
1. Einführung
In diesem Codelab erfahren Sie, wie Sie die Cloud SQL for MySQL-Integration in Vertex AI verwenden, indem Sie die Vektorsuche mit Vertex AI Embeddings kombinieren.

Voraussetzungen
- Grundkenntnisse in Google Cloud und der Google Cloud Console
- Grundkenntnisse in der Befehlszeile und Cloud Shell
Lerninhalte
- Cloud SQL for PostgreSQL-Instanz bereitstellen
- Datenbank erstellen und Cloud SQL AI-Integration aktivieren
- Daten in die Datenbank laden
- Cloud SQL Studio verwenden
- Vertex AI-Einbettungsmodell in Cloud SQL verwenden
- Vertex AI Studio verwenden
- Ergebnisse mit dem generativen Modell von Vertex AI anreichern
- Leistung mit Vektorindex verbessern
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
- Ein Webbrowser wie Chrome, der die Google Cloud Console und die Cloud Shell unterstützt
2. Einrichtung und Anforderungen
Projekteinrichtung
- Melden Sie sich in der Google Cloud Console an. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.
Verwenden Sie stattdessen ein privates Konto anstelle eines Kontos einer Bildungseinrichtung.
- Erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Klicken Sie zum Erstellen eines neuen Projekts in der Google Cloud Console in der Kopfzeile auf die Schaltfläche „Projekt auswählen“, um ein Pop-up-Fenster zu öffnen.

Klicken Sie im Fenster „Projekt auswählen“ auf die Schaltfläche „Neues Projekt“, um ein Dialogfeld für das neue Projekt zu öffnen.
Geben Sie im Dialogfeld den gewünschten Projektnamen ein und wählen Sie den Speicherort aus.
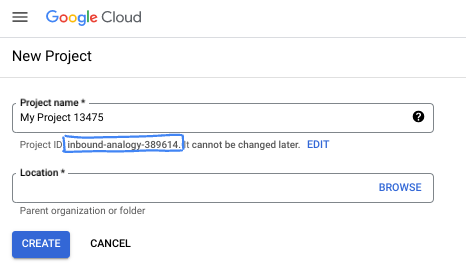
- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Der Projektname wird von Google APIs nicht verwendet und kann jederzeit geändert werden.
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich. Sie kann also nicht mehr geändert werden, nachdem sie festgelegt wurde. In der Google Cloud Console wird automatisch eine eindeutige ID generiert, die Sie aber anpassen können. Wenn Ihnen die generierte ID nicht gefällt, können Sie eine weitere zufällige ID generieren oder eine eigene ID angeben, um die Verfügbarkeit zu prüfen. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen, die in der Regel mit dem Platzhalter PROJECT_ID angegeben wird.
- Zur Information: Es gibt einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten
Abrechnung aktivieren
Sie haben zwei Möglichkeiten, die Abrechnung zu aktivieren. Sie können entweder Ihr privates Abrechnungskonto verwenden oder Guthaben mit den folgenden Schritten einlösen.
Google Cloud-Guthaben einlösen (optional)
Für diesen Workshop benötigen Sie ein Rechnungskonto mit Guthaben. Verwenden Sie die Guthabenpunkte aus dem Banner oben in diesem Codelab, um loszulegen. Wenn Sie bereits mit einem Rechnungskonto verbunden sind, können Sie diesen Schritt überspringen.
Privates Rechnungskonto einrichten
Wenn Sie die Abrechnung mit Google Cloud-Guthaben einrichten, können Sie diesen Schritt überspringen.
Hier können Sie die Abrechnung in der Cloud Console aktivieren, um ein privates Rechnungskonto einzurichten.
Hinweise:
- Die für dieses Lab anfallenden Kosten für Cloud-Ressourcen sollten weniger als 3 $ betragen.
- Sie können die Schritte am Ende dieses Labs ausführen, um Ressourcen zu löschen und so weitere Kosten zu vermeiden.
- Neue Nutzer haben Anspruch auf den kostenlosen Testzeitraum mit einem Guthaben von 300 $.
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:
Alternativ können Sie auch die Tasten „G“ und „S“ drücken. Wenn Sie sich in der Google Cloud Console befinden oder diesen Link verwenden, wird Cloud Shell durch diese Sequenz aktiviert.
Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
3. Hinweis
API aktivieren
Wenn Sie Cloud SQL, Compute Engine, Netzwerkdienste und Vertex AI verwenden möchten, müssen Sie die entsprechenden APIs in Ihrem Google Cloud-Projekt aktivieren.
Prüfen Sie im Cloud Shell-Terminal, ob Ihre Projekt-ID eingerichtet ist:
gcloud config set project [YOUR-PROJECT-ID]
Legen Sie die Umgebungsvariable PROJECT_ID fest:
PROJECT_ID=$(gcloud config get-value project)
Aktivieren Sie alle erforderlichen Dienste:
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Erwartete Ausgabe
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Einführung der APIs
- Mit der Cloud SQL Admin API (
sqladmin.googleapis.com) können Sie Cloud SQL-Instanzen programmatisch erstellen, konfigurieren und verwalten. Sie stellt die Steuerungsebene für den vollständig verwalteten relationalen Datenbankdienst von Google bereit, der MySQL, PostgreSQL und SQL Server unterstützt. Sie übernimmt Aufgaben wie die Bereitstellung, Sicherung, Hochverfügbarkeit und Skalierung. - Mit der Compute Engine API (
compute.googleapis.com) können Sie virtuelle Maschinen (VMs), nichtflüchtige Speicher und Netzwerkeinstellungen erstellen und verwalten. Sie bietet die erforderliche IaaS-Grundlage (Infrastructure-as-a-Service) für die Ausführung Ihrer Arbeitslasten und das Hosting der zugrunde liegenden Infrastruktur für viele verwaltete Dienste. - Mit der Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) können Sie die Metadaten und Konfiguration Ihres Google Cloud-Projekts programmatisch verwalten. Damit können Sie Ressourcen organisieren, IAM-Richtlinien (Identity and Access Management) verarbeiten und Berechtigungen in der gesamten Projekthierarchie validieren. - Mit der Service Networking API (
servicenetworking.googleapis.com) können Sie die Einrichtung privater Verbindungen zwischen Ihrem VPC-Netzwerk (Virtual Private Cloud) und den verwalteten Diensten von Google automatisieren. Er ist insbesondere erforderlich, um den Zugriff über private IP-Adressen für Dienste wie AlloyDB einzurichten, damit diese sicher mit Ihren anderen Ressourcen kommunizieren können. - Mit der Vertex AI API (
aiplatform.googleapis.com) können Sie in Ihren Anwendungen Machine-Learning-Modelle erstellen, bereitstellen und skalieren. Es bietet die einheitliche Schnittstelle für alle KI-Dienste von Google Cloud, einschließlich des Zugriffs auf generative KI-Modelle (wie Gemini) und des benutzerdefinierten Modelltrainings.
