
1. Visão geral
Vamos analisar a arquitetura enorme que criamos nas últimas quatro partes:
Parte 1: usamos o BigQuery Knowledge Catalog para transformar PDFs de receitas do Froyo em tabelas relacionais estruturadas.
Parte 2: criamos uma ponte transacional de ETL zero, federando nosso data warehouse do BigQuery diretamente no AlloyDB.
Parte 3: orquestramos um aplicativo multiagente (FroyoOS) usando o Kit de Desenvolvimento de Agente e o MCP Toolbox.
Parte 4: provamos que nosso agente era seguro para produção criando um pipeline de avaliação de faixa dupla.
Nossas operações estão funcionando perfeitamente. Mas e os desenvolvedores e analistas de negócios que precisam entender as enormes quantidades de dados geradas por esse sistema?
Hoje, vamos falar sobre o futuro da análise. Vamos começar no editor de código Antigravity IDE com o Google Cloud Data Agent Kit e depois passar para o console do Google Cloud para visualizar nossos dados usando a análise de conversas do BigQuery.
Vamos começar a criar!
O que você vai aprender
Neste último codelab da série Agentic Data Cloud, você vai reunir todas as partes da sua arquitetura para oferecer insights de negócios úteis. Você vai aprender:
- Análise de dados com foco no ambiente de desenvolvimento integrado:como instalar e configurar o ANTIGRAVITY IDE e o Google Cloud Data Agent Kit para consultar sua arquitetura diretamente do ambiente de desenvolvimento.
- BigQuery conversacional:como criar, configurar e instruir os agentes de dados do BigQuery para automatizar tarefas complexas de SQL e previsões usando linguagem natural.
- Democratização de dados:como publicar seus agentes na empresa, tornando-os acessíveis a analistas e usuários comerciais em toda a organização.
- Visualização de insights:como integrar perfeitamente a análise de conversas do seu agente ao Data Studio para criar painéis dinâmicos e prontos para previsão.
- O ecossistema da Data Cloud agêntica:como articular o valor da sua arquitetura de ponta a ponta, desde dados brutos não estruturados na Parte 1 até painéis prontos para executivos na Parte 5.
Requisitos
2. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Confira se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud.

- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com seu ID do projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se você quiser autenticar
gcloud auth login
- Se o projeto não estiver definido, use este comando:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Ative as APIs necessárias: execute este comando para ativar todas as APIs necessárias:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. Como expandir o data warehouse
Lembra das tabelas do BigQuery que criamos com nossos dados não estruturados?
Para fazer análises significativas, precisamos de dados históricos de transações. No BigQuery, em nosso conjunto de dados froyo_data, vamos criar três novas tabelas para simular anos de operações de franquia:
- froyo_data.pedidos: cabeçalhos de pedidos históricos (datas, IDs de lojas, totais)
- froyo_data.order_items: detalhes do item de linha (quantidades, preços)
- froyo_data.customer_allergen_data: uma tabela de CRM que rastreia as alergias conhecidas dos nossos clientes fiéis.
Vamos adicionar essas tabelas relacionadas a vendas e clientes ao conjunto de dados para preparar nosso caso de uso de análise.
- Acesse o terminal do Cloud Shell no console do Google Cloud.
- Acesse a pasta raiz do seu espaço de trabalho ou a pasta raiz do projeto froyo-data (em que trabalhamos nas últimas partes desta série).
- Faça o download dos três arquivos de dados históricos (em arquivos CSV) para seu diretório de trabalho executando os comandos a seguir um por um:
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/customer_allergen_data.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/order_items.csv
wget https://raw.githubusercontent.com/AbiramiSukumaran/froyo-data/main/orders.csv
- Depois que esses arquivos aparecerem na raiz do diretório de trabalho, acesse o terminal do Cloud Shell.
- Navegue até o diretório em que esses três arquivos estão no terminal do Cloud Shell.
- Verifique se o BigQuery tem o conjunto de dados chamado "froyo_data" da parte 1 desta série. Caso contrário, volte e crie o conjunto de dados e as tabelas.
- Execute os seguintes comandos no terminal do Cloud Shell:
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.orders \
./orders.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.order_items \
./order_items.csv
bq load \
--autodetect \
--source_format=CSV \
--skip_leading_rows=1 \
--allow_quoted_newlines \
--quote="" \
froyo_data.customer_allergen_data \
./customer_allergen_data.csv
Isso vai criar as três tabelas adicionais no conjunto de dados froyo_data.
4. A experiência do desenvolvedor: conheça o "Data Agent Kit"
Tradicionalmente, se um desenvolvedor quisesse analisar dados ou escrever consultas complexas de machine learning, ele precisaria alternar constantemente o contexto entre o ambiente de desenvolvimento integrado, os consoles de banco de dados e a documentação.
Nada disso. Com a extensão Google Cloud Data Agent Kit, recém-lançada, seu ambiente de desenvolvimento integrado se torna uma potência de dados.
ANTIGRAVITY IDE
O ANTIGRAVITY IDE é o ambiente de desenvolvimento de última geração do Google que prioriza agentes e foi criado especificamente para a era da IA. Ele integra nativamente janelas de contexto multimodais e o uso autônomo de ferramentas diretamente no editor, permitindo que os desenvolvedores orquestrem recursos de nuvem e pipelines de dados complexos sem sair do código.
Como configurar a IDE ANTIGRAVITY
- Baixe a IDE: acesse antigravity.google e baixe a IDE Antigravity para seu sistema operacional (Windows, macOS ou Linux).
- Instalar e iniciar: execute o instalador e abra o aplicativo.
- Clique em "Continuar com o Google", selecione sua conta do Gmail e autorize.
- Depois de fazer login, crie uma pasta de trabalho (espaço de trabalho/ projeto). Vamos chamar de "Data Cloud de agentes".
Ele vai aparecer na lista "Projetos" à esquerda:
- Inicie uma conversa preliminar com o agente: "oi".
- No canto superior direito, observe o botão "Abrir IDE"!!!
Mas, antes de clicar nisso, você precisa instalar o Antigravity IDE. Acesse a página antigravity.google/download e role para baixo até a seção "IDE do Antigravity". Faça o download da variante que você precisa.
Depois de fazer o download, volte para a instância aberta do Antigravity e clique no botão "Abrir ambiente de desenvolvimento integrado" no canto superior direito.
- Você vai ver os pop-ups sobre permissões. Continue abrindo.
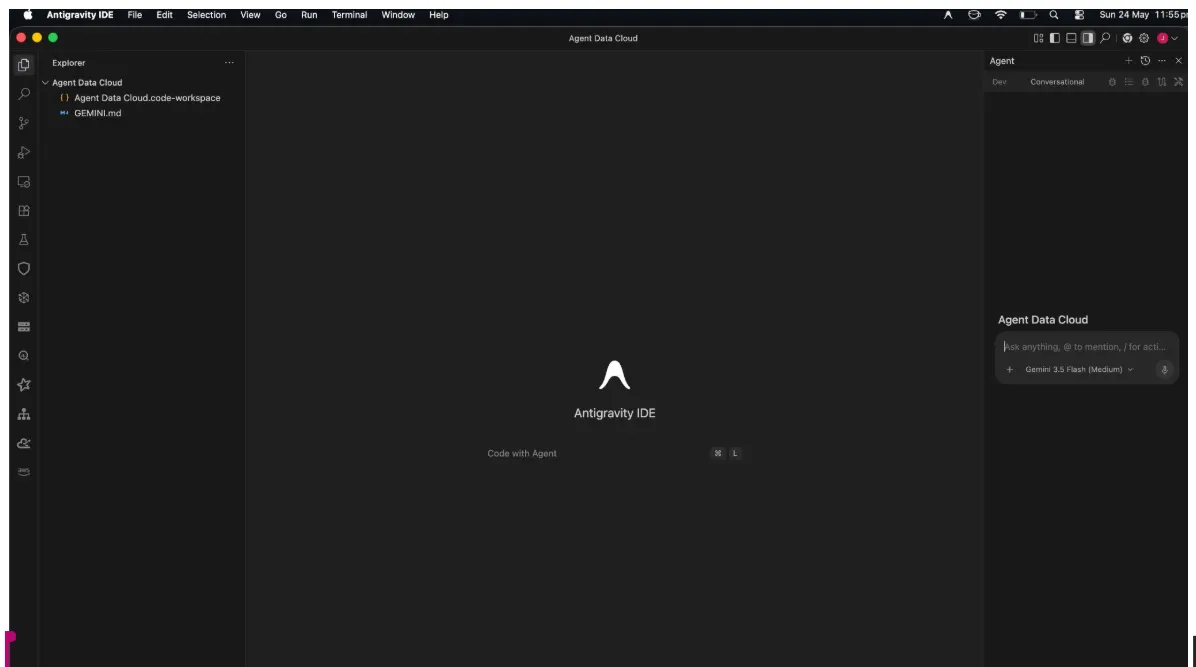
No lado direito, você vê o painel do agente, à esquerda, o explorador de projetos e, no centro, o espaço para seu desenvolvimento.
Configurar a extensão do Data Agent Kit
- Instale a extensão: abra o Extensions Marketplace no ambiente de desenvolvimento integrado ANTIGRAVITY. Pesquise e instale a extensão do Google Cloud Data Agent Kit.
- Clique no botão "Instalar". Depois disso, a extensão vai aparecer no painel de navegação.
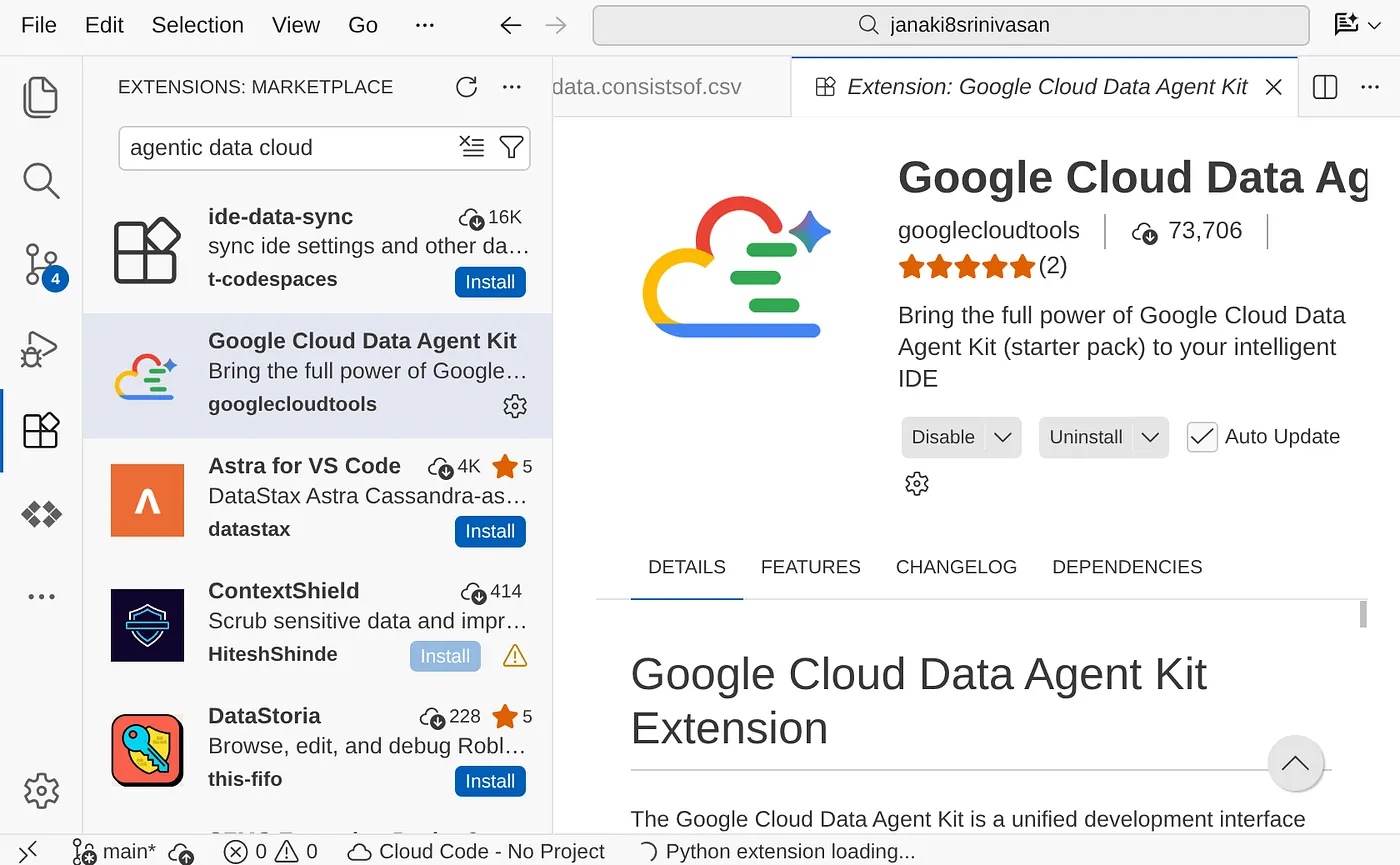
- Clique nele para abrir o explorador do Google Cloud Data Agent Kit. Acesse a seção "CONFIGURAÇÕES" e clique em "Configurações". Coloque os detalhes e a região do projeto e salve.
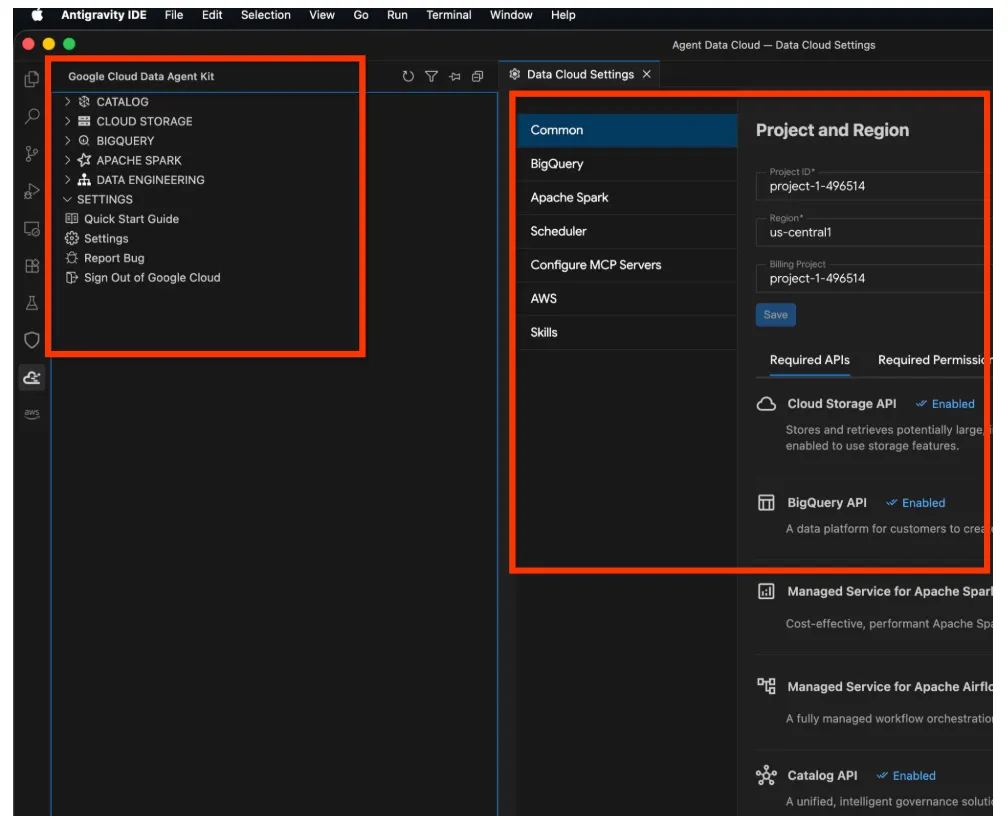
- Agora clique no "Explorador de projetos" na parte de cima do painel de navegação. Isso vai abrir o explorador de projetos no painel do explorador.
- Clique com o botão direito do mouse no espaço do explorador e crie um arquivo chamado GEMINI.md.
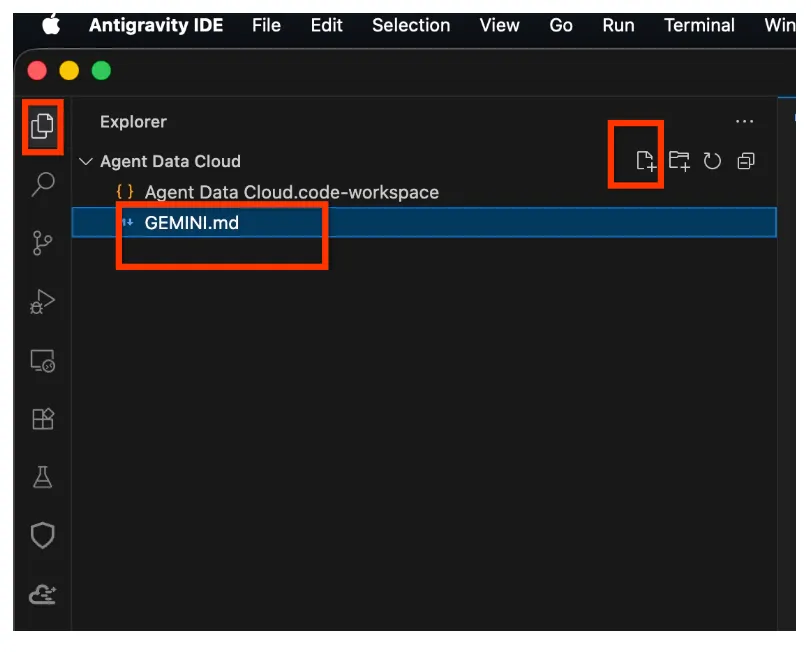
- Cole o seguinte em GEMINI.md (não se esqueça de substituir <<YOUR_PROJECT_ID>> pelo seu valor):
## 1. Project Context
- **Project ID**: <<YOUR_PROJECT_ID>>
- **Domain**: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
- **Data**: All froyo, customer, order related information is processed and stored in BigQuery `froyo_data` dataset.
## 2. Execution & Data Processing Rules
- **CRITICAL RULE - Structured Specs**: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named `froyo_data`.
- **CRITICAL RULE - Customer Data**: Existing Froyo customer data resides in BigQuery in the tables `customers_allergen_data`.
- ** CRITICAL RULE - Sales Data**: Sales data is present in tables `orders` and `order_items`.
- ** CRITICAL RULE - General: When you are referencing a dataset, ensure you are using it with the dataset ID (`froyo_data`) . For example, to query orders table in this dataset you should use `froyo_data.orders`.
Agora você tem um agente de IA altamente capaz diretamente no seu ambiente de desenvolvimento integrado, pronto para escrever código, gerar SQL e analisar sua arquitetura.
Agora temos um desafio analítico fascinante: podemos correlacionar nossas vendas históricas com os dados complexos e inferidos de alérgenos que extraímos de PDFs na Parte 1?
5. Como inferir inteligência usando o agente do IDE
Vamos pedir ao agente do ambiente de desenvolvimento integrado para fazer o trabalho pesado. Abra a janela de conversa do Agent Data Kit no ambiente de desenvolvimento integrado do ANTIGRAVITY e envie o seguinte comando:
Does Midnight Swirl contain any allergen?
Ele vai pedir uma série de permissões. Conceda as que forem aplicáveis.
Por fim, ele vai recuperar a resposta para você no final da análise:
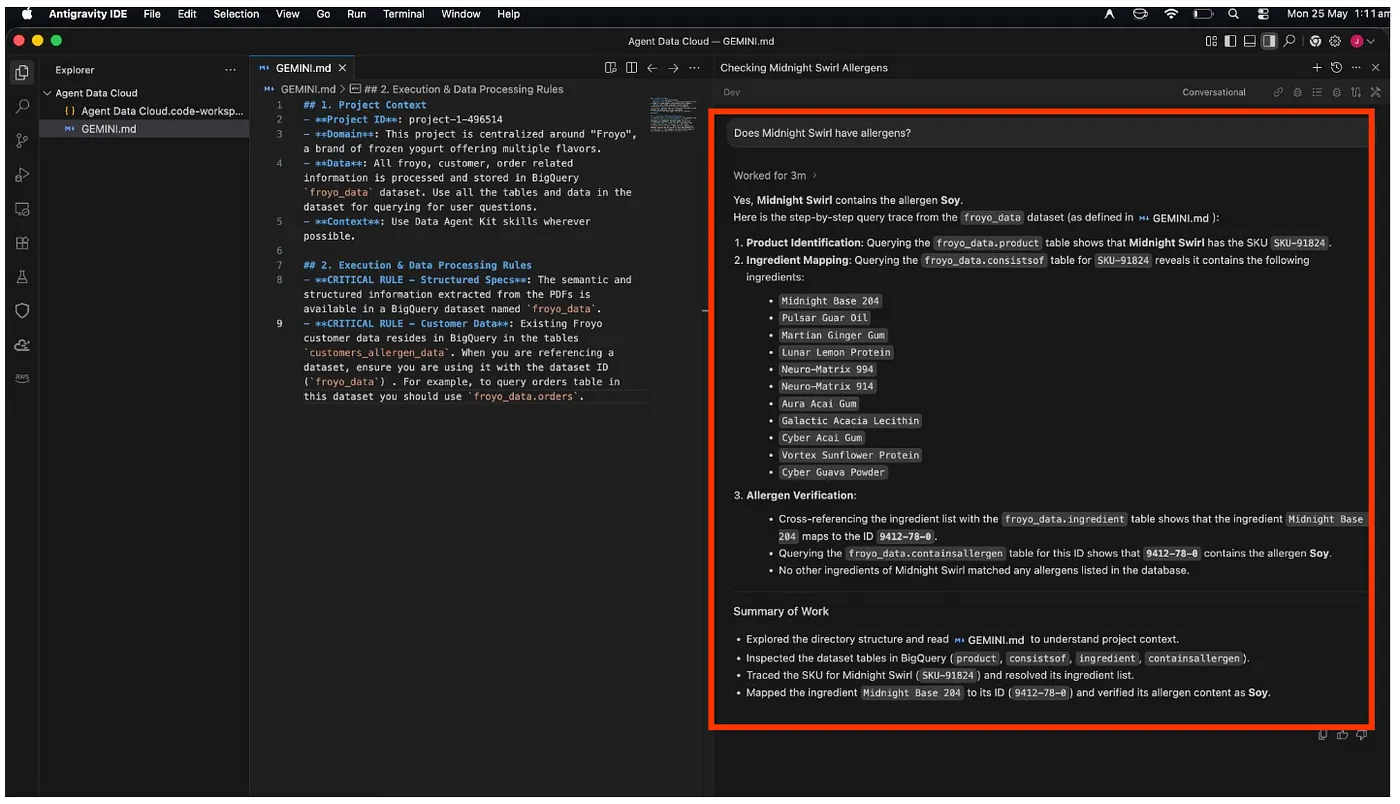
Eba!!! Ele identificou corretamente que o item Midnight Swirl tem soja.
Agora vamos fazer uma pergunta um pouco mais complexa. Envie o seguinte comando no IDE Antigravity:
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
Resposta:
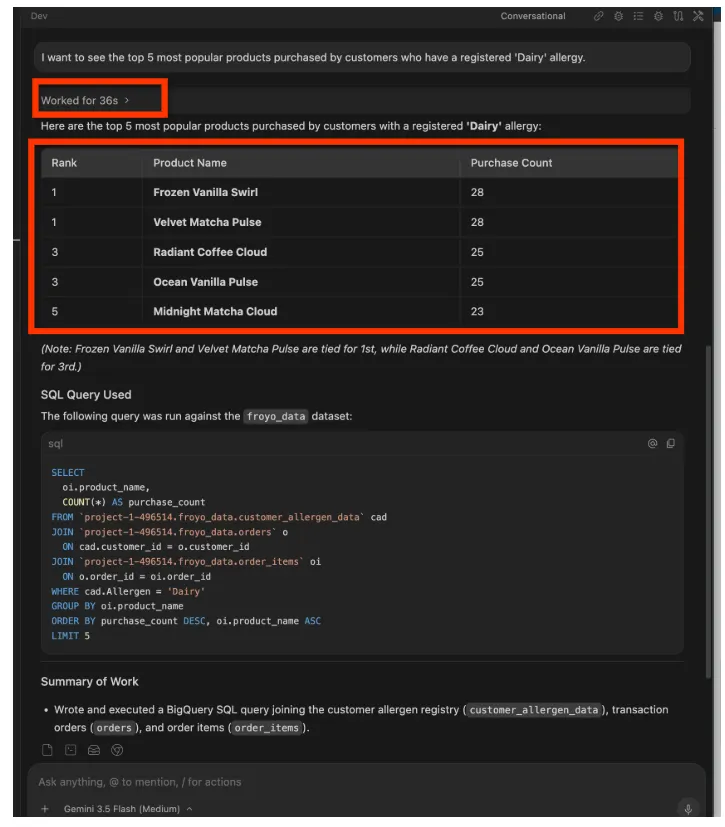
Você pode continuar. Teste comandos como:
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
Sem precisar pesquisar a sintaxe do BQML, o Agent Data Kit insere o código exato CREATE MODEL e ML.FORECAST no seu editor. É possível executar isso diretamente no seu ambiente do BigQuery sem sair do ambiente de desenvolvimento integrado ANTIGRAVITY.
Que incrível!!!
6. Análise Conversacional no BigQuery
Embora os desenvolvedores adorem o ambiente de desenvolvimento integrado, os usuários comerciais e executivos usam o console do Cloud. Eles não querem ver SQL, apenas respostas.
