
1. Ringkasan
Di lab ini, Anda akan menggunakan Alat Simulasi untuk menganalisis model XGBoost yang dilatih pada data keuangan. Setelah menganalisis model, Anda akan men-deploy-nya ke Vertex AI baru di Cloud.
Yang Anda pelajari
Anda akan mempelajari cara:
- Melatih model XGBoost pada set data hipotek publik di notebook yang dihosting
- Menganalisis model menggunakan What-if Tool
- Men-deploy model XGBoost ke Vertex AI
Total biaya untuk menjalankan lab ini di Google Cloud adalah sekitar $1.
2. Pengantar Vertex AI
Lab ini menggunakan penawaran produk AI terbaru yang tersedia di Google Cloud. Vertex AI mengintegrasikan penawaran ML di Google Cloud ke dalam pengalaman pengembangan yang lancar. Sebelumnya, model yang dilatih dengan AutoML dan model kustom dapat diakses melalui layanan terpisah. Penawaran baru ini menggabungkan kedua model ini menjadi satu API, beserta produk baru lainnya. Anda juga dapat memigrasikan project yang sudah ada ke Vertex AI. Jika Anda memiliki masukan, harap lihat halaman dukungan.
Vertex AI mencakup banyak produk yang berbeda untuk mendukung alur kerja ML secara menyeluruh. Lab ini akan berfokus pada produk yang disorot di bawah: Prediction dan Notebooks.

3. Penjelasan singkat tentang XGBoost
XGBoost adalah framework machine learning yang menggunakan pohon keputusan dan gradient boosting untuk membuat model prediktif. Model ini bekerja dengan menggabungkan beberapa pohon keputusan berdasarkan skor yang terkait dengan berbagai node daun dalam pohon.
Diagram di bawah adalah visualisasi model pohon keputusan sederhana yang mengevaluasi apakah pertandingan olahraga harus dimainkan berdasarkan prakiraan cuaca:

Mengapa kita menggunakan XGBoost untuk model ini? Meskipun jaringan neural tradisional telah terbukti berperforma terbaik pada data tidak terstruktur seperti gambar dan teks, pohon keputusan sering kali berperforma sangat baik pada data terstruktur seperti set data hipotek yang akan kita gunakan dalam codelab ini.
4. Menyiapkan lingkungan Anda
Anda memerlukan project Google Cloud Platform dengan penagihan yang diaktifkan untuk menjalankan codelab ini. Untuk membuat project, ikuti petunjuk di sini.
Langkah 1: Aktifkan Compute Engine API
Buka Compute Engine dan pilih Aktifkan jika belum diaktifkan. Anda akan memerlukan ini untuk membuat instance notebook.
Langkah 2: Aktifkan Vertex AI API
Buka bagian Vertex di Konsol Cloud Anda, lalu klik Aktifkan Vertex AI API.

Langkah 3: Buat instance Notebook
Dari bagian Vertex di Konsol Cloud Anda, klik Notebook:

Dari sana, pilih Instance Baru. Kemudian, pilih jenis instance TensorFlow Enterprise 2.3 tanpa GPU:

Gunakan opsi default, lalu klik Buat. Setelah instance dibuat, pilih Open JupyterLab.
Langkah 4: Instal XGBoost
Setelah instance JupyterLab Anda terbuka, Anda harus menambahkan paket XGBoost.
Untuk melakukannya, pilih Terminal dari peluncur:

Kemudian, jalankan perintah berikut untuk menginstal XGBoost versi terbaru yang didukung oleh Vertex AI:
pip3 install xgboost==1.2
Setelah selesai, buka instance Notebook Python 3 dari peluncur. Anda siap untuk mulai menggunakan notebook.
Langkah 5: Impor paket Python
Di sel pertama notebook Anda, tambahkan impor berikut dan jalankan sel. Anda dapat menjalankannya dengan menekan tombol panah kanan di menu atas atau menekan command-enter:
import pandas as pd
import xgboost as xgb
import numpy as np
import collections
import witwidget
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.utils import shuffle
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
5. Mendownload dan memproses data
Kita akan menggunakan set data hipotek dari ffiec.gov untuk melatih model XGBoost. Kami telah melakukan beberapa praproses pada set data asli dan membuat versi yang lebih kecil untuk Anda gunakan dalam melatih model. Model akan memprediksi apakah permohonan hipotek tertentu akan disetujui atau tidak.
Langkah 1: Download set data yang telah diproses sebelumnya
Kami telah menyediakan versi set data untuk Anda di Google Cloud Storage. Anda dapat mendownloadnya dengan menjalankan perintah gsutil berikut di notebook Jupyter:
!gsutil cp 'gs://mortgage_dataset_files/mortgage-small.csv' .
Langkah 2: Baca set data dengan Pandas
Sebelum membuat DataFrame Pandas, kita akan membuat dict dari jenis data setiap kolom sehingga Pandas membaca set data kita dengan benar:
COLUMN_NAMES = collections.OrderedDict({
'as_of_year': np.int16,
'agency_code': 'category',
'loan_type': 'category',
'property_type': 'category',
'loan_purpose': 'category',
'occupancy': np.int8,
'loan_amt_thousands': np.float64,
'preapproval': 'category',
'county_code': np.float64,
'applicant_income_thousands': np.float64,
'purchaser_type': 'category',
'hoepa_status': 'category',
'lien_status': 'category',
'population': np.float64,
'ffiec_median_fam_income': np.float64,
'tract_to_msa_income_pct': np.float64,
'num_owner_occupied_units': np.float64,
'num_1_to_4_family_units': np.float64,
'approved': np.int8
})
Selanjutnya, kita akan membuat DataFrame, dengan meneruskan jenis data yang kita tentukan di atas. Penting untuk mengacak data jika set data asli diurutkan dengan cara tertentu. Kita menggunakan utilitas sklearn bernama shuffle untuk melakukannya, yang kita impor di sel pertama:
data = pd.read_csv(
'mortgage-small.csv',
index_col=False,
dtype=COLUMN_NAMES
)
data = data.dropna()
data = shuffle(data, random_state=2)
data.head()
data.head() memungkinkan kita melihat pratinjau lima baris pertama set data di Pandas. Anda akan melihat sesuatu seperti ini setelah menjalankan sel di atas:

Berikut adalah fitur yang akan kita gunakan untuk melatih model kita. Jika men-scroll hingga ke bagian akhir, Anda akan melihat kolom terakhir approved, yang merupakan hal yang kita prediksi. Nilai 1 menunjukkan bahwa aplikasi tertentu disetujui, dan 0 menunjukkan bahwa aplikasi tersebut ditolak.
Untuk melihat distribusi nilai yang disetujui / ditolak dalam set data dan membuat array numpy dari label, jalankan perintah berikut:
# Class labels - 0: denied, 1: approved
print(data['approved'].value_counts())
labels = data['approved'].values
data = data.drop(columns=['approved'])
Sekitar 66% set data berisi aplikasi yang disetujui.
Langkah 3: Membuat kolom dummy untuk nilai kategoris
Set data ini berisi campuran nilai kategoris dan numerik, tetapi XGBoost mengharuskan semua fitur bersifat numerik. Daripada merepresentasikan nilai kategoris menggunakan one-hot encoding, untuk model XGBoost, kita akan memanfaatkan fungsi get_dummies Pandas.
get_dummies mengambil kolom dengan beberapa kemungkinan nilai dan mengonversinya menjadi serangkaian kolom yang masing-masing hanya berisi 0 dan 1. Misalnya, jika kita memiliki kolom "warna" dengan kemungkinan nilai "biru" dan "merah", get_dummies akan mengubahnya menjadi 2 kolom bernama "color_blue" dan "color_red" dengan semua nilai boolean 0 dan 1.
Untuk membuat kolom dummy untuk fitur kategoris, jalankan kode berikut:
dummy_columns = list(data.dtypes[data.dtypes == 'category'].index)
data = pd.get_dummies(data, columns=dummy_columns)
data.head()
Saat melihat pratinjau data kali ini, Anda akan melihat fitur tunggal (seperti purchaser_type yang digambarkan di bawah) yang dibagi menjadi beberapa kolom:

Langkah 4: Memisahkan data menjadi set pelatihan dan pengujian
Konsep penting dalam machine learning adalah pemisahan data pelatihan / pengujian. Kita akan mengambil sebagian besar data dan menggunakannya untuk melatih model, dan kita akan menyisihkan sisanya untuk menguji model pada data yang belum pernah dilihat sebelumnya.
Tambahkan kode berikut ke notebook Anda, yang menggunakan fungsi Scikit-learn train_test_split untuk membagi data kita:
x,y = data.values,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
Sekarang Anda siap membangun dan melatih model.
6. Membangun, melatih, dan mengevaluasi model XGBoost
Langkah 1: Tentukan dan latih model XGBoost
Membuat model di XGBoost itu mudah. Kita akan menggunakan class XGBClassifier untuk membuat model, dan hanya perlu meneruskan parameter objective yang tepat untuk tugas klasifikasi tertentu. Dalam hal ini, kita menggunakan reg:logistic karena kita memiliki masalah klasifikasi biner dan kita ingin model menghasilkan satu nilai dalam rentang (0,1): 0 untuk tidak disetujui dan 1 untuk disetujui.
Kode berikut akan membuat model XGBoost:
model = xgb.XGBClassifier(
objective='reg:logistic'
)
Anda dapat melatih model dengan satu baris kode, memanggil metode fit() dan meneruskan data dan label pelatihan ke dalamnya.
model.fit(x_train, y_train)
Langkah 2: Evaluasi akurasi model Anda
Sekarang kita dapat menggunakan model terlatih untuk membuat prediksi pada data pengujian dengan fungsi predict().
Kemudian, kita akan menggunakan fungsi accuracy_score() Scikit-learn untuk menghitung akurasi model berdasarkan performanya pada data pengujian. Kita akan meneruskan nilai kebenaran dasar bersama dengan nilai prediksi model untuk setiap contoh dalam set pengujian:
y_pred = model.predict(x_test)
acc = accuracy_score(y_test, y_pred.round())
print(acc, '\n')
Anda akan melihat akurasi sekitar 87%, tetapi akurasi Anda akan sedikit bervariasi karena selalu ada elemen keacakan dalam machine learning.
Langkah 3: Simpan model Anda
Untuk men-deploy model, jalankan kode berikut untuk menyimpannya ke file lokal:
model.save_model('model.bst')
7. Menggunakan What-If Tool untuk menafsirkan model Anda
Langkah 1: Buat visualisasi Alat Simulasi
Untuk menghubungkan Alat Simulasi ke model lokal, Anda harus meneruskan subset contoh pengujian beserta nilai kebenaran nyata untuk contoh tersebut. Mari buat array Numpy dari 500 contoh pengujian kita beserta label kebenaran nyatanya:
num_wit_examples = 500
test_examples = np.hstack((x_test[:num_wit_examples],y_test[:num_wit_examples].reshape(-1,1)))
Membuat instance Alat What-if semudah membuat objek WitConfigBuilder dan meneruskan model yang ingin kita analisis.
Karena Alat Simulasi mengharapkan daftar skor untuk setiap class dalam model kita (dalam hal ini 2), kita akan menggunakan metode predict_proba XGBoost dengan Alat Simulasi:
config_builder = (WitConfigBuilder(test_examples.tolist(), data.columns.tolist() + ['mortgage_status'])
.set_custom_predict_fn(model.predict_proba)
.set_target_feature('mortgage_status')
.set_label_vocab(['denied', 'approved']))
WitWidget(config_builder, height=800)
Perhatikan bahwa visualisasi akan memerlukan waktu satu menit untuk dimuat. Saat dimuat, Anda akan melihat tampilan berikut:

Sumbu y menunjukkan prediksi model, dengan 1 menjadi prediksi approved dengan keyakinan tinggi, dan 0 menjadi prediksi denied dengan keyakinan tinggi. Sumbu x hanyalah rentang semua titik data yang dimuat.
Langkah 2: Jelajahi setiap titik data
Tampilan default di Alat Simulasi adalah tab Editor titik data. Di sini, Anda dapat mengklik setiap titik data untuk melihat fiturnya, mengubah nilai fitur, dan melihat bagaimana perubahan tersebut memengaruhi prediksi model pada setiap titik data.
Dalam contoh di bawah, kita memilih titik data yang mendekati batas 0,5. Permohonan hipotek yang terkait dengan titik data tertentu ini berasal dari CFPB. Kami mengubah fitur tersebut menjadi 0 dan juga mengubah nilai agency_code_Department of Housing and Urban Development (HUD) menjadi 1 untuk melihat apa yang akan terjadi pada prediksi model jika pinjaman ini berasal dari HUD:
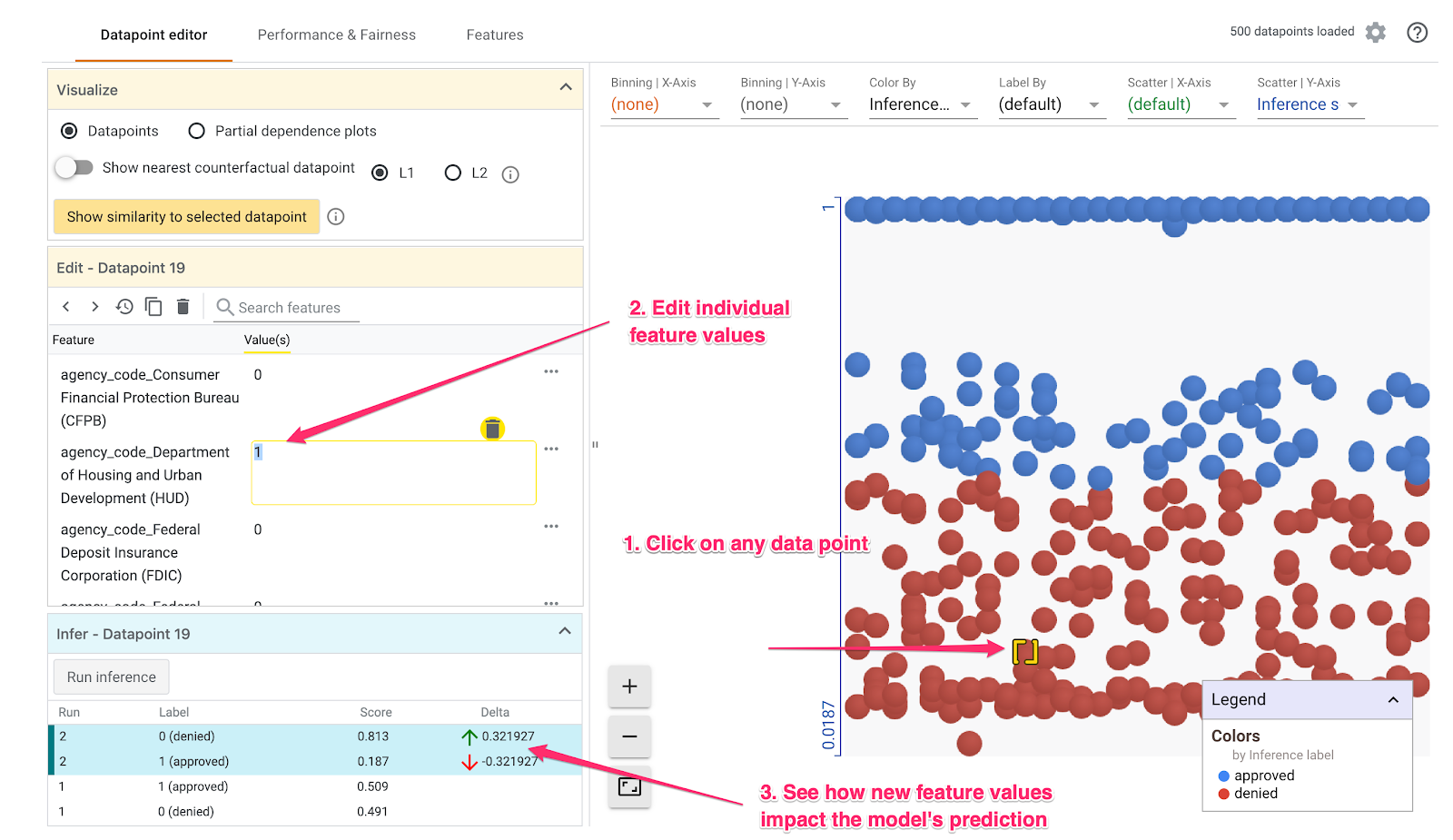
Seperti yang dapat kita lihat di bagian kiri bawah Alat Simulasi, perubahan fitur ini menurunkan prediksi approved model secara signifikan sebesar 32%. Hal ini dapat menunjukkan bahwa lembaga yang memberikan pinjaman memiliki dampak yang besar pada output model, tetapi kita perlu melakukan analisis lebih lanjut untuk memastikannya.
Di bagian kiri bawah UI, kita juga dapat melihat nilai kebenaran nyata untuk setiap titik data dan membandingkannya dengan prediksi model:

Langkah 3: Analisis kontrafaktual
Selanjutnya, klik titik data mana pun dan geser penggeser Tampilkan titik data kontrafaktual terdekat ke kanan:

Memilih opsi ini akan menampilkan titik data yang memiliki nilai fitur paling serupa dengan titik data asli yang Anda pilih, tetapi prediksi yang berlawanan. Kemudian, Anda dapat men-scroll nilai fitur untuk melihat perbedaan kedua titik data (perbedaan ditandai dengan warna hijau dan tebal).
Langkah 4: Lihat plot ketergantungan parsial
Untuk melihat pengaruh setiap fitur terhadap prediksi model secara keseluruhan, centang kotak Plot ketergantungan parsial dan pastikan Plot ketergantungan parsial global dipilih:

Di sini kita dapat melihat bahwa pinjaman yang berasal dari HUD memiliki kemungkinan yang sedikit lebih tinggi untuk ditolak. Grafik ini berbentuk demikian karena kode lembaga adalah fitur boolean, sehingga nilainya hanya dapat berupa 0 atau 1.
applicant_income_thousands adalah fitur numerik, dan dalam plot ketergantungan parsial, kita dapat melihat bahwa pendapatan yang lebih tinggi sedikit meningkatkan kemungkinan permohonan disetujui, tetapi hanya hingga sekitar $200 ribu. Setelah $200 ribu, fitur ini tidak memengaruhi prediksi model.
Langkah 5: Pelajari performa dan keadilan secara keseluruhan
Selanjutnya, buka tab Performa & Keadilan. Bagian ini menampilkan statistik performa keseluruhan pada hasil model di set data yang diberikan, termasuk matriks kebingungan, kurva PR, dan kurva ROC.
Pilih mortgage_status sebagai Fitur Kebenaran Nyata untuk melihat matriks konfusi:

Matriks konfusi ini menunjukkan prediksi model kita yang benar dan salah sebagai persentase dari total. Jika Anda menjumlahkan kotak Ya Sebenarnya / Ya yang Diprediksi dan Tidak Sebenarnya / Tidak yang Diprediksi, jumlahnya akan sama dengan akurasi model Anda (dalam hal ini sekitar 87%, meskipun model Anda mungkin sedikit berbeda karena ada elemen keacakan dalam melatih model ML).
Anda juga dapat bereksperimen dengan penggeser batas, menaikkan dan menurunkan skor klasifikasi positif yang perlu ditampilkan model sebelum memutuskan untuk memprediksi approved untuk pinjaman, dan melihat bagaimana hal itu mengubah akurasi, positif palsu, dan negatif palsu. Dalam hal ini, akurasi tertinggi berada di sekitar nilai minimum .55.
Selanjutnya, di dropdown Slice by di sebelah kiri, pilih loan_purpose_Home_purchase:

Sekarang Anda akan melihat performa pada dua subset data Anda: slice "0" ditampilkan saat pinjaman bukan untuk pembelian rumah, dan slice "1" ditampilkan saat pinjaman untuk pembelian rumah. Periksa akurasi, rasio positif palsu, dan rasio negatif palsu antara dua slice untuk mencari perbedaan performa.
Jika Anda meluaskan baris untuk melihat matriks kebingungan, Anda dapat melihat bahwa model memprediksi "disetujui" untuk ~70% aplikasi pinjaman untuk pembelian rumah dan hanya 46% pinjaman yang bukan untuk pembelian rumah (persentase pastinya akan bervariasi pada model Anda):

Jika Anda memilih Paritas demografi dari tombol pilihan di sebelah kiri, kedua nilai minimum akan disesuaikan sehingga model memprediksi approved untuk persentase pelamar yang serupa di kedua irisan. Apa pengaruhnya terhadap akurasi, positif palsu, dan negatif palsu untuk setiap slice?
Langkah 6: Jelajahi distribusi fitur
Terakhir, buka tab Fitur di What-If Tool. Bagian ini menunjukkan distribusi nilai untuk setiap fitur dalam set data Anda:

Anda dapat menggunakan tab ini untuk memastikan set data Anda seimbang. Misalnya, tampaknya hanya sedikit pinjaman dalam set data yang berasal dari Farm Service Agency. Untuk meningkatkan akurasi model, kami dapat mempertimbangkan untuk menambahkan lebih banyak pinjaman dari lembaga tersebut jika datanya tersedia.
Kami telah menjelaskan beberapa ide eksplorasi Alat Perbandingan di sini. Jangan ragu untuk terus menggunakan alat ini, ada banyak area lain yang bisa dijelajahi.
8. Men-deploy model ke Vertex AI
Kita telah membuat model berfungsi secara lokal, tetapi akan lebih baik jika kita dapat membuat prediksi di model tersebut dari mana saja (bukan hanya notebook ini). Pada langkah ini, kita akan men-deploy-nya ke cloud.
Langkah 1: Buat bucket Cloud Storage untuk model kita
Pertama, mari kita tentukan beberapa variabel lingkungan yang akan kita gunakan di seluruh codelab ini. Isi nilai di bawah dengan nama project Google Cloud Anda, nama bucket Cloud Storage yang ingin Anda buat (harus unik secara global), dan nama versi untuk versi pertama model Anda:
# Update the variables below to your own Google Cloud project ID and GCS bucket name. You can leave the model name we've specified below:
GCP_PROJECT = 'your-gcp-project'
MODEL_BUCKET = 'gs://storage_bucket_name'
MODEL_NAME = 'xgb_mortgage'
Sekarang kita siap membuat bucket penyimpanan untuk menyimpan file model XGBoost. Kita akan mengarahkan Vertex AI ke file ini saat men-deploy.
Jalankan perintah gsutil ini dari dalam notebook Anda untuk membuat bucket penyimpanan regional:
!gsutil mb -l us-central1 $MODEL_BUCKET
Langkah 2: Salin file model ke Cloud Storage
Selanjutnya, kita akan menyalin file model tersimpan XGBoost ke Cloud Storage. Jalankan perintah gsutil berikut:
!gsutil cp ./model.bst $MODEL_BUCKET
Buka browser penyimpanan di Konsol Cloud Anda untuk mengonfirmasi bahwa file telah disalin:

Langkah 3: Buat model dan deploy ke endpoint
Kita hampir siap men-deploy model ke cloud. Di Vertex AI, model dapat memiliki beberapa endpoint. Pertama-tama, kita akan membuat model, lalu membuat endpoint dalam model tersebut dan men-deploy-nya.
Pertama, gunakan gcloud CLI untuk membuat model Anda:
!gcloud beta ai models upload \
--display-name=$MODEL_NAME \
--artifact-uri=$MODEL_BUCKET \
--container-image-uri=us-docker.pkg.dev/cloud-aiplatform/prediction/xgboost-cpu.1-2:latest \
--region=us-central1
Parameter artifact-uri akan mengarah ke lokasi Penyimpanan tempat Anda menyimpan model XGBoost. Parameter container-image-uri memberi tahu Vertex AI container bawaan mana yang akan digunakan untuk inferensi. Setelah perintah ini selesai, buka bagian model di konsol Vertex Anda untuk mendapatkan ID model baru Anda. Anda dapat menemukannya di sini:

Salin ID tersebut dan simpan ke variabel:
MODEL_ID = "your_model_id"
Sekarang saatnya membuat endpoint dalam model ini. Kita dapat melakukannya dengan perintah gcloud ini:
!gcloud beta ai endpoints create \
--display-name=xgb_mortgage_v1 \
--region=us-central1
Setelah selesai, Anda akan melihat lokasi endpoint Anda yang dicatat dalam output notebook kami. Cari baris yang menyatakan bahwa endpoint dibuat dengan jalur yang terlihat seperti berikut: projects/project_ID/locations/us-central1/endpoints/endpoint_ID. Kemudian, ganti nilai di bawah dengan ID endpoint yang Anda buat di atas:
ENDPOINT_ID = "your_endpoint_id"
Untuk men-deploy endpoint, jalankan perintah gcloud di bawah:
!gcloud beta ai endpoints deploy-model $ENDPOINT_ID \
--region=us-central1 \
--model=$MODEL_ID \
--display-name=xgb_mortgage_v1 \
--machine-type=n1-standard-2 \
--traffic-split=0=100
Deployment endpoint akan memerlukan waktu ~5-10 menit hingga selesai. Saat endpoint Anda di-deploy, buka bagian model di konsol Anda. Klik model Anda dan Anda akan melihat endpoint Anda di-deploy:

Jika deployment berhasil diselesaikan, Anda akan melihat tanda centang hijau di tempat indikator pemuatan berada.
Langkah 4: Uji model yang di-deploy
Untuk memastikan model yang di-deploy berfungsi, uji menggunakan gcloud untuk membuat prediksi. Pertama, simpan file JSON dengan contoh dari set pengujian kami:
%%writefile predictions.json
{
"instances": [
[2016.0, 1.0, 346.0, 27.0, 211.0, 4530.0, 86700.0, 132.13, 1289.0, 1408.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, 0.0]
]
}
Uji model Anda dengan menjalankan perintah gcloud ini:
!gcloud beta ai endpoints predict $ENDPOINT_ID \
--json-request=predictions.json \
--region=us-central1
Anda akan melihat prediksi model Anda dalam output. Contoh khusus ini disetujui, jadi Anda akan melihat nilai yang mendekati 1.
9. Pembersihan
Jika Anda ingin terus menggunakan notebook ini, sebaiknya matikan notebook saat tidak digunakan. Dari UI Notebook di Konsol Cloud Anda, pilih notebook, lalu pilih Stop:

Jika Anda ingin menghapus semua resource yang telah dibuat di lab ini, cukup hapus instance notebook, bukan menghentikannya.
Untuk menghapus endpoint yang Anda deploy, buka bagian Endpoints di konsol Vertex Anda, lalu klik ikon hapus:

Untuk menghapus Bucket Penyimpanan menggunakan menu Navigasi di Cloud Console, jelajahi Penyimpanan, pilih bucket Anda, lalu klik Hapus:
