
1. סקירה כללית
עיבוד שפה טבעית (NLP) הוא תחום מחקר שמתמקד בהפקת תובנות וביצוע ניתוחים על נתונים טקסטואליים. כמות הטקסט שנוצר באינטרנט ממשיכה לגדול, ולכן יותר מתמיד, ארגונים מחפשים דרכים להשתמש בטקסט כדי להפיק מידע שרלוונטי לעסקים שלהם.
אפשר להשתמש ב-NLP לכל דבר, החל מתרגום שפות ועד ניתוח סנטימנטים, יצירת משפטים מאפס ועוד. אנחנו עדיין עורכים מחקרים שיעזרו לנו להרחיב את היכולות של מודלים מסוג LLM בעזרת כלים חיצוניים.
נלמד איך להשתמש ב-NLP על כמויות גדולות של נתונים טקסטואליים בקנה מידה נרחב. זו בהחלט יכולה להיות משימה מאתגרת! למזלנו, נשתמש בספריות כמו Spark MLlib ו-spark-nlp כדי להקל על התהליך.
2. תרחיש השימוש שלנו
מדען הנתונים הראשי בארגון (הבדיוני) שלנו, FoodCorp, רוצה ללמוד עוד על מגמות בתעשיית המזון. יש לנו גישה למאגר של נתוני טקסט בצורה של פוסטים מ-subreddit של Reddit בנושא אוכל, r/food, ונשתמש בו כדי לבדוק על מה אנשים מדברים.
אחת הגישות לעשות זאת היא באמצעות שיטת NLP שנקראת "מודלים של נושאים". מודלים של נושאים הם שיטה סטטיסטית שיכולה לזהות מגמות במשמעויות הסמנטיות של קבוצת מסמכים. במילים אחרות, אנחנו יכולים לבנות מודל של נושאים על אוסף הנתונים של 'פוסטים' ב-Reddit, שיפיק רשימה של 'נושאים' או קבוצות של מילים שמתארות מגמה.
כדי לבנות את המודל, נשתמש באלגוריתם שנקרא Latent Dirichlet Allocation (הקצאת דיריכלה סמויה, LDA), שמשמש לעיתים קרובות לקיבוץ טקסטים. כאן אפשר לקרוא מבוא מצוין ל-LDA.
3. יצירת פרויקט
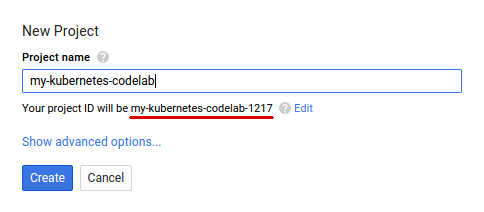
אם עדיין אין לכם חשבון Google (Gmail או Google Apps), אתם צריכים ליצור חשבון. נכנסים ל-Google Cloud Platform Console ( console.cloud.google.com) ויוצרים פרויקט חדש:


בשלב הבא, כדי להשתמש במשאבים של Google Cloud, צריך להפעיל את החיוב ב-Cloud Console.
העלות של ההשתתפות ב-Codelab הזה לא אמורה להיות גבוהה מכמה דולרים, אבל היא יכולה להיות גבוהה יותר אם תחליטו להשתמש ביותר משאבים או אם תשאירו אותם פועלים. בסוף כל אחד מה-codelabs PySpark-BigQuery ו-Spark-NLP יש הסבר על "ניקוי".
משתמשים חדשים ב-Google Cloud Platform זכאים לתקופת ניסיון בחינם בשווי 300$.
4. הגדרת הסביבה
קודם צריך להפעיל את Dataproc ואת Compute Engine APIs.
לוחצים על סמל התפריט בפינה השמאלית העליונה.

בתפריט הנפתח, בוחרים באפשרות 'API Manager'.
לוחצים על Enable APIs and Services.

