
1. Genel Bakış
Bu laboratuvarda, Keras sınıflandırıcı oluşturmayı öğreneceksiniz. Çiçekleri tanımak için mükemmel sinir ağı katmanları kombinasyonunu bulmaya çalışmak yerine, öncelikle güçlü bir önceden eğitilmiş modeli veri kümemize uyarlamak için transfer öğrenimi adı verilen bir teknik kullanacağız.
Bu laboratuvarda, sinir ağları hakkında gerekli teorik açıklamalar yer alır ve derin öğrenme hakkında bilgi edinmek isteyen geliştiriciler için iyi bir başlangıç noktasıdır.
Bu laboratuvar, "TPU'da Keras" serisinin 2. bölümüdür. Bu işlemleri aşağıdaki sırayla veya bağımsız olarak yapabilirsiniz.
- TPU hızında veri ardışık düzenleri: tf.data.Dataset ve TFRecords
- [BU LABORATUVAR] Aktarım öğrenimiyle ilk Keras modeliniz
- Keras ve TPU'larla evrişimli nöral ağlar
- Keras ve TPU'lar ile; modern evrişimli sinir ağları, SqueezeNet, Xception

Neler öğreneceksiniz?
- Yumuşak maksimum katmanı ve çapraz entropi kaybı içeren kendi Keras görüntü sınıflandırıcınızı oluşturmak için
- Kendi modellerinizi oluşturmak yerine transfer öğrenimini kullanarak hile yapmak 😈
Geri bildirim
Bu kod laboratuvarında yanlış bir şey görürseniz lütfen bize bildirin. Geri bildirimler GitHub sorunları [geri bildirim bağlantısı] üzerinden gönderilebilir.
2. Google Colaboratory hızlı başlangıç
Bu laboratuvarda Google Collaboratory kullanılır ve sizin tarafınızda herhangi bir kurulum yapılması gerekmez. Colaboratory, eğitim amaçlı kullanılan online bir not defteri platformudur. Ücretsiz CPU, GPU ve TPU eğitimi sunar.

Bu örnek not defterini açıp birkaç hücreyi çalıştırarak Colaboratory hakkında bilgi edinebilirsiniz.
TPU arka ucu seçme

Colab menüsünde Çalışma zamanı > Çalışma zamanı türünü değiştir'i ve ardından TPU'yu seçin. Bu kod laboratuvarında, donanım hızlandırmalı eğitim için desteklenen güçlü bir TPU (Tensor İşleme Birimi) kullanacaksınız. Çalışma zamanına bağlantı ilk yürütmede otomatik olarak gerçekleşir veya sağ üst köşedeki "Bağlan" düğmesini kullanabilirsiniz.
Not defteri yürütme

Bir hücreyi tıklayıp Üst Karakter+ENTER tuşlarını kullanarak hücreleri teker teker çalıştırın. Ayrıca Çalışma zamanı > Tümünü çalıştır seçeneğini kullanarak not defterinin tamamını çalıştırabilirsiniz.
İçindekiler

Tüm not defterlerinde içindekiler tablosu bulunur. Sol taraftaki siyah oku kullanarak açabilirsiniz.
Gizli hücreler

Bazı hücrelerde yalnızca başlık gösterilir. Bu, Colab'e özgü bir not defteri özelliğidir. İçindeki kodu görmek için bunları çift tıklayabilirsiniz ancak genellikle çok ilginç değildir. Genellikle destek veya görselleştirme işlevleri. İçindeki işlevlerin tanımlanması için bu hücreleri çalıştırmanız gerekir.
Kimlik doğrulama

Colab, yetkili bir hesapla kimliğinizi doğruladığınız sürece özel Google Cloud Storage paketlerinize erişebilir. Yukarıdaki kod snippet'i bir kimlik doğrulama sürecini tetikleyecektir.
3. [INFO] Nöral ağ sınıflandırıcı 101
Özet
Bir sonraki paragraftaki kalın harflerle yazılmış tüm terimleri biliyorsanız bir sonraki alıştırmaya geçebilirsiniz. Derin öğrenmeye yeni başlıyorsanız hoş geldiniz. Lütfen okumaya devam edin.
Keras, katman dizisi olarak oluşturulan modeller için Sequential API'yi sunar. Örneğin, üç yoğun katman kullanan bir görüntü sınıflandırıcı, Keras'ta şu şekilde yazılabilir:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[192, 192, 3]),
tf.keras.layers.Dense(500, activation="relu"),
tf.keras.layers.Dense(50, activation="relu"),
tf.keras.layers.Dense(5, activation='softmax') # classifying into 5 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
Yoğun nöral ağ
Bu, görüntüleri sınıflandırmak için kullanılan en basit nöral ağdır. Katmanlar halinde düzenlenmiş "nöronlardan" oluşur. İlk katman, giriş verilerini işler ve çıkışlarını diğer katmanlara aktarır. Her nöron önceki katmandaki tüm nöronlara bağlı olduğundan bu katmana "yoğun" adı verilir.

Tüm piksellerinin RGB değerlerini uzun bir vektör haline getirip giriş olarak kullanarak bu tür bir ağa resim besleyebilirsiniz. Bu, görüntü tanıma için en iyi teknik olmasa da daha sonra iyileştirilecektir.
Nöronlar, etkinleştirmeler, RELU
Bir "nöron", tüm girişlerinin ağırlıklı toplamını hesaplar, "bias" adı verilen bir değer ekler ve sonucu "aktivasyon işlevi" olarak adlandırılan bir işlev aracılığıyla besler. Ağırlıklar ve önyargı ilk başta bilinmez. Bu ağırlıklar rastgele başlatılır ve nöral ağın çok sayıda bilinen veri üzerinde eğitilmesiyle "öğrenilir".
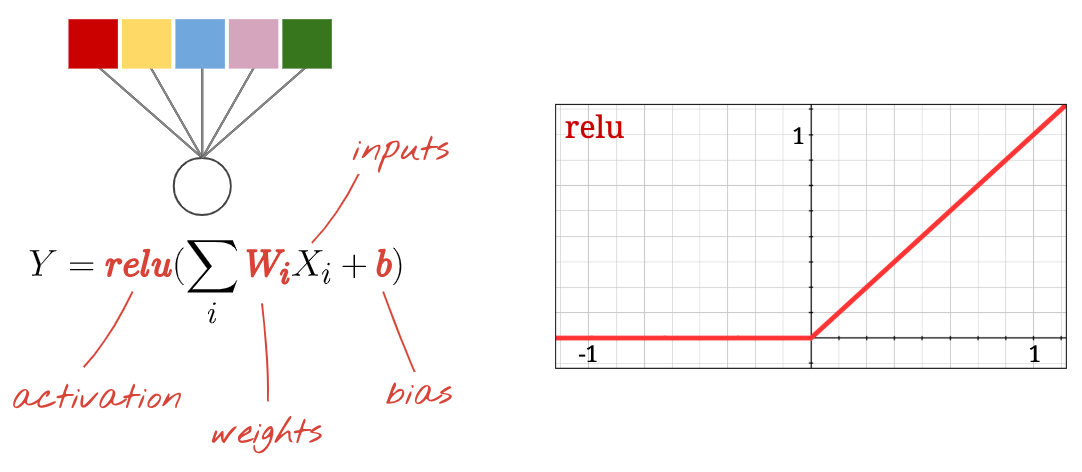
En popüler etkinleştirme işlevine Doğrusal Birimi Düzeltilmiş (Rectified Linear Unit) anlamına gelen RELU adı verilir. Yukarıdaki grafikte de görebileceğiniz gibi, bu çok basit bir fonksiyondur.
Softmax etkinleştirme
Çiçekleri 5 kategoriye (gül, lale, karahindiba, papatya, ayçiçeği) ayırdığımız için yukarıdaki ağ 5 nöronlu bir katmanla sona eriyor. Ara katmanlardaki nöronlar, klasik RELU etkinleştirme işlevi kullanılarak etkinleştirilir. Ancak son katmanda, bu çiçeğin gül, lale vb. olma olasılığını temsil eden 0 ile 1 arasındaki sayıları hesaplamak istiyoruz. Bunun için "softmax" adlı bir etkinleştirme işlevini kullanacağız.
Bir vektöre softmax uygulamak için her öğenin üstel değeri alınır ve ardından vektör normalleştirilir. Genellikle değerlerin toplamı 1 olacak ve olasılık olarak yorumlanabilecek şekilde L1 normu (mutlak değerlerin toplamı) kullanılır.


Çapraz entropi kaybı (Cross-entropy loss)
Sinir ağımız artık giriş resimlerinden tahminler ürettiğine göre, bu tahminlerin ne kadar iyi olduğunu (yani ağın bize söyledikleri ile doğru cevaplar arasındaki mesafeyi) ölçmemiz gerekiyor. Bu mesafeye genellikle "etiketler" adı verilir. Veri kümesindeki tüm resimler için doğru etiketlere sahip olduğumuzu unutmayın.
Herhangi bir mesafe işe yarar ancak sınıflandırma sorunları için "çapraz entropi mesafesi" olarak adlandırılan mesafe en etkili olanıdır. Buna hata veya "kayıp" işlevimiz diyeceğiz:

Gradyan inişi
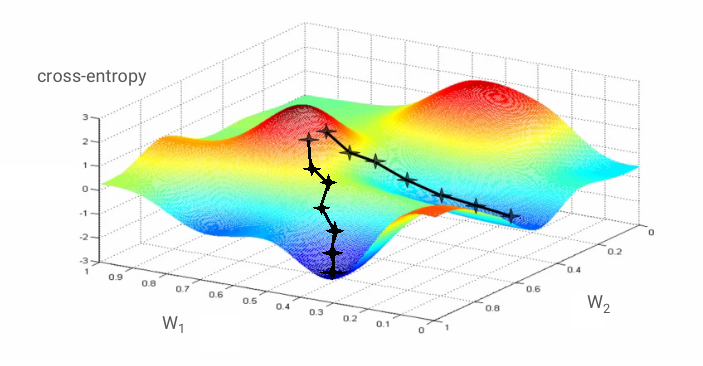
Nöral ağı "eğitmek" aslında çapraz entropi kayıp fonksiyonunu en aza indirmek için ağırlıkları ve önyargıları ayarlamak üzere eğitim resimlerini ve etiketlerini kullanmak anlamına gelir. İşleyiş şekli şöyledir:
Çapraz entropi, ağırlıkların, önyargıların, eğitim görüntüsünün piksellerinin ve bilinen sınıfının bir fonksiyonudur.
Çapraz entropinin tüm ağırlıklar ve tüm sapmalarla ilgili kısmi türevlerini hesaplarsak belirli bir resim, etiket ve ağırlıkların ve sapmaların mevcut değeri için hesaplanan bir "gradyan" elde ederiz. Milyonlarca ağırlık ve önyargı olabileceği için gradyanı hesaplamanın çok fazla iş gerektireceğini unutmayın. Neyse ki Tensorflow bunu bizim için yapar. Bir gradyanın matematiksel özelliği "yukarı"yı göstermesidir. Çapraz entropinin düşük olduğu yere gitmek istediğimiz için ters yönde ilerliyoruz. Ağırlıkları ve önyargıları gradyanın bir kısmı kadar güncelleriz. Ardından, eğitim döngüsünde bir sonraki eğitim resimleri ve etiket gruplarını kullanarak aynı işlemi tekrar tekrar yaparız. Bu işlemin, çapraz entropinin minimum olduğu bir noktada birleşeceği umulur ancak bu minimum değerin benzersiz olacağı garanti edilmez.
Mini toplu işleme ve momentum
Gradyanınızı yalnızca bir örnek resim üzerinde hesaplayıp ağırlıkları ve önyargıları hemen güncelleyebilirsiniz. Ancak bunu örneğin 128 resimlik bir grup üzerinde yapmak, farklı örnek resimlerin getirdiği kısıtlamaları daha iyi temsil eden bir gradyan sağlar ve bu nedenle çözüme daha hızlı ulaşma olasılığı daha yüksektir. Mini toplu işin boyutu ayarlanabilir bir parametredir.
Bazen "stokastik gradyan inişi" olarak da adlandırılan bu tekniğin daha pratik bir faydası vardır: Gruplarla çalışmak, daha büyük matrislerle çalışmak anlamına da gelir ve bunlar genellikle GPU'larda ve TPU'larda optimize edilmesi daha kolaydır.
Ancak yakınsama yine de biraz kaotik olabilir ve gradyan vektörü tamamen sıfırsa durabilir. Bu, minimum bir değer bulduğumuz anlamına mı geliyor? Her zaman değil Bir gradyan bileşeni, minimum veya maksimumda sıfır olabilir. Milyonlarca öğeden oluşan bir gradyan vektöründe, tüm öğeler sıfırsa her sıfırın bir minimuma ve hiçbirinin bir maksimum noktaya karşılık gelme olasılığı oldukça düşüktür. Çok boyutlu bir uzayda eyer noktaları oldukça yaygındır ve bu noktalarda durmak istemeyiz.

Resim: Eyer noktası. Eğim 0'dır ancak tüm yönlerde minimum değildir. (Resim ilişkilendirmesi Wikimedia: Nicoguaro - Own work, CC BY 3.0)
Çözüm, optimizasyon algoritmasına biraz ivme kazandırmaktır. Böylece algoritma, durmadan eyer noktalarını geçebilir.
Sözlük
Grup veya mini grup: Eğitim her zaman eğitim verisi grupları ve etiketleri üzerinde gerçekleştirilir. Bu sayede algoritmanın yakınlaşmasına yardımcı olursunuz. "Toplu iş" boyutu genellikle veri tensörlerinin ilk boyutudur. Örneğin, [100, 192, 192, 3] şeklindeki bir tensör, piksel başına üç değer (RGB) içeren 192x192 piksellik 100 resim içerir.
Çapraz entropi kaybı: Sınıflandırıcılarda sıklıkla kullanılan özel bir kayıp işlevi.
Yoğun katman: Her nöronun önceki katmandaki tüm nöronlara bağlı olduğu bir nöron katmanı.
Özellikler: Nöral ağın girişlerine bazen "özellikler" denir. İyi tahminler elde etmek için bir veri kümesinin hangi bölümlerinin (veya bölüm kombinasyonlarının) bir nöral ağa besleneceğini belirleme sanatına "özellik mühendisliği" adı verilir.
Etiketler: Denetimli sınıflandırma sorununda "sınıflar" veya doğru yanıtlar için kullanılan başka bir ad
Öğrenme hızı: Ağırlıkların ve yanlılıkların eğitim döngüsünün her yinelemesinde güncellendiği gradyanın kesri.
logits: Bir nöron katmanının, etkinleştirme işlevi uygulanmadan önceki çıkışlarına "logits" adı verilir. Bu terim, bir zamanlar en popüler etkinleştirme işlevi olan "sigmoid işlevi" olarak da bilinen "lojistik işlev"den gelir. "Neuron outputs before logistic function" (Lojistik işlevden önceki nöron çıkışları) ifadesi "logits" (logitler) olarak kısaltıldı.
kayıp (loss): Nöral ağ çıkışlarını doğru cevaplarla karşılaştıran hata işlevi
Nöron: Girişlerinin ağırlıklı toplamını hesaplar, bir önyargı ekler ve sonucu bir etkinleştirme işlevinden geçirir.
One-hot kodlama: 5 sınıftan 3. sınıf, 5 öğeli bir vektör olarak kodlanır. 3. öğe 1 olmak üzere diğer tüm öğeler sıfırdır.
relu: doğrultulmuş doğrusal birim. Nöronlar için popüler bir etkinleştirme işlevi.
sigmoid: Bir zamanlar popüler olan ve özel durumlarda hâlâ kullanışlı olan başka bir etkinleştirme işlevi.
softmax: Bir vektör üzerinde işlem yapan, en büyük bileşen ile diğer tüm bileşenler arasındaki farkı artıran ve aynı zamanda vektörü olasılık vektörü olarak yorumlanabilmesi için toplamı 1 olacak şekilde normalleştiren özel bir etkinleştirme işlevi. Sınıflandırıcılarda son adım olarak kullanılır.
tensor: "Tensor", matrise benzer ancak rastgele sayıda boyuta sahiptir. 1 boyutlu tensörler vektördür. 2 boyutlu tensör bir matristir. Daha sonra 3, 4, 5 veya daha fazla boyuta sahip tensörleriniz olabilir.
4. Transfer Öğrenimi
Resim sınıflandırma sorununda yoğun katmanlar muhtemelen yeterli olmayacaktır. Evrişimli katmanlar ve bunları düzenlemenin birçok yolu hakkında bilgi edinmemiz gerekiyor.
Ancak kısayol da kullanabiliriz. Tamamen eğitilmiş evrişimli nöral ağları indirebilirsiniz. Son katmanlarını (softmax sınıflandırma başlığı) kesip kendi katmanınızla değiştirmeniz mümkündür. Eğitilmiş tüm ağırlıklar ve önyargılar olduğu gibi kalır, yalnızca eklediğiniz softmax katmanını yeniden eğitirsiniz. Bu tekniğe aktarımlı öğrenme adı verilir ve sinir ağının önceden eğitildiği veri kümesi sizinkine "yeterince yakın" olduğu sürece bu teknik inanılmaz bir şekilde çalışır.
Uygulamalı
Lütfen aşağıdaki not defterini açın, hücreleri çalıştırın (Shift-ENTER) ve "ÇALIŞMA GEREKLİ" etiketini gördüğünüz her yerde talimatları uygulayın.

Keras Flowers transfer learning (playground).ipynb
Ek bilgiler
Transfer öğrenimi sayesinde hem en iyi araştırmacılar tarafından geliştirilen gelişmiş konvolüsyonel nöral ağ mimarilerinden hem de büyük bir görüntü veri kümesi üzerinde önceden eğitilmiş modellerden yararlanabilirsiniz. Bizim durumumuzda, çiçeklere yeterince yakın olan, birçok bitki ve dış mekan sahnesi içeren bir görüntü veritabanı olan ImageNet üzerinde eğitilmiş bir ağdan transfer öğrenimi yapacağız.

Resim: Önceden eğitilmiş karmaşık bir evrişimli nöral ağı kara kutu olarak kullanma ve yalnızca sınıflandırma başlığını yeniden eğitme. Buna transfer öğrenimi denir. Evrişimli katmanların bu karmaşık düzenlemelerinin nasıl çalıştığını daha sonra göreceğiz. Şu an için bu sorun başka bir kullanıcıyı etkiliyor.
Keras'ta transfer öğrenimi
Keras'ta, tf.keras.applications.* koleksiyonundan önceden eğitilmiş bir modeli başlatabilirsiniz. Örneğin, MobileNet V2, boyut olarak makul kalırken çok iyi bir evrişimli mimaridir. include_top=False seçeneğini belirleyerek, kendi softmax katmanınızı ekleyebilmeniz için önceden eğitilmiş modeli son softmax katmanı olmadan alırsınız:
pretrained_model = tf.keras.applications.MobileNetV2(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = False
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(5, activation='softmax')
])
pretrained_model.trainable = False ayarına da dikkat edin. Yalnızca softmax katmanınızı eğitmeniz için önceden eğitilmiş modelin ağırlıklarını ve yanlılıklarını dondurur. Bu işlem genellikle nispeten az ağırlık içerir ve çok büyük bir veri kümesi gerektirmeden hızlı bir şekilde yapılabilir. Ancak çok fazla veriniz varsa aktarımlı öğrenme, pretrained_model.trainable = True ile daha da iyi sonuçlar verebilir. Önceden eğitilmiş ağırlıklar daha sonra mükemmel başlangıç değerleri sağlar ve yine de eğitilerek sorununuzla daha iyi eşleşecek şekilde ayarlanabilir.
Son olarak, yoğun softmax katmanınızdan önce eklenen Flatten() katmanına dikkat edin. Yoğun katmanlar, düz veri vektörleri üzerinde çalışır ancak önceden eğitilmiş modelin bunu döndürüp döndürmediğini bilmiyoruz. Bu nedenle eğriyi düzleştirmemiz gerekiyor. Bir sonraki bölümde, evrişimli mimarileri incelerken evrişimli katmanlar tarafından döndürülen veri biçimini açıklayacağız.
Bu yaklaşımla yaklaşık% 75 doğruluk elde edebilirsiniz.
Çözüm
Çözüm not defterini burada bulabilirsiniz. Takılırsanız bu özelliği kullanabilirsiniz.
Keras Flowers transfer learning (solution).ipynb
İşlediğimiz konular
- 🤔 Keras'ta sınıflandırıcı nasıl yazılır?
- 🤓 softmax son katmanı ve çapraz entropi kaybı ile yapılandırılmış
- 😈 Transfer learning
- 🤔 İlk modelinizi eğitme
- 🧐 Eğitim sırasında kaybı ve doğruluğu
Lütfen bu kontrol listesini zihninizde gözden geçirin.
5. Tebrikler!
Artık Keras modeli oluşturabilirsiniz. Evrişimli katmanları nasıl bir araya getireceğinizi öğrenmek için lütfen bir sonraki laboratuvara geçin.
- TPU hızında veri ardışık düzenleri: tf.data.Dataset ve TFRecords
- [BU LABORATUVAR] Aktarım öğrenimiyle ilk Keras modeliniz
- Keras ve TPU'larla evrişimli nöral ağlar
- Keras ve TPU'lar ile; modern evrişimli sinir ağları, SqueezeNet, Xception
TPU'ların uygulamadaki yeri
TPU'lar ve GPU'lar Cloud AI Platform'da kullanılabilir:
Son olarak, geri bildirimlerinizi öğrenmekten memnuniyet duyarız. Bu laboratuvarda yanlış bir şey görürseniz veya iyileştirilmesi gerektiğini düşünürseniz lütfen bize bildirin. Geri bildirimler GitHub sorunları [geri bildirim bağlantısı] üzerinden gönderilebilir.

|

