
1. 總覽
在現今快速變化的零售環境中,提供卓越的客戶服務並打造個人化購物體驗至關重要。我們將帶您踏上技術之旅,瞭解如何建立知識驅動的聊天應用程式,回答顧客問題、引導產品探索,以及提供量身打造的搜尋結果。這項創新解決方案結合了 AlloyDB 的資料儲存功能、用於瞭解情境的內部分析引擎、用於驗證相關性的 Gemini (大型語言模型),以及用於快速啟動智慧對話式助理的 Google 代理程式建構工具。
挑戰:現代零售業顧客期望獲得即時回覆,以及符合個人偏好的產品推薦。傳統的搜尋方法往往無法提供這種程度的個人化服務。
解決方案:我們的知識導向即時通訊應用程式可直接解決這項挑戰。這項功能會運用從零售資料衍生的豐富知識庫,瞭解顧客意圖、智慧回覆,並提供極為相關的結果。
建構項目
在本實驗室 (第 1 部分) 中,您將:
- 建立 AlloyDB 執行個體並載入電子商務資料集
- 在 AlloyDB 中啟用 pgvector 和生成式 AI 模型擴充功能
- 根據產品說明生成嵌入
- 針對使用者搜尋文字執行即時餘弦相似度搜尋
- 在無伺服器 Cloud Run 函式中部署解決方案
實驗室的第二部分將介紹 Agent Builder 的步驟。
需求條件
2. 架構
資料流程:讓我們進一步瞭解資料在系統中的流動方式:
擷取:
首先,請將零售資料 (包括庫存、產品說明和顧客互動) 擷取至 AlloyDB。
Analytics Engine:
我們將使用 AlloyDB 做為分析引擎,執行下列作業:
- 擷取背景資訊:引擎會分析 AlloyDB 中儲存的資料,瞭解產品、類別、消費者行為等之間的關係 (如適用)。
- 建立嵌入:系統會為使用者查詢和 AlloyDB 中儲存的資訊產生嵌入 (文字的數學表示)。
- 向量搜尋:引擎會執行相似度搜尋,比較查詢嵌入項目與產品說明、評論和其他相關資料的嵌入項目。這會找出 25 個最相關的「最鄰近項目」。
Gemini 驗證:
這些可能的回答會送交 Gemini 評估。Gemini 會判斷這些資訊是否確實相關,以及是否適合分享給使用者。
生成回覆:
經過驗證的回應會建構為 JSON 陣列,整個引擎則會封裝到無伺服器 Cloud Run 函式中,並從 Agent Builder 叫用。
對話式互動:
Agent Builder 會以自然語言格式向使用者呈現回覆,方便進行來回對話。我們會在後續實驗室中說明這部分內容。
3. 事前準備
建立專案
- 在 Google Cloud 控制台的專案選取器頁面中,選取或建立 Google Cloud 專案。
- 確認 Cloud 專案已啟用計費功能。瞭解如何檢查專案是否已啟用計費功能。
- 您將使用 Cloud Shell,這是 Google Cloud 中執行的指令列環境,預先載入了 bq。點選 Google Cloud 控制台頂端的「啟用 Cloud Shell」。

- 連至 Cloud Shell 後,請使用下列指令確認驗證已完成,專案也已設為獲派的專案 ID:
gcloud auth list
- 在 Cloud Shell 中執行下列指令,確認 gcloud 指令已瞭解您的專案。
gcloud config list project
- 如果未設定專案,請使用下列指令來設定:
gcloud config set project <YOUR_PROJECT_ID>
- 啟用必要的 API。
gcloud services enable alloydb.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
除了使用 gcloud 指令,您也可以透過控制台搜尋各項產品,或使用這個連結。
如果遺漏任何 API,您隨時可以在導入過程中啟用。
如要瞭解 gcloud 指令和用法,請參閱說明文件。
4. 資料庫設定
在本實驗室中,我們將使用 AlloyDB 做為資料庫,儲存零售資料。並使用「叢集」保存所有資源,例如資料庫和記錄檔。每個叢集都有一個「主要執行個體」,可做為資料的存取點。資料表會保存實際資料。
我們來建立 AlloyDB 叢集、執行個體和資料表,以便載入電子商務資料集。
建立叢集和執行個體
- 在 Cloud 控制台中前往 AlloyDB 頁面。如要在 Cloud 控制台尋找大部分的頁面,只要使用控制台的搜尋列搜尋即可。
- 在該頁面中選取「建立叢集」:

- 畫面上會顯示類似下方的內容。使用下列值建立叢集和執行個體:
- 叢集 ID:「
shopping-cluster」 - 密碼:「
alloydb」 - 與 PostgreSQL 15 相容
- 區域:「
us-central1」 - 網路:「
default」

- 選取預設網路後,畫面上會顯示如下資訊。選取「設定連線」
 。
。 - 然後選取「使用系統自動分配的 IP 範圍」,並點選「繼續」。確認資訊後,選取「建立連結」。

- 設定網路後,即可繼續建立叢集。點按「建立叢集」,完成叢集設定,如下所示:

請務必將執行個體 ID 變更為「shopping-instance"」。
請注意,建立叢集約需 10 分鐘。成功後,畫面應會顯示類似下方的訊息:

5. 資料擷取
現在要新增包含商店資料的表格。前往 AlloyDB,選取主要叢集,然後選取 AlloyDB Studio:

您可能需要等待執行個體建立完成。完成後,請使用建立叢集時建立的憑證登入 AlloyDB。使用下列資料向 PostgreSQL 進行驗證:
- 使用者名稱:「
postgres」 - 資料庫:「
postgres」 - 密碼:「
alloydb」
成功驗證 AlloyDB Studio 後,即可在編輯器中輸入 SQL 指令。如要新增多個編輯器視窗,請按一下最後一個視窗右側的加號。

您會在編輯器視窗中輸入 AlloyDB 指令,並視需要使用「執行」、「格式化」和「清除」選項。
啟用擴充功能
我們會使用 pgvector 和 google_ml_integration 擴充功能建構這個應用程式。pgvector 擴充功能可讓您儲存及搜尋向量嵌入。google_ml_integration 擴充功能提供多種函式,可存取 Vertex AI 預測端點,並在 SQL 中取得預測結果。執行下列 DDL,啟用這些擴充功能:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
如要查看資料庫已啟用的擴充功能,請執行下列 SQL 指令:
select extname, extversion from pg_extension;
建立資料表
使用下列 DDL 陳述式建立資料表:
CREATE TABLE
apparels ( id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
embedding vector(768) );
成功執行上述指令後,您應該就能在資料庫中查看資料表。螢幕截圖範例如下:
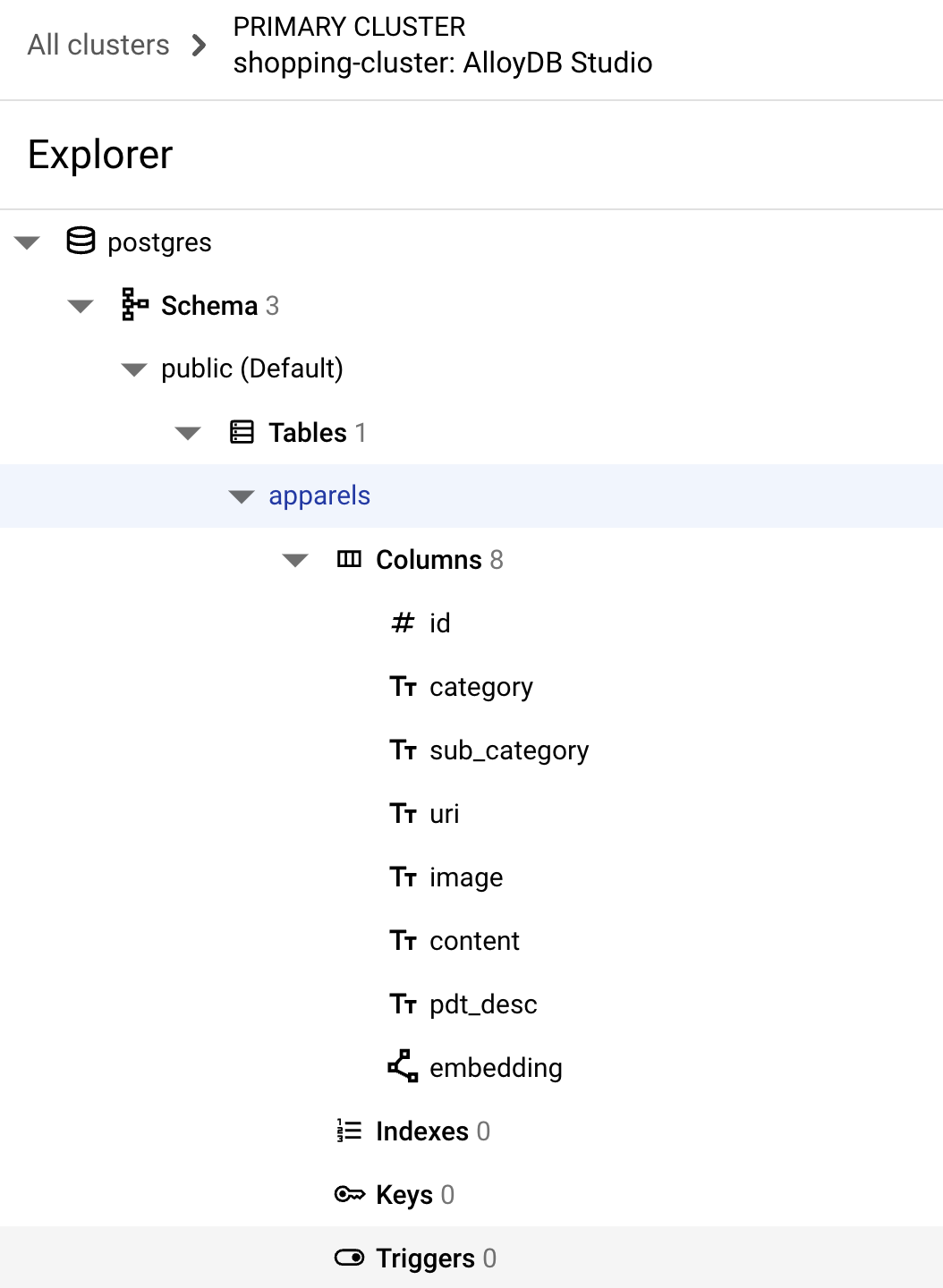
擷取資料
在本實驗室中,我們在 SQL 檔案中提供約 200 筆記錄的測試資料。其中包含 id, category, sub_category, uri, image 和 content。其他欄位會在實驗室的後續部分填寫。
從該處複製 20 行/插入陳述式,然後將這些行貼到空白的編輯器分頁中,並選取「執行」。
如要查看資料表內容,請展開「Explorer」專區,直到看到名為 apparels 的資料表為止。選取三點圖示 (⋮),即可查看查詢資料表的選項。系統會在新編輯器分頁中開啟 SELECT 陳述式。

