
1. 簡介
Document AI 是一項文件解讀解決方案,可將文件、電子郵件等非結構化的資料擷取出來,讓您更輕鬆地解讀、分析和消化這些資料。
有了 Document AI Workbench,您就能使用自己的訓練資料建立完全自訂的模型,提高文件處理的準確率。
在本實驗室中,您將建立自訂文件擷取處理器、匯入資料集、為範例文件加上標籤,並訓練處理器。
本實驗室使用的文件資料集來自 Kaggle 的 Fake W-2 (US Tax Form) 資料集,具有 CC0:公共領域授權。
必要條件
本程式碼研究室以其他 Document AI 程式碼研究室的內容為基礎。
建議您先完成下列程式碼研究室,再繼續操作。
- 使用 Document AI 來執行光學字元辨識 (Python)
- 使用 Document AI 剖析表單 (Python)
- 使用 Document AI 的專用處理器 (Python)
- 使用 Python 管理 Document AI 處理器
- Document AI:迴圈中的人
- Document AI:訓練
課程內容
- 建立自訂文件擷取器處理器。
- 使用註解工具為 Document AI 訓練資料加上標籤。
- 訓練新版模型。
- 評估新模型版本的準確度。
軟硬體需求
2. 開始設定
本程式碼研究室假設您已完成入門程式碼研究室中列出的 Document AI 設定步驟。
請先完成下列步驟再繼續:
3. 建立處理器
您必須先建立自訂文件擷取器的處理器,才能在本實驗室中使用。
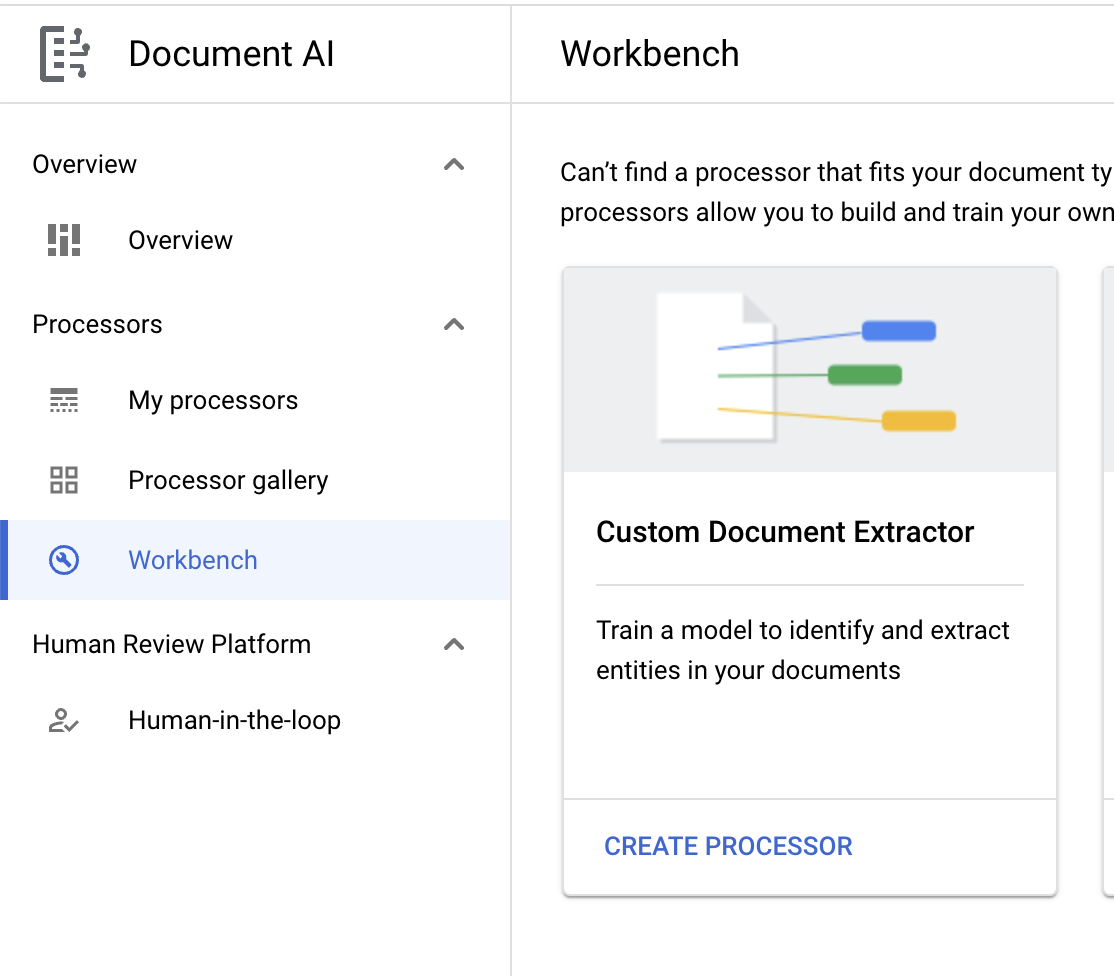
- 點選「建立自訂處理器」,然後選取「自訂文件擷取器」。
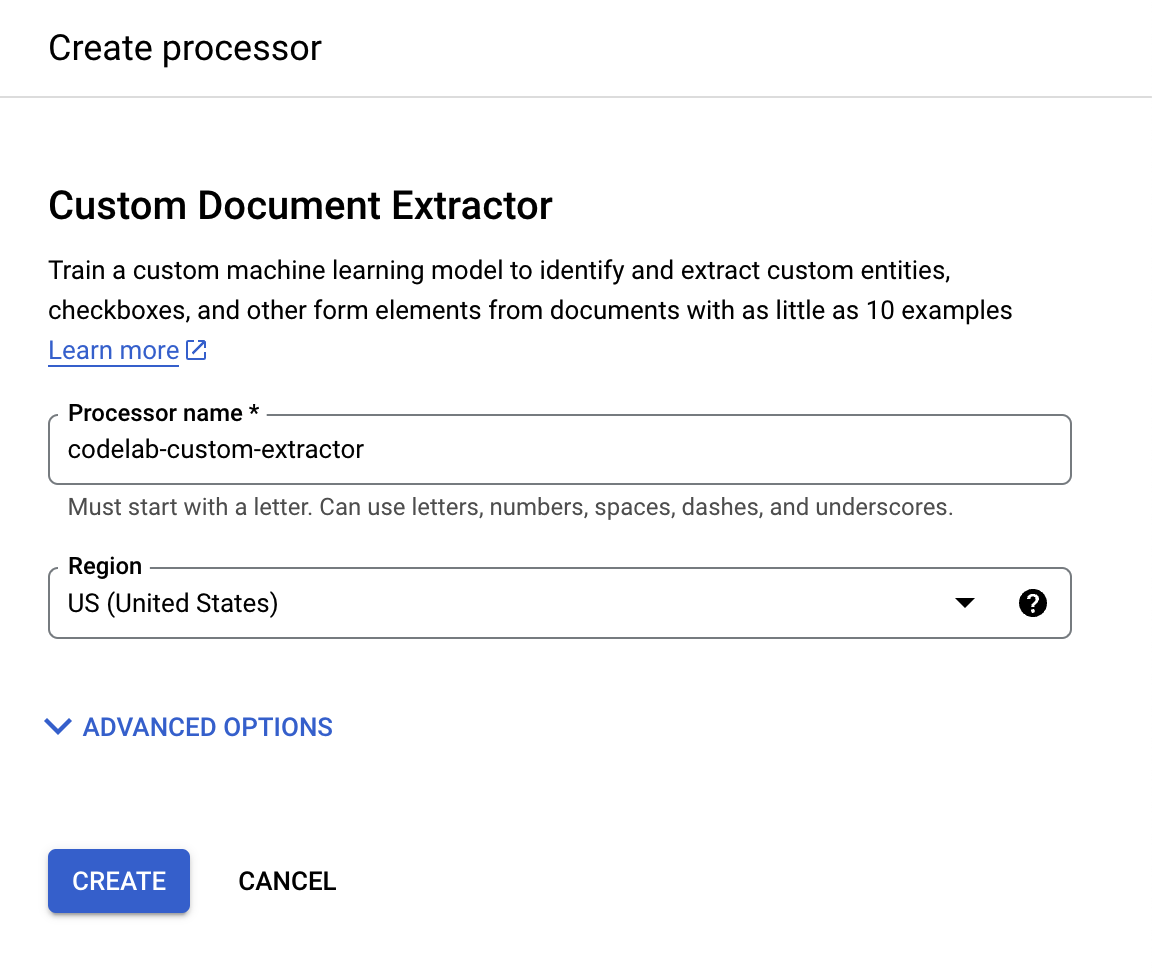
- 將名稱設為
codelab-custom-extractor(或是您可以記住的其他名稱),然後從清單中選取最接近的區域。
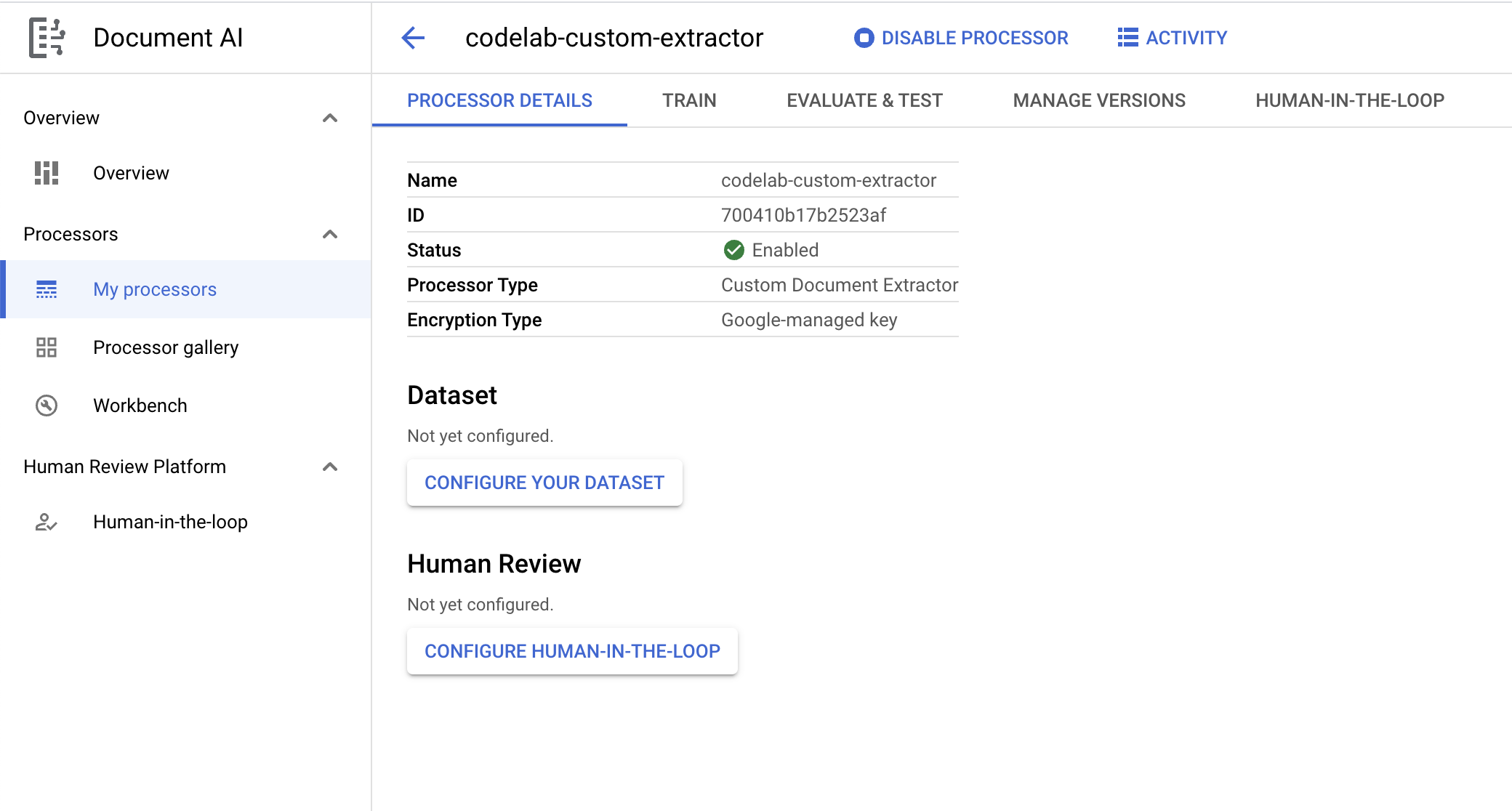
- 點按「建立」即可建立處理器。接著,您應該會看到「處理器總覽」頁面。
4. 建立資料集
如要訓練處理器,我們必須建立具有訓練和測試資料的資料集,以協助處理器識別要擷取的實體。
- 在「處理器總覽」頁面,按一下「設定資料集」。
- 您現在應該會位於「Configure Dataset」(設定資料集) 頁面。如要指定儲存訓練文件和標籤的儲存空間,請按一下「顯示進階選項」。否則,只要按一下「繼續」即可。
- 等待系統建立資料集,然後系統會將您導向「訓練」頁面。
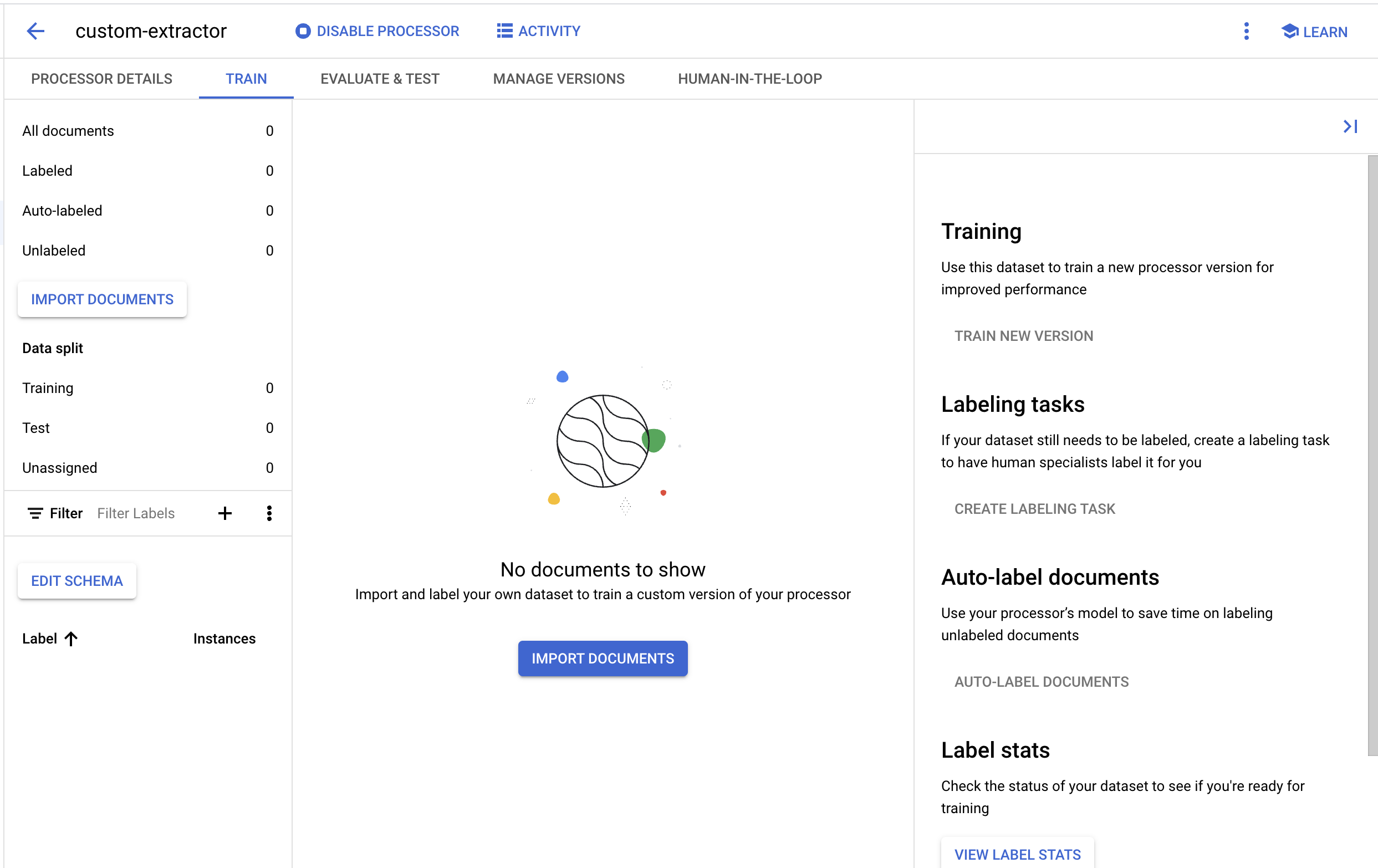
5. 匯入測試文件
現在,請將 W2 PDF 範例匯入資料集。
- 按一下「Import Documents」(匯入文件)
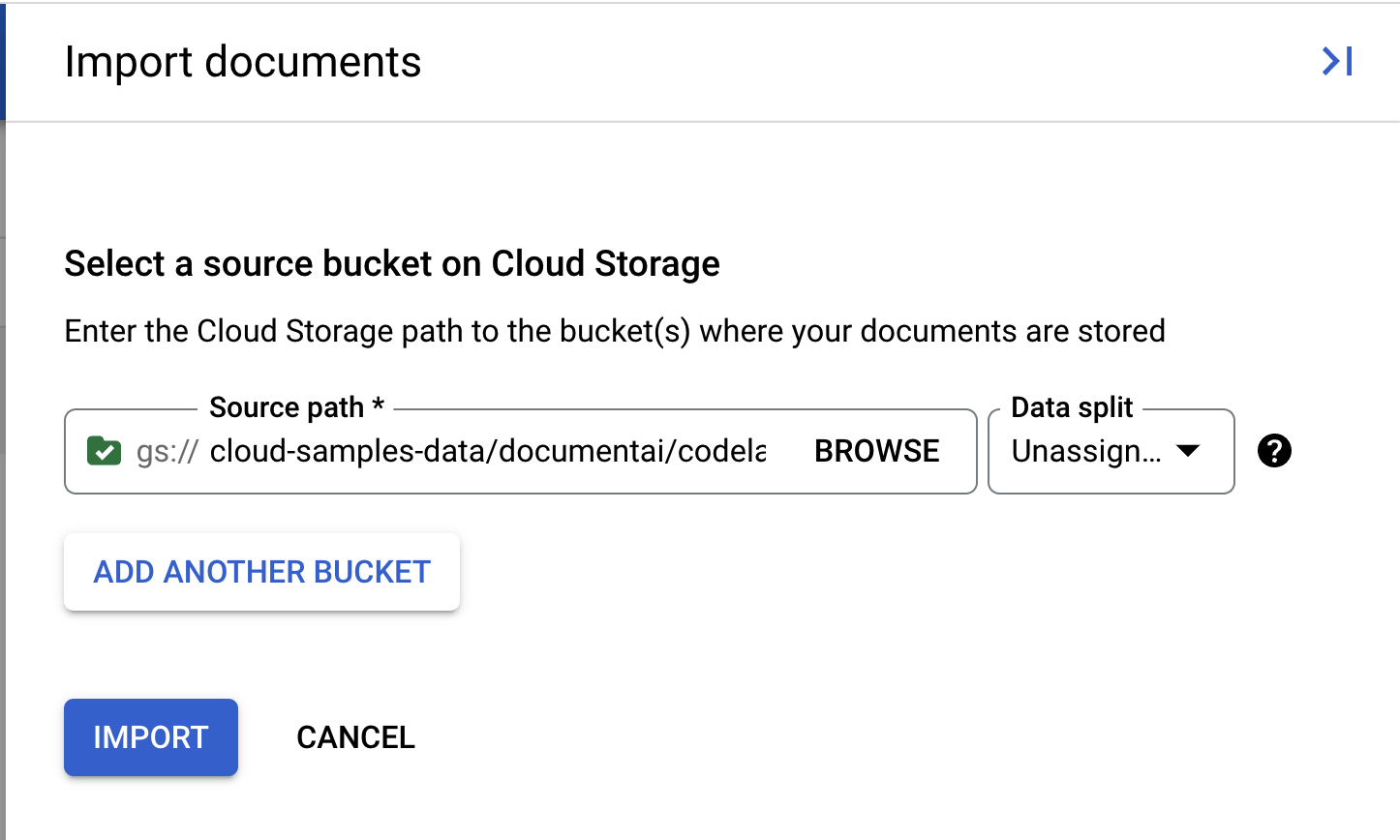
- 我們提供範例 PDF,供您在本實驗室中使用。複製下列連結並貼到「來源路徑」方塊中。目前請將「資料分割」保留為「未指派」。其他方塊則不勾選。按一下「匯入」。
cloud-samples-data/documentai/codelabs/custom/extractor/pdfs
- 等待系統匯入文件。這項作業應會在 1 分鐘內完成。
- 匯入完成後,您應該會在「Training」(訓練) 頁面中看到文件。
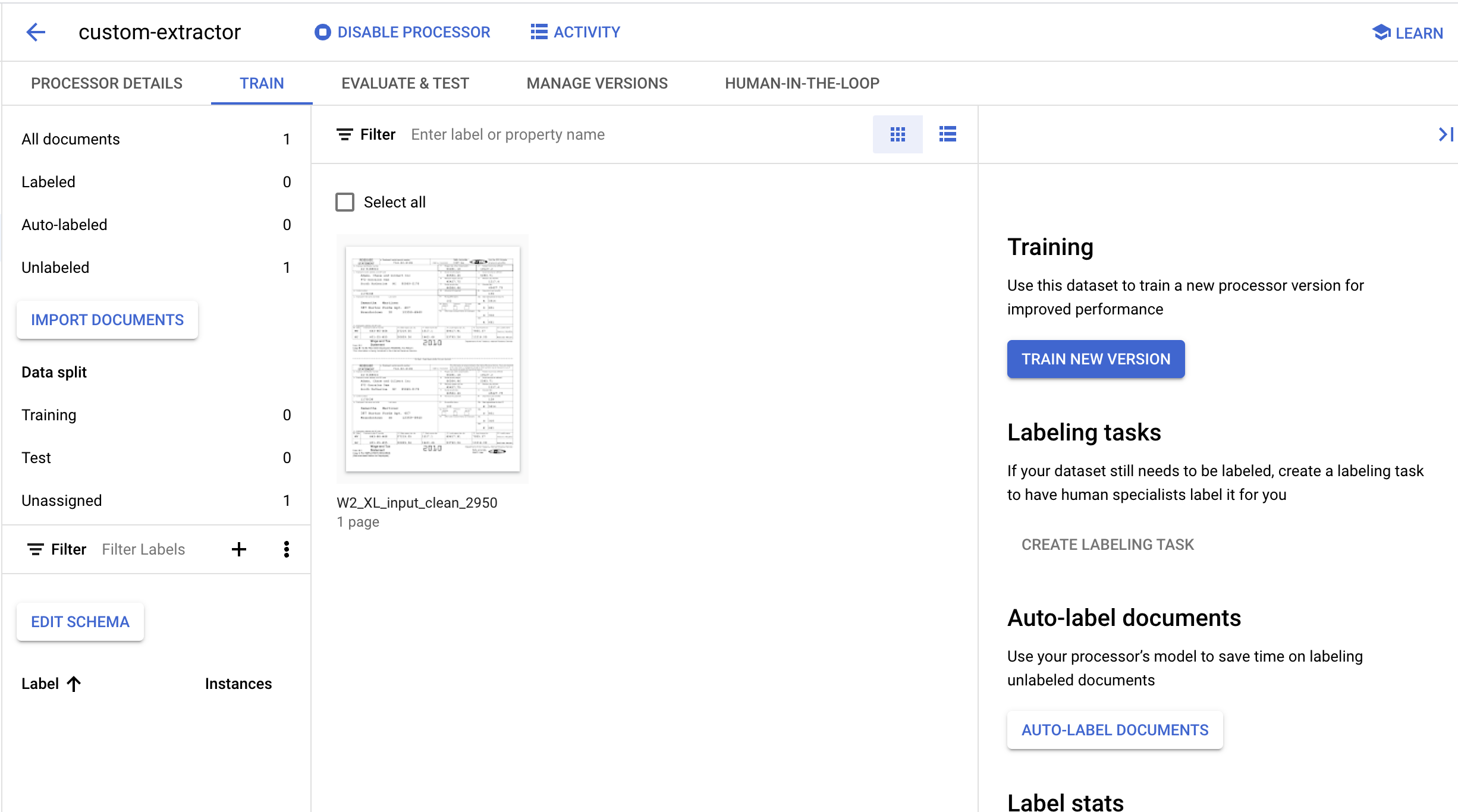
6. 建立標籤
由於我們要建立新的處理器類型,因此需要建立自訂標籤,告訴 Document AI 要擷取哪些欄位。
- 按一下左下角的「編輯結構定義」。
- 您現在應該已進入「架構管理」控制台。
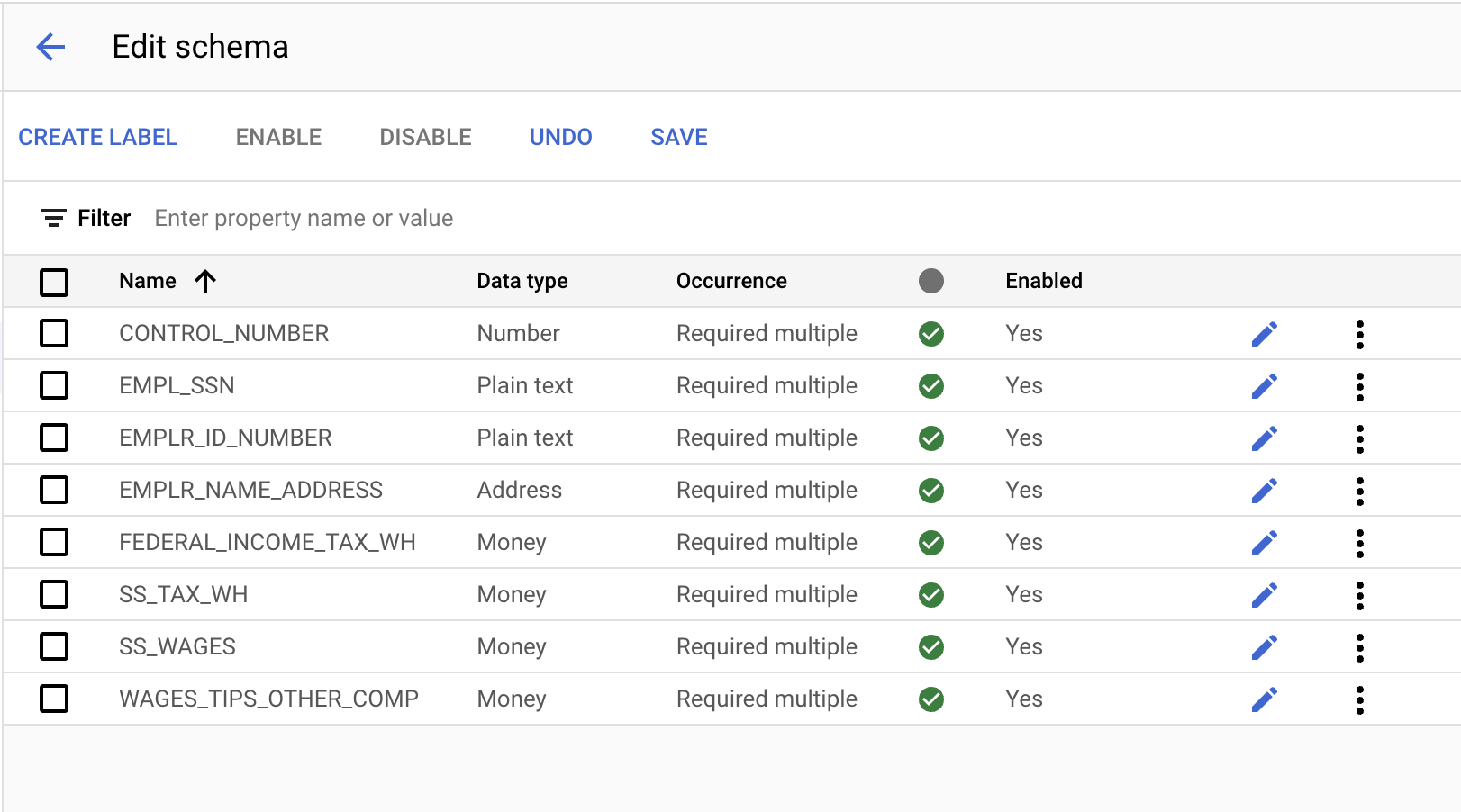
- 使用「建立標籤」按鈕建立下列標籤。
名稱 | 資料類型 | 發生次數 |
| 數字 | 必要 (可出現多次) |
| 純文字 | 必要 (可出現多次) |
| 純文字 | 必要 (可出現多次) |
| 地址 | 必要 (可出現多次) |
| 金額 | 必要 (可出現多次) |
| 金額 | 必要 (可出現多次) |
| 金額 | 必要 (可出現多次) |
| 金額 | 必要 (可出現多次) |
- 完成後,控制台應如下所示。完成後,請按一下「儲存」。
- 按一下返回箭頭,返回「訓練」頁面。請注意,我們建立的標籤會顯示在左下角。
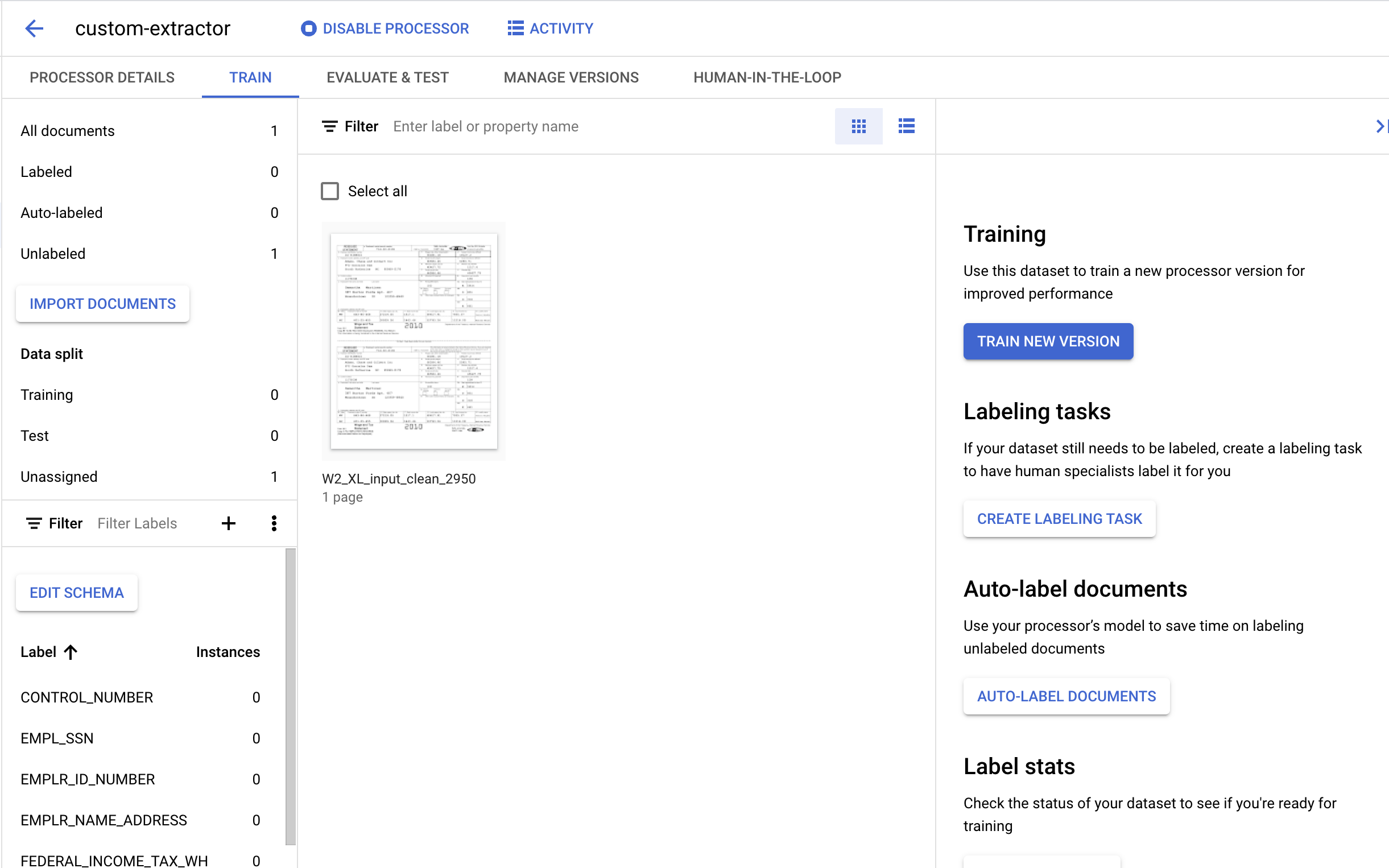
7. 為測試文件加上標籤
接著,我們會找出要擷取實體的文字元素和標籤。這些標籤將用於訓練模型,以便剖析這類特定文件結構並識別正確類型。
- 按兩下先前匯入的文件,即可進入標籤控制台。看起來應該會像這樣
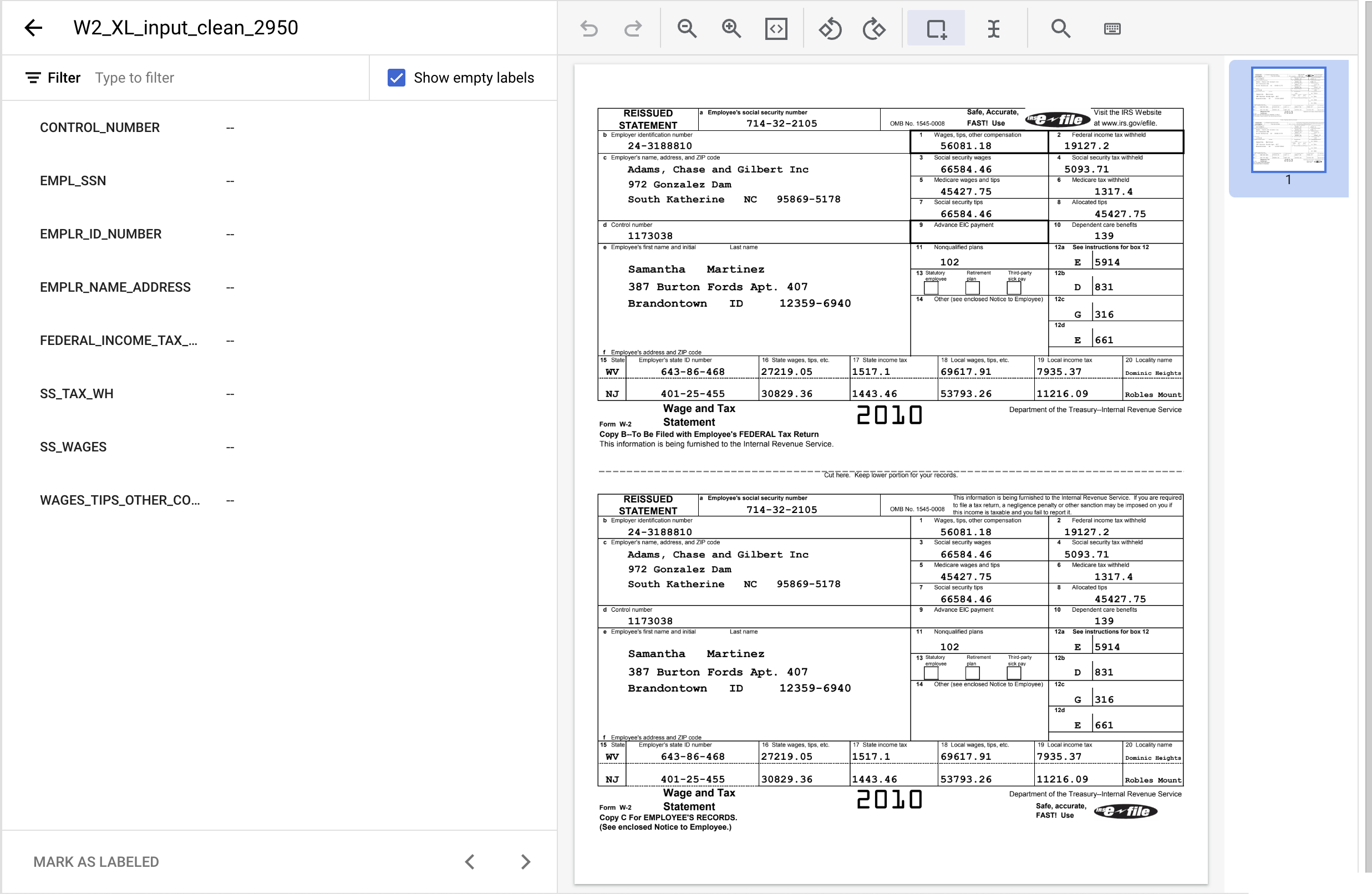
- 按一下「Bounding Box」工具,然後醒目顯示「1173038」文字,並指派
CONTROL_NUMBER標籤。您可以使用文字篩選器搜尋標籤名稱。
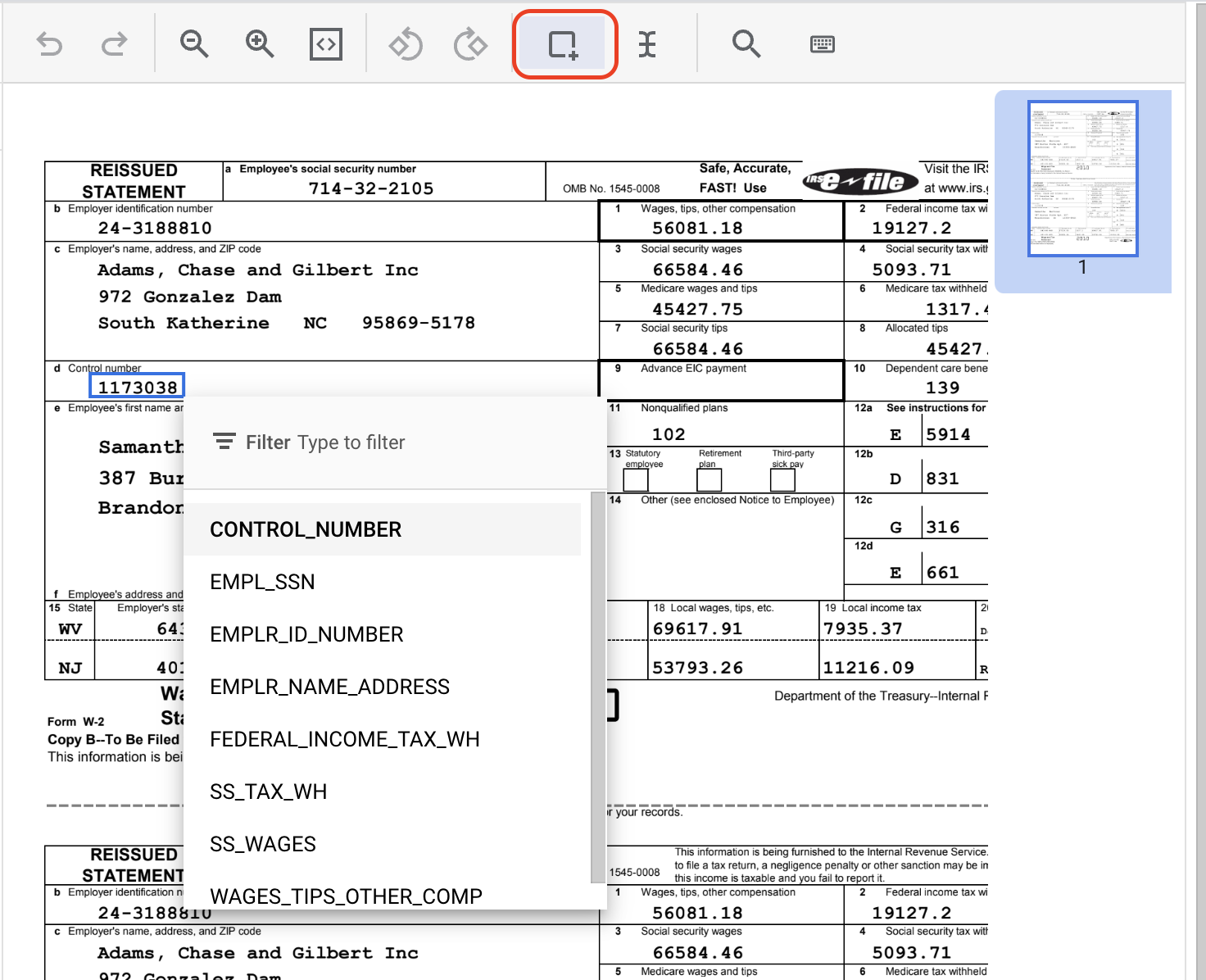
- 完成其他
CONTROL_NUMBER執行個體的標籤。標籤完成後應如下所示。
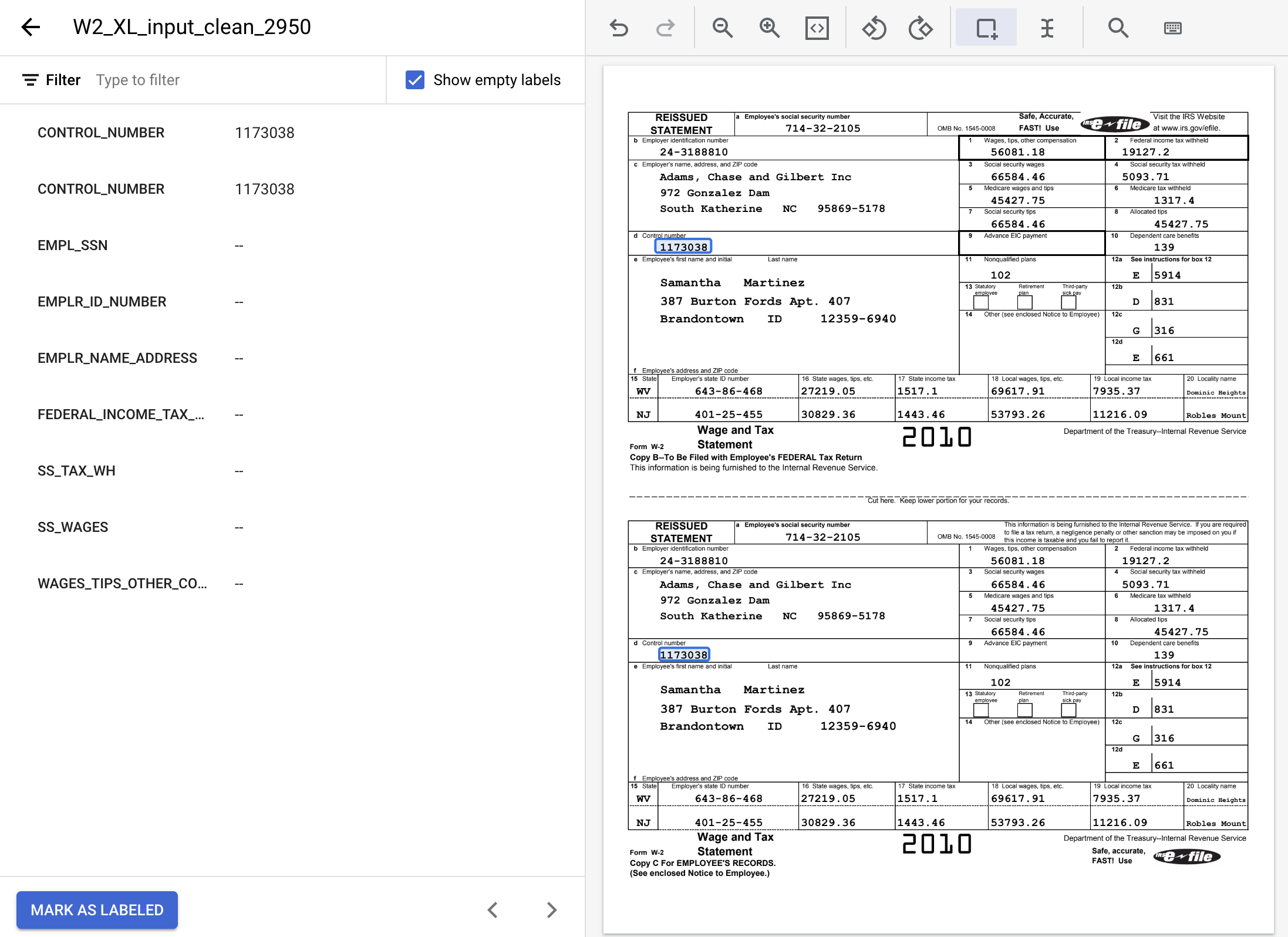
- 醒目顯示下列文字值的所有例項,並指派適當的標籤。
標籤名稱 | Text |
| 24-3188810 |
| 19127.2 |
| 5093.71 |
| 66584.46 |
| 56081.18 |
| 714-32-2105 |
| Adams, Chase and Gilbert Inc 972 Gonzalez Dam South Katherine NC 95869-5178 |
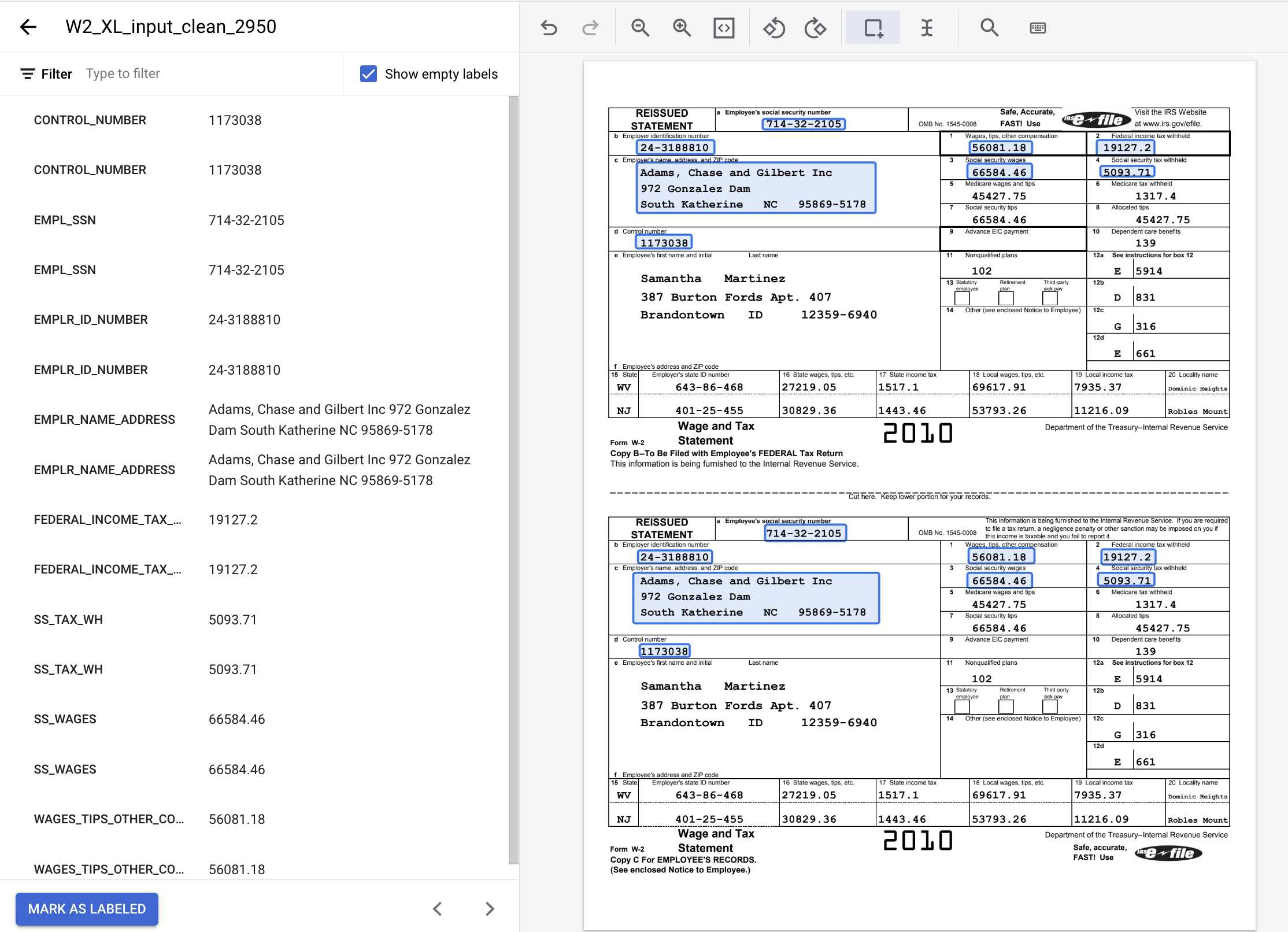
- 完成後,加上標籤的文件應如下所示。請注意,如要調整這些標籤,可以點選文件中的邊界方塊,或左側選單中的標籤名稱/值。完成標籤作業後,請按一下「Mark As Labeled」(標示為已加上標籤),然後返回資料集管理控制台。
8. 將文件指派給訓練集
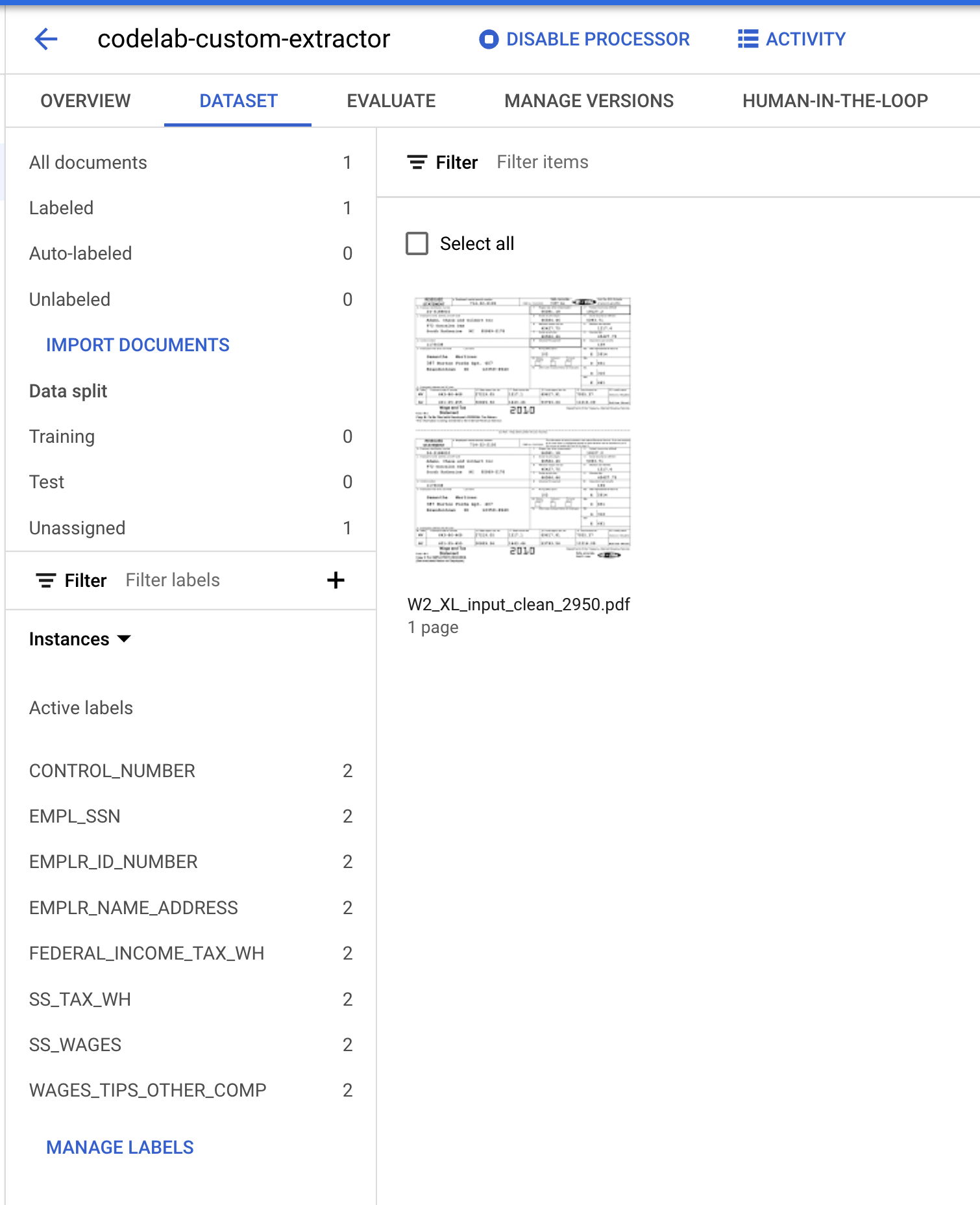
您現在應該會返回資料集管理控制台。請注意,標記和未標記的文件數量,以及每個標籤的例項數量都已變更。
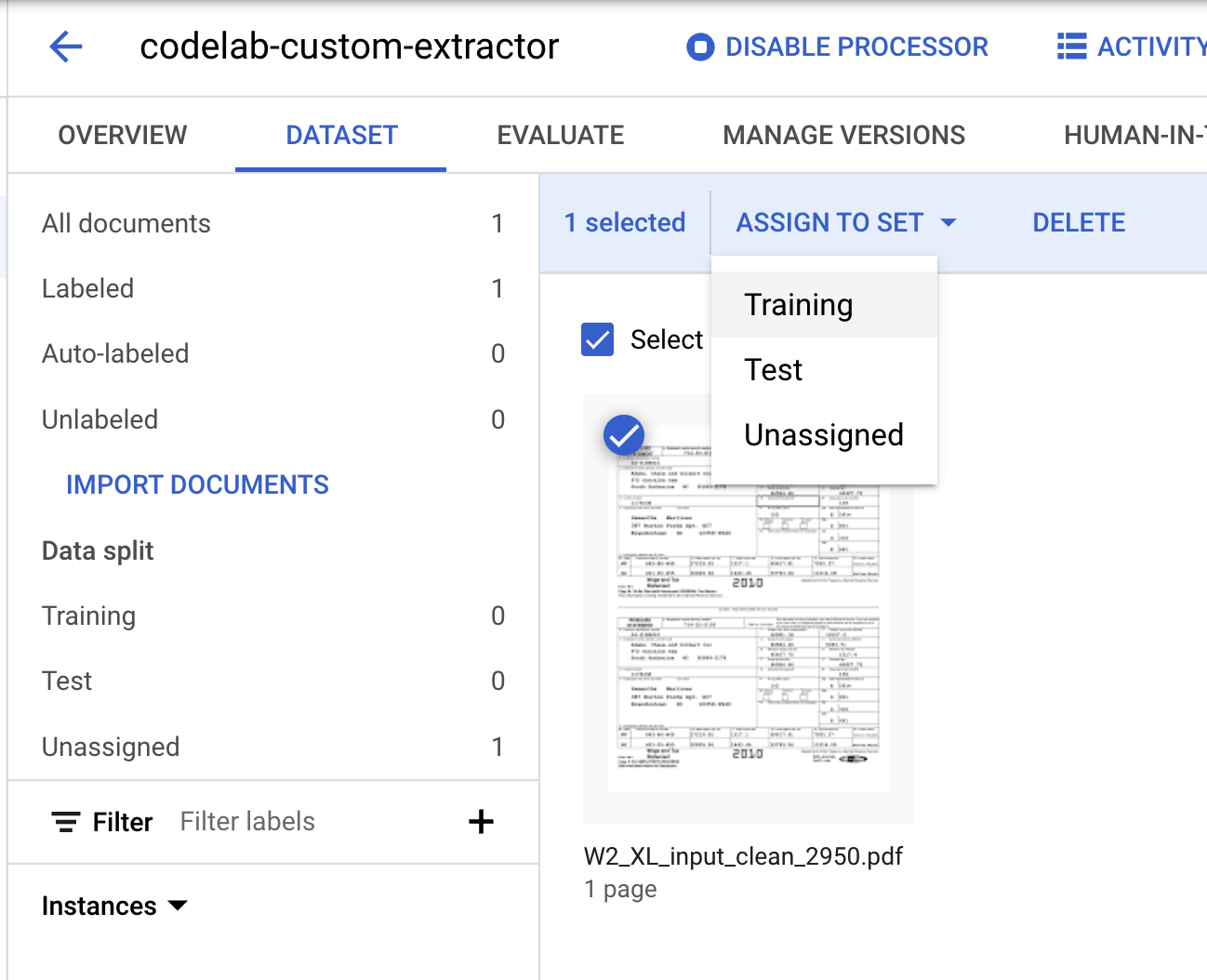
- 我們需要將這份文件指派給「訓練」或「測試」集。按一下文件,依序點選「指派給集合」和「訓練」。
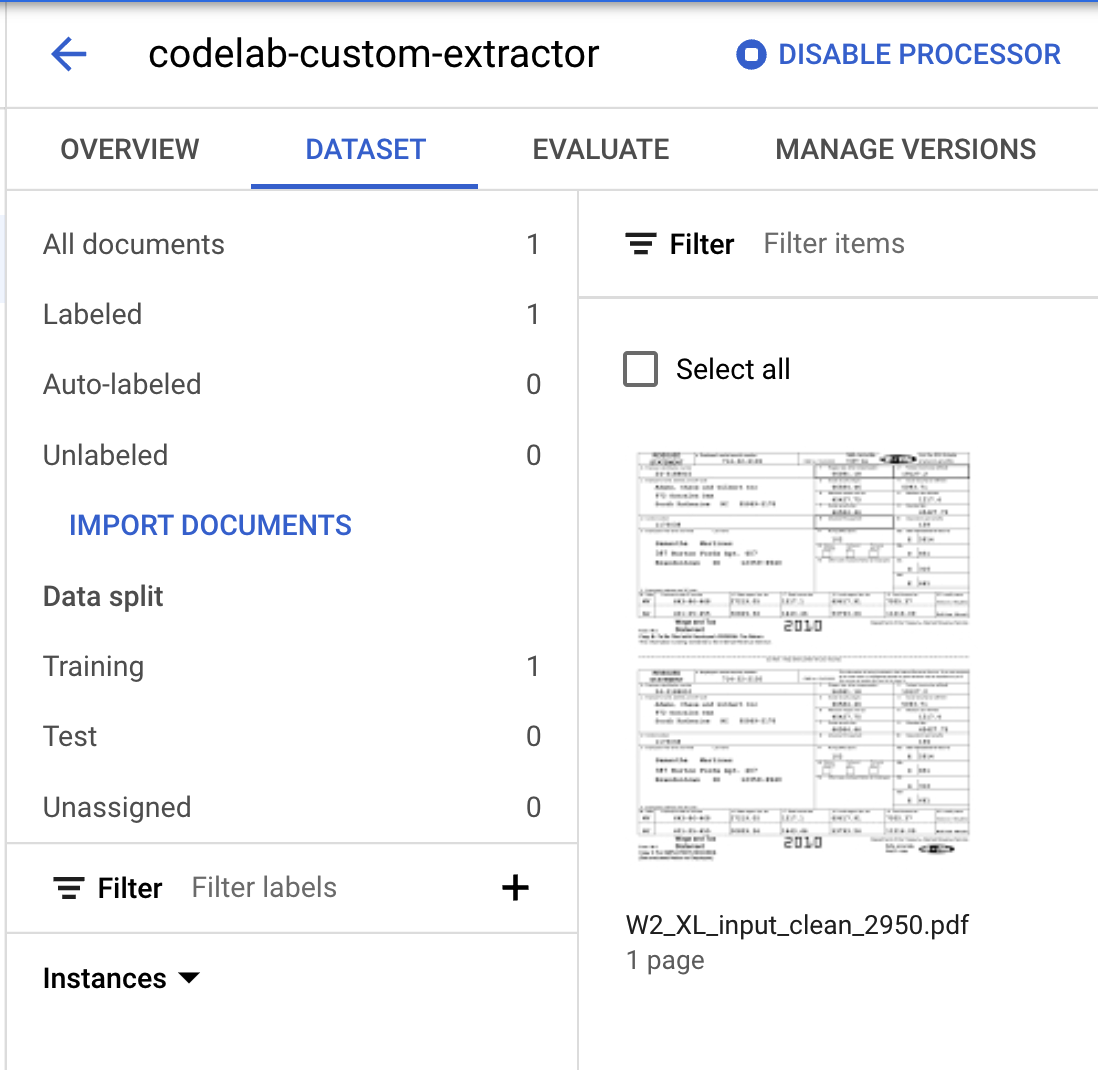
- 請注意,資料分割的數字已變更。
9. 匯入預先加上標籤的資料
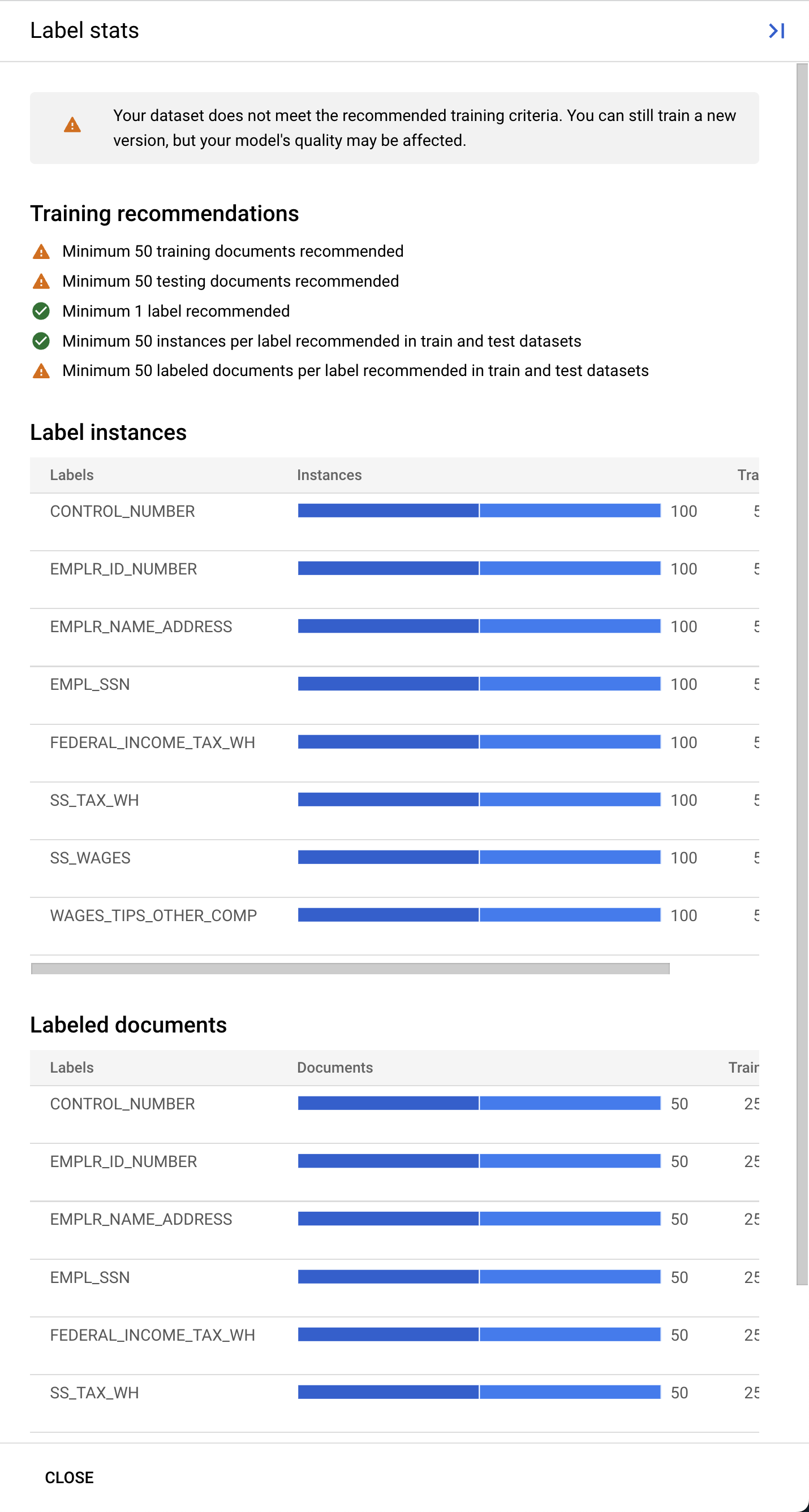
Document AI 自訂處理器在訓練集和測試集中至少需要 10 份文件,以及每個集合中每個標籤的 10 個執行個體。
建議您每個組合至少加入 50 份文件,每個標籤包含 50 個例項,以獲得最佳成效。訓練資料越多,通常就越準確。
手動為所有文件加上標籤需要很長時間,因此我們提供了一些預先加上標籤的文件,您可以在這個實驗室中匯入這些文件。
您可以匯入 Document.json 格式的預先標記文件檔案。這些結果可能來自於呼叫處理器,並使用人機迴圈 (HITL) 驗證準確度。
aside negative
注意:匯入預先標記的資料時,強烈建議在訓練模型前手動檢查註解。
- 按一下「匯入文件」。
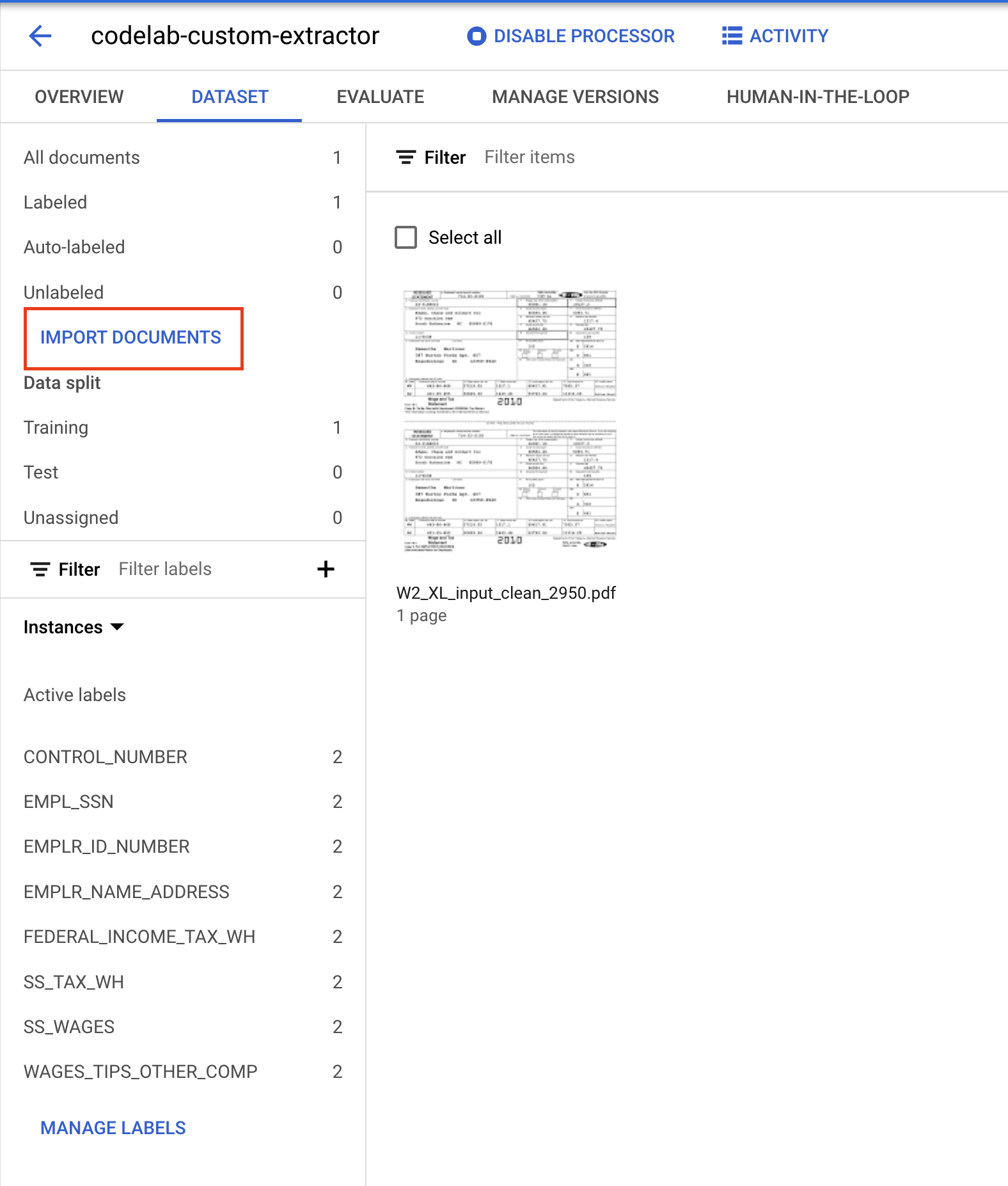
- 複製/貼上下列 Cloud Storage 路徑,並指派給「訓練」集。
cloud-samples-data/documentai/codelabs/custom/extractor/training
- 按一下「Add Another Folder」(新增其他資料夾)。然後複製/貼上下列 Cloud Storage 路徑,並指派給「測試」集。
cloud-samples-data/documentai/codelabs/custom/extractor/test
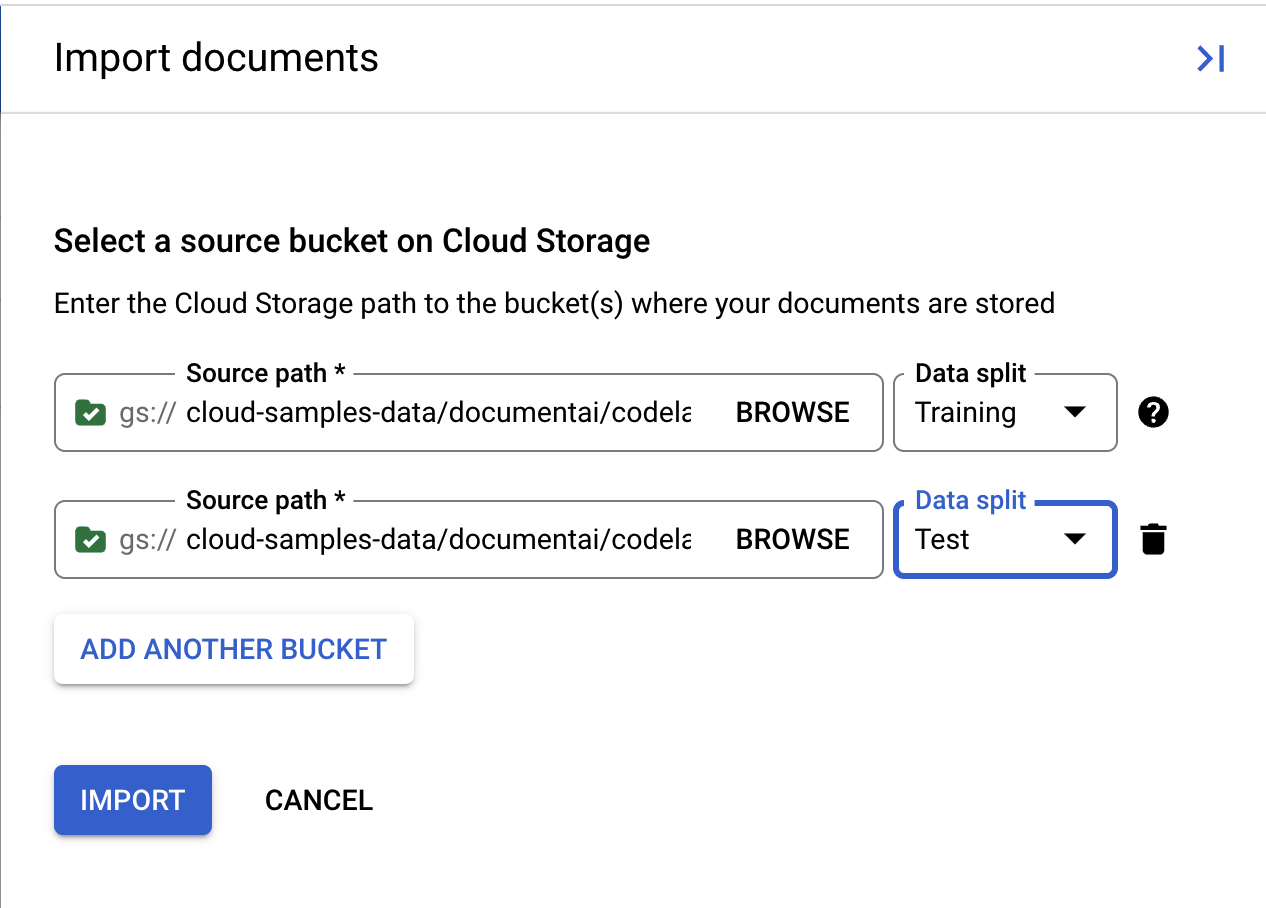
- 按一下「Import」(匯入),然後等待系統匯入文件。這次需要處理的文件較多,因此時間會比上次長。這項作業約耗時 6 分鐘,您可以先離開這個頁面,稍後再返回查看。
- 完成後,您應該會在「訓練」頁面看到這些文件。
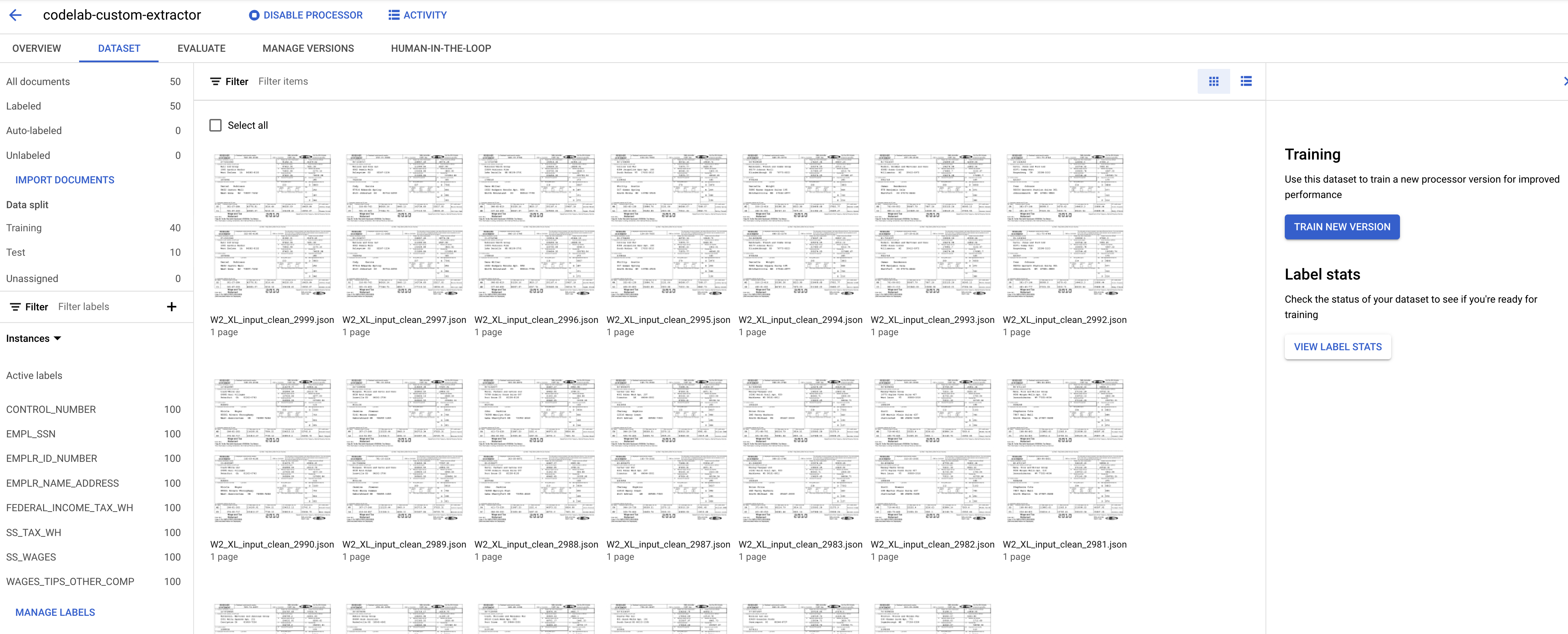
10. 訓練模型
現在,我們已準備好開始訓練自訂文件擷取器。
- 按一下「訓練新版本」
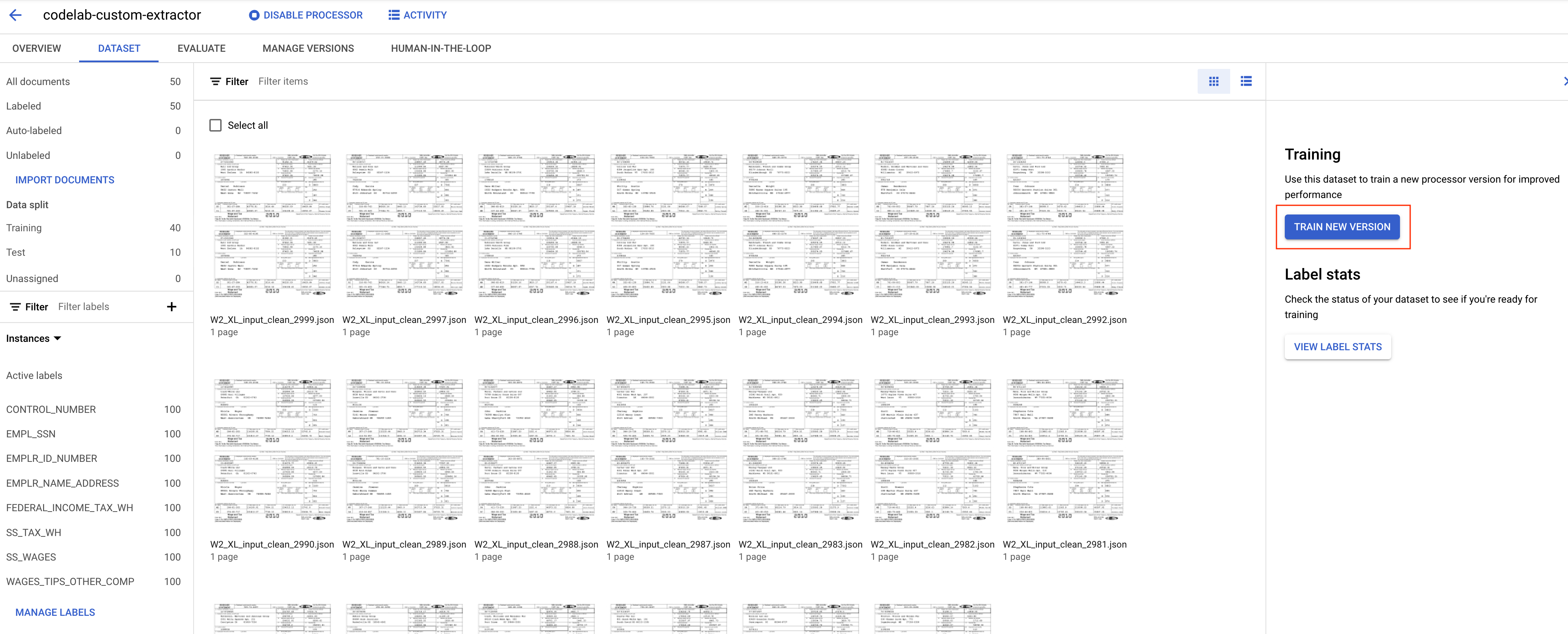
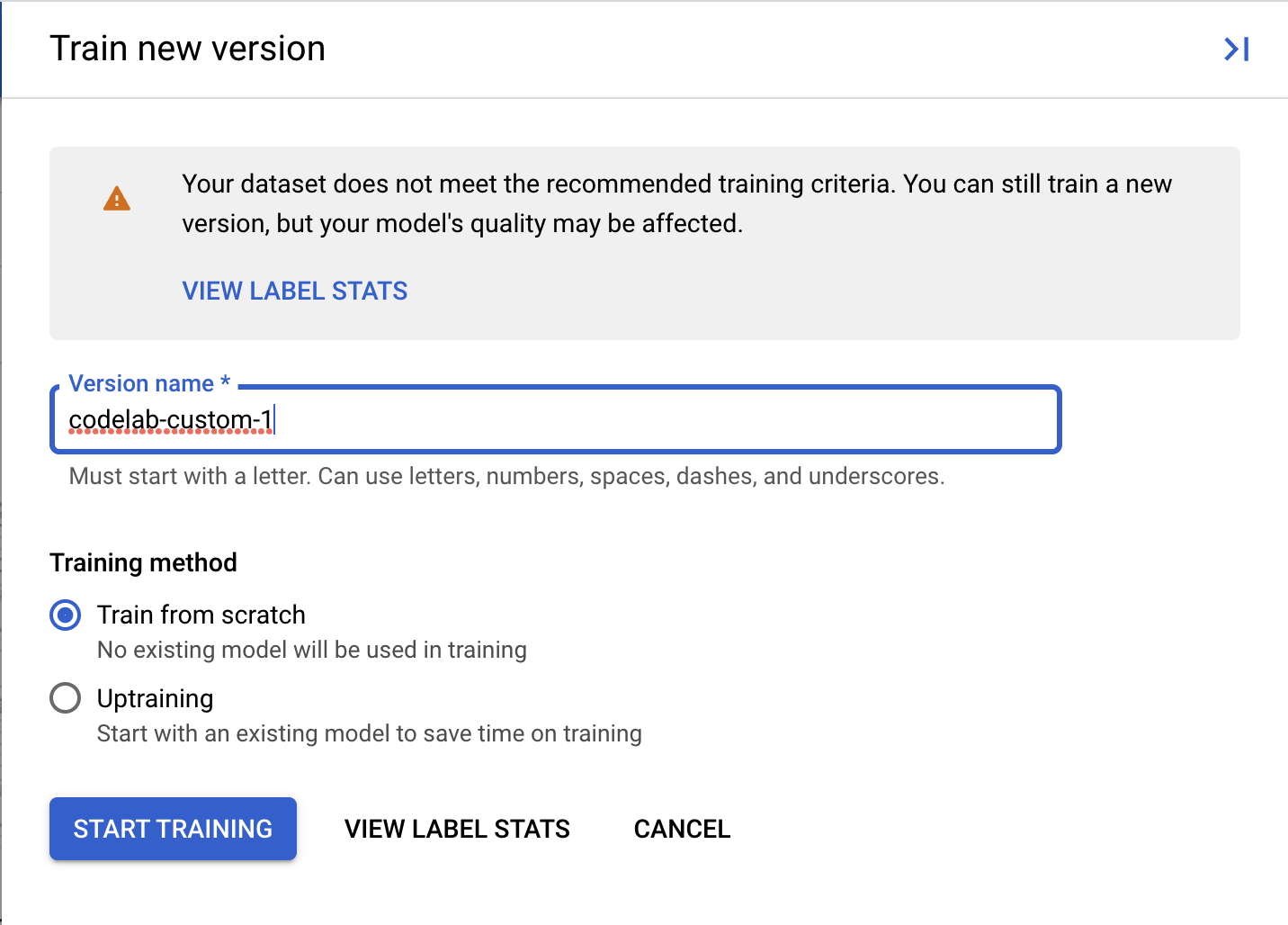
- 為版本命名,例如
codelab-custom-1。在「訓練方法」中,選取「從頭開始訓練」。
- (選用) 你也可以選取「查看標籤統計資料」,查看資料集中標籤的指標。
- 按一下「開始訓練」即可開始訓練程序。系統應會將您重新導向至「資料集管理」頁面。您可以在右側查看訓練狀態。訓練作業需要數小時才能完成。您可以先離開這個頁面,稍後再返回查看。
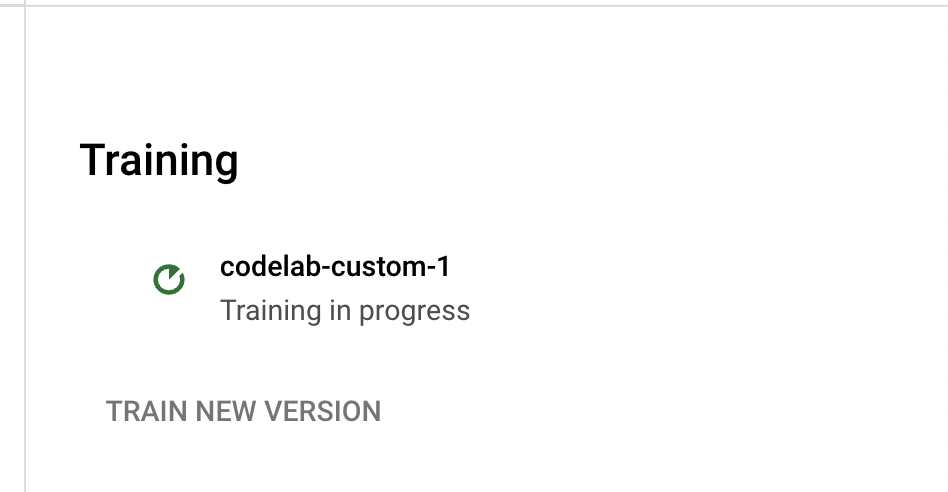
- 按一下版本名稱,系統會將您導向「管理版本」頁面,其中會顯示版本 ID 和訓練工作的目前狀態。
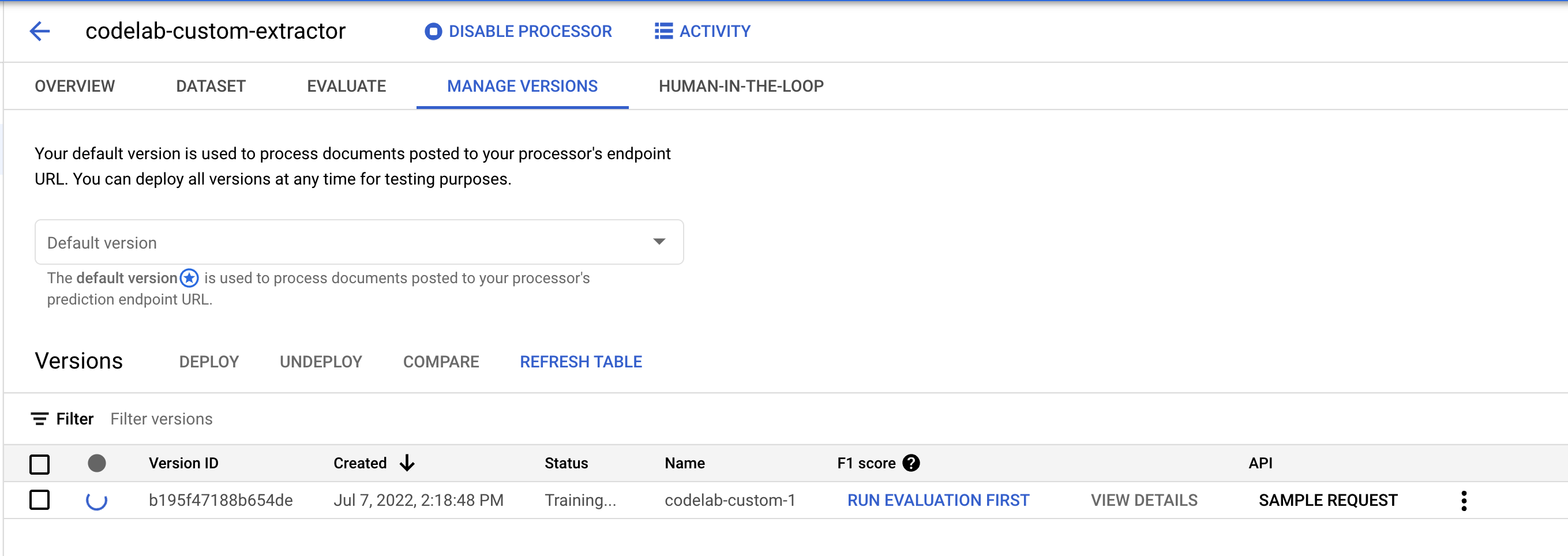
11. 測試新模型版本
訓練工作完成後 (在我的測試中約需 1 小時),您就可以測試新版模型,並開始用於預測。
- 前往「管理版本」頁面。您可以在這裡查看目前的狀態和 F1 分數。
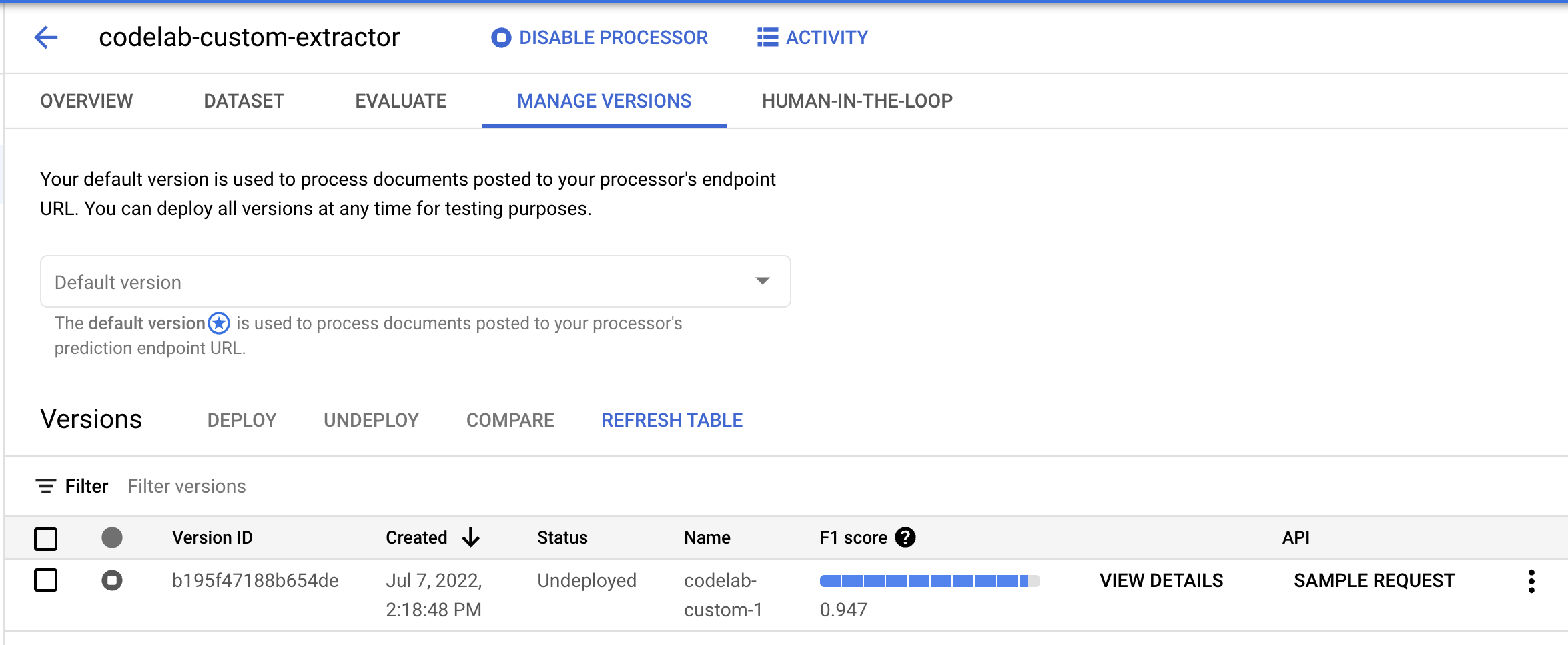
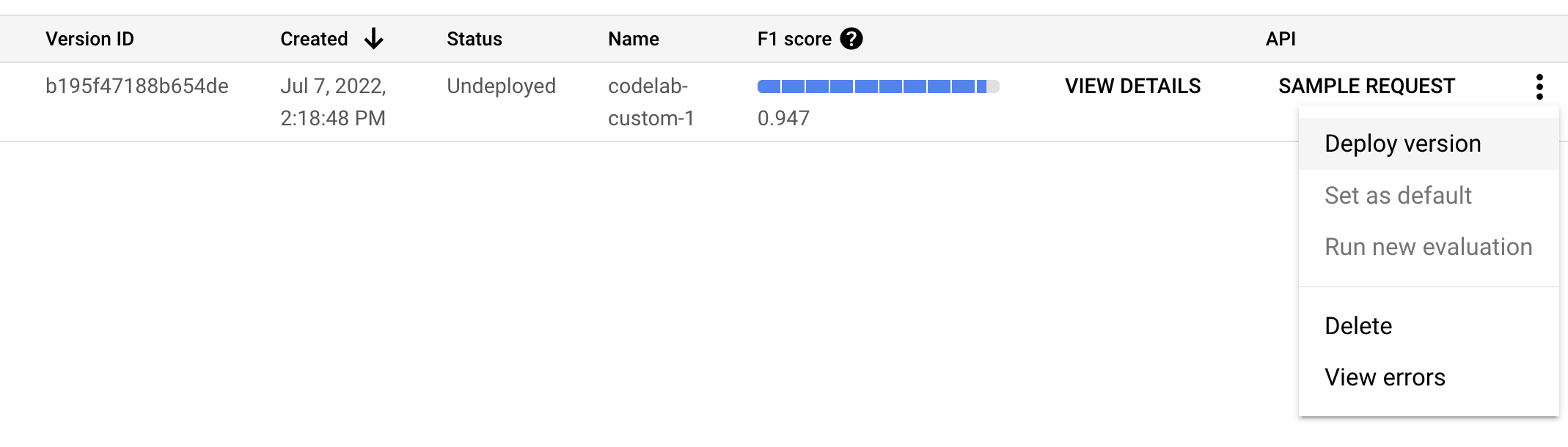
- 我們需要先部署這個模型版本,才能使用。按一下右側的垂直圓點,然後選取「Deploy Version」(部署版本)。
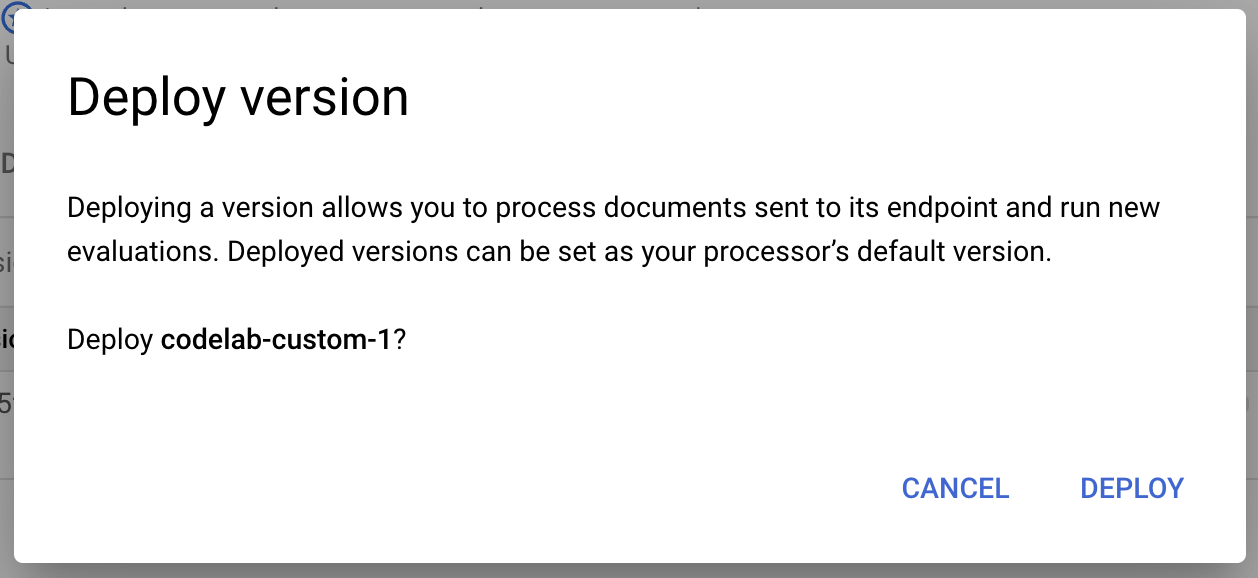
- 等待版本部署完成時,請從彈出式視窗中選取「Deploy」(部署)。這項作業要幾分鐘才能完成。部署完成後,您也可以將這個版本設為預設版本。
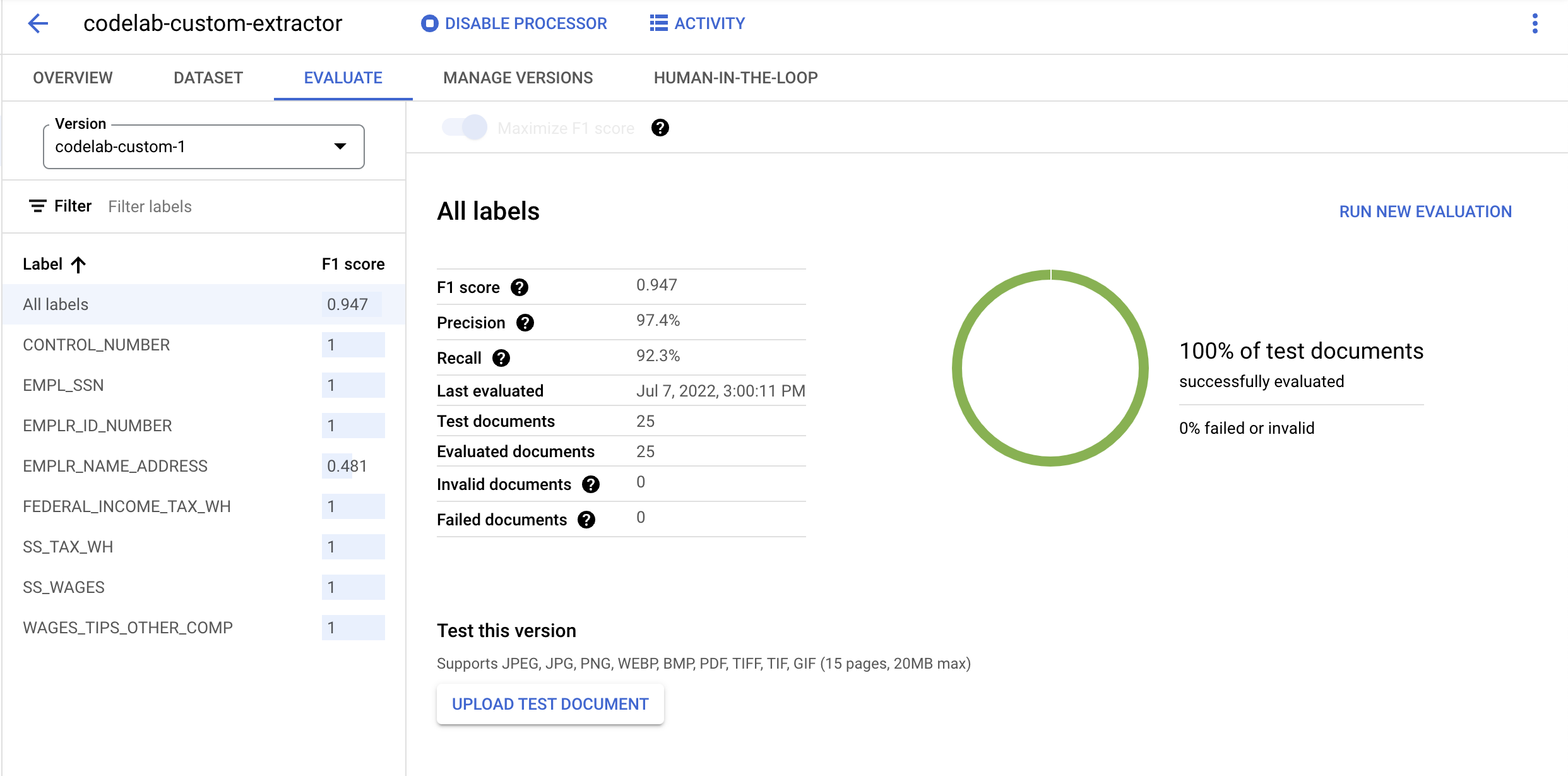
- 部署完成後,請前往「評估」分頁。在這個頁面中,您可以查看整份文件和個別標籤的評估指標,包括 F1 分數、精確度和召回率。如要進一步瞭解這些指標,請參閱 AutoML 說明文件。
- 下載下方連結的 PDF 檔案。這是未納入訓練集或測試集的 W2 樣本。
- 按一下「上傳測試文件」,然後選取 PDF 檔案。
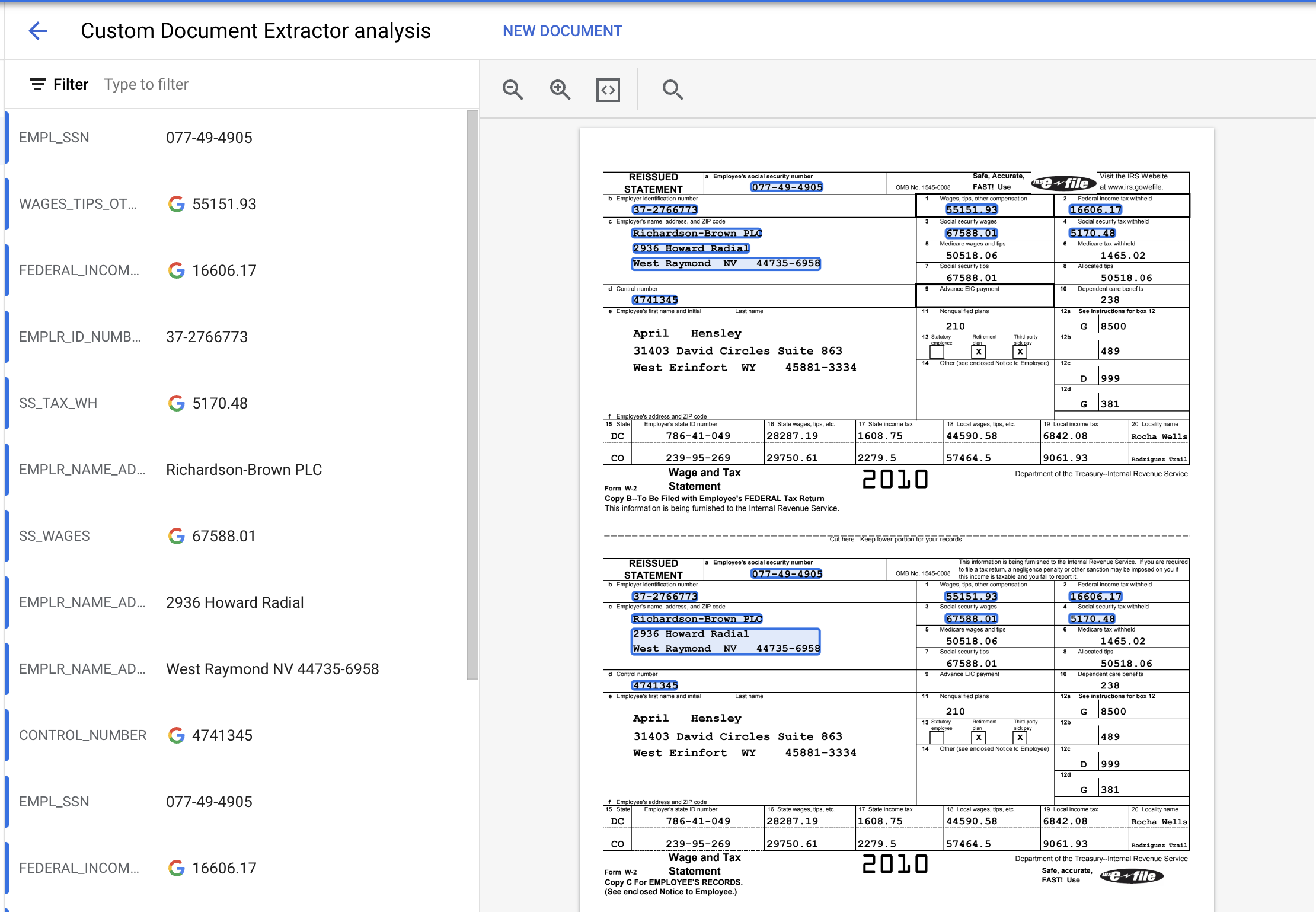
- 擷取的實體應如下所示。
12. 選用:自動為新匯入的文件加上標籤
部署經過訓練的處理器版本後,您可以在匯入新文件時使用自動加上標籤功能,節省標籤時間。
- 在「Train」(訓練) 頁面上,按一下「Import Documents」(匯入文件)。
- 複製及貼上下列 路徑。這個目錄包含 5 個未加上標籤的 W2 PDF。在「Data split」(資料分割) 下拉式清單中選取「Training」(訓練)。
cloud-samples-data/documentai/Custom/W2/AutoLabel - 在「自動加上標籤」專區中,勾選「使用自動加上標籤功能匯入」核取方塊。
- 選取現有的處理器版本來為文件加上標籤。
- 例如:
2af620b2fd4d1fcf
- 按一下「Import」(匯入),然後等待系統匯入文件。您可以先離開這個頁面,稍後再返回查看。
- 完成後,文件就會顯示在「Auto-labeling」(自動加上標籤) 區段的「Train」(訓練) 頁面中。
- 您不得將自動加上標籤的文件用於訓練或測試,除非您將其標示為已加上標籤。如要查看已自動加上標籤的文件,請前往「Auto-labeled」(已自動加上標籤) 專區。
- 選取第一份文件即可進入標籤控制台。
- 確認標籤、定界框和值是否正確。為省略的任何值加上標籤。
- 完成後,請選取「標示為已加上標籤」。
- 為每個自動加上標籤的文件重複執行標籤驗證,然後返回「Train」(訓練) 頁面來使用這些資料進行訓練。
13. 結語
恭喜!您已成功使用 Document AI 訓練自訂文件擷取器處理器。現在,就像使用任何專業處理器一樣,您可以透過這個處理器剖析這類格式的文件。
您可以參閱專業處理器程式碼研究室,瞭解如何處理處理回應。
清除
如要避免系統向您的 Google Cloud 帳戶收取您在本教學課程中所用資源的相關費用:
資源
- Document AI Workbench 說明文件
- The Future of Documents - YouTube 播放清單
- Document AI 說明文件
- Document AI Python 用戶端程式庫
- Document AI 範例
授權
這項內容採用的授權為 Creative Commons 姓名標示 2.0 通用授權。