בתיבת החיפוש, מחפשים את Compute Engine. לוחצים על Google Compute Engine API ברשימת התוצאות שמופיעה.
בדף Google Compute Engine לוחצים על הפעלה.

אחרי שמפעילים את האפשרות, לוחצים על החץ שמצביע ימינה כדי לחזור.
עכשיו מחפשים את Google Dataproc API ומפעילים אותו.

אחר כך, לוחצים על הלחצן בפינה השמאלית העליונה של מסוף הענן כדי לפתוח את Cloud Shell:
אנחנו הולכים להגדיר כמה משתני סביבה שנוכל להשתמש בהם בהמשך ה-codelab. קודם בוחרים שם לאשכול Dataproc שייווצר, למשל my-cluster, ומגדירים אותו בסביבה. אתם יכולים להשתמש בכל שם שתרצו.
CLUSTER_NAME=my-cluster
לאחר מכן, בוחרים תחום מתוך האפשרויות הזמינות כאן. דוגמה: us-east1-b.
REGION=us-east1
לבסוף, צריך להגדיר את דלי המקור שממנו המשימה תקרא נתונים. יש לנו נתונים לדוגמה שזמינים בדלי bm_reddit, אבל אתם יכולים להשתמש בנתונים שיצרתם מתוך PySpark לעיבוד מוקדם של נתונים ב-BigQuery אם השלמתם את המדריך הזה לפני המדריך הנוכחי.
BUCKET_NAME=bm_reddit
אחרי שמגדירים את משתני הסביבה, מריצים את הפקודה הבאה כדי ליצור את אשכול Dataproc:
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--region ${REGION} \
--metadata 'PIP_PACKAGES=google-cloud-storage spark-nlp==2.7.2' \
--worker-machine-type n1-standard-8 \
--num-workers 4 \
--image-version 1.4-debian10 \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--optional-components=JUPYTER,ANACONDA \
--enable-component-gateway
בואו נסביר כל אחת מהפקודות האלה:
gcloud beta dataproc clusters create ${CLUSTER_NAME}: יתחיל את היצירה של אשכול Dataproc עם השם שסיפקתם קודם. הוספנו כאן את beta כדי להפעיל תכונות בטא של Dataproc, כמו Component Gateway, שנדון בהן בהמשך.
--zone=${ZONE}: הגדרת המיקום של האשכול.
--worker-machine-type n1-standard-8: זהו הסוג של המכונה שבה יש להשתמש עבור העובדים שלנו.
--num-workers 4: יהיו לנו ארבעה עובדים באשכול.
--image-version 1.4-debian9: מציין את גרסת התמונה של Dataproc שבה נשתמש.
--initialization-actions ...: Initialization Actions הם סקריפטים בהתאמה אישית שמופעלים כשיוצרים אשכולות ועובדים. אפשר ליצור אותם על ידי משתמשים ולאחסן אותם בקטגוריית GCS, או להפנות אליהם מקטגוריית dataproc-initialization-actions ציבורית. פעולת האתחול שכלולה כאן תאפשר התקנות של חבילות Python באמצעות Pip, כפי שסופק עם הדגל --metadata.
--metadata 'PIP_PACKAGES=google-cloud-storage spark-nlp': רשימה מופרדת ברווחים של חבילות להתקנה ב-Dataproc. במקרה הזה, נתקין את google-cloud-storage ספריית הלקוח של Python spark-nlp.
--optional-components=ANACONDA: Optional Components הם חבילות נפוצות שמשמשות עם Dataproc, שמותקנות אוטומטית באשכולות Dataproc במהלך היצירה. היתרונות של שימוש ברכיבים אופציונליים לעומת פעולות אתחול כוללים זמני הפעלה מהירים יותר ובדיקה של רכיבים אופציונליים לגרסאות ספציפיות של Dataproc. באופן כללי, הם אמינים יותר.
--enable-component-gateway: האפשרות הזו מאפשרת לנו לנצל את שער הרכיבים של Dataproc כדי להציג ממשקי משתמש נפוצים כמו Zeppelin, Jupyter או Spark History. הערה: חלק מהאפשרויות האלה דורשות את הרכיב האופציונלי המשויך.
למידע נוסף על Dataproc, אפשר לעיין ב-codelab הזה.
לאחר מכן, מריצים את הפקודות הבאות ב-Cloud Shell כדי לשכפל את מאגר הקוד עם הקוד לדוגמה ולעבור לספרייה הנכונה:
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
cd cloud-dataproc/codelabs/spark-nlp
5. Spark MLlib
Spark MLlib היא ספרייה של למידת מכונה שניתנת להרחבה ונכתבה ב-Apache Spark. הספרייה MLlib מתבססת על היעילות של Spark ועל חבילה של אלגוריתמים מדויקים של למידת מכונה, ולכן היא יכולה לנתח כמויות גדולות של נתונים. יש לו ממשקי API ב-Java, ב-Scala, ב-Python וב-R. ב-Codelab הזה נתמקד ספציפית ב-Python.
MLlib מכיל קבוצה גדולה של טרנספורמציות ואומדנים. טרנספורמציה היא כלי שיכול לשנות את הנתונים, בדרך כלל באמצעות פונקציה transform(), ואילו אומדן הוא אלגוריתם מוכן מראש שאפשר לאמן את הנתונים שלכם באמצעות פונקציה fit().
דוגמאות לטרנספורמציות:
- טוקניזציה (יצירת וקטור של מספרים ממחרוזת של מילים)
- קידוד one-hot (יצירת וקטור דליל של מספרים שמייצגים מילים שמופיעות במחרוזת)
- מסיר מילות עצירה (מילים שלא מוסיפות ערך סמנטי למחרוזת)
דוגמאות להערכות:
- סיווג (האם זה תפוח או תפוז?)
- רגרסיה (כמה התפוח הזה צריך לעלות?)
- סידור באשכולות (עד כמה התפוחים דומים זה לזה?)
- עצי החלטה (אם הצבע הוא כתום, אז זה כתום. אחרת, זה תפוח)
- הפחתת ממדים (האם אפשר להסיר תכונות ממערך הנתונים שלנו ועדיין להבחין בין תפוח לבין תפוז?).
MLlib מכיל גם כלים לשיטות נפוצות אחרות בלמידת מכונה, כמו כוונון היפר-פרמטרים ובחירה שלהם, וכן אימות צולב.
בנוסף, MLlib מכיל את Pipelines API, שמאפשר לכם לבנות צינורות עיבוד נתונים לטרנספורמציה באמצעות טרנספורמטורים שונים שאפשר להפעיל מחדש.
6. Spark-NLP
Spark-nlp היא ספרייה שנוצרה על ידי John Snow Labs לביצוע יעיל של משימות עיבוד שפה טבעית באמצעות Spark. הוא מכיל כלים מובנים שנקראים 'הערות' למשימות נפוצות כמו:
- טוקניזציה (יצירת וקטור של מספרים ממחרוזת של מילים)
- יצירת הטמעות מילים (הגדרת הקשר בין מילים באמצעות וקטורים)
- תגי חלקי דיבור (אילו מילים הן שמות עצם? מהם הפעלים?)
השילוב של spark-nlp עם TensorFlow לא נדון ב-codelab הזה, אבל הוא אפשרי.
הדבר הכי חשוב הוא ש-Spark-NLP מרחיב את היכולות של Spark MLlib על ידי אספקת רכיבים שאפשר לשלב בקלות ב-MLlib Pipelines.
7. שיטות מומלצות לעיבוד שפה טבעית
לפני שנוכל לחלץ מידע שימושי מהנתונים שלנו, אנחנו צריכים לבצע כמה פעולות ניקוי. אלה השלבים של העיבוד המקדים שנבצע:
יצירת טוקנים
הדבר הראשון שאנחנו רוצים לעשות בדרך כלל הוא 'ליצור טוקנים' לנתונים. התהליך הזה כולל לקיחת נתונים ופיצול שלהם על סמך 'טוקנים' או מילים. בדרך כלל, בשלב הזה אנחנו מסירים את סימני הפיסוק ומשנים את כל המילים לאותיות קטנות. לדוגמה, נניח שיש לנו את המחרוזת הבאה: What time is it? אחרי טוקניזציה, המשפט הזה יכלול ארבעה טוקנים: what" , "time", "is", "it". אנחנו לא רוצים שהמודל יתייחס למילה what כשתי מילים שונות עם שני סוגי אותיות רישיות שונים. בנוסף, סימני פיסוק בדרך כלל לא עוזרים לנו ללמוד טוב יותר על הסקה מהמילים, ולכן אנחנו מסירים גם אותם.
נירמול
לעתים קרובות אנחנו רוצים לבצע 'נרמול' של הנתונים. המערכת תחליף מילים עם משמעות דומה במילה זהה. לדוגמה, אם המילים fought, battled ו-dueled מזוהות בטקסט, יכול להיות שהנירמול יחליף את המילים battled ו-dueled במילה fought.
Stemming
הגזירה תחליף מילים במשמעות השורש שלהן. לדוגמה, המילים car, cars ו-car's יוחלפו במילה car, כי כל המילים האלה מתייחסות לאותו הדבר.
הסרת מילות עצירה
מילות קישור הן מילים כמו "ו" ו "את" שבדרך כלל לא מוסיפות ערך למשמעות הסמנטית של משפט. בדרך כלל אנחנו רוצים לבצע הסרה שלהם כדי להפחית את הרעש בקבוצות הנתונים של הטקסט.
8. התקדמות בתהליך
בואו נסתכל על המשימה שאנחנו הולכים להפעיל. הקוד זמין בכתובת cloud-dataproc/codelabs/spark-nlp/topic_model.py. כדאי להקדיש כמה דקות לקריאת התגובות כדי להבין מה קורה. בהמשך נדגיש גם כמה מהסעיפים:
# Python imports
import sys
# spark-nlp components. Each one is incorporated into our pipeline.
from sparknlp.annotator import Lemmatizer, Stemmer, Tokenizer, Normalizer
from sparknlp.base import DocumentAssembler, Finisher
# A Spark Session is how we interact with Spark SQL to create Dataframes
from pyspark.sql import SparkSession
# These allow us to create a schema for our data
from pyspark.sql.types import StructField, StructType, StringType, LongType
# Spark Pipelines allow us to sequentially add components such as transformers
from pyspark.ml import Pipeline
# These are components we will incorporate into our pipeline.
from pyspark.ml.feature import StopWordsRemover, CountVectorizer, IDF
# LDA is our model of choice for topic modeling
from pyspark.ml.clustering import LDA
# Some transformers require the usage of other Spark ML functions. We import them here
from pyspark.sql.functions import col, lit, concat
# This will help catch some PySpark errors
from pyspark.sql.utils import AnalysisException
# Assign bucket where the data lives
try:
bucket = sys.argv[1]
except IndexError:
print("Please provide a bucket name")
sys.exit(1)
# Create a SparkSession under the name "reddit". Viewable via the Spark UI
spark = SparkSession.builder.appName("reddit topic model").getOrCreate()
# Create a three column schema consisting of two strings and a long integer
fields = [StructField("title", StringType(), True),
StructField("body", StringType(), True),
StructField("created_at", LongType(), True)]
schema = StructType(fields)
# We'll attempt to process every year / month combination below.
years = ['2016', '2017', '2018', '2019']
months = ['01', '02', '03', '04', '05', '06',
'07', '08', '09', '10', '11', '12']