授予權限
執行下列陳述式,將 embedding 函式的執行權授予使用者 postgres:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
為 AlloyDB 服務帳戶授予 Vertex AI 使用者角色
前往 Cloud Shell 終端機並輸入下列指令:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
6. Context
返回 AlloyDB 執行個體頁面。
如要建立嵌入內容,我們需要 context,也就是要納入單一欄位的所有資訊。我們會建立產品說明 (以下稱為 pdt_desc) 來完成這項作業。在本範例中,我們會使用每項產品的所有資訊,但您使用自己的資料時,可以隨意設計資料,只要對您的業務有意義即可。
從新建立執行個體的 AlloyDB Studio 執行下列陳述式。這會使用比對內容資料更新 pdt_desc 欄位:
UPDATE
apparels
SET
pdt_desc = CONCAT('This product category is: ', category, ' and sub_category is: ', sub_category, '. The description of the product is as follows: ', content, '. The product image is stored at: ', uri)
WHERE
id IS NOT NULL;
這項 DML 會使用資料表中的所有可用欄位和其他依附元件 (如果您的用途有任何依附元件) 的資訊,建立簡單的內容摘要。如要更精確地分類資訊及建立內容,請隨意設計資料,找出對貴商家有意義的資料。
7. 為情境建立嵌入
電腦處理數字比處理文字容易得多。嵌入系統會將文字轉換為一系列浮點數,這些數字應代表文字,無論文字的措辭、使用的語言等為何。
例如描述海邊的地點。例如「水上」、「海濱」、「從房間走到海邊」、「sur la mer」、「на берегу океана」等。這些字詞看起來不同,但元件資訊或機器學習術語 (即嵌入) 應該非常接近。
資料和內容都準備就緒後,我們將執行 SQL,將產品說明的嵌入內容新增至 embedding 欄位中的資料表。您可以使用各種嵌入模型。我們使用 Vertex AI 的 text-embedding-004。請務必在整個專案中使用相同的嵌入模型!
注意:如果您使用先前建立的 Google Cloud 專案,可能需要繼續使用舊版文字嵌入模型,例如 textembedding-gecko。
UPDATE
apparels
SET
embedding = embedding( 'text-embedding-004',
pdt_desc)
WHERE
TRUE;
再次查看 apparels 表格,即可看到一些嵌入內容。請務必重新執行 SELECT 陳述式,查看變更。
SELECT
id,
category,
sub_category,
content,
embedding
FROM
apparels;
這項查詢應會傳回嵌入向量,看起來像是浮點數陣列,如下所示:

注意:在免費方案下建立的 Google Cloud 專案,可能會遇到配額問題,也就是每秒允許的嵌入要求數量。建議您使用 ID 的篩選查詢,然後在產生嵌入內容時,選擇性地選取 1 到 5 筆記錄等。
8. 執行向量搜尋
資料表、資料和嵌入都已準備就緒,現在就來對使用者搜尋文字執行即時向量搜尋。
假設使用者提出以下問題:
「I want womens tops, pink casual only pure cotton.」(我想要女裝上衣,粉紅色休閒款,材質為純棉。)
您可以執行下列查詢來找出相符項目:
SELECT
id,
category,
sub_category,
content,
pdt_desc AS description
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-004',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5;
讓我們詳細瞭解這項查詢:
在這項查詢中,
- 使用者的搜尋文字為:「I want womens tops, pink casual only pure cotton.」(我想要女裝上衣,僅限粉紅色休閒款,材質為純棉)。
- 我們要在
embedding()方法中使用模型text-embedding-004,將其轉換為嵌入。上一個步驟中,我們已將嵌入函式套用至表格中的所有項目,因此這個步驟應該很熟悉。 - 「
<=>」代表使用「餘弦相似度」距離方法。如要查看所有可用的相似度測量方式,請參閱 pgvector 說明文件。 - 我們會將嵌入方法的結果轉換為向量型別,使其與資料庫中儲存的向量相容。
- LIMIT 5 代表我們要為搜尋文字擷取 5 個最鄰近的項目。
結果如下所示:

如您在結果中看到的,相符項目與搜尋文字相當接近。請嘗試變更顏色,看看結果會如何變化。
重要注意事項:
假設我們現在想使用 ScaNN 索引,提高這項向量搜尋結果的效能 (查詢時間)、效率和召回率。請參閱這篇網誌中的步驟,比較有索引和沒有索引的結果差異。為方便您操作,以下列出建立索引的步驟:
- 由於我們已建立叢集、執行個體、內容和嵌入,因此只需使用下列陳述式安裝 ScaNN 擴充功能:
CREATE EXTENSION IF NOT EXISTS alloydb_scann;
- 接著,我們要建立索引 (ScaNN):
CREATE INDEX apparel_index ON apparels
USING scann (embedding cosine)
WITH (num_leaves=54);
在上述 DDL 中,apparel_index 是索引的名稱
「apparels」是我的表格
「scann」是索引方法
「embedding」是我要建立索引的表格欄
「cosine」是我要用於索引的距離方法
「54」是要套用至這個索引的分區數量。請設為 1 到 1048576 之間的任何值。如要進一步瞭解如何決定這個值,請參閱「調整 ScaNN 索引」。
我使用資料點數的平方根,如 ScaNN 存放區 中建議 (分割時,num_leaves 應約為資料點數的平方根)。
- 使用下列查詢檢查索引是否已建立:
SELECT * FROM pg_stat_ann_indexes;
- 使用與不含索引時相同的查詢,執行向量搜尋:
select * from apparels
ORDER BY embedding <=> CAST(embedding('textembedding-gecko', 'white tops for girls without any print') as vector(768))
LIMIT 20
上述查詢與實驗室步驟 8 中使用的查詢相同。不過,現在我們已為該欄位建立索引。
- 使用簡單的搜尋查詢測試索引 (方法是捨棄索引):
white tops for girls without any print
在 INDEXED 嵌入資料中,使用上述搜尋文字查詢 Vector Search,可獲得優質的搜尋結果並提升效率。使用索引後,效率大幅提升 (執行時間:不使用 ScaNN 時為 10.37 毫秒,使用 ScaNN 時為 0.87 毫秒)。如要進一步瞭解這個主題,請參閱這篇網誌。
9. 使用 LLM 驗證比對結果
在繼續操作並建立服務,以便向應用程式傳回最佳相符項目之前,請先使用生成式 AI 模型驗證這些潛在回覆是否確實相關,且可安全地與使用者分享。
確認執行個體已設定為 Gemini
請先檢查叢集和執行個體是否已啟用 Google ML 整合。在 AlloyDB Studio 中,輸入下列指令:
show google_ml_integration.enable_model_support;
如果值顯示為「on」,您可以略過接下來的 2 個步驟,直接設定 AlloyDB 和 Vertex AI 模型整合。
- 前往 AlloyDB 叢集的主要執行個體,然後按一下「編輯主要執行個體」

- 前往「進階設定選項」中的「Flags」部分。並確認
google_ml_integration.enable_model_support flag已設為「on」,如下所示:
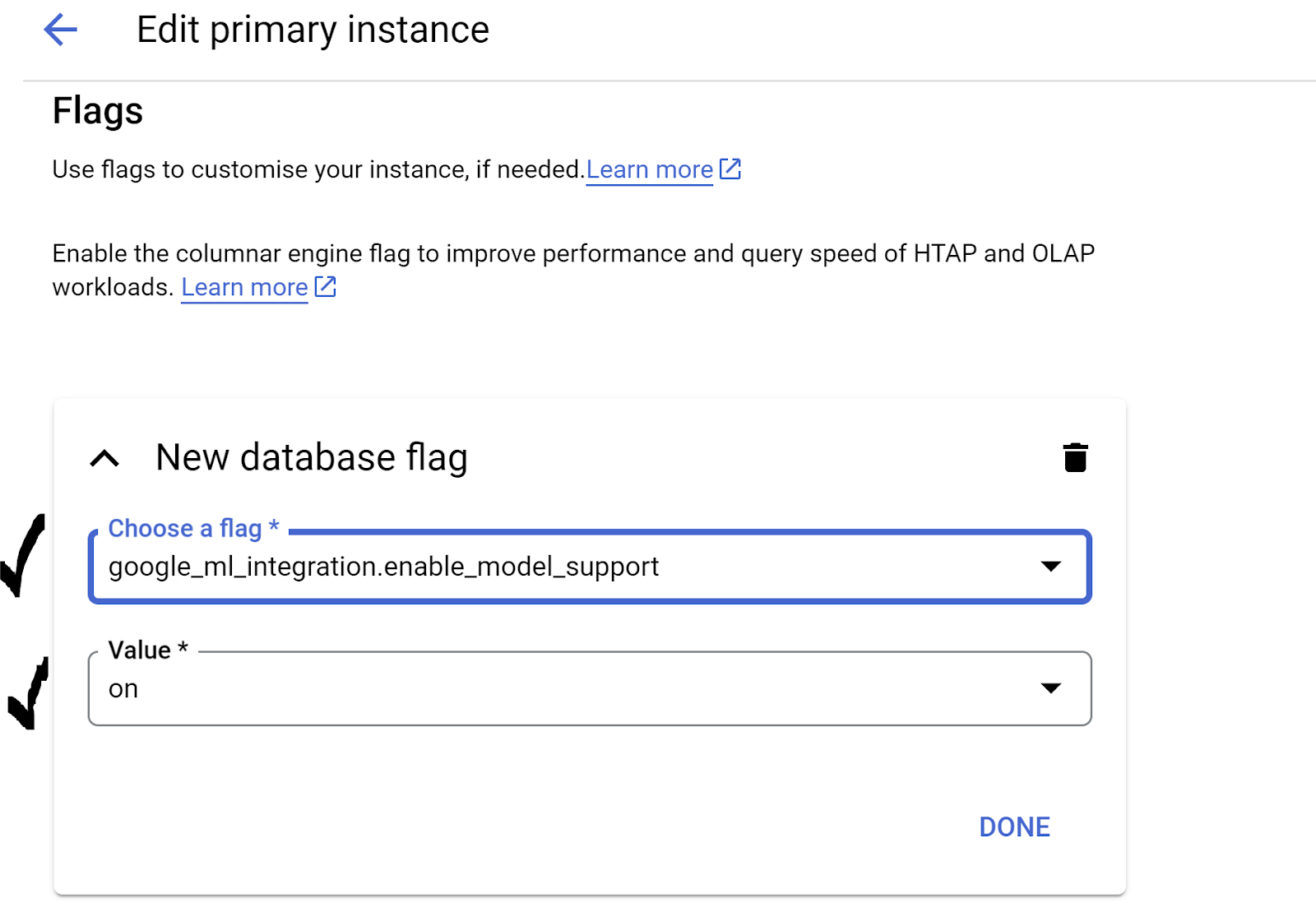
如果未設為「on」,請設為「on」,然後按一下「UPDATE INSTANCE」按鈕。這個步驟需要幾分鐘才能完成。
整合 AlloyDB 和 Vertex AI 模型
現在您可以連線至 AlloyDB Studio,並執行下列 DML 陳述式,從 AlloyDB 設定 Gemini 模型存取權 (請使用標示位置的專案 ID)。執行指令前,系統可能會警告您有語法錯誤,但指令應該可以正常執行。
首先,我們建立 Gemini 1.5 模型連線,如下所示。請記得將下方指令中的 $PROJECT_ID 替換為您的 Google Cloud 專案 ID。
CALL
google_ml.create_model( model_id => 'gemini-1.5',
model_request_url => 'https://us-central1-aiplatform.googleapis.com/v1/projects/$PROJECT_ID/locations/us-central1/publishers/google/models/gemini-1.5-pro:streamGenerateContent',
model_provider => 'google',
model_auth_type => 'alloydb_service_agent_iam');
您可以在 AlloyDB Studio 中執行下列指令,查看設定可存取的模型:
select model_id,model_type from google_ml.model_info_view;
最後,我們需要授予資料庫使用者執行 ml_predict_row 函式的權限,透過 Google Vertex AI 模型執行預測。執行下列指令:
GRANT EXECUTE ON FUNCTION ml_predict_row to postgres;
注意:如果您使用現有的 Google Cloud 雲端專案和現有的 AlloyDB 叢集/執行個體,且這些項目是先前建立的,可能需要捨棄 gemini-1.5 模型舊的參照,並使用上述 CALL 陳述式重新建立,然後再次對函式 ml_predict_row 執行授權,以免在後續叫用 gemini-1.5 時發生問題。
評估回覆
雖然我們會在下一節中使用一個大型查詢,確保查詢的回應合理,但查詢可能難以理解。我們現在就來看看這些片段,並在幾分鐘內瞭解它們如何整合。
- 首先,我們會向資料庫傳送要求,取得與使用者查詢最接近的 5 個結果。為了簡化操作,我們將查詢硬式編碼,但請放心,稍後我們會將其插入查詢中。我們將納入
apparels資料表中的產品說明,並新增兩個欄位,一個是說明與索引的組合,另一個則是原始要求。所有資料都會儲存在名為xyz的資料表中 (這只是暫時的資料表名稱)。
CREATE TABLE
xyz AS
SELECT
id || ' - ' || pdt_desc AS literature,
pdt_desc AS content,
'I want womens tops, pink casual only pure cotton.' AS user_text
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-004',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5;
這項查詢的輸出內容會是與使用者查詢最相似的 5 列。新資料表 xyz 會包含 5 個資料列,每個資料列都會有下列資料欄:
literaturecontentuser_text
- 為判斷回覆的有效性,我們會使用複雜的查詢,說明如何評估回覆。並在
xyz資料表中,將user_text和content用於查詢。
"Read this user search text: ', user_text,
' Compare it against the product inventory data set: ', content,
' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
- 接著,我們將使用該查詢,檢查
xyz資料表中的回應「品質」。
CREATE TABLE
x AS
SELECT
json_array_elements( google_ml.predict_row( model_id => 'gemini-1.5',
request_body => CONCAT('{
"contents": [
{ "role": "user",
"parts":
[ { "text": "Read this user search text: ', user_text, ' Compare it against the product inventory data set: ', content, ' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
} ]
}
] }'
)::json))-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'
AS LLM_RESPONSE
FROM
xyz;
predict_row會以 JSON 格式傳回結果。程式碼「-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'"」用於從該 JSON 擷取實際文字。如要查看實際傳回的 JSON,可以移除這段程式碼。- 最後,如要取得 LLM 欄位,只要從 x 資料表擷取即可:
SELECT
LLM_RESPONSE
FROM
x;
- 這可以合併為單一的下一個查詢,如下所示。
如果您已執行上述查詢來檢查中繼結果,請先從 AlloyDB 資料庫中刪除/移除 xyz 和 x 資料表,再執行這項查詢。
SELECT
LLM_RESPONSE
FROM (
SELECT
json_array_elements( google_ml.predict_row( model_id => 'gemini-1.5',
request_body => CONCAT('{
"contents": [
{ "role": "user",
"parts":
[ { "text": "Read this user search text: ', user_text, ' Compare it against the product inventory data set: ', content, ' Return a response with 3 values: 1) MATCH: if the 2 contexts are at least 85% matching or not: YES or NO 2) PERCENTAGE: percentage of match, make sure that this percentage is accurate 3) DIFFERENCE: A clear short easy description of the difference between the 2 products. Remember if the user search text says that some attribute should not be there, and the record has it, it should be a NO match."
} ]
}
] }'
)::json))-> 'candidates' -> 0 -> 'content' -> 'parts' -> 0 -> 'text'
AS LLM_RESPONSE
FROM (
SELECT
id || ' - ' || pdt_desc AS literature,
pdt_desc AS content,
'I want womens tops, pink casual only pure cotton.' user_text
FROM
apparels
ORDER BY
embedding <=> embedding('text-embedding-004',
'I want womens tops, pink casual only pure cotton.')::vector
LIMIT
5 ) AS xyz ) AS X;
雖然這可能還是有點難懂,但希望您能稍微瞭解。結果會顯示是否有相符的內容、相符的百分比,以及評分的說明。
請注意,Gemini 模型預設會啟用串流功能,因此實際回覆會分散在多行:
10. 將應用程式帶到網頁
準備好將這個應用程式帶到網路上嗎?請按照下列步驟,使用 Cloud Run 函式將這個知識引擎設為無伺服器:
- 前往 Google Cloud 控制台的 Cloud Run Functions,建立新的 Cloud Run Function,或使用連結:https://console.cloud.google.com/functions/add。
- 選取「Cloud Run function」做為環境。提供函式名稱「retail-engine」,並選擇「us-central1」做為區域。將「驗證」設為「允許未經驗證的叫用」,然後按一下「下一步」。選擇「Java 17」做為執行階段,並選擇「Inline Editor」做為原始碼。
- 根據預設,進入點會設為「
gcfv2.HelloHttpFunction」。請將 Cloud Run 函式HelloHttpFunction.java和pom.xml中的預留位置程式碼,分別換成 Java 檔案和 XML 中的程式碼。 - 請記得在 Java 檔案中,將 $PROJECT_ID 預留位置和 AlloyDB 連線憑證換成您的值。AlloyDB 憑證是我們在本程式碼研究室一開始使用的憑證。如果使用不同的值,請在 Java 檔案中修改。
- 按一下「Deploy」(部署)。
部署完成後,為了允許 Cloud 函式存取 AlloyDB 資料庫執行個體,我們將建立 VPC 連接器。
重要步驟:
設定部署作業後,您應該就能在 Google Cloud Run Functions 控制台中看到函式。搜尋新建立的函式 (retail-engine),點選該函式,然後按一下「編輯」並變更下列項目:
- 前往「執行階段、建構作業、連線和安全性設定」
- 將逾時時間增加至 180 秒
- 前往「連線」分頁:

- 在 Ingress 設定下方,確認已選取「允許所有流量」。
- 在「輸出設定」下方,按一下「網路」下拉式選單,然後選取「新增虛擬私有雲連接器」選項,並按照彈出式對話方塊中顯示的操作說明進行操作:

- 提供 VPC 連接器的名稱,並確認區域與執行個體相同。將「網路」值保留為預設值,並將「子網路」設為「自訂 IP 範圍」,IP 範圍為 10.8.0.0 或類似的可用範圍。
- 展開「顯示縮放設定」,確認設定完全符合下列條件:

- 按一下「CREATE」,這個連接器現在應該會列在輸出設定中。
- 選取新建立的連接器
- 選擇透過這個虛擬私有雲連接器轉送所有流量。
- 依序點選「NEXT」和「DEPLOY」。
11. 測試應用程式
部署更新後的 Cloud 函式後,您應該會看到下列格式的端點:
https://us-central1-YOUR_PROJECT_ID.cloudfunctions.net/retail-engine
您可以在 Cloud Shell 終端機中執行下列指令進行測試:
gcloud functions call retail-engine --region=us-central1 --gen2 --data '{"search": "I want some kids clothes themed on Disney"}'
或者,您也可以按照下列步驟測試 Cloud Run 函式:
PROJECT_ID=$(gcloud config get-value project)
curl -X POST https://us-central1-$PROJECT_ID.cloudfunctions.net/retail-engine \
-H 'Content-Type: application/json' \
-d '{"search":"I want some kids clothes themed on Disney"}' \
| jq .
結果如下:

大功告成!在 AlloyDB 資料上使用 Embeddings 模型執行相似度向量搜尋,就是這麼簡單。
建構對話式代理!
服務專員是在本實驗室的第 2 部分中建構。
12. 清理
如果您打算完成本實驗室的第 2 部分,請略過這個步驟,因為這會刪除目前的專案。
如要避免系統向您的 Google Cloud 帳戶收取本文章所用資源的費用,請按照下列步驟操作:
13. 恭喜
恭喜!您已使用 AlloyDB、pgvector 和向量搜尋功能,成功執行相似度搜尋。結合 AlloyDB、Vertex AI 和 Vector Search 的功能,我們在提供情境和向量搜尋功能方面取得重大進展,讓這類搜尋功能更易於使用、效率更高,且真正以意義為導向。本實驗室的下一部分將說明如何建構代理程式。