
1. Einführung
In diesem Codelab erfahren Sie, wie Sie AlloyDB AI verwenden, indem Sie die Vektorsuche mit Vertex AI-Einbettungen kombinieren. Dieses Lab ist Teil einer Lab-Sammlung, die sich mit AlloyDB AI-Funktionen befasst. Weitere Informationen
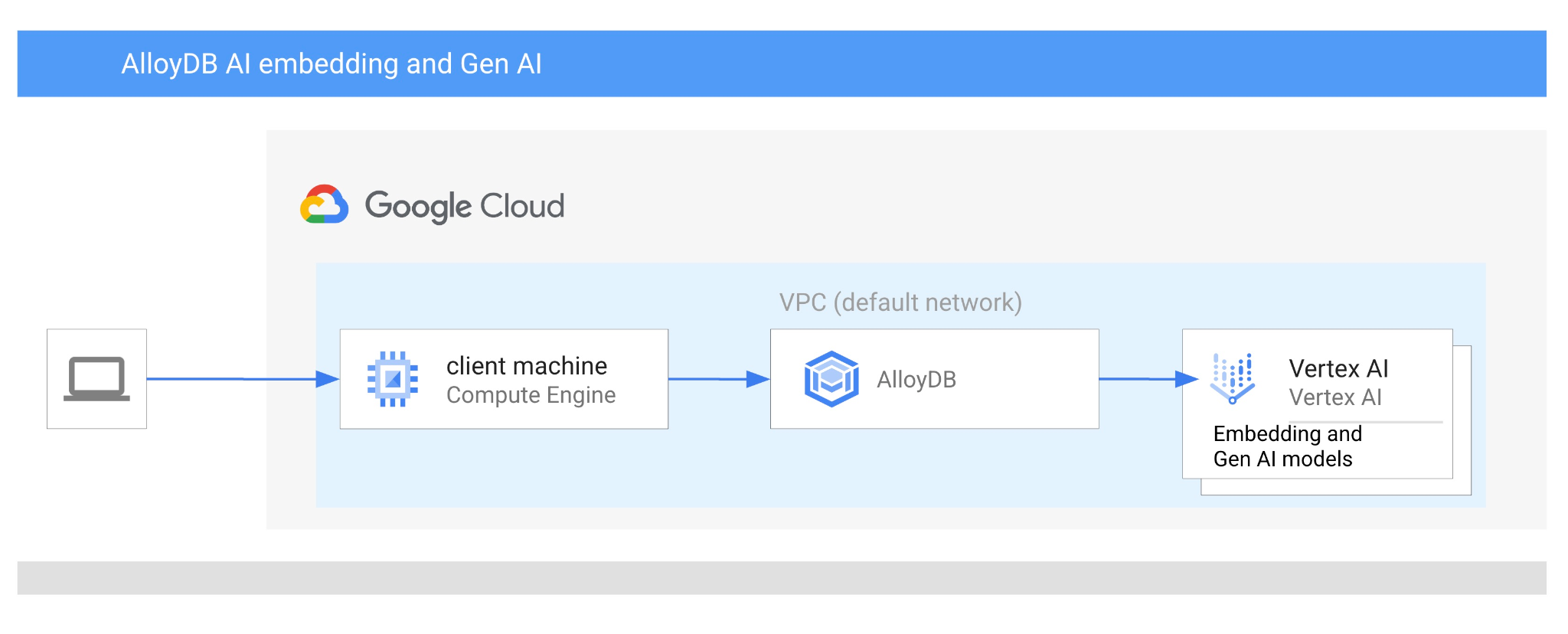
Voraussetzungen
- Grundlegende Kenntnisse der Google Cloud Console
- Grundkenntnisse in der Befehlszeile und Google Shell
Lerninhalte
- AlloyDB-Cluster und primäre Instanz bereitstellen
- Verbindung zu AlloyDB über eine Google Compute Engine-VM herstellen
- Datenbank erstellen und AlloyDB AI aktivieren
- Daten in die Datenbank laden
- AlloyDB Studio verwenden
- Vertex AI-Modell für Einbettungen in AlloyDB verwenden
- Vertex AI Studio verwenden
- Ergebnisse mit dem generativen Modell von Vertex AI anreichern
- Leistung mit Vektorindex verbessern
Voraussetzungen
- Ein Google Cloud-Konto und ein Google Cloud-Projekt
- Ein Webbrowser wie Chrome
2. Einrichtung und Anforderungen
Projekteinrichtung
- Melden Sie sich in der Google Cloud Console an. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.
Verwenden Sie stattdessen ein privates Konto anstelle eines Kontos einer Bildungseinrichtung.
- Erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Klicken Sie zum Erstellen eines neuen Projekts in der Google Cloud Console in der Kopfzeile auf die Schaltfläche „Projekt auswählen“, um ein Pop-up-Fenster zu öffnen.

Klicken Sie im Fenster „Projekt auswählen“ auf die Schaltfläche „Neues Projekt“, um ein Dialogfeld für das neue Projekt zu öffnen.
Geben Sie im Dialogfeld den gewünschten Projektnamen ein und wählen Sie den Speicherort aus.
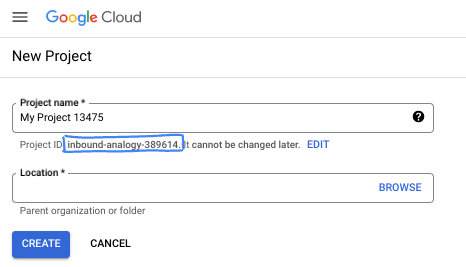
- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Der Projektname wird von Google APIs nicht verwendet und kann jederzeit geändert werden.
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich. Sie kann also nicht mehr geändert werden, nachdem sie festgelegt wurde. In der Google Cloud Console wird automatisch eine eindeutige ID generiert, die Sie aber anpassen können. Wenn Ihnen die generierte ID nicht gefällt, können Sie eine weitere zufällige ID generieren oder eine eigene ID angeben, um die Verfügbarkeit zu prüfen. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen, die in der Regel mit dem Platzhalter PROJECT_ID angegeben wird.
- Zur Information: Es gibt einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten
Abrechnung aktivieren
Sie haben zwei Möglichkeiten, die Abrechnung zu aktivieren. Sie können entweder Ihr privates Abrechnungskonto verwenden oder Guthaben mit den folgenden Schritten einlösen.
Google Cloud-Guthaben einlösen (optional)
Für diesen Workshop benötigen Sie ein Rechnungskonto mit Guthaben. Verwenden Sie die Guthabenpunkte aus dem Banner oben in diesem Codelab, um loszulegen. Wenn Sie bereits mit einem Rechnungskonto verbunden sind, können Sie diesen Schritt überspringen.
Privates Rechnungskonto einrichten
Wenn Sie die Abrechnung mit Google Cloud-Guthaben einrichten, können Sie diesen Schritt überspringen.
Hier können Sie die Abrechnung in der Cloud Console aktivieren, um ein privates Rechnungskonto einzurichten.
Hinweise:
- Die für dieses Lab anfallenden Kosten für Cloud-Ressourcen sollten weniger als 3 $ betragen.
- Sie können die Schritte am Ende dieses Labs ausführen, um Ressourcen zu löschen und so weitere Kosten zu vermeiden.
- Neue Nutzer haben Anspruch auf den kostenlosen Testzeitraum mit einem Guthaben von 300 $.
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Klicken Sie in der Google Cloud Console rechts oben in der Symbolleiste auf das Cloud Shell-Symbol:
Alternativ können Sie auch die Tasten „G“ und „S“ drücken. Wenn Sie sich in der Google Cloud Console befinden oder diesen Link verwenden, wird Cloud Shell durch diese Sequenz aktiviert.
Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern. Anschließend sehen Sie in etwa Folgendes:

Diese virtuelle Maschine verfügt über sämtliche Entwicklertools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Alle Aufgaben in diesem Codelab können in einem Browser ausgeführt werden. Sie müssen nichts installieren.
3. Hinweis
API aktivieren
Ausgabe:
Wenn Sie AlloyDB, Compute Engine, Netzwerkdienste und Vertex AI verwenden möchten, müssen Sie die entsprechenden APIs in Ihrem Google Cloud-Projekt aktivieren.
