
1. Introduction
In this lab, you will learn how to use BigQuery Machine Learning for inference with remote models ( Gemini models) to analyze movie poster images and generate summaries of the movies based on the posters directly in your BigQuery data warehouse.

Pictured above: A sample of the movie poster images you will analyze.
BigQuery is a fully managed, AI-ready data analytics platform that helps you maximize value from your data and is designed to be multi-engine, multi-format, and multi-cloud. One of its key features is BigQuery Machine Learning for inference, which lets you create and run machine learning (ML) models by using GoogleSQL queries.
Gemini is a family of generative AI models developed by Google that is designed for multimodal use cases.
Running ML models using GoogleSQL Queries
Usually, performing ML or artificial intelligence (AI) on large datasets requires extensive programming and knowledge of ML frameworks. This limits solution development to a small group of specialists within each company. With BigQuery Machine Learning for inference, SQL practitioners can use existing SQL tools and skills to build models, and generate results from LLMs and Cloud AI APIs.
Prerequisites
- A basic understanding of the Google Cloud Console
- Experience with BigQuery is a plus
What you'll learn
- How to configure your environment and account to use APIs
- How to create a Cloud Resource connection in BigQuery
- How to create a dataset and object table in BigQuery for movie poster images
- How to create the Gemini remote models in BigQuery
- How to prompt the Gemini model to provide movie summaries for each poster
- How to generate text embeddings for the movie represented in each poster
- How to use BigQuery
VECTOR_SEARCHto match movie poster images with closely related movies in the dataset
What you'll need
- A Google Cloud Account and Google Cloud Project, with billing enabled
- A web browser such as Chrome
2. Setup and Requirements
Self-paced environment setup
- Sign-in to the Google Cloud Console and create a new project or reuse an existing one. If you don't already have a Gmail or Google Workspace account, you must create one.

- The Project name is the display name for this project's participants. It is a character string not used by Google APIs. You can always update it.
- The Project ID is unique across all Google Cloud projects and is immutable (cannot be changed after it has been set). The Cloud Console auto-generates a unique string; usually you don't care what it is. In most codelabs, you'll need to reference your Project ID (typically identified as
PROJECT_ID). If you don't like the generated ID, you might generate another random one. Alternatively, you can try your own, and see if it's available. It can't be changed after this step and remains for the duration of the project. - For your information, there is a third value, a Project Number, which some APIs use. Learn more about all three of these values in the documentation.
- Next, you'll need to enable billing in the Cloud Console to use Cloud resources/APIs. Running through this codelab won't cost much, if anything at all. To shut down resources to avoid incurring billing beyond this tutorial, you can delete the resources you created or delete the project. New Google Cloud users are eligible for the $300 USD Free Trial program.
Start Cloud Shell
While Google Cloud can be operated remotely from your laptop, in this codelab you will be using Google Cloud Shell, a command line environment running in the Cloud.
From the Google Cloud Console, click the Cloud Shell icon on the top right toolbar:

It should only take a few moments to provision and connect to the environment. When it is finished, you should see something like this:

This virtual machine is loaded with all the development tools you'll need. It offers a persistent 5GB home directory, and runs on Google Cloud, greatly enhancing network performance and authentication. All of your work in this codelab can be done within a browser. You do not need to install anything.
3. Before you begin
There are a few setup steps for working with Gemini models in BigQuery, including enabling APIs, creating a Cloud resource connection, and granting the service account for the Cloud resource connection certain permissions. These steps are one-time per project, and will be covered in the next few sections.
Enable APIs
Inside Cloud Shell, make sure that your project ID is setup:
gcloud config set project [YOUR-PROJECT-ID]
Set environment variable PROJECT_ID:
PROJECT_ID=$(gcloud config get-value project)
Configure your default region to use for the Vertex AI models. Read more about available locations for Vertex AI. In the example we are using the us-central1 region.
gcloud config set compute/region us-central1
Set environment variable REGION:
REGION=$(gcloud config get-value compute/region)
Enable all necessary services:
gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Expected output after running all above commands:
student@cloudshell:~ (test-project-001-402417)$ gcloud config set project test-project-001-402417
Updated property [core/project].
student@cloudshell:~ (test-project-001-402417)$ PROJECT_ID=$(gcloud config get-value project)
Your active configuration is: [cloudshell-14650]
student@cloudshell:~ (test-project-001-402417)$
student@cloudshell:~ (test-project-001-402417)$ gcloud services enable bigqueryconnection.googleapis.com \
aiplatform.googleapis.com
Operation "operations/acat.p2-4470404856-1f44ebd8-894e-4356-bea7-b84165a57442" finished successfully.
4. Create a Cloud Resource connection
In this task, you will create a Cloud Resource connection, which enables BigQuery to access image files in Cloud Storage and make calls to Vertex AI.
- In the Google Cloud Console, on the Navigation menu (
 ), click BigQuery.
), click BigQuery.
- To create a connection, click + ADD, and then click Connections to external data sources.
- In the Connection type list, select Vertex AI remote models, remote functions and BigLake (Cloud Resource).
- In the Connection ID field, enter gemini_conn for your connection.
- For Location type, select Multi-region and then, from dropdown select US multi-region.
- Use the defaults for the other settings.
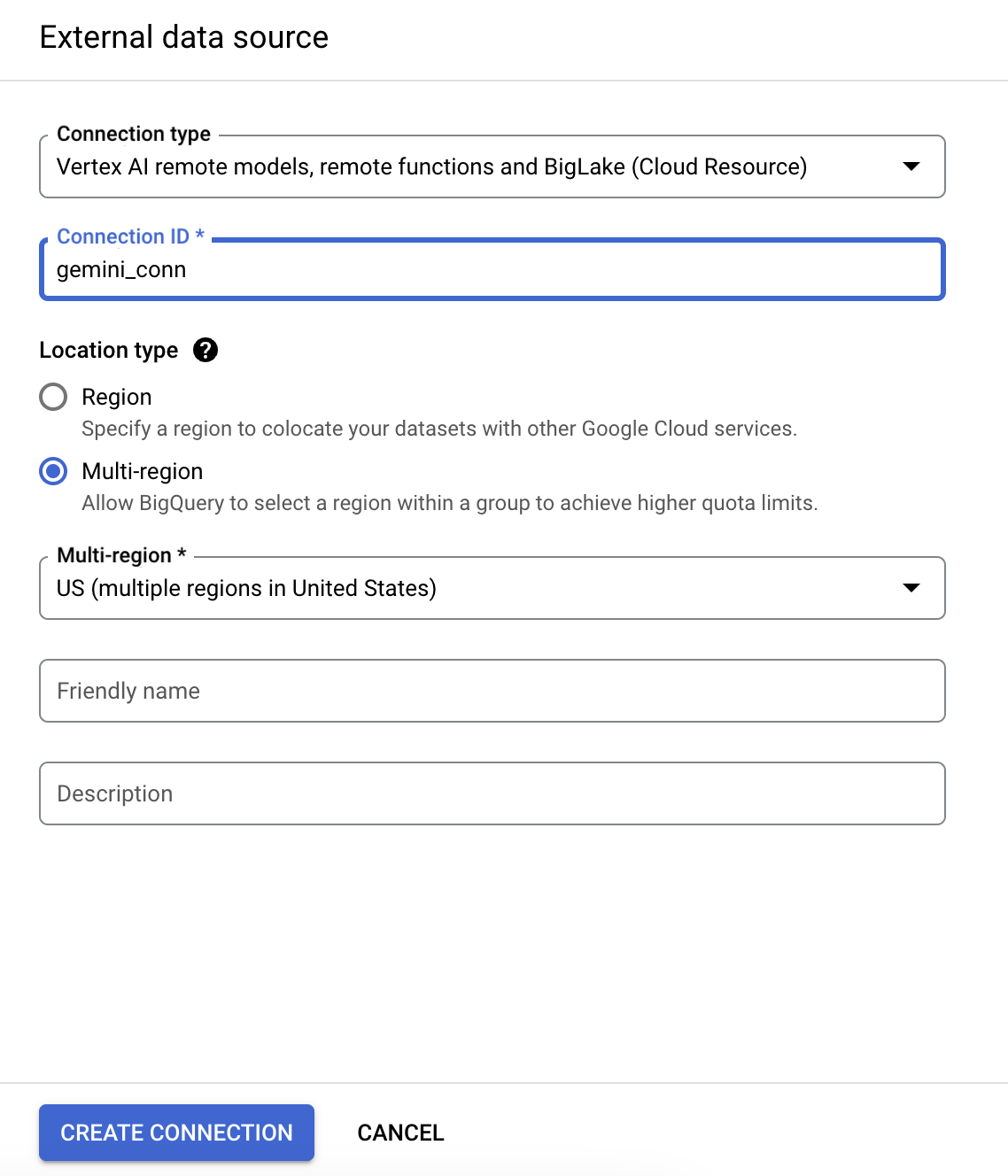
- Click Create connection.
- Click GO TO CONNECTION.
- In the Connection info pane, copy the service account ID to a text file for use in the next task. You will also see that the connection is added under the External Connections section of your project in the BigQuery Explorer.
5. Grant IAM permissions to the connection's service account
In this task, you grant the Cloud Resource connection's service account IAM permissions, through a role, to enable it access the Vertex AI services.
- In the Google Cloud console, on the Navigation menu, click IAM & Admin.
- Click Grant Access.
- In the