
1. 개요
지난 4부에서 구축한 대규모 아키텍처를 잠시 살펴보겠습니다.
1부: BigQuery Knowledge Catalog를 사용하여 원시 Froyo 레시피 PDF를 구조화된 관계형 테이블로 변환했습니다.
2부: BigQuery 웨어하우스를 AlloyDB에 직접 페더레이션하는 제로 ETL 트랜잭션 브리지를 구축했습니다.
3부: 에이전트 개발 키트와 MCP 도구 상자를 사용하여 멀티 에이전트 애플리케이션 (FroyoOS)을 오케스트레이션했습니다.
4부: 이중 트랙 평가 파이프라인을 빌드하여 에이전트가 프로덕션에 안전함을 입증했습니다.
YouTube 운영은 완벽하게 진행되고 있습니다. 하지만 이 시스템에서 생성되는 방대한 양의 데이터를 이해해야 하는 개발자와 비즈니스 분석사는 어떻게 해야 할까요?
오늘은 애널리틱스의 미래를 살펴보겠습니다. 코드 편집기인 Antigravity IDE에서 Google Cloud Data Agent Kit로 시작한 다음 Google Cloud 콘솔로 이동하여 BigQuery Conversational Analytics를 사용하여 데이터를 시각화합니다.
빌드를 시작해 보겠습니다.
학습할 내용
Agentic Data Cloud 시리즈의 마지막 Codelab에서는 아키텍처의 모든 부분을 결합하여 실행 가능한 비즈니스 인사이트를 제공합니다. 학습할 내용은
- IDE 우선 분석: 개발 환경에서 직접 아키텍처를 쿼리하기 위해 ANTIGRAVITY IDE와 Google Cloud 데이터 에이전트 키트를 설치하고 구성하는 방법을 알아봅니다.
- 대화형 BigQuery: 자연어를 사용하여 복잡한 SQL 작업과 예측을 자동화하도록 BigQuery 데이터 에이전트를 만들고, 구성하고, 지시하는 방법
- 데이터 민주화: 조직 전반의 분석가와 비즈니스 사용자가 액세스할 수 있도록 에이전트를 엔터프라이즈에 게시하는 방법
- 인사이트 시각화: 상담사의 대화 분석을 데이터 스튜디오에 원활하게 통합하여 예측 가능한 동적 대시보드를 만드는 방법
- Agentic Data Cloud 생태계: 1부의 원시 비정형 데이터부터 5부의 경영진용 대시보드까지 엔드 투 엔드 아키텍처의 가치를 설명하는 방법
요구사항
2. 시작하기 전에
프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있어야 하므로 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
- Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.

- Cloud Shell에 연결되면 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 인증을 원하는 경우
gcloud auth login
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- 필요한 API 사용 설정: 다음 명령어를 실행하여 필요한 모든 API를 사용 설정합니다.
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. 데이터 웨어하우스 확장
구조화되지 않은 데이터로 만든 BigQuery 테이블을 기억하시나요?
의미 있는 분석을 수행하려면 과거 거래 데이터가 필요합니다. BigQuery의 froyo_data 데이터 세트에서 프랜차이즈 운영 연도를 시뮬레이션하기 위해 세 개의 새 테이블을 만들어 보겠습니다.
- froyo_data.orders: 과거 주문 헤더 (날짜, 매장 ID, 합계)
- froyo_data.order_items: 주문 상품 세부정보 (수량, 가격)
- froyo_data.customer_allergen_data: 충성도 높은 고객의 알려진 알레르기를 추적하는 CRM 테이블
분석 사용 사례를 준비하기 위해 판매 및 고객 관련 테이블을 데이터 세트에 추가해 보겠습니다.
- Google Cloud 콘솔에서 Cloud Shell 터미널로 이동합니다.
- 워크스페이스의 루트 폴더 또는 이 시리즈의 지난 몇 부분에서 작업한 froyo-data 프로젝트 루트 폴더로 이동합니다.
- 다음 명령어를 하나씩 실행하여 3개의 과거 데이터 파일 (csv 파일)을 작업 디렉터리에 다운로드합니다.
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/customer_allergen_data.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/order_items.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/orders.csv
- 작업 디렉터리의 루트에 해당 파일이 표시되면 터미널로 전환하여 Cloud Shell 터미널로 이동합니다.
- Cloud Shell 터미널에서 이 3개 파일이 있는 디렉터리로 이동합니다.
- BigQuery에 이 시리즈의 1부에서 사용한 'froyo_data'라는 데이터 세트가 있는지 확인합니다 (없는 경우 돌아가서 데이터 세트와 테이블을 만드세요).
- Cloud Shell 터미널에서 다음 명령어를 실행합니다.
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.orders \
./orders.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.order_items \
./order_items.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.customer_allergen_data \
./customer_allergen_data.csv
이렇게 하면 froyo_data 데이터 세트에 테이블 3개가 추가로 생성됩니다.
4. 개발자 환경 - '데이터 에이전트 키트' 소개
기존에는 개발자가 데이터를 분석하거나 복잡한 머신러닝 쿼리를 작성하려면 IDE, 데이터베이스 콘솔, 문서 간에 컨텍스트를 지속적으로 전환해야 했습니다.
더 이상은 그럴 필요가 없습니다. 새로 출시된 Google Cloud Data Agent Kit 확장 프로그램을 사용하면 IDE가 데이터 강자로 거듭납니다.
ANTIGRAVITY IDE
ANTIGRAVITY IDE는 AI 시대를 위해 특별히 설계된 Google의 차세대 에이전트 중심 개발 환경입니다. 대규모 멀티모달 컨텍스트 창과 자율 도구 사용을 편집기에 직접 통합하여 개발자가 코드를 벗어나지 않고도 클라우드 리소스를 오케스트레이션하고 복잡한 데이터 파이프라인을 오케스트레이션할 수 있습니다.
ANTIGRAVITY IDE 설정
- IDE 다운로드: antigravity.google로 이동하여 운영체제 (Windows, macOS 또는 Linux)에 맞는 Antigravity IDE를 다운로드합니다.
- 설치 및 실행: 설치 프로그램을 실행하고 애플리케이션을 엽니다.
- 'Google로 계속'을 클릭하고 Gmail 계정을 선택한 후 승인합니다.
- 로그인한 후 작업 폴더 (작업공간/ 프로젝트)를 만듭니다. '에이전트 데이터 클라우드'라고 하겠습니다.
왼쪽의 '프로젝트' 목록에 표시됩니다.
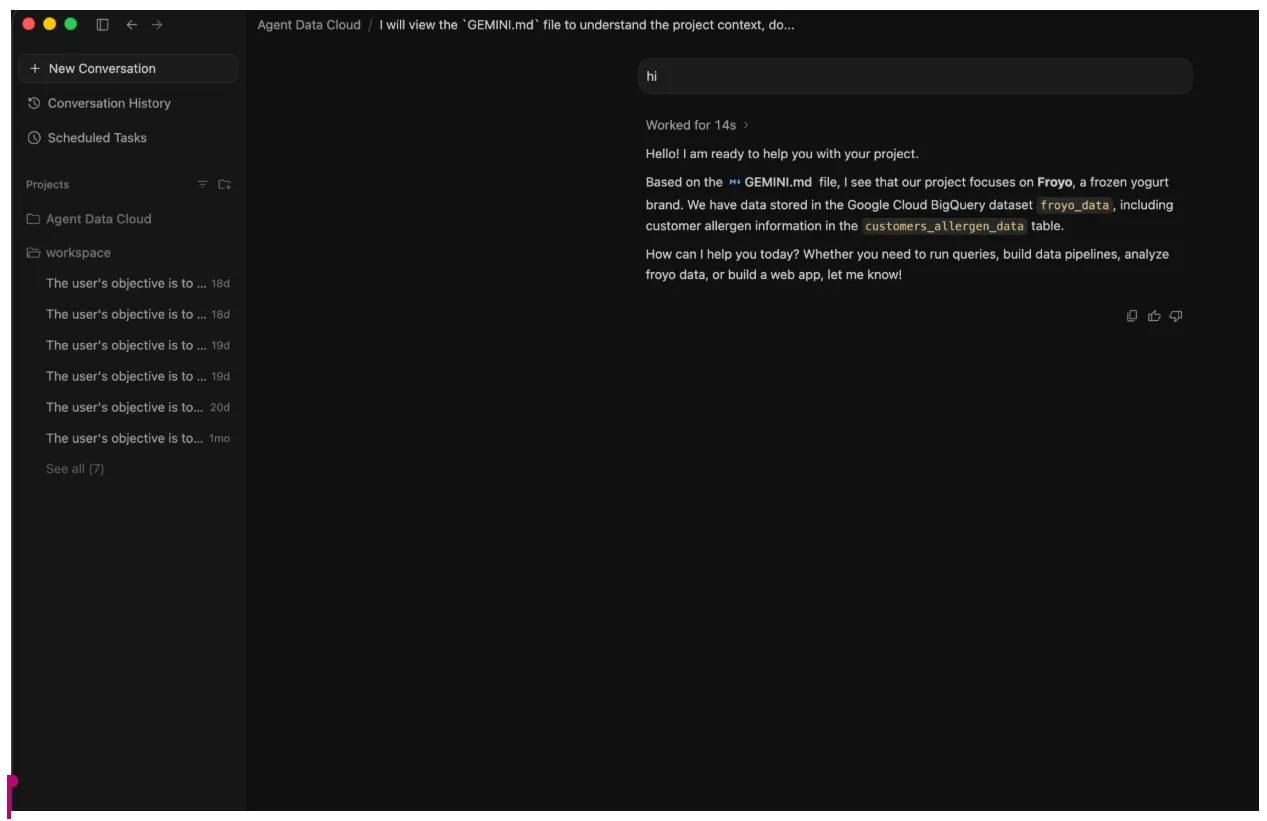
- 상담사와 간단한 채팅을 시작합니다('안녕하세요').
- 오른쪽 상단에 IDE 열기 버튼이 있습니다.
하지만 이 버튼을 클릭하기 전에 Antigravity IDE를 설치해야 합니다. antigravity.google/download 페이지로 이동하여 Antigravity IDE 섹션까지 아래로 스크롤한 후 필요한 버전을 다운로드합니다.
다운로드한 후 열려 있는 Antigravity 인스턴스로 돌아가 오른쪽 상단에 있는 Open IDE 버튼을 클릭합니다.
- 권한에 관한 팝업이 표시되면 계속 열어 보세요.
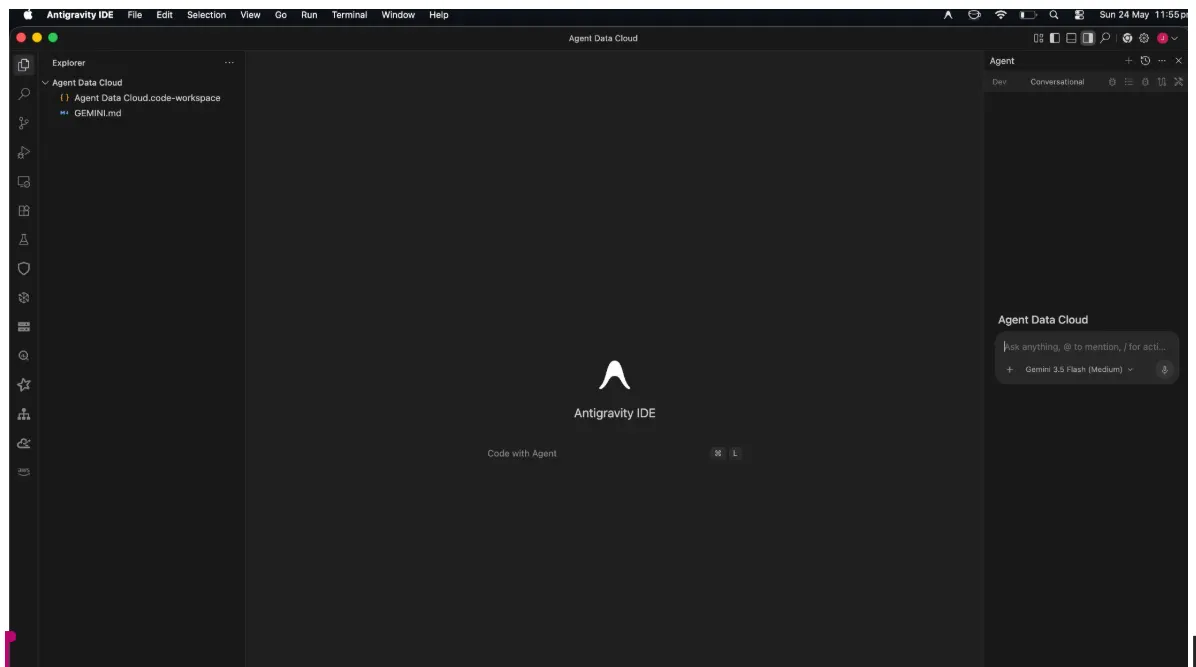
오른쪽에는 에이전트 창이 있고 왼쪽에는 프로젝트 탐색기가 있으며 중앙에는 개발 공간이 있습니다.
데이터 에이전트 키트 확장 프로그램 설정
- 확장 프로그램 설치: ANTIGRAVITY IDE 내에서 확장 프로그램 마켓플레이스를 엽니다. Google Cloud Data Agent Kit 확장 프로그램을 검색하여 설치합니다.
- 설치 버튼을 클릭하면 설치가 완료된 후 탐색 창에 확장 프로그램이 표시됩니다.
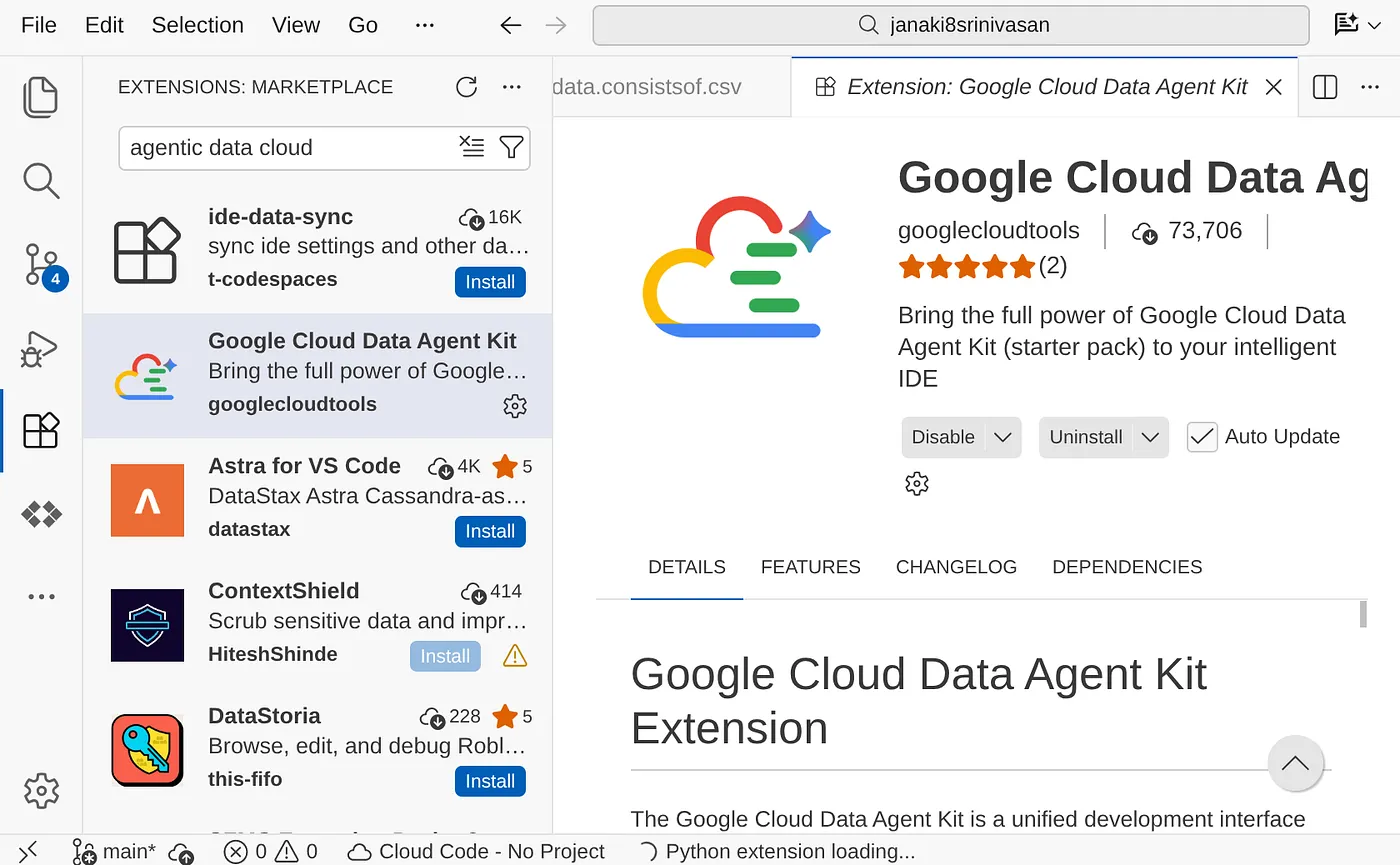
- 이 버튼을 클릭하면 Google Cloud 데이터 에이전트 키 탐색기가 열립니다. 설정 섹션으로 이동하여 설정을 클릭합니다. 프로젝트 세부정보와 리전을 입력하고 저장합니다.