APIs aktivieren
Prüfen Sie in Cloud Shell im Terminal, ob Ihre Projekt-ID eingerichtet ist:
gcloud config set project [YOUR-PROJECT-ID]
Legen Sie die Umgebungsvariable PROJECT_ID fest:
PROJECT_ID=$(gcloud config get-value project)
Aktivieren Sie alle erforderlichen APIs:
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Erwartete Ausgabe
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
Einführung der APIs
- Mit der AlloyDB API (
alloydb.googleapis.com) können Sie AlloyDB for PostgreSQL-Cluster erstellen, verwalten und skalieren. AlloyDB for PostgreSQL ist ein vollständig verwalteter, PostgreSQL-kompatibler Datenbankdienst für anspruchsvolle Unternehmensarbeitslasten für Transaktionen und Analysen. - Mit der Compute Engine API (
compute.googleapis.com) können Sie virtuelle Maschinen (VMs), nichtflüchtige Speicher und Netzwerkeinstellungen erstellen und verwalten. Sie bietet die erforderliche IaaS-Grundlage (Infrastructure-as-a-Service) für die Ausführung Ihrer Arbeitslasten und das Hosting der zugrunde liegenden Infrastruktur für viele verwaltete Dienste. - Mit der Cloud Resource Manager API (
cloudresourcemanager.googleapis.com) können Sie die Metadaten und Konfiguration Ihres Google Cloud-Projekts programmatisch verwalten. Damit können Sie Ressourcen organisieren, IAM-Richtlinien (Identity and Access Management) verarbeiten und Berechtigungen in der gesamten Projekthierarchie validieren. - Mit der Service Networking API (
servicenetworking.googleapis.com) können Sie die Einrichtung privater Verbindungen zwischen Ihrem VPC-Netzwerk (Virtual Private Cloud) und den verwalteten Diensten von Google automatisieren. Er ist insbesondere erforderlich, um den Zugriff über private IP-Adressen für Dienste wie AlloyDB einzurichten, damit diese sicher mit Ihren anderen Ressourcen kommunizieren können. - Mit der Vertex AI API (
aiplatform.googleapis.com) können Sie in Ihren Anwendungen Machine-Learning-Modelle erstellen, bereitstellen und skalieren. Es bietet die einheitliche Schnittstelle für alle KI-Dienste von Google Cloud, einschließlich des Zugriffs auf generative KI-Modelle (wie Gemini) und des benutzerdefinierten Modelltrainings.
Optional können Sie Ihre Standardregion so konfigurieren, dass die Vertex AI-Einbettungsmodelle verwendet werden. Weitere Informationen zu verfügbaren Standorten für Vertex AI Im Beispiel wird die Region „us-central1“ verwendet.
gcloud config set compute/region us-central1
4. AlloyDB bereitstellen
Bevor wir einen AlloyDB-Cluster erstellen, benötigen wir einen verfügbaren privaten IP-Adressbereich in unserer VPC, der von der zukünftigen AlloyDB-Instanz verwendet werden soll. Wenn wir sie nicht haben, müssen wir sie erstellen, sie zur Verwendung durch interne Google-Dienste zuweisen und erst dann können wir den Cluster und die Instanz erstellen.
Privaten IP-Bereich erstellen
Wir müssen die Konfiguration für den Zugriff auf private Dienste in unserer VPC für AlloyDB konfigurieren. Wir gehen hier davon aus, dass das VPC-Standardnetzwerk im Projekt vorhanden ist und für alle Aktionen verwendet wird.
Erstellen Sie den privaten IP-Bereich:
gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Private Verbindung über den zugewiesenen IP-Bereich erstellen:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ gcloud compute addresses create psa-range \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--description="VPC private service access" \
--network=default
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/global/addresses/psa-range].
student@cloudshell:~ (test-project-402417)$ gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=psa-range \
--network=default
Operation "operations/pssn.p24-4470404856-595e209f-19b7-4669-8a71-cbd45de8ba66" finished successfully.
student@cloudshell:~ (test-project-402417)$
AlloyDB-Cluster erstellen
In diesem Abschnitt erstellen wir einen AlloyDB-Cluster in der Region „us-central1“.
Legen Sie ein Passwort für den Postgres-Nutzer fest. Sie können ein eigenes Passwort definieren oder eine Zufallsfunktion verwenden, um eines zu generieren.
export PGPASSWORD=`openssl rand -hex 12`
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ export PGPASSWORD=`openssl rand -hex 12`
Notieren Sie sich das PostgreSQL-Passwort für die spätere Verwendung.
echo $PGPASSWORD
Sie benötigen dieses Passwort später, um als Postgres-Nutzer eine Verbindung zur Instanz herzustellen. Schreiben Sie sie auf oder kopieren Sie sie, damit Sie sie später verwenden können.
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ echo $PGPASSWORD bbefbfde7601985b0dee5723
Cluster im kostenlosen Testzeitraum erstellen
Wenn Sie AlloyDB noch nicht verwendet haben, können Sie einen kostenlosen Testcluster erstellen:
Legen Sie die Region und den Namen des AlloyDB-Clusters fest. Wir verwenden die Region „us-central1“ und „alloydb-aip-01“ als Clusternamen:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Führen Sie den folgenden Befehl aus, um den Cluster zu erstellen:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Erwartete Konsolenausgabe:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION \
--subscription-type=TRIAL
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Erstellen Sie in derselben Cloud Shell-Sitzung eine primäre AlloyDB-Instanz für unseren Cluster. Wenn die Verbindung getrennt wird, müssen Sie die Umgebungsvariablen für die Region und den Clusternamen noch einmal definieren.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--cluster=$ADBCLUSTER
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=8 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
AlloyDB Standard-Cluster erstellen
Wenn es nicht Ihr erster AlloyDB-Cluster im Projekt ist, fahren Sie mit der Erstellung eines Standardclusters fort.
Legen Sie die Region und den Namen des AlloyDB-Clusters fest. Wir verwenden die Region „us-central1“ und „alloydb-aip-01“ als Clusternamen:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
Führen Sie den folgenden Befehl aus, um den Cluster zu erstellen:
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Erwartete Konsolenausgabe:
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud alloydb clusters create $ADBCLUSTER \
--password=$PGPASSWORD \
--network=default \
--region=$REGION
Operation ID: operation-1697655441138-6080235852277-9e7f04f5-2012fce4
Creating cluster...done.
Erstellen Sie in derselben Cloud Shell-Sitzung eine primäre AlloyDB-Instanz für unseren Cluster. Wenn die Verbindung getrennt wird, müssen Sie die Umgebungsvariablen für die Region und den Clusternamen noch einmal definieren.
gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--cluster=$ADBCLUSTER
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ gcloud alloydb instances create $ADBCLUSTER-pr \
--instance-type=PRIMARY \
--cpu-count=2 \
--region=$REGION \
--availability-type ZONAL \
--cluster=$ADBCLUSTER
Operation ID: operation-1697659203545-6080315c6e8ee-391805db-25852721
Creating instance...done.
5. Verbindung zu AlloyDB herstellen
AlloyDB wird über eine reine private Verbindung bereitgestellt. Daher benötigen wir eine VM mit installiertem PostgreSQL-Client, um mit der Datenbank zu arbeiten.
GCE-VM bereitstellen
Erstellen Sie eine GCE-VM in derselben Region und VPC wie der AlloyDB-Cluster.
Führen Sie in Cloud Shell Folgendes aus:
export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
student@cloudshell:~ (test-project-402417)$ export ZONE=us-central1-a
gcloud compute instances create instance-1 \
--zone=$ZONE \
--create-disk=auto-delete=yes,boot=yes,image=projects/debian-cloud/global/images/$(gcloud compute images list --filter="family=debian-12 AND family!=debian-12-arm64" --format="value(name)") \
--scopes=https://www.googleapis.com/auth/cloud-platform
Created [https://www.googleapis.com/compute/v1/projects/test-project-402417/zones/us-central1-a/instances/instance-1].
NAME: instance-1
ZONE: us-central1-a
MACHINE_TYPE: n1-standard-1
PREEMPTIBLE:
INTERNAL_IP: 10.128.0.2
EXTERNAL_IP: 34.71.192.233
STATUS: RUNNING
Postgres Client installieren
PostgreSQL-Clientsoftware auf der bereitgestellten VM installieren
Stellen Sie eine Verbindung zur VM her.
gcloud compute ssh instance-1 --zone=us-central1-a
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-402417)$ gcloud compute ssh instance-1 --zone=us-central1-a Updating project ssh metadata...working..Updated [https://www.googleapis.com/compute/v1/projects/test-project-402417]. Updating project ssh metadata...done. Waiting for SSH key to propagate. Warning: Permanently added 'compute.5110295539541121102' (ECDSA) to the list of known hosts. Linux instance-1.us-central1-a.c.gleb-test-short-001-418811.internal 6.1.0-18-cloud-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.76-1 (2024-02-01) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. student@instance-1:~$
Installieren Sie die Software, indem Sie den folgenden Befehl in der VM ausführen:
sudo apt-get update
sudo apt-get install --yes postgresql-client
Erwartete Konsolenausgabe:
student@instance-1:~$ sudo apt-get update sudo apt-get install --yes postgresql-client Get:1 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable InRelease [5146 B] Get:2 https://packages.cloud.google.com/apt cloud-sdk-bullseye InRelease [6406 B] Hit:3 https://deb.debian.org/debian bullseye InRelease Get:4 https://deb.debian.org/debian-security bullseye-security InRelease [48.4 kB] Get:5 https://packages.cloud.google.com/apt google-compute-engine-bullseye-stable/main amd64 Packages [1930 B] Get:6 https://deb.debian.org/debian bullseye-updates InRelease [44.1 kB] Get:7 https://deb.debian.org/debian bullseye-backports InRelease [49.0 kB] ...redacted... update-alternatives: using /usr/share/postgresql/13/man/man1/psql.1.gz to provide /usr/share/man/man1/psql.1.gz (psql.1.gz) in auto mode Setting up postgresql-client (13+225) ... Processing triggers for man-db (2.9.4-2) ... Processing triggers for libc-bin (2.31-13+deb11u7) ...
Verbindung zur Instanz herstellen
Stellen Sie mit psql eine Verbindung zur primären Instanz von der VM aus her.
Auf demselben Cloud Shell-Tab mit der geöffneten SSH-Sitzung zur VM „instance-1“.
