
1. Zanim zaczniesz
Może Ci się wydawać, że statystyki zbiorcze nie ujawniają żadnych informacji o osobach, których dotyczą. Istnieje jednak wiele sposobów, w jakie osoba przeprowadzająca atak może uzyskać informacje poufne o osobach na podstawie statystyk zbiorczych.
W tym module dowiesz się, jak generować prywatne statystyki za pomocą agregacji z prywatnością różnicową z PipelineDP, aby chronić prywatność poszczególnych osób. PipelineDP to platforma w języku Python, która umożliwia stosowanie prywatności różnicowej do dużych zbiorów danych za pomocą systemów przetwarzania wsadowego, takich jak Apache Spark i Apache Beam. Więcej informacji o obliczaniu statystyk prywatności różnicowej w Go znajdziesz w samouczku Privacy on Beam.
Prywatne oznacza, że dane wyjściowe są generowane w taki sposób, aby nie ujawniać żadnych informacji prywatnych o osobach, których dotyczą dane. Możesz to osiągnąć dzięki prywatności różnicowej, czyli silnej koncepcji anonimizacji, która polega na agregowaniu danych od wielu użytkowników w celu ochrony ich prywatności. Wszystkie metody anonimizacji wykorzystują agregację, ale nie wszystkie metody agregacji zapewniają anonimizację. Prywatność różnicowa zapewnia natomiast mierzalne gwarancje dotyczące wycieku informacji i prywatności.
Wymagania wstępne
- znajomość Pythona,
- Znajomość podstawowej agregacji danych
- Znajomość bibliotek pandas, Spark i Beam.
Czego się nauczysz
- Podstawowe informacje o prywatności różnicowej
- Obliczanie statystyk podsumowujących z zastosowaniem prywatności różnicowej za pomocą PipelineDP
- Jak dostosować wyniki za pomocą dodatkowych parametrów prywatności i użyteczności
Czego potrzebujesz
- Jeśli chcesz uruchomić codelab w swoim środowisku, na komputerze musi być zainstalowany Python 3.7 lub nowszy.
- Jeśli chcesz przejść codelab bez własnego środowiska, musisz mieć dostęp do Colaboratory.
2. Prywatność różnicowa
Aby lepiej zrozumieć prywatność różnicową, przyjrzyj się temu prostemu przykładowi.
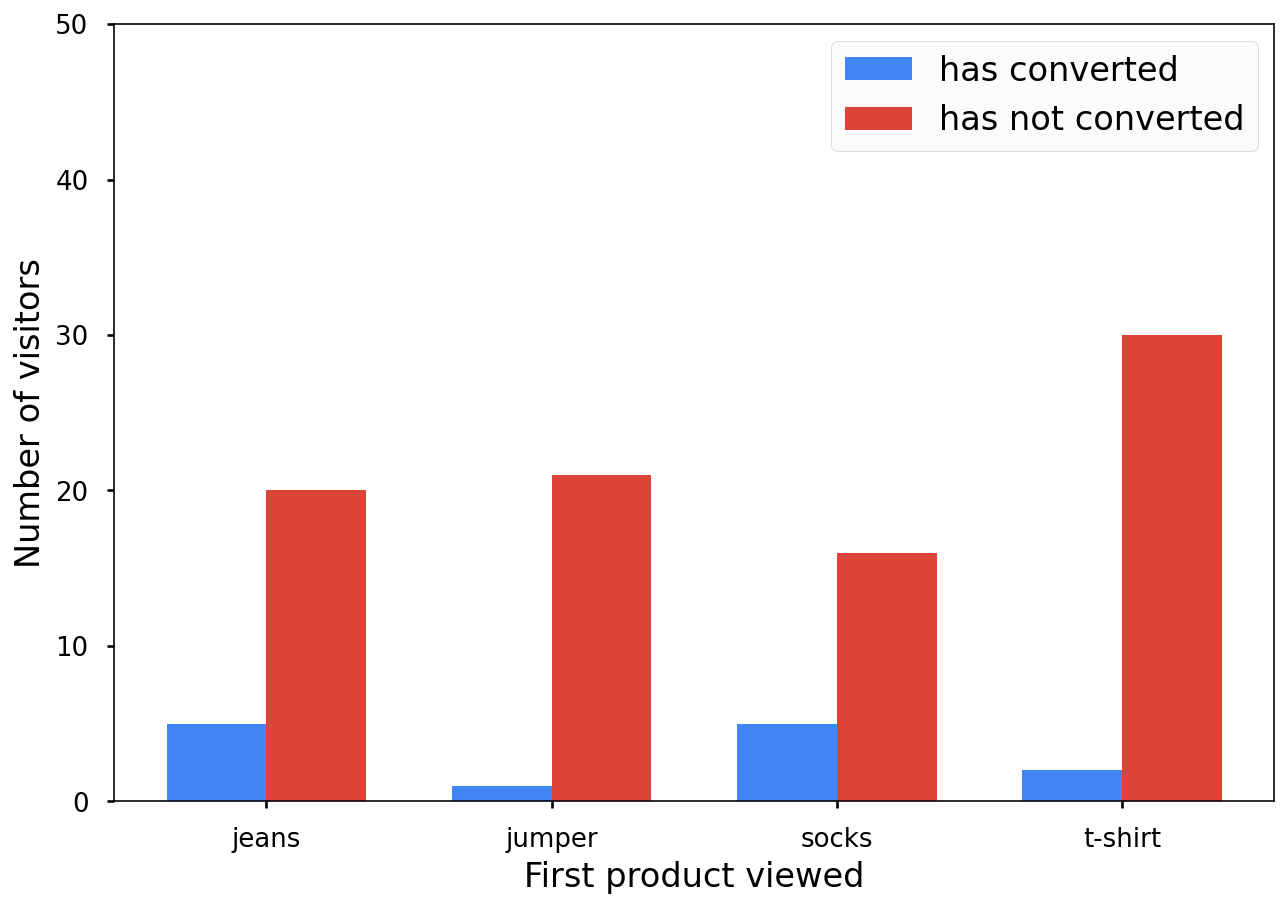
Wyobraź sobie, że pracujesz w dziale marketingu internetowego sklepu odzieżowego i chcesz dowiedzieć się, które z Twoich produktów mają największe szanse na sprzedaż.
Ten wykres pokazuje, które produkty klienci oglądali jako pierwsze po wejściu na stronę sklepu: t-shirty, swetry, skarpety czy dżinsy. Koszulki są najpopularniejszym produktem, a skarpetki – najmniej popularnym.

Wygląda to na przydatne rozwiązanie, ale jest pewien haczyk. Jeśli chcesz uwzględnić dodatkowe informacje, np. czy klienci dokonali zakupu lub który produkt obejrzeli jako drugi, ryzykujesz ujawnienie danych poszczególnych osób.
Ten wykres pokazuje, że tylko 1 klient najpierw obejrzał sweter, a potem dokonał zakupu:
Z punktu widzenia prywatności nie jest to najlepsze rozwiązanie. Anonimizowane statystyki nie powinny ujawniać indywidualnych wkładów, więc co zrobić? Dodajesz do wykresów słupkowych losowy szum, aby były nieco mniej dokładne.
Ten wykres słupkowy nie jest całkowicie dokładny, ale jest przydatny i nie ujawnia indywidualnych wkładów:

Prywatność różnicowa polega na dodaniu odpowiedniej ilości losowego szumu, aby zamaskować indywidualny wkład.
Ten przykład jest zbyt uproszczony. Prawidłowe wdrożenie prywatności różnicowej jest bardziej skomplikowane i wiąże się z wieloma nieoczekiwanymi niuansami. Podobnie jak w przypadku kryptografii, tworzenie własnej implementacji prywatności różnicowej może nie być dobrym pomysłem. Zamiast tego możesz użyć PipelineDP.
3. Pobieranie i instalowanie PipelineDP
Aby wykonać to ćwiczenie, nie musisz instalować PipelineDP, ponieważ cały odpowiedni kod i wykresy znajdziesz w tym dokumencie.
Aby wypróbować PipelineDP, uruchomić go samodzielnie lub użyć go później:
- Pobierz i zainstaluj PipelineDP:
pip install pipeline-dp
Jeśli chcesz uruchomić przykład za pomocą Apache Beam:
- Pobierz i zainstaluj Apache Beam:
pip install apache_beam
Kod tego ćwiczenia i zbiór danych znajdziesz w katalogu PipelineDP/examples/codelab/.
4. Obliczanie danych o konwersjach na podstawie pierwszego wyświetlonego produktu
Załóżmy, że pracujesz w internetowym sklepie odzieżowym i chcesz się dowiedzieć, które z różnych kategorii produktów generują najwięcej konwersji o najwyższej wartości, gdy są wyświetlane jako pierwsze. Chcesz udostępnić te informacje agencji marketingowej i innym zespołom wewnętrznym, ale nie chcesz, aby wyciekły informacje o poszczególnych klientach.
Aby obliczyć statystyki konwersji według pierwszego wyświetlonego produktu w witrynie:
- Sprawdź przykładowy zbiór danych o wizytach w witrynie w katalogu
PipelineDP/examples/codelab/.
Ten zrzut ekranu przedstawia przykładowy zbiór danych. Zawiera identyfikator użytkownika, produkty, które użytkownik wyświetlił, informację o tym, czy odwiedzający dokonał konwersji, a jeśli tak, to wartość tej konwersji.
user_id | product_view_0 | product_view_1 | product_view_2 | product_view_3 | product_view_4 | has_conversion | conversion_value |
0 | dżinsy, | t_shirt | t_shirt | brak | brak | fałsz | 0,0 |
1 | dżinsy, | t_shirt | dżinsy, | zworka, | brak | fałsz | 0,0 |
2 | t_shirt | zworka, | t_shirt | t_shirt | brak | prawda | 105,19 |
3 | t_shirt | t_shirt | dżinsy, | brak | brak | fałsz | 0,0 |
4 | t_shirt | skarpety | dżinsy, | dżinsy, | brak | fałsz | 0,0 |
Interesują Cię te dane:
view_counts: liczba pierwszych wyświetleń każdego produktu przez użytkowników Twojej witryny.total_conversion_value: łączna kwota pieniędzy wydanych przez użytkowników, którzy dokonali konwersji.conversion_rate: odsetek użytkowników, którzy dokonali konwersji.
- Generuj dane w sposób nieprywatny:
conversion_metrics = df.groupby(['product_view_0'
])[['conversion_value', 'has_conversion']].agg({
'conversion_value': [len, np.sum],
'has_conversion': np.mean
})
conversion_metrics = conversion_metrics.rename(
columns={
'len': 'view_counts',
'sum': 'total_conversion_value',
'mean': 'conversion_rate'
}).droplevel(
0, axis=1)
Jak już wiesz, te statystyki mogą ujawniać informacje o osobach w zbiorze danych. Na przykład tylko 1 osoba dokonała konwersji po tym, jak najpierw zobaczyła sweter. Przy 22 wyświetleniach współczynnik konwersji wynosi około 0, 05. Teraz musisz przekształcić każdy wykres słupkowy w prywatny.
- Zdefiniuj parametry prywatności za pomocą klasy
pipeline_dp.NaiveBudgetAccountant, a następnie określ argumentyepsilonidelta, których chcesz użyć w analizie.
Sposób ustawienia tych argumentów zależy od konkretnego problemu. Więcej informacji znajdziesz w sekcji Opcjonalnie: dostosuj parametry prywatności różnicowej.
Ten fragment kodu używa przykładowych wartości:
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=1e-5)
- Zainicjuj instancję
LocalBackend:
ops = pipeline_dp.LocalBackend()
Możesz użyć instancji LocalBackend, ponieważ program jest uruchamiany lokalnie bez dodatkowych platform, takich jak Beam czy Spark.
- Zainicjuj instancję
DPEngine:
dp_engine = pipeline_dp.DPEngine(budget_accountant, ops)
Biblioteka PipelineDP umożliwia określanie dodatkowych parametrów za pomocą klasy pipeline_dp.AggregateParams, co wpływa na generowanie statystyk prywatnych.
params = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.COUNT],
max_partitions_contributed=1,
max_contributions_per_partition=1)
- Określ, że chcesz obliczyć dane
counti użyć rozkładu szumuLAPLACE. - Ustaw argument
max_partitions_contributedna wartość1.
Ten argument ogranicza liczbę różnych wizyt, które użytkownik może wygenerować. Oczekujesz, że użytkownicy będą odwiedzać witrynę raz dziennie, i nie zależy Ci na tym, czy zrobią to kilka razy w ciągu dnia.
- Ustaw argument
max_contributions_per_partitionsna wartość1.
Ten argument określa, ile razy pojedynczy użytkownik może przyczynić się do powstania poszczególnych partycji lub w tym przypadku kategorii produktów.
- Utwórz instancję
data_extractor, która określa, gdzie znaleźć polaprivacy_id,partitionivalue.
Kod powinien wyglądać jak ten fragment kodu:
def run_pipeline(data, ops):
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=1e-5)
dp_engine = pipeline_dp.DPEngine(budget_accountant, ops)
params = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.COUNT],
max_partitions_contributed=1, # A single user can only contribute to one partition.
max_contributions_per_partition=1, # For a single partition, only one contribution per user is used.
)
data_extractors = pipeline_dp.DataExtractors(
privacy_id_extractor=lambda row: row.user_id,
partition_extractor=lambda row: row.product_view_0
value_extractor=lambda row: row.has_conversion)
dp_result = dp_engine.aggregate(data, params, data_extractors)
budget_accountant.compute_budgets()
return dp_result
- Dodaj ten kod, aby przekształcić strukturę DataFrame biblioteki pandas w listę wierszy, na podstawie których możesz bezpośrednio obliczać statystyki prywatności różnicowej:
rows = [index_row[1] for index_row in df.iterrows()]
dp_result_local = run_pipeline(rows, ops) # Returns generator
list(dp_result_local)
Gratulacje! Obliczyłeś(-aś) pierwszą statystykę z ochroną prywatności różnicowej.
Ten wykres pokazuje wynik z liczby uzyskanej za pomocą mechanizmu prywatności różnicowej obok liczby nieprywatnej obliczonej wcześniej:

Wykres słupkowy, który uzyskasz po uruchomieniu kodu, może się różnić od tego, co jest w porządku. Ze względu na szum w prywatności różnicowej za każdym razem, gdy uruchamiasz kod, otrzymujesz inny wykres słupkowy, ale możesz zauważyć, że są one podobne do oryginalnego wykresu słupkowego bez ochrony prywatności.
Pamiętaj, że ze względu na gwarancje prywatności bardzo ważne jest, aby potok nie był uruchamiany wielokrotnie. Więcej informacji znajdziesz w artykule Obliczanie wielu statystyk.
5. Korzystanie z partycji publicznych
W poprzedniej sekcji mogłeś(-aś) zauważyć, że usunęliśmy wszystkie dane o wizytach w przypadku partycji, czyli użytkowników, którzy po raz pierwszy zobaczyli skarpety w Twojej witrynie.
Wynika to z wyboru partycji lub ustalania progów, co jest ważnym krokiem w zapewnianiu gwarancji prywatności różnicowej, gdy istnienie partycji wyjściowych zależy od samych danych użytkownika. W takim przypadku samo istnienie partycji w danych wyjściowych może ujawnić, że w danych znajduje się informacja o konkretnym użytkowniku. Więcej informacji o tym, dlaczego narusza to prywatność, znajdziesz w tym poście na blogu. Aby zapobiec naruszeniu prywatności, PipelineDP zachowuje tylko partycje z odpowiednią liczbą użytkowników.
Jeśli lista partycji wyjściowych nie zależy od prywatnych danych użytkowników, nie musisz wykonywać tego kroku wyboru partycji. W Twoim przykładzie tak jest, ponieważ znasz wszystkie możliwe kategorie produktów, które klient może zobaczyć jako pierwsze.
Aby używać partycji:
- Utwórz listę możliwych partycji:
public_partitions_products = ['jeans', 'jumper', 'socks', 't-shirt']
- Przekaż listę do funkcji
run_pipeline(), która ustawi ją jako dodatkowe dane wejściowe dla klasypipeline_dp.AggregateParams:
run_pipeline(
rows, ops, total_delta=0, public_partitions=public_partitions_products)
# Returns generator
params = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.COUNT],
max_partitions_contributed=1,
max_contributions_per_partition=1,
public_partitions=public_partitions_products)
Jeśli używasz partycji publicznych i LAPLACE szumu, możesz ustawić argument total_delta na wartość 0.
W wyniku widać teraz, że raportowane są dane wszystkich podziałów lub produktów.

Partycje publiczne nie tylko pozwalają zachować więcej partycji, ale też dodają mniej więcej o połowę mniej szumu, ponieważ nie wykorzystujesz budżetu prywatności na wybór partycji. Różnica między surowymi a prywatnymi liczbami jest więc nieco mniejsza niż w przypadku poprzedniego uruchomienia.
Korzystając z partycji publicznych, pamiętaj o 2 ważnych kwestiach:
- Zachowaj ostrożność podczas tworzenia listy partycji na podstawie nieprzetworzonych danych. Jeśli nie zrobisz tego w sposób zapewniający prywatność różnicową, Twój potok nie będzie już gwarantować prywatności różnicowej. Więcej informacji znajdziesz w artykule Zaawansowane: tworzenie partycji na podstawie danych.
- Jeśli w przypadku niektórych partycji publicznych nie ma danych, musisz zastosować do nich szum, aby zachować prywatność różnicową. Jeśli na przykład użyjesz dodatkowego produktu, takiego jak spodnie, który nie występuje w Twoim zbiorze danych ani na stronie, nadal będzie to szum, a wyniki mogą wykazywać wizyty w produktach, których nie było.
Zaawansowane: tworzenie partycji na podstawie danych
Jeśli w tym samym potoku uruchamiasz wiele agregacji z tą samą listą niepublicznych partycji wyjściowych, możesz raz uzyskać listę partycji za pomocą metody dp_engine.select_private_partitions() i przekazać ją do każdej agregacji jako dane wejściowe public_partitions. Jest to nie tylko bezpieczne z punktu widzenia ochrony prywatności, ale też pozwala dodać mniej szumu, ponieważ budżet prywatności jest wykorzystywany do wyboru partycji tylko raz w przypadku całego potoku.
def get_private_product_views(data, ops):
"""Obtains the list of product_views in a private manner.
This does not calculate any private metrics; it merely obtains the list of
product_views but does so while making sure the result is differentially private.
"""
# Set the total privacy budget.
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=1e-5)
# Create a DPEngine instance.
dp_engine = pipeline_dp.DPEngine(budget_accountant, ops)
# Specify how to extract privacy_id, partition_key, and value from a
# single element.
data_extractors = pipeline_dp.DataExtractors(
partition_extractor=lambda row: row.product_view_0,
privacy_id_extractor=lambda row: row.user_id)
# Run aggregation.
dp_result = dp_engine.select_partitions(
data, pipeline_dp.SelectPrivatePartitionsParams(
max_partitions_contributed=1),
data_extractors=data_extractors)
budget_accountant.compute_budgets()
return dp_result
6. Obliczanie wielu statystyk
Teraz, gdy wiesz już, jak działa PipelineDP, możesz zobaczyć, jak używać go w bardziej zaawansowanych przypadkach. Jak wspomnieliśmy na początku, interesują Cię 3 rodzaje statystyk. Biblioteka PipelineDP umożliwia obliczanie wielu statystyk jednocześnie, o ile mają one te same parametry w instancji AggregateParams, co zobaczysz później. Jest to nie tylko bardziej przejrzyste i łatwiejsze w obliczeniach wielu rodzajów danych naraz, ale też lepsze pod względem prywatności.
Jeśli pamiętasz parametry epsilon i delta, które przekazujesz do klasy NaiveBudgetAccountant, reprezentują one coś, co nazywa się budżetem na potrzeby prywatności. Jest to wskaźnik ilości prywatności użytkownika, która wycieka z danych.
Ważne jest, aby pamiętać, że budżet ochrony prywatności jest sumą. Jeśli uruchomisz potok z określonymi wartościami epsilon ε i delta δ tylko raz, wykorzystasz budżet (ε,δ). Jeśli zastosujesz go po raz drugi, wydasz budżet całkowity (2ε, 2δ). Podobnie, jeśli obliczysz kilka statystyk za pomocą metody NaiveBudgetAccountant, a następnie zastosujesz budżet ochrony prywatności ε,δ, wydasz łącznie budżet (2ε, 2δ). Oznacza to obniżenie gwarancji prywatności.
Aby to obejść, musisz użyć jednej instancji NaiveBudgetAccountant z łącznym budżetem, którego chcesz użyć, gdy potrzebujesz obliczyć wiele statystyk na podstawie tych samych danych. Następnie musisz określić wartości epsilon i delta, których chcesz użyć w przypadku każdego rodzaju agregacji. Ostatecznie uzyskasz tę samą ogólną gwarancję prywatności, ale im wyższe wartości epsilon i delta ma dana agregacja, tym większa jest jej dokładność.
Aby zobaczyć, jak to działa, możesz obliczyć statystyki count, mean i sum.
Statystyki obliczasz na podstawie 2 rodzajów danych: conversion_value, które służą do wnioskowania o wysokości wygenerowanych przychodów na podstawie tego, który produkt został wyświetlony jako pierwszy, oraz has_conversion, które służą do obliczania liczby użytkowników odwiedzających Twoją witrynę i średniego współczynnika konwersji.
W przypadku każdego rodzaju danych musisz osobno określić parametry, które będą służyć do obliczania statystyk prywatnych. Budżet prywatności jest dzielony na 2 rodzaje danych. Obliczasz 2 rodzaje statystyk na podstawie danych has_conversion, więc chcesz przypisać do nich 2/3 początkowego budżetu, a pozostałą 1/3 do danych conversion_value.
Aby obliczyć wiele statystyk:
- Skonfiguruj księgowego budżetu prywatności, podając łączne wartości
epsilonidelta, których chcesz używać w przypadku 3 rodzajów statystyk:
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=0)
- Zainicjuj
DPEngine, aby obliczyć dane:
dp_engine = pipeline_dp.DPEngine(budget_accountant, ops)
- Określ parametry tego rodzaju danych.
params_conversion_value_metrics = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.SUM],
max_partitions_contributed=1,
max_contributions_per_partition=1,
min_value=0,
max_value=100,
public_partitions=public_partitions,
budget_weight=1/3)
Ostatni argument opcjonalnie określa wagę budżetu prywatności. Możesz przypisać wszystkim argumentom tę samą wagę, ale w tym przypadku chcesz ustawić ten argument na jedną trzecią, jak wyjaśniliśmy wcześniej.
Możesz też ustawić argumenty min_value i max_value, aby określić dolną i górną granicę stosowaną do wartości wnoszonej przez jednostkę ochrony prywatności w partycji. Te parametry są wymagane, jeśli chcesz obliczyć prywatną sumę lub średnią. Nie spodziewasz się wartości ujemnych, więc możesz przyjąć 0 i 100 jako rozsądne granice.
- Wyodrębnij odpowiednie dane, a następnie przekaż je do funkcji agregującej:
data_extractors_conversion_value_metrics = pipeline_dp.DataExtractors(
privacy_id_extractor=lambda row: row.user_id,
partition_extractor=lambda row: row.product_view_0,
value_extractor=lambda row: row.conversion_value)
dp_result_conversion_value_metrics = (
dp_engine.aggregate(data, params_conversion_value_metrics,
data_extractors_conversion_value_metrics))
- Wykonaj te same czynności, aby obliczyć 2 rodzaje danych na podstawie zmiennej
has_conversion:
params_conversion_rate_metrics = pipeline_dp.AggregateParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
metrics=[pipeline_dp.Metrics.COUNT, pipeline_dp.Metrics.MEAN],
max_partitions_contributed=1,
max_contributions_per_partition=1,
min_value=0,
max_value=1,
public_partitions=public_partitions,
budget_weight=2/3)
data_extractors_conversion_rate_metrics = pipeline_dp.DataExtractors(
privacy_id_extractor=lambda row: row.user_id,
partition_extractor=lambda row: row.product_view_0,
value_extractor=lambda row: row.has_conversion)
dp_result_conversion_rate_metrics = (
dp_engine.aggregate(data, params_conversion_rate_metrics,
data_extractors_conversion_rate_metrics))
Jedyna zmiana dotyczy instancji pipeline_dp.AggregateParams, w której teraz definiujesz mean i count jako agregacje i przypisujesz do tego obliczenia 2/3 budżetu prywatności. Ponieważ chcesz mieć te same granice udziału w przypadku obu statystyk i obliczać je na podstawie tej samej zmiennej has_conversion, możesz połączyć je w tym samym wystąpieniu pipeline_dp.AggregateParams i obliczać je w tym samym czasie.
- Wywołaj metodę
budget_accountant.compute_budgets():
budget_accountant.compute_budgets()
Możesz wykreślić wszystkie 3 rodzaje statystyk prywatnych w porównaniu z ich pierwotnymi statystykami. W zależności od dodanego szumu wyniki mogą wykraczać poza prawdopodobną skalę. W tym przypadku w przypadku skoczków zobaczysz ujemny współczynnik konwersji i ujemną łączną wartość konwersji, ponieważ dodany szum jest symetryczny względem zera. W celu dalszych analiz i przetwarzania najlepiej nie przetwarzać ręcznie statystyk prywatnych, ale jeśli chcesz dodać te wykresy do raportu, możesz później po prostu ustawić minimum na zero bez naruszania gwarancji prywatności.

7. Uruchamianie potoku za pomocą Beam
Przetwarzanie danych wymaga obecnie obsługi ogromnych ilości informacji, których nie można przetworzyć lokalnie. Zamiast tego wiele osób korzysta z platform do przetwarzania danych na dużą skalę, takich jak Beam czy Spark, i uruchamia potoki w chmurze.
PipelineDP obsługuje Beam i Spark przy niewielkich zmianach w kodzie.
Aby uruchomić potok za pomocą Beam z interfejsem private_beam API:
- Zainicjuj zmienną
runner, a następnie utwórz potok, w którym zastosujesz operacje ochrony prywatności do reprezentacjirowsw Beam:
runner = fn_api_runner.FnApiRunner() # local runner
with beam.Pipeline(runner=runner) as pipeline:
beam_data = pipeline | beam.Create(rows)
- Utwórz zmienną
budget_accountantz wymaganymi parametrami ochrony prywatności:
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=0)
- Utwórz zmienną
pcollub zmienną kolekcji prywatnej, która gwarantuje, że wszystkie agregacje są zgodne z Twoimi wymaganiami dotyczącymi ochrony prywatności:
pcol = beam_data | pbeam.MakePrivate(
budget_accountant=budget_accountant,
privacy_id_extractor=lambda
row: row.user_id)
- Określ parametry agregacji prywatnej w odpowiedniej klasie.
W tym przypadku używasz klasy pipeline_dp.aggregate_params.SumParams(), ponieważ obliczasz sumę wyświetleń produktu.
- Przekaż parametry agregacji do metody
pbeam.Sum, aby obliczyć statystykę:
dp_result = pcol | pbeam.Sum(params)
- Ostatecznie kod powinien wyglądać tak, jak ten fragment kodu:
import pipeline_dp.private_beam as pbeam
runner = fn_api_runner.FnApiRunner() # local runner
with beam.Pipeline(runner=runner) as pipeline:
beam_data = pipeline | beam.Create(rows)
budget_accountant = pipeline_dp.NaiveBudgetAccountant(
total_epsilon=1, total_delta=0)
# Create private collection.
pcol = beam_data | pbeam.MakePrivate(
budget_accountant=budget_accountant,
privacy_id_extractor=lambda row:
row.user_id)
# Specify parameters.
params = pipeline_dp.aggregate_params.SumParams(
noise_kind=pipeline_dp.NoiseKind.LAPLACE,
max_partitions_contributed=1,
max_contributions_per_partition=1,
min_value=0,
max_value=100,
public_partitions=public_partitions_product_views,
partition_extractor=lambda row: row.product_view_0,
value_extractor=lambda row:row.conversion_value)
dp_result = pcol | pbeam.Sum(params)
budget_accountant.compute_budgets()
dp_result | beam.Map(print)
8. Opcjonalnie: dostosuj parametry prywatności i użyteczności
W tym samouczku wspomnieliśmy o kilku parametrach, takich jak epsilon, delta i max_partitions_contributed. Można je z grubsza podzielić na 2 kategorie: parametry związane z prywatnością i parametry związane z użytecznością.
Parametry prywatności
Parametry epsilon i delta wyrażają liczbowo poziom prywatności, który zapewniasz dzięki prywatności różnicowej. Mówiąc dokładniej, jest to miara tego, ile informacji o danych może uzyskać potencjalna osoba przeprowadzająca atak na podstawie zanonimizowanych danych wyjściowych. Im wyższa wartość parametrów, tym więcej informacji o danych uzyskuje atakujący, co stanowi zagrożenie dla prywatności. Z drugiej strony im niższe są wartości parametrów epsilon i delta, tym więcej szumu musisz dodać do danych wyjściowych, aby je zanonimizować, i tym większa musi być liczba unikalnych użytkowników w każdym podziale, aby zachować ich w zanonimizowanych danych wyjściowych. W tym przypadku występuje kompromis między użytecznością a prywatnością.
W PipelineDP musisz określić pożądane gwarancje prywatności anonimizowanych danych wyjściowych, gdy ustawiasz całkowity budżet na potrzeby prywatności w instancji NaiveBudgetAccountant. Jeśli jednak chcesz, aby gwarancje dotyczące prywatności były zachowane, musisz ostrożnie używać osobnej NaiveBudgetAccountant instancji dla każdej agregacji lub uruchamiać potok wiele razy, aby uniknąć nadmiernego wykorzystania budżetu.
Więcej informacji o prywatności różnicowej i znaczeniu parametrów prywatności znajdziesz w tym artykule.
Parametry narzędzia
Parametry pomocnicze nie wpływają na gwarancje prywatności, ale mają wpływ na dokładność, a co za tym idzie, na użyteczność danych wyjściowych. Są one podawane w instancji AggregateParams i służą do skalowania dodawanego szumu.
Parametrem narzędziowym podanym w instancji AggregateParams i mającym zastosowanie do wszystkich agregacji jest parametr max_partitions_contributed. Partycja odpowiada kluczowi danych zwracanych przez operację agregacji PipelineDP, więc parametr max_partitions_contributed ogranicza liczbę różnych wartości klucza, które użytkownik może przekazać do danych wyjściowych. Jeśli użytkownik przyczyni się do większej liczby kluczy niż wartość parametru max_partitions_contributed, niektóre jego działania zostaną pominięte, tak aby ich liczba odpowiadała wartości parametru max_partitions_contributed.
Podobnie większość agregacji ma parametr max_contributions_per_partition. Są one też podawane w instancji AggregateParams, a każda agregacja może mieć dla nich osobne wartości. Ograniczają one wkład użytkownika w przypadku każdego klucza.
Szum dodawany do danych wyjściowych jest skalowany przez parametry max_partitions_contributed i max_contributions_per_partition, więc istnieje tu kompromis: większe wartości przypisane do każdego parametru oznaczają, że zachowujesz więcej danych, ale uzyskujesz bardziej zaszumiony wynik.
Niektóre agregacje wymagają parametrów min_value i max_value, które określają granice udziału każdego użytkownika. Jeśli użytkownik poda wartość niższą niż wartość przypisana do parametru min_value, zostanie ona zwiększona do wartości tego parametru. Podobnie jeśli użytkownik poda wartość większą niż wartość parametru max_value, zostanie ona zmniejszona do wartości parametru. Aby zachować więcej oryginalnych wartości, musisz określić większe granice. Szum jest skalowany według rozmiaru granic, więc większe granice pozwalają zachować więcej danych, ale w rezultacie otrzymujesz bardziej zaszumiony wynik.
Parametr noise_kind obsługuje w PipelineDP 2 różne mechanizmy szumu: szum GAUSSIAN i szum LAPLACE. Rozkład LAPLACE zapewnia większą użyteczność przy niskich granicach wkładu, dlatego PipelineDP używa go domyślnie. Jeśli jednak chcesz użyć GAUSSIANszumu dystrybucji, możesz go określić w AggregateParamsinstancji.
9. Gratulacje
Brawo! Ukończono ćwiczenia z programowania PipelineDP i zdobyto wiele informacji o prywatności różnicowej i PipelineDP.