# This is the subreddit we're working with.
subreddit = "food"
# Create a base dataframe.
reddit_data = spark.createDataFrame([], schema)
# Keep a running list of all files that will be processed
files_read = []
for year in years:
for month in months:
# In the form of <project-id>.<dataset>.<table>
gs_uri = f"gs://{bucket}/reddit_posts/{year}/{month}/{subreddit}.csv.gz"
# If the table doesn't exist we will simply continue and not
# log it into our "tables_read" list
try:
reddit_data = (
spark.read.format('csv')
.options(codec="org.apache.hadoop.io.compress.GzipCodec")
.load(gs_uri, schema=schema)
.union(reddit_data)
)
files_read.append(gs_uri)
except AnalysisException:
continue
if len(files_read) == 0:
print('No files read')
sys.exit(1)
# Replacing null values with their respective typed-equivalent is usually
# easier to work with. In this case, we'll replace nulls with empty strings.
# Since some of our data doesn't have a body, we can combine all of the text
# for the titles and bodies so that every row has useful data.
df_train = (
reddit_data
# Replace null values with an empty string
.fillna("")
.select(
# Combine columns
concat(
# First column to concatenate. col() is used to specify that we're referencing a column
col("title"),
# Literal character that will be between the concatenated columns.
lit(" "),
# Second column to concatenate.
col("body")
# Change the name of the new column
).alias("text")
)
)
# Now, we begin assembling our pipeline. Each component here is used to some transformation to the data.
# The Document Assembler takes the raw text data and convert it into a format that can
# be tokenized. It becomes one of spark-nlp native object types, the "Document".
document_assembler = DocumentAssembler().setInputCol("text").setOutputCol("document")
# The Tokenizer takes data that is of the "Document" type and tokenizes it.
# While slightly more involved than this, this is effectively taking a string and splitting
# it along ths spaces, so each word is its own string. The data then becomes the
# spark-nlp native type "Token".
tokenizer = Tokenizer().setInputCols(["document"]).setOutputCol("token")
# The Normalizer will group words together based on similar semantic meaning.
normalizer = Normalizer().setInputCols(["token"]).setOutputCol("normalizer")
# The Stemmer takes objects of class "Token" and converts the words into their
# root meaning. For instance, the words "cars", "cars'" and "car's" would all be replaced
# with the word "car".
stemmer = Stemmer().setInputCols(["normalizer"]).setOutputCol("stem")
# The Finisher signals to spark-nlp allows us to access the data outside of spark-nlp
# components. For instance, we can now feed the data into components from Spark MLlib.
finisher = Finisher().setInputCols(["stem"]).setOutputCols(["to_spark"]).setValueSplitSymbol(" ")
# Stopwords are common words that generally don't add much detail to the meaning
# of a body of text. In English, these are mostly "articles" such as the words "the"
# and "of".
stopword_remover = StopWordsRemover(inputCol="to_spark", outputCol="filtered")
# Here we implement TF-IDF as an input to our LDA model. CountVectorizer (TF) keeps track
# of the vocabulary that's being created so we can map our topics back to their
# corresponding words.
# TF (term frequency) creates a matrix that counts how many times each word in the
# vocabulary appears in each body of text. This then gives each word a weight based
# on its frequency.
tf = CountVectorizer(inputCol="filtered", outputCol="raw_features")
# Here we implement the IDF portion. IDF (Inverse document frequency) reduces
# the weights of commonly-appearing words.
idf = IDF(inputCol="raw_features", outputCol="features")
# LDA creates a statistical representation of how frequently words appear
# together in order to create "topics" or groups of commonly appearing words.
lda = LDA(k=10, maxIter=10)
# We add all of the transformers into a Pipeline object. Each transformer
# will execute in the ordered provided to the "stages" parameter
pipeline = Pipeline(
stages = [
document_assembler,
tokenizer,
normalizer,
stemmer,
finisher,
stopword_remover,
tf,
idf,
lda
]
)
# We fit the data to the model.
model = pipeline.fit(df_train)