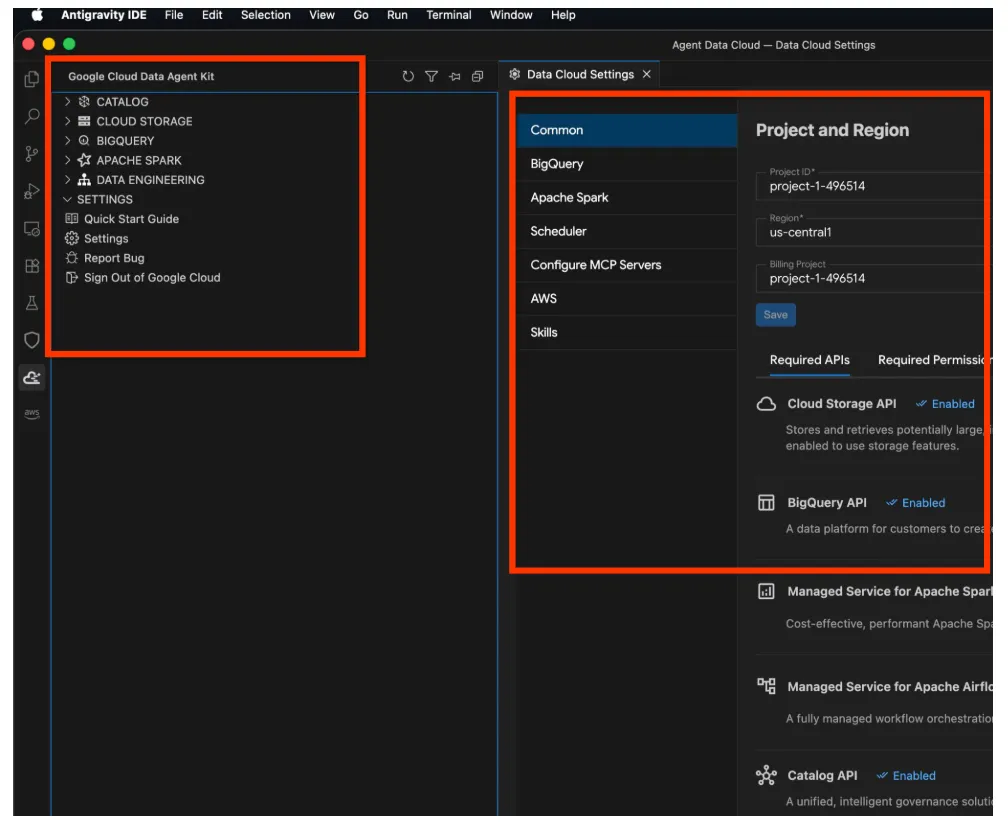
- 이제 탐색 창 상단의 프로젝트 탐색기를 클릭합니다. 탐색기 창에 프로젝트 탐색기가 열립니다.
- 탐색기 공간을 마우스 오른쪽 버튼으로 클릭하고 'GEMINI.md'라는 새 파일을 만듭니다.
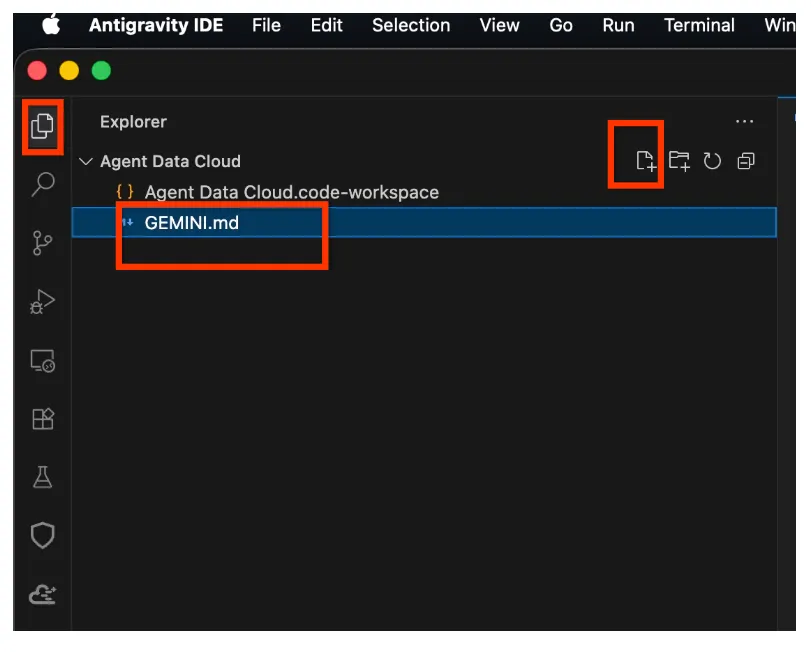
- GEMINI.md에 다음을 붙여넣습니다(<<YOUR_PROJECT_ID>>를 값으로 바꿔야 함).
## 1. Project Context
- **Project ID**: <<YOUR_PROJECT_ID>>
- **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
- **Data**: All froyo, customer, order related information is processed and stored in BigQuery `froyo_data` dataset.
## 2. Execution & Data Processing Rules
- **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `froyo_data`.
- **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the tables `customers_allergen_data`.
- ** CRITICAL RULE - Sales Data**: Sales data is present in tables `orders` and `order_items`.
- ** CRITICAL RULE - General: When you are referencing a dataset, ensure you are using it with the dataset ID (`froyo_data`) . For example, to query orders table in this dataset you should use `froyo_data.orders`.
이제 IDE에 바로 앉아 코드를 작성하고, SQL을 생성하고, 아키텍처를 분석할 수 있는 고성능 AI 에이전트가 있습니다.
이제 흥미로운 분석 과제가 있습니다. 이전 판매 데이터와 1부에서 PDF에서 추출한 복잡하고 추론된 알레르기 유발 물질 데이터를 연관시킬 수 있을까요?
5. IDE 에이전트를 통한 인텔리전스 추론
IDE 에이전트에게 힘든 작업을 맡겨 보겠습니다. ANTIGRAVITY IDE 내에서 바로 에이전트 데이터 키트 채팅 창을 열고 다음과 같이 프롬프트를 표시합니다.
Does Midnight Swirl contain any allergen?
일련의 권한을 요청하면 해당하는 권한을 허용합니다.
마지막으로 분석이 끝나면 대답을 가져옵니다.
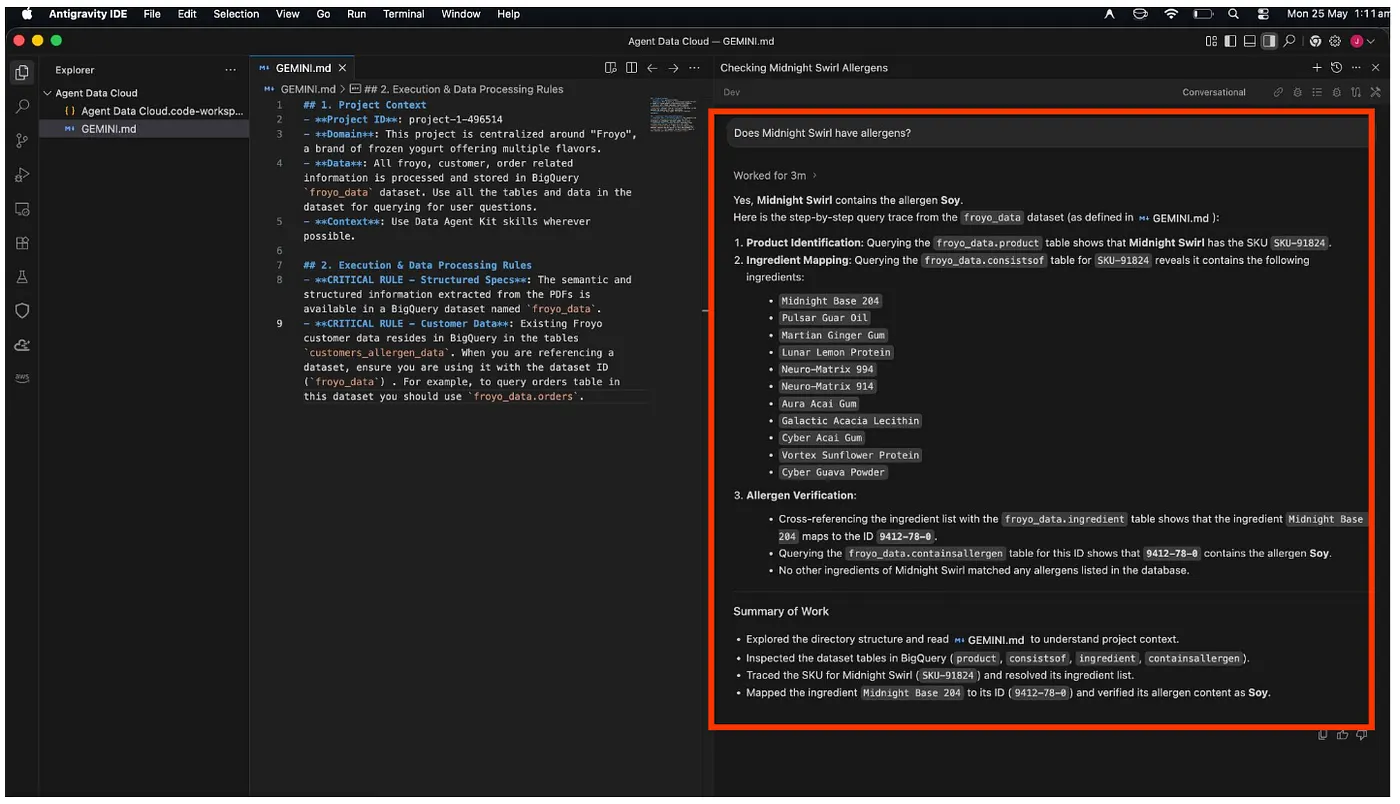
와!!! Midnight Swirl 항목에 콩이 포함되어 있다고 올바르게 식별했습니다.