Verwenden Sie den angegebenen AlloyDB-Passwortwert (PGPASSWORD) und die AlloyDB-Cluster-ID, um von der GCE-VM aus eine Verbindung zu AlloyDB herzustellen:
export PGPASSWORD=<Noted password>
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)")
psql "host=$INSTANCE_IP user=postgres sslmode=require"
Erwartete Konsolenausgabe:
student@instance-1:~$ export PGPASSWORD=CQhOi5OygD4ps6ty student@instance-1:~$ ADBCLUSTER=alloydb-aip-01 student@instance-1:~$ REGION=us-central1 student@instance-1:~$ INSTANCE_IP=$(gcloud alloydb instances describe $ADBCLUSTER-pr --cluster=$ADBCLUSTER --region=$REGION --format="value(ipAddress)") gleb@instance-1:~$ psql "host=$INSTANCE_IP user=postgres sslmode=require" psql (15.6 (Debian 15.6-0+deb12u1), server 15.5) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, compression: off) Type "help" for help. postgres=>
Schließen Sie die psql-Sitzung:
exit
6. Datenbank vorbereiten
Wir müssen eine Datenbank erstellen, die Vertex AI-Integration aktivieren, Datenbankobjekte erstellen und die Daten importieren.
Erforderliche Berechtigungen für AlloyDB erteilen
Fügen Sie dem AlloyDB-Dienst-Agent Vertex AI-Berechtigungen hinzu.
Öffnen Sie oben über das Pluszeichen (+) einen weiteren Cloud Shell-Tab.
Führen Sie im neuen Cloud Shell-Tab Folgendes aus:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project) Your active configuration is: [cloudshell-11039] student@cloudshell:~ (test-project-001-402417)$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \ --role="roles/aiplatform.user" Updated IAM policy for project [test-project-001-402417]. bindings: - members: - serviceAccount:service-4470404856@gcp-sa-alloydb.iam.gserviceaccount.com role: roles/aiplatform.user - members: ... etag: BwYIEbe_Z3U= version: 1
Schließen Sie den Tab, indem Sie den Befehl „exit“ auf dem Tab ausführen:
exit
Datenbank erstellen
Schnellstart: Datenbank erstellen
Führen Sie in der GCE-VM-Sitzung Folgendes aus:
Datenbank erstellen:
psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db"
Erwartete Konsolenausgabe:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres" -c "CREATE DATABASE quickstart_db" CREATE DATABASE student@instance-1:~$
Vertex AI-Integration aktivieren
Aktivieren Sie die Vertex AI-Einbindung und die pgvector-Erweiterungen in der Datenbank.
Führen Sie auf der GCE-VM Folgendes aus:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE"
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector"
Erwartete Konsolenausgabe:
student@instance-1:~$ psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE" psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "CREATE EXTENSION IF NOT EXISTS vector" CREATE EXTENSION CREATE EXTENSION student@instance-1:~$
Daten importieren
Laden Sie die vorbereiteten Daten herunter und importieren Sie sie in die neue Datenbank.
Führen Sie auf der GCE-VM Folgendes aus:
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header"
gcloud storage cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header"
Erwartete Konsolenausgabe:
student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_demo_schema.sql |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" SET SET SET SET SET set_config ------------ (1 row) SET SET SET SET SET SET CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE TABLE ALTER TABLE CREATE SEQUENCE ALTER TABLE ALTER SEQUENCE ALTER TABLE ALTER TABLE ALTER TABLE student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_products.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_products from stdin csv header" COPY 941 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_inventory.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_inventory from stdin csv header" COPY 263861 student@instance-1:~$ gsutil cat gs://cloud-training/gcc/gcc-tech-004/cymbal_stores.csv |psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db" -c "\copy cymbal_stores from stdin csv header" COPY 4654 student@instance-1:~$
7. Einbettungen berechnen
Nach dem Import der Daten haben wir unsere Produktdaten in der Tabelle „cymbal_products“, das Inventar mit der Anzahl der verfügbaren Produkte in jedem Geschäft in der Tabelle „cymbal_inventory“ und die Liste der Geschäfte in der Tabelle „cymbal_stores“ erhalten. Wir müssen die Vektordaten anhand von Beschreibungen für unsere Produkte berechnen. Dazu verwenden wir die Funktion embedding. Mit der Funktion verwenden wir die Vertex AI-Integration, um Vektordaten basierend auf den Produktbeschreibungen zu berechnen und der Tabelle hinzuzufügen. Weitere Informationen zur verwendeten Technologie finden Sie in der Dokumentation.
Das ist für einige wenige Zeilen einfach, aber wie kann man es effizient gestalten, wenn es Tausende sind? Hier wird gezeigt, wie Sie Einbettungen für große Tabellen generieren und verwalten. Weitere Informationen zu den verschiedenen Optionen und Techniken
Schnelle Generierung von Einbettungen aktivieren
Stellen Sie über psql von Ihrer VM aus eine Verbindung zur Datenbank her. Verwenden Sie dazu die IP-Adresse der AlloyDB-Instanz und das Postgres-Passwort:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Prüfen Sie die Version der Erweiterung „google_ml_integration“.
SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration';
Die Version sollte 1.5.2 oder höher sein. Hier ein Beispiel für die Ausgabe:
quickstart_db=> SELECT extversion FROM pg_extension WHERE extname = 'google_ml_integration'; extversion ------------ 1.5.2 (1 row)
Die Standardversion sollte 1.5.2 oder höher sein. Wenn in Ihrer Instanz eine ältere Version angezeigt wird, muss sie wahrscheinlich aktualisiert werden. Prüfen Sie, ob die Wartung für die Instanz deaktiviert wurde.
Dann müssen wir das Datenbank-Flag bestätigen. Das Flag „google_ml_integration.enable_faster_embedding_generation“ muss aktiviert sein. Prüfen Sie in derselben psql-Sitzung den Wert des Flags.
show google_ml_integration.enable_faster_embedding_generation;
Wenn das Flag an der richtigen Position ist, sieht die erwartete Ausgabe so aus:
quickstart_db=> show google_ml_integration.enable_faster_embedding_generation; google_ml_integration.enable_faster_embedding_generation ---------------------------------------------------------- on (1 row)
Wenn „Aus“ angezeigt wird, müssen wir die Instanz aktualisieren. Sie können dies über die Webkonsole oder mit dem gcloud-Befehl tun, wie in der Dokumentation beschrieben. Hier sehen Sie, wie Sie das mit dem gcloud-Befehl tun können:
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Es kann einige Minuten dauern, bis der Flag-Wert auf „on“ umgestellt wird. Danach können Sie mit den nächsten Schritten fortfahren.
Einbettungsspalte erstellen
Stellen Sie mit psql eine Verbindung zur Datenbank her und erstellen Sie in der Tabelle „cymbal_products“ mit der Einbettungsfunktion eine virtuelle Spalte mit den Vektordaten. Die Einbettungsfunktion gibt Vektordaten aus Vertex AI basierend auf den Daten aus der Spalte „product_description“ zurück.
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Führen Sie in der psql-Sitzung nach dem Herstellen der Verbindung zur Datenbank Folgendes aus:
ALTER TABLE cymbal_products ADD COLUMN embedding vector(768);
Mit dem Befehl wird die virtuelle Spalte erstellt und mit Vektordaten gefüllt.
Erwartete Konsolenausgabe:
quickstart_db=> ALTER TABLE cymbal_products ADD COLUMN embedding vector(768); ALTER TABLE quickstart_db=>
Jetzt können wir Einbettungen mit Batches mit jeweils 50 Zeilen generieren. Sie können mit verschiedenen Batchgrößen experimentieren und sehen, ob sich die Ausführungszeit ändert. Führen Sie in derselben psql-Sitzung Folgendes aus:
Aktivieren Sie die Zeitmessung, um zu ermitteln, wie viel Zeit benötigt wird:
\timing
Führen Sie diesen Befehl aus:
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
Die Konsolenausgabe zeigt, dass die Einbettung in weniger als 2 Sekunden generiert wurde:
quickstart_db=> CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'embedding',
batch_size => 50
);
NOTICE: Initialize embedding completed successfully for table cymbal_products
CALL
Time: 1458.704 ms (00:01.459)
quickstart_db=>
Standardmäßig werden die Einbettungen nicht aktualisiert, wenn die entsprechende Spalte „product_description“ aktualisiert wird oder eine neue Zeile eingefügt wird. Sie können dies jedoch tun, indem Sie den Parameter incremental_refresh_mode definieren. Wir erstellen eine Spalte namens product_embeddings, die automatisch aktualisiert werden kann.