Vamos começar:
- Conceder a si mesmo os papéis necessários
Navegue até a página do IAM do projeto e conceda a si mesmo o papel de proprietário do agente de dados do Gemini Data Analytics:
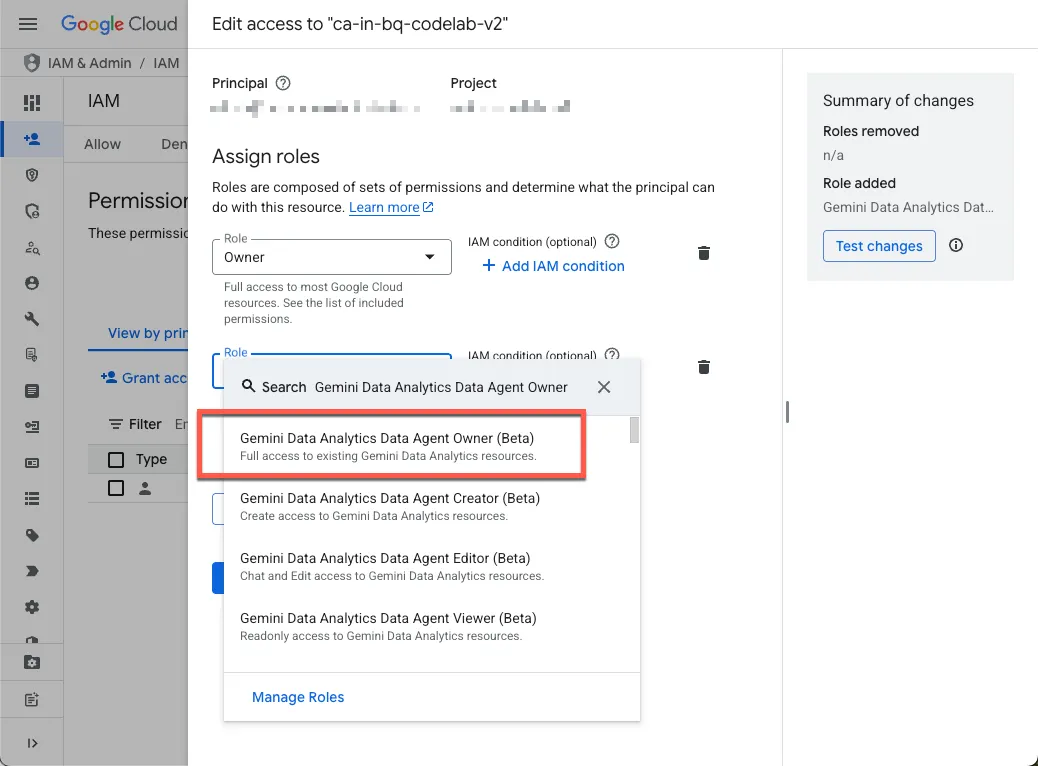
Esse papel concede permissão para criar, editar, compartilhar e excluir todos os agentes de dados no projeto.
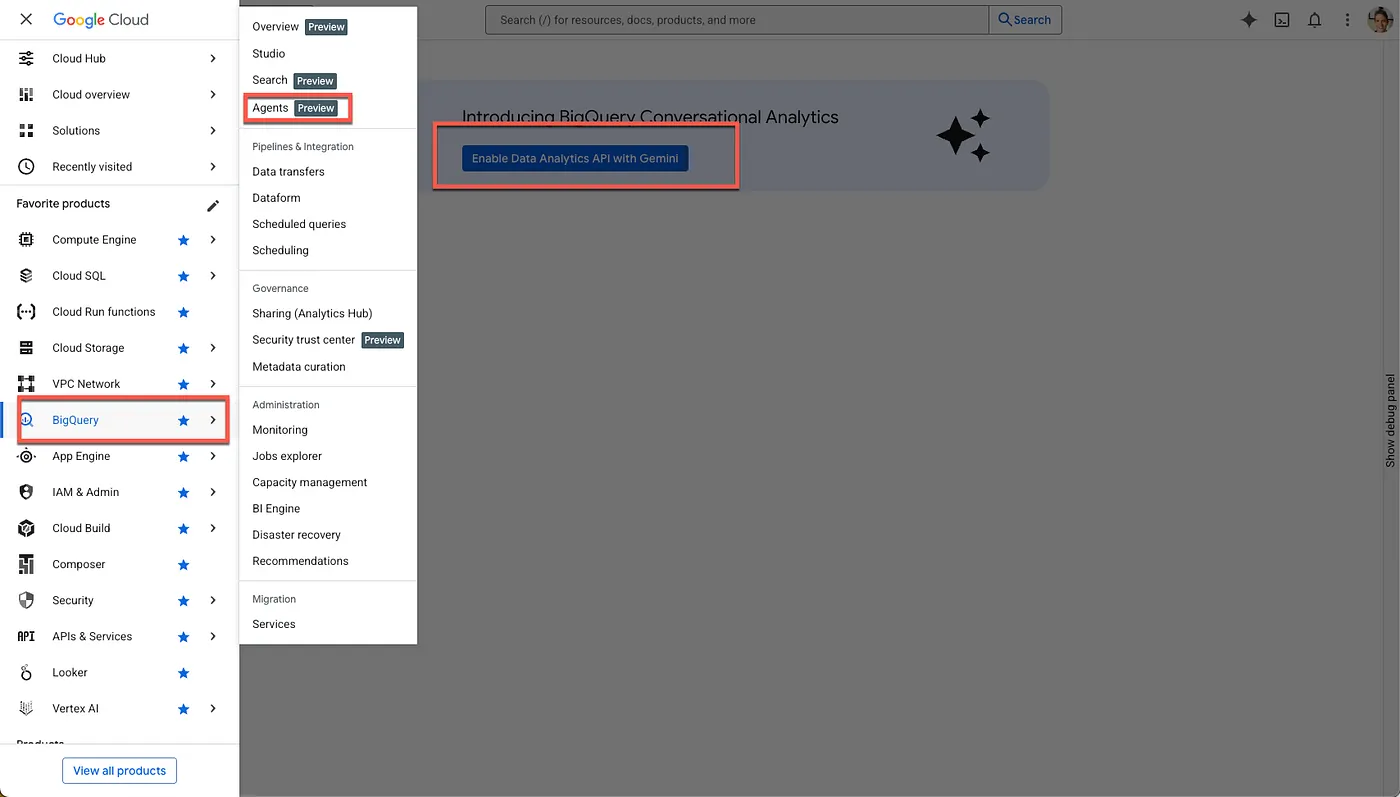
- Ative as APIs necessárias
Acesse o BigQuery no console do Google Cloud. Use o menu de navegação da barra lateral ou o menu de pesquisa na parte de cima da página para acessar BigQuery > Agentes.
Clique em Ativar a API Data Analytics com o Gemini:
Ative a API BigQuery e a API Gemini para Google Cloud:
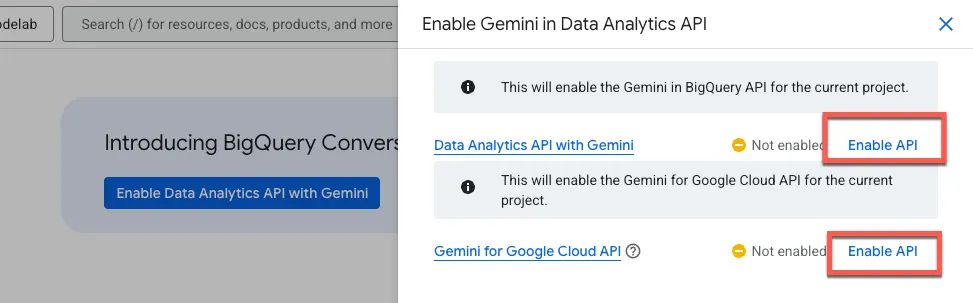
Agora você vai ver a nova página do agente:
- Configurar informações do agente
Nome do agente: Froyo Agent
Descrição do agente: ajuda a responder perguntas sobre produtos de iogurte congelado, alérgenos, ingredientes, receitas, clientes, pedidos e vendas.
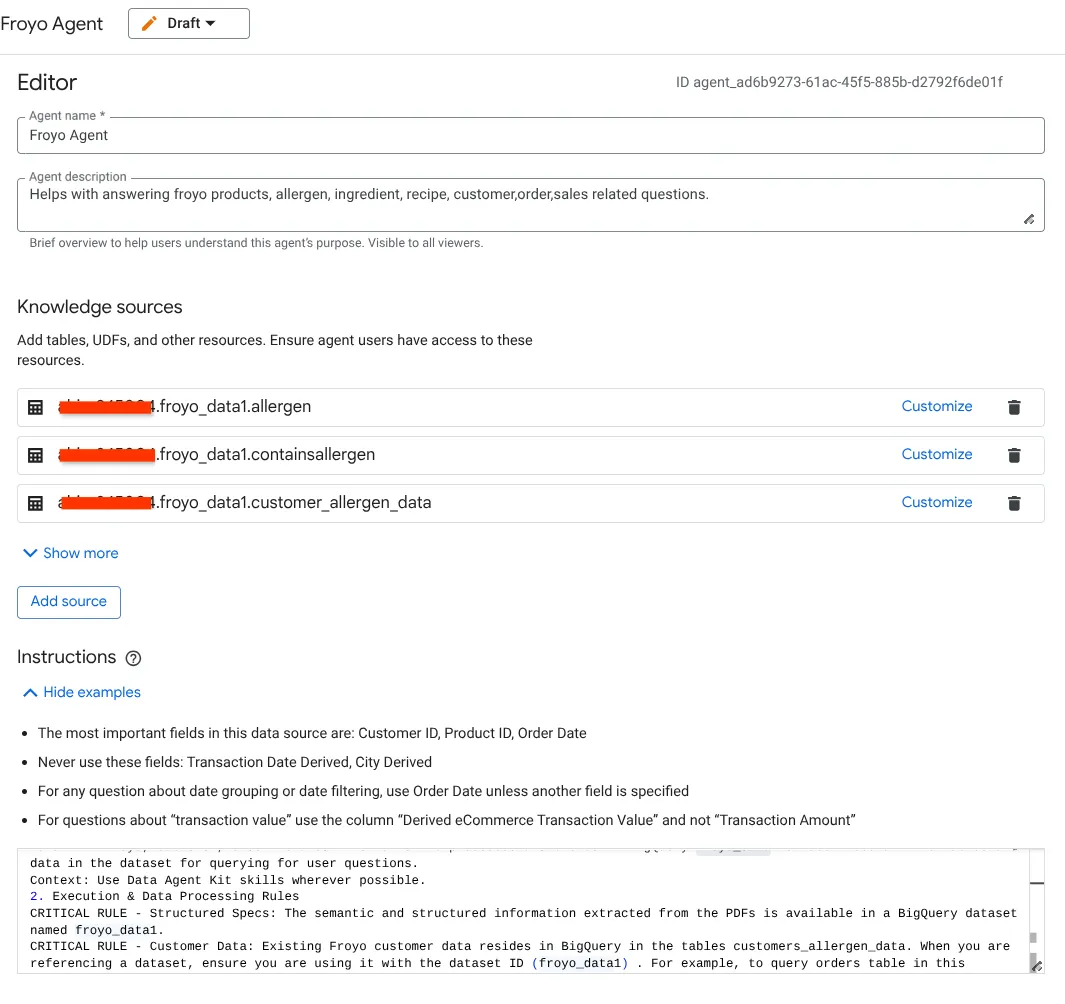
- Acesse a seção "Fontes de conhecimento" e selecione todas as tabelas abaixo do seu conjunto de dados:
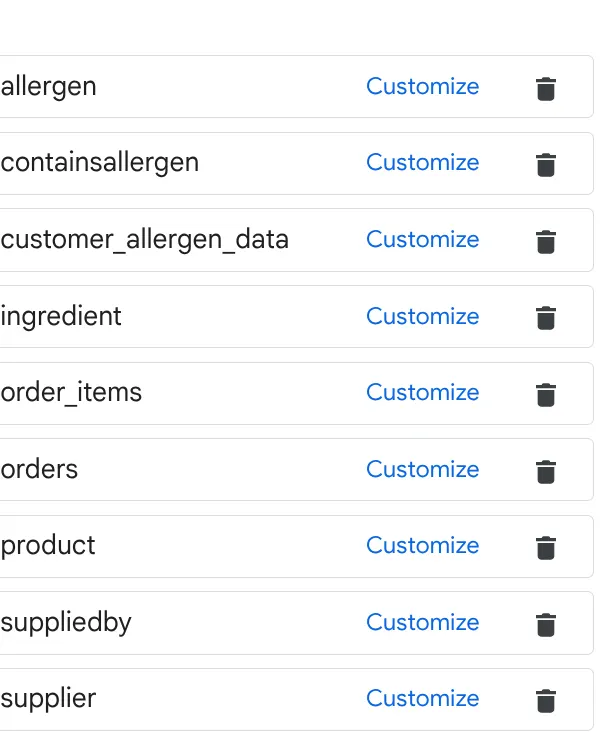
a. Adicione as tabelas na imagem acima e clique em "Adicionar origem".
b. Para cada fonte, clique no botão Personalizar à direita. O formulário abaixo vai aparecer:
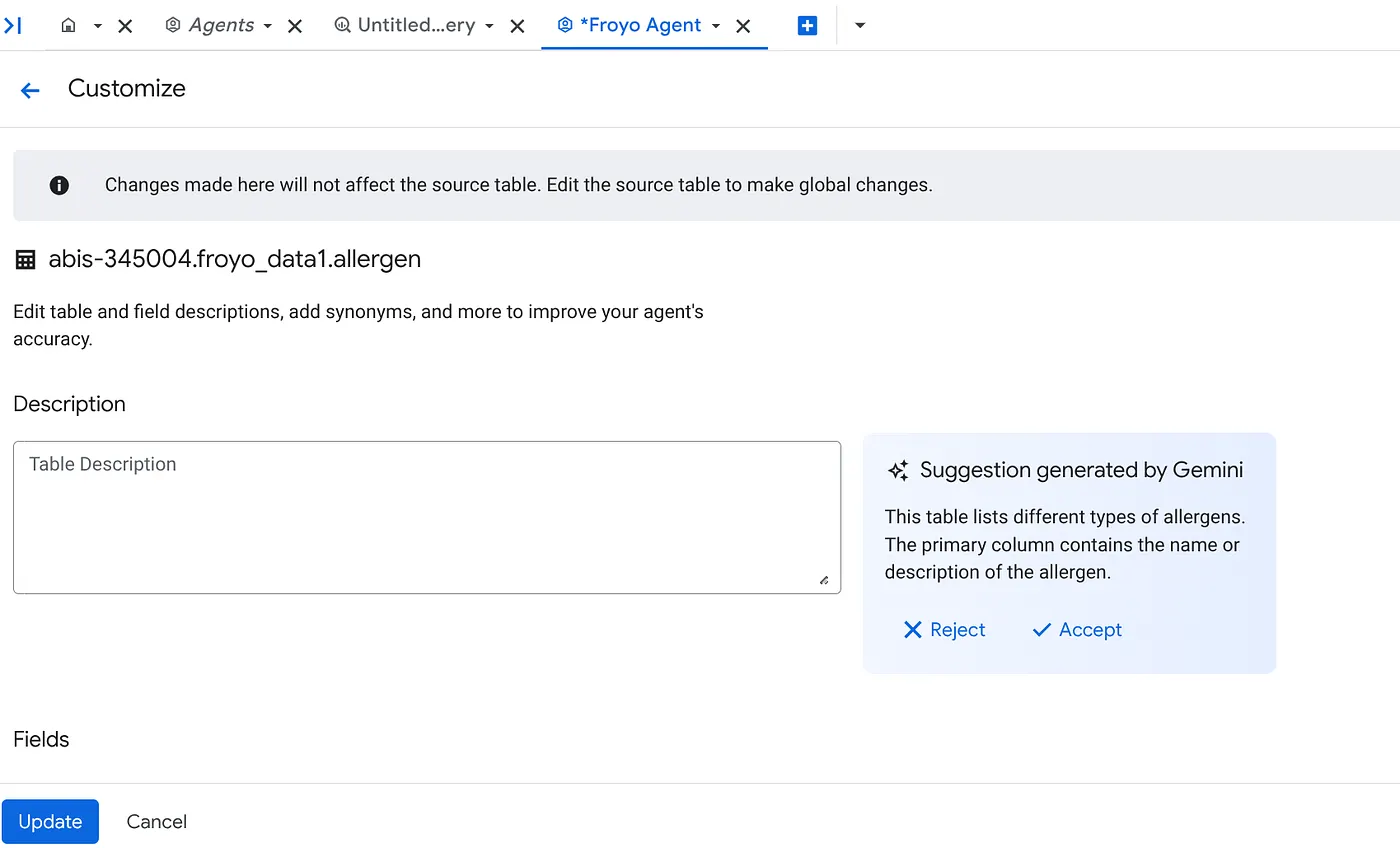
c. Clique em "Aceitar" para a descrição da tabela.
d. Clique em "Aceitar" para cada uma das descrições dos campos também.
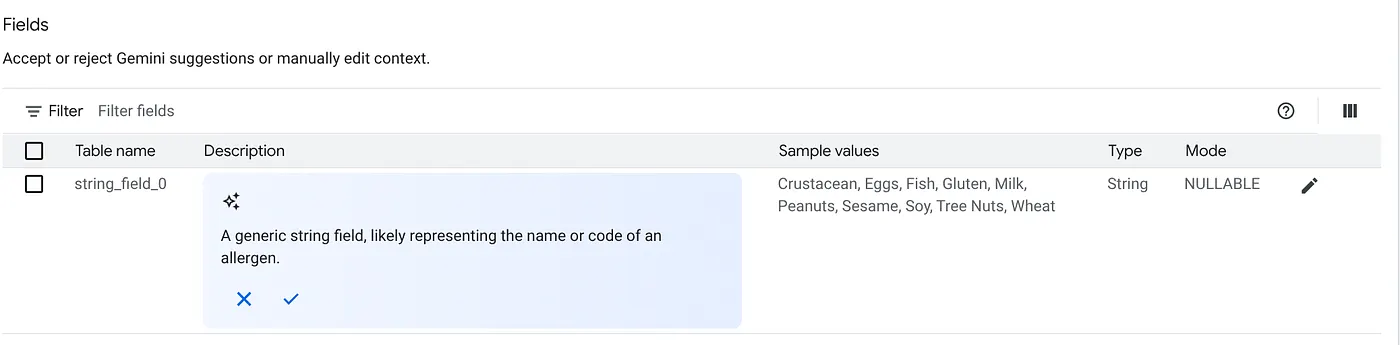
e. Clique em "Atualizar".
Repita esse processo para todas as tabelas na origem.
- Instruções de configuração
Coloque as mesmas instruções que usamos em Antigravity IDE GEMINI.md aqui:
1. Project Context
Project ID: <<YOUR_PROJECT_ID>>
Domain: This project is centralized around "Froyo", a brand of frozen yogurt offering multiple flavors.
Data: All froyo, customer, order related information is processed and stored in BigQuery froyo_data dataset. Use all the tables and data in the dataset for querying for user questions.
Context: Use Data Agent Kit skills wherever possible.
2. Execution & Data Processing Rules
CRITICAL RULE - Structured Specs: The semantic and structured information extracted from the PDFs is available in a BigQuery dataset named froyo_data.
CRITICAL RULE - Customer Data: Existing Froyo customer data resides in BigQuery in the tables customers_allergen_data. When you are referencing a dataset, ensure you are using it with the dataset ID (froyo_data) . For example, to query orders table in this dataset you should use froyo_data.orders.
- Salve o agente.
7. Converse com seus dados!
- Teste na seção de visualização à direita:
Faça sua pergunta:
Does midnight swirl contain any allergen?
Esta é a resposta:
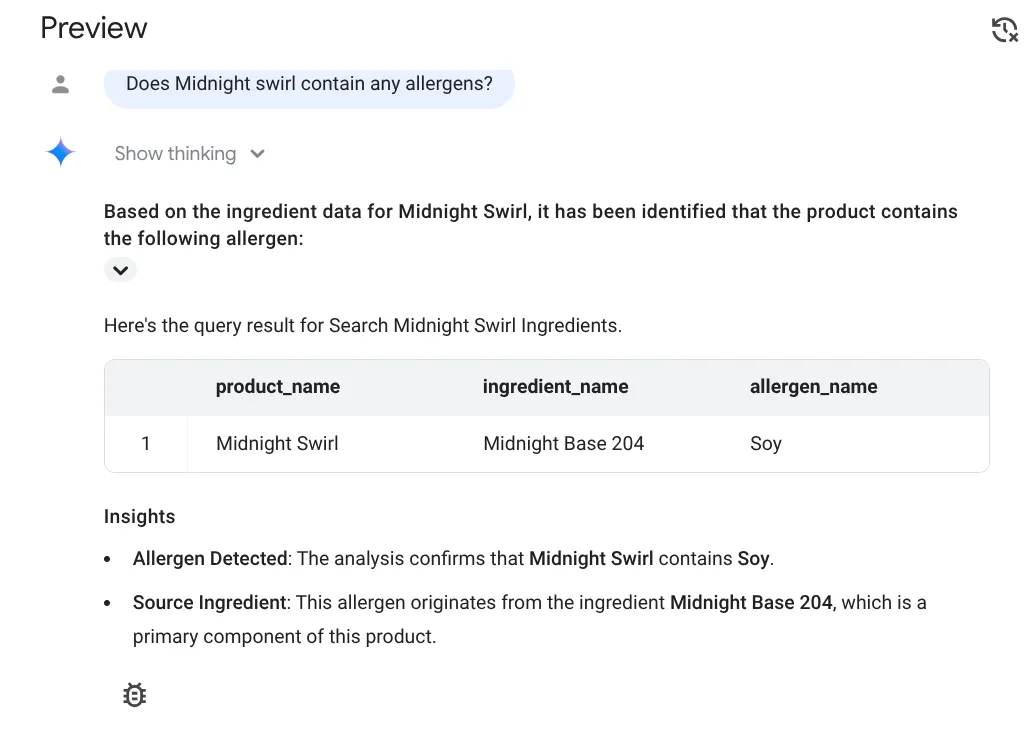
Agora vamos fazer a pergunta complicada:
I want to see the top 5 most popular products purchased by
customers who have a registered 'Dairy' allergy.
Resposta:
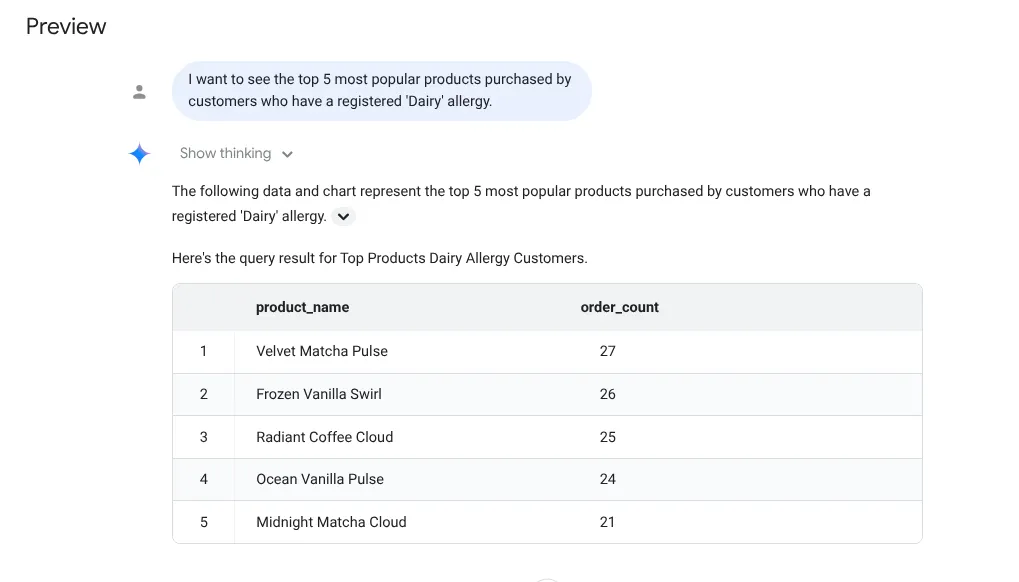
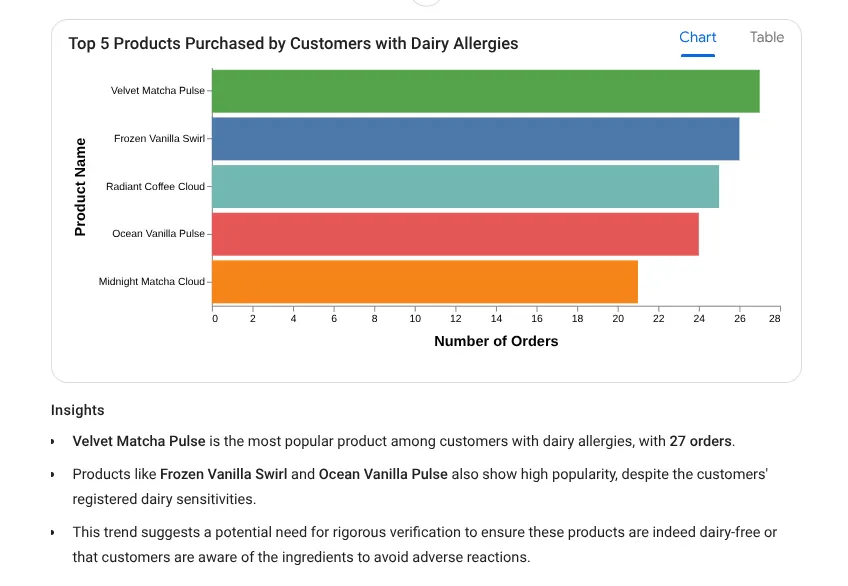
Vamos testar um comando de insight detalhado agora:
Forecast the sales volume of our top non-dairy products
for the next 30 days based on historical data.
É possível ver que ele mostra a consulta usada, com o resultado da tabela e o gráfico:
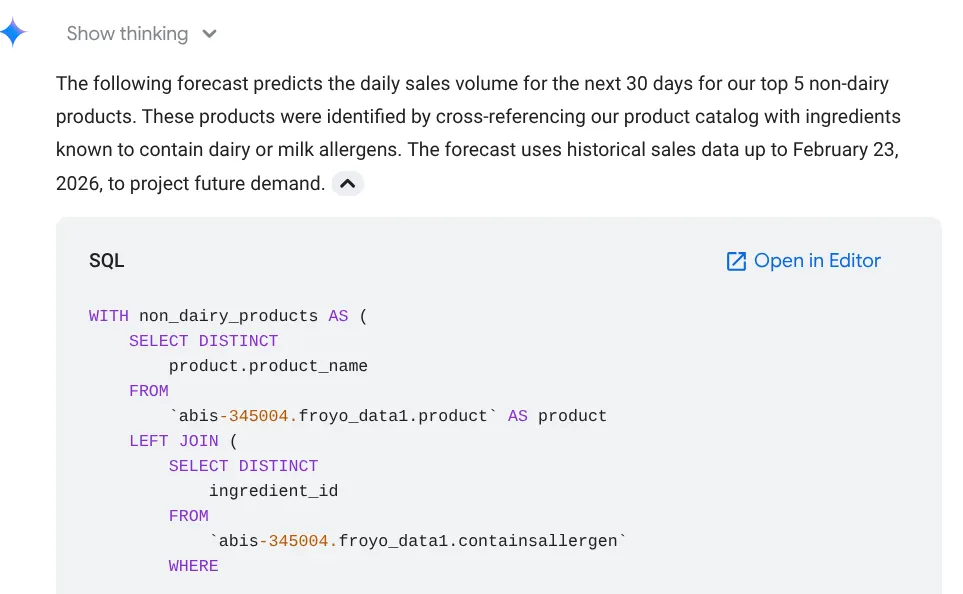
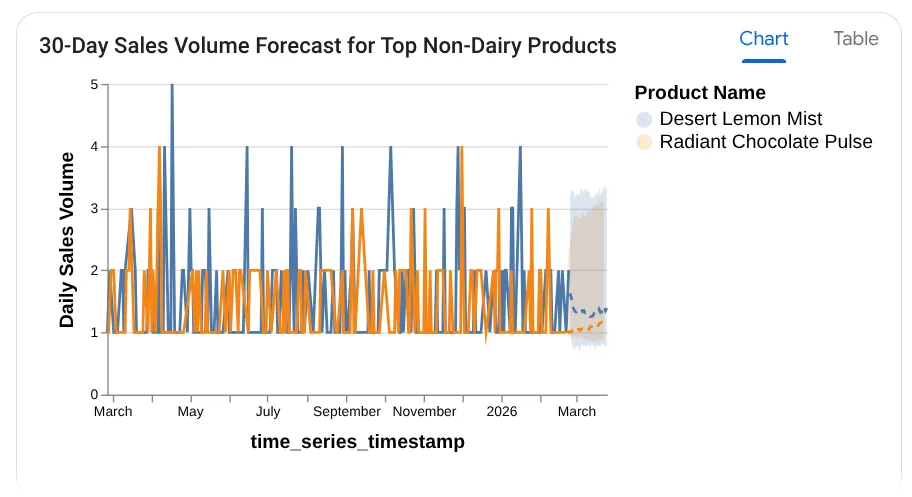

Uau! Isso combinou bem com os gráficos e insights. Chegou a hora da pergunta final sobre produtos.
8. O teste final
Faça a pergunta:
What will be the top most selling product of 2026
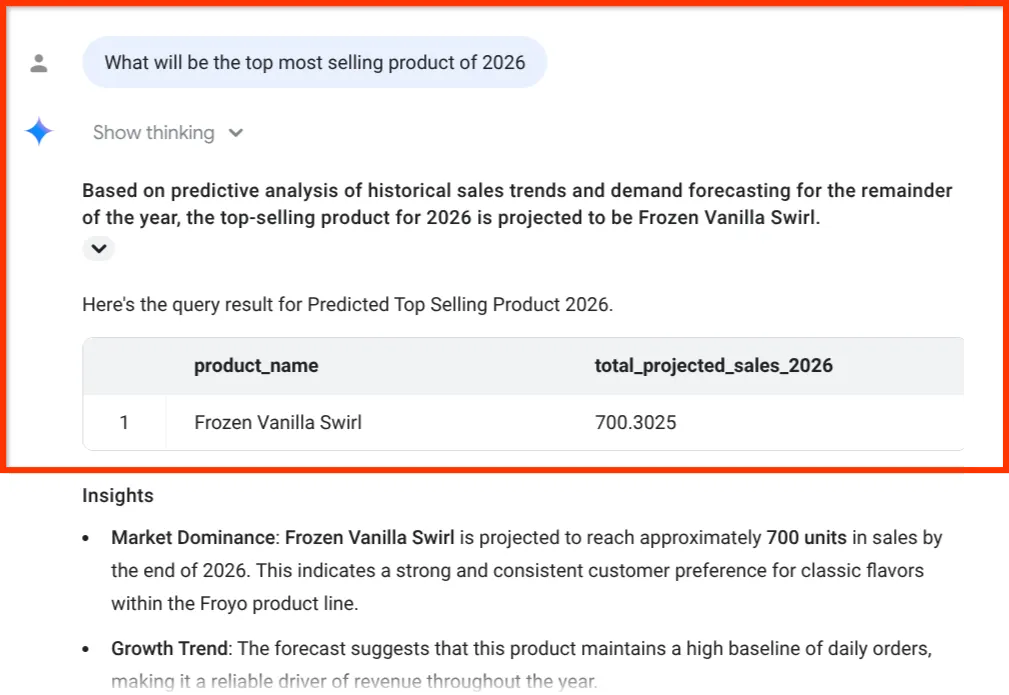

Confira esse insight final. O agente de dados do BigQuery não apenas nos deu um número, mas vinculou explicitamente a previsão de vendas à nossa cadeia de suprimentos de inventário e ingredientes, exatamente os dados que extraímos de PDFs desorganizados na Parte 1.
9. Publicar seu agente na empresa
Clique no botão Publicar na parte de cima do agente de prévia.
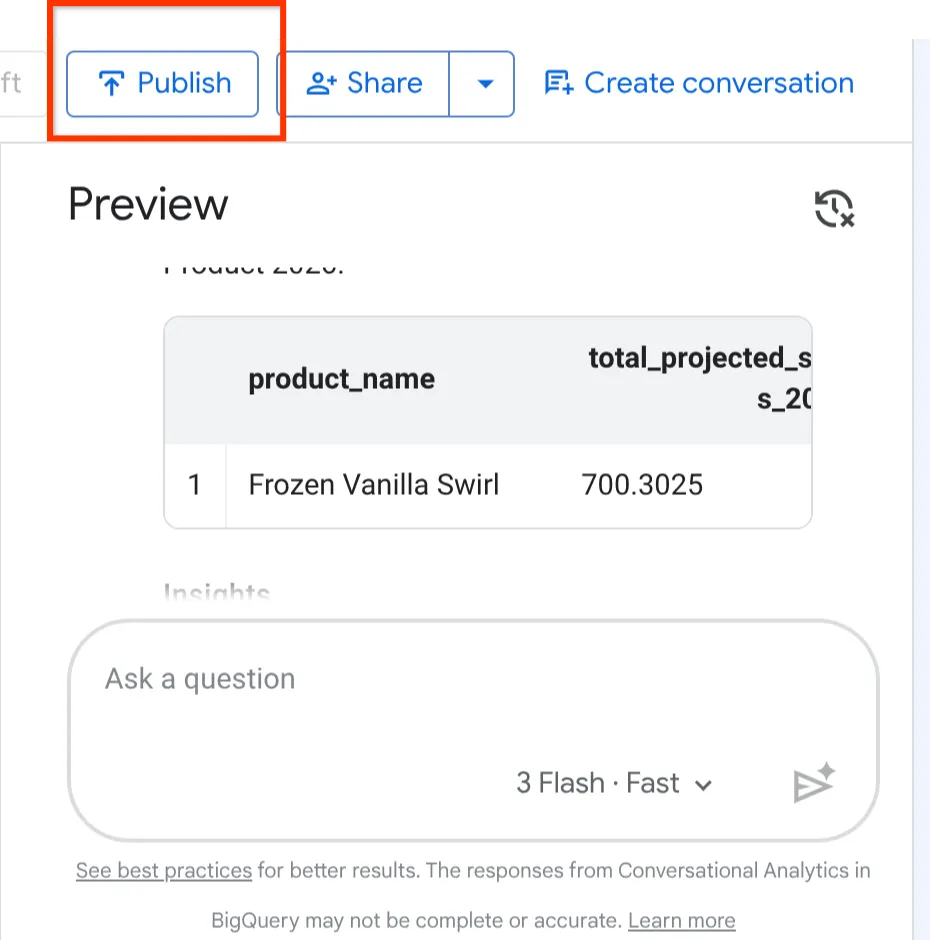
Agora que criamos, configuramos e testamos nosso agente Froyo, é hora de lançá-lo para o restante da empresa.
No canto superior direito da página de configuração do agente, clique no botão "Publicar".
Ao publicar, seu agente fica disponível instantaneamente em três canais corporativos eficientes para você e para quem você compartilhar:
- BigQuery: agora, seus analistas de dados podem conversar com esse agente diretamente no hub de agentes ou no espaço de trabalho SQL do BigQuery Studio.
- API Conversational Analytics: seus desenvolvedores podem acessar esse agente por uma API REST, permitindo que eles integrem essas análises de conversação exatas aos seus próprios aplicativos da Web internos personalizados.
- Data Studio: seus executivos podem interagir com esse agente e criar painéis de conversa dinâmicos diretamente no Data Studio.
Conseguimos tirar nossos dados dos silos e colocá-los diretamente nas mãos das pessoas que precisam deles, exatamente onde elas já trabalham.
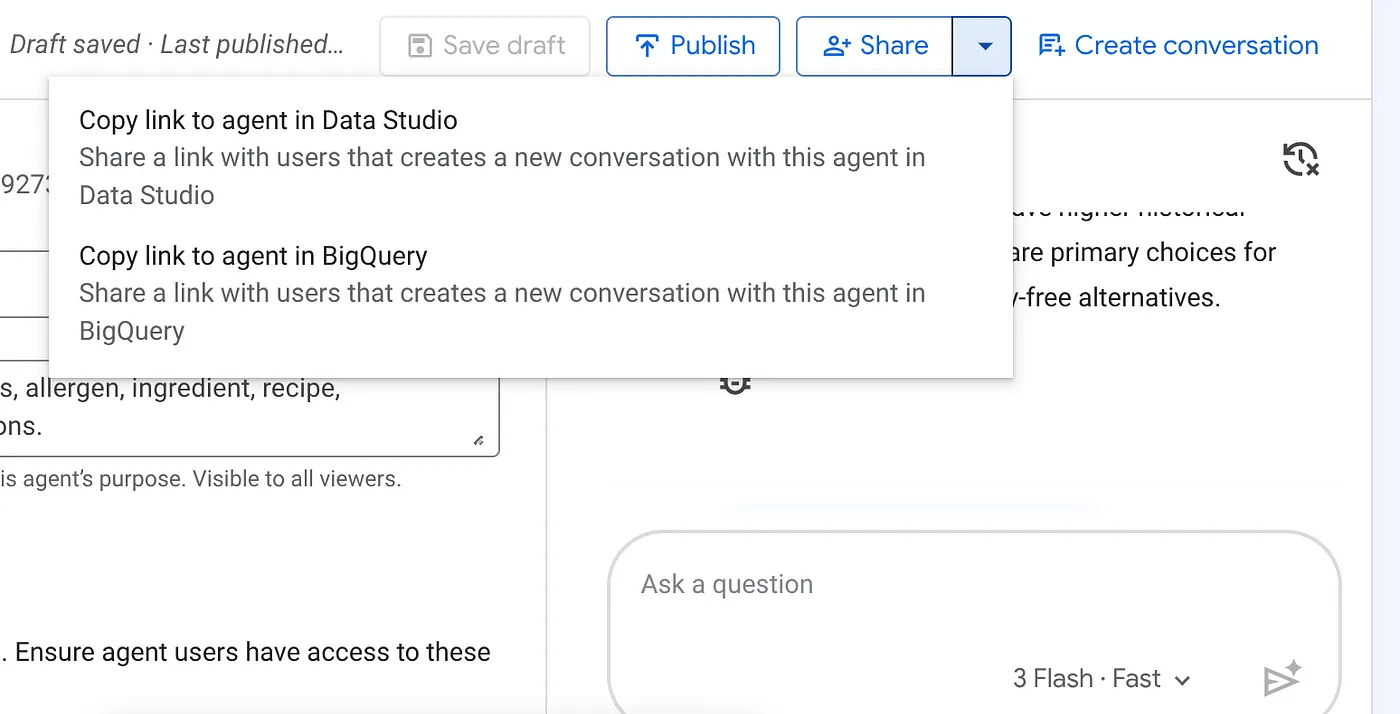
Clique no menu suspenso do botão "Compartilhar" na parte de cima do agente do BigQuery publicado e selecione a opção "Copiar link para o agente no Data Studio" na lista:
Cole o link no navegador e pressione "Enter". Confirme o alerta de acesso à interação do agente:
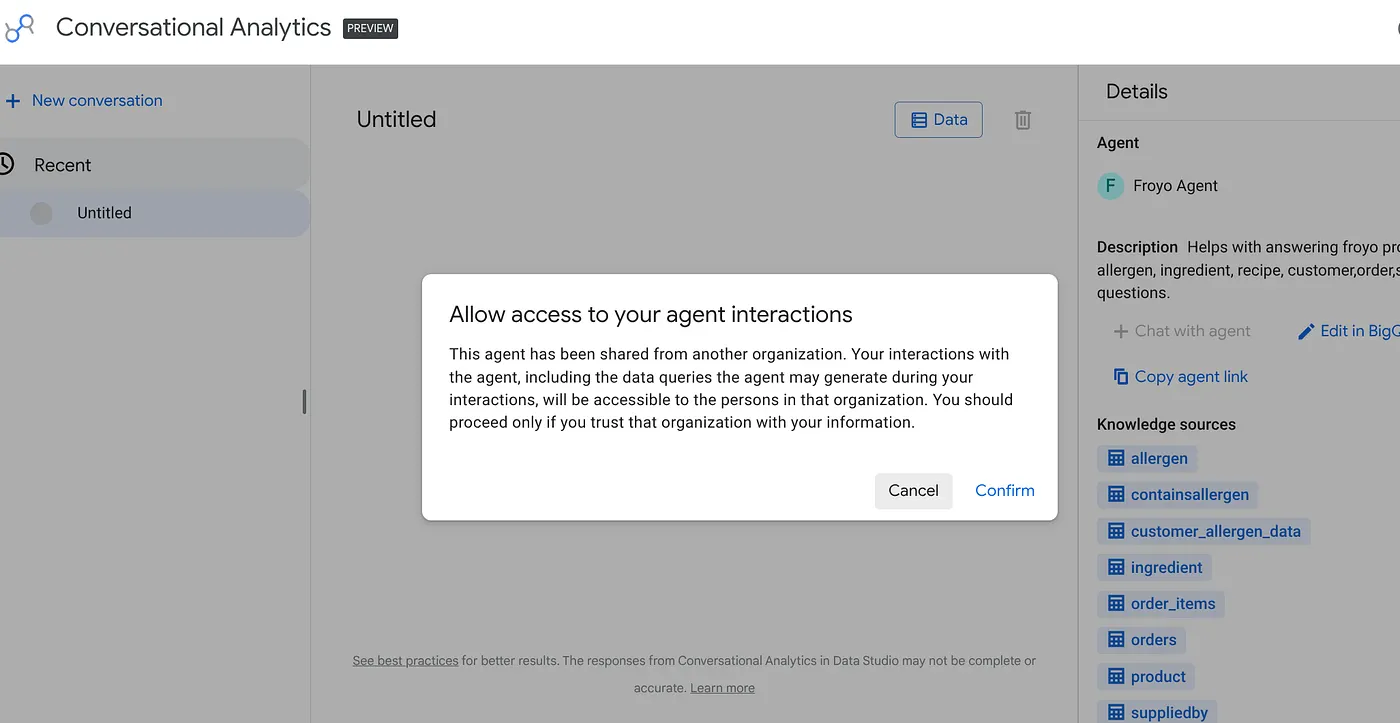
Você pode iniciar conversas e visualizações interativas com o agente recém-publicado do Data Studio, assim como sua liderança e outras equipes que precisam dessas informações.
10. Limpar
Depois de concluir este laboratório, não se esqueça de remover as permissões de todos os usuários para o agente do BigQuery que você acabou de criar.
11. Parabéns!
Você criou oficialmente um Data Cloud agêntico.
Você não criou apenas um chatbot simples. Ao longo dessas cinco sessões, você projetou um sistema de IA empresarial completo, moderno e avaliado do zero. Você passou de "dados ocultos" para inteligência transacional em tempo real e, finalmente, para previsão de negócios conversacional.
12. A perspectiva completa
Vamos analisar o que conseguimos fazer nesta série. Não criamos apenas um chatbot simples. Criamos uma nuvem de dados agêntica completa e moderna:
Parte 1: desbloqueamos dados ocultos transformando PDFs em tabelas relacionais estruturadas usando o Knowledge Catalog.
Parte 2: dividimos os silos de dados federando nosso data warehouse analítico diretamente em um banco de dados transacional do AlloyDB.
Parte 3: capacitar os usuários criando um SO multiagente que executa ferramentas de banco de dados seguras de maneira integrada usando o protocolo MCP
Parte 4: garantimos a segurança implementando um pipeline de avaliação rigoroso para detectar alucinações e jailbreaks.
Parte 5: insights democratizados usando a ANTIGRAVITY IDE e a Análise Conversacional no BigQuery.
Este é o futuro do software empresarial. O agente de IA não é mais apenas um wrapper em torno de um LLM. É um mecanismo de orquestração totalmente integrado, avaliado e seguro que fica em cima de uma plataforma de dados unificada.