
1. Présentation
Un agent est un programme autonome qui communique avec un modèle d'IA pour effectuer une opération basée sur un objectif à l'aide des outils et du contexte dont il dispose. Il est capable de prendre des décisions autonomes basées sur la vérité.
Lorsque votre application comporte plusieurs agents qui travaillent ensemble de manière autonome et collaborative pour atteindre un objectif plus vaste, chacun étant responsable d'un domaine d'expertise spécifique, elle devient un système multi-agents.
Agent Development Kit (ADK)
Agent Development Kit (ADK) est un framework flexible et modulaire permettant de développer et de déployer des agents IA. ADK permet de créer des applications sophistiquées en composant plusieurs instances d'agent distinctes dans un système multi-agents (MAS).
Dans ADK, un système multi-agents est une application dans laquelle différents agents, formant souvent une hiérarchie, collaborent ou se coordonnent pour atteindre un objectif plus vaste. Cette structure offre des avantages considérables, y compris une modularité, une spécialisation, une réutilisabilité et une facilité de maintenance améliorées, ainsi que la possibilité de définir des flux de contrôle structurés à l'aide d'agents de workflow dédiés.
Points à retenir pour un système multi-agents
Tout d'abord, il est important de bien comprendre et de justifier la spécialisation de chaque agent. — "sais-tu pourquoi tu as besoin d'un sous-agent spécifique pour quelque chose ?", commence par trouver la réponse.
Deuxièmement, comment les rassembler avec un agent racine pour les distribuer et les interpréter.
Troisièmement, il existe plusieurs types de routage d'agent que vous pouvez trouver dans cette documentation. Choisissez celui qui convient le mieux au flux de votre application. Quels sont les différents contextes et états dont vous avez besoin pour le contrôle de flux de votre système multi-agents ?
Ce que vous allez faire
Créons un système multi-agents pour gérer les rénovations de cuisine à l'aide de MCP Toolbox for AlloyDB et d'ADK.
- Agent de proposition de rénovation
- Agent de vérification des autorisations et de la conformité
- Vérification de l'état des commandes (outil utilisant MCP Toolbox for Databases)
Agent de proposition de rénovation, pour générer le document de proposition de rénovation de la cuisine.
un agent chargé des autorisations et de la conformité, pour gérer les tâches liées aux autorisations et à la conformité.
Agent de vérification de l'état des commandes, pour vérifier l'état des commandes de matériel en travaillant sur la base de données de gestion des commandes que nous avons configurée dans AlloyDB. Toutefois, pour cette partie de la base de données, nous utiliserons MCP Toolbox for AlloyDB afin d'implémenter la logique de récupération de l'état des commandes.
2. MCP
MCP signifie Model Context Protocol. Il s'agit d'une norme ouverte développée par Anthropic qui permet aux agents d'IA de se connecter de manière cohérente à des outils, services et données externes. Il fonctionne essentiellement comme une norme commune pour les applications d'IA, ce qui leur permet d'interagir de manière fluide avec différentes sources de données et différents outils.
- Il utilise un modèle client-serveur, dans lequel les applications d'IA (les hôtes) exécutent le client MCP, qui communique avec les serveurs MCP.
- Lorsqu'un agent d'IA a besoin d'accéder à un outil ou à des données spécifiques, il envoie une requête structurée au client MCP, qui la transmet au serveur MCP approprié.
- Permet aux modèles d'IA d'accéder à des données et outils externes sans nécessiter de code personnalisé pour chaque intégration.
- Simplifie le processus de création d'agents et de workflows complexes sur les grands modèles de langage (LLM).
MCP Toolbox for Databases
MCP Toolbox for Databases de Google est un serveur MCP Open Source pour les bases de données. Il a été conçu pour une qualité de production et un niveau d'entreprise. Il vous permet de développer des outils plus facilement, plus rapidement et de manière plus sécurisée en gérant les complexités telles que le regroupement de connexions, l'authentification, etc.
Permettez à vos agents d'accéder aux données de votre base de données !!! Comment ?
Développement simplifié : intégrez des outils à votre agent en moins de 10 lignes de code, réutilisez des outils entre plusieurs agents ou frameworks, et déployez plus facilement de nouvelles versions d'outils.
Meilleures performances : bonnes pratiques telles que le regroupement de connexions, l'authentification et plus encore.
Sécurité renforcée : authentification intégrée pour un accès plus sécurisé à vos données
Observabilité de bout en bout : métriques et traçage prêts à l'emploi avec prise en charge intégrée d'OpenTelemetry.
Il faut souligner que cela précède le MCP !!!
MCP Toolbox for Databases se situe entre le framework d'orchestration de votre application agentique et votre base de données. Il fournit un plan de contrôle utilisé pour modifier, distribuer ou appeler des outils. Il simplifie la gestion de vos outils en vous offrant un emplacement centralisé pour les stocker et les mettre à jour. Vous pouvez ainsi partager des outils entre les agents et les applications, et les mettre à jour sans nécessairement redéployer votre application.
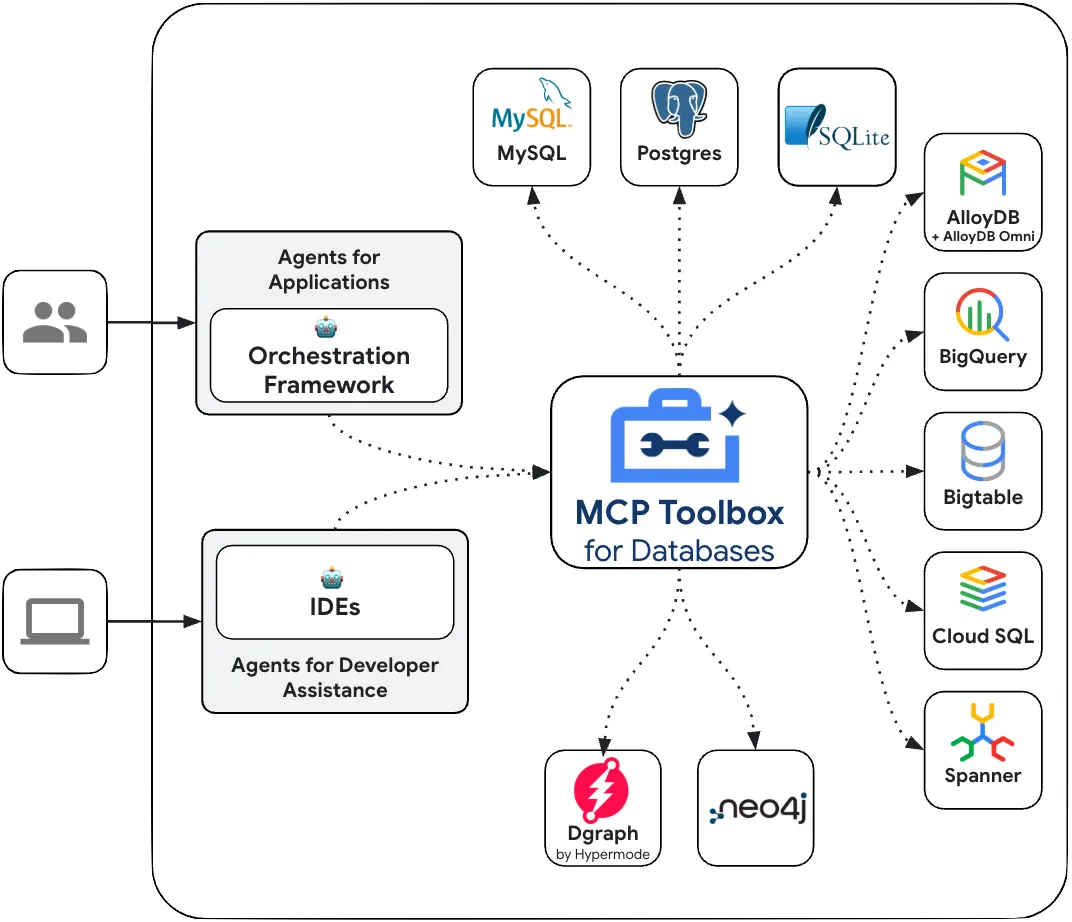
Nous aurons un agent racine qui orchestrera ces agents en fonction des besoins.
Conditions requises
3. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet .
- Cliquez sur ce lien pour activer Cloud Shell. Vous pouvez basculer entre le terminal Cloud Shell (pour exécuter des commandes cloud) et l'éditeur (pour créer des projets) en cliquant sur le bouton correspondant dans Cloud Shell.
- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API suivantes en exécutant les commandes suivantes :
gcloud services enable artifactregistry.googleapis.com \cloudbuild.googleapis.com \run.googleapis.com \aiplatform.googleapis.com \alloydb.googleapis.com
- Assurez-vous d'avoir Python 3.9 ou version ultérieure.
- Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
4. Configuration d'ADK
- Créer et activer un environnement virtuel (recommandé)
À partir de votre terminal Cloud Shell, créez un environnement virtuel :
python -m venv .venv
Activez l'environnement virtuel :
source .venv/bin/activate
- Installer ADK
pip install google-adk
5. Structure du projet
- Dans le terminal Cloud Shell, exécutez les commandes suivantes une par une pour créer les dossiers racine et de projet :
mkdir agentic-apps
cd agentic-apps
mkdir renovation-agent
- Accédez à l'éditeur Cloud Shell et créez la structure de projet suivante en créant les fichiers (vides au début) :
renovation-agent/
__init__.py
agent.py
.env
6. Code source
- Accédez à init.py et mettez à jour le contenu comme suit :
from . import agent
- Accédez à agent.py et mettez à jour le fichier avec le contenu suivant à partir du chemin d'accès suivant :
https://github.com/AbiramiSukumaran/renovation-agent-adk-mcp-toolbox/blob/main/agent.py
Dans agent.py, nous importons les dépendances nécessaires, récupérons les paramètres de configuration du fichier .env et définissons le root_agent qui utilise un outil pour appeler l'outil de la boîte à outils.
- Accédez à requirements.txt et mettez-le à jour avec le contenu suivant :
https://github.com/AbiramiSukumaran/renovation-agent-adk-mcp-toolbox/blob/main/requirements.txt
7. Configuration de la base de données
Dans l'un des outils utilisés par l'ordering_agent, appelé "check_status", nous accédons à la base de données des commandes AlloyDB pour obtenir l'état des commandes. Dans cette section, nous allons configurer un cluster et une instance de base de données AlloyDB.
Créer un cluster et une instance
- Accédez à la page AlloyDB de la console Cloud. Pour trouver la plupart des pages de la console Cloud, le plus simple est de les rechercher à l'aide de la barre de recherche de la console.
- Sélectionnez CRÉER UN CLUSTER sur cette page :

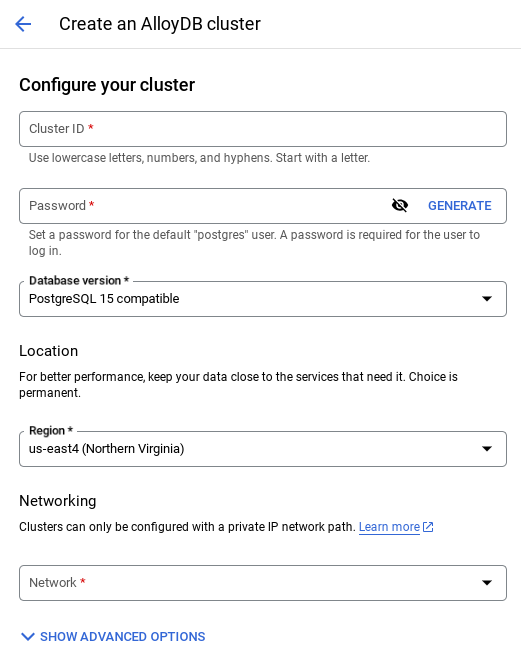
- Un écran semblable à celui ci-dessous s'affiche. Créez un cluster et une instance avec les valeurs suivantes (assurez-vous que les valeurs correspondent si vous clonez le code de l'application à partir du dépôt) :
- ID du cluster : "
vector-cluster" - password : "
alloydb" - Compatible avec PostgreSQL 16 (la dernière version est recommandée)
- Région : "
us-central1" - Networking : "
default"
- Lorsque vous sélectionnez le réseau par défaut, un écran semblable à celui ci-dessous s'affiche.
Sélectionnez CONFIGURER LA CONNEXION.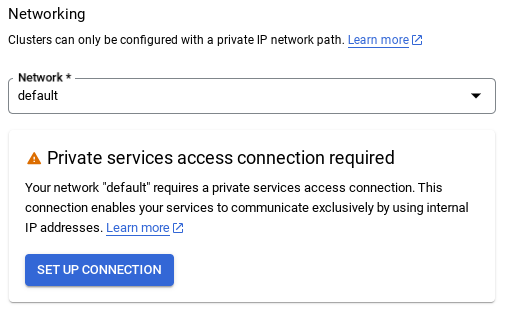
- Sélectionnez ensuite Utiliser une plage d'adresses IP automatiquement allouée, puis cliquez sur "Continuer". Après avoir vérifié les informations, sélectionnez CRÉER UNE CONNEXION.
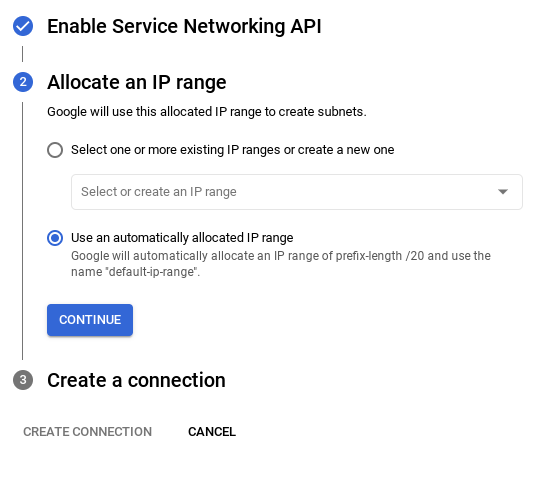
6. IMPORTANT : Veillez à modifier l'ID d'instance (que vous trouverez lors de la configuration du cluster / de l'instance) en
vector-instance. Si vous ne pouvez pas le modifier, n'oubliez pas d'utiliser l'ID de votre instance dans toutes les références à venir.
- Avant de configurer Toolbox, activons la connectivité IP publique dans notre instance AlloyDB afin que le nouvel outil puisse accéder à la base de données.
- Accédez à la section "Connectivité à l'adresse IP publique", cochez la case "Activer l'adresse IP publique", puis saisissez l'adresse IP de votre machine Cloud Shell.
- Pour obtenir l'adresse IP de votre machine Cloud Shell, accédez au terminal Cloud Shell et saisissez "ifconfig". Dans le résultat, identifiez l'adresse inet eth0 et remplacez les deux derniers chiffres par 0.0 avec une taille de masque "/16". Par exemple, il ressemblerait à "XX.XX.0.0/16", où XX sont des nombres.
- Collez cette adresse IP dans la zone de texte "Réseaux" de la page de modification de l'instance, sous "Réseaux externes autorisés".
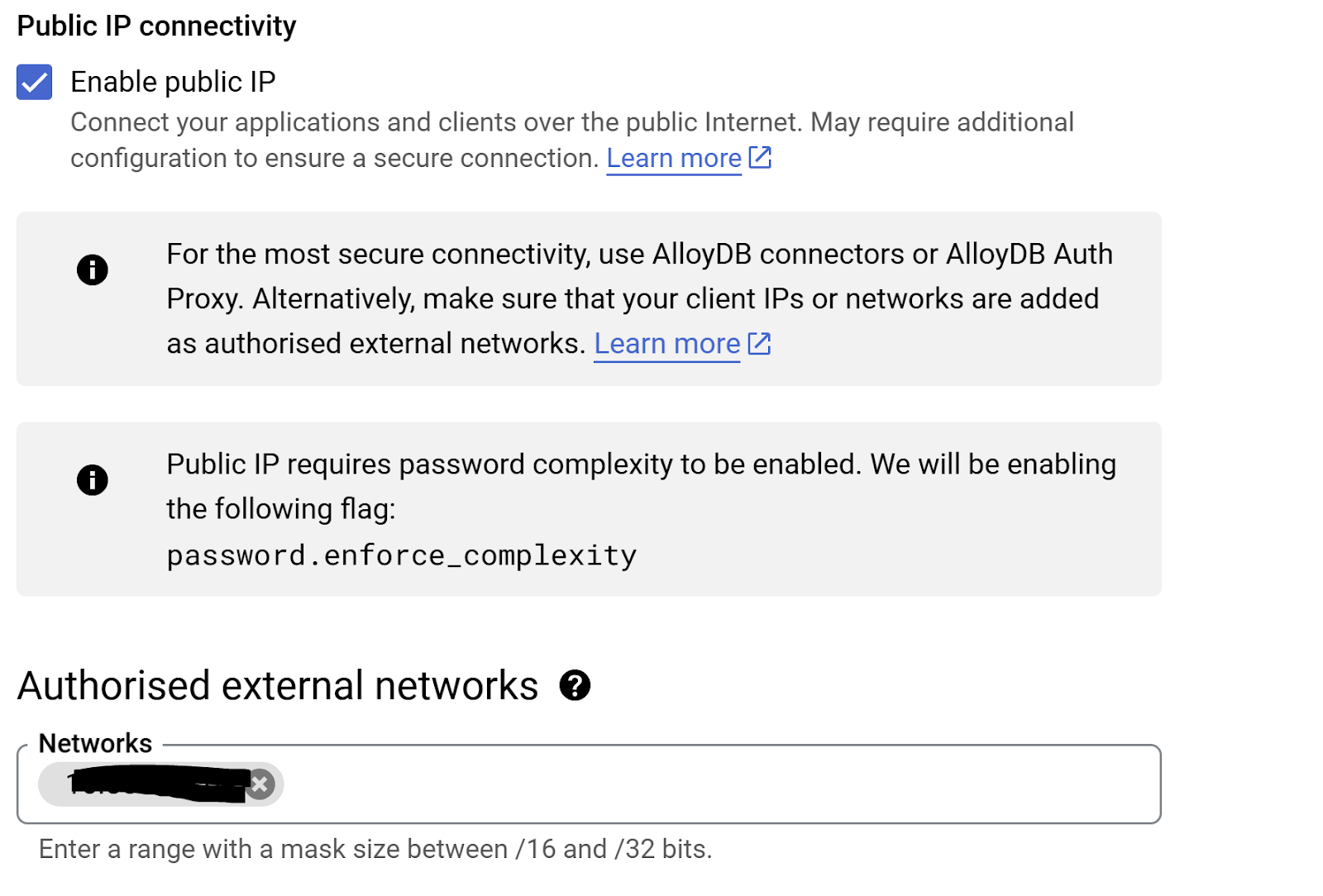
- Une fois votre réseau configuré, vous pouvez continuer à créer votre cluster. Cliquez sur CRÉER UN CLUSTER pour terminer la configuration du cluster, comme indiqué ci-dessous :
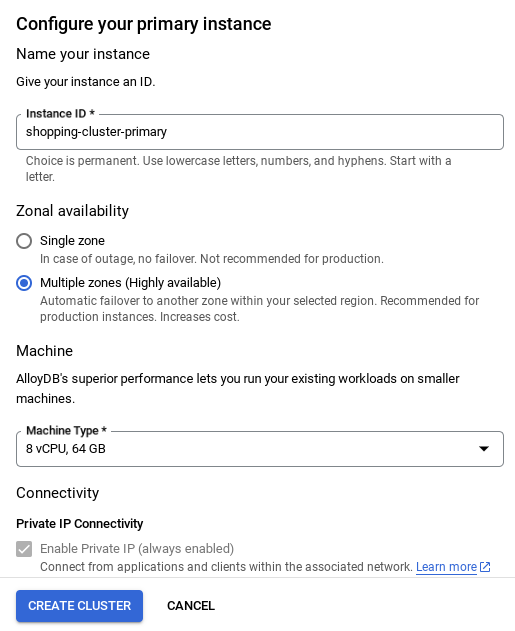
Notez que la création du cluster prendra environ 10 minutes. Une fois l'opération terminée, un écran affichant l'aperçu du cluster que vous venez de créer devrait s'afficher.
Ingestion de données
Il est maintenant temps d'ajouter un tableau contenant les données sur le magasin. Accédez à AlloyDB, sélectionnez le cluster principal, puis AlloyDB Studio :
Vous devrez peut-être attendre que votre instance soit créée. Une fois le cluster créé, connectez-vous à AlloyDB à l'aide des identifiants que vous avez créés. Utilisez les données suivantes pour vous authentifier auprès de PostgreSQL :
- Nom d'utilisateur : "
postgres" - Base de données : "
postgres" - Mot de passe : "
alloydb"
Une fois l'authentification réussie dans AlloyDB Studio, les commandes SQL sont saisies dans l'éditeur. Vous pouvez ajouter plusieurs fenêtres de l'éditeur en cliquant sur le signe plus à droite de la dernière fenêtre.
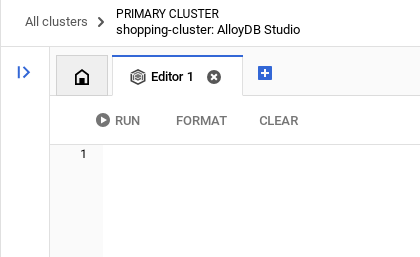
Vous saisirez les commandes pour AlloyDB dans les fenêtres de l'éditeur, en utilisant les options "Exécuter", "Mettre en forme" et "Effacer" selon les besoins.
Créer une table
Vous pouvez créer une table à l'aide de l'instruction LDD ci-dessous dans AlloyDB Studio :
-- Table DDL for Procurement Material Order Status
CREATE TABLE material_order_status (
order_id VARCHAR(50) PRIMARY KEY,
material_name VARCHAR(100) NOT NULL,
supplier_name VARCHAR(100) NOT NULL,
order_date DATE NOT NULL,
estimated_delivery_date DATE,
actual_delivery_date DATE,
quantity_ordered INT NOT NULL,
quantity_received INT,
unit_price DECIMAL(10, 2) NOT NULL,
total_amount DECIMAL(12, 2),
order_status VARCHAR(50) NOT NULL, -- e.g., "Ordered", "Shipped", "Delivered", "Cancelled"
delivery_address VARCHAR(255),
contact_person VARCHAR(100),
contact_phone VARCHAR(20),
tracking_number VARCHAR(100),
notes TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
quality_check_passed BOOLEAN, -- Indicates if the material passed quality control
quality_check_notes TEXT, -- Notes from the quality control check
priority VARCHAR(20), -- e.g., "High", "Medium", "Low"
project_id VARCHAR(50), -- Link to a specific project
receiver_name VARCHAR(100), -- Name of the person who received the delivery
return_reason TEXT, -- Reason for returning material if applicable
po_number VARCHAR(50) -- Purchase order number
);
Insérer des enregistrements
Copiez l'instruction de requête insert du script database_script.sql mentionné ci-dessus dans l'éditeur.
Cliquez sur Exécuter.
Maintenant que l'ensemble de données est prêt, configurons MCP Toolbox for Databases pour qu'il serve de plan de contrôle pour toutes nos interactions avec la base de données des commandes dans AlloyDB.
8. Configurer MCP Toolbox for Databases
Toolbox se situe entre le framework d'orchestration de votre application et votre base de données. Il fournit un plan de contrôle utilisé pour modifier, distribuer ou appeler des outils. Il simplifie la gestion de vos outils en vous fournissant un emplacement centralisé pour les stocker et les mettre à jour. Vous pouvez ainsi partager des outils entre les agents et les applications, et les mettre à jour sans avoir à redéployer votre application.
Vous pouvez voir qu'AlloyDB fait partie des bases de données compatibles avec MCP Toolbox for Databases. Comme nous l'avons déjà provisionné dans la section précédente, configurons Toolbox.
- Accédez à votre terminal Cloud Shell et assurez-vous que votre projet est sélectionné et affiché dans l'invite du terminal. Exécutez la commande ci-dessous depuis votre terminal Cloud Shell pour accéder au répertoire de votre projet :
cd adk-renovation-agent
- Exécutez la commande ci-dessous pour télécharger et installer la boîte à outils dans votre nouveau dossier :
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
- Accédez à l'éditeur Cloud Shell (pour le mode d'édition de code) et, dans le dossier racine du projet, ajoutez un fichier nommé "tools.yaml".
sources:
alloydb-orders:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "<<YOUR_ALLOYDB_CLUSTER>>"
instance: "<<YOUR_ALLOYDB_INSTANCE>>"
database: "<<YOUR_ALLOYDB_DATABASE>>"
user: "<<YOUR_ALLOYDB_USER>>"
password: "<<YOUR_ALLOYDB_PASSWORD>>"
tools:
get-order-data:
kind: postgres-sql
source: alloydb-orders
description: Get the status of an order based on the material description.
parameters:
- name: description
type: string
description: A description of the material to search for its order status.
statement: |
select order_status from material_order_status where lower(material_name) like lower($1)
LIMIT 1;
Dans la partie requête (voir le paramètre "statement" ci-dessus), nous récupérons simplement la valeur du champ order_status lorsque le nom du matériel correspond au texte de recherche de l'utilisateur.
Comprendre tools.yaml
Les sources représentent les différentes sources de données avec lesquelles un outil peut interagir. Une source représente une source de données avec laquelle un outil peut interagir. Vous pouvez définir des sources sous forme de mappage dans la section "sources" de votre fichier tools.yaml. En règle générale, une configuration de source contient toutes les informations nécessaires pour se connecter à la base de données et interagir avec elle.
Les outils définissent les actions qu'un agent peut effectuer, comme lire et écrire dans une source. Un outil représente une action que votre agent peut effectuer, comme exécuter une instruction SQL. Vous pouvez définir des outils sous forme de mappage dans la section "tools" de votre fichier tools.yaml. En règle générale, un outil a besoin d'une source sur laquelle agir.
Pour en savoir plus sur la configuration de votre fichier tools.yaml, consultez cette documentation.
Exécutons le serveur MCP Toolbox for Databases
Exécutez la commande suivante (à partir du dossier mcp-toolbox) pour démarrer le serveur :
./toolbox --tools-file "tools.yaml"
Si vous ouvrez le serveur en mode Aperçu sur le Web dans le cloud, vous devriez voir le serveur Toolbox en cours d'exécution avec votre nouvel outil nommé get-order-data.
Par défaut, le serveur MCP Toolbox s'exécute sur le port 5000. Utilisons Cloud Shell pour tester cela.
Cliquez sur "Aperçu sur le Web" dans Cloud Shell, comme indiqué ci-dessous :
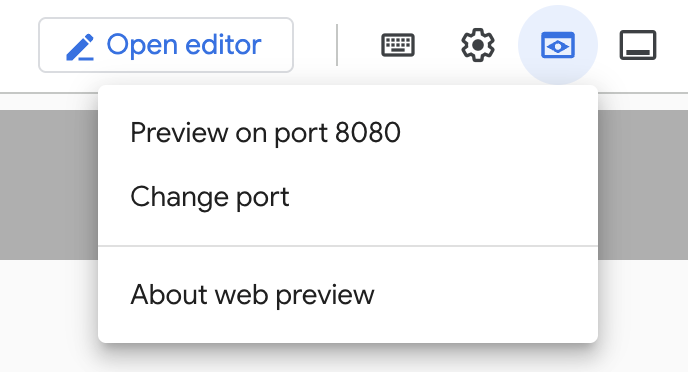
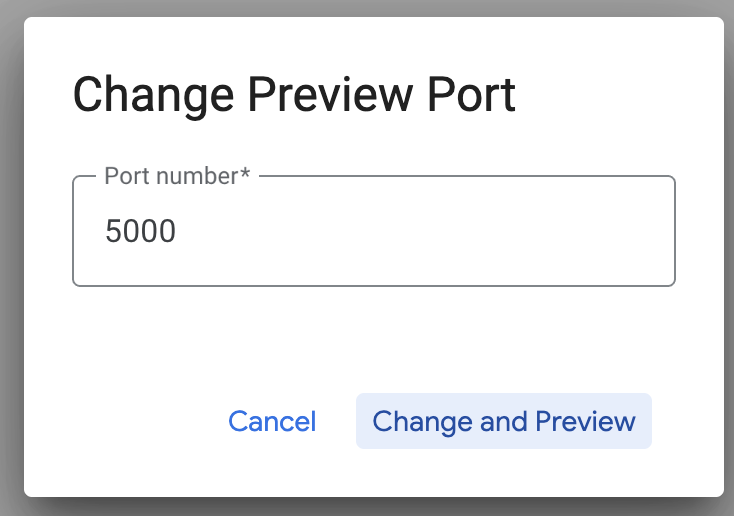
Cliquez sur "Change port" (Modifier le port), définissez le port sur 5000 comme indiqué ci-dessous, puis cliquez sur "Change and Preview" (Modifier et prévisualiser).
Vous devriez obtenir le résultat suivant :
La boîte à outils MCP pour les bases de données décrit un SDK Python qui vous permet de valider et de tester les outils. Pour en savoir plus, consultez cette page. Nous allons passer cette étape et passer directement à l'Agent Development Kit (ADK) dans la section suivante, qui utilisera ces outils.
Déployons notre boîte à outils sur Cloud Run.
Commençons par le serveur MCP Toolbox et hébergeons-le sur Cloud Run. Nous obtiendrons ainsi un point de terminaison public que nous pourrons intégrer à n'importe quelle autre application et/ou aux applications Agent. Les instructions pour héberger ce service sur Cloud Run sont disponibles ici. Nous allons maintenant passer en revue les étapes clés.
- Lancez un terminal Cloud Shell ou utilisez-en un existant. Accédez au dossier du projet où se trouvent le fichier binaire de la boîte à outils et tools.yaml. Dans ce cas, il s'agit d'adk-renovation-agent.
- Définissez la variable PROJECT_ID pour qu'elle pointe vers l'ID de votre projet Google Cloud.
export PROJECT_ID="<<YOUR_GOOGLE_CLOUD_PROJECT_ID>>"
- Activez ces services Google Cloud
gcloud services enable run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com
- Créons un compte de service distinct qui servira d'identité au service Toolbox que nous allons déployer sur Google Cloud Run.
gcloud iam service-accounts create toolbox-identity
- Nous nous assurons également que ce compte de service dispose des rôles appropriés, c'est-à-dire qu'il peut accéder à Secret Manager et communiquer avec AlloyDB.
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/alloydb.client
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/serviceusage.serviceUsageConsumer
- Nous allons importer le fichier tools.yaml en tant que secret :
gcloud secrets create tools --data-file=tools.yaml
Si vous avez déjà un secret et que vous souhaitez mettre à jour sa version, exécutez la commande suivante :
gcloud secrets versions add tools --data-file=tools.yaml
Définissez une variable d'environnement sur l'image de conteneur que vous souhaitez utiliser pour Cloud Run :
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
- La dernière étape de la commande de déploiement habituelle sur Cloud Run :
gcloud run deploy toolbox \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools:latest" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--allow-unauthenticated
Cela devrait lancer le processus de déploiement du serveur Toolbox avec notre fichier tools.yaml configuré sur Cloud Run. Si le déploiement réussit, un message semblable à celui-ci s'affiche :
Deploying container to Cloud Run service [toolbox] in project [YOUR_PROJECT_ID] region [us-central1]
OK Deploying new service... Done.
OK Creating Revision...
OK Routing traffic...
OK Setting IAM Policy...
Done.
Service [toolbox] revision [toolbox-00001-zsk] has been deployed and is serving 100 percent of traffic.
Service URL: https://toolbox-<SOME_ID>.us-central1.run.app
Vous pouvez maintenant utiliser votre nouvel outil déployé dans votre application agentique.
Connectons l'outil de boîte à outils à notre agent !
Nous avons déjà créé la source pour notre application d'agent. Modifions-le pour inclure un nouvel outil MCP Toolbox for Databases que nous venons de déployer dans Cloud Run.
- Observez votre fichier requirements.txt avec la source du dépôt :
Nous incluons la dépendance pour MCP Toolbox for Databases dans requirements.txt.
https://github.com/AbiramiSukumaran/renovation-agent-adk-mcp-toolbox/blob/main/requirements.txt
- Observez votre fichier agent.py avec le code du dépôt :
Nous incluons l'outil qui appelle le point de terminaison de la boîte à outils pour récupérer les données de commande d'un matériau spécifique commandé.
https://github.com/AbiramiSukumaran/renovation-agent-adk-mcp-toolbox/blob/main/agent.py
9. Configuration du modèle
La capacité de votre agent à comprendre les requêtes des utilisateurs et à générer des réponses repose sur un grand modèle de langage (LLM). Votre agent doit effectuer des appels sécurisés à ce service LLM externe, ce qui nécessite des identifiants d'authentification. Sans authentification valide, le service LLM refusera les requêtes de l'agent, qui ne pourra pas fonctionner.
- Obtenez une clé API depuis Google AI Studio.
- À l'étape suivante, lorsque vous configurez le fichier .env, remplacez
<<your API KEY>>par la valeur de votre clé API.
10. Configurer les variables d'environnement
- Configurez les valeurs des paramètres dans le fichier .env du modèle. Dans mon cas, le fichier .env contient les variables suivantes :
GOOGLE_GENAI_USE_VERTEXAI=FALSE
GOOGLE_API_KEY=<<your API KEY>>
GOOGLE_CLOUD_LOCATION=us-central1 <<or your region>>
GOOGLE_CLOUD_PROJECT=<<your project id>>
PROJECT_ID=<<your project id>>
GOOGLE_CLOUD_REGION=us-central1 <<or your region>>
Remplacez les espaces réservés par vos valeurs.
11. Exécuter votre agent
- Dans le terminal, accédez au répertoire parent de votre projet d'agent :
cd renovation-agent
- Installez les dépendances :
pip install -r requirements.txt
- Vous pouvez exécuter la commande suivante dans votre terminal Cloud Shell pour exécuter l'agent :
adk run .
- Pour l'exécuter dans une UI Web provisionnée par ADK, vous pouvez exécuter la commande suivante :
adk web
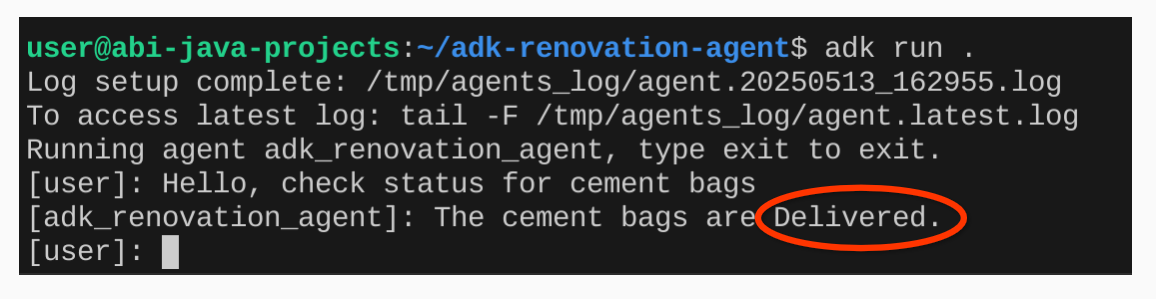
- Effectuez un test avec les requêtes suivantes :
user>>
Hello. Check order status for Cement Bags.
12. Résultat
13. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet article soient facturées sur votre compte Google Cloud, procédez comme suit :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
14. Félicitations
Félicitations ! Vous avez créé une application multi-agents à l'aide d'ADK et de MCP Toolbox for Databases. Pour en savoir plus, consultez la documentation produit : Kit de développement d'agents et MCP Toolbox for Databases.