4. Cloud SQL-Instanz erstellen
Erstellen Sie eine Cloud SQL-Instanz mit Datenbankeinbindung in Vertex AI.
Datenbankpasswort erstellen
Legen Sie ein Passwort für den Standarddatenbanknutzer fest. Sie können ein eigenes Passwort definieren oder eine Zufallsfunktion verwenden, um eines zu generieren:
export CLOUDSQL_PASSWORD=`openssl rand -hex 12`
Notieren Sie sich den generierten Wert für das Passwort:
echo $CLOUDSQL_PASSWORD
Cloud SQL for MySQL-Instanz erstellen
Das Flag „cloudsql_vector“ kann beim Erstellen einer Instanz aktiviert werden. Die Vektorunterstützung ist derzeit für MySQL 8.0 R20241208.01_00 oder höher verfügbar.
Führen Sie in der Cloud Shell-Sitzung Folgendes aus:
gcloud sql instances create my-cloudsql-instance \
--database-version=MYSQL_8_4 \
--tier=db-custom-2-8192 \
--region=us-central1 \
--enable-google-ml-integration \
--edition=ENTERPRISE \
--root-password=$CLOUDSQL_PASSWORD
Wir können unsere Verbindung über Cloud Shell überprüfen.
gcloud sql connect my-cloudsql-instance --user=root
Führen Sie den Befehl aus und geben Sie Ihr Passwort ein, wenn Sie dazu aufgefordert werden.
Erwartete Ausgabe:
$gcloud sql connect my-cloudsql-instance --user=root Allowlisting your IP for incoming connection for 5 minutes...done. Connecting to database with SQL user [root].Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 71 Server version: 8.4.4-google (Google) Copyright (c) 2000, 2025, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>
Beenden Sie die MySQL-Sitzung vorerst mit der Tastenkombination Strg + D oder mit dem Befehl „exit“.
exit
Vertex AI-Einbindung aktivieren
Gewähren Sie dem internen Cloud SQL-Dienstkonto die erforderlichen Berechtigungen, damit die Vertex AI-Integration verwendet werden kann.
Rufen Sie die E‑Mail-Adresse des internen Cloud SQL-Dienstkontos ab und exportieren Sie sie als Variable.
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe my-cloudsql-instance --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
Gewähren Sie dem Cloud SQL-Dienstkonto Zugriff auf Vertex AI:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" \
--role="roles/aiplatform.user"
Weitere Informationen zum Erstellen und Konfigurieren von Instanzen finden Sie in der Cloud SQL-Dokumentation.
5. Datenbank vorbereiten
Als Nächstes müssen wir eine Datenbank erstellen und die Vektorunterstützung aktivieren.
Datenbank erstellen
Erstellen Sie eine Datenbank mit dem Namen quickstart_db. Dazu haben Sie verschiedene Möglichkeiten, z. B. Befehlszeilen-Datenbankclients wie mysql für MySQL, SDK oder Cloud SQL Studio. Wir verwenden das SDK (gcloud) zum Erstellen der Datenbank.
Führen Sie in Cloud Shell den Befehl zum Erstellen der Datenbank aus.
gcloud sql databases create quickstart_db --instance=my-cloudsql-instance
6. Daten laden
Jetzt müssen wir Objekte in der Datenbank erstellen und Daten laden. Wir verwenden fiktive Daten des Cymbal Store. Die Daten sind im SQL-Format (für das Schema) und im CSV-Format (für die Daten) verfügbar.
Cloud Shell ist unsere Hauptumgebung, um eine Verbindung zu einer Datenbank herzustellen, alle Objekte zu erstellen und die Daten zu laden.
Zuerst müssen wir die öffentliche IP-Adresse unserer Cloud Shell der Liste der autorisierten Netzwerke für unsere Cloud SQL-Instanz hinzufügen. Führen Sie in Cloud Shell folgenden Befehl aus:
gcloud sql instances patch my-cloudsql-instance --authorized-networks=$(curl ifconfig.me)
Wenn Ihre Sitzung verloren gegangen ist, Sie sie zurückgesetzt haben oder Sie mit einem anderen Tool arbeiten, exportieren Sie die Variable CLOUDSQL_PASSWORD noch einmal:
export CLOUDSQL_PASSWORD=...your password defined for the instance...
Jetzt können wir alle erforderlichen Objekte in unserer Datenbank erstellen. Dazu verwenden wir das MySQL-Dienstprogramm mysql in Kombination mit dem Dienstprogramm curl, das die Daten aus der öffentlichen Quelle abruft.
Führen Sie in Cloud Shell folgenden Befehl aus:
export INSTANCE_IP=$(gcloud sql instances describe my-cloudsql-instance --format="value(ipAddresses.ipAddress)")
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_mysql_schema.sql | mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
Was haben wir im vorherigen Befehl genau gemacht? Wir haben eine Verbindung zu unserer Datenbank hergestellt und den heruntergeladenen SQL-Code ausgeführt, wodurch Tabellen, Indexe und Sequenzen erstellt wurden.
