
1. סקירה כללית
בואו נסתכל רגע על הארכיטקטורה העצומה שבנינו בארבעת החלקים האחרונים:
חלק 1: השתמשנו ב-BigQuery Knowledge Catalog כדי להפוך קובצי PDF של מתכון פרויו לטבלאות יחסיות ומובנות.
חלק 2: יצרנו גשר טרנזקציונלי ללא ETL, שמאחד את מחסן הנתונים שלנו ב-BigQuery ישירות לתוך AlloyDB.
חלק 3: יצרנו אפליקציה מרובת-סוכנים (FroyoOS) באמצעות ערכה לפיתוח סוכנים (ADK) ו-MCP Toolbox.
חלק 4: בנינו צינור הערכה דו-מסלולי כדי להוכיח שהסוכן שלנו בטוח לשימוש בסביבת ייצור.
הפעולות שלנו מתבצעות בצורה חלקה. אבל מה לגבי המפתחים והאנליסטים העסקיים שצריכים להבין את הכמויות העצומות של הנתונים שהמערכת הזו מייצרת?
היום נסקור את עתיד האנליטיקה. נתחיל ישירות בתוך עורך הקוד Antigravity IDE עם Google Cloud Data Agent Kit, ואז נעבור אל מסוף Google Cloud כדי להמחיש את הנתונים באמצעות ניתוח שיחות ב-BigQuery.
בואו נתחיל לבנות!
מה תלמדו
בשיעור Codelab האחרון בסדרה Agentic Data Cloud, תלמדו איך לחבר את כל חלקי הארכיטקטורה כדי לקבל תובנות עסקיות פרקטיות. תלמדו:
- IDE-First Analytics: איך להתקין ולהגדיר את ANTIGRAVITY IDE ואת Google Cloud Data Agent Kit כדי לשלוח שאילתות לארכיטקטורה ישירות מסביבת הפיתוח.
- BigQuery לשיחות: איך ליצור, להגדיר ולתת הוראות לסוכני נתונים של BigQuery כדי לבצע אוטומציה של משימות מורכבות של SQL וחיזוי באמצעות שפה טבעית.
- הנגשת נתונים: איך לפרסם את הסוכנים בארגון כדי שאנליסטים ומשתמשים עסקיים יוכלו לגשת אליהם.
- המחשה ויזואלית של תובנות: איך לשלב בצורה חלקה את ניתוח השיחות של הסוכן ב-Data Studio כדי ליצור מרכזי בקרה דינמיים שמוכנים לחיזוי.
- הסביבה העסקית של Agentic Data Cloud: איך להסביר את הערך של הארכיטקטורה מקצה לקצה – מנתונים גולמיים לא מובְנים בחלק 1 ועד לוחות בקרה שמוכנים להצגה למנהלים בחלק 5.
דרישות
2. לפני שמתחילים
יצירת פרויקט
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- מוודאים שהחיוב מופעל בפרויקט ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט.
- תשתמשו ב-Cloud Shell, סביבת שורת פקודה שפועלת ב-Google Cloud. לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud.

- אחרי שמתחברים ל-Cloud Shell, בודקים שכבר בוצע אימות ושהפרויקט מוגדר למזהה הפרויקט באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט.
gcloud config list project
- אם רוצים לבצע אימות
gcloud auth login
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- מפעילים את ממשקי ה-API הנדרשים: מריצים את הפקודה הבאה כדי להפעיל את כל ממשקי ה-API הנדרשים:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. הרחבת מחסן הנתונים
זוכרים את הטבלאות ב-BigQuery שיצרנו מהנתונים הלא מובְנים?
כדי לבצע ניתוח משמעותי, אנחנו צריכים נתוני עסקאות היסטוריים. ב-BigQuery, במערך הנתונים froyo_data, ניצור שלוש טבלאות חדשות כדי לדמות נתונים של שנים של פעילות זיכיון:
- froyo_data.orders: כותרות היסטוריות של הזמנות (תאריכים, מזהי חנויות, סכומים כוללים)
- froyo_data.order_items: פרטים של פריטים בהזמנה (כמויות, מחירים)
- froyo_data.customer_allergen_data: טבלת CRM למעקב אחרי אלרגיות ידועות של לקוחות נאמנים
בואו נוסיף את הטבלאות האלה שקשורות למכירות וללקוחות למערך הנתונים הזה, כדי להתכונן לתרחיש השימוש שלנו בניתוח נתונים.
- נכנסים אל Cloud Shell Terminal ממסוף Google Cloud.
- עוברים לתיקיית הבסיס של סביבת העבודה או לתיקיית הבסיס של פרויקט froyo-data (שעבדנו עליו בחלקים הקודמים של הסדרה הזו).
- מורידים את 3 קובצי הנתונים ההיסטוריים (בקובצי CSV) לספריית העבודה על ידי הפעלת הפקודות הבאות אחת אחרי השנייה:
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/customer_allergen_data.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/order_items.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/orders.csv
- אחרי שהקבצים האלה יופיעו בספריית הבסיס של ספריית העבודה, עוברים לטרמינל של Cloud Shell.
- בטרמינל של Cloud Shell, עוברים לספרייה שבה נמצאים 3 הקבצים האלה.
- מוודאים שב-BigQuery יש לכם את מערך הנתונים בשם froyo_data מחלק 1 בסדרה הזו (אם לא, חוזרים אחורה ויוצרים את מערך הנתונים והטבלאות).
- מריצים את הפקודות הבאות מטרמינל Cloud Shell:
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.orders \
./orders.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.order_items \
./order_items.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.customer_allergen_data \
./customer_allergen_data.csv
פעולה זו אמורה ליצור את 3 הטבלאות הנוספות במערך הנתונים froyo_data.
4. חוויית המפתחים – הכירו את 'ערכת כלי הסוכן לניהול נתונים'
באופן מסורתי, אם מפתח רצה לנתח נתונים או לכתוב שאילתות מורכבות של למידת מכונה, הוא היה צריך להחליף הקשר כל הזמן בין סביבת הפיתוח המשולבת (IDE), מסופי מסדי הנתונים והתיעוד.
לא יותר. עם התוסף החדש Google Cloud Data Agent Kit, סביבת הפיתוח המשולבת שלכם הופכת למרכז נתונים רב עוצמה.
ANTIGRAVITY IDE
ANTIGRAVITY IDE היא סביבת פיתוח מהדור הבא של Google, שנועדה במיוחד לעידן ה-AI. הוא משלב באופן מובנה חלונות הקשר מרובי-מודלים עצומים ושימוש אוטונומי בכלי עריכה ישירות בעורך, ומאפשר למפתחים לתזמן משאבי ענן ולתזמן צינורות עיבוד נתונים מורכבים בלי לצאת מהקוד.
הגדרת ANTIGRAVITY IDE
- מורידים את סביבת הפיתוח המשולבת (IDE): נכנסים אל antigravity.google ומורידים את Antigravity IDE למערכת ההפעלה שלכם (Windows, macOS או Linux).
- התקנה והפעלה: מריצים את קובץ ההתקנה ופותחים את האפליקציה.
- לוחצים על 'המשך עם Google', בוחרים את חשבון Gmail ומאשרים.
- אחרי שמתחברים, יוצרים תיקיית עבודה (סביבת עבודה או פרויקט). נקרא לו Agent Data Cloud.
הוא אמור להופיע ברשימת הפרויקטים בצד ימין:
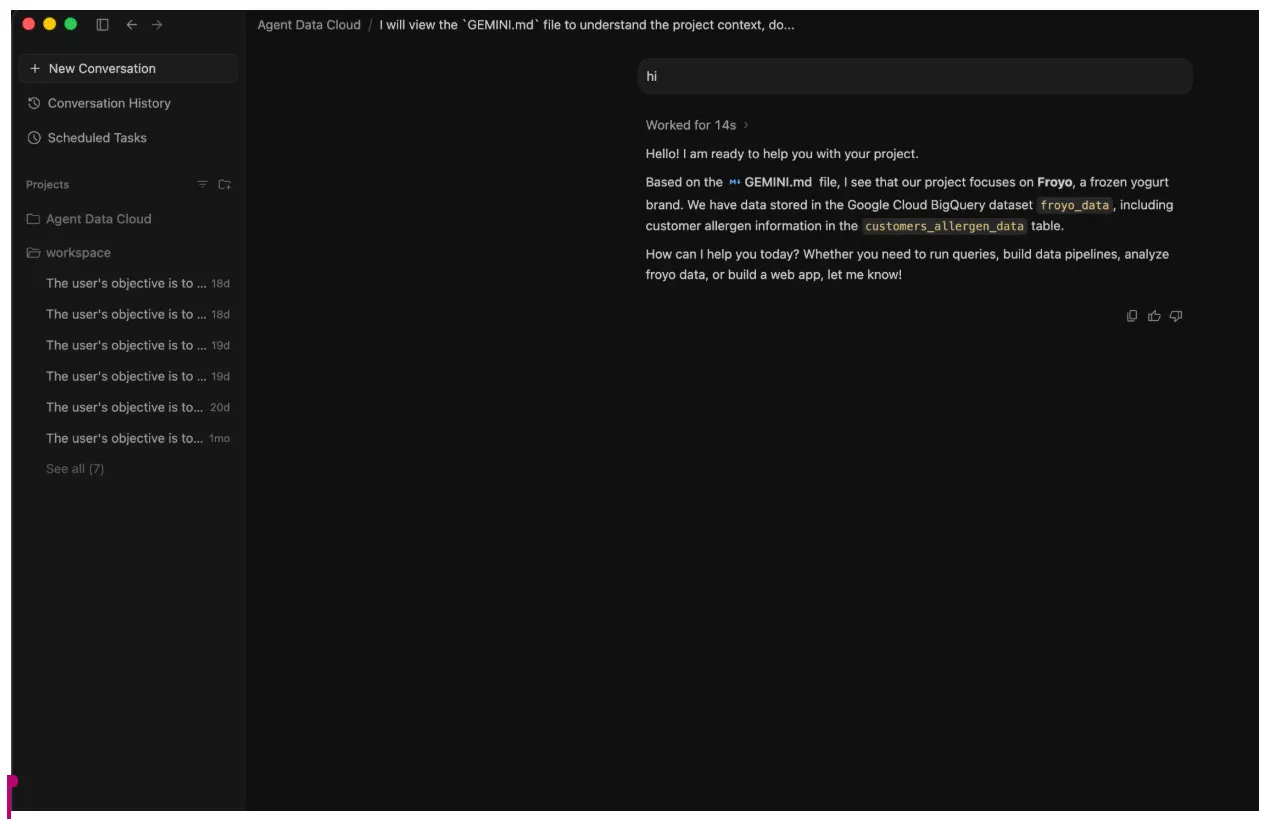
- מתחילים שיחה מקדימה עם הנציג – "שלום".
- בפינה השמאלית העליונה, שימו לב ללחצן Open IDE (פתיחת סביבת פיתוח משולבת)!!!
אבל לפני שתוכלו ללחוץ על זה, תצטרכו להתקין את Antigravity IDE. עוברים לדף antigravity.google/download וגוללים למטה לקטע Antigravity IDE. מורידים את הגרסה הרצויה.
אחרי ההורדה, חוזרים למופע הפתוח של Antigravity ולוחצים על הלחצן Open IDE (פתיחת סביבת פיתוח משולבת) בפינה השמאלית העליונה.
- חלונות קופצים לגבי הרשאות אמורים להופיע. צריך להמשיך לפתוח אותם.
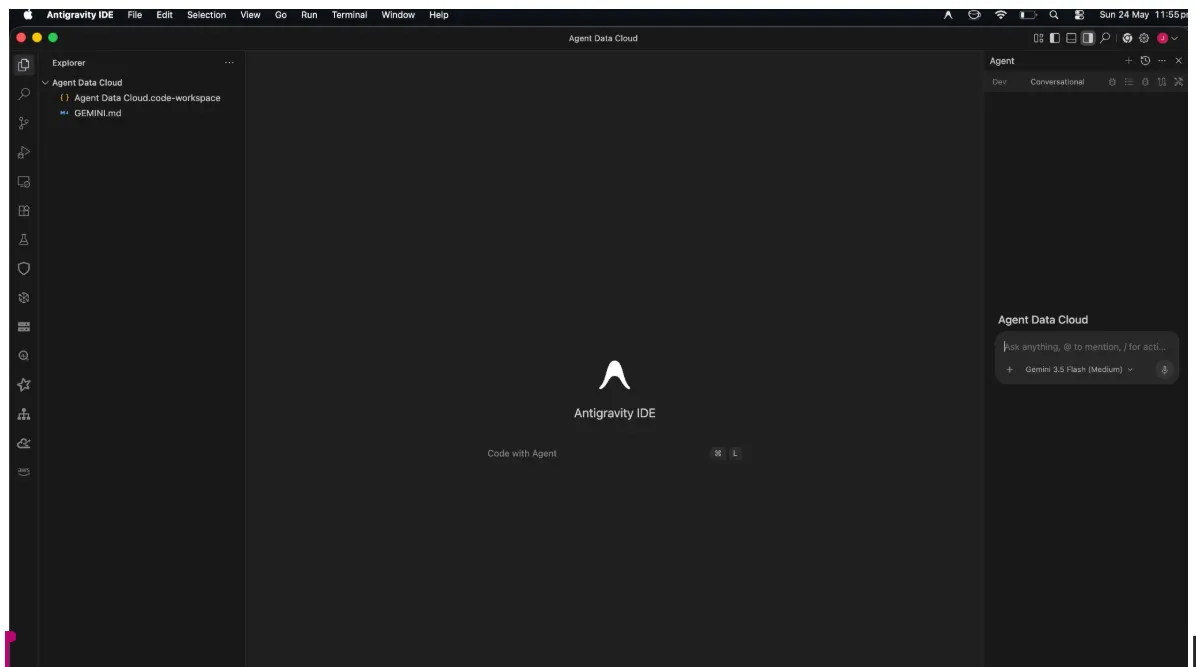
בצד שמאל מופיעה חלונית הסוכן, בצד ימין מופיע סייר הפרויקטים ובמרכז מופיע המרחב לפיתוח.
הגדרת התוסף Data Agent Kit
- מתקינים את התוסף: פותחים את זירת התוספים ב-ANTIGRAVITY IDE. מחפשים את התוסף Google Cloud Data Agent Kit ומתקינים אותו.
- לוחצים על לחצן ההתקנה, וכשההתקנה מסתיימת, התוסף מופיע בחלונית הניווט.
- לוחצים על האפשרות הזו ונפתח סייר ערכת הכלים של Google Cloud Data Agent. עוברים לקטע SETTINGS ולוחצים על Settings. מזינים את פרטי הפרויקט והאזור ושומרים.
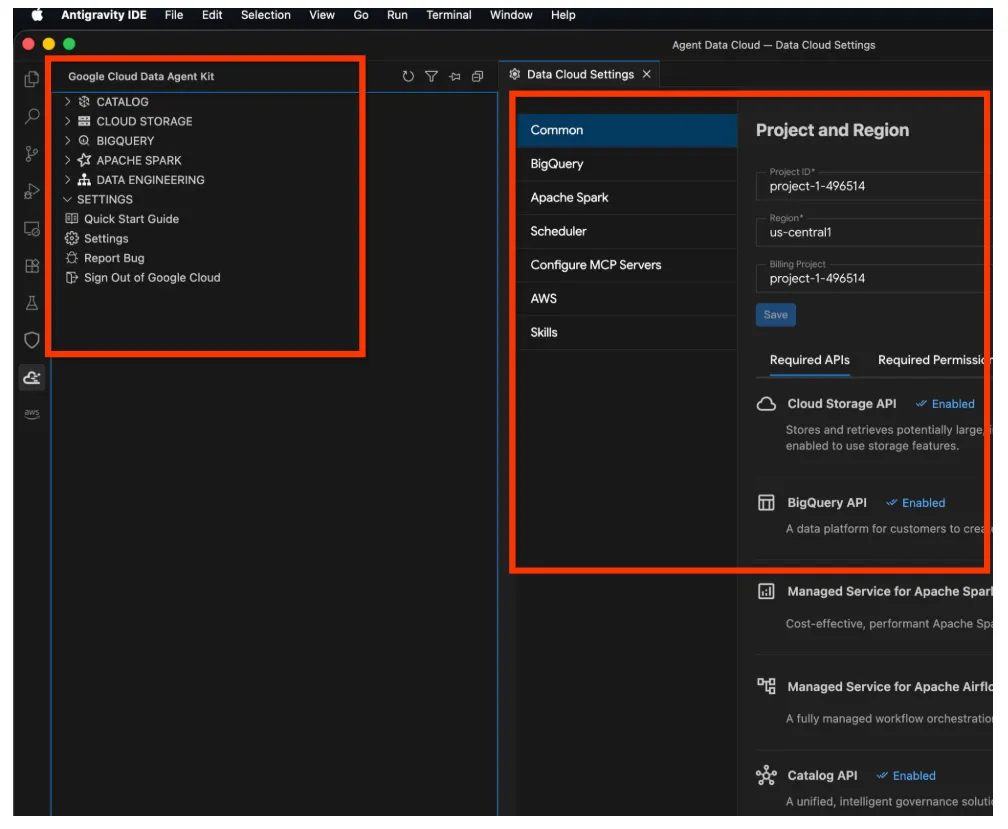
- עכשיו לוחצים על סייר הפרויקטים בחלק העליון של חלונית הניווט. חלון סייר הפרויקטים אמור להיפתח בחלונית הסייר.
- לוחצים לחיצה ימנית על המרחב של סייר הקבצים ויוצרים קובץ חדש בשם GEMINI.md.
- מדביקים את הטקסט הבא בקובץ GEMINI.md (לא לשכוח להחליף את <<YOUR_PROJECT_ID>> בערך שלכם):
## 1. Project Context
- **Project ID**: <<YOUR_PROJECT_ID>>
- **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
- **Data**: All froyo, customer, order related information is processed and stored in BigQuery `froyo_data` dataset.
## 2. Execution & Data Processing Rules
- **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `froyo_data`.
- **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the tables `customers_allergen_data`.
- ** CRITICAL RULE - Sales Data**: Sales data is present in tables `orders` and `order_items`.
- ** CRITICAL RULE - General: When you are referencing a dataset, ensure you are using it with the dataset ID (`froyo_data`) . For example, to query orders table in this dataset you should use `froyo_data.orders`.
עכשיו יש לכם סוכן AI עם יכולות מתקדמות שמוכן לכתוב קוד, ליצור SQL ולנתח את הארכיטקטורה שלכם ישירות בסביבת הפיתוח המשולבת (IDE).
עכשיו יש לנו אתגר אנליטי מעניין: האם אפשר ליצור קורלציה בין נתוני המכירות ההיסטוריים שלנו לבין נתוני האלרגנים המורכבים והמשוערים שחילצנו מקובצי PDF בחלק 1?
5. הסקת מסקנות לגבי מודיעין באמצעות סוכן ה-IDE
נבקש מסוכן ה-IDE שלנו לעשות את העבודה הקשה. פותחים את חלון הצ'אט של Agent Data Kit ישירות ב-ANTIGRAVITY IDE ומזינים את ההנחיה הבאה:
Does Midnight Swirl contain any allergen?
תופיע בקשה לאישור של סדרת הרשאות. צריך לאשר את ההרשאות הרלוונטיות.
בסוף הניתוח, הוא יאחזר את התשובה בשבילכם:
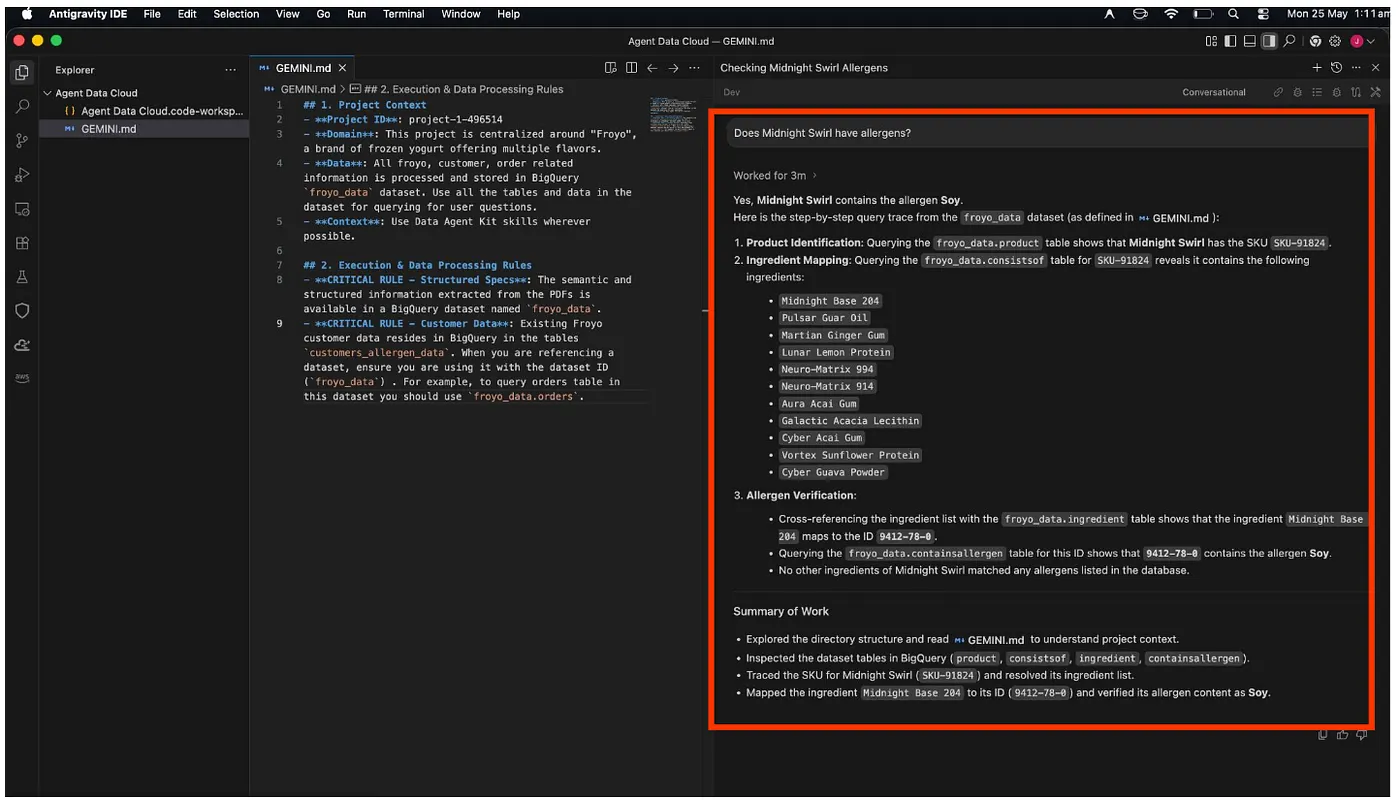
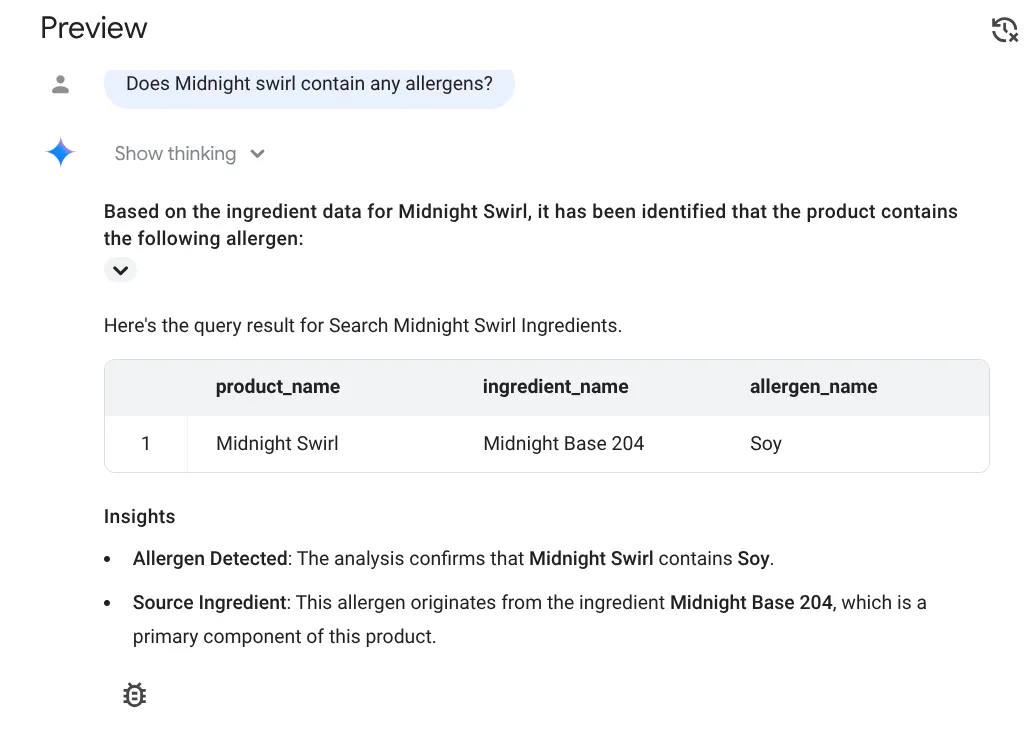
יש!!! המערכת זיהתה נכון את הסויה במוצר Midnight Swirl.
עכשיו נשאל שאלה קצת יותר מורכבת. שולחים את ההנחיה הבאה ב-Antigravity IDE:
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
תשובה:
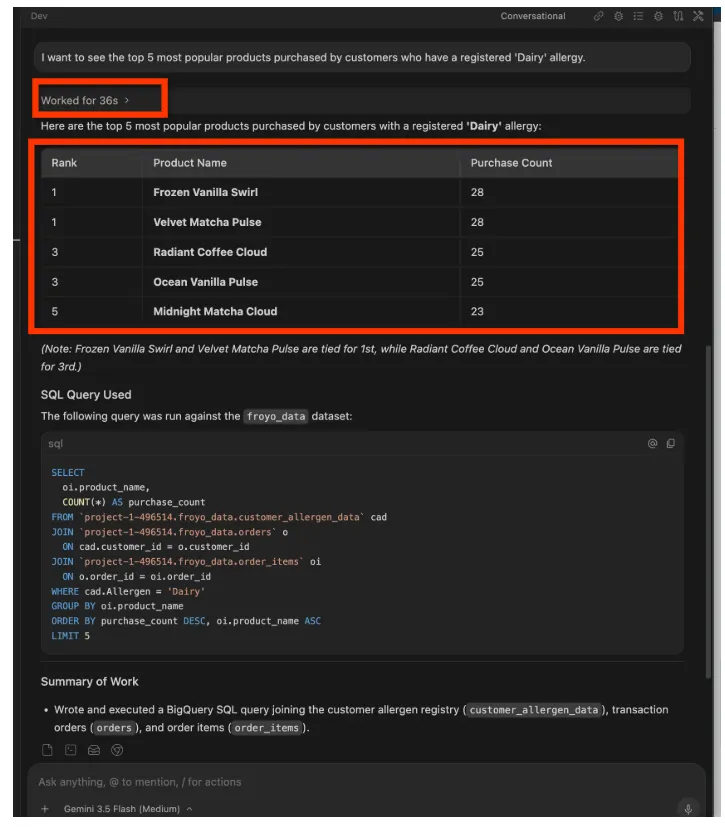
אפשר להמשיך. הנה כמה דוגמאות להנחיות:
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
בלי שתצטרכו לחפש את התחביר של BQML, ערכת הנתונים של Agent תכניס את הקוד המדויק של CREATE MODEL ו-ML.FORECAST לעורך שלכם. אפשר להריץ את הפקודה הזו ישירות בסביבת BigQuery בלי לצאת מ-ANTIGRAVITY IDE.
איזה יופי!!!
6. ניתוח נתוני שיחות ב-BigQuery
המפתחים אוהבים את סביבת הפיתוח המשולבת, אבל משתמשים עסקיים ומנהלים משתמשים במסוף הענן. הם לא רוצים לראות SQL, הם רק רוצים תשובות.
בואו נתחיל:
- הקצאת התפקידים הנדרשים לעצמכם
עוברים לדף IAM של הפרויקט ומקצים לעצמכם את התפקיד Gemini Data Analytics Data Agent Owner (בעלים של סוכן נתונים של Gemini Data Analytics):
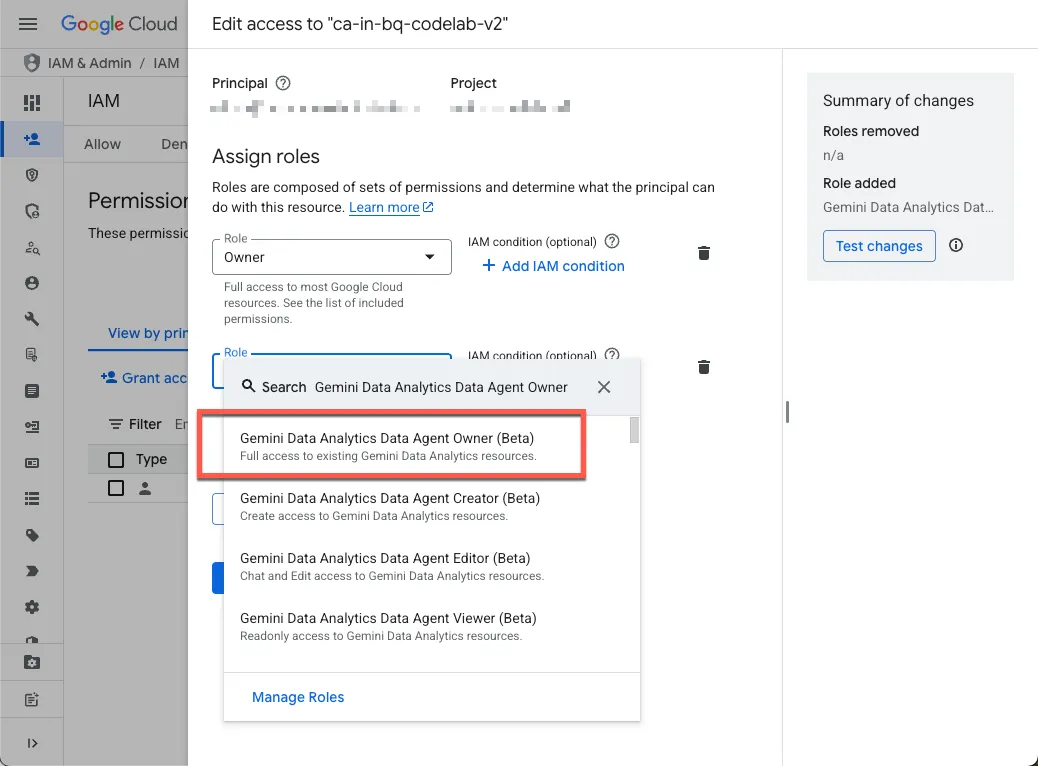
התפקיד הזה מעניק לכם הרשאה ליצור, לערוך, לשתף ולמחוק את כל סוכני הנתונים בפרויקט.
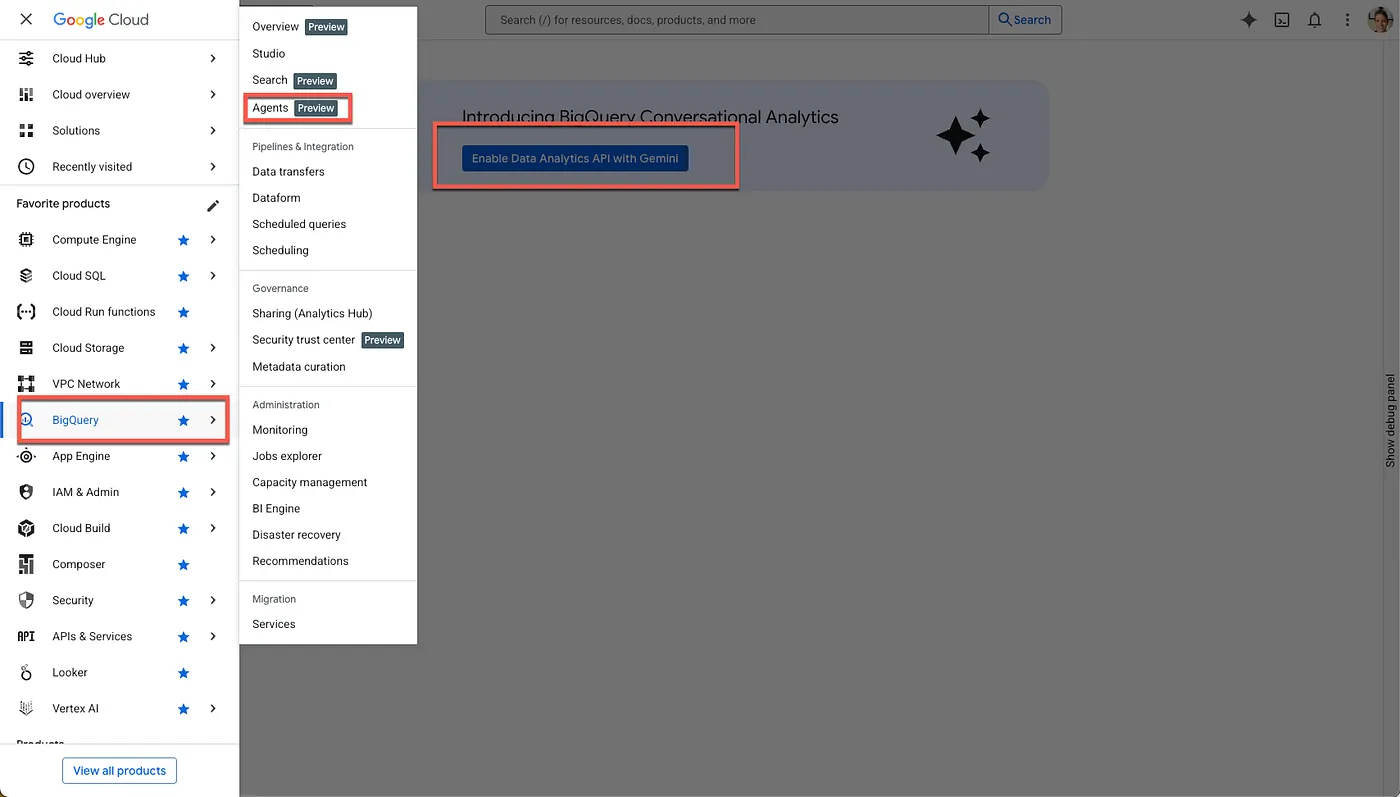
- הפעלת ממשקי ה-API הנדרשים
עוברים אל BigQuery במסוף Google Cloud. משתמשים בתפריט הניווט שבסרגל הצד או בתפריט החיפוש בחלק העליון של הדף כדי לנווט אל BigQuery > Agents.
לוחצים על 'הפעלת Data Analytics API עם Gemini':
מפעילים את Gemini ב-BigQuery API ואת Gemini for Google Cloud API:
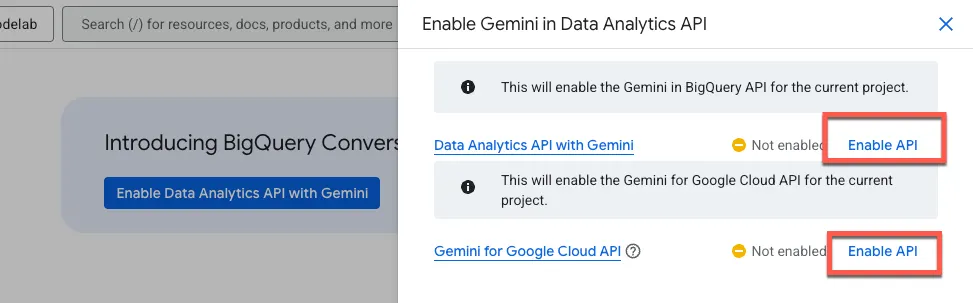
עכשיו אמור להופיע הדף של הנציג החדש:
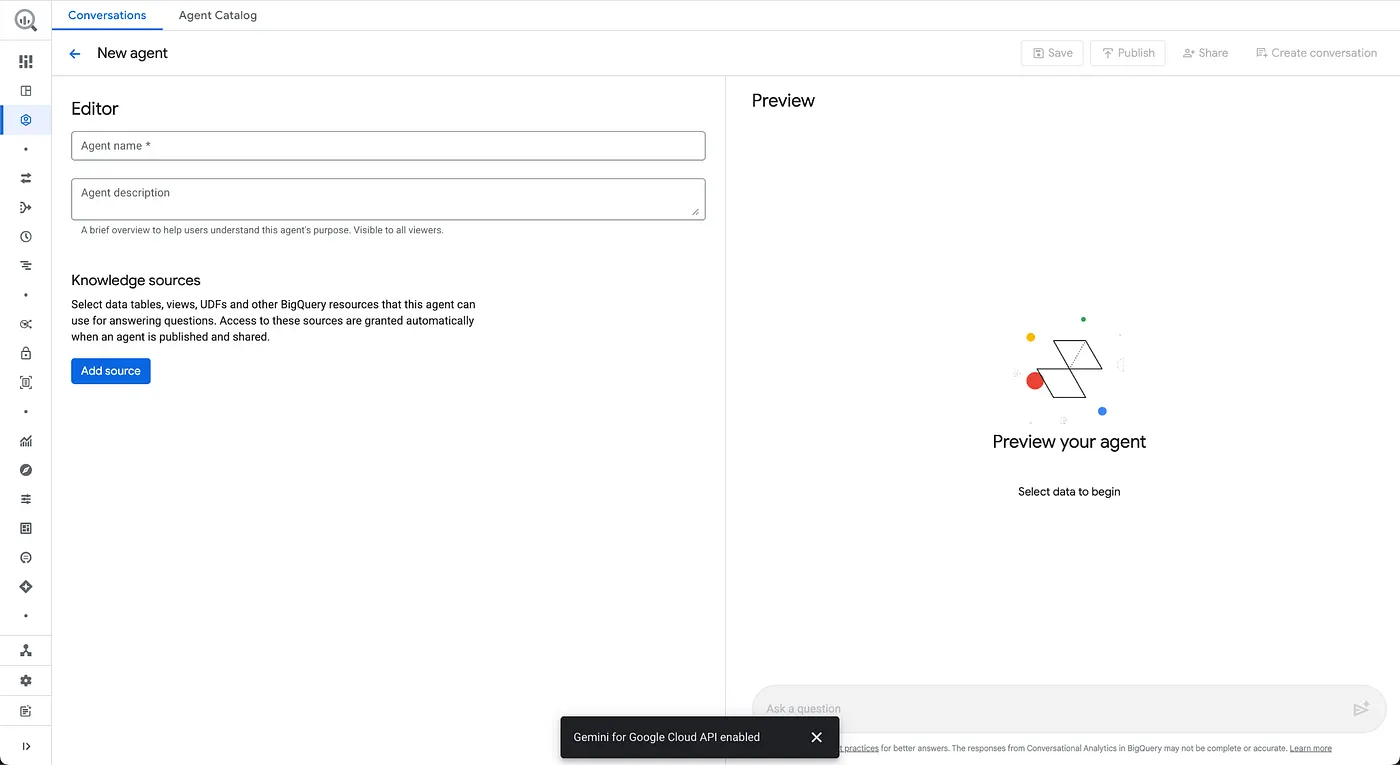
- הגדרת פרטי הנציג
שם הנציג: Froyo Agent
תיאור הסוכן: עוזר לענות על שאלות שקשורות למוצרי פרוזן יוגורט, אלרגנים, רכיבים, מתכונים, לקוחות, הזמנות ומכירות.
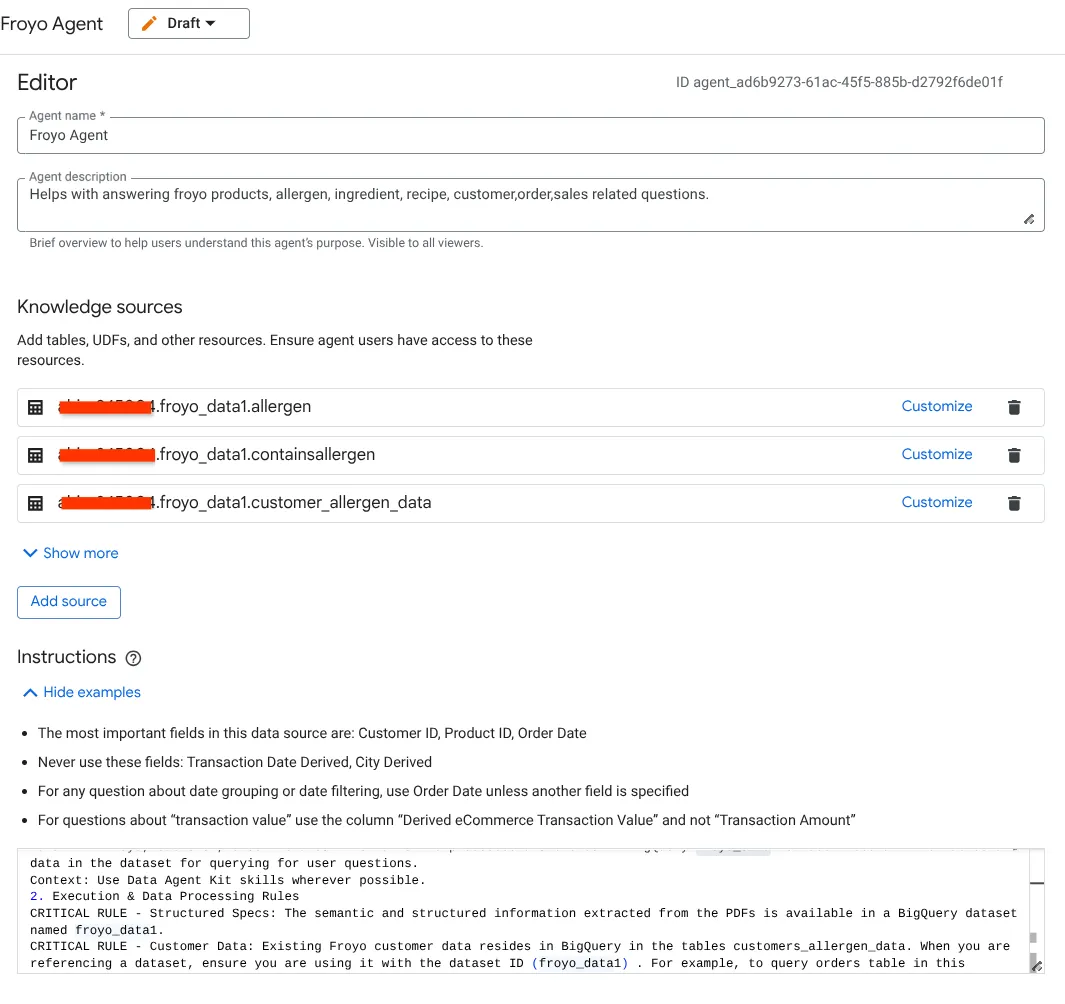
- עוברים לקטע 'מקורות מידע' ובוחרים את כל הטבלאות שמופיעות מתחת למערך הנתונים:
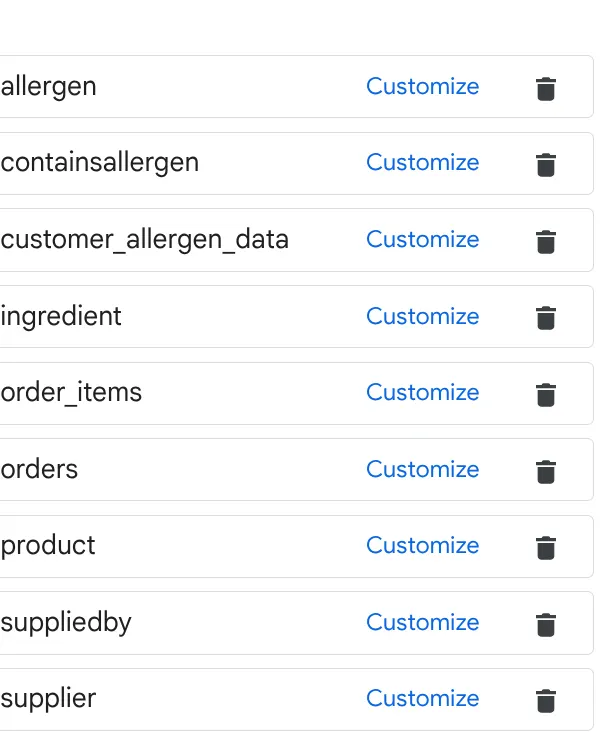
א. מוסיפים את הטבלאות שבתמונה שלמעלה ולוחצים על 'הוספת מקור'.
ב. לכל מקור, לוחצים על הלחצן התאמה אישית בצד שמאל. יוצג לכם הטופס הבא:
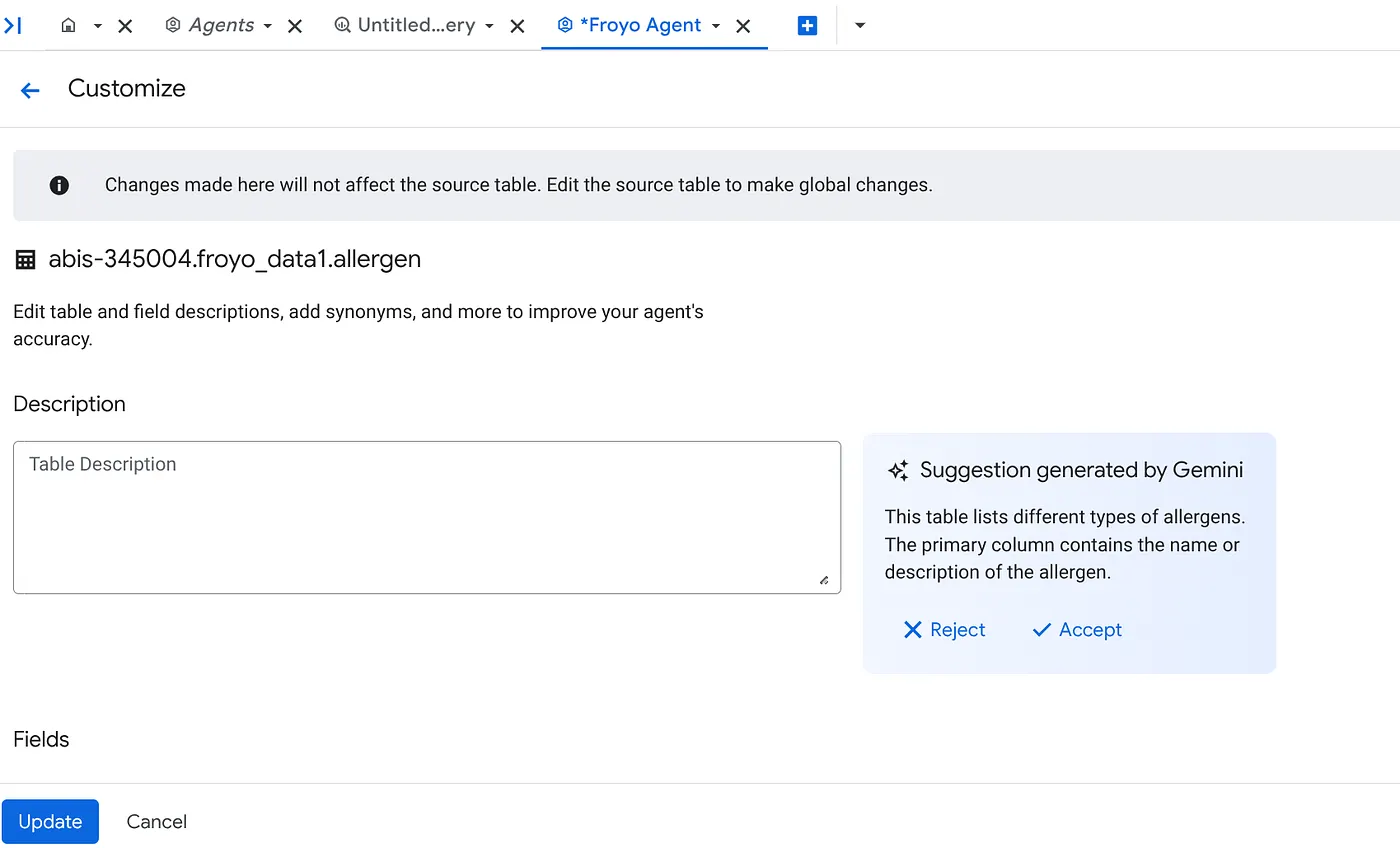
ג. לוחצים על 'אישור' לתיאור הטבלה.
ד. לוחצים על 'אישור' גם לתיאורים של כל אחד מהשדות.
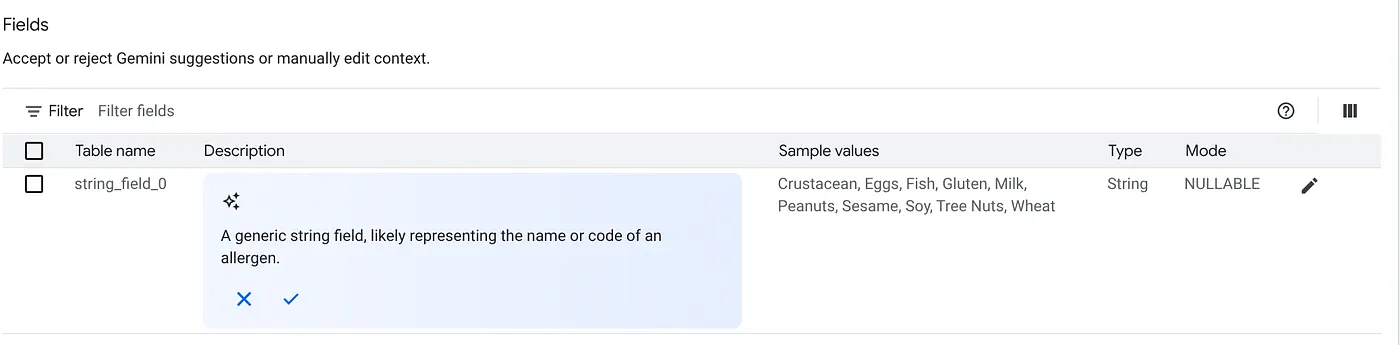
ה. לוחצים על 'עדכון'.
צריך לחזור על הפעולה הזו לכל הטבלאות במקור.
- הוראות להגדרה
מזינים כאן את אותן ההוראות שבהן השתמשנו ב-Antigravity IDE GEMINI.md:
1. Project Context
Project ID: <<YOUR_PROJECT_ID>>
Domain: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
Data: All froyo, customer, order related information is processed and stored in BigQuery froyo_data dataset. Use all the tables and data in the dataset for querying for user questions.
Context: Use Data Agent Kit skills wherever possible.
2. Execution & Data Processing Rules
CRITICAL RULE - Structured Specs: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named froyo_data.
CRITICAL RULE - Customer Data: Existing Froyo customer data resides in BigQuery in the tables customers_allergen_data. When you are referencing a dataset, ensure you are using it with the dataset ID (froyo_data) . For example, to query orders table in this dataset you should use froyo_data.orders.
- שומרים את הסוכן.
7. רוצה להתחיל צ'אט עם סוכן כדי לנתח את הנתונים?
- בודקים אותו בקטע התצוגה המקדימה בצד שמאל:
שואלים את השאלה:
Does midnight swirl contain any allergen?
התשובה:
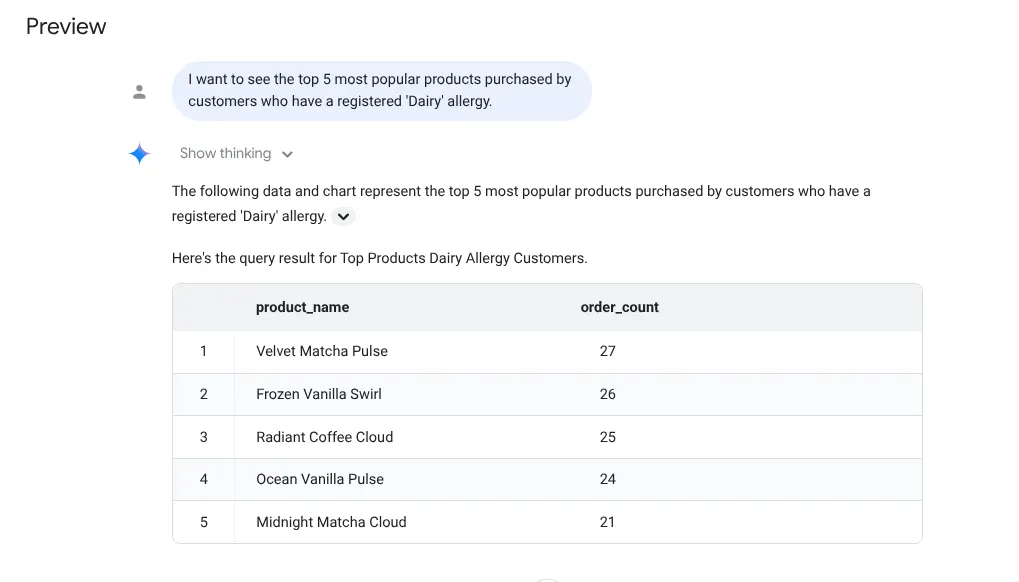
עכשיו נשאל את השאלה המורכבת:
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
תשובה:
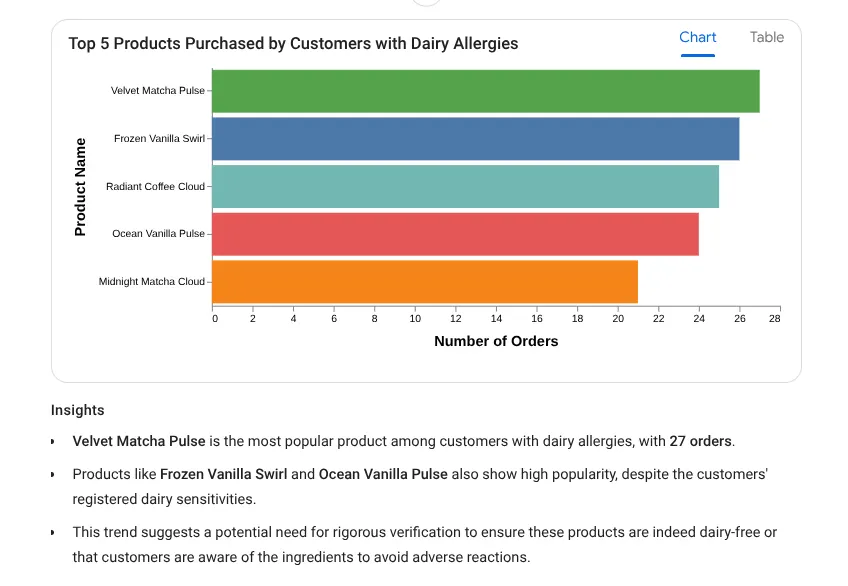
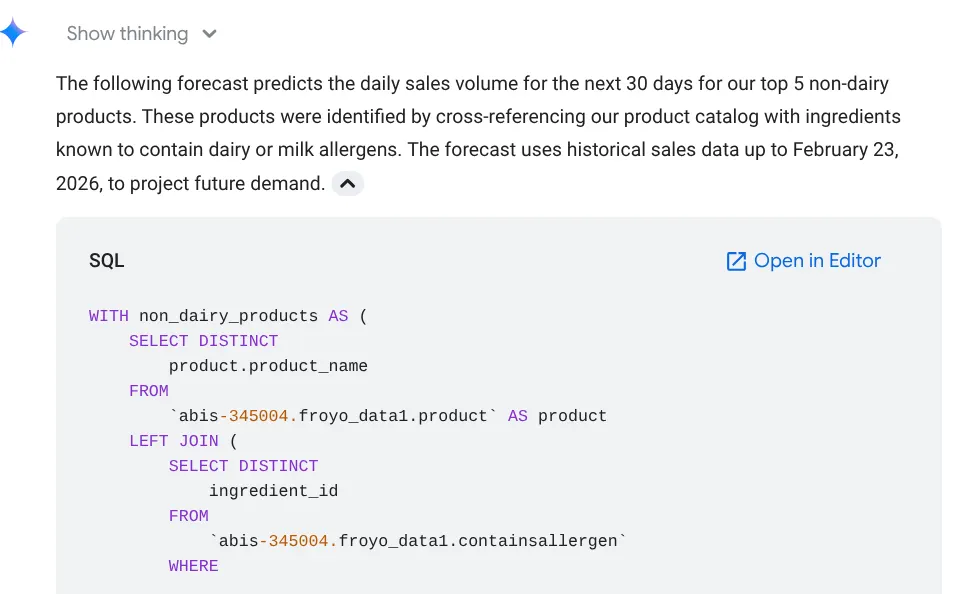
בואו ננסה עכשיו הנחיה לקבלת תובנה מעמיקה:
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
אפשר לראות שהשאילתה שבה נעשה שימוש מוצגת, עם תוצאת הטבלה והתרשים:
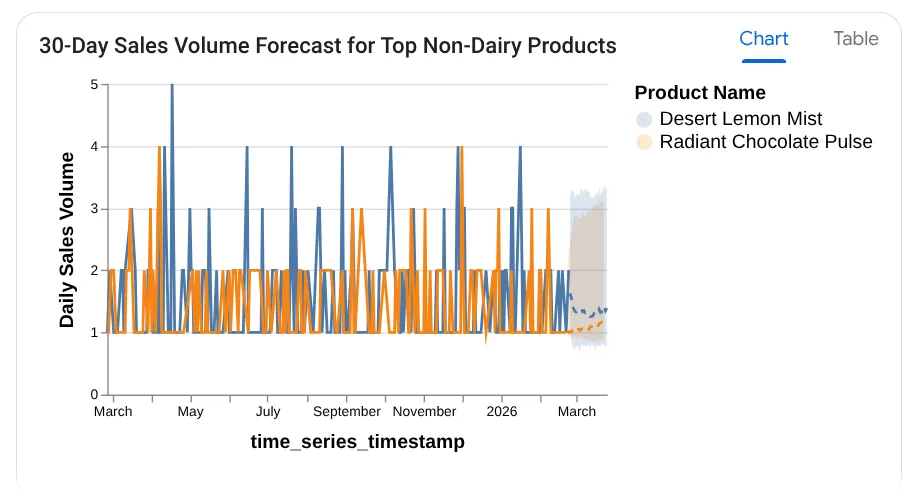

וואו! הוא השתלב היטב עם התרשימים והתובנות. הגיע הזמן לשאלה החשובה ביותר לגבי מוצרים.
8. המבחן האולטימטיבי
שואלים את השאלה:
What will be the top most selling product of 2026
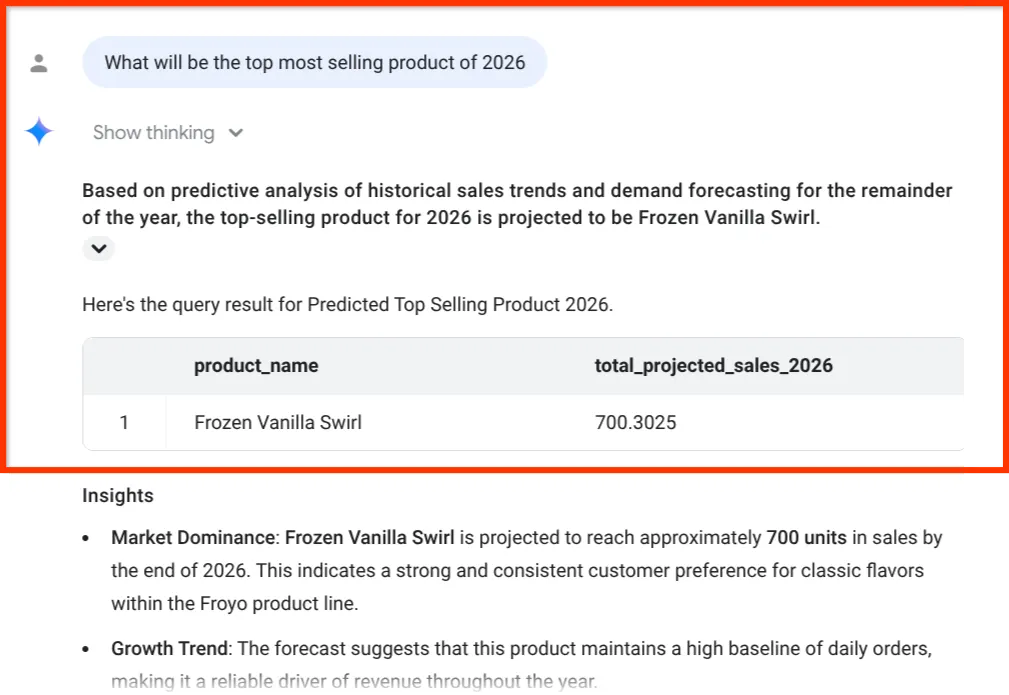

כדאי לעיין בתובנה הסופית. הסוכן של BigQuery Data לא סיפק לנו רק מספר, אלא קשר באופן מפורש בין תחזית המכירות לבין המלאי ושרשרת האספקה של המרכיבים – הנתונים המדויקים שחילצנו מקובצי PDF מבולגנים בחלק 1!
9. פרסום הסוכן בארגון
לוחצים על הלחצן פרסום בחלק העליון של סוכן התצוגה המקדימה.
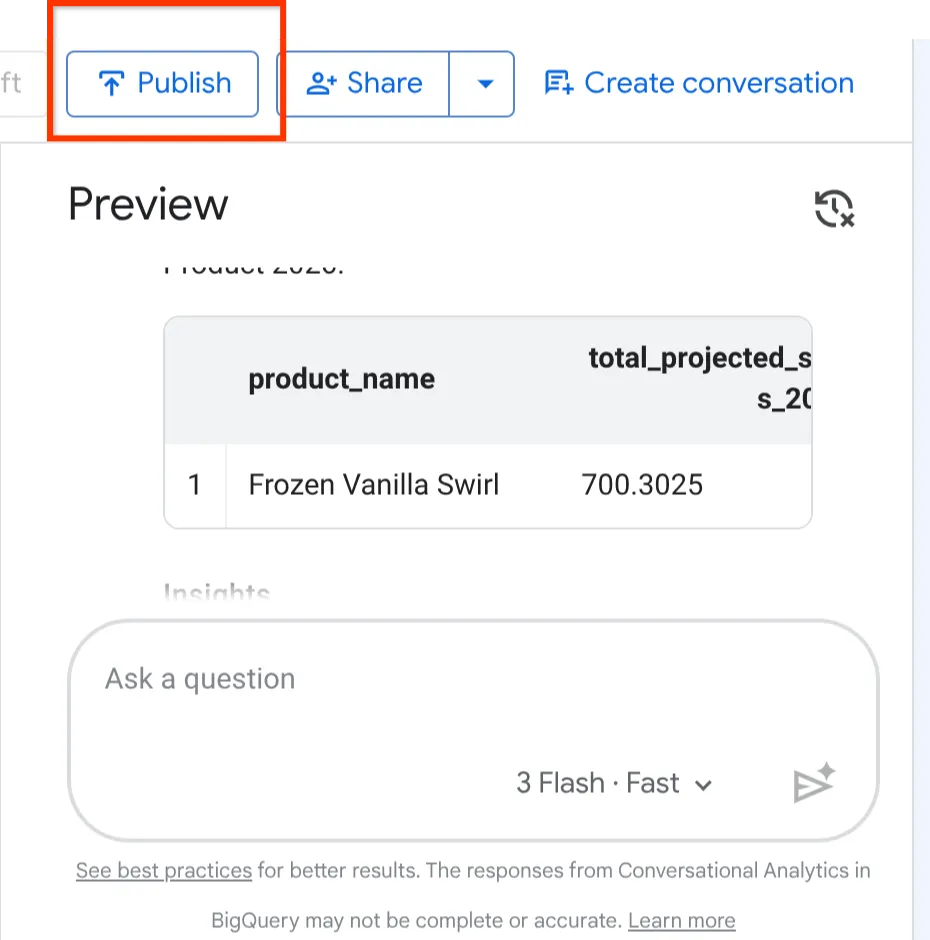
אחרי שבנינו, הגדרנו ובדקנו את סוכן Froyo, הגיע הזמן להשיק אותו לשאר העסק.
בפינה השמאלית העליונה של דף הגדרת הסוכן, לוחצים על הלחצן Publish (פרסום).
כשמפרסמים את הסוכן, הוא הופך לזמין באופן מיידי בשלושה ערוצים חזקים לארגונים, לכם ולכל מי ששיתפתם איתו את הסוכן:
- BigQuery: עכשיו אנליסטים של נתונים יכולים לשוחח עם הסוכן הזה ישירות ממרכז הסוכנים או מתוך סביבת העבודה של BigQuery Studio SQL.
- Conversational Analytics API: המפתחים יכולים לגשת לסוכן הזה באמצעות API בארכיטקטורת REST, וכך לשלב את ניתוח השיחות הזה באפליקציות אינטרנט פנימיות בהתאמה אישית.
- Data Studio: מנהלים בכירים יכולים ליצור אינטראקציה עם הסוכן הזה וליצור מרכזי בקרה דינמיים לשיחות ישירות ב-Data Studio.
הצלחנו להוציא את הנתונים שלנו מתוך סילו ולהעביר אותם ישירות לאנשים שזקוקים להם, בדיוק במקום שבו הם כבר עובדים!
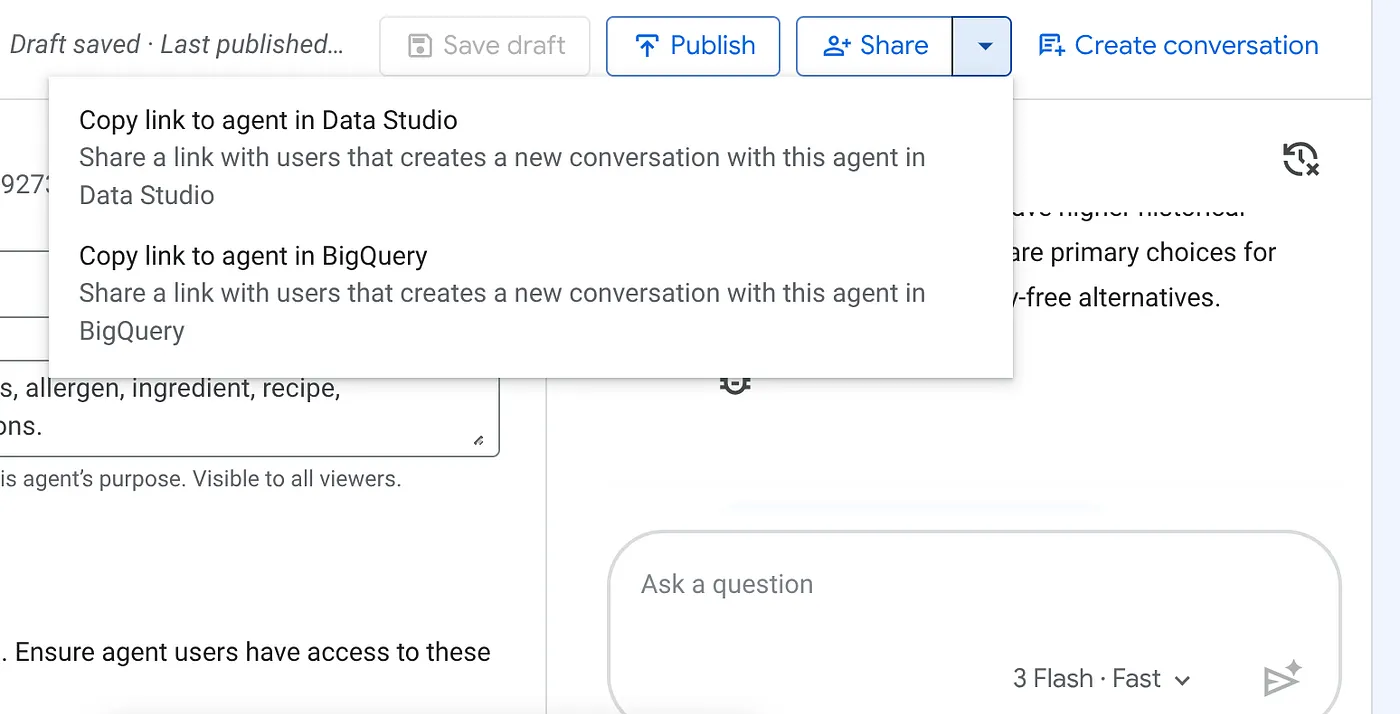
לוחצים על התפריט הנפתח של לחצן השיתוף בחלק העליון של סוכן BigQuery שפורסם ובוחרים באפשרות 'העתקת הקישור לסוכן ב-Data Studio' מהרשימה:
מדביקים את הקישור בדפדפן ומקישים על Enter. צריך לאשר את ההתראה על גישה לאינטראקציה עם הסוכן:
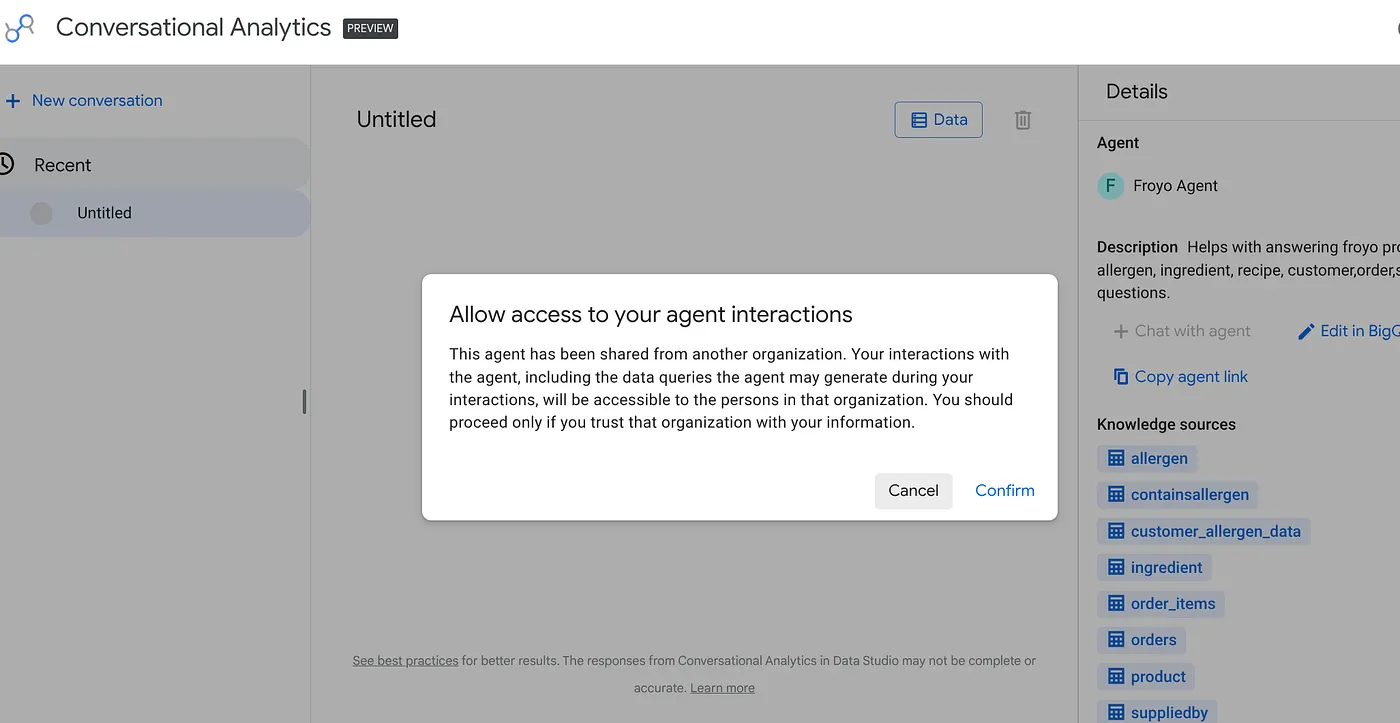
אתם יכולים להתחיל שיחות אינטראקטיביות וליצור תצוגות חזותיות עם הסוכן שפורסם לאחרונה מ-Data Studio, וכך גם צוותי הניהול וצוותים אחרים שזקוקים למידע הזה.
10. הסרת המשאבים
בסיום המעבדה, אל תשכחו להסיר את ההרשאות של כל המשתמשים לסוכן BigQuery שיצרתם.
11. מעולה!
יצרתם Agentic Data Cloud!
לא יצרתם רק צ'אטבוט פשוט. במהלך חמשת המפגשים האלה, תכננתם בהצלחה מערכת AI ארגונית מלאה, מודרנית ומוערכת מאפס. עברתם מ'נתונים לא גלויים' לניתוח טרנזקציות בזמן אמת, ולבסוף לחיזוי עסקי באמצעות שיחות.
12. התמונה המלאה
כדאי לעצור לרגע ולבדוק מה השגנו בסדרה הזו. לא בנינו רק צ'אטבוט פשוט. תכננו Agentic Data Cloud מלא ומודרני:
חלק 1: ביטול הנעילה של נתונים לא גלויים על ידי הפיכת קובצי PDF לטבלאות יחסיות מובְנות באמצעות Knowledge Catalog.
חלק 2: ביטול של סילו נתונים באמצעות איחוד של מחסן הנתונים לצורכי ניתוח ישירות למסד נתונים טרנזקציוני של AlloyDB.
חלק 3: שיפור היכולות של המשתמשים באמצעות יצירת מערכת הפעלה מרובת סוכנים שמבצעת בצורה חלקה כלים מאובטחים למסדי נתונים באמצעות פרוטוקול MCP
חלק 4: הטמענו צינור הערכה קפדני כדי לזהות הזיות ופריצות, וכך להבטיח בטיחות.
חלק 5: תובנות נגישות לכולם באמצעות ANTIGRAVITY IDE וניתוח נתוני שיחות ב-BigQuery.
זה העתיד של תוכנות לארגונים. סוכן ה-AI הוא כבר לא רק עטיפה של LLM. זהו מנוע תזמור מאובטח, משולב ומאומת, שנמצא מעל פלטפורמת נתונים מאוחדת.