
1. 소개
이 Codelab은 거버넌스 인식 생성형 AI 에이전트를 빌드하는 방법을 살펴보는 2부작 시리즈의 일부입니다.
(BigQuery 테이블에 Knowledge Catalog 관점을 적용하고 Gemini CLI를 통해 로컬에서 규칙을 테스트하여 데이터 기반을 설정하는 방법을 다루는 이 시리즈의 첫 번째 부분을 읽어보세요. 👉 1부 읽어보기)
하지만 로컬 CLI에서 테스트하는 것은 시작에 불과합니다. 전체 회사에 이 기능을 출시하려면 중앙 집중식 보안, 표준화된 AI 도구 연결, 에이전트의 로직을 조정하고 익숙한 채팅 인터페이스를 제공하는 적절한 애플리케이션 프레임워크가 필요합니다.
이 두 번째 부분에서는 이러한 과제를 해결하고 프로덕션으로 확장합니다. Cloud Run에서 호스팅되는 중앙 MCP 서버에 거버넌스 규칙을 배포합니다. 그런 다음 Google의 에이전트 개발 키트 (ADK)를 사용하여 실제 에이전트 애플리케이션을 빌드하고 전문적인 웹 UI를 포함하여 MCP 도구에 연결합니다.
기본 요건
- 결제가 사용 설정된 Google Cloud 프로젝트.
- Cloud Run, IAM 서비스 계정, Python에 관한 기본적인 이해가 있어야 합니다.
- 1부에서 만든 BigQuery 데이터 세트 및 Knowledge Catalog 관점. (삭제했더라도 걱정하지 마세요. 아래에서 다시 만들 수 있는 빠른 스크립트를 제공합니다.)
학습할 내용
- 모델 컨텍스트 프로토콜 (MCP)을 사용하여 AI 에이전트가 Google Cloud 데이터와 상호작용하는 방식을 표준화하는 방법
- Cloud Run에 보안 MCP 서버를 배포하는 방법
- 에이전트 개발 키트 (ADK)를 사용하여 AI 에이전트를 빌드하고 MCP 백엔드에 연결하는 방법
- ADK의 기본 제공 개발자 UI를 실행하여 관리되는 에이전트와 상호작용하는 방법
필요한 항목
- Google Cloud Shell에 액세스
주요 개념
- 모델 컨텍스트 프로토콜 (MCP): MCP를 AI 에이전트의 '범용 USB-C 케이블'이라고 생각하세요. 모든 AI 모델에 맞춤 API 통합 코드를 작성하는 대신 MCP는 AI가 엔터프라이즈 데이터 도구 (예: Knowledge Catalog 및 BigQuery)에 안전하게 연결할 수 있는 표준 방법을 제공합니다.
- 에이전트 개발 키트 (ADK): Google에서 AI 에이전트의 엔드 투 엔드 개발을 간소화하기 위해 설계한 유연한 오픈소스 프레임워크입니다. 에이전트 생성에 소프트웨어 엔지니어링 원칙을 적용하여 복잡한 도구를 조정하고, 상태를 관리하고, 테스트 및 배포를 위한 기본 제공 개발자 UI를 쉽게 실행할 수 있습니다.
2. 설정 및 요건
Cloud Shell 시작
Google Cloud를 노트북에서 원격으로 실행할 수 있지만, 이 Codelab에서는 Cloud에서 실행되는 명령줄 환경인 Google Cloud Shell을 사용합니다.
Google Cloud 콘솔의 오른쪽 상단 툴바에 있는 Cloud Shell 아이콘을 클릭합니다.
환경을 프로비저닝하고 연결하는 데 몇 분 정도 소요됩니다. 완료되면 다음과 같이 표시됩니다.

가상 머신에는 필요한 개발 도구가 모두 들어있습니다. 영구적인 5GB 홈 디렉터리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 이 Codelab의 모든 작업은 브라우저 내에서 수행할 수 있습니다. 아무것도 설치할 필요가 없습니다.
환경 초기화
Cloud Shell을 열고 모든 명령어가 올바른 인프라를 타겟팅하도록 프로젝트 변수를 설정합니다.
export PROJECT_ID=$(gcloud config get-value project)
gcloud config set project $PROJECT_ID
export REGION="us-central1"
체크포인트: 재개 또는 재빌드?
이 Codelab은 2부이므로 에이전트가 작동하려면 1부의 관리되는 데이터가 필요합니다. 경로를 선택하세요.
경로 A: 1부를 방금 완료했으며 리소스가 아직 실행 중입니다.
좋습니다. 작업 디렉터리로 이동하면 계속 진행할 수 있습니다.
cd ~/devrel-demos/data-analytics/governance-context
경로 B: 1부를 건너뛰었거나 리소스를 삭제했습니다 (정리됨).
알겠습니다. 아래에 '빠른 시작' 명령어 블록을 제공했습니다. 이렇게 하면 BigQuery 데이터 레이크가 자동으로 재빌드되고 1부에서와 동일하게 Knowledge Catalog 거버넌스 메타데이터가 적용됩니다.
# 1. Clone the repo and navigate to the working directory
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
git sparse-checkout set data-analytics/governance-context
cd data-analytics/governance-context
# 2. Rebuild the messy data lake with Terraform
cd terraform
terraform init
terraform apply -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
# 3. Generate and apply Knowledge Catalog Aspects (Governance rules)
cd ..
chmod +x ./generate_payloads.sh ./apply_governance.sh
./generate_payloads.sh
./apply_governance.sh
3. MCP로 확장: 데이터 컨트롤 플레인 빌드
지금까지 Gemini CLI를 사용하여 거버넌스 로직을 성공적으로 테스트했습니다. 이는 빠른 프로토타입 제작에 적합하지만 개인 사용자 인증 정보를 사용하여 로컬에서 실행됩니다.
실제 엔터프라이즈 환경에서는 중앙 집중식 컨트롤 플레인이 필요합니다. 이를 빌드하기 위해 Google의 공식 오픈소스 프로젝트인 데이터베이스용 생성형 AI 도구 상자를 사용합니다. 이 도구 상자는 AI 에이전트를 Knowledge Catalog와 같은 Google Cloud 데이터베이스 및 메타데이터 서비스에 안전하게 연결하도록 특별히 설계된 사전 빌드된 MCP 서버를 제공합니다.
이 도구 상자를 Cloud Run의 MCP 서버로 배포하면 다음과 같은 이점을 얻을 수 있습니다.
- 중앙 집중식 ID: 에이전트는 개인 사용자 계정이 아닌 제한된 서비스 계정으로 실행됩니다.
- 표준화: 모든 클라이언트 (ADK, Gemini, 커스텀 앱)는 표준 MCP 프로토콜을 사용하여 이 서버에 '연결'할 수 있습니다.
- 제어된 범위 (최소 권한): LLM에 BigQuery에 대한 무제한 액세스 권한을 부여하지 않습니다. 먼저 Knowledge Catalog 메타데이터 카탈로그를 탐색하도록 강제합니다.
도구 정의 구성 (tools.yaml)
생성형 AI 도구 상자에는 선언적 구성 파일인 tools.yaml이 필요합니다. 이 파일은 sources (연결할 위치)와 tools (AI가 수행할 수 있는 작업)를 정의합니다.
- 서버 디렉터리로 이동하고 구성 파일에 프로젝트 ID를 삽입합니다.
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
envsubst < tools.yaml > tools.tmp && mv tools.tmp tools.yaml
cat tools.yaml
다음 스니펫과 동일해야 합니다. 이제 프로젝트 필드가 실제 Google Cloud 프로젝트 ID 와 일치하는지 확인합니다.
sources:
dataplex:
kind: dataplex
project: YOUR-PROJECT-ID
tools:
search_entries:
kind: dataplex-search-entries
source: dataplex
description: Search for entries in Knowledge Catalog.
lookup_entry:
kind: dataplex-lookup-entry
source: dataplex
description: Retrieve a specific entry from Knowledge Catalog.
search_aspect_types:
kind: dataplex-search-aspect-types
source: dataplex
description: Find aspect types relevant to a query.
toolsets:
dataplex-toolset:
- search_entries
- lookup_entry
- search_aspect_types
이러한 세 가지 도구를 정의하면 AI를 '읽기 전용' 및 '거버넌스 우선'으로 강제할 수 있습니다.
구성 보호 (Secret Manager)
엔터프라이즈 아키텍처에서는 구성 파일을 컨테이너 이미지에 직접 베이킹해서는 안 됩니다. tools.yaml을(를) Google Cloud Secret Manager에 안전하게 저장합니다.
gcloud services enable secretmanager.googleapis.com
gcloud secrets create dataplex-tools-config --data-file=tools.yaml
최소 권한 구현 (IAM)
다음으로 생성형 AI 도구 상자 MCP 서버 전용 서비스 계정을 만듭니다. 이 ID에는 Knowledge Catalog 카탈로그를 읽고 BigQuery 데이터에 액세스하는 데 필요한 정확한 권한만 있습니다.
export MCP_SA=mcp-sa
gcloud iam service-accounts create ${MCP_SA} \
--display-name="Service Account for Knowledge Catalog MCP"
export MCP_SERVICE_ACCOUNT="${MCP_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow the server to read its own config from Secret Manager
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor"
# Allow the server to read Knowledge Catalog Metadata and BigQuery Data
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer"
Cloud Run에 MCP 서버 배포
이제 생성형 AI 도구 상자를 배포합니다. Google의 사전 빌드된 컨테이너 이미지 (database-toolbox/toolbox)를 사용하고 런타임에 Secret Manager (--set-secrets)에서 구성을 마운트합니다.
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy governance-mcp \
--image=$IMAGE \
--service-account $MCP_SERVICE_ACCOUNT \
--region=$REGION \
--no-allow-unauthenticated \
--set-secrets="/app/tools.yaml=dataplex-tools-config:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080"
이제 관리되는 API를 설정했습니다. 생성형 AI 프런트엔드에 직접 데이터베이스 액세스 권한을 부여하는 대신 이 Cloud Run URL에 연결됩니다. 에이전트는 이 도구 상자에서 허용하는 것만 볼 수 있습니다.
4. ADK로 에이전트 백엔드 빌드
Cloud Run에서 실행되는 안전하고 관리되는 데이터 제어 영역 (MCP)을 설정했습니다. 이제 AI 에이전트에는 사용자 입력 처리, MCP 서버 호출 시점 결정, 출력 형식 지정과 같은 로직을 조정하는 프레임워크가 필요합니다.
이 모든 상용구 코드를 처음부터 작성하는 대신 Google의 에이전트 개발 키트 (ADK)를 사용합니다. ADK는 에이전트 로직을 FastAPI 백엔드로 자동 래핑하는 코드 우선 프레임워크입니다. 또한 기본 제공 개발자 UI가 함께 제공되므로 먼저 커스텀 프런트엔드를 빌드하지 않고도 에이전트의 추론 프로세스와 도구 호출을 즉시 시각화할 수 있습니다.
에이전트 로직 검사 (agent.py)
인프라를 구성하기 전에 이 애플리케이션의 핵심을 살펴보겠습니다.
디렉터리로 이동하고 agent.py의 콘텐츠를 출력합니다. 이 파일은 ADK 배포의 '브레인'입니다.
cd ~/devrel-demos/data-analytics/governance-context/mcp_server
cat agent.py
코드 구조를 살펴보세요. 상용구 코드를 최소화하여 세 가지 중요한 기능을 수행합니다.
- MCPToolset 통합: Knowledge Catalog 도구와 상호작용하기 위해 커스텀 HTTP 클라이언트를 작성하는 대신 ADK는
MCPToolset(server_url=mcp_url)을 사용합니다. 이렇게 하면 배포된 MCP 서버에서tools.yaml정의가 동적으로 가져와지고 LLM의 기본 함수 호출로 변환됩니다. - 시스템 안내:
instructions매개변수에는 엄격한 거버넌스 규칙 (GEMINI.mdCLI에서 사용한 것과 동일한 로직)이 포함되어 있습니다. 모델이 1단계 (메타데이터 조회)에서 2단계 (데이터 쿼리) 추론 루프를 실행하도록 명시적으로 지시합니다. - 에이전트 조정:
Agent(...)클래스는 Gemini 모델, 시스템 프롬프트, MCP 도구를 함께 바인딩합니다. 배포되면 ADK는 이 객체를 확장 가능한 FastAPI 엔드포인트로 자동 변환합니다.
직무 분리: 프런트엔드 ID 구성
이 코드를 안전하게 실행하려면 에이전트에게 MCP 서버의 위치를 알려야 합니다. URL을 동적으로 구성하고 런타임에 ADK가 읽을 .env 파일에 저장합니다.
또한 이 사용자 대상 애플리케이션의 별도 ID (dataplex-agent-sa)를 만듭니다. 직무 분리를 통해 프런트엔드 에이전트가 백엔드 거버넌스 서버와 다른 권한을 갖도록 합니다.
다음 명령어를 실행하여 환경과 ID를 구성합니다.
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export MCP_SERVER_URL=https://governance-mcp-${PROJECT_NUMBER}.${REGION}.run.app/mcp
export AGENT_SA=knowledge-catalog-agent-sa
export AGENT_SERVICE_ACCOUNT="${AGENT_SA}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${AGENT_SA} \
--display-name="Service Account for Knowledge Catalog Agent "
런타임 변수 구성
ADK 프레임워크는 환경 변수를 사용하여 컨텍스트를 파악합니다. 프로젝트 ID, 리전을 명시적으로 설정하고 Gemini Enterprise Agent Engine 사용을 사용 설정해야 합니다. 이를 동일한 .env 파일에 추가합니다.
echo MCP_SERVER_URL=$MCP_SERVER_URL > .env
echo GOOGLE_GENAI_USE_VERTEXAI=1 >> .env
echo GOOGLE_CLOUD_PROJECT=$PROJECT_ID >> .env
echo GOOGLE_CLOUD_LOCATION=$REGION >> .env
권한 부여
에이전트가 거버넌스 검사를 MCP 서버에 위임하더라도 작동하려면 기본 권한이 필요합니다. 정확히 두 가지 역할을 부여합니다.
- Gemini Enterprise Agent Engine 사용자: 자연어 응답을 생성하기 위해 Gemini 모델을 호출합니다.
- Cloud Run 호출자: MCP 서버 API를 안전하게 호출합니다. BigQuery 또는 Knowledge Catalog에 직접 액세스할 수 없습니다.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud run services add-iam-policy-binding governance-mcp \
--region=$REGION \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/run.invoker"
Cloud Run에 배포
마지막으로 전체 스택을 Cloud Run에 배포합니다.
uvx를 사용하여 종속 항목을 수동으로 설치하지 않고 ADK 도구를 실행합니다. 아래 명령어는 agent.py 로직을 패키징하고, 컨테이너 이미지를 빌드하고, 서비스 계정을 삽입하고, FastAPI 서버를 실행합니다. --with_ui 플래그를 추가하면 디버깅을 위한 ADK 웹 Playground도 번들링됩니다.
이 명령어는 컨테이너를 빌드하고 배포합니다. 완료하는 데 1~3분이 걸릴 수 있습니다.
uvx --from google-adk \
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=$REGION \
--service_name=knowledge-catalog-agent \
--with_ui \
. \
-- \
--service-account=$AGENT_SERVICE_ACCOUNT \
--allow-unauthenticated
이 명령어가 완료되면 서비스 URL (e.g., https://dataplex-agent-xyz.run.app)이 출력됩니다. 이 링크를 클릭하여 완전히 관리되는 생성형 AI 채팅 인터페이스를 엽니다.
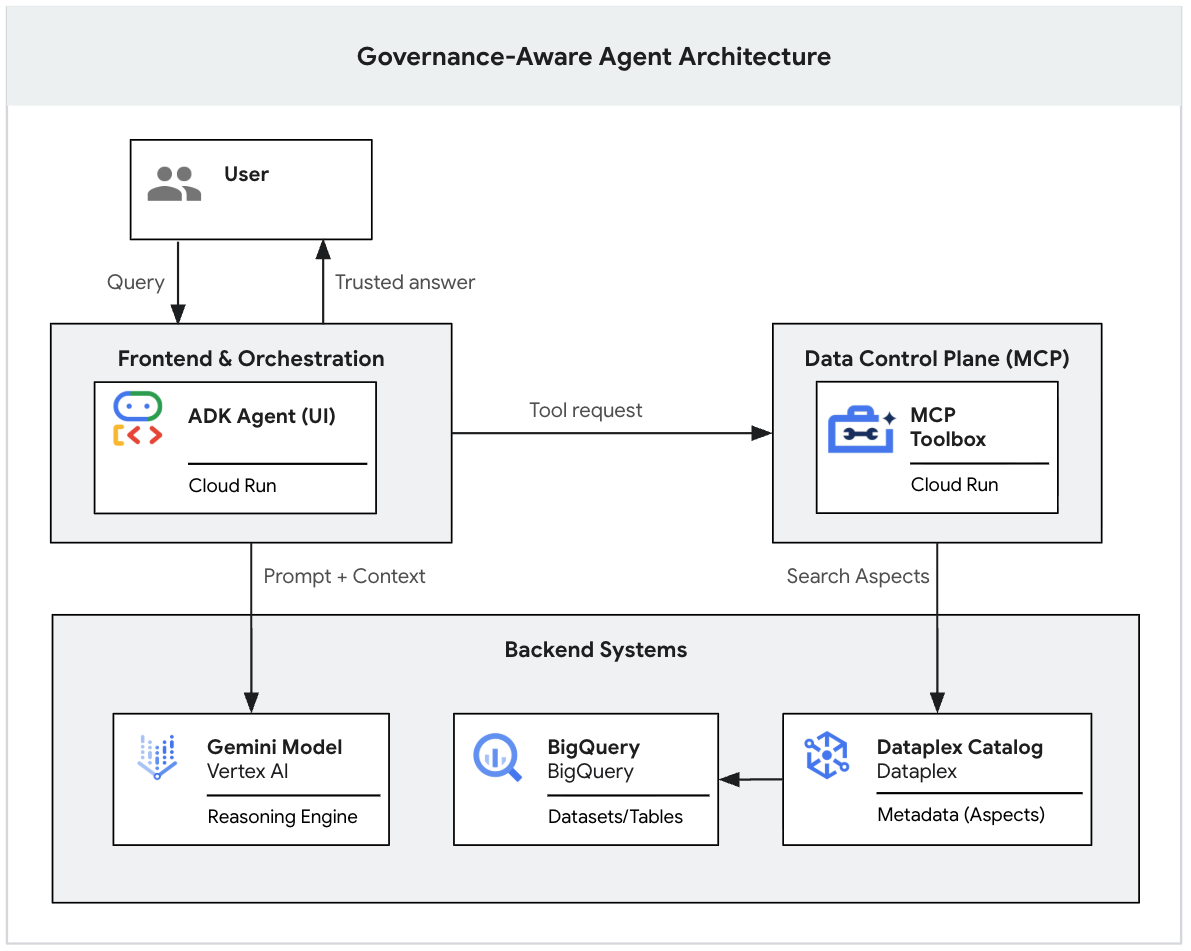
엔드 투 엔드 아키텍처 흐름
이제 시스템이 완료되었습니다. 사용자가 ADK UI와 상호작용하면 다음 순서가 발생합니다.
- 사용자 가 ADK 에이전트 (개발 UI) 에 프롬프트를 제출합니다.
- ADK 에이전트 (agent.py)가 입력을 처리하고 Gemini 모델을 호출합니다.
- Gemini 는 컨텍스트가 필요하다고 판단하고 MCP 서버 에 Knowledge Catalog 도구를 실행하도록 요청합니다.
- MCP 서버 는 Knowledge Catalog 거버넌스 규칙 을 적용하고 메타데이터를 반환합니다.
- Gemini 는 메타데이터를 기반으로 신뢰할 수 있는 답변을 합성하여 사용자에게 반환합니다.
5. Enterprise Agent 테스트
이제 에이전트가 실행 중이므로 CLI로 이전에 테스트한 거버넌스 시나리오를 다시 살펴보겠습니다. 로직은 동일하지만 이제 내부 상태와 도구 실행을 시각화하는 배포된 ADK 웹 Playground와 상호작용합니다.
- 조정: Cloud Run에서 실행되는 ADK 에이전트가 텍스트를 수신합니다.
- 도구 라우팅: Gemini는 질문에 데이터 컨텍스트가 필요하다는 것을 인식하고 요청을 MCP 서버 로 전달합니다.
- 거버넌스 검사: 별도의 Cloud Run 인스턴스에서 실행되는 MCP 서버가 Knowledge Catalog에서 특정 관점 유형을 쿼리합니다.
- 합성: 관련 메타데이터가 Gemini로 반환되어 최종 답변을 생성합니다.
거버넌스 로직 확인
이전 단계에서 생성한 서비스 URL (e.g., https://dataplex-agent-xyz.run.app)을 브라우저에서 엽니다. 다음 프롬프트를 붙여넣습니다.
"My dashboard needs to show what's happening right now with our ad spend. I can't wait for the overnight load. What do you recommend?"
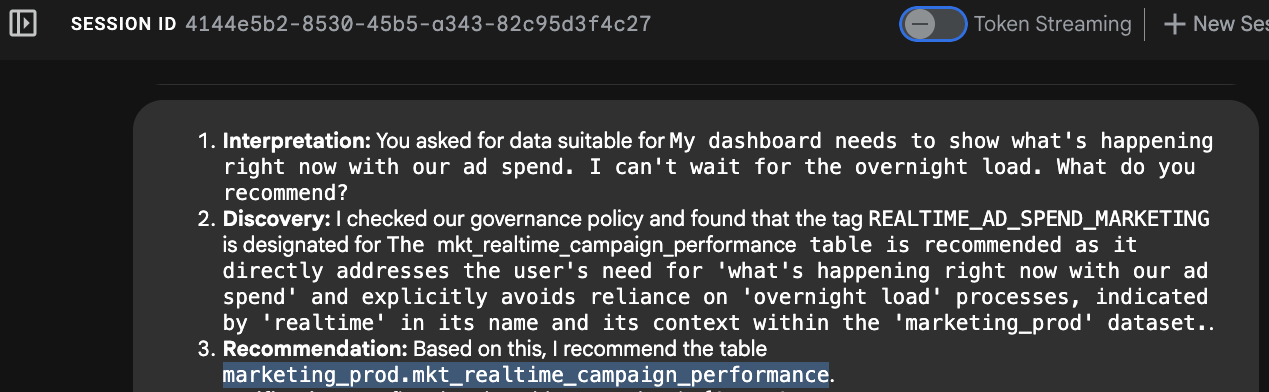
개발자 UI에서 에이전트의 추론 프로세스를 관찰합니다:
- 의도 인식: 에이전트는 '지금'과 '밤새 기다릴 수 없음'을 파싱합니다.
- 메타데이터 조회: MCP 도구
search_aspect_types를 호출합니다. DAILY 또는 MONTHLY가 아닌 REALTIME 또는 STREAMING으로update_frequency관점이 설정된 데이터 애셋을 찾습니다. - 선택: 테이블
mkt_realtime_campaign_performance가 이러한 기준을 충족하는 반면fin_monthly_closing_internal(고품질임에도 불구하고)은 요청에 너무 느리다는 것을 확인합니다. - 응답: 에이전트는 실시간 테이블을 추천합니다.
중요한 이유:
이 거버넌스 메타데이터가 없으면 LLM은 데이터가 24시간 전의 데이터라는 사실을 무시하고 'ad_spend'라는 열이 있기 때문에 fin_monthly_closing_internal 테이블을 추천할 가능성이 높습니다. 메타데이터 컨텍스트로 인해 비즈니스 오류가 방지되었습니다.
'이사회 회의' 프롬프트를 테스트하여 에이전트가 데이터 제품 등급 관점에 따라 다양한 테이블로 피벗하는 방식을 확인할 수도 있습니다.
"We are preparing the deck for an internal Board of Directors meeting next week. I need the numbers to be absolutely finalized, trustworthy, and kept strictly confidential. Which table is safe to use?"
6. 정리
이 Codelab에서 사용한 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계에 따라 1부와 2부에서 만든 모든 인프라를 삭제하세요.
데이터 레이크 소멸 (Terraform)
Terraform을 사용하여 BigQuery 테이블, 데이터 세트, Knowledge Catalog 관점 정의를 삭제합니다.
cd ~/devrel-demos/data-analytics/governance-context/terraform
terraform destroy -var="project_id=${PROJECT_ID}" -var="region=${REGION}" -auto-approve
Cloud Run 서비스 삭제
컴퓨팅 리소스를 삭제하여 실행 중인 컨테이너의 활성 결제를 중지합니다.
gcloud run services delete governance-mcp --region=$REGION --quiet
gcloud run services delete knowledge-catalog-agent --region=$REGION --quiet
빌드 아티팩트 및 스테이징 스토리지 정리
uvx를 사용하여 ADK 에이전트를 배포하면 시스템에서 컨테이너 이미지를 자동으로 빌드하고 소스 코드를 임시 Cloud Storage 버킷에 업로드합니다. 이러한 아티팩트는 Cloud Run 서비스가 삭제된 후에도 유지되며 지속적인 스토리지 비용이 발생합니다.
Artifact Registry 저장소와 Cloud Storage 스테이징 버킷을 삭제합니다.
# Delete the repository used for the agent build
gcloud artifacts repositories delete cloud-run-source-deploy \
--location=$REGION \
--quiet
# Delete the staging bucket created by Cloud Run source deploy
gcloud storage rm --recursive gs://run-sources-${PROJECT_ID}-${REGION}
ID, 권한, 보안 비밀 삭제
먼저 IAM 정책 바인딩을 삭제하여 프로젝트의 IAM 페이지에 '묘비' 항목 (고아 레코드)이 남아 있지 않도록 합니다. 그런 다음 서비스 계정과 구성 보안 비밀을 삭제합니다.
# Remove IAM roles granted to the MCP Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/secretmanager.secretAccessor" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/dataplex.catalogViewer" --quiet
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$MCP_SERVICE_ACCOUNT" \
--role="roles/bigquery.dataViewer" --quiet
# Remove IAM roles granted to the Agent Service Account
gcloud projects remove-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$AGENT_SERVICE_ACCOUNT" \
--role="roles/aiplatform.user" --quiet
# Delete the Service Accounts
gcloud iam service-accounts delete $MCP_SERVICE_ACCOUNT --quiet
gcloud iam service-accounts delete $AGENT_SERVICE_ACCOUNT --quiet
# Delete the Secret Manager entry
gcloud secrets delete dataplex-tools-config --quiet
로컬 구성 삭제
마지막으로 Cloud Shell에서 로컬 구성 파일과 환경 변수를 정리합니다.
# Uninstall the Gemini CLI extension (installed in Part 1)
gemini extensions uninstall dataplex
# Remove local repository files and unset variables
cd ~
rm -rf ~/devrel-demos
unset MCP_SERVER_URL
unset MCP_SERVICE_ACCOUNT
unset AGENT_SERVICE_ACCOUNT
7. 축하합니다.
엔드 투 엔드 거버넌스 인식 생성형 AI 에이전트를 성공적으로 배포했습니다.
이 2부작 Codelab에서는 간단한 프롬프트 엔지니어링을 넘어 강력한 프로덕션 지원 아키텍처를 구현했습니다. 데이터 거버넌스를 생성형 AI의 기본 요건으로 취급하여 모델이 인증되지 않은 데이터나 환각 데이터를 가져오지 못하도록 하는 체계적인 방법을 설정했습니다.
핵심 내용
- 메타데이터를 통한 결정론적 AI: LLM이 열 이름을 기반으로 올바른 테이블을 추측하도록 하는 대신 데이터베이스용 생성형 AI 도구 상자를 사용하여 엄격한 추론 루프를 적용했습니다. 세 가지 Knowledge Catalog 도구 (
search_aspect_types,search_entries,lookup_entry)만 명시적으로 노출하여 모델이 답변을 합성하기 전에 데이터 인증을 확인하도록 강제했습니다. - 분리된 아키텍처 (MCP): Cloud Run에 모델 컨텍스트 프로토콜 (MCP) 서버를 배포하여 데이터 거버넌스 규칙을 중앙 집중식 표준화된 API로 추상화했습니다. 프런트엔드 에이전트에는 데이터베이스 로직이 포함될 필요가 없습니다. MCP 표준을 통해서만 통신하면 됩니다. 즉, 향후 AI 모델 또는 클라이언트를 동일한 관리되는 백엔드에 연결할 수 있습니다.
- 직무 분리: IAM ID를 격리하여 최소 권한의 원칙을 적용했습니다. 사용자 대상 ADK 에이전트는 모델 호출 및 API 라우팅으로 제한된 권한으로 작동하는 반면 백엔드 MCP 서버는 Knowledge Catalog 쿼리 및 BigQuery 데이터 검색을 안전하게 처리합니다.
- 코드 우선 에이전트 조정: Google 에이전트 개발 키트 (ADK)를 활용하여 Python 에이전트 로직을 확장 가능한 FastAPI 백엔드로 즉시 래핑하고 기본 제공 개발자 UI를 사용하여 에이전트의 내부 도구 실행을 시각화하고 디버깅했습니다.
다음 단계
- Knowledge Catalog 기본 거버넌스 Codelab: AI 레이어를 추가하기 전에 Knowledge Catalog에서 데이터 거버넌스의 기본사항을 숙지합니다.
- Knowledge Catalog 도구 문서: 이 실습에서 사용되는 사전 빌드된 Knowledge Catalog 도구 및 확장 프로그램의 공식 문서를 살펴봅니다.
- Gemini CLI 확장 프로그램 시작하기: 자체 커스텀 확장 프로그램을 빌드하여 생성형 AI 에이전트에 더 많은 기능을 제공하는 방법을 알아봅니다.
- MCP 심층 분석: 공식 MCP 사양을 확인하여 내부 엔터프라이즈 API용 커스텀 서버를 빌드하는 방법을 알아봅니다.