Als Nächstes laden Sie die Daten für „cymbal_products“. Wir verwenden dieselben curl- und mysql-Dienstprogramme.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_products.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_products FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
Dann geht es mit „cymbal_stores“ weiter.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_stores.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_stores FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
Außerdem gibt es die Spalte „cymbal_inventory“ mit der Anzahl der einzelnen Produkte in den einzelnen Geschäften.
curl -LJ https://raw.githubusercontent.com/GoogleCloudPlatform/devrel-demos/main/infrastructure/cymbal-store-embeddings/cymbal_inventory.csv | mysql --enable-local-infile --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db -e "LOAD DATA LOCAL INFILE '/dev/stdin' INTO TABLE cymbal_inventory FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '\"' LINES TERMINATED BY '\n' IGNORE 1 LINES;"
Wenn Sie eigene Beispieldaten und CSV-Dateien haben, die mit dem Cloud SQL-Importtool in der Cloud Console kompatibel sind, können Sie diese anstelle des hier beschriebenen Ansatzes verwenden.
7. Einbettungen erstellen
Als Nächstes erstellen wir Einbettungen für unsere Produktbeschreibungen mit dem Modell „textembedding-005“ von Google Vertex AI und speichern sie in der neuen Spalte in der Tabelle „cymbal_products“.
Zum Speichern der Vektordaten müssen wir die Vektorfunktionen in unserer Cloud SQL-Instanz aktivieren. Führen Sie in Cloud Shell Folgendes aus:
gcloud sql instances patch my-cloudsql-instance \
--database-flags=cloudsql_vector=on
Stellen Sie eine Verbindung zur Datenbank her:
mysql --host=$INSTANCE_IP --user=root --password=$CLOUDSQL_PASSWORD quickstart_db
Erstellen Sie mit der Einbettungsfunktion eine neue Spalte embedding in der Tabelle „cymbal_products“. In dieser neuen Spalte werden die Vektoreinbettungen auf Grundlage des Texts in der Spalte product_description gespeichert.
