
1. Введение
BigQuery — это бессерверное, масштабируемое и экономичное хранилище данных. Просто перенесите свои данные в BigQuery, и мы позаботимся о сложной работе, чтобы вы могли сосредоточиться на действительно важном — управлении своим бизнесом. Вы можете контролировать доступ как к проекту, так и к своим данным в соответствии с потребностями вашего бизнеса, например, предоставляя другим возможность просматривать или запрашивать ваши данные.
В этой лабораторной работе вы откроете для себя аналитические возможности BigQuery. Вы научитесь импортировать набор данных из хранилища Google Cloud Storage и освоите пользовательский интерфейс BigQuery, работая с набором данных по розничному банковскому сектору. Кроме того, эта лабораторная работа научит вас использовать ключевые функции BigQuery, которые значительно упростят вашу повседневную аналитику, такие как экспорт результатов запросов в электронную таблицу, просмотр и выполнение запросов из истории запросов, просмотр производительности запросов и создание табличных представлений для использования другими командами и отделами.
Что вы узнаете
В этой лабораторной работе вы научитесь выполнять следующие задачи:
- Загрузка новых данных в BigQuery
- Ознакомьтесь с пользовательским интерфейсом BigQuery.
- Выполнение запросов в BigQuery
- Просмотр производительности запроса
- Создание представлений в BigQuery
- Безопасный обмен наборами данных с другими пользователями.
2. Введение: Понимание пользовательского интерфейса BigQuery
В этом разделе вы узнаете, как перемещаться по пользовательскому интерфейсу BigQuery, просматривать доступные наборы данных и выполнять простой запрос.
Загрузка пользовательского интерфейса BQ
- Введите "BigQuery", расположенное в верхней части консоли Google Cloud Platform.
- Выберите BigQuery из списка вариантов. Обязательно выберите вариант с логотипом BigQuery, изображением лупы.
Просмотр наборов данных и выполнение запросов
- В левой панели в разделе «Ресурсы» щелкните по своему проекту BigQuery.
- Нажмите на
bq_demo, чтобы просмотреть таблицы в этом наборе данных. - В поле поиска введите "card", чтобы увидеть список таблиц и наборов данных, содержащих "card" в своем названии.
- Выберите таблицу "card_transactions" из списка результатов поиска.
- Чтобы просмотреть метаданные для этой таблицы, щелкните вкладку «Подробности» в панели
card_transactions. - Нажмите на вкладку «Предварительный просмотр», чтобы увидеть предварительный просмотр таблицы.
[ Конкурентное преимущество]: Интеграция с Google Data Catalog означает, что метаданные BigQuery можно управлять вместе с другими источниками данных, такими как озера данных или оперативные источники данных. Это один из примеров, демонстрирующих, что Google Cloud — это не просто реляционное хранилище данных, а целая платформа для аналитической обработки данных.
- Нажмите на значок лупы, чтобы выполнить запрос к таблице "card_transactions". В редакторе запросов BigQuery появится автоматически сгенерированный текст.
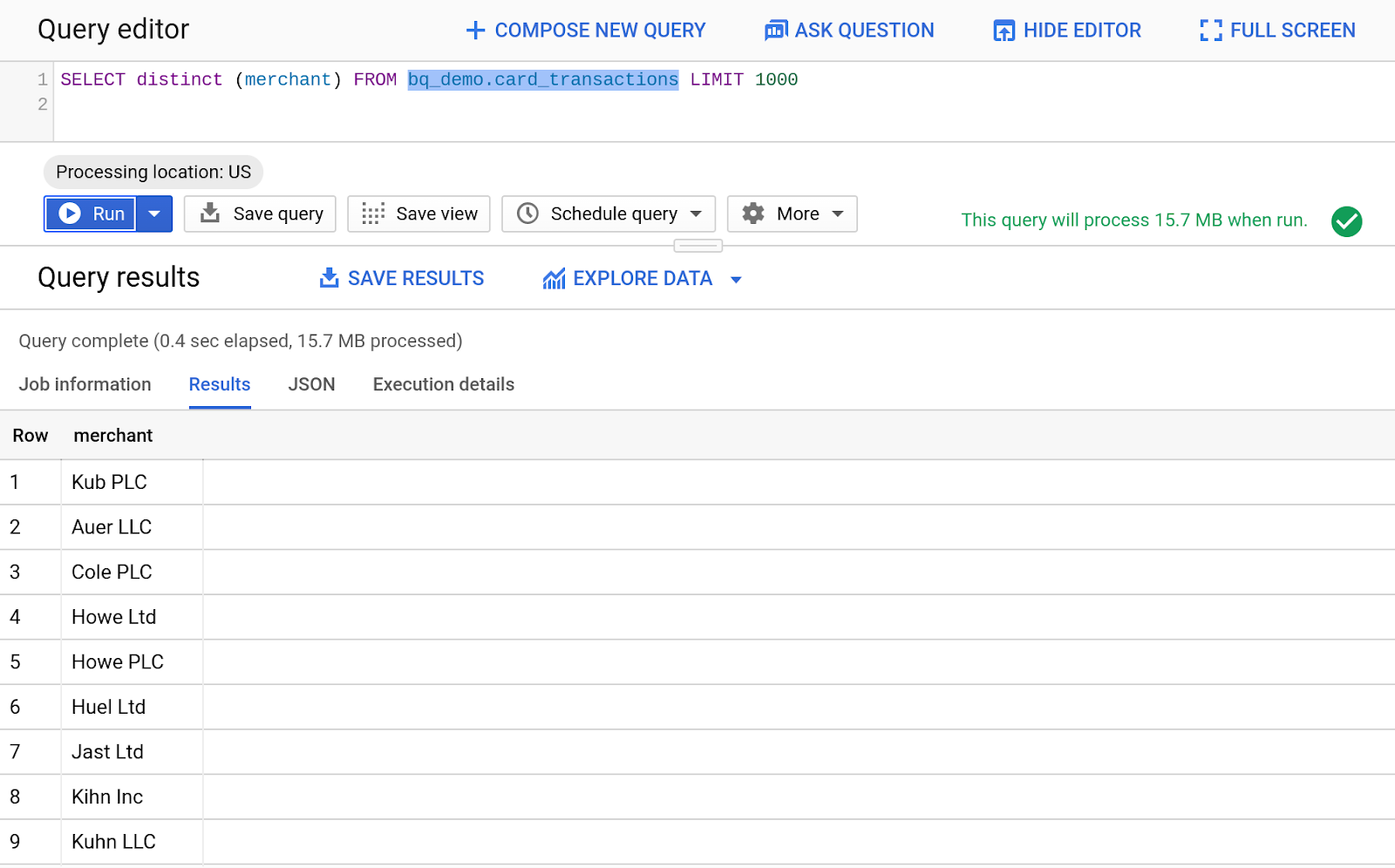
- Введите приведенный ниже код, чтобы отобразить уникальные продавцы из таблицы Card_Transactions.
SELECT distinct (merchant) FROM bq_demo.card_transactions LIMIT 1000
- Нажмите кнопку «Выполнить», чтобы запустить запрос.
3. Создание наборов данных и обмен представлениями.
Совместное использование данных и управление ими имеют решающее значение, и это можно сделать интуитивно понятным в пользовательском интерфейсе BQ. В этом разделе вы узнаете, как создать новый набор данных, заполнить его представлением и поделиться этим набором данных.
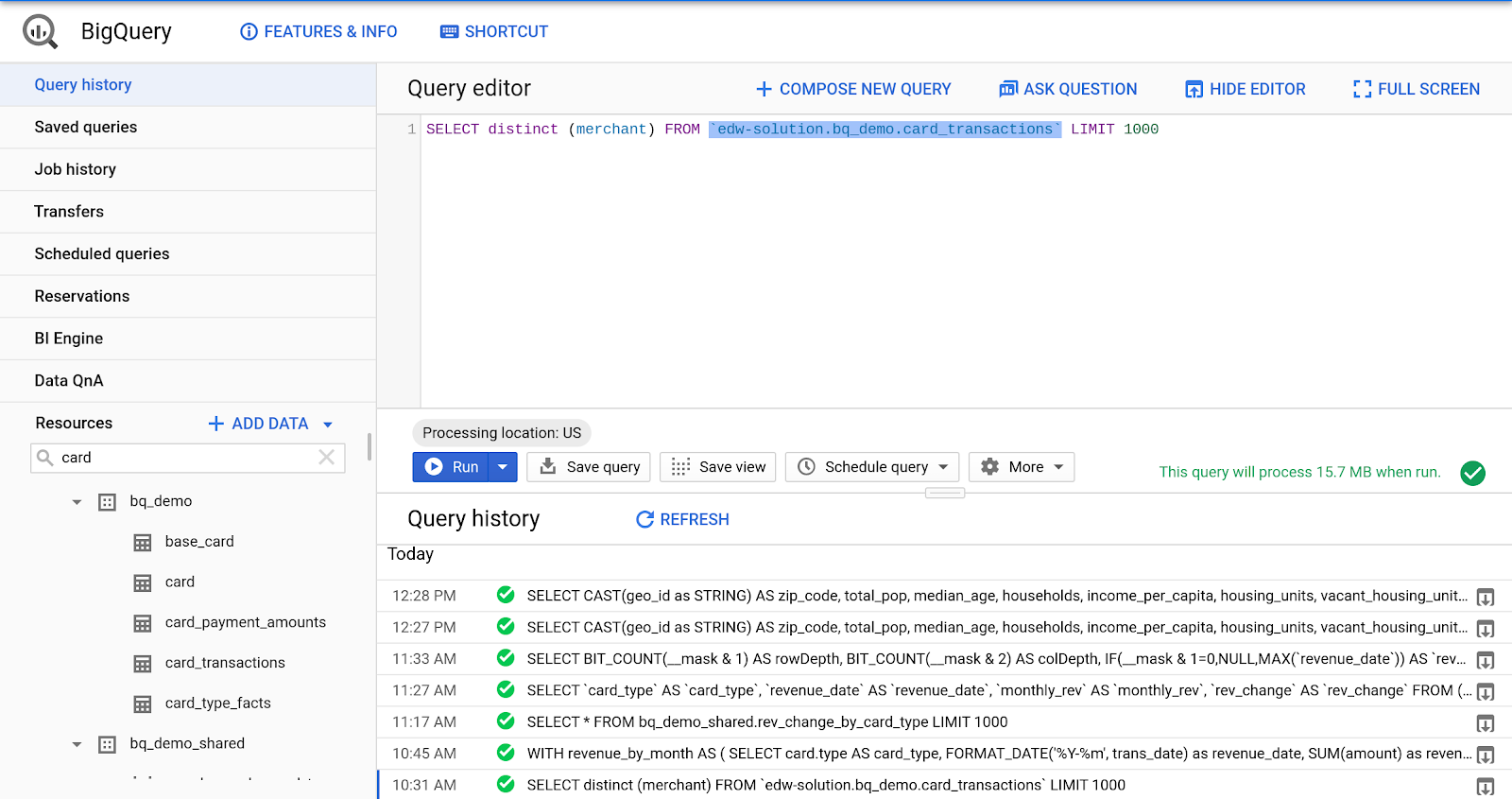
Просмотр истории запросов
- В левой панели консоли GCP нажмите «История запросов».
- В панели «История запросов» нажмите кнопку «Обновить».
- Чтобы просмотреть результаты запроса, нажмите на изображение/стрелку загрузки в правом крайнем углу запроса.
Создание нового набора данных
- Выберите [название вашего проекта] на панели ресурсов в пользовательском интерфейсе BigQuery.
- В панели информации о проекте выберите «Создать новый набор данных».
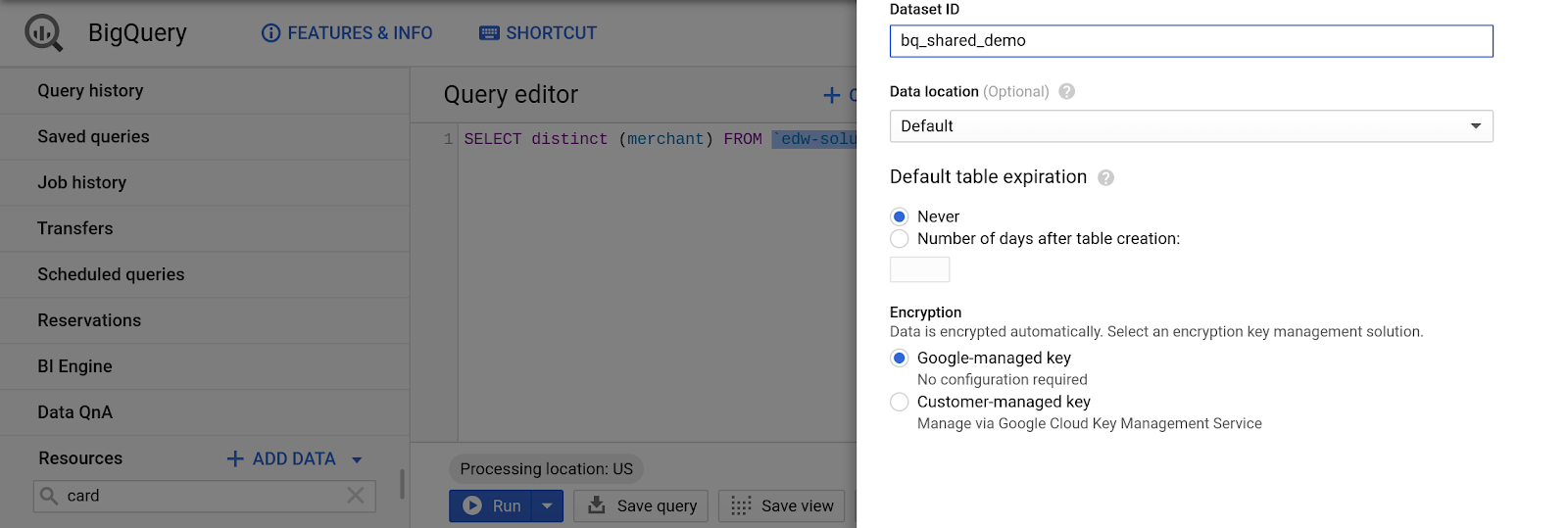
- Для идентификатора набора данных:
bq_demo_shared
- Оставьте все остальные поля со значениями по умолчанию.
- Нажмите кнопку «Создать набор данных».
Создание представлений
[ Конкурентное преимущество]: BigQuery полностью соответствует стандарту ANSI SQL и поддерживает как простые, так и сложные объединения нескольких таблиц, а также богатый набор аналитических функций. Мы постоянно улучшаем поддержку распространенных типов данных SQL и функций, используемых в традиционных хранилищах данных, чтобы упростить процесс миграции.
- В верхней части панели редактора запросов выберите пункт «Создать новый запрос».
- Вставьте следующий код в редактор запросов.
WITH revenue_by_month AS (
SELECT
card.type AS card_type,
FORMAT_DATE('%Y-%m', trans_date) as revenue_date,
SUM(amount) as revenue
FROM bq_demo.card_transactions
JOIN bq_demo.card ON card_transactions.cc_number = card.card_number
WHERE trans_date DATE_ADD(CURRENT_DATE, INTERVAL -1 YEAR)
GROUP BY card_type, revenue_date
)
SELECT
card_type,
revenue_date,
revenue as monthly_rev,
revenue - LAG(revenue) OVER (ORDER BY card_type, revenue_date ASC) as rev_change
FROM revenue_by_month
ORDER BY card_type, revenue_date ASC;
- Нажмите «Сохранить просмотр».
- Выберите свой текущий проект в поле «Название проекта».
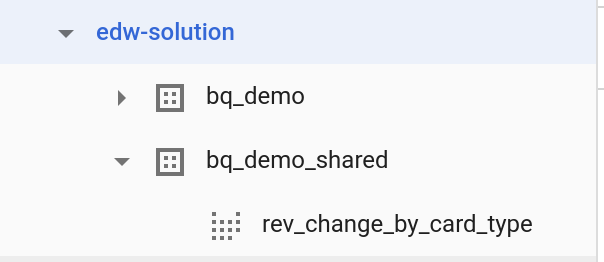
- Выберите только что созданный набор данных:
bq_demo_shared
- Для имени таблицы:
rev_change_by_card_type
- Нажмите «Сохранить».
Обмен мнениями и наборами данных
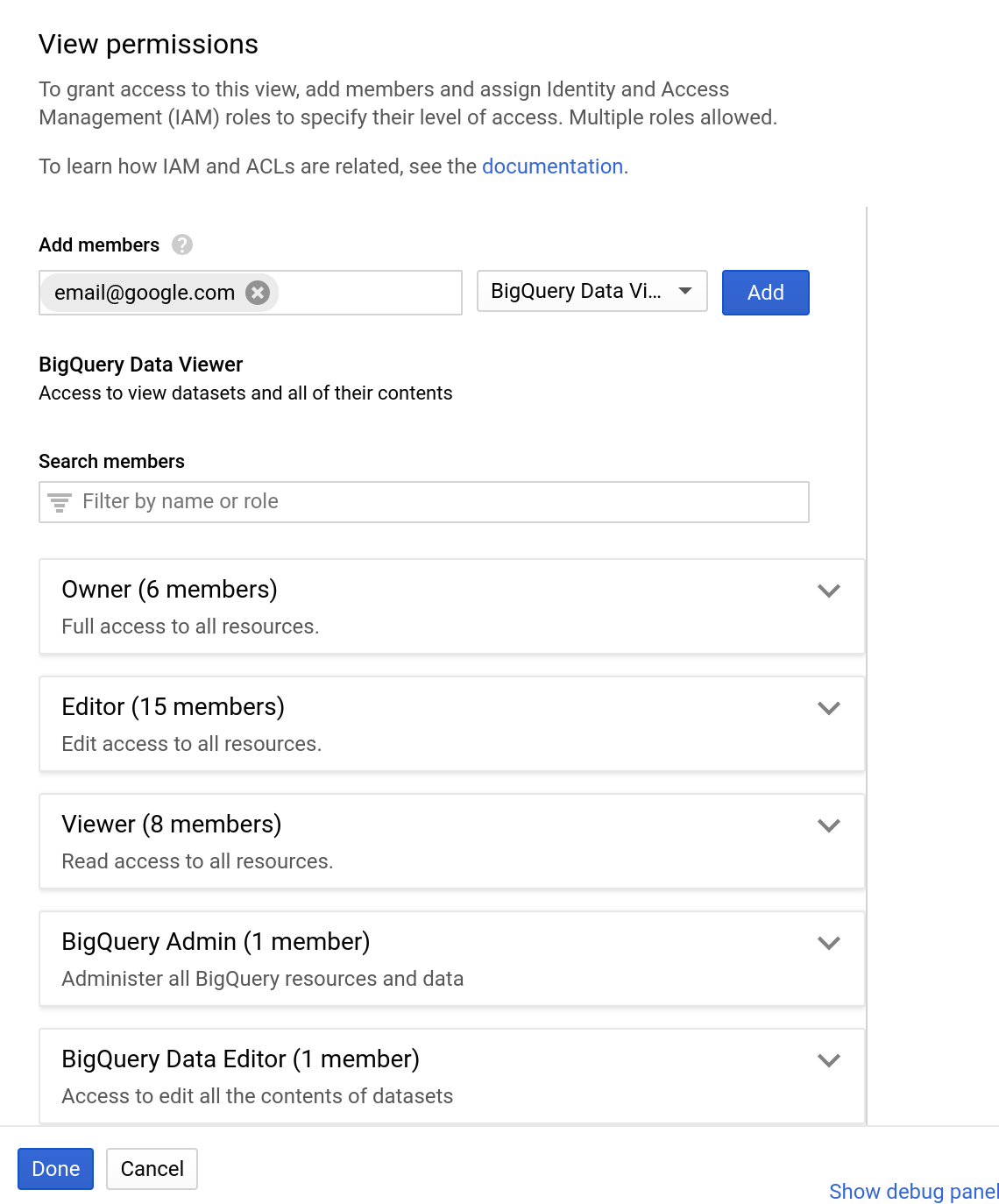
- В пользовательском интерфейсе BigQuery выберите набор данных "bq_demo_shared" на левой панели ресурсов.
- В панели информации о наборе данных нажмите кнопку «Поделиться набором данных».
- Введите адрес электронной почты
- Выберите "BigQuery Data Viewer" в раскрывающемся меню "Роль".
- Нажмите «Добавить»
- Нажмите «Готово».
Анализ данных в таблицах
[ Конкурентное преимущество]: Еще одно преимущество BigQuery по сравнению с конкурентами — это BI Engine. BI Engine позволяет выполнять запросы на сводную информацию типа BI менее чем за секунду благодаря механизму кэширования в оперативной памяти. В настоящее время это поддерживается Google Data Studio, но вскоре эта функция станет доступна для ускорения всех запросов в BigQuery.
Например:
Snowflake использует сторонние инструменты бизнес-аналитики для создания панелей мониторинга и визуализации данных, в то время как GCP предлагает ряд интегрированных инструментов бизнес-аналитики, включая Connected Sheets, Data Studio и Looker.
- В пользовательском интерфейсе BigQuery выберите представление "rev_change_by_card_type" на левой панели ресурсов.
- Нажмите на значок лупы, чтобы просмотреть изображение.

- Тип:
ВЫБИРАТЬ *
FROM bq_demo_shared.rev_change_by_card_type
- Нажмите «Выполнить»
- В области результатов нажмите на значок «Экспорт».
- Выберите «Просмотр данных с помощью таблиц».
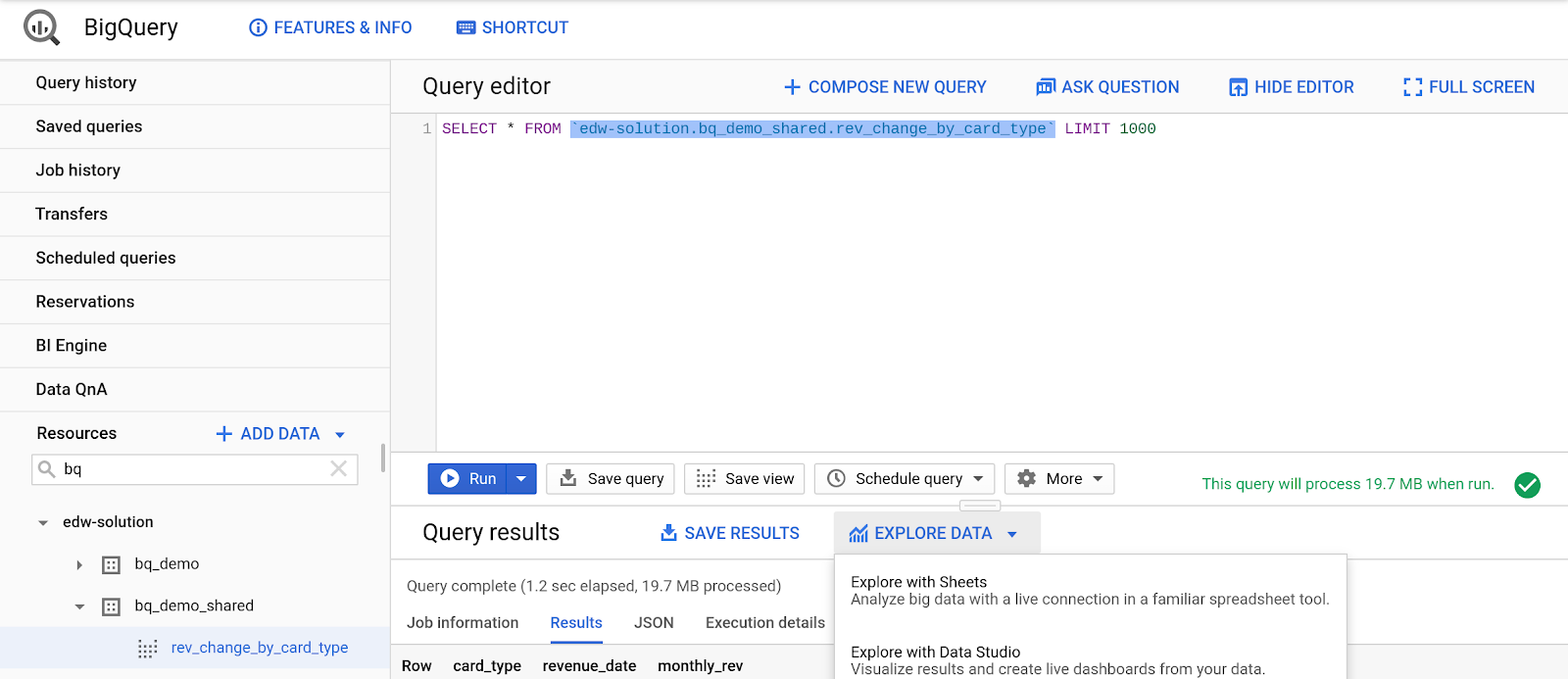
- Нажмите «Начать анализ».
- Выберите "Сводная таблица"
- Выберите «Создать новый лист»
- Нажмите «Создать».
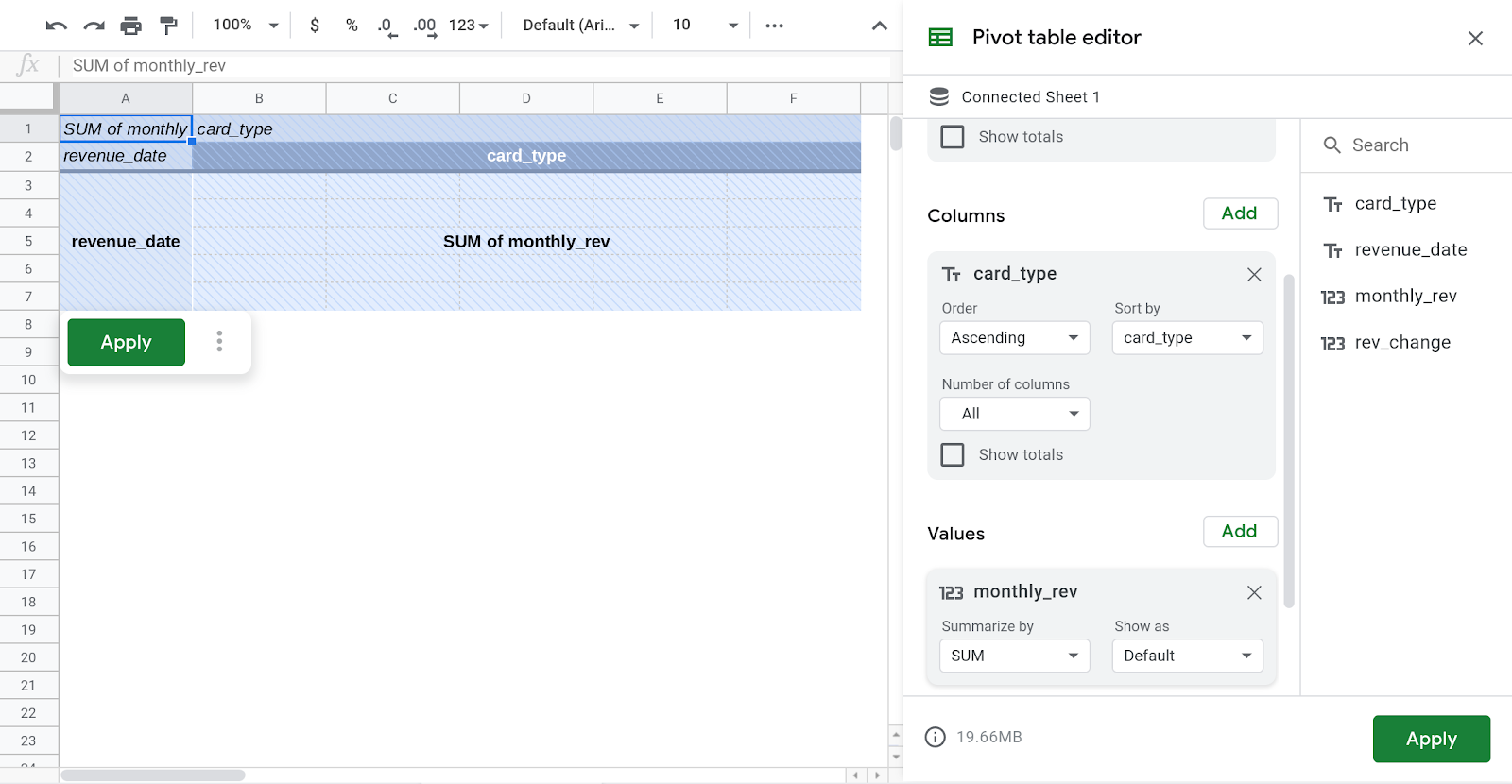
- Добавьте поле "revenue_date" в раздел "Строка" редактора сводной таблицы, расположенного справа от окна "Листы".
- Добавьте параметр "card_type" в раздел "Столбцы" редактора сводной таблицы.
- Добавьте "monthly_rev" в раздел "Столбцы" редактора сводных таблиц.
- Нажмите «Применить».
- Перейдите в верхнюю панель инструментов интерфейса Google Sheets и выберите «Вставить диаграмму».
4. Настройка: Интеграция данных
В этом разделе вы узнаете, как создать новую таблицу и выполнить объединение таблиц (JOIN) с одним из множества общедоступных наборов данных, доступных в Google Cloud.
[Конкурентный тезис]:
BigQuery уже много лет поддерживает совместное использование наборов данных. Клиенты в любом проекте могут запрашивать как общедоступные наборы данных, так и наборы данных из других проектов, которыми они поделились.
BigQuery может поддерживать хранилища данных (data lakes) в GCS с помощью внешних таблиц. Помимо пакетной загрузки, BigQuery поддерживает потоковую передачу данных в базу данных со скоростью до сотен мегабайт в секунду. Snowflake не поддерживает потоковую передачу данных.
Импорт данных в новую таблицу
- В панели ресурсов выберите набор данных bq_demo.
- В панели информации о наборе данных выберите «Создать таблицу».
- Выберите Google Cloud Storage в качестве источника.
- В текстовом поле "Путь к файлу":
gs://retail-banking-looker/district
- Выберите формат файла CSV.
- Введите «район» в поле «Название таблицы».
- Установите флажок для параметра «Автоматическое определение схемы».
- Нажмите «Создать таблицу».
Запрос к общедоступному набору данных
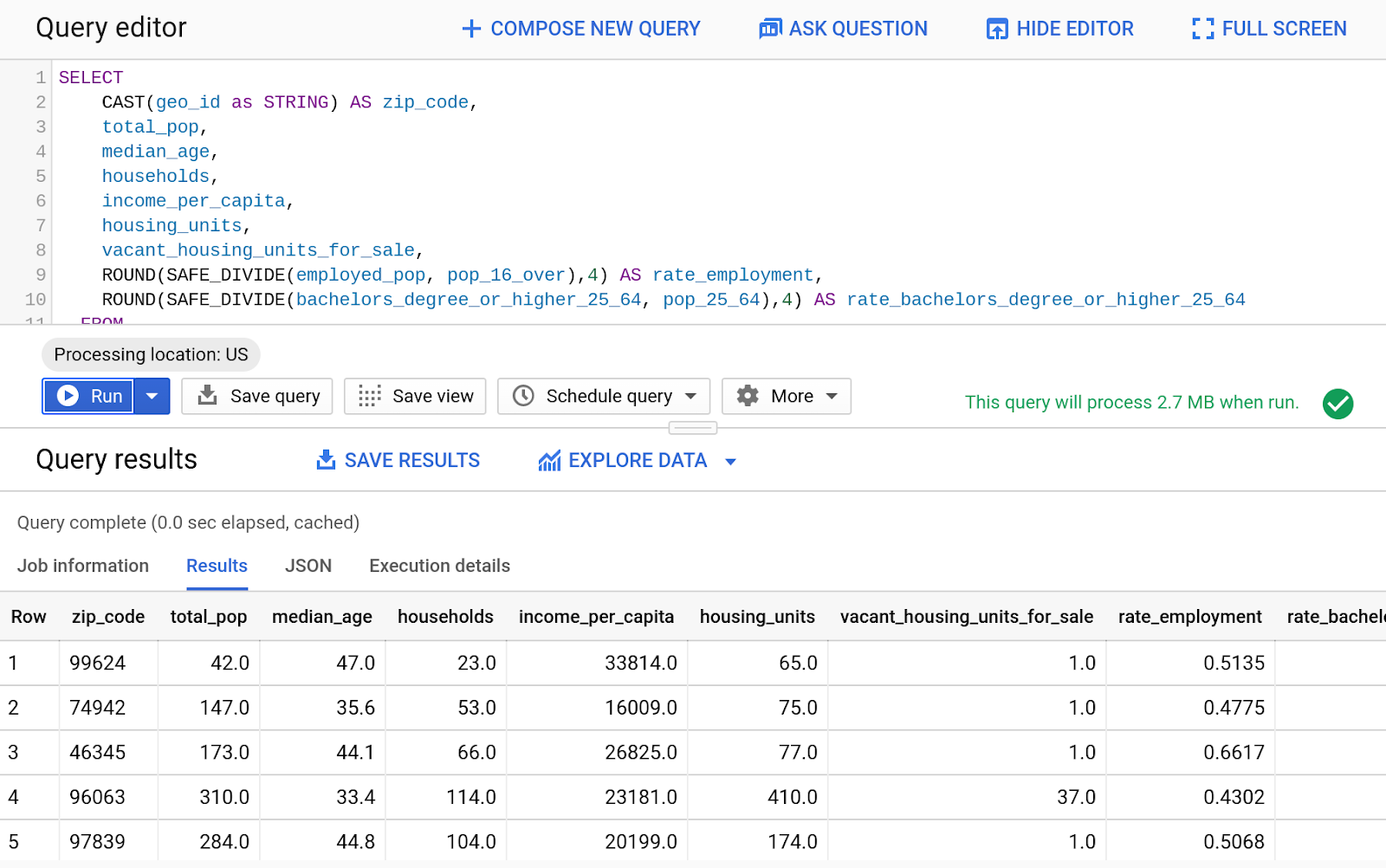
- В редакторе запросов введите следующий запрос:
SELECT
CAST(geo_id as STRING) AS zip_code,
total_pop,
median_age,
households,
income_per_capita,
housing_units,
vacant_housing_units_for_sale,
ROUND(SAFE_DIVIDE(employed_pop, pop_16_over),4) AS rate_employment,
ROUND(SAFE_DIVIDE(bachelors_degree_or_higher_25_64, pop_25_64),4) AS rate_bachelors_degree_or_higher_25_64
FROM
`bigquery-public-data.census_bureau_acs.zip_codes_2017_5yr`;
- Нажмите «Выполнить»
- Посмотреть результаты
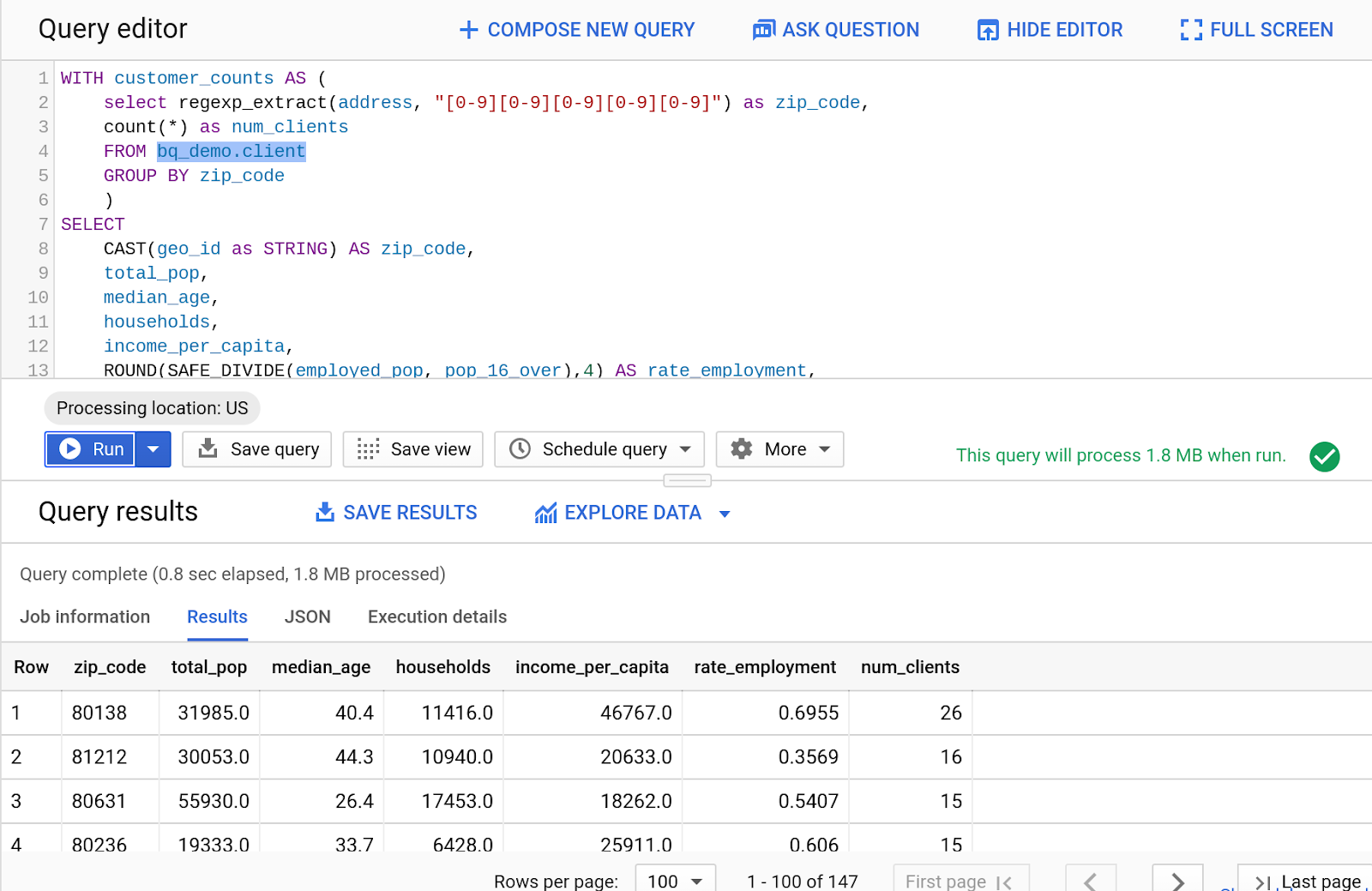
- Теперь объединим эти общедоступные данные с другим запросом. Введите следующий SQL-код в редакторе запросов:
WITH customer_counts AS (
select regexp_extract(address, "[0-9][0-9][0-9][0-9][0-9]") as zip_code,
count(*) as num_clients
FROM bq_demo.client
GROUP BY zip_code
)
SELECT
CAST(geo_id as STRING) AS zip_code,
total_pop,
median_age,
households,
income_per_capita,
ROUND(SAFE_DIVIDE(employed_pop, pop_16_over),4) AS rate_employment,
num_clients
FROM
`bigquery-public-data.census_bureau_acs.zip_codes_2017_5yr`
JOIN customer_counts on zip_code = geo_id
ORDER BY num_clients DESC
- Нажмите «Выполнить»
- Посмотреть результаты
5. Управление мощностью
Работа с игровыми автоматами и бронированием
BQ предлагает несколько моделей ценообразования, чтобы удовлетворить ваши потребности. Большинство крупных клиентов в основном используют фиксированную ставку для предсказуемого ценообразования с зарезервированной мощностью. Для увеличения мощности сверх базового уровня BQ предлагает гибкие слоты, которые позволяют вам увеличивать мощность на лету, а затем автоматически уменьшать ее без влияния на выполняемые запросы. BQ также имеет модель сканирования байтов, которая позволяет платить только за выполненные запросы.
[ Конкурентный аргумент: Некоторые конкуренты работают исключительно по модели фиксированной мощности, где клиентам приходится выделять виртуальное хранилище данных для каждой рабочей нагрузки в своей организации. В дополнение к модели низкой стоимости за запрос, которая упрощает начало работы с BigQuery, мы поддерживаем модель ценообразования с фиксированной ставкой, где неиспользуемая мощность может распределяться между набором рабочих нагрузок. ]
- Перейдите во вкладку «Бронирование».
- Нажмите на кнопку «Купить слоты».
- Выберите "Flex" в качестве продолжительности.
- Выберите 500 слотов.
- Подтвердите покупку.
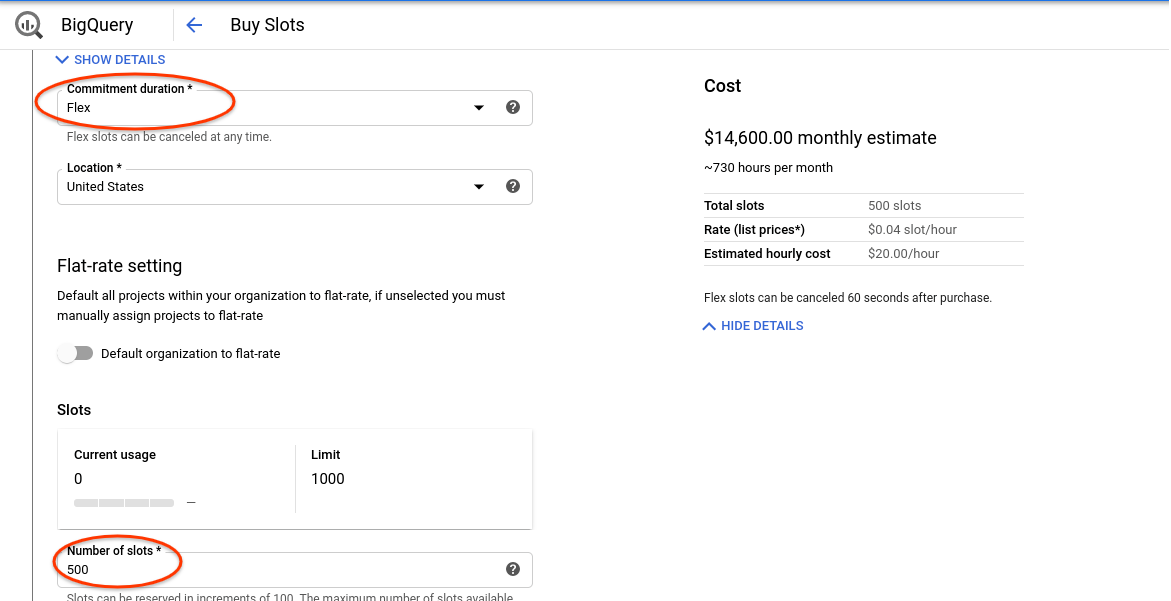
- Нажмите «Просмотреть подтверждения бронирования слотов».
- Нажмите «Создать бронирование».
- Имя пользователя "demo" в качестве имени бронирования
- Выберите Соединенные Штаты в качестве местоположения.
- Тип 500 для игровых автоматов (все доступны)
- Назначения щелчком мыши
- Выберите текущий проект для организации проекта.
- Выберите «демо» в качестве идентификатора бронирования.
- Нажмите «Создать».