
1. ภาพรวม
Lab นี้จะแนะนำเครื่องมือต่างๆ ใน AI Platform Notebooks เพื่อสำรวจข้อมูลและสร้างต้นแบบโมเดล ML
สิ่งที่คุณจะได้เรียนรู้
โดยคุณจะได้เรียนรู้วิธีต่อไปนี้
- สร้างและปรับแต่งอินสแตนซ์ Notebook ของ AI Platform
- ติดตามโค้ด Notebook ด้วย Git ซึ่งผสานรวมเข้ากับ AI Platform Notebook โดยตรง
- ใช้ What-If Tool ภายใน Notebook
ค่าใช้จ่ายทั้งหมดในการเรียกใช้ Lab นี้ใน Google Cloud อยู่ที่ประมาณ $1 ดูรายละเอียดทั้งหมดเกี่ยวกับราคา AI Platform Notebooks ได้ที่นี่
2. สร้างอินสแตนซ์ AI Platform Notebooks
คุณจะต้องมีโปรเจ็กต์ Google Cloud Platform ที่เปิดใช้การเรียกเก็บเงินเพื่อเรียกใช้ Codelab นี้ หากต้องการสร้างโปรเจ็กต์ ให้ทำตามวิธีการที่นี่
ขั้นตอนที่ 2: เปิดใช้ Compute Engine API
ไปที่ Compute Engine แล้วเลือกเปิดใช้หากยังไม่ได้เปิดใช้ คุณจะต้องใช้ข้อมูลนี้เพื่อสร้างอินสแตนซ์ Notebook
ขั้นตอนที่ 3: สร้างอินสแตนซ์ Notebook
ไปที่ส่วน AI Platform Notebooks ใน Cloud Console แล้วคลิกอินสแตนซ์ใหม่ จากนั้นเลือกประเภทอินสแตนซ์ TensorFlow 2 Enterprise ล่าสุดที่ไม่มี GPU ดังนี้

ตั้งชื่ออินสแตนซ์หรือใช้ค่าเริ่มต้น จากนั้นเราจะไปดูตัวเลือกการปรับแต่ง คลิกปุ่มปรับแต่ง

AI Platform Notebooks มีตัวเลือกการปรับแต่งมากมาย เช่น ภูมิภาคที่อินสแตนซ์ของคุณได้รับการติดตั้งใช้งาน ประเภทอิมเมจ ขนาดเครื่อง จำนวน GPU และอื่นๆ เราจะใช้ค่าเริ่มต้นสำหรับภูมิภาคและสภาพแวดล้อม สำหรับการกำหนดค่าเครื่อง เราจะใช้เครื่อง n1-standard-8

เราจะไม่เพิ่ม GPU และจะใช้ค่าเริ่มต้นสำหรับดิสก์บูท เครือข่าย และสิทธิ์ เลือกสร้างเพื่อสร้างอินสแตนซ์ ซึ่งอาจใช้เวลาดำเนินการสักครู่
เมื่อสร้างอินสแตนซ์แล้ว คุณจะเห็นเครื่องหมายถูกสีเขียวข้างอินสแตนซ์ใน UI ของ Notebook เลือกเปิด JupyterLab เพื่อเปิดอินสแตนซ์และเริ่มสร้างต้นแบบ

เมื่อเปิดอินสแตนซ์ ให้สร้างไดเรกทอรีใหม่ชื่อ codelab นี่คือไดเรกทอรีที่เราจะใช้ตลอดแล็บนี้

คลิกไดเรกทอรี codelab ที่สร้างขึ้นใหม่โดยดับเบิลคลิก แล้วเลือกสมุดบันทึก Python 3 จากตัวเรียกใช้

เปลี่ยนชื่อ Notebook เป็น demo.ipynb หรือชื่ออื่นๆ ที่ต้องการ
ขั้นตอนที่ 4: นำเข้าแพ็กเกจ Python
สร้างเซลล์ใหม่ใน Notebook แล้วนำเข้าไลบรารีที่เราจะใช้ในโค้ดแล็บนี้
import pandas as pd
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
import json
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from google.cloud import bigquery
from witwidget.notebook.visualization import WitWidget, WitConfigBuilder
3. เชื่อมต่อข้อมูล BigQuery กับ Notebook
BigQuery ซึ่งเป็นคลังข้อมูลขนาดใหญ่ของ Google Cloud ได้เผยแพร่ชุดข้อมูลจำนวนมากต่อสาธารณะเพื่อให้คุณสำรวจได้ AI Platform Notebooks รองรับการผสานรวมโดยตรงกับ BigQuery โดยไม่ต้องมีการตรวจสอบสิทธิ์
สำหรับฟีเจอร์ทดลองนี้ เราจะใช้ชุดข้อมูลการเกิด ซึ่งมีข้อมูลการเกิดเกือบทั้งหมดในสหรัฐอเมริกาในช่วงระยะเวลา 40 ปี รวมถึงน้ำหนักแรกเกิดของเด็กและข้อมูลประชากรของพ่อแม่ของทารก เราจะใช้ฟีเจอร์บางส่วนเพื่อคาดการณ์น้ำหนักแรกเกิดของทารก
ขั้นตอนที่ 1: ดาวน์โหลดข้อมูล BigQuery ไปยัง Notebook
เราจะใช้ไลบรารีของไคลเอ็นต์ Python สำหรับ BigQuery เพื่อดาวน์โหลดข้อมูลลงใน Pandas DataFrame ชุดข้อมูลเดิมมีขนาด 21 GB และมี 123 ล้านแถว เราจะใช้เพียง 10,000 แถวจากชุดข้อมูลเพื่อให้ทุกอย่างเรียบง่าย
สร้างคำค้นหาและดูตัวอย่าง DataFrame ที่ได้ด้วยโค้ดต่อไปนี้ ในที่นี้ เราจะรับฟีเจอร์ 4 รายการจากชุดข้อมูลเดิม พร้อมกับน้ำหนักของทารก (สิ่งที่โมเดลจะคาดการณ์) แม้ว่าชุดข้อมูลจะมีมาหลายปีแล้ว แต่สำหรับโมเดลนี้ เราจะใช้เฉพาะข้อมูลหลังจากปี 2000
query="""
SELECT
weight_pounds,
is_male,
mother_age,
plurality,
gestation_weeks
FROM
publicdata.samples.natality
WHERE year > 2000
LIMIT 10000
"""
df = bigquery.Client().query(query).to_dataframe()
df.head()
หากต้องการดูสรุปของฟีเจอร์ที่เป็นตัวเลขในชุดข้อมูล ให้เรียกใช้คำสั่งต่อไปนี้
df.describe()
ซึ่งแสดงค่าเฉลี่ย ส่วนเบี่ยงเบนมาตรฐาน ค่าต่ำสุด และเมตริกอื่นๆ สำหรับคอลัมน์ตัวเลข สุดท้าย มาดูข้อมูลในคอลัมน์บูลีนที่ระบุเพศของทารกกัน เราสามารถทำได้โดยใช้เมธอด value_counts ของ Pandas ดังนี้
df['is_male'].value_counts()
ดูเหมือนว่าชุดข้อมูลจะมีความสมดุลเกือบ 50/50 ตามเพศ
ขั้นตอนที่ 2: เตรียมชุดข้อมูลสำหรับการฝึก
ตอนนี้เราได้ดาวน์โหลดชุดข้อมูลลงใน Notebook เป็น Pandas DataFrame แล้ว เราสามารถทำการประมวลผลล่วงหน้าและแยกชุดข้อมูลออกเป็นชุดการฝึกและชุดทดสอบได้
ก่อนอื่น ให้ทิ้งแถวที่มีค่า Null ออกจากชุดข้อมูลและสับเปลี่ยนข้อมูล
df = df.dropna()
df = shuffle(df, random_state=2)
จากนั้นแยกคอลัมน์ป้ายกำกับเป็นตัวแปรแยกต่างหาก แล้วสร้าง DataFrame ที่มีเฉพาะฟีเจอร์ของเรา เนื่องจาก is_male เป็นบูลีน เราจะแปลงเป็นจำนวนเต็มเพื่อให้อินพุตทั้งหมดในโมเดลเป็นตัวเลข
labels = df['weight_pounds']
data = df.drop(columns=['weight_pounds'])
data['is_male'] = data['is_male'].astype(int)
ตอนนี้หากคุณแสดงตัวอย่างชุดข้อมูลโดยเรียกใช้ data.head() คุณควรเห็นฟีเจอร์ 4 รายการที่เราจะใช้สำหรับการฝึก
4. เริ่มต้น Git
AI Platform Notebooks มีการผสานรวมกับ Git โดยตรง คุณจึงควบคุมเวอร์ชันได้โดยตรงภายในสภาพแวดล้อม Notebook ซึ่งรองรับการคอมมิตโค้ดใน UI ของ Notebook โดยตรง หรือผ่านเทอร์มินัลที่มีใน JupyterLab ในส่วนนี้ เราจะเริ่มต้นที่เก็บ Git ใน Notebook และทำการคอมมิตครั้งแรกผ่าน UI
ขั้นตอนที่ 1: เริ่มต้นที่เก็บ Git
จากไดเรกทอรี Codelab ให้เลือก Git แล้วเลือก Init จากแถบเมนูด้านบนใน JupyterLab

เมื่อระบบถามว่าต้องการเปลี่ยนไดเรกทอรีนี้ให้เป็นที่เก็บ Git ไหม ให้เลือกใช่ จากนั้นเลือกไอคอน Git ในแถบด้านข้างทางซ้ายเพื่อดูสถานะของไฟล์และการคอมมิต

ขั้นตอนที่ 2: ทำการคอมมิตครั้งแรก
ใน UI นี้ คุณสามารถเพิ่มไฟล์ลงในการคอมมิต ดูความแตกต่างของไฟล์ (เราจะพูดถึงในภายหลัง) และคอมมิตการเปลี่ยนแปลงได้ มาเริ่มกันด้วยการคอมมิตไฟล์ Notebook ที่เราเพิ่งเพิ่ม
เลือกช่องข้างdemo.ipynbไฟล์ Notebook เพื่อจัดเตรียมสำหรับการคอมมิต (คุณสามารถละเว้นไดเรกทอรี .ipynb_checkpoints/ ได้) ป้อนข้อความคอมมิตในกล่องข้อความ แล้วคลิกเครื่องหมายถูกเพื่อคอมมิตการเปลี่ยนแปลง

ป้อนชื่อและอีเมลเมื่อได้รับข้อความแจ้ง จากนั้นกลับไปที่แท็บประวัติเพื่อดูคอมมิตแรก

โปรดทราบว่าภาพหน้าจออาจไม่ตรงกับ UI ของคุณอย่างแน่นอนเนื่องจากมีการอัปเดตตั้งแต่เผยแพร่ Lab นี้
5. สร้างและฝึกโมเดล TensorFlow
เราจะใช้ชุดข้อมูลการเกิดของ BigQuery ที่ดาวน์โหลดลงใน Notebook เพื่อสร้างโมเดลที่คาดการณ์น้ำหนักของทารก ในแล็บนี้ เราจะมุ่งเน้นที่เครื่องมือสมุดบันทึกแทนที่จะเป็นความแม่นยำของโมเดลเอง
ขั้นตอนที่ 1: แยกข้อมูลออกเป็นชุดการฝึกและชุดการทดสอบ
เราจะใช้ยูทิลิตี Scikit Learn train_test_split เพื่อแยกข้อมูลก่อนสร้างโมเดล
x,y = data,labels
x_train,x_test,y_train,y_test = train_test_split(x,y)
ตอนนี้เราก็พร้อมที่จะสร้างโมเดล TensorFlow แล้ว
ขั้นตอนที่ 2: สร้างและฝึกโมเดล TensorFlow
เราจะสร้างโมเดลนี้โดยใช้ Sequentialmodel API ของ tf.keras ซึ่งช่วยให้เรากำหนดโมเดลเป็นเลเยอร์ซ้อนกันได้ โค้ดทั้งหมดที่เราต้องใช้ในการสร้างโมเดลอยู่ตรงนี้
model = Sequential([
Dense(64, activation='relu', input_shape=(len(x_train.iloc[0]),)),
Dense(32, activation='relu'),
Dense(1)]
)
จากนั้นเราจะคอมไพล์โมเดลเพื่อให้ฝึกได้ ในที่นี้ เราจะเลือกตัวเพิ่มประสิทธิภาพของโมเดล ฟังก์ชันการสูญเสีย และเมตริกที่ต้องการให้โมเดลบันทึกระหว่างการฝึก เนื่องจากนี่คือโมเดลการถดถอย (คาดการณ์ค่าตัวเลข) เราจึงใช้ข้อผิดพลาดกำลังสองเฉลี่ยแทนความแม่นยำเป็นเมตริก
model.compile(optimizer=tf.keras.optimizers.RMSprop(),
loss=tf.keras.losses.MeanSquaredError(),
metrics=['mae', 'mse'])
คุณสามารถใช้ฟังก์ชัน model.summary() ที่สะดวกของ Keras เพื่อดูรูปร่างและจำนวนพารามิเตอร์ที่ฝึกได้ของโมเดลในแต่ละเลเยอร์
ตอนนี้เราก็พร้อมที่จะฝึกโมเดลแล้ว สิ่งที่เราต้องทำคือเรียกใช้เมธอด fit() โดยส่งข้อมูลฝึกฝนและป้ายกำกับให้ ในที่นี้ เราจะใช้พารามิเตอร์ validation_split ที่ไม่บังคับ ซึ่งจะเก็บข้อมูลฝึกฝนส่วนหนึ่งไว้เพื่อตรวจสอบโมเดลในแต่ละขั้นตอน ในอุดมคติ คุณต้องการเห็นการสูญเสียการฝึกและการตรวจสอบทั้งคู่ลดลง แต่โปรดทราบว่าในตัวอย่างนี้ เรามุ่งเน้นที่เครื่องมือสร้างโมเดลและ Notebook มากกว่าคุณภาพของโมเดล
model.fit(x_train, y_train, epochs=10, validation_split=0.1)
ขั้นตอนที่ 3: สร้างการคาดการณ์ในตัวอย่างการทดสอบ
หากต้องการดูว่าโมเดลทำงานได้ดีเพียงใด ให้สร้างการคาดการณ์ทดสอบในตัวอย่าง 10 รายการแรกจากชุดข้อมูลทดสอบ
num_examples = 10
predictions = model.predict(x_test[:num_examples])
จากนั้นเราจะทำซ้ำการคาดการณ์ของโมเดลโดยเปรียบเทียบกับการคาดการณ์กับค่าจริง
for i in range(num_examples):
print('Predicted val: ', predictions[i][0])
print('Actual val: ',y_test.iloc[i])
print()
ขั้นตอนที่ 4: ใช้ git diff และคอมมิตการเปลี่ยนแปลง
ตอนนี้คุณได้ทำการเปลี่ยนแปลง Notebook แล้ว คุณสามารถลองใช้ฟีเจอร์ git diff ที่มีอยู่ใน UI ของ Git สำหรับ Notebook ได้ ตอนนี้ demo.ipynb Notebook ควรอยู่ในส่วน "เปลี่ยนแปลง" ใน UI วางเมาส์เหนือชื่อไฟล์ แล้วคลิกไอคอน Diff

ซึ่งจะช่วยให้คุณเห็นความแตกต่างของการเปลี่ยนแปลงได้ เช่น ดังต่อไปนี้

คราวนี้เราจะคอมมิตการเปลี่ยนแปลงผ่านบรรทัดคำสั่งโดยใช้เทอร์มินัล จากเมนู Git ในแถบเมนูด้านบนของ JupyterLab ให้เลือกคำสั่ง Git ในเทอร์มินัล หากคุณเปิดแท็บ Git ของแถบด้านข้างซ้ายไว้ขณะเรียกใช้คำสั่งด้านล่าง คุณจะเห็นการเปลี่ยนแปลงที่แสดงใน UI ของ Git
ในอินสแตนซ์เทอร์มินัลใหม่ ให้เรียกใช้คำสั่งต่อไปนี้เพื่อจัดเตรียมไฟล์ Notebook สำหรับการคอมมิต
git add demo.ipynb
จากนั้นเรียกใช้คำสั่งต่อไปนี้เพื่อคอมมิตการเปลี่ยนแปลง (คุณสามารถใช้ข้อความคอมมิตใดก็ได้ที่ต้องการ)
git commit -m "Build and train TF model"
จากนั้นคุณจะเห็นคอมมิตล่าสุดในประวัติ

6. ใช้ What-If Tool จาก Notebook โดยตรง
เครื่องมือ What-If เป็นอินเทอร์เฟซแบบอินเทอร์แอกทีฟที่ออกแบบมาเพื่อช่วยให้คุณเห็นภาพชุดข้อมูลและเข้าใจเอาต์พุตของโมเดล ML ได้ดียิ่งขึ้น ซึ่งเป็นเครื่องมือโอเพนซอร์สที่สร้างโดยทีม PAIR ของ Google แม้ว่าจะใช้ได้กับโมเดลทุกประเภท แต่ก็มีฟีเจอร์บางอย่างที่สร้างขึ้นสำหรับ Cloud AI Platform โดยเฉพาะ
What-If Tool ติดตั้งไว้ล่วงหน้าในอินสแตนซ์สมุดบันทึกของ Cloud AI Platform ที่มี TensorFlow ในที่นี้ เราจะใช้เพื่อดูว่าโมเดลทำงานโดยรวมเป็นอย่างไร และตรวจสอบลักษณะการทำงานของโมเดลในจุดข้อมูลจากชุดทดสอบ
ขั้นตอนที่ 1: เตรียมข้อมูลสำหรับ What-If Tool
เราจะส่งตัวอย่างจากชุดทดสอบพร้อมป้ายกำกับข้อมูลที่ระบุว่าถูกต้องโดยเจ้าหน้าที่สำหรับตัวอย่างเหล่านั้น (y_test) เพื่อให้คุณใช้ What-If Tool ได้อย่างเต็มประสิทธิภาพ วิธีนี้จะช่วยให้เราเปรียบเทียบสิ่งที่โมเดลคาดการณ์กับข้อมูลที่ระบุว่าถูกต้องโดยเจ้าหน้าที่ได้ เรียกใช้บรรทัดโค้ดด้านล่างเพื่อสร้าง DataFrame ใหม่ที่มีตัวอย่างการทดสอบและป้ายกำกับ
wit_data = pd.concat([x_test, y_test], axis=1)
ในแล็บนี้ เราจะเชื่อมต่อ What-If Tool กับโมเดลที่เราเพิ่งฝึกใน Notebook ในการดำเนินการดังกล่าว เราต้องเขียนฟังก์ชันที่เครื่องมือจะใช้เพื่อเรียกใช้จุดข้อมูลทดสอบเหล่านี้กับโมเดลของเรา
def custom_predict(examples_to_infer):
preds = model.predict(examples_to_infer)
return preds
ขั้นตอนที่ 2: สร้างอินสแตนซ์ของ What-If Tool
เราจะสร้างอินสแตนซ์ของ What-If Tool โดยส่งตัวอย่าง 500 รายการจากชุดข้อมูลทดสอบที่ต่อกัน + ป้ายกำกับความจริงพื้นฐานที่เราเพิ่งสร้างขึ้น เราสร้างอินสแตนซ์ของ WitConfigBuilder เพื่อตั้งค่าเครื่องมือ โดยส่งข้อมูล ฟังก์ชันการคาดการณ์ที่กำหนดเองที่เรากำหนดไว้ข้างต้น พร้อมกับเป้าหมาย (สิ่งที่เรากำลังคาดการณ์) และประเภทโมเดล
config_builder = (WitConfigBuilder(wit_data[:500].values.tolist(), data.columns.tolist() + ['weight_pounds'])
.set_custom_predict_fn(custom_predict)
.set_target_feature('weight_pounds')
.set_model_type('regression'))
WitWidget(config_builder, height=800)
คุณควรเห็นลักษณะดังนี้เมื่อ What-If Tool โหลด

ในแกน x คุณจะเห็นจุดข้อมูลการทดสอบที่กระจายออกตามค่าถ่วงน้ำหนักที่โมเดลคาดการณ์ weight_pounds
ขั้นตอนที่ 3: สำรวจลักษณะการทำงานของโมเดลด้วย What-If Tool
คุณทำสิ่งเจ๋งๆ ได้มากมายด้วยเครื่องมือ What-If เราจะมาดูตัวอย่างบางส่วนกัน ก่อนอื่น มาดูเครื่องมือแก้ไขจุดข้อมูลกัน คุณเลือกจุดข้อมูลใดก็ได้เพื่อดูฟีเจอร์ของจุดข้อมูลนั้น และเปลี่ยนค่าฟีเจอร์ เริ่มต้นโดยคลิกจุดข้อมูลใดก็ได้
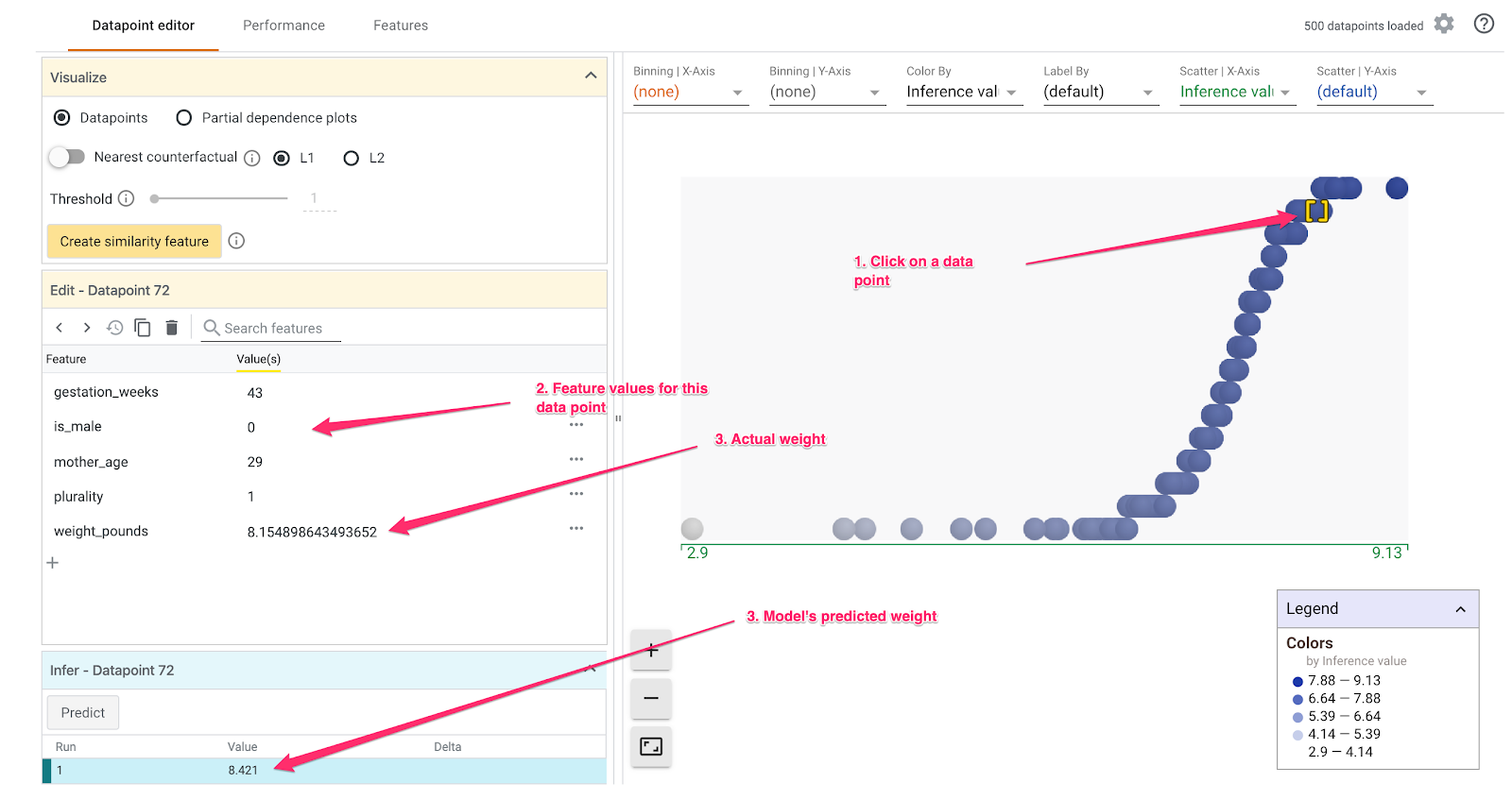
ทางด้านซ้าย คุณจะเห็นค่าฟีเจอร์สำหรับจุดข้อมูลที่เลือก นอกจากนี้ คุณยังเปรียบเทียบป้ายกำกับข้อมูลที่ระบุว่าถูกต้องโดยเจ้าหน้าที่ของจุดข้อมูลนั้นกับค่าที่โมเดลคาดการณ์ได้ด้วย ในแถบด้านข้างซ้าย คุณยังเปลี่ยนค่าฟีเจอร์และเรียกใช้การคาดการณ์ของโมเดลอีกครั้งเพื่อดูผลกระทบที่การเปลี่ยนแปลงนี้มีต่อโมเดลได้ด้วย เช่น เราสามารถเปลี่ยน gestation_weeks เป็น 30 สำหรับจุดข้อมูลนี้ได้โดยดับเบิลคลิกที่จุดข้อมูลนั้นแล้วเรียกใช้การคาดการณ์อีกครั้ง

คุณสามารถสร้างภาพข้อมูลที่กำหนดเองได้ทุกประเภทโดยใช้เมนูแบบเลื่อนลงในส่วนพล็อตของเครื่องมือ What-If ตัวอย่างเช่น นี่คือแผนภูมิที่มีน้ำหนักที่คาดการณ์ของโมเดลในแกน x อายุของมารดาในแกน y และจุดที่ระบายสีตามข้อผิดพลาดในการอนุมาน (สีเข้มกว่าหมายถึงความแตกต่างระหว่างน้ำหนักที่คาดการณ์กับน้ำหนักจริงที่สูงกว่า) ในที่นี้ ดูเหมือนว่าเมื่อน้ำหนักลดลง ข้อผิดพลาดของโมเดลจะเพิ่มขึ้นเล็กน้อย

จากนั้นเลือกปุ่มแผนภาพการขึ้นต่อกันบางส่วนทางด้านซ้าย ซึ่งแสดงให้เห็นว่าฟีเจอร์แต่ละรายการมีอิทธิพลต่อการคาดการณ์ของโมเดลอย่างไร ตัวอย่างเช่น เมื่อเวลาในการตั้งครรภ์เพิ่มขึ้น น้ำหนักทารกที่โมเดลคาดการณ์ไว้ก็จะเพิ่มขึ้นด้วย

หากต้องการดูไอเดียเพิ่มเติมในการสำรวจด้วย What-If Tool โปรดดูลิงก์ที่จุดเริ่มต้นของส่วนนี้
7. ไม่บังคับ: เชื่อมต่อที่เก็บ Git ในเครื่องกับ GitHub
สุดท้าย เราจะมาดูวิธีเชื่อมต่อที่เก็บ git ในอินสแตนซ์ Notebook กับที่เก็บในบัญชี GitHub หากต้องการทำขั้นตอนนี้ คุณจะต้องมีบัญชี GitHub
ขั้นตอนที่ 1: สร้างที่เก็บใหม่ใน GitHub
สร้างที่เก็บใหม่ในบัญชี GitHub ตั้งชื่อและคำอธิบายของที่เก็บ ตัดสินใจว่าต้องการให้ที่เก็บเป็นแบบสาธารณะหรือไม่ แล้วเลือกสร้างที่เก็บ (คุณไม่จำเป็นต้องเริ่มต้นด้วย README) ในหน้าถัดไป คุณจะทำตามวิธีการเพื่อพุชที่เก็บที่มีอยู่จากบรรทัดคำสั่ง
เปิดหน้าต่างเทอร์มินัล แล้วเพิ่มที่เก็บใหม่เป็นรีโมต แทนที่ username ใน URL ของที่เก็บด้านล่างด้วยชื่อผู้ใช้ GitHub ของคุณ และแทนที่ your-repo ด้วยชื่อของที่เก็บที่คุณเพิ่งสร้าง
git remote add origin git@github.com:username/your-repo.git
ขั้นตอนที่ 2: ตรวจสอบสิทธิ์ไปยัง GitHub ในอินสแตนซ์ Notebook
จากนั้นคุณจะต้องตรวจสอบสิทธิ์กับ GitHub จากภายในอินสแตนซ์ Notebook กระบวนการนี้จะแตกต่างกันไปโดยขึ้นอยู่กับว่าคุณได้เปิดใช้การตรวจสอบสิทธิ์แบบ 2 ปัจจัยใน GitHub หรือไม่
หากไม่แน่ใจว่าจะเริ่มต้นจากตรงไหน ให้ทำตามขั้นตอนในเอกสารประกอบของ GitHub เพื่อสร้างคีย์ SSH แล้วเพิ่มคีย์ใหม่ลงใน GitHub
ขั้นตอนที่ 3: ตรวจสอบว่าคุณได้ลิงก์ที่เก็บ GitHub อย่างถูกต้องแล้ว
เรียกใช้ git remote -v ในเทอร์มินัลเพื่อให้แน่ใจว่าคุณได้ตั้งค่าอย่างถูกต้อง คุณควรเห็นที่เก็บใหม่แสดงเป็นรีโมต เมื่อเห็น URL ของที่เก็บ GitHub และตรวจสอบสิทธิ์กับ GitHub จาก Notebook แล้ว คุณก็พร้อมที่จะพุชไปยัง GitHub โดยตรงจากอินสแตนซ์ Notebook
หากต้องการซิงค์ที่เก็บ Git ของ Notebook ในเครื่องกับที่เก็บ GitHub ที่สร้างขึ้นใหม่ ให้คลิกปุ่มอัปโหลดไปยังระบบคลาวด์ที่ด้านบนของแถบด้านข้าง Git

รีเฟรชที่เก็บ GitHub แล้วคุณจะเห็นโค้ด Notebook พร้อมกับคอมมิตก่อนหน้า หากผู้อื่นมีสิทธิ์เข้าถึงที่เก็บ GitHub ของคุณและคุณต้องการดึงการเปลี่ยนแปลงล่าสุดลงใน Notebook ให้คลิกไอคอนดาวน์โหลดจากระบบคลาวด์เพื่อซิงค์การเปลี่ยนแปลงเหล่านั้น
ในแท็บประวัติของ UI ของ Git ใน Notebook คุณจะดูได้ว่าคอมมิตในเครื่องซิงค์กับ GitHub หรือไม่ ในตัวอย่างนี้ origin/master จะสอดคล้องกับที่เก็บของเราใน GitHub

เมื่อใดก็ตามที่คุณทำการคอมมิตใหม่ เพียงคลิกปุ่มอัปโหลดไปยังระบบคลาวด์อีกครั้งเพื่อพุชการเปลี่ยนแปลงเหล่านั้นไปยังที่เก็บ GitHub
8. ยินดีด้วย
คุณทำสิ่งต่างๆ มากมายในห้องทดลองนี้ 👏👏👏
กล่าวโดยสรุปคือ คุณได้เรียนรู้วิธีการต่อไปนี้
- สร้างและปรับแต่งอินสแตนซ์ Notebook ของ AI Platform
- เริ่มต้นที่เก็บ Git ในเครื่องในอินสแตนซ์นั้น เพิ่มคอมมิตผ่าน UI ของ Git หรือบรรทัดคำสั่ง ดู Git Diff ใน UI ของ Git ใน Notebook
- สร้างและฝึกโมเดล TensorFlow 2 แบบง่าย
- ใช้ What-If Tool ภายในอินสแตนซ์ Notebook
- เชื่อมต่อที่เก็บ Git ของ Notebook กับที่เก็บภายนอกใน GitHub
9. ล้างข้อมูล
หากต้องการใช้ Notebook นี้ต่อไป ขอแนะนำให้ปิดเมื่อไม่ได้ใช้งาน จาก UI ของ Notebook ใน Cloud Console ให้เลือก Notebook แล้วเลือกหยุด

หากต้องการลบทรัพยากรทั้งหมดที่คุณสร้างไว้ใน Lab นี้ ให้ลบอินสแตนซ์ Notebook แทนการหยุด
ใช้เมนูการนำทางใน Cloud Console เพื่อไปที่ Storage แล้วลบทั้ง 2 Bucket ที่คุณสร้างขึ้นเพื่อจัดเก็บชิ้นงานโมเดล