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768) using varbinary;
UPDATE cymbal_products SET embedding = mysql.ml_embedding('text-embedding-005', product_description);
Das Generieren von Vektoreinbettungen für 2.000 Zeilen dauert in der Regel weniger als 5 Minuten, kann aber manchmal etwas länger dauern und ist oft viel schneller abgeschlossen.
8. Ähnlichkeitssuche ausführen
Wir können jetzt unsere Suche mit einer Ähnlichkeitssuche auf Grundlage der Vektorwerte durchführen, die für die Beschreibungen berechnet wurden, und des Vektorwerts, den wir mit demselben Einbettungsmodell für unsere Anfrage generieren.
Die SQL-Abfrage kann über dieselbe Befehlszeilenschnittstelle oder alternativ über Cloud SQL Studio ausgeführt werden. Mehrzeilige und komplexe Abfragen lassen sich am besten in Cloud SQL Studio verwalten.
Nutzer erstellen
Wir benötigen einen neuen Nutzer, der Cloud SQL Studio verwenden kann. Wir erstellen einen Nutzer vom Typ „Schüler“ mit integrierter Authentifizierung und demselben Passwort wie für den Root-Nutzer.
Führen Sie in Cloud Shell Folgendes aus:
gcloud sql users create student --instance=my-cloudsql-instance --password=$CLOUDSQL_PASSWORD --host=%
Cloud SQL Studio starten
Klicken Sie in der Konsole auf die Cloud SQL-Instanz, die wir zuvor erstellt haben.
Wenn es im rechten Bereich geöffnet ist, sehen wir Cloud SQL Studio. Klicke darauf.
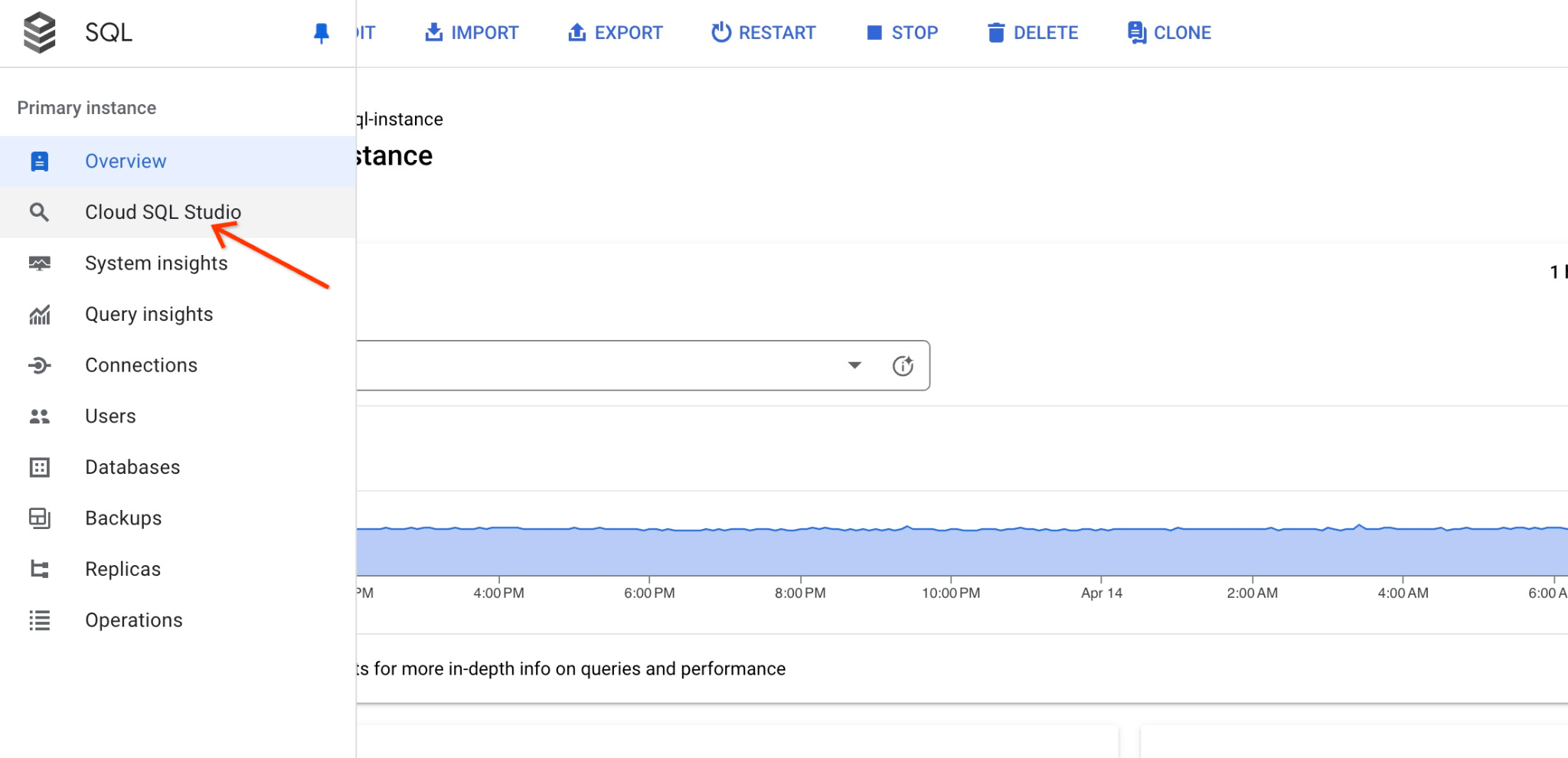
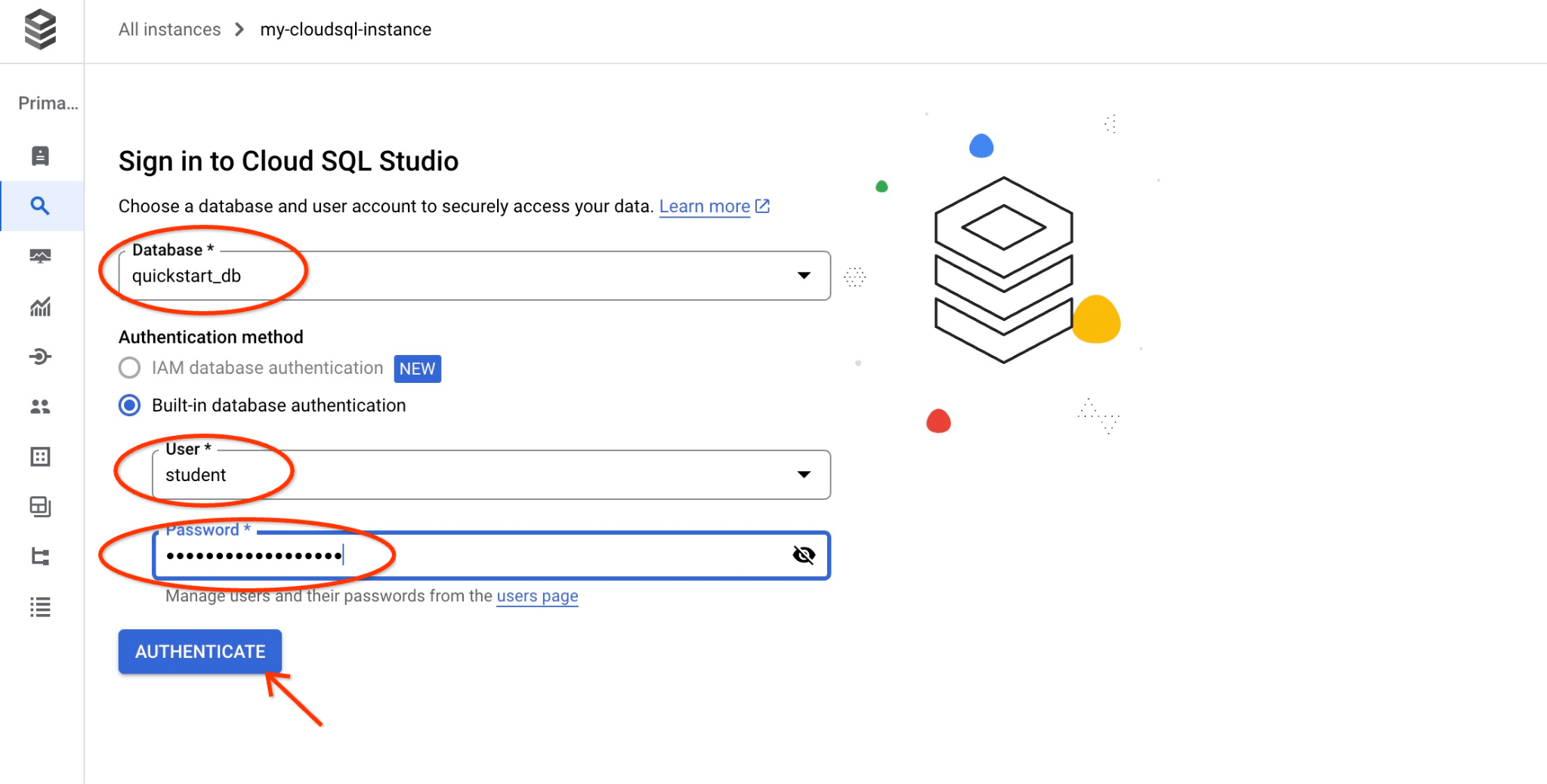
Daraufhin wird ein Dialogfeld geöffnet, in dem Sie den Datenbanknamen und Ihre Anmeldedaten angeben können:
- Datenbank: quickstart_db
- Nutzer: student
- Passwort: Das von Ihnen notierte Passwort für den Nutzer
Klicken Sie auf den Button „AUTHENTICATE“ (AUTHENTIFIZIEREN).
Dadurch wird das nächste Fenster geöffnet. Klicken Sie dort auf der rechten Seite auf den Tab „Editor“, um den SQL-Editor zu öffnen.
