
1. Wprowadzenie
To ćwiczenie jest częścią 2-częściowej serii, w której pokazujemy, jak utworzyć agenta generatywnej AI uwzględniającego zarządzanie.
(Pierwszą część tej serii, w której opisujemy, jak stworzyć podstawy danych przez zastosowanie aspektów Knowledge Catalog do tabel BigQuery i przetestowanie reguł lokalnie za pomocą interfejsu wiersza poleceń Gemini, możesz przeczytać tutaj: 👉 Przeczytaj część 1)
Testowanie w lokalnym interfejsie wiersza poleceń to jednak dopiero początek. Aby wdrożyć to rozwiązanie w całej firmie, potrzebujesz scentralizowanego zabezpieczenia, standardowych połączeń z narzędziami AI i odpowiedniej platformy aplikacji do zarządzania logiką agenta oraz zapewnienia znanego interfejsu czatu.
W tej drugiej części rozwiążesz te problemy i przejdziesz do wdrożenia w środowisku produkcyjnym. Wdrożysz reguły zarządzania na centralnym serwerze MCP hostowanym w Cloud Run. Następnie użyjesz pakietu Agent Development Kit (ADK) od Google, aby utworzyć rzeczywistą aplikację agenta i połączyć ją z narzędziami MCP, w tym z profesjonalnym interfejsem internetowym.
Wymagania wstępne
- Projekt Google Cloud z włączonymi płatnościami.
- Podstawowa wiedza o Cloud Run, kontach usługi IAM i Pythonie.
- Zbiory danych BigQuery i aspekty Knowledge Catalog utworzone w części 1. (Nie martw się, jeśli je usuniesz. Poniżej znajdziesz skrypt, który pozwoli Ci je szybko odtworzyć).
Czego się nauczysz
- Jak używać protokołu Model Context Protocol (MCP) do standaryzowania sposobu, w jaki agenci AI wchodzą w interakcję z danymi Google Cloud.
- Jak wdrożyć bezpieczny serwer MCP w Cloud Run.
- Jak utworzyć agenta AI za pomocą pakietu Agent Development Kit (ADK) i połączyć go z backendem MCP.
- Jak uruchomić wbudowany interfejs deweloperski pakietu ADK, aby wchodzić w interakcję z agentem uwzględniającym zarządzanie.
Czego potrzebujesz
- Dostęp do Google Cloud Shell.
Kluczowe pojęcia
- Model Context Protocol (MCP): MCP to „uniwersalny kabel USB-C” dla agentów AI. Zamiast pisać niestandardowy kod integracji interfejsu API dla każdego modelu AI, MCP zapewnia standardowy sposób, w jaki AI może bezpiecznie łączyć się z narzędziami do danych w Twojej firmie (takimi jak Knowledge Catalog i BigQuery).
- Agent Development Kit (ADK): elastyczna platforma open source od Google, która upraszcza kompleksowe tworzenie agentów AI. Stosuje zasady inżynierii oprogramowania do tworzenia agentów, co pozwala zarządzać złożonymi narzędziami, stanem i łatwo uruchamiać wbudowany interfejs deweloperski na potrzeby testowania i wdrażania.
2. Konfiguracja i wymagania
Uruchamianie Cloud Shell
Chociaż możesz zdalnie korzystać z Google Cloud na laptopie, w tym ćwiczeniu będziesz używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Uzyskanie dostępu do środowiska i połączenie się z nim może zająć kilka chwil. Gdy to się uda, zobaczysz coś takiego:

Ta maszyna wirtualna jest wyposażona we wszystkie narzędzia deweloperskie, których będziesz potrzebować. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym ćwiczeniu możesz wykonać w przeglądarce. Nie musisz niczego instalować.
Inicjowanie środowiska
Otwórz Cloud Shell i ustaw zmienne projektu, aby mieć pewność, że wszystkie polecenia są kierowane do odpowiedniej infrastruktury.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
Punkt kontrolny: wznowienie czy ponowne utworzenie?
Ponieważ jest to część 2, agent do działania potrzebuje danych uwzględniających zarządzanie z części 1. Wybierz ścieżkę:
Ścieżka A: właśnie skończyłem(-am) część 1 i moje zasoby nadal działają.
Świetnie. Przejdź do katalogu roboczego i możesz kontynuować.
cd ~/devrel-demos/data-analytics/governance-context
Ścieżka B: pominąłem(-am) część 1 LUB usunąłem(-am) zasoby (wyczyszczone).
To żaden problem. Poniżej znajdziesz blok poleceń „Fast-Track”. Automatycznie odbuduje on jezioro danych BigQuery i zastosuje metadane zarządzania Knowledge Catalog dokładnie tak, jak w części 1.
# 1. Clone the repo and navigate to the working directory
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
# 2. Rebuild the messy data lake with Terraform
cd terraform
terraform init
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
# 3. Generate and apply Knowledge Catalog Aspects (Governance rules)
cd ..
chmod +x ./generate_payloads.sh ./apply_governance.sh
./generate_payloads.sh
./apply_governance.sh
3. Skalowanie za pomocą MCP: tworzenie platformy sterującej danymi
Do tej pory udało Ci się przetestować logikę zarządzania za pomocą interfejsu wiersza poleceń Gemini. Jest to doskonałe rozwiązanie do szybkiego prototypowania, ale działa lokalnie przy użyciu Twoich danych logowania.
W rzeczywistym środowisku firmowym potrzebujesz scentralizowanej platformy sterującej danymi. Aby ją utworzyć, użyjemy GenAI Toolbox for Databases, czyli oficjalnego projektu open source od Google. Ten zestaw narzędzi zawiera wstępnie skonfigurowany serwer MCP, który został zaprojektowany specjalnie do bezpiecznego łączenia agentów AI z bazami danych Google Cloud i usługami metadanych, takimi jak Knowledge Catalog.
Wdrożenie tego zestawu narzędzi jako serwera MCP w Cloud Run pozwala nam osiągnąć te korzyści:
- Scentralizowana tożsamość: agent działa jako ograniczone konto usługi, a nie jako Twoje osobiste konto użytkownika.
- Standaryzacja: każdy klient (ADK, Gemini, aplikacje niestandardowe) może „podłączyć się” do tego serwera za pomocą standardowego protokołu MCP.
- Kontrolowany zakres (jak najmniejsze uprawnienia): nie przyznajemy LLM nieograniczonego dostępu do BigQuery. Zmuszamy go do najpierw przejścia przez katalog metadanych Knowledge Catalog.
Konfigurowanie definicji narzędzia (tools.yaml)
Zestaw narzędzi generatywnej AI wymaga deklaratywnego pliku konfiguracyjnego tools.yaml. Ten plik definiuje sources (gdzie się połączyć) i tools (co może robić AI).
- Przejdź do katalogu serwera i wstaw identyfikator projektu do pliku konfiguracyjnego:
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
envsubst < tools.yaml > tools.tmp && mv tools.tmp tools.yaml
cat tools.yaml
Powinien on wyglądać identycznie jak ten fragment kodu. Sprawdź, czy pole project jest teraz zgodne z Twoim rzeczywistym identyfikatorem projektu Google Cloud.
sources:
dataplex:
kind: dataplex
project: YOUR-PROJECT-ID
tools:
search_entries:
kind: dataplex-search-entries
source: dataplex
description: Search for entries in Knowledge Catalog.
lookup_entry:
kind: dataplex-lookup-entry
source: dataplex
description: Retrieve a specific entry from Knowledge Catalog.
search_aspect_types:
kind: dataplex-search-aspect-types
source: dataplex
description: Find aspect types relevant to a query.
toolsets:
dataplex-toolset:
- search_entries
- lookup_entry
- search_aspect_types
Definiując te 3 narzędzia, możemy wymusić, aby AI działała w trybie „tylko do odczytu” i „zarządzanie na pierwszym miejscu”.
