile.glob(FILENAME_PATTERN)
dataset = tf.data.TFRecordDataset(filenames, num_parallel_reads=AUTOTUNE)
dataset = dataset.with_options(ignore_order)
dataset = dataset.map(...) # do the TFRecord decoding here - see below
TFRecord cheat sheet
Three types of data can be stored in TFRecords: byte strings (list of bytes), 64 bit integers and 32 bit floats. They are always stored as lists, a single data element will be a list of size 1. You can use the following helper functions to store data into TFRecords.
writing byte strings
# warning, the input is a list of byte strings, which are themselves lists of bytes
def _bytestring_feature(list_of_bytestrings):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=list_of_bytestrings))
writing integers
def _int_feature(list_of_ints): # int64
return tf.train.Feature(int64_list=tf.train.Int64List(value=list_of_ints))
writing floats
def _float_feature(list_of_floats): # float32
return tf.train.Feature(float_list=tf.train.FloatList(value=list_of_floats))
writing a TFRecord, using the helpers above
# input data in my_img_bytes, my_class, my_height, my_width, my_floats
with tf.python_io.TFRecordWriter(filename) as out_file:
feature = {
"image": _bytestring_feature([my_img_bytes]), # one image in the list
"class": _int_feature([my_class]), # one class in the list
"size": _int_feature([my_height, my_width]), # fixed length (2) list of ints
"float_data": _float_feature(my_floats) # variable length list of floats
}
tf_record = tf.train.Example(features=tf.train.Features(feature=feature))
out_file.write(tf_record.SerializeToString())
To read data from TFRecords, you must first declare the layout of the records you have stored. In the declaration, you can access any named field as a fixed length list or a variable length list:
reading from TFRecords
def read_tfrecord(data):
features = {
# tf.string = byte string (not text string)
"image": tf.io.FixedLenFeature([], tf.string), # shape [] means scalar, here, a single byte string
"class": tf.io.FixedLenFeature([], tf.int64), # shape [] means scalar, i.e. a single item
"size": tf.io.FixedLenFeature([2], tf.int64), # two integers
"float_data": tf.io.VarLenFeature(tf.float32) # a variable number of floats
}
# decode the TFRecord
tf_record = tf.io.parse_single_example(data, features)
# FixedLenFeature fields are now ready to use
sz = tf_record['size']
# Typical code for decoding compressed images
image = tf.io.decode_jpeg(tf_record['image'], channels=3)
# VarLenFeature fields require additional sparse.to_dense decoding
float_data = tf.sparse.to_dense(tf_record['float_data'])
return image, sz, float_data
# decoding a tf.data.TFRecordDataset
dataset = dataset.map(read_tfrecord)
# now a dataset of triplets (image, sz, float_data)
Useful code snippets:
reading single data elements
tf.io.FixedLenFeature([], tf.string) # for one byte string
tf.io.FixedLenFeature([], tf.int64) # for one int
tf.io.FixedLenFeature([], tf.float32) # for one float
reading fixed size lists of elements
tf.io.FixedLenFeature([N], tf.string) # list of N byte strings
tf.io.FixedLenFeature([N], tf.int64) # list of N ints
tf.io.FixedLenFeature([N], tf.float32) # list of N floats
reading a variable number of data items
tf.io.VarLenFeature(tf.string) # list of byte strings
tf.io.VarLenFeature(tf.int64) # list of ints
tf.io.VarLenFeature(tf.float32) # list of floats
A VarLenFeature returns a sparse vector and an additional step is required after decoding the TFRecord:
dense_data = tf.sparse.to_dense(tf_record['my_var_len_feature'])
It is also possible to have optional fields in TFRecords. If you specify a default value when reading a field, then the default value is returned instead of an error if the field is missing.
tf.io.FixedLenFeature([], tf.int64, default_value=0) # this field is optional
What we've covered
- 🤔 sharding data files for fast access from GCS
- 😓 how to write TFRecords. (You forgot the syntax already? That's OK, bookmark this page as a cheat sheet)
- 🤔 loading a Dataset from TFRecords using TFRecordDataset
Please take a moment to go through this checklist in your head.
6. Congratulations!
You can now feed a TPU with data. Please continue to the next lab
- [THIS LAB] TPU-speed data pipelines: tf.data.Dataset and TFRecords
- Your first Keras model, with transfer learning
- Convolutional neural networks, with Keras and TPUs
- Modern convnets, squeezenet, Xception, with Keras and TPUs
TPUs in practice
TPUs and GPUs are available on Cloud AI Platform:
- On Deep Learning VMs
- In AI Platform Notebooks
- In AI Platform Training jobs
Finally, we love feedback. Please tell us if you see something amiss in this lab or if you think it should be improved. Feedback can be provided through GitHub issues [ feedback link].

|
|

