
1. Panoramica
Diamo un'occhiata all'architettura massiccia che abbiamo creato nelle ultime quattro parti:
Parte 1: abbiamo utilizzato BigQuery Knowledge Catalog per trasformare i PDF grezzi delle ricette di Froyo in tabelle relazionali strutturate.
Parte 2: abbiamo creato un bridge transazionale Zero-ETL, federando il nostro data warehouse BigQuery direttamente in AlloyDB.
Parte 3: abbiamo orchestrato un'applicazione multi-agente (FroyoOS) utilizzando Agent Development Kit e MCP Toolbox.
Parte 4: abbiamo dimostrato che il nostro agente è sicuro per la produzione creando una pipeline di valutazione a doppio binario.
Le nostre operazioni funzionano perfettamente. Ma cosa dire degli sviluppatori e dei business analyst che devono comprendere le enormi quantità di dati generate da questo sistema?
Oggi esploreremo il futuro dell'analisi. Inizieremo direttamente nell'editor di codice Antigravity IDE con Google Cloud Data Agent Kit, per poi passare alla console Google Cloud per visualizzare i dati utilizzando BigQuery Conversational Analytics.
Iniziamo a creare.
Obiettivi didattici
In questo ultimo codelab della serie Agentic Data Cloud, metterai insieme tutti i componenti della tua architettura per fornire approfondimenti aziendali utili. Scoprirai:
- IDE-First Analytics:come installare e configurare l'IDE ANTIGRAVITY e il Google Cloud Data Agent Kit per eseguire query sull'architettura direttamente dal tuo ambiente di sviluppo.
- BigQuery conversazionale:come creare, configurare e istruire gli agenti di dati BigQuery per automatizzare attività SQL complesse e previsioni utilizzando il linguaggio naturale.
- Democratizzazione dei dati:come pubblicare gli agenti nell'azienda, rendendoli accessibili ad analisti e utenti aziendali in tutta l'organizzazione.
- Visualizzazione degli insight:come integrare perfettamente l'analisi conversazionale del tuo agente in Data Studio per creare dashboard dinamiche e pronte per le previsioni.
- L'ecosistema Agentic Data Cloud:come articolare il valore della tua architettura end-to-end, dai dati non strutturati non elaborati nella Parte 1 ai dashboard pronti per i dirigenti nella Parte 5.
Requisiti
2. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se vuoi autenticarti
gcloud auth login
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Abilita le API richieste: esegui questo comando per abilitare tutte le API richieste:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. Espansione del data warehouse
Ricordi le tabelle BigQuery che abbiamo creato dai nostri dati non strutturati?
Per eseguire analisi significative, abbiamo bisogno dei dati storici delle transazioni. In BigQuery, nel set di dati froyo_data, creiamo tre nuove tabelle per simulare anni di attività in franchising:
- froyo_data.orders: intestazioni degli ordini storici (date, ID negozio, totali)
- froyo_data.order_items: dettagli delle voci di ordine (quantità, prezzi)
- froyo_data.customer_allergen_data: una tabella CRM che tiene traccia delle allergie note dei nostri clienti fedeli
Aggiungiamo queste tabelle relative alle vendite e ai clienti al set di dati in preparazione del nostro caso d'uso di analisi.
- Vai a terminale Cloud Shell dalla console Google Cloud.
- Vai alla cartella principale del tuo spazio di lavoro o alla cartella principale del progetto froyo-data (su cui abbiamo lavorato nelle ultime due parti di questa serie).
- Scarica i tre file di dati storici (in formato CSV) nella directory di lavoro eseguendo i seguenti comandi uno alla volta:
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/customer_allergen_data.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/order_items.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/orders.csv
- Una volta visualizzati i file nella radice della directory di lavoro, vai al terminale Cloud Shell attivandolo.
- Vai alla directory in cui si trovano questi tre file nel terminale Cloud Shell.
- Assicurati che BigQuery abbia il set di dati denominato "froyo_data" della parte 1 di questa serie (in caso contrario, torna indietro e crea il set di dati e le tabelle).
- Esegui questi comandi dal terminale Cloud Shell:
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.orders \
./orders.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.order_items \
./order_items.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.customer_allergen_data \
./customer_allergen_data.csv
In questo modo dovrebbero essere create le tre tabelle aggiuntive nel set di dati froyo_data.
4. L'esperienza dello sviluppatore: entra nel "Data Agent Kit"
Tradizionalmente, se uno sviluppatore voleva analizzare i dati o scrivere query di machine learning complesse, doveva cambiare costantemente contesto tra IDE, console di database e documentazione.
Non più. Con l'estensione Google Cloud Data Agent Kit appena lanciata, il tuo IDE diventa un potente strumento per la gestione dei dati.
ANTIGRAVITY IDE
ANTIGRAVITY IDE è l'ambiente di sviluppo di nuova generazione di Google, agent-first, progettato specificamente per l'era dell'AI. Integra in modo nativo finestre contestuali multimodali di grandi dimensioni e l'utilizzo autonomo degli strumenti direttamente nell'editor, consentendo agli sviluppatori di orchestrare le risorse cloud e le pipeline di dati complesse senza mai uscire dal codice.
Configurazione dell'IDE ANTIGRAVITY
- Scarica l'IDE: vai su antigravity.google e scarica l'IDE Antigravity per il tuo sistema operativo (Windows, macOS o Linux).
- Installa e avvia: esegui il programma di installazione e apri l'applicazione.
- Fai clic su Continua con Google, seleziona il tuo account Gmail e autorizza.
- Una volta effettuato l'accesso, crea una cartella di lavoro (workspace/ progetto). Chiamiamolo "Agent Data Cloud".
Dovrebbe essere visualizzato nell'elenco "Progetti" a sinistra:
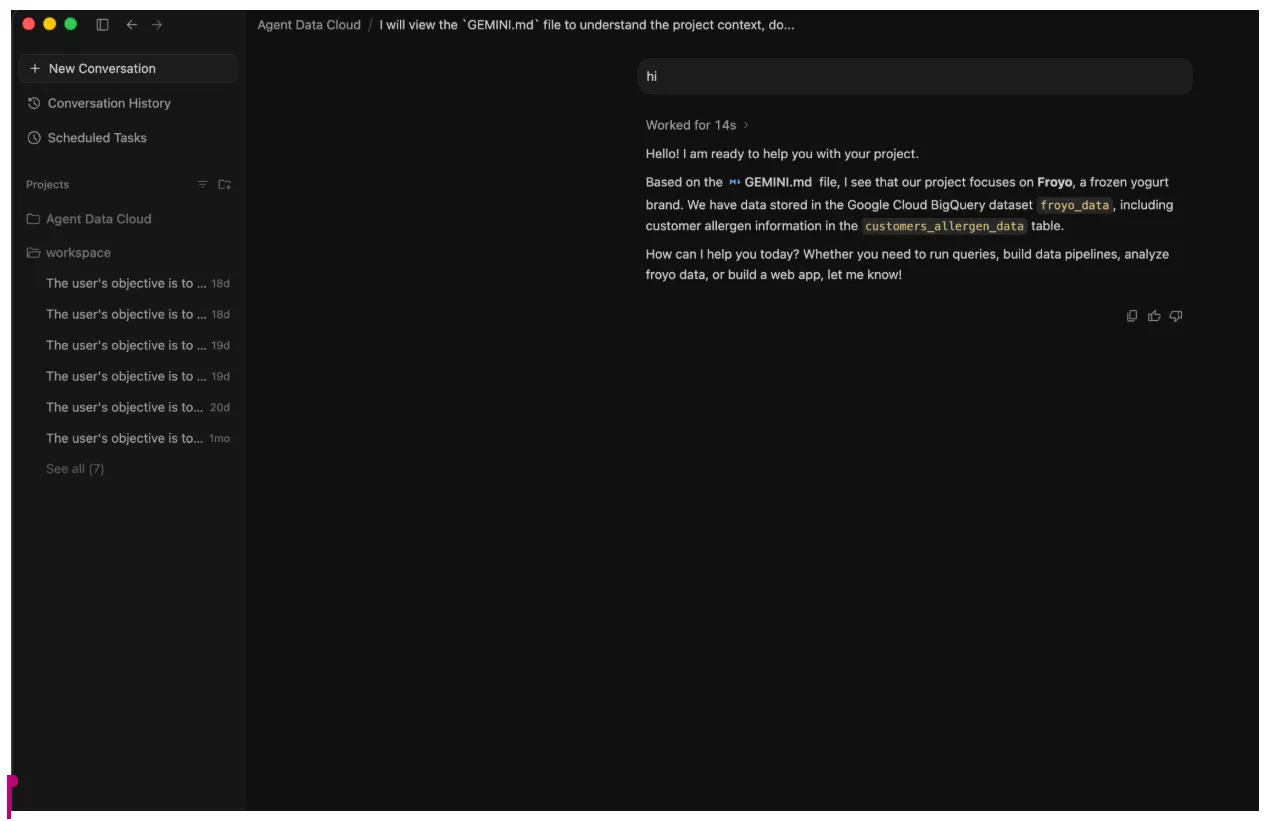
- Inizia una chat preliminare con l'agente, ad esempio con un semplice "ciao".
- Nell'angolo in alto a destra, prendi nota del pulsante Apri IDE.
Ma prima di poter fare clic, devi installare Antigravity IDE. Vai alla pagina antigravity.google/download e scorri verso il basso fino alla sezione Antigravity IDE, scarica la variante che ti serve.
Una volta scaricato, torna all'istanza di Antigravity aperta e fai clic sul pulsante Apri IDE nell'angolo in alto a destra.
- Dovresti vedere i popup relativi alle autorizzazioni. Continua ad aprirli.
