
1. Tổng quan
Trong phòng thí nghiệm này, bạn sẽ sử dụng Vertex AI để chạy một quy trình huấn luyện tuỳ chỉnh.
Lớp học này nằm trong loạt video Nguyên mẫu đến sản xuất. Bạn sẽ tạo một mô hình phân loại hình ảnh bằng cách sử dụng tập dữ liệu Flowers. Bạn có thể xem video đi kèm để tìm hiểu thêm:
.
Kiến thức bạn sẽ học được
Bạn sẽ tìm hiểu cách:
- Tạo một sổ tay được quản lý trong Vertex AI Workbench
- Định cấu hình và chạy một quy trình huấn luyện tuỳ chỉnh từ giao diện người dùng Vertex AI
- Định cấu hình và chạy một quy trình huấn luyện tuỳ chỉnh bằng Vertex AI Python SDK
Tổng chi phí để chạy bài tập thực hành này trên Google Cloud là khoảng 1 USD.
2. Giới thiệu về Vertex AI
Phòng thí nghiệm này sử dụng sản phẩm AI mới nhất hiện có trên Google Cloud. Vertex AI tích hợp các sản phẩm ML trên Google Cloud thành một trải nghiệm phát triển liền mạch. Trước đây, các mô hình được huấn luyện bằng AutoML và các mô hình tuỳ chỉnh có thể truy cập thông qua các dịch vụ riêng biệt. Sản phẩm mới này kết hợp cả hai thành một API duy nhất, cùng với các sản phẩm mới khác. Bạn cũng có thể di chuyển các dự án hiện có sang Vertex AI.
Vertex AI có nhiều sản phẩm để hỗ trợ quy trình làm việc ML toàn diện. Phòng thí nghiệm này sẽ tập trung vào các sản phẩm được làm nổi bật bên dưới: Training và Workbench

3. Thiết lập môi trường
Bạn cần có một dự án trên Google Cloud Platform đã bật tính năng thanh toán để chạy lớp học lập trình này. Để tạo một dự án, hãy làm theo hướng dẫn tại đây.
Bước 1: Bật Compute Engine API
Chuyển đến Compute Engine rồi chọn Bật nếu bạn chưa bật.
Bước 2: Bật Artifact Registry API
Chuyển đến Artifact Registry rồi chọn Bật nếu bạn chưa bật. Bạn sẽ dùng thông tin này để tạo một vùng chứa cho công việc huấn luyện tuỳ chỉnh.
Bước 3: Bật Vertex AI API
Chuyển đến mục Vertex AI trong Bảng điều khiển Cloud rồi nhấp vào Bật Vertex AI API.
Bước 4: Tạo một phiên bản Vertex AI Workbench
Trong phần Vertex AI của Cloud Console, hãy nhấp vào Workbench:

Bật Notebooks API nếu bạn chưa bật.

Sau khi bật, hãy nhấp vào MANAGED NOTEBOOKS (SỔ TAY ĐƯỢC QUẢN LÝ):

Sau đó, chọn SỔ TAY MỚI.

Đặt tên cho sổ tay của bạn, rồi trong mục Quyền, hãy chọn Tài khoản dịch vụ

Chọn Cài đặt nâng cao.
Trong phần Bảo mật, hãy chọn "Bật thiết bị đầu cuối" nếu bạn chưa bật.

Bạn có thể giữ nguyên tất cả các chế độ cài đặt nâng cao khác.
Tiếp theo, hãy nhấp vào Tạo. Thực thể sẽ mất vài phút để được cấp phép.
Sau khi tạo phiên bản, hãy chọn MỞ JUPYTERLAB.

4. Đóng gói mã xử lý ứng dụng huấn luyện vào vùng chứa
Bạn sẽ gửi công việc huấn luyện này đến Vertex AI bằng cách đặt mã xử lý ứng dụng huấn luyện vào một vùng chứa Docker và đẩy vùng chứa này đến Google Artifact Registry. Bằng cách sử dụng phương pháp này, bạn có thể huấn luyện một mô hình được xây dựng bằng bất kỳ khung nào.
Để bắt đầu, từ trình đơn Trình chạy, hãy mở cửa sổ dòng lệnh trong phiên bản sổ tay của bạn:

Bước 1: Tạo một bộ chứa Cloud Storage
Trong quy trình huấn luyện này, bạn sẽ xuất mô hình TensorFlow đã huấn luyện sang một bộ chứa Cloud Storage. Bạn cũng sẽ lưu trữ dữ liệu để huấn luyện trong một bộ chứa Cloud Storage.
Trong Terminal, hãy chạy lệnh sau để xác định một biến môi trường cho dự án của bạn, nhớ thay thế your-cloud-project bằng mã dự án:
PROJECT_ID='your-cloud-project'
Tiếp theo, hãy chạy lệnh sau trong Terminal để tạo một nhóm mới trong dự án của bạn.
BUCKET="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET
Bước 2: Sao chép dữ liệu vào bộ chứa Cloud Storage
Chúng ta cần đưa tập dữ liệu về hoa vào Cloud Storage. Để minh hoạ, trước tiên, bạn sẽ tải tập dữ liệu xuống phiên bản Workbench này, sau đó sao chép tập dữ liệu đó vào một bộ chứa.
Tải dữ liệu xuống và giải nén.
wget https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
tar xvzf flower_photos.tgz
Sau đó, hãy sao chép tệp đó vào nhóm bạn vừa tạo. Chúng ta thêm -r vì muốn sao chép toàn bộ thư mục và -m để thực hiện thao tác sao chép đa xử lý, giúp tăng tốc độ.
gsutil -m cp -r flower_photos $BUCKET
Bước 3: Viết mã huấn luyện
Tạo một thư mục mới có tên là flowers rồi chuyển đến thư mục đó:
mkdir flowers
cd flowers
Chạy lệnh sau để tạo một thư mục cho mã huấn luyện và một tệp Python nơi bạn sẽ thêm mã.
mkdir trainer
touch trainer/task.py
Bây giờ, bạn sẽ có những nội dung sau trong thư mục flowers/:
+ trainer/
+ task.py
Để biết thêm thông tin chi tiết về cách cấu trúc mã xử lý ứng dụng huấn luyện, hãy xem tài liệu.
Tiếp theo, hãy mở tệp task.py bạn vừa tạo rồi sao chép mã bên dưới.
Bạn cần thay thế {your-gcs-bucket} bằng tên của bộ chứa Cloud Storage mà bạn vừa tạo.
Thông qua công cụ FUSE của Cloud Storage, các hoạt động huấn luyện trên Vertex AI Training có thể truy cập vào dữ liệu trên Cloud Storage dưới dạng tệp trong hệ thống tệp cục bộ. Khi bạn bắt đầu một quy trình huấn luyện tuỳ chỉnh, quy trình này sẽ thấy một thư mục /gcs chứa tất cả các vùng chứa Cloud Storage của bạn dưới dạng thư mục con. Đó là lý do khiến các đường dẫn dữ liệu trong mã huấn luyện bắt đầu bằng /gcs.
import tensorflow as tf
import numpy as np
import os
## Replace {your-gcs-bucket} !!
BUCKET_ROOT='/gcs/{your-gcs-bucket}'
# Define variables
NUM_CLASSES = 5
EPOCHS=10
BATCH_SIZE = 32
IMG_HEIGHT = 180
IMG_WIDTH = 180
DATA_DIR = f'{BUCKET_ROOT}/flower_photos'
def create_datasets(data_dir, batch_size):
'''Creates train and validation datasets.'''
train_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
validation_dataset = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(IMG_HEIGHT, IMG_WIDTH),
batch_size=batch_size)
train_dataset = train_dataset.cache().shuffle(1000).prefetch(buffer_size=tf.data.AUTOTUNE)
validation_dataset = validation_dataset.cache().prefetch(buffer_size=tf.data.AUTOTUNE)
return train_dataset, validation_dataset
def create_model():
'''Creates model.'''
model = tf.keras.Sequential([
tf.keras.layers.Resizing(IMG_HEIGHT, IMG_WIDTH),
tf.keras.layers.Rescaling(1./255, input_shape=(IMG_HEIGHT, IMG_WIDTH, 3)),
tf.keras.layers.Conv2D(16, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(NUM_CLASSES, activation='softmax')
])
return model
# CREATE DATASETS
train_dataset, validation_dataset = create_datasets(DATA_DIR, BATCH_SIZE)
# CREATE/COMPILE MODEL
model = create_model()
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
# TRAIN MODEL
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=EPOCHS
