1. Panoramica
In questo lab utilizzerai Vertex AI per ottenere previsioni online e batch da un modello addestrato personalizzato.
Questo lab fa parte della serie di video Dal prototipo alla produzione. Assicurati di completare il lab precedente prima di provare questo. Puoi guardare il video di accompagnamento per saperne di più:
.
Cosa imparerai
Al termine del corso sarai in grado di:
- Caricare modelli in Vertex AI Model Registry
- Eseguire il deployment di un modello in un endpoint
- Ottenere previsioni online e batch con l'interfaccia utente e l'SDK
Il costo totale per eseguire questo lab su Google Cloud è di circa 1$.
2. Introduzione a Vertex AI
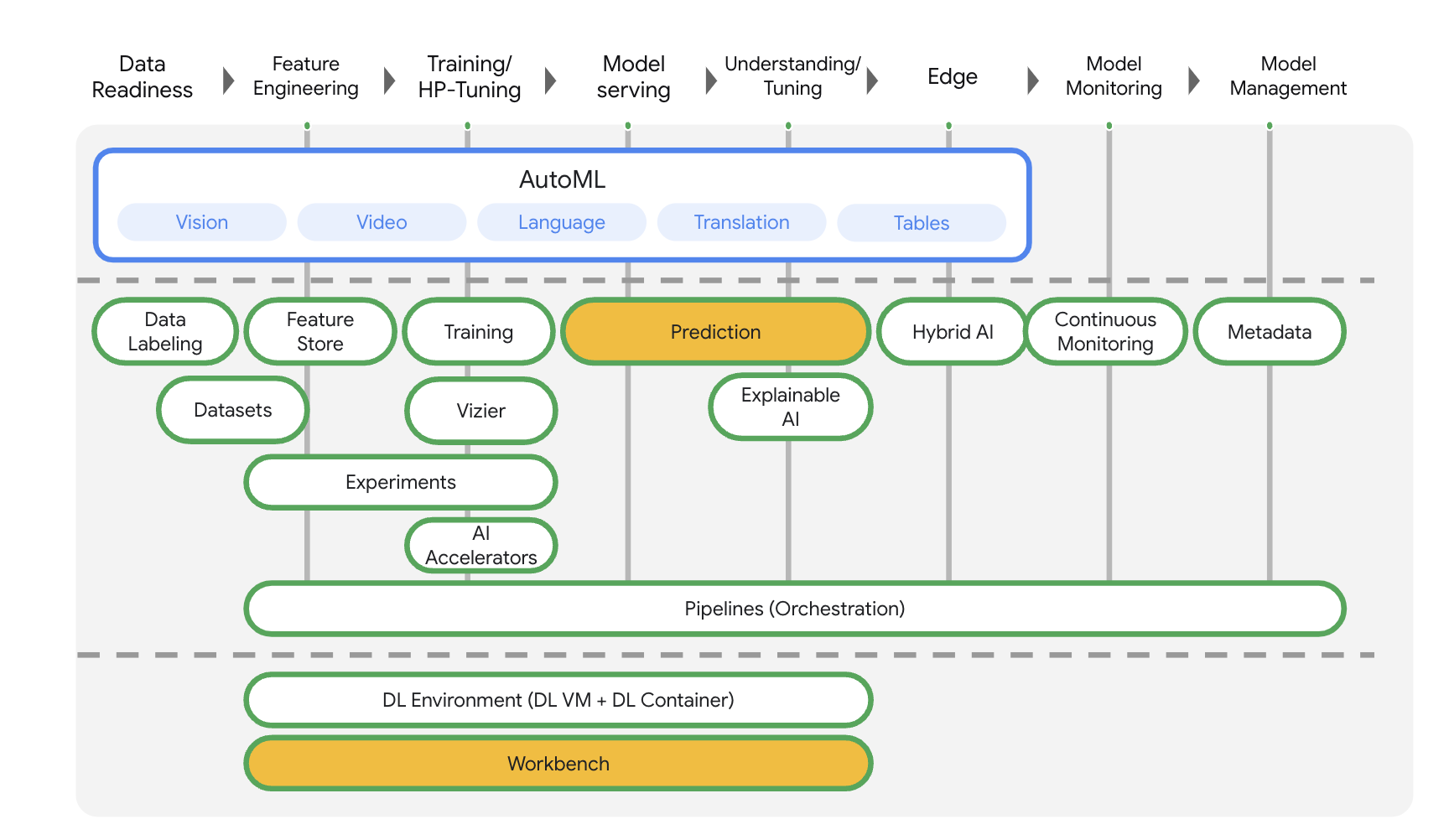
Questo lab utilizza la più recente offerta di prodotti AI disponibile su Google Cloud. Vertex AI integra le offerte ML di Google Cloud in un'esperienza di sviluppo fluida. In precedenza, i modelli addestrati con AutoML e i modelli personalizzati erano accessibili tramite servizi separati. La nuova offerta combina entrambi in un'unica API, insieme ad altri nuovi prodotti. Puoi anche migrare progetti esistenti su Vertex AI.
Vertex AI include molti prodotti diversi per supportare i flussi di lavoro ML end-to-end. Questo lab si concentrerà sui prodotti evidenziati di seguito: Predictions e Workbench.
3. Configura l'ambiente
Completa i passaggi descritti nel lab Addestrare modelli personalizzati con Vertex AI per configurare l'ambiente.
4. Carica il modello nel registro
Prima di poter utilizzare il modello per ottenere previsioni, dobbiamo caricarlo in Vertex AI Model Registry, un repository in cui puoi gestire il ciclo di vita dei tuoi modelli ML.
Puoi caricare i modelli quando configuri un job di addestramento personalizzato, come mostrato di seguito.
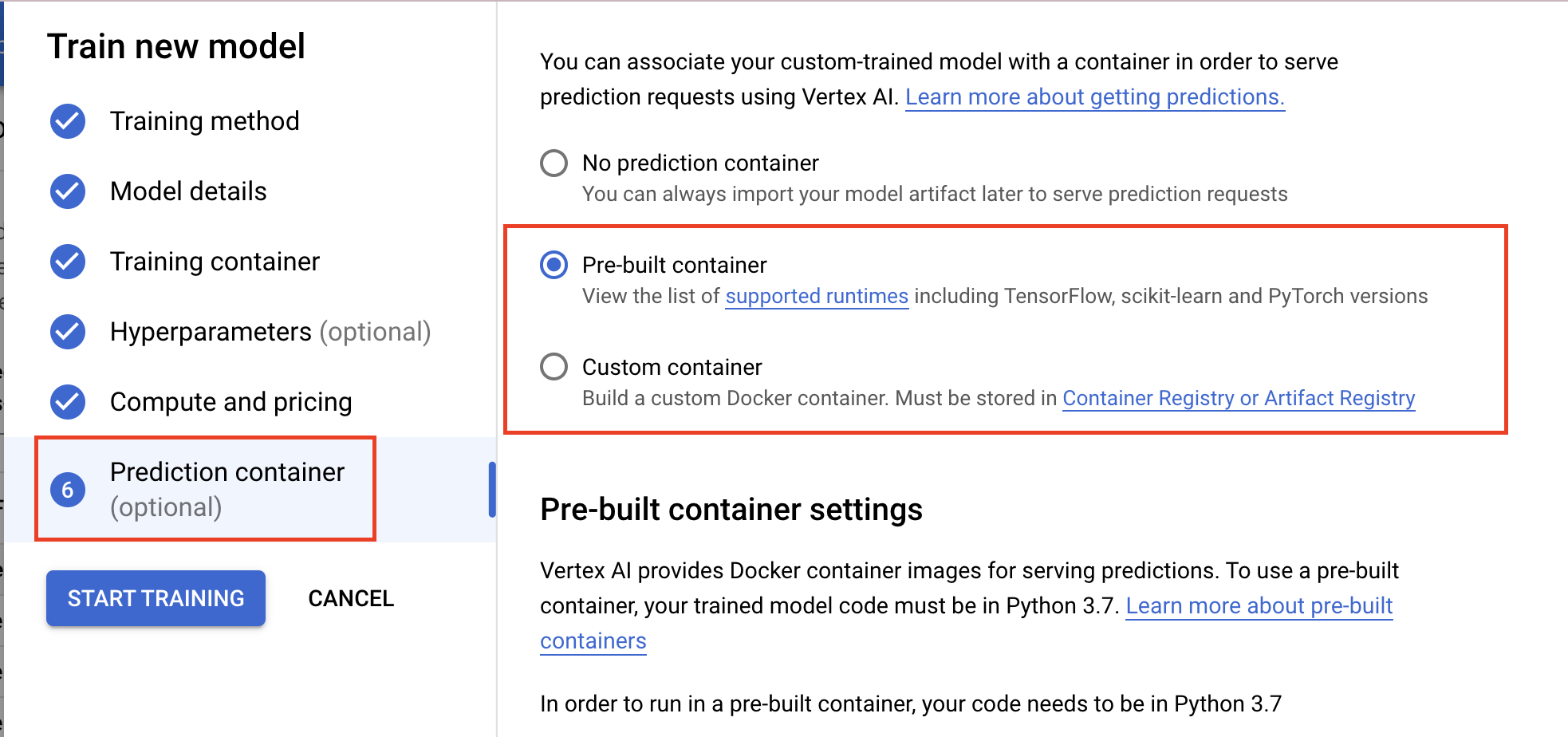
In alternativa, puoi importare i modelli al termine del job di addestramento, a condizione che tu memorizzi gli artefatti del modello salvato in un bucket Cloud Storage. Questa è l'opzione che utilizzeremo in questo lab.
Vai alla sezione Modelli della console.
Seleziona IMPORT.

Seleziona Importa come nuovo modello e poi fornisci un nome per il modello.

In Impostazioni modello , importa il modello con un container predefinito e utilizza TensorFlow 2.8. Puoi visualizzare l'elenco completo dei container di previsione predefiniti qui.
Poi fornisci il percorso del bucket Cloud Storage in cui hai salvato gli artefatti del modello nel job di addestramento personalizzato. Dovrebbe essere simile a gs://{PROJECT_ID}-bucket/model_output.
Saltiamo la sezione Spiegabilità, ma se vuoi saperne di più su Vertex Explainable AI, consulta la documentazione.
Quando il modello viene importato, lo vedrai nel registro.

Tieni presente che, se vuoi eseguire questa operazione tramite l'SDK anziché l'interfaccia utente, puoi eseguire il seguente comando dal blocco note di Workbench per caricare il modello.
from google.cloud import aiplatform
my_model = aiplatform.Model.upload(display_name='flower-model',
artifact_uri='gs://{PROJECT_ID}-bucket/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
5. Esegui il deployment del modello in un endpoint
In Vertex AI possiamo eseguire due tipi di job di previsione: batch e online.
Le previsioni in batch sono una richiesta asincrona. È una buona soluzione quando non hai bisogno di una risposta immediata e vuoi elaborare i dati accumulati in un'unica richiesta.
D'altra parte, se vuoi ottenere previsioni a bassa latenza dai dati passati al modello in tempo reale, devi utilizzare la previsione online.
Ora che il modello è nel registro, possiamo utilizzarlo per le previsioni batch.
Tuttavia, se vogliamo ottenere previsioni online, dobbiamo eseguire il deployment del modello in un endpoint. In questo modo, gli artefatti del modello salvato vengono associati alle risorse fisiche per le previsioni a bassa latenza.
Per eseguire il deployment in un endpoint, seleziona i tre puntini all'estrema destra del modello, quindi seleziona Esegui il deployment nell'endpoint.

Assegna un nome all'endpoint, lascia invariate le altre impostazioni e fai clic su CONTINUA.

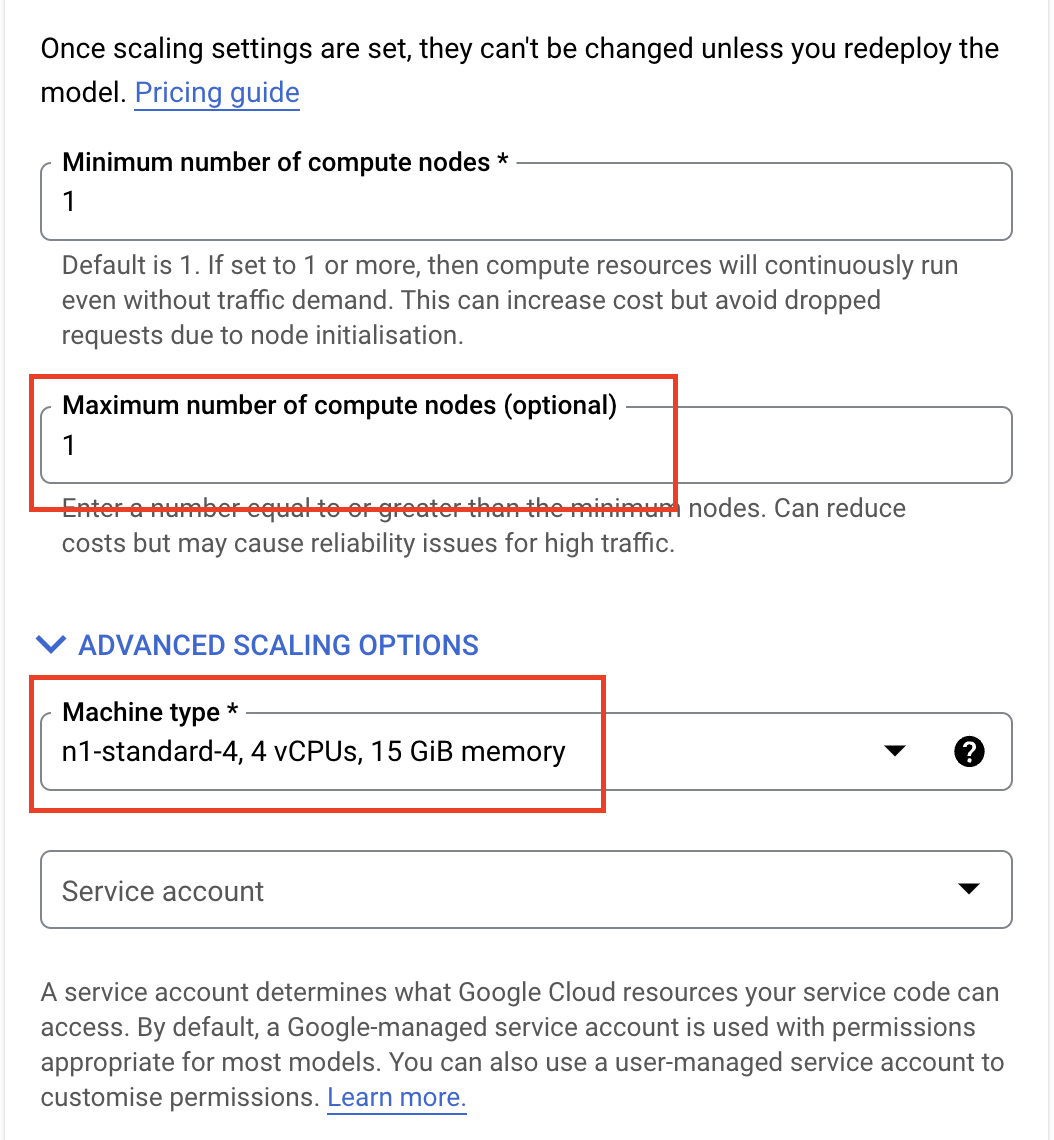
Gli endpoint supportano la scalabilità automatica, il che significa che puoi impostare un valore minimo e massimo e i nodi di calcolo verranno scalati per soddisfare la domanda di traffico entro questi limiti.
Poiché questo lab è solo a scopo dimostrativo e non utilizzeremo questo endpoint per il traffico elevato, puoi impostare il Numero massimo di nodi di calcolo su 1 e selezionare n1-standard-4 come Tipo di macchina.
Saltiamo il monitoraggio del modello, ma se vuoi saperne di più su questa funzionalità, consulta la documentazione.
Quindi fai clic su ESEGUI IL DEPLOYMENT.
Il deployment richiederà alcuni minuti, ma al termine vedrai che lo stato del deployment del modello è cambiato in Deployment su Vertex AI.
