
১. সংক্ষিপ্ত বিবরণ
চলুন, গত চারটি পর্বে আমরা যে বিশাল স্থাপত্যটি গড়ে তুলেছি, তার দিকে একবার চোখ বুলিয়ে নিই:
পর্ব ১ : আমরা BigQuery Knowledge Catalog ব্যবহার করে ফ্রয়ো রেসিপির সাধারণ পিডিএফ ফাইলগুলোকে স্ট্রাকচার্ড, রিলেশনাল টেবিলে রূপান্তর করেছি।
পর্ব ২ : আমরা একটি জিরো-ইটিএল ট্রানজ্যাকশনাল ব্রিজ তৈরি করেছি, যার মাধ্যমে আমাদের BigQuery ডেটা ডেটা ওয়্যারহাউসকে সরাসরি AlloyDB-এর সাথে ফেডারেট করা হয়েছে।
পর্ব ৩ : আমরা এজেন্ট ডেভেলপমেন্ট কিট এবং এমসিপি টুলবক্স ব্যবহার করে একটি মাল্টি-এজেন্ট অ্যাপ্লিকেশন (ফ্রয়োওএস) অর্কেস্ট্রেট করেছি।
পর্ব ৪ : একটি ডুয়াল-ট্র্যাক ইভ্যালুয়েশন পাইপলাইন তৈরির মাধ্যমে আমরা প্রমাণ করেছি যে আমাদের এজেন্টটি প্রোডাকশনের জন্য নিরাপদ।
আমাদের কার্যক্রম ত্রুটিহীনভাবে চলছে। কিন্তু সেই ডেভেলপার এবং বিজনেস অ্যানালিস্টদের কী হবে, যাদের এই সিস্টেম দ্বারা উৎপন্ন বিপুল পরিমাণ ডেটা বুঝতে হবে?
আজ আমরা অ্যানালিটিক্সের ভবিষ্যৎ অন্বেষণ করব। আমরা আমাদের কোড এডিটর Antigravity IDE-এর ভেতরেই Google Cloud Data Agent Kit দিয়ে শুরু করব এবং তারপর BigQuery Conversational Analytics ব্যবহার করে আমাদের ডেটা ভিজ্যুয়ালাইজ করার জন্য Google Cloud কনসোলে যাব।
চলুন নির্মাণ শুরু করা যাক!
আপনি যা শিখবেন
এজেন্টিক ডেটা ক্লাউড সিরিজের এই চূড়ান্ত কোডল্যাবে, আপনি কার্যকরী ব্যবসায়িক অন্তর্দৃষ্টি প্রদানের জন্য আপনার আর্কিটেকচারের সমস্ত অংশকে একত্রিত করবেন। আপনি শিখবেন:
- আইডিই-ফার্স্ট অ্যানালিটিক্স: আপনার ডেভেলপমেন্ট এনভায়রনমেন্ট থেকে সরাসরি আর্কিটেকচার কোয়েরি করার জন্য অ্যান্টিগ্র্যাভিটি আইডিই এবং গুগল ক্লাউড ডেটা এজেন্ট কিট কীভাবে ইনস্টল ও কনফিগার করবেন।
- কথোপকথনমূলক BigQuery: স্বাভাবিক ভাষা ব্যবহার করে জটিল SQL কাজ ও পূর্বাভাস স্বয়ংক্রিয় করতে BigQuery ডেটা এজেন্ট কীভাবে তৈরি, কনফিগার এবং নির্দেশ দেওয়া যায়।
- ডেটার গণতন্ত্রীকরণ: কীভাবে আপনার এজেন্টগুলোকে এন্টারপ্রাইজে প্রকাশ করবেন, যাতে সেগুলো প্রতিষ্ঠান জুড়ে বিশ্লেষক এবং ব্যবসায়িক ব্যবহারকারীদের কাছে সহজলভ্য হয়।
- অন্তর্দৃষ্টির দৃশ্যায়ন: গতিশীল ও পূর্বাভাসের জন্য প্রস্তুত ড্যাশবোর্ড তৈরি করতে কীভাবে আপনার এজেন্টের কথোপকথনমূলক অ্যানালিটিক্সকে ডেটা স্টুডিও -তে নির্বিঘ্নে একীভূত করবেন।
- এজেন্টিক ডেটা ক্লাউড ইকোসিস্টেম: আপনার এন্ড-টু-এন্ড আর্কিটেকচারের গুরুত্ব কীভাবে তুলে ধরবেন — প্রথম পর্বের কাঁচা অসংগঠিত ডেটা থেকে পঞ্চম পর্বের নির্বাহী-উপযোগী ড্যাশবোর্ড পর্যন্ত।
প্রয়োজনীয়তা
- একটি ব্রাউজার, যেমন ক্রোম বা ফায়ারফক্স ।
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
- SQL সম্পর্কে প্রাথমিক ধারণা।
২. শুরু করার আগে
একটি প্রকল্প তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন ।
- আপনি ক্লাউড শেল ব্যবহার করবেন, যা গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ। গুগল ক্লাউড কনসোলের শীর্ষে থাকা ‘Activate Cloud Shell’-এ ক্লিক করুন।

- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি নিম্নলিখিত কমান্ডটি ব্যবহার করে যাচাই করে নিন যে আপনি ইতিমধ্যেই প্রমাণীকৃত এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে:
gcloud auth list
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে অবগত আছে কিনা, তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান।
gcloud config list project
- আপনি যদি প্রমাণীকরণ করতে চান
gcloud auth login
- আপনার প্রজেক্টটি সেট করা না থাকলে, এটি সেট করতে নিম্নলিখিত কমান্ডটি ব্যবহার করুন:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- প্রয়োজনীয় API-গুলো সক্রিয় করুন: সমস্ত প্রয়োজনীয় API সক্রিয় করতে এই কমান্ডটি চালান:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
৩. ডেটা ওয়্যারহাউস সম্প্রসারণ
আমাদের অসংগঠিত ডেটা থেকে তৈরি করা BigQuery টেবিলগুলোর কথা মনে আছে?
অর্থপূর্ণ বিশ্লেষণ করার জন্য আমাদের ঐতিহাসিক লেনদেনের ডেটা প্রয়োজন। BigQuery-তে, আমাদের froyo_data ডেটাসেটের অধীনে, ফ্র্যাঞ্চাইজি কার্যক্রমের বছরগুলো অনুকরণ করার জন্য চলুন তিনটি নতুন টেবিল তৈরি করি:
- froyo_data. orders : ঐতিহাসিক অর্ডারের শিরোনাম (তারিখ, স্টোর আইডি, মোট পরিমাণ)
- froyo_data. order_items : লাইন-আইটেমের বিবরণ (পরিমাণ, মূল্য)
- froyo_data. customer_allergen_data : একটি CRM টেবিল যা আমাদের বিশ্বস্ত গ্রাহকদের পরিচিত অ্যালার্জিগুলো ট্র্যাক করে।
আমাদের অ্যানালিটিক্স ব্যবহারের প্রস্তুতির জন্য, চলুন এই বিক্রয় এবং গ্রাহক সম্পর্কিত টেবিলগুলো সেই ডেটাসেটে যোগ করি।
- আপনার গুগল ক্লাউড কনসোল থেকে ক্লাউড শেল টার্মিনালে যান।
- আপনার ওয়ার্কস্পেসের রুট ফোল্ডারে অথবা froyo-data প্রোজেক্টের রুট ফোল্ডারে যান (যেটি নিয়ে আমরা এই সিরিজের বিগত কয়েকটি পর্বে কাজ করে আসছি)।
- নিচের কমান্ডগুলো এক এক করে চালিয়ে ৩টি ঐতিহাসিক ডেটা ফাইল (csv ফাইল হিসেবে) আপনার ওয়ার্কিং ডিরেক্টরিতে ডাউনলোড করুন:
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/customer_allergen_data.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/order_items.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/orders.csv
- আপনার ওয়ার্কিং ডিরেক্টরির রুটে ফাইলগুলো দেখতে পেলে, টার্মিনালে টগল করে আপনার ক্লাউড শেল টার্মিনালে যান।
- আপনার ক্লাউড শেল টার্মিনালে সেই ডিরেক্টরিতে প্রবেশ করুন যেখানে এই তিনটি ফাইল রয়েছে।
- নিশ্চিত করুন যে আপনার BigQuery-তে এই সিরিজের প্রথম পর্বের 'froyo_data' নামের ডেটাসেটটি আছে (যদি না থাকে, তাহলে ফিরে গিয়ে ডেটাসেট এবং টেবিলগুলো তৈরি করুন)।
- আপনার ক্লাউড শেল টার্মিনাল থেকে নিম্নলিখিত কমান্ডগুলি চালান:
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.orders \
./orders.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.order_items \
./order_items.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.customer_allergen_data \
./customer_allergen_data.csv
এটি আপনার froyo_data ডেটাসেটে ৩টি অতিরিক্ত টেবিল তৈরি করবে।
৪. ডেভেলপার অভিজ্ঞতা — ‘ডেটা এজেন্ট কিট’-এর আগমন
ঐতিহ্যগতভাবে, কোনো ডেভেলপার যদি ডেটা বিশ্লেষণ করতে বা জটিল মেশিন লার্নিং কোয়েরি লিখতে চাইতেন, তাহলে তাঁদেরকে ক্রমাগত IDE, ডেটাবেস কনসোল এবং ডকুমেন্টেশনের মধ্যে কাজ পরিবর্তন করতে হতো।
আর নয়। সদ্য চালু হওয়া Google Cloud Data Agent Kit এক্সটেনশনের মাধ্যমে আপনার IDE একটি ডেটা পাওয়ারহাউসে পরিণত হয়।
অ্যান্টিগ্র্যাভিটি আইডিই
অ্যান্টিগ্র্যাভিটি আইডিই হলো গুগলের পরবর্তী প্রজন্মের, এজেন্ট-কেন্দ্রিক ডেভেলপমেন্ট এনভায়রনমেন্ট, যা বিশেষভাবে এআই যুগের জন্য ডিজাইন করা হয়েছে। এটি সরাসরি এডিটরের মধ্যে বিশাল মাল্টি-মোডাল কনটেক্সট উইন্ডো এবং স্বয়ংক্রিয় টুল ব্যবহারের সুবিধা যুক্ত করে, যা ডেভেলপারদের তাদের কোড থেকে বের না হয়েই ক্লাউড রিসোর্স এবং জটিল ডেটা পাইপলাইন পরিচালনা করার সুযোগ দেয়।
অ্যান্টিগ্র্যাভিটি আইডিই সেট আপ করা
- IDE ডাউনলোড করুন: antigravity.google ওয়েবসাইটে যান এবং আপনার অপারেটিং সিস্টেমের (Windows, macOS, বা Linux) জন্য Antigravity IDE ডাউনলোড করুন।
- ইনস্টল ও চালু করুন: ইনস্টলারটি চালান এবং অ্যাপ্লিকেশনটি খুলুন।
- Google-এর সাথে চালিয়ে যান-এ ক্লিক করুন, আপনার Gmail অ্যাকাউন্টটি নির্বাচন করুন এবং অনুমোদন করুন।
- একবার লগ ইন করার পর, একটি ওয়ার্কিং ফোল্ডার (ওয়ার্কস্পেস/প্রজেক্ট) তৈরি করুন। চলুন এর নাম দিই "এজেন্ট ডেটা ক্লাউড"।
এটি বামদিকের "প্রকল্প" তালিকায় প্রদর্শিত হবে:
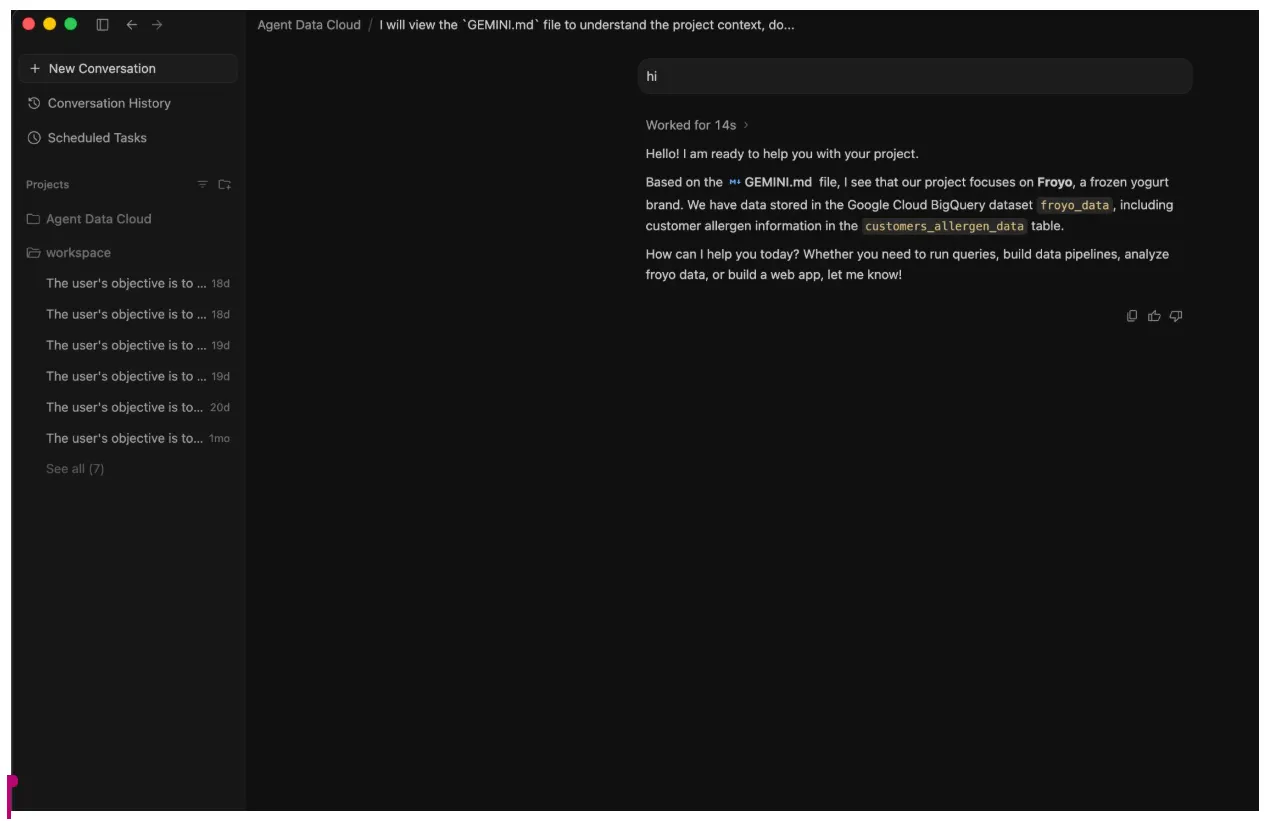
- এজেন্টের সাথে প্রাথমিক আলাপ করুন — ‘হাই’।
- উপরের ডান কোণায় ওপেন আইডিই (Open IDE) বাটনটি লক্ষ্য করুন!!!
কিন্তু ওটাতে ক্লিক করার আগে, আপনাকে Antigravity IDE ইনস্টল করতে হবে। antigravity.google/download পেজে যান এবং Antigravity IDE সেকশন পর্যন্ত স্ক্রল করে নিচে নামুন, এরপর আপনার প্রয়োজনীয় সংস্করণটি ডাউনলোড করুন।
ডাউনলোড হয়ে গেলে, আপনার খোলা Antigravity ইনস্ট্যান্সে ফিরে যান এবং উপরের ডান কোণায় থাকা Open IDE বোতামে ক্লিক করুন।
- আপনি অনুমতি সংক্রান্ত পপ-আপগুলো দেখতে পাবেন, সেটি খুলতে থাকুন!
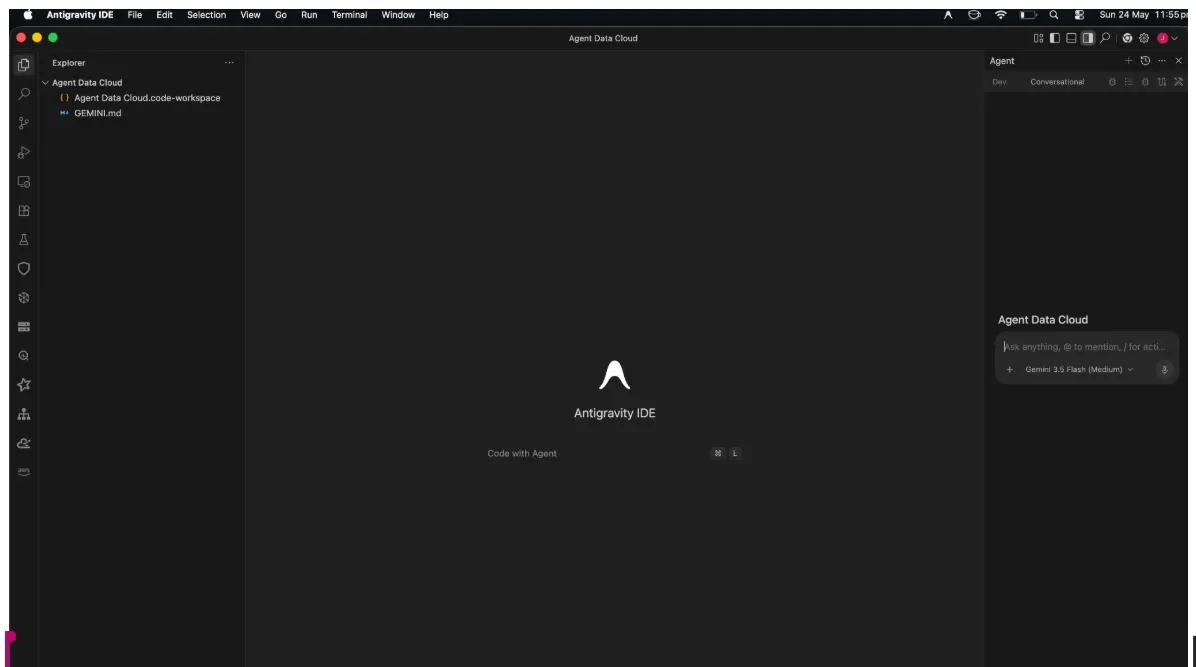
ডানদিকে আপনি এজেন্ট পেইন, বামদিকে প্রজেক্ট এক্সপ্লোরার এবং মাঝখানে আপনার ডেভেলপমেন্টের জন্য নির্ধারিত স্থানটি দেখতে পাবেন।
ডেটা এজেন্ট কিট এক্সটেনশন সেট আপ করুন
- এক্সটেনশনটি ইনস্টল করুন: ANTIGRAVITY IDE-এর ভেতরে এক্সটেনশন মার্কেটপ্লেসটি খুলুন। Google Cloud Data Agent Kit এক্সটেনশনটি খুঁজে বের করে ইনস্টল করুন।
- ইনস্টল বোতামে ক্লিক করুন এবং এটি সম্পন্ন হলে, আপনি নেভিগেশন প্যানে এক্সটেনশনটি দেখতে পাবেন।
- ওটাতে ক্লিক করলে গুগল ক্লাউড ডেটা এজেন্ট কিট এক্সপ্লোরার খুলে যাবে, সেটিংস (SETTINGS) সেকশনে গিয়ে সেটিংস-এ ক্লিক করুন। সেখানে আপনার প্রোজেক্টের বিবরণ ও অঞ্চল লিখে সেভ করুন।
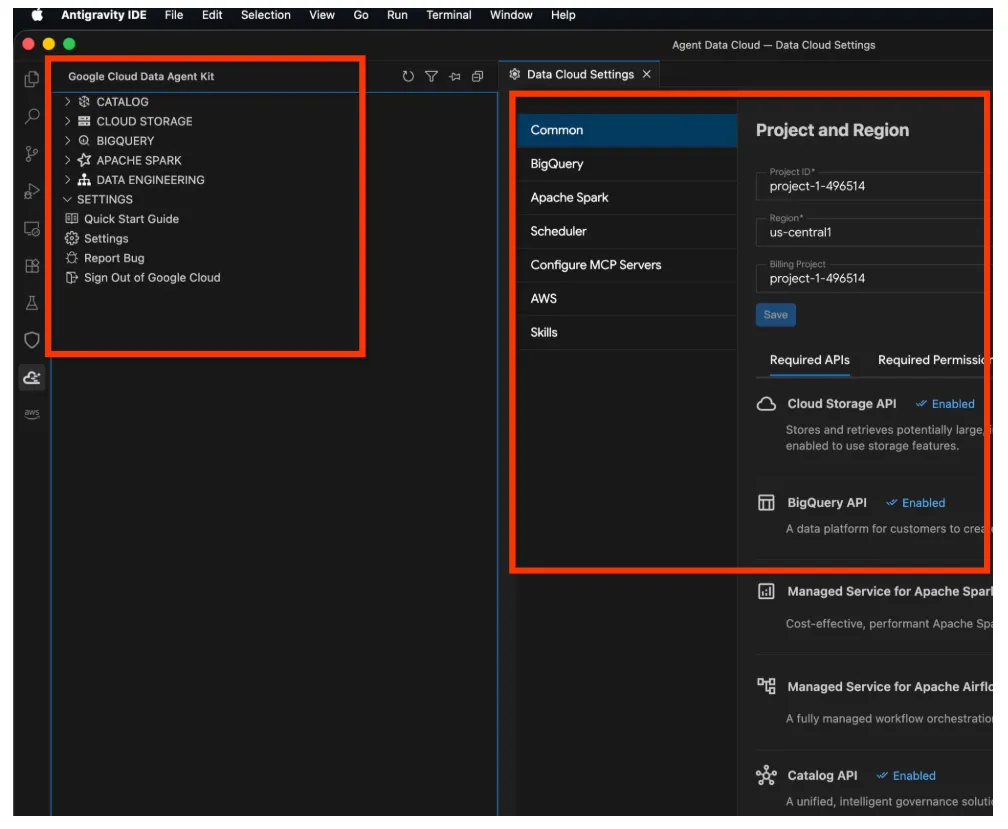
- এখন নেভিগেশন পেনের উপরে থাকা প্রজেক্ট এক্সপ্লোরার-এ ক্লিক করুন। এটি এক্সপ্লোরার পেনে আপনার প্রজেক্ট এক্সপ্লোরারটি খুলে দেবে।
- এক্সপ্লোরার স্পেসে রাইট ক্লিক করে " GEMINI.md " নামে একটি নতুন ফাইল তৈরি করুন।
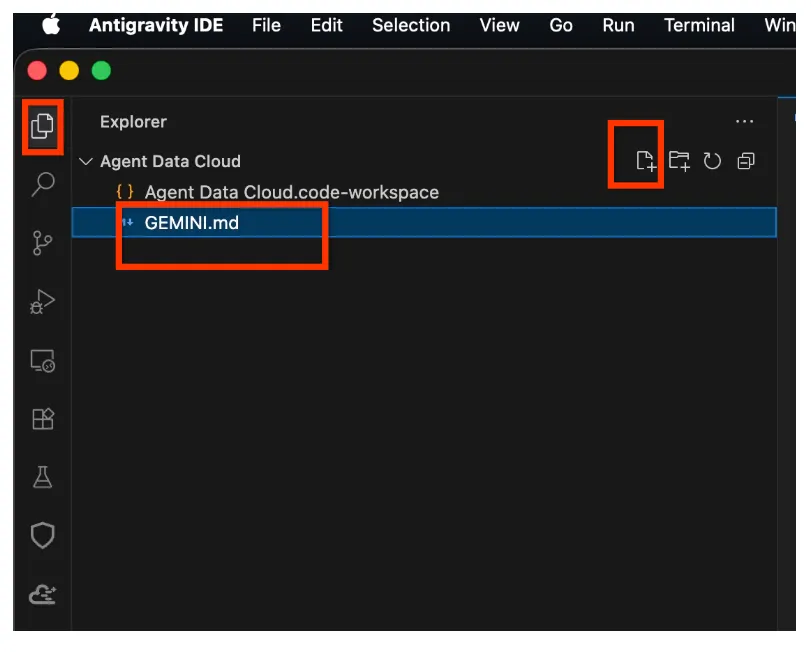
- GEMINI.md-এ নিম্নলিখিতটি পেস্ট করুন (<<YOUR_PROJECT_ID>>-কে আপনার মান দিয়ে প্রতিস্থাপন করতে ভুলবেন না):
## 1. Project Context
- **Project ID**: <<YOUR_PROJECT_ID>>
- **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
- **Data**: All froyo, customer, order related information is processed and stored in BigQuery `froyo_data` dataset.
## 2. Execution & Data Processing Rules
- **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `froyo_data`.
- **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the tables `customers_allergen_data`.
- ** CRITICAL RULE - Sales Data**: Sales data is present in tables `orders` and `order_items`.
- ** CRITICAL RULE - General: When you are referencing a dataset, ensure you are using it with the dataset ID (`froyo_data`) . For example, to query orders table in this dataset you should use `froyo_data.orders`.
এখন আপনার IDE-তেই একটি অত্যন্ত সক্ষম AI এজেন্ট রয়েছে, যা কোড লিখতে, SQL তৈরি করতে এবং আপনার আর্কিটেকচার বিশ্লেষণ করতে প্রস্তুত।
এখন আমাদের সামনে একটি আকর্ষণীয় বিশ্লেষণমূলক চ্যালেঞ্জ রয়েছে: আমরা কি আমাদের ঐতিহাসিক বিক্রয়ের সাথে সেই জটিল, অনুমানভিত্তিক অ্যালার্জেন তথ্যের সম্পর্ক স্থাপন করতে পারি, যা আমরা প্রথম পর্বে পিডিএফ থেকে সংগ্রহ করেছিলাম?
৫. IDE এজেন্টের মাধ্যমে ইন্টেলিজেন্স অনুমান করা
চলুন, আমাদের IDE এজেন্টকে এই কঠিন কাজটি করতে বলি। আপনার ANTIGRAVITY IDE-এর ভেতরেই Agent Data Kit চ্যাট উইন্ডোটি খুলুন এবং এটিকে নিম্নলিখিত নির্দেশ দিন:
Does Midnight Swirl contain any allergen?
এটি একাধিক অনুমতি চাইবে, প্রযোজ্য ক্ষেত্রে অনুমতি দিন।
অবশেষে এটি তার বিশ্লেষণ শেষে আপনার জন্য প্রতিক্রিয়াটি সংগ্রহ করবে:
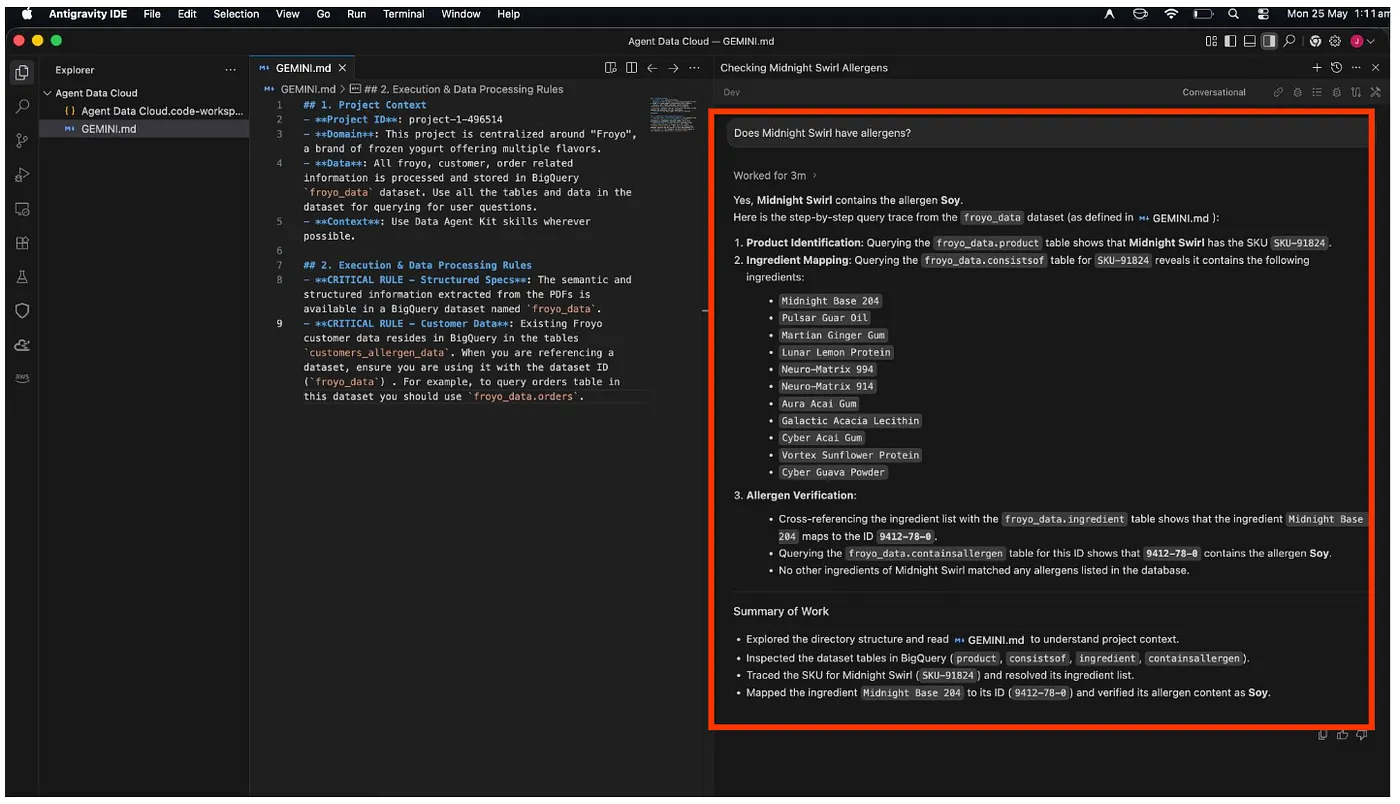
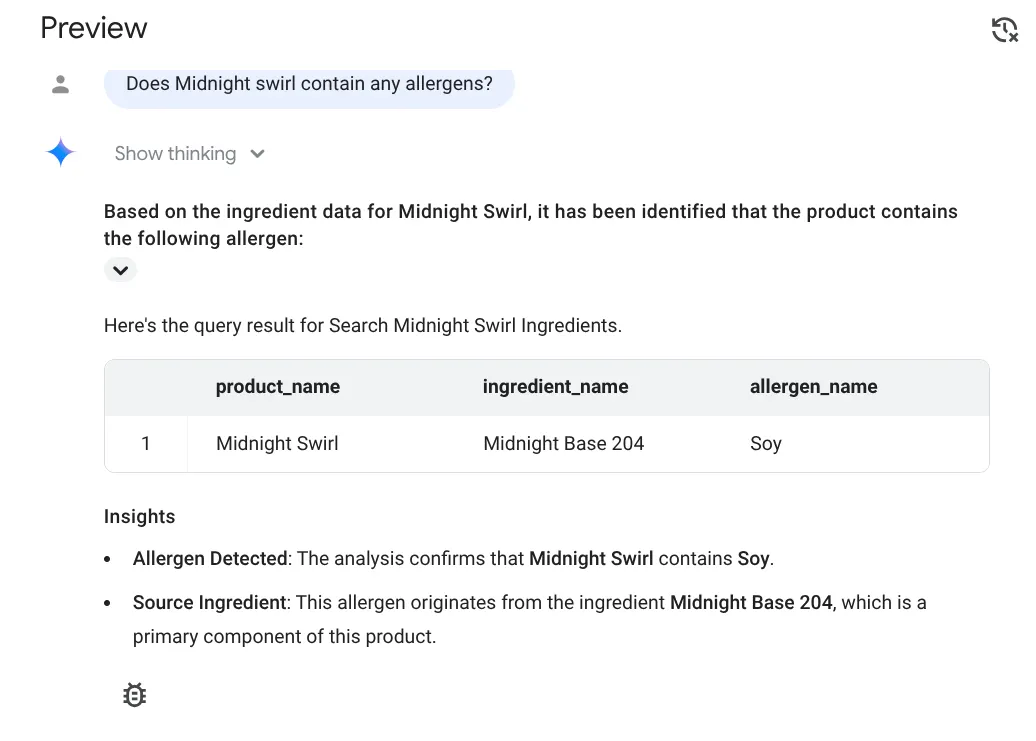
দারুণ!!! এটি সঠিকভাবে শনাক্ত করেছে যে মিডনাইট সুইর্ল আইটেমটিতে সয়া রয়েছে।
এবার আরেকটু জটিল একটি প্রশ্ন করা যাক। Antigravity IDE-তে নিম্নলিখিত প্রম্পটটি পাঠান:
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
প্রতিক্রিয়া:
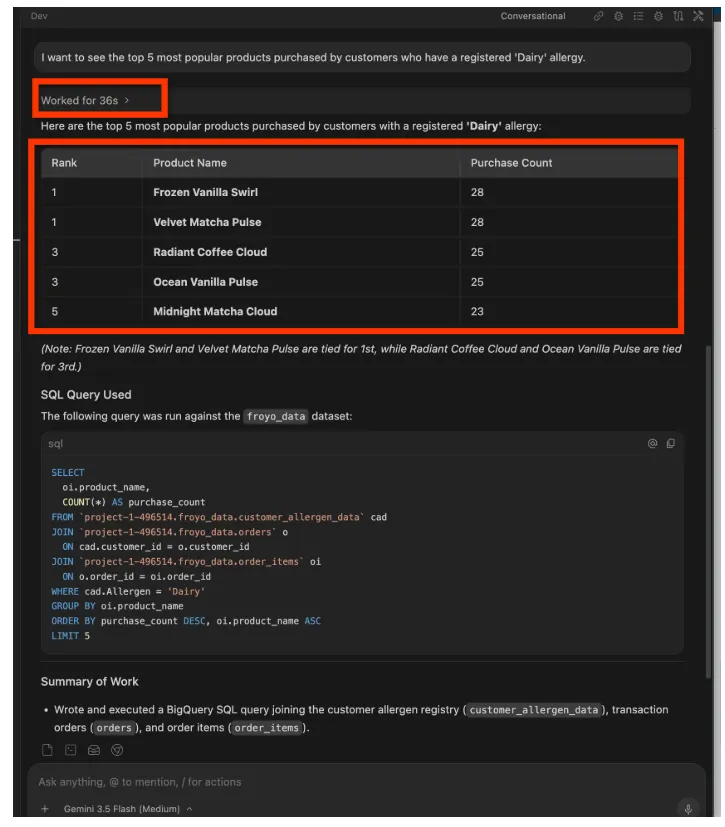
আপনি চালিয়ে যেতে পারেন। এই ধরনের নির্দেশনা চেষ্টা করুন:
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
BQML সিনট্যাক্স খোঁজার প্রয়োজন ছাড়াই, এজেন্ট ডেটা কিট আপনার এডিটরে হুবহু CREATE MODEL এবং ML.FORECAST কোড বসিয়ে দেয়। ANTIGRAVITY IDE থেকে বের না হয়েই এটি সরাসরি আপনার BigQuery এনভায়রনমেন্টে চালানো যায়!
এটা কী অসাধারণ!!!
৬. BigQuery-তে কথোপকথনমূলক বিশ্লেষণ
ডেভেলপাররা IDE পছন্দ করলেও, ব্যবসায়িক ব্যবহারকারী এবং নির্বাহীরা ক্লাউড কনসোলই ব্যবহার করেন। তারা SQL দেখতে চান না, তারা শুধু উত্তর চান।
চলুন শুরু করা যাক:
- নিজেকে প্রয়োজনীয় ভূমিকাগুলো মঞ্জুর করুন।
প্রজেক্টটির IAM পেজে যান এবং নিজেকে Gemini Data Analytics Data Agent Owner রোলটি প্রদান করুন:
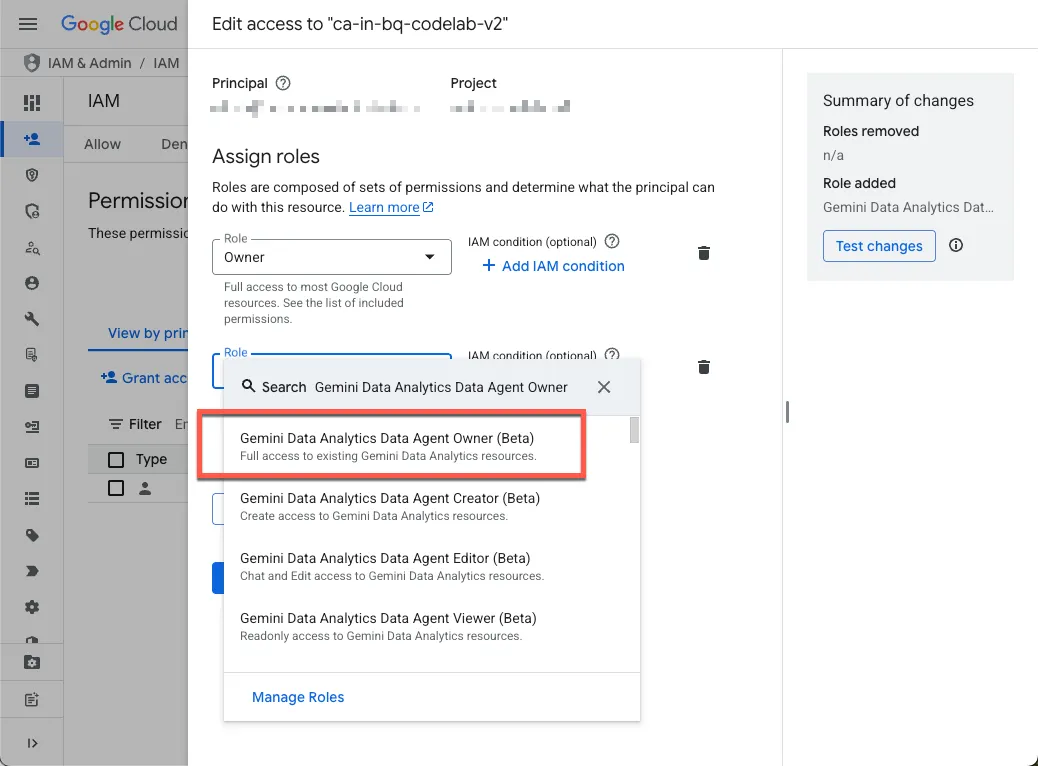
এই ভূমিকাটি আপনাকে প্রকল্পের সমস্ত ডেটা এজেন্ট তৈরি, সম্পাদনা, শেয়ার এবং মুছে ফেলার অনুমতি দেয়।
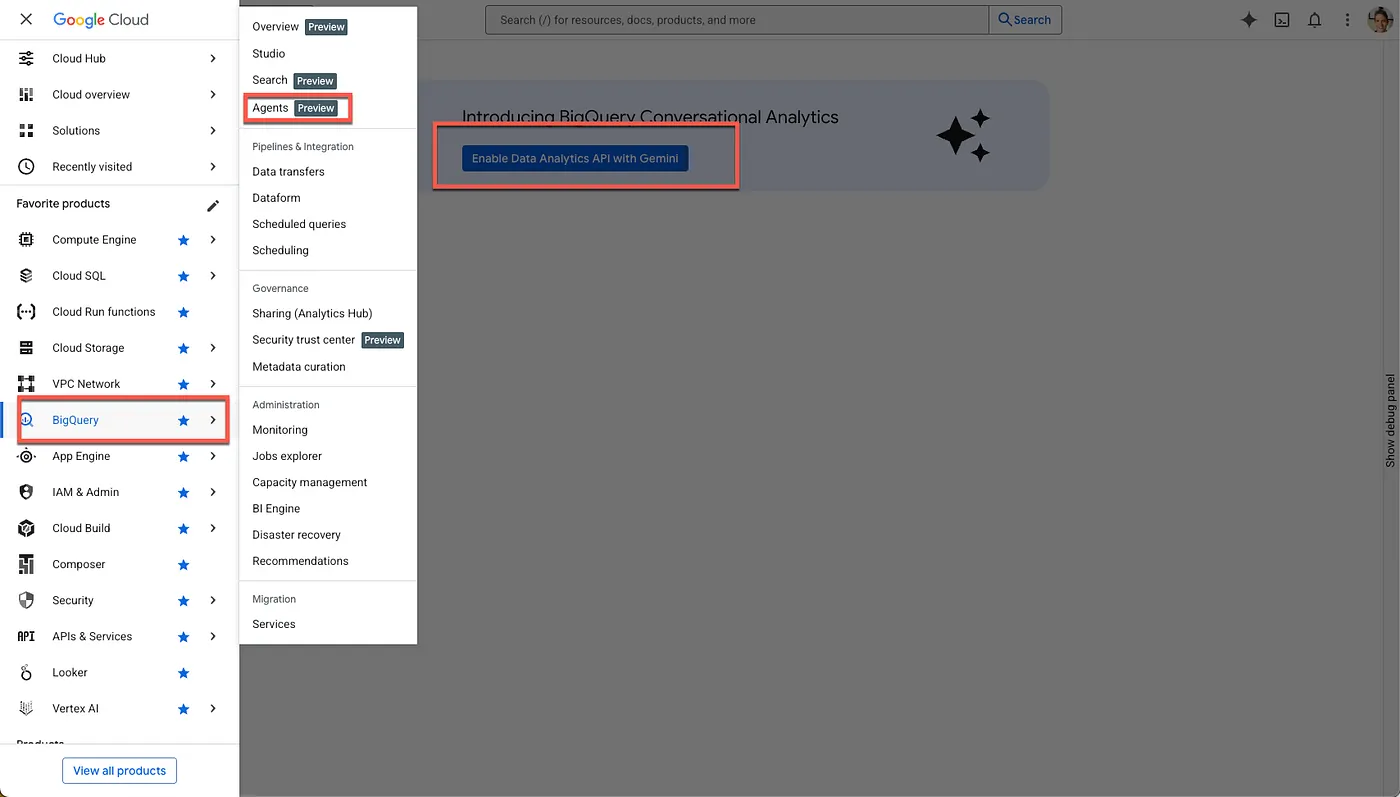
- প্রয়োজনীয় API গুলি সক্রিয় করুন
Google Cloud Console-এ BigQuery-তে যান। পৃষ্ঠার শীর্ষে থাকা সাইডবার নেভিগেশন মেনু বা সার্চ মেনু ব্যবহার করে BigQuery > Agents-এ নেভিগেট করুন।
জেমিনির সাথে ডেটা অ্যানালিটিক্স এপিআই সক্রিয় করতে ক্লিক করুন:
Gemini in BigQuery API এবং Gemini for Google Cloud API উভয়ই সক্রিয় করুন:
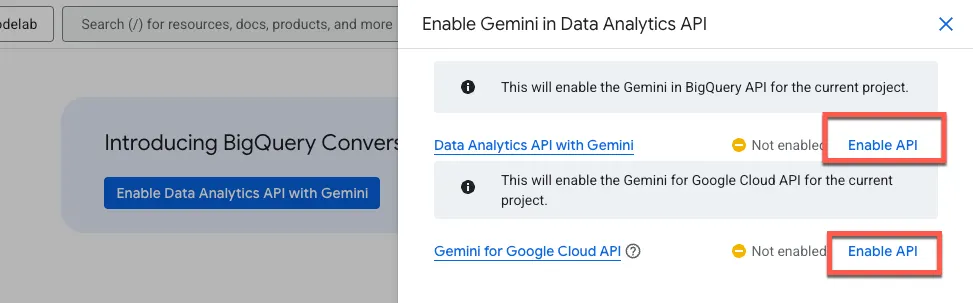
এখন আপনি নতুন এজেন্ট পৃষ্ঠাটি দেখতে পাবেন:
- এজেন্ট তথ্য কনফিগার করুন
এজেন্টের নাম : ফ্রয়ো এজেন্ট
এজেন্টের বিবরণ : ফ্রোজেন ইয়োগার্ট পণ্য, অ্যালার্জেন, উপাদান, রেসিপি, গ্রাহক, অর্ডার ও বিক্রয় সম্পর্কিত প্রশ্নের উত্তর দিতে সাহায্য করে।
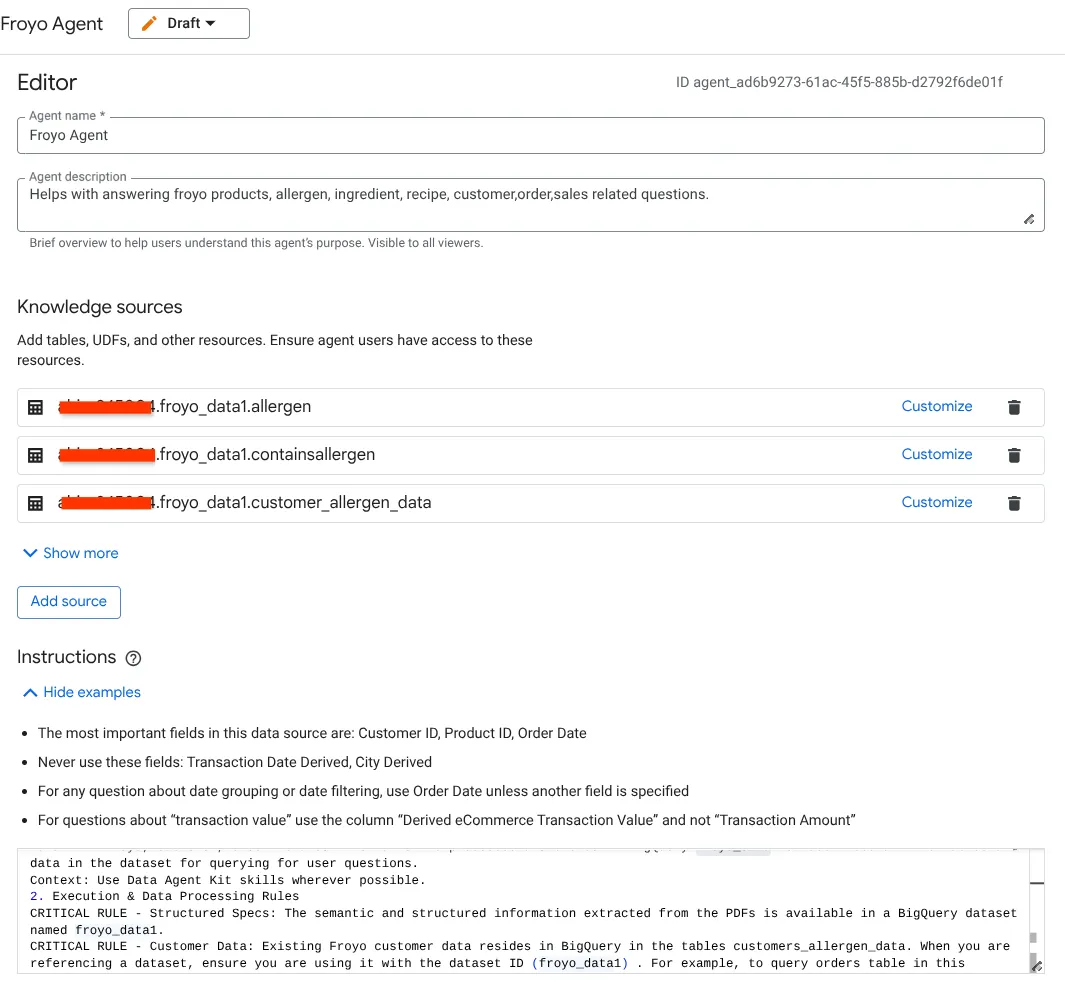
- নলেজ সোর্সেস বিভাগে যান এবং আপনার ডেটাসেট থেকে নিচের সমস্ত টেবিল নির্বাচন করুন:
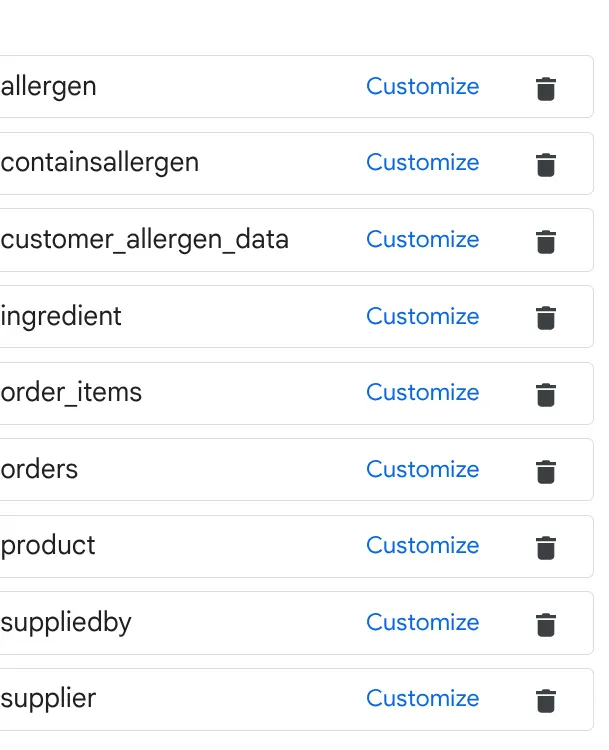
ক. উপরের ছবিতে টেবিলগুলো যোগ করুন এবং 'Add Source'-এ ক্লিক করুন।
খ. প্রতিটি সোর্সের জন্য, ডানদিকে থাকা কাস্টমাইজ বাটনটিতে ক্লিক করুন। আপনি নিচের ফর্মটি দেখতে পাবেন:
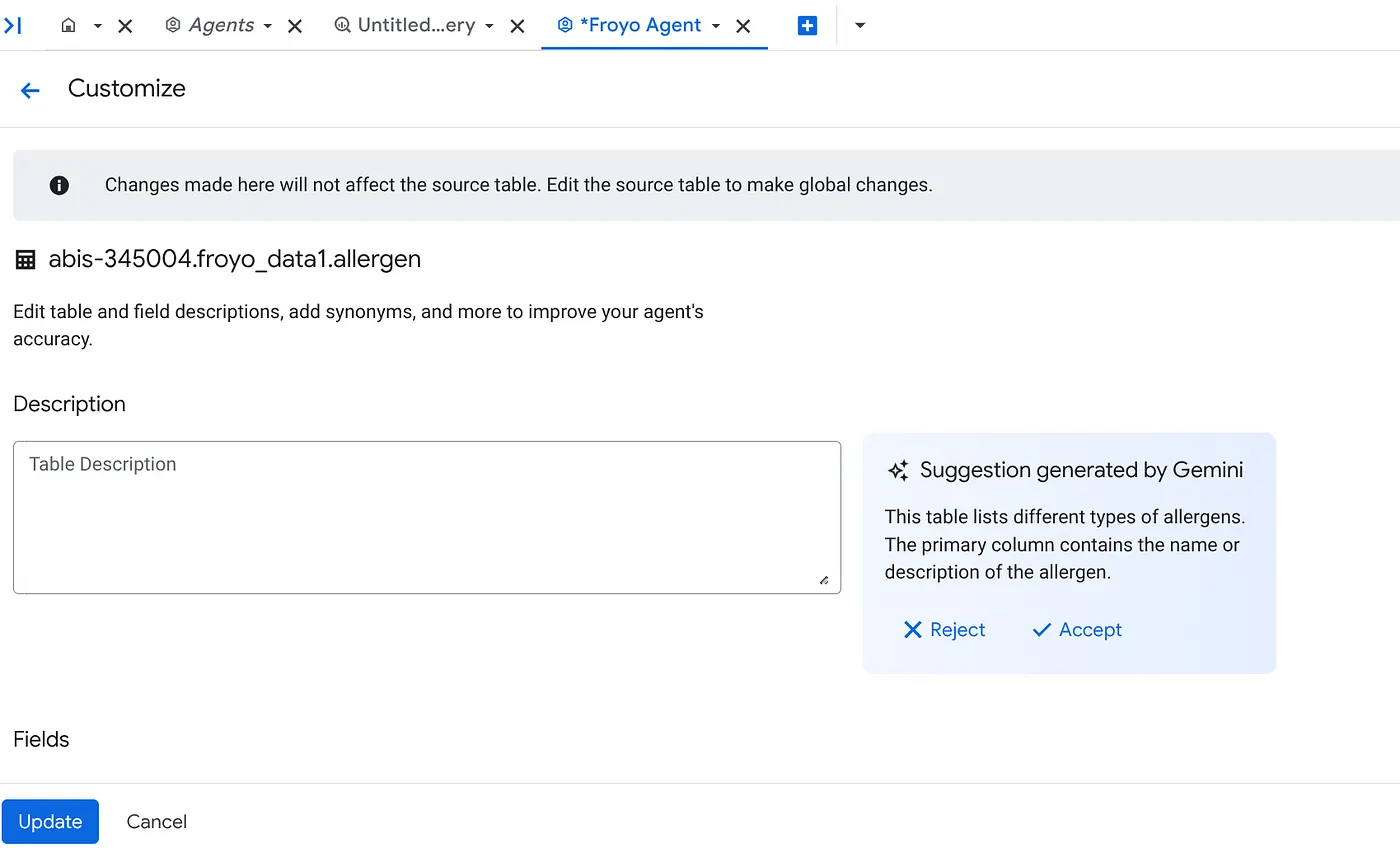
গ. টেবিলের বিবরণের জন্য 'Accept'-এ ক্লিক করুন।
d. প্রতিটি ফিল্ডের বিবরণের ক্ষেত্রেও 'Accept'-এ ক্লিক করুন।
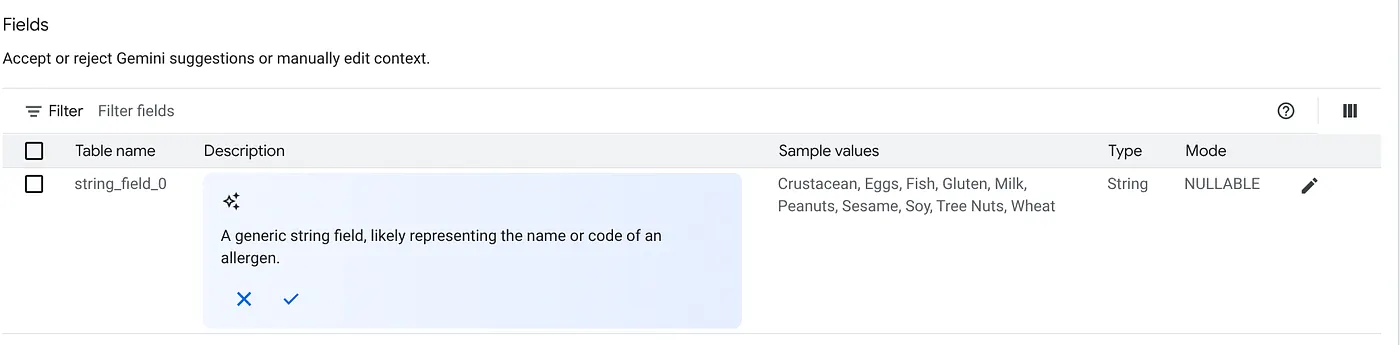
e. আপডেট-এ ক্লিক করুন।
সোর্সের সমস্ত টেবিলের জন্য আপনাকে এটি পুনরাবৃত্তি করতে হবে।
- কনফিগার নির্দেশাবলী
Antigravity IDE GEMINI.md-এ আমরা যে নির্দেশাবলী ব্যবহার করেছিলাম, সেগুলো এখানে রাখুন:
1. Project Context
Project ID: <<YOUR_PROJECT_ID>>
Domain: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
Data: All froyo, customer, order related information is processed and stored in BigQuery froyo_data dataset. Use all the tables and data in the dataset for querying for user questions.
Context: Use Data Agent Kit skills wherever possible.
2. Execution & Data Processing Rules
CRITICAL RULE - Structured Specs: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named froyo_data.
CRITICAL RULE - Customer Data: Existing Froyo customer data resides in BigQuery in the tables customers_allergen_data. When you are referencing a dataset, ensure you are using it with the dataset ID (froyo_data) . For example, to query orders table in this dataset you should use froyo_data.orders.
- আপনার এজেন্টকে বাঁচান।
৭. আপনার ডেটার সাথে চ্যাট করুন!
- ডানদিকের প্রিভিউ সেকশনে এটি পরীক্ষা করে দেখুন:
আপনার প্রশ্নটি জিজ্ঞাসা করুন:
Does midnight swirl contain any allergen?
এই হলো উত্তর:
এবার জটিল প্রশ্নটি করা যাক:
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
প্রতিক্রিয়া:
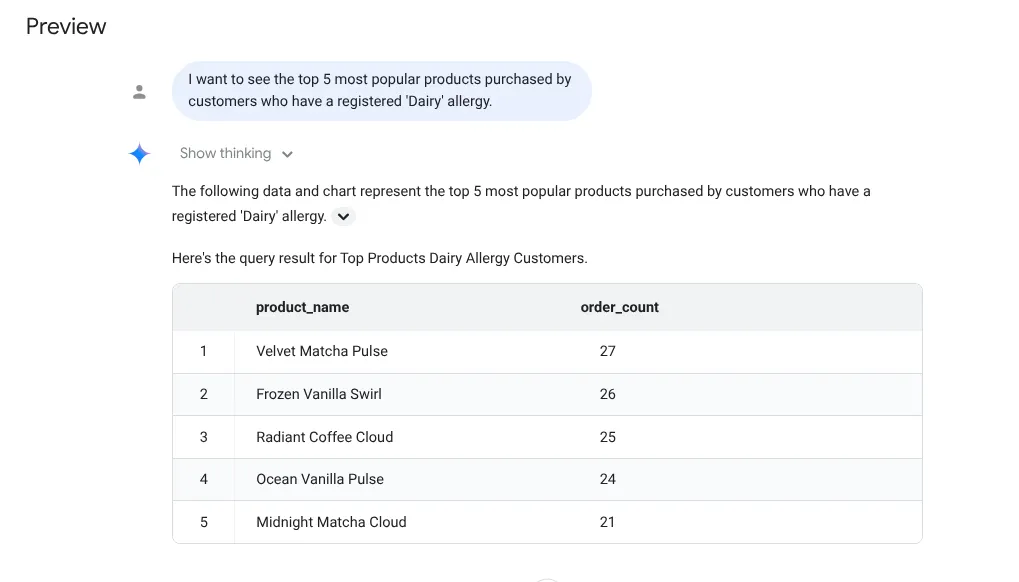
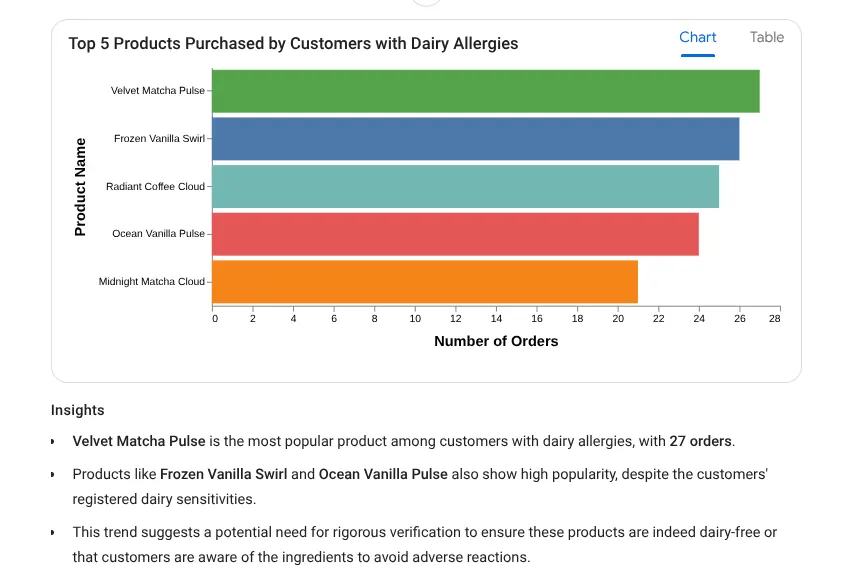
চলুন এখন একটি গভীর অন্তর্দৃষ্টিমূলক প্রশ্ন চেষ্টা করা যাক:
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
আপনি দেখতে পাচ্ছেন, এটি চার্টসহ টেবিলের ফলাফলের সাথে ব্যবহৃত কোয়েরিটিও দেখাচ্ছে:
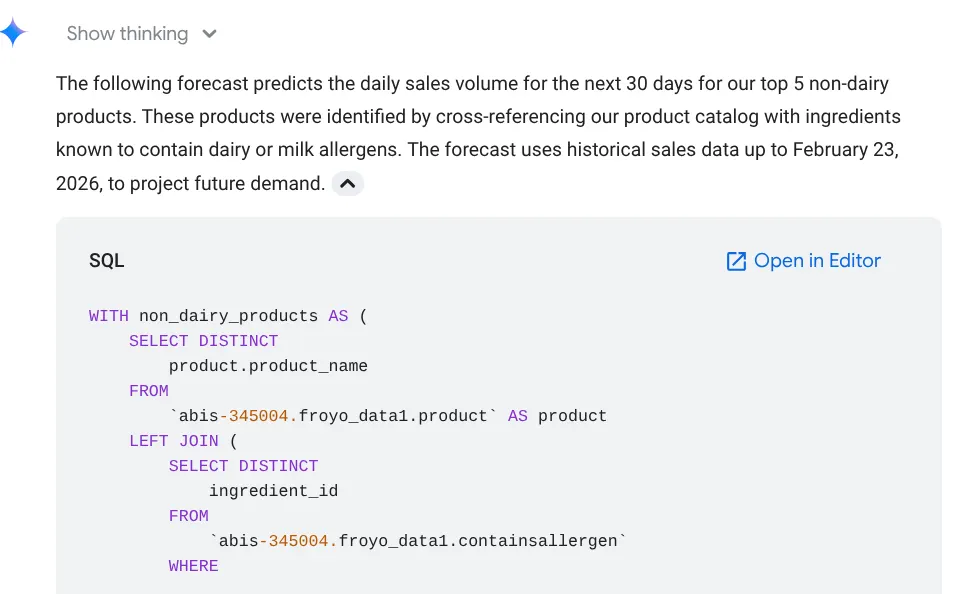
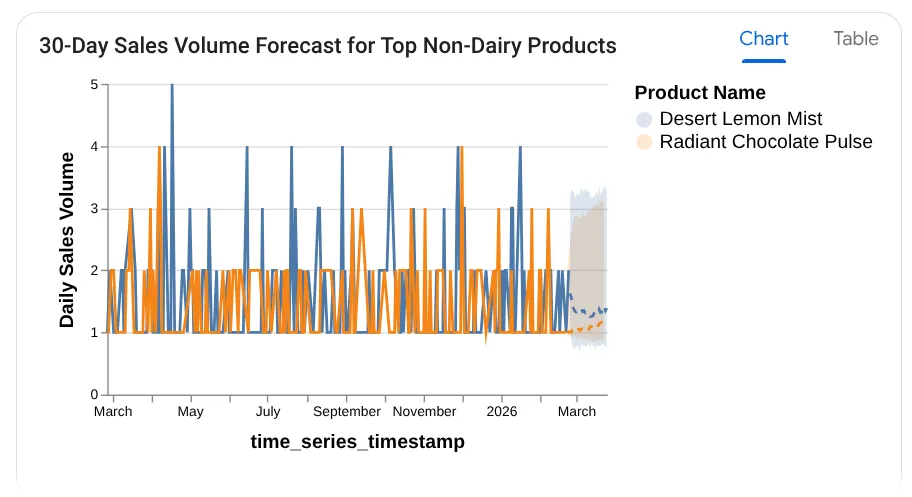

বাহ! তাহলে চার্ট আর ইনসাইটগুলো বেশ ভালোই হলো। এবার প্রোডাক্ট সংক্রান্ত চূড়ান্ত প্রশ্নটির পালা।
৮. চূড়ান্ত পরীক্ষা
প্রশ্নটি করুন:
What will be the top most selling product of 2026
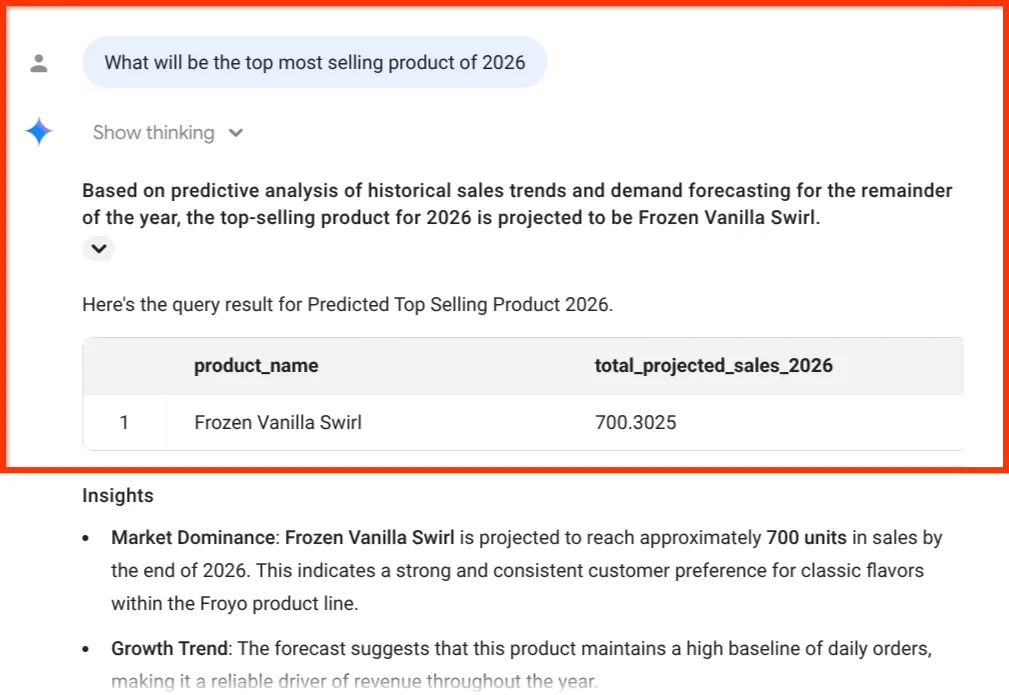

চূড়ান্ত পর্যবেক্ষণটি দেখুন। BigQuery ডেটা এজেন্ট শুধু আমাদের একটি সংখ্যাই দেয়নি; এটি বিক্রয়ের পূর্বাভাসকে আমাদের ইনভেন্টরি এবং উপকরণ সরবরাহ শৃঙ্খলের সাথে সুস্পষ্টভাবে যুক্ত করেছে — ঠিক সেই ডেটা, যা আমরা প্রথম পর্বে অগোছালো পিডিএফ ফাইলগুলো থেকে বের করেছিলাম!
৯. এন্টারপ্রাইজের কাছে আপনার এজেন্ট প্রকাশ করা
প্রিভিউ এজেন্টের উপরে থাকা পাবলিশ বাটনটিতে ক্লিক করুন।
এখন যেহেতু আমরা আমাদের ফ্রোয়ো এজেন্ট তৈরি, কনফিগার এবং পরীক্ষা করে ফেলেছি, এটিকে ব্যবসার বাকি অংশের জন্য উন্মুক্ত করার সময় এসেছে।
এজেন্ট কনফিগারেশন পেজের উপরের ডান কোণায় থাকা পাবলিশ বাটনটিতে ক্লিক করুন।
প্রকাশ করার মাধ্যমে, আপনার এজেন্টটি তাৎক্ষণিকভাবে তিনটি শক্তিশালী এন্টারপ্রাইজ চ্যানেলে আপনার এবং আপনি যাদের সাথে এটি শেয়ার করবেন তাদের জন্য উপলব্ধ হয়ে যায়:
- BigQuery : আপনার ডেটা বিশ্লেষকরা এখন এজেন্ট হাব থেকে অথবা সরাসরি তাদের BigQuery Studio SQL ওয়ার্কস্পেসের ভেতর থেকে এই এজেন্টের সাথে চ্যাট করতে পারবেন।
- কথোপকথনমূলক অ্যানালিটিক্স এপিআই : আপনার ডেভেলপাররা একটি REST API-এর মাধ্যমে এই এজেন্টটি অ্যাক্সেস করতে পারবেন, যা তাদেরকে এই নির্দিষ্ট কথোপকথনমূলক অ্যানালিটিক্স আপনার নিজস্ব কাস্টম অভ্যন্তরীণ ওয়েব অ্যাপ্লিকেশনগুলিতে একীভূত করার সুযোগ দেবে।
- ডেটা স্টুডিও : আপনার নির্বাহীরা এই এজেন্টের সাথে যোগাযোগ করতে এবং সরাসরি ডেটা স্টুডিওর ভেতরেই ডায়নামিক কনভারসেশনাল ড্যাশবোর্ড তৈরি করতে পারেন।
আমরা সফলভাবে আমাদের ডেটা বিচ্ছিন্ন অবস্থা থেকে বের করে এনে সরাসরি সেইসব মানুষের হাতে পৌঁছে দিয়েছি যাদের এটি প্রয়োজন, ঠিক সেখানেই যেখানে তারা ইতিমধ্যেই কাজ করেন!
আপনার প্রকাশিত BigQuery Agent-এর উপরে থাকা Share বাটনের ড্রপ-ডাউনে ক্লিক করুন এবং তালিকা থেকে "Copy Link to agent in data studio" বিকল্পটি নির্বাচন করুন:
আপনার ব্রাউজারে ওই লিঙ্কটি পেস্ট করে এন্টার চাপুন। এজেন্ট ইন্টারঅ্যাকশন অ্যাক্সেস অ্যালার্টের জন্য নিশ্চিতকরণ প্রদান করুন:
ডেটা স্টুডিও-র সদ্য প্রকাশিত এজেন্টটির সাহায্যে আপনি ইন্টারেক্টিভ কথোপকথন ও ভিজ্যুয়ালাইজেশন শুরু করতে পারেন এবং আপনার নেতৃত্ব ও অন্যান্য দল, যাদের এই তথ্য প্রয়োজন, তারাও তা করতে পারবে!
১০. পরিষ্কার করুন
এই ল্যাবটি সম্পন্ন হয়ে গেলে, আপনার তৈরি করা BigQuery Agent-টির জন্য সকল ব্যবহারকারীর অনুমতি অপসারণ করতে ভুলবেন না।
১১. অভিনন্দন!
আপনি আনুষ্ঠানিকভাবে একটি এজেন্টিক ডেটা ক্লাউড তৈরি করেছেন!
আপনি শুধু একটি সাধারণ চ্যাটবট তৈরি করেননি। এই পাঁচটি সেশনের মাধ্যমে, আপনি সফলভাবে একেবারে গোড়া থেকে একটি সম্পূর্ণ, আধুনিক এবং মূল্যায়িত এন্টারপ্রাইজ এআই সিস্টেমের নকশা তৈরি করেছেন। আপনি ‘ডার্ক ডেটা’ থেকে রিয়েল-টাইম ট্রানজ্যাকশনাল ইন্টেলিজেন্স এবং অবশেষে কনভারসেশনাল বিজনেস ফোরকাস্টিং-এর দিকে অগ্রসর হয়েছেন।
১২. সম্পূর্ণ চিত্র
একটু পিছিয়ে এসে দেখুন এই সিরিজে আমরা কী অর্জন করেছি। আমরা শুধু একটি সাধারণ চ্যাটবট তৈরি করিনি। আমরা একটি সম্পূর্ণ, আধুনিক এজেন্টিক ডেটা ক্লাউডের স্থাপত্য নকশা তৈরি করেছি:
পর্ব ১ : নলেজ ক্যাটালগ ব্যবহার করে পিডিএফ ফাইলকে স্ট্রাকচার্ড রিলেশনাল টেবিলে রূপান্তর করার মাধ্যমে ডার্ক ডেটা উন্মোচন করা হয়েছে।
পর্ব ২ : আমাদের অ্যানালিটিক্যাল ডেটা ওয়্যারহাউসকে সরাসরি একটি AlloyDB ট্রানজ্যাকশনাল ডেটাবেসের সাথে সংযুক্ত করার মাধ্যমে ডেটা সাইলো ভেঙে ফেলা হয়েছে।
পর্ব ৩ : একটি মাল্টি-এজেন্ট ওএস তৈরির মাধ্যমে ব্যবহারকারীদের ক্ষমতায়ন, যা এমসিপি প্রোটোকলের মাধ্যমে সুরক্ষিত ডাটাবেস টুলগুলো নির্বিঘ্নে কার্যকর করে।
পর্ব ৪ : বিভ্রম এবং জেল থেকে পালানো শনাক্ত করার জন্য একটি কঠোর মূল্যায়ন প্রক্রিয়া বাস্তবায়নের মাধ্যমে নিরাপত্তা নিশ্চিত করা হয়েছিল।
পর্ব ৫: অ্যান্টিগ্র্যাভিটি আইডিই এবং বিগকোয়েরিতে কনভারসেশনাল অ্যানালিটিক্স ব্যবহার করে অন্তর্দৃষ্টির গণতান্ত্রিকীকরণ।
এটাই এন্টারপ্রাইজ সফটওয়্যারের ভবিষ্যৎ। এআই এজেন্ট এখন আর শুধু এলএলএম-এর একটি র্যাপার নয়। এটি একটি সমন্বিত ডেটা প্ল্যাটফর্মের উপর অবস্থিত একটি সম্পূর্ণ একীভূত, পরীক্ষিত এবং সুরক্ষিত অর্কেস্ট্রেশন ইঞ্জিন।