
1. 简介

上次更新日期:2020 年 2 月 28 日
此 Codelab 演示了一种数据注入模式,用于将 CSV 格式的医疗保健数据实时注入到 BigQuery 中。在此实验中,我们将使用 Cloud Data Fusion 实时数据流水线。我们已生成真实的医疗保健测试数据,并将其提供在 Google Cloud Storage 存储分区 (gs://hcls_testing_data_fhir_10_patients/csv/) 中供您使用。
在此 Codelab 中,您将学习:
- 如何使用 Cloud Data Fusion 将 CSV 数据(实时加载)从 Pub/Sub 提取到 BigQuery。
- 了解如何在 Cloud Data Fusion 中直观地构建数据集成流水线,以实时加载、转换和遮盖医疗保健数据。
运行此演示需要哪些条件?
- 您需要有 GCP 项目的访问权限。
- 您必须被分配 GCP 项目的所有者角色。
- 采用 CSV 格式的医疗保健数据,包括标题。
如果您没有 GCP 项目,请按照这些步骤创建新的 GCP 项目。
CSV 格式的医疗保健数据已预加载到 gs://hcls_testing_data_fhir_10_patients/csv/ 中的 GCS 存储分区中。每个 CSV 资源文件都有唯一的架构结构。例如,Patients.csv 的架构与 Providers.csv 的架构不同。预加载的架构文件位于 gs://hcls_testing_data_fhir_10_patients/csv_schemas。
如果您需要新数据集,可以随时使用 SyntheaTM 生成。然后,将其上传到 GCS,而不是在“复制输入数据”这一步中从存储分区复制。
2. GCP 项目设置
为您的环境初始化 shell 变量。
如需查找 PROJECT_ID,请参阅识别项目。
<!-- CODELAB: Initialize shell variables -> <!-- Your current GCP Project ID -> export PROJECT_ID=<PROJECT_ID> <!-- A new GCS Bucket in your current Project - INPUT -> export BUCKET_NAME=<BUCKET_NAME> <!-- A new BQ Dataset ID - OUTPUT -> export DATASET_ID=<DATASET_ID>
使用 gsutil 工具创建 GCS 存储分区以存储输入数据和错误日志。
gsutil mb -l us gs://$BUCKET_NAME
获取对合成数据集的访问权限。
- 使用您用于登录 Cloud 控制台的电子邮件地址,向 hcls-solutions-external+subscribe@google.com 发送电子邮件,申请加入。
- 您会收到一封电子邮件,其中包含有关如何确认操作的说明。
- 使用相应选项回复电子邮件,以加入群组。请勿点击
 按钮。
按钮。 - 收到确认邮件后,您可以继续执行 Codelab 中的下一步。
复制输入数据。
gsutil -m cp -r gs://hcls_testing_data_fhir_10_patients/csv gs://$BUCKET_NAME
创建 BigQuery 数据集。
bq mk --location=us --dataset $PROJECT_ID:$DATASET_ID
安装并初始化 Google Cloud SDK,并创建 Pub/Sub 主题和订阅。
gcloud init gcloud pubsub topics create your-topic gcloud pubsub subscriptions create --topic your-topic your-sub
3. Cloud Data Fusion 环境设置
请按照以下步骤启用 Cloud Data Fusion API 并授予所需权限:
启用 API。
- 前往 GCP Console API 库。
- 从项目列表中,选择一个项目。
- 在 API 库中,选择要启用的 API(Cloud Data Fusion API、Cloud Pub/Sub API)。如果您在查找 API 时需要帮助,请使用搜索字段和过滤器。
- 在 API 页面上,点击启用。
创建 Cloud Data Fusion 实例。
- 在 GCP 控制台中,选择您的 ProjectID。
- 从左侧菜单中选择 Data Fusion,然后点击页面中间的“创建实例”按钮(首次创建),或点击顶部菜单中的“创建实例”按钮(额外创建)。


- 提供实例名称。选择企业版。

- 点击“创建”按钮。
设置实例权限。
创建完实例后,请按照以下步骤为与实例关联的服务账号授予项目权限:
- 点击实例名称,导航到实例详细信息页面。

- 复制服务账号。

- 前往项目的 IAM 页面。
- 在“IAM 权限”页面上点击添加按钮,为服务账号授予 Cloud Data Fusion API Service Agent 角色。将“服务账号”粘贴到“新成员”字段中,然后选择“Service Management” -> “Cloud Data Fusion API Server Agent”角色。