Se vuoi eseguire il deployment di un modello tramite l'SDK, esegui il comando riportato di seguito.
my_model = aiplatform.Model("projects/{PROJECT_NUMBER}/locations/us-central1/models/{MODEL_ID}")
endpoint = my_model.deploy(
deployed_model_display_name='my-endpoint',
traffic_split={"0": 100},
machine_type="n1-standard-4",
accelerator_count=0,
min_replica_count=1,
max_replica_count=1,
)
6. Ricevi previsioni
Previsioni online
Quando il modello viene sottoposto a deployment in un endpoint, puoi accedervi come a qualsiasi altro endpoint REST, il che significa che puoi chiamarlo da una funzione Cloud, un chatbot, un'app web e così via.
A scopo dimostrativo, chiameremo questo endpoint da Workbench.
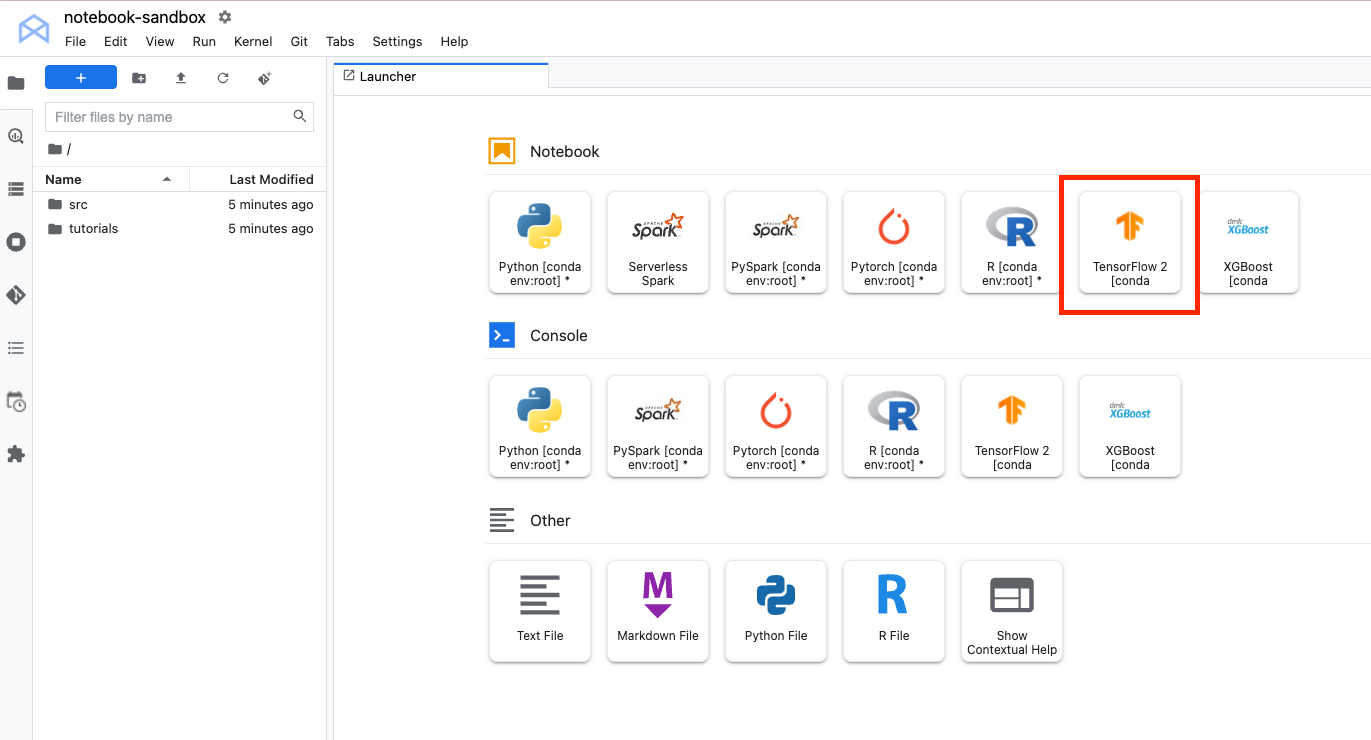
Torna al notebook che hai creato nel lab precedente. Dal launcher, crea un nuovo blocco note TensorFlow 2.
Importa l'SDK Vertex AI Python, NumPy e PIL.
from google.cloud import aiplatform
import numpy as np
from PIL import Image
Scarica l'immagine qui sotto e caricala nell'istanza di Workbench. Testeremo il modello su questa immagine di un dente di leone.

Innanzitutto, definisci l'endpoint. Dovrai sostituire {PROJECT_NUMBER} e {ENDPOINT_ID} di seguito.
endpoint = aiplatform.Endpoint(
endpoint_name="projects/{PROJECT_NUMBER}/locations/us-central1/endpoints/{ENDPOINT_ID}")
Puoi trovare l'endpoint_id nella sezione Endpoint della console Cloud.

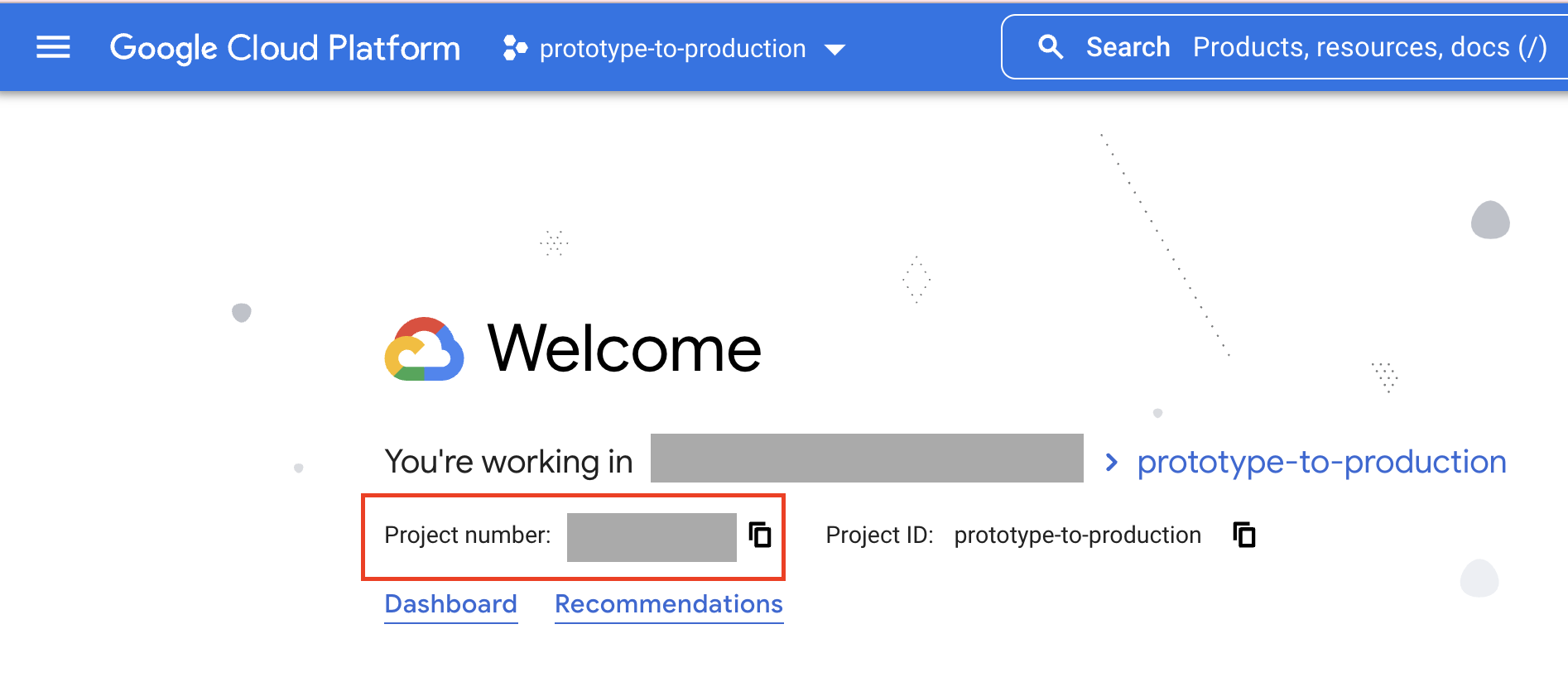
Puoi trovare il numero di progetto nella home page della console. Tieni presente che questo valore è diverso dall'ID progetto.
Il codice riportato di seguito apre e ridimensiona l'immagine con PIL.
IMAGE_PATH = "test-image.jpg"
im = Image.open(IMAGE_PATH)
Poi, converti i dati NumPy in tipo float32 e in un elenco. Eseguiamo la conversione in un elenco perché i dati NumPy non sono serializzabili in JSON, quindi non possiamo inviarli nel corpo della richiesta.
x_test = np.asarray(im).astype(np.float32).tolist()
Infine, chiama endpoint.predict.
endpoint.predict(instances=x_test).predictions
Il risultato ottenuto è l'output del modello, ovvero un livello softmax con 5 unità. Se vuoi scrivere una logica personalizzata per restituire l'etichetta stringa anziché l'indice, puoi utilizzare le routine di previsione personalizzate.
Previsioni batch
Esistono diversi modi per formattare i dati per le previsioni in batch. Per semplicità, scaricheremo i dati NumPy in un file JSON e salveremo il file in Cloud Storage.
with open('test-data.json', 'w') as fp:
json.dump(x_test, fp)
!gsutil cp test-data.json gs://{YOUR_BUCKET}
Poi, definisci il modello. Questa operazione è simile alla definizione dell'endpoint, tranne per il fatto che dovrai fornire l'MODEL_ID anziché un ENDPOINT_ID.
my_model=aiplatform.Model("projects/{PROJECT_NUMBER}/locations/us-central1/models/{MODEL_ID}")
Puoi trovare l'ID modello selezionando il nome e la versione del modello nella sezione Modelli della console, quindi selezionando DETTAGLI VERSIONE.

Infine, utilizza l'SDK per chiamare un job di previsioni in batch, passando il percorso di Cloud Storage in cui hai archiviato il file JSON e fornendo una località di Cloud Storage in cui archiviare i risultati della previsione.
batch_prediction_job = my_model.batch_predict(
job_display_name='flower_batch_predict',
gcs_source='gs://{YOUR_BUCKET}/test-data.json',
gcs_destination_prefix='gs://{YOUR_BUCKET}/prediction-results',
machine_type='n1-standard-4',)
Puoi monitorare l'avanzamento del job nella sezione Previsioni batch della console. Tieni presente che l'esecuzione di un job di previsioni in batch per una singola immagine non è efficiente.

Passaggi successivi
In questo esempio, abbiamo convertito prima l'immagine di test in NumPy prima di effettuare la chiamata di previsione. Per casi d'uso più realistici, probabilmente ti consigliamo di inviare l'immagine stessa e di non doverla caricare prima in NumPy. Per farlo, dovrai modificare la funzione di gestione di TensorFlow per decodificare i byte dell'immagine. Questa operazione richiede un po' più di lavoro, ma sarà molto più efficiente per le immagini più grandi e la creazione di applicazioni. Puoi vedere un esempio in questo blocco note.
🎉 Congratulazioni! 🎉
Hai imparato come utilizzare Vertex AI per:
- Caricare modelli in Vertex AI Model Registry
- Ottenere previsioni batch e online
Per saperne di più sulle diverse parti di Vertex, consulta la documentazione.
7. Esegui la pulizia
Se non prevedi di utilizzarli, ti consigliamo di annullare il deployment dei modelli dall'endpoint. Puoi anche eliminare completamente l'endpoint. Puoi sempre rieseguire il deployment di un modello in un endpoint, se necessario.

I blocchi note gestiti di Workbench vanno in timeout automaticamente dopo 180 minuti di inattività, quindi non devi preoccuparti di arrestare l'istanza. Se vuoi arrestare manualmente l'istanza, fai clic sul pulsante Arresta nella sezione Vertex AI Workbench della console. Se vuoi eliminare completamente il blocco note, fai clic sul pulsante Elimina.

Per eliminare il bucket di archiviazione, utilizza il menu di navigazione nella console Cloud, vai ad Archiviazione, seleziona il bucket e fai clic su Elimina: