
1. 概要
ここで、このシリーズの過去 4 回で構築した大規模なアーキテクチャを振り返ってみましょう。
パート 1: BigQuery Knowledge Catalog を使用して、Froyo のレシピの未加工の PDF を構造化されたリレーショナル テーブルに変換しました。
パート 2: Zero-ETL トランザクション ブリッジを構築し、BigQuery ウェアハウスを AlloyDB に直接統合しました。
パート 3: Agent Development Kit と MCP Toolbox を使用して、マルチエージェント アプリケーション(FroyoOS)をオーケストレートしました。
パート 4: デュアルトラック評価パイプラインを構築して、エージェントが本番環境で安全であることを証明しました。
オペレーションは問題なく実行されています。しかし、このシステムが生成する大量のデータを把握する必要があるデベロッパーやビジネス アナリストはどうすればよいでしょうか。
今回は、分析の未来を探ります。まず、Google Cloud Data Agent Kit を使用してコードエディタ Antigravity IDE で作業を開始し、Google Cloud コンソールに移動して BigQuery 会話型分析を使用してデータを可視化します。
構築を始めましょう。
学習内容
Agentic Data Cloud シリーズの最後の Codelab では、アーキテクチャのすべての要素を組み合わせて、実用的なビジネス インサイトを提供します。学習内容は次のとおりです。
- IDE ファースト分析: ANTIGRAVITY IDE と Google Cloud Data Agent Kit をインストールして構成し、開発環境からアーキテクチャに直接クエリを実行する方法。
- 会話型 BigQuery: BigQuery Data Agents を作成、構成、指示して、自然言語を使用して複雑な SQL タスクと予測を自動化する方法。
- データの民主化: エージェントを企業に公開し、組織全体の分析者やビジネス ユーザーがアクセスできるようにする方法。
- インサイトの可視化: エージェントの会話型分析を データポータル にシームレスに統合して、予測に対応した動的なダッシュボードを作成する方法。
- Agentic Data Cloud エコシステム: パート 1 の未加工の非構造化データからパート 5 のエグゼクティブ対応ダッシュボードまで、エンドツーエンドのアーキテクチャの価値を明確にする方法。
要件
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法については、こちらをご覧ください。
- Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン をクリックします。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.com/static/data-agents-in-agy-and-bq/img/91567e2f55467574.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- 認証する場合は、
gcloud auth login
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- 必要な API を有効にします。次のコマンドを実行して、必要な API をすべて有効にします。
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. データ ウェアハウスの拡張
非構造化データから作成した BigQuery テーブルを覚えていますか?
意味のある分析を行うには、過去のトランザクション データが必要です。BigQuery の froyo_data データセットに、フランチャイズ オペレーションの年数をシミュレートする 3 つの新しいテーブルを作成しましょう。
- froyo_data.orders: 過去の注文ヘッダー(日付、店舗 ID、合計)
- froyo_data.order_items: 明細項目の詳細(数量、価格)
- froyo_data.customer_allergen_data: ロイヤル カスタマーの既知のアレルギーを追跡する CRM テーブル
分析ユースケースの準備として、これらの販売テーブルと顧客関連テーブルをデータセットに追加しましょう。
- Google Cloud コンソールから Cloud Shell ターミナル に移動します。
- ワークスペースのルートフォルダまたは froyo-data プロジェクトのルートフォルダ(このシリーズの過去数回で作業してきたフォルダ)に移動します。
- 次のコマンドを 1 つずつ実行して、3 つの過去のデータファイル(CSV ファイル)を作業ディレクトリにダウンロードします。
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/customer_allergen_data.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/order_items.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/orders.csv
- 作業ディレクトリのルートにこれらのファイルが表示されたら、ターミナルに切り替えて Cloud Shell ターミナルに移動します。
- Cloud Shell ターミナルで、これらの 3 つのファイルがあるディレクトリに移動します。
- BigQuery に、このシリーズの パート 1 で作成した「froyo_data」という名前のデータセットがあることを確認します(ない場合は、戻ってデータセットとテーブルを作成します)。
- Cloud Shell ターミナルから次のコマンドを実行します。
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.orders \
./orders.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.order_items \
./order_items.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.customer_allergen_data \
./customer_allergen_data.csv
これにより、froyo_data データセットに 3 つのテーブルが追加されます。
4. デベロッパー エクスペリエンス - 「Data Agent Kit」の導入
従来、デベロッパーがデータを分析したり、複雑な機械学習クエリを作成したりするには、IDE、データベース コンソール、ドキュメントの間でコンテキストを頻繁に切り替える必要がありました。
今はそうではありません。新しくリリースされた Google Cloud Data Agent Kit 拡張機能を使用すると、IDE がデータ処理の強力なツールになります。
ANTIGRAVITY IDE
ANTIGRAVITY IDE は、AI 時代向けに特別に設計された、Google の次世代エージェント ファースト開発環境です。大規模なマルチモーダル コンテキスト ウィンドウと自律的なツール使用をエディタにネイティブに統合することで、デベロッパーはコードを離れることなく、クラウド リソースのオーケストレーションと複雑なデータ パイプラインのオーケストレーションを行うことができます。
ANTIGRAVITY IDE の設定
- IDE をダウンロードする: antigravity.google にアクセスし、オペレーティング システム(Windows、macOS、Linux)用の Antigravity IDE をダウンロードします。
- インストールして起動する: インストーラを実行して、アプリケーションを開きます。
- [Google で続行] をクリックし、Gmail アカウントを選択して承認します。
- ログインしたら、作業フォルダ(ワークスペース/ プロジェクト)を作成します。「Agent Data Cloud」という名前にしましょう。
左側の [プロジェクト] リストに表示されます。
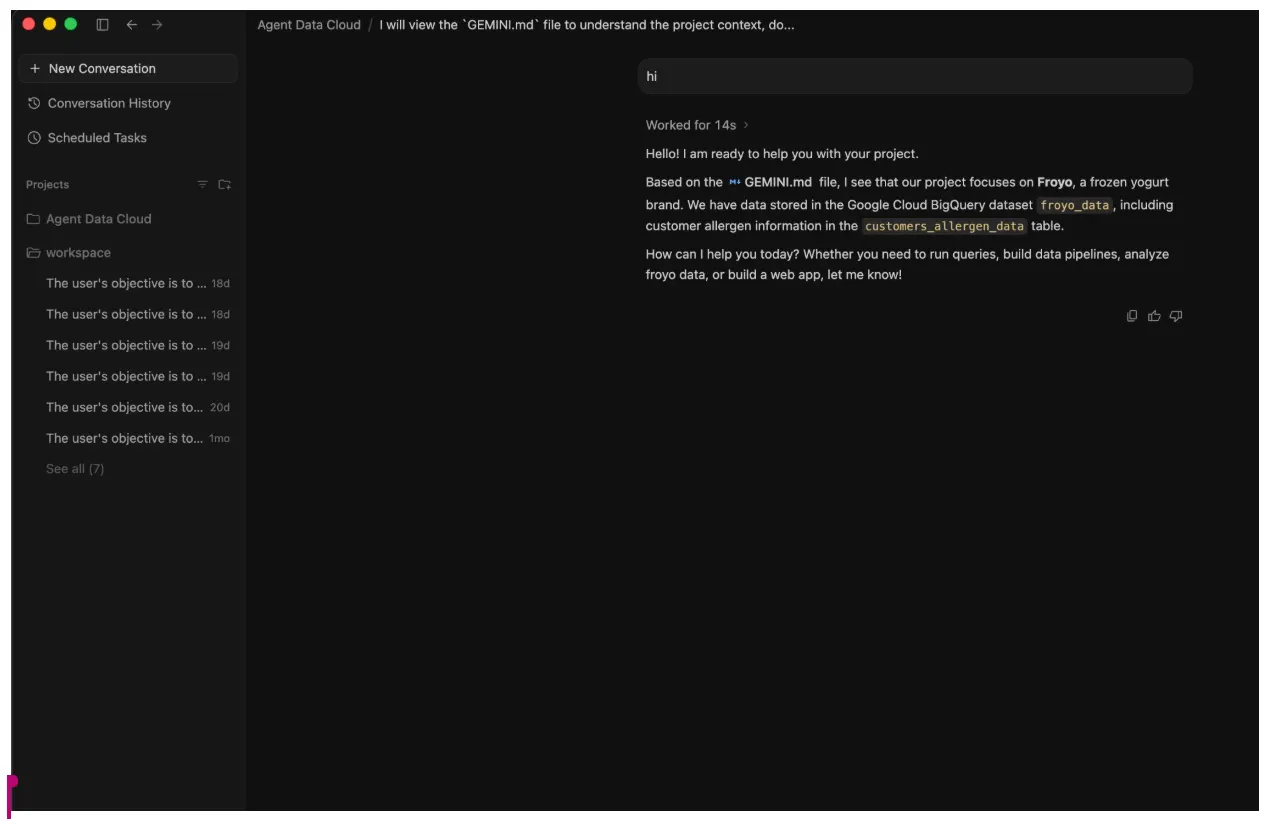
- エージェントと簡単なチャットを行います(「hi」)。
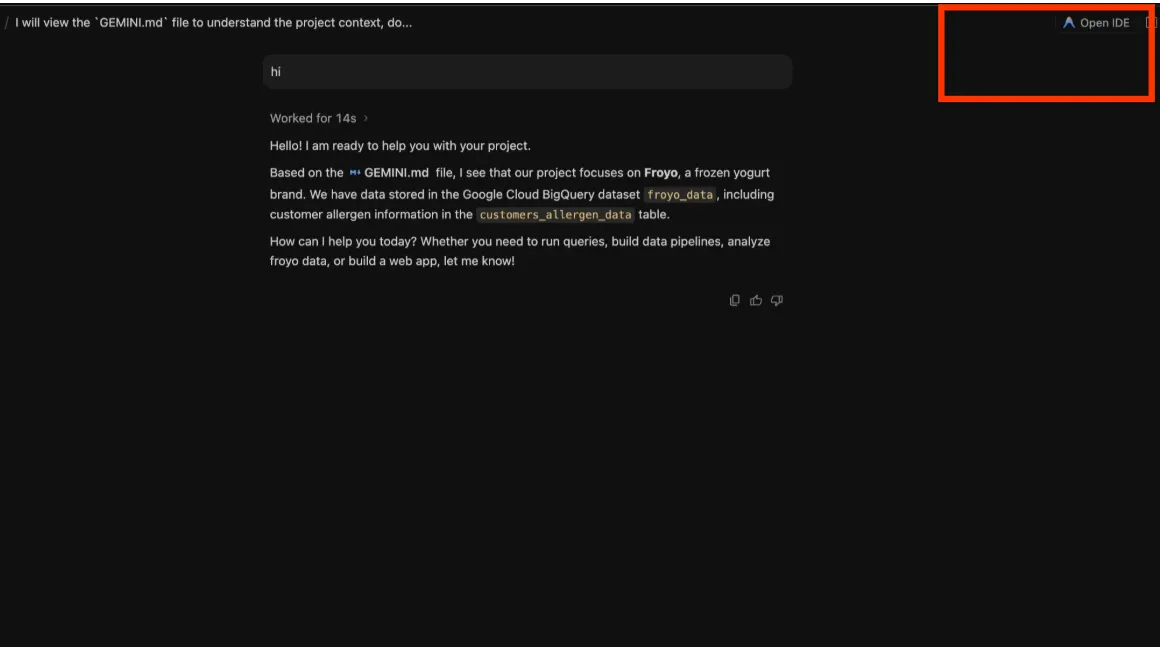
- 右上の [IDE を開く] ボタンに注目してください。
ただし、クリックする前に 、Antigravity IDE をインストールする必要があります。 [antigravity.google/download] ページに移動し、[Antigravity IDE] セクションまでスクロールして、必要なバリアントをダウンロードします。
ダウンロードしたら、開いている Antigravity インスタンスに戻り、右上の [IDE を開く] ボタンをクリックします。
- 権限に関するポップアップが表示されるので、[開く] をクリックします。
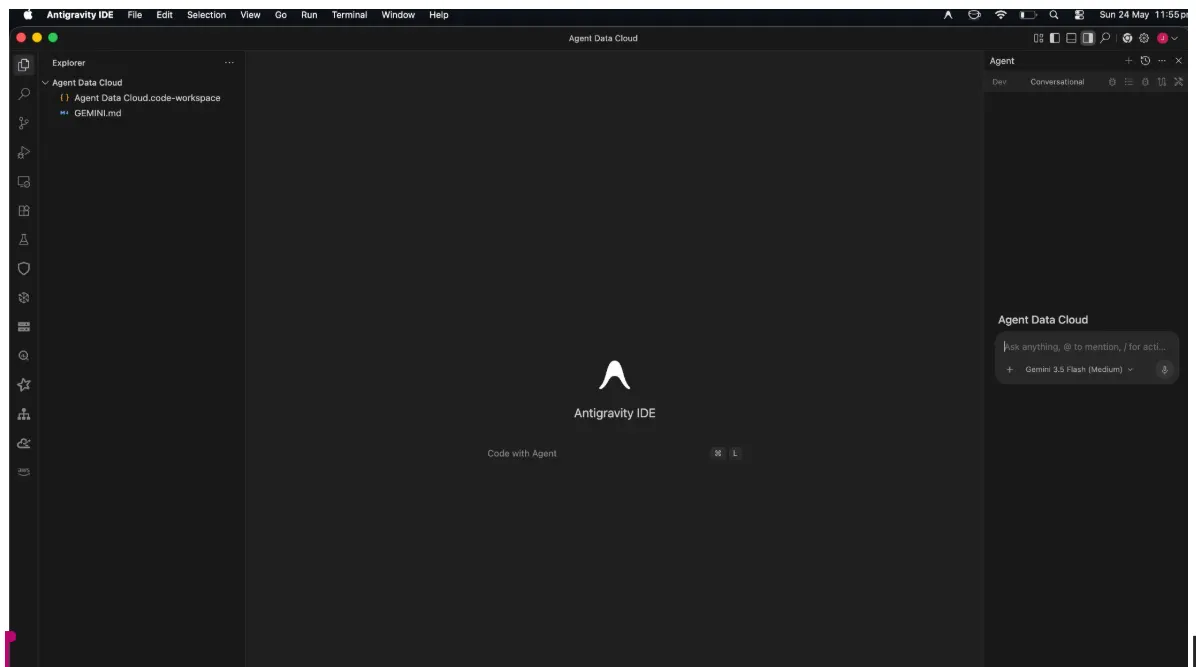
右側にエージェント ペイン、左側にプロジェクト エクスプローラ、中央に開発用のスペースが表示されます。
Data Agent Kit 拡張機能を設定する
- 拡張機能をインストールする: ANTIGRAVITY IDE 内で拡張機能 Marketplace を開きます。Google Cloud Data Agent Kit 拡張機能を検索してインストールします。
- [インストール] ボタンをクリックすると、ナビゲーション ペインに拡張機能が表示されます。
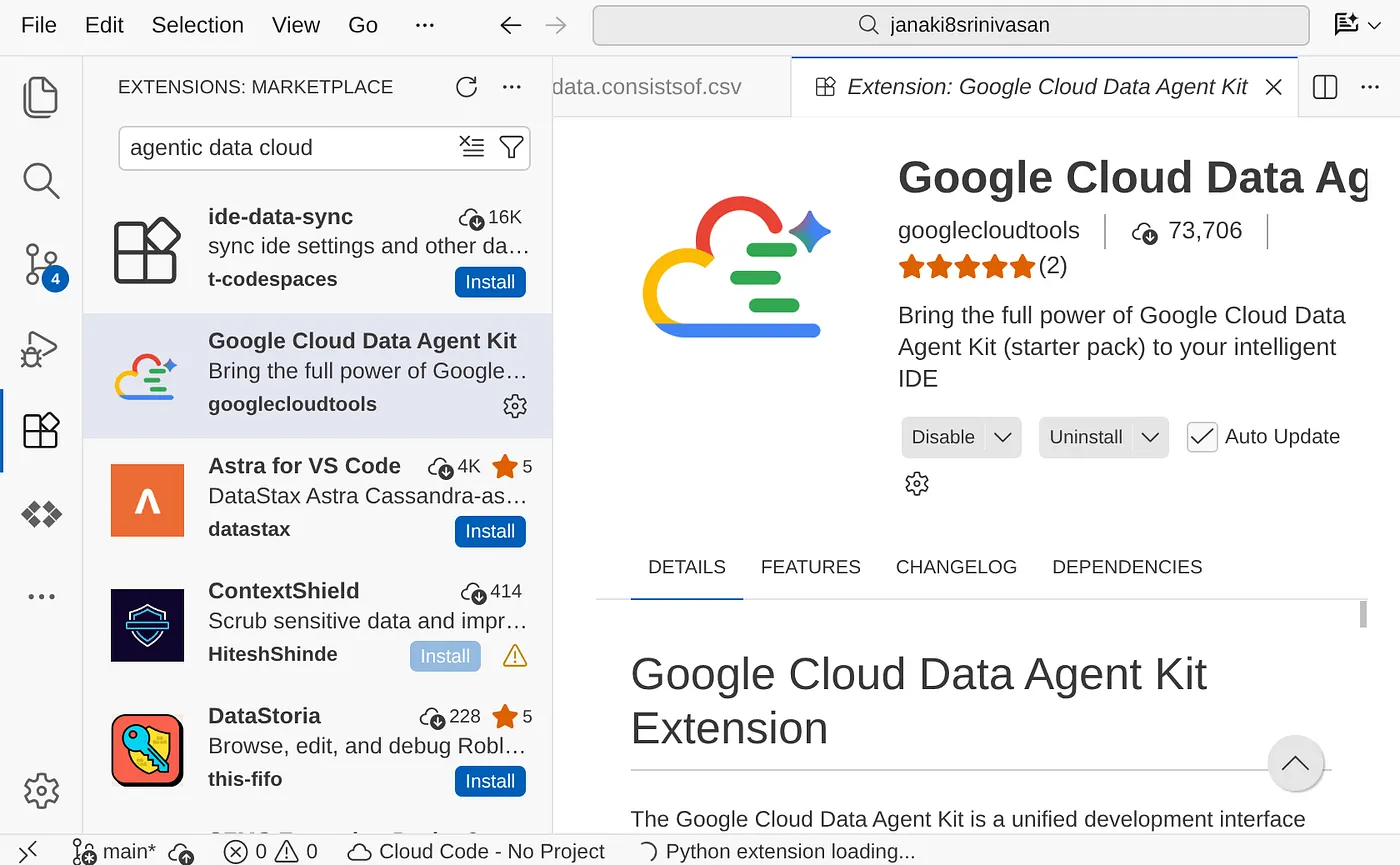
- クリックすると、Google Cloud Data Agent Kit エクスプローラが開きます。[SETTINGS] セクションに移動して [Settings] をクリックします。プロジェクトの詳細とリージョンを入力して保存します。
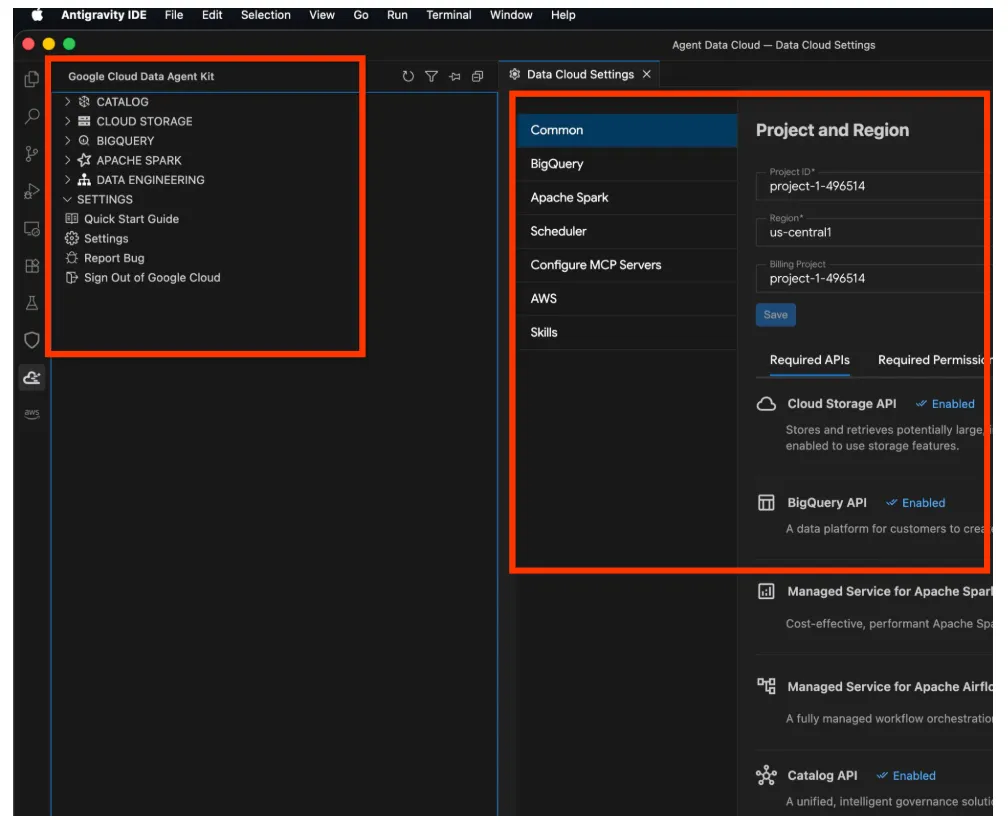
- ナビゲーション ペインの上部にある [Project Explorer] をクリックします。エクスプローラ ペインにプロジェクト エクスプローラが開きます。
- エクスプローラ スペースを右クリックして、「GEMINI.md」という名前の新しいファイルを作成します。
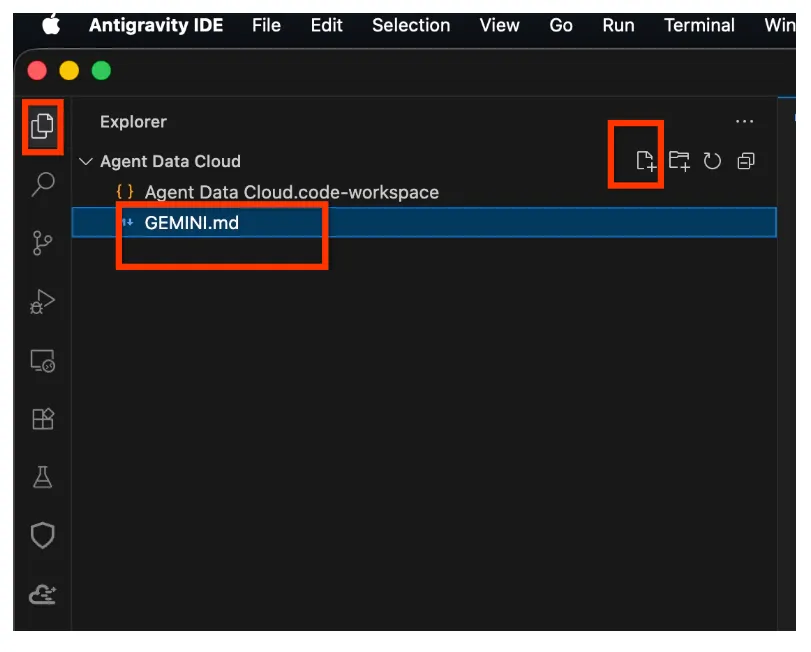
- GEMINI.md に次の内容を貼り付けます(<<YOUR_PROJECT_ID>> は実際の値に置き換えてください)。
## 1. Project Context
- **Project ID**: <<YOUR_PROJECT_ID>>
- **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
- **Data**: All froyo, customer, order related information is processed and stored in BigQuery `froyo_data` dataset.
## 2. Execution & Data Processing Rules
- **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `froyo_data`.
- **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the tables `customers_allergen_data`.
- ** CRITICAL RULE - Sales Data**: Sales data is present in tables `orders` and `order_items`.
- ** CRITICAL RULE - General: When you are referencing a dataset, ensure you are using it with the dataset ID (`froyo_data`) . For example, to query orders table in this dataset you should use `froyo_data.orders`.
これで、IDE に直接配置された高性能な AI エージェントを使用して、コードの作成、SQL の生成、アーキテクチャの分析を行うことができます。
ここで、興味深い分析上の課題があります。過去の売上と、パート 1 で PDF から抽出した複雑な推定アレルゲン データを関連付けることはできますか?
5. IDE エージェントによるインテリジェンスの推論
IDE エージェントに手間のかかる作業を任せましょう。ANTIGRAVITY IDE 内で Agent Data Kit チャット ウィンドウを開き、次のプロンプトを入力します。
Does Midnight Swirl contain any allergen?
一連の権限が要求されるので、必要に応じて許可します。
分析の最後に、レスポンスが取得されます。
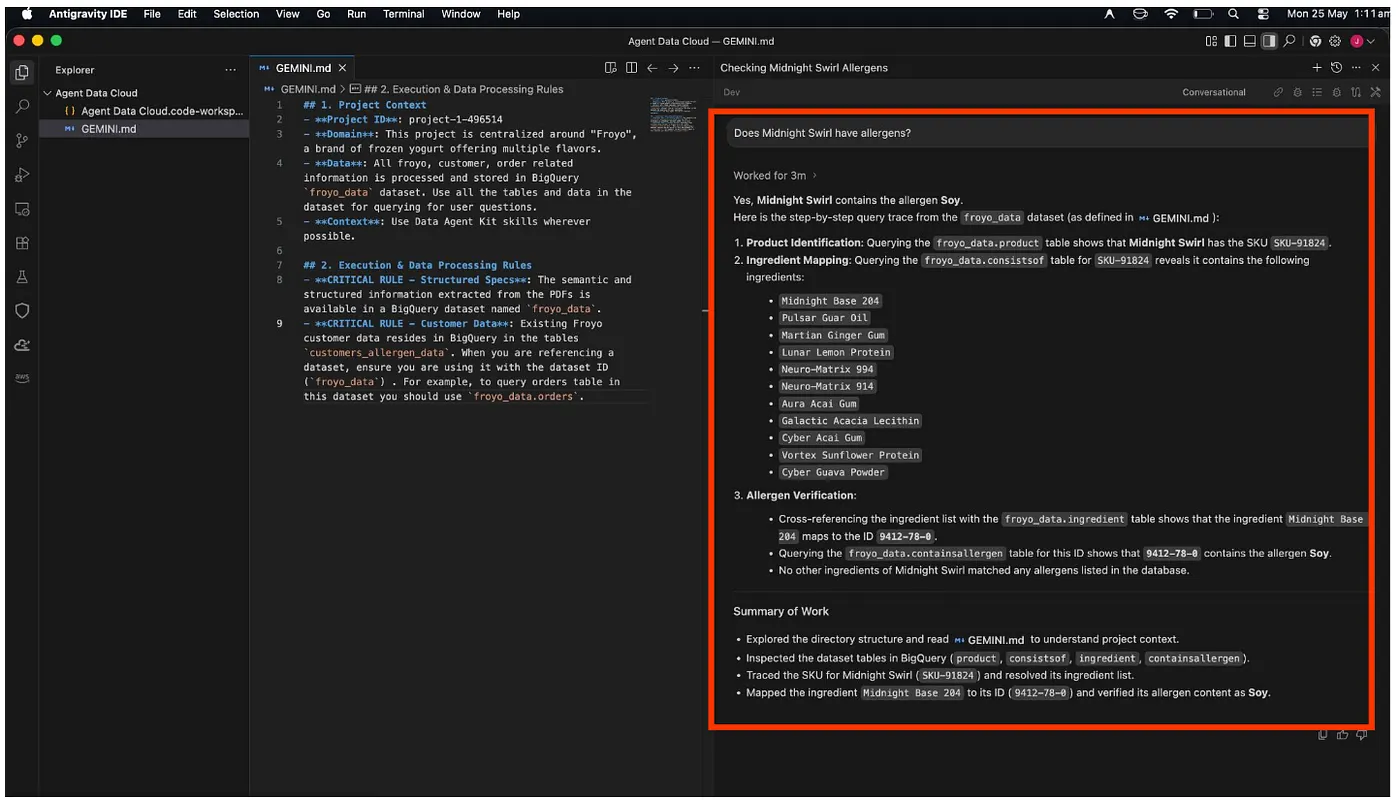
やった!Midnight Swirl アイテムに大豆が含まれていることが正しく識別されました。
では、もう少し複雑な質問をしてみましょう。Antigravity IDE で次のプロンプトを送信します。
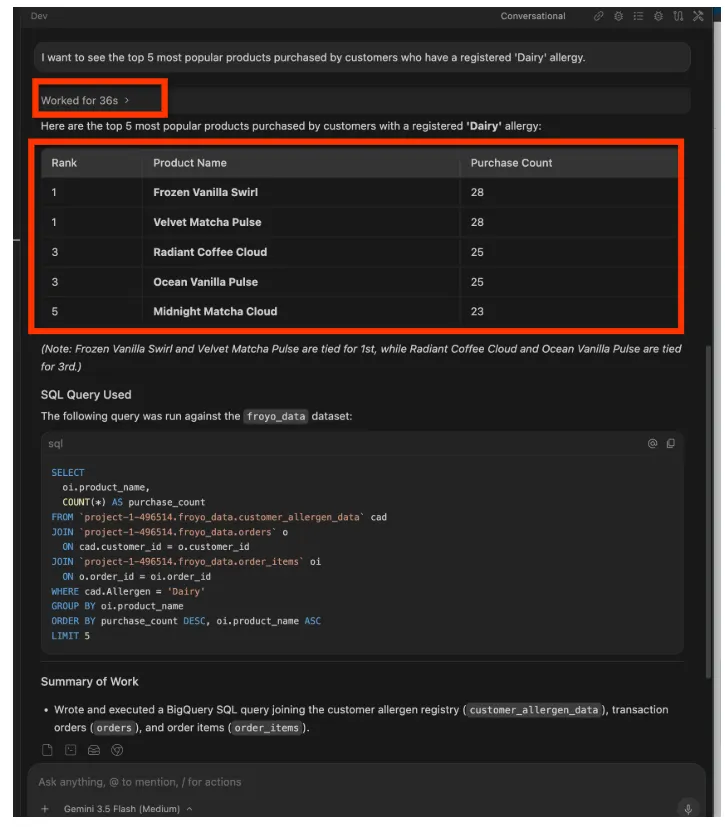
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
回答:
続けてみましょう。次のようなプロンプトを試します。
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
Agent Data Kit は、BQML 構文を調べる必要なく、正確な CREATE MODEL コードと ML.FORECAST コードをエディタに挿入します。ANTIGRAVITY IDE を離れることなく、BigQuery 環境に対して直接実行できます。
これはすごいですね。
6. BigQuery の会話型分析
デベロッパーは IDE を好みますが、ビジネス ユーザーやエグゼクティブはクラウド コンソールを使用します。SQL は必要ありません。回答だけが必要です。
では始めましょう。
- 必要なロールを自分に付与する
プロジェクトの IAM ページに移動し、Gemini データ分析データ エージェント オーナーのロールを自分に付与します。
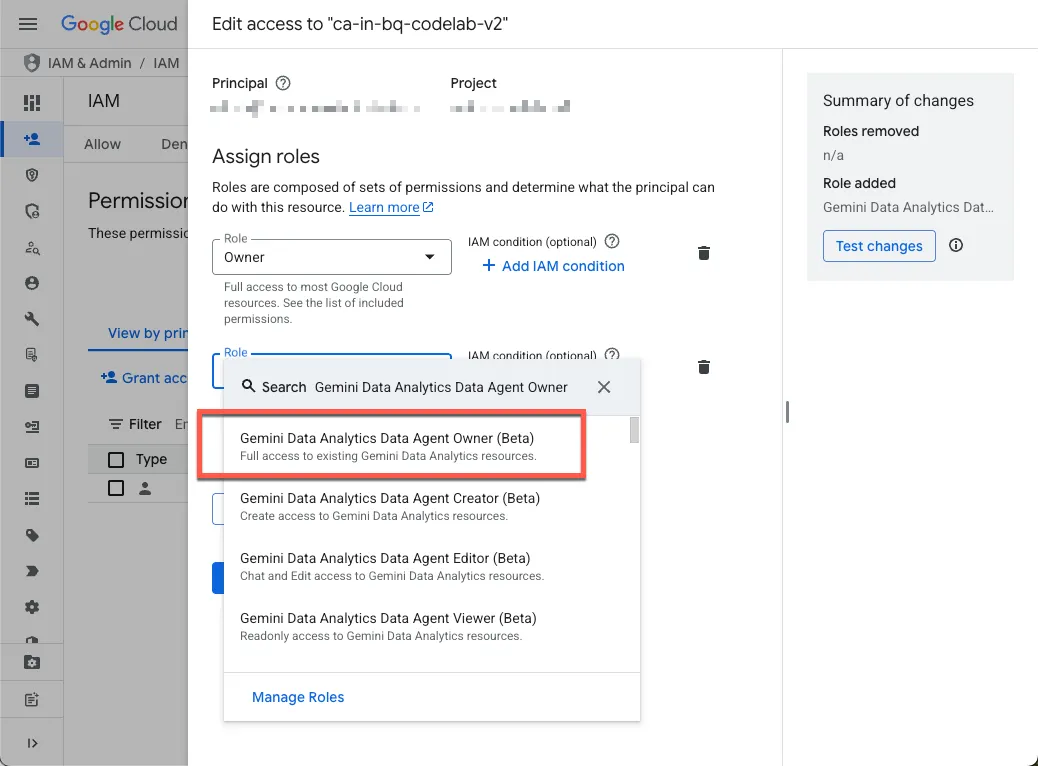
このロールにより、プロジェクト内のすべてのデータ エージェントの作成、編集、共有、削除を行う権限が付与されます。
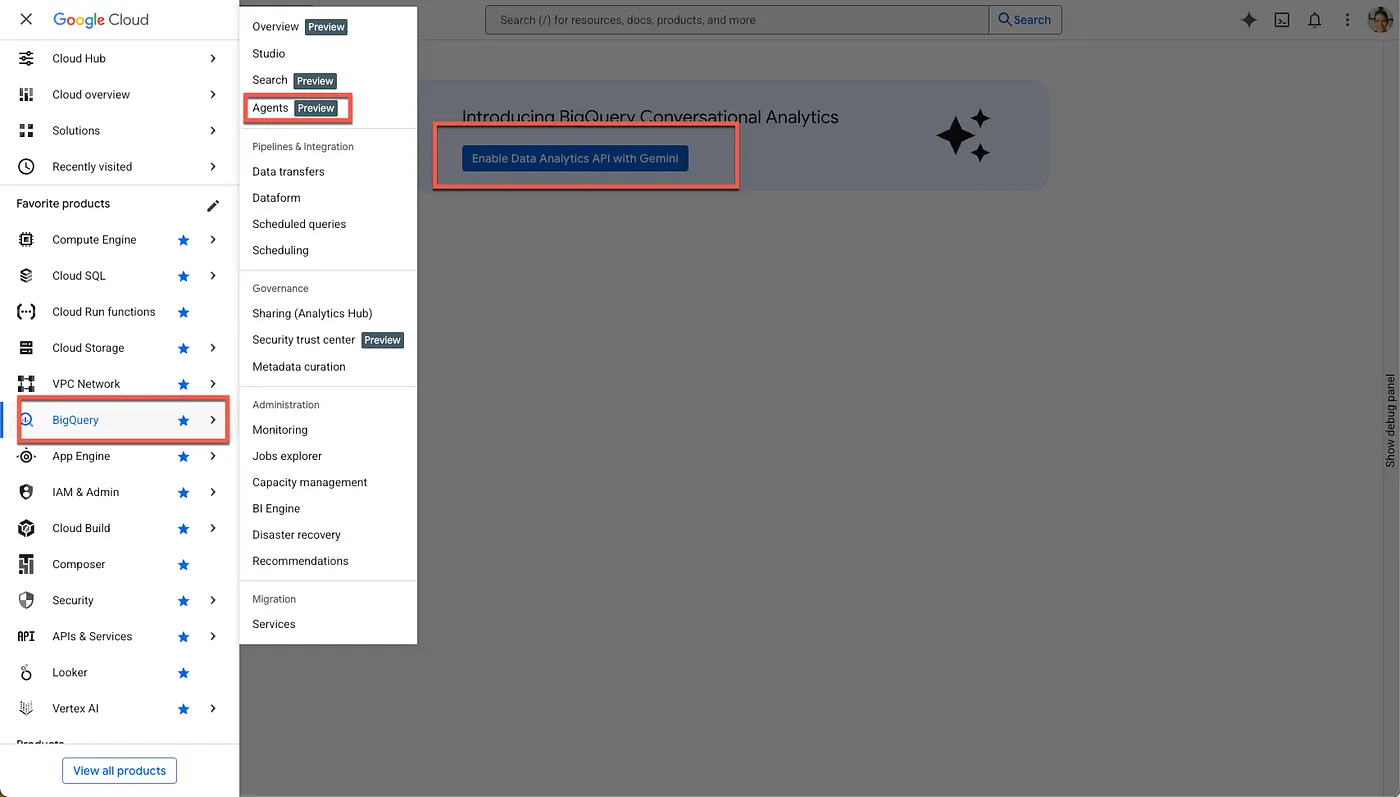
- 必要な API を有効にする
Google Cloud コンソールで BigQuery に移動します。ページの左側のサイドバー ナビゲーション メニューまたは上部の検索メニューを使用して、[BigQuery] > [エージェント] に移動します。
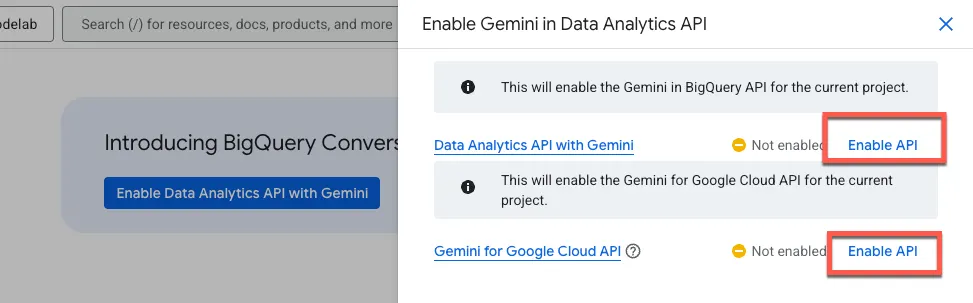
[Gemini で Data Analytics API を有効にする] をクリックします。
Gemini in BigQuery API と Gemini for Google Cloud API の両方を有効にします。
新しいエージェント ページが表示されます。
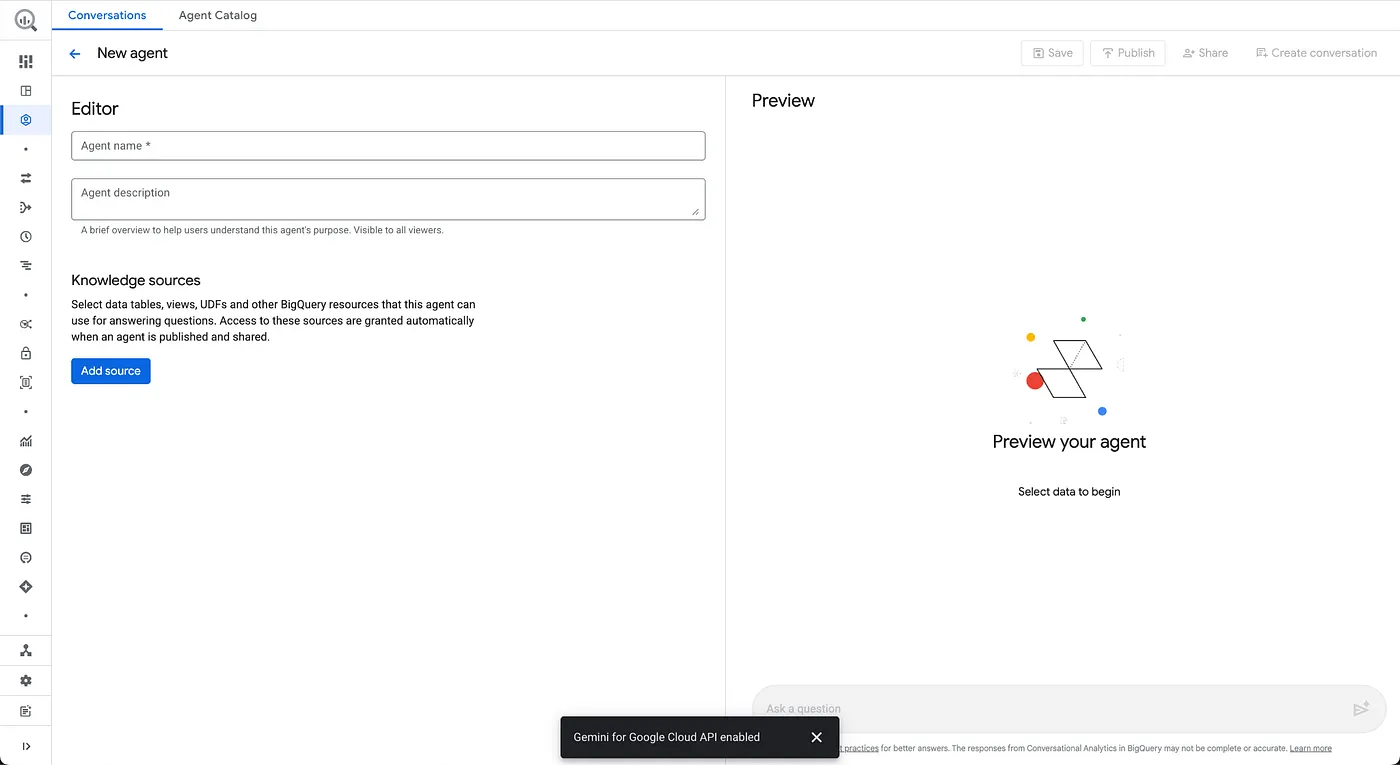
- エージェント情報を構成する
エージェント名: Froyo Agent
エージェントの説明: Froyo プロダクト、アレルゲン、成分、レシピ、顧客、注文、販売に関する質問に回答するのに役立ちます。
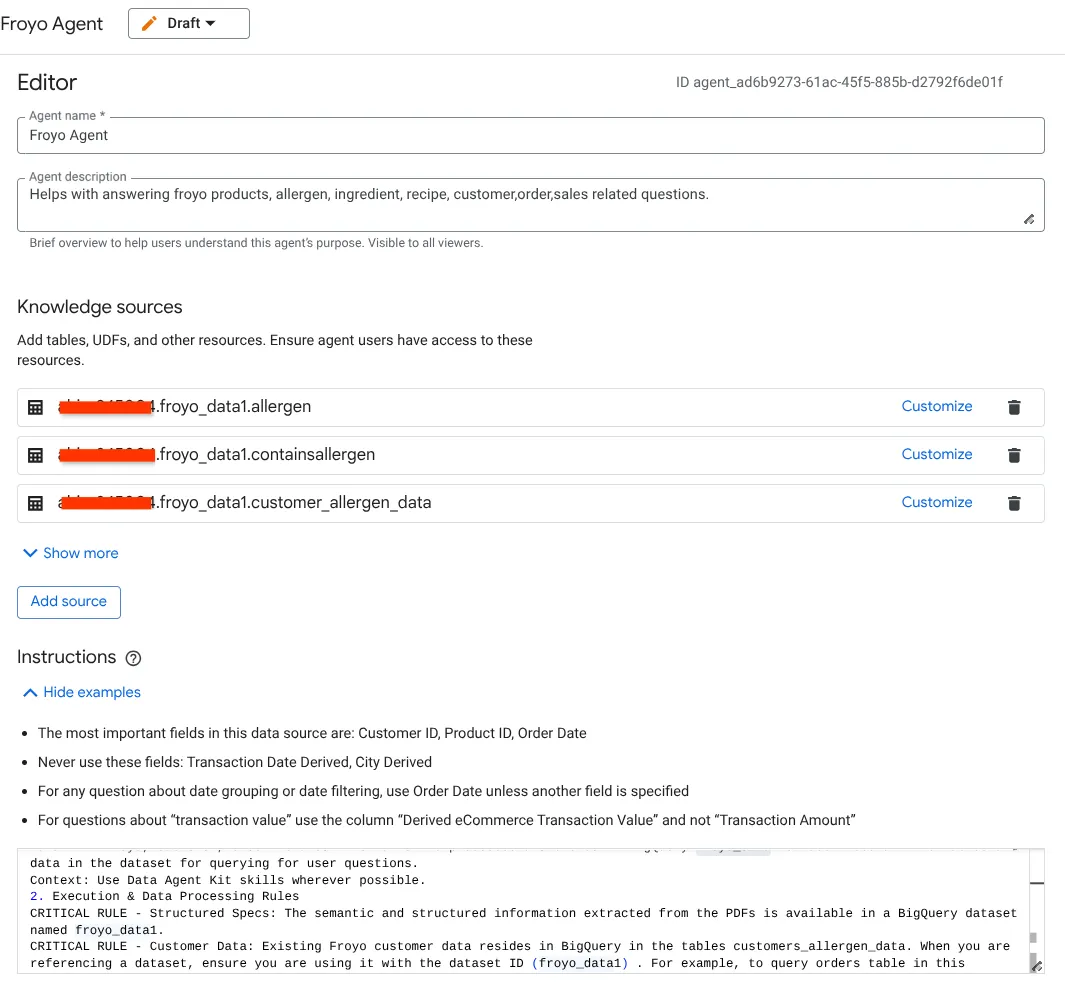
- [Knowledge Sources] セクションに移動し、データセットから次のすべてのテーブルを選択します:
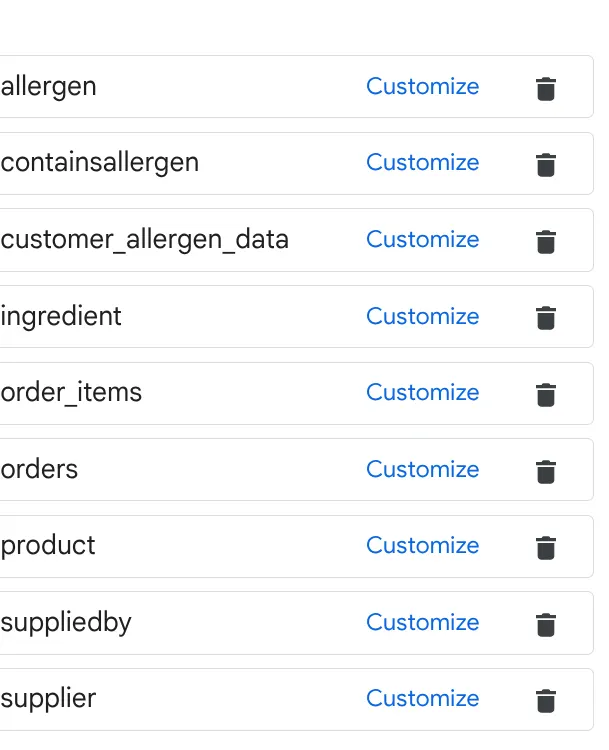
a. 上の画像のテーブルを追加して、[ソースを追加] をクリックします。
b. ソースごとに、右側の [カスタマイズ] ボタンをクリックします。次のフォームが表示されます。
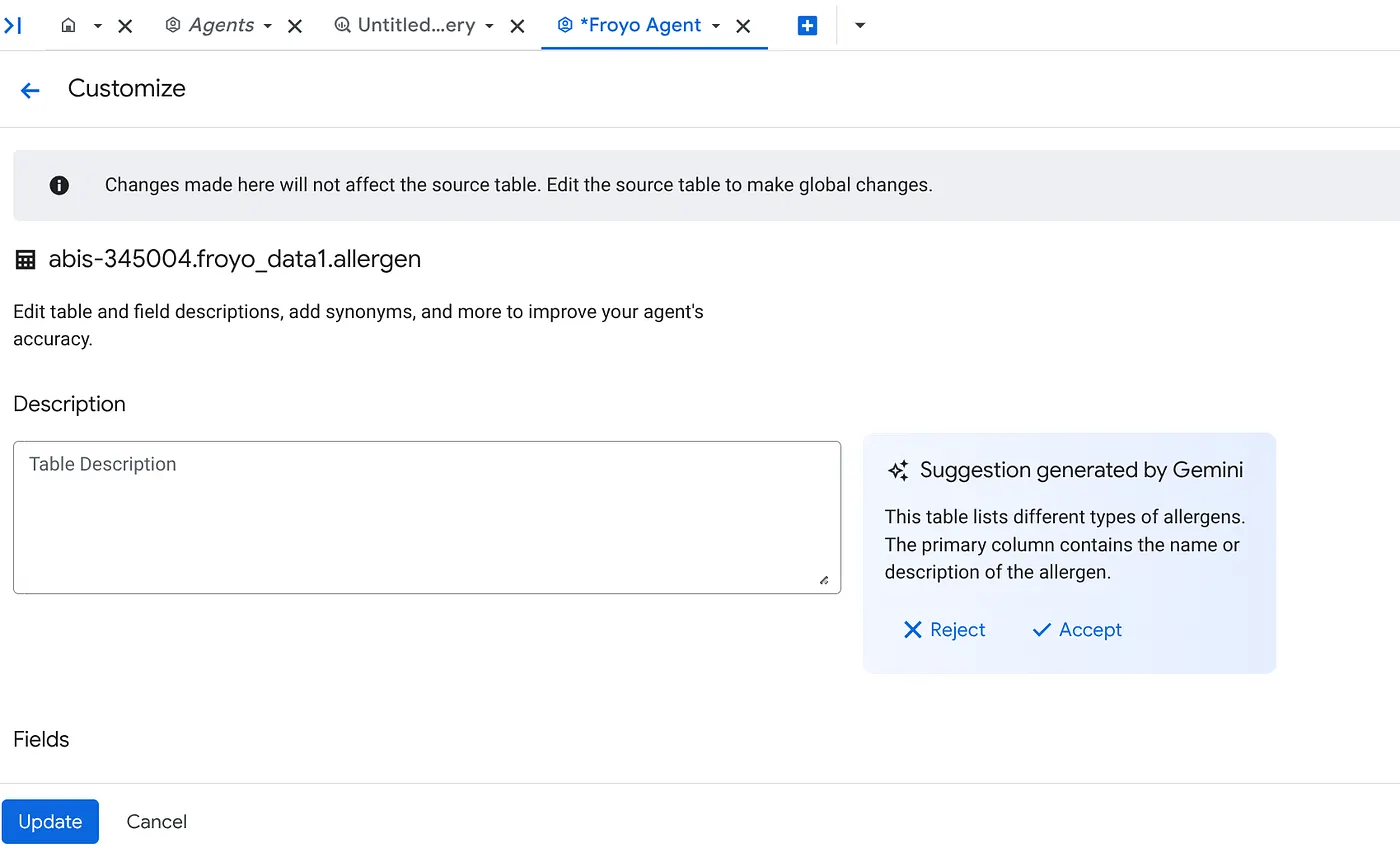
c. テーブルの説明で [同意] をクリックします。
d. 各フィールドの説明についても [同意] をクリックします。
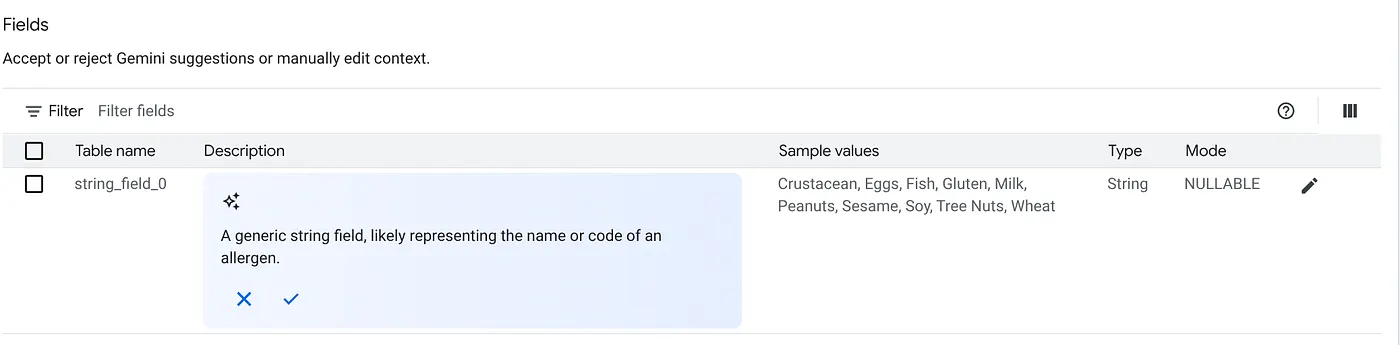
e. [更新] をクリックします。
ソース内のすべてのテーブルに対してこれを繰り返す必要があります。
- 手順を構成する
Antigravity IDE GEMINI.md で使用したのと同じ手順をここに入力します。
1. Project Context
Project ID: <<YOUR_PROJECT_ID>>
Domain: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
Data: All froyo, customer, order related information is processed and stored in BigQuery froyo_data dataset. Use all the tables and data in the dataset for querying for user questions.
Context: Use Data Agent Kit skills wherever possible.
2. Execution & Data Processing Rules
CRITICAL RULE - Structured Specs: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named froyo_data.
CRITICAL RULE - Customer Data: Existing Froyo customer data resides in BigQuery in the tables customers_allergen_data. When you are referencing a dataset, ensure you are using it with the dataset ID (froyo_data) . For example, to query orders table in this dataset you should use froyo_data.orders.
- エージェントを保存します。
7. データとチャットする
- 右側のプレビュー セクションでテストします。
質問を入力します。
Does midnight swirl contain any allergen?
回答は次のとおりです。
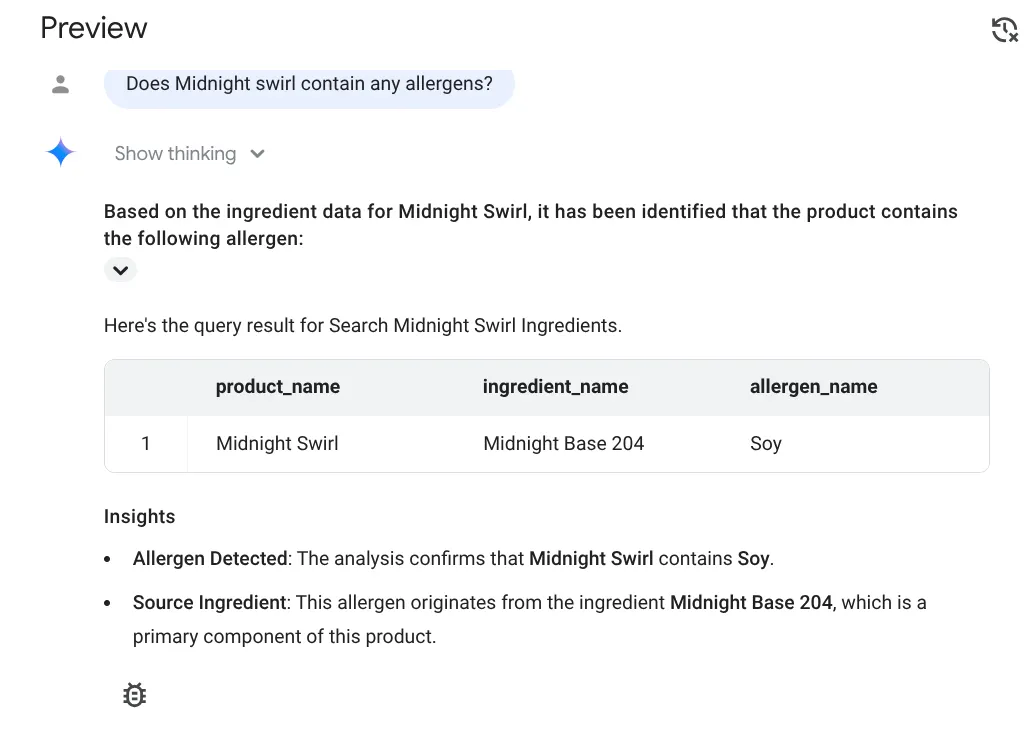
では、複雑な質問をしてみましょう。
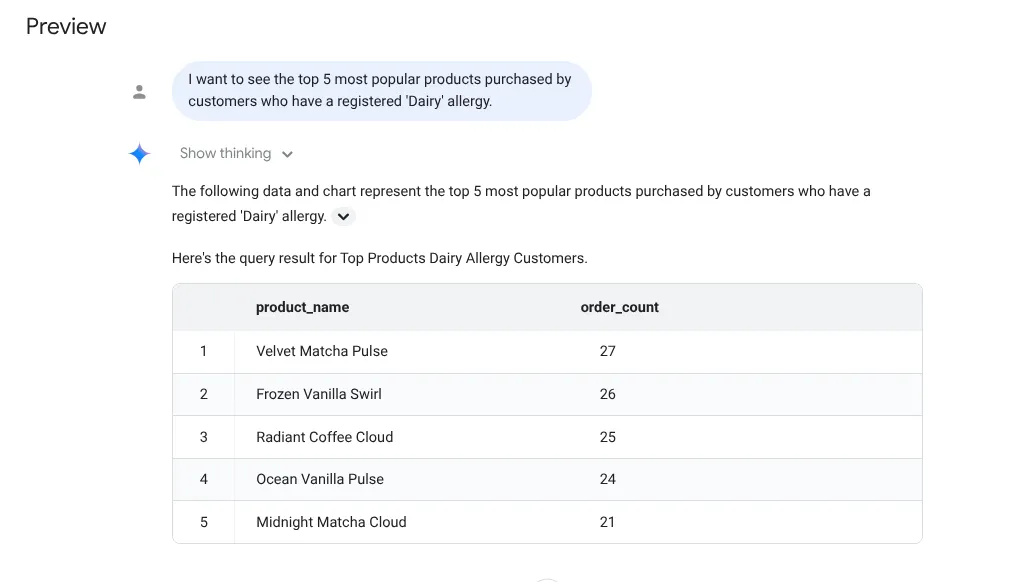
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
回答:
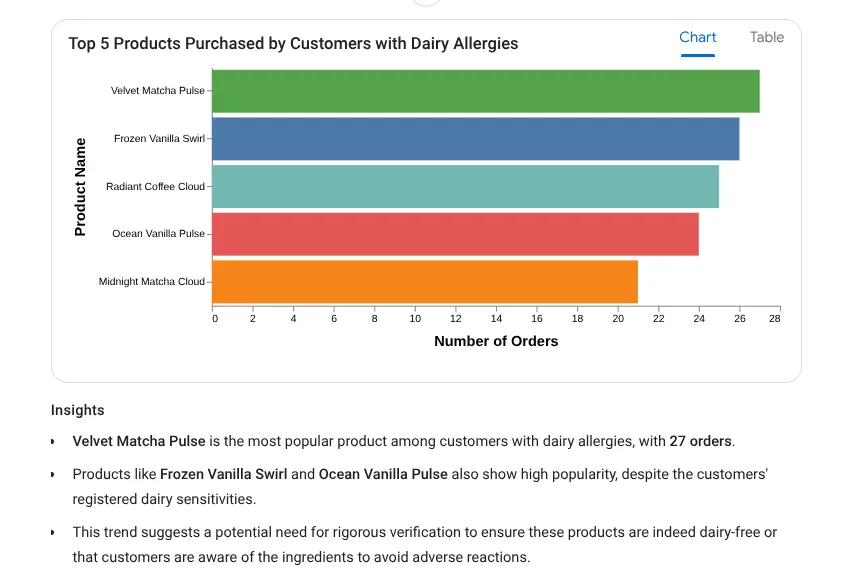
では、詳細なインサイト プロンプトを試してみましょう。
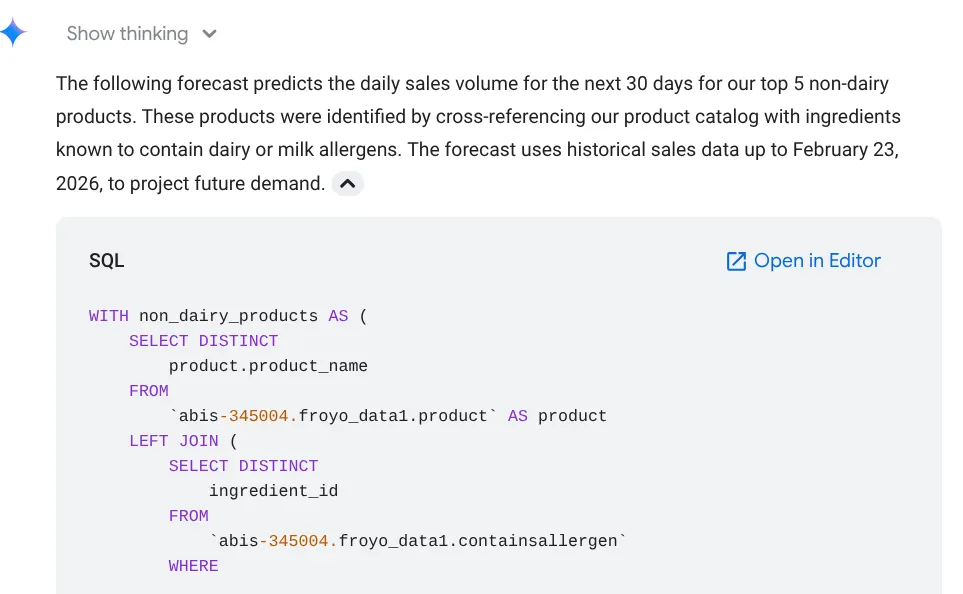
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
使用するクエリがテーブルの結果とともにグラフで表示されます。
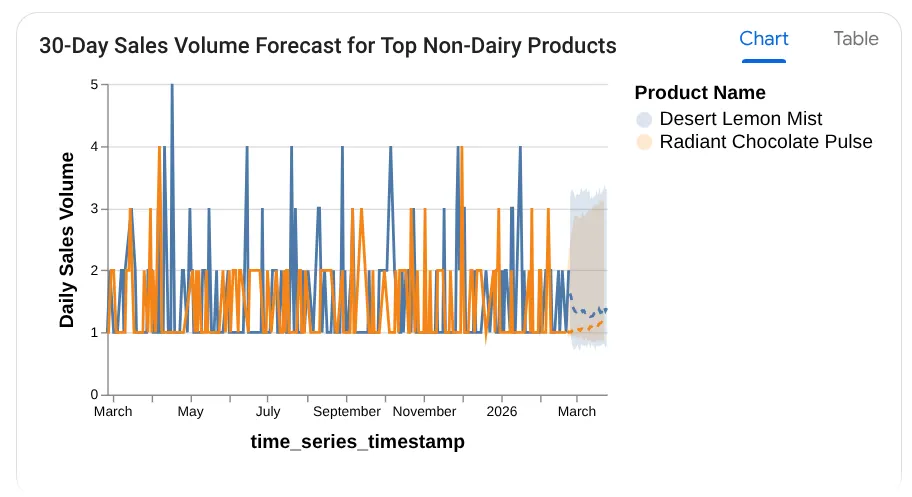

すごいですね。グラフとインサイトはうまくいきました。プロダクトに関する最後の質問です。
8. 最終テスト
質問を入力します。
What will be the top most selling product of 2026
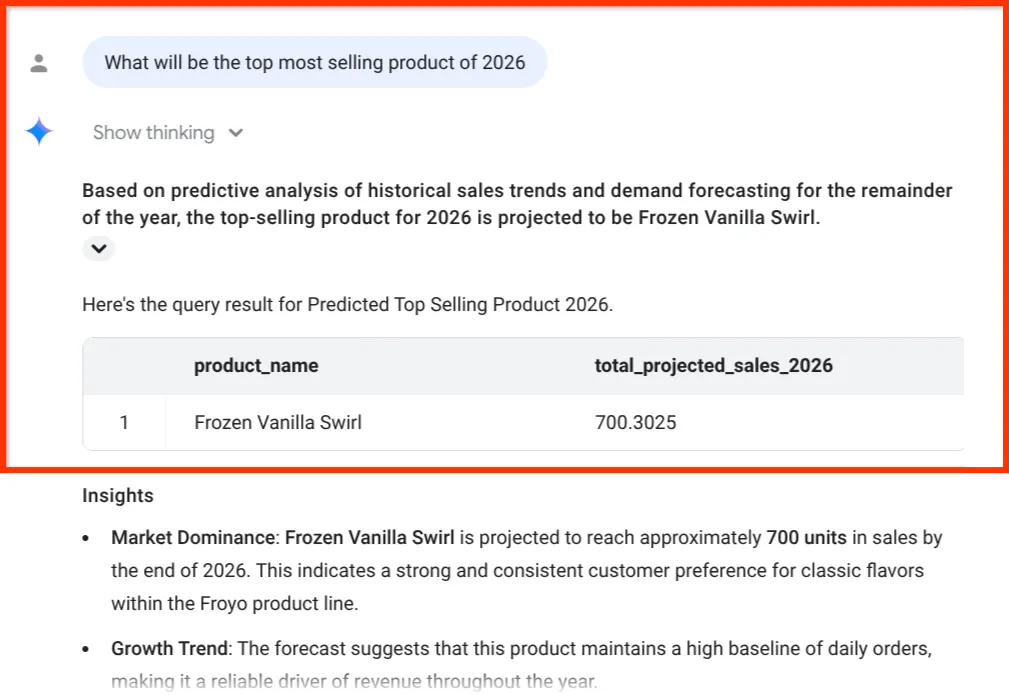

最後のインサイトを見てください。BigQuery Data Agent は単に数値を提示しただけでなく、売上予測を在庫と成分のサプライ チェーンに明示的に関連付けました。これは、パート 1 で雑然とした PDF から抽出したデータです。
9. エージェントを企業に公開する
プレビュー エージェントの上部にある [公開] ボタンをクリックします。
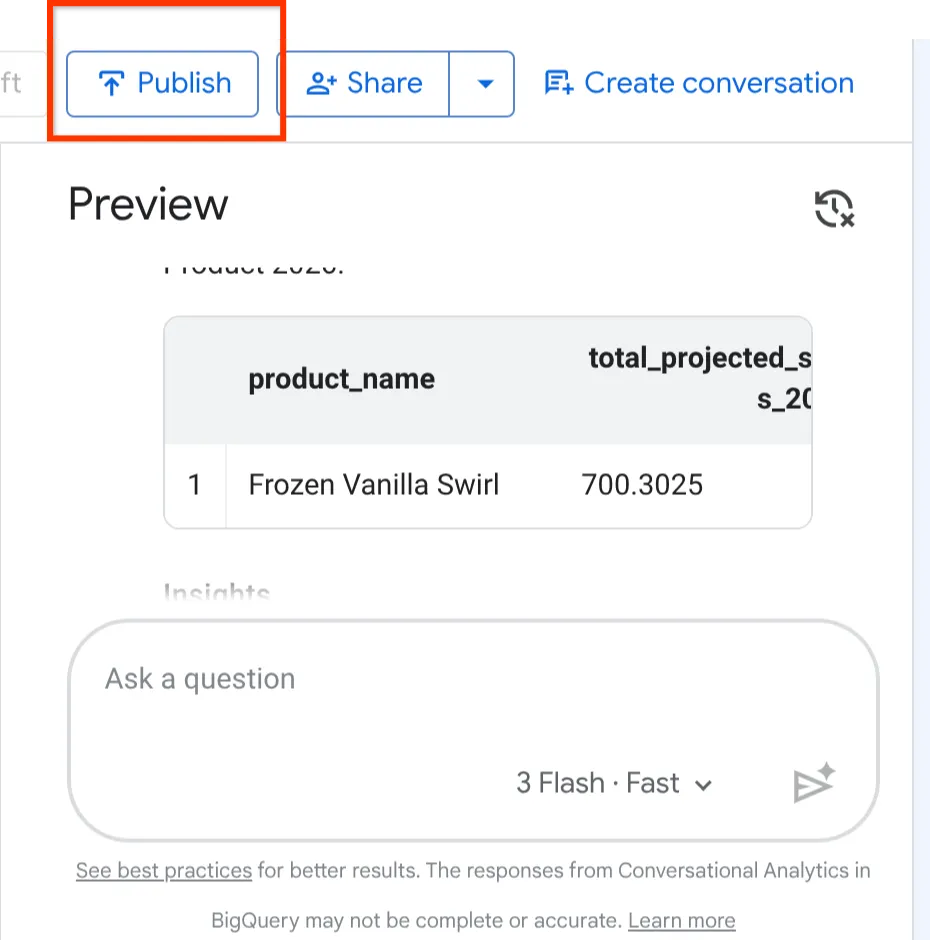
Froyo エージェントの構築、構成、テストが完了したので、ビジネスの他の部分にリリースします。
エージェント構成ページの右上にある [公開] ボタンをクリックします。
公開すると、エージェントはあなたと共有ユーザーが利用できるよう、3 つの強力なエンタープライズ チャネルで即座に利用可能になります。
- BigQuery: データ アナリストは、エージェント ハブから直接、または BigQuery Studio SQL ワークスペース内からこのエージェントとチャットできるようになりました。
- 会話型分析 API: デベロッパーは REST API を介してこのエージェントにアクセスできるため、これらの会話型分析を独自のカスタム内部ウェブ アプリケーションに統合できます。
- データポータル: エグゼクティブは、このエージェントとやり取りして、データポータル内で動的な会話型ダッシュボードを直接作成できます。
これで、データをサイロから取り出し、必要なユーザーがすでに作業している場所に直接配置することができました。
公開した BigQuery エージェントの上部にある [共有] ボタンのプルダウンをクリックし、リストから [データポータルのエージェントへのリンクをコピー] オプションを選択します。
そのリンクをブラウザに貼り付けて、Enter キーを押します。エージェントの操作アクセス アラートを確認します。
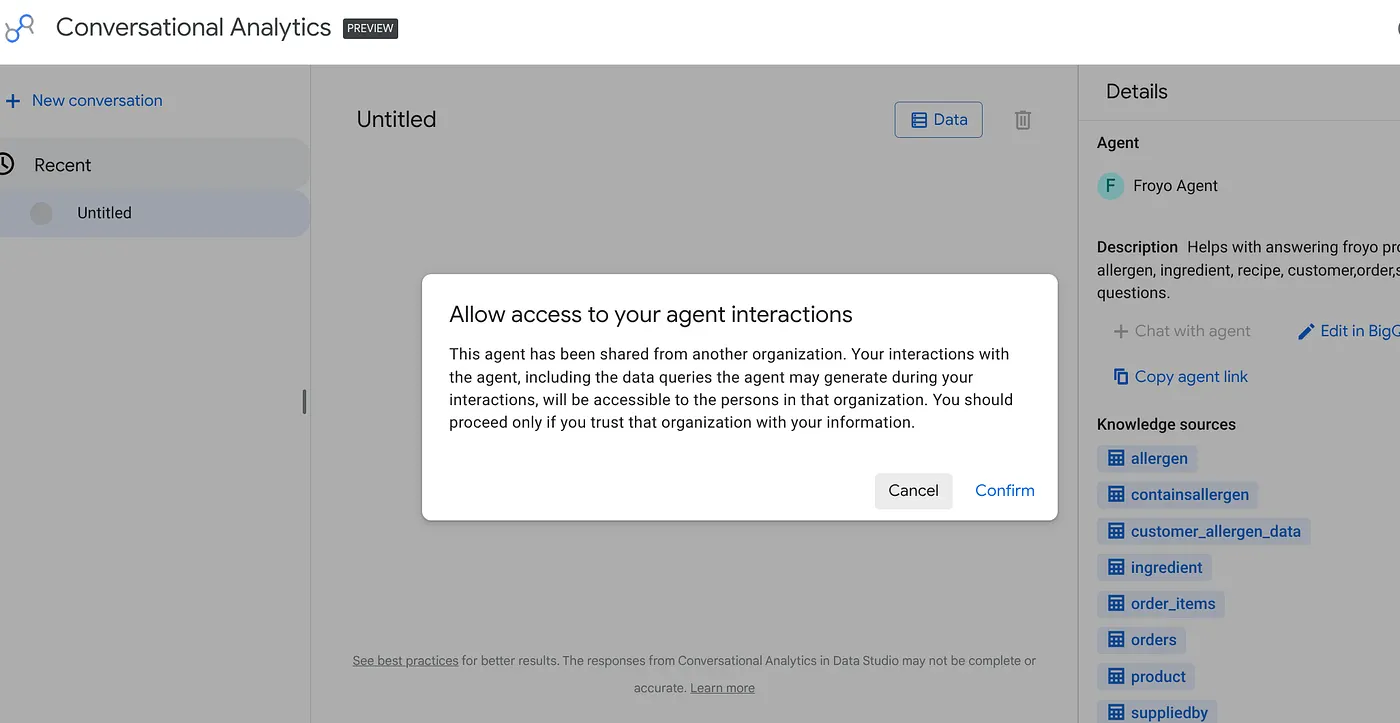
データポータルから、新しく公開されたエージェントとのインタラクティブな会話と可視化を開始できます。この情報を必要とするリーダーや他のチームも同様です。
10. クリーンアップ
このラボが完了したら、作成した BigQuery エージェントに対するすべてのユーザーの権限を削除してください。
11. 完了
Agentic Data Cloud が正式に構築されました。
単なる chatbot を構築したわけではありません。この 5 回のセッションで、完全で最新の評価済みエンタープライズ AI システムをゼロから構築しました。「ダークデータ」からリアルタイムのトランザクション インテリジェンス、そして会話型ビジネス予測へと移行しました。
12. 全体像
一歩下がって、このシリーズで達成したことを振り返ってみましょう。単なる chatbot を構築したわけではありません。完全で最新の Agentic Data Cloud を構築しました。
パート 1: Knowledge Catalog を使用して PDF を構造化されたリレーショナル テーブルに変換し、ダークデータを解放しました。
パート 2: 分析用ウェアハウスを AlloyDB トランザクション データベースに直接統合することで、データサイロを解消しました。
パート 3: MCP プロトコルを介して安全なデータベース ツールをシームレスに実行するマルチエージェント OS を構築することで、ユーザーを強化しました。
パート 4: 厳格な評価パイプラインを実装して、ハルシネーションとジェイルブレイクを捕捉することで安全性を確保しました。
パート 5: ANTIGRAVITY IDE と BigQuery の会話型分析を使用して、インサイトを民主化しました。
これがエンタープライズ ソフトウェアの未来です。AI エージェントは、単なる LLM のラッパーではなくなりました。統合データ プラットフォーム上に配置された、完全に統合され、評価され、安全なオーケストレーション エンジンです。