- 点击 + 添加其他角色(或修改 Cloud Data Fusion API 服务代理),以添加 Pub/Sub 订阅者角色。

- 点击保存。
完成上述步骤后,您可以点击 Cloud Data Fusion 实例页面或实例详情页面上的查看实例链接,开始使用 Cloud Data Fusion。
设置防火墙规则。
- 前往 GCP 控制台 -> VPC 网络 -> 防火墙规则,检查是否存在 default-allow-ssh 规则。

- 如果不是,请添加一条防火墙规则,允许所有入站 SSH 流量进入默认网络。
使用命令行:
gcloud beta compute --project={PROJECT_ID} firewall-rules create default-allow-ssh --direction=INGRESS --priority=1000 --network=default --action=ALLOW --rules=tcp:22 --source-ranges=0.0.0.0/0 --enable-logging
使用界面:点击“创建防火墙规则”,然后填写以下信息:


4. 为流水线构建节点
现在,我们已在 GCP 中设置了 Cloud Data Fusion 环境,接下来我们按照以下步骤开始在 Cloud Data Fusion 中构建数据流水线:
- 在 Cloud Data Fusion 窗口中,点击“操作”列中的“查看实例”链接。您将被重定向到另一个页面。点击提供的 网址 以打开 Cloud Data Fusion 实例。您在欢迎弹出式窗口中点击“开始导览”或“不用了,谢谢”按钮的选择。
- 展开“汉堡”菜单,选择“流水线”>“列表”

- 点击右上角的绿色 + 按钮,然后选择创建流水线。或者,点击“创建”流水线链接。

- 显示流水线 Studio 之后,在左上角,从下拉菜单中选择数据流水线 - 实时。

- 在“数据流水线”界面中,您会在左侧面板上看到不同的部分,例如“过滤条件”“来源”“转换”“分析”“接收器”“错误处理程序”和“提醒”,您可以在其中选择流水线的一个或多个节点。

选择一个来源节点。
- 在左侧“插件”调色板的“来源”部分下,双击“数据流水线”界面中显示的 Google Cloud Pub/Sub 节点。
- 指向 PubSub 源节点,然后点击属性。

- 填写必填字段。设置以下字段:
- 标签 = {任意文本}
- 参考名称 = {任意文本}
- 项目 ID = 自动检测
- 订阅 = 在“创建 Pub/Sub 主题”部分中创建的订阅(例如 your-sub)
- 主题 = 在“创建 Pub/Sub 主题”部分中创建的主题(例如,your-topic)
- 如需详细说明,请点击文档。点击“验证”按钮以验证所有输入信息。绿色“未发现任何错误”表示成功。

- 如需关闭“Pub/Sub 属性”,请点击 X 按钮。
选择转换 节点。
- 在左侧“插件”面板的“转换”部分下,双击“数据流水线”界面中显示的 Projection 节点。将 Pub/Sub 源节点连接到 Projection 转换节点。
- 指向投影节点,然后点击属性。

- 填写必填字段。设置以下字段:
- 转换 = 将消息从字节类型转换为字符串类型。
- 要舍弃的字段 = {任意字段}
- 要保留的字段 = {message、timestamp 和 attributes}(例如,从 Pub/Sub 发送的属性:key=‘filename':value=‘patients')
- 要重命名的字段 = {message, timestamp}
- 如需详细说明,请点击文档。点击“验证”按钮以验证所有输入信息。绿色“未发现任何错误”表示成功。

- 在左侧“插件”调色板的“转换”部分下,双击“数据流水线”界面中显示的 Wrangler 节点。将“投影”转换节点连接到“Wrangler”转换节点。指向 Wrangler 节点,然后点击属性。

