
1. Übersicht
Sehen wir uns noch einmal die umfangreiche Architektur an, die wir in den letzten vier Teilen erstellt haben:
Teil 1: Wir haben den BigQuery Knowledge Catalog verwendet, um rohe Froyo-Rezept-PDFs in strukturierte relationale Tabellen umzuwandeln.
Teil 2: Wir haben eine Zero-ETL-Transaktionsbrücke entwickelt, mit der wir unser BigQuery-Data Warehouse direkt in AlloyDB föderieren.
Teil 3: Wir haben eine Multi-Agenten-Anwendung (FroyoOS) mit dem Agent Development Kit und der MCP Toolbox orchestriert.
Teil 4: Wir haben bewiesen, dass unser Agent für die Produktion sicher ist, indem wir eine zweigleisige Evaluierungspipeline erstellt haben.
Unsere Abläufe laufen reibungslos. Was ist aber mit den Entwicklern und Datenanalysten, die die riesigen Datenmengen verstehen müssen, die dieses System generiert?
Heute geht es um die Zukunft von Analytics. Wir beginnen direkt in unserem Code-Editor Antigravity IDE mit dem Google Cloud Data Agent Kit und wechseln dann zur Google Cloud Console, um unsere Daten mit BigQuery Conversational Analytics zu visualisieren.
Legen wir los!
Lerninhalte
In diesem letzten Codelab der Reihe Agentische Daten-Cloud führen Sie alle Komponenten Ihrer Architektur zusammen, um umsetzbare geschäftliche Erkenntnisse zu gewinnen. Lerninhalte:
- IDE-First Analytics:Hier erfahren Sie, wie Sie die ANTIGRAVITY IDE und das Google Cloud Data Agent Kit installieren und konfigurieren, um Ihre Architektur direkt über Ihre Entwicklungsumgebung abzufragen.
- Konversationelles BigQuery:Hier erfahren Sie, wie Sie BigQuery Data Agents erstellen, konfigurieren und anweisen, um komplexe SQL-Aufgaben und Prognosen mithilfe natürlicher Sprache zu automatisieren.
- Demokratisierung von Daten:Hier erfahren Sie, wie Sie Ihre Agents für das Unternehmen veröffentlichen und Analysten und Geschäftsnutzern im gesamten Unternehmen zugänglich machen.
- Erkenntnisse visualisieren:Hier erfahren Sie, wie Sie die Konversationsanalysen Ihres Kundenservicemitarbeiters nahtlos in Data Studio einbinden, um dynamische Dashboards zu erstellen, die für Prognosen geeignet sind.
- Das Agentische Daten-Cloud-Ökosystem:So formulieren Sie den Wert Ihrer End-to-End-Architektur – von unstrukturierten Rohdaten in Teil 1 bis hin zu Dashboards für Führungskräfte in Teil 5.
Voraussetzungen
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Sie sich authentifizieren möchten,
gcloud auth login
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs: Führen Sie diesen Befehl aus, um alle erforderlichen APIs zu aktivieren:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. Erweiterung des Data Warehouse
Erinnern Sie sich an die BigQuery-Tabellen, die wir aus unseren unstrukturierten Daten erstellt haben?
Für aussagekräftige Analysen benötigen wir historische Transaktionsdaten. Erstellen wir in BigQuery unter dem Dataset froyo_data drei neue Tabellen, um Jahre des Franchisebetriebs zu simulieren:
- froyo_data.orders: Bisherige Bestellüberschriften (Datumsangaben, Store-IDs, Summen)
- froyo_data.order_items: Details zu Positionen (Mengen, Preise)
- froyo_data.customer_allergen_data: Eine CRM-Tabelle, in der die bekannten Allergien unserer treuen Kunden erfasst werden.
Fügen wir diesem Dataset diese umsatz- und kundenbezogenen Tabellen hinzu, um es für unseren Analyseanwendungsfall vorzubereiten.
- Rufen Sie in der Google Cloud Console das Cloud Shell-Terminal auf.
- Rufen Sie das Stammverzeichnis Ihres Arbeitsbereichs oder das Stammverzeichnis des Projekts „froyo-data“ auf, an dem wir in den letzten Teilen dieser Reihe gearbeitet haben.
- Laden Sie die drei Dateien mit Verlaufsdaten (in CSV-Dateien) in Ihr Arbeitsverzeichnis herunter, indem Sie die folgenden Befehle nacheinander ausführen:
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/customer_allergen_data.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/order_items.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/orders.csv
- Sobald Sie diese Dateien im Stammverzeichnis Ihres Arbeitsverzeichnisses sehen, wechseln Sie zum Cloud Shell-Terminal.
- Wechseln Sie im Cloud Shell-Terminal in das Verzeichnis, in dem sich diese drei Dateien befinden.
- Prüfen Sie, ob in Ihrem BigQuery-Projekt das Dataset „froyo_data“ aus Teil 1 dieser Reihe vorhanden ist. Falls nicht, erstellen Sie das Dataset und die Tabellen.
- Führen Sie die folgenden Befehle in Ihrem Cloud Shell-Terminal aus:
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.orders \
./orders.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.order_items \
./order_items.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.customer_allergen_data \
./customer_allergen_data.csv
Dadurch sollten die drei zusätzlichen Tabellen in Ihrem Dataset „froyo_data“ erstellt werden.
4. Die Entwicklererfahrung – Einführung des „Data Agent Kit“
Bisher mussten Entwickler, die Daten analysieren oder komplexe Machine-Learning-Abfragen schreiben wollten, ständig zwischen ihrer IDE, Datenbankkonsolen und Dokumentation wechseln.
Das ist kein Problem mehr. Mit der neu eingeführten Erweiterung Google Cloud Data Agent Kit wird Ihre IDE zu einem leistungsstarken Tool für Daten.
ANTIGRAVITY-IDE
ANTIGRAVITY IDE ist die Entwicklungsumgebung der nächsten Generation von Google, bei der der KI-Agent im Mittelpunkt steht und die speziell für das KI-Zeitalter entwickelt wurde. Er bietet eine native Integration von großen multimodalen Kontextfenstern und autonomer Tool-Nutzung direkt in den Editor. So können Entwickler Cloud-Ressourcen und komplexe Datenpipelines orchestrieren, ohne den Code verlassen zu müssen.
ANTIGRAVITY IDE einrichten
- IDE herunterladen: Rufen Sie antigravity.google auf und laden Sie die Antigravity-IDE für Ihr Betriebssystem (Windows, macOS oder Linux) herunter.
- Installieren und starten: Führen Sie das Installationsprogramm aus und öffnen Sie die Anwendung.
- Klicken Sie auf „Mit Google fortfahren“, wählen Sie Ihr Gmail-Konto aus und autorisieren Sie es.
- Erstellen Sie nach der Anmeldung einen Arbeitsordner (Arbeitsbereich/ Projekt). Nennen wir sie „Agent Data Cloud“.
Es sollte in der Liste „Projekte“ auf der linken Seite angezeigt werden:
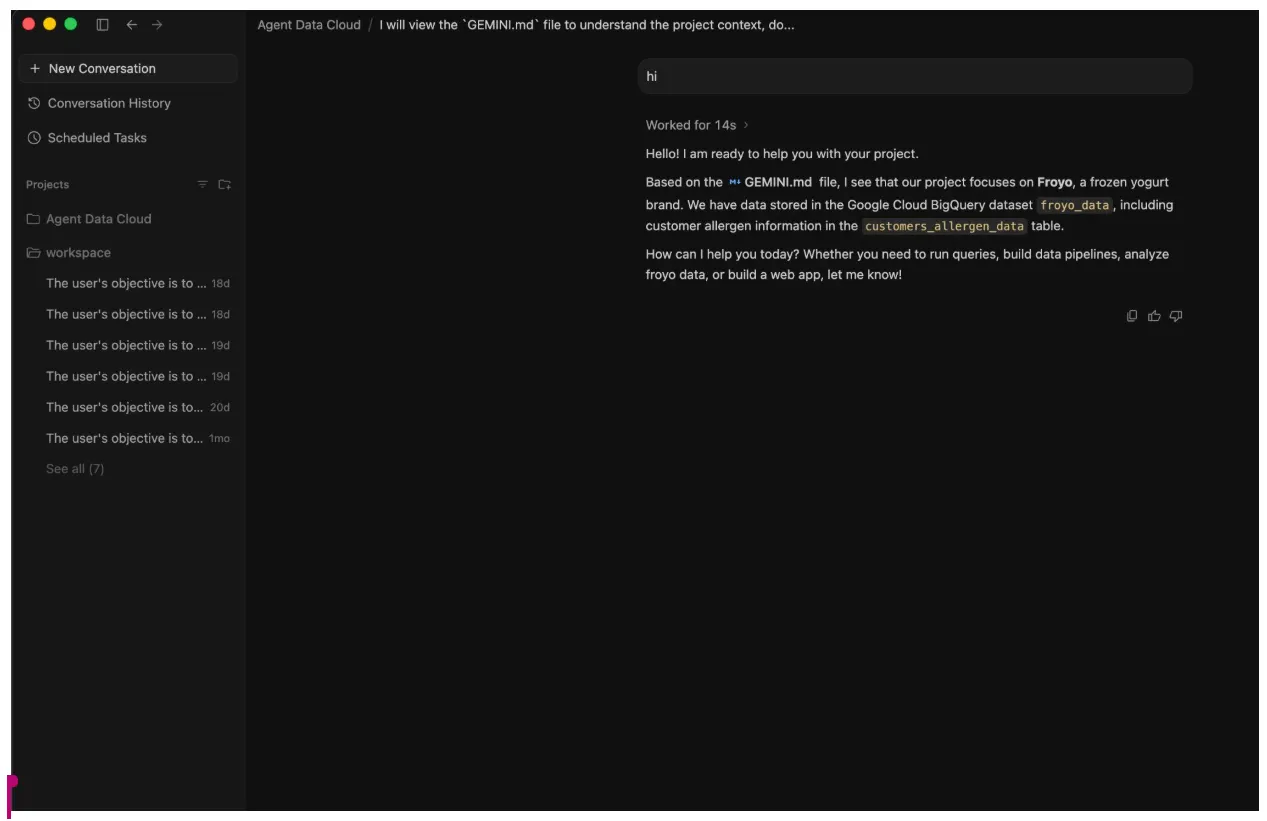
- Führen Sie einen ersten Chat mit dem KI-Agenten durch – „Hallo“.
- Achten Sie rechts oben auf den Button „IDE öffnen“!!!
Bevor Sie darauf klicken können,müssen Sie Antigravity IDE installieren. Rufen Sie die Seite antigravity.google/download auf und scrollen Sie nach unten zum Abschnitt „Antigravity IDE“. Laden Sie die gewünschte Variante herunter.
Kehren Sie nach dem Herunterladen zu Ihrer geöffneten Antigravity-Instanz zurück und klicken Sie oben rechts auf die Schaltfläche „IDE öffnen“.
- Es sollten Pop-ups zu Berechtigungen angezeigt werden. Öffnen Sie sie weiter.
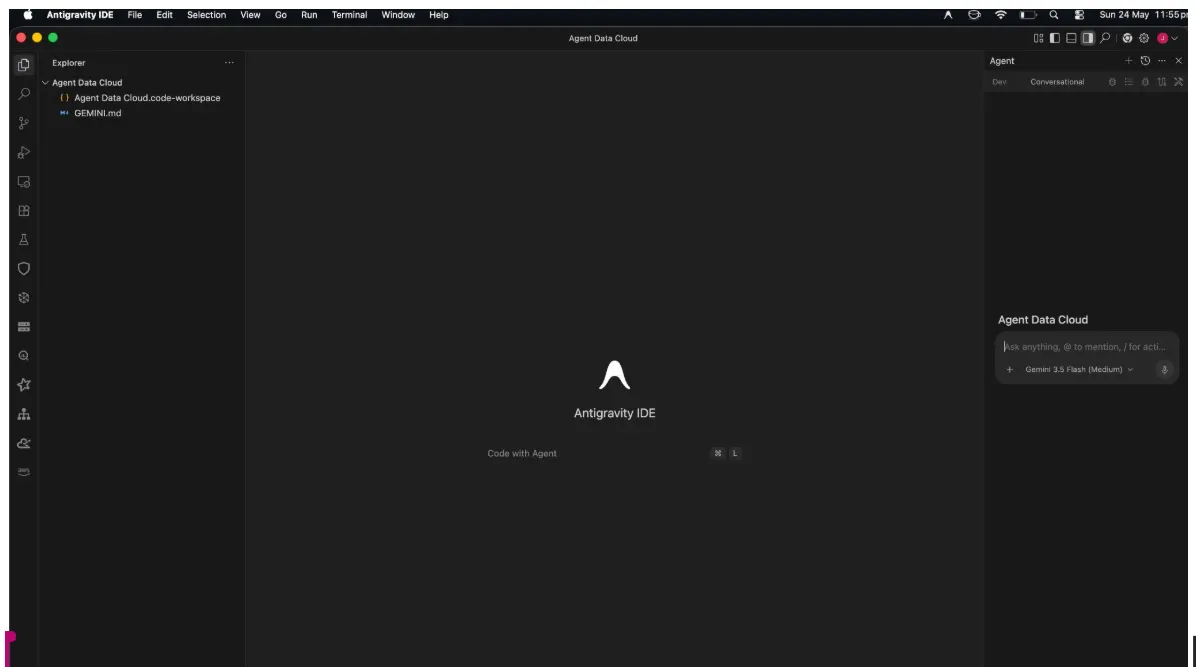
Rechts sehen Sie den Agent-Bereich, links den Projektexplorer und in der Mitte den Bereich für Ihre Entwicklung.
Data Agent Kit-Erweiterung einrichten
- Erweiterung installieren: Öffnen Sie den Erweiterungs-Marketplace in der ANTIGRAVITY IDE. Suchen Sie nach der Erweiterung „Google Cloud Data Agent Kit“ und installieren Sie sie.
- Klicken Sie auf die Schaltfläche „Installieren“. Danach wird die Erweiterung im Navigationsbereich angezeigt.
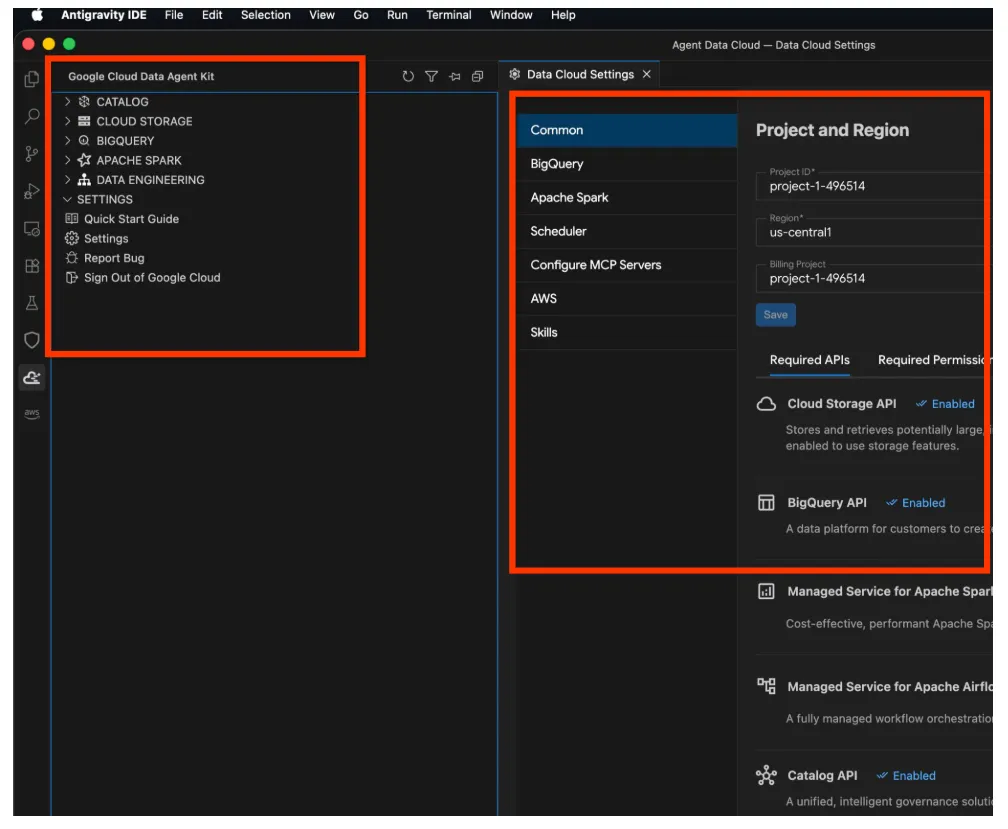
- Klicken Sie darauf, um den Google Cloud Data Agent Kit-Explorer zu öffnen. Rufen Sie den Bereich „SETTINGS“ (EINSTELLUNGEN) auf und klicken Sie auf „Settings“ (Einstellungen). Geben Sie dort Ihre Projektdetails und die Region ein und speichern Sie die Änderungen.
- Klicken Sie nun oben im Navigationsbereich auf „Project Explorer“. Dadurch sollte der Projektexplorer im Explorer-Bereich geöffnet werden.
- Klicken Sie mit der rechten Maustaste in den Explorer-Bereich und erstellen Sie eine neue Datei namens GEMINI.md.
- Fügen Sie Folgendes in GEMINI.md ein und ersetzen Sie <<YOUR_PROJECT_ID>> durch Ihren Wert:
## 1. Project Context
- **Project ID**: <<YOUR_PROJECT_ID>>
- **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
- **Data**: All froyo, customer, order related information is processed and stored in BigQuery `froyo_data` dataset.
## 2. Execution & Data Processing Rules
- **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `froyo_data`.
- **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the tables `customers_allergen_data`.
- ** CRITICAL RULE - Sales Data**: Sales data is present in tables `orders` and `order_items`.
- ** CRITICAL RULE - General: When you are referencing a dataset, ensure you are using it with the dataset ID (`froyo_data`) . For example, to query orders table in this dataset you should use `froyo_data.orders`.
Sie haben jetzt einen leistungsstarken KI-Agenten direkt in Ihrer IDE, der Code schreiben, SQL generieren und Ihre Architektur analysieren kann.
Wir stehen nun vor einer spannenden analytischen Herausforderung: Können wir unsere bisherigen Verkaufszahlen mit den komplexen, abgeleiteten Allergeninformationen in Beziehung setzen, die wir in Teil 1 aus PDFs extrahiert haben?
5. Intelligenz über den IDE-Agenten ableiten
Lassen wir unseren IDE-Agenten die Arbeit erledigen. Öffnen Sie das Chatfenster des Agent Data Kit direkt in Ihrer ANTIGRAVITY-IDE und geben Sie Folgendes ein:
Does Midnight Swirl contain any allergen?
Sie werden aufgefordert, eine Reihe von Berechtigungen zu erteilen.
Am Ende der Analyse wird die Antwort für Sie abgerufen:
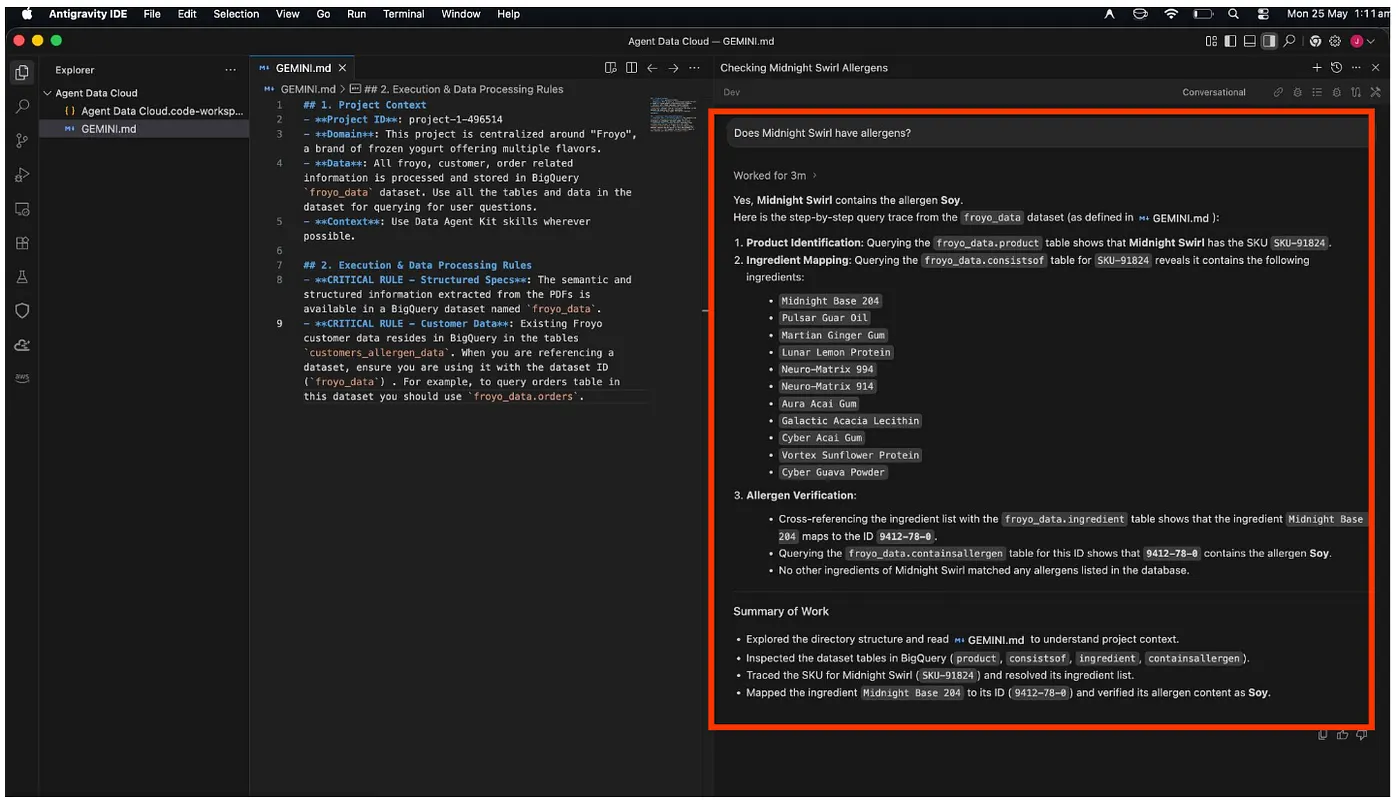
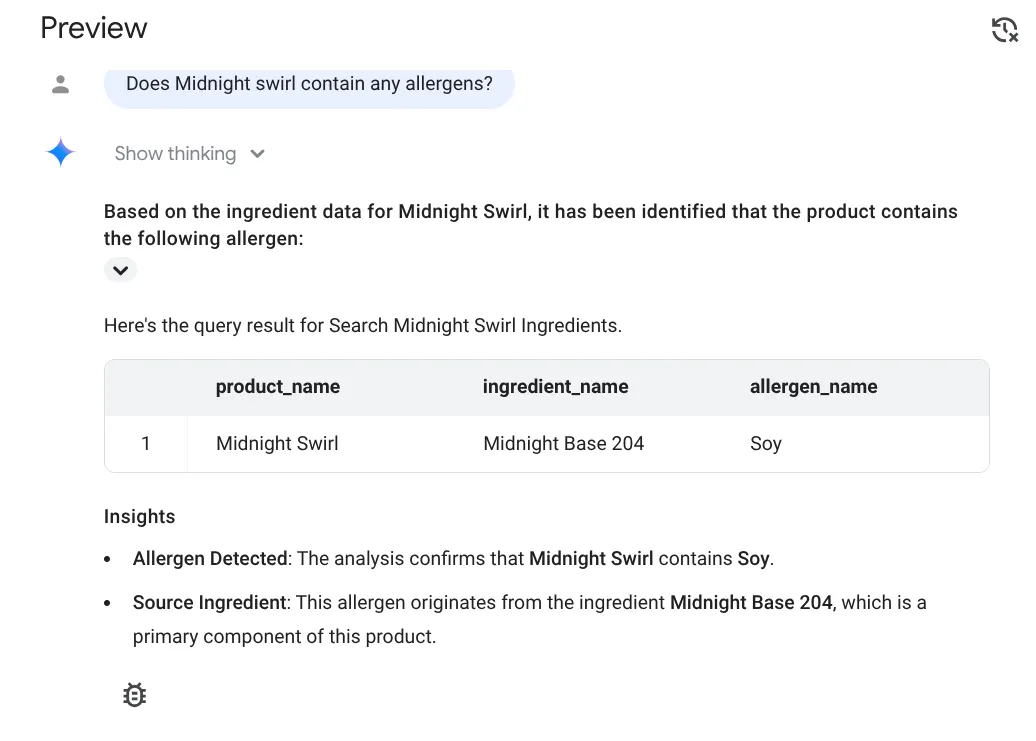
Juhu!!! Es wurde korrekt erkannt, dass das Produkt „Midnight Swirl“ Soja enthält.
Stellen wir nun eine etwas komplexere Frage. Geben Sie den folgenden Prompt in die Antigravity IDE ein:
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
Antwort
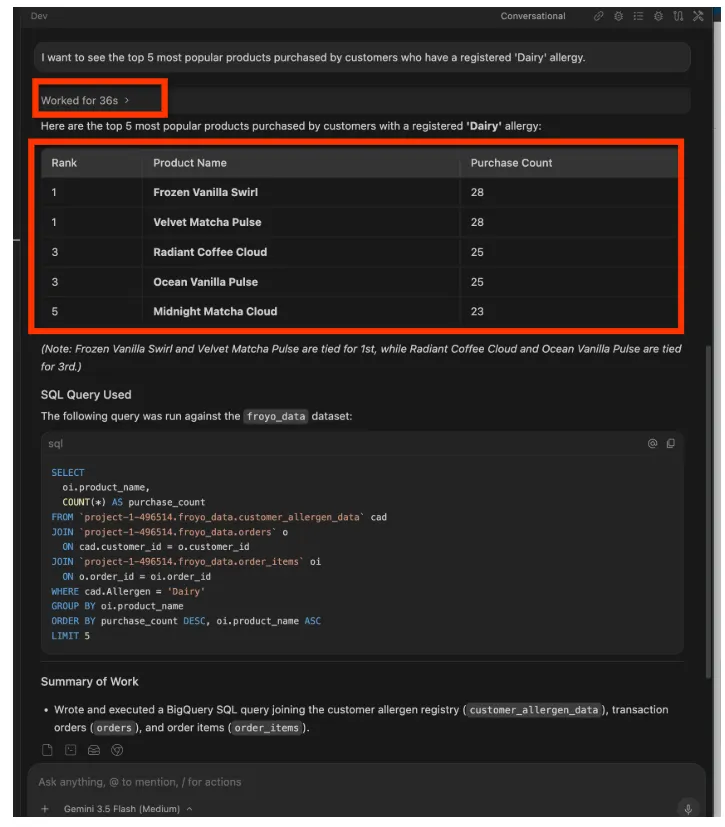
Du kannst weitermachen. Probieren Sie Prompts wie die folgenden aus:
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
Ohne die BQML-Syntax nachschlagen zu müssen, wird der genaue CREATE MODEL- und ML.FORECAST-Code in Ihren Editor eingefügt. Sie können diese direkt in Ihrer BigQuery-Umgebung ausführen, ohne die ANTIGRAVITY IDE zu verlassen.
Das ist ja unglaublich!!!
6. Konversationelle Analysen in BigQuery
Entwickler lieben die IDE, aber Geschäftsanwender und Führungskräfte nutzen die Cloud Console. Sie möchten kein SQL sehen, sondern nur Antworten.
Gehen Sie so vor:
- Sich selbst erforderliche Rollen zuweisen
Rufen Sie die IAM-Seite des Projekts auf und weisen Sie sich selbst die Rolle „Gemini Data Analytics Data Agent Owner“ zu:
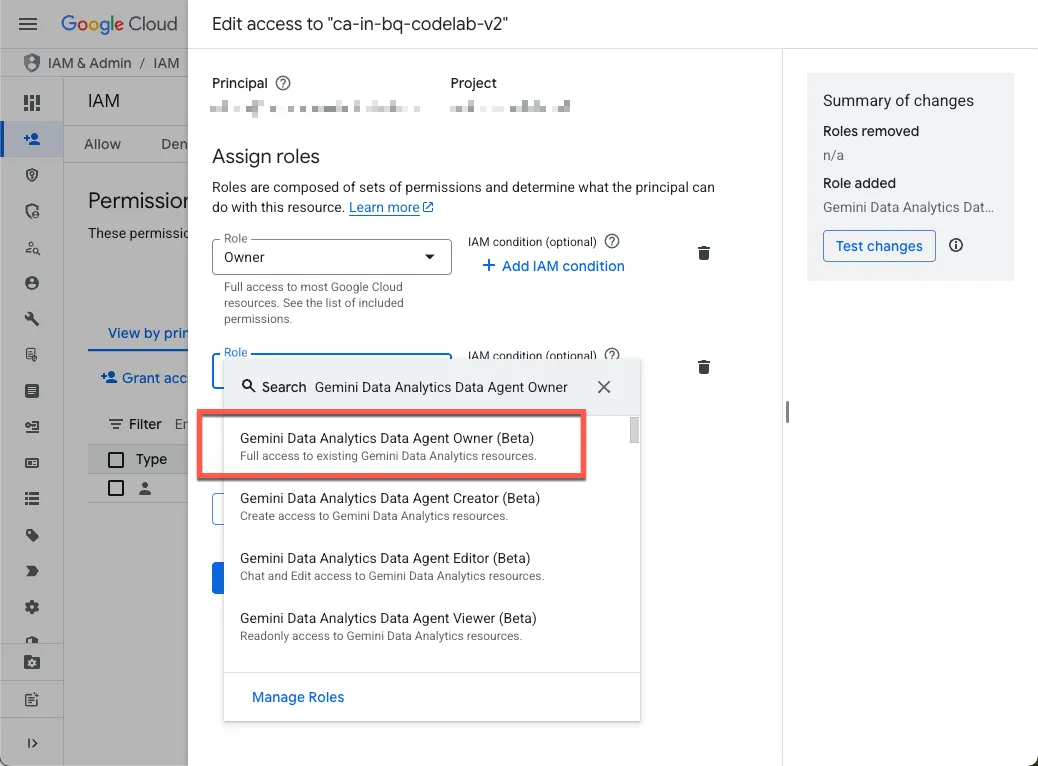
Mit dieser Rolle können Sie alle Daten-Agents im Projekt erstellen, bearbeiten, freigeben und löschen.
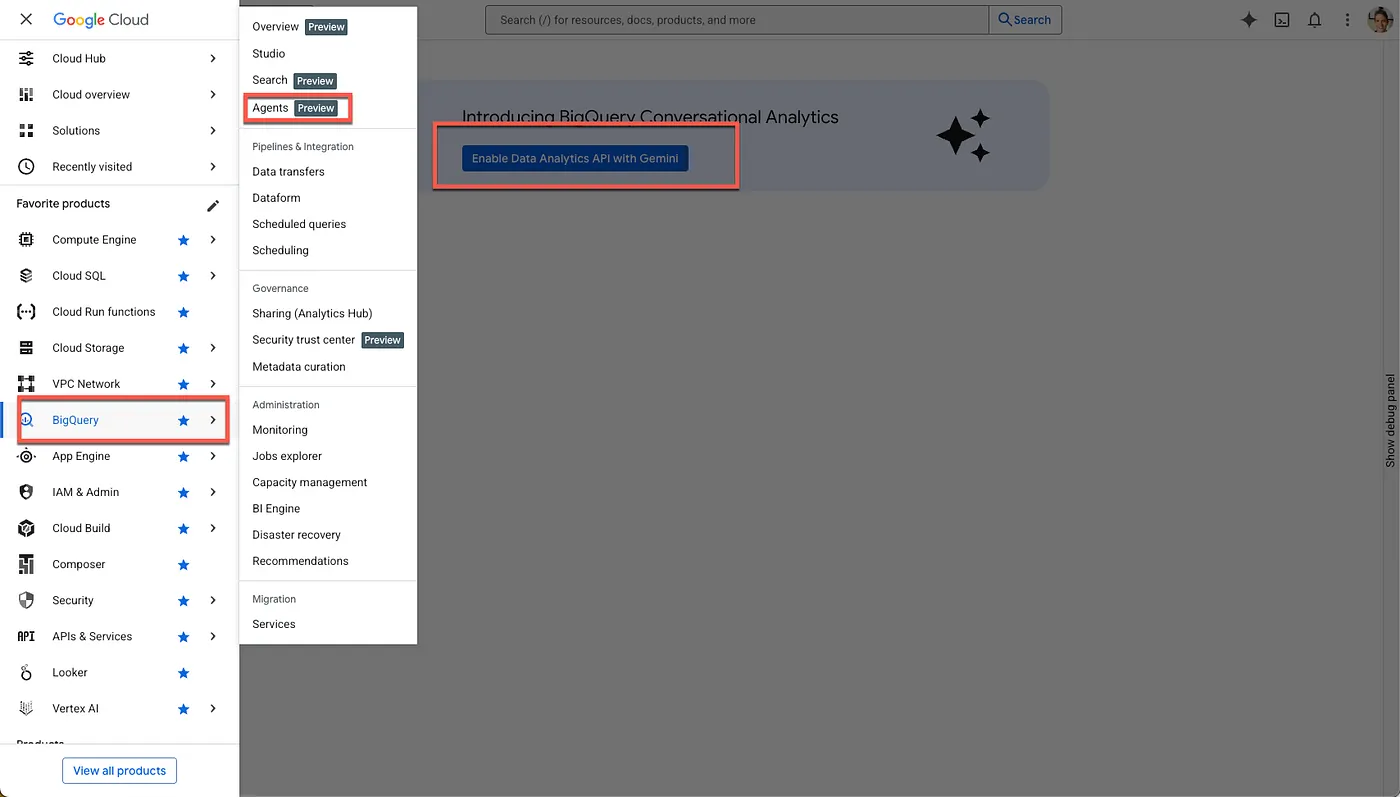
- Aktivieren der erforderlichen APIs
Rufen Sie BigQuery in der Google Cloud Console auf. Verwenden Sie das Navigationsmenü in der Seitenleiste oder das Suchmenü oben auf der Seite, um zu „BigQuery“ > „Agents“ zu gelangen.
Klicken Sie auf „Data Analytics API mit Gemini aktivieren“:
Aktivieren Sie sowohl die Gemini in BigQuery API als auch die Gemini for Google Cloud API:
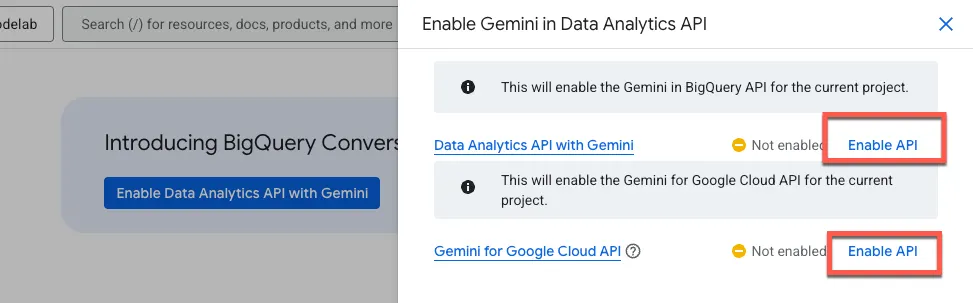
Sie sollten jetzt die neue Agent-Seite sehen:
- Agent-Informationen konfigurieren
Name des Kundenservicemitarbeiters: Froyo Agent
Agent-Beschreibung: Hilft bei der Beantwortung von Fragen zu Froyo-Produkten, Allergenen, Inhaltsstoffen, Rezepten, Kunden, Bestellungen und Verkäufen.
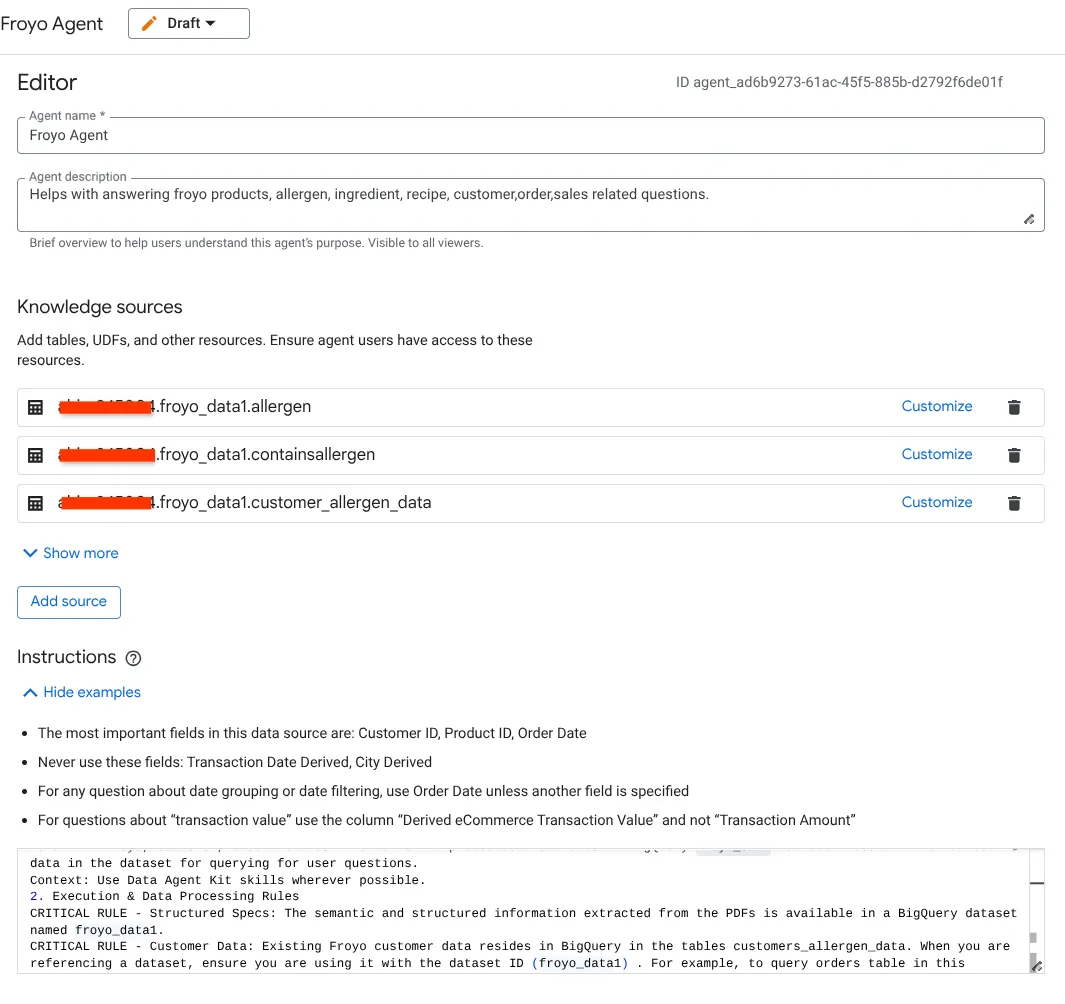
- Rufen Sie den Bereich „Wissensquellen“ auf und wählen Sie alle Tabellen unten aus Ihrem Dataset aus:
a. Fügen Sie die Tabellen im Bild oben hinzu und klicken Sie auf „Quelle hinzufügen“.
b. Klicken Sie für jede Quelle rechts auf die Schaltfläche Anpassen. Das folgende Formular wird angezeigt:
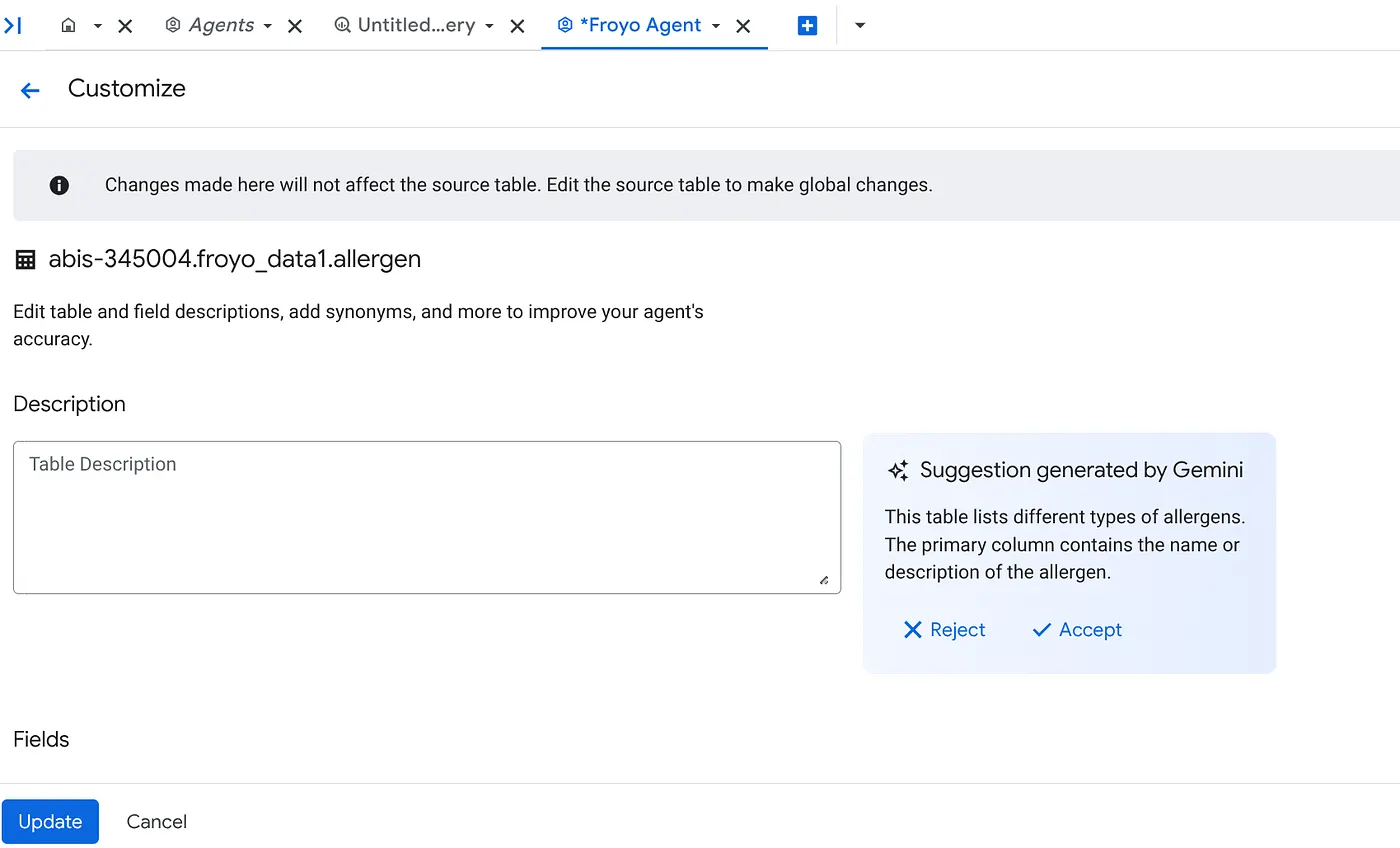
c. Klicken Sie für die Tabellenbeschreibung auf „Akzeptieren“.
d. Klicken Sie auch für jede der Feldbeschreibungen auf „Akzeptieren“.
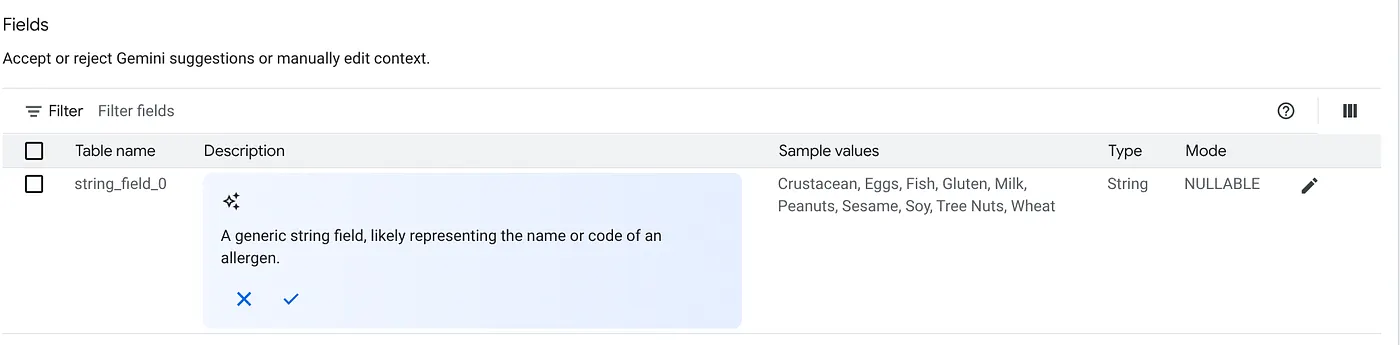
e. Klicken Sie auf „Aktualisieren“.
Sie müssen diesen Vorgang für alle Tabellen in der Quelle wiederholen.
- Anweisungen konfigurieren
Fügen Sie hier dieselbe Anleitung ein, die wir in Antigravity IDE GEMINI.md verwendet haben:
1. Project Context
Project ID: <<YOUR_PROJECT_ID>>
Domain: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
Data: All froyo, customer, order related information is processed and stored in BigQuery froyo_data dataset. Use all the tables and data in the dataset for querying for user questions.
Context: Use Data Agent Kit skills wherever possible.
2. Execution & Data Processing Rules
CRITICAL RULE - Structured Specs: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named froyo_data.
CRITICAL RULE - Customer Data: Existing Froyo customer data resides in BigQuery in the tables customers_allergen_data. When you are referencing a dataset, ensure you are using it with the dataset ID (froyo_data) . For example, to query orders table in this dataset you should use froyo_data.orders.
- Speichern Sie den Agent.
7. Mit Daten chatten
- Testen Sie es im Vorschauabschnitt auf der rechten Seite:
Frage stellen:
Does midnight swirl contain any allergen?
Hier ist die Antwort:
Stellen wir nun die komplizierte Frage:
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
Antwort
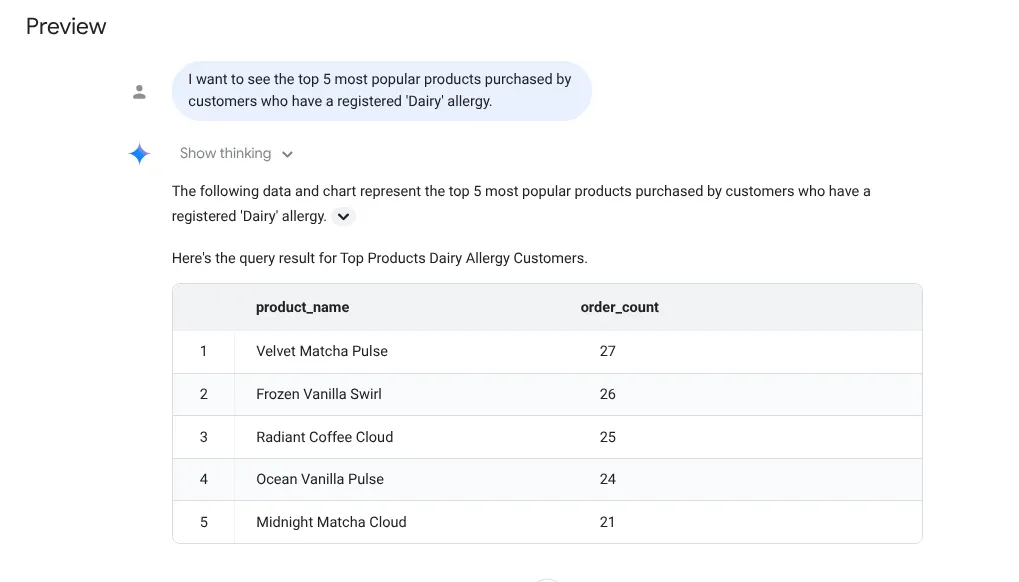
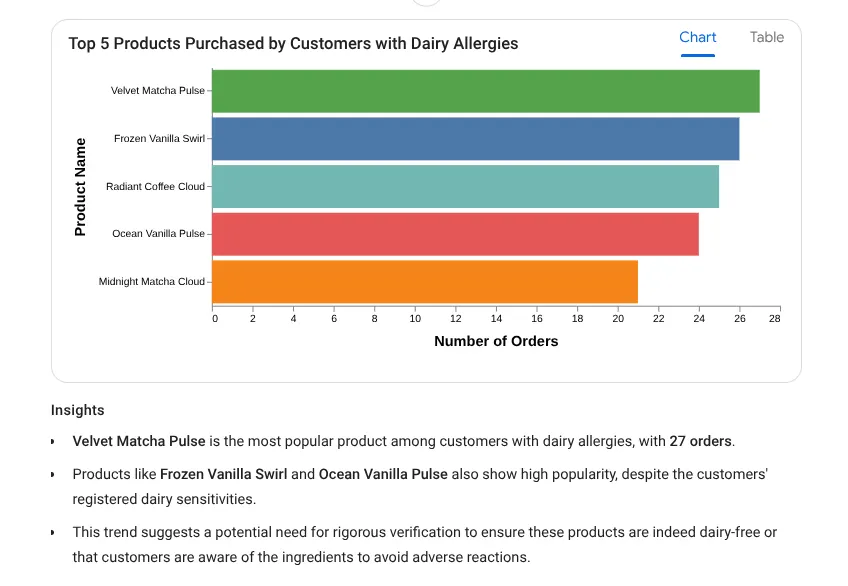
Probieren wir jetzt einen Prompt für detaillierte Statistiken aus:
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
Hier sehen Sie die verwendete Abfrage, das Tabellenergebnis und das Diagramm:
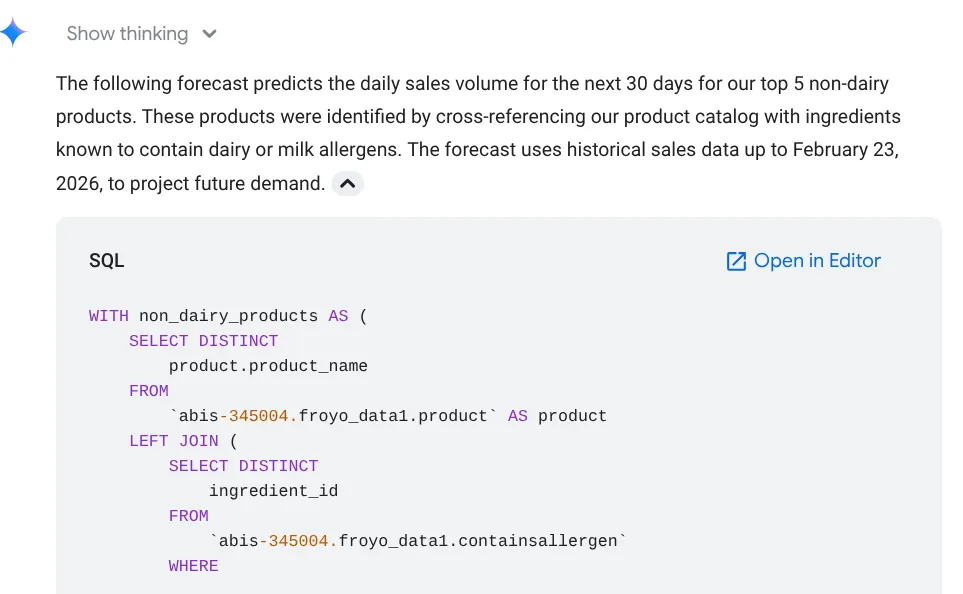
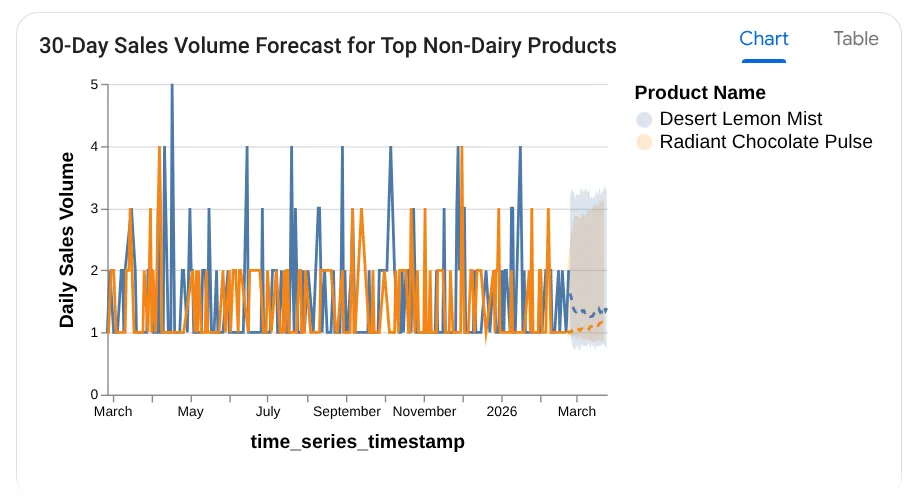

Wow! Das hat gut zu den Diagrammen und Statistiken gepasst. Zeit für die ultimative Frage zu Produkten.
8. Der ultimative Test
Frage stellen:
What will be the top most selling product of 2026
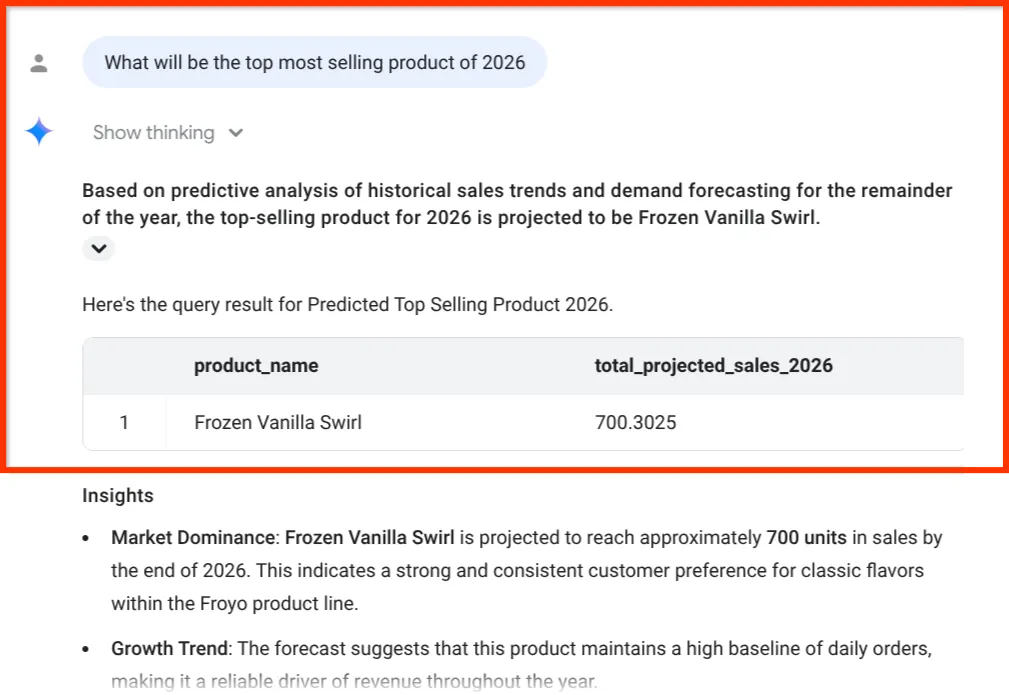

Sehen Sie sich diese letzte Statistik an. Der BigQuery Data Agent hat uns nicht nur eine Zahl geliefert, sondern die Umsatzprognose explizit an unsere Lagerbestände und die Lieferkette für Zutaten gebunden – genau die Daten, die wir in Teil 1 aus unübersichtlichen PDFs extrahiert haben.
9. KI-Agent für Unternehmen veröffentlichen
Klicken Sie oben im Vorschau-Agent auf den Button Veröffentlichen.
Nachdem wir unseren Froyo-Agent erstellt, konfiguriert und getestet haben, ist es an der Zeit, ihn für den Rest des Unternehmens freizugeben.
Klicken Sie rechts oben auf der Seite „Agent-Konfiguration“ auf die Schaltfläche „Veröffentlichen“.
Durch die Veröffentlichung ist Ihr KI‑Agent sofort über drei leistungsstarke Enterprise-Kanäle für Sie und alle Personen verfügbar, für die Sie ihn freigeben:
- BigQuery: Ihre Datenanalysten können jetzt direkt über den Hub für KI-Agents oder in ihrem BigQuery Studio-SQL-Arbeitsbereich mit diesem Agent chatten.
- Conversational Analytics API: Ihre Entwickler können über eine REST API auf diesen Agent zugreifen und so diese Conversational Analytics in Ihre eigenen benutzerdefinierten internen Webanwendungen einbinden.
- Data Studio: Führungskräfte können mit diesem Agent interagieren und dynamische Konversations-Dashboards direkt in Data Studio erstellen.
Wir haben unsere Daten erfolgreich aus den Silos geholt und sie direkt den Personen zur Verfügung gestellt, die sie benötigen – und zwar genau dort, wo sie ohnehin arbeiten.
Klicken Sie oben auf die Drop-down-Liste der Schaltfläche „Freigeben“ Ihres veröffentlichten BigQuery-Agents und wählen Sie in der Liste die Option „Link zum Agent in Data Studio kopieren“ aus:
Fügen Sie den Link in Ihren Browser ein und drücken Sie die Eingabetaste. Bestätigen Sie die Benachrichtigung zum Zugriff auf Agenteninteraktionen:
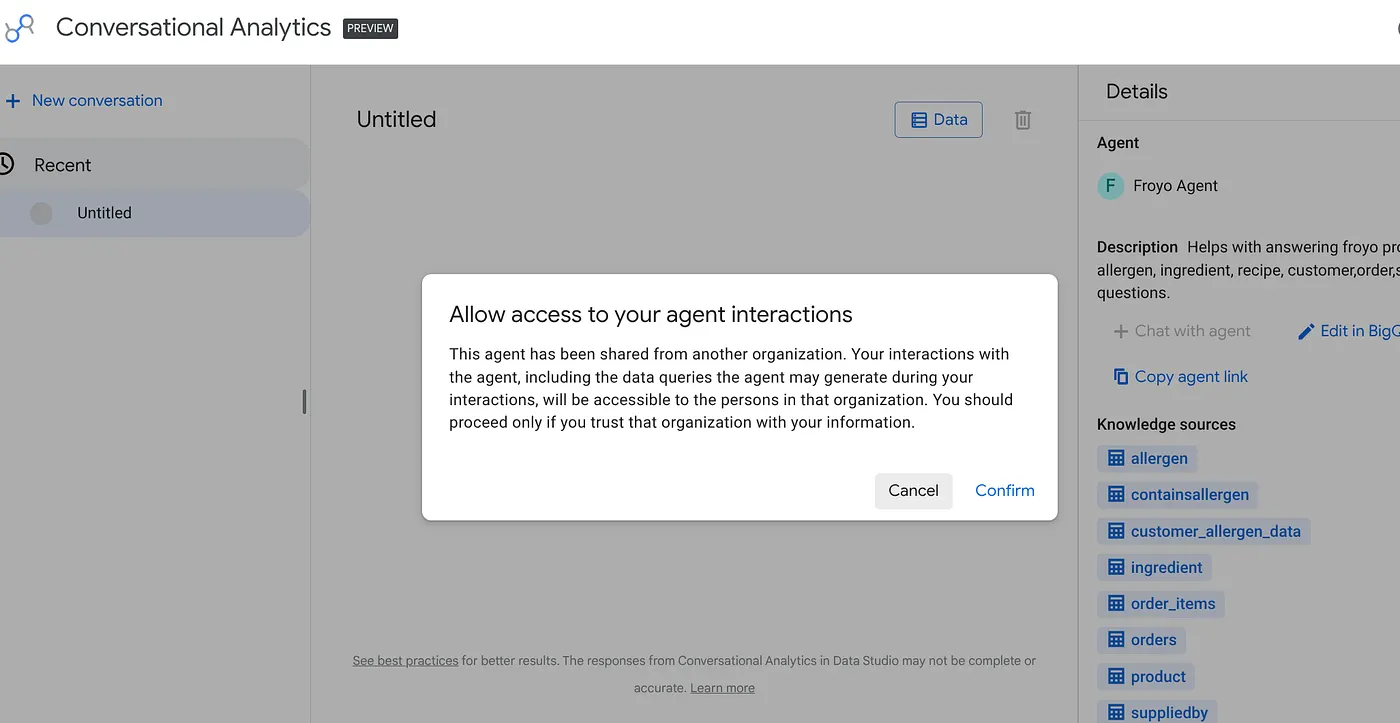
Sie können interaktive Unterhaltungen und Visualisierungen mit dem neu veröffentlichten KI-Agenten in Data Studio starten. Das gilt auch für Führungskräfte und andere Teams, die diese Informationen benötigen.
10. Bereinigen
Vergessen Sie nicht, nach Abschluss dieses Labs die Berechtigungen für alle Nutzer für den gerade erstellten BigQuery-Agent zu entfernen.
11. Glückwunsch!
Sie haben offiziell eine Agentische Daten-Cloud erstellt!
Sie haben nicht nur einen einfachen Chatbot erstellt. In diesen fünf Sessions haben Sie ein vollständiges, modernes und bewertetes KI-System für Unternehmen von Grund auf konzipiert. Sie sind von „Dark Data“ zu Transaktionsinformationen in Echtzeit und schließlich zu Conversational Business Forecasting übergegangen.
12. Das Gesamtbild
Sehen wir uns noch einmal an, was wir in dieser Reihe erreicht haben. Wir haben nicht nur einen einfachen Chatbot entwickelt. Wir haben eine vollständige, moderne Agentische Daten-Cloud entwickelt:
Teil 1: Mit Knowledge Catalog wurden bisher nicht zugängliche Dark Data erschlossen, indem PDFs in strukturierte relationale Tabellen umgewandelt wurden.
Teil 2: Datensilos wurden aufgelöst, indem unser Analyse-Data Warehouse direkt in eine AlloyDB-Transaktionsdatenbank eingebunden wurde.
Teil 3: Nutzer durch die Entwicklung eines Multi-Agenten-Betriebssystems unterstützen, das sichere Datenbanktools nahtlos über das MCP-Protokoll ausführt
Teil 4: Sicherheit durch Implementierung einer strengen Evaluierungspipeline, um Halluzinationen und Jailbreaks zu erkennen.
Teil 5: Informationen mit ANTIGRAVITY IDE und konversationeller Analyse in BigQuery allgemein verfügbar machen.
Das ist die Zukunft von Unternehmenssoftware. Der KI-Agent ist nicht mehr nur ein Wrapper um ein LLM. Sie ist eine vollständig integrierte, geprüfte und sichere Orchestrierungs-Engine, die auf einer einheitlichen Datenplattform basiert.