# Now that we have completed a pipeline, we want to output the topics as human-readable.
# To do this, we need to grab the vocabulary generated from our pipeline, grab the topic
# model and do the appropriate mapping. The output from each individual component lives
# in the model object. We can access them by referring to them by their position in
# the pipeline via model.stages[<ind>]
# Let's create a reference our vocabulary.
vocab = model.stages[-3].vocabulary
# Next, let's grab the topics generated by our LDA model via describeTopics(). Using collect(),
# we load the output into a Python array.
raw_topics = model.stages[-1].describeTopics().collect()
# Lastly, let's get the indices of the vocabulary terms from our topics
topic_inds = [ind.termIndices for ind in raw_topics]
# The indices we just grab directly map to the term at position <ind> from our vocabulary.
# Using the below code, we can generate the mappings from our topic indices to our vocabulary.
topics = []
for topic in topic_inds:
_topic = []
for ind in topic:
_topic.append(vocab[ind])
topics.append(_topic)
# Let's see our topics!
for i, topic in enumerate(topics, start=1):
print(f"topic {i}: {topic}")
הרצת המשימה
עכשיו נריץ את העבודה. מריצים את הפקודה הבאה:
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME}\
--region ${REGION}\
--properties=spark.jars.packages=com.johnsnowlabs.nlp:spark-nlp_2.11:2.7.2\
--driver-log-levels root=FATAL \
topic_model.py \
-- ${BUCKET_NAME}
הפקודה הזו מאפשרת לנו להשתמש ב-Dataproc Jobs API. הכללת הפקודה pyspark מציינת לאשכול שמדובר בעבודת PySpark. אנחנו מספקים את שם האשכול, פרמטרים אופציונליים מתוך הפרמטרים שזמינים כאן ואת שם הקובץ שמכיל את העבודה. במקרה שלנו, אנחנו מספקים את הפרמטר --properties שמאפשר לנו לשנות מאפיינים שונים של Spark, Yarn או Dataproc. אנחנו משנים את מאפיין Spark packages, שמאפשר לנו להודיע ל-Spark שאנחנו רוצים לכלול את spark-nlp כחלק מהעבודה שלנו. אנחנו מספקים גם את הפרמטרים --driver-log-levels root=FATAL שיבטלו את רוב הפלט של היומן מ-PySpark, למעט שגיאות. באופן כללי, יומני Spark נוטים להיות רועשים.
לבסוף, -- ${BUCKET} הוא ארגומנט של שורת הפקודה לסקריפט Python עצמו, שמספק את שם הקטגוריה. שימו לב לרווח בין -- ל-${BUCKET}.
אחרי כמה דקות של הרצת העבודה, אמור להופיע פלט שמכיל את המודלים שלנו:

מדהים!! האם אפשר להסיק מגמות על סמך הפלט של המודל? מה דעתך על שלנו?
מהפלט שלמעלה אפשר להסיק שיש מגמה בנושא 8 שקשור לאוכל לארוחת בוקר, ובנושא 9 שקשור לקינוחים.
9. הסרת המשאבים
כדי למנוע חיובים מיותרים בחשבון GCP אחרי שתסיימו את המדריך למתחילים הזה:
- מוחקים את הקטגוריה של Cloud Storage עבור הסביבה שיצרתם
- מחיקת סביבת Dataproc.
אם יצרתם פרויקט רק בשביל ה-Codelab הזה, אתם יכולים גם למחוק אותו:
- במסוף GCP, נכנסים לדף Projects.
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על מחיקה.
- בתיבה, כותבים את מזהה הפרויקט ולוחצים על Shut down כדי למחוק את הפרויקט.
רישיון
עבודה זו מורשית תחת רישיון Creative Commons שמותנה בייחוס 3.0 גנרי, ורישיון Apache 2.0.