- 点击操作下拉菜单,然后选择导入以导入已保存的架构(例如:gs://hcls_testing_data_fhir_10_patients/csv_schemas/ schema (Patients).json)。
- 点击最后一个字段旁边的 + 按钮,在输出架构中添加 TIMESTAMP 字段(如果该字段不存在),然后勾选“Null”框。
- 填写必填字段。设置以下字段:
- 标签 = {任意文本}
- 输入字段名称 = {*}
- 前提条件 = {attributes.get("filename") != "patients"},用于区分从 PubSub 源节点发送的每种类型的记录或消息(例如,患者、提供方、过敏症等)。
- 如需详细说明,请点击文档。点击“验证”按钮以验证所有输入信息。绿色“未发现任何错误”表示成功。
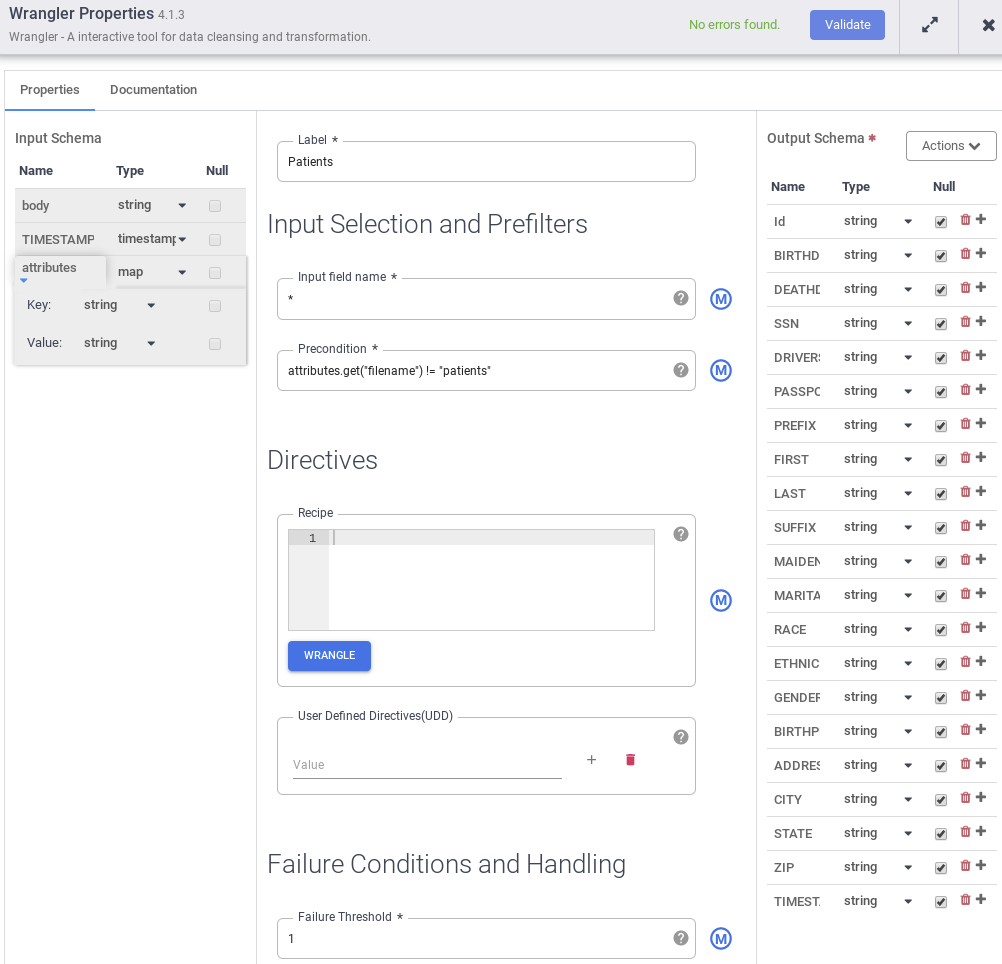
- 按首选顺序设置列名称,并舍弃不需要的字段。复制以下代码段并粘贴到“配方”框中。
drop attributes parse-as-csv :body ',' false drop body set columns TIMESTAMP,Id,BIRTHDATE,DEATHDATE,SSN,DRIVERS,PASSPORT,PREFIX,FIRST,LAST,SUFFIX,MAIDEN,MARITAL,RACE,ETHNICITY,GENDER,BIRTHPLACE,ADDRESS,CITY,STATE,ZIP mask-number SSN xxxxxxx####

- 如需了解数据遮盖和去标识化,请参阅 Batch-Codelab - CSV to BigQuery via CDF。或者在“配方”框中添加以下代码段 mask-number SSN xxxxxxx####
- 如需关闭“转换属性”窗口,请点击 X 按钮。
选择接收器节点。
- 在左侧“插件”选项面板的“接收器”部分,双击“数据流水线”界面中显示的 BigQuery 节点。将 Wrangler 转换节点连接到 BigQuery 接收器节点。
- 指向 BigQuery 接收器节点,然后点击“属性”。
- 填写必填字段:
- 标签 = {任意文本}
- 参考名称 = {任意文本}
- 项目 ID = 自动检测
- 数据集 = 当前项目中使用的 BigQuery 数据集(例如,DATASET_ID)
- 表 = {表名称}
- 如需详细说明,请点击文档。点击“验证”按钮以验证所有输入信息。绿色“未发现任何错误”表示成功。

- 如需关闭“BigQuery 属性”,请点击 X 按钮。
5. 构建实时数据流水线
在上一部分中,我们创建了在 Cloud Data Fusion 中构建数据流水线所需的节点。在本部分中,我们将连接各个节点以构建实际的流水线。
连接流水线中的所有节点
- 拖动源节点右边缘的连接箭头 > 并放置在目标节点的左边缘上。
- 流水线可以有多个分支,这些分支从同一 PubSub Source 节点获取已发布的消息。

- 为流水线命名。
大功告成。您刚刚创建了第一个要部署和运行的实时数据流水线。
通过 Cloud Pub/Sub 发送消息
使用 Pub/Sub 界面:
- 依次前往 GCP 控制台 -> Pub/Sub -> 主题,选择 your-topic,然后点击顶部菜单中的“发布消息”。

- 一次只能在“消息”字段中放置一个记录行。点击 + 添加属性按钮。提供键 = filename,值 = <记录类型>(例如,患者、提供方、过敏症等)。
- 点击“发布”按钮即可发送消息。
使用 gcloud 命令:
- 手动提供消息。
gcloud pubsub topics publish <your-topic> --attribute <key>=<value> --message \ "paste one record row here"
- 使用 cat 和 sed Unix 命令半自动提供消息。此命令可以重复运行,并使用不同的参数。
gcloud pubsub topics publish <your-topic> --attribute <key>=<value> --message \ "$(gsutil cat gs://$BUCKET_NAME/csv/<value>.csv | sed -n '#p')"
6. 配置、部署和运行流水线
现在,我们已经开发了数据流水线,接下来可以在 Cloud Data Fusion 中部署并运行它。

- 保留配置默认值。
- 点击预览以预览数据。再次点击 **预览**,即可切换回上一个窗口。您还可以点击 **运行**,在预览模式下运行流水线。

- 点击日志以查看日志。
- 点击保存以保存所有更改。
- 在构建新流水线时,点击导入以导入已保存的流水线配置。
- 点击导出以导出流水线配置。
- 点击部署以部署流水线。
- 部署后,点击运行并等待流水线完成运行过程。

- 您可以随时点击停止来停止流水线运行。
- 您可以选择操作按钮下的“复制”来复制流水线。
- 您可以选择操作按钮下的“导出”来导出流水线配置。

- 点击摘要可显示运行历史记录、记录、错误日志和警告的图表。
7. 验证
在本部分中,我们将验证数据流水线的执行情况。
- 验证流水线是否已成功执行并持续运行。

- 验证 BigQuery 表是否已根据时间戳加载更新后的记录。在此示例中,2019-06-25 有两条患者记录或消息和一条过敏记录或消息发布到了 Pub/Sub 主题。
bq query --nouse_legacy_sql 'select (select count(*) from \ '$PROJECT_ID.$DATASET_ID.Patients' where TIMESTAMP > "2019-06-25 \ 01:29:00.0000 UTC" ) as Patients, (select count(*) from \ '$PROJECT_ID.$DATASET_ID.Allergies' where TIMESTAMP > "2019-06-25 \ 01:29:00.0000 UTC") as Allergies;'
Waiting on bqjob_r14c8b94c1c0fe06a_0000016b960df4e1_1 ... (0s) Current status: DONE
+----------+-----------+
| Patients | Allergies |
+----------+-----------+
| 2 | 1 |
+----------+-----------+
- 验证发布到 <your-topic> 的消息是否已由 <your-sub> 订阅者接收。
gcloud pubsub subscriptions pull --auto-ack <your-sub>

查看结果
在实时流水线运行期间,将消息发布到 Pub/Sub 主题后,如需查看结果,请执行以下操作:
- 在 BigQuery 界面中查询表。前往 BigQuery 界面
- 将以下查询中的项目名称、数据集和表更新为您自己的项目名称、数据集和表。

8. 清理
为避免因本教程中使用的资源导致您的 Google Cloud Platform 账号产生费用,请执行以下操作:
学完本教程后,您可以清理在 GCP 上创建的资源,以避免这些资源占用配额,日后产生费用。以下部分介绍如何删除或关闭这些资源。
删除 BigQuery 数据集
请按照以下说明删除您在本教程中创建的 BigQuery 数据集。
删除 GCS 存储分区
按照以下说明删除您在本教程中创建的 GCS 存储分区。
删除 Cloud Data Fusion 实例
请按照以下说明删除 Cloud Data Fusion 实例。
删除项目
若要避免产生费用,最简单的方法是删除您为本教程创建的项目。
如需删除项目,请执行以下操作:
- 在 GCP Console 中,前往项目页面。前往“项目”页面
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关停以删除项目。
9. 恭喜
恭喜!您已成功完成本 Codelab,了解了如何使用 Cloud Data Fusion 将医疗保健数据提取到 BigQuery 中。
您已将 CSV 数据发布到 Pub/Sub 主题,然后加载到 BigQuery 中。
您直观地构建了一个数据集成流水线,用于实时加载、转换和屏蔽医疗保健数据。
现在,您已经了解了在 Google Cloud Platform 上使用 BigQuery 开启医疗保健数据分析之旅所需的主要步骤。