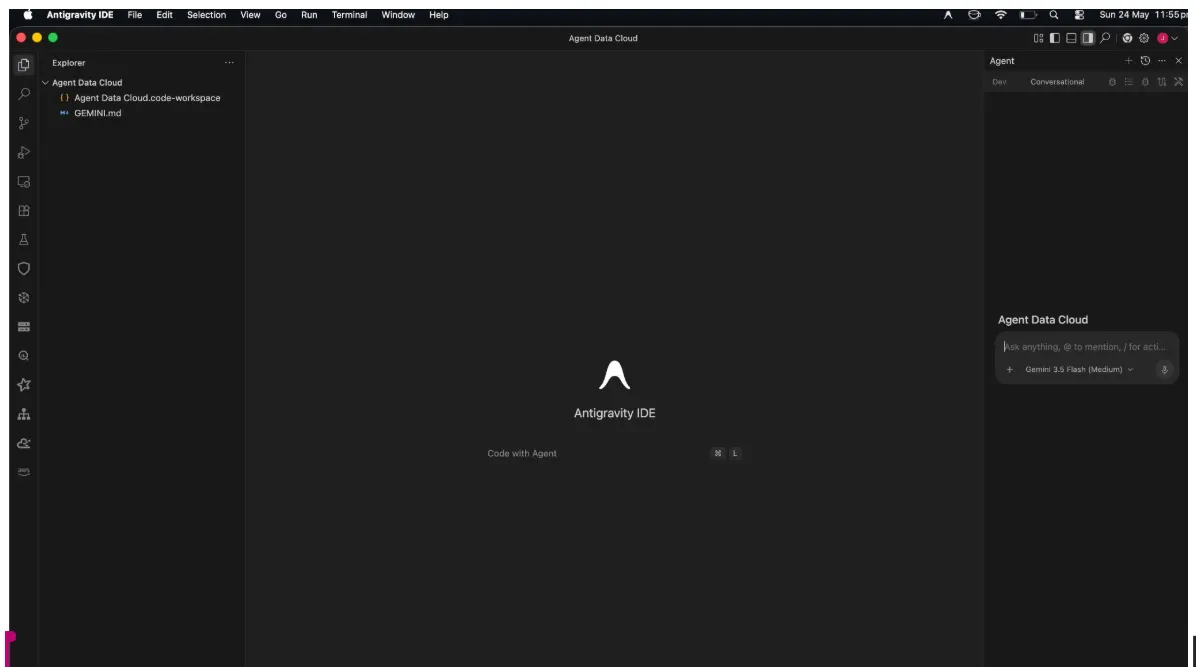
Sul lato destro vedi il riquadro dell'agente, a sinistra l'esploratore del progetto e al centro lo spazio per lo sviluppo.
Configurare l'estensione Data Agent Kit
- Installa l'estensione: apri il marketplace delle estensioni all'interno dell'IDE ANTIGRAVITY. Cerca e installa l'estensione Google Cloud Data Agent Kit.
- Fai clic sul pulsante Installa e, al termine dell'operazione, potrai visualizzare l'estensione nel riquadro di navigazione.
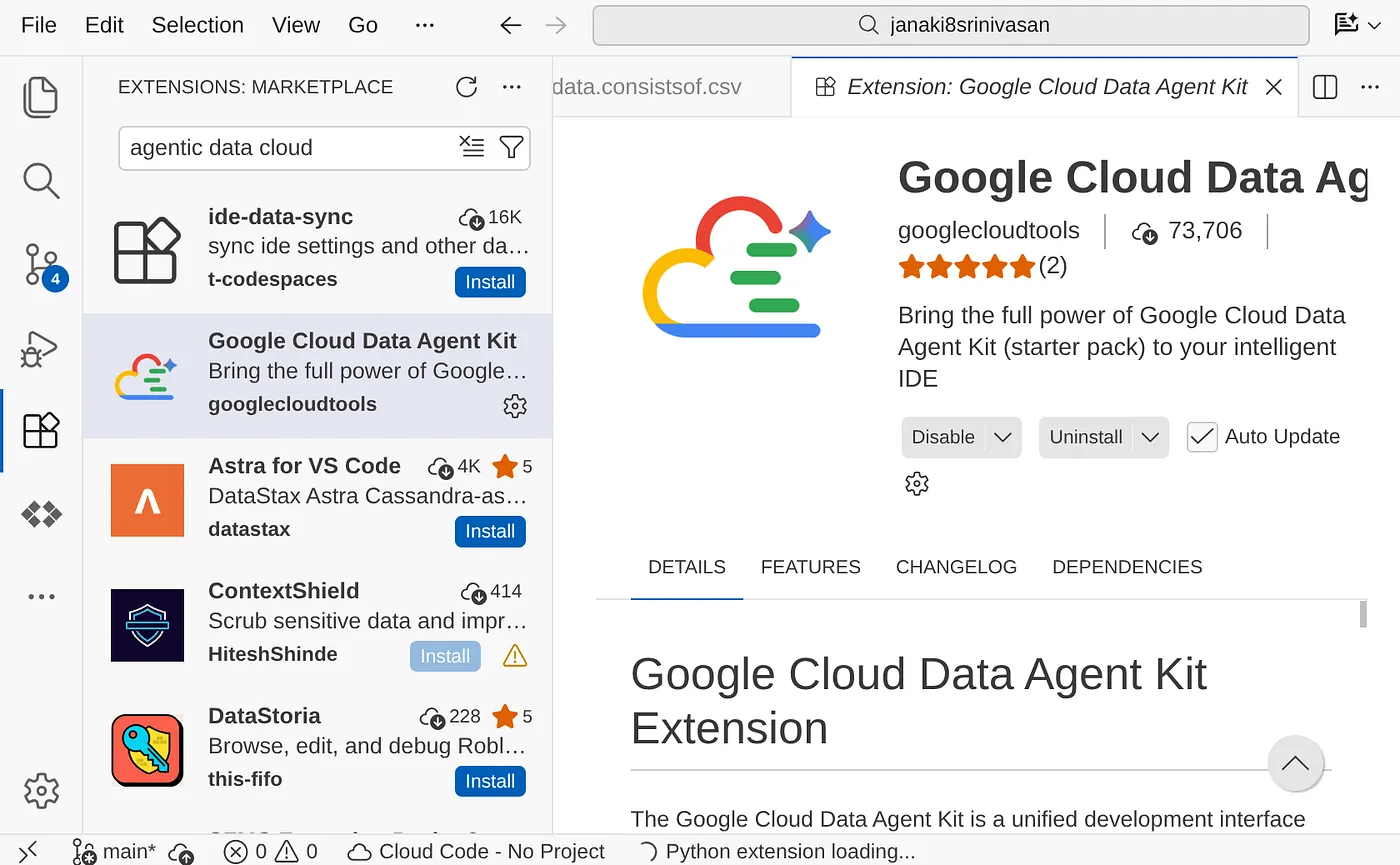
- Fai clic e si aprirà l'explorer di Google Cloud Data Agent Kit. Vai alla sezione SETTINGS (IMPOSTAZIONI) e fai clic su Settings (Impostazioni). Inserisci i dettagli del progetto e la regione e salva.
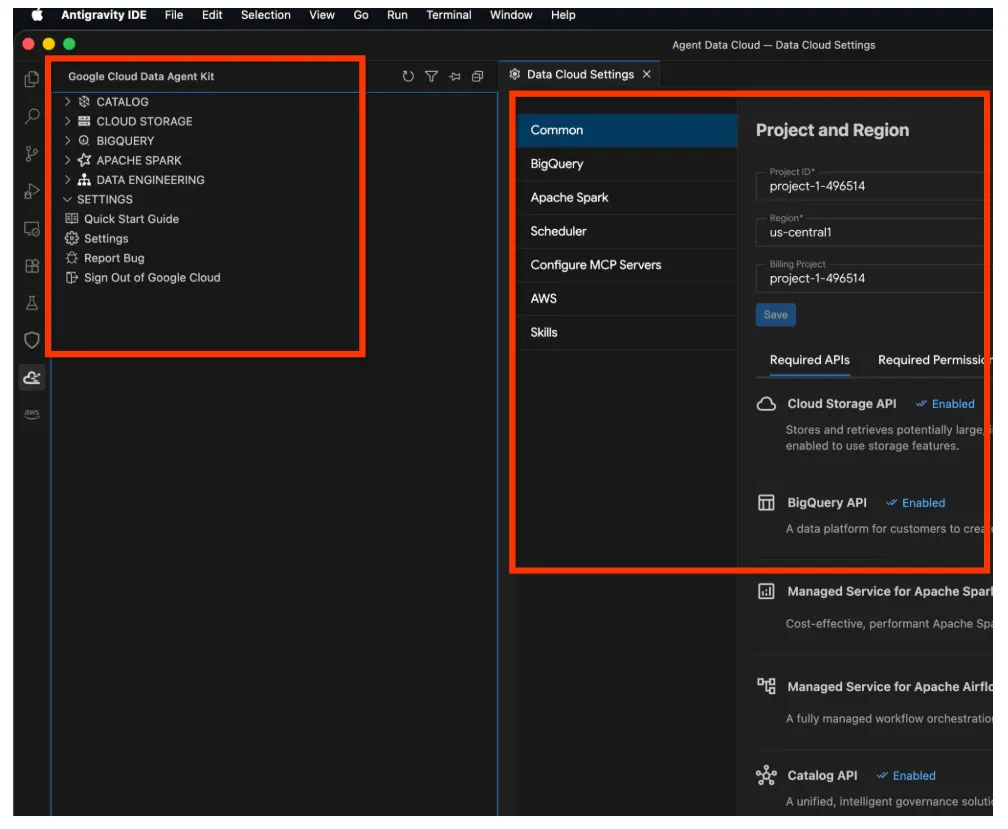
- Ora fai clic su Esplora progetti nella parte superiore del riquadro di navigazione. Dovrebbe aprirsi l'esploratore del progetto nel riquadro di esplorazione.
- Fai clic con il tasto destro del mouse nello spazio dell'explorer e crea un nuovo file denominato "GEMINI.md".
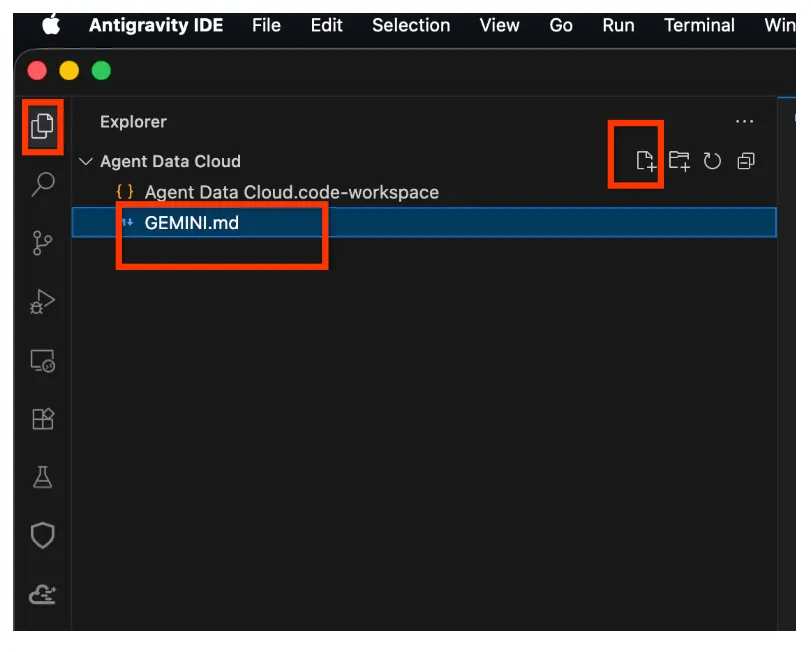
- Incolla il seguente codice in GEMINI.md (non dimenticare di sostituire <<YOUR_PROJECT_ID>> con il tuo valore):
## 1. Project Context
- **Project ID**: <<YOUR_PROJECT_ID>>
- **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
- **Data**: All froyo, customer, order related information is processed and stored in BigQuery `froyo_data` dataset.
## 2. Execution & Data Processing Rules
- **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `froyo_data`.
- **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the tables `customers_allergen_data`.
- ** CRITICAL RULE - Sales Data**: Sales data is present in tables `orders` and `order_items`.
- ** CRITICAL RULE - General: When you are referencing a dataset, ensure you are using it with the dataset ID (`froyo_data`) . For example, to query orders table in this dataset you should use `froyo_data.orders`.
Ora hai un agente AI altamente competente direttamente nel tuo IDE, pronto a scrivere codice, generare SQL e analizzare la tua architettura.
Ora abbiamo una sfida analitica affascinante: possiamo correlare le nostre vendite storiche con i dati complessi e dedotti sugli allergeni che abbiamo estratto dai PDF nella prima parte?
5. Inferenza dell'intelligence tramite l'agente IDE
Chiediamo al nostro agente IDE di fare il lavoro più pesante. Apri la finestra di chat di Agent Data Kit direttamente nell'IDE ANTIGRAVITY e inserisci il seguente prompt:
Does Midnight Swirl contain any allergen?
Ti verrà chiesto di concedere una serie di autorizzazioni, consentile in base alle tue esigenze.
Infine, recupererà la risposta per te al termine dell'analisi:
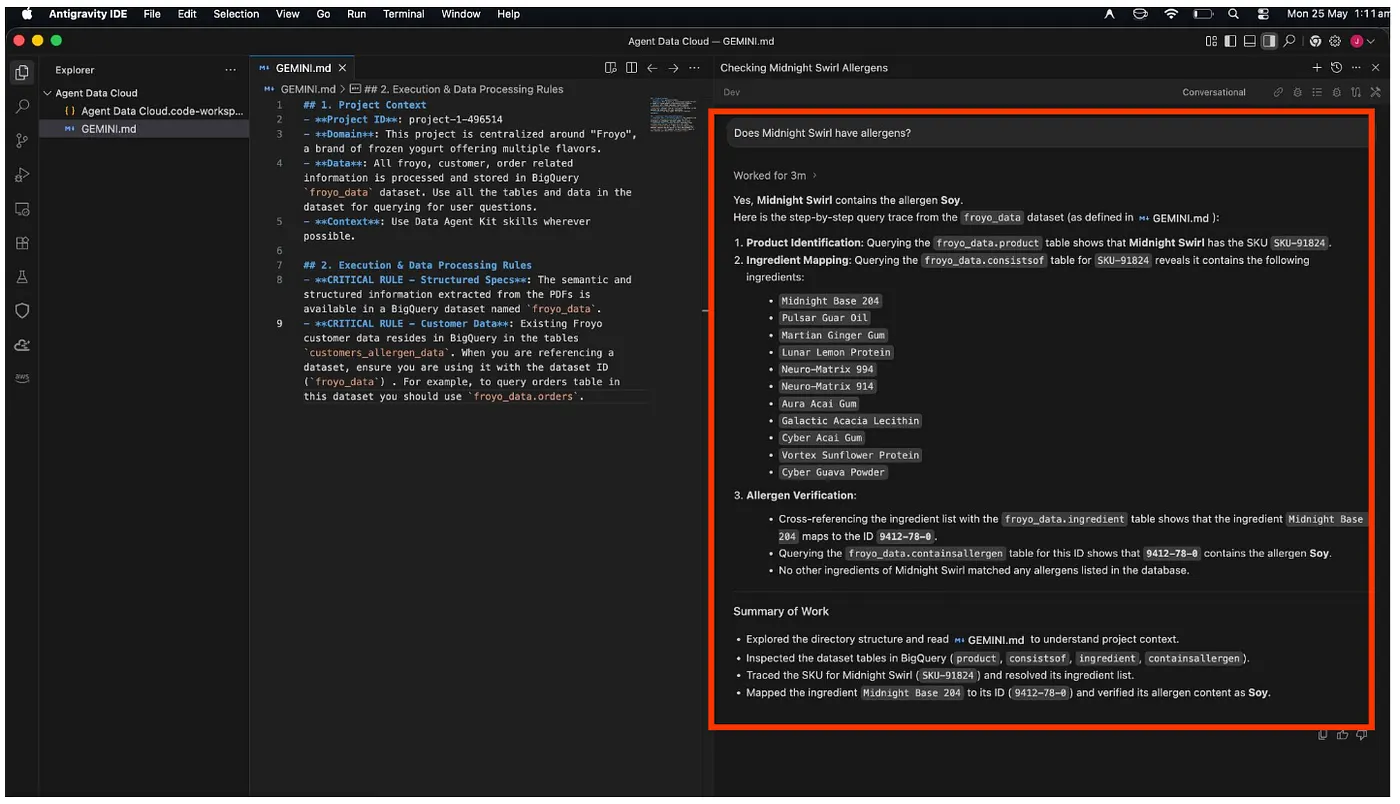
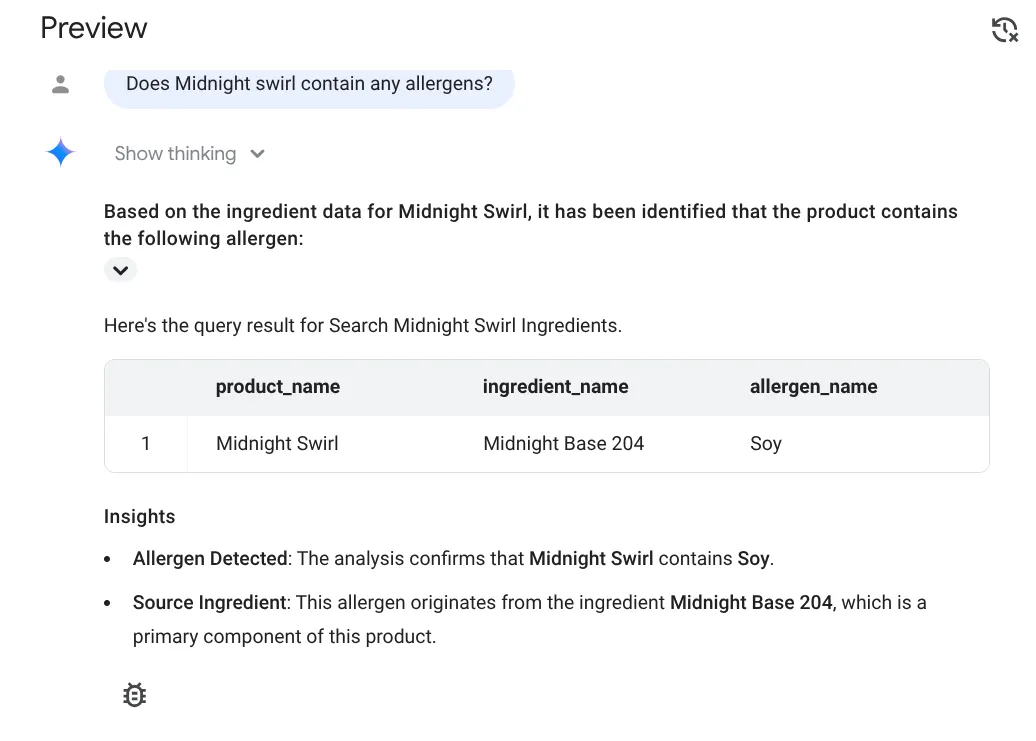
Evviva!!! Ha identificato correttamente che l'articolo Midnight Swirl contiene soia.
Ora proviamo con una domanda un po' più complessa. Invia il seguente prompt nell'IDE Antigravity:
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
Risposta:
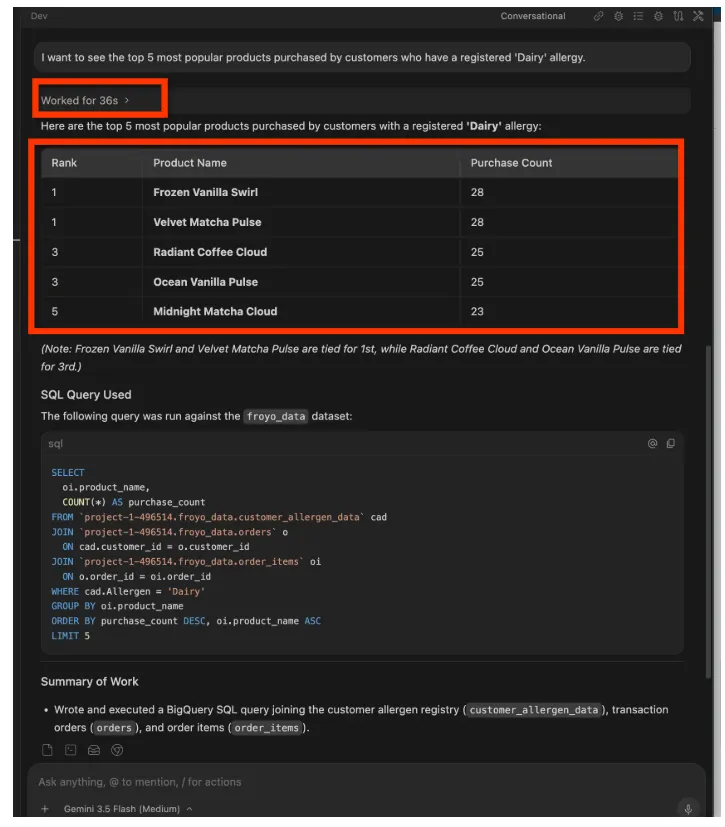
Puoi continuare. Prova prompt come:
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
Senza la necessità di cercare la sintassi BQML, Agent Data Kit inserisce il codice CREATE MODEL e ML.FORECAST esatto nell'editor. Puoi eseguire questa operazione direttamente nel tuo ambiente BigQuery senza mai uscire dall'IDE ANTIGRAVITY.
Incredibile!
6. Analisi conversazionale in BigQuery
Gli sviluppatori adorano l'IDE, mentre gli utenti aziendali e i dirigenti utilizzano la console cloud. Non vogliono vedere SQL, ma solo le risposte.
Iniziamo:
- Concedere a te i ruoli richiesti
Vai alla pagina IAM del progetto e concediti il ruolo Gemini Data Analytics Data Agent Owner:
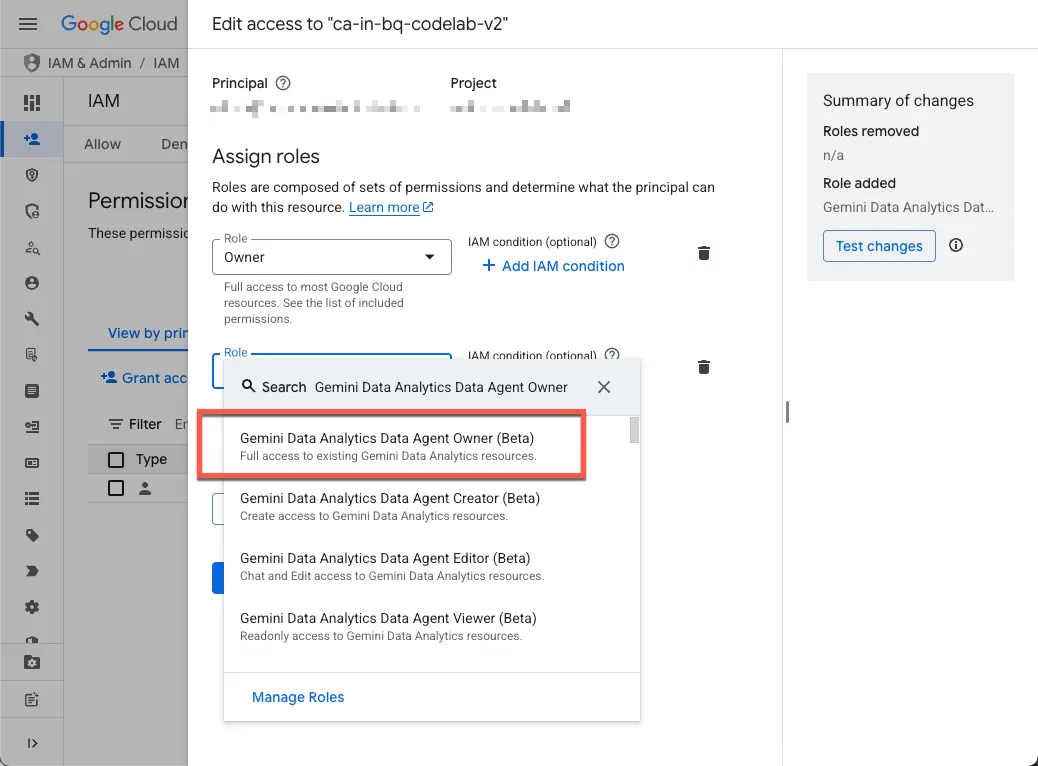
Questo ruolo ti concede l'autorizzazione per creare, modificare, condividere ed eliminare tutti gli agenti di dati nel progetto.
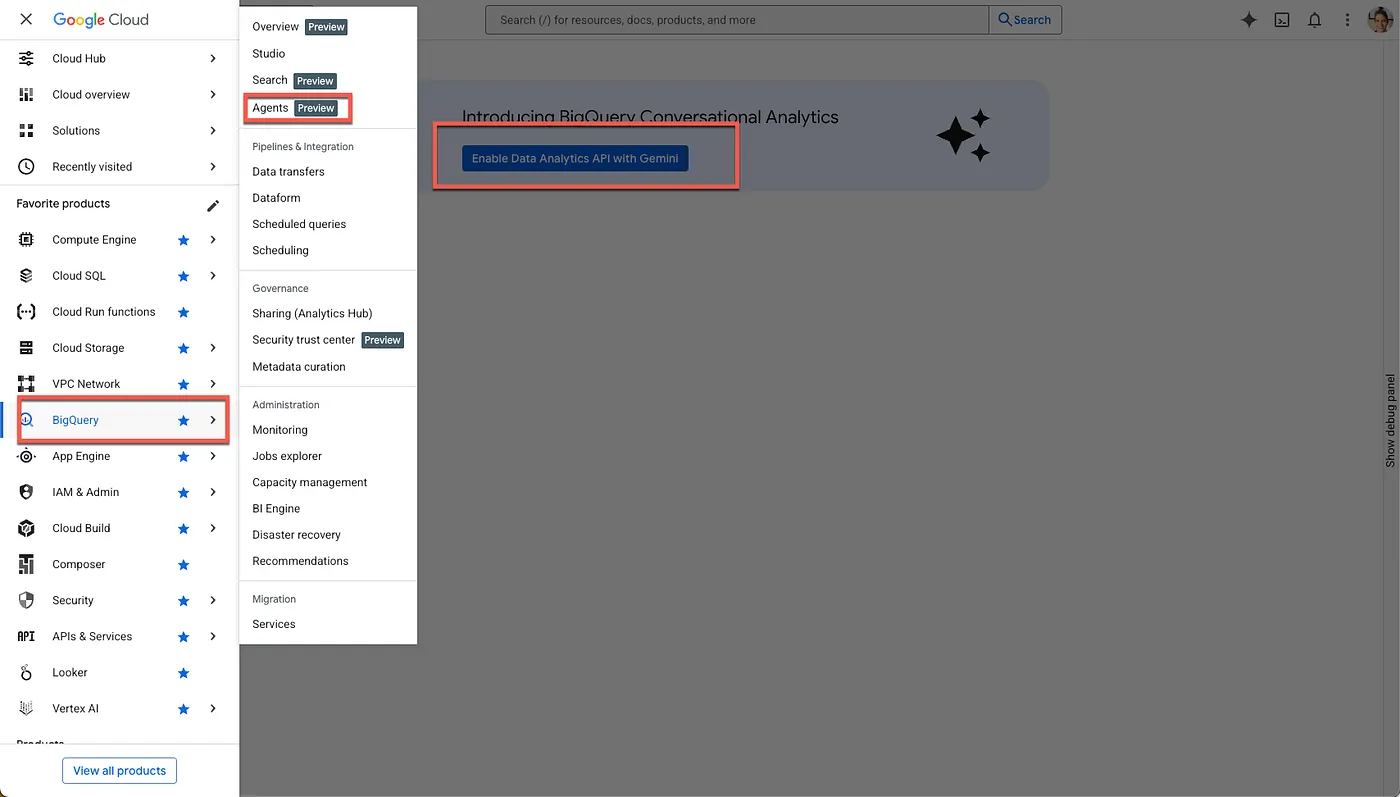
- Abilita le API richieste
Vai a BigQuery nella console Google Cloud. Utilizza il menu di navigazione della barra laterale o il menu di ricerca nella parte superiore della pagina per andare a BigQuery > Agenti.
Fai clic su Abilita l'API Data Analytics con Gemini:
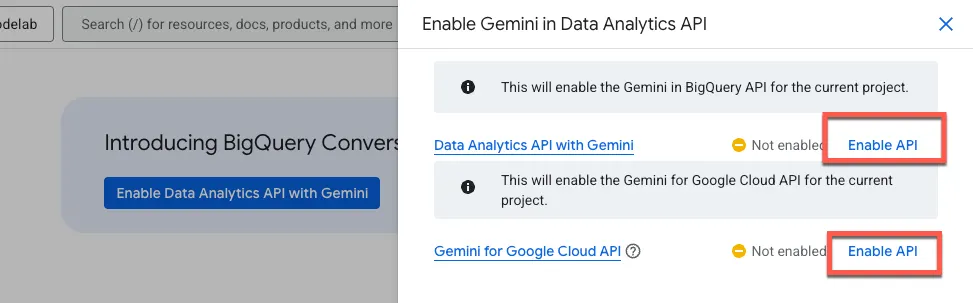
Attiva sia l'API BigQuery sia l'API Gemini for Google Cloud:
Ora dovresti vedere la nuova pagina dell'agente:
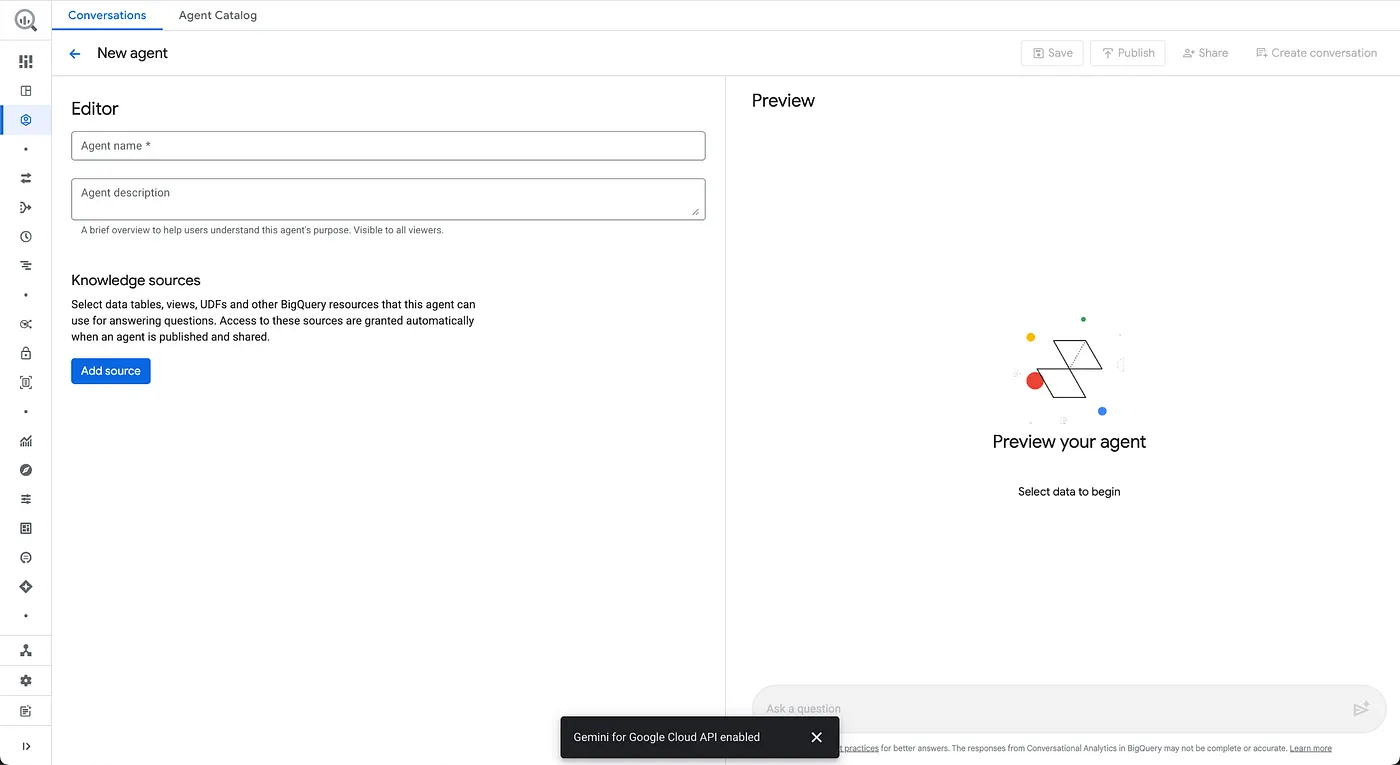
- Configurare le informazioni dell'agente
Nome agente: Froyo Agent
Descrizione dell'agente: aiuta a rispondere a domande relative a prodotti surgelati, allergeni, ingredienti, ricette, clienti, ordini e vendite.
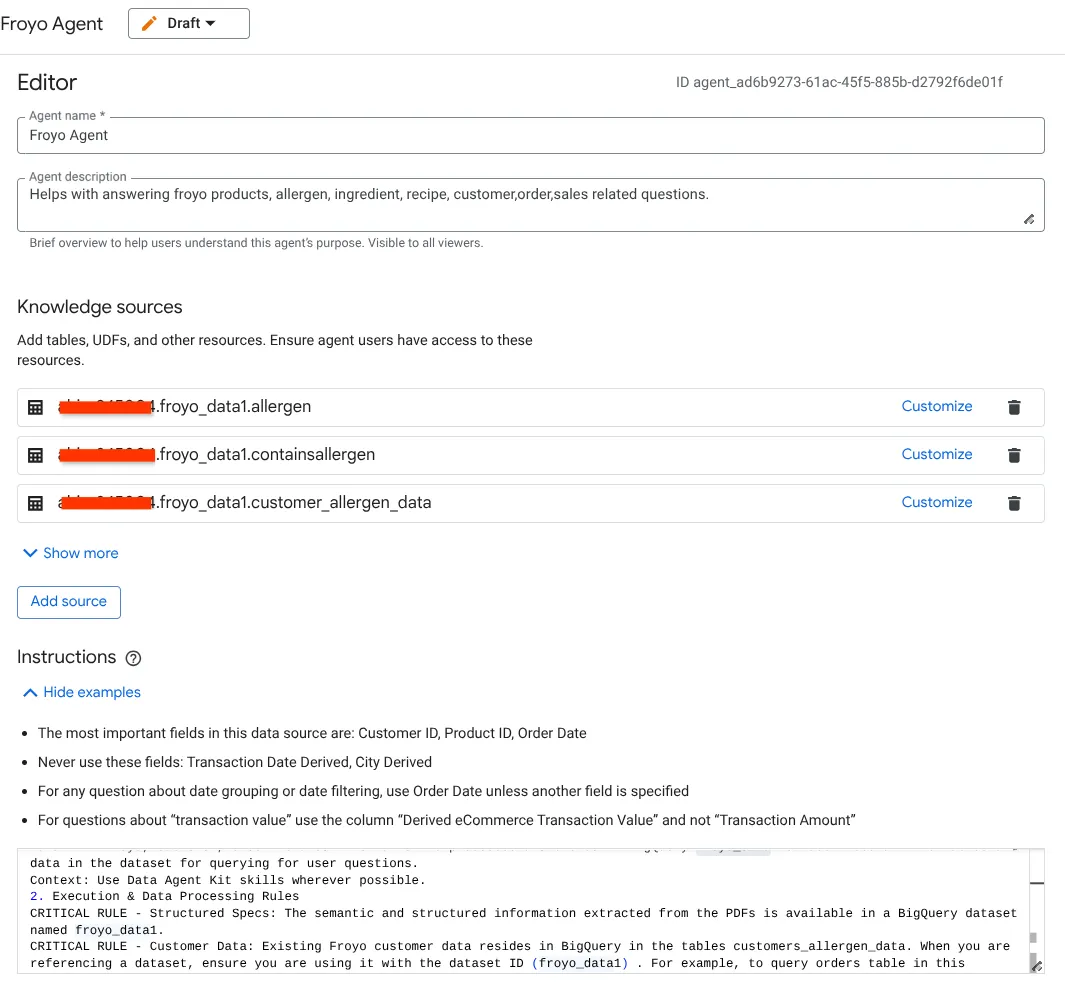
- Vai alla sezione Origini della conoscenza e seleziona tutte le tabelle seguenti dal tuo set di dati:
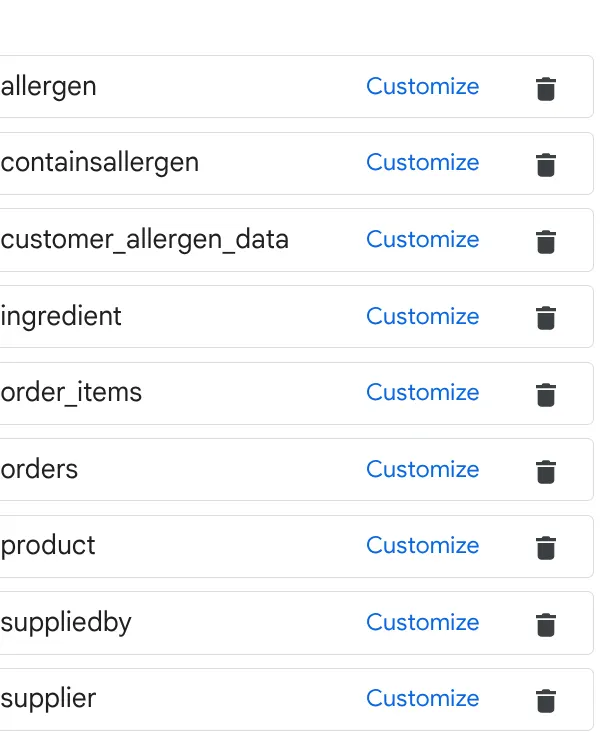
a. Aggiungi le tabelle nell'immagine sopra e fai clic su Aggiungi origine.
b. Per ogni fonte, fai clic sul pulsante Personalizza a destra. Verrà visualizzato il modulo seguente:
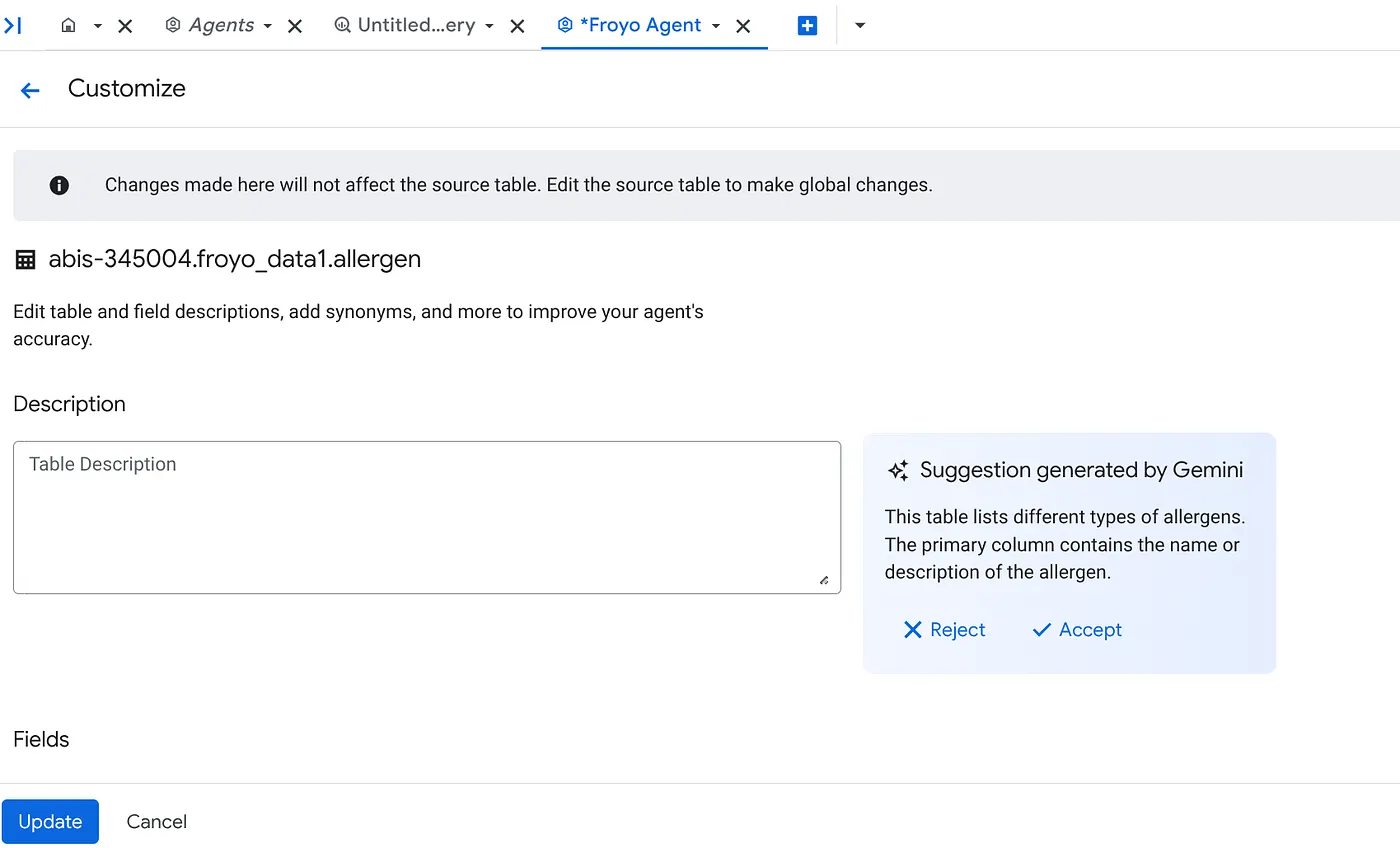
c. Fai clic su "Accetta" per la descrizione della tabella.
d. Fai clic su "Accetta" anche per le descrizioni di ciascun campo.
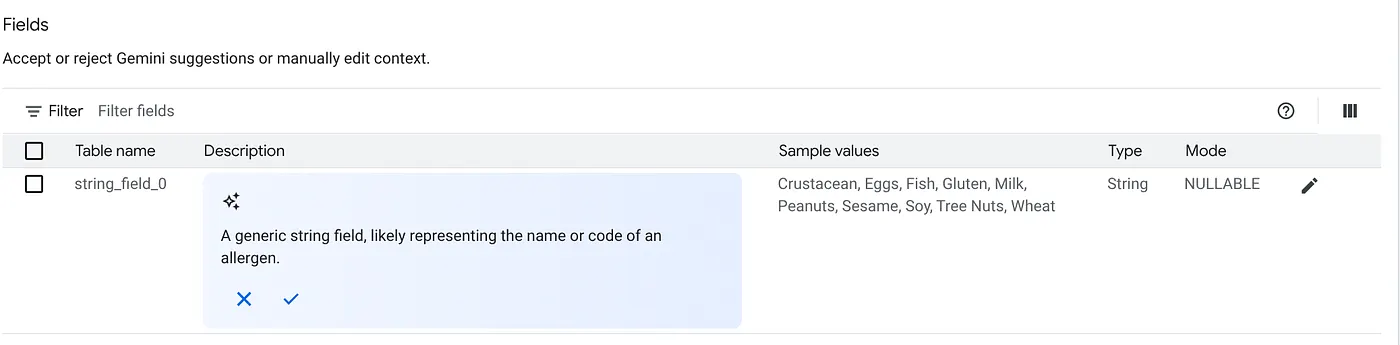
e. Fai clic su Aggiorna.
Devi ripetere questa operazione per tutte le tabelle dell'origine.
- Configura le istruzioni
Inserisci qui le stesse istruzioni che abbiamo utilizzato in Antigravity IDE GEMINI.md:
1. Project Context
Project ID: <<YOUR_PROJECT_ID>>
Domain: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
Data: All froyo, customer, order related information is processed and stored in BigQuery froyo_data dataset. Use all the tables and data in the dataset for querying for user questions.
Context: Use Data Agent Kit skills wherever possible.
2. Execution & Data Processing Rules
CRITICAL RULE - Structured Specs: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named froyo_data.
CRITICAL RULE - Customer Data: Existing Froyo customer data resides in BigQuery in the tables customers_allergen_data. When you are referencing a dataset, ensure you are using it with the dataset ID (froyo_data) . For example, to query orders table in this dataset you should use froyo_data.orders.
- Salva l'agente.
7. Chatta con i tuoi dati.
- Testalo nella sezione di anteprima a destra:
Poni la tua domanda:
Does midnight swirl contain any allergen?
Ecco la risposta:
Ora poniamo la domanda complicata:
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
Risposta:
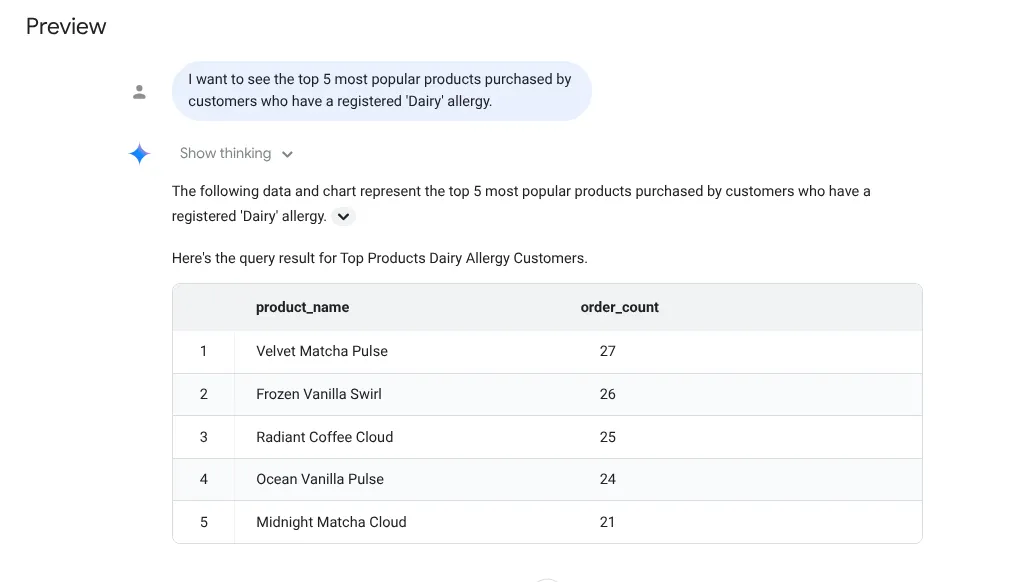
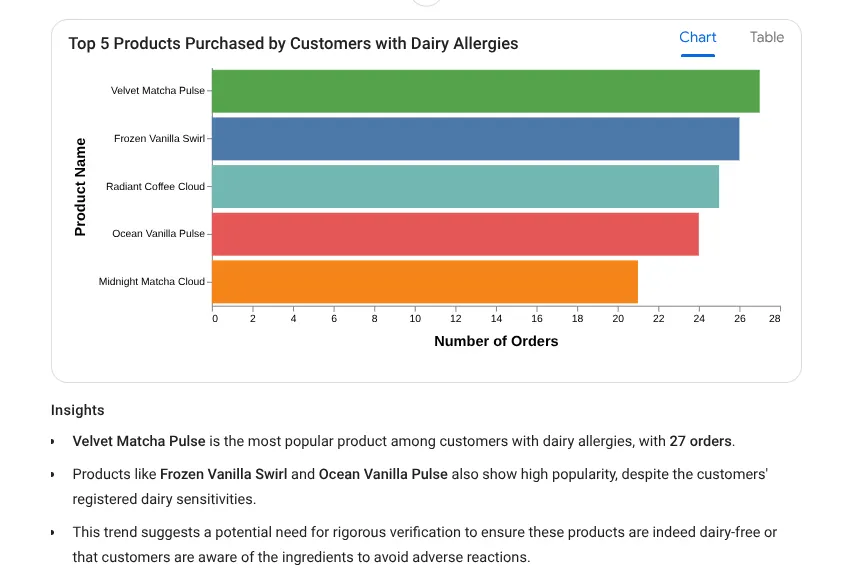
Proviamo ora un prompt per approfondimenti:
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
Come puoi vedere, mostra la query utilizzata, con il risultato della tabella insieme al grafico:
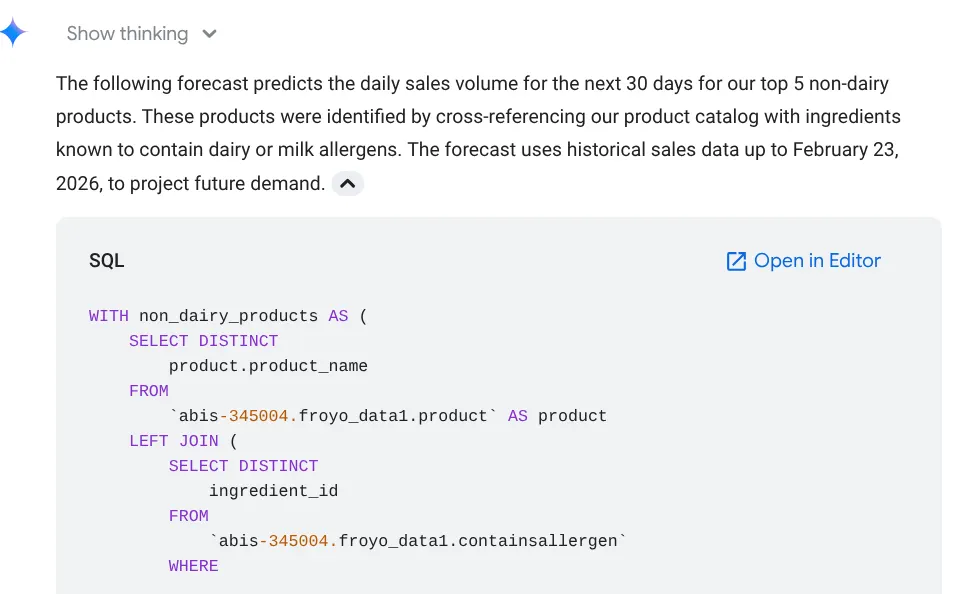
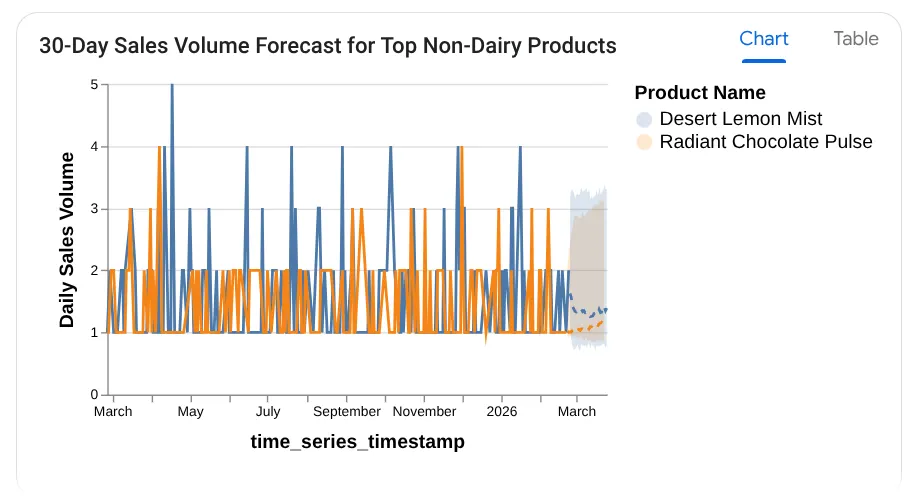

Wow! Quindi è andata bene con i grafici e gli approfondimenti. È il momento della domanda definitiva sui prodotti.
8. The Ultimate Test
Poni la domanda:
What will be the top most selling product of 2026
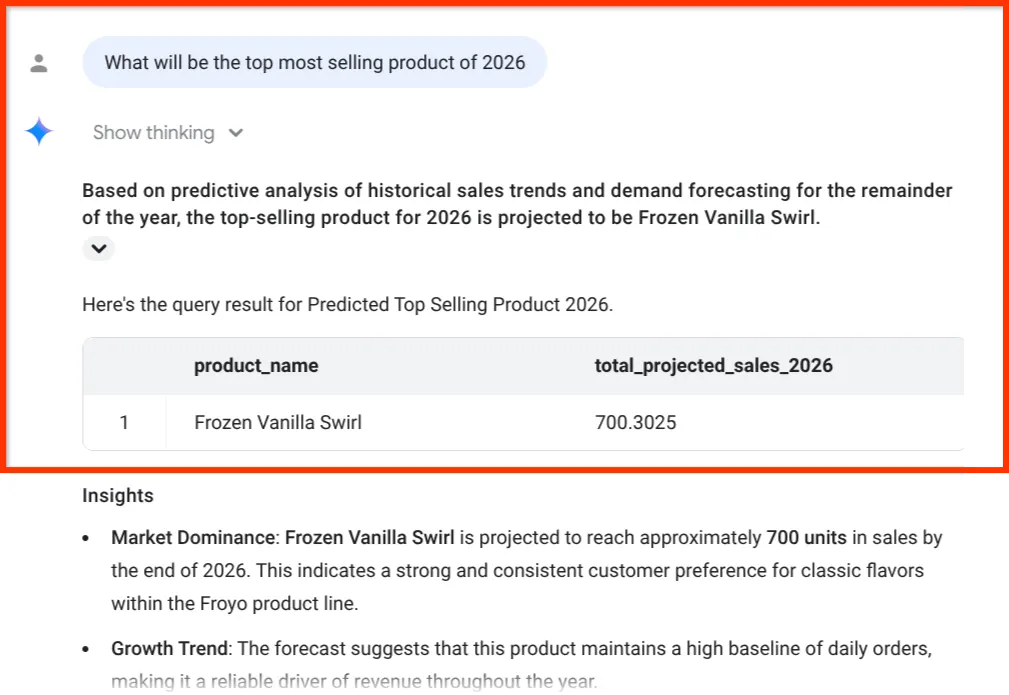

Guarda l'ultimo approfondimento. BigQuery Data Agent non ci ha fornito solo un numero, ma ha collegato esplicitamente la previsione delle vendite alla nostra catena di fornitura di inventario e ingredienti, ovvero i dati esatti che abbiamo estratto dai PDF disordinati nella prima parte.
9. Pubblicare l'agente nell'enterprise
Fai clic sul pulsante Pubblica nella parte superiore dell'agente di anteprima.
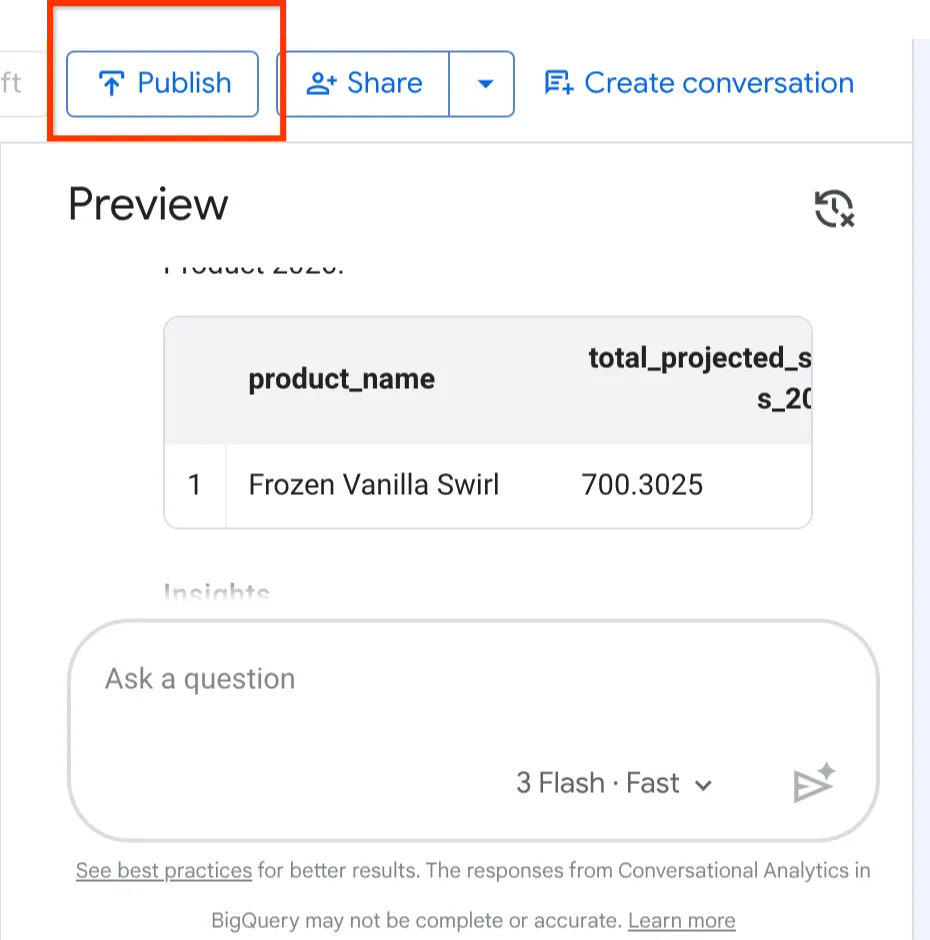
Ora che abbiamo creato, configurato e testato il nostro agente Froyo, è il momento di rilasciarlo al resto dell'attività.
Nell'angolo in alto a destra della pagina di configurazione dell'agente, fai clic sul pulsante Pubblica.
Con la pubblicazione, il tuo agente diventa immediatamente disponibile su tre potenti canali aziendali per te e per tutte le persone con cui lo condividi:
- BigQuery: ora gli analisti di dati possono chattare con questo agente direttamente dall'hub Agenti o all'interno dello spazio di lavoro SQL di BigQuery Studio.
- API Analisi conversazionale: i tuoi sviluppatori possono accedere a questo agente tramite un'API REST, il che consente loro di integrare queste analisi conversazionali esatte nelle tue applicazioni web interne personalizzate.
- Data Studio: i tuoi dirigenti possono interagire con questo agente e creare dashboard conversazionali dinamiche direttamente in Data Studio.
Siamo riusciti a estrarre i nostri dati dai silos e a metterli direttamente nelle mani delle persone che ne hanno bisogno, esattamente dove lavorano già.
Fai clic sul menu a discesa del pulsante Condividi nella parte superiore dell'agente BigQuery pubblicato e seleziona l'opzione "Copia link all'agente in Data Studio" dall'elenco:
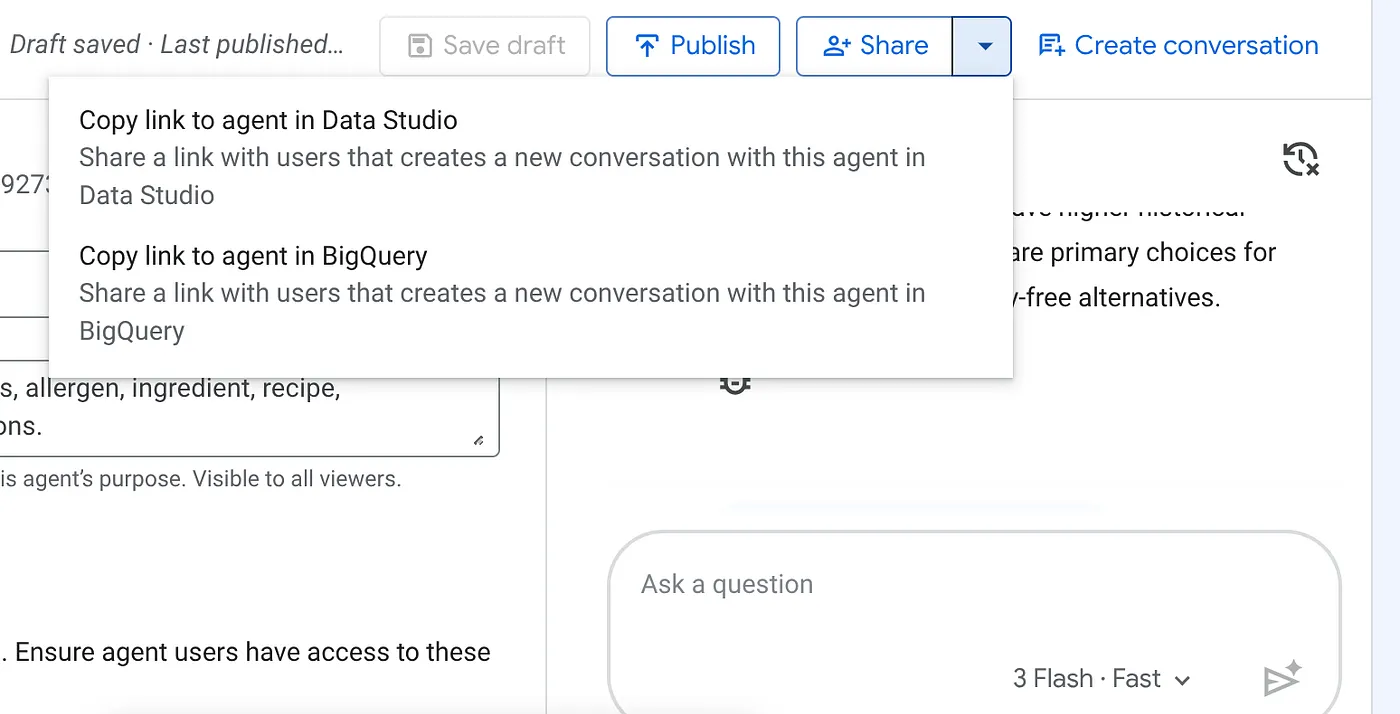
Incolla il link nel browser e premi Invio. Fornisci la conferma per l'avviso di accesso all'interazione con l'agente:
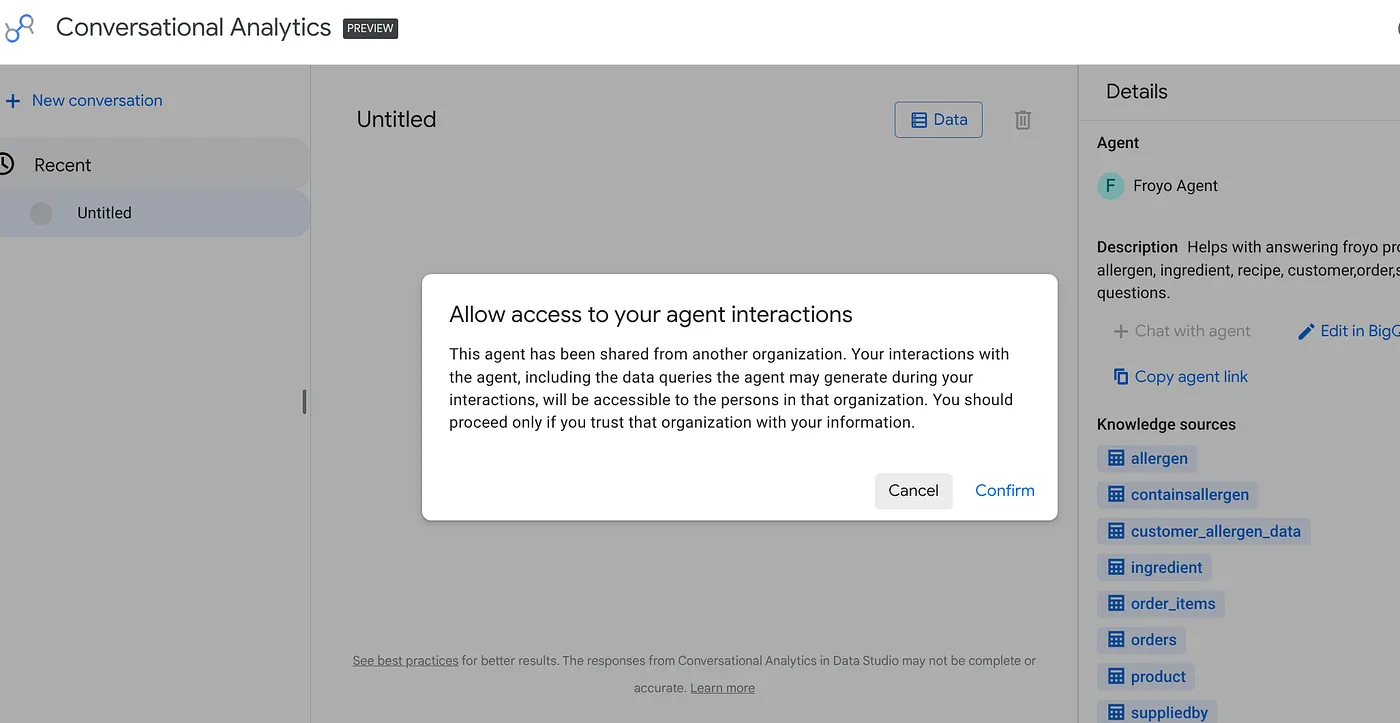
Tu e i tuoi leader e altri team che hanno bisogno di queste informazioni potete avviare conversazioni e visualizzazioni interattive con l'agente appena pubblicato da Data Studio.
10. Esegui la pulizia
Al termine di questo lab, non dimenticare di rimuovere le autorizzazioni per tutti gli utenti per l'agente BigQuery che hai appena creato.
11. Complimenti!
Hai creato ufficialmente un Agentic Data Cloud.
Non hai creato un semplice chatbot. Nel corso di queste cinque sessioni, hai progettato con successo un sistema di AI aziendale completo, moderno e valutato da zero. Sei passato dai "dati oscuri " all'intelligence transazionale in tempo reale e infine alla previsione aziendale conversazionale.
12. Il quadro completo
Facciamo un passo indietro e vediamo cosa abbiamo ottenuto in questa serie. Non abbiamo creato un semplice chatbot. Abbiamo progettato un Agentic Data Cloud completo e moderno:
Parte 1: sblocco dei dati oscuri trasformando i PDF in tabelle relazionali strutturate utilizzando Knowledge Catalog.
Parte 2: abbiamo suddiviso i silos di dati federando il nostro data warehouse analitico direttamente in un database transazionale AlloyDB.
Parte 3: utenti potenziati grazie alla creazione di un sistema operativo multi-agente che esegue senza problemi strumenti di database sicuri tramite il protocollo MCP
Parte 4: sicurezza garantita grazie all'implementazione di una rigorosa pipeline di valutazione per rilevare allucinazioni e jailbreak.
Parte 5: approfondimenti democratizzati utilizzando ANTIGRAVITY IDE e l'analisi conversazionale in BigQuery.
Questo è il futuro del software aziendale. L'agente AI non è più solo un wrapper intorno a un LLM. Si tratta di un motore di orchestrazione completamente integrato, valutato e sicuro che si trova in cima a una piattaforma di dati unificata.