
1. Einführung
BigQuery ist ein serverloses, hoch skalierbares und kostengünstiges Data Warehouse. Verschieben Sie einfach Ihre Daten zu BigQuery und überlassen Sie uns den Rest, damit Sie sich auf das Wesentliche konzentrieren können: Ihr Geschäft. Sie können den Zugriff auf das Projekt und auf Ihre Daten entsprechend Ihren Unternehmensanforderungen steuern und anderen Personen das Aufrufen oder Abfragen Ihrer Daten ermöglichen.
In diesem Lab lernen Sie die Analysemöglichkeiten von BigQuery kennen. Sie erfahren, wie Sie ein Dataset aus einem Google Cloud Storage-Bucket importieren und sich mit der BigQuery-Benutzeroberfläche vertraut machen, indem Sie mit einem Dataset für das Retail Banking arbeiten. Außerdem lernen Sie in diesem Lab, wie Sie wichtige Funktionen in BigQuery nutzen, die Ihre täglichen Analysen erheblich erleichtern. Dazu gehören das Exportieren von Abfrageergebnissen in eine Tabelle, das Aufrufen und Ausführen von Abfragen aus Ihrem Abfrageverlauf, das Aufrufen der Abfrageleistung und das Erstellen von Tabellenansichten, die von anderen Teams und Abteilungen verwendet werden können.
Lerninhalte
Aufgaben in diesem Lab:
- Neue Daten in BigQuery laden
- Mit der BigQuery-UI vertraut machen
- Abfragen in BigQuery ausführen
- Abfrageleistung ansehen
- Ansichten in BigQuery erstellen
- Datasets sicher für andere freigeben
2. Einführung: Die BigQuery-UI
In diesem Abschnitt erfahren Sie, wie Sie in der BigQuery-Benutzeroberfläche navigieren, verfügbare Datasets ansehen und eine einfache Abfrage ausführen.
BQ-Benutzeroberfläche wird geladen
- Geben Sie oben in der Google Cloud Console „BigQuery“ ein.
- Wählen Sie BigQuery aus der Optionsliste aus. Wählen Sie die Option mit dem BigQuery-Logo (Lupe) aus.
Datasets ansehen und Abfragen ausführen
- Klicken Sie im linken Bereich unter „Ressource“ auf Ihr BigQuery-Projekt.
- Klicken Sie auf
bq_demo, um die Tabellen in diesem Dataset aufzurufen. - Geben Sie in das Suchfeld „card“ ein, um eine Liste von Tabellen und Datasets aufzurufen, deren Namen „card“ enthalten.
- Wählen Sie in der Suchergebnisliste die Tabelle „card_transactions“ aus.
- Klicken Sie im Bereich
card_transactionsauf den Tab „Details“, um die Metadaten für diese Tabelle aufzurufen. - Klicken Sie auf den Tab „Vorschau“, um eine Vorschau der Tabelle aufzurufen.
[Wettbewerbsvorteil ]: Durch die Integration in Google Data Catalog können BigQuery-Metadaten zusammen mit anderen Datenquellen wie Data Lakes oder operativen Datenquellen verwaltet werden. Dieses Beispiel zeigt, dass Google Cloud nicht nur ein relationales Data Warehouse, sondern eine vollständige Plattform für Analysedaten ist.
- Klicken Sie auf das Lupensymbol, um die Tabelle „card_transactions“ abzufragen. Im BigQuery-Abfrageeditor wird automatisch generierter Text eingefügt.
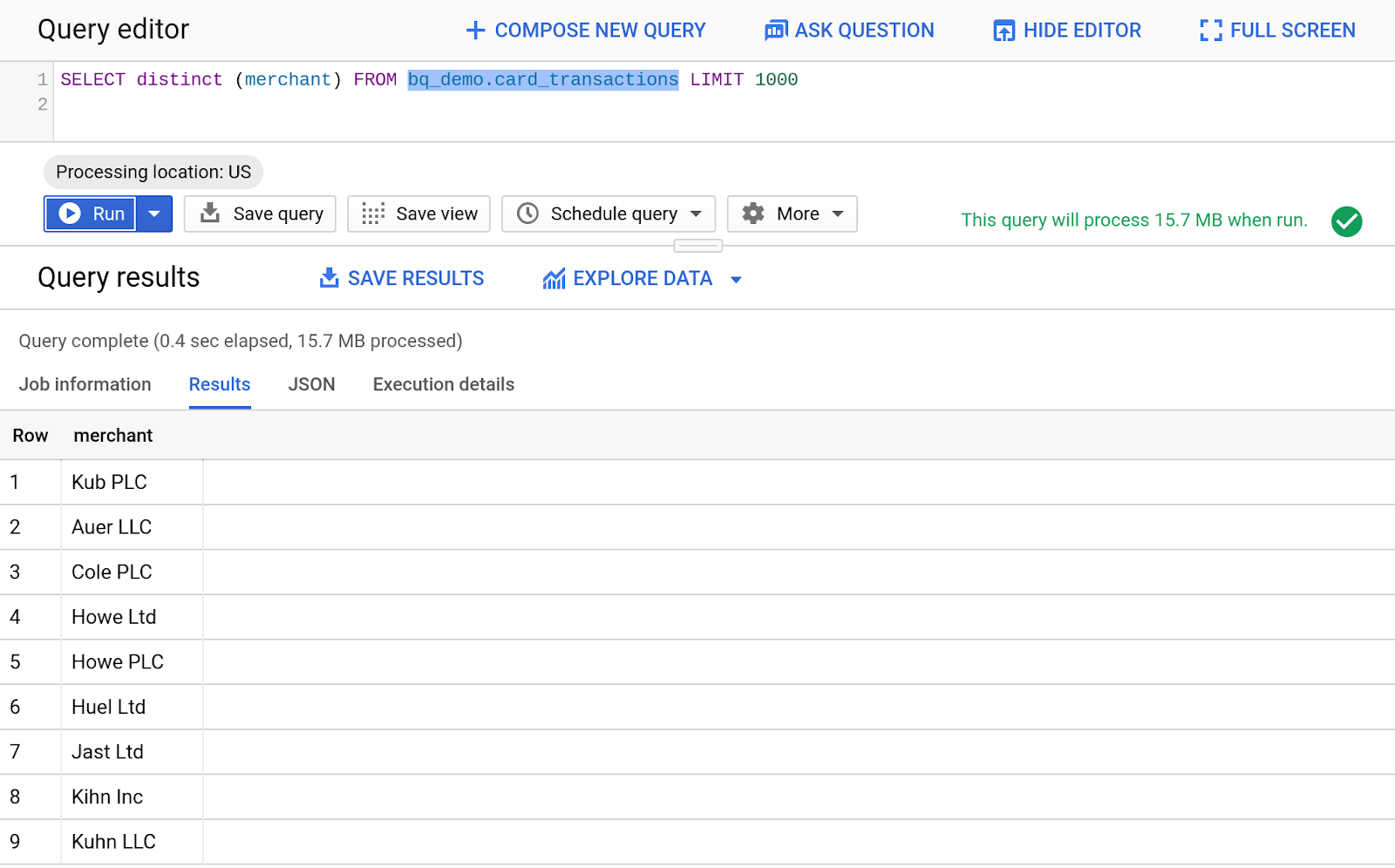
- Geben Sie den folgenden Code ein, um uns eindeutige Händler aus der Tabelle „Card_Transactions“ zu zeigen.
SELECT distinct (merchant) FROM bq_demo.card_transactions LIMIT 1000
- Klicken Sie auf die Schaltfläche „Ausführen“, um die Abfrage auszuführen.
3. Datasets erstellen und Ansichten freigeben
Die Freigabe von Daten und die Governance sind von entscheidender Bedeutung und können intuitiv über die BQ-Benutzeroberfläche erfolgen. In diesem Abschnitt erfahren Sie, wie Sie ein neues Dataset erstellen, es mit einer Ansicht füllen und freigeben.
Abfrageverlauf ansehen
- Klicken Sie im linken Bereich der GCP Console auf „Abfrageverlauf“.
- Klicken Sie im Bereich „Abfrageverlauf“ auf „Aktualisieren“.
- Klicken Sie ganz rechts neben der Anfrage auf das Symbol zum Herunterladen des Bildes bzw. auf den Pfeil, um die Ergebnisse der Anfrage aufzurufen.
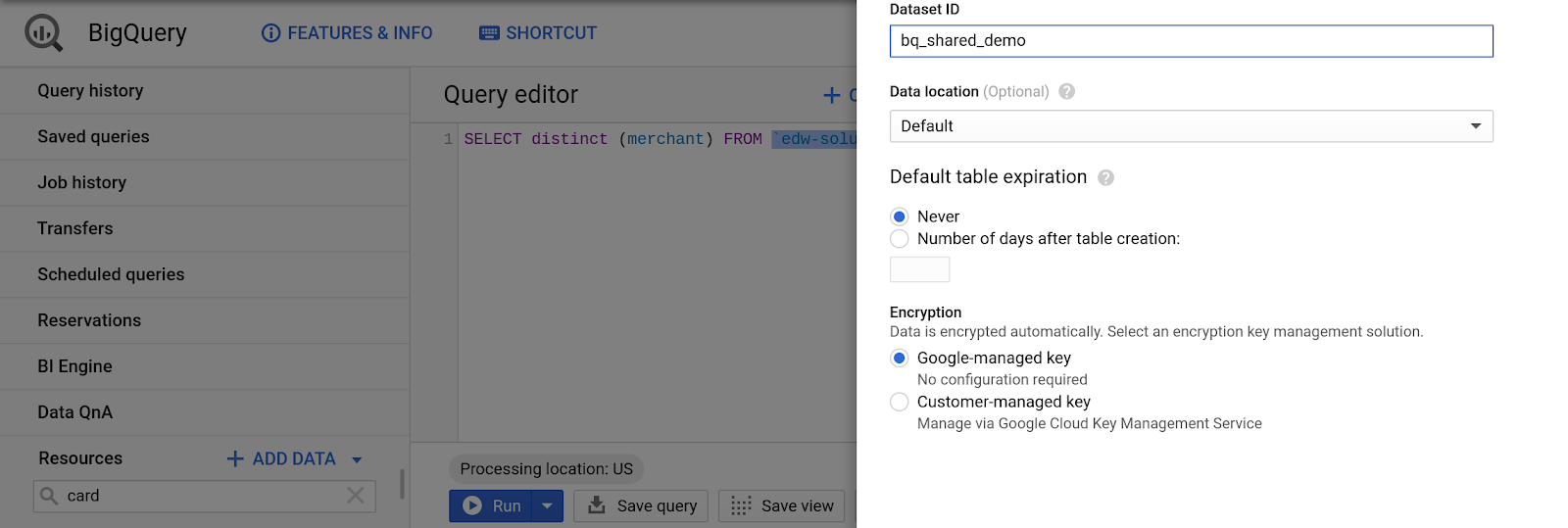
Neues Dataset erstellen
- Wählen Sie in der BigQuery-UI im Bereich „Ressourcen“ [Ihr Projektname] aus.
- Wählen Sie im Bereich mit den Projektinformationen „Neues Dataset erstellen“ aus.
- Für „Dataset-ID“:
bq_demo_shared
- Übernehmen Sie für alle anderen Felder die Standardwerte.
- Klicken Sie auf „Dataset erstellen“.
Ansichten erstellen
[Wettbewerbsvorteil ]: BigQuery ist vollständig ANSI-SQL-konform und unterstützt sowohl einfache als auch komplexe Joins mit mehreren Tabellen sowie umfangreiche Analysefunktionen. Wir haben kontinuierlich die Unterstützung für gängige SQL-Datentypen und -Funktionen verbessert, die in herkömmlichen Data Warehouses verwendet werden, um die Migration zu erleichtern.
- Wählen Sie oben im Bereich „Abfrageeditor“ die Option „Neue Abfrage erstellen“ aus.
- Fügen Sie den folgenden Code in den Abfrageeditor ein.
WITH revenue_by_month AS (
SELECT
card.type AS card_type,
FORMAT_DATE('%Y-%m', trans_date) as revenue_date,
SUM(amount) as revenue
FROM bq_demo.card_transactions
JOIN bq_demo.card ON card_transactions.cc_number = card.card_number
WHERE trans_date DATE_ADD(CURRENT_DATE, INTERVAL -1 YEAR)
GROUP BY card_type, revenue_date
)
SELECT
card_type,
revenue_date,
revenue as monthly_rev,
revenue - LAG(revenue) OVER (ORDER BY card_type, revenue_date ASC) as rev_change
FROM revenue_by_month
ORDER BY card_type, revenue_date ASC;
- Klicken Sie auf „Ansicht speichern“.
- Wählen Sie Ihr aktuelles Projekt für „Projektname“ aus.
- Wählen Sie das neu erstellte Dataset aus:
bq_demo_shared
- Tabellenname:
rev_change_by_card_type
- Klicken Sie auf „Speichern“.
Ansichten und Datasets freigeben
- Wählen Sie in der BigQuery-UI im linken Ressourcenbereich das Dataset „bq_demo_shared“ aus.
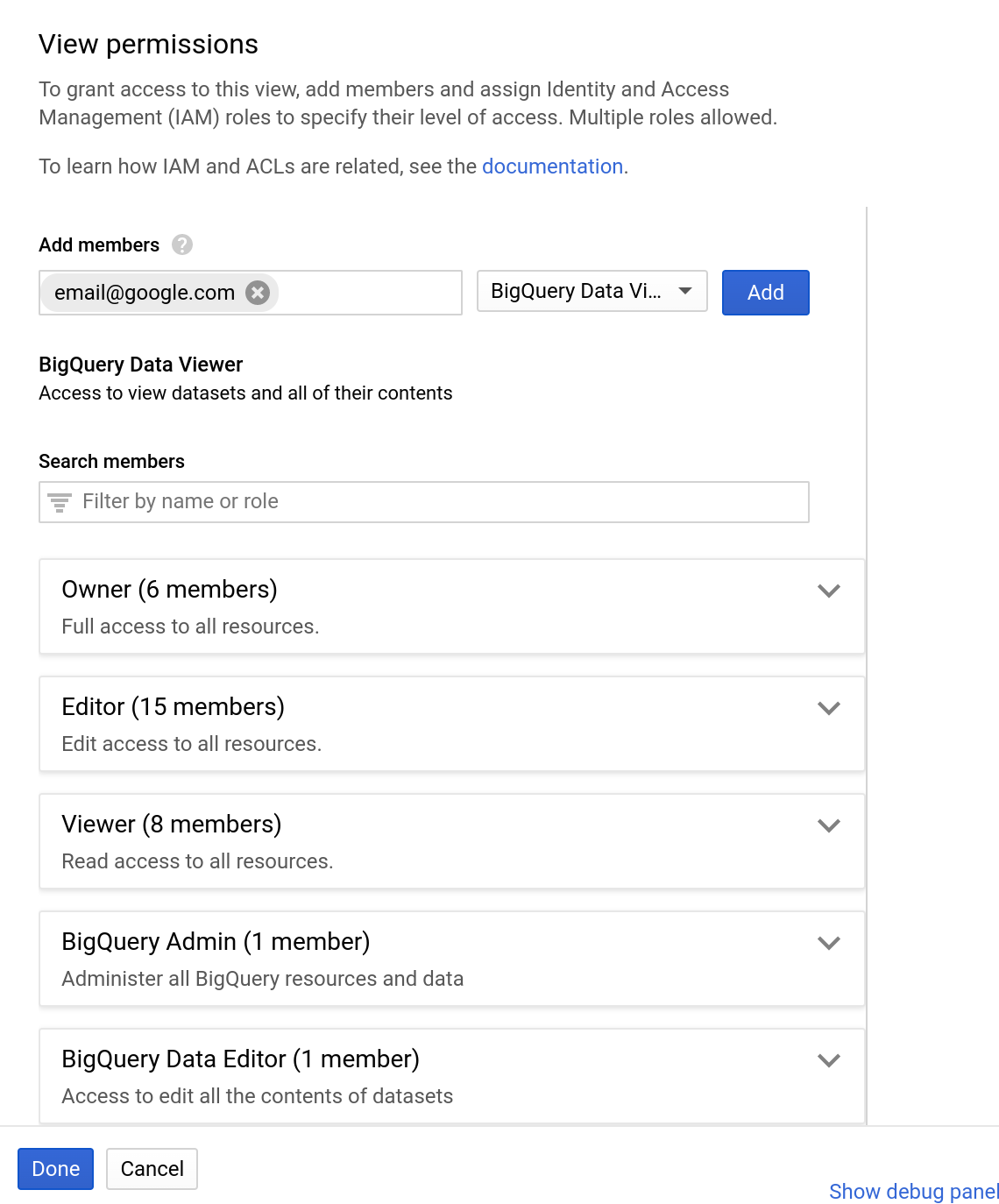
- Klicken Sie im Bereich mit den Dataset-Informationen auf „Dataset freigeben“.
- E‑Mail-Adresse eingeben
- Wählen Sie im Drop-down-Menü „Rolle“ die Option „BigQuery Data Viewer“ aus.
- Klicken Sie auf „Hinzufügen“
- Klicken Sie auf Fertig .
Datenanalyse in Google Sheets
[Competitive Talking Point] : Ein weiterer Vorteil von BigQuery gegenüber seinen Mitbewerbern ist die BI Engine. Mit BI Engine können Sie dafür sorgen, dass Zusammenfassungsabfragen vom Typ BI durch In-Memory-Caching in weniger als einer Sekunde zurückgegeben werden. Das wird derzeit von Google Data Studio unterstützt, ist aber bald verfügbar, um alle Abfragen in BigQuery zu beschleunigen.
Beispiel:
Snowflake setzt für Dashboards und Datenvisualisierung auf BI-Tools von Drittanbietern, während GCP eine Reihe integrierter BI-Tools wie verbundene Tabellenblätter, Data Studio und Looker bietet.
- Wählen Sie im linken Ressourcenbereich der BigQuery-Benutzeroberfläche die Ansicht „rev_change_by_card_type“ aus.
- Klicken Sie auf die Lupe, um die Ansicht abzufragen.

- Typ:
SELECT *
FROM bq_demo_shared.rev_change_by_card_type
- Klicken Sie auf „Ausführen“.
- Klicken Sie im Bereich „Ergebnisse“ auf das Exportsymbol.
- „Daten mit Google Tabellen analysieren“ auswählen
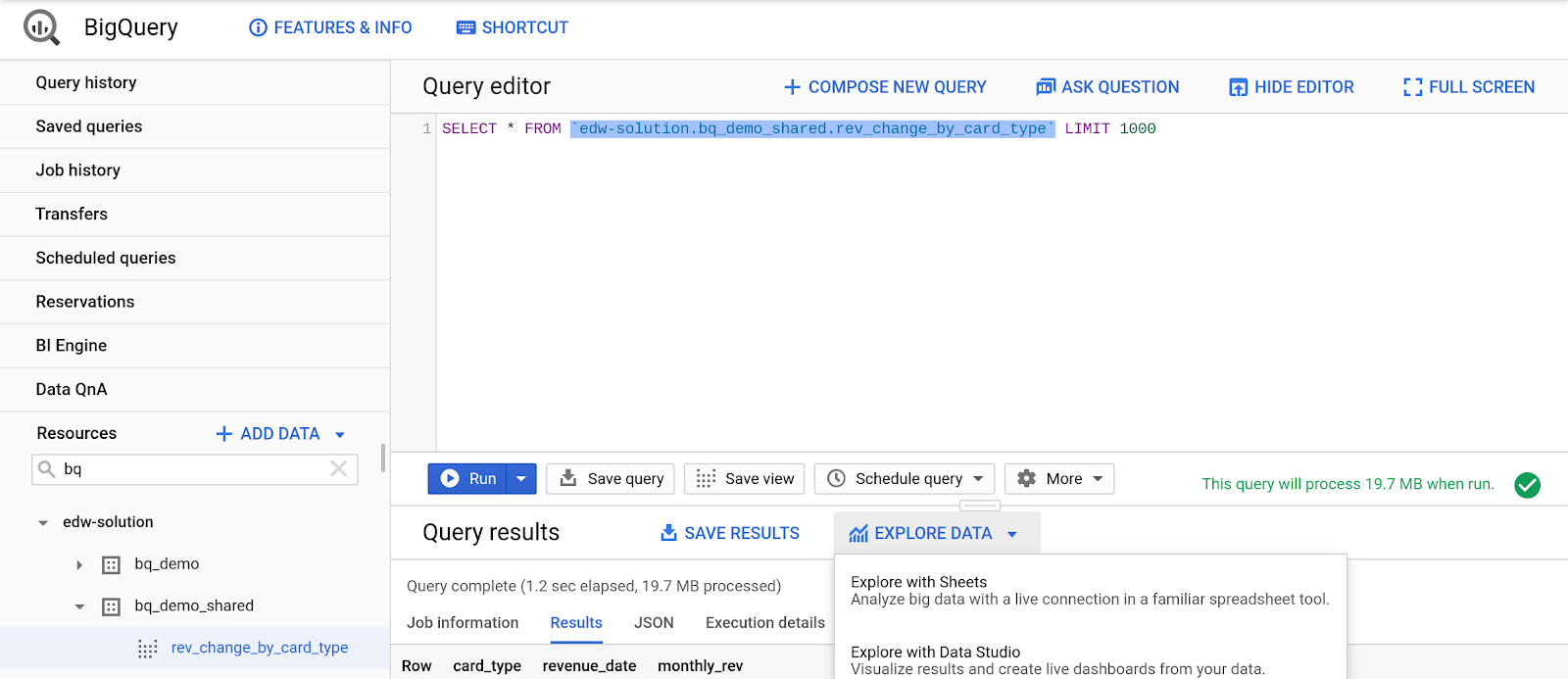
- Klicken Sie auf „Start Analyzing“ (Analyse starten).
- Wählen Sie „Pivot-Tabelle“ aus.
- Wählen Sie „Neues Tabellenblatt“ aus.
- Klicken Sie auf "Erstellen".
- Fügen Sie „revenue_date“ im Bereich „Zeile“ des Editors für Pivot-Tabellen rechts im Google Sheets-Fenster hinzu.
- Fügen Sie „card_type“ im Bereich „Spalte“ des Editors für Pivot-Tabellen hinzu.
- Fügen Sie „monthly_rev“ im Editor für Pivot-Tabellen im Bereich „Spalte“ hinzu.
- Klickt auf "Übernehmen".
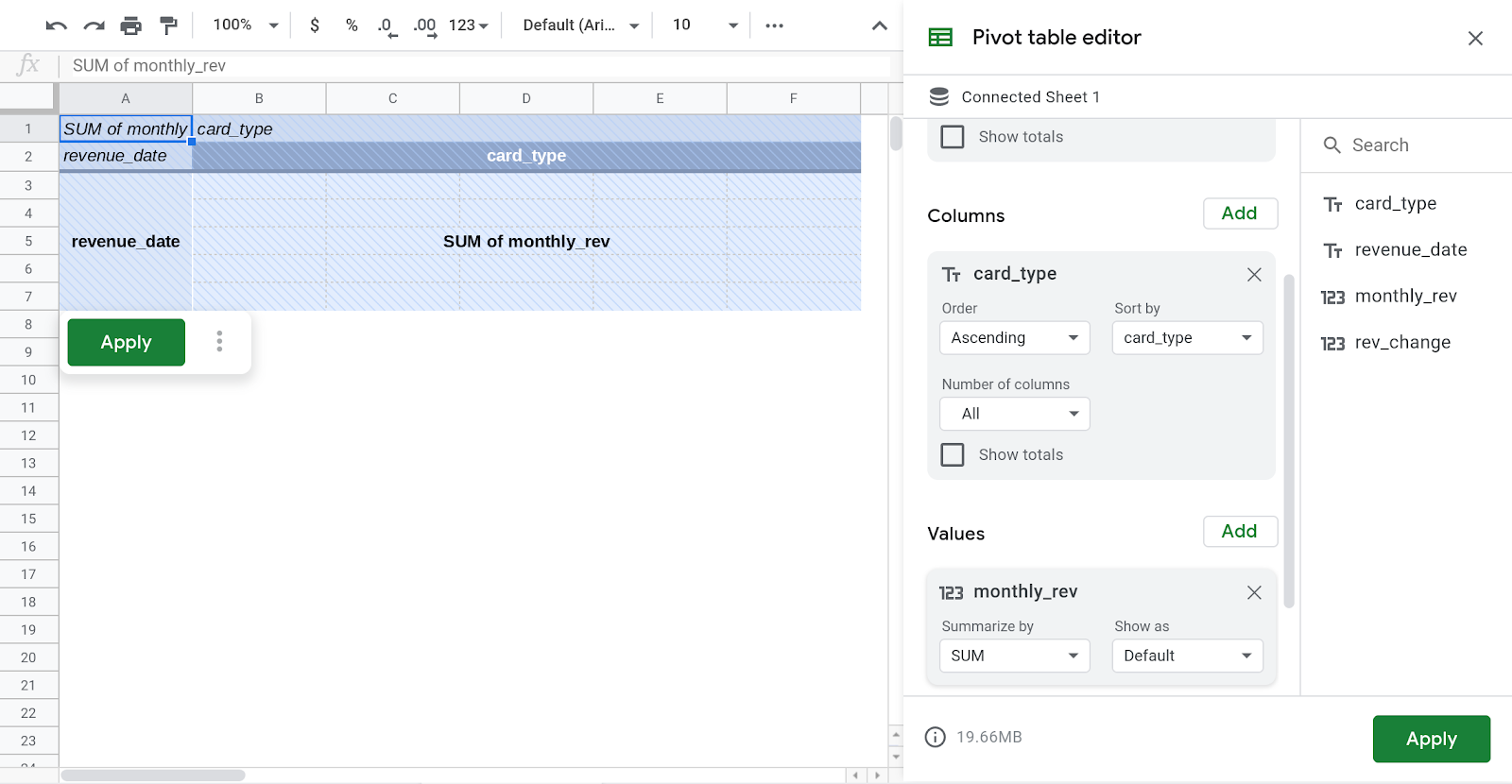
- Klicken Sie oben in der Sheets-Benutzeroberfläche auf „Einfügen“ „Diagramm“.
4. Einrichtung: Datenintegration
In diesem Abschnitt erfahren Sie, wie Sie eine neue Tabelle erstellen und JOINS für eines der vielen öffentlichen Datasets ausführen, die in Google Cloud verfügbar sind.
[Competitive Talking Point]:
BigQuery unterstützt seit Jahren freigegebene Datasets. Kunden in einem beliebigen Projekt können sowohl öffentliche Datasets als auch Datasets in anderen Projekten abfragen, die für sie freigegeben wurden.
BigQuery kann Data Lakes in GCS mithilfe externer Tabellen unterstützen. Zusätzlich zum Bulk-Laden unterstützt BigQuery das Streamen von Daten in die Datenbank mit Raten von Hunderten von MB pro Sekunde. Snowflake unterstützt keine Streamingdaten.
Daten in eine neue Tabelle importieren
- Wählen Sie im Bereich „Ressourcen“ das Dataset „bq_demo“ aus.
- Wählen Sie im Bereich mit den Dataset-Informationen „Tabelle erstellen“ aus.
- Google Cloud Storage als Quelle auswählen
- Gehen Sie im Textfeld für den Dateipfad so vor:
gs://retail-banking-looker/district
- CSV als Dateiformat auswählen
- Geben Sie „district“ als Tabellennamen ein.
- Aktivieren Sie das Kästchen für „Schema automatisch erkennen“.
- Klicken Sie auf „Tabelle erstellen“.
Öffentliches Dataset abfragen
- Geben Sie im Abfrageeditor die folgende Abfrage ein:
SELECT
CAST(geo_id as STRING) AS zip_code,
total_pop,
median_age,
households,
income_per_capita,
housing_units,
vacant_housing_units_for_sale,
ROUND(SAFE_DIVIDE(employed_pop, pop_16_over),4) AS rate_employment,
ROUND(SAFE_DIVIDE(bachelors_degree_or_higher_25_64, pop_25_64),4) AS rate_bachelors_degree_or_higher_25_64
FROM
`bigquery-public-data.census_bureau_acs.zip_codes_2017_5yr`;
- Klicken Sie auf „Ausführen“.
- Ergebnisse ansehen
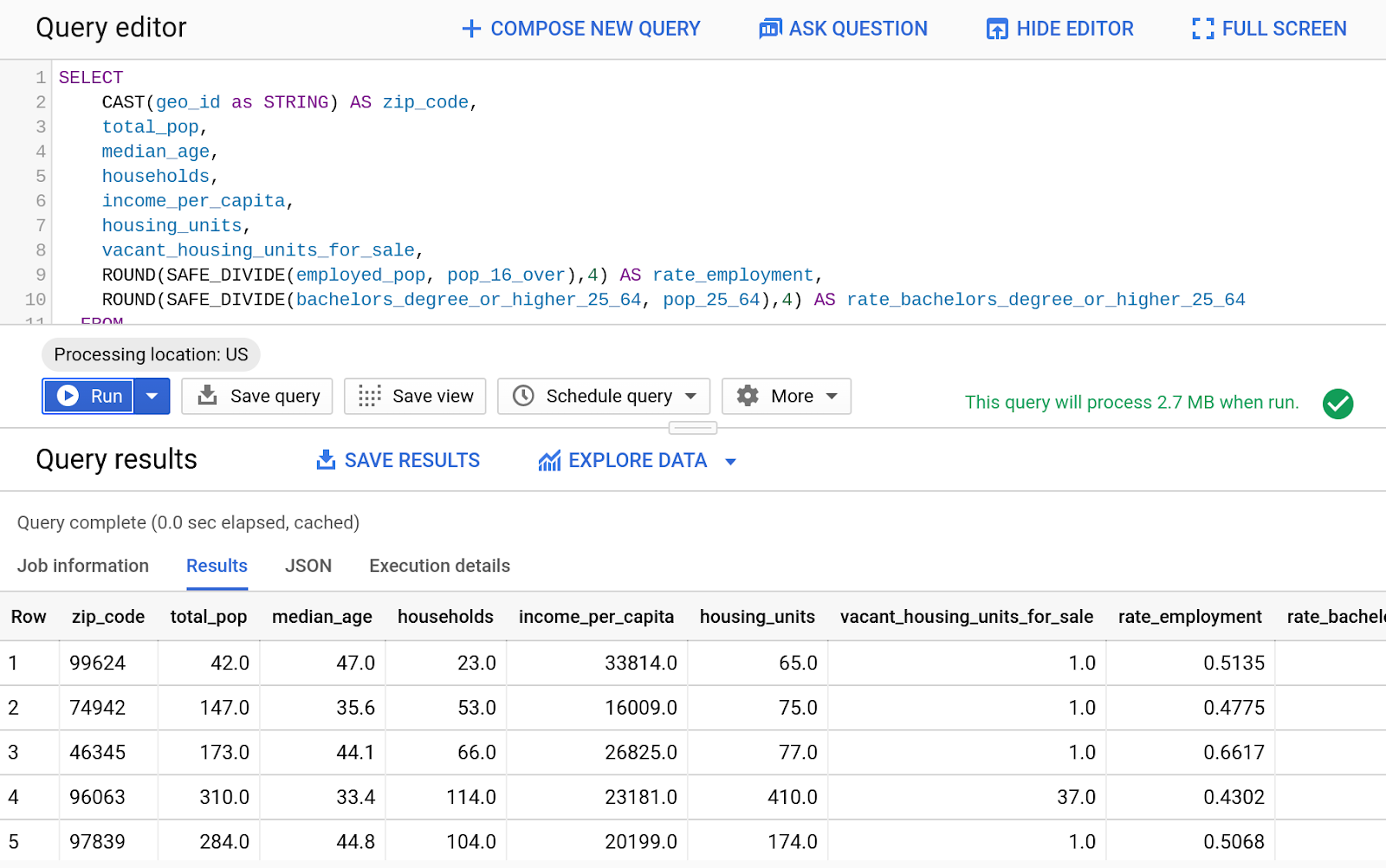
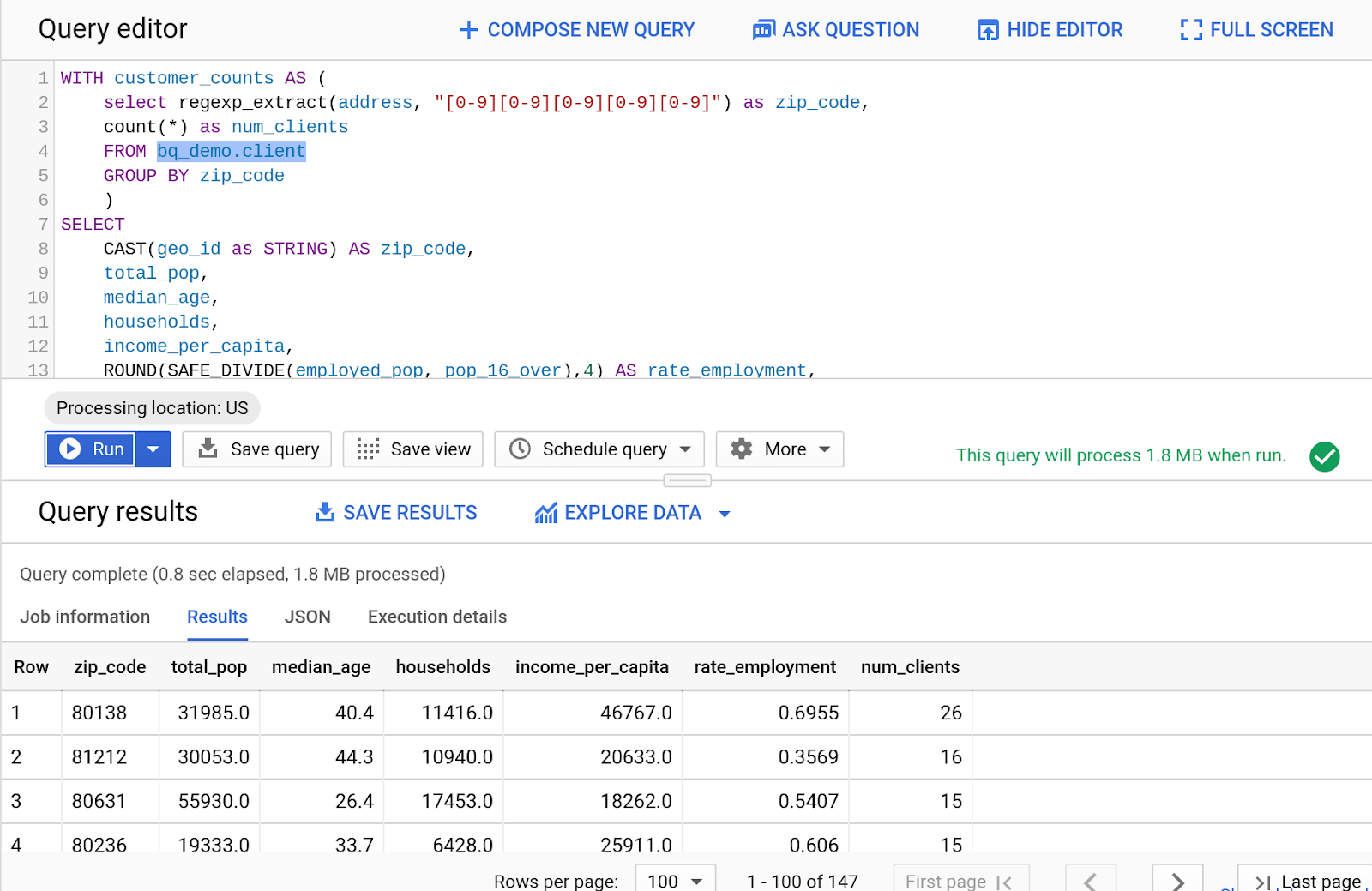
- Nun kombinieren wir diese öffentlichen Daten mit einer anderen Abfrage. Geben Sie den folgenden SQL-Code in den Abfrageeditor ein:
WITH customer_counts AS (
select regexp_extract(address, "[0-9][0-9][0-9][0-9][0-9]") as zip_code,
count(*) as num_clients
FROM bq_demo.client
GROUP BY zip_code
)
SELECT
CAST(geo_id as STRING) AS zip_code,
total_pop,
median_age,
households,
income_per_capita,
ROUND(SAFE_DIVIDE(employed_pop, pop_16_over),4) AS rate_employment,
num_clients
FROM
`bigquery-public-data.census_bureau_acs.zip_codes_2017_5yr`
JOIN customer_counts on zip_code = geo_id
ORDER BY num_clients DESC
- Klicken Sie auf „Ausführen“.
- Ergebnisse ansehen
5. Kapazitätsverwaltung
Mit Slots und Reservierungen arbeiten
BQ bietet mehrere Preismodelle, die Ihren Anforderungen entsprechen. Die meisten großen Kunden nutzen hauptsächlich die Pauschale, um von vorhersehbaren Preisen mit reservierter Kapazität zu profitieren. Für Spitzenlasten, die über diese Basiskapazität hinausgehen, bietet BQ Flex-Slots. Damit können Sie die Kapazität im Handumdrehen erhöhen und dann automatisch wieder verringern, ohne dass laufende Abfragen beeinträchtigt werden. BQ bietet auch ein Byte-Scan-Modell, bei dem Sie nur für die ausgeführten Abfragen bezahlen.
[Wettbewerbsvorteil : Einige Wettbewerber arbeiten ausschließlich mit einem Modell mit fester Kapazität, bei dem Kunden für jede Arbeitslast in ihrer Organisation ein virtuelles Warehouse zuweisen müssen. Zusätzlich zu einem kostengünstigen Modell pro Abfrage, das den Einstieg in BigQuery erleichtert, unterstützen wir ein Pauschalpreismodell für die Kapazität, bei dem die Leerlaufkapazität für eine Reihe von Arbeitslasten freigegeben werden kann.]
- Rufen Sie den Tab „Reservierungen“ auf.
- Klicken Sie auf „Slots kaufen“.
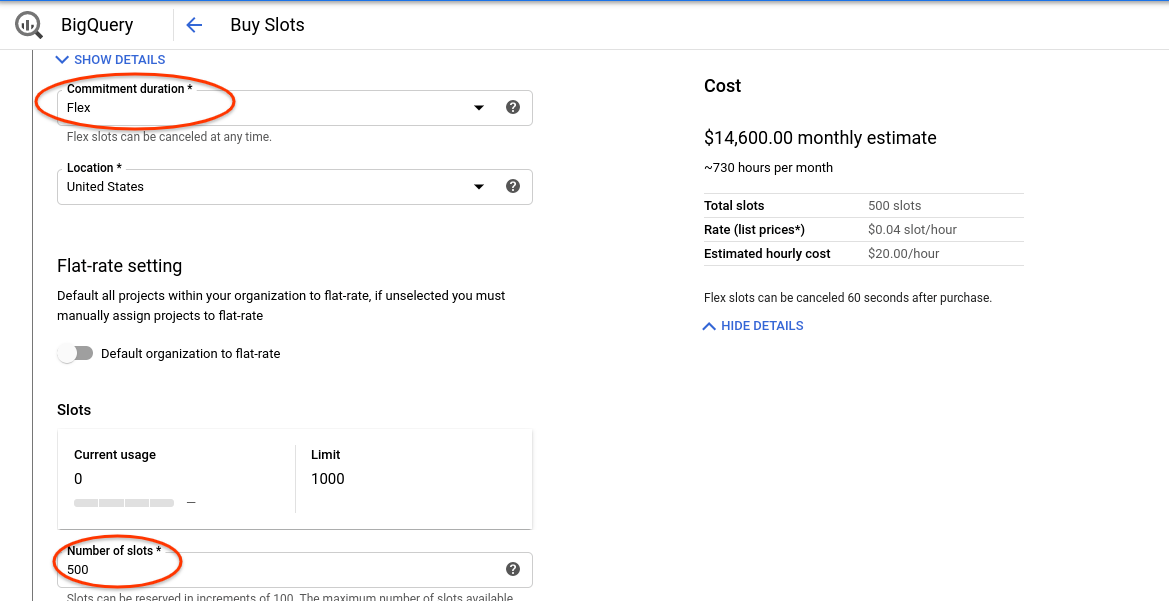
- Wählen Sie „Flexibel“ als Dauer aus.
- Wählen Sie 500 Slots aus.
- Bestätigen Sie den Kauf.
- Klicken Sie auf „Slot-Zusicherungen anzeigen“.
- Klicken Sie auf „Reservierung erstellen“.
- Nutzer „demo“ als Reservierungsname
- USA als Standort auswählen
- Geben Sie „500“ für Slots ein (alle verfügbar).
- Klicken Sie auf „Aufgaben“.
- Aktuelles Projekt für Organisationsprojekt auswählen
- Wählen Sie „demo“ für die Reservierungs-ID aus.
- Klicke auf „Erstellen“.