
1. Présentation
Prenons un moment pour examiner l'architecture massive que nous avons créée au cours des quatre dernières parties :
Partie 1 : Nous avons utilisé le Knowledge Catalog BigQuery pour transformer les PDF bruts de recettes de Froyo en tables relationnelles structurées.
Partie 2 : Nous avons créé un pont transactionnel sans ETL, en fédérant notre entrepôt BigQuery directement dans AlloyDB.
Partie 3 : nous avons orchestré une application multi-agents (FroyoOS) à l'aide d'Agent Development Kit et de MCP Toolbox.
Partie 4 : Nous avons prouvé que notre agent était sûr pour la production en créant un pipeline d'évaluation à double canal.
Nos opérations se déroulent parfaitement. Mais qu'en est-il des développeurs et des analystes commerciaux qui doivent comprendre les quantités massives de données générées par ce système ?
Aujourd'hui, nous allons explorer l'avenir de l'analyse. Nous allons commencer directement dans notre éditeur de code Antigravity IDE avec Google Cloud Data Agent Kit, puis passer à la console Google Cloud pour visualiser nos données à l'aide de BigQuery Conversational Analytics.
Commençons à créer !
Points abordés
Dans ce dernier atelier de programmation de la série Agentic Data Cloud, vous allez rassembler tous les éléments de votre architecture pour fournir des insights commerciaux exploitables. Vous pourrez découvrir :
- IDE-First Analytics : découvrez comment installer et configurer l'IDE ANTIGRAVITY et le kit d'agent de données Google Cloud pour interroger votre architecture directement depuis votre environnement de développement.
- BigQuery conversationnel : découvrez comment créer, configurer et donner des instructions aux agents de données BigQuery pour automatiser des tâches SQL complexes et des prévisions à l'aide du langage naturel.
- Démocratisation des données : découvrez comment publier vos agents pour l'entreprise afin de les rendre accessibles aux analystes et aux utilisateurs professionnels de l'ensemble de l'organisation.
- Visualiser les insights : découvrez comment intégrer facilement les données analytiques conversationnelles de votre agent dans Data Studio pour créer des tableaux de bord dynamiques et prêts pour les prévisions.
- Écosystème Agentic Data Cloud : découvrez comment exprimer la valeur de votre architecture de bout en bout, des données brutes non structurées de la partie 1 aux tableaux de bord prêts pour les cadres de la partie 5.
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si vous souhaitez vous authentifier
gcloud auth login
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises : exécutez cette commande pour activer toutes les API requises :
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. Développer l'entrepôt de données
Vous vous souvenez des tables BigQuery que nous avons créées à partir de nos données non structurées ?
Pour effectuer des analyses pertinentes, nous avons besoin de données de transaction historiques. Dans BigQuery, sous l'ensemble de données froyo_data, créons trois tables pour simuler des années d'opérations de franchise :
- froyo_data.orders : en-têtes de commandes historiques (dates, ID de magasin, totaux)
- froyo_data.order_items : détails des articles de la commande (quantités, prix)
- froyo_data.customer_allergen_data : tableau CRM qui suit les allergies connues de nos clients fidèles
Ajoutons ces tables liées aux ventes et aux clients à cet ensemble de données en vue de notre cas d'utilisation analytique.
- Accédez à Terminal Cloud Shell depuis la console Google Cloud.
- Accédez au dossier racine de votre espace de travail ou au dossier racine du projet froyo-data (sur lequel nous avons travaillé dans les deux premières parties de cette série).
- Téléchargez les trois fichiers de données historiques (au format CSV) dans votre répertoire de travail en exécutant les commandes suivantes, une par une :
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/customer_allergen_data.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/order_items.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/orders.csv
- Une fois ces fichiers affichés à la racine de votre répertoire de travail, accédez à votre terminal Cloud Shell en basculant vers le terminal.
- Accédez au répertoire contenant ces trois fichiers dans le terminal Cloud Shell.
- Assurez-vous que votre BigQuery contient l'ensemble de données "froyo_data" de la partie 1 de cette série (si ce n'est pas le cas, revenez en arrière et créez l'ensemble de données et les tables).
- Exécutez les commandes suivantes à partir de votre terminal Cloud Shell :
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.orders \
./orders.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.order_items \
./order_items.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.customer_allergen_data \
./customer_allergen_data.csv
Cela devrait créer les trois tables supplémentaires dans votre ensemble de données froyo_data.
4. L'expérience des développeurs : découvrez le "kit d'agent de données"
Traditionnellement, si un développeur souhaitait analyser des données ou écrire des requêtes de machine learning complexes, il devait constamment changer de contexte entre son IDE, les consoles de base de données et la documentation.
Plus maintenant. Avec l'extension Google Cloud Data Agent Kit récemment lancée, votre IDE devient un outil puissant pour les données.
IDE ANTIGRAVITY
L'IDE ANTIGRAVITY est l'environnement de développement nouvelle génération de Google, axé sur les agents et conçu spécifiquement pour l'ère de l'IA. Il intègre nativement de grandes fenêtres de contexte multimodales et l'utilisation autonome d'outils directement dans l'éditeur, ce qui permet aux développeurs d'orchestrer les ressources cloud et les pipelines de données complexes sans jamais quitter leur code.
Configurer l'IDE ANTIGRAVITY
- Téléchargez l'IDE : accédez à antigravity.google et téléchargez l'IDE Antigravity pour votre système d'exploitation (Windows, macOS ou Linux).
- Installer et lancer : exécutez le programme d'installation et ouvrez l'application.
- Cliquez sur "Continuer avec Google", sélectionnez votre compte Gmail et autorisez l'accès.
- Une fois connecté, créez un dossier de travail (espace de travail/ projet). Appelons-le "Agent Data Cloud".
Il devrait apparaître dans la liste "Projets" sur la gauche :
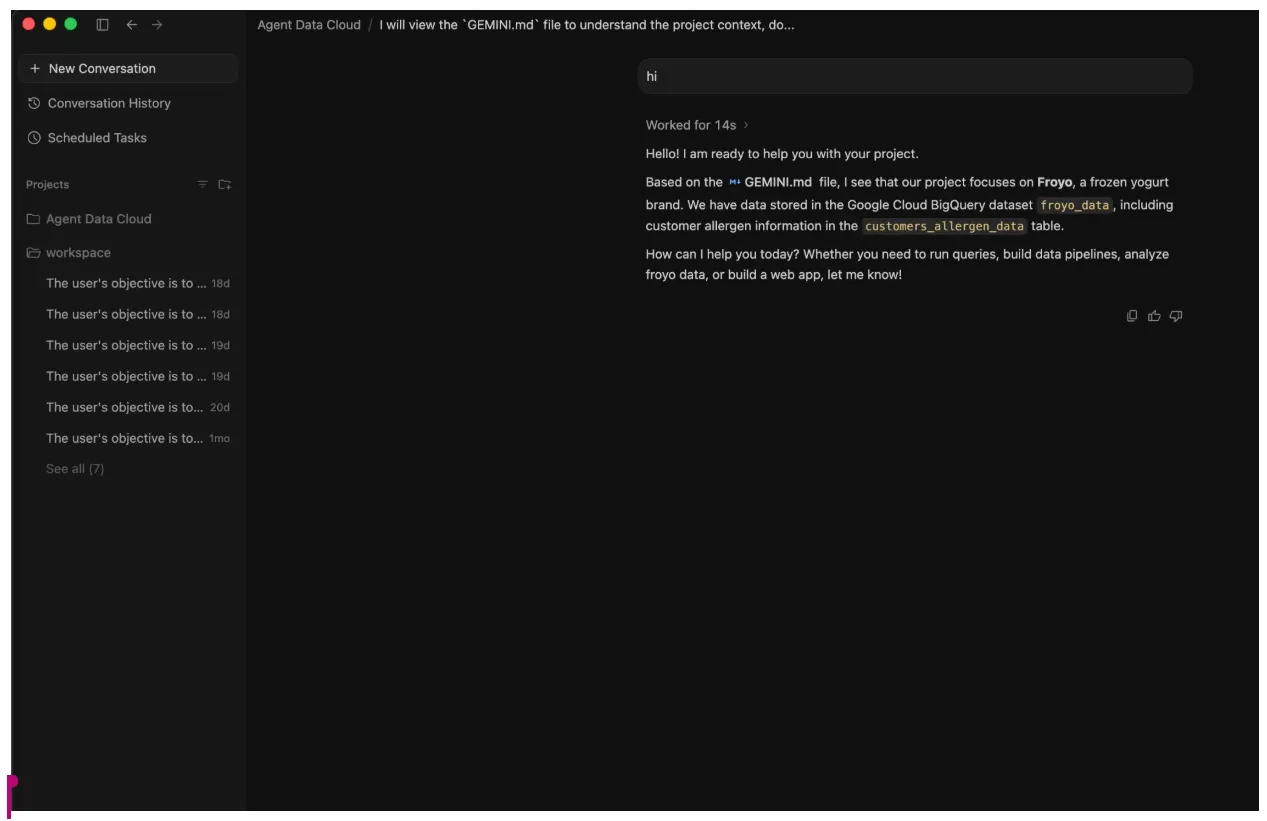
- Engagez une conversation préliminaire avec l'agent en lui disant "bonjour".
- En haut à droite, notez le bouton "Open IDE" (Ouvrir l'IDE).
Mais avant de pouvoir cliquer dessus,vous devez installer Antigravity IDE. Accédez à la page antigravity.google/download et faites défiler la page jusqu'à la section "Antigravity IDE" (IDE Antigravity). Téléchargez la variante dont vous avez besoin.
Une fois le fichier téléchargé, revenez à votre instance Antigravity ouverte et cliquez sur le bouton "Open IDE" (Ouvrir l'IDE) en haut à droite.
- Vous devriez voir les pop-ups concernant les autorisations. Continuez à les ouvrir.
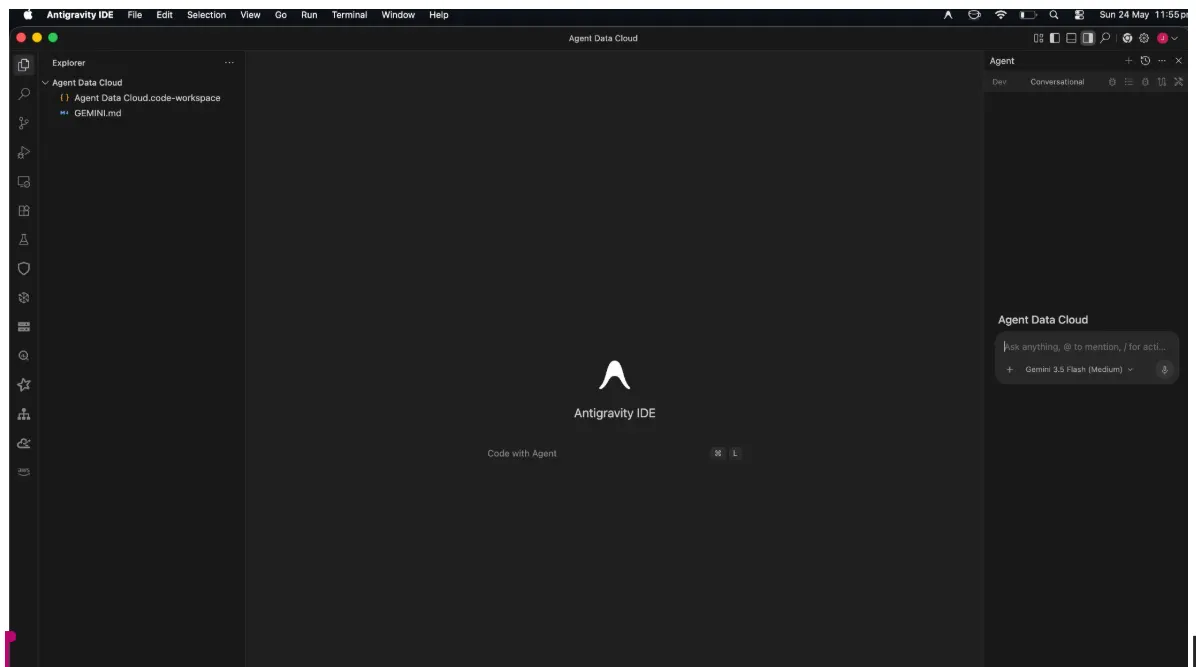
Sur la droite, vous voyez le volet de l'agent, sur la gauche l'explorateur de projet et au centre l'espace pour votre développement.
Configurer l'extension Data Agent Kit
- Installez l'extension : ouvrez le marketplace des extensions dans l'IDE ANTIGRAVITY. Recherchez et installez l'extension Google Cloud Data Agent Kit.
- Cliquez sur le bouton "Installer". Une fois l'opération terminée, vous pourrez voir l'extension dans le volet de navigation.
- Cliquez dessus pour ouvrir l'explorateur Google Cloud Data Agent Kit, accédez à la section "SETTINGS" (PARAMÈTRES), puis cliquez sur "Settings" (Paramètres). Saisissez les détails de votre projet et la région, puis enregistrez.
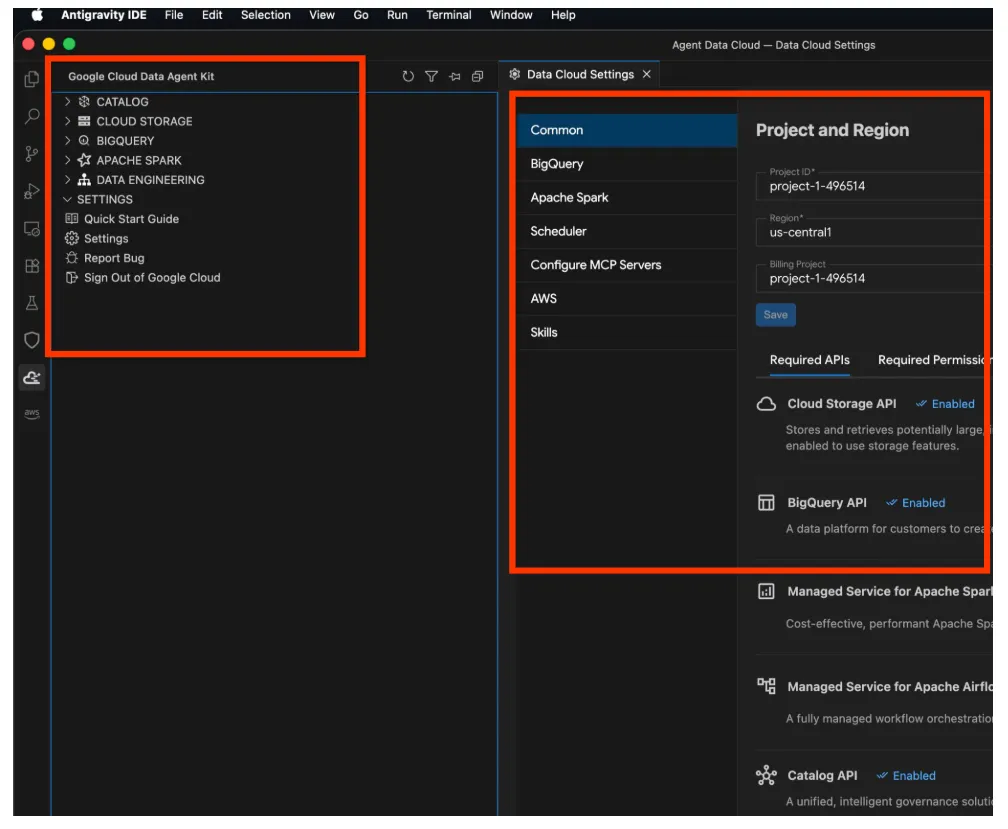
- Cliquez ensuite sur l'explorateur de projet en haut du panneau de navigation. L'explorateur de projet devrait s'ouvrir dans le volet "Explorateur".
- Effectuez un clic droit dans l'espace de l'explorateur, puis créez un fichier nommé GEMINI.md.
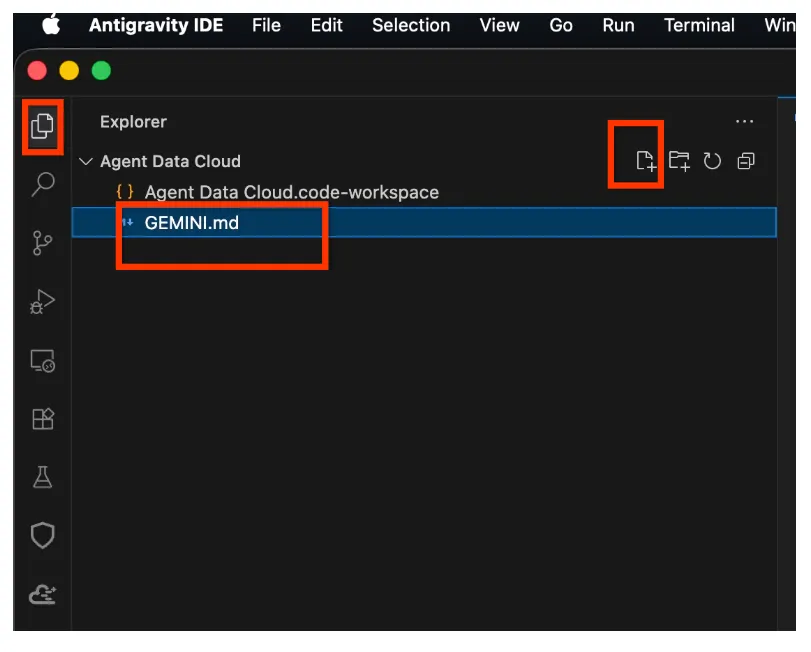
- Collez ce qui suit dans GEMINI.md (n'oubliez pas de remplacer <<YOUR_PROJECT_ID>> par votre valeur) :
## 1. Project Context
- **Project ID**: <<YOUR_PROJECT_ID>>
- **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
- **Data**: All froyo, customer, order related information is processed and stored in BigQuery `froyo_data` dataset.
## 2. Execution & Data Processing Rules
- **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `froyo_data`.
- **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the tables `customers_allergen_data`.
- ** CRITICAL RULE - Sales Data**: Sales data is present in tables `orders` and `order_items`.
- ** CRITICAL RULE - General: When you are referencing a dataset, ensure you are using it with the dataset ID (`froyo_data`) . For example, to query orders table in this dataset you should use `froyo_data.orders`.
Vous disposez désormais d'un agent IA très performant directement dans votre IDE, prêt à écrire du code, à générer du code SQL et à analyser votre architecture.
Nous sommes désormais confrontés à un défi analytique fascinant : pouvons-nous corréler nos ventes historiques avec les données complexes et inférées sur les allergènes que nous avons extraites des PDF dans la partie 1 ?
5. Inférence de l'intelligence via l'agent IDE
Demandons à notre agent IDE de faire le gros du travail. Ouvrez la fenêtre de chat Agent Data Kit directement dans votre IDE ANTIGRAVITY et saisissez la requête suivante :
Does Midnight Swirl contain any allergen?
Vous serez invité à accorder une série d'autorisations. Faites-le le cas échéant.
Enfin, il récupérera la réponse pour vous à la fin de son analyse :
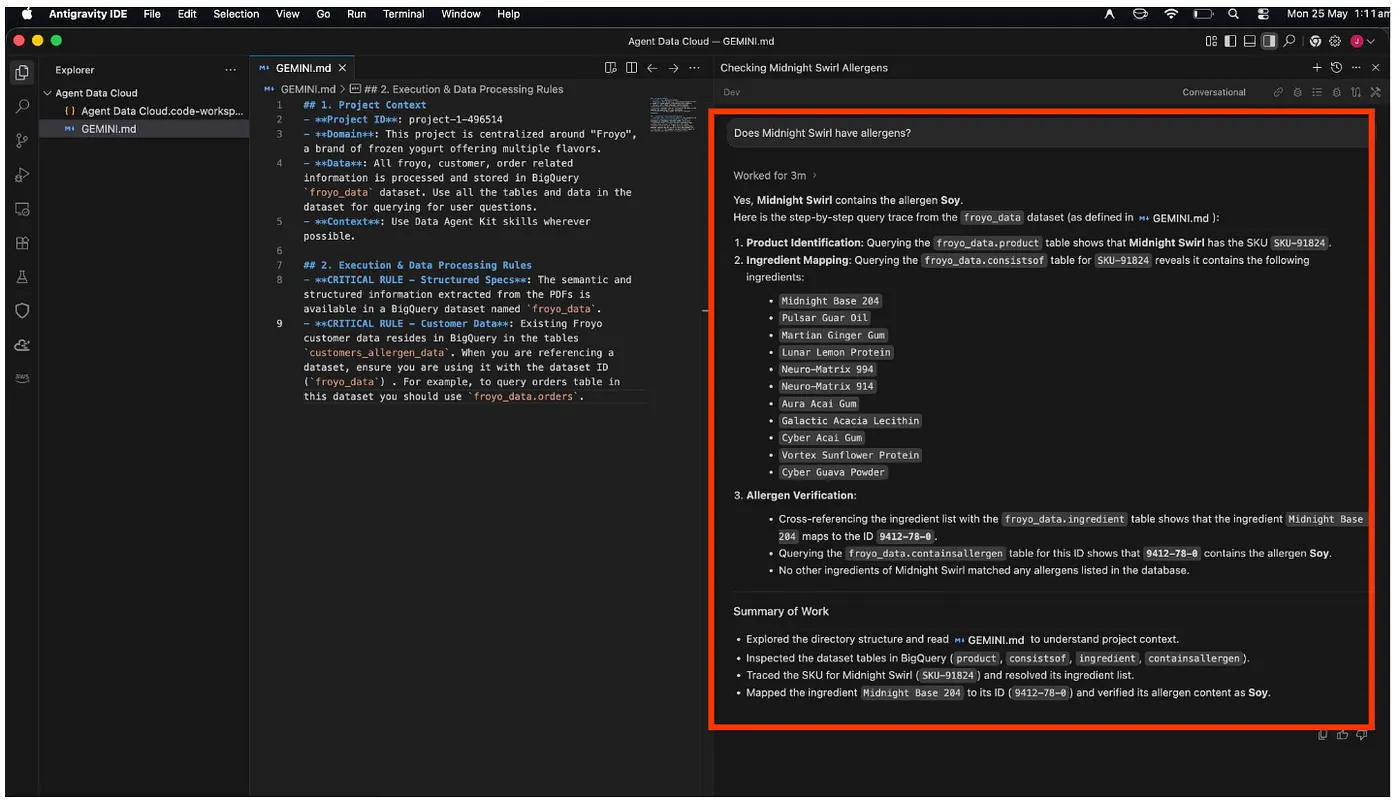
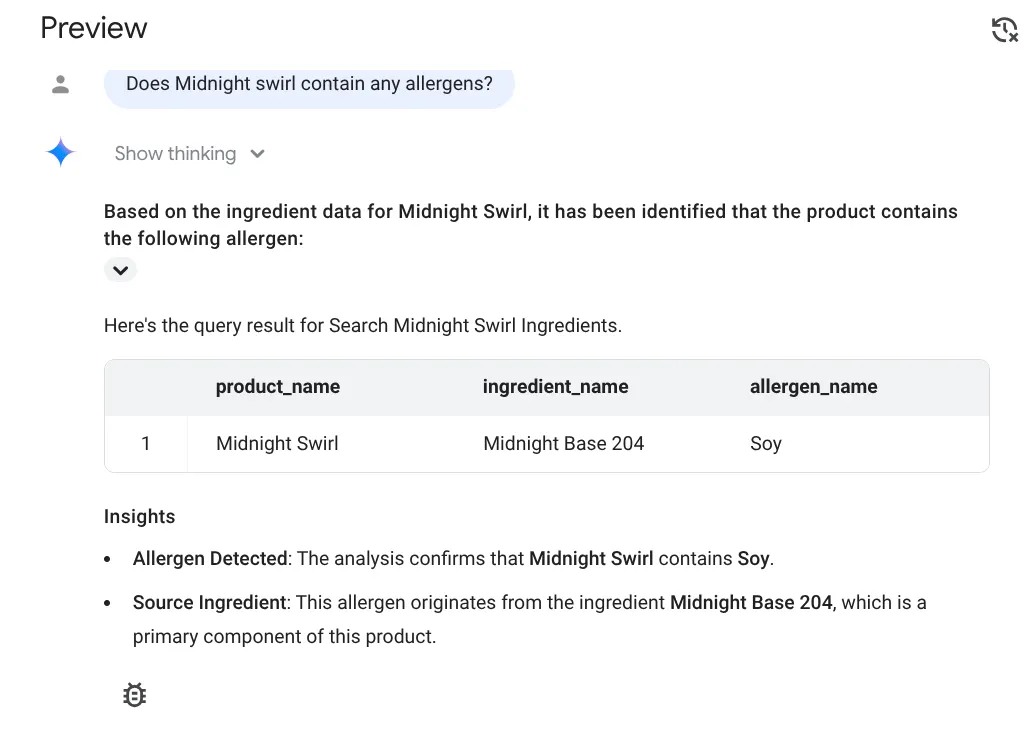
Super ! Il a correctement identifié que l'article Midnight Swirl contient du soja.
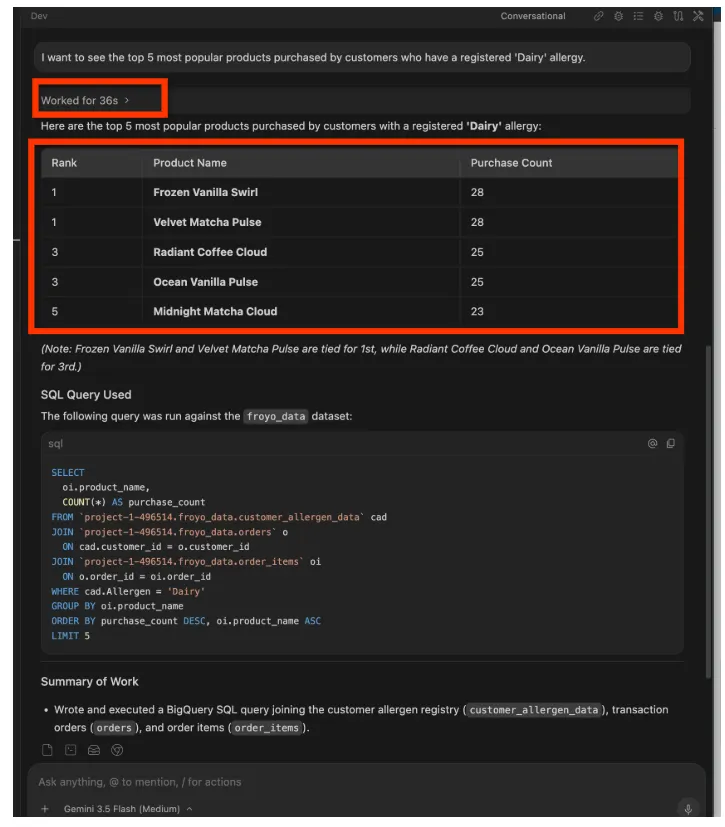
Posons maintenant une question un peu plus complexe. Envoyez le prompt suivant dans l'IDE Antigravity :
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
Réponse :
Vous pouvez continuer. Quelques idées de requêtes :
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
Sans avoir à rechercher la syntaxe BQML, le kit de données de l'agent insère le code CREATE MODEL et ML.FORECAST exact dans votre éditeur. Vous pouvez exécuter cette requête directement dans votre environnement BigQuery sans jamais quitter l'IDE ANTIGRAVITY.
C'est incroyable !
6. Conversational Analytics dans BigQuery
Si les développeurs apprécient l'IDE, les utilisateurs professionnels et les cadres préfèrent la console Cloud. Ils ne veulent pas voir de code SQL, ils veulent juste des réponses.
Allons-y !
- Accorder à votre compte les rôles requis
Accédez à la page IAM du projet et accordez-vous le rôle "Propriétaire de l'agent de données Gemini Data Analytics" :
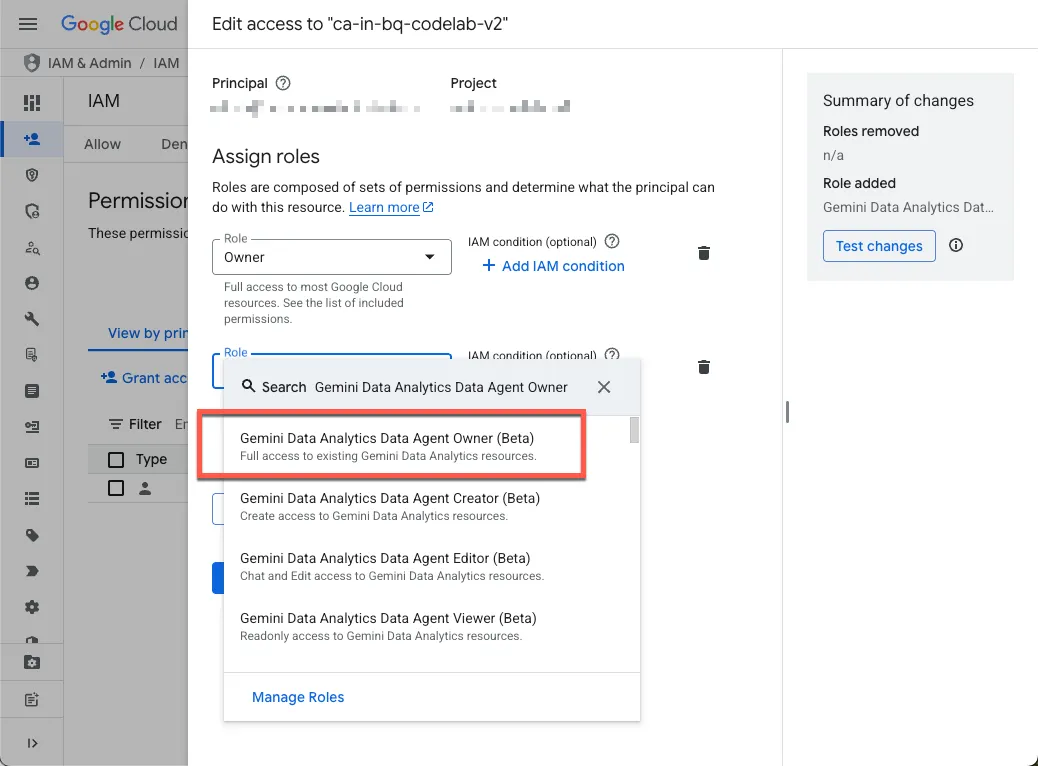
Ce rôle vous permet de créer, modifier, partager et supprimer tous les agents de données du projet.
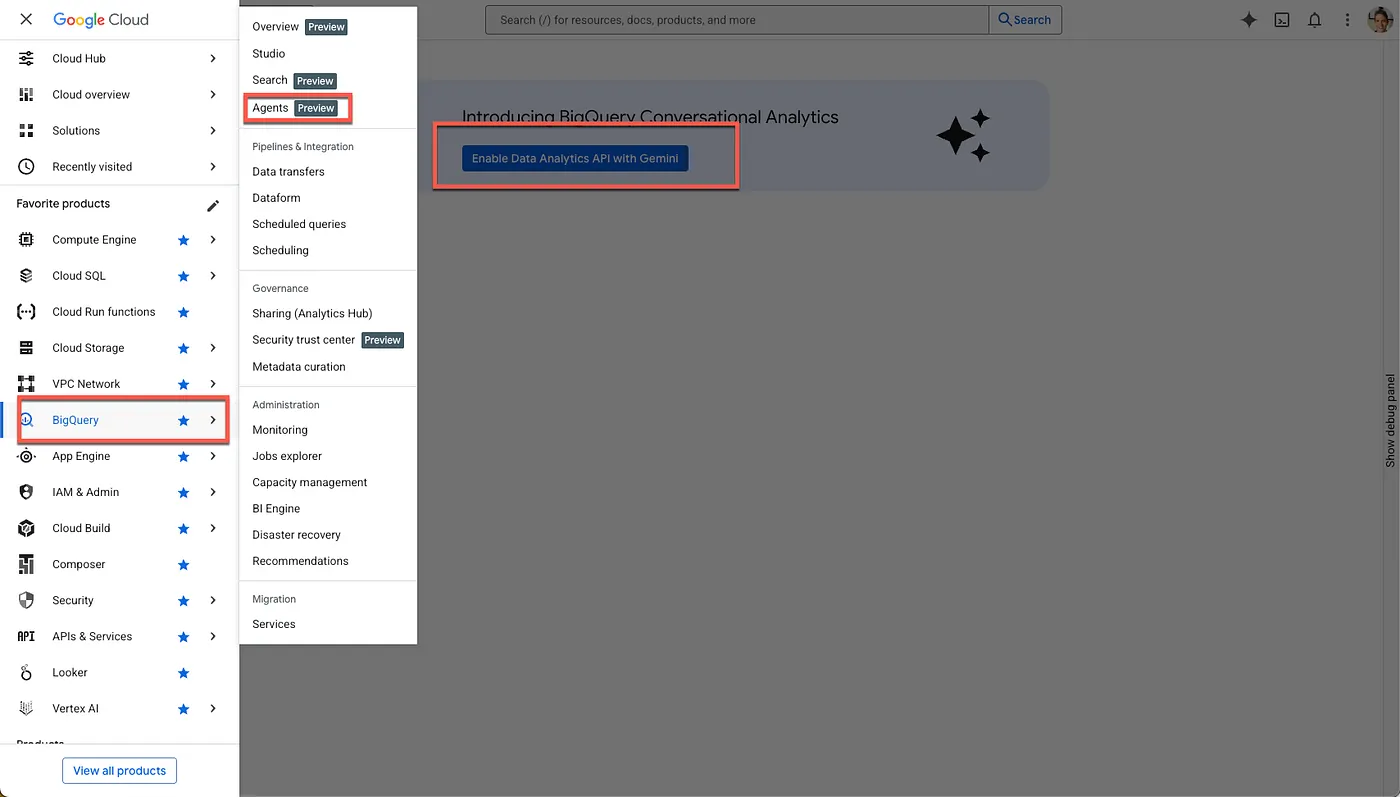
- Activer les API requises
Accédez à BigQuery dans la console Google Cloud. Utilisez le menu de navigation de la barre latérale ou le menu de recherche en haut de la page pour accéder à BigQuery > Agents.
Cliquez sur Activer l'API Data Analytics avec Gemini :
Activez l'API Gemini dans BigQuery et l'API Gemini pour Google Cloud :
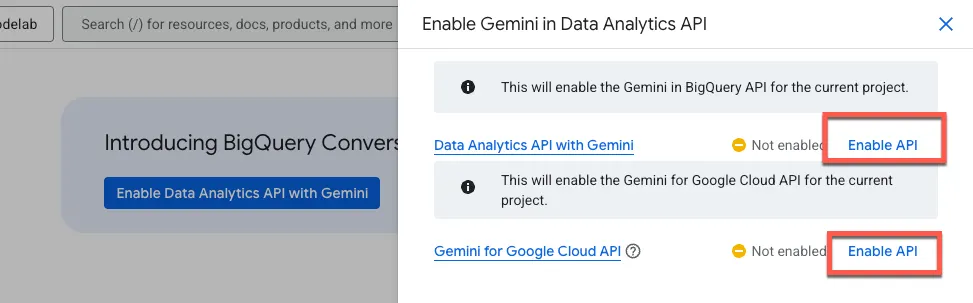
La nouvelle page de l'agent doit s'afficher :
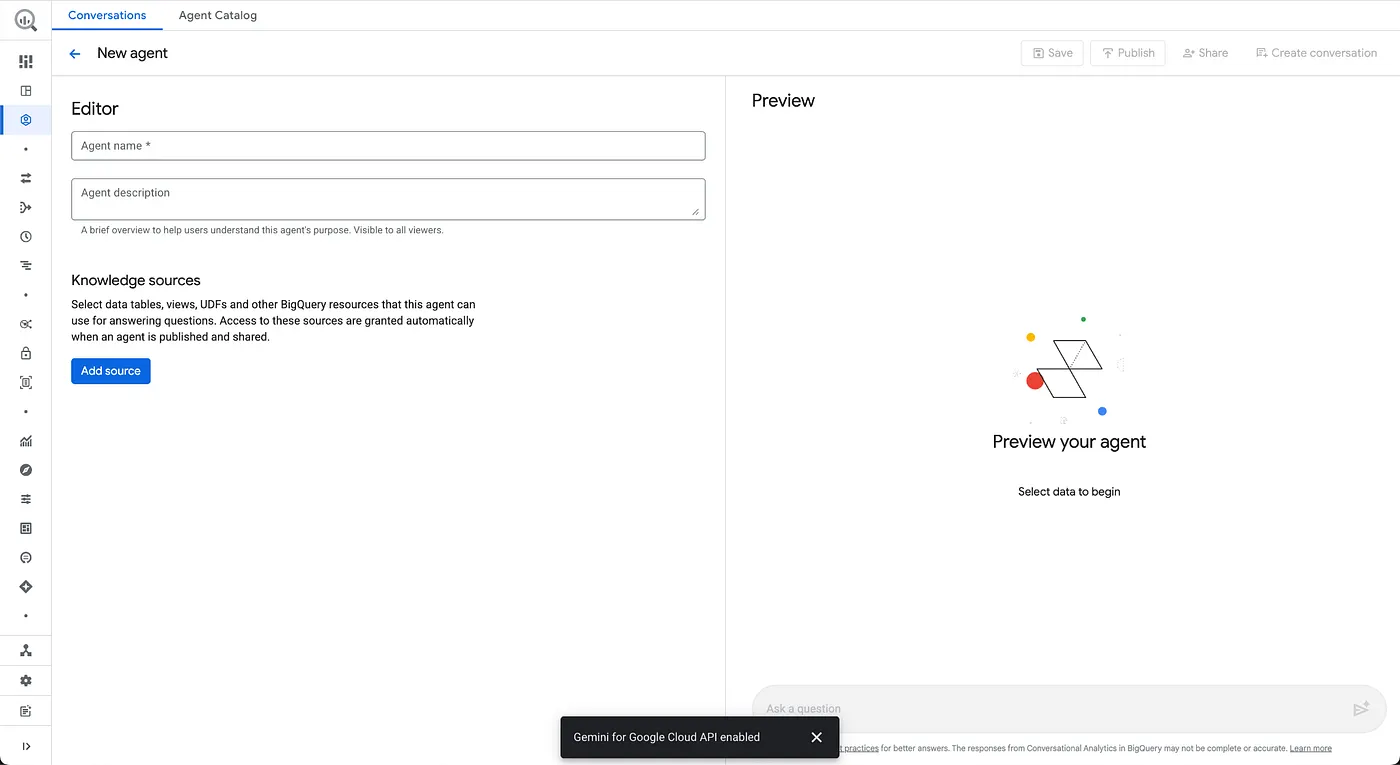
- Configurer les informations sur l'agent
Nom de l'agent : Agent Froyo
Description de l'agent : aide à répondre aux questions sur les produits glacés, les allergènes, les ingrédients, les recettes, les clients, les commandes et les ventes.
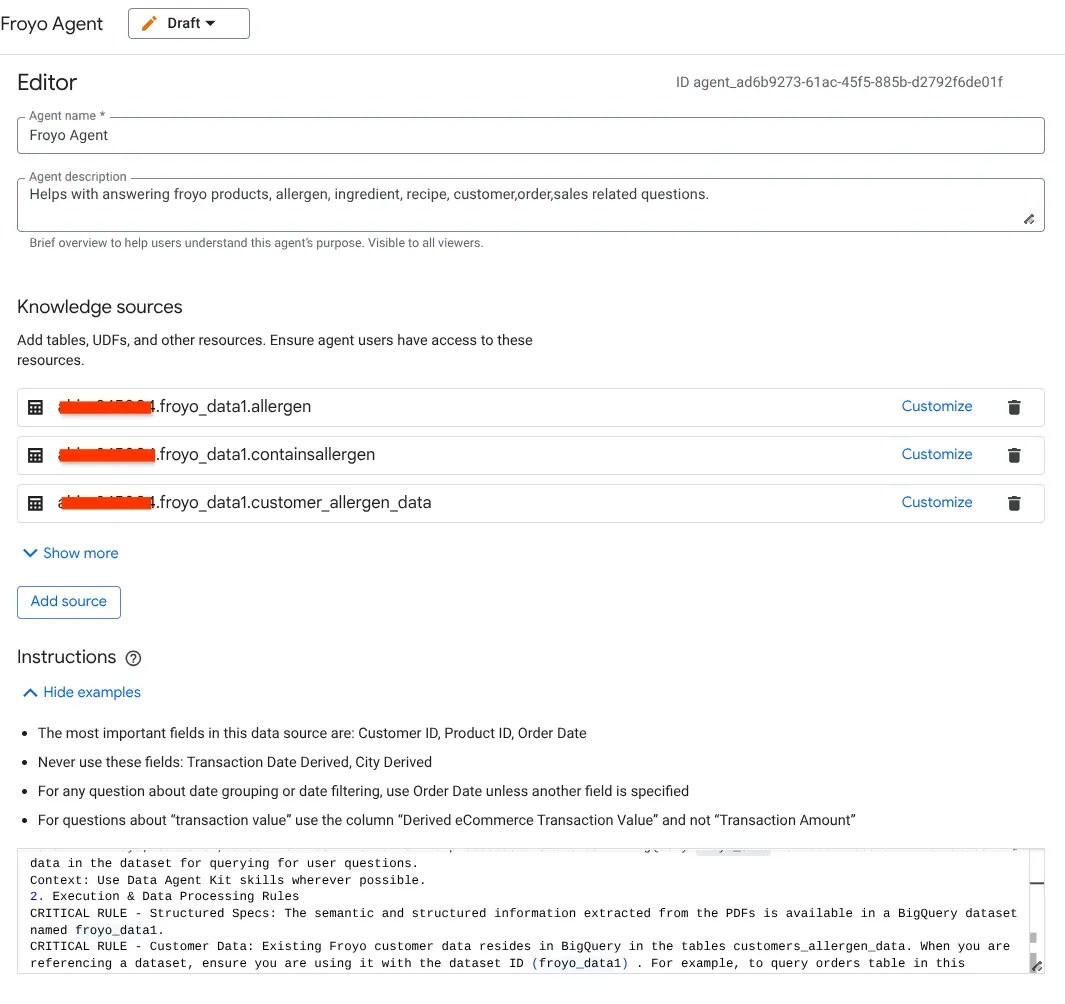
- Accédez à la section "Sources de connaissances" et sélectionnez tous les tableaux ci-dessous à partir de votre ensemble de données :
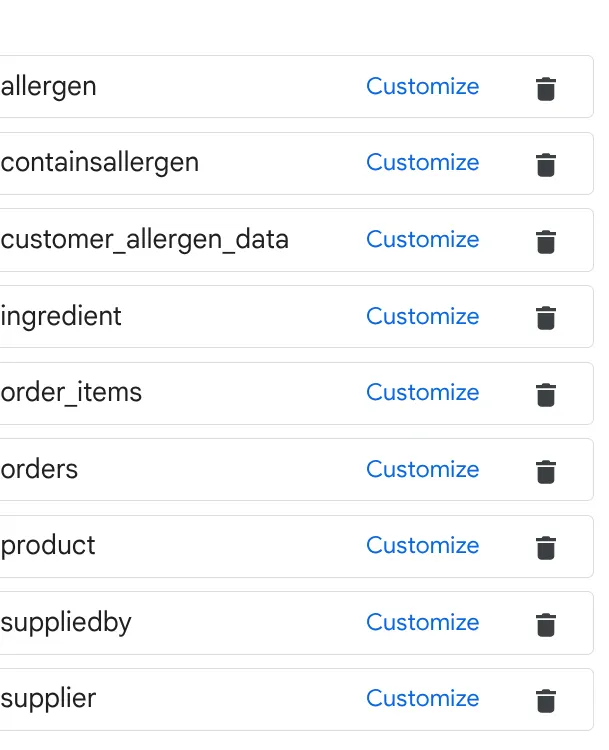
a. Ajoutez les tableaux de l'image ci-dessus, puis cliquez sur "Ajouter une source".
b. Pour chaque source, cliquez sur le bouton Personnaliser à droite. Le formulaire ci-dessous s'affiche :
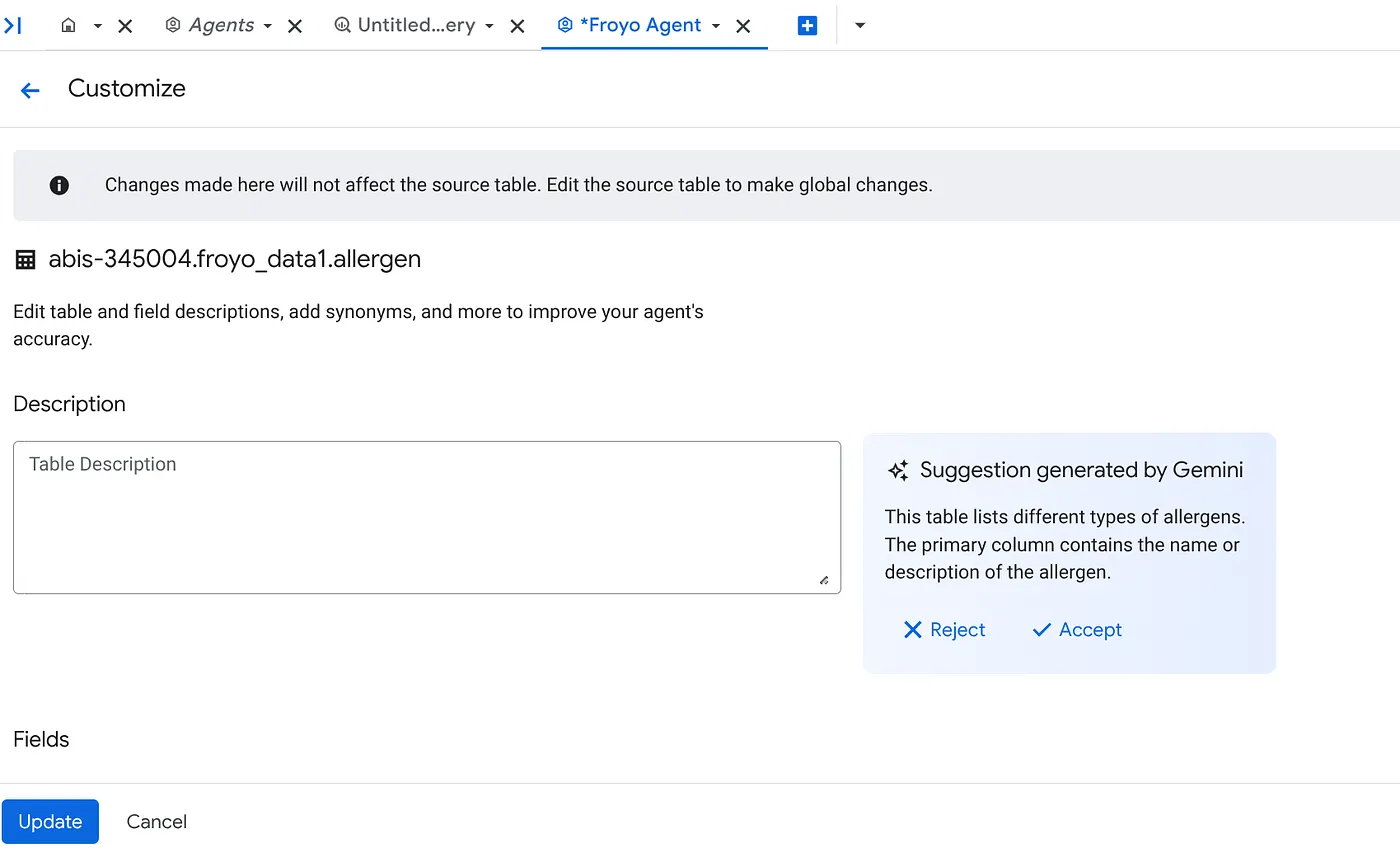
c. Cliquez sur "Accepter" pour la description de la table.
d. Cliquez également sur "Accepter" pour la description de chaque champ.
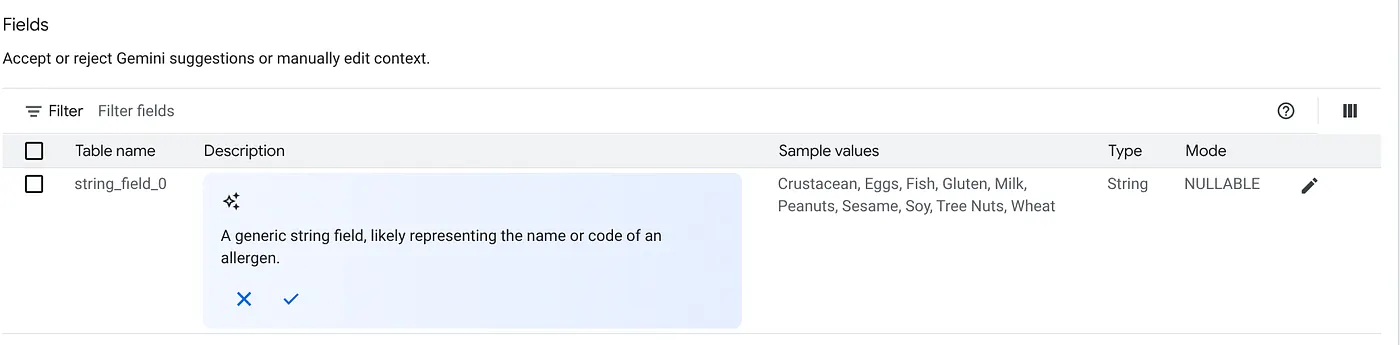
e. Cliquez sur "Mettre à jour".
Vous devez répéter cette opération pour toutes les tables de la source.
- Configurer les instructions
Collez ici les instructions que nous avons utilisées dans GEMINI.md d'Antigravity IDE :
1. Project Context
Project ID: <<YOUR_PROJECT_ID>>
Domain: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
Data: All froyo, customer, order related information is processed and stored in BigQuery froyo_data dataset. Use all the tables and data in the dataset for querying for user questions.
Context: Use Data Agent Kit skills wherever possible.
2. Execution & Data Processing Rules
CRITICAL RULE - Structured Specs: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named froyo_data.
CRITICAL RULE - Customer Data: Existing Froyo customer data resides in BigQuery in the tables customers_allergen_data. When you are referencing a dataset, ensure you are using it with the dataset ID (froyo_data) . For example, to query orders table in this dataset you should use froyo_data.orders.
- Enregistrez votre agent.
7. Discutez avec vos données !
- Testez-le dans la section d'aperçu à droite :
Posez votre question :
Does midnight swirl contain any allergen?
Voici la réponse :
Posons maintenant la question complexe :
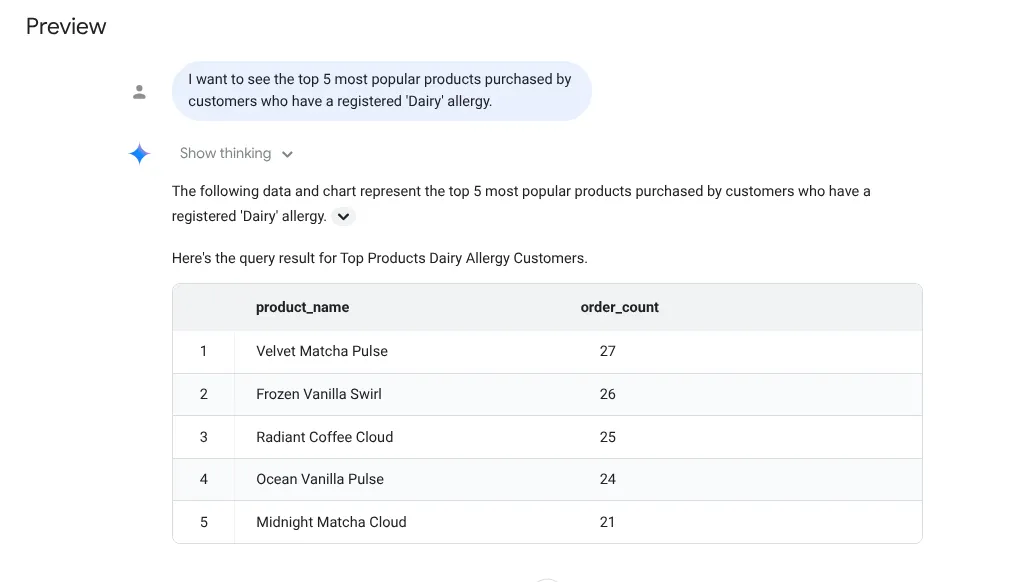
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
Réponse :
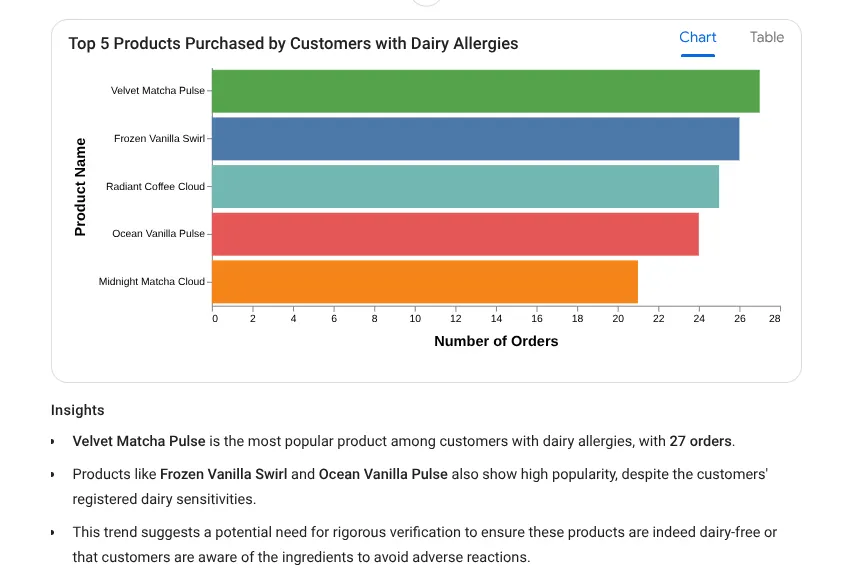
Essayons maintenant une requête d'insight approfondi :
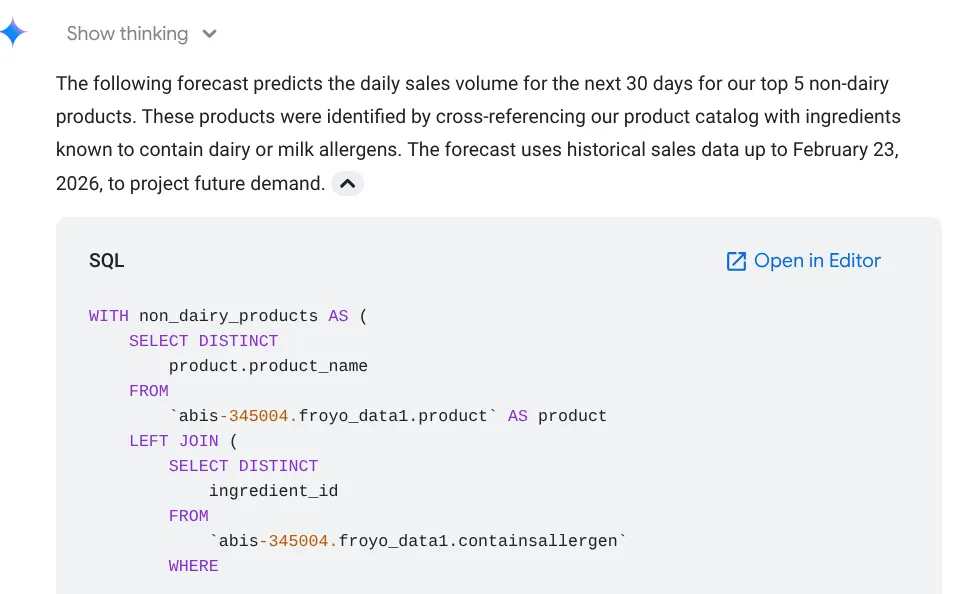
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
Vous pouvez voir qu'il affiche la requête qu'il utilise, avec le résultat du tableau et le graphique :
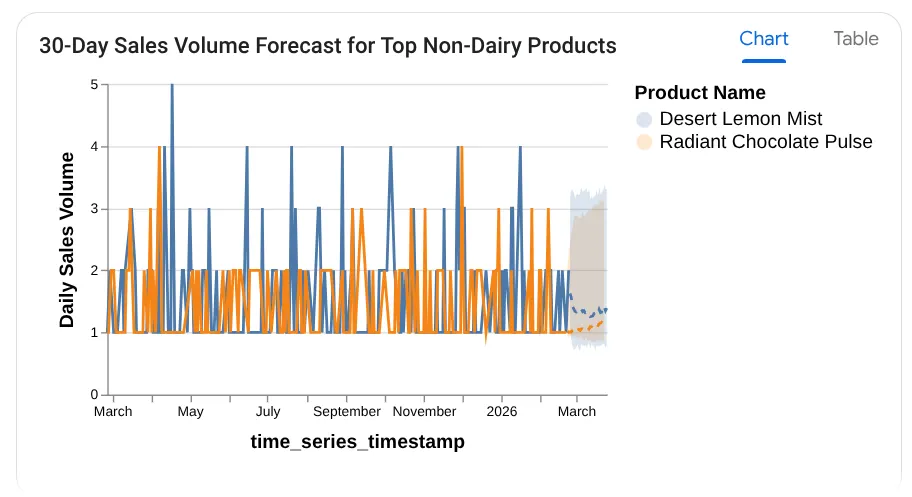

Impressionnant ! Tout s'est bien passé avec les graphiques et les insights. Il est temps de poser la question ultime sur les produits.
8. Le test ultime
Posez la question :
What will be the top most selling product of 2026
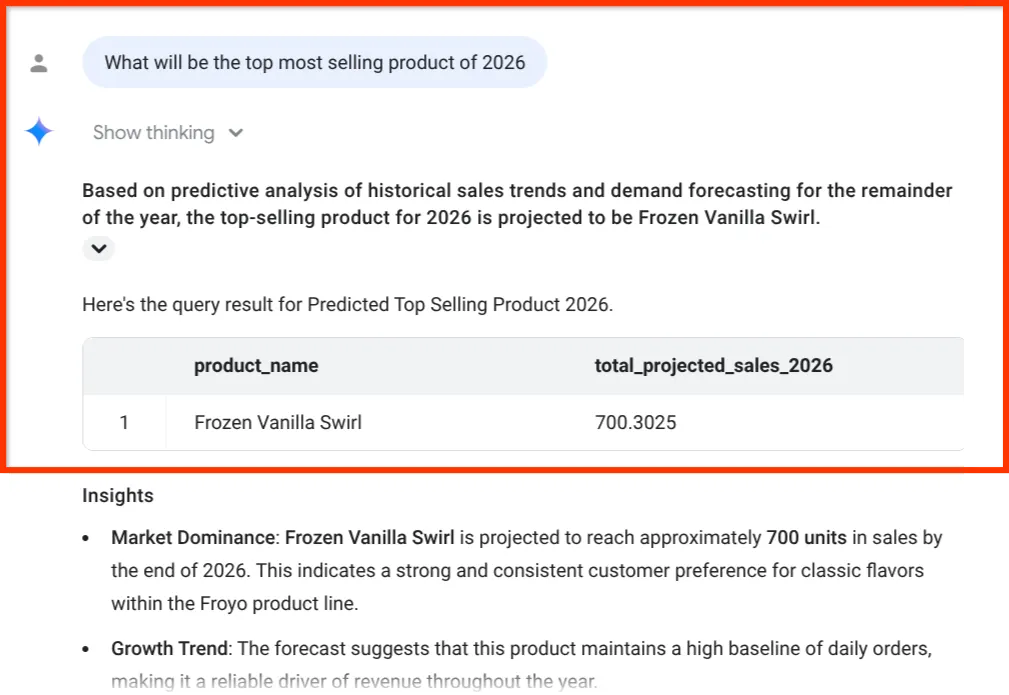

Regardez cet insight final. Le BigQuery Data Agent ne nous a pas seulement donné un chiffre. Il a explicitement associé les prévisions de ventes à notre inventaire et à notre chaîne d'approvisionnement en ingrédients, soit les données exactes que nous avions extraites de PDF désordonnés dans la partie 1.
9. Publier votre agent dans l'entreprise
Cliquez sur le bouton Publier en haut de l'agent d'aperçu.
Maintenant que nous avons créé, configuré et testé notre agent Froyo, il est temps de le déployer dans le reste de l'entreprise.
En haut à droite de la page de configuration de l'agent, cliquez sur le bouton "Publier".
En publiant votre agent, vous le rendez instantanément disponible sur trois puissants canaux d'entreprise pour vous et pour toutes les personnes avec lesquelles vous le partagez :
- BigQuery : vos analystes de données peuvent désormais discuter avec cet agent directement depuis le hub d'agents ou dans leur espace de travail SQL BigQuery Studio.
- API Conversational Analytics : vos développeurs peuvent accéder à cet agent via une API REST, ce qui leur permet d'intégrer ces analyses conversationnelles exactes dans vos propres applications Web internes personnalisées.
- Data Studio : vos dirigeants peuvent interagir avec cet agent et créer des tableaux de bord conversationnels dynamiques directement dans Data Studio.
Nous avons réussi à sortir nos données des silos et à les mettre directement à la disposition des personnes qui en ont besoin, là où elles travaillent déjà.
Cliquez sur le menu déroulant du bouton "Partager" en haut de votre agent BigQuery publié, puis sélectionnez l'option "Copier le lien vers l'agent dans Data Studio" dans la liste :
Collez ce lien dans votre navigateur et appuyez sur Entrée. Confirmez l'alerte d'accès aux interactions avec l'agent :
Vous pouvez lancer des conversations et des visualisations interactives avec l'agent nouvellement publié depuis Data Studio. Votre équipe de direction et les autres équipes qui ont besoin de ces informations peuvent également le faire.
10. Effectuer un nettoyage
Une fois cet atelier terminé, n'oubliez pas de supprimer les autorisations accordées à tous les utilisateurs pour l'agent BigQuery que vous venez de créer.
11. Félicitations !
Vous avez officiellement créé un Agentic Data Cloud.
Vous n'avez pas créé un simple chatbot. Au cours de ces cinq sessions, vous avez réussi à concevoir de A à Z un système d'IA d'entreprise complet, moderne et évalué. Vous êtes passé des "données obscures " à l'intelligence transactionnelle en temps réel, puis à la prévision commerciale conversationnelle.
12. Le tableau complet
Prenons un peu de recul pour examiner ce que nous avons accompli dans cette série. Nous n'avons pas simplement créé un chatbot. Nous avons conçu un Cloud de données agentique complet et moderne :
Partie 1 : Déverrouillez les données obscures en transformant les PDF en tables relationnelles structurées à l'aide de Knowledge Catalog.
Partie 2 : Nous avons décloisonné les données en fédérant notre entrepôt de données analytiques directement dans une base de données transactionnelle AlloyDB.
Partie 3 : Donner plus de pouvoir aux utilisateurs en créant un OS multi-agents qui exécute de manière fluide des outils de base de données sécurisés via le protocole MCP
Partie 4 : Nous avons assuré la sécurité en implémentant un pipeline d'évaluation rigoureux pour détecter les hallucinations et les tentatives de piratage.
Partie 5 : Démocratiser les insights à l'aide d'ANTIGRAVITY IDE et de Conversational Analytics dans BigQuery.
C'est l'avenir des logiciels d'entreprise. L'agent d'IA n'est plus un simple wrapper autour d'un LLM. Il s'agit d'un moteur d'orchestration entièrement intégré, évalué et sécurisé, qui repose sur une plate-forme de données unifiée.