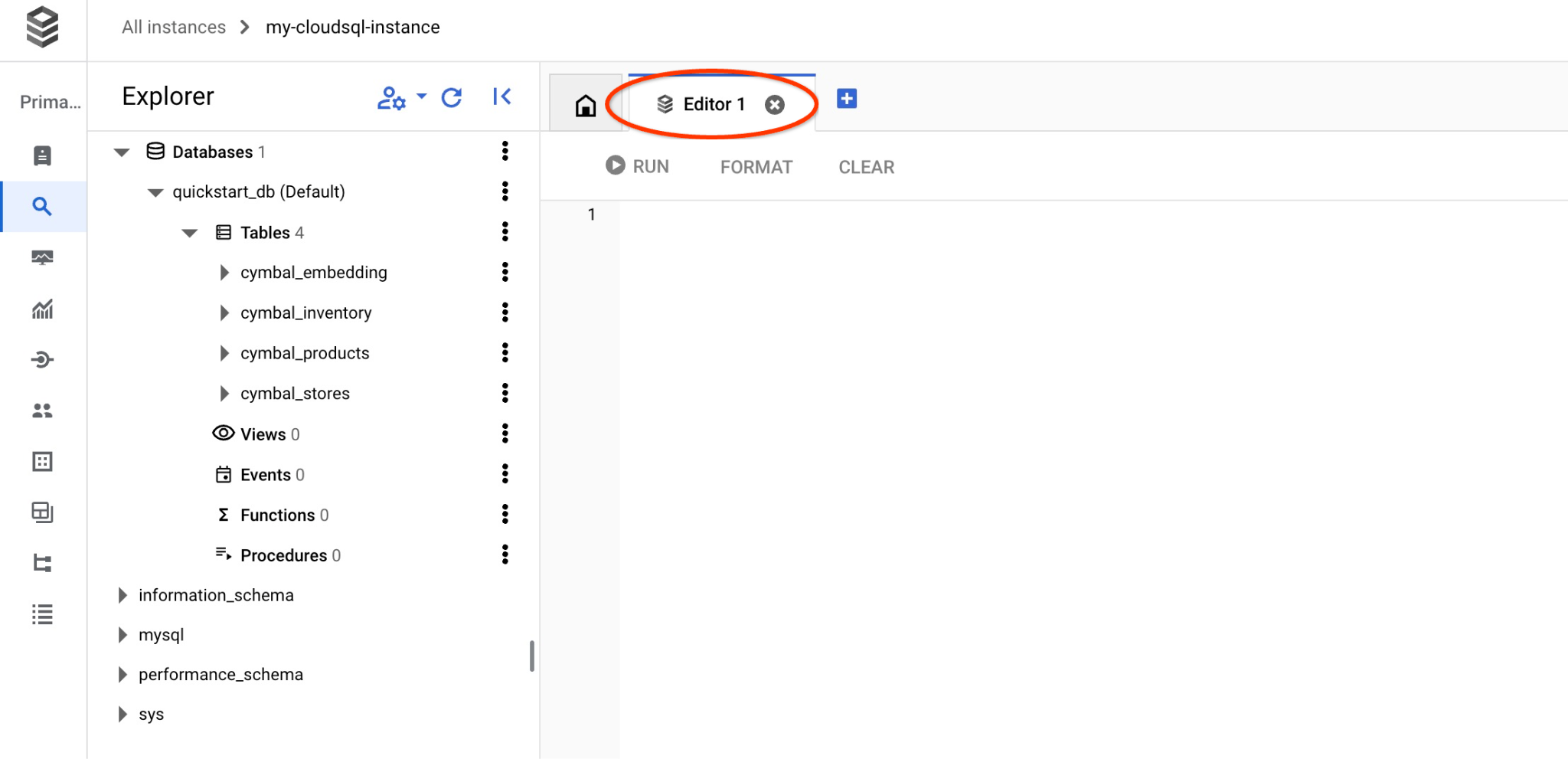
Jetzt können wir unsere Abfragen ausführen.
Abfrage ausführen
Führen Sie eine Abfrage aus, um eine Liste der verfügbaren Produkte zu erhalten, die der Anfrage eines Kunden am ehesten entsprechen. Die Anfrage, die wir an Vertex AI senden, um den Vektorwert zu erhalten, lautet: „Welche Obstbäume wachsen hier gut?“
Abfrage mit cosine_distance für die KNN-Vektorsuche (exakt) ausführen
Hier ist die Abfrage, die Sie ausführen können, um mit der Funktion „cosine_distance“ die fünf am besten geeigneten Elemente für unsere Anfrage auszuwählen:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cosine_distance(cp.embedding ,@query_vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Kopieren Sie die Abfrage und fügen Sie sie in den Cloud SQL Studio-Editor ein. Klicken Sie dann auf „AUSFÜHREN“ oder fügen Sie sie in Ihre Befehlszeilensitzung ein, in der Sie eine Verbindung zur Datenbank „quickstart_db“ herstellen.
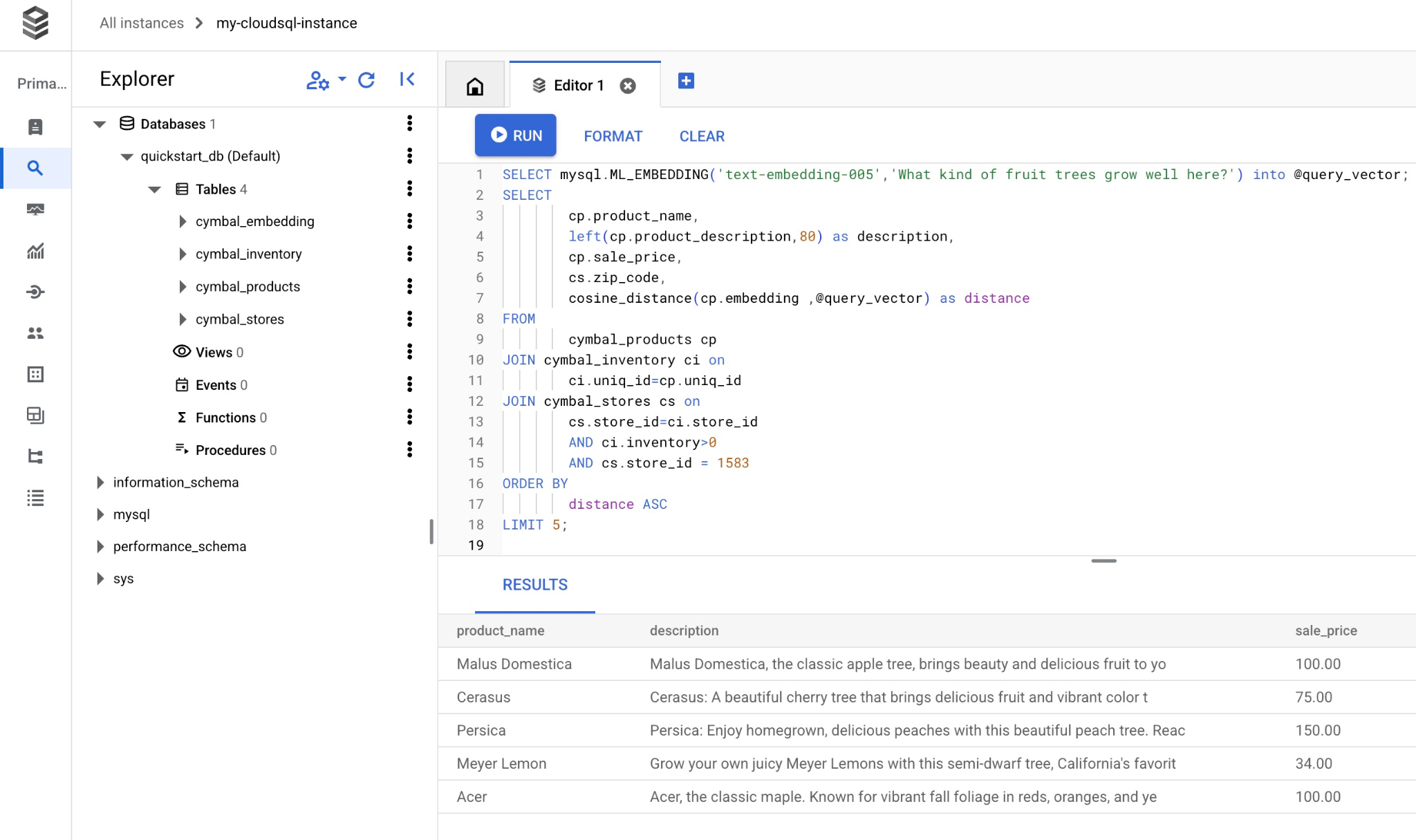
Hier ist eine Liste der Produkte, die der Anfrage entsprechen.
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set (0.13 sec)
Die Ausführung der Abfrage mit der Funktion „cosine_distance“ hat 0,13 Sekunden gedauert.
Abfrage mit „approx_distance“ für die KNN-Vektorsuche (exakt) ausführen
Nun führen wir dieselbe Abfrage aus, aber mit der KNN-Suche mit der Funktion „approx_distance“. Wenn wir keinen ANN-Index für unsere Einbettungen haben, wird im Hintergrund automatisch auf die genaue Suche zurückgegriffen:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Hier ist eine Liste der Produkte, die von der Abfrage zurückgegeben wurden.
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| product_name | description | sale_price | zip_code | distance |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
| Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 |
| Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 |
| Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 |
| Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 |
| Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 |
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+
5 rows in set, 1 warning (0.12 sec)
Die Ausführung der Abfrage hat nur 0,12 Sekunden gedauert. Wir haben dieselben Ergebnisse wie für die Funktion „cosine_distance“ erhalten.
9. LLM-Antwort mit abgerufenen Daten verbessern
Wir können die GenAI-LLM-Antwort auf eine Clientanwendung mithilfe des Ergebnisses der ausgeführten Abfrage verbessern und eine aussagekräftige Ausgabe vorbereiten, indem wir die bereitgestellten Abfrageergebnisse als Teil des Prompts für ein generatives Fundierungs-Sprachmodell von Vertex AI verwenden.
Dazu müssen wir ein JSON mit unseren Ergebnissen aus der Vektorsuche generieren und dieses generierte JSON dann als Ergänzung zu einem Prompt für ein LLM-Modell in Vertex AI verwenden, um eine aussagekräftige Ausgabe zu erstellen. Im ersten Schritt generieren wir das JSON, dann testen wir es in Vertex AI Studio und im letzten Schritt binden wir es in eine SQL-Anweisung ein, die in einer Anwendung verwendet werden kann.
Ausgabe im JSON-Format generieren
Ändern Sie die Abfrage, um die Ausgabe im JSON-Format zu generieren, und geben Sie nur eine Zeile zurück, die an Vertex AI übergeben werden soll.
Hier ist ein Beispiel für die Abfrage mit der ANN-Suche:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1)
SELECT json_arrayagg(json_object('product_name',product_name,'description',description,'sale_price',sale_price,'zip_code',zip_code,'product_id',product_id)) FROM trees;
Und hier ist das erwartete JSON in der Ausgabe:
[{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}]
Prompt in Vertex AI Studio ausführen
Wir können das generierte JSON verwenden, um es als Teil des Prompts für das generative KI-Textmodell in Vertex AI Studio bereitzustellen.
Öffnen Sie den Vertex AI Studio-Prompt in der Cloud Console.
Möglicherweise werden Sie aufgefordert, zusätzliche APIs zu aktivieren. Sie können die Anfrage jedoch ignorieren. Wir benötigen keine zusätzlichen APIs, um das Lab abzuschließen.
Geben Sie einen Prompt in Studio ein.
Das ist der Prompt, den wir verwenden werden:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
[place your JSON here]
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
So sieht es aus, wenn wir den JSON-Platzhalter durch die Antwort auf die Anfrage ersetzen:
You are a friendly advisor helping to find a product based on the customer's needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Here is the list of products:
{"zip_code": 93230, "product_id": "23e41a71d63d8bbc9bdfa1d118cfddc5", "sale_price": 100.00, "description": "Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo", "product_name": "Malus Domestica"}
The customer asked "What tree is growing the best here?"
You should give information about the product, price and some supplemental information.
Do not ask any additional questions and assume location based on the zip code provided in the list of products.
Hier ist das Ergebnis, wenn wir den Prompt mit unseren JSON-Werten und dem Modell „gemini-2.5-flash“ ausführen:
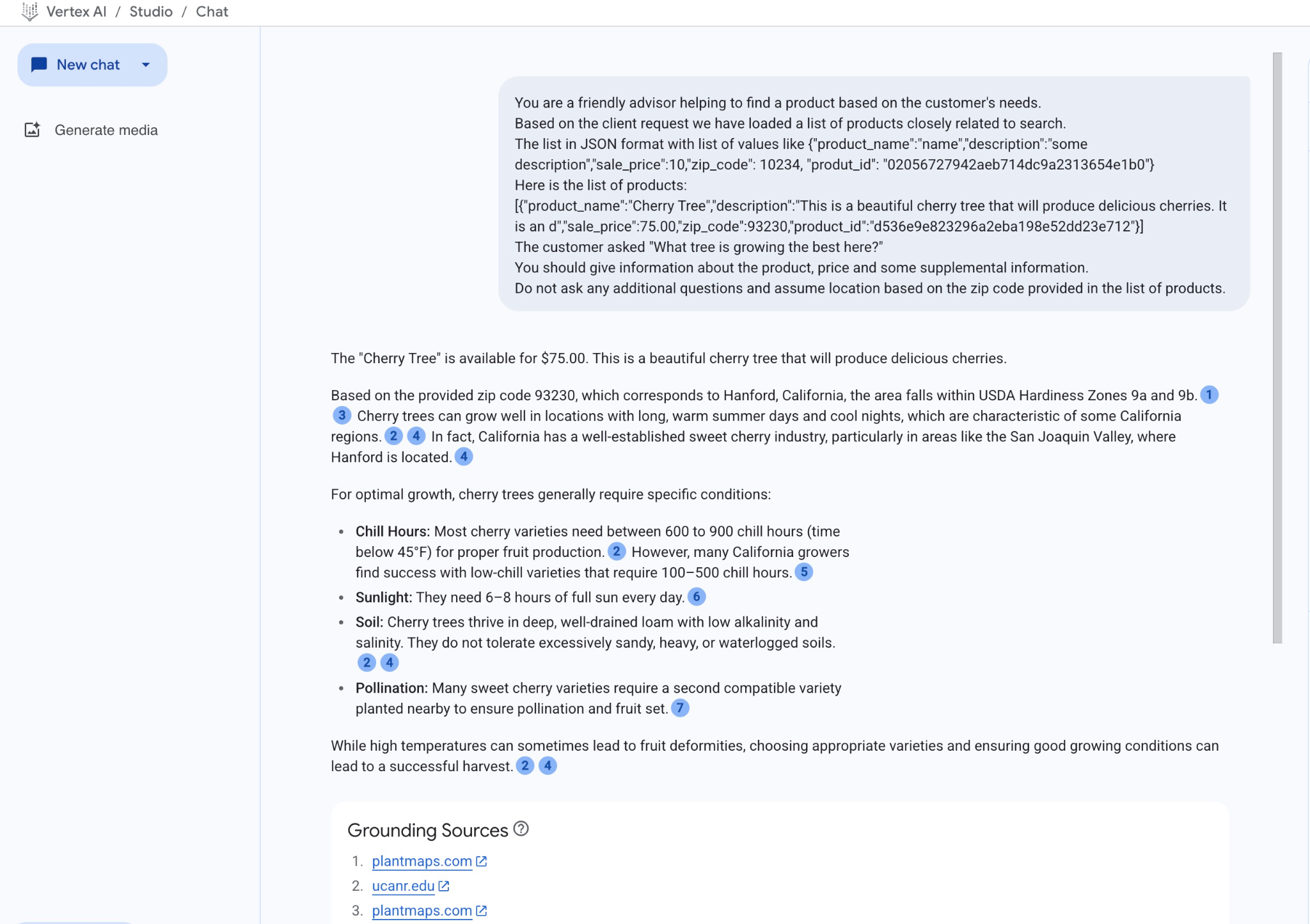
Die Antwort, die wir in diesem Beispiel vom Modell erhalten haben, basiert auf den Ergebnissen der semantischen Suche und dem am besten passenden Produkt, das in der angegebenen Postleitzahl verfügbar ist.
Prompt in SQL ausführen
Wir können die Cloud SQL AI-Integration mit Vertex AI auch verwenden, um die ähnliche Antwort von einem generativen Modell direkt in der Datenbank mit SQL zu erhalten.
Jetzt können wir die generierte Antwort in einer Unterabfrage mit JSON-Ergebnissen verwenden, um sie als Teil des Prompts für das generative KI-Textmodell mit SQL bereitzustellen.
Führen Sie die Abfrage in der MySQL- oder Cloud SQL Studio-Sitzung für die Datenbank aus.
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine')) ASC
LIMIT 1),
prompt AS (
SELECT
CONCAT( 'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:', json_arrayagg(json_object('product_name',trees.product_name,'description',trees.description,'sale_price',trees.sale_price,'zip_code',trees.zip_code,'product_id',trees.product_id)) , 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information') AS prompt_text
FROM
trees),
response AS (
SELECT
mysql.ML_PREDICT_ROW('publishers/google/models/gemini-2.0-flash-001:generateContent',
json_object('contents',
json_object('role',
'user',
'parts',
json_array(
json_object('text',
prompt_text))))) AS resp
FROM
prompt)
SELECT
JSON_EXTRACT(resp, '$.candidates[0].content.parts[0].text')
FROM
response;
Hier sehen Sie die Beispielausgabe. Ihre Ausgabe kann je nach Modellversion und Parametern unterschiedlich ausfallen:
"Okay, I see you're looking for fruit trees that grow well in your area. Based on the available product, the **Malus Domestica** (Apple Tree) is a great option to consider!\n\n* **Product:** Malus Domestica (Apple Tree)\n* **Description:** This classic apple tree grows to about 30 feet tall and provides beautiful seasonal color with green leaves in summer and fiery colors in the fall. It's known for its strength and provides good shade. Most importantly, it produces delicious apples!\n* **Price:** \\$100.00\n* **Growing Zones:** This particular apple tree is well-suited for USDA zones 4-8. Since your zip code is 93230, you are likely in USDA zone 9a or 9b. While this specific tree is rated for zones 4-8, with proper care and variety selection, apple trees can still thrive in slightly warmer climates. You may need to provide extra care during heat waves.\n\n**Recommendation:** I would recommend investigating varieties of Malus Domestica suited to slightly warmer climates or contacting a local nursery/arborist to verify if it is a good fit for your local climate conditions.\n"
Die Ausgabe erfolgt im Markdown-Format.