ALTER TABLE cymbal_products ADD COLUMN product_embedding vector(768);
CALL ai.initialize_embeddings(
model_id => 'text-embedding-005',
table_name => 'cymbal_products',
content_column => 'product_description',
embedding_column => 'product_embedding',
batch_size => 50,
incremental_refresh_mode => 'transactional'
);
Wenn wir jetzt eine neue Zeile in die Tabelle einfügen,
INSERT INTO "cymbal_products" ("uniq_id", "crawl_timestamp", "product_url", "product_name", "product_description", "list_price", "sale_price", "brand", "item_number", "gtin", "package_size", "category", "postal_code", "available", "product_embedding", "embedding") VALUES ('fd604542e04b470f9e6348e640cff794', NOW(), 'https://example.com/new_product', 'New Cymbal Product', 'This is a new cymbal product description.', 199.99, 149.99, 'Example Brand', 'EB123', '1234567890', 'Single', 'Cymbals', '12345', TRUE, NULL, NULL);
Mit der folgenden Abfrage können wir den Unterschied zwischen den Spalten vergleichen:
SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
In der Ausgabe sehen wir, dass die Spalte embedding leer bleibt, während die Spalte product_embedding automatisch aktualisiert wird.
quickstart_db=> SELECT uniq_id,embedding, (product_embedding::real[])[1:5] as product_embedding FROM cymbal_products WHERE uniq_id='fd604542e04b470f9e6348e640cff794';
uniq_id | embedding | product_embedding
----------------------------------+-----------+---------------------------------------------------------------
fd604542e04b470f9e6348e640cff794 | | {0.015003494,-0.005349732,-0.059790313,-0.0087091,-0.0271452}
(1 row)
Time: 3.295 ms
8. Ähnlichkeitssuche ausführen
Wir können jetzt unsere Suche mit der Ähnlichkeitssuche basierend auf Vektorwerten ausführen, die für die Beschreibungen und den Vektorwert berechnet wurden, den wir für unsere Anfrage erhalten.
Die SQL-Abfrage kann über dieselbe psql-Befehlszeilenschnittstelle oder alternativ über AlloyDB Studio ausgeführt werden. Mehrzeilige und komplexe Ausgaben werden in AlloyDB Studio möglicherweise besser dargestellt.
Verbindung zu AlloyDB Studio herstellen
In den folgenden Kapiteln können alle SQL-Befehle, für die eine Verbindung zur Datenbank erforderlich ist, alternativ in AlloyDB Studio ausgeführt werden. Um den Befehl auszuführen, müssen Sie die Webkonsolenschnittstelle für Ihren AlloyDB-Cluster öffnen. Klicken Sie dazu auf die primäre Instanz.
Klicken Sie dann links auf AlloyDB Studio:
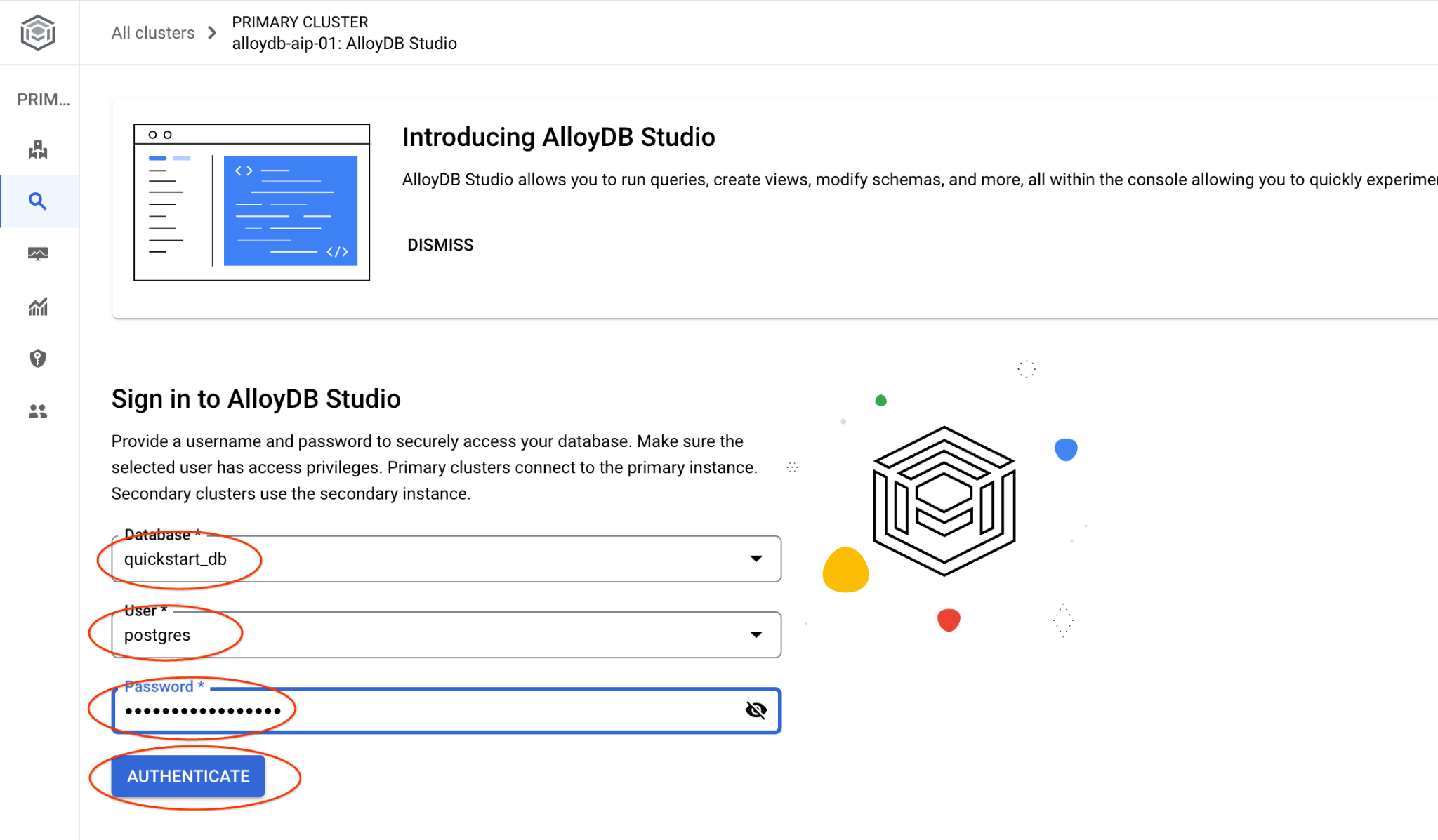
Wählen Sie die Datenbank „quickstart_db“ und den Nutzer „postgres“ aus und geben Sie das Passwort an, das beim Erstellen des Clusters angegeben wurde. Klicken Sie dann auf die Schaltfläche „Authentifizieren“.
Die AlloyDB Studio-Benutzeroberfläche wird geöffnet. Wenn Sie die Befehle in der Datenbank ausführen möchten, klicken Sie rechts auf den Tab „Editor 1“.
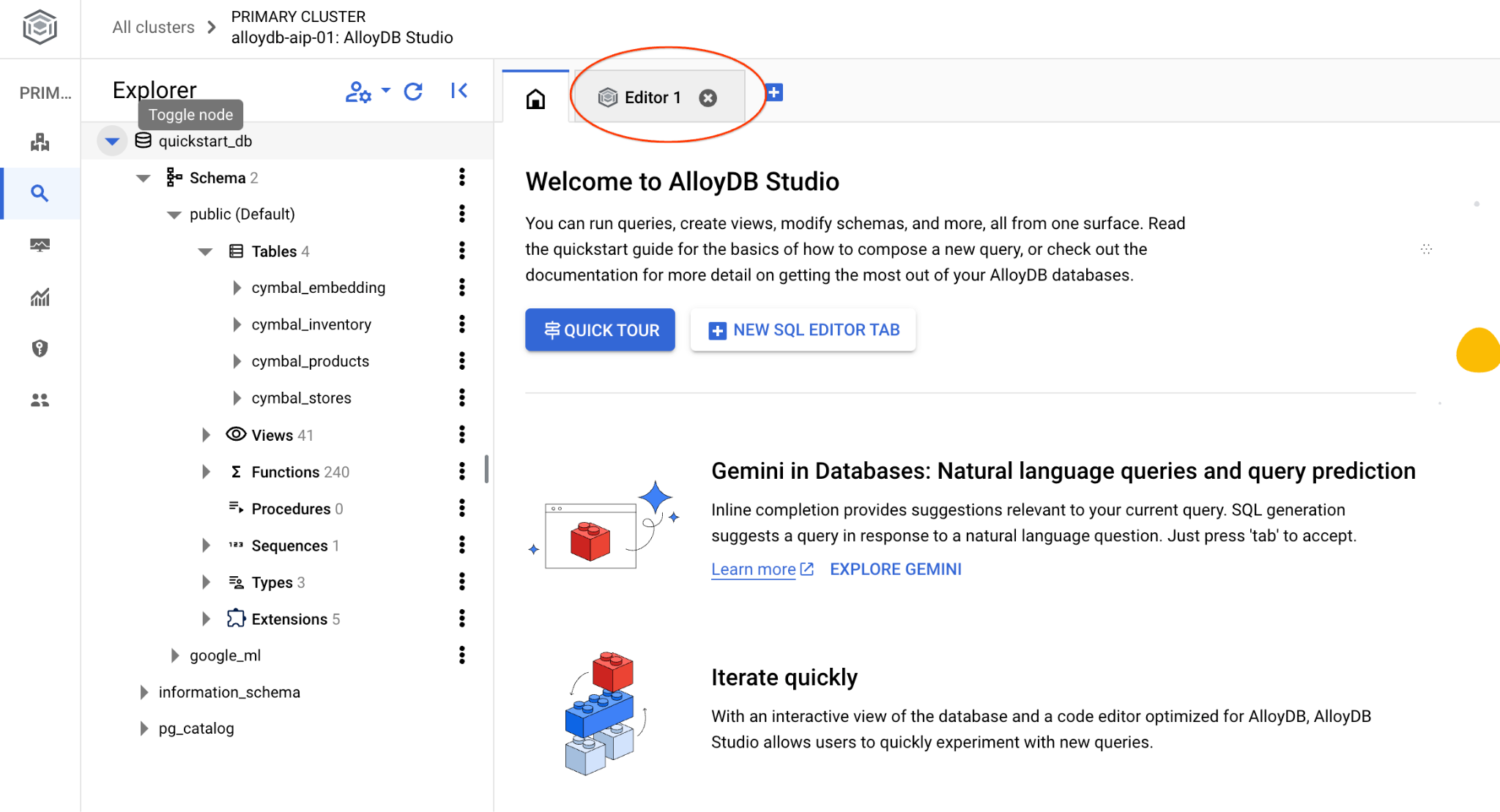
Dadurch wird eine Schnittstelle geöffnet, in der Sie SQL-Befehle ausführen können.
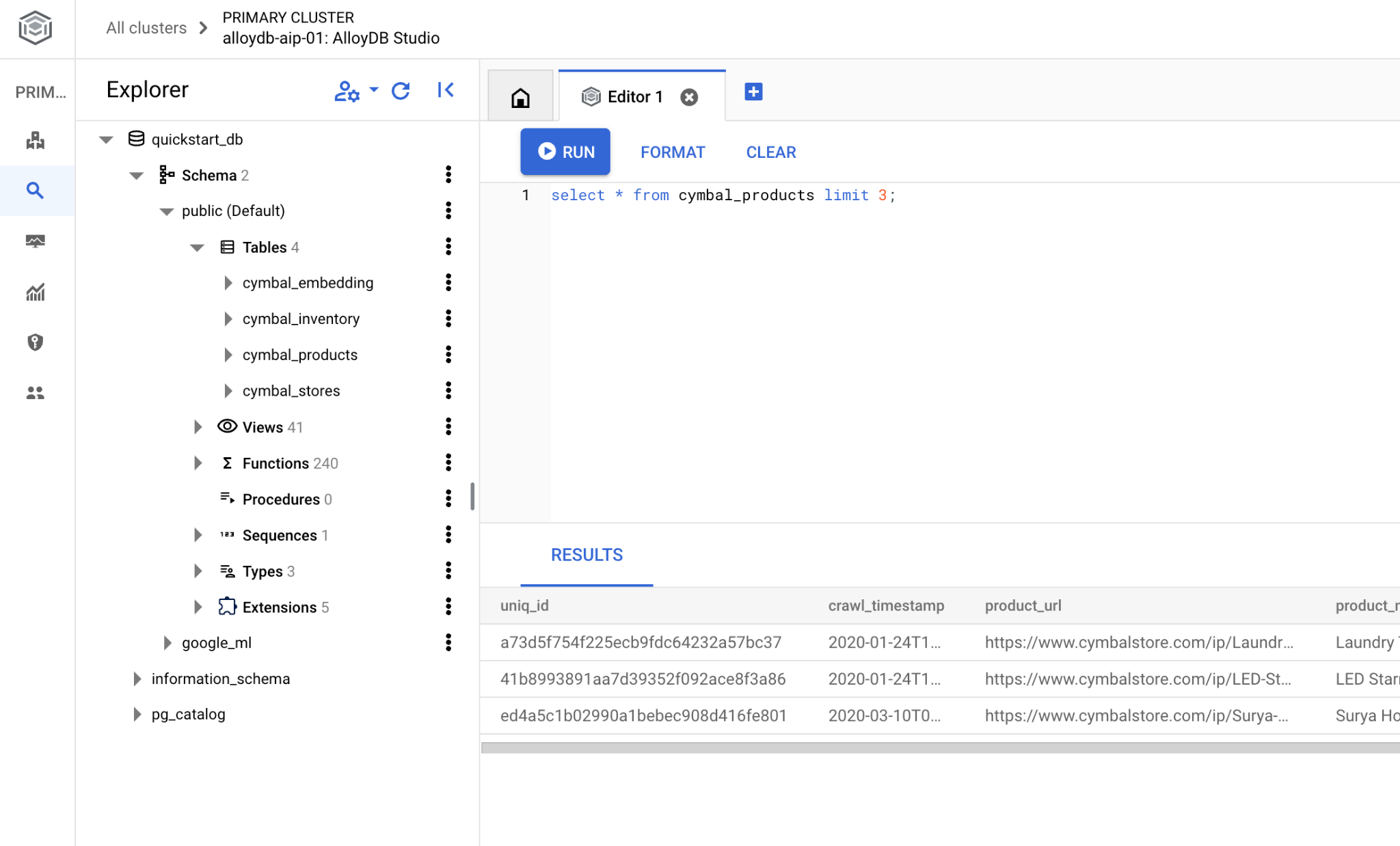
Wenn Sie lieber die Befehlszeile psql verwenden möchten, folgen Sie dem alternativen Weg und stellen Sie eine Verbindung zur Datenbank über Ihre VM-SSH-Sitzung her, wie in den vorherigen Kapiteln beschrieben.
Ähnlichkeitssuche über psql ausführen
Wenn die Datenbankverbindung getrennt wurde, stellen Sie mit psql oder AlloyDB Studio eine neue Verbindung zur Datenbank her.
Stellen Sie eine Verbindung zur Datenbank her:
psql "host=$INSTANCE_IP user=postgres dbname=quickstart_db"
Führen Sie eine Abfrage aus, um eine Liste der verfügbaren Produkte zu erhalten, die der Anfrage eines Kunden am ehesten entsprechen. Die Anfrage, die wir an Vertex AI senden, um den Vektorwert zu erhalten, lautet: „Welche Obstbäume wachsen hier gut?“
Mit der folgenden Abfrage können Sie die ersten zehn Elemente auswählen, die am besten für unsere Anfrage geeignet sind:
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
Und hier ist die erwartete Ausgabe:
quickstart_db=> SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) as distance
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
distance ASC
LIMIT 10;
product_name | description | sale_price | zip_code | distance
-------------------------+----------------------------------------------------------------------------------+------------+----------+---------------------
Cherry Tree | This is a beautiful cherry tree that will produce delicious cherries. It is an d | 75.00 | 93230 | 0.43922018972266397
Meyer Lemon Tree | Meyer Lemon trees are California's favorite lemon tree! Grow your own lemons by | 34 | 93230 | 0.4685112926118228
Toyon | This is a beautiful toyon tree that can grow to be over 20 feet tall. It is an e | 10.00 | 93230 | 0.4835677149651668
California Lilac | This is a beautiful lilac tree that can grow to be over 10 feet tall. It is an d | 5.00 | 93230 | 0.4947204525907498
California Peppertree | This is a beautiful peppertree that can grow to be over 30 feet tall. It is an e | 25.00 | 93230 | 0.5054166905547247
California Black Walnut | This is a beautiful walnut tree that can grow to be over 80 feet tall. It is a d | 100.00 | 93230 | 0.5084219510932597
California Sycamore | This is a beautiful sycamore tree that can grow to be over 100 feet tall. It is | 300.00 | 93230 | 0.5140519790508755
Coast Live Oak | This is a beautiful oak tree that can grow to be over 100 feet tall. It is an ev | 500.00 | 93230 | 0.5143126438081371
Fremont Cottonwood | This is a beautiful cottonwood tree that can grow to be over 100 feet tall. It i | 200.00 | 93230 | 0.5174774727252058
Madrone | This is a beautiful madrona tree that can grow to be over 80 feet tall. It is an | 50.00 | 93230 | 0.5227400803389093
9. Antwort verbessern
Sie können die Antwort auf eine Clientanwendung mithilfe des Ergebnisses der Anfrage verbessern und eine aussagekräftige Ausgabe vorbereiten, indem Sie die bereitgestellten Anfrageergebnisse als Teil des Prompts für das generative Foundation-Sprachmodell von Vertex AI verwenden.
Dazu möchten wir eine JSON-Datei mit den Ergebnissen der Vektorsuche generieren und diese generierte JSON-Datei als Ergänzung zu einem Prompt für ein LLM-Textmodell in Vertex AI verwenden, um eine aussagekräftige Ausgabe zu erstellen. Im ersten Schritt generieren wir das JSON, dann testen wir es in Vertex AI Studio und im letzten Schritt binden wir es in eine SQL-Anweisung ein, die in einer Anwendung verwendet werden kann.
Ausgabe im JSON-Format generieren
Ändern Sie die Abfrage, um die Ausgabe im JSON-Format zu generieren, und geben Sie nur eine Zeile zurück, die an Vertex AI übergeben werden soll.
Hier ein Beispiel für eine Abfrage:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Und hier ist das erwartete JSON in der Ausgabe:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Prompt in Vertex AI Studio ausführen
Wir können das generierte JSON verwenden, um es als Teil des Prompts für das generative KI-Textmodell in Vertex AI Studio bereitzustellen.
Öffnen Sie Vertex AI Studio in der Cloud Console.
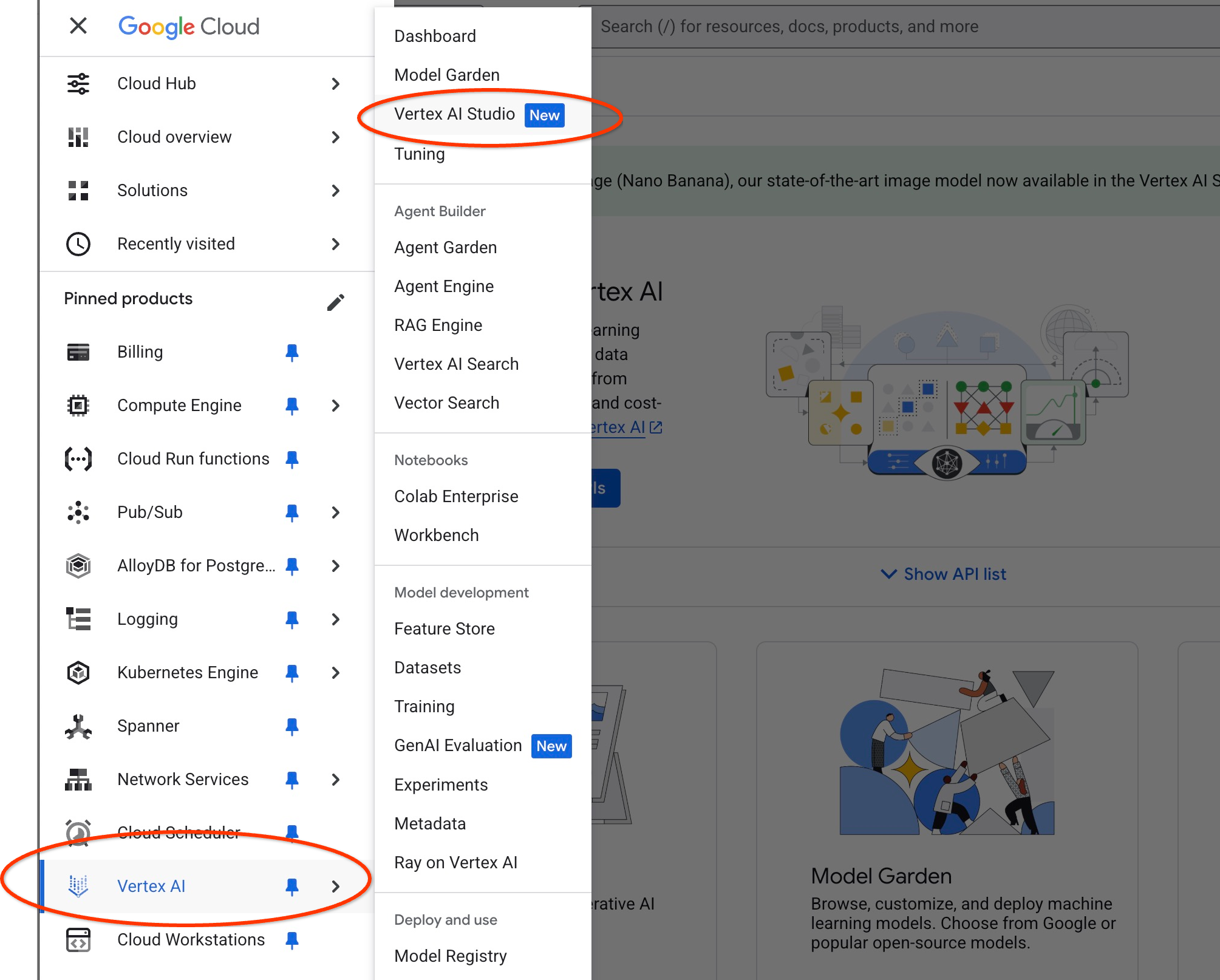
Wenn Sie das Tool noch nicht verwendet haben, werden Sie möglicherweise aufgefordert, den Nutzungsbedingungen zuzustimmen. Klicken Sie auf die Schaltfläche „Zustimmen und fortfahren“.
Geben Sie Ihren Prompt in die Benutzeroberfläche ein.
Möglicherweise werden Sie aufgefordert, zusätzliche APIs zu aktivieren. Sie können die Anfrage jedoch ignorieren. Wir benötigen keine zusätzlichen APIs, um das Lab abzuschließen.
Hier ist der Prompt, den wir mit der JSON-Ausgabe der ersten Anfrage zu den Bäumen verwenden werden:
Du bist ein freundlicher Berater, der Kunden hilft, ein Produkt zu finden, das ihren Anforderungen entspricht.
Auf Grundlage der Kundenanfrage haben wir eine Liste mit Produkten geladen, die eng mit der Suche zusammenhängen.
Die Liste im JSON-Format mit einer Liste von Werten wie {"product_name":"name","description":"some description","sale_price":10,"zip_code": 10234, "produt_id": "02056727942aeb714dc9a2313654e1b0"}
Hier ist die Liste der Produkte:
{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. Es ist ein d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}
Der Kunde hat gefragt: „Welcher Baum wächst hier am besten?“
Sie sollten Informationen zum Produkt, zum Preis und einige zusätzliche Informationen angeben.
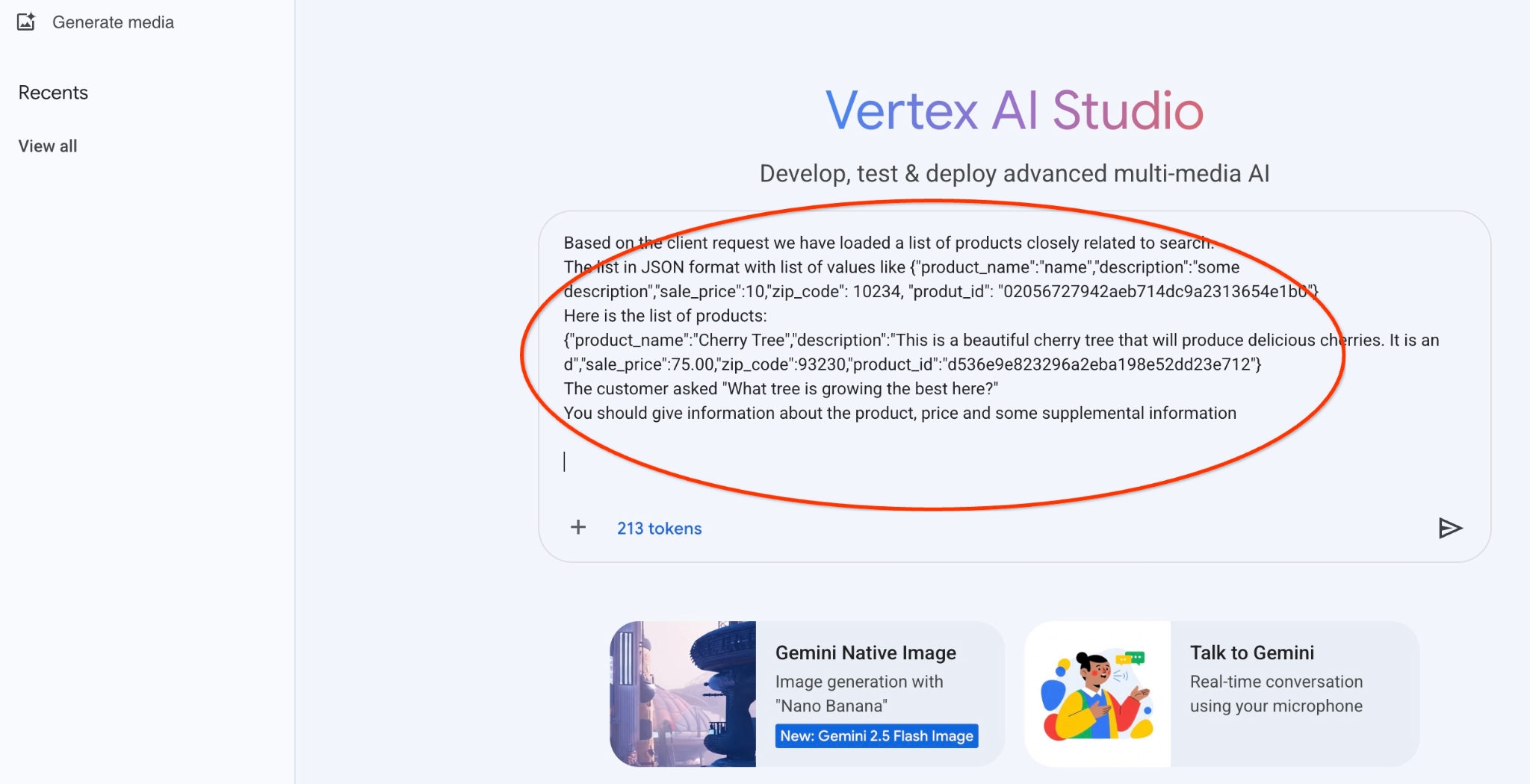
Hier ist das Ergebnis, wenn wir den Prompt mit unseren JSON-Werten und dem Modell „gemini-2.5-flash-light“ ausführen:
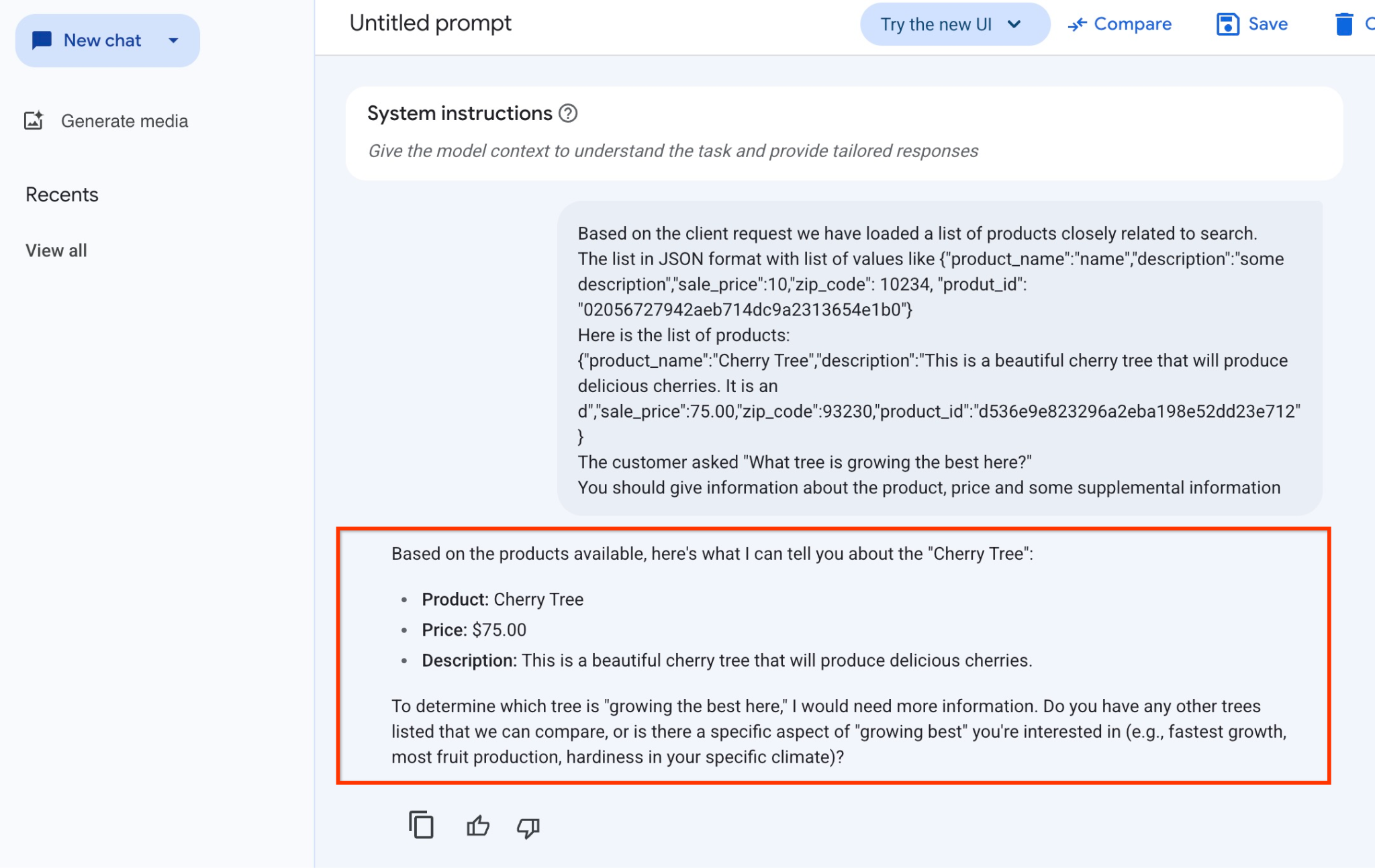
Die Antwort, die wir in diesem Beispiel vom Modell erhalten haben, folgt. Ihre Antwort kann sich aufgrund von Änderungen an Modellen und Parametern im Laufe der Zeit unterscheiden:
„Basierend auf den verfügbaren Produkten kann ich dir Folgendes zum Thema ‚Kirschbaum‘ sagen:
Produkt: Cherry Tree
Preis: 75,00 $
Beschreibung: Dies ist ein wunderschöner Kirschbaum, der köstliche Kirschen trägt.
Um herauszufinden, welcher Baum hier am besten wächst, benötige ich weitere Informationen. Gibt es andere Bäume, die wir vergleichen können, oder interessiert Sie ein bestimmter Aspekt des „besten Wachstums“ (z.B. schnellstes Wachstum, höchste Obstproduktion, Widerstandsfähigkeit in Ihrem spezifischen Klima)?“
Prompt in PSQL ausführen
Wir können die AlloyDB AI-Integration mit Vertex AI verwenden, um dieselbe Antwort von einem generativen Modell mit SQL direkt in der Datenbank zu erhalten. Um das Modell „gemini-1.5-flash“ verwenden zu können, müssen wir es zuerst registrieren.
Prüfen Sie die Erweiterung „google_ml_integration“. Die Version sollte 1.4.2 oder höher sein.
Stellen Sie über psql eine Verbindung zur Datenbank „quickstart_db“ her (wie oben beschrieben) oder verwenden Sie AlloyDB Studio und führen Sie Folgendes aus:
SELECT extversion from pg_extension where extname='google_ml_integration';
Prüfen Sie das Datenbank-Flag „google_ml_integration.enable_model_support“.
show google_ml_integration.enable_model_support;
Die erwartete Ausgabe der psql-Sitzung ist „on“:
postgres=> show google_ml_integration.enable_model_support; google_ml_integration.enable_model_support -------------------------------------------- on (1 row)
