
1. مقدمة
في هذا الدرس التطبيقي حول الترميز، ستتعلّم كيفية استخدام أدوات معالجة متخصّصة في Document AI لتصنيف المستندات المتخصّصة وتحليلها باستخدام لغة Python. بالنسبة إلى التصنيف والتقسيم، سنستخدم مثالاً لملف PDF يحتوي على فواتير وإيصالات وبيانات المرافق. بعد ذلك، سنستخدم فاتورة كمثال على التحليل واستخراج الكيانات.
سيعمل هذا الإجراء ورمز المثال مع أي مستند متخصص متوافق مع Document AI.
المتطلبات الأساسية
يستند هذا الدرس التطبيقي حول الترميز إلى المحتوى المقدَّم في دروس تطبيقية أخرى حول Document AI.
ننصحك بإكمال Codelabs التالية قبل المتابعة:
- التعرّف البصري على الأحرف (OCR) باستخدام Document AI وPython
- تحليل النماذج باستخدام Document AI (Python)
ما ستتعلمه
- كيفية تصنيف نقاط التقسيم وتحديدها للمستندات المتخصّصة
- كيفية استخراج الكيانات المنظَّمة باستخدام أدوات معالجة متخصّصة
المتطلبات
2. الإعداد
يفترض هذا الدرس العملي أنك أكملت خطوات إعداد Document AI المُدرَجة في الدرس العملي التمهيدي.
يُرجى إكمال الخطوات التالية قبل المتابعة:
عليك أيضًا تثبيت Pandas، وهي مكتبة شائعة لتحليل البيانات في Python.
pip3 install --upgrade pandas
3- إنشاء معالِجات متخصّصة
يجب أولاً إنشاء مثيلات للمعالِجات التي ستستخدمها في هذا البرنامج التعليمي.
- في وحدة التحكّم، انتقِل إلى نظرة عامة على منصة Document AI.
- انقر على إنشاء معالج، ثم انتقِل للأسفل إلى متخصّص واختَر أداة تقسيم مستندات الشراء.
- أدخِل الاسم "codelab-procurement-splitter" (أو أي اسم آخر يمكنك تذكّره) واختَر أقرب منطقة في القائمة.
- انقر على إنشاء لإنشاء المعالج.
- انسخ رقم تعريف المعالج. يجب استخدام هذا المعرّف في الرمز البرمجي لاحقًا.
- كرِّر الخطوات من 2 إلى 6 باستخدام محلّل الفواتير (الذي يمكنك تسميته "codelab-invoice-parser").
معالج الاختبار في وحدة التحكّم
يمكنك تجربة أداة "محلّل الفواتير" في وحدة التحكّم من خلال تحميل مستند.
انقر على "تحميل المستند" (Upload Document) واختَر فاتورة لتحليلها. يمكنك تنزيل نموذج الفاتورة هذا واستخدامه إذا لم يكن لديك نموذج متاح للاستخدام.

يجب أن تبدو مخرجاتك على هذا النحو:
4. تنزيل مستندات نموذجية
لدينا بعض المستندات النموذجية التي يمكن استخدامها في هذا الدرس التطبيقي.
يمكنك تنزيل ملفات PDF باستخدام الروابط التالية. بعد ذلك، حمِّلها إلى مثيل Cloud Shell.
بدلاً من ذلك، يمكنك تنزيلها من حزمة Cloud Storage العامة باستخدام gsutil.
gsutil cp gs://cloud-samples-data/documentai/codelabs/specialized-processors/procurement_multi_document.pdf .
gsutil cp gs://cloud-samples-data/documentai/codelabs/specialized-processors/google_invoice.pdf .
5- تصنيف المستندات وتقسيمها
في هذه الخطوة، ستستخدم واجهة برمجة التطبيقات للمعالجة على الإنترنت لتصنيف نقاط التقسيم المنطقية في مستند متعدّد الصفحات ورصدها.
يمكنك أيضًا استخدام واجهة برمجة التطبيقات للمعالجة الدفعية إذا أردت إرسال ملفات متعددة أو إذا كان حجم الملف يتجاوز الحدّ الأقصى لعدد الصفحات في المعالجة على الإنترنت. يمكنك مراجعة كيفية إجراء ذلك في الدرس التطبيقي حول الترميز الخاص بتقنية التعرّف البصري على الأحرف في Document AI.
إنّ الرمز البرمجي لإجراء طلب بيانات من واجهة برمجة التطبيقات هو نفسه بالنسبة إلى معالج عام باستثناء معرّف المعالج.
أداة تقسيم/تصنيف عمليات الشراء
أنشئ ملفًا باسم classification.py واستخدِم الرمز البرمجي أدناه.
استبدِل PROCUREMENT_SPLITTER_ID بمعرّف أداة معالجة تقسيم المشتريات التي أنشأتها سابقًا. استبدِل YOUR_PROJECT_ID وYOUR_PROJECT_LOCATION برقم تعريف مشروعك على Cloud وموقع المعالج على التوالي.
classification.py
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as file:
file_content = file.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=file_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(name=resource_name, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "PROCUREMENT_SPLITTER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "procurement_multi_document.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
print("Document processing complete.")
types = []
confidence = []
pages = []
# Each Document.entity is a classification
for entity in document.entities:
classification = entity.type_
types.append(classification)
confidence.append(f"{entity.confidence:.0%}")
# entity.page_ref contains the pages that match the classification
pages_list = []
for page_ref in entity.page_anchor.page_refs:
pages_list.append(page_ref.page)
pages.append(pages_list)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame({"Classification": types, "Confidence": confidence, "Pages": pages})
print(df)
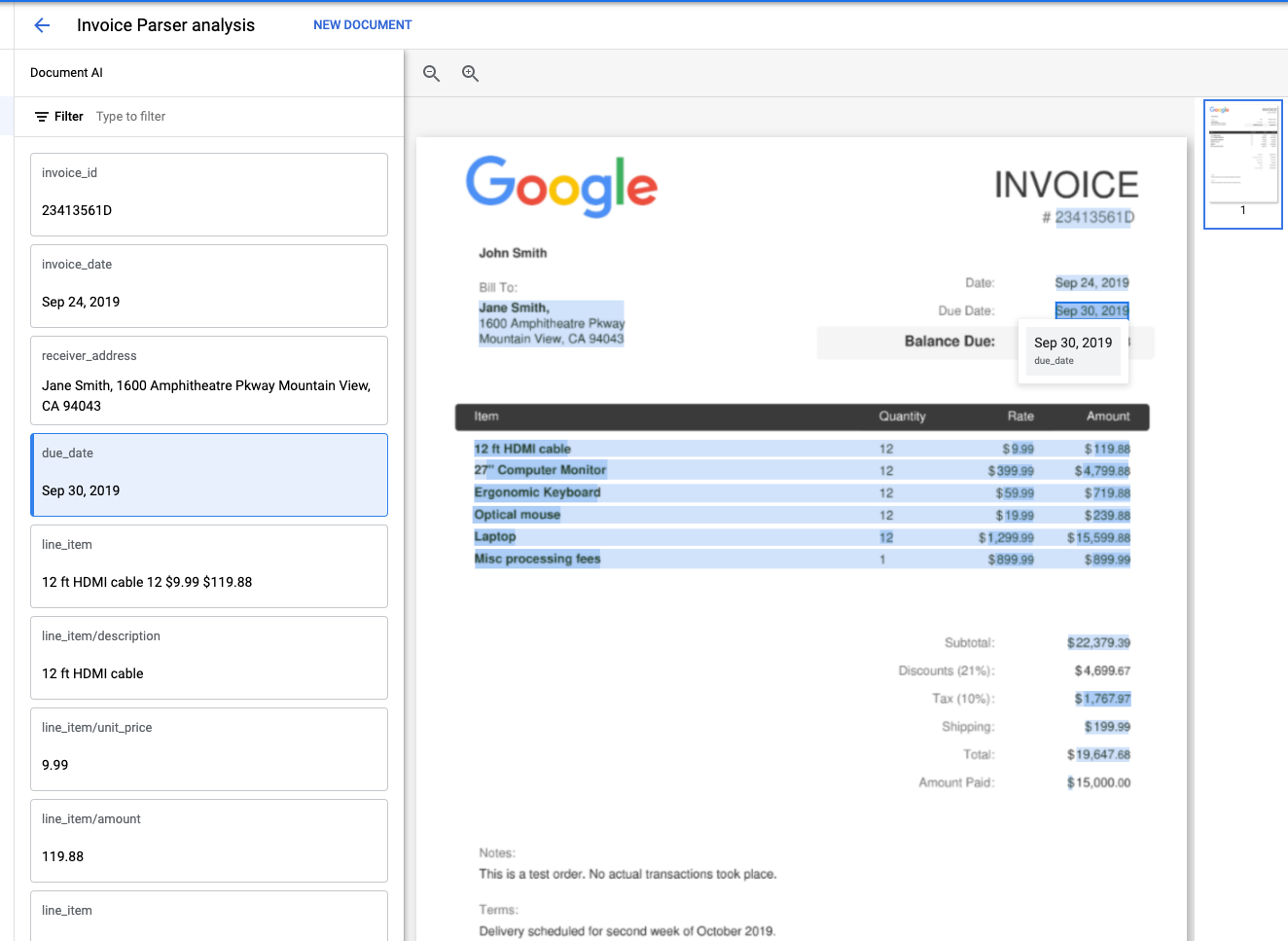
يجب أن تبدو مخرجاتك على النحو التالي:
$ python3 classification.py
Document processing complete.
Classification Confidence Pages
0 invoice_statement 100% [0]
1 receipt_statement 98% [1]
2 other 81% [2]
3 utility_statement 100% [3]
4 restaurant_statement 100% [4]
لاحظ أنّ أداة تقسيم/تصنيف مستندات الشراء حدّدت بشكل صحيح أنواع المستندات في الصفحات من 0 إلى 1 ومن 3 إلى 4.
تحتوي الصفحة 2 على نموذج عام لجمع المعلومات الطبية، لذا صنّفها المصنّف بشكل صحيح على أنّها other.
6. استخراج الكيانات
يمكنك الآن استخراج الكيانات المخطّطة من الملفات، بما في ذلك نتائج الثقة والخصائص والقيم العادية.
إنّ الرمز البرمجي لإجراء طلب البيانات من واجهة برمجة التطبيقات مطابق للخطوة السابقة، ويمكن إجراء ذلك باستخدام الطلبات على الإنترنت أو الطلبات المجمّعة.
سنصل إلى المعلومات التالية من الجهات:
- نوع الكيان
- (مثل
invoice_date،receiver_name،total_amount)
- (مثل
- القيم الأولية
- قيم البيانات كما تظهر في ملف المستند الأصلي
- القيم العادية
- قيم البيانات بتنسيق موحّد وعادي، إذا كان ذلك منطبقًا
- يمكن أن يشمل أيضًا تحسينات من الرسم البياني المعرفي للمؤسسات
- قيم الثقة
- مدى "تأكّد" النموذج من دقة القيم
يمكن أن تتضمّن بعض أنواع الكيانات، مثل line_item، سمات، وهي كيانات مدمجة مثل line_item/unit_price وline_item/description.
يعمل هذا المثال على تسوية البنية المتداخلة لتسهيل العرض.
أداة تحليل الفواتير
أنشئ ملفًا باسم extraction.py واستخدِم الرمز البرمجي أدناه.
استبدِل INVOICE_PARSER_ID بمعرّف معالج "محلّل الفواتير" الذي أنشأته سابقًا واستخدِم الملف google_invoice.pdf
extraction.py
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as file:
file_content = file.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=file_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(name=resource_name, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "INVOICE_PARSER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "google_invoice.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
types = []
raw_values = []
normalized_values = []
confidence = []
# Grab each key/value pair and their corresponding confidence scores.
for entity in document.entities:
types.append(entity.type_)
raw_values.append(entity.mention_text)
normalized_values.append(entity.normalized_value.text)
confidence.append(f"{entity.confidence:.0%}")
# Get Properties (Sub-Entities) with confidence scores
for prop in entity.properties:
types.append(prop.type_)
raw_values.append(prop.mention_text)
normalized_values.append(prop.normalized_value.text)
confidence.append(f"{prop.confidence:.0%}")
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame(
{
"Type": types,
"Raw Value": raw_values,
"Normalized Value": normalized_values,
"Confidence": confidence,
}
)
print(df)
يجب أن تبدو مخرجاتك على النحو التالي:
$ python3 extraction.py
Type Raw Value Normalized Value Confidence
0 vat $1,767.97 100%
1 vat/tax_amount $1,767.97 1767.97 USD 0%
2 invoice_date Sep 24, 2019 2019-09-24 99%
3 due_date Sep 30, 2019 2019-09-30 99%
4 total_amount 19,647.68 19647.68 97%
5 total_tax_amount $1,767.97 1767.97 USD 92%
6 net_amount 22,379.39 22379.39 91%
7 receiver_name Jane Smith, 83%
8 invoice_id 23413561D 67%
9 receiver_address 1600 Amphitheatre Pkway\nMountain View, CA 94043 66%
10 freight_amount $199.99 199.99 USD 56%
11 currency $ USD 53%
12 supplier_name John Smith 19%
13 purchase_order 23413561D 1%
14 receiver_tax_id 23413561D 0%
15 supplier_iban 23413561D 0%
16 line_item 9.99 12 12 ft HDMI cable 119.88 100%
17 line_item/unit_price 9.99 9.99 90%
18 line_item/quantity 12 12 77%
19 line_item/description 12 ft HDMI cable 39%
20 line_item/amount 119.88 119.88 92%
21 line_item 12 399.99 27" Computer Monitor 4,799.88 100%
22 line_item/quantity 12 12 80%
23 line_item/unit_price 399.99 399.99 91%
24 line_item/description 27" Computer Monitor 15%
25 line_item/amount 4,799.88 4799.88 94%
26 line_item Ergonomic Keyboard 12 59.99 719.88 100%
27 line_item/description Ergonomic Keyboard 32%
28 line_item/quantity 12 12 76%
29 line_item/unit_price 59.99 59.99 92%
30 line_item/amount 719.88 719.88 94%
31 line_item Optical mouse 12 19.99 239.88 100%
32 line_item/description Optical mouse 26%
33 line_item/quantity 12 12 78%
34 line_item/unit_price 19.99 19.99 91%
35 line_item/amount 239.88 239.88 94%
36 line_item Laptop 12 1,299.99 15,599.88 100%
37 line_item/description Laptop 83%
38 line_item/quantity 12 12 76%
39 line_item/unit_price 1,299.99 1299.99 90%
40 line_item/amount 15,599.88 15599.88 94%
41 line_item Misc processing fees 899.99 899.99 1 100%
42 line_item/description Misc processing fees 22%
43 line_item/unit_price 899.99 899.99 91%
44 line_item/amount 899.99 899.99 94%
45 line_item/quantity 1 1 63%
7. اختياري: تجربة معالِجات متخصّصة أخرى
لقد استخدمت ميزة Document AI للمشتريات بنجاح لتصنيف المستندات وتحليل الفواتير. تتيح Document AI أيضًا استخدام الحلول المتخصصة الأخرى المدرَجة هنا:
يمكنك اتّباع الإجراء نفسه واستخدام الرمز نفسه للتعامل مع أي معالج متخصص.
إذا أردت تجربة الحلول المتخصّصة الأخرى، يمكنك إعادة تشغيل المختبر باستخدام أنواع معالجات أخرى ومستندات نموذجية متخصّصة.
مستندات نموذجية
في ما يلي بعض المستندات النموذجية التي يمكنك استخدامها لتجربة أدوات المعالجة المتخصّصة الأخرى.
Solution | نوع المعالج | المستند |
الهوية | ||
إقراض | ||
إقراض | ||
عقود |
يمكنك العثور على مستندات نموذجية أخرى ونتائج المعالجة في المستندات.
8. تهانينا
تهانينا، لقد استخدمت Document AI بنجاح لتصنيف البيانات واستخراجها من المستندات المتخصّصة. ننصحك بتجربة أنواع أخرى من المستندات المتخصصة.
تنظيف
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد المستخدَمة في هذا البرنامج التعليمي، اتّبِع الخطوات التالية:
- في Cloud Console، انتقِل إلى صفحة إدارة الموارد.
- في قائمة المشاريع، اختَر مشروعك ثم انقر على "حذف".
- في مربّع الحوار، اكتب رقم تعريف المشروع، ثم انقر على "إيقاف" لحذف المشروع.
مزيد من المعلومات
يمكنك مواصلة التعرّف على Document AI من خلال تجربة Codelabs التالية.
- إدارة معالِجات Document AI باستخدام Python
- Document AI: Human in the Loop
- Document AI Workbench: Uptraining
- Document AI Workbench: أدوات معالجة مخصّصة
المراجع
- مستقبل المستندات - قائمة تشغيل على YouTube
- مستندات Document AI
- مكتبة برامج Document AI Python
- أمثلة على Document AI
الترخيص
يخضع هذا العمل لترخيص المشاع الإبداعي مع نسب العمل إلى مؤلفه 2.0 Generic License.