이제 조금 더 복잡한 질문을 해 보겠습니다. Antigravity IDE에서 다음 프롬프트를 전송합니다.
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
대답:
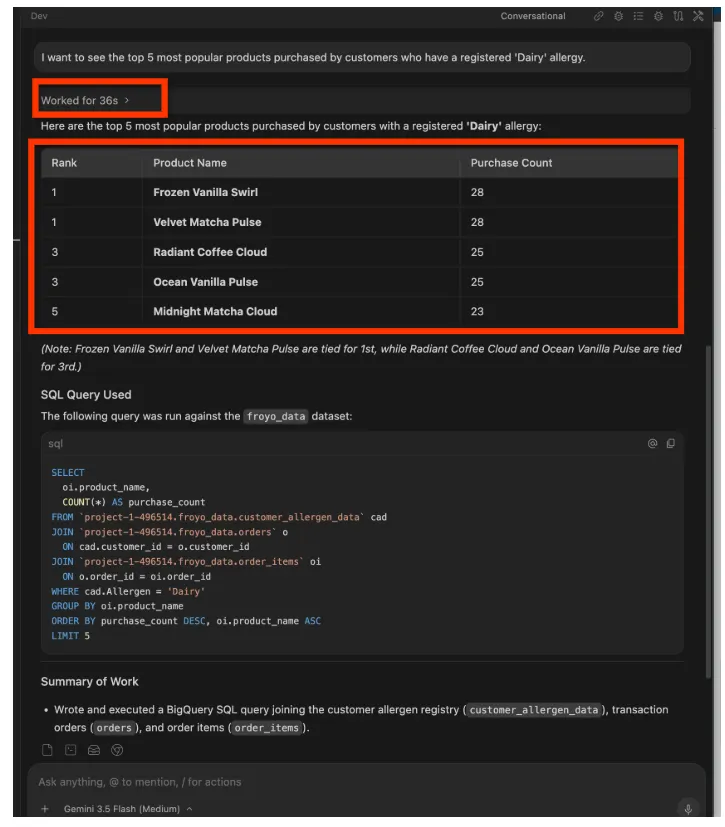
계속 진행할 수 있습니다. 다음과 같은 프롬프트를 사용해 보세요.
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
BQML 구문을 조회할 필요 없이 에이전트 데이터 키트가 정확한 CREATE MODEL 및 ML.FORECAST 코드를 편집기에 삽입합니다. ANTIGRAVITY IDE를 벗어나지 않고도 BigQuery 환경에서 직접 실행할 수 있습니다.
정말 멋지네요!
6. BigQuery의 대화형 분석
개발자는 IDE를 선호하지만 비즈니스 사용자와 임원은 클라우드 콘솔을 사용합니다. SQL을 보고 싶어 하는 것이 아니라 답변을 원합니다.
그럼 시작해보겠습니다.
- 필요한 역할 부여
프로젝트의 IAM 페이지로 이동하여 Gemini 데이터 분석 데이터 에이전트 소유자 역할을 부여합니다.
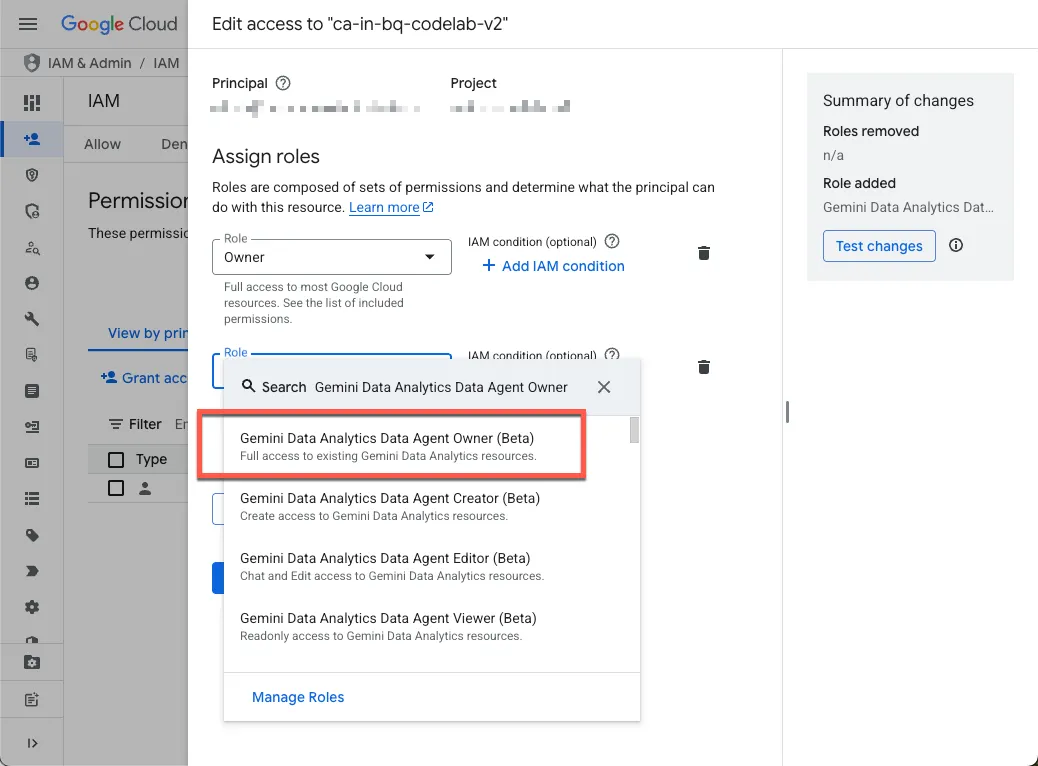
이 역할은 프로젝트의 모든 데이터 에이전트를 생성, 수정, 공유, 삭제할 수 있는 권한을 부여합니다.
- 필요한 API 사용 설정
Google Cloud 콘솔에서 BigQuery로 이동합니다. 페이지 상단의 사이드바 탐색 메뉴 또는 검색 메뉴를 사용하여 BigQuery > 에이전트로 이동합니다.
Gemini 기반 Data Analytics API 사용을 클릭합니다.
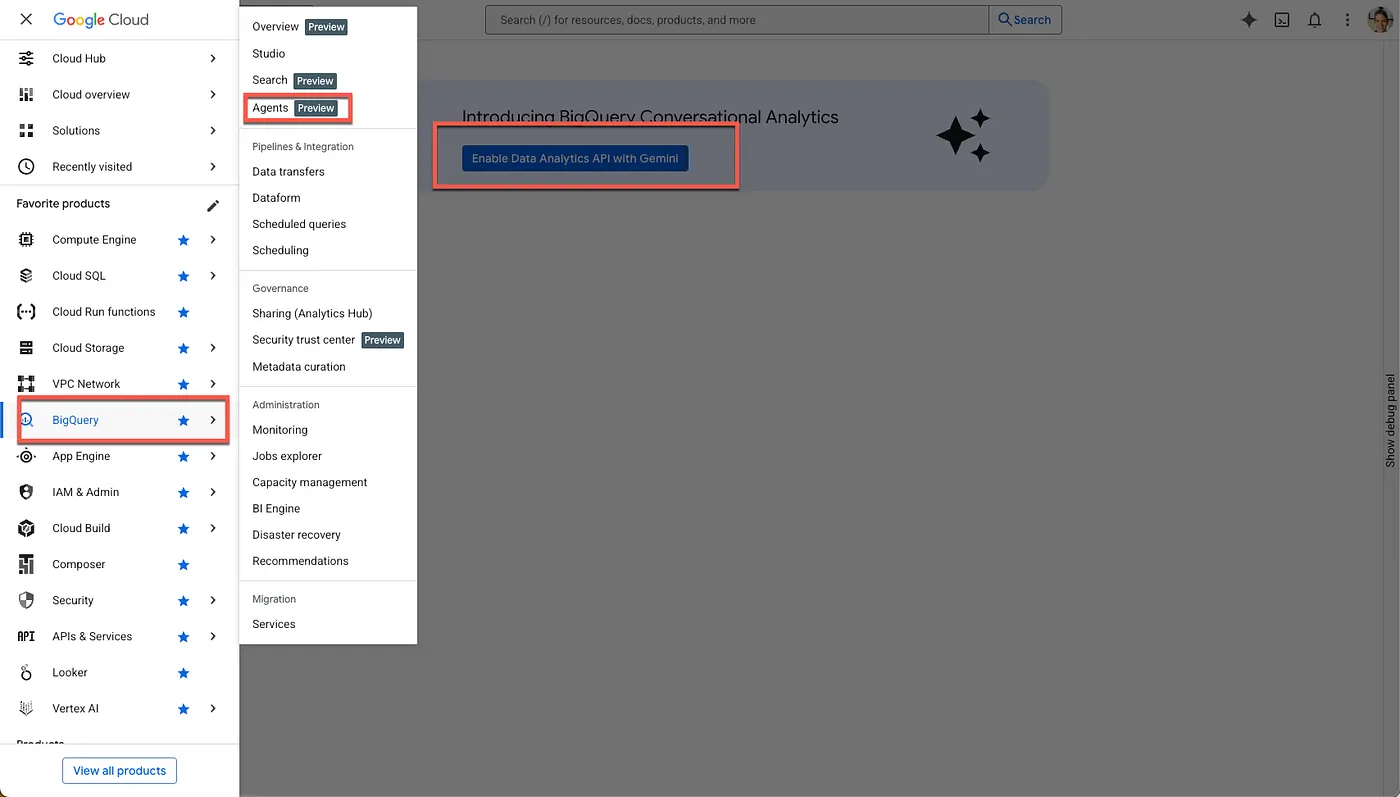
BigQuery의 Gemini API와 Google Cloud를 위한 Gemini API를 모두 사용 설정합니다.