10. Index für die nächsten Nachbarn erstellen
Unser Dataset ist relativ klein und die Reaktionszeit hängt hauptsächlich von Interaktionen mit KI-Modellen ab. Wenn Sie jedoch Millionen von Vektoren haben, kann die Vektorsuche einen erheblichen Teil unserer Reaktionszeit in Anspruch nehmen und das System stark belasten. Um das zu verbessern, können wir einen Index für unsere Vektoren erstellen.
ScaNN-Index erstellen
Wir verwenden für unseren Test den ScANN-Indextyp.
Um den Index für unsere Einbettungsspalte zu erstellen, müssen wir die Distanzmessung für die Einbettungsspalte definieren. Eine detaillierte Beschreibung der Parameter finden Sie in der Dokumentation.
CREATE VECTOR INDEX cymbal_products_embedding_idx ON cymbal_products(embedding) USING SCANN DISTANCE_MEASURE=COSINE;
Antwort vergleichen
Jetzt können wir die Vektorsuchanfrage noch einmal ausführen und die Ergebnisse ansehen.
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Erwartete Ausgabe:
+-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | product_name | description | sale_price | zip_code | distance | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ | Malus Domestica | Malus Domestica, the classic apple tree, brings beauty and delicious fruit to yo | 100.00 | 93230 | 0.37740096545831603 | | Cerasus | Cerasus: A beautiful cherry tree that brings delicious fruit and vibrant color t | 75.00 | 93230 | 0.405704177142419 | | Persica | Persica: Enjoy homegrown, delicious peaches with this beautiful peach tree. Reac | 150.00 | 93230 | 0.41031799106722877 | | Meyer Lemon | Grow your own juicy Meyer Lemons with this semi-dwarf tree, California's favorit | 34.00 | 93230 | 0.42823360959352186 | | Acer | Acer, the classic maple. Known for vibrant fall foliage in reds, oranges, and ye | 100.00 | 93230 | 0.42953897057301615 | +-----------------+----------------------------------------------------------------------------------+------------+----------+---------------------+ 5 rows in set (0.08 sec)
Die Ausführungszeit hat sich nur geringfügig geändert, was bei einem so kleinen Dataset zu erwarten ist. Bei großen Datasets mit Millionen von Vektoren sollte der Unterschied viel deutlicher zu sehen sein.
Mit dem Befehl EXPLAIN können wir uns den Ausführungsplan ansehen:
SELECT mysql.ML_EMBEDDING('text-embedding-005','What kind of fruit trees grow well here?') into @query_vector;
EXPLAIN ANALYZE SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
approx_distance(cp.embedding ,@query_vector, 'distance_measure=cosine') as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 5;
Ausführungsplan (Ausschnitt):
...
-> Nested loop inner join (cost=443 rows=5) (actual time=1.14..1.18 rows=5 loops=1)
-> Vector index scan on cp (cost=441 rows=5) (actual time=1.1..1.1 rows=5 loops=1)
-> Single-row index lookup on cp using PRIMARY (uniq_id=cp.uniq_id) (cost=0.25 rows=1) (actual time=0.0152..0.0152 rows=1 loops=5)
...
Wir sehen, dass ein Vektorindex-Scan für „cp“ (Alias für die Tabelle „cymbal_products“) verwendet wurde.
Sie können mit Ihren eigenen Daten experimentieren oder verschiedene Suchanfragen testen, um zu sehen, wie die semantische Suche in MySQL funktioniert.
11. Umgebung bereinigen
Cloud SQL-Instanz löschen
Cloud SQL-Instanz löschen, wenn Sie das Lab abgeschlossen haben
Definieren Sie in Cloud Shell die Projekt- und Umgebungsvariablen, wenn die Verbindung getrennt wurde und alle vorherigen Einstellungen verloren gegangen sind:
export INSTANCE_NAME=my-cloudsql-instance
export PROJECT_ID=$(gcloud config get-value project)
Löschen Sie die Instanz:
gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID
Erwartete Konsolenausgabe:
student@cloudshell:~$ gcloud sql instances delete $INSTANCE_NAME --project=$PROJECT_ID All of the instance data will be lost when the instance is deleted. Do you want to continue (Y/n)? y Deleting Cloud SQL instance...done. Deleted [https://sandbox.googleapis.com/v1beta4/projects/test-project-001-402417/instances/my-cloudsql-instance].
12. Glückwunsch
Herzlichen Glückwunsch zum Abschluss des Codelabs.
Google Cloud-Lernpfad
Dieses Lab ist Teil des Lernpfads „Produktionsreife KI mit Google Cloud“.
- Gesamten Lehrplan ansehen
- Teile deinen Fortschritt mit dem Hashtag
#ProductionReadyAI.
Behandelte Themen
- Cloud SQL for PostgreSQL-Instanz bereitstellen
- Datenbank erstellen und Cloud SQL AI-Integration aktivieren
- Daten in die Datenbank laden
- Cloud SQL Studio verwenden
- Vertex AI-Einbettungsmodell in Cloud SQL verwenden
- Vertex AI Studio verwenden
- Ergebnisse mit dem generativen Modell von Vertex AI anreichern
- Leistung mit Vektorindex verbessern
Ähnliches Codelab für AlloyDB oder Codelab für Cloud SQL for Postgres ausprobieren
13. Umfrage
Ausgabe: