
1. Panoramica
In questo lab utilizzerai Vertex AI per creare una pipeline che addestra un modello Keras personalizzato in TensorFlow. Utilizzeremo quindi la nuova funzionalità disponibile in Vertex AI Experiments per monitorare e confrontare le esecuzioni dei modelli al fine di identificare la combinazione di iperparametri che produce il rendimento migliore.
Cosa imparerai
Al termine del corso sarai in grado di:
- Addestra un modello Keras personalizzato per prevedere le valutazioni dei giocatori (ad es. regressione)
- Utilizzare l'SDK Kubeflow Pipelines per creare pipeline ML scalabili
- Crea ed esegui una pipeline in 5 passaggi che acquisisce i dati da Cloud Storage, li ridimensiona, addestra il modello, lo valuta e salva il modello risultante in Cloud Storage
- Sfrutta Vertex ML Metadata per salvare gli artefatti del modello, come modelli e metriche del modello
- Utilizza Vertex AI Experiments per confrontare i risultati delle varie esecuzioni della pipeline
Il costo totale per eseguire questo lab su Google Cloud è di circa 1$.
2. Introduzione a Vertex AI
Questo lab utilizza la più recente offerta di prodotti AI disponibile su Google Cloud. Vertex AI integra le offerte ML di Google Cloud in un'esperienza di sviluppo fluida. In precedenza, i modelli addestrati con AutoML e i modelli personalizzati erano accessibili tramite servizi separati. La nuova offerta combina entrambi in un'unica API, insieme ad altri nuovi prodotti. Puoi anche migrare progetti esistenti su Vertex AI.
Vertex AI include molti prodotti diversi per supportare i flussi di lavoro ML end-to-end. Questo lab si concentrerà sui prodotti evidenziati di seguito: Experiments, Pipelines, ML Metadata e Workbench.

3. Panoramica del caso d'uso
Utilizzeremo un popolare set di dati sul calcio proveniente dalla serie di videogiochi FIFA di EA Sports. Include oltre 25.000 partite di calcio e più di 10.000 giocatori per le stagioni 2008-2016. I dati sono stati pre-elaborati in anticipo, così puoi iniziare subito a lavorare. Utilizzerai questo set di dati per tutto il lab, che ora si trova in un bucket Cloud Storage pubblico. Forniremo maggiori dettagli su come accedere al set di dati più avanti nel codelab. Il nostro obiettivo finale è prevedere la valutazione complessiva di un giocatore in base a varie azioni di gioco, come intercetti e falli.
Perché Vertex AI Experiments è utile per la data science?
La data science è di natura sperimentale, dopotutto si chiamano scienziati. I data scientist validi si basano su ipotesi e utilizzano il metodo per tentativi ed errori per testare varie ipotesi con la speranza che le iterazioni successive portino a un modello più performante.
Sebbene i team di data science abbiano adottato la sperimentazione, spesso hanno difficoltà a tenere traccia del proprio lavoro e della "ricetta segreta" scoperta grazie ai loro sforzi di sperimentazione. Questo accade per diversi motivi:
- Il monitoraggio dei job di addestramento può diventare complicato, rendendo facile perdere di vista ciò che funziona rispetto a ciò che non funziona
- Questo problema si aggrava quando si esamina un team di data science, in quanto non tutti i membri potrebbero monitorare gli esperimenti o persino condividere i risultati con altri.
- L'acquisizione dei dati richiede molto tempo e la maggior parte dei team utilizza metodi manuali (ad es.fogli o documenti) che generano informazioni incoerenti e incomplete da cui trarre insegnamenti.
In breve:Vertex AI Experiments fa il lavoro per te, aiutandoti a monitorare e confrontare più facilmente i tuoi esperimenti
Perché Vertex AI Experiments per i giochi?
Storicamente, i giochi sono stati un terreno fertile per il machine learning e gli esperimenti di ML. I giochi non solo producono miliardi di eventi in tempo reale al giorno, ma utilizzano tutti questi dati sfruttando il machine learning e gli esperimenti ML per migliorare le esperienze di gioco, fidelizzare i giocatori e valutare i diversi giocatori sulla loro piattaforma. Per questo motivo, abbiamo pensato che un set di dati sui giochi si adattasse bene al nostro esercizio complessivo di sperimentazione.
4. Configura l'ambiente
Per eseguire questo codelab, devi avere un progetto Google Cloud Platform con la fatturazione abilitata. Per creare un progetto, segui le istruzioni riportate qui.
