
1. खास जानकारी
इस कोडलैब में, Google Cloud Platform पर Dataproc के साथ Apache Spark का इस्तेमाल करके, डेटा प्रोसेसिंग पाइपलाइन बनाने का तरीका बताया जाएगा. डेटा साइंस और डेटा इंजीनियरिंग में, एक स्टोरेज लोकेशन से डेटा को पढ़ना, उसमें बदलाव करना, और उसे किसी दूसरी स्टोरेज लोकेशन में लिखना एक सामान्य प्रोसेस है. डेटा में आम तौर पर किए जाने वाले बदलावों में, डेटा के कॉन्टेंट में बदलाव करना, काम की जानकारी हटाना, और फ़ाइल टाइप बदलना शामिल है.
इस कोडलैब में, आपको Apache Spark के बारे में जानकारी मिलेगी. साथ ही, Dataproc के साथ PySpark (Apache Spark का Python API), BigQuery, Google Cloud Storage, और Reddit से मिले डेटा का इस्तेमाल करके, एक सैंपल पाइपलाइन चलाने का तरीका भी बताया जाएगा.
2. Apache Spark के बारे में जानकारी (ज़रूरी नहीं)
वेबसाइट के मुताबिक, " Apache Spark, बड़े पैमाने पर डेटा प्रोसेस करने के लिए एक यूनीफ़ाइड ऐनलिटिक्स इंजन है." इसकी मदद से, डेटा का विश्लेषण और उसे प्रोसेस किया जा सकता है. साथ ही, इसे मेमोरी में सेव किया जा सकता है. इससे, कई अलग-अलग मशीनों और नोड पर एक साथ काफ़ी डेटा प्रोसेस किया जा सकता है. इसे मूल रूप से 2014 में, MapReduce को अपग्रेड करने के लिए रिलीज़ किया गया था. यह अब भी बड़े पैमाने पर कंप्यूटेशन करने के लिए, सबसे लोकप्रिय फ़्रेमवर्क में से एक है. Apache Spark को Scala में लिखा गया है. इसलिए, इसके एपीआई Scala, Java, Python, और R में उपलब्ध हैं. इसमें कई लाइब्रेरी होती हैं. जैसे, डेटा पर SQL क्वेरी करने के लिए Spark SQL, डेटा को स्ट्रीम करने के लिए Spark Streaming, मशीन लर्निंग के लिए MLlib, और ग्राफ़ प्रोसेसिंग के लिए GraphX. ये सभी Apache Spark इंजन पर काम करती हैं.
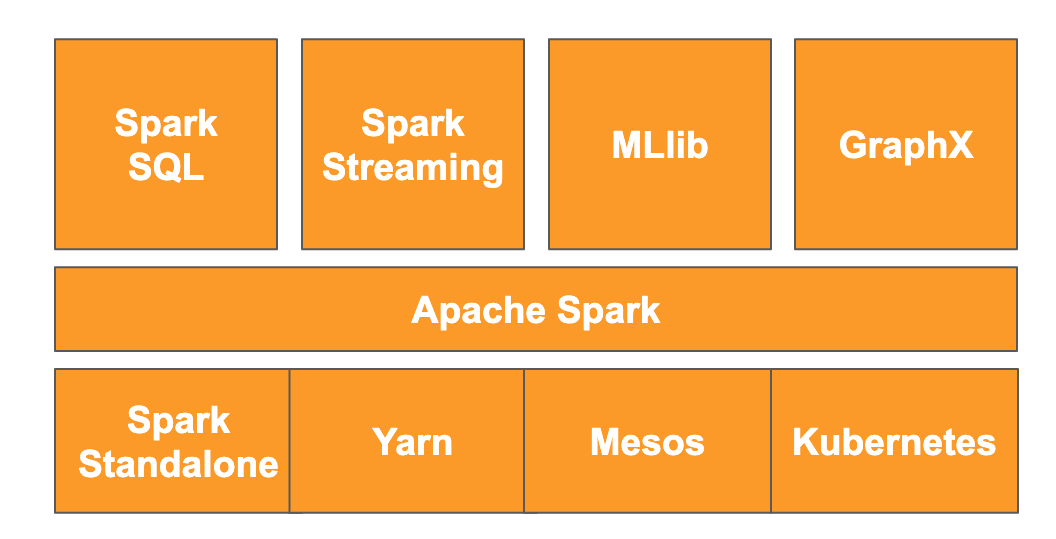
Spark को अपने-आप चलाया जा सकता है. इसके अलावा, इसे स्केल करने के लिए, संसाधन मैनेज करने वाली सेवा का इस्तेमाल किया जा सकता है. जैसे, Yarn, Mesos या Kubernetes. इस कोडलैब के लिए, Dataproc का इस्तेमाल किया जाएगा. यह Yarn का इस्तेमाल करता है.
Spark में डेटा को मेमोरी में लोड किया जाता है. इसे आरडीडी या रेज़िलिएंट डिस्ट्रिब्यूटेड डेटासेट कहा जाता है. इसके बाद से, Spark के डेवलपमेंट में दो नए, कॉलम वाले डेटा टाइप जोड़े गए हैं: डेटासेट, जो टाइप किया गया है, और डेटाफ़्रेम, जो टाइप नहीं किया गया है. RDD का इस्तेमाल किसी भी तरह के डेटा के लिए किया जा सकता है. वहीं, डेटासेट और डेटाफ़्रेम को टेबल वाले डेटा के लिए ऑप्टिमाइज़ किया जाता है. डेटासेट सिर्फ़ Java और Scala API के साथ उपलब्ध हैं. इसलिए, हम इस कोडलैब के लिए PySpark Dataframe API का इस्तेमाल करेंगे. ज़्यादा जानकारी के लिए, कृपया Apache Spark का दस्तावेज़ देखें.
3. इस्तेमाल का उदाहरण
डेटा इंजीनियर को अक्सर ऐसे डेटा की ज़रूरत होती है जिसे डेटा साइंटिस्ट आसानी से ऐक्सेस कर सकें. हालांकि, डेटा अक्सर शुरुआत में सही नहीं होता. इसका मतलब है कि मौजूदा स्थिति में, इसे आंकड़ों के विश्लेषण के लिए इस्तेमाल करना मुश्किल होता है. इसलिए, इसे इस्तेमाल करने से पहले साफ़ करना ज़रूरी होता है. इसका एक उदाहरण, वेब से स्क्रैप किया गया डेटा है. इसमें अजीब तरह की एन्कोडिंग या गैर-ज़रूरी एचटीएमएल टैग शामिल हो सकते हैं.
इस लैब में, आपको BigQuery से Reddit पोस्ट के तौर पर डेटा के सेट को Dataproc पर होस्ट किए गए Spark क्लस्टर में लोड करना होगा. इसके बाद, काम की जानकारी निकालनी होगी और प्रोसेस किए गए डेटा को Google Cloud Storage में ज़िप की गई CSV फ़ाइलों के तौर पर सेव करना होगा.
आपकी कंपनी के मुख्य डेटा वैज्ञानिक को, अपनी टीमों से नैचुरल लैंग्वेज प्रोसेसिंग से जुड़ी अलग-अलग समस्याओं पर काम कराना है. खास तौर पर, उन्हें "r/food" सबरेडिट में मौजूद डेटा का विश्लेषण करने में दिलचस्पी है. आपको डेटा डंप करने के लिए एक पाइपलाइन बनानी होगी. इसकी शुरुआत जनवरी 2017 से अगस्त 2019 तक के डेटा को बैकफ़िल करने से होगी.
4. BigQuery Storage API के ज़रिए BigQuery को ऐक्सेस करना
tabledata.list API method का इस्तेमाल करके, BigQuery से डेटा पुल करने में ज़्यादा समय लग सकता है. साथ ही, डेटा की मात्रा बढ़ने पर यह तरीका असरदार नहीं रहता. यह तरीका, JSON ऑब्जेक्ट की सूची दिखाता है. साथ ही, पूरे डेटासेट को पढ़ने के लिए, एक बार में एक पेज को क्रम से पढ़ना ज़रूरी होता है.
BigQuery Storage API, आरपीसी पर आधारित प्रोटोकॉल का इस्तेमाल करके, BigQuery में डेटा ऐक्सेस करने की प्रोसेस को बेहतर बनाता है. यह एक साथ डेटा को पढ़ने और लिखने के साथ-साथ, अलग-अलग सीरियलाइज़ेशन फ़ॉर्मैट के साथ काम करता है. जैसे, Apache Avro और Apache Arrow. इससे, परफ़ॉर्मेंस में काफ़ी सुधार होता है. खास तौर पर, बड़े डेटा सेट पर काम करते समय.
इस कोडलैब में, BigQuery और Spark के बीच डेटा को पढ़ने और लिखने के लिए, spark-bigquery-connector का इस्तेमाल किया जाएगा.
5. प्रोजेक्ट बनाना
console.cloud.google.com पर जाकर, Google Cloud Platform Console में साइन इन करें और एक नया प्रोजेक्ट बनाएं:



इसके बाद, Google Cloud संसाधनों का इस्तेमाल करने के लिए, आपको Cloud Console में बिलिंग चालू करनी होगी.
इस कोडलैब को पूरा करने में आपको कुछ डॉलर से ज़्यादा खर्च नहीं करने पड़ेंगे. हालांकि, अगर आपने ज़्यादा संसाधनों का इस्तेमाल करने का फ़ैसला किया है या उन्हें चालू रखा है, तो यह ज़्यादा हो सकता है. इस कोडलैब के आखिरी सेक्शन में, आपको अपने प्रोजेक्ट को क्लीन अप करने के बारे में जानकारी मिलेगी.
Google Cloud Platform के नए उपयोगकर्ताओं को, मुफ़्त में आज़माने के लिए 300 डॉलर का क्रेडिट मिलता है.
6. अपना एनवायरमेंट सेट अप करना
अब आपको अपना एनवायरमेंट सेट अप करना होगा. इसके लिए:
- Compute Engine, Dataproc, और BigQuery Storage API चालू करना
- प्रोजेक्ट सेटिंग कॉन्फ़िगर करना
- Dataproc क्लस्टर बनाना
- Google Cloud Storage बकेट बनाना
एपीआई चालू करना और एनवायरमेंट कॉन्फ़िगर करना
Cloud Console के सबसे ऊपर दाएं कोने में मौजूद बटन दबाकर, Cloud Shell खोलें.
Cloud Shell लोड होने के बाद, Compute Engine, Dataproc, और BigQuery Storage API चालू करने के लिए, यहां दिए गए निर्देश चलाएं:
gcloud services enable compute.googleapis.com \
dataproc.googleapis.com \
bigquerystorage.googleapis.com
अपने प्रोजेक्ट का प्रोजेक्ट आईडी सेट करें. इसे ढूंढने के लिए, प्रोजेक्ट चुनने वाले पेज पर जाएं और अपना प्रोजेक्ट खोजें. यह आपके प्रोजेक्ट के नाम से अलग हो सकता है.

अपना प्रोजेक्ट आईडी सेट करने के लिए, यह कमांड चलाएं:
gcloud config set project <project_id>
यहां दी गई सूची में से कोई विकल्प चुनकर, अपने प्रोजेक्ट का क्षेत्र सेट करें. us-central1, इसका एक उदाहरण है.
gcloud config set dataproc/region <region>
अपने Dataproc क्लस्टर के लिए कोई नाम चुनें और उसके लिए एनवायरमेंट वैरिएबल बनाएं.
CLUSTER_NAME=<cluster_name>
Dataproc क्लस्टर बनाना
नीचे दिए गए कमांड को चलाकर, Dataproc क्लस्टर बनाएं:
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--worker-machine-type n1-standard-8 \
--num-workers 8 \
--image-version 1.5-debian \
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \
--metadata 'PIP_PACKAGES=google-cloud-storage' \
--optional-components=ANACONDA \
--enable-component-gateway
इस कमांड को पूरा होने में कुछ मिनट लगेंगे. कमांड को छोटे-छोटे हिस्सों में बांटने के लिए:
इससे, आपके दिए गए नाम से Dataproc क्लस्टर बनाने की प्रोसेस शुरू हो जाएगी. beta API का इस्तेमाल करने से, Dataproc की बीटा सुविधाएं चालू हो जाएंगी. जैसे, Component Gateway.
gcloud beta dataproc clusters create ${CLUSTER_NAME}
इससे आपके वर्कर के लिए, मशीन का टाइप सेट हो जाएगा.
--worker-machine-type n1-standard-8
इससे आपके क्लस्टर में काम करने वालों की संख्या सेट हो जाएगी.
--num-workers 8
इससे Dataproc का इमेज वर्शन सेट हो जाएगा.
--image-version 1.5-debian
इससे क्लस्टर पर इस्तेमाल की जाने वाली शुरुआती कार्रवाइयां कॉन्फ़िगर होंगी. यहां, pip को शुरू करने की कार्रवाई शामिल की जा रही है.
--initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh
यह क्लस्टर में शामिल किया जाने वाला मेटाडेटा है. यहां pip इनिशियलाइज़ेशन ऐक्शन के लिए मेटाडेटा दिया जा रहा है.
--metadata 'PIP_PACKAGES=google-cloud-storage'
इससे क्लस्टर पर इंस्टॉल किए जाने वाले वैकल्पिक कॉम्पोनेंट सेट हो जाएंगे.
--optional-components=ANACONDA
इससे कॉम्पोनेंट गेटवे चालू हो जाएगा. इसकी मदद से, Zeppelin, Jupyter या Spark History जैसे सामान्य यूज़र इंटरफ़ेस (यूआई) देखने के लिए, Dataproc के कॉम्पोनेंट गेटवे का इस्तेमाल किया जा सकता है
--enable-component-gateway
Dataproc के बारे में ज़्यादा जानकारी के लिए, कृपया यह कोडलैब देखें.
Google Cloud Storage बकेट बनाना
आपको अपने काम के आउटपुट के लिए, Google Cloud Storage बकेट की ज़रूरत होगी. अपनी बकेट के लिए कोई यूनीक नाम तय करें. इसके बाद, नई बकेट बनाने के लिए यहां दिया गया कमांड चलाएं. सभी उपयोगकर्ताओं के लिए, सभी Google Cloud प्रोजेक्ट में बकेट के नाम यूनीक होते हैं. इसलिए, आपको अलग-अलग नामों से कुछ बार कोशिश करनी पड़ सकती है. अगर आपको ServiceException नहीं मिलता है, तो इसका मतलब है कि बकेट बन गई है.
BUCKET_NAME=<bucket_name>
gsutil mb gs://${BUCKET_NAME}
7. एक्सप्लोरेट्री डेटा ऐनलिसिस
प्रीप्रोसेसिंग करने से पहले, आपको उस डेटा के बारे में ज़्यादा जानना चाहिए जिसका इस्तेमाल किया जा रहा है. इसके लिए, डेटा एक्सप्लोर करने के दो तरीकों के बारे में जानें. सबसे पहले, BigQuery वेब यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करके कुछ रॉ डेटा देखा जाएगा. इसके बाद, PySpark और Dataproc का इस्तेमाल करके, हर सबरेडिट के लिए पोस्ट की संख्या कैलकुलेट की जाएगी.
BigQuery वेब यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करना
अपना डेटा देखने के लिए, BigQuery वेब यूज़र इंटरफ़ेस (यूआई) का इस्तेमाल करें. Cloud Console में मौजूद मेन्यू आइकॉन से नीचे की ओर स्क्रोल करें. इसके बाद, BigQuery वेब यूज़र इंटरफ़ेस (यूआई) खोलने के लिए, "BigQuery" दबाएं.
इसके बाद, BigQuery वेब यूज़र इंटरफ़ेस (यूआई) के क्वेरी एडिटर में यहां दिया गया निर्देश चलाएं. इससे, जनवरी 2017 के डेटा की 10 पूरी लाइनें दिखेंगी:
select * from fh-bigquery.reddit_posts.2017_01 limit 10;
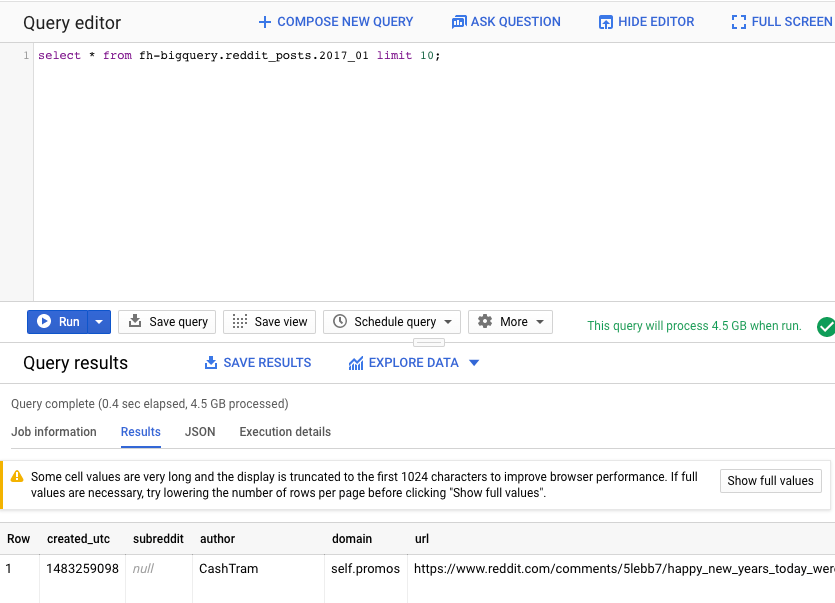
पेज पर स्क्रोल करके, उपलब्ध सभी कॉलम के साथ-साथ कुछ उदाहरण भी देखे जा सकते हैं. खास तौर पर, आपको दो कॉलम दिखेंगे. इनमें हर पोस्ट का टेक्स्ट वाला कॉन्टेंट मौजूद होता है: "title" और "selftext". "selftext" पोस्ट का मुख्य हिस्सा होता है. साथ ही, "created_utc" जैसे अन्य कॉलम पर भी ध्यान दें. यह पोस्ट बनाने का यूटीसी समय है. "subreddit" वह सबरेडिट है जिसमें पोस्ट मौजूद है.
PySpark जॉब को लागू करना
सैंपल कोड के साथ रेपो को क्लोन करने और सही डायरेक्ट्री में cd करने के लिए, Cloud Shell में ये कमांड चलाएं:
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
PySpark का इस्तेमाल करके, यह पता लगाया जा सकता है कि हर सबरेडिट के लिए कितनी पोस्ट मौजूद हैं. Cloud Editor खोलकर, अगले चरण में स्क्रिप्ट cloud-dataproc/codelabs/spark-bigquery को लागू करने से पहले, उसे पढ़ा जा सकता है:
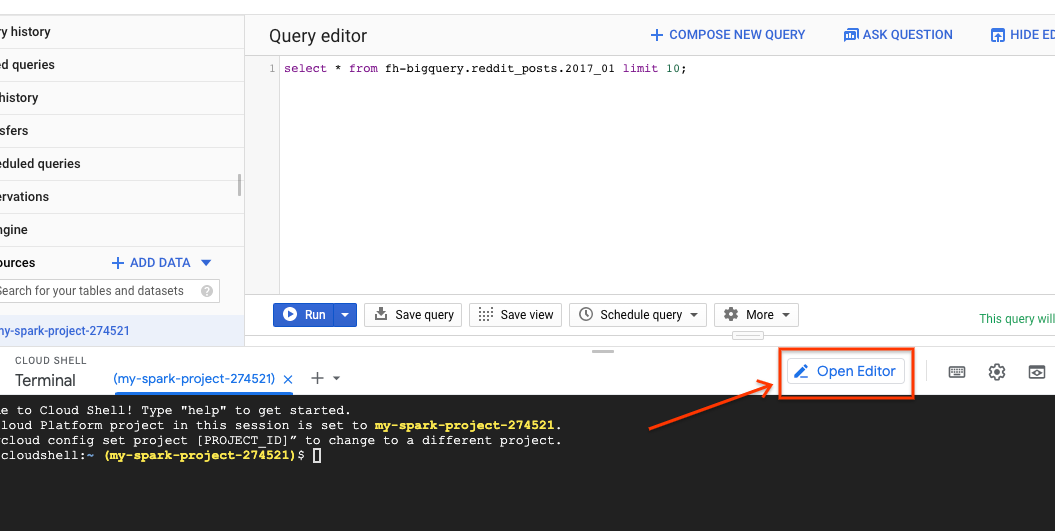
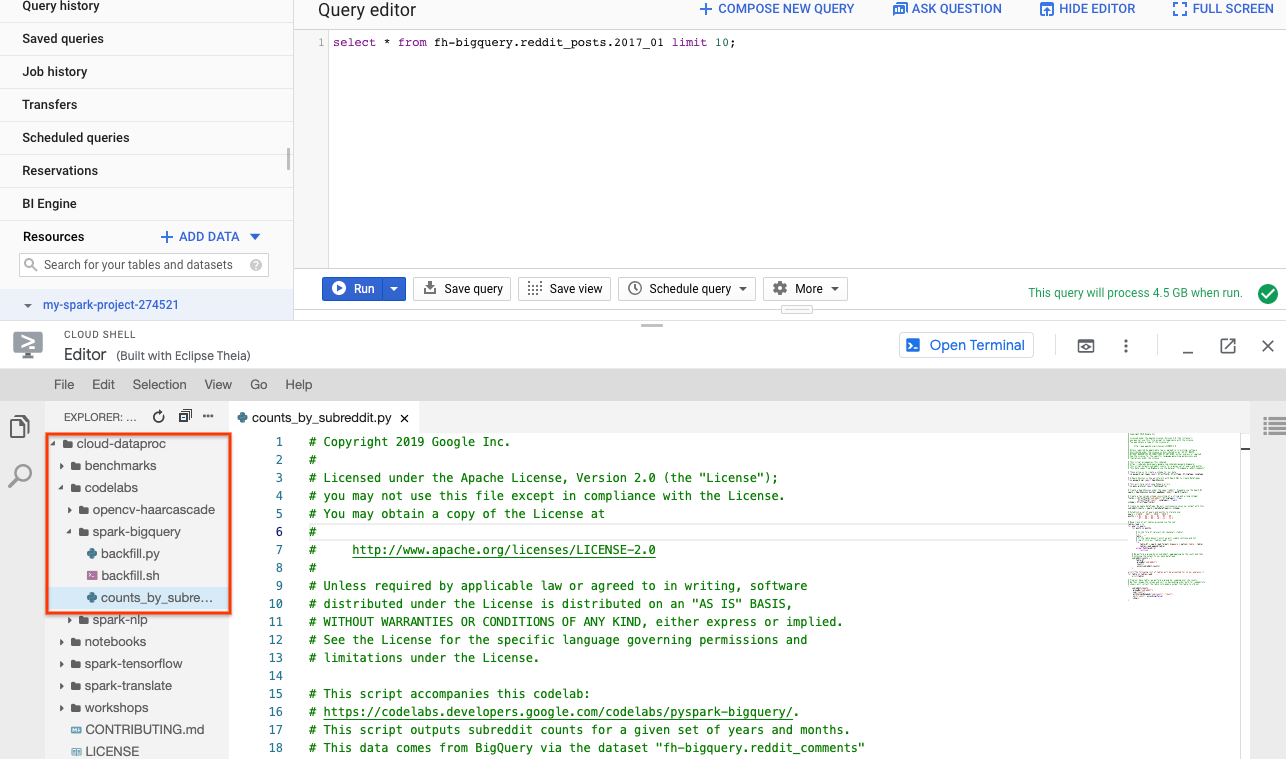
Cloud Editor में "टर्मिनल खोलें" बटन पर क्लिक करके, Cloud Shell पर वापस जाएं. इसके बाद, अपना पहला PySpark जॉब चलाने के लिए, यह कमांड चलाएं:
cd ~/cloud-dataproc/codelabs/spark-bigquery
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME} \
--jars gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar \
--driver-log-levels root=FATAL \
counts_by_subreddit.py
इस कमांड की मदद से, Jobs API के ज़रिए Dataproc को जॉब सबमिट किए जा सकते हैं. यहां नौकरी के टाइप को pyspark के तौर पर दिखाया गया है. क्लस्टर का नाम, ज़रूरी नहीं कि पैरामीटर और जॉब वाली फ़ाइल का नाम दिया जा सकता है. यहां --jars पैरामीटर दिया गया है. इससे आपको अपनी नौकरी के साथ spark-bigquery-connector को शामिल करने की अनुमति मिलती है. --driver-log-levels root=FATAL का इस्तेमाल करके, लॉग आउटपुट लेवल भी सेट किए जा सकते हैं. इससे गड़बड़ियों को छोड़कर, सभी लॉग आउटपुट बंद हो जाएंगे. स्पार्क लॉग में काफ़ी ज़्यादा डेटा होता है.
इसे पूरा होने में कुछ मिनट लगेंगे. इसके बाद, आपको कुछ ऐसा आउटपुट दिखेगा:
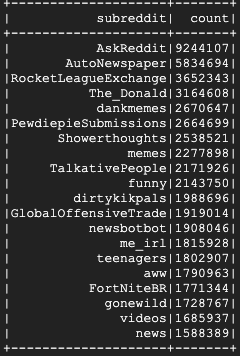
8. Dataproc और Spark के यूज़र इंटरफ़ेस (यूआई) के बारे में जानना
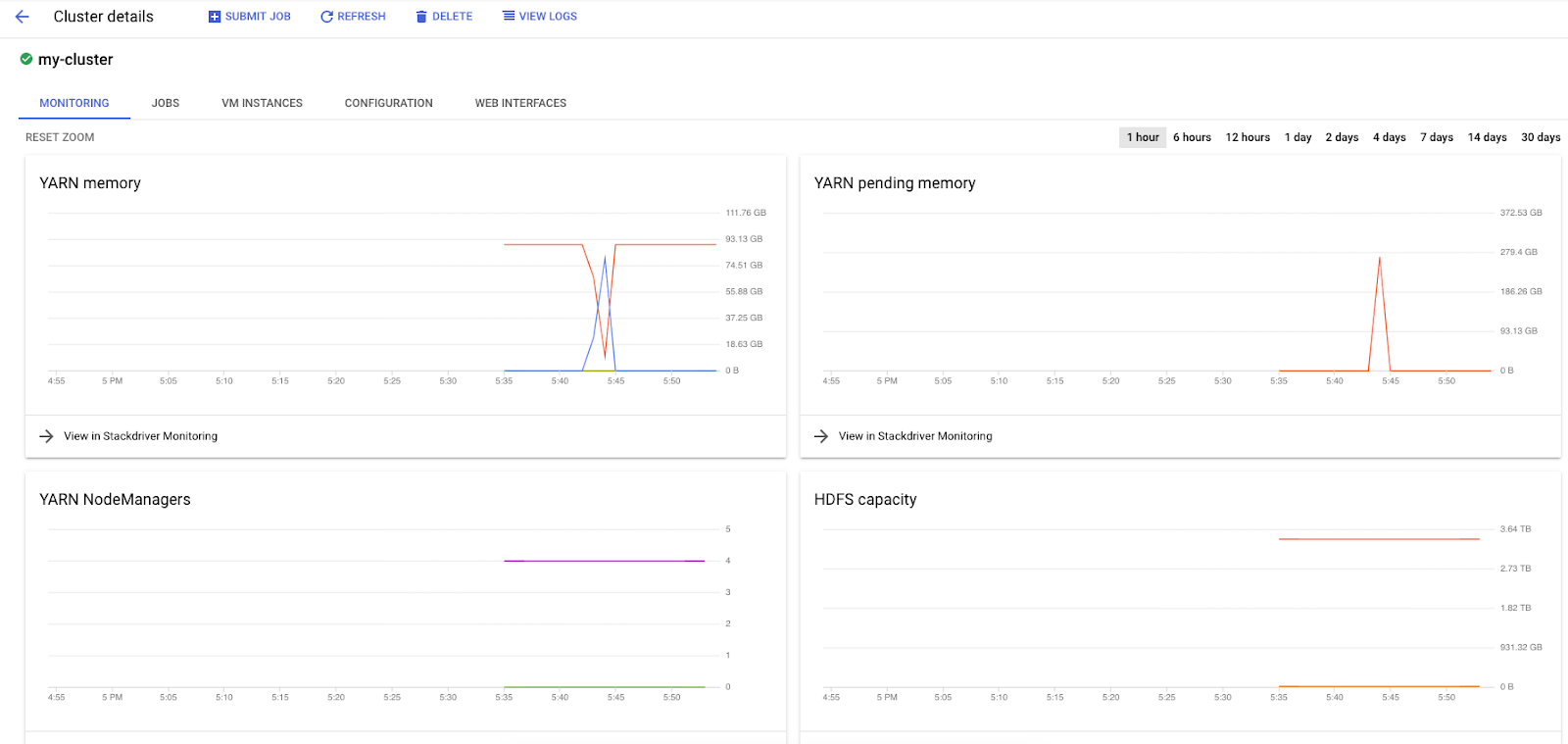
Dataproc पर Spark जॉब चलाने के दौरान, आपके पास दो यूज़र इंटरफ़ेस (यूआई) का ऐक्सेस होता है. इनकी मदद से, अपनी जॉब / क्लस्टर की स्थिति देखी जा सकती है. पहला विकल्प Dataproc का यूज़र इंटरफ़ेस (यूआई) है. इसे देखने के लिए, मेन्यू आइकॉन पर क्लिक करें और नीचे की ओर स्क्रोल करके Dataproc पर जाएं. यहां आपको मौजूदा समय में उपलब्ध मेमोरी, मेमोरी का इस्तेमाल करने के लिए लंबित अनुरोध, और वर्कर की संख्या दिख सकती है.
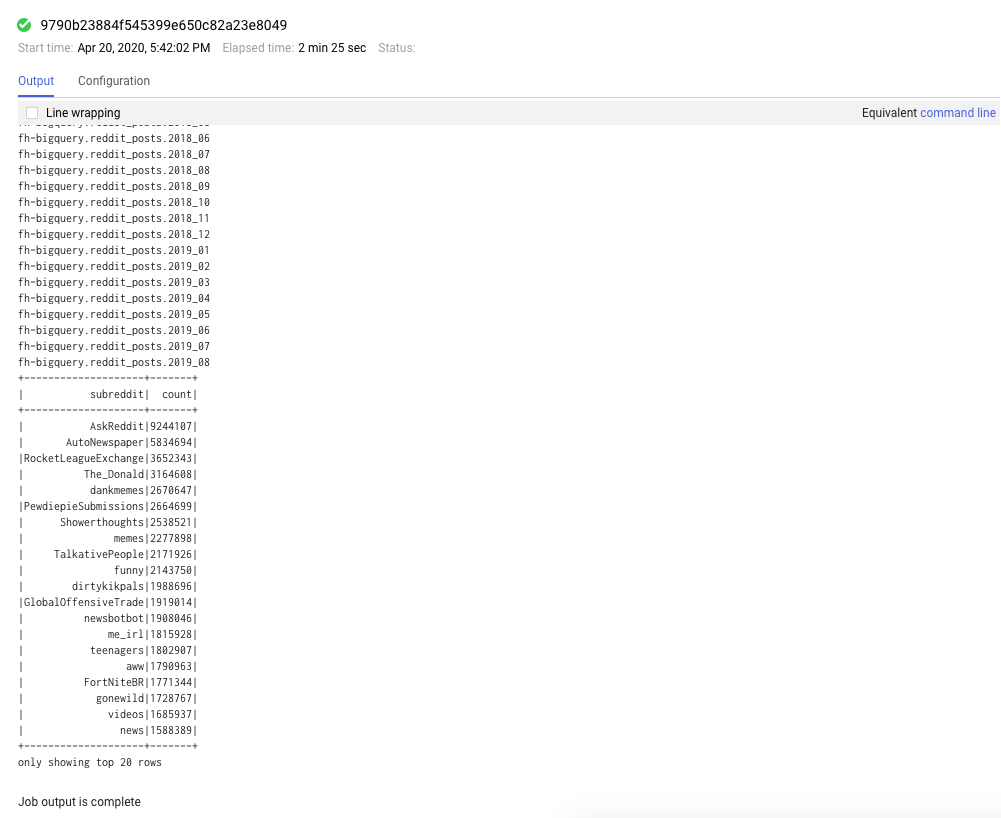
पूरे हो चुके टास्क देखने के लिए, 'टास्क' टैब पर भी क्लिक किया जा सकता है. किसी नौकरी के लिए, नौकरी का आईडी पर क्लिक करके, नौकरी की जानकारी देखी जा सकती है. जैसे, उन नौकरियों के लॉग और आउटपुट. 
Spark यूज़र इंटरफ़ेस (यूआई) भी देखा जा सकता है. जॉब पेज पर, बैक ऐरो पर क्लिक करें. इसके बाद, वेब इंटरफ़ेस पर क्लिक करें. आपको कॉम्पोनेंट गेटवे में कई विकल्प दिखेंगे. इनमें से कई को क्लस्टर सेट अप करते समय, वैकल्पिक कॉम्पोनेंट के ज़रिए चालू किया जा सकता है. इस लैब के लिए, "Spark History Server" पर क्लिक करें.

इससे यह विंडो खुलनी चाहिए:

पूरी हो चुकी सभी नौकरियां यहां दिखेंगी. नौकरी के बारे में ज़्यादा जानकारी पाने के लिए, किसी भी application_id पर क्लिक करें. इसी तरह, फ़िलहाल चल रही सभी नौकरियों को देखने के लिए, लैंडिंग पेज पर सबसे नीचे मौजूद "अधूरे आवेदन दिखाएं" पर क्लिक करें.
9. बैकफ़िल जॉब चलाया जा रहा है
अब आपको एक ऐसा जॉब चलाना होगा जो डेटा को मेमोरी में लोड करता है, ज़रूरी जानकारी निकालता है, और आउटपुट को Google Cloud Storage बकेट में डंप करता है. आपको Reddit पर की गई हर टिप्पणी के लिए, "टाइटल", "ब्यौरा" (कच्चा टेक्स्ट) और "बनाए जाने का टाइमस्टैंप" निकालना होगा. इसके बाद, इस डेटा को CSV फ़ाइल में बदलें, इसे ज़िप करें, और इसे gs://${BUCKET_NAME}/reddit_posts/YYYY/MM/food.csv.gz के यूआरआई वाले बकेट में लोड करें.
Cloud Editor में जाकर, cloud-dataproc/codelabs/spark-bigquery/backfill.sh के लिए कोड को फिर से पढ़ा जा सकता है. यह cloud-dataproc/codelabs/spark-bigquery/backfill.py में कोड को लागू करने के लिए रैपर स्क्रिप्ट है.
cd ~/cloud-dataproc/codelabs/spark-bigquery
bash backfill.sh ${CLUSTER_NAME} ${BUCKET_NAME}
आपको जल्द ही कई टास्क पूरे होने के मैसेज दिखेंगे. इस प्रोसेस में 15 मिनट तक लग सकते हैं. gsutil का इस्तेमाल करके, अपने स्टोरेज बकेट की दोबारा जांच की जा सकती है. इससे यह पुष्टि की जा सकती है कि डेटा आउटपुट सही तरीके से हुआ है. सभी जॉब पूरे होने के बाद, यह कमांड चलाएं:
gsutil ls gs://${BUCKET_NAME}/reddit_posts/*/*/food.csv.gz
आपको यह आउटपुट दिखेगा:
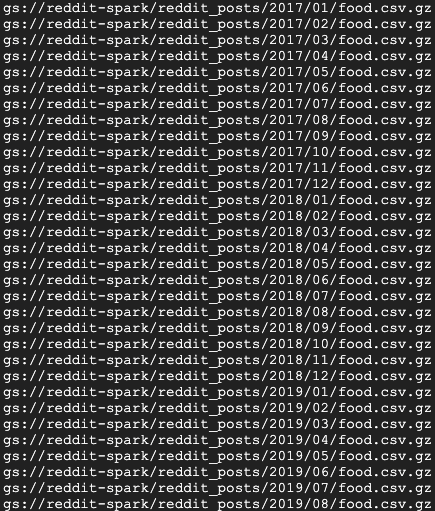
बधाई हो, आपने Reddit पर की गई टिप्पणियों के डेटा के लिए बैकफ़िल की प्रोसेस पूरी कर ली है! अगर आपको इस डेटा के आधार पर मॉडल बनाने के तरीके के बारे में जानना है, तो कृपया Spark-NLP कोडलैब पर जाएं.
10. साफ़-सफ़ाई सेवा
क्विकस्टार्ट पूरा होने के बाद, अपने GCP खाते पर बेवजह के शुल्क से बचने के लिए:
- आपने जिस एनवायरमेंट के लिए Cloud Storage बकेट बनाया है उसे मिटाएं
- Dataproc एनवायरमेंट मिटाएं.
अगर आपने यह प्रोजेक्ट सिर्फ़ इस कोडलैब के लिए बनाया है, तो आपके पास इसे मिटाने का विकल्प भी है:
- GCP Console में, प्रोजेक्ट पेज पर जाएं.
- प्रोजेक्ट की सूची में, वह प्रोजेक्ट चुनें जिसे मिटाना है. इसके बाद, मिटाएं पर क्लिक करें.
- बॉक्स में प्रोजेक्ट आईडी डालें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें.
लाइसेंस
इस काम के लिए, Creative Commons एट्रिब्यूशन 3.0 जेनेरिक लाइसेंस और Apache 2.0 लाइसेंस के तहत लाइसेंस मिला है.