
1. Tổng quan
Trong phòng thí nghiệm này, bạn sẽ sử dụng Vertex AI để nhận kết quả dự đoán trực tuyến và hàng loạt từ một mô hình được huấn luyện tuỳ chỉnh.
Lớp học này nằm trong loạt video Nguyên mẫu đến sản xuất. Hãy nhớ hoàn thành phòng thí nghiệm trước khi thử phòng thí nghiệm này. Bạn có thể xem video đi kèm để tìm hiểu thêm:
.
Kiến thức bạn sẽ học được
Bạn sẽ tìm hiểu cách:
- Tải mô hình lên Vertex AI Model Registry
- Triển khai một mô hình đến một điểm cuối
- Nhận thông tin dự đoán trực tuyến và hàng loạt bằng giao diện người dùng và SDK
Tổng chi phí để chạy bài tập thực hành này trên Google Cloud là khoảng 1 USD.
2. Giới thiệu về Vertex AI
Phòng thí nghiệm này sử dụng sản phẩm AI mới nhất hiện có trên Google Cloud. Vertex AI tích hợp các sản phẩm ML trên Google Cloud thành một trải nghiệm phát triển liền mạch. Trước đây, các mô hình được huấn luyện bằng AutoML và các mô hình tuỳ chỉnh có thể truy cập thông qua các dịch vụ riêng biệt. Sản phẩm mới này kết hợp cả hai thành một API duy nhất, cùng với các sản phẩm mới khác. Bạn cũng có thể di chuyển các dự án hiện có sang Vertex AI.
Vertex AI có nhiều sản phẩm để hỗ trợ quy trình làm việc ML toàn diện. Phòng thí nghiệm này sẽ tập trung vào các sản phẩm được làm nổi bật bên dưới: Dự đoán và Workbench

3. Thiết lập môi trường
Hoàn tất các bước trong phòng thí nghiệm Huấn luyện các mô hình tuỳ chỉnh bằng Vertex AI để thiết lập môi trường của bạn.
4. Tải mô hình lên sổ đăng ký
Trước khi có thể sử dụng mô hình để nhận kết quả dự đoán, chúng ta cần tải mô hình đó lên Vertex AI Model Registry. Đây là một kho lưu trữ nơi bạn có thể quản lý vòng đời của các mô hình học máy.
Bạn có thể tải các mô hình lên khi định cấu hình một quy trình huấn luyện tuỳ chỉnh, như minh hoạ dưới đây.

Hoặc bạn có thể nhập các mô hình sau khi hoàn tất quy trình huấn luyện, miễn là bạn lưu trữ các cấu phần phần mềm mô hình đã lưu trong một bộ chứa Cloud Storage. Đây là lựa chọn mà chúng ta sẽ sử dụng trong lớp học lập trình này.
Chuyển đến phần Mô hình trong bảng điều khiển.

Chọn IMPORT

Chọn Nhập dưới dạng mô hình mới rồi đặt tên cho mô hình của bạn

Trong phần Model settings (Cài đặt mô hình), hãy nhập mô hình bằng một vùng chứa dựng sẵn và sử dụng TensorFlow 2.8. Bạn có thể xem danh sách đầy đủ các vùng chứa dự đoán được tạo sẵn tại đây.
Sau đó, hãy cung cấp đường dẫn đến bộ chứa bộ nhớ trên đám mây nơi bạn đã lưu các cấu phần phần mềm mô hình trong quy trình huấn luyện tuỳ chỉnh. Mã này sẽ có dạng như gs://{PROJECT_ID}-bucket/model_output
Chúng ta sẽ bỏ qua phần Khả năng giải thích, nhưng nếu bạn muốn tìm hiểu thêm về Vertex AI giải thích, hãy xem tài liệu.
Khi nhập mô hình, bạn sẽ thấy mô hình đó trong sổ đăng ký.

Xin lưu ý rằng nếu muốn thực hiện việc này thông qua SDK thay vì giao diện người dùng, bạn có thể chạy lệnh sau từ sổ tay Workbench để tải mô hình lên.
from google.cloud import aiplatform
my_model = aiplatform.Model.upload(display_name='flower-model',
artifact_uri='gs://{PROJECT_ID}-bucket/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
5. Triển khai mô hình đến điểm cuối
Có hai loại công việc dự đoán mà chúng ta có thể chạy trong Vertex AI: hàng loạt và trực tuyến.
Dự đoán theo lô là một tài nguyên không đồng bộ. Đây là lựa chọn phù hợp khi bạn không cần phản hồi ngay lập tức và muốn xử lý dữ liệu tích luỹ trong một yêu cầu duy nhất.
Mặt khác, nếu muốn nhận được các dự đoán có độ trễ thấp từ dữ liệu được truyền đến mô hình của bạn ngay lập tức, bạn sẽ sử dụng tính năng dự đoán trực tuyến.
Giờ đây, khi mô hình đã có trong sổ đăng ký, chúng ta có thể sử dụng mô hình này để dự đoán hàng loạt.
Nhưng nếu muốn nhận được các dự đoán trực tuyến, chúng ta cần triển khai mô hình đến một điểm cuối. Thao tác này sẽ liên kết các cấu phần phần mềm mô hình đã lưu với tài nguyên thực để đưa ra dự đoán có độ trễ thấp.
Để triển khai đến một điểm cuối, hãy chọn biểu tượng ba dấu chấm ở ngoài cùng bên phải của mô hình, rồi chọn Triển khai đến điểm cuối.

Đặt tên cho điểm cuối, sau đó giữ nguyên các chế độ cài đặt còn lại rồi nhấp vào TIẾP TỤC

Các điểm cuối hỗ trợ phương thức tự động cấp tài nguyên bổ sung, tức là bạn có thể đặt mức tối thiểu và tối đa, đồng thời các nút tính toán sẽ mở rộng quy mô để đáp ứng nhu cầu lưu lượng truy cập trong phạm vi đó.
Vì phòng thí nghiệm này chỉ dùng để minh hoạ và chúng ta sẽ không sử dụng điểm cuối này cho lưu lượng truy cập cao, nên bạn có thể đặt Số lượng tối đa các nốt tính toán thành 1 và chọn n1-standard-4 làm Loại máy.

Chúng ta sẽ bỏ qua phần Giám sát mô hình. Tuy nhiên, nếu bạn muốn tìm hiểu thêm về tính năng này, hãy xem tài liệu.
Sau đó, hãy nhấp vào TRIỂN KHAI
Quá trình triển khai sẽ mất vài phút. Sau khi hoàn tất, bạn sẽ thấy trạng thái triển khai của mô hình đã thay đổi thành Đã triển khai trên Vertex AI.
Nếu bạn muốn triển khai một mô hình thông qua SDK, hãy chạy lệnh bên dưới.
my_model = aiplatform.Model("projects/{PROJECT_NUMBER}/locations/us-central1/models/{MODEL_ID}")
endpoint = my_model.deploy(
deployed_model_display_name='my-endpoint',
traffic_split={"0": 100},
machine_type="n1-standard-4",
accelerator_count=0,
min_replica_count=1,
max_replica_count=1,
)
6. Xem thông tin dự đoán
Dự đoán trực tuyến
Khi mô hình của bạn được triển khai đến một điểm cuối, bạn có thể truy cập vào mô hình đó như bất kỳ điểm cuối REST nào khác. Điều này có nghĩa là bạn có thể gọi mô hình đó từ Cloud Functions, chatbot, ứng dụng web, v.v.
Để minh hoạ, chúng ta sẽ gọi điểm cuối này từ Workbench.
Quay lại sổ tay bạn đã tạo trong phòng thí nghiệm trước. Từ trình chạy, hãy tạo một sổ tay TensorFlow 2 mới.

Nhập Vertex AI Python SDK, numpy và PIL
from google.cloud import aiplatform
import numpy as np
from PIL import Image
Tải hình ảnh bên dưới xuống rồi tải lên phiên bản workbench của bạn. Chúng ta sẽ kiểm thử mô hình trên hình ảnh này về một cây bồ công anh.

Trước tiên, hãy xác định điểm cuối. Bạn cần thay thế {PROJECT_NUMBER} và {ENDPOINT_ID} bên dưới.
endpoint = aiplatform.Endpoint(
endpoint_name="projects/{PROJECT_NUMBER}/locations/us-central1/endpoints/{ENDPOINT_ID}")
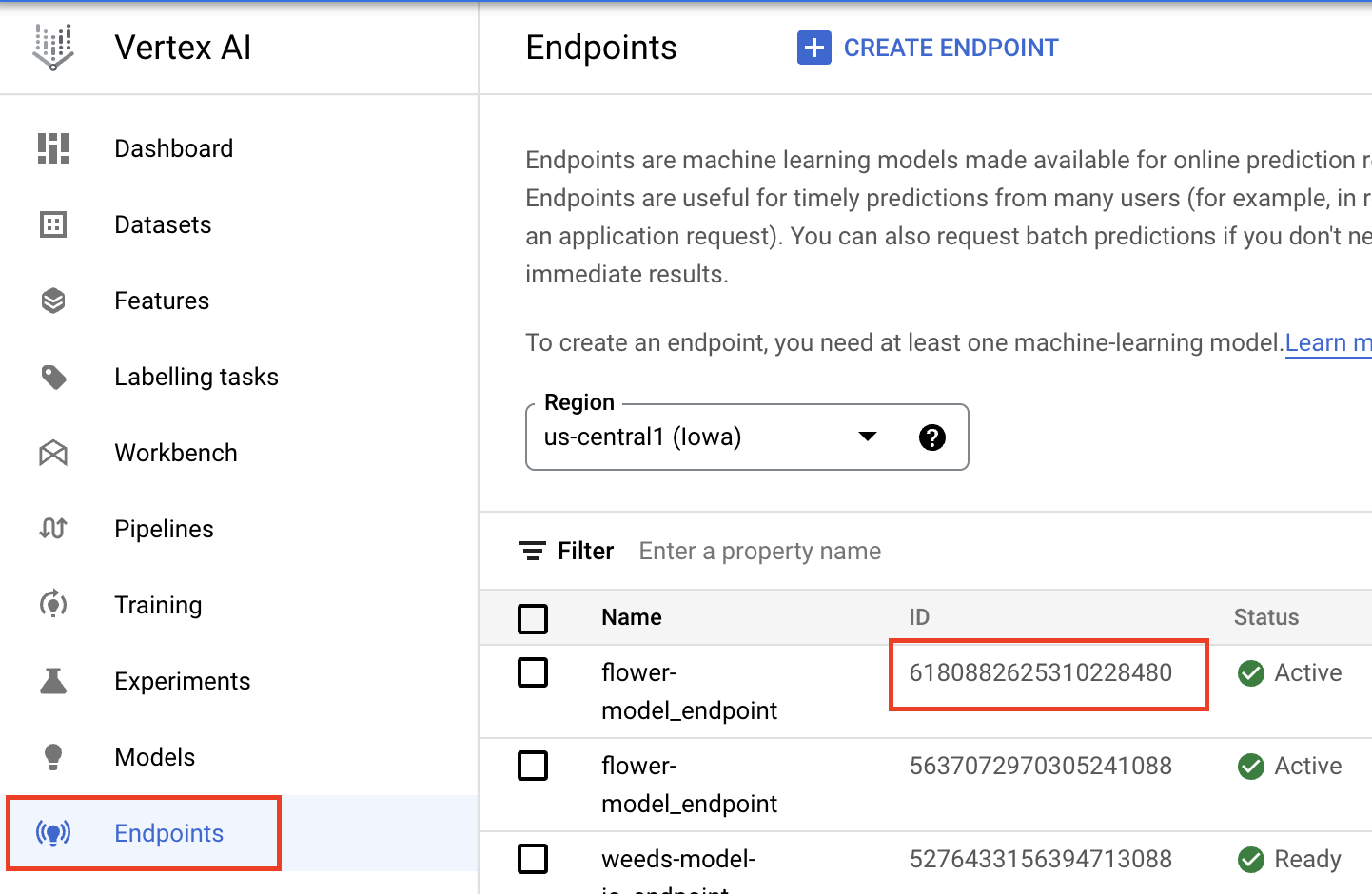
Bạn có thể tìm thấy endpoint_id trong phần Điểm cuối của Bảng điều khiển đám mây.
Bạn có thể tìm thấy Số dự án trên trang chủ của bảng điều khiển. Xin lưu ý rằng mã này khác với mã dự án.

Đoạn mã dưới đây sẽ mở và đổi kích thước hình ảnh bằng PIL.
IMAGE_PATH = "test-image.jpg"
im = Image.open(IMAGE_PATH)
Sau đó, hãy chuyển đổi dữ liệu numpy thành kiểu float32 và thành một danh sách. Chúng ta chuyển đổi thành một danh sách vì dữ liệu numpy không thể chuyển đổi tuần tự thành JSON nên chúng ta không thể gửi dữ liệu đó trong nội dung yêu cầu.
x_test = np.asarray(im).astype(np.float32).tolist()
Cuối cùng, hãy gọi endpoint.predict.
endpoint.predict(instances=x_test).predictions
Kết quả bạn nhận được là đầu ra của mô hình, tức là một lớp softmax có 5 đơn vị. Nếu muốn viết logic tuỳ chỉnh để trả về nhãn chuỗi thay vì chỉ mục, bạn có thể sử dụng các quy trình dự đoán tuỳ chỉnh.
Dự đoán theo lô
Có nhiều cách để định dạng dữ liệu cho tính năng dự đoán hàng loạt. Để đơn giản, chúng ta sẽ kết xuất dữ liệu numpy vào một tệp json và lưu tệp đó vào Cloud Storage.
with open('test-data.json', 'w') as fp:
json.dump(x_test, fp)
!gsutil cp test-data.json gs://{YOUR_BUCKET}
Tiếp theo, hãy xác định mô hình. Thao tác này tương tự như việc xác định điểm cuối, ngoại trừ việc bạn cần cung cấp MODEL_ID thay vì ENDPOINT_ID.
my_model=aiplatform.Model("projects/{PROJECT_NUMBER}/locations/us-central1/models/{MODEL_ID}")
Bạn có thể tìm thấy mã mô hình bằng cách chọn tên và phiên bản mô hình trong phần Models (Mô hình) của bảng điều khiển, sau đó chọn VERSION DETAILS (THÔNG TIN CHI TIẾT VỀ PHIÊN BẢN)

Cuối cùng, hãy dùng SDK để gọi một công việc dự đoán hàng loạt, truyền vào đường dẫn Cloud Storage nơi bạn lưu trữ tệp json và cung cấp một vị trí Cloud Storage để lưu trữ kết quả dự đoán.
batch_prediction_job = my_model.batch_predict(
job_display_name='flower_batch_predict',
gcs_source='gs://{YOUR_BUCKET}/test-data.json',
gcs_destination_prefix='gs://{YOUR_BUCKET}/prediction-results',
machine_type='n1-standard-4',)
Bạn có thể theo dõi tiến trình của công việc trong phần Dự đoán hàng loạt của bảng điều khiển. Xin lưu ý rằng việc chạy một quy trình dự đoán hàng loạt cho một hình ảnh duy nhất không hiệu quả.

Bước tiếp theo
Trong ví dụ này, trước tiên, chúng ta chuyển đổi hình ảnh kiểm thử thành NumPy trước khi thực hiện lệnh gọi dự đoán. Đối với các trường hợp sử dụng thực tế hơn, có lẽ bạn sẽ muốn gửi chính hình ảnh đó mà không cần tải hình ảnh vào NumPy trước. Để làm việc này, bạn cần điều chỉnh hàm phân phát TensorFlow để giải mã các byte hình ảnh. Việc này đòi hỏi bạn phải bỏ ra nhiều công sức hơn, nhưng sẽ hiệu quả hơn nhiều đối với các hình ảnh lớn và việc tạo ứng dụng. Bạn có thể xem ví dụ trong sổ tay này.
🎉 Xin chúc mừng! 🎉
Bạn đã tìm hiểu cách sử dụng Vertex AI để:
- Tải mô hình lên Vertex AI Model Registry
- Nhận thông tin dự đoán theo lô và trực tuyến
Để tìm hiểu thêm về các phần khác nhau của Vertex, hãy xem tài liệu.
7. Dọn dẹp
Bạn nên huỷ triển khai các mô hình khỏi điểm cuối nếu không có ý định sử dụng chúng. Bạn cũng có thể xoá hoàn toàn điểm cuối. Bạn luôn có thể triển khai lại một mô hình đến một điểm cuối nếu cần.

Sổ tay do Workbench quản lý sẽ tự động hết thời gian chờ sau 180 phút không hoạt động, nên bạn không cần lo lắng về việc tắt phiên bản. Nếu bạn muốn tắt thực thể theo cách thủ công, hãy nhấp vào nút Dừng trong phần Vertex AI Workbench của bảng điều khiển. Nếu bạn muốn xoá hoàn toàn sổ tay, hãy nhấp vào nút Xoá.

Để xoá Thùng lưu trữ, hãy sử dụng trình đơn Điều hướng trong Cloud Console, duyệt tìm Bộ nhớ, chọn thùng của bạn rồi nhấp vào Xoá:
