
1. مقدمة
Document AI هو حلّ لفهم المستندات يستند إلى بيانات غير منظَّمة، مثل المستندات والرسائل الإلكترونية وما إلى ذلك، ويسهّل فهم البيانات وتحليلها واستخدامها.
باستخدام Document AI Workbench، يمكنك تحقيق دقة أعلى في معالجة المستندات من خلال إنشاء نماذج مخصّصة بالكامل باستخدام بيانات التدريب الخاصة بك.
في هذا الدرس التطبيقي، ستنشئ معالجًا مخصّصًا لاستخراج المستندات، وتستورد مجموعة بيانات، وتصنّف مستندات الأمثلة، وتدرّب المعالج.
مجموعة بيانات المستندات المستخدَمة في هذا المختبر مأخوذة من مجموعة بيانات نموذج W-2 مزيّف (نموذج الإقرار الضريبي الأمريكي) على Kaggle بموجب ترخيص CC0: Public Domain License.
المتطلبات الأساسية
يستند هذا الدرس التطبيقي حول الترميز إلى المحتوى المقدَّم في دروس تطبيقية أخرى حول Document AI.
ننصحك بإكمال Codelabs التالية قبل المتابعة.
- التعرّف البصري على الأحرف (OCR) باستخدام Document AI (Python)
- تحليل النماذج باستخدام Document AI (Python)
- المعالِجات المتخصّصة باستخدام Document AI (Python)
- إدارة معالِجات Document AI باستخدام Python
- Document AI: Human in the Loop
- Document AI: Uptraining
ما ستتعلمه
- أنشئ معالجًا مخصّصًا لاستخراج المستندات.
- تصنيف بيانات تدريب Document AI باستخدام أداة التعليق التوضيحي
- تدريب إصدار جديد من النموذج
- قيِّم دقة إصدار النموذج الجديد.
المتطلبات
2. الإعداد
يفترض هذا الدرس العملي أنك أكملت خطوات إعداد Document AI المُدرَجة في الدرس العملي التمهيدي.
يُرجى إكمال الخطوات التالية قبل المتابعة:
3- إنشاء معالج
يجب أولاً إنشاء معالج "أداة استخراج المستندات المخصّصة" لاستخدامه في هذا المختبر.
- في وحدة التحكّم، انتقِل إلى صفحة نظرة عامة على Document AI.

- انقر على إنشاء معالج مخصّص واختَر أداة استخراج المستندات المخصّصة.

- أدخِل الاسم
codelab-custom-extractor(أو أي اسم آخر يمكنك تذكُّره) واختَر المنطقة الأقرب في القائمة.
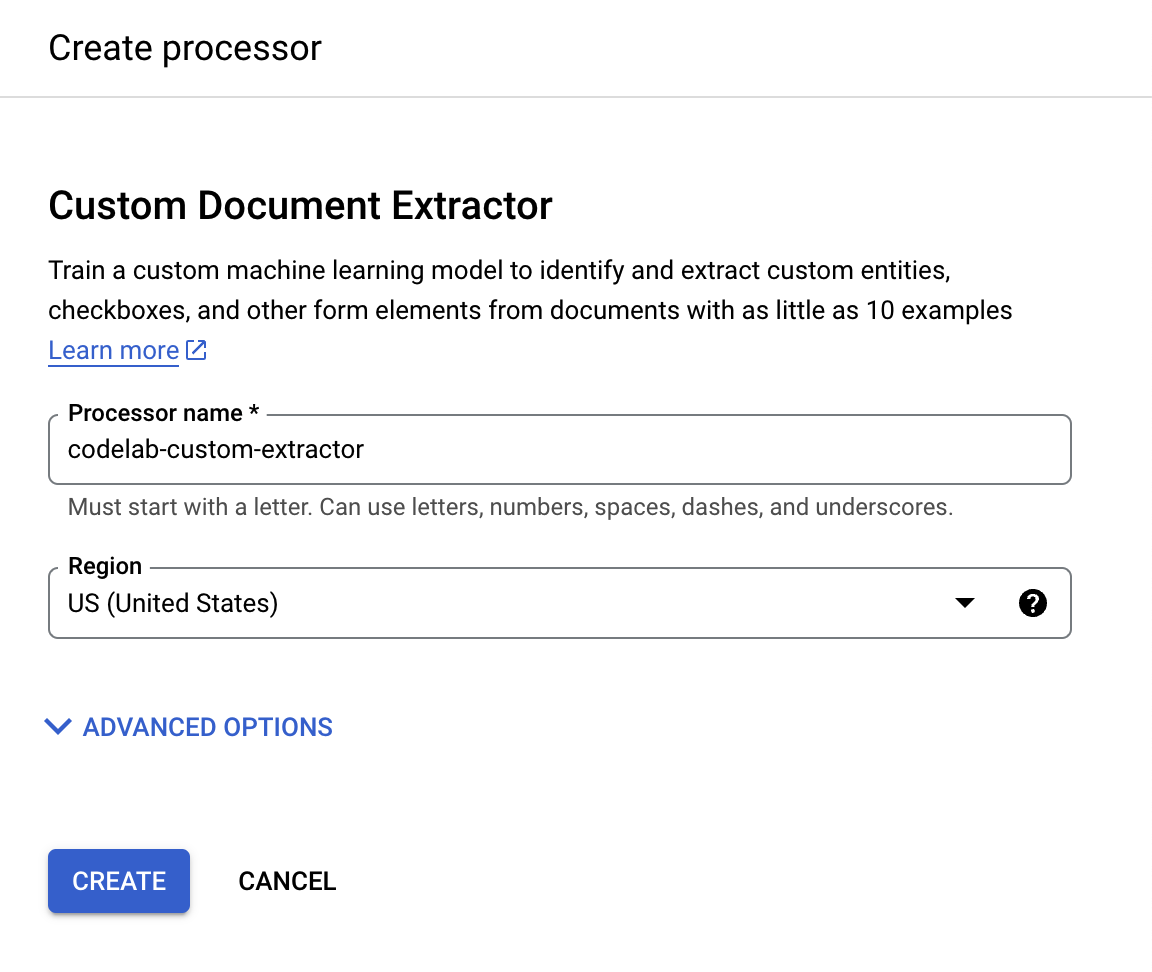
- انقر على إنشاء لإنشاء المعالج. من المفترض أن تظهر لك بعد ذلك صفحة "نظرة عامة على جهة المعالجة".

4. إنشاء مجموعة بيانات
من أجل تدريب المعالج، علينا إنشاء مجموعة بيانات تتضمّن بيانات التدريب والاختبار لمساعدة المعالج في تحديد الكيانات التي نريد استخراجها.
- في صفحة "نظرة عامة على المعالج"، انقر على إعداد مجموعة البيانات.
- من المفترض أن تكون الآن في صفحة إعداد مجموعة البيانات. إذا أردت تحديد حزمة خاصة بك لتخزين مستندات التدريب والتصنيفات، انقر على عرض الخيارات المتقدّمة. بخلاف ذلك، ما عليك سوى النقر على متابعة.
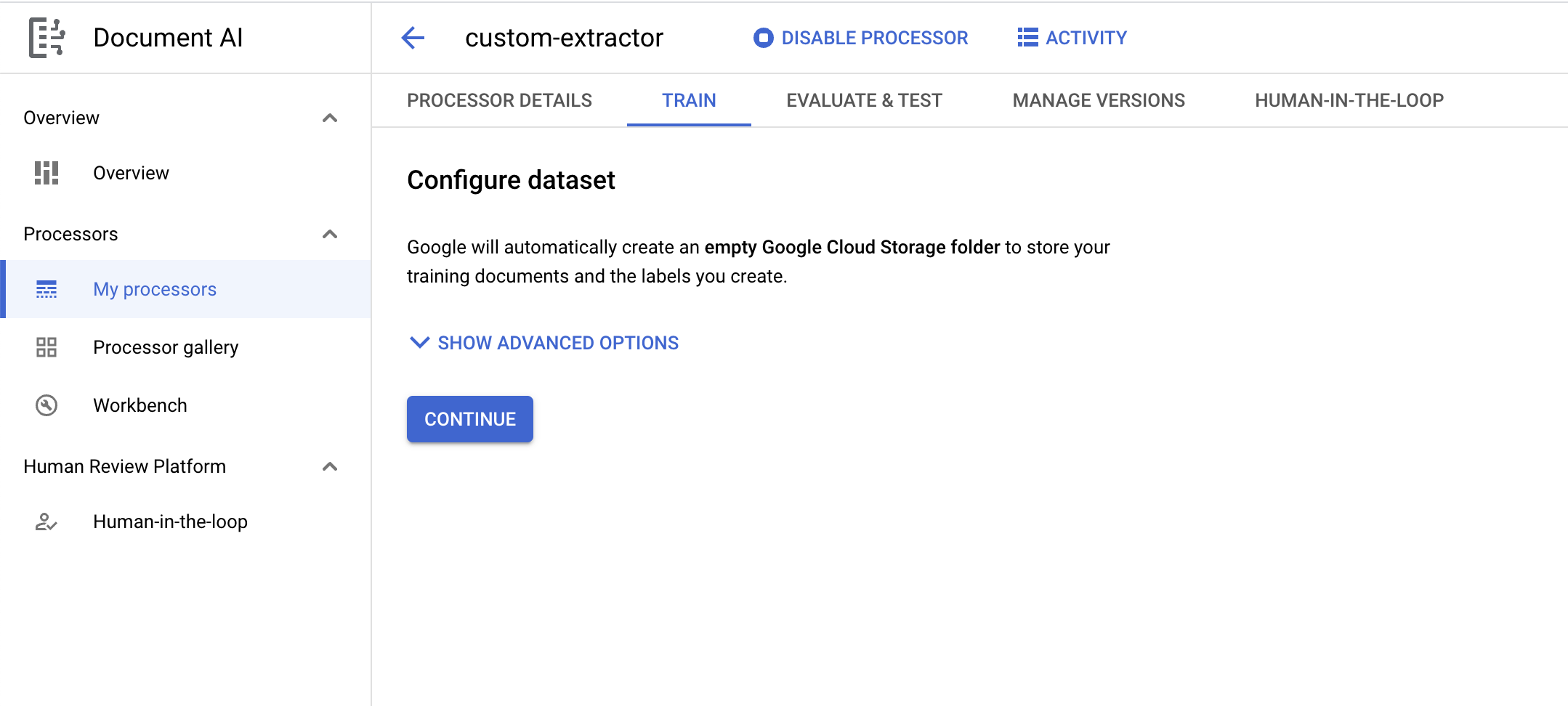
- انتظِر إلى أن يتم إنشاء مجموعة البيانات، ثم سيتم توجيهك إلى صفحة التدريب.
5- استيراد مستند اختبار
الآن، لنستورد نموذجًا لملف W2 pdf إلى مجموعة البيانات.
- انقر على استيراد المستندات

- لدينا نموذج ملف PDF يمكنك استخدامه في هذا الدرس التطبيقي. انسخ الرابط التالي والصقه في المربّع مسار المصدر. اترك "تقسيم البيانات" على "غير محدّد" في الوقت الحالي. لا تضع علامة في المربّعات الأخرى. انقر على استيراد.
cloud-samples-data/documentai/codelabs/custom/extractor/pdfs

- انتظِر إلى حين استيراد المستند. من المفترض أن يستغرق هذا الإجراء أقل من دقيقة واحدة.
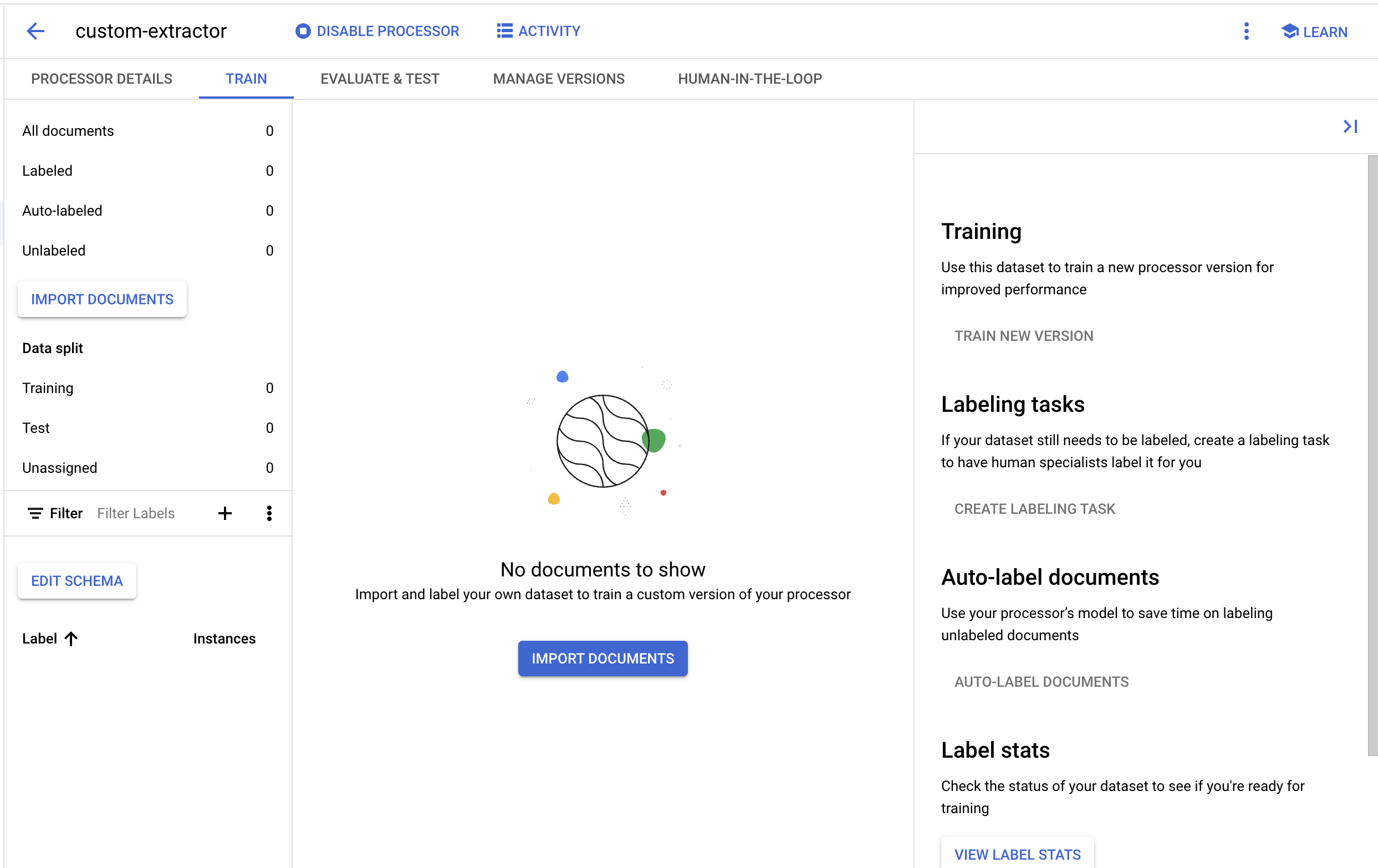
- عند اكتمال عملية الاستيراد، من المفترض أن يظهر المستند في صفحة التدريب.

6. إنشاء التصنيفات
بما أنّنا بصدد إنشاء نوع معالج جديد، سنحتاج إلى إنشاء تصنيفات مخصّصة لإخبار Document AI بالحقول التي نريد استخراجها.
- انقر على تعديل المخطط في أسفل يمين الصفحة.

- يُفترض أن تكون الآن في "وحدة تحكّم إدارة المخطط".
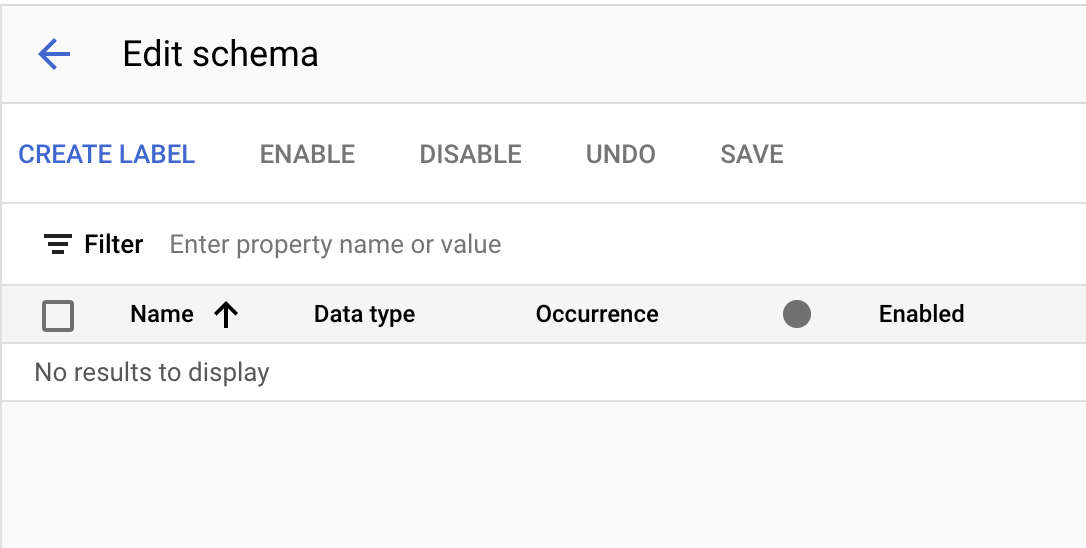
- أنشئ التصنيفات التالية باستخدام الزر إنشاء تصنيف.
الاسم | نوع البيانات | التكرار |
| العدد | المضاعف المطلوب |
| نص عادي | المضاعف المطلوب |
| نص عادي | المضاعف المطلوب |
| العنوان | المضاعف المطلوب |
| المال | المضاعف المطلوب |
| المال | المضاعف المطلوب |
| المال | المضاعف المطلوب |
| المال | المضاعف المطلوب |
- يجب أن تبدو "وحدة التحكّم" على النحو التالي عند اكتمالها. انقر على حفظ عند الانتهاء.

- انقر على سهم الرجوع للعودة إلى صفحة التدريب. لاحظ أنّ التصنيفات التي أنشأناها تظهر في أسفل يمين الشاشة.

7. تصنيف مستند الاختبار
بعد ذلك، سنحدّد عناصر النص والتصنيفات للكيانات التي نريد استخراجها. سيتم استخدام هذه التصنيفات لتدريب النموذج على تحليل بنية المستند المحدّدة هذه وتحديد الأنواع الصحيحة.
- انقر مرّتين على المستند الذي استوردناه سابقًا للدخول إلى وحدة تحكّم التصنيف. من المفترض أن يبدو مماثلاً لهذا.

- انقر على أداة "المربّع المحيط"، ثمّ ظلّل النص "1173038" وأضِف التصنيف
CONTROL_NUMBER. يمكنك استخدام فلتر النص للبحث عن أسماء التصنيفات.
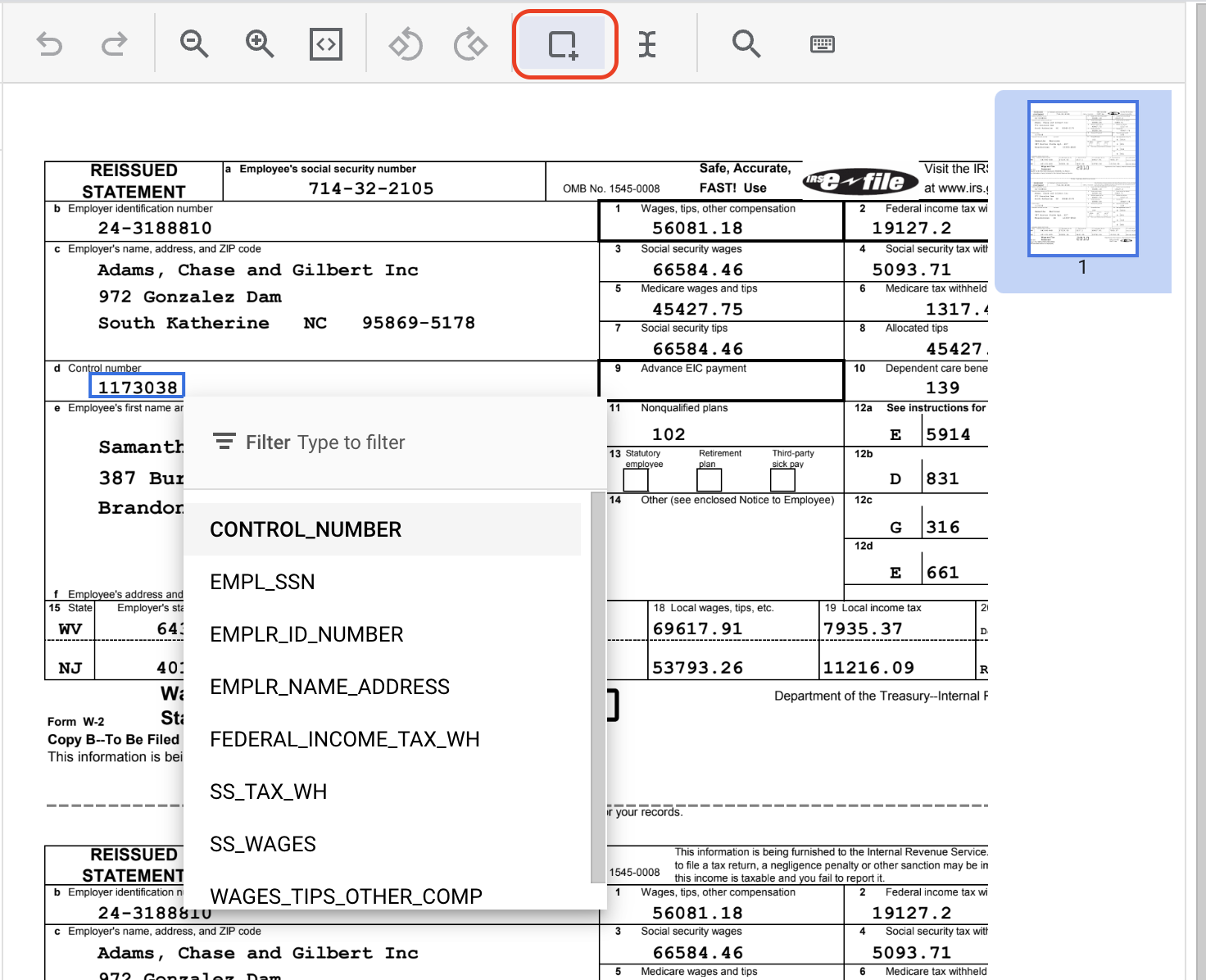
- أكمِل هذه الخطوات مع المثال الآخر من
CONTROL_NUMBER. من المفترض أن يظهر بالشكل التالي بعد تصنيفه.
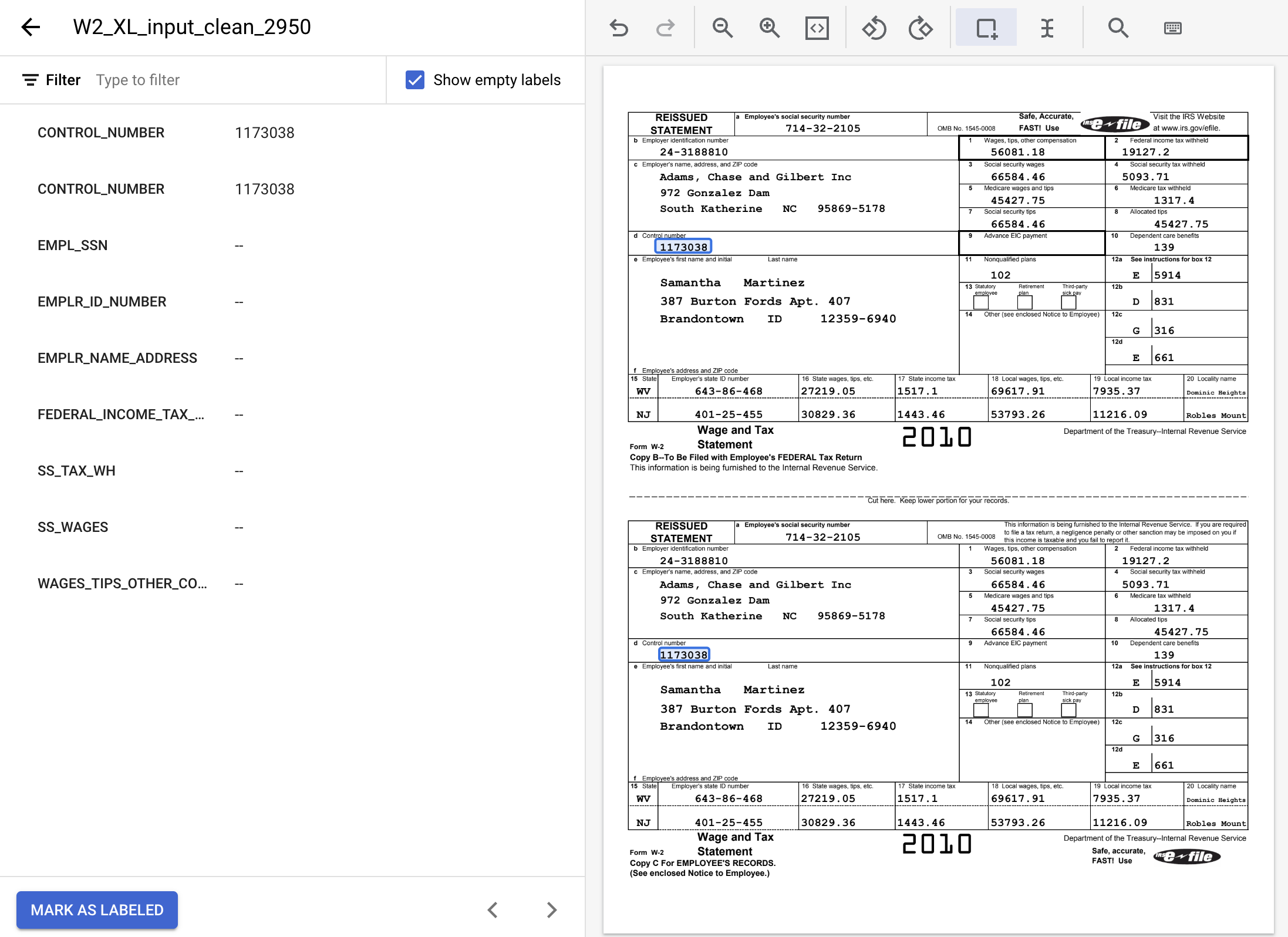
- ميِّز جميع مثيلات القيم النصية التالية وأضِف التصنيفات المناسبة.
اسم التصنيف | Text |
| 24-3188810 |
| 19127.2 |
| 5093.71 |
| 66584.46 |
| 56081.18 |
| 714-32-2105 |
| Adams, Chase and Gilbert Inc 972 Gonzalez Dam South Katherine NC 95869-5178 |
- يجب أن يبدو المستند المصنّف على هذا النحو عند اكتماله. يمكنك إجراء تعديلات على هذه التصنيفات من خلال النقر على مربّع الإحاطة في المستند أو اسم التصنيف/قيمته في القائمة الجانبية اليمنى. انقر على وضع علامة "تمت إضافة التصنيف" عند الانتهاء من إضافة التصنيفات، ثم ارجع إلى "وحدة تحكّم إدارة مجموعات البيانات".

8. تعيين مستند لمجموعة التدريب
من المفترض أن تكون قد عدت الآن إلى "وحدة تحكّم إدارة مجموعات البيانات". لاحظ أنّ عدد المستندات المصنَّفة وغير المصنَّفة وعدد مرات ظهور كل تصنيف قد تغيّر.

- علينا تصنيف هذا المستند ضمن مجموعة "التدريب" أو مجموعة "الاختبار". انقر على المستند، ثم على تعيين إلى مجموعة، ثم على التدريب.
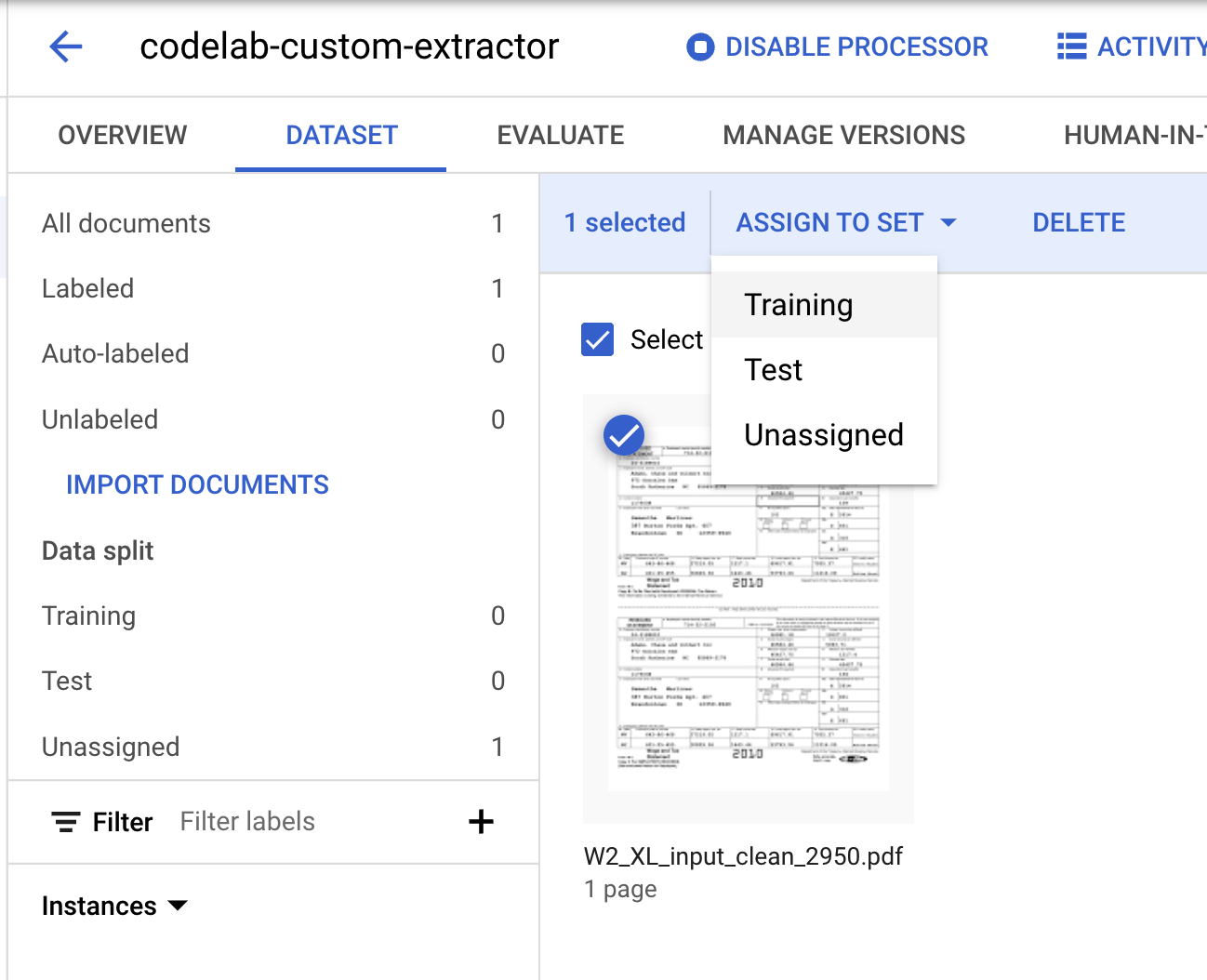
- لاحظ أنّ أرقام تقسيم البيانات قد تغيّرت.

9- استيراد البيانات المصنَّفة مسبقًا
تتطلّب "أدوات المعالجة المخصّصة" في Document AI توفّر 10 مستندات على الأقل في كلّ من مجموعتَي التدريب والاختبار، بالإضافة إلى 10 أمثلة لكلّ تصنيف في كلّ مجموعة.
يُنصح بأن تتضمّن كل مجموعة 50 مستندًا على الأقل مع 50 مثالاً لكل تصنيف لتحقيق أفضل أداء. وبشكل عام، يؤدي توفّر المزيد من بيانات التدريب إلى زيادة الدقة.
سيستغرق تصنيف جميع المستندات يدويًا وقتًا طويلاً، لذا لدينا بعض المستندات المصنَّفة مسبقًا التي يمكنك استيرادها لهذا المختبر.
يمكنك استيراد ملفات المستندات المصنَّفة مسبقًا بتنسيق Document.json. يمكن أن تكون هذه النتائج من خلال استدعاء معالج والتحقّق من الدقة باستخدام المشاركة البشرية (HITL).
aside negative
ملاحظة: عند استيراد بيانات مصنّفة مسبقًا، ننصح بشدة بمراجعة التعليقات التوضيحية يدويًا قبل تدريب النموذج.
- انقر على استيراد المستندات.

- انسخ مسار Cloud Storage التالي وألصقه، ثم خصِّصه لمجموعة التدريب.
cloud-samples-data/documentai/codelabs/custom/extractor/training
- انقر على إضافة مجلد آخر. بعد ذلك، انسخ/الصِق مسار Cloud Storage التالي وعيّنه لمجموعة الاختبار.
cloud-samples-data/documentai/codelabs/custom/extractor/test
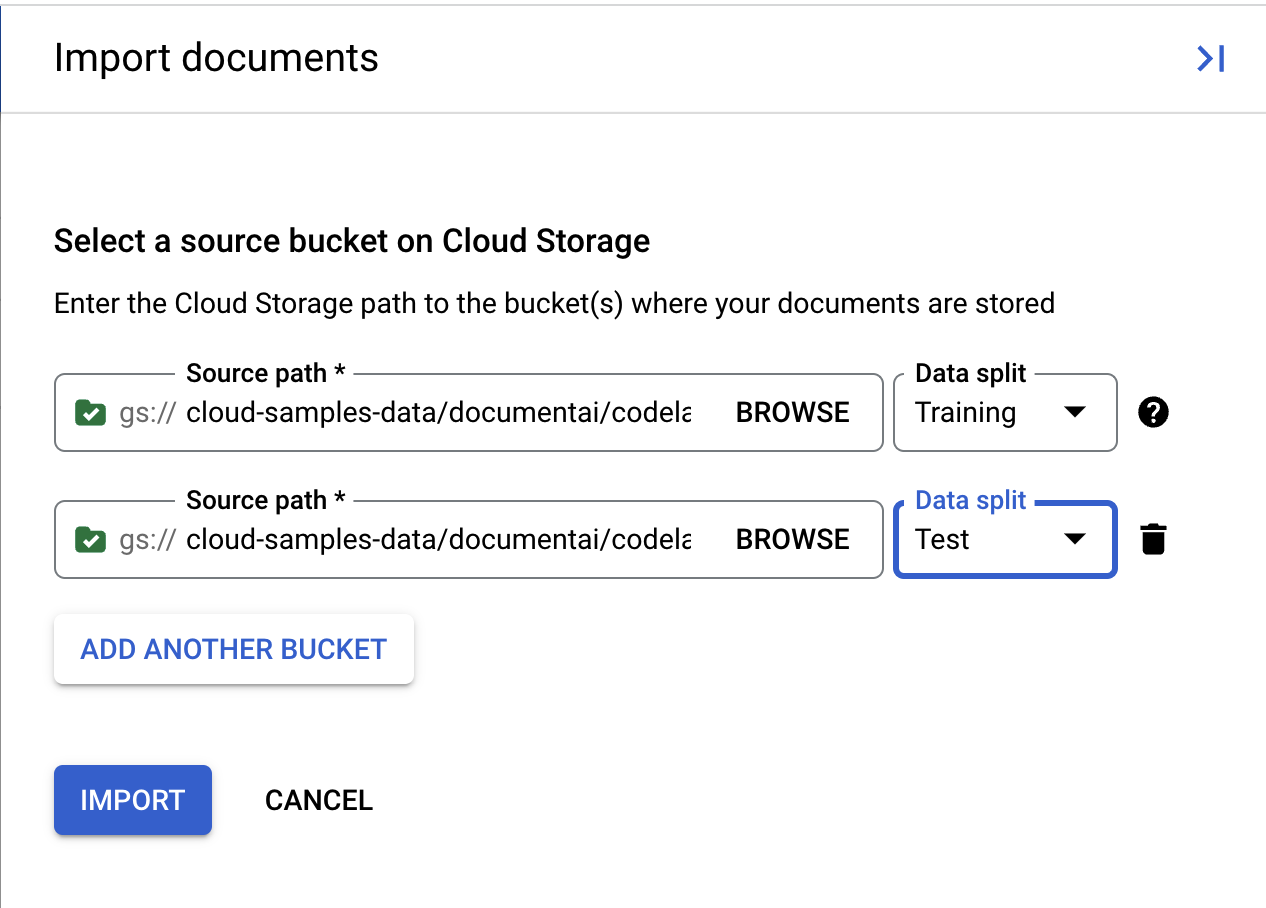
- انقر على استيراد وانتظِر إلى أن يتم استيراد المستندات. ستستغرق هذه العملية وقتًا أطول من المرة السابقة لأنّ هناك المزيد من المستندات التي يجب معالجتها. من المفترض أن تستغرق هذه العملية 6 دقائق تقريبًا، ويمكنك مغادرة هذه الصفحة والرجوع إليها لاحقًا.
- بعد اكتمال العملية، من المفترض أن تظهر المستندات في صفحة التدريب.

10. تدريب النموذج
الآن، نحن جاهزون لبدء تدريب أداة استخراج المستندات المخصّصة.
- انقر على تدريب إصدار جديد.

- أدخِل اسمًا للنسخة يمكنك تذكّره، مثل
codelab-custom-1. بالنسبة إلى "طريقة التدريب"، اختَر "التدريب من البداية".

- (اختياري) يمكنك أيضًا النقر على عرض إحصاءات التصنيفات للاطّلاع على مقاييس حول التصنيفات في مجموعة البيانات.

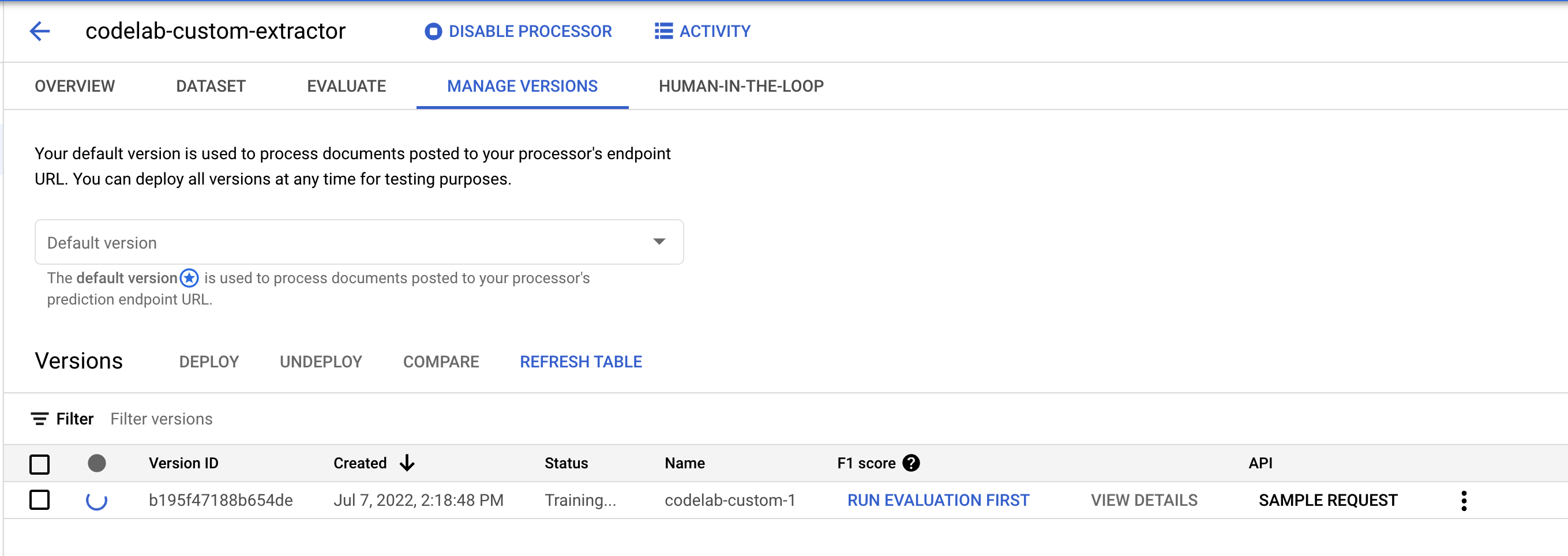
- انقر على بدء التدريب لبدء عملية التدريب. من المفترض أن تتم إعادة توجيهك إلى صفحة "إدارة مجموعات البيانات". يمكنك الاطّلاع على حالة التدريب على الجانب الأيسر. سيستغرق إكمال التدريب بضع ساعات. يمكنك مغادرة هذه الصفحة والرجوع إليها لاحقًا.

- إذا نقرت على اسم الإصدار، سيتم توجيهك إلى صفحة إدارة الإصدارات التي تعرض رقم تعريف الإصدار والحالة الحالية لمهمة التدريب.
11. اختبار إصدار النموذج الجديد
بعد اكتمال مهمة التدريب (استغرقت حوالي ساعة واحدة في اختباراتي)، يمكنك الآن تجربة إصدار النموذج الجديد وبدء استخدامه للتوقعات.
- انتقِل إلى صفحة إدارة النُسخ. يمكنك هنا الاطّلاع على الحالة الحالية ومقياس F1.
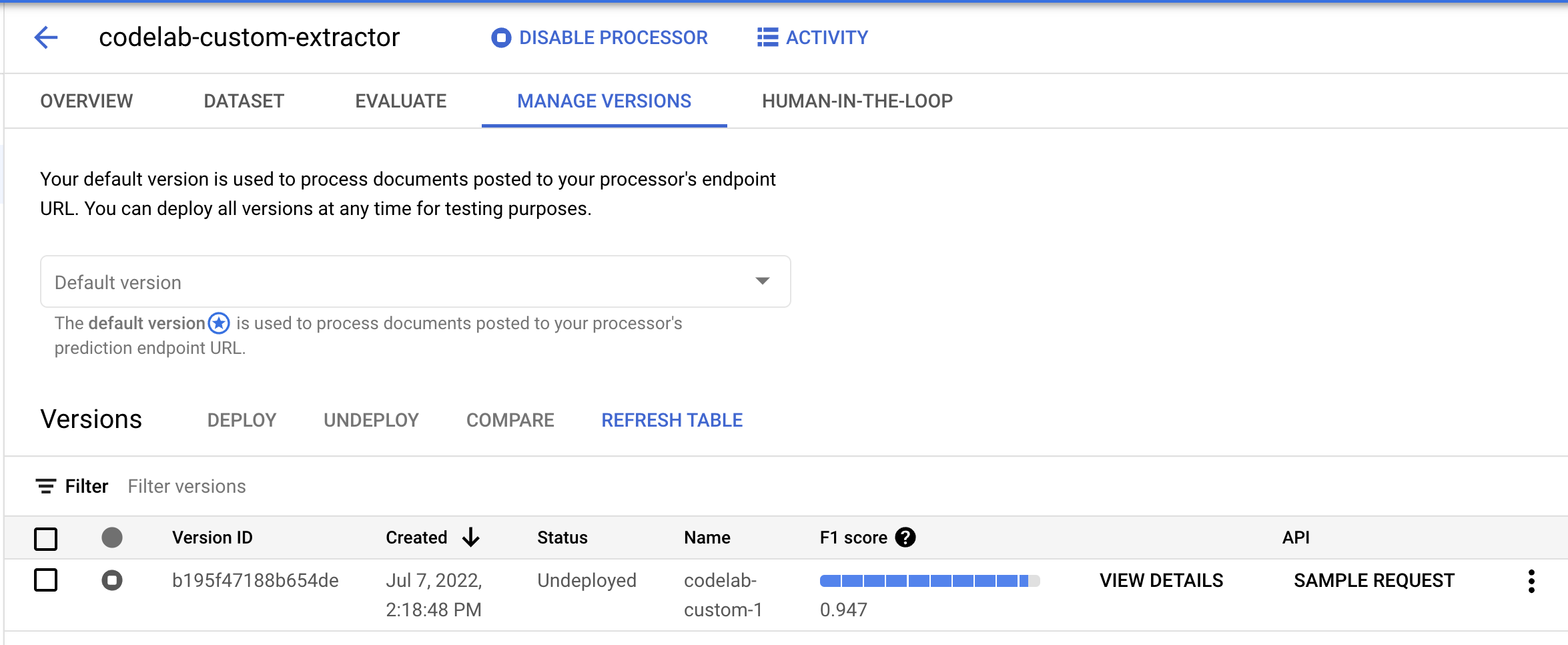
- يجب تفعيل إصدار النموذج هذا قبل استخدامه. انقر على النقاط العمودية على الجانب الأيسر واختَر نشر الإصدار.

- انقر على نشر من النافذة المنبثقة، ثم انتظر إلى أن يتم نشر الإصدار. سيستغرق إكمال هذه الخطوة بضع دقائق. بعد نشر هذا الإصدار، يمكنك أيضًا ضبطه على أنّه الإصدار التلقائي.

- بعد الانتهاء من عملية النشر، انتقِل إلى علامة التبويب تقييم. في هذه الصفحة، يمكنك الاطّلاع على مقاييس التقييم، بما في ذلك مقياس دقة الاختبار ومقياس صحة النموذج والتذكّر للمستند الكامل بالإضافة إلى التصنيفات الفردية. يمكنك الاطّلاع على مزيد من المعلومات حول هذه المقاييس في مستندات AutoML.

- نزِّل ملف PDF المرتبط أدناه. هذه عيّنة من نموذج W2 لم يتم تضمينها في مجموعة التدريب أو الاختبار.
- انقر على تحميل مستند اختباري واختَر ملف PDF.
- يجب أن تبدو الكيانات المستخرَجة على النحو التالي.

12. اختياري: تصنيف المستندات المستورَدة حديثًا تلقائيًا
بعد نشر إصدار معالج مدرَّب، يمكنك استخدام التصنيف التلقائي لتوفير الوقت في عملية التصنيف عند استيراد مستندات جديدة.
- في صفحة التدريب، انقر على استيراد المستندات.
- انسخ مسار التالي وألصِقه. يحتوي هذا الدليل على 5 ملفات PDF من نموذج W2 بدون تصنيف. من القائمة المنسدلة تقسيم البيانات، اختَر التدريب.
cloud-samples-data/documentai/Custom/W2/AutoLabel - في قسم وضع التصنيفات التلقائي، ضَع علامة في مربّع الاختيار الاستيراد مع وضع التصنيفات التلقائي.
- اختَر إصدارًا حاليًا من أداة المعالجة لتصنيف المستندات.
- مثلاً:
2af620b2fd4d1fcf
- انقر على استيراد وانتظِر إلى أن يتم استيراد المستندات. يمكنك مغادرة هذه الصفحة والرجوع إليها لاحقًا.
- عند اكتمال العملية، ستظهر المستندات في صفحة التدريب ضمن قسم التصنيف التلقائي.
- لا يمكنك استخدام المستندات التي تم تصنيفها تلقائيًا للتدريب أو الاختبار بدون وضع علامة عليها للإشارة إلى أنّها مصنَّفة. انتقِل إلى قسم المستندات التي تمّت تسميتها تلقائيًا لعرض المستندات التي تمّت تسميتها تلقائيًا.
- اختَر المستند الأول للدخول إلى وحدة تحكّم التصنيف.
- تأكَّد من صحة التصنيفات والمربّعات المحيطة والقيم. ضع تصنيفًا لأي قيم تم حذفها.
- انقر على وضع علامة "تمت إضافة تصنيف" عند الانتهاء.
- كرِّر عملية التحقّق من التصنيف لكل مستند تم تصنيفه تلقائيًا، ثم ارجع إلى صفحة التدريب لاستخدام البيانات في التدريب.
13. الخاتمة
تهانينا، لقد استخدمت Document AI بنجاح لتدريب معالج "أداة استخراج المستندات المخصّصة". يمكنك الآن استخدام أداة المعالجة هذه لتحليل المستندات بهذا التنسيق تمامًا كما تفعل مع أي أداة معالجة متخصّصة.
يمكنك الرجوع إلى Specialized Processors Codelab لمراجعة كيفية التعامل مع استجابة المعالجة.
تنظيف
لتجنُّب تحمّل رسوم في حسابك على Google Cloud مقابل الموارد المستخدَمة في هذا البرنامج التعليمي، اتّبِع الخطوات التالية:
- في Cloud Console، انتقِل إلى صفحة إدارة الموارد.
- في قائمة المشاريع، اختَر مشروعك ثم انقر على "حذف".
- في مربّع الحوار، اكتب رقم تعريف المشروع، ثم انقر على "إيقاف" لحذف المشروع.
المراجع
- مستندات Document AI Workbench
- مستقبل المستندات - قائمة تشغيل على YouTube
- مستندات Document AI
- مكتبة برامج Document AI Python
- أمثلة على Document AI
الترخيص
يخضع هذا العمل لترخيص المشاع الإبداعي مع نسب العمل إلى مؤلفه 2.0 Generic License.