Passaggio 1: abilita l'API Compute Engine
Vai a Compute Engine e seleziona Abilita se non è già abilitato.
Passaggio 2: attiva l'API Vertex AI
Accedi alla sezione Vertex AI della tua console Cloud e fai clic su Abilita API Vertex AI.

Passaggio 3: crea un'istanza di Vertex AI Workbench
Nella sezione Vertex AI della console Cloud, fai clic su Workbench:
Abilita l'API Notebooks, se non l'hai ancora fatto.

Una volta attivata, fai clic su BLOCCHI NOTE GESTITI:

Poi seleziona NUOVO QUADERNO.
Assegna un nome al notebook, quindi fai clic su Impostazioni avanzate.

In Impostazioni avanzate, attiva l'arresto per inattività e imposta il numero di minuti su 60. Ciò significa che il notebook si spegnerà automaticamente quando non viene utilizzato, in modo da non sostenere costi non necessari.

Passaggio 4: apri il notebook
Una volta creata l'istanza, seleziona Apri JupyterLab.

Passaggio 5: esegui l'autenticazione (solo la prima volta)
La prima volta che utilizzi una nuova istanza, ti verrà chiesto di autenticarti. Per farlo, segui i passaggi nell'interfaccia utente.

Passaggio 6: seleziona il kernel appropriato
I notebook gestiti forniscono più kernel in una singola UI. Seleziona il kernel per TensorFlow 2 (locale).

5. Passaggi di configurazione iniziali nel notebook
Prima di creare la pipeline, dovrai eseguire una serie di passaggi aggiuntivi per configurare l'ambiente all'interno del notebook. Questi passaggi includono: l'installazione di eventuali pacchetti aggiuntivi, l'impostazione delle variabili, la creazione del bucket Cloud Storage, la copia del set di dati di gioco da un bucket di Storage pubblico, l'importazione delle librerie e la definizione di costanti aggiuntive.
Passaggio 1: installa pacchetti aggiuntivi
Dovremo installare dipendenze di pacchetti aggiuntive non attualmente installate nell'ambiente notebook. Un esempio include l'SDK KFP.
!pip3 install --user --force-reinstall 'google-cloud-aiplatform>=1.15' -q --no-warn-conflicts
!pip3 install --user kfp -q --no-warn-conflicts
A questo punto, riavvia il kernel del notebook per poter utilizzare i pacchetti scaricati all'interno del notebook.
# Automatically restart kernel after installs
import os
if not os.getenv("IS_TESTING"):
# Automatically restart kernel after installs
import IPython
app = IPython.Application.instance()
app.kernel.do_shutdown(True)
Passaggio 2: imposta le variabili
Vogliamo definire il nostro PROJECT_ID. Se non conosci il tuo Project_ID, potresti riuscire a recuperare il tuo PROJECT_ID utilizzando gcloud.
import os
PROJECT_ID = ""
# Get your Google Cloud project ID from gcloud
if not os.getenv("IS_TESTING"):
shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null
PROJECT_ID = shell_output[0]
print("Project ID: ", PROJECT_ID)
In caso contrario, imposta PROJECT_ID qui.
if PROJECT_ID == "" or PROJECT_ID is None:
PROJECT_ID = "[your-project-id]" # @param {type:"string"}
Vogliamo anche impostare la variabile REGION, che viene utilizzata nel resto di questo blocco note. Di seguito sono riportate le regioni supportate per Vertex AI. Ti consigliamo di scegliere la regione più vicina a te.
- Americhe: us-central1
- Europa: europe-west4
- Asia Pacifico: asia-east1
Non utilizzare un bucket multiregionale per l'addestramento con Vertex AI. Non tutte le regioni forniscono supporto per tutti i servizi Vertex AI. Scopri di più sulle regioni di Vertex AI.
#set your region
REGION = "us-central1" # @param {type: "string"}
Infine, imposteremo una variabile TIMESTAMP. Questa variabile viene utilizzata per evitare conflitti di nomi tra gli utenti sulle risorse create. Crea un TIMESTAMP per ogni sessione di istanza e lo aggiungi al nome delle risorse create in questo tutorial.
#set timestamp to avoid collisions between multiple users
from datetime import datetime
TIMESTAMP = datetime.now().strftime("%Y%m%d%H%M%S")
Passaggio 3: crea un bucket Cloud Storage
Dovrai specificare e utilizzare un bucket temporaneo Cloud Storage. Il bucket di staging è la posizione in cui vengono conservati tutti i dati associati alle risorse del set di dati e del modello nelle varie sessioni.
Imposta il nome del bucket Cloud Storage di seguito. I nomi dei bucket devono essere univoci a livello globale in tutti i progetti Google Cloud, inclusi quelli esterni alla tua organizzazione.
#set cloud storage bucket
BUCKET_NAME = "[insert bucket name here]" # @param {type:"string"}
BUCKET_URI = f"gs://{BUCKET_NAME}"
Se il bucket NON esiste già, puoi eseguire la cella seguente per creare il bucket Cloud Storage.
! gsutil mb -l $REGION -p $PROJECT_ID $BUCKET_URI
Puoi quindi verificare l'accesso al bucket Cloud Storage eseguendo la cella seguente.
#verify access
! gsutil ls -al $BUCKET_URI
Passaggio 4: copia il nostro set di dati sui giochi
Come accennato in precedenza, utilizzerai un popolare set di dati di gioco dei videogio di successo di EA Sports, FIFA. Abbiamo eseguito il lavoro di pre-elaborazione per te, quindi dovrai solo copiare il set di dati dal bucket di archiviazione pubblico e spostarlo in quello che hai creato.
# copy the data over to your cloud storage bucket
DATASET_URI = "gs://cloud-samples-data/vertex-ai/structured_data/player_data"
!gsutil cp -r $DATASET_URI $BUCKET_URI
Passaggio 5: importa le librerie e definisci costanti aggiuntive
Successivamente, vogliamo importare le nostre librerie per Vertex AI, KFP e così via.
import logging
import os
import time
logger = logging.getLogger("logger")
logging.basicConfig(level=logging.INFO)
import kfp.v2.compiler as compiler
# Pipeline Experiments
import kfp.v2.dsl as dsl
# Vertex AI
from google.cloud import aiplatform as vertex_ai
from kfp.v2.dsl import Artifact, Input, Metrics, Model, Output, component
from typing import NamedTuple
Definiremo anche altre costanti a cui faremo riferimento nel resto del notebook, ad esempio i percorsi dei file dei nostri dati di addestramento.
#import libraries and define constants
# Experiments
TASK = "regression"
MODEL_TYPE = "tensorflow"
EXPERIMENT_NAME = f"{PROJECT_ID}-{TASK}-{MODEL_TYPE}-{TIMESTAMP}"
# Pipeline
PIPELINE_URI = f"{BUCKET_URI}/pipelines"
TRAIN_URI = f"{BUCKET_URI}/player_data/data.csv"
LABEL_URI = f"{BUCKET_URI}/player_data/labels.csv"
MODEL_URI = f"{BUCKET_URI}/model"
DISPLAY_NAME = "experiments-demo-gaming-data"
BQ_DATASET = "player_data"
BQ_LOCATION = "US"
VIEW_NAME = 'dataset_test'
PIPELINE_JSON_PKG_PATH = "experiments_demo_gaming_data.json"
PIPELINE_ROOT = f"gs://{BUCKET_URI}/pipeline_root"
6. Creiamo la nostra pipeline
Ora possiamo iniziare a divertirci e a sfruttare Vertex AI per creare la nostra pipeline di addestramento. Inizializzeremo l'SDK Vertex AI, configureremo il job di addestramento come componente della pipeline, creeremo la pipeline, invieremo le esecuzioni della pipeline e utilizzeremo l'SDK Vertex AI per visualizzare gli esperimenti e monitorarne lo stato.
Passaggio 1: inizializza l'SDK Vertex AI
Inizializza l'SDK Vertex AI, impostando PROJECT_ID e BUCKET_URI.
#initialize vertex AI SDK
vertex_ai.init(project=PROJECT_ID, staging_bucket=BUCKET_URI)
Passaggio 2: configura il job di addestramento come componente della pipeline
Per iniziare a eseguire i nostri esperimenti, dobbiamo specificare il job di addestramento definendolo come componente della pipeline. La pipeline accetterà come input i dati di addestramento e gli iperparametri (ad es. DROPOUT_RATE, LEARNING_RATE, EPOCHS) e restituirà le metriche del modello (ad es. MAE e RMSE) e un artefatto del modello.
@component(
packages_to_install=[
"numpy==1.21.0",
"pandas==1.3.5",
"scikit-learn==1.0.2",
"tensorflow==2.9.0",
]
)
def custom_trainer(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
metrics: Output[Metrics],
model_metadata: Output[Model],
):
# import libraries
import logging
import uuid
from pathlib import Path as path
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from tensorflow.keras.metrics import Metric
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
import numpy as np
from math import sqrt
import os
import tempfile
# set variables and use gcsfuse to update prefixes
gs_prefix = "gs://"
gcsfuse_prefix = "/gcs/"
train_path = train_uri.replace(gs_prefix, gcsfuse_prefix)
label_path = label_uri.replace(gs_prefix, gcsfuse_prefix)
model_path = model_uri.replace(gs_prefix, gcsfuse_prefix)
def get_logger():
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
handler = logging.StreamHandler()
handler.setFormatter(
logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
)
logger.addHandler(handler)
return logger
def get_data(
train_path: str,
label_path: str
) -> (pd.DataFrame):
#load data into pandas dataframe
data_0 = pd.read_csv(train_path)
labels_0 = pd.read_csv(label_path)
#drop unnecessary leading columns
data = data_0.drop('Unnamed: 0', axis=1)
labels = labels_0.drop('Unnamed: 0', axis=1)
#save as numpy array for reshaping of data
labels = labels.values
data = data.values
# Split the data
labels = labels.reshape((labels.size,))
train_data, test_data, train_labels, test_labels = train_test_split(data, labels, test_size=0.2, shuffle=True, random_state=7)
#Convert data back to pandas dataframe for scaling
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
train_labels = pd.DataFrame(train_labels)
test_labels = pd.DataFrame(test_labels)
#Scale and normalize the training dataset
scaler = StandardScaler()
scaler.fit(train_data)
train_data = pd.DataFrame(scaler.transform(train_data), index=train_data.index, columns=train_data.columns)
test_data = pd.DataFrame(scaler.transform(test_data), index=test_data.index, columns=test_data.columns)
return train_data,train_labels, test_data, test_labels
""" Train your Keras model passing in the training data and values for learning rate, dropout rate,and the number of epochs """
def train_model(
learning_rate: float,
dropout_rate: float,
epochs: float,
train_data: pd.DataFrame,
train_labels: pd.DataFrame):
# Train tensorflow model
param = {"learning_rate": learning_rate, "dropout_rate": dropout_rate, "epochs": epochs}
model = Sequential()
model.add(Dense(500, input_dim=train_data.shape[1], activation= "relu"))
model.add(Dropout(param['dropout_rate']))
model.add(Dense(100, activation= "relu"))
model.add(Dense(50, activation= "relu"))
model.add(Dense(1))
model.compile(
tf.keras.optimizers.Adam(learning_rate= param['learning_rate']),
loss='mse',
metrics=[tf.keras.metrics.RootMeanSquaredError(),tf.keras.metrics.MeanAbsoluteError()])
model.fit(train_data, train_labels, epochs= param['epochs'])
return model
# Get Predictions
def get_predictions(model, test_data):
dtest = pd.DataFrame(test_data)
pred = model.predict(dtest)
return pred
# Evaluate predictions with MAE
def evaluate_model_mae(pred, test_labels):
mae = mean_absolute_error(test_labels, pred)
return mae
# Evaluate predictions with RMSE
def evaluate_model_rmse(pred, test_labels):
rmse = np.sqrt(np.mean((test_labels - pred)**2))
return rmse
#Save your trained model in GCS
def save_model(model, model_path):
model_id = str(uuid.uuid1())
model_path = f"{model_path}/{model_id}"
path(model_path).parent.mkdir(parents=True, exist_ok=True)
model.save(model_path + '/model_tensorflow')
# Main ----------------------------------------------
train_data, train_labels, test_data, test_labels = get_data(train_path, label_path)
model = train_model(learning_rate, dropout_rate, epochs, train_data,train_labels )
pred = get_predictions(model, test_data)
mae = evaluate_model_mae(pred, test_labels)
rmse = evaluate_model_rmse(pred, test_labels)
save_model(model, model_path)
# Metadata ------------------------------------------
#convert numpy array to pandas series
mae = pd.Series(mae)
rmse = pd.Series(rmse)
#log metrics and model artifacts with ML Metadata. Save metrics as a list.
metrics.log_metric("mae", mae.to_list())
metrics.log_metric("rmse", rmse.to_list())
model_metadata.uri = model_uri
Passaggio 3: crea la pipeline
Ora configureremo il workflow utilizzando Domain Specific Language (DSL) disponibile in KFP e compileremo la pipeline in un file JSON.
# define our workflow
@dsl.pipeline(name="gaming-custom-training-pipeline")
def pipeline(
train_uri: str,
label_uri: str,
dropout_rate: float,
learning_rate: float,
epochs: int,
model_uri: str,
):
custom_trainer(
train_uri,label_uri, dropout_rate,learning_rate,epochs, model_uri
)
#compile our pipeline
compiler.Compiler().compile(pipeline_func=pipeline, package_path="gaming_pipeline.json")
Passaggio 4: invia le esecuzioni della pipeline
Il lavoro più difficile è stato fatto configurando il componente e definendo la pipeline. Siamo pronti a inviare varie esecuzioni della pipeline che abbiamo specificato sopra. Per farlo, dobbiamo definire i valori per i diversi iperparametri come segue:
runs = [
{"dropout_rate": 0.001, "learning_rate": 0.001,"epochs": 20},
{"dropout_rate": 0.002, "learning_rate": 0.002,"epochs": 25},
{"dropout_rate": 0.003, "learning_rate": 0.003,"epochs": 30},
{"dropout_rate": 0.004, "learning_rate": 0.004,"epochs": 35},
{"dropout_rate": 0.005, "learning_rate": 0.005,"epochs": 40},
]
Con gli iperparametri definiti, possiamo utilizzare un for loop per inserire correttamente le diverse esecuzioni della pipeline:
for i, run in enumerate(runs):
job = vertex_ai.PipelineJob(
display_name=f"{EXPERIMENT_NAME}-pipeline-run-{i}",
template_path="gaming_pipeline.json",
pipeline_root=PIPELINE_URI,
parameter_values={
"train_uri": TRAIN_URI,
"label_uri": LABEL_URI,
"model_uri": MODEL_URI,
**run,
},
)
job.submit(experiment=EXPERIMENT_NAME)
Passaggio 5: utilizza l'SDK Vertex AI per visualizzare gli esperimenti
L'SDK Vertex AI ti consente di monitorare lo stato delle esecuzioni della pipeline. Puoi anche utilizzarlo per restituire parametri e metriche delle esecuzioni della pipeline nell'esperimento Vertex AI. Utilizza il seguente codice per visualizzare i parametri associati alle esecuzioni e il relativo stato attuale.
# see state/status of all the pipeline runs
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
Puoi utilizzare il codice riportato di seguito per ricevere aggiornamenti sullo stato delle esecuzioni della pipeline.
#check on current status
while True:
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
if all(
pipeline_state != "COMPLETE" for pipeline_state in pipeline_experiments_df.state
):
print("Pipeline runs are still running...")
if any(
pipeline_state == "FAILED"
for pipeline_state in pipeline_experiments_df.state
):
print("At least one Pipeline run failed")
break
else:
print("Pipeline experiment runs have completed")
break
time.sleep(60)
Puoi anche chiamare job della pipeline specifici utilizzando run_name.
# Call the pipeline runs based on the experiment run name
pipeline_experiments_df = vertex_ai.get_experiment_df(EXPERIMENT_NAME)
job = vertex_ai.PipelineJob.get(pipeline_experiments_df.run_name[0])
print(job.resource_name)
print(job._dashboard_uri())
Infine, puoi aggiornare lo stato delle esecuzioni a intervalli prestabiliti (ad esempio ogni 60 secondi) per vedere gli stati passare da RUNNING a FAILED o COMPLETE.
# wait 60 seconds and view state again
import time
time.sleep(60)
vertex_ai.get_experiment_df(EXPERIMENT_NAME)
7. Identificare l'esecuzione con il rendimento migliore
Ottimo, ora abbiamo i risultati delle esecuzioni della pipeline. Ti starai chiedendo cosa puoi imparare dai risultati. L'output degli esperimenti deve contenere cinque righe, una per ogni esecuzione della pipeline. Avrà un aspetto simile al seguente:

Sia il MAE che l'RMSE sono misure dell'errore medio di previsione del modello, quindi nella maggior parte dei casi è preferibile un valore inferiore per entrambe le metriche. In base all'output di Vertex AI Experiments, la nostra esecuzione più riuscita in entrambe le metriche è stata l'ultima, con un dropout_rate di 0,001, un learning_rate di 0,001 e un numero totale di epochs pari a 20. In base a questo esperimento, questi parametri del modello verranno utilizzati in produzione, in quanto garantiscono il miglior rendimento del modello.
Con questo, hai completato il lab.
🎉 Congratulazioni! 🎉
Hai imparato come utilizzare Vertex AI per:
- Addestra un modello Keras personalizzato per prevedere le valutazioni dei giocatori (ad es. regressione)
- Utilizzare l'SDK Kubeflow Pipelines per creare pipeline ML scalabili
- Crea ed esegui una pipeline di 5 passaggi che acquisisce i dati da GCS, li ridimensiona, addestra il modello, lo valuta e salva il modello risultante in GCS
- Sfrutta Vertex ML Metadata per salvare gli artefatti del modello, come modelli e metriche del modello
- Utilizza Vertex AI Experiments per confrontare i risultati delle varie esecuzioni della pipeline
Per saperne di più sulle diverse parti di Vertex, consulta la documentazione.
8. Esegui la pulizia
Per evitare addebiti, ti consigliamo di eliminare le risorse create durante questo lab.
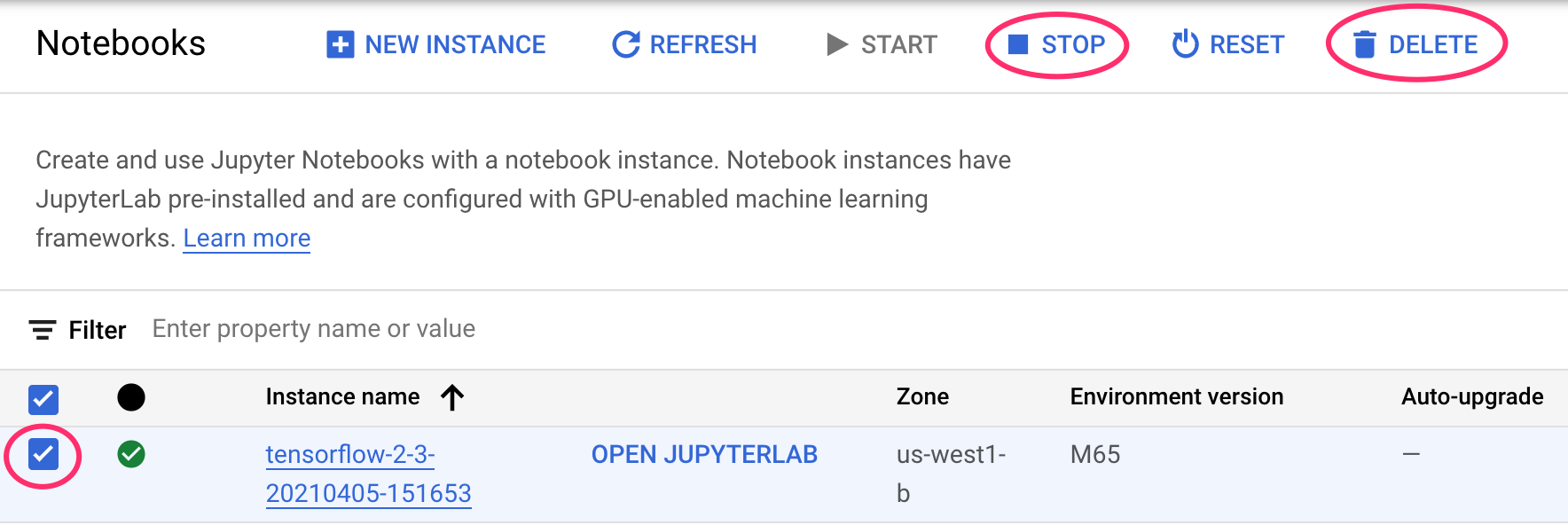
Passaggio 1: arresta o elimina l'istanza di Notebooks
Se vuoi continuare a utilizzare il blocco note creato in questo lab, ti consigliamo di disattivarlo quando non lo usi. Dall'interfaccia utente di Notebooks nella console Cloud, seleziona il blocco note, quindi seleziona Interrompi. Se vuoi eliminare completamente l'istanza, seleziona Elimina:
Passaggio 2: elimina il bucket Cloud Storage
Per eliminare il bucket di archiviazione, utilizza il menu di navigazione nella console Google Cloud, vai a Storage, seleziona il bucket e fai clic su Elimina:
