
۱. مرور کلی
بیایید لحظهای به معماری عظیمی که در چهار بخش گذشته ساختهایم نگاهی بیندازیم:
بخش ۱ : ما از کاتالوگ دانش BigQuery برای تبدیل فایلهای PDF خام دستور پخت غذاهای Froyo به جداول رابطهای ساختاریافته استفاده کردیم.
بخش ۲ : ما یک پل تراکنشی Zero-ETL ساختیم و انبار BigQuery خود را مستقیماً به AlloyDB متصل کردیم.
بخش ۳ : ما یک برنامه چندعاملی (FroyoOS) را با استفاده از کیت توسعه عامل و جعبه ابزار MCP راهاندازی کردیم.
بخش ۴ : ما با ساخت یک خط لوله ارزیابی دوگانه، ایمن بودن عامل خود را برای تولید اثبات کردیم.
عملیات ما بینقص در حال اجرا است. اما در مورد توسعهدهندگان و تحلیلگران کسبوکار که باید حجم عظیم دادههایی را که این سیستم تولید میکند، درک کنند، چه؟
امروز، ما قصد داریم آیندهی علم تجزیه و تحلیل را بررسی کنیم. ما مستقیماً از ویرایشگر کد Antigravity IDE با Google Cloud Data Agent Kit شروع خواهیم کرد و سپس به کنسول Google Cloud میرویم تا دادههای خود را با استفاده از BigQuery Conversational Analytics تجسم کنیم.
بیایید شروع به ساختن کنیم!
آنچه یاد خواهید گرفت
در این کدلاگ نهایی از مجموعه Agentic Data Cloud ، شما تمام بخشهای معماری خود را کنار هم قرار خواهید داد تا بینشهای تجاری کاربردی ارائه دهید. شما یاد خواهید گرفت:
- IDE-First Analytics: نحوه نصب و پیکربندی ANTIGRAVITY IDE و Google Cloud Data Agent Kit برای پرس و جو از معماری شما مستقیماً از محیط توسعهتان.
- مکالمه در BigQuery: نحوه ایجاد، پیکربندی و آموزش BigQuery Data Agents برای خودکارسازی وظایف پیچیده SQL و پیشبینی با استفاده از زبان طبیعی.
- دموکراتیزه کردن دادهها: چگونه عوامل خود را در سازمان منتشر کنید و آنها را برای تحلیلگران و کاربران تجاری در سراسر سازمان در دسترس قرار دهید.
- تجسم بینشها: چگونه تجزیه و تحلیل مکالمهای نماینده خود را به طور یکپارچه در Data Studio ادغام کنید تا داشبوردهای پویا و آماده برای پیشبینی ایجاد کنید.
- اکوسیستم ابری دادههای ایجنتیک: چگونه ارزش معماری سرتاسری خود را بیان کنید - از دادههای خام بدون ساختار در بخش ۱ تا داشبوردهای آماده برای مدیران در بخش ۵.
الزامات
۲. قبل از شروع
ایجاد یک پروژه
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- شما از Cloud Shell ، یک محیط خط فرمان که در Google Cloud اجرا میشود، استفاده خواهید کرد. روی Activate Cloud Shell در بالای کنسول Google Cloud کلیک کنید.

- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر میخواهید احراز هویت کنید
gcloud auth login
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- فعال کردن API های مورد نیاز: برای فعال کردن تمام API های مورد نیاز، این دستور را اجرا کنید:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
۳. گسترش انبار داده
جداول BigQuery که از دادههای بدون ساختار خود ایجاد کردیم را به خاطر دارید؟
برای انجام برخی تحلیلهای معنادار، به دادههای تراکنشهای تاریخی نیاز داریم. در BigQuery، در زیر مجموعه داده froyo_data ، سه جدول جدید برای شبیهسازی سالهای عملیات فرانشیز ایجاد میکنیم:
- froyo_data.orders : سربرگهای سفارشهای قبلی (تاریخها، شناسههای فروشگاه، جمع کل)
- froyo_data.order_items : جزئیات هر سطر (مقدار، قیمت)
- froyo_data.customer_allergen_data : یک جدول CRM که آلرژیهای شناختهشده مشتریان وفادار ما را ردیابی میکند.
بیایید این جداول مربوط به فروش و مشتری را به آن مجموعه داده اضافه کنیم تا مورد استفاده تحلیلی خود را آماده کنیم.
- از کنسول گوگل کلود خود به Cloud Shell Terminal بروید.
- به پوشه ریشه فضای کاری خود یا پوشه ریشه پروژه froyo-data (که در چند بخش قبلی این مجموعه روی آن کار میکردیم) بروید.
- با اجرای دستورات زیر به صورت یک به یک، ۳ فایل دادههای تاریخی (در قالب فایلهای csv) را در دایرکتوری کاری خود دانلود کنید:
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/customer_allergen_data.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/order_items.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/orders.csv
- وقتی آن فایلها را در ریشه دایرکتوری کاری خود مشاهده کردید، با رفتن به ترمینال، به ترمینال Cloud Shell خود بروید.
- به دایرکتوری که این 3 فایل را در ترمینال Cloud Shell خود دارید، بروید.
- مطمئن شوید که BigQuery شما مجموعه دادهای با نام "froyo_data" از بخش اول این مجموعه را دارد (اگر اینطور نیست، برگردید و مجموعه داده و جداول را ایجاد کنید).
- دستورات زیر را از ترمینال Cloud Shell خود اجرا کنید:
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.orders \
./orders.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.order_items \
./order_items.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.customer_allergen_data \
./customer_allergen_data.csv
این باید ۳ جدول اضافی در مجموعه داده froyo_data شما ایجاد کند.
۴. تجربه توسعهدهنده - وارد «کیت عامل داده» شوید
به طور سنتی، اگر یک توسعهدهنده میخواست دادهها را تجزیه و تحلیل کند یا کوئریهای پیچیده یادگیری ماشین بنویسد، مجبور بود دائماً بین IDE، کنسولهای پایگاه داده و مستندات خود جابجا شود.
دیگر نه. با افزونهی جدید Google Cloud Data Agent Kit ، IDE شما به یک نیروگاه داده تبدیل میشود.
محیط برنامهنویسی ضد جاذبه
محیط توسعه آنتیگراویتی (ANTIGRAVITY IDE) نسل بعدی گوگل و محیط توسعه مبتنی بر عامل است که بهطور خاص برای حوزه هوش مصنوعی طراحی شده است. این محیط، پنجرههای متنی چندوجهی عظیم و استفاده از ابزار مستقل را بهطور مستقیم در ویرایشگر ادغام میکند و به توسعهدهندگان اجازه میدهد تا منابع ابری و خطوط لوله داده پیچیده را بدون ترک کد خود، هماهنگ کنند.
راهاندازی محیط برنامهنویسی ضد جاذبه (ANTIGRAVITY IDE)
- دانلود IDE: به antigravity.google بروید و Antigravity IDE را برای سیستم عامل خود (ویندوز، macOS یا لینوکس) دانلود کنید.
- نصب و راهاندازی: نصبکننده را اجرا کنید و برنامه را باز کنید.
- روی «ادامه با گوگل» کلیک کنید، حساب Gmail خود را انتخاب کنید و تأیید کنید.
- پس از ورود به سیستم، یک پوشه کاری (workspace/project) ایجاد کنید. بیایید آن را "ابر دادههای عامل" بنامیم.
باید در لیست "پروژهها" در سمت چپ ظاهر شود:
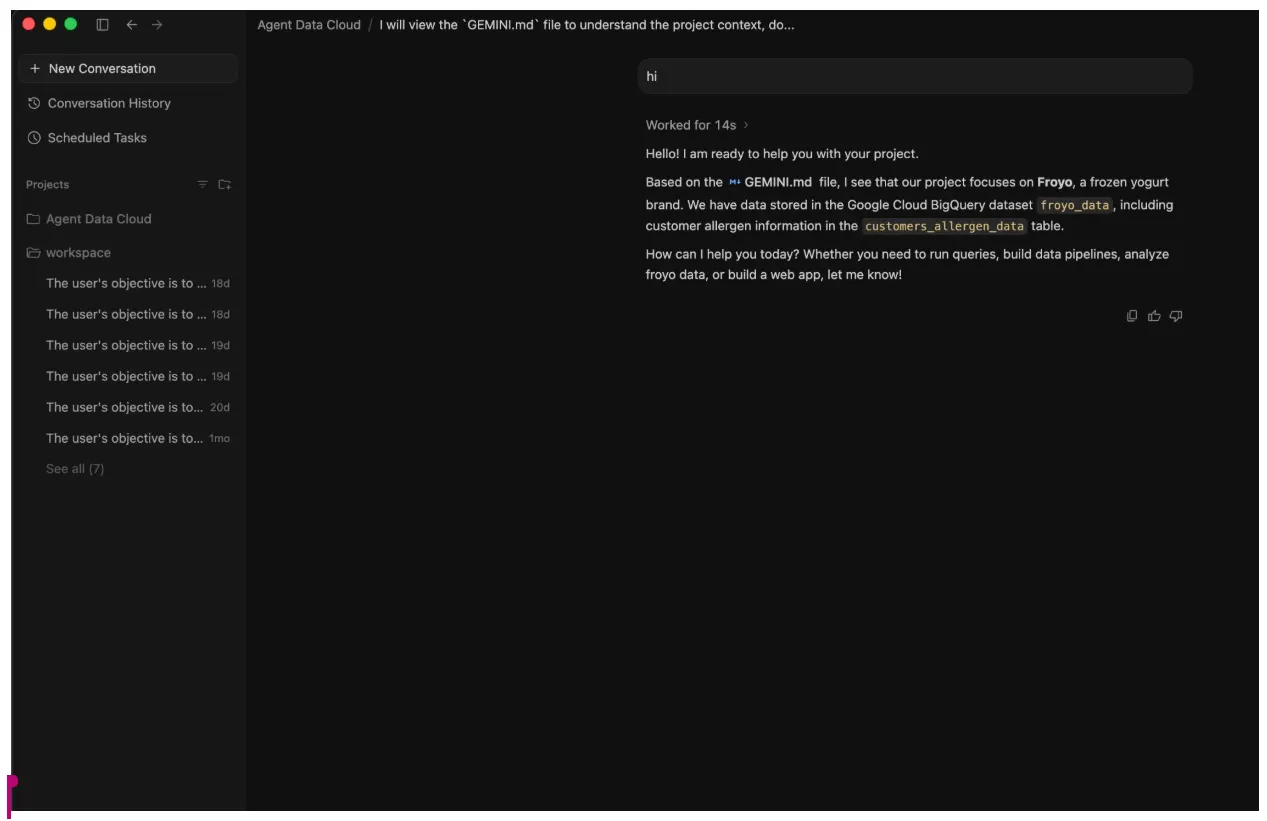
- یک گفتگوی اولیه با نماینده داشته باشید - "سلام".
- در گوشه بالا سمت راست، دکمه Open IDE را یادداشت کنید!!!
اما قبل از اینکه بتوانید روی آن کلیک کنید، باید Antigravity IDE را نصب کنید. به صفحه antigravity.google/download بروید و به بخش Antigravity IDE بروید، نوع مورد نیاز خود را دانلود کنید.
پس از دانلود، به محیط Antigravity خود که باز کردهاید برگردید و روی دکمهی Open IDE در گوشهی بالا سمت راست کلیک کنید.
- شما باید پنجرههای بازشو مربوط به مجوزها را ببینید، به باز کردن آن ادامه دهید!
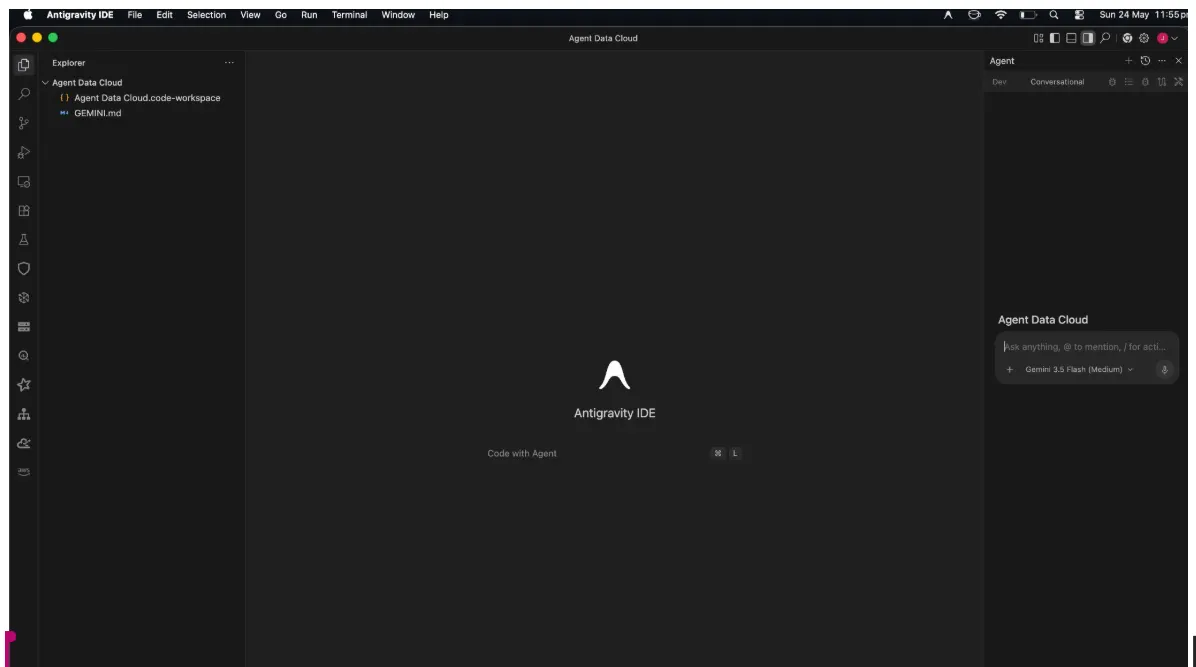
در سمت راست، پنجرهی عامل (agent pane)، در سمت چپ، پنجرهی کاوشگر پروژه (project explorer) و در مرکز، فضای لازم برای توسعهی شما را مشاهده میکنید.
افزونه Data Agent Kit را تنظیم کنید
- نصب افزونه: بازار افزونهها را در محیط ANTIGRAVITY باز کنید. افزونه Google Cloud Data Agent Kit را جستجو و نصب کنید.
- روی دکمهی نصب کلیک کنید و پس از اتمام، میتوانید آن افزونه را در پنل ناوبری مشاهده کنید.
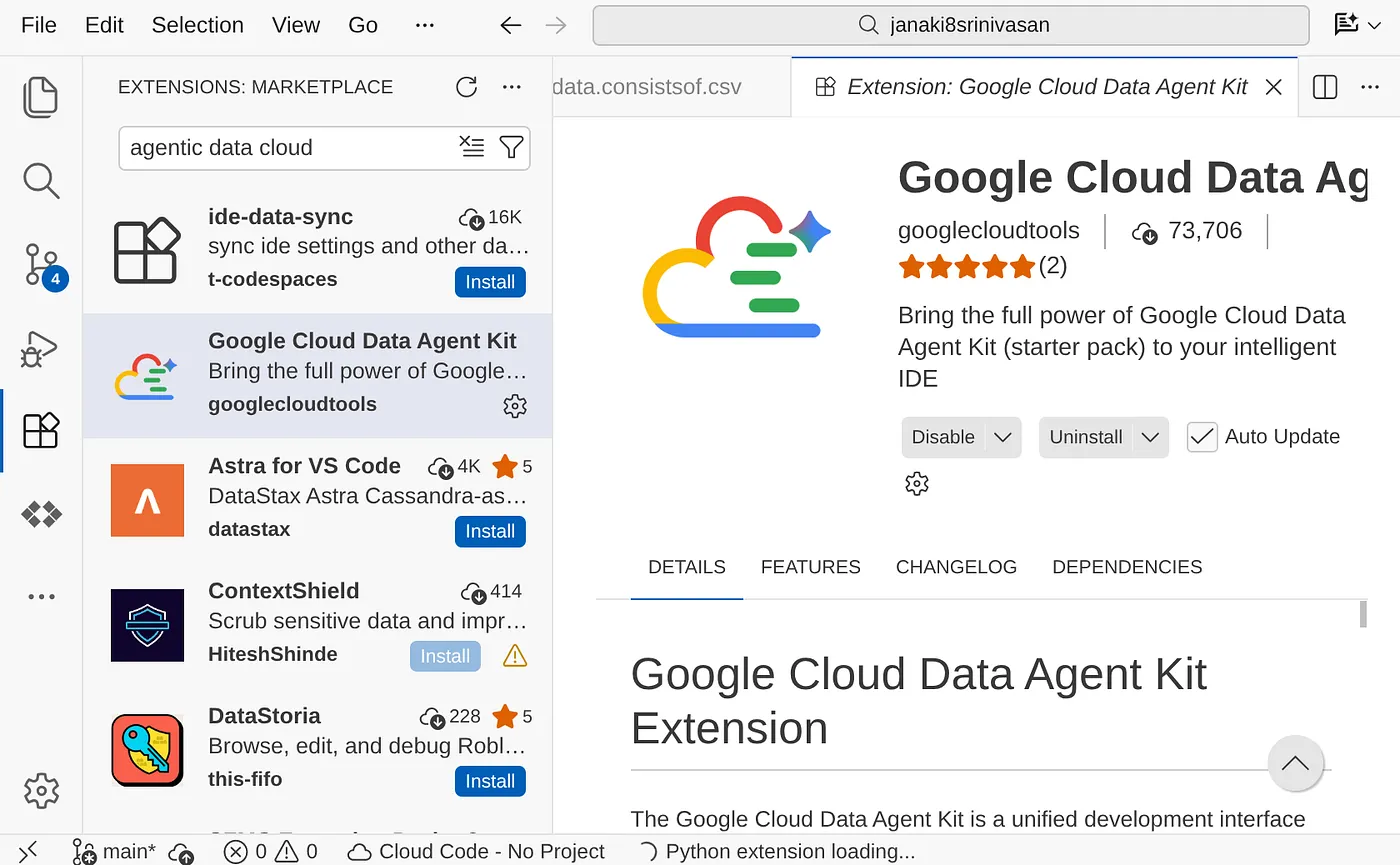
- روی آن کلیک کنید تا پنجرهی کاوشگر Google Cloud Data Agent Kit باز شود، به بخش تنظیمات (SETTINGS) بروید و روی تنظیمات (Settings) کلیک کنید. جزئیات پروژه و منطقهی جغرافیایی خود را در آنجا وارد کرده و ذخیره کنید.
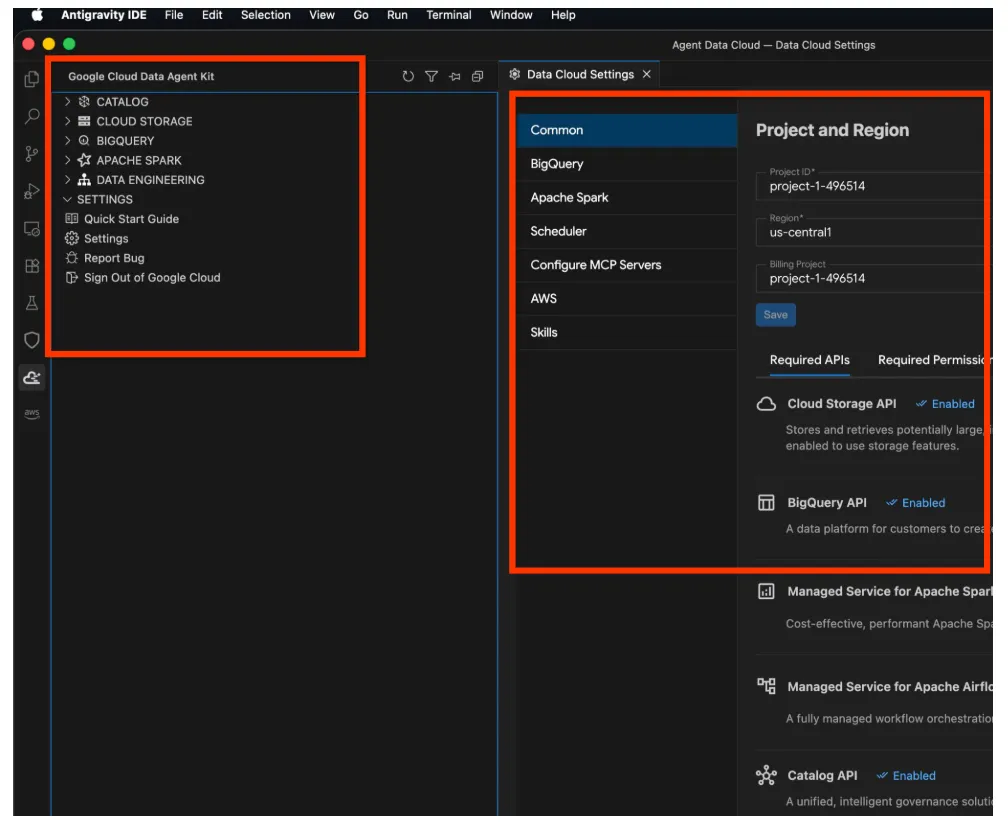
- حالا روی Project Explorer در بالای پنل Navigation کلیک کنید. باید project explorer شما در پنل explorer باز شود.
- روی فضای اکسپلورر کلیک راست کرده و یک فایل جدید با نام « GEMINI.md » ایجاد کنید.
- کد زیر را در GEMINI.md قرار دهید (فراموش نکنید که <<YOUR_PROJECT_ID>> را با مقدار خود جایگزین کنید):
## 1. Project Context
- **Project ID**: <<YOUR_PROJECT_ID>>
- **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
- **Data**: All froyo, customer, order related information is processed and stored in BigQuery `froyo_data` dataset.
## 2. Execution & Data Processing Rules
- **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `froyo_data`.
- **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the tables `customers_allergen_data`.
- ** CRITICAL RULE - Sales Data**: Sales data is present in tables `orders` and `order_items`.
- ** CRITICAL RULE - General: When you are referencing a dataset, ensure you are using it with the dataset ID (`froyo_data`) . For example, to query orders table in this dataset you should use `froyo_data.orders`.
حالا، شما یک عامل هوش مصنوعی بسیار توانمند دارید که مستقیماً در IDE شما نشسته است و آماده نوشتن کد، تولید SQL و تجزیه و تحلیل معماری شماست.
اکنون یک چالش تحلیلی جذاب داریم: آیا میتوانیم فروشهای تاریخی خود را با دادههای پیچیده و استنباطی آلرژن که از فایلهای PDF در بخش 1 استخراج کردهایم، مرتبط کنیم؟
۵. استنتاج اطلاعات از طریق عامل IDE
بیایید از عامل IDE خود بخواهیم که کارهای سنگین را انجام دهد. پنجره چت Agent Data Kit را درست در داخل IDE ANTIGRAVITY خود باز کنید و موارد زیر را از آن درخواست کنید:
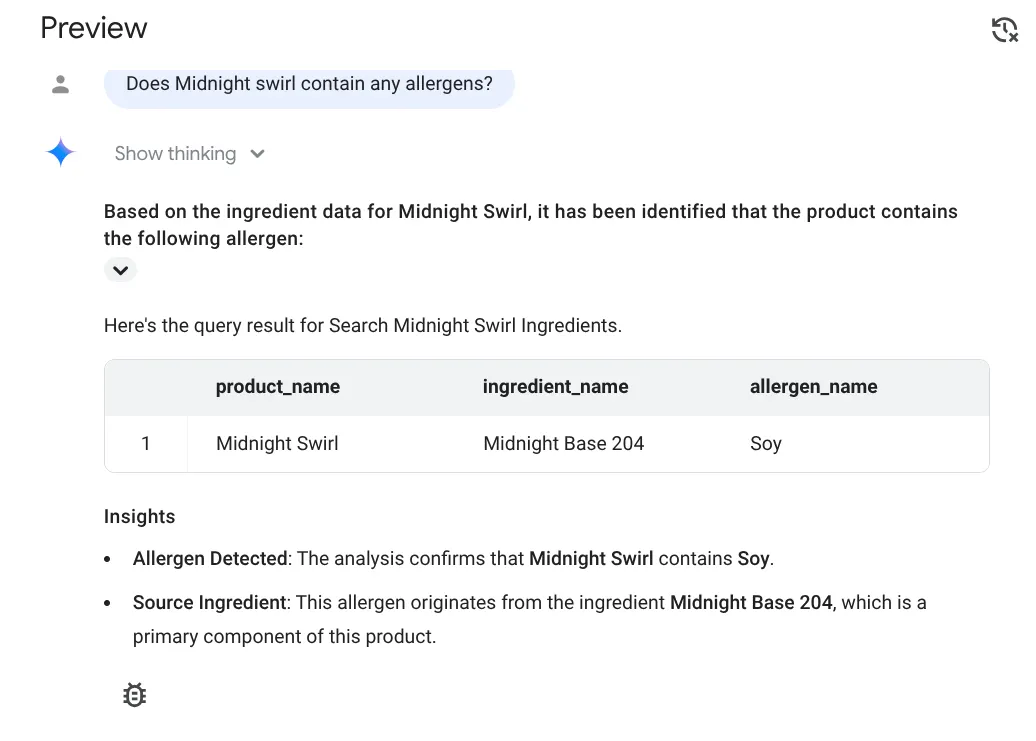
Does Midnight Swirl contain any allergen?
از شما یک سری مجوزها را درخواست میکند، در صورت لزوم اجازه دهید.
در نهایت، در پایان تحلیل خود، پاسخ را برای شما بازیابی خواهد کرد:
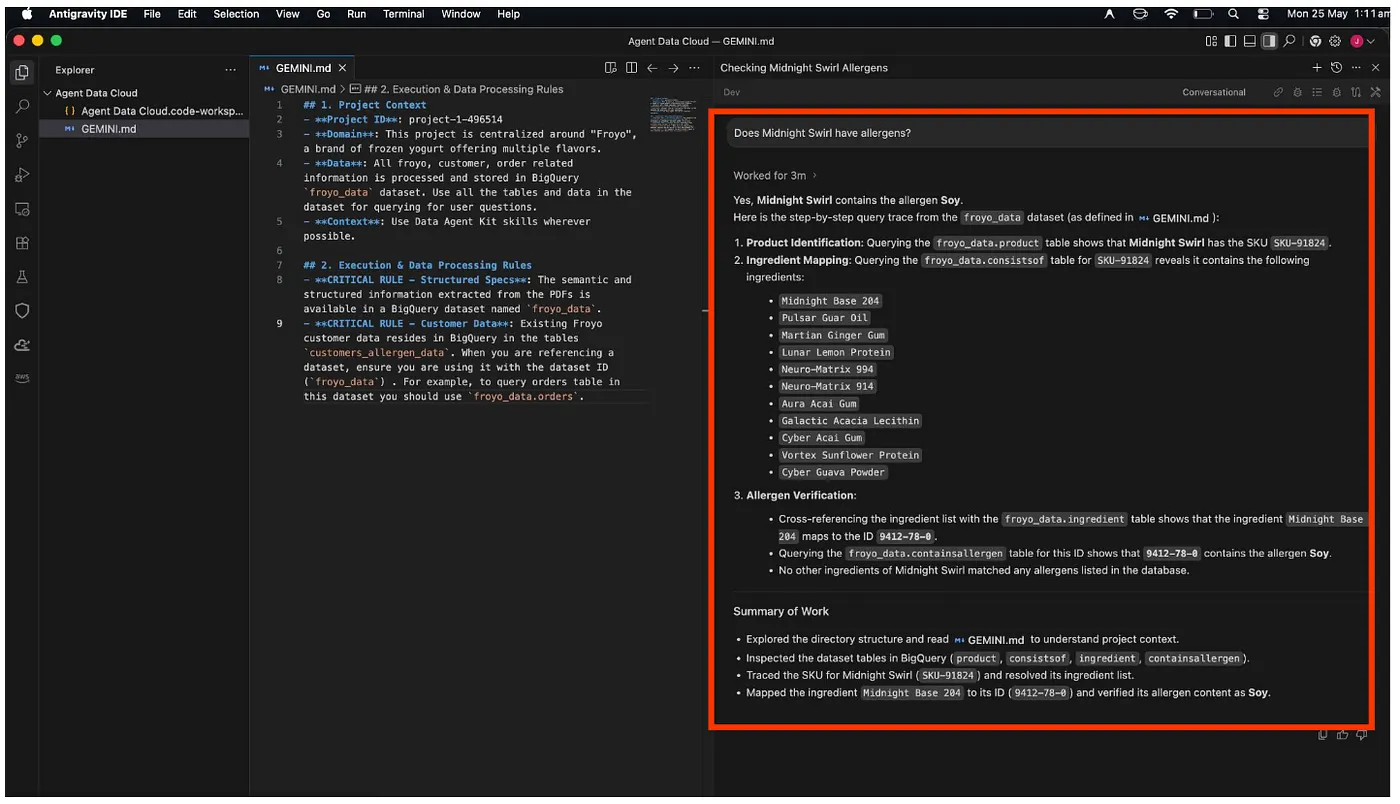
هورا!!! به درستی تشخیص داد که آیتم Midnight Swirl حاوی سویا است.
حالا بیایید یک سوال کمی پیچیدهتر بپرسیم. دستور زیر را در Antigravity IDE ارسال کنید:
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
پاسخ:
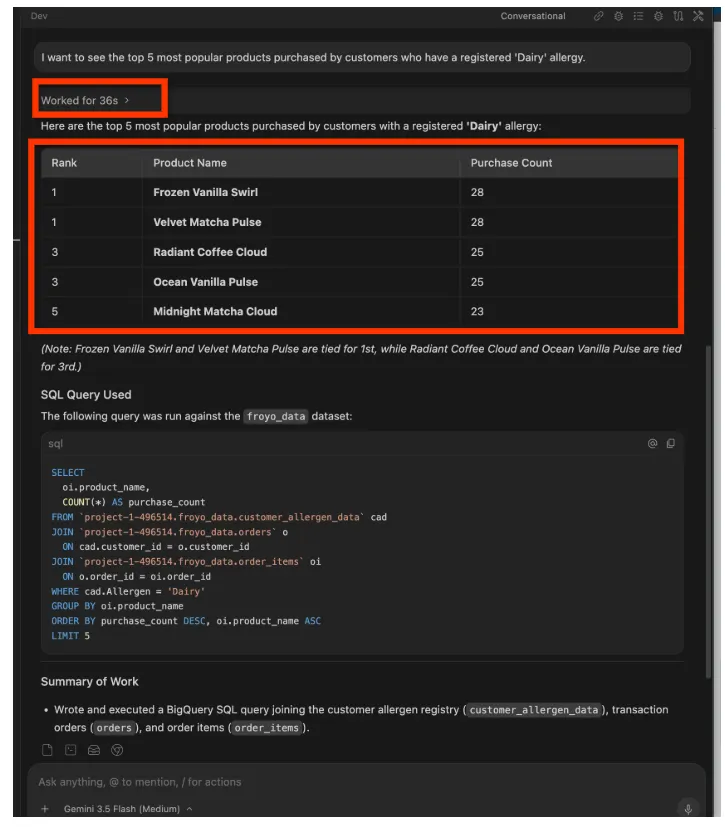
میتوانید ادامه دهید. از جملاتی مانند موارد زیر استفاده کنید:
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
بدون نیاز به جستجوی سینتکس BQML، کیت داده عامل (Agent Data Kit) کد دقیق CREATE MODEL و ML.FORECAST را در ویرایشگر شما قرار میدهد. میتواند این کدها را مستقیماً در محیط BigQuery شما اجرا کند، بدون اینکه از ANTIGRAVITY IDE خارج شوید!
چقدر این شگفتانگیزه!!!
۶. تحلیل مکالمهای در BigQuery
در حالی که توسعهدهندگان عاشق IDE هستند، کاربران تجاری و مدیران در کنسول ابری زندگی میکنند. آنها نمیخواهند SQL را ببینند، فقط پاسخها را میخواهند.
بیایید شروع کنیم:
- به خودتان نقشهای مورد نیاز را اعطا کنید
به صفحه IAM پروژه بروید و نقش مالک عامل داده Gemini Data Analytics را به خود اختصاص دهید:
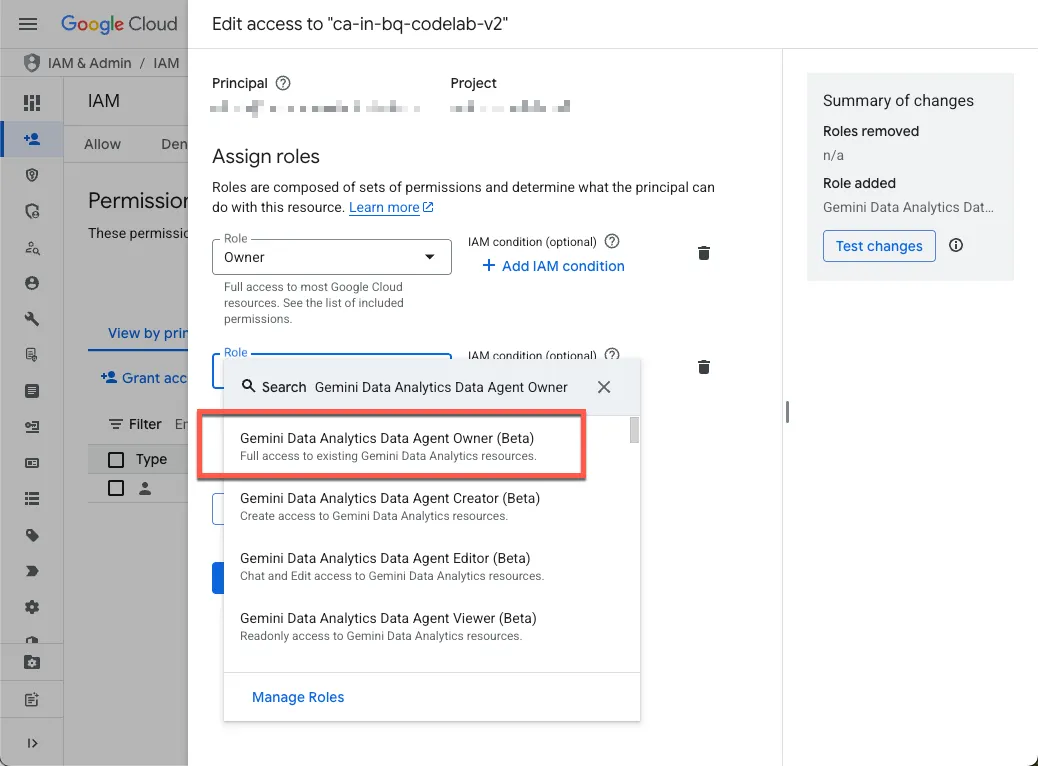
این نقش به شما اجازه ایجاد، ویرایش، اشتراکگذاری و حذف همه عوامل داده در پروژه را میدهد.
- فعال کردن API های مورد نیاز
به BigQuery در کنسول Google Cloud بروید. از منوی ناوبری نوار کناری یا منوی جستجو در بالای صفحه برای رفتن به BigQuery > Agents استفاده کنید.
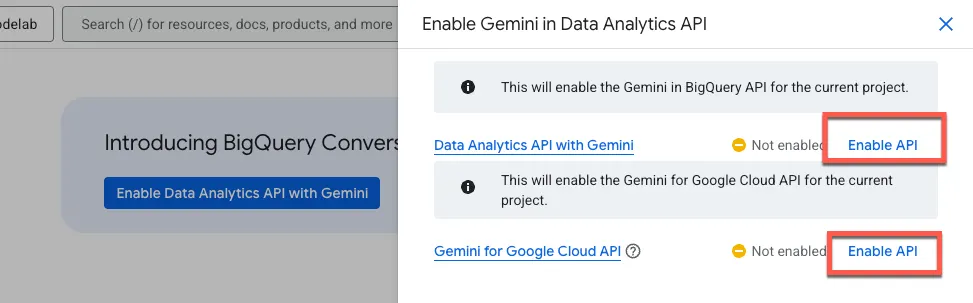
روی فعال کردن API تجزیه و تحلیل دادهها با Gemini کلیک کنید:
فعال کردن Gemini در BigQuery API و Gemini برای Google Cloud API :
اکنون باید صفحه نماینده جدید را مشاهده کنید:
- پیکربندی اطلاعات عامل
نام نماینده : نماینده فرویو
شرح نماینده : در پاسخگویی به سوالات مربوط به محصولات فرویو، آلرژنها، مواد تشکیلدهنده، دستور پخت، مشتری، سفارش و فروش کمک میکند.
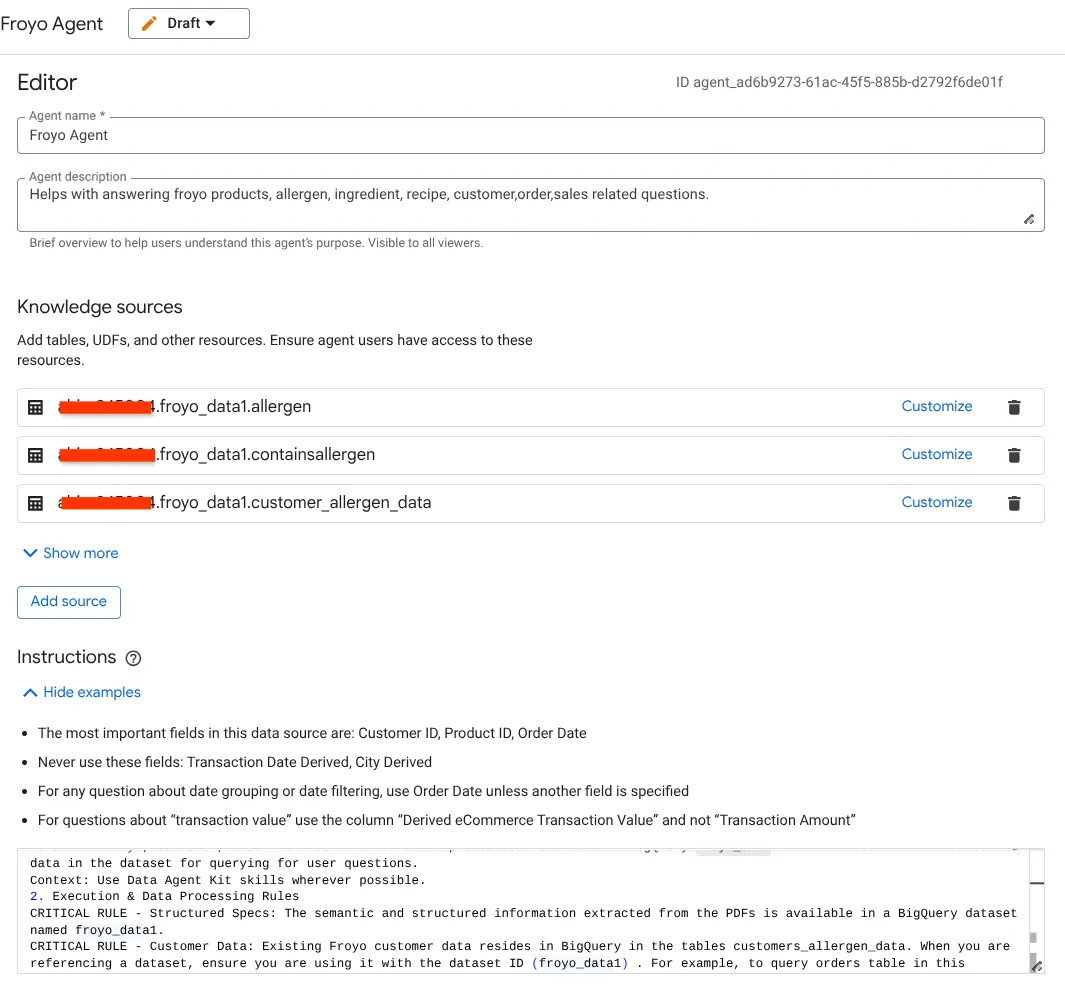
- به بخش منابع دانش بروید و تمام جداول زیر را از مجموعه دادههای خود انتخاب کنید:
الف) جداول موجود در تصویر بالا را اضافه کنید و روی «افزودن منبع» کلیک کنید.
ب. برای هر منبع، روی دکمه سفارشیسازی در سمت راست کلیک کنید. فرم زیر را مشاهده خواهید کرد:
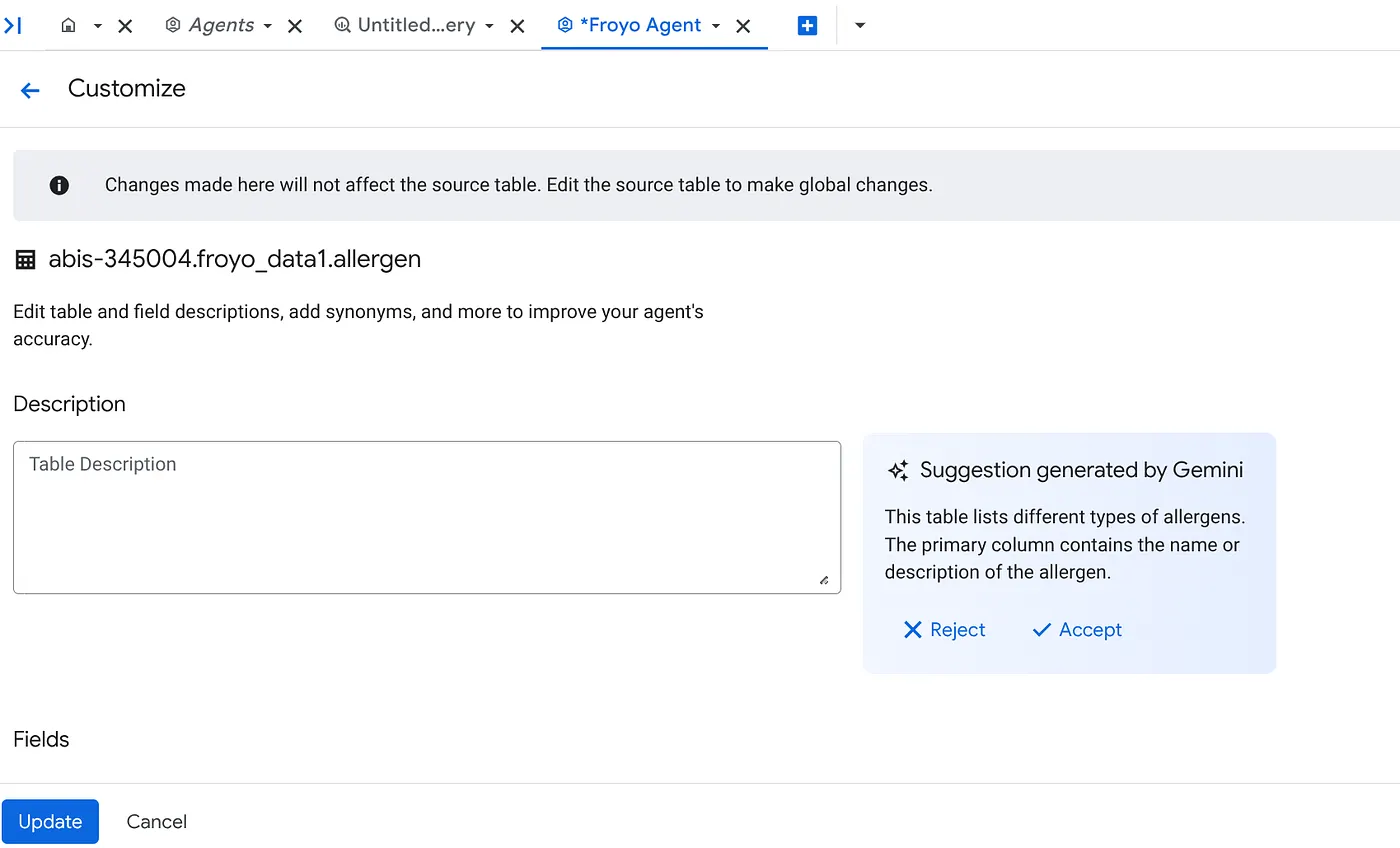
ج. برای مشاهده توضیحات جدول، روی «پذیرش» کلیک کنید.
د. برای توضیحات هر فیلد نیز روی «پذیرش» کلیک کنید.
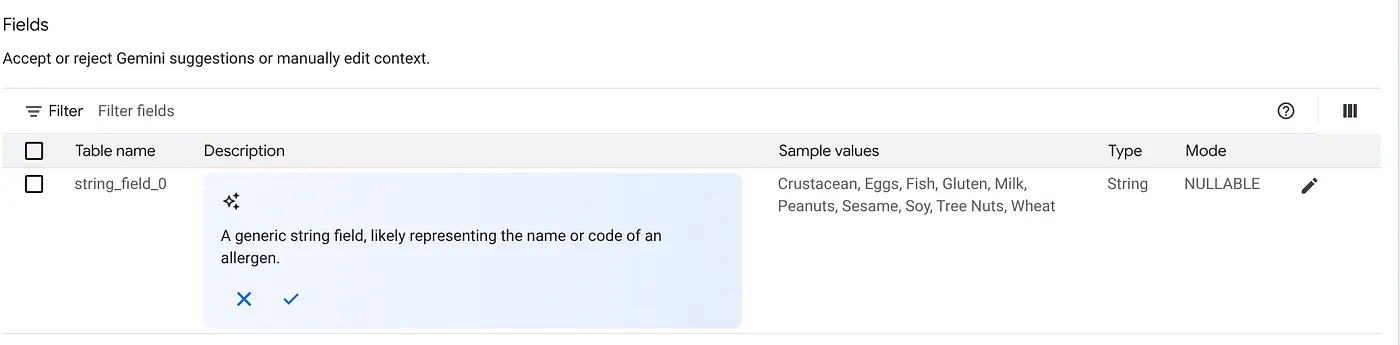
ه. روی بهروزرسانی کلیک کنید.
شما باید این کار را برای تمام جداول موجود در منبع تکرار کنید.
- دستورالعملهای پیکربندی
همان دستورالعملهایی که در Antigravity IDE GEMINI.md استفاده کردیم را اینجا قرار دهید:
1. Project Context
Project ID: <<YOUR_PROJECT_ID>>
Domain: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
Data: All froyo, customer, order related information is processed and stored in BigQuery froyo_data dataset. Use all the tables and data in the dataset for querying for user questions.
Context: Use Data Agent Kit skills wherever possible.
2. Execution & Data Processing Rules
CRITICAL RULE - Structured Specs: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named froyo_data.
CRITICAL RULE - Customer Data: Existing Froyo customer data resides in BigQuery in the tables customers_allergen_data. When you are referencing a dataset, ensure you are using it with the dataset ID (froyo_data) . For example, to query orders table in this dataset you should use froyo_data.orders.
- نماینده خود را نجات دهید.
۷. با دادههایتان چت کنید!
- آن را در بخش پیشنمایش سمت راست آزمایش کنید:
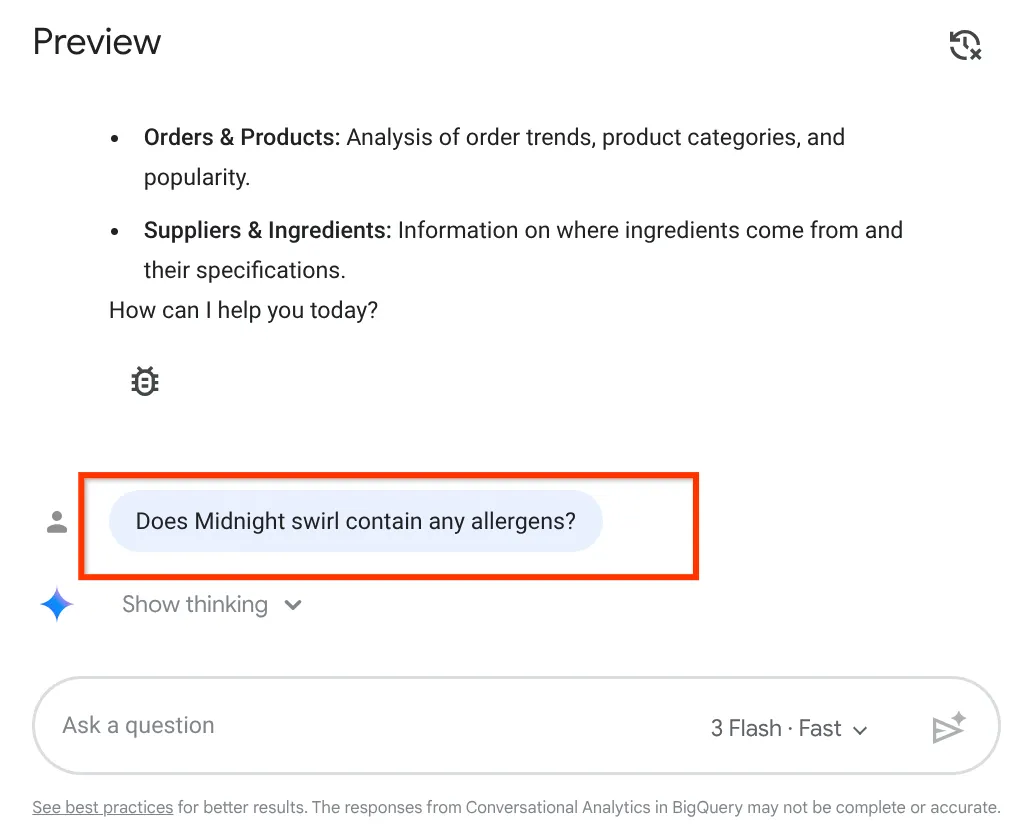
سوال خود را بپرسید:
Does midnight swirl contain any allergen?
پاسخ اینجاست:
حالا بیایید سوال پیچیده را بپرسیم:
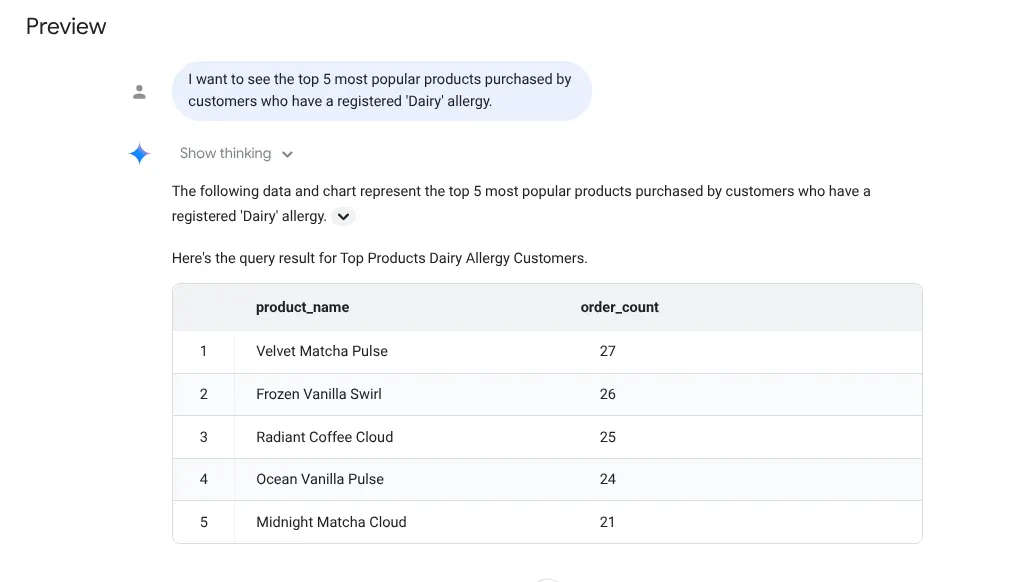
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
پاسخ:
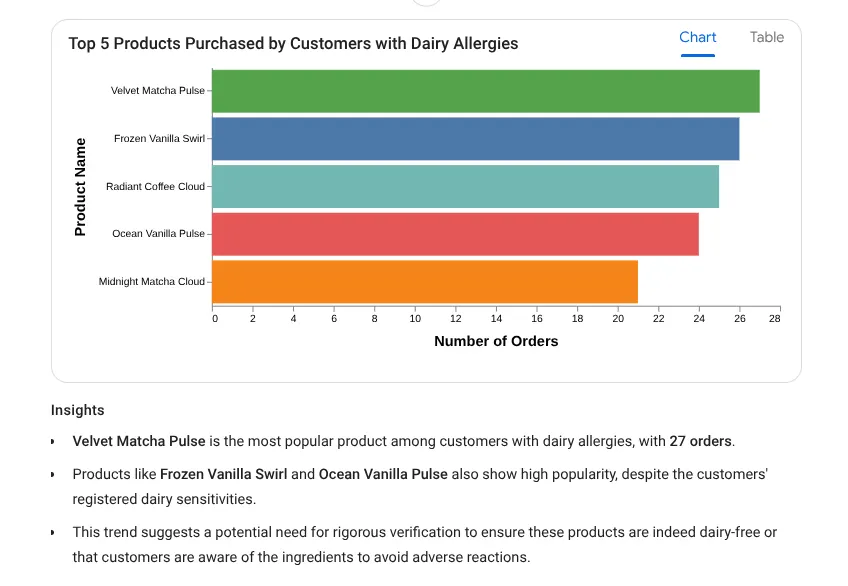
بیایید اکنون یک سوال بینش عمیق را امتحان کنیم:
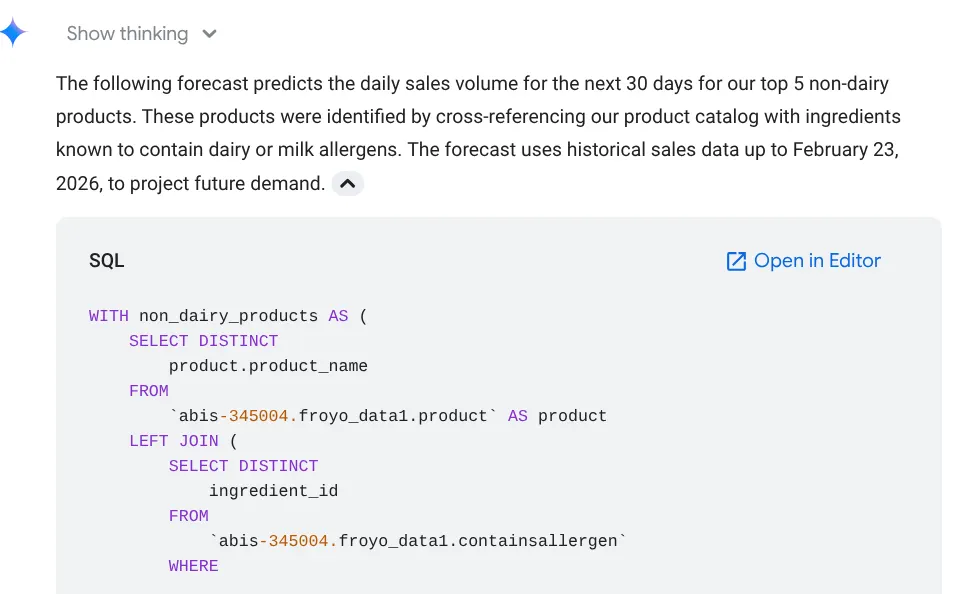
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
میتوانید ببینید که کوئری مورد استفاده خود را به همراه نتیجه جدول به همراه نمودار نشان میدهد:
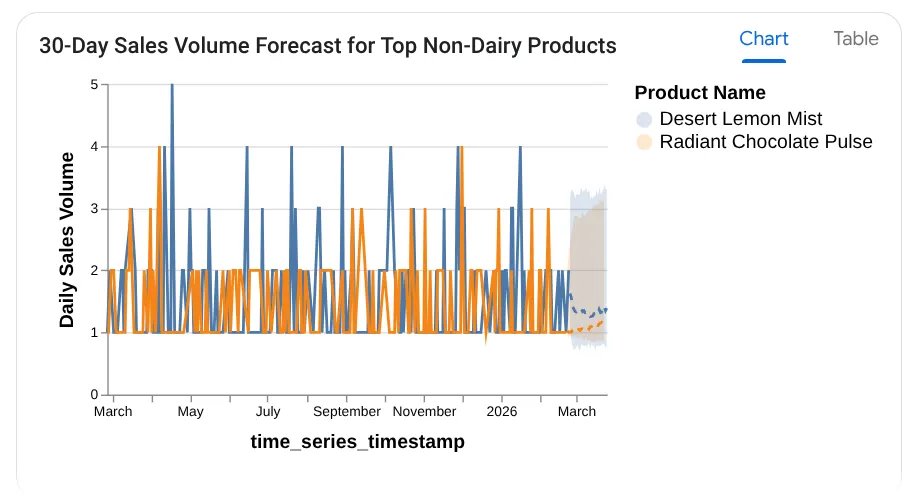

وای! خب، نمودارها و بینشها خوب پیش رفتند. وقت سوال نهایی در مورد محصولات است.
۸. آزمون نهایی
سوال را بپرسید:
What will be the top most selling product of 2026
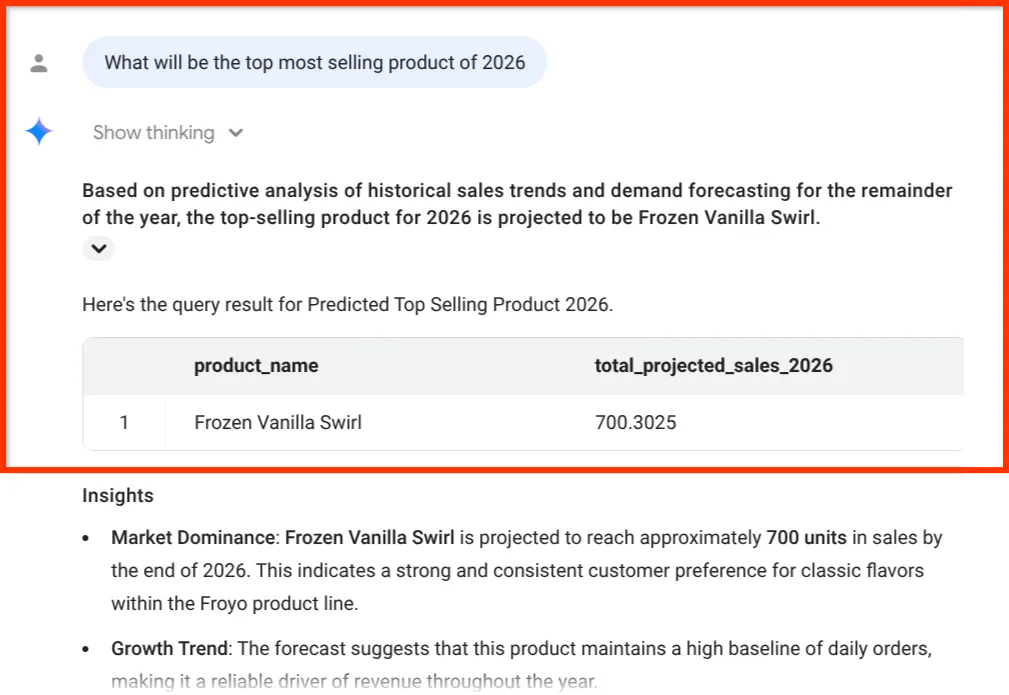

به آخرین نکته توجه کنید. نماینده داده BigQuery فقط به ما یک عدد نداد؛ بلکه صریحاً پیشبینی فروش را به موجودی و زنجیره تأمین مواد اولیه ما مرتبط کرد - دقیقاً همان دادههایی که در بخش اول از فایلهای PDF بههمریخته استخراج کردیم!
۹. انتشار نماینده خود به شرکت
روی دکمهی انتشار در بالای پیشنمایش کلیک کنید.
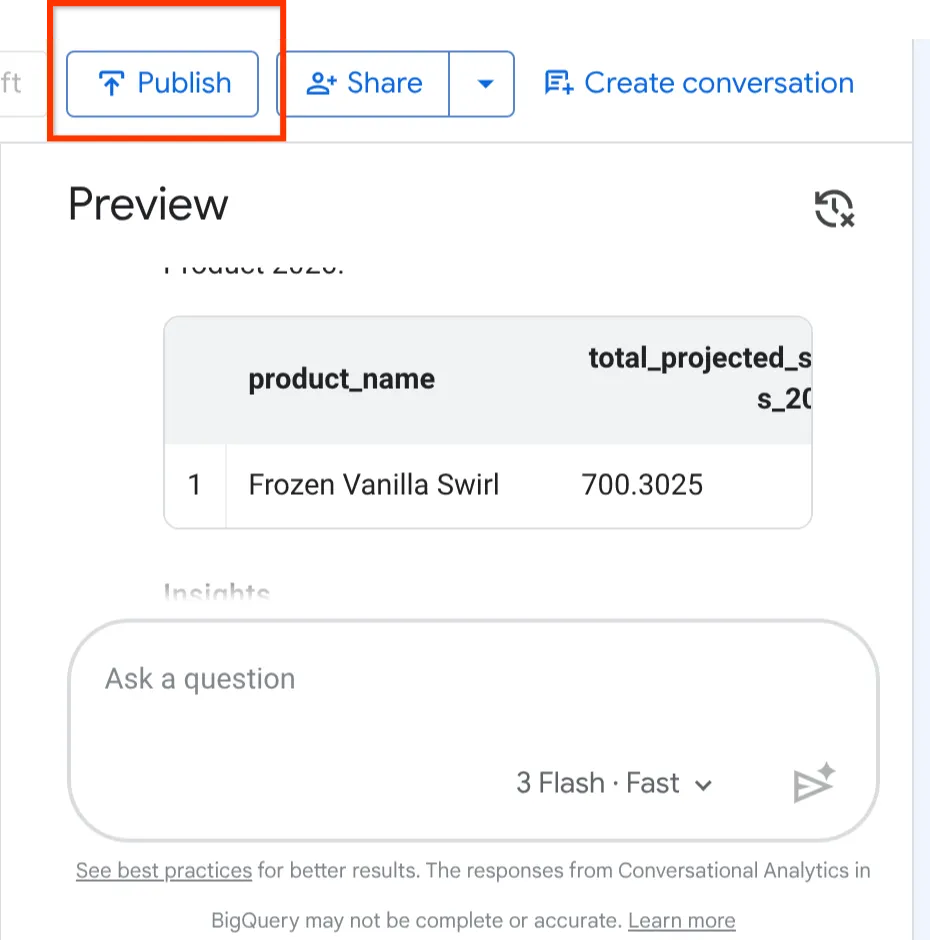
حالا که Froyo Agent خود را ساخته، پیکربندی و آزمایش کردهایم، وقت آن رسیده که آن را برای بقیهی کسبوکار منتشر کنیم.
در گوشه سمت راست بالای صفحه پیکربندی نماینده، روی دکمه انتشار کلیک کنید.
با انتشار، نماینده شما فوراً از طریق سه کانال قدرتمند سازمانی برای شما و هر کسی که آن را با او به اشتراک میگذارید، در دسترس قرار میگیرد:
- BigQuery : تحلیلگران داده شما اکنون میتوانند مستقیماً از هاب Agents یا مستقیماً در فضای کاری BigQuery Studio SQL خود با این عامل چت کنند.
- API تحلیل مکالمهای : توسعهدهندگان شما میتوانند از طریق یک API REST به این عامل دسترسی داشته باشند و این به آنها امکان میدهد تا این تحلیلهای مکالمهای دقیق را در برنامههای وب داخلی سفارشی خود ادغام کنند.
- استودیو داده : مدیران شما میتوانند با این عامل تعامل داشته باشند و داشبوردهای مکالمهای پویا را مستقیماً درون استودیو داده ایجاد کنند.
ما با موفقیت دادههای خود را از انبارها خارج کرده و مستقیماً در اختیار افرادی که به آن نیاز دارند، قرار دادهایم، دقیقاً همان جایی که آنها از قبل کار میکنند!
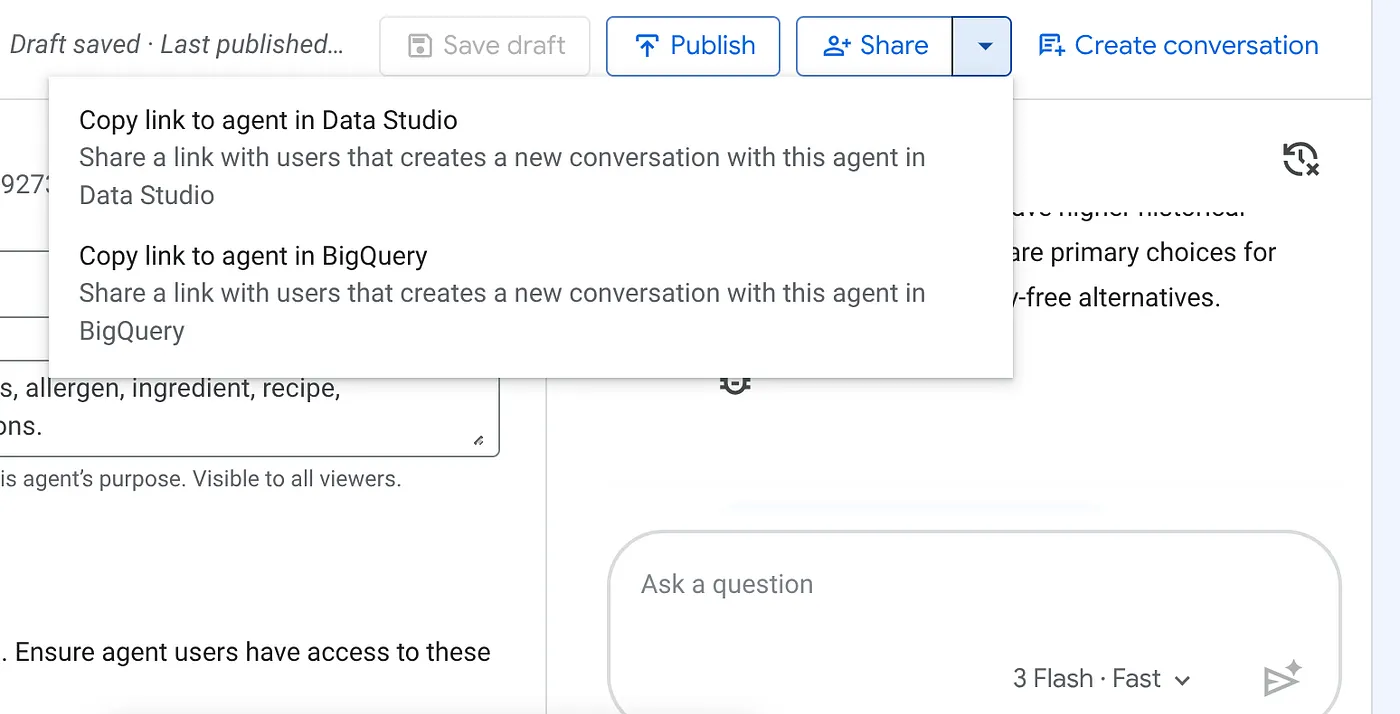
روی منوی کشویی دکمه اشتراکگذاری (Share) در بالای عامل BigQuery منتشر شده خود کلیک کنید و گزینه "کپی لینک به عامل در data studio" را از لیست انتخاب کنید:
آن لینک را در مرورگر خود جایگذاری کنید و اینتر را بزنید. برای هشدار دسترسی به تعامل با اپراتور، تأییدیه ارائه دهید:
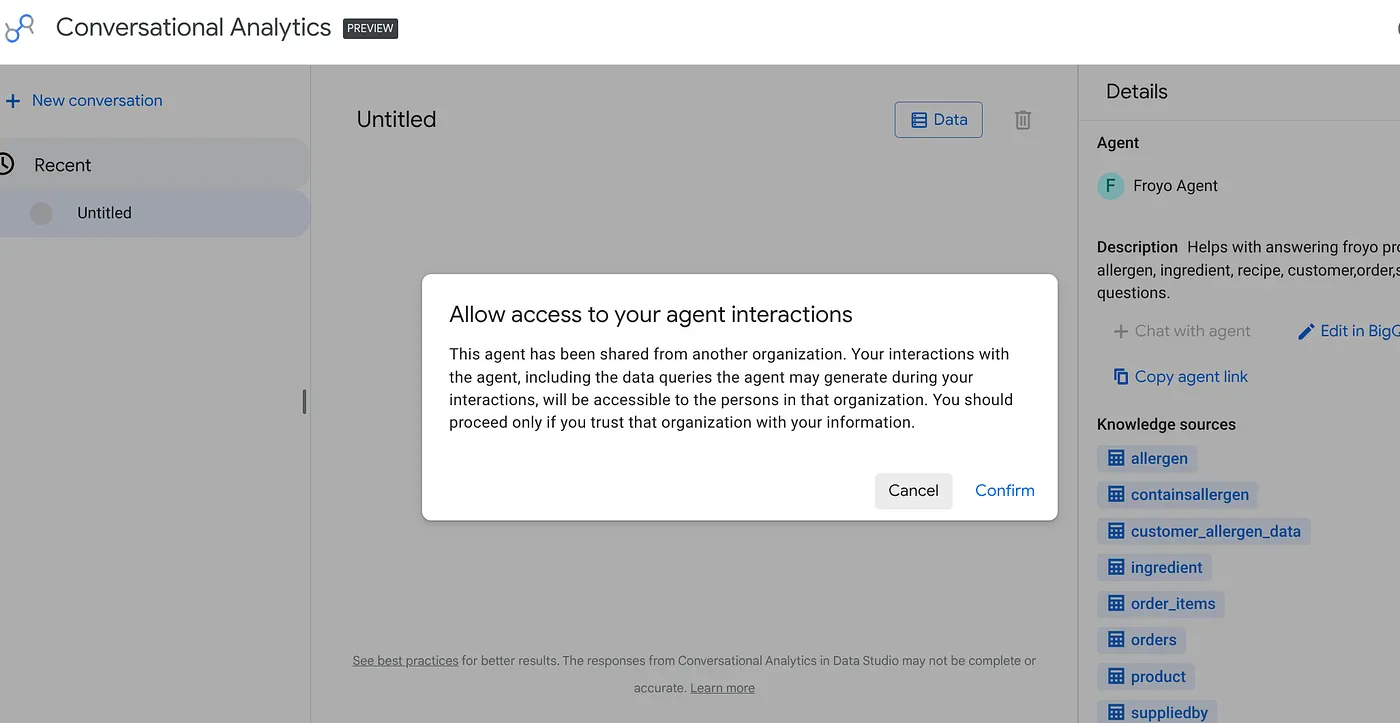
شما میتوانید مکالمات و مصورسازیهای تعاملی را با عامل تازه منتشر شده از Data Studio شروع کنید، و همچنین رهبری شما و سایر تیمهایی که به این اطلاعات نیاز دارند!
۱۰. تمیز کردن
پس از اتمام این آزمایش، فراموش نکنید که مجوزهای مربوط به همه کاربران BigQuery Agent که ایجاد کردهاید را حذف کنید.
۱۱. تبریک میگویم!
شما رسماً یک ابر دادهی عاملمحور (Agentic Data Cloud) ساختهاید!
شما فقط یک چتبات ساده نساختید. در طول این پنج جلسه، شما با موفقیت یک سیستم هوش مصنوعی سازمانی کامل، مدرن و ارزیابیشده را از پایه معماری کردید. شما از «دادههای تاریک» به هوش تراکنشی بلادرنگ و در نهایت به پیشبینی کسبوکار محاورهای رسیدهاید.
۱۲. تصویر کامل
یک قدم به عقب بردارید و به آنچه در این مجموعه به دست آوردهایم نگاهی بیندازید. ما فقط یک چتبات ساده نساختیم. ما یک ابر داده عاملگرای کامل و مدرن را معماری کردیم:
بخش ۱ : رمزگشایی دادههای تاریک با تبدیل فایلهای PDF به جداول رابطهای ساختاریافته با استفاده از کاتالوگ دانش.
بخش ۲ : با ادغام مستقیم انبار تحلیلی خود در یک پایگاه داده تراکنشی AlloyDB، سیلوهای داده را تجزیه کردیم.
بخش ۳ : توانمندسازی کاربران با ساخت یک سیستم عامل چندعاملی که ابزارهای پایگاه داده امن را از طریق پروتکل MCP به طور یکپارچه اجرا میکند
بخش ۴ : تضمین ایمنی با اجرای یک خط لوله ارزیابی دقیق برای شناسایی توهمات و فرار از زندان.
بخش ۵: بینشهای دموکراتیک با استفاده از ANTIGRAVITY IDE و تجزیه و تحلیل مکالمهای در BigQuery.
این آینده نرمافزارهای سازمانی است. عامل هوش مصنوعی دیگر فقط یک پوشش پیرامون یک LLM نیست. این یک موتور هماهنگسازی کاملاً یکپارچه، ارزیابیشده و ایمن است که بر روی یک پلتفرم داده یکپارچه قرار دارد.