이제 새 에이전트 페이지가 표시됩니다.
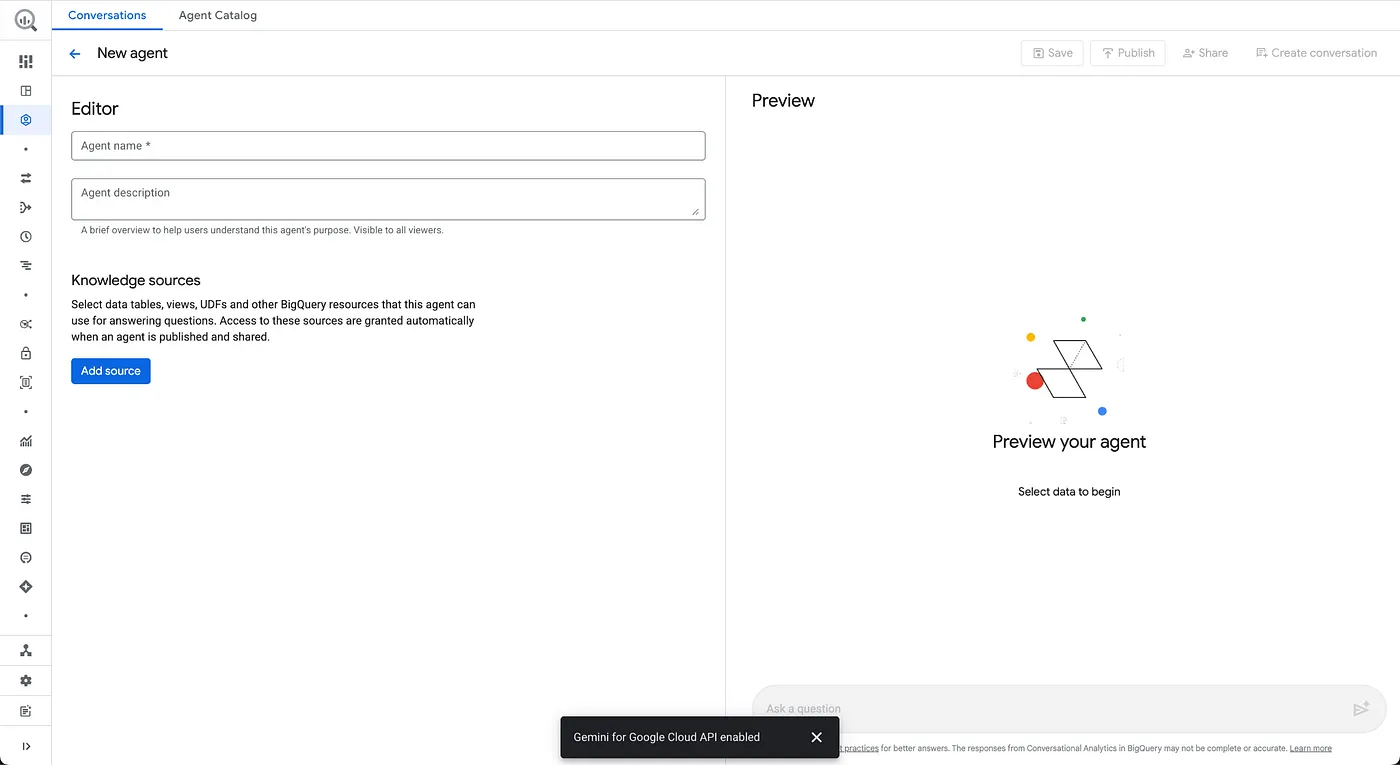
- 에이전트 정보 구성
상담사 이름: Froyo Agent
상담사 설명: 프로요 제품, 알레르기 유발 물질, 성분, 레시피, 고객,주문,판매 관련 질문에 답변하는 데 도움을 줍니다.
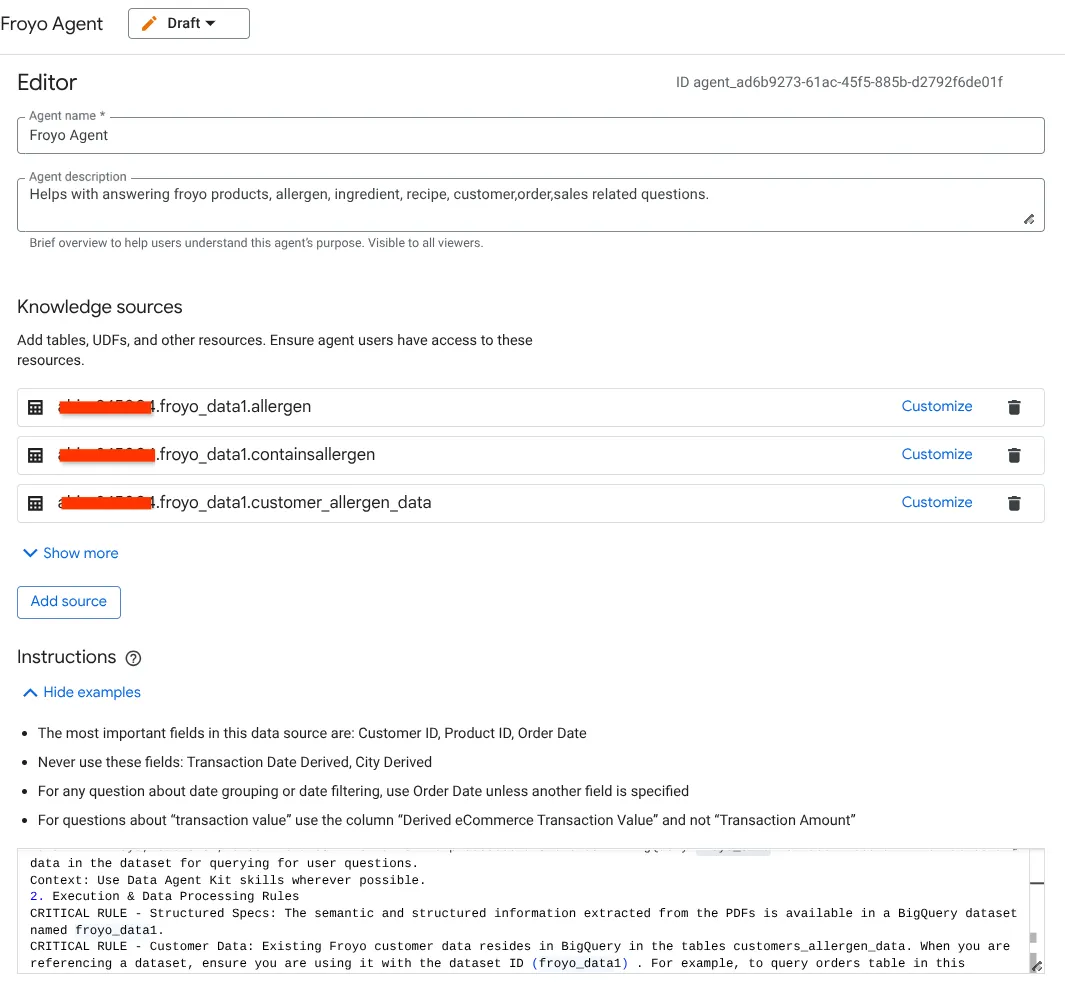
- 지식 소스 섹션으로 이동하여 데이터 세트에서 아래의 모든 표를 선택합니다.
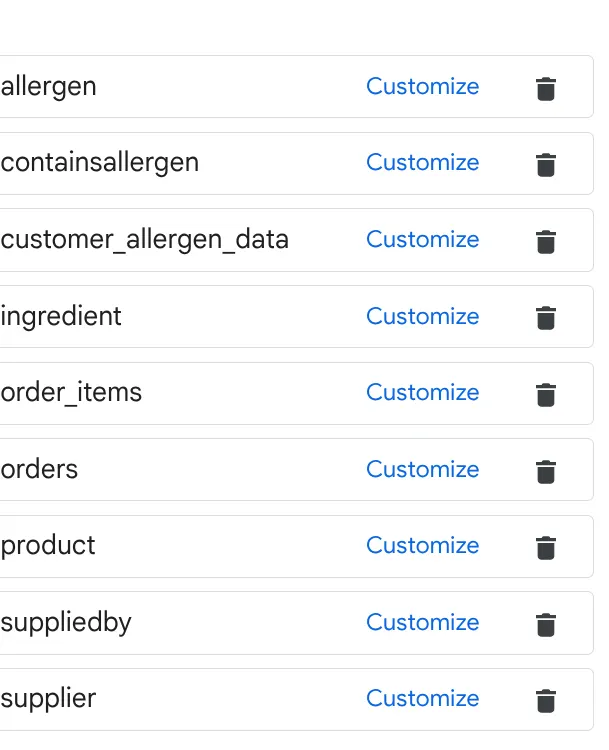
a. 위 이미지의 표를 추가하고 '소스 추가'를 클릭합니다.
b. 각 소스에서 오른쪽에 있는 맞춤설정 버튼을 클릭합니다. 아래 양식이 표시됩니다.
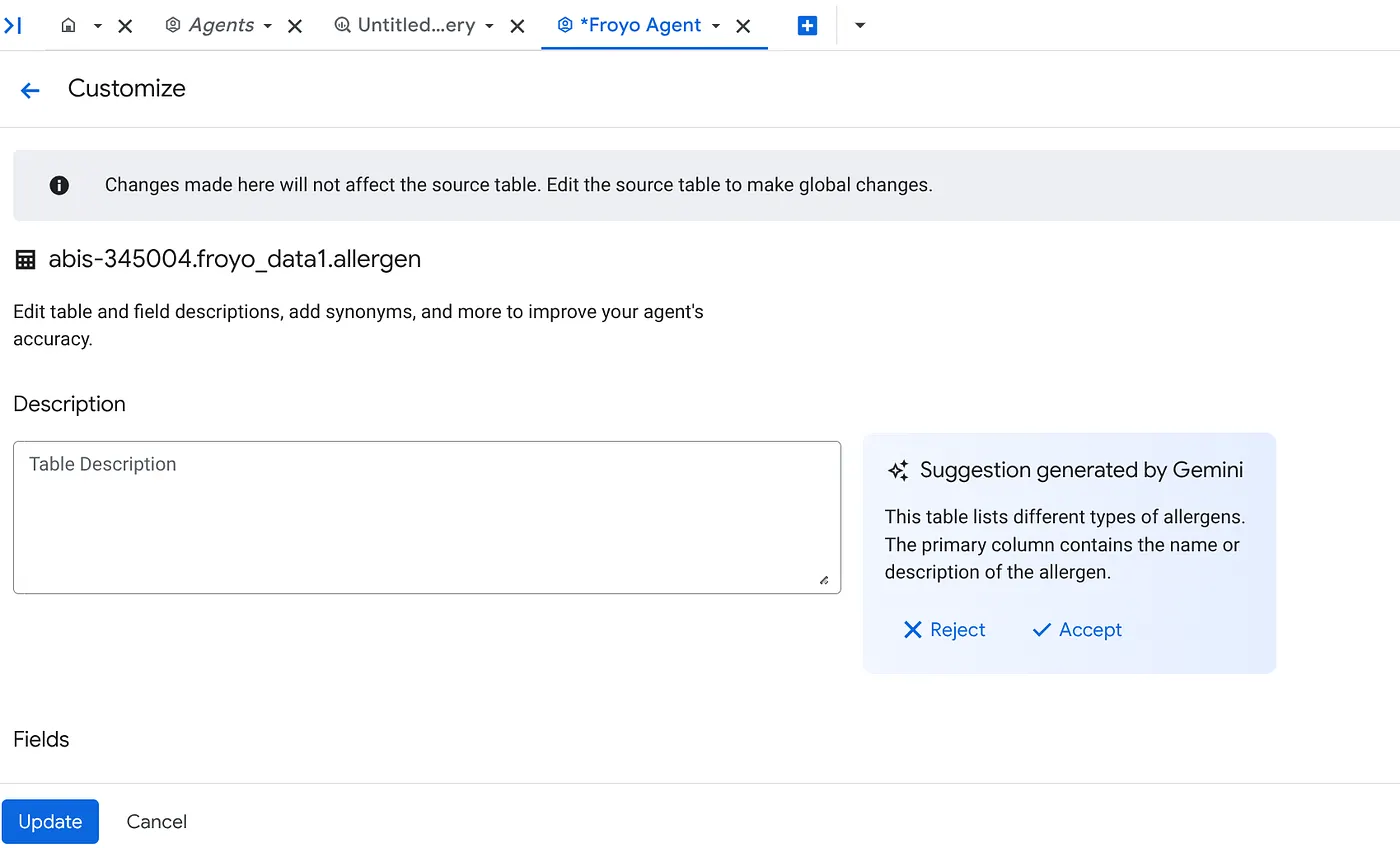
c. 표 설명에 대해 '수락'을 클릭합니다.
d. 각 필드의 설명에 대해서도 '수락'을 클릭합니다.
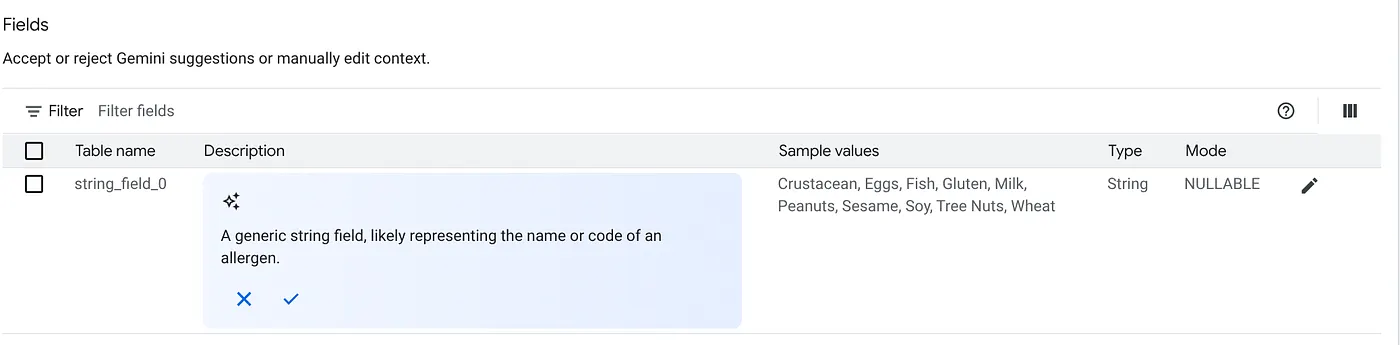
e. '업데이트'를 클릭합니다.
소스의 모든 테이블에 대해 이 작업을 반복해야 합니다.
- 구성 안내
Antigravity IDE GEMINI.md에서 사용한 것과 동일한 안내를 여기에 넣으세요.
1. Project Context
Project ID: <<YOUR_PROJECT_ID>>
Domain: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
Data: All froyo, customer, order related information is processed and stored in BigQuery froyo_data dataset. Use all the tables and data in the dataset for querying for user questions.
Context: Use Data Agent Kit skills wherever possible.
2. Execution & Data Processing Rules
CRITICAL RULE - Structured Specs: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named froyo_data.
CRITICAL RULE - Customer Data: Existing Froyo customer data resides in BigQuery in the tables customers_allergen_data. When you are referencing a dataset, ensure you are using it with the dataset ID (froyo_data) . For example, to query orders table in this dataset you should use froyo_data.orders.
- 에이전트를 저장합니다.
7. 데이터와 채팅하기
- 오른쪽 미리보기 섹션에서 테스트합니다.
질문하기:
Does midnight swirl contain any allergen?
대답은 다음과 같습니다.
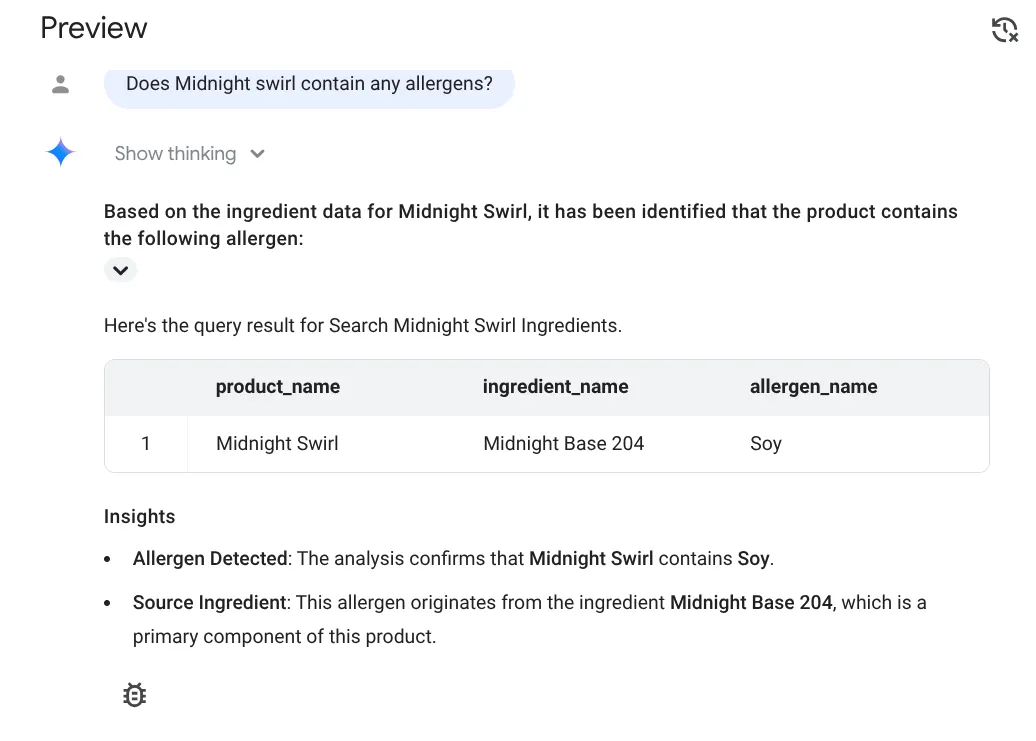
이제 복잡한 질문을 해 보겠습니다.
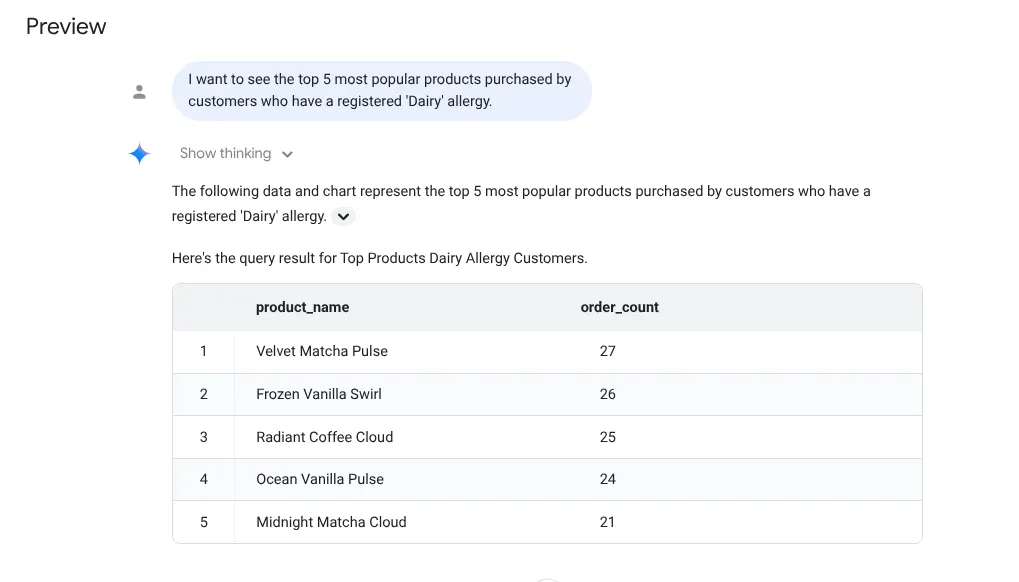
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
대답:
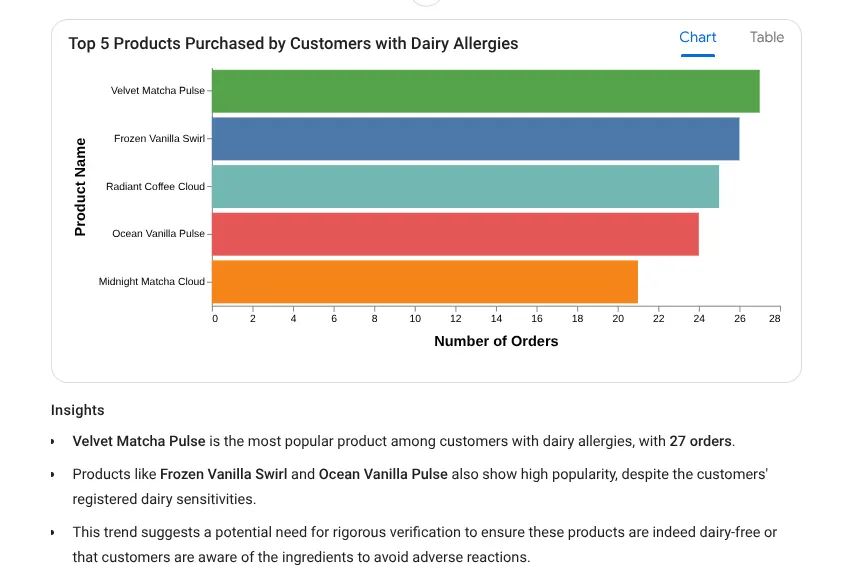
이제 심층적인 통찰력을 제공하는 프롬프트를 사용해 보겠습니다.
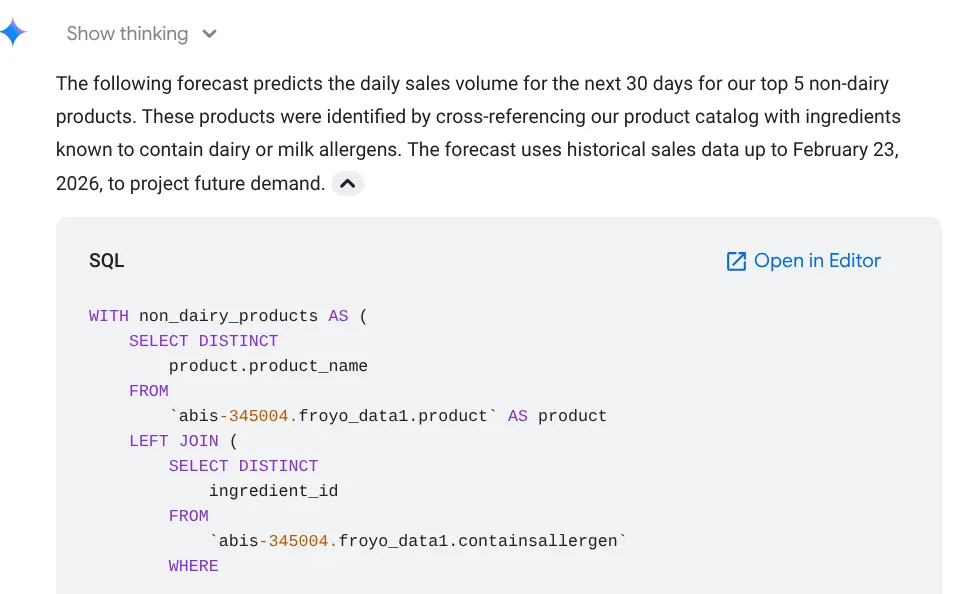
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
사용된 쿼리가 표 결과 및 차트와 함께 표시됩니다.
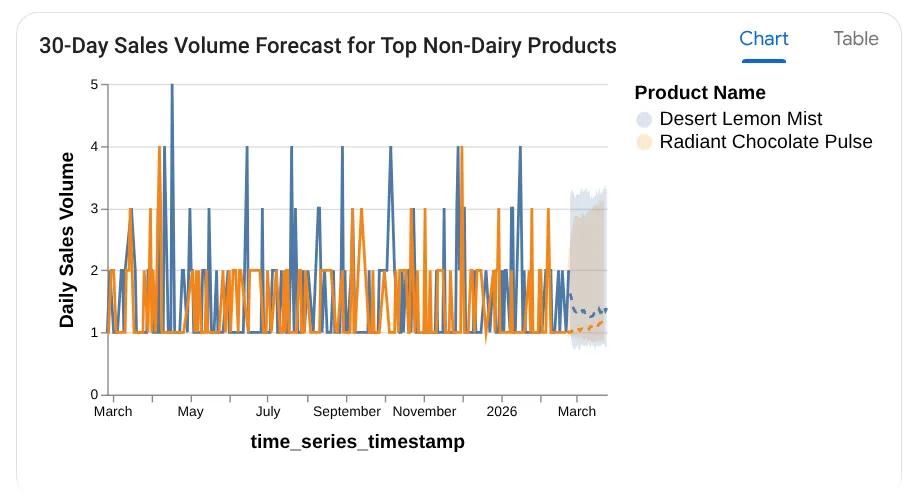

와우! 그래서 차트와 통계가 잘 어울렸습니다. 제품에 관한 마지막 질문입니다.
8. 궁극의 테스트
질문하기:
What will be the top most selling product of 2026
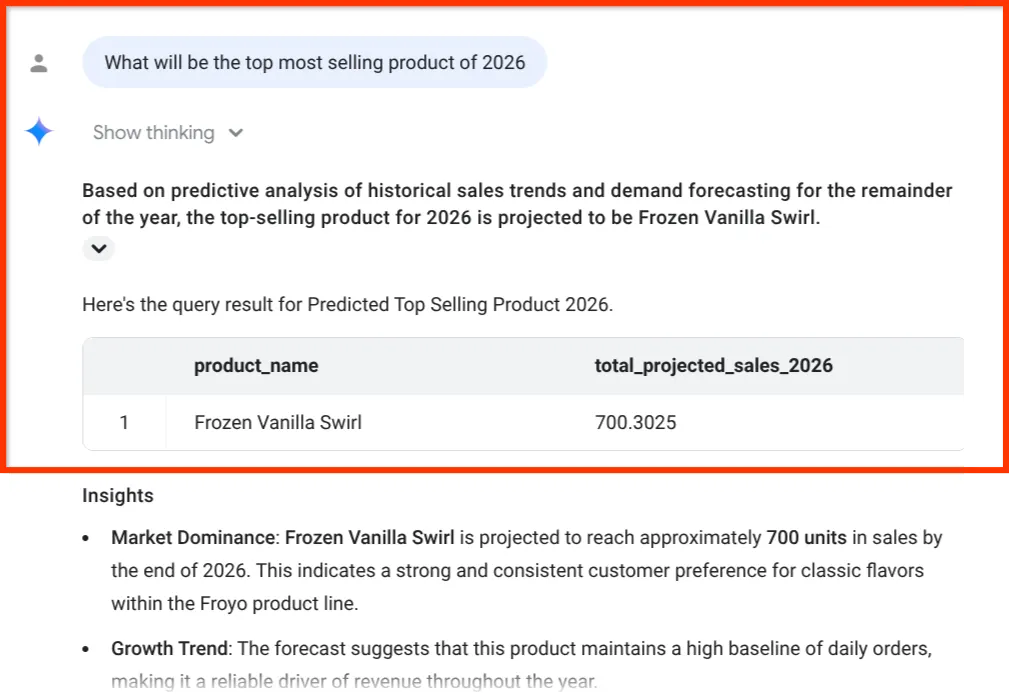

마지막 통계를 확인하세요. BigQuery 데이터 에이전트는 숫자만 제공한 것이 아니라 판매 예측을 인벤토리 및 재료 공급망과 명시적으로 연결했습니다. 이는 1부에서 정리되지 않은 PDF에서 추출한 정확한 데이터입니다.
9. 엔터프라이즈에 에이전트 게시
미리보기 에이전트 상단에 있는 게시 버튼을 클릭합니다.
이제 Froyo Agent를 빌드하고 구성하고 테스트했으므로 나머지 비즈니스에 출시할 차례입니다.
에이전트 구성 페이지의 오른쪽 상단에서 게시 버튼을 클릭합니다.
게시하면 나와 내가 공유한 모든 사용자가 세 가지 강력한 엔터프라이즈 채널에서 에이전트를 즉시 사용할 수 있습니다.
- BigQuery: 이제 데이터 분석가가 에이전트 허브 또는 BigQuery Studio SQL 작업공간에서 바로 이 에이전트와 채팅할 수 있습니다.
- Conversational Analytics API: 개발자가 REST API를 통해 이 에이전트에 액세스하여 이러한 정확한 대화형 분석을 자체 맞춤 내부 웹 애플리케이션에 통합할 수 있습니다.
- 데이터 스튜디오: 임원진은 이 에이전트와 상호작용하고 데이터 스튜디오 내에서 직접 동적 대화형 대시보드를 만들 수 있습니다.
Google은 사일로에서 데이터를 가져와 이미 근무하고 있는 사람들에게 직접 제공하는 데 성공했습니다.
게시된 BigQuery 에이전트 상단의 공유 버튼 드롭다운을 클릭하고 목록에서 '데이터 스튜디오의 에이전트 링크 복사' 옵션을 선택합니다.
브라우저에 링크를 붙여넣고 Enter 키를 누릅니다. 상담사 상호작용 액세스 알림에 대한 확인을 제공합니다.
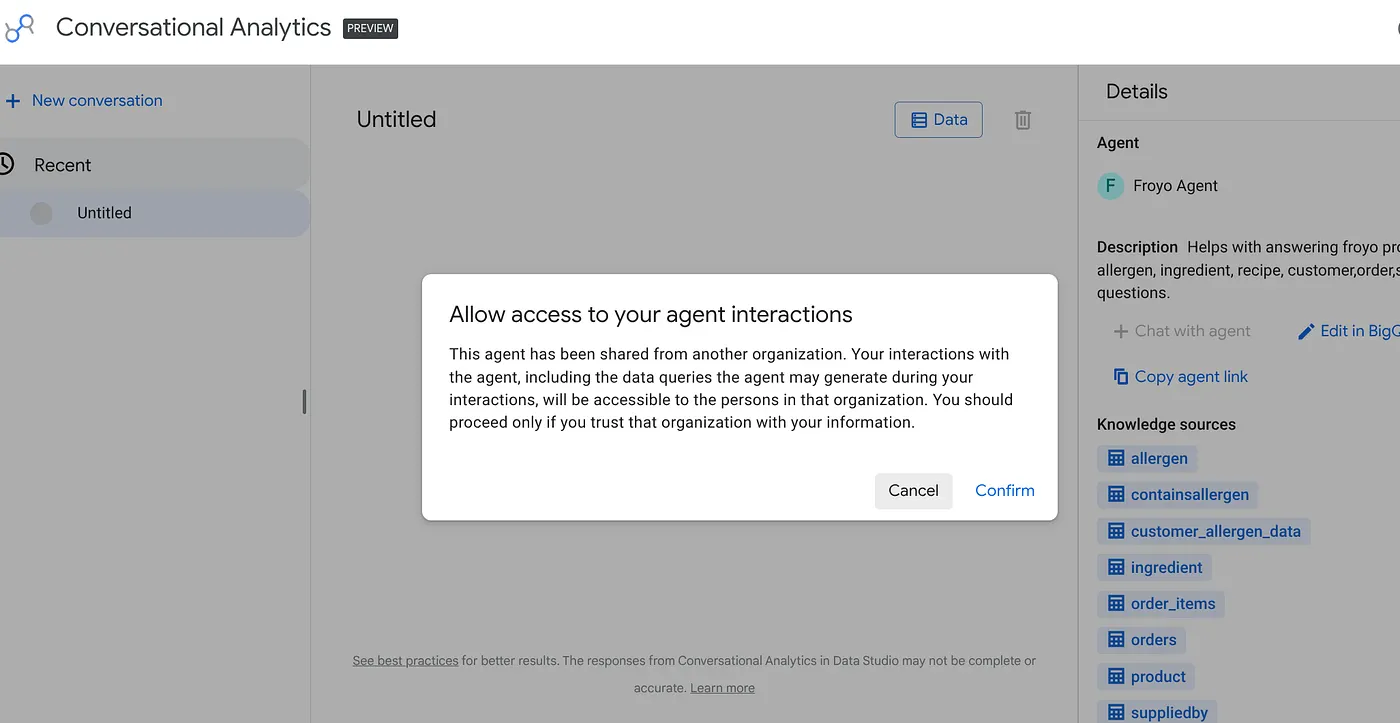
데이터 스튜디오에서 새로 게시된 에이전트와 대화형으로 소통하고 시각화할 수 있으며, 이 정보가 필요한 리더십 및 기타 팀도 마찬가지입니다.
10. 삭제
이 실습을 완료한 후 방금 만든 BigQuery 에이전트에 대한 모든 사용자의 권한을 삭제해야 합니다.
11. 축하합니다.
이제 공식적으로 Agentic Data Cloud를 빌드했습니다.
단순한 챗봇을 만든 것이 아닙니다. 이 5개의 세션을 통해 처음부터 완전하고 현대적이며 평가된 엔터프라이즈 AI 시스템을 성공적으로 설계했습니다. '다크 데이터'에서 실시간 거래 인텔리전스로, 마지막으로 대화형 비즈니스 예측으로 이동했습니다.
12. 전체적인 그림
한 걸음 물러서서 이 시리즈에서 달성한 내용을 살펴보세요. 단순한 챗봇을 만든 것이 아닙니다. Google은 완전한 최신 Agentic Data Cloud를 설계했습니다.
1부: Knowledge Catalog를 사용하여 PDF를 구조화된 관계형 테이블로 변환하여 잠긴 다크 데이터를 해제했습니다.
2부: 분석 웨어하우스를 AlloyDB 트랜잭션 데이터베이스에 직접 페더레이션하여 데이터 사일로를 해체했습니다.
3부: MCP 프로토콜을 통해 보안 데이터베이스 도구를 원활하게 실행하는 멀티 에이전트 OS를 빌드하여 사용자 지원
4부: 환각 및 제한 해제를 포착하기 위해 엄격한 평가 파이프라인을 구현하여 안전을 보장했습니다.
5부: ANTIGRAVITY IDE 및 BigQuery의 대화형 분석을 사용하여 유용한 정보를 대중화합니다.
이것이 엔터프라이즈 소프트웨어의 미래입니다. AI 에이전트는 더 이상 LLM의 래퍼가 아닙니다. 통합 데이터 플랫폼 위에 있는 완전히 통합되고 평가되고 안전한 오케스트레이션 엔진입니다.