)
# SAVE MODEL
model.save(f'{BUCKET_ROOT}/model_output')
Bước 4: Tạo một Dockerfile
Để chứa mã của bạn trong một vùng chứa, bạn cần tạo một Dockerfile. Trong Dockerfile, bạn sẽ đưa tất cả các lệnh cần thiết để chạy hình ảnh. Thao tác này sẽ cài đặt tất cả các thư viện cần thiết và thiết lập điểm truy cập cho mã huấn luyện.
Trong Terminal, hãy tạo một Dockerfile trống trong thư mục gốc của thư mục flowers:
touch Dockerfile
Bây giờ, bạn sẽ có những nội dung sau trong thư mục flowers/:
+ Dockerfile
+ trainer/
+ task.py
Mở Dockerfile rồi sao chép nội dung sau vào đó:
FROM gcr.io/deeplearning-platform-release/tf2-gpu.2-8
WORKDIR /
# Copies the trainer code to the docker image.
COPY trainer /trainer
# Sets up the entry point to invoke the trainer.
ENTRYPOINT ["python", "-m", "trainer.task"]
Hãy xem các lệnh trong tệp này.
Lệnh FROM chỉ định hình ảnh cơ sở, là hình ảnh mẹ mà hình ảnh bạn tạo sẽ được xây dựng dựa trên đó. Là hình ảnh cơ sở, bạn sẽ sử dụng Hình ảnh Docker GPU của Deep Learning Container TensorFlow Enterprise 2.8. Deep Learning Containers trên Google Cloud được cài đặt sẵn nhiều khung học máy và khoa học dữ liệu phổ biến.
Lệnh WORKDIR chỉ định thư mục trên hình ảnh nơi các chỉ dẫn tiếp theo được chạy.
Lệnh COPY sẽ sao chép mã huấn luyện viên vào hình ảnh Docker. Xin lưu ý rằng trong ví dụ này, chúng ta chỉ có một tệp python trong thư mục trình huấn luyện, nhưng đối với một ví dụ thực tế hơn, bạn có thể có thêm các tệp. Có thể là một data.py, xử lý việc tiền xử lý dữ liệu và một model.py, chỉ có mã mô hình, v.v. Để biết mã huấn luyện phức tạp hơn, hãy xem tài liệu Python về đóng gói các dự án Python.
Nếu muốn thêm bất kỳ thư viện nào khác, bạn có thể dùng lệnh RUN để cài đặt pip (ví dụ: RUN pip install -r requirements.txt). Tuy nhiên, chúng ta không cần thêm bất kỳ thư viện nào khác cho ví dụ này.
Cuối cùng, lệnh ENTRYPOINT sẽ thiết lập điểm truy cập để gọi trình huấn luyện. Đây là những gì sẽ chạy khi chúng ta bắt đầu công việc huấn luyện. Trong trường hợp này, đó là việc thực thi tệp task.py.
Bạn có thể tìm hiểu thêm về cách viết Dockerfile cho Vertex AI Training tại đây.
Bước 4: Tạo vùng chứa
Từ cửa sổ dòng lệnh của sổ tay Workbench, hãy chạy lệnh sau để xác định một biến môi trường cho dự án của bạn, nhớ thay thế your-cloud-project bằng mã dự án:
PROJECT_ID='your-cloud-project'
Tạo một kho lưu trữ trong Artifact Registry
REPO_NAME='flower-app'
gcloud artifacts repositories create $REPO_NAME --repository-format=docker \
--location=us-central1 --description="Docker repository"
Xác định một biến bằng URI của hình ảnh vùng chứa trong Google Artifact Registry:
IMAGE_URI=us-central1-docker.pkg.dev/$PROJECT_ID/$REPO_NAME/flower_image:latest
Định cấu hình docker
gcloud auth configure-docker \
us-central1-docker.pkg.dev
Sau đó, hãy tạo vùng chứa bằng cách chạy lệnh sau từ gốc của thư mục flower:
docker build ./ -t $IMAGE_URI
Cuối cùng, hãy đẩy nó vào Artifact Registry:
docker push $IMAGE_URI
Sau khi đẩy vùng chứa lên Artifact Registry, bạn có thể bắt đầu một quy trình huấn luyện.
5. Chạy một quy trình huấn luyện tuỳ chỉnh trên Vertex AI
Phòng thí nghiệm này sử dụng hoạt động huấn luyện tuỳ chỉnh thông qua một vùng chứa tuỳ chỉnh trên Google Artifact Registry, nhưng bạn cũng có thể chạy một công việc huấn luyện bằng Vùng chứa được tạo sẵn.
Để bắt đầu, hãy chuyển đến phần Huấn luyện trong phần Vertex của bảng điều khiển Cloud:

Bước 1: Định cấu hình quy trình huấn luyện
Nhấp vào Tạo để nhập các tham số cho công việc huấn luyện của bạn.

- Trong mục Tập dữ liệu, hãy chọn Không có tập dữ liệu được quản lý
- Sau đó, hãy chọn Khoá huấn luyện tuỳ chỉnh (nâng cao) làm phương pháp huấn luyện rồi nhấp vào Tiếp tục.
- Chọn Huấn luyện mô hình mới rồi nhập
flowers-model(hoặc bất cứ tên nào bạn muốn đặt cho mô hình) vào Tên mô hình - Nhấp vào Tiếp tục
Trong bước Cài đặt vùng chứa, hãy chọn Vùng chứa tuỳ chỉnh:

Trong hộp đầu tiên (Hình ảnh vùng chứa), hãy nhập giá trị của biến IMAGE_URI trong phần trước. Đó phải là: us-central1-docker.pkg.dev/{PROJECT_ID}/flower-app/flower_image:latest, với mã dự án của riêng bạn. Để trống các trường còn lại rồi nhấp vào Tiếp tục.
Bỏ qua bước Siêu tham số bằng cách nhấp lại vào Tiếp tục.
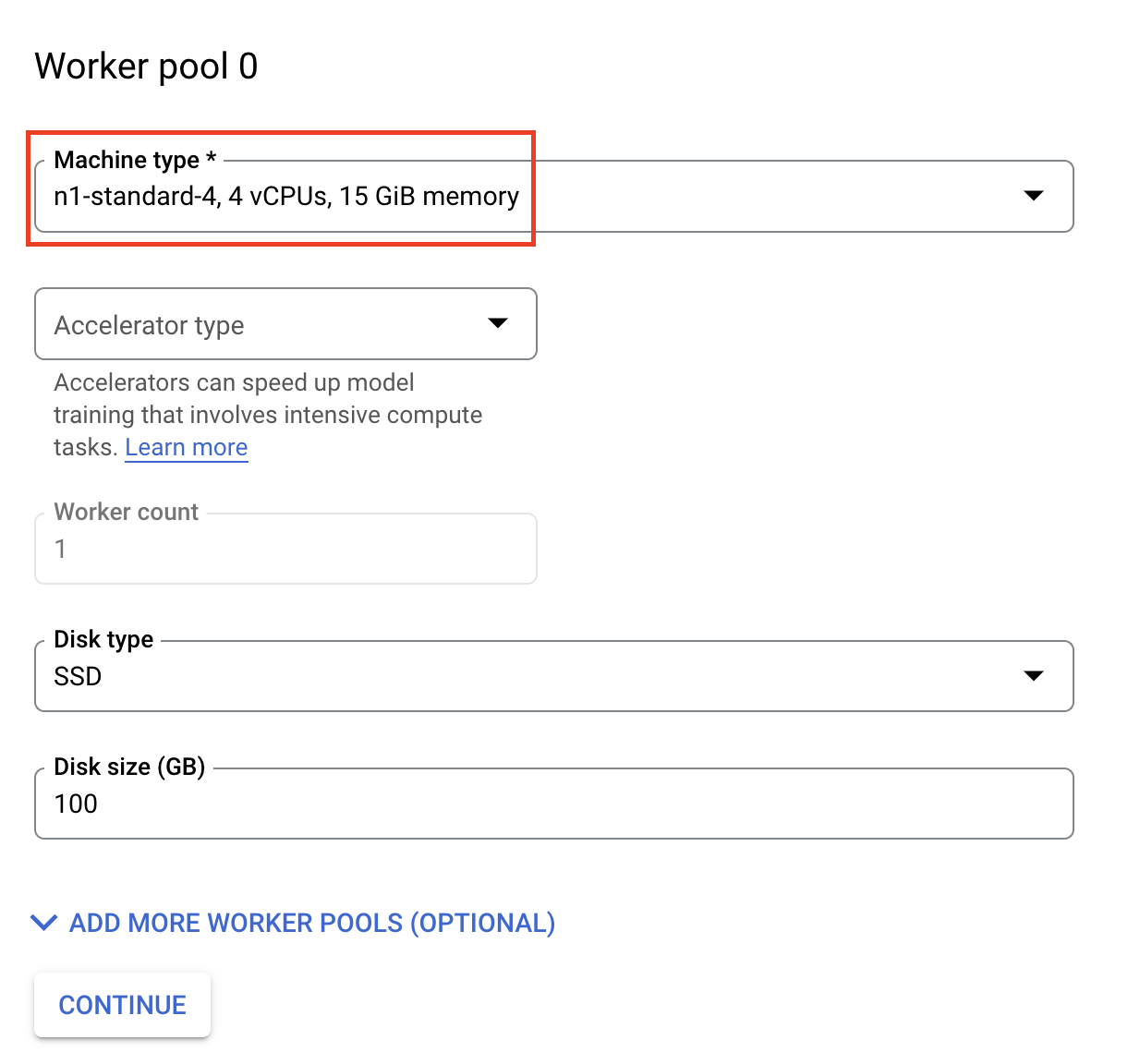
Bước 2: Định cấu hình cụm tính toán
Định cấu hình Nhóm nhân viên 0 như sau:
Hiện tại, bạn sẽ bỏ qua bước 6 và định cấu hình vùng chứa dự đoán trong bài tập tiếp theo của loạt bài này.
Nhấp vào BẮT ĐẦU HUẤN LUYỆN để bắt đầu công việc huấn luyện. Trong phần Đào tạo của bảng điều khiển, bạn sẽ thấy công việc mới khởi chạy trong thẻ TRAINING PIPELINES (PIPELINE ĐÀO TẠO):

🎉 Xin chúc mừng! 🎉
Bạn đã tìm hiểu cách sử dụng Vertex AI để:
- Khởi chạy một lệnh huấn luyện tuỳ chỉnh cho mã huấn luyện được cung cấp trong một vùng chứa tuỳ chỉnh. Bạn đã sử dụng một mô hình TensorFlow trong ví dụ này, nhưng bạn có thể huấn luyện một mô hình được xây dựng bằng bất kỳ khung nào bằng cách sử dụng các vùng chứa tuỳ chỉnh hoặc vùng chứa tích hợp.
Để tìm hiểu thêm về các phần khác nhau của Vertex, hãy xem tài liệu.
6. [Không bắt buộc] Sử dụng Vertex AI Python SDK
Phần trước đã hướng dẫn cách chạy quy trình huấn luyện thông qua giao diện người dùng. Trong phần này, bạn sẽ thấy một cách khác để gửi lệnh huấn luyện bằng cách sử dụng Vertex AI Python SDK.
Quay lại thực thể sổ tay của bạn và tạo một sổ tay TensorFlow 2 từ Trình chạy:

Nhập Vertex AI SDK.
from google.cloud import aiplatform
Sau đó, hãy tạo một CustomContainerTrainingJob. Bạn cần thay thế {PROJECT_ID} trong container_uri bằng tên dự án của mình và thay thế {BUCKET} trong staging_bucket bằng nhóm bạn đã tạo trước đó.
my_job = aiplatform.CustomContainerTrainingJob(display_name='flower-sdk-job',
container_uri='us-central1-docker.pkg.dev/{PROJECT_ID}/flower-app/flower_image:latest',
staging_bucket='gs://{BUCKET}')
Sau đó, hãy chạy lệnh.
my_job.run(replica_count=1,
machine_type='n1-standard-8',
accelerator_type='NVIDIA_TESLA_V100',
accelerator_count=1)
Để minh hoạ, công việc này được định cấu hình để chạy trên một máy lớn hơn so với phần trước. Ngoài ra, chúng tôi đang chạy bằng GPU. Nếu bạn không chỉ định machine-type, accelerator_type hoặc accelerator_count, thì công việc sẽ chạy theo mặc định trên một n1-standard-4.
Trong phần Huấn luyện của bảng điều khiển, bạn sẽ thấy công việc huấn luyện của mình trong thẻ CÔNG VIỆC TUỲ CHỈNH.
7. Dọn dẹp
Vì sổ tay được quản lý trong Vertex AI Workbench có tính năng tắt khi không hoạt động, nên chúng ta không cần lo lắng về việc tắt phiên bản. Nếu bạn muốn tắt thực thể theo cách thủ công, hãy nhấp vào nút Dừng trong phần Vertex AI Workbench của bảng điều khiển. Nếu bạn muốn xoá hoàn toàn sổ tay, hãy nhấp vào nút Xoá.

Để xoá Thùng lưu trữ, hãy sử dụng trình đơn Điều hướng trong Cloud Console, duyệt tìm Bộ nhớ, chọn thùng của bạn rồi nhấp vào Xoá:
