
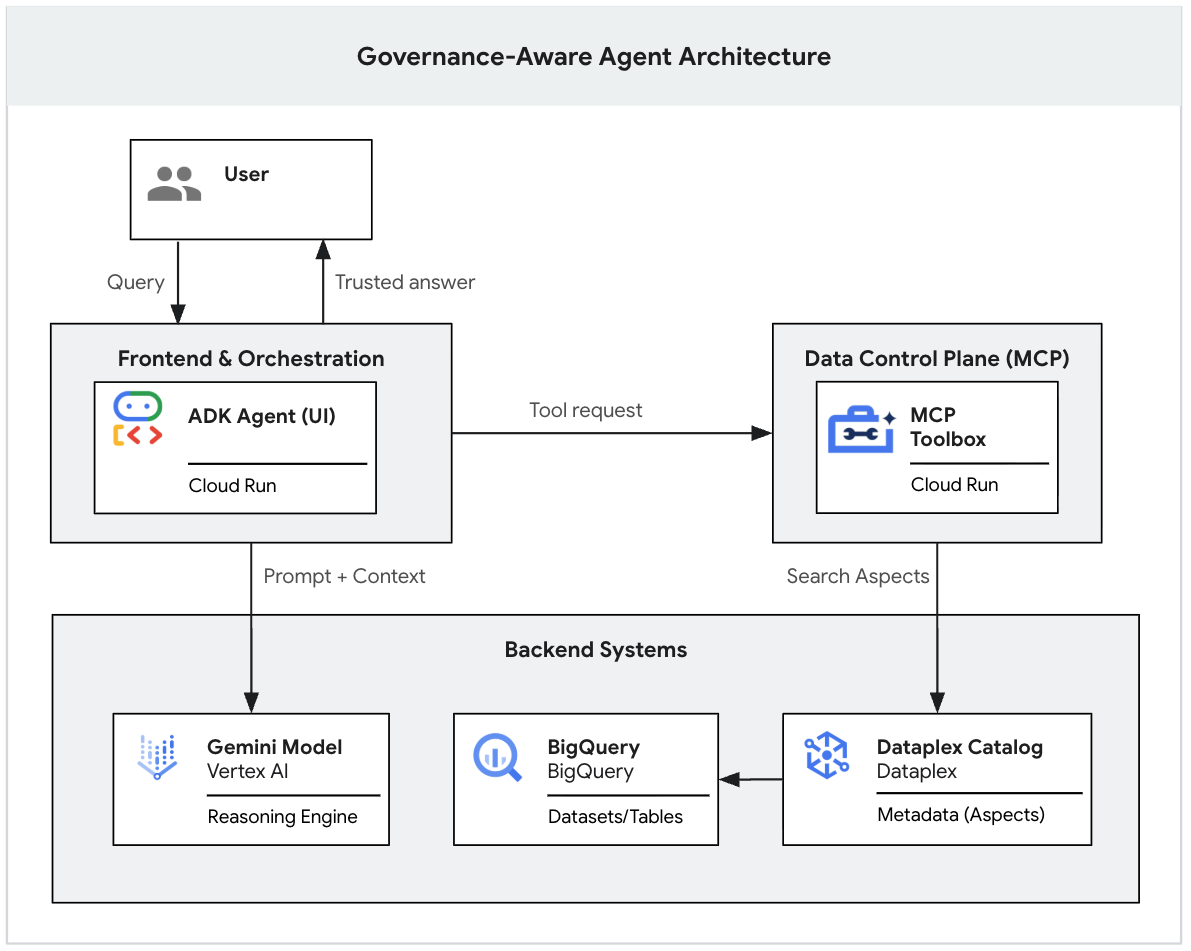
1. Wprowadzenie
Modele generatywnej AI są potężnymi narzędziami do wnioskowania, ale brakuje im kontekstu instytucjonalnego. Jeśli dyrektor zapyta agenta AI: „Jakie są nasze przychody w pierwszym kwartale?”, agent może znaleźć w jeziorze danych dziesiątki tabel o nazwie „przychody”. Niektóre z nich to rygorystyczne raporty finansowe, inne to szacunki marketingowe w czasie rzeczywistym, a wiele z nich to prawdopodobnie przestarzałe piaskownice.
Bez wyraźnego uzasadnienia agent AI wybierze tabelę na podstawie prostego podobieństwa nazw, co doprowadzi do uzyskania "przekonująco błędnych" odpowiedzi na podstawie niezweryfikowanych danych.
To ćwiczenie jest częścią 2-częściowej serii, w której pokazujemy, jak zbudować agenta generatywnej AI uwzględniającego zarządzanie.
W pierwszej części zbudujesz fundament danych. Skonfigurujesz realistyczne, „nieuporządkowane” jezioro danych w BigQuery, zastosujesz rygorystyczne tagi metadanych (aspekty Knowledge Catalog), aby odróżnić prawidłowe dane od szumu, i użyjesz interfejsu wiersza poleceń Gemini, aby lokalnie sprawdzić, czy LLM ściśle przestrzega reguł zarządzania.
(Drugą część tej serii, w której opisujemy, jak wdrożyć ten lokalny prototyp w bezpiecznej aplikacji internetowej klasy korporacyjnej za pomocą protokołu Model Context Protocol (MCP) i Cloud Run, możesz przeczytać tutaj. 👉 Przeczytaj część 2)
Wymagania wstępne
- Projekt Google Cloud z włączonymi płatnościami.
- Podstawowa wiedza na temat BigQuery, Knowledge Catalog Universal Catalog i Terraform.
- Dostęp do Google Cloud Shell.
Czego się nauczysz
- Wdrażanie realistycznego, wielowarstwowego jeziora danych za pomocą Terraform.
- Projektowanie rygorystycznych szablonów metadanych (typów aspektów) w Knowledge Catalog, aby odróżnić oficjalne produkty danych od nieprzetworzonych tabel piaskownicy.
- Lokalne weryfikowanie reguł zarządzania za pomocą interfejsu wiersza poleceń Gemini przed napisaniem kodu aplikacji.
Czego potrzebujesz
- Dostęp do Google Cloud Shell.
- Terraform (wstępnie zainstalowany w Cloud Shell).
- Interfejs wiersza poleceń Gemini (wstępnie zainstalowany w Cloud Shell).
Kluczowe pojęcia
- Knowledge Catalog Universal Catalog: ujednolicona usługa zarządzania metadanymi. Używamy jej do wzbogacania metadanych technicznych (schematów) o kontekst biznesowy (zarządzanie).
- Typ aspektu: ustrukturyzowany szablon metadanych. W przeciwieństwie do tagów w postaci tekstu dowolnego, aspekty wymuszają silne typowanie (wyliczenia, wartości logiczne), dzięki czemu są wiarygodne dla maszyn.
2. Konfiguracja i wymagania
Uruchamianie Cloud Shell
Chociaż Google Cloud można obsługiwać zdalnie z laptopa, w tym ćwiczeniu będziesz używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Uzyskanie dostępu do środowiska i połączenie się z nim może zająć kilka chwil. Gdy to się uda, zobaczysz coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym ćwiczeniu możesz wykonać w przeglądarce. Nie musisz niczego instalować.
Inicjowanie środowiska
Otwórz Cloud Shell i ustaw zmienne projektu, aby mieć pewność, że wszystkie polecenia będą kierowane do właściwej infrastruktury.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
Włączanie interfejsów API
Aby wykonać tę instrukcję, włącz niezbędne usługi Google Cloud.
gcloud services enable \
artifactregistry.googleapis.com \
bigqueryunified.googleapis.com \
cloudaicompanion.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
datacatalog.googleapis.com \
run.googleapis.com
Klonowanie repozytorium
Pobierz kod infrastruktury i skrypty automatyzacji z repozytorium GitHub. Aby zaoszczędzić miejsce na dysku w Cloud Shell, pobierzemy tylko folder potrzebny do tego ćwiczenia.
# Perform a shallow clone to get only the latest repository structure without the full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Specify and download only the folder we need for this lab
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
Tworzenie „nieuporządkowanego” jeziora danych
Środowiska danych w rzeczywistym świecie rzadko są czyste. Aby zasymulować rzeczywistość, potrzebujemy połączenia „oficjalnych” hurtowni danych i niezaufanych tabel „piaskownicy”.
Do wdrożenia tego środowiska użyjemy Terraform. Konfiguracja obejmuje 2 zadania:
- Infrastruktura: tworzy typy aspektów Knowledge Catalog oraz zbiory danych i tabele BigQuery.
- Wczytywanie danych: uruchamia zadania INSERT w BigQuery, aby natychmiast po utworzeniu wypełnić tabele przykładowymi danymi.
- Otwórz katalog
terraformi zainicjuj go.
cd terraform
terraform init
- Zastosuj konfigurację. Może to potrwać około minuty.
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Punkt kontrolny: masz teraz w pełni wypełnione, ale całkowicie niezarządzane jezioro danych. Dla AI każda tabela wygląda dokładnie tak samo.
3. Stosowanie zarządzania
To kluczowy etap inżynieryjny. Obecnie tabele finance_mart.fin_monthly_closing_internal i analyst_sandbox.tmp_data_dump_v2_final_real wyglądają dla LLM identycznie. Są to po prostu obiekty z kolumnami.
Jako inżynier ds. zarządzania musisz dołączyć do tych tabel aspekt (certyfikowaną etykietę metadanych), aby je odróżnić. W prawdziwym przedsiębiorstwie zautomatyzujesz to za pomocą potoków CI/CD. My zasymulujemy tę automatyzację za pomocą skryptów.
Generowanie ładunków danych zarządzania
Klucze aspektów Knowledge Catalog muszą być globalnie unikalne (z prefiksem identyfikatora projektu). Skrypt ./generate_payloads.sh będzie dynamicznie generować pliki metadanych YAML.
cd ..
chmod +x ./generate_payloads.sh
./generate_payloads.sh
Dane wyjściowe:
Spowoduje to utworzenie folderu „./aspect_payloads” zawierającego 4 pliki YAML, które definiują scenariusze zarządzania (Gold/Internal, Gold/Public, Silver/Realtime, Bronze/Sandbox).
Stosowanie aspektów za pomocą interfejsu wiersza poleceń
Zanim uruchomisz skrypt, przyjrzyjmy się temu, co właściwie stosujemy, aby wyjaśnić ten proces. Uruchom to polecenie, aby zobaczyć strukturę wewnętrznego ładunku danych finansowych:
cat aspect_payloads/fin_internal.yaml
Wyświetli się ta zawartość.
your-project-id.us-central1.official-data-product-spec:
data:
product_tier: GOLD_CRITICAL
data_domain: FINANCE
usage_scope: INTERNAL_ONLY
update_frequency: DAILY_BATCH
is_certified: true
Zwróć uwagę, jak ten plik YAML wyraźnie definiuje kontekst biznesowy, np. ustawiając flagę is_certified: true i przypisując poziom GOLD_CRITICAL. Dzięki temu AI ma jasne, ustrukturyzowane reguły do oceny zamiast zgadywania na podstawie nazw tabel.
Teraz uruchom skrypt aplikacji. Spowoduje to iterację po tabelach BigQuery i wykonanie polecenia gcloud dataplex entries update, aby dołączyć te rygorystyczne metadane.
chmod +x ./apply_governance.sh
./apply_governance.sh
Weryfikacja (opcjonalnie)
Zanim przejdziesz dalej, sprawdź, czy metadane zostały prawidłowo zastosowane w konsoli.
- W konsoli Google Cloud otwórz stronę Knowledge Catalog Universal Catalog. Jeśli w menu nawigacyjnym po lewej stronie nie widzisz opcji „Knowledge Catalog Universal Catalog”, użyj paska wyszukiwania u góry okna konsoli Google Cloud, wpisz Knowledge Catalog i wybierz wynik w sekcji „Najlepsze wyniki” lub „Usługi i strony”.
- Wyszukaj
fin_monthly_closing_internal. W wynikach powinna się pojawić tabela BigQuery. Kliknij nazwę tabeli, aby otworzyć stronę z informacjami.
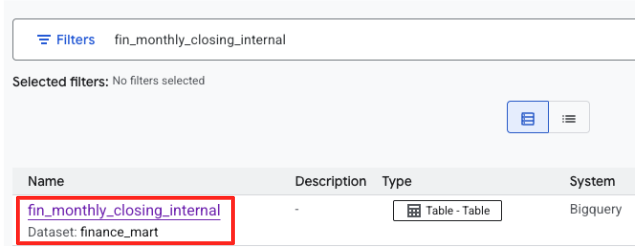
- Na stronie z informacjami o tabeli znajdź sekcję „Opcjonalne tagi i aspekty” u dołu.
- Znajdziesz tam aspekt
official-data-product-spec. Sprawdź, czy wartości są zgodne ze scenariuszem „Gold Internal”, który zastosowaliśmy.
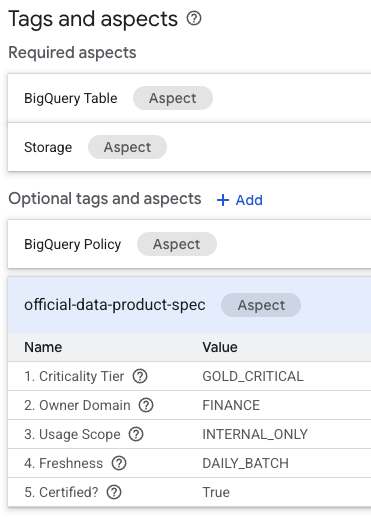
Potwierdziliśmy, że technicznie identyczne tabele BigQuery (fin_monthly_closing_internal i tmp_data_dump_v2_final_real) są logicznie rozróżniane przez metadane odczytywane przez maszyny.
4. Konfigurowanie i prototypowanie agenta
Zanim zbudujemy aplikację internetową (co zrobimy w części 2), sprawdzimy lokalnie logikę zarządzania. Musimy zainstalować rozszerzenie Knowledge Catalog i skonfigurować prompt systemowy.
Instalowanie rozszerzenia
W Cloud Shell zainstaluj rozszerzenie Knowledge Catalog. Poprosi Cię o potwierdzenie i podanie szczegółów konfiguracji.
export DATAPLEX_PROJECT="${PROJECT_ID}"
gemini extensions install https://github.com/gemini-cli-extensions/dataplex
(Wpisz Y, aby zaakceptować instalację, a gdy pojawi się prośba, wpisz identyfikator projektu).
Definiowanie pliku zasad
Plik GEMINI.md zawiera logikę, która tłumaczy abstrakcyjne reguły (np. „Potrzebuję bezpiecznych danych”) na ścisłe wyszukiwania techniczne.
Ten plik jest obecnie ogólny. Agent musi dokładnie wiedzieć, w którym projekcie Google Cloud ma szukać, aby nie halucynować tabel z publicznego internetu ani innych kontekstów.
- Wstaw do pliku zasad swój
PROJECT_ID.
envsubst < GEMINI.md > GEMINI.md.tmp && mv GEMINI.md.tmp GEMINI.md
- Sprawdź plik, aby zrozumieć algorytm, którego uczymy AI.
cat GEMINI.md
Zwróć uwagę na 2 kwestie w tym pliku:
- Zakres projektu: sprawdź etap 2. Upewnij się, że projectid:
${PROJECT_ID}został zastąpiony rzeczywistym identyfikatorem projektu(e.g., projectid:my-lab-project). Jeśli ta zmienna nie zostanie zastąpiona, agent będzie przeszukiwać wszystkie projekty, do których masz dostęp, co doprowadzi do nieprawidłowych odpowiedzi. - Algorytm: zwróć uwagę na logikę etapów 1 i 2. Wyraźnie instruujemy model, aby NIE zgadywał kodu SQL. Najpierw musi wyszukać prawidłową definicję tagu (etap 1), a dopiero potem dane (etap 2).
Uruchamianie agenta i testowanie scenariuszy
Uruchom sesję interfejsu wiersza poleceń Gemini, tym razem wczytując zasady zarządzania jako kontekst systemowy.
gemini
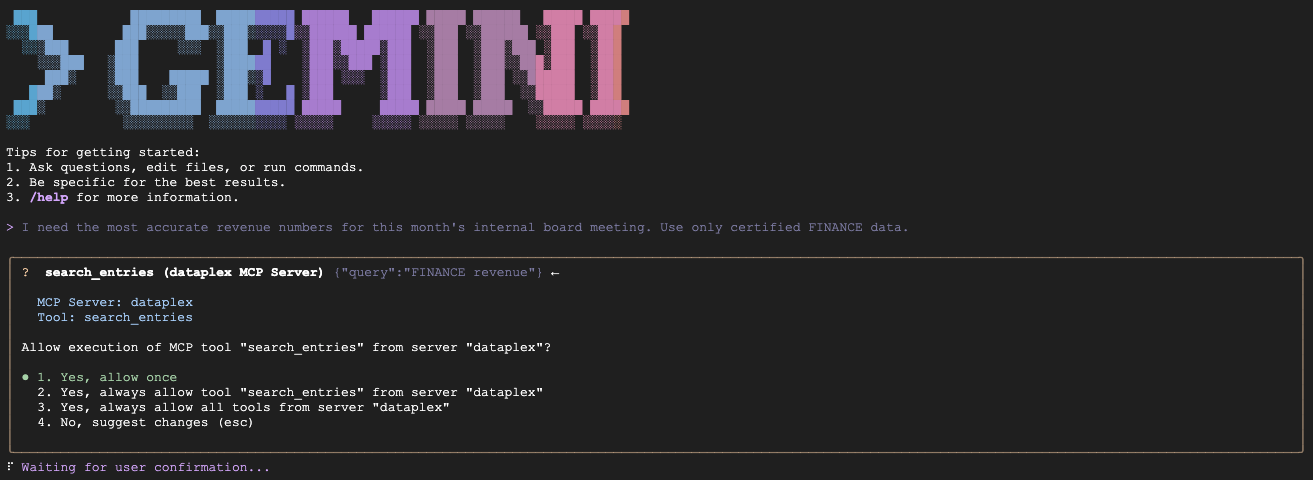
Uwaga: może się okazać, że wczytanych jest kilka plików kontekstu (np. GEMINI.md i inne). To zupełnie normalne. Interfejs wiersza poleceń wczytuje lokalny plik GEMINI.md z regułami specyficznymi dla tego projektu oraz instrukcje domyślne dla samego rozszerzenia Knowledge Catalog.
Sprawdzanie instalacji
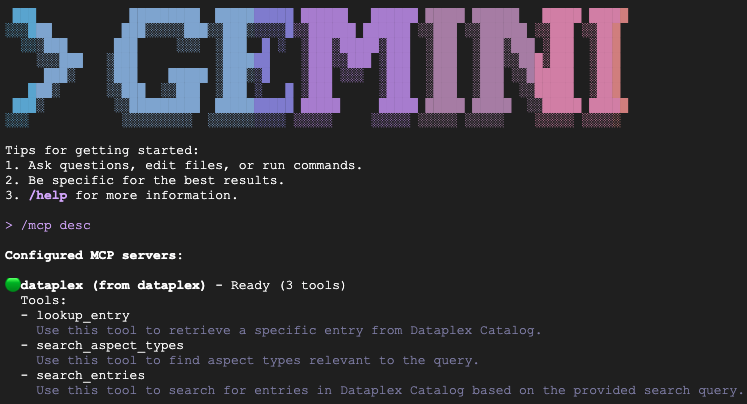
Wpisz /mcp desc, aby potwierdzić, że rozszerzenie Knowledge Catalog jest aktywne. Powinna się wyświetlić usługa dataplex jako skonfigurowany serwer MCP z dostępnymi narzędziami.
Testowanie scenariuszy (prototypowanie)
Wklejaj kolejno te prompty do uruchomionej sesji agenta, aby sprawdzić, czy przestrzega on Twoich reguł.
- Scenariusz A (certyfikowanie danych dyrektora finansowego):
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
Oczekiwane: zapytania fin_monthly_closing_internal, ponieważ semantycznie pasuje do GOLD_CRITICAL (dokładne) i INTERNAL_ONLY (posiedzenie zarządu) w swoim aspekcie.
- Scenariusz B (ujawnienie publiczne):
"I need to share our quarterly financial summary with an external consulting firm. It is critical that we do not leak any raw or internal metrics. Which dataset is officially scrubbed and explicitly approved for external sharing?"
Oczekiwane: agent musi pominąć miesięczną tabelę wewnętrzną i wybrać wyłącznie fin_quarterly_public_report, ponieważ jest to jedyny zasób oznaczony tagiem EXTERNAL_READY.
- Scenariusz C (potrzeby operacyjne):
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
Oczekiwane: agent wybiera mkt_realtime_campaign_performance, ponieważ identyfikuje częstotliwość aktualizacji REALTIME_STREAMING, traktując ją priorytetowo w stosunku do poziomu GOLD_CRITICAL danych finansowych.
- Scenariusz D (eksperymentowanie w piaskownicy):
"I'm just playing around with some new ML models and need a lot of raw data. It doesn't need to be perfect, just a sandbox environment."
Oczekiwane: agent wybiera tmp_data_dump_v2_final_real, ponieważ semantycznie pasuje do BRONZE_ADHOC (nieprzetworzone dane) i is_certified: false (środowisko piaskownicy) w swoim aspekcie.
(Aby zamknąć sesję Gemini, wpisz /quit)
5. Gratulacje! Co dalej?
Udało Ci się zbudować fundament danych zarządzanych i udowodnić, że AI może ściśle przestrzegać reguł metadanych za pomocą lokalnego prototypu interfejsu wiersza poleceń.
Dotarłeś(-aś) do punktu kontrolnego. Wybierz następny krok:
Opcja A: chcę teraz przejść do części 2.
Jeśli chcesz przekształcić ten lokalny prototyp w bezpieczną aplikację internetową klasy produkcyjnej za pomocą protokołu Model Context Protocol (MCP) i Cloud Run:
👉 Link do ćwiczenia z programowania w części 2
Opcja B: część 2 wykonam później lub chciałem(-am) tylko ukończyć część 1.
Jeśli chcesz na dziś zakończyć pracę i uniknąć kosztów chmury, musisz zwolnić miejsce na zasoby.
Nie martw się. W części 2 udostępnimy „skrypt szybkiego śledzenia”, który całkowicie odbuduje to środowisko z części 1 w zaledwie 2 minuty, dzięki czemu będziesz mieć możliwość kontynuowania pracy od miejsca, w którym została przerwana.
👉 Przejdź do sekcji Zwalnianie miejsca.
6. Zwalnianie miejsca (tylko w przypadku opcji B)
Jeśli zatrzymujesz się w tym miejscu, usuń zasoby, aby uniknąć opłat.
Usuwanie jeziora danych (Terraform)
Jeśli jesteś obecnie w środowisku interfejsu wiersza poleceń Gemini, zamknij sesję, naciskając 2 razy Ctrl+C lub wpisując /quit. Następnie uruchom te polecenia:
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Odinstalowywanie dodatku do interfejsu wiersza poleceń Gemini i usuwanie plików lokalnych
gemini extensions uninstall dataplex
cd ~
rm -rf ~/devrel-demos