Zabezpieczanie konfiguracji (Secret Manager)
W architekturze firmowej nigdy nie należy wbudowywać plików konfiguracyjnych bezpośrednio w obrazy kontenerów. Plik tools.yaml będziemy bezpiecznie przechowywać w Google Cloud Secret Manager.
gcloud services enable secretmanager.googleapis.com
gcloud secrets create dataplex-tools-config --data-file=tools.yaml
Implementowanie zasady jak najmniejszych uprawnień (IAM)
Następnie utworzymy dedykowane konto usługi dla serwera MCP zestawu narzędzi generatywnej AI. Ta tożsamość będzie mieć tylko uprawnienia wymagane do odczytywania katalogu Knowledge Catalog i uzyskiwania dostępu do danych BigQuery.
export MCP_SA=mcp-sa
gcloud iam service-accounts create ${MCP_SA} \
--display-name="Service Account for Knowledge Catalog MCP"
export MCP_SERVICE_ACCOUNT="${MCP_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow the server to read its own config from Secret Manager
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor"
# Allow the server to read Knowledge Catalog Metadata and BigQuery Data
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer"
Wdrażanie serwera MCP w Cloud Run
Teraz wdrażamy zestaw narzędzi generatywnej AI. Używamy wstępnie utworzonego obrazu kontenera Google (database-toolbox/toolbox) i montujemy konfigurację z Secret Manager (--set-secrets) w czasie działania.
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy governance-mcp \
--image=$IMAGE \
--service-account $MCP_SERVICE_ACCOUNT \
--region=$REGION \
--no-allow-unauthenticated \
--set-secrets="/app/tools.yaml=dataplex-tools-config:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080"
Udało Ci się utworzyć interfejs API uwzględniający zarządzanie. Zamiast przyznawać frontendowi generatywnej AI bezpośredni dostęp do bazy danych, połączysz go z tym adresem URL Cloud Run. Agent może zobaczyć tylko to, co pozwala mu ten zestaw narzędzi.
4. Tworzenie backendu agenta za pomocą pakietu ADK
Udało Ci się utworzyć bezpieczną płaszczyznę sterowania danymi (MCP) uwzględniającą zarządzanie, która działa w Cloud Run. Teraz agent AI potrzebuje platformy do zarządzania swoją logiką, np. do przetwarzania danych wejściowych użytkownika, decydowania, kiedy wywołać serwer MCP, i formatowania danych wyjściowych.
Zamiast pisać cały ten powtarzalny kod od zera, użyjemy pakietu Agent Development Kit (ADK) od Google. ADK to platforma oparta na kodzie, która automatycznie opakowuje logikę agenta w backend FastAPI. Ponadto zawiera wbudowany interfejs deweloperski, który umożliwia natychmiastowe wizualizowanie procesu wnioskowania agenta i wywołań narzędzi bez konieczności tworzenia niestandardowego frontendu.
Sprawdzanie logiki agenta (agent.py)
Zanim skonfigurujemy infrastrukturę, przyjrzyjmy się rdzeniowi tej aplikacji.
Przejdź do katalogu i wyświetl zawartość pliku agent.py. Ten plik to „mózg” wdrożenia pakietu ADK.
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
cat agent.py
Przyjrzyj się strukturze kodu. Wykonuje on 3 krytyczne funkcje przy minimalnej ilości kodu:
- Integracja MCPToolset: zamiast pisać niestandardowe klienty HTTP do interakcji z narzędziami Knowledge Catalog, pakiet ADK używa
MCPToolset(server_url=mcp_url). Dynamicznie pobiera definicjętools.yamlz wdrożonego serwera MCP i tłumaczy ją na natywne wywołania funkcji dla LLM. - Instrukcje systemowe: parametr
instructionszawiera ścisłe reguły zarządzania (tę samą logikę, której użyliśmy w interfejsie wiersza poleceńGEMINI.md). Jawnie nakazuje modelowi wykonanie pętli rozumowania od fazy 1 (wyszukiwanie metadanych) do fazy 2 (zapytanie o dane). - Orkiestracja agenta: klasa
Agent(...)łączy model Gemini, prompt systemowy i narzędzia MCP. Po wdrożeniu pakiet ADK automatycznie przekształca ten obiekt w skalowalny punkt końcowy FastAPI.
Podział obowiązków: konfigurowanie tożsamości frontendu
Aby ten kod działał bezpiecznie, musimy poinformować agenta, gdzie znajduje się serwer MCP. Dynamicznie utworzymy adres URL i zapiszemy go w pliku .env, który pakiet ADK odczyta w czasie działania.
Utworzymy też osobną tożsamość (dataplex-agent-sa) dla tej aplikacji przeznaczonej dla użytkowników. Ten podział obowiązków zapewnia, że agent frontendu ma inne uprawnienia niż serwer zarządzania backendu.
Aby skonfigurować środowisko i tożsamość, uruchom te polecenia:
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export MCP_SERVER_URL=https://governance-mcp-${PROJECT_NUMBER}.${REGION}.run.app/mcp
export AGENT_SA=knowledge-catalog-agent-sa
export AGENT_SERVICE_ACCOUNT="${AGENT_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${AGENT_SA} \
--display-name="Service Account for Knowledge Catalog Agent "
Konfigurowanie zmiennych środowiskowych
Platforma ADK korzysta ze zmiennych środowiskowych, aby zrozumieć swój kontekst. Musimy jawnie ustawić identyfikator projektu, region i włączyć użycie silnika agenta Gemini Enterprise. Dodamy je do tego samego pliku .env.
echo MCP_SERVER_URL=$MCP_SERVER_URL > .env
echo GOOGLE_GENAI_USE_VERTEXAI=1 >> .env
echo GOOGLE_CLOUD_PROJECT=$PROJECT_ID >> .env
echo GOOGLE_CLOUD_LOCATION=$REGION >> .env
Przyznawanie uprawnień
Nawet jeśli agent przekazuje sprawdzanie zarządzania na serwer MCP, nadal potrzebuje podstawowych uprawnień do działania. Przyznajemy dokładnie 2 role:
- Użytkownik silnika agenta Gemini Enterprise: do wywoływania modelu Gemini w celu generowania odpowiedzi w języku naturalnym.
- Wywołujący Cloud Run: do bezpiecznego wywoływania interfejsu API serwera MCP. Nie ma bezpośredniego dostępu do BigQuery ani Knowledge Catalog.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud run services add-iam-policy-binding governance-mcp \
--region=$REGION \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/run.invoker"
Wdrażanie w Cloud Run
Na koniec wdrażamy pełny stos w Cloud Run.
Używamy uvx, aby uruchomić narzędzie ADK bez ręcznego instalowania zależności. Poniższe polecenie pakuje logikę agent.py, tworzy obraz kontenera, wstawia konto usługi i uruchamia serwer FastAPI. Dodanie flagi --with_ui powoduje też dołączenie do debugowania pakietu ADK Web Playground.
To polecenie tworzy kontener i go wdraża. Może to potrwać 1–3 minuty.
uvx --from google-adk \
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=$REGION \
--service_name=knowledge-catalog-agent \
--with_ui \
. \
-- \
--service-account=$AGENT_SERVICE_ACCOUNT \
--allow-unauthenticated
Po zakończeniu tego polecenia zostanie wyświetlony adres URL usługi (e.g., https://dataplex-agent-xyz.run.app). Kliknij ten link, aby otworzyć w pełni zarządzany interfejs czatu generatywnej AI.
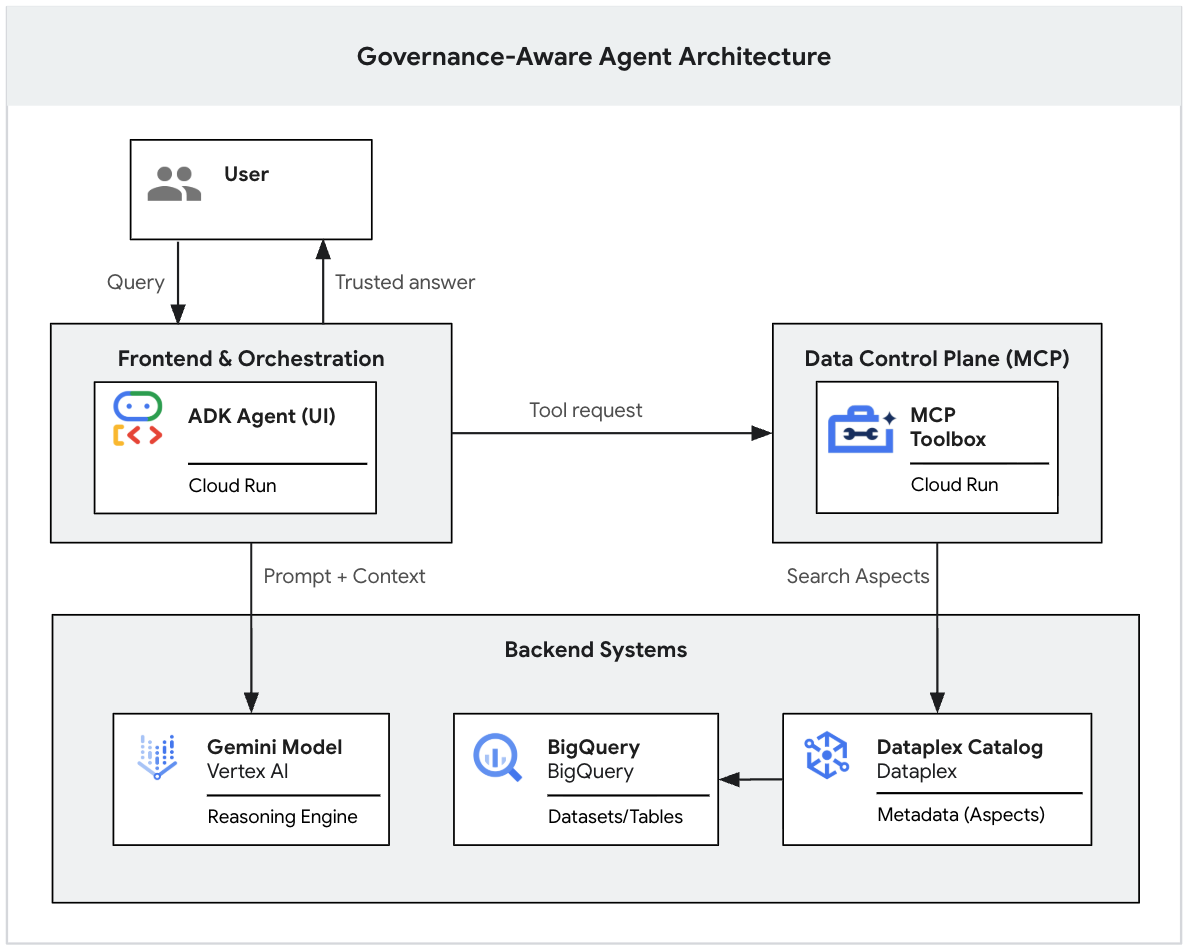
Kompleksowy przepływ architektury
Udało Ci się ukończyć system. Gdy użytkownik wchodzi w interakcję z interfejsem ADK, następuje ta sekwencja:
- Użytkownik przesyła prompta w agencie ADK (interfejs deweloperski).
- Agent ADK (agent.py) przetwarza dane wejściowe i wywołuje model Gemini.
- Gemini stwierdza, że potrzebuje kontekstu, i prosi serwer MCP o wykonanie narzędzi Knowledge Catalog.
- Serwer MCP egzekwuje reguły zarządzania Knowledge Catalog i zwraca metadane.
- Gemini syntetyzuje zaufaną odpowiedź na podstawie metadanych i zwraca ją użytkownikowi.
5. Testowanie agenta firmowego
Teraz, gdy agent jest aktywny, wróćmy do scenariuszy zarządzania testowanych wcześniej za pomocą interfejsu wiersza poleceń. Logika pozostaje taka sama, ale teraz wchodzisz w interakcję z wdrożonym pakietem ADK Web Playground, który wizualizuje stan wewnętrzny i wykonywanie narzędzi.
- Orkiestracja: agent ADK (działający w Cloud Run) otrzymuje Twój tekst.
- Routing narzędzi: Gemini rozpoznaje, że Twoje pytanie wymaga kontekstu danych, i przekazuje żądanie do serwera MCP.
- Sprawdzanie zarządzania: serwer MCP (działający w osobnej instancji Cloud Run) wysyła zapytanie do Knowledge Catalog o konkretne typy aspektów.
- Synteza: odpowiednie metadane są zwracane do Gemini, aby wygenerować ostateczną odpowiedź.
Sprawdzanie logiki zarządzania
W przeglądarce otwórz adres URL usługi wygenerowany w poprzednim kroku (e.g., https://dataplex-agent-xyz.run.app). Wklej ten prompt:
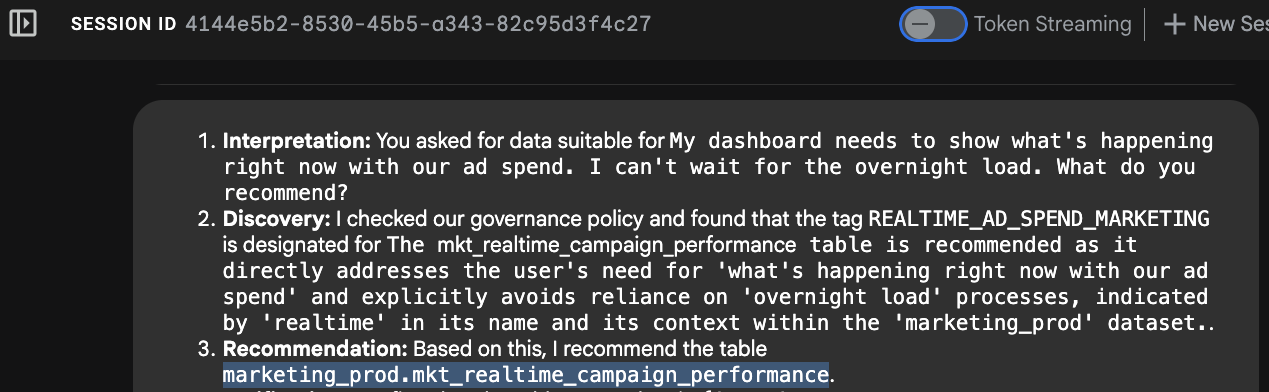
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
Obserwuj proces rozumowania agenta w interfejsie deweloperskim:
- Rozpoznawanie intencji: agent analizuje „teraz” i „nie mogę się doczekać nocy”.
- Wyszukiwanie metadanych: wywołuje narzędzie MCP
search_aspect_types. Szuka zasobów danych, w których aspektupdate_frequencyjest ustawiony na REALTIME lub STREAMING, a nie DAILY lub MONTHLY. - Wybór: stwierdza, że tabela
mkt_realtime_campaign_performancespełnia te kryteria, natomiastfin_monthly_closing_internal(mimo że jest wysokiej jakości) jest zbyt wolna na potrzeby Twojego żądania. - Odpowiedź: agent zaleca tabelę w czasie rzeczywistym.
Dlaczego to jest ważne:
Bez tych metadanych zarządzania LLM prawdopodobnie zaleciłby tabelę fin_monthly_closing_internal tylko dlatego, że ma kolumnę o nazwie „ad_spend”, ignorując fakt, że dane są sprzed 24 godzin. Kontekst metadanych zapobiegł błędowi biznesowemu.
Możesz też przetestować prompt „Board Meeting”, aby zobaczyć, jak agent przechodzi do różnych tabel na podstawie aspektu Data Product Tier:
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
6. Zwalnianie miejsca
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym ćwiczeniu, wykonaj te czynności, aby zniszczyć całą infrastrukturę utworzoną w części 1 i 2.
Niszczenie jeziora danych (Terraform)
Użyj Terraform, aby usunąć tabele, zbiory danych i definicje aspektów Knowledge Catalog.
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Usuwanie usług Cloud Run
Usuń zasoby obliczeniowe, aby zatrzymać aktywne rozliczenia za działające kontenery.
gcloud run services delete governance-mcp --region=$REGION --quiet
gcloud run services delete knowledge-catalog-agent --region=$REGION --quiet
Zwalnianie miejsca zajmowanego przez artefakty kompilacji i dane tymczasowe
Gdy wdrożysz agenta ADK za pomocą uvx, system automatycznie utworzy obraz kontenera i prześle kod źródłowy do tymczasowego zasobnika Cloud Storage. Te artefakty pozostaną nawet po usunięciu usługi Cloud Run i będą generować bieżące koszty przechowywania.
Usuń repozytorium Artifact Registry i zasobnik tymczasowy Cloud Storage:
# Delete the repository used for the agent build
gcloud artifacts repositories delete cloud-run-source-deploy \
--location=$REGION \
--quiet
# Delete the staging bucket created by Cloud Run source deploy
gcloud storage rm --recursive gs://run-sources-${PROJECT_ID}-${REGION}
Usuwanie tożsamości, uprawnień i obiektów tajnych
Najpierw usuń powiązania zasad uprawnień, aby zapobiec pozostawaniu w projekcie wpisów „tombstone” (osieroconych rekordów) na stronie uprawnień. Następnie usuń konta usługi i obiekty tajne konfiguracji.
# Remove IAM roles granted to the MCP Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer" --quiet
# Remove IAM roles granted to the Agent Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" --quiet
# Delete the Service Accounts
gcloud iam service-accounts delete $MCP_SERVICE_ACCOUNT --quiet
gcloud iam service-accounts delete $AGENT_SERVICE_ACCOUNT --quiet
# Delete the Secret Manager entry
gcloud secrets delete dataplex-tools-config --quiet
Usuwanie konfiguracji lokalnej
Na koniec wyczyść lokalne pliki konfiguracyjne i zmienne środowiskowe w Cloud Shell.
# Uninstall the Gemini CLI extension (installed in Part 1)
gemini extensions uninstall dataplex
# Remove local repository files and unset variables
cd ~
rm -rf ~/devrel-demos
unset MCP_SERVER_URL
unset MCP_SERVICE_ACCOUNT
unset AGENT_SERVICE_ACCOUNT
7. Gratulacje!
Udało Ci się wdrożyć kompleksowego agenta generatywnej AI uwzględniającego zarządzanie.
W tym 2-częściowym ćwiczeniu wyszedłeś(-aś) poza proste inżynierowanie promptów, aby wdrożyć solidną architekturę gotową do wdrożenia w środowisku produkcyjnym. Traktując zarządzanie danymi jako warunek wstępny generatywnej AI, stworzyłeś(-aś) systematyczną metodę zapobiegania pobieraniu przez model niecertyfikowanych lub halucynacyjnych danych.
Podsumowanie
- Deterministyczna AI dzięki metadanym: zamiast polegać na LLM w zakresie odgadywania prawidłowej tabeli na podstawie nazw kolumn, wymusiłeś(-aś) ścisłą pętlę rozumowania za pomocą GenAI Toolbox for Databases. Jawnie udostępniając tylko 3 narzędzia Knowledge Catalog (
search_aspect_types,search_entries,lookup_entry), zmusiłeś(-aś) model do weryfikowania certyfikatów danych przed syntetyzowaniem odpowiedzi. - Architektura rozłączona (MCP): wdrażając serwer protokołu Model Context Protocol (MCP) w Cloud Run, wyodrębniłeś(-aś) reguły zarządzania danymi do scentralizowanego, standardowego interfejsu API. Agent frontendu nie musi zawierać logiki bazy danych. Wystarczy, że będzie komunikować się za pomocą standardu MCP. Oznacza to, że możesz podłączyć dowolny przyszły model AI lub klienta do tego samego backendu uwzględniającego zarządzanie.
- Podział obowiązków: zastosowałeś(-aś) zasadę jak najmniejszych uprawnień przez izolowanie tożsamości IAM. Agent ADK przeznaczony dla użytkowników działa z uprawnieniami ograniczonymi do wywoływania modelu i routingu interfejsu API, a serwer MCP backendu bezpiecznie obsługuje zapytania Knowledge Catalog i pobieranie danych BigQuery.
- Orkiestracja agenta oparta na kodzie: użyłeś(-aś) pakietu Google Agent Development Kit (ADK), aby natychmiast opakować logikę agenta Pythona w skalowalny backend FastAPI, korzystając z wbudowanego interfejsu deweloperskiego do wizualizowania i debugowania wewnętrznych wykonań narzędzi agenta.
Co dalej?
- Ćwiczenie podstawowe dotyczące zarządzania w Knowledge Catalog: opanuj podstawy zarządzania danymi w Knowledge Catalog, zanim dodasz warstwę AI.
- Dokumentacja narzędzi Knowledge Catalog: zapoznaj się z oficjalną dokumentacją wstępnie utworzonych narzędzi i rozszerzeń Knowledge Catalog używanych w tym laboratorium.
- Pierwsze kroki z dodatkami do interfejsu wiersza poleceń Gemini: dowiedz się, jak tworzyć własne niestandardowe rozszerzenia, aby zwiększyć możliwości agentów generatywnej AI.
- Szczegółowe informacje o MCP: zapoznaj się z oficjalną specyfikacją MCP, aby dowiedzieć się, jak tworzyć niestandardowe serwery dla wewnętrznych interfejsów API firmy.