Wenn „Aus“ angezeigt wird, muss das Datenbank-Flag „google_ml_integration.enable_model_support“ auf „Ein“ gesetzt werden. Dazu können Sie die AlloyDB-Webkonsolenschnittstelle verwenden oder den folgenden gcloud-Befehl ausführen.
PROJECT_ID=$(gcloud config get-value project)
REGION=us-central1
ADBCLUSTER=alloydb-aip-01
gcloud beta alloydb instances update $ADBCLUSTER-pr \
--database-flags google_ml_integration.enable_faster_embedding_generation=on,google_ml_integration.enable_model_support=on \
--region=$REGION \
--cluster=$ADBCLUSTER \
--project=$PROJECT_ID \
--update-mode=FORCE_APPLY
Die Ausführung des Befehls im Hintergrund dauert etwa 1 bis 3 Minuten. Anschließend können Sie die Markierung noch einmal bestätigen.
Für unsere Anfrage benötigen wir zwei Modelle. Das erste ist das bereits verwendete Modell text-embedding-005 und das zweite eines der generischen Gemini-Modelle von Google.
Wir beginnen mit dem Texteinbettungsmodell. Registrieren Sie den Modelllauf in psql oder AlloyDB Studio mit dem folgenden Code:
CALL
google_ml.create_model(
model_id => 'text-embedding-005',
model_provider => 'google',
model_qualified_name => 'text-embedding-005',
model_type => 'text_embedding',
model_auth_type => 'alloydb_service_agent_iam',
model_in_transform_fn => 'google_ml.vertexai_text_embedding_input_transform',
model_out_transform_fn => 'google_ml.vertexai_text_embedding_output_transform');
Das nächste Modell, das wir registrieren müssen, ist gemini-2.0-flash-001. Es wird verwendet, um die benutzerfreundliche Ausgabe zu generieren.
CALL
google_ml.create_model(
model_id => 'gemini-2.5-flash',
model_request_url => 'publishers/google/models/gemini-2.5-flash:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'alloydb_service_agent_iam');
Sie können die Liste der registrierten Modelle jederzeit überprüfen, indem Sie Informationen aus google_ml.model_info_view auswählen.
select model_id,model_type from google_ml.model_info_view;
Hier ein Beispiel für die Ausgabe:
quickstart_db=> select model_id,model_type from google_ml.model_info_view;
model_id | model_type
-------------------------+----------------
textembedding-gecko | text_embedding
textembedding-gecko@001 | text_embedding
text-embedding-005 | text_embedding
gemini-2.5-flash | generic
(4 rows)
Jetzt können wir das generierte JSON in einer Unterabfrage verwenden, um es als Teil des Prompts für das generative KI-Textmodell mit SQL bereitzustellen.
Führen Sie die Abfrage in der psql- oder AlloyDB Studio-Sitzung für die Datenbank aus.
WITH trees AS (
SELECT
cp.product_name,
cp.product_description AS description,
cp.sale_price,
cs.zip_code,
cp.uniq_id AS product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci ON
ci.uniq_id = cp.uniq_id
JOIN cymbal_stores cs ON
cs.store_id = ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005',
'What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1),
prompt AS (
SELECT
'You are a friendly advisor helping to find a product based on the customer''s needs.
Based on the client request we have loaded a list of products closely related to search.
The list in JSON format with list of values like {"product_name":"name","product_description":"some description","sale_price":10}
Here is the list of products:' || json_agg(trees) || 'The customer asked "What kind of fruit trees grow well here?"
You should give information about the product, price and some supplemental information' AS prompt_text
FROM
trees),
response AS (
SELECT
json_array_elements(google_ml.predict_row( model_id =>'gemini-2.5-flash',
request_body => json_build_object('contents',
json_build_object('role',
'user',
'parts',
json_build_object('text',
prompt_text)))))->'candidates'->0->'content'->'parts'->0->'text' AS resp
FROM
prompt)
SELECT
string_agg(resp::text,
' ')
FROM
response;
Hier sehen Sie die erwartete Ausgabe. Ihre Ausgabe kann je nach Modellversion und Parametern unterschiedlich ausfallen:
"Hello there! I can certainly help you with finding a great fruit tree for your area.\n\nBased on what grows well, we have a wonderful **Cherry Tree** that could be a perfect fit!\n\nThis beautiful cherry tree is an excellent choice for producing delicious cherries right in your garden. It's an deciduous tree that typically" " grows to about 15 feet tall. Beyond its fruit, it offers lovely aesthetics with dark green leaves in the summer that transition to a beautiful red in the fall, making it great for shade and privacy too.\n\nCherry trees generally prefer a cool, moist climate and sandy soil, and they are best suited for USDA Zones" " 4-9. Given the zip code you're inquiring about (93230), which is typically in USDA Zone 9, this Cherry Tree should thrive wonderfully!\n\nYou can get this magnificent tree for just **$75.00**.\n\nLet me know if you have any other questions!" "
10. Vektorindex erstellen
Unser Dataset ist recht klein und die Reaktionszeit hängt hauptsächlich von der Interaktion mit KI-Modellen ab. Wenn Sie jedoch Millionen von Vektoren haben, kann die Vektorsuche einen erheblichen Teil der Reaktionszeit in Anspruch nehmen und das System stark belasten. Um das zu verbessern, können wir einen Index für unsere Vektoren erstellen.
ScaNN-Index erstellen
Um den SCANN-Index zu erstellen, müssen wir eine weitere Erweiterung aktivieren. Die Erweiterung „alloydb_scann“ bietet eine Schnittstelle für die Arbeit mit dem ANN-Typ-Vektorindex mit dem Google ScaNN-Algorithmus.
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
Erwartete Ausgabe:
quickstart_db=> CREATE EXTENSION IF NOT EXISTS alloydb_scann; CREATE EXTENSION Time: 27.468 ms quickstart_db=>
Der Index kann im manuellen oder automatischen Modus erstellt werden. Der Modus „MANUAL“ ist standardmäßig aktiviert. Sie können einen Index erstellen und ihn wie jeden anderen Index verwalten. Wenn Sie den AUTO-Modus aktivieren, können Sie den Index erstellen, ohne dass Sie ihn warten müssen. Hier finden Sie eine detaillierte Beschreibung aller Optionen. Im Folgenden wird beschrieben, wie Sie den AUTO-Modus aktivieren und den Index erstellen. In unserem Fall haben wir nicht genügend Zeilen, um den Index im AUTO-Modus zu erstellen. Daher erstellen wir ihn im MANUAL-Modus.
Im folgenden Beispiel lasse ich die meisten Parameter auf dem Standardwert und gebe nur eine Anzahl von Partitionen (num_leaves) für den Index an:
CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products
USING scann (embedding cosine)
WITH (num_leaves=31, max_num_levels = 2);
Weitere Informationen zum Optimieren von Indexparametern finden Sie in der Dokumentation.
Erwartete Ausgabe:
quickstart_db=> CREATE INDEX cymbal_products_embeddings_scann ON cymbal_products USING scann (embedding cosine) WITH (num_leaves=31, max_num_levels = 2); CREATE INDEX quickstart_db=>
Antwort vergleichen
Jetzt können wir die Vektorsuchanfrage im EXPLAIN-Modus ausführen und prüfen, ob der Index verwendet wurde.
EXPLAIN (analyze)
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Erwartete Ausgabe (zur besseren Lesbarkeit gekürzt):
... Aggregate (cost=16.59..16.60 rows=1 width=32) (actual time=2.875..2.877 rows=1 loops=1) -> Subquery Scan on trees (cost=8.42..16.59 rows=1 width=142) (actual time=2.860..2.862 rows=1 loops=1) -> Limit (cost=8.42..16.58 rows=1 width=158) (actual time=2.855..2.856 rows=1 loops=1) -> Nested Loop (cost=8.42..6489.19 rows=794 width=158) (actual time=2.854..2.855 rows=1 loops=1) -> Nested Loop (cost=8.13..6466.99 rows=794 width=938) (actual time=2.742..2.743 rows=1 loops=1) -> Index Scan using cymbal_products_embeddings_scann on cymbal_products cp (cost=7.71..111.99 rows=876 width=934) (actual time=2.724..2.724 rows=1 loops=1) Order By: (embedding <=> '[0.008864171,0.03693164,-0.024245683,-0.00355923,0.0055611245,0.015985578,...<redacted>...5685,-0.03914233,-0.018452475,0.00826032,-0.07372604]'::vector) -> Index Scan using walmart_inventory_pkey on cymbal_inventory ci (cost=0.42..7.26 rows=1 width=37) (actual time=0.015..0.015 rows=1 loops=1) Index Cond: ((store_id = 1583) AND (uniq_id = (cp.uniq_id)::text)) ...
Aus der Ausgabe geht deutlich hervor, dass für die Abfrage „Index Scan using cymbal_products_embeddings_scann on cymbal_products“ verwendet wurde.
Wenn wir die Abfrage ohne „EXPLAIN“ ausführen:
WITH trees as (
SELECT
cp.product_name,
left(cp.product_description,80) as description,
cp.sale_price,
cs.zip_code,
cp.uniq_id as product_id
FROM
cymbal_products cp
JOIN cymbal_inventory ci on
ci.uniq_id=cp.uniq_id
JOIN cymbal_stores cs on
cs.store_id=ci.store_id
AND ci.inventory>0
AND cs.store_id = 1583
ORDER BY
(cp.embedding <=> embedding('text-embedding-005','What kind of fruit trees grow well here?')::vector) ASC
LIMIT 1)
SELECT json_agg(trees) FROM trees;
Erwartete Ausgabe:
[{"product_name":"Cherry Tree","description":"This is a beautiful cherry tree that will produce delicious cherries. It is an d","sale_price":75.00,"zip_code":93230,"product_id":"d536e9e823296a2eba198e52dd23e712"}]
Wir sehen, dass es sich bei dem Ergebnis um denselben Kirschbaum handelt, der bei unserer Suche ohne Index oben stand. Manchmal ist das nicht der Fall und die Antwort gibt nicht denselben Baum, sondern einige andere Bäume von oben zurück. Der Index bietet also eine gute Leistung und ist dennoch genau genug, um gute Ergebnisse zu liefern.
Sie können verschiedene für die Vektoren verfügbare Indexe ausprobieren. Weitere Labs und Beispiele mit Langchain-Integration finden Sie auf der Dokumentationsseite.
11. Umgebung bereinigen
Löschen Sie die AlloyDB-Instanzen und den Cluster, wenn Sie das Lab abgeschlossen haben.
AlloyDB-Cluster und alle Instanzen löschen
Wenn Sie die Testversion von AlloyDB verwendet haben. Löschen Sie den Testcluster nicht, wenn Sie planen, andere Labs und Ressourcen damit zu testen. Sie können keinen weiteren Testcluster im selben Projekt erstellen.
Der Cluster wird mit der Option „force“ zerstört, wodurch auch alle zum Cluster gehörenden Instanzen gelöscht werden.
Definieren Sie in Cloud Shell die Projekt- und Umgebungsvariablen, wenn die Verbindung getrennt wurde und alle vorherigen Einstellungen verloren gegangen sind:
gcloud config set project <your project id>
export REGION=us-central1
export ADBCLUSTER=alloydb-aip-01
export PROJECT_ID=$(gcloud config get-value project)
Löschen Sie den Cluster:
gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ gcloud alloydb clusters delete $ADBCLUSTER --region=$REGION --force All of the cluster data will be lost when the cluster is deleted. Do you want to continue (Y/n)? Y Operation ID: operation-1697820178429-6082890a0b570-4a72f7e4-4c5df36f Deleting cluster...done.
AlloyDB-Sicherungen löschen
Löschen Sie alle AlloyDB-Sicherungen für den Cluster:
for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ for i in $(gcloud alloydb backups list --filter="CLUSTER_NAME: projects/$PROJECT_ID/locations/$REGION/clusters/$ADBCLUSTER" --format="value(name)" --sort-by=~createTime) ; do gcloud alloydb backups delete $(basename $i) --region $REGION --quiet; done Operation ID: operation-1697826266108-60829fb7b5258-7f99dc0b-99f3c35f Deleting backup...done.
Jetzt können wir unsere VM löschen.
GCE-VM löschen
Führen Sie in Cloud Shell Folgendes aus:
export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Erwartete Konsolenausgabe:
student@cloudshell:~ (test-project-001-402417)$ export GCEVM=instance-1
export ZONE=us-central1-a
gcloud compute instances delete $GCEVM \
--zone=$ZONE \
--quiet
Deleted
12. Glückwunsch
Herzlichen Glückwunsch zum Abschluss des Codelabs.
Dieses Lab ist Teil des Lernpfads „Produktionsreife KI mit Google Cloud“.
- Gesamten Lehrplan ansehen
- Teile deinen Fortschritt mit dem Hashtag
#ProductionReadyAI.
Behandelte Themen
- AlloyDB-Cluster und primäre Instanz bereitstellen
- Verbindung zu AlloyDB über eine Google Compute Engine-VM herstellen
- Datenbank erstellen und AlloyDB AI aktivieren
- Daten in die Datenbank laden
- AlloyDB Studio verwenden
- Vertex AI-Modell für Einbettungen in AlloyDB verwenden
- Vertex AI Studio verwenden
- Ergebnisse mit dem generativen Modell von Vertex AI anreichern
- Leistung mit Vektorindex verbessern
13. Umfrage
Ausgabe: