
1. Przegląd
Przyjrzyjmy się architekturze, którą zbudowaliśmy w 4 poprzednich częściach:
Część 1. Użyliśmy usługi BigQuery Knowledge Catalog, aby przekształcić nieprzetworzone pliki PDF z przepisami na froyo w uporządkowane tabele relacyjne.
Część 2. Utworzyliśmy transakcyjny most Zero-ETL, który federuje naszą hurtownię BigQuery bezpośrednio z AlloyDB.
Część 3. Za pomocą pakietu Agent Development Kit i zestawu narzędzi MCP utworzyliśmy aplikację wieloagentową (FroyoOS).
Część 4. Udowodniliśmy, że nasz agent jest bezpieczny do wdrożenia w wersji produkcyjnej, tworząc dwutorowy potok oceny.
Nasze operacje przebiegają bez zarzutu. A co z deweloperami i analitykami biznesowymi, którzy muszą zrozumieć ogromne ilości danych generowanych przez ten system?
Dziś przyjrzymy się przyszłości analityki. Zaczniemy od edytora kodu Antigravity IDE z pakietem Google Cloud Data Agent Kit, a następnie przejdziemy do konsoli Google Cloud, aby wizualizować dane za pomocą analityki konwersacyjnej BigQuery.
Zacznijmy tworzyć.
Czego się nauczysz
W tym ostatnim ćwiczeniu z serii Agentic Data Cloud połączysz wszystkie elementy architektury, aby dostarczać przydatne statystyki biznesowe. Dowiesz się:
- Analityka oparta na IDE: jak zainstalować i skonfigurować środowisko IDE ANTIGRAVITY oraz zestaw narzędzi Google Cloud Data Agent Kit, aby wykonywać zapytania dotyczące architektury bezpośrednio ze środowiska programistycznego.
- BigQuery konwersacyjne: jak tworzyć, konfigurować i instruować agentów danych BigQuery, aby automatyzować złożone zadania SQL i prognozowanie za pomocą języka naturalnego.
- Demokratyzacja danych: jak udostępniać agentów w firmie, aby analitycy i użytkownicy biznesowi w całej organizacji mieli do nich dostęp.
- Wizualizacja statystyk: jak płynnie zintegrować analitykę konwersacyjną agenta z Studio danych, aby tworzyć dynamiczne panele gotowe do prognozowania.
- Ekosystem Agentic Data Cloud: jak przedstawić wartość architektury kompleksowej – od nieprzetworzonych danych nieustrukturyzowanych w części 1 po pulpity gotowe do prezentacji kadrze kierowniczej w części 5.
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie włączone są płatności.
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli chcesz się uwierzytelnić
gcloud auth login
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API: aby włączyć wszystkie wymagane interfejsy API, uruchom to polecenie:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. Rozbudowa hurtowni danych
Pamiętasz tabele BigQuery, które utworzyliśmy na podstawie nieustrukturyzowanych danych?
Aby przeprowadzić wartościowe analizy, potrzebujemy historycznych danych o transakcjach. W BigQuery w zbiorze danych froyo_data utwórzmy 3 nowe tabele, aby zasymulować lata działalności franczyzy:
- froyo_data.orders: historyczne nagłówki zamówień (daty, identyfikatory sklepów, sumy)
- froyo_data.order_items: szczegóły elementów zamówienia (ilości, ceny)
- froyo_data.customer_allergen_data: tabela CRM, która śledzi znane alergie naszych lojalnych klientów.
Dodajmy do tego zbioru danych tabele związane ze sprzedażą i klientami, aby przygotować go do analizy.
- Otwórz terminal Cloud Shell w konsoli Google Cloud.
- Przejdź do folderu głównego obszaru roboczego lub do folderu głównego projektu froyo-data (nad którym pracowaliśmy w kilku poprzednich częściach tej serii).
- Pobierz 3 pliki danych historycznych (w formacie CSV) do katalogu roboczego, wykonując kolejno te polecenia:
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/customer_allergen_data.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/order_items.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/orders.csv
- Gdy zobaczysz te pliki w katalogu głównym katalogu roboczego, przejdź do terminala Cloud Shell.
- W terminalu Cloud Shell otwórz katalog, w którym znajdują się te 3 pliki.
- Upewnij się, że w BigQuery masz zbiór danych o nazwie „froyo_data” z części 1 tej serii (jeśli nie, wróć i utwórz zbiór danych oraz tabele).
- Uruchom w terminalu Cloud Shell te polecenia:
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.orders \
./orders.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.order_items \
./order_items.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.customer_allergen_data \
./customer_allergen_data.csv
W zbiorze danych froyo_data powinny zostać utworzone 3 dodatkowe tabele.
4. The Developer Experience — Enter the "Data Agent Kit"
Tradycyjnie, jeśli deweloper chciał analizować dane lub pisać złożone zapytania dotyczące uczenia maszynowego, musiał ciągle przełączać się między środowiskiem IDE, konsolami baz danych i dokumentacją.
To już nie jest problem. Dzięki nowo udostępnionemu rozszerzeniu Google Cloud Data Agent Kit Twoje środowisko IDE stanie się potężnym narzędziem do pracy z danymi.
ANTIGRAVITY IDE
ANTIGRAVITY IDE to środowisko programistyczne Google nowej generacji oparte na agentach, zaprojektowane specjalnie z myślą o erze AI. Jest on natywnie zintegrowany z ogromnymi oknami kontekstowymi obejmującymi wiele rodzajów danych i autonomicznym korzystaniem z narzędzi bezpośrednio w edytorze, co pozwala programistom zarządzać zasobami w chmurze i złożonymi potokami danych bez opuszczania kodu.
Konfigurowanie środowiska ANTIGRAVITY IDE
- Pobierz IDE: wejdź na stronę antigravity.google i pobierz IDE Antigravity dla swojego systemu operacyjnego (Windows, macOS lub Linux).
- Zainstaluj i uruchom: uruchom instalator i otwórz aplikację.
- Kliknij „Kontynuuj z Google”, wybierz konto Gmail i autoryzuj.
- Po zalogowaniu utwórz folder roboczy (obszar roboczy lub projekt). Nazwijmy ją „Agent Data Cloud”.
Powinien on pojawić się na liście „Projekty” po lewej stronie:
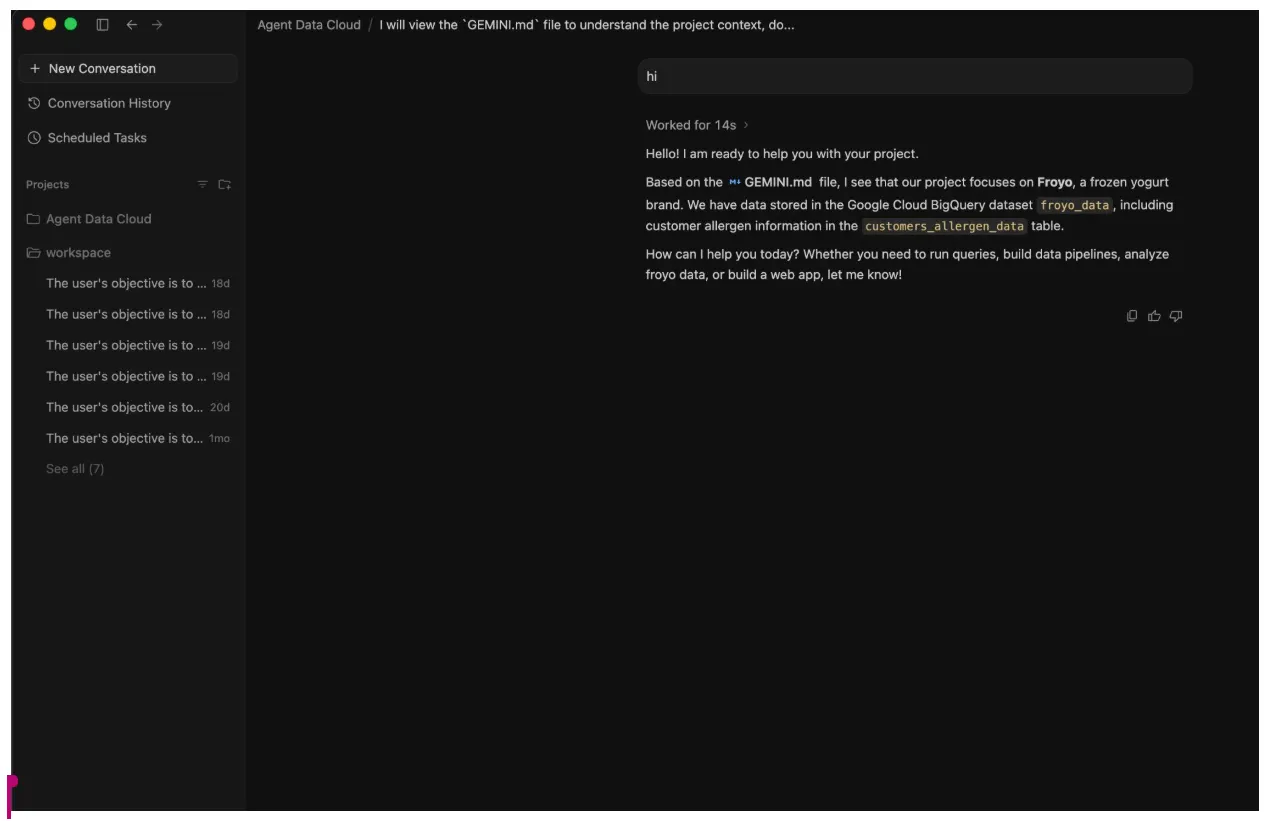
- Rozpocznij wstępny czat z pracownikiem obsługi klienta – napisz „cześć”.
- W prawym górnym rogu znajdź przycisk Otwórz IDE.
Zanim jednak to zrobisz, musisz zainstalować Antigravity IDE. Otwórz stronę antigravity.google/download i przewiń w dół do sekcji Antigravity IDE. Pobierz odpowiednią wersję.
Po pobraniu wróć do otwartej instancji Antigravity i w prawym górnym rogu kliknij przycisk Open IDE (Otwórz IDE).
- Powinny pojawić się wyskakujące okienka z prośbą o uprawnienia. Otwórz je.
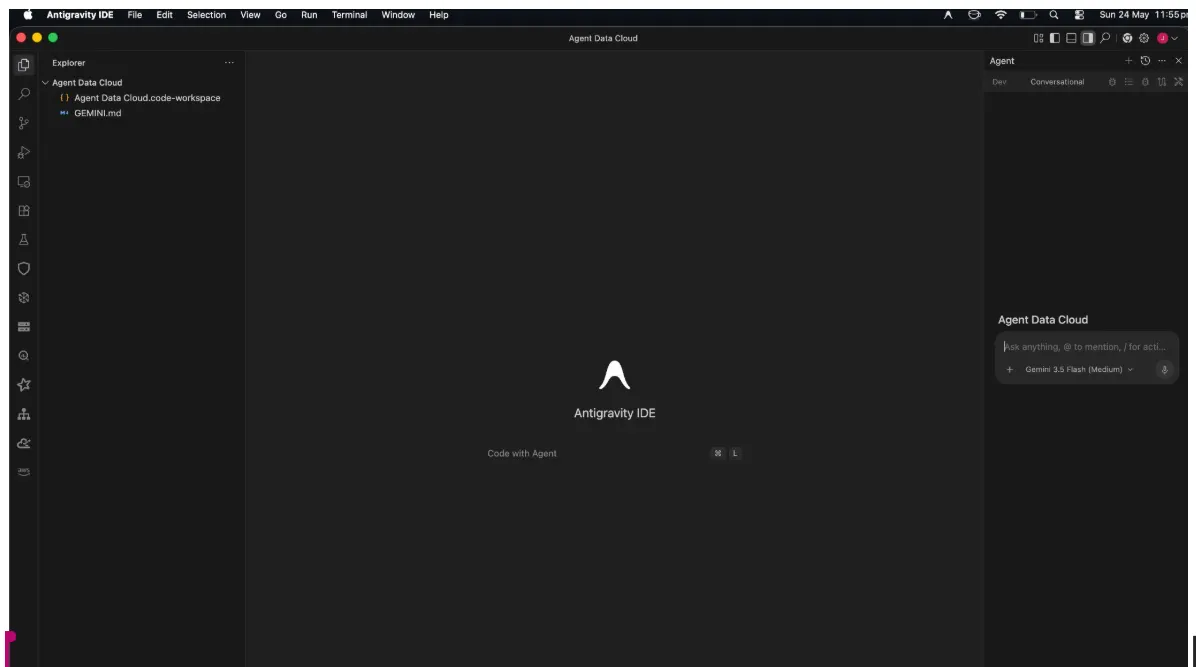
Po prawej stronie zobaczysz panel agenta, po lewej – eksplorator projektu, a pośrodku – miejsce na rozwój.
Konfigurowanie rozszerzenia Data Agent Kit
- Zainstaluj rozszerzenie: otwórz platformę rozszerzeń w ANTIGRAVITY IDE. Wyszukaj i zainstaluj rozszerzenie Google Cloud Data Agent Kit.
- Kliknij przycisk Zainstaluj. Po zakończeniu instalacji rozszerzenie będzie widoczne w panelu nawigacyjnym.
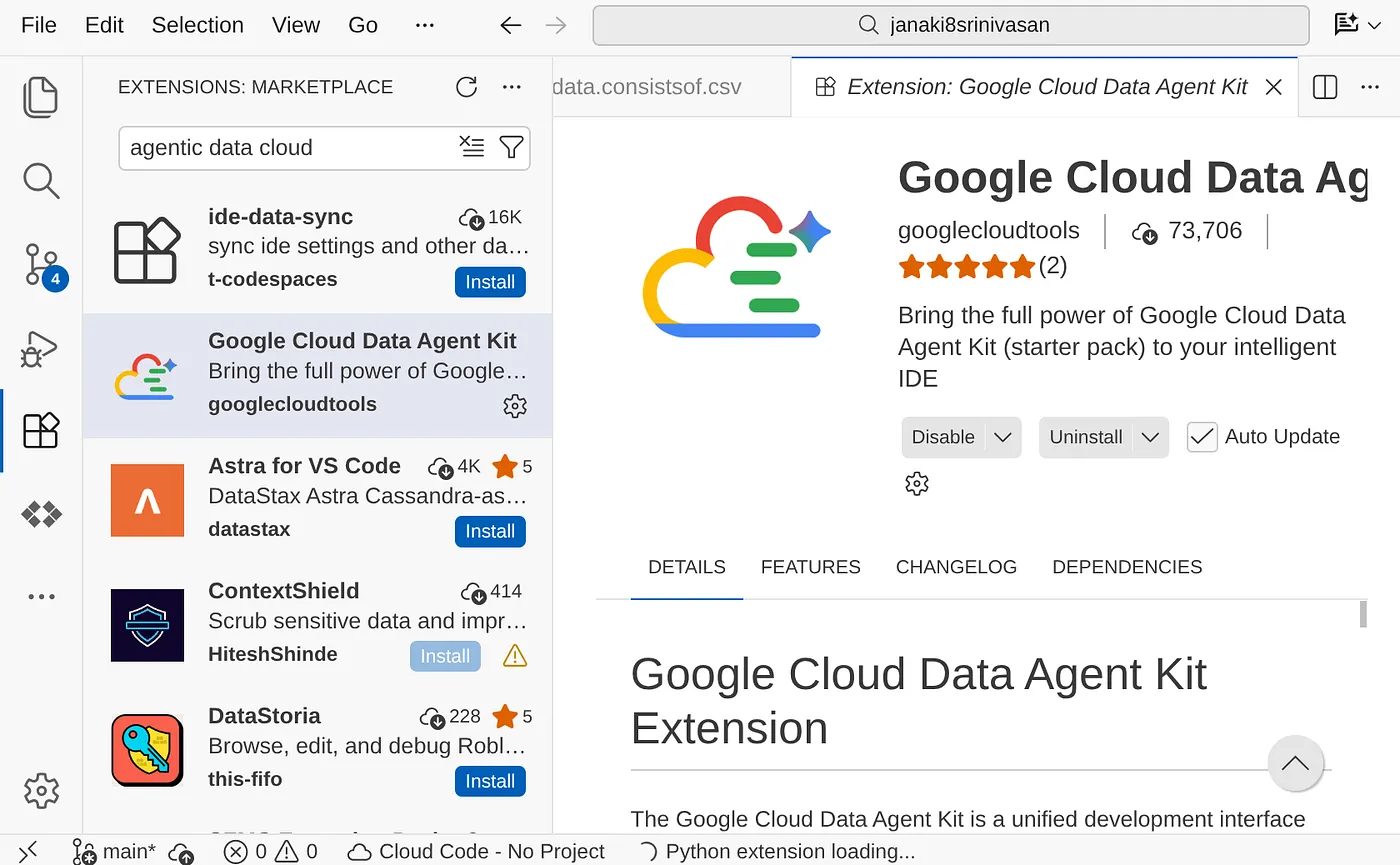
- Kliknij tę opcję, aby otworzyć eksplorator zestawu narzędzi Google Cloud Data Agent Kit. Przejdź do sekcji USTAWIENIA i kliknij Ustawienia. Wpisz szczegóły projektu i region, a następnie zapisz zmiany.
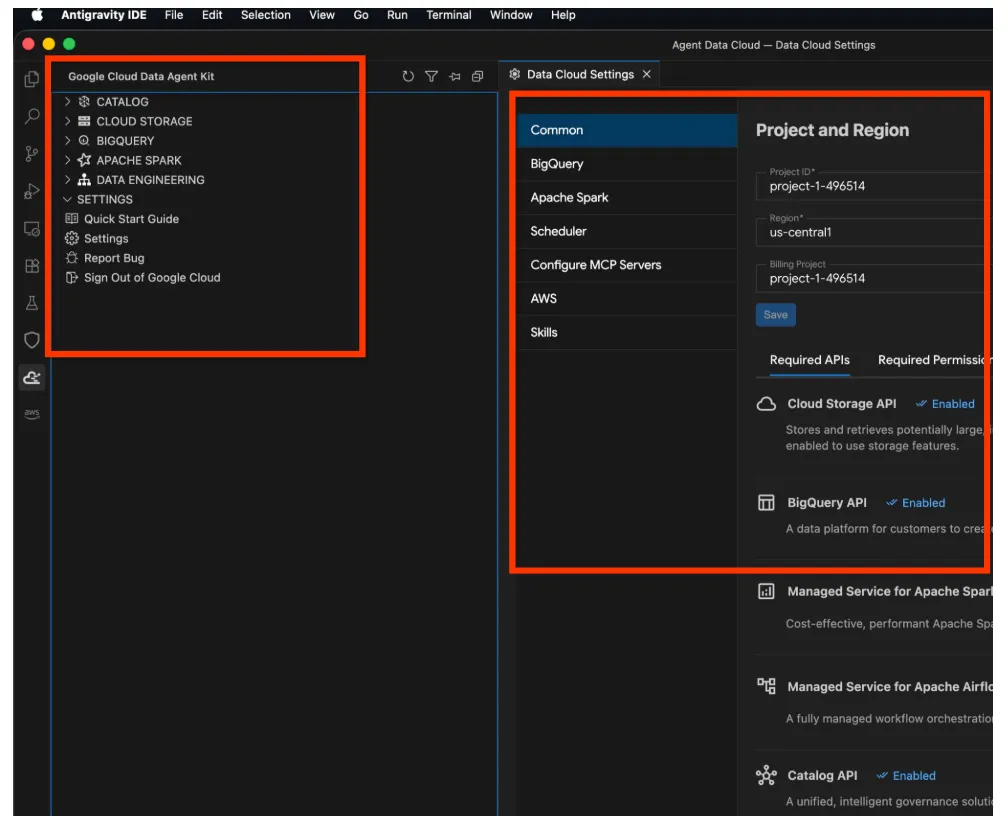
- Teraz kliknij Eksplorator projektu u góry panelu nawigacyjnego. W panelu eksploratora powinien otworzyć się eksplorator projektu.
- Kliknij prawym przyciskiem myszy obszar eksploratora i utwórz nowy plik o nazwie „GEMINI.md”.
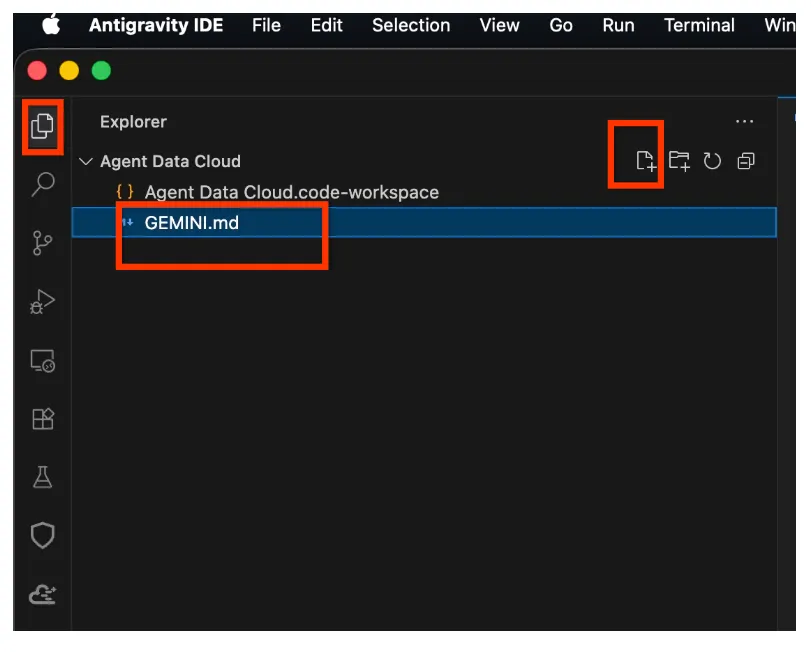
- Wklej poniższy kod do pliku GEMINI.md (nie zapomnij zastąpić ciągu <<YOUR_PROJECT_ID>> swoją wartością):
## 1. Project Context
- **Project ID**: <<YOUR_PROJECT_ID>>
- **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
- **Data**: All froyo, customer, order related information is processed and stored in BigQuery `froyo_data` dataset.
## 2. Execution & Data Processing Rules
- **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `froyo_data`.
- **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the tables `customers_allergen_data`.
- ** CRITICAL RULE - Sales Data**: Sales data is present in tables `orders` and `order_items`.
- ** CRITICAL RULE - General: When you are referencing a dataset, ensure you are using it with the dataset ID (`froyo_data`) . For example, to query orders table in this dataset you should use `froyo_data.orders`.
W środowisku IDE masz teraz zaawansowanego agenta AI, który może pisać kod, generować zapytania SQL i analizować architekturę.
Mamy teraz fascynujące wyzwanie analityczne: czy możemy skorelować naszą historyczną sprzedaż ze złożonymi, wywnioskowanymi danymi o alergenach, które wyodrębniliśmy z plików PDF w części 1?
5. Wyciąganie wniosków na podstawie informacji za pomocą agenta IDE
Poprośmy agenta IDE o wykonanie najbardziej uciążliwych zadań. Otwórz okno czatu Agent Data Kit bezpośrednio w środowisku ANTIGRAVITY IDE i wpisz w nim to polecenie:
Does Midnight Swirl contain any allergen?
Poprosi o przyznanie szeregu uprawnień. Zezwól na nie w odpowiednich przypadkach.
Na koniec po zakończeniu analizy otrzymasz odpowiedź:
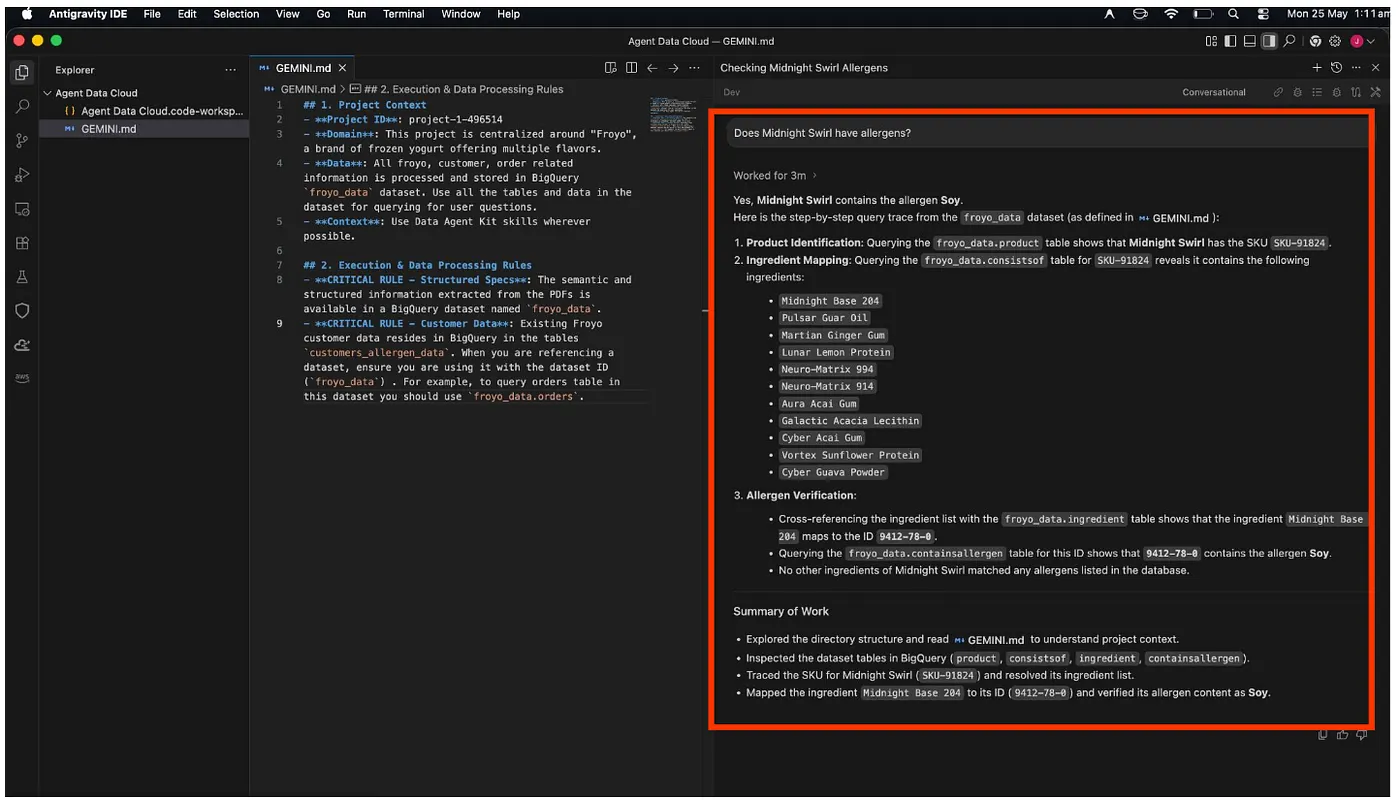
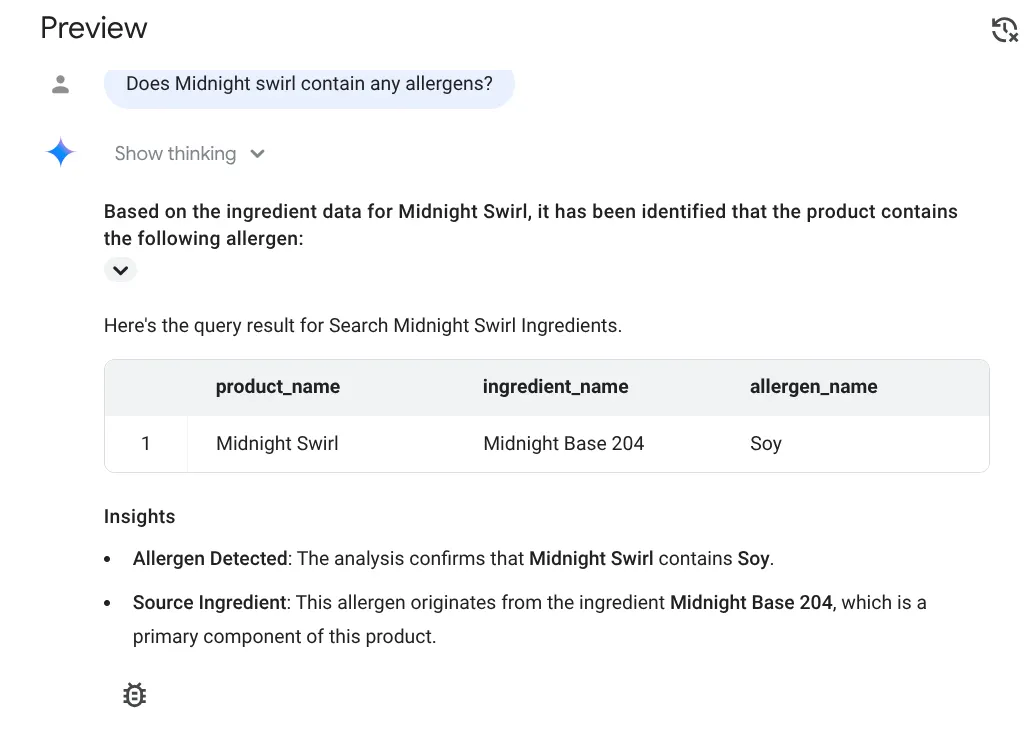
Super!!! Prawidłowo wykryto, że produkt Midnight Swirl zawiera soję.
Teraz zadajmy nieco bardziej złożone pytanie. Wyślij ten prompt w środowisku IDE Antigravity:
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
Odpowiedź:
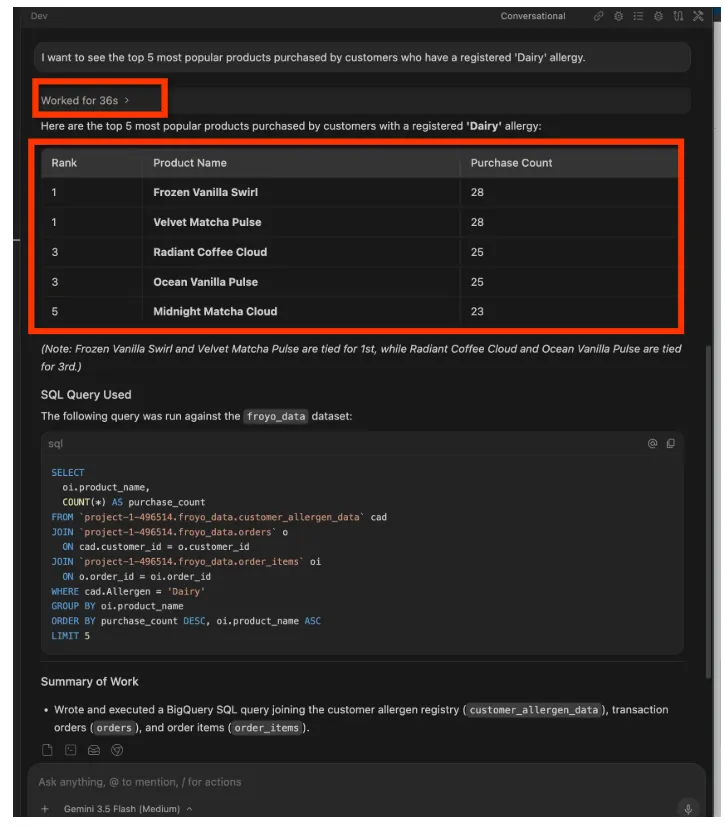
Możesz kontynuować. Wypróbuj prompty takie jak:
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
Bez konieczności wyszukiwania składni BQML Agent Data Kit umieszcza w edytorze dokładny kod CREATE MODEL i ML.FORECAST. Możesz uruchomić to bezpośrednio w środowisku BigQuery bez opuszczania środowiska IDE ANTIGRAVITY.
To niesamowite!
6. Analiza konwersacyjna w BigQuery
Deweloperzy uwielbiają IDE, ale użytkownicy biznesowi i kierownictwo korzystają z konsoli w chmurze. Nie chcą widzieć kodu SQL, tylko odpowiedzi.
Zaczynamy:
- Przyznawanie sobie wymaganych ról
Otwórz stronę Uprawnienia projektu i przypisz sobie rolę Właściciel agenta danych Gemini Data Analytics:
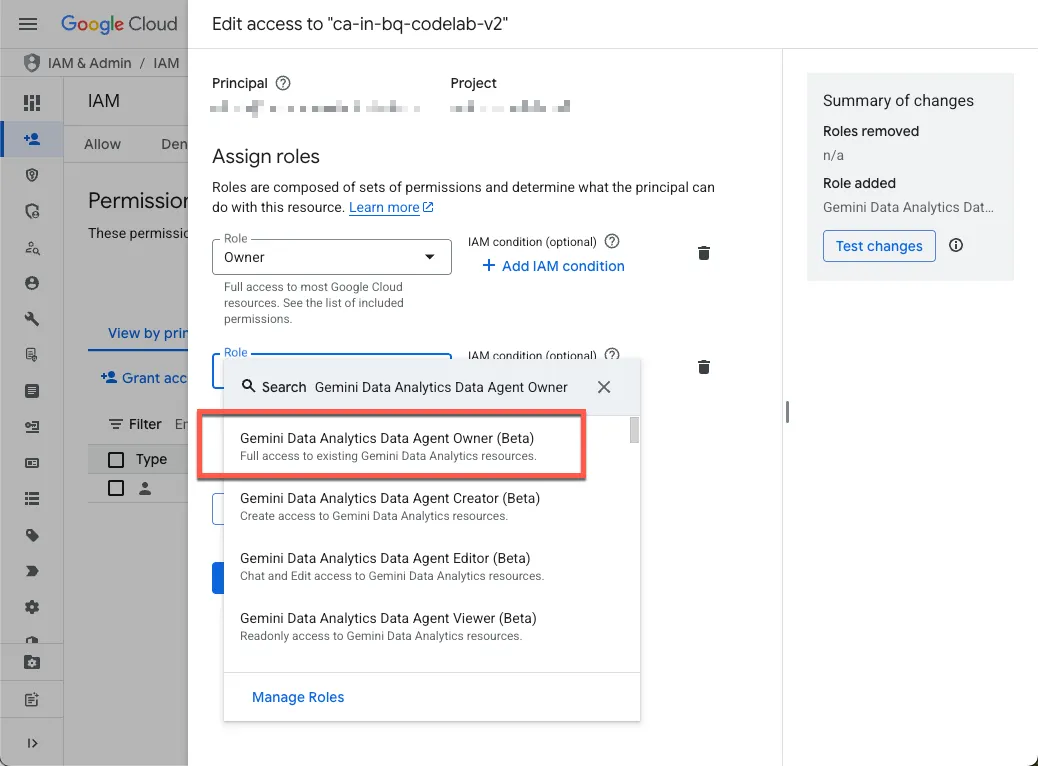
Ta rola przyznaje uprawnienia do tworzenia, edytowania, udostępniania i usuwania wszystkich agentów danych w projekcie.
- Włącz wymagane interfejsy API
Otwórz BigQuery w konsoli Google Cloud. Aby przejść do sekcji BigQuery > Agenci, użyj menu nawigacyjnego na pasku bocznym lub menu wyszukiwania u góry strony.
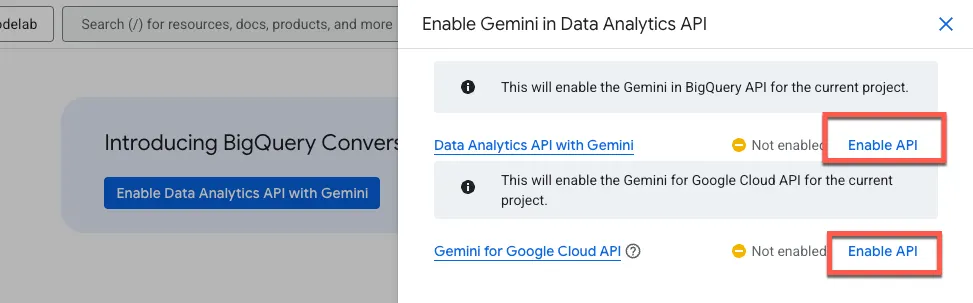
Kliknij Włącz API Data Analytics z Gemini:
Włącz Gemini in BigQuery API i Gemini for Google Cloud API:
Powinna wyświetlić się strona nowego agenta:
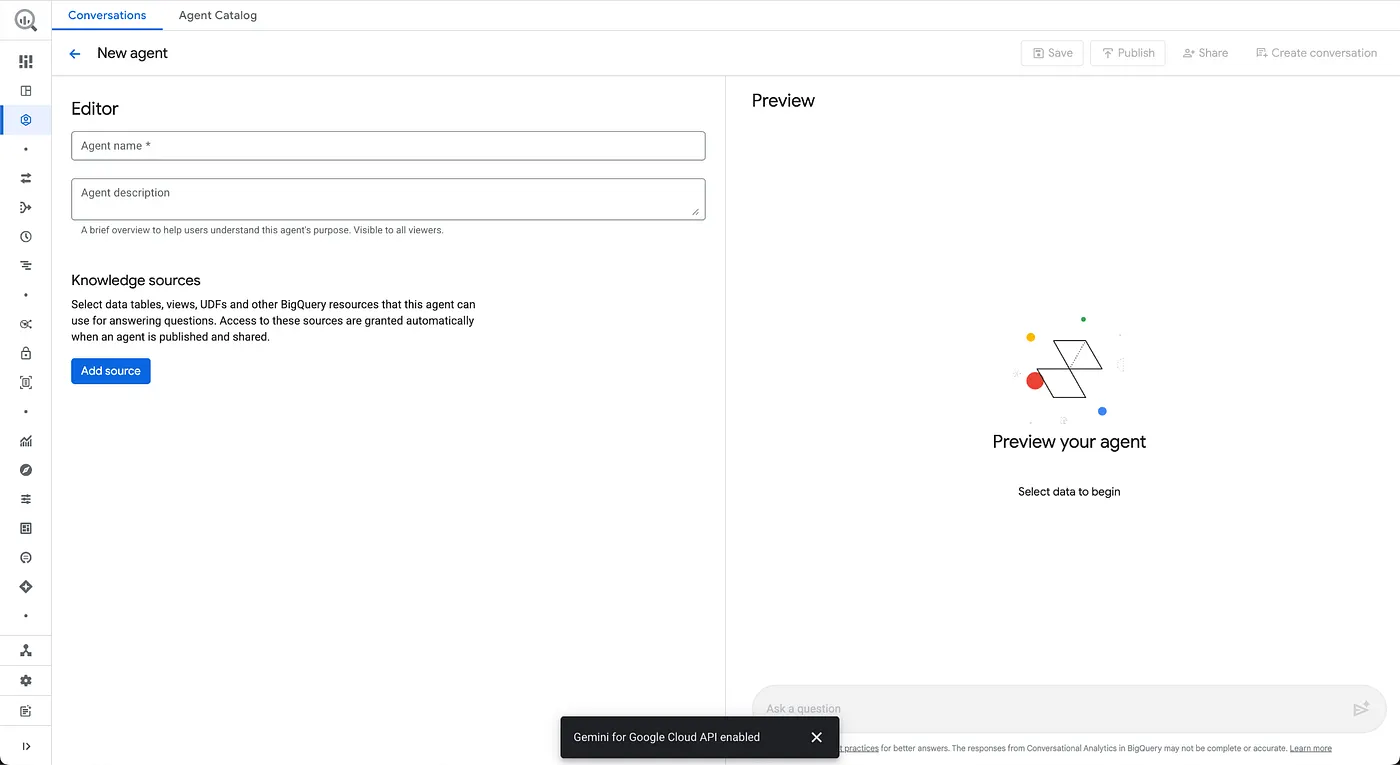
- Konfigurowanie informacji o agencie
Nazwa agenta: Froyo Agent
Opis agenta: pomaga odpowiadać na pytania dotyczące produktów, alergenów, składników, przepisów, klientów, zamówień i sprzedaży.
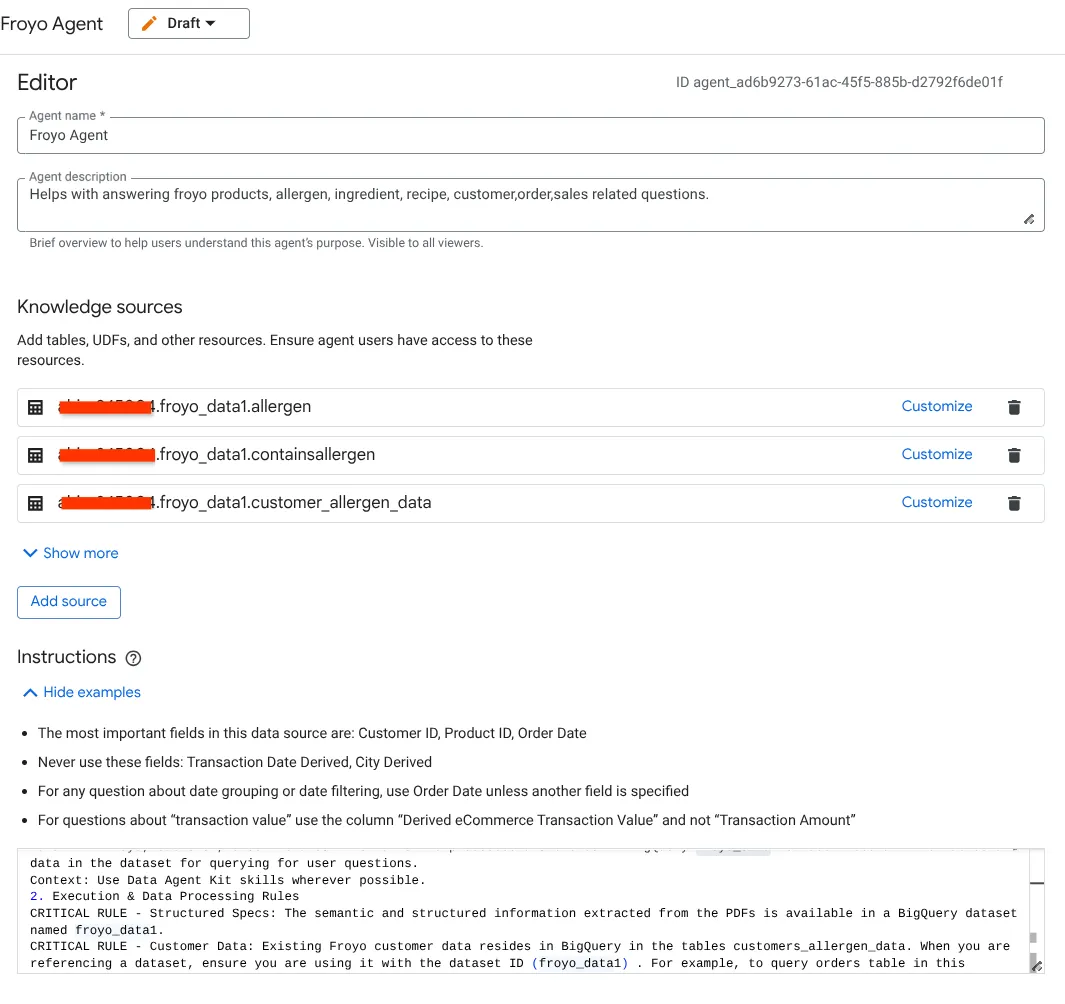
- Przejdź do sekcji Źródła wiedzy i wybierz wszystkie tabele z poniższej listy w swoim zbiorze danych:
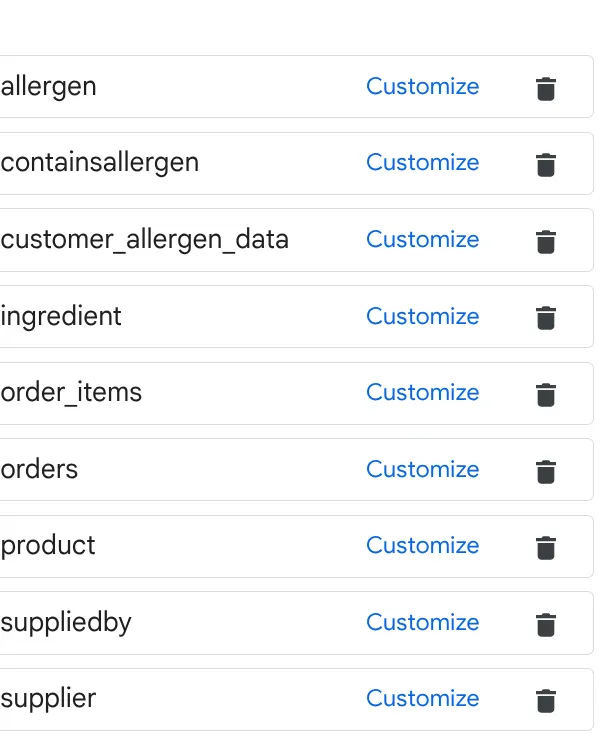
a. Dodaj tabele widoczne na obrazie powyżej i kliknij Dodaj źródło.
b. Przy każdym źródle kliknij po prawej stronie przycisk Dostosuj. Zobaczysz poniższy formularz:
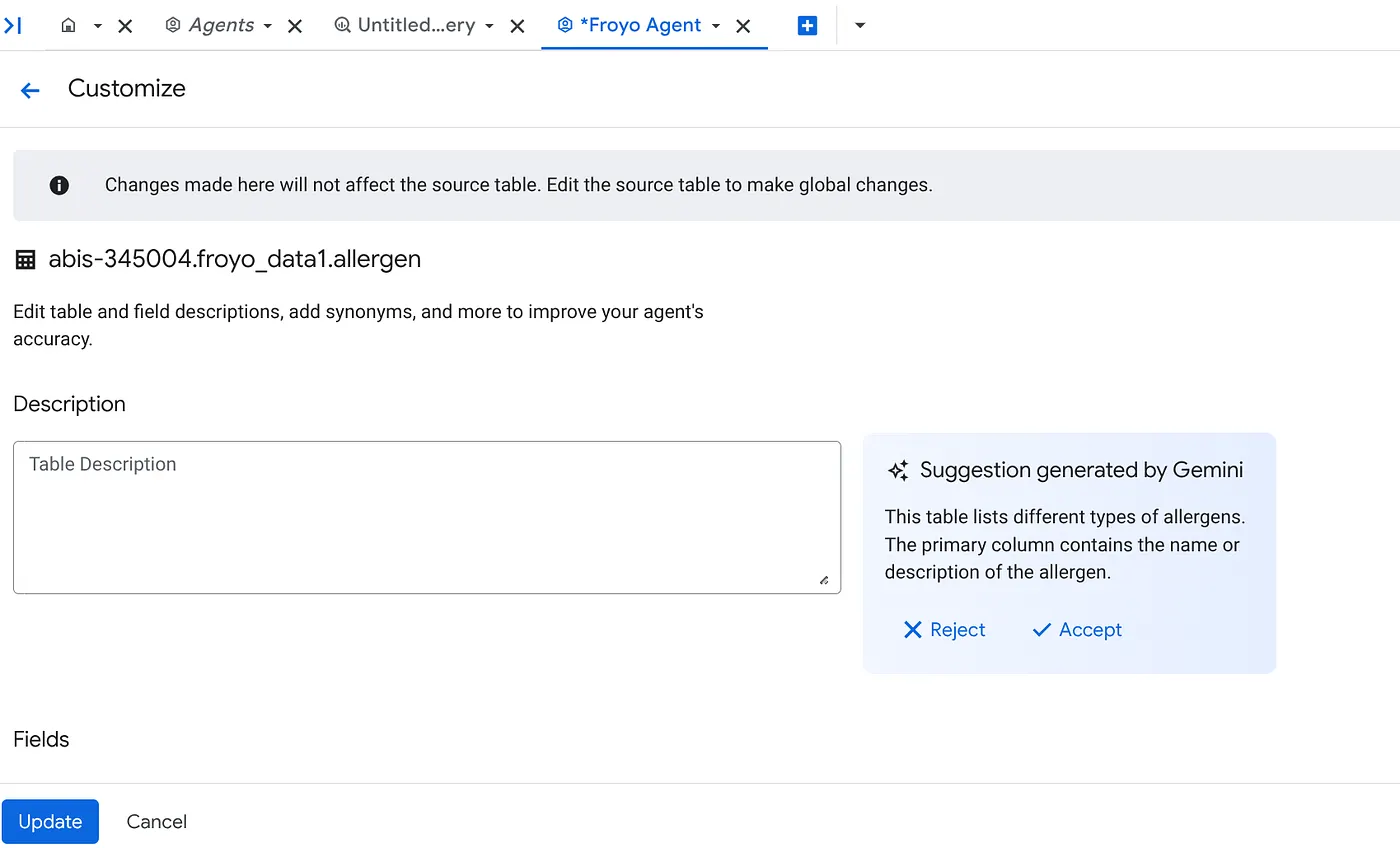
c. Kliknij „Akceptuj” w przypadku opisu tabeli.
d. Kliknij „Akceptuję” w przypadku opisu każdego pola.
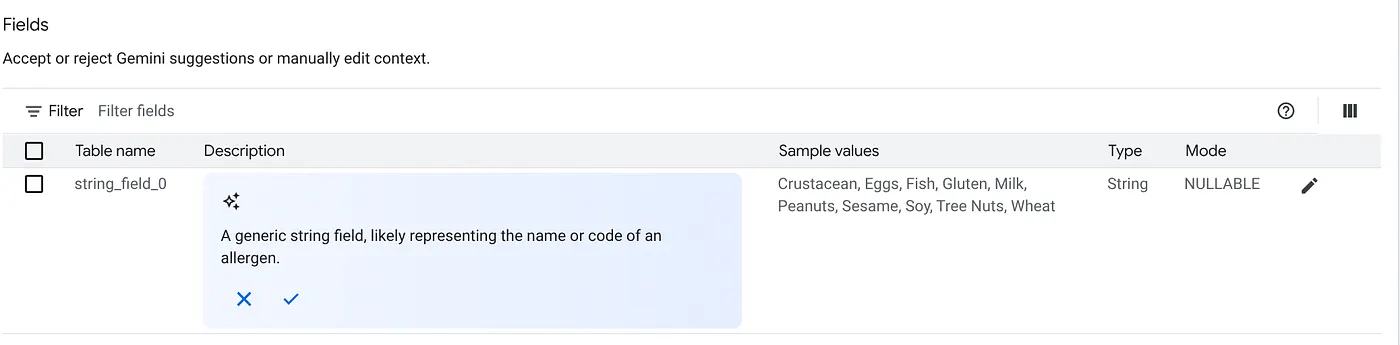
e. Kliknij Aktualizuj.
Musisz powtórzyć tę czynność dla wszystkich tabel w źródle.
- Instrukcje konfiguracji
Wklej tutaj te same instrukcje, których użyliśmy w pliku GEMINI.md w środowisku IDE Antigravity:
1. Project Context
Project ID: <<YOUR_PROJECT_ID>>
Domain: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
Data: All froyo, customer, order related information is processed and stored in BigQuery froyo_data dataset. Use all the tables and data in the dataset for querying for user questions.
Context: Use Data Agent Kit skills wherever possible.
2. Execution & Data Processing Rules
CRITICAL RULE - Structured Specs: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named froyo_data.
CRITICAL RULE - Customer Data: Existing Froyo customer data resides in BigQuery in the tables customers_allergen_data. When you are referencing a dataset, ensure you are using it with the dataset ID (froyo_data) . For example, to query orders table in this dataset you should use froyo_data.orders.
- Zapisz agenta.
7. Czatuj z danymi
- Przetestuj go w sekcji podglądu po prawej stronie:
Zadaj pytanie:
Does midnight swirl contain any allergen?
Odpowiedź:
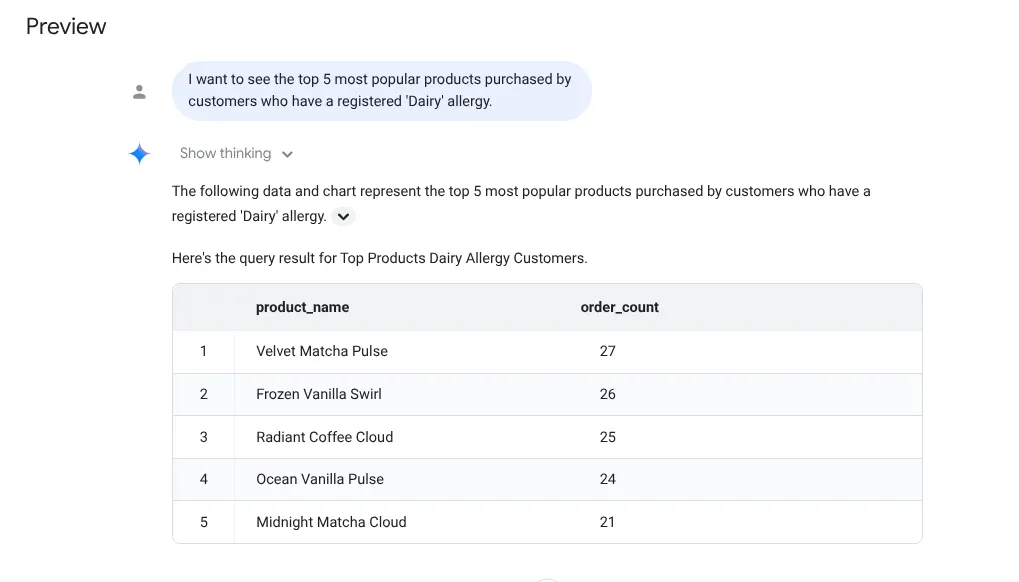
Teraz zadajmy skomplikowane pytanie:
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
Odpowiedź:
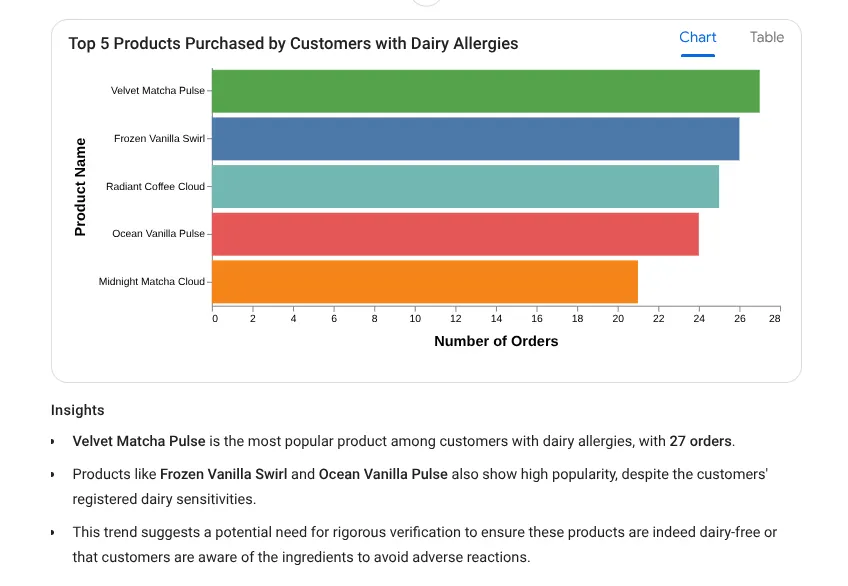
Wypróbujmy teraz prompta z dokładnymi statystykami:
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
Widać, że wyświetla użyte zapytanie, a także tabelę wyników i wykres:
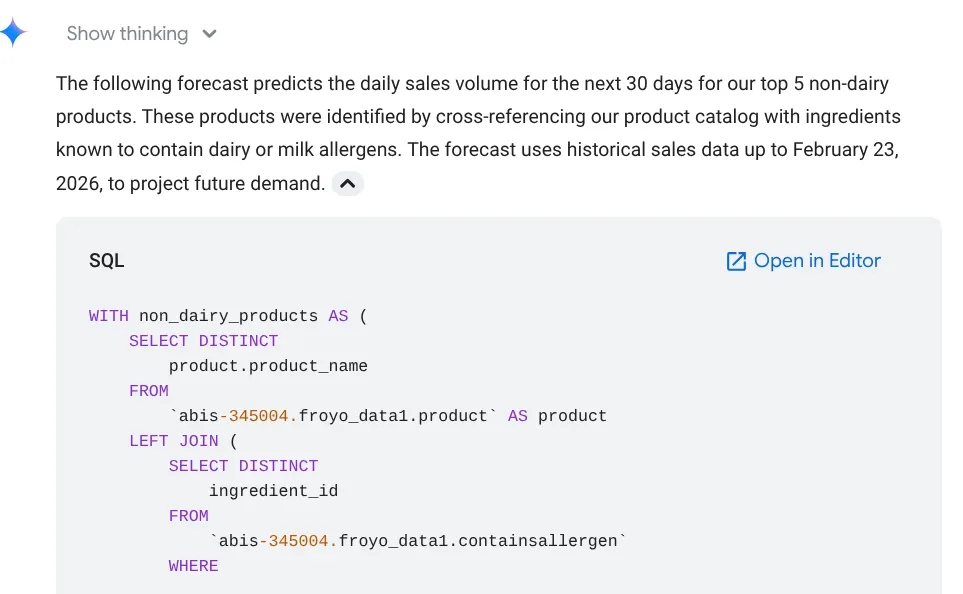
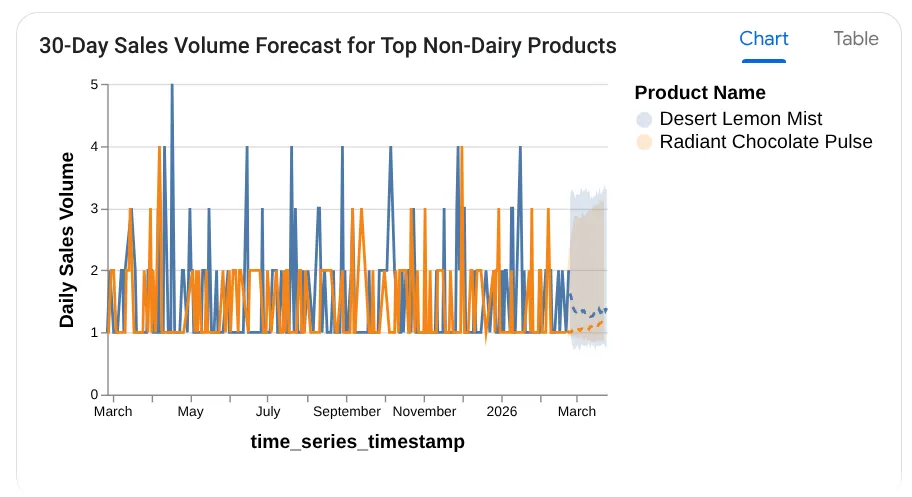

Niesamowite! Dlatego dobrze pasuje do wykresów i statystyk. Czas na najważniejsze pytanie dotyczące produktów.
8. Najtrudniejszy test
Zadaj pytanie:
What will be the top most selling product of 2026
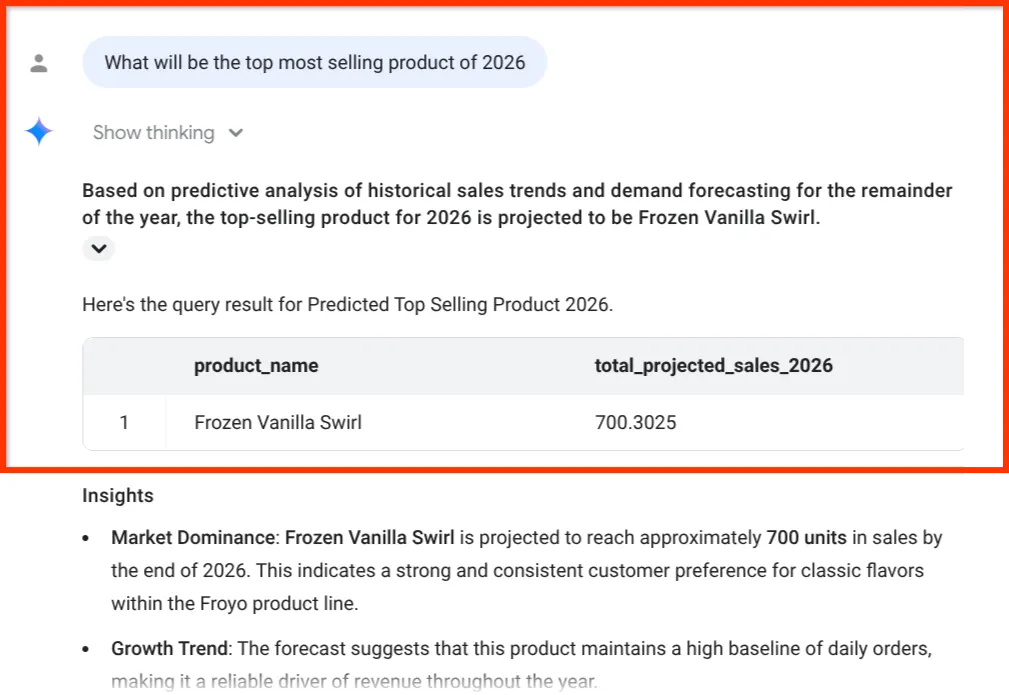

Spójrz na te ostatnie statystyki. Agent danych BigQuery nie tylko podał nam liczbę, ale też wyraźnie powiązał prognozę sprzedaży z naszymi zapasami i łańcuchem dostaw składników – czyli z danymi, które w części 1 wyodrębniliśmy z nieuporządkowanych plików PDF.
9. Publikowanie agenta w firmie
Kliknij przycisk Opublikuj u góry agenta podglądu.
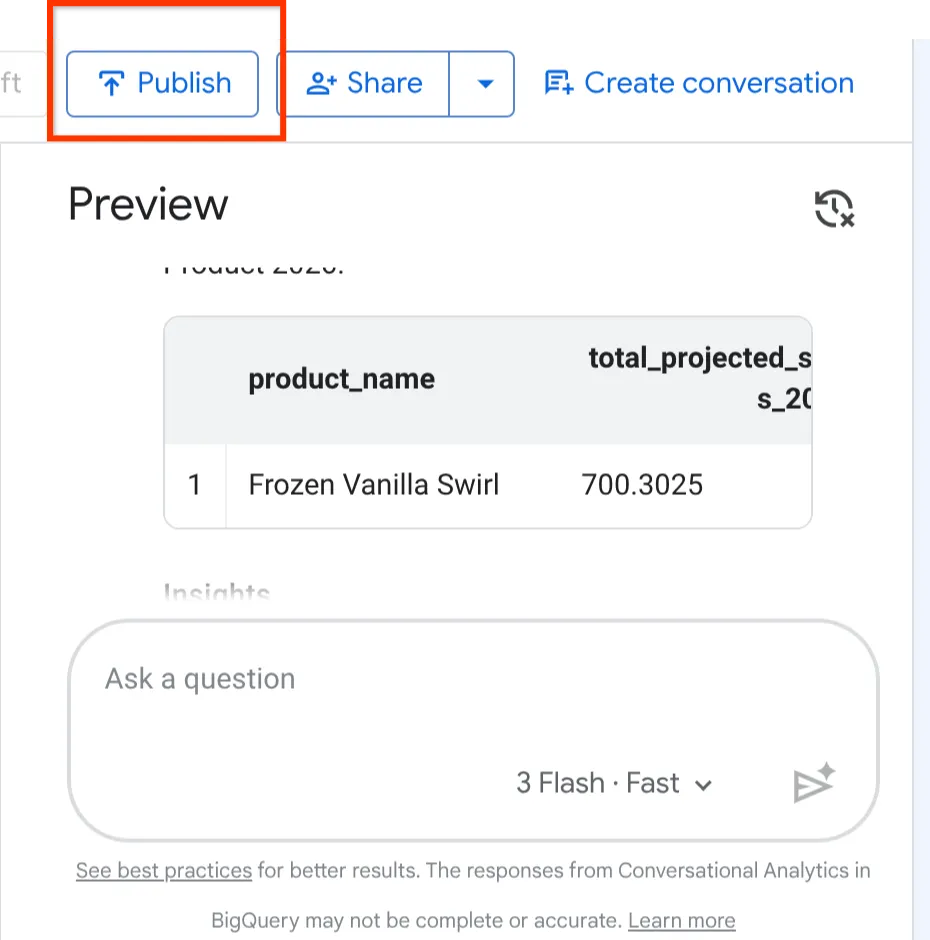
Po utworzeniu, skonfigurowaniu i przetestowaniu agenta Froyo możemy udostępnić go reszcie firmy.
W prawym górnym rogu strony konfiguracji agenta kliknij przycisk Opublikuj.
Po opublikowaniu Twój agent będzie natychmiast dostępny w 3 zaawansowanych kanałach dla firm, z których możesz korzystać Ty i wszystkie osoby, którym go udostępnisz:
- BigQuery analitycy danych mogą teraz rozmawiać z tym agentem bezpośrednio z centrum agentów lub w przestrzeni roboczej SQL BigQuery Studio.
- Interfejs Conversational Analytics API: Twoi programiści mogą uzyskać dostęp do tego agenta za pomocą interfejsu REST API, co pozwala im zintegrować te dokładne analizy konwersacyjne z własnymi niestandardowymi wewnętrznymi aplikacjami internetowymi.
- Studio danych: Twoi menedżerowie mogą wchodzić w interakcje z tym agentem i tworzyć dynamiczne panele konwersacyjne bezpośrednio w narzędziu Studio danych.
Udało nam się wyeliminować silosy danych i przekazać dane bezpośrednio osobom, które ich potrzebują, dokładnie tam, gdzie już pracują.
Kliknij menu przycisku Udostępnij u góry opublikowanego agenta BigQuery i wybierz z listy opcję „Skopiuj link do agenta w narzędziu Studio danych”:
Wklej ten link w przeglądarce i naciśnij Enter. Potwierdź alert dotyczący dostępu do interakcji z agentem:
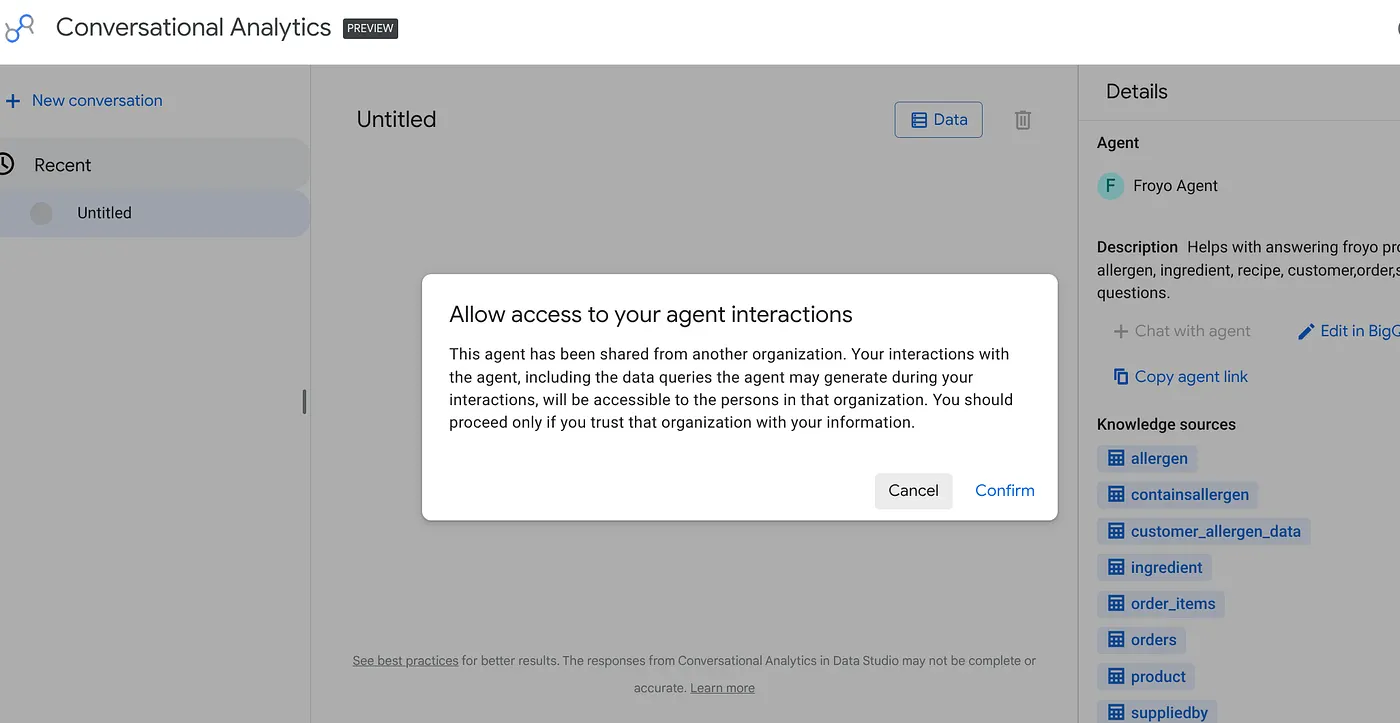
Możesz rozpocząć interaktywne rozmowy i wizualizacje z nowo opublikowanym agentem w Studio danych. Mogą to też robić Twoi przełożeni i inne zespoły, które potrzebują tych informacji.
10. Czyszczenie danych
Po ukończeniu tego laboratorium nie zapomnij usunąć uprawnień wszystkich użytkowników do utworzonego właśnie agenta BigQuery.
11. Gratulacje!
Udało Ci się utworzyć Agentic Data Cloud.
Nie utworzono prostego czatbota. W trakcie tych 5 sesji udało Ci się od podstaw zaprojektować kompletny, nowoczesny i oceniony system AI dla przedsiębiorstw. Przeszliście od „ciemnych danych” do analizy transakcyjnej w czasie rzeczywistym, a następnie do prognozowania biznesowego opartego na konwersacjach.
12. Pełny obraz
Zastanów się, co udało nam się osiągnąć w tej serii. Nie stworzyliśmy zwykłego czatbota. Stworzyliśmy kompletną, nowoczesną platformę Agentic Data Cloud:
Część 1. Odblokowanie ciemnych danych przez przekształcenie plików PDF w uporządkowane tabele relacyjne za pomocą Knowledge Catalog.
Część 2. Wyeliminowaliśmy ograniczenia w dostępie do danych, federując naszą hurtownię analityczną bezpośrednio z transakcyjną bazą danych AlloyDB.
Część 3. Zwiększanie możliwości użytkowników przez utworzenie systemu operacyjnego opartego na wielu agentach, który bezproblemowo wykonuje bezpieczne narzędzia do baz danych za pomocą protokołu MCP
Część 4: zapewnienie bezpieczeństwa przez wdrożenie rygorystycznego procesu oceny, który pozwala wykrywać halucynacje i obejścia zabezpieczeń.
Część 5. Ułatwianie dostępu do statystyk dzięki ANTIGRAVITY IDE i analityce konwersacyjnej w BigQuery.
To przyszłość oprogramowania dla firm. Agent AI nie jest już tylko nakładką na LLM. Jest to w pełni zintegrowany, oceniony i bezpieczny mechanizm orkiestracji, który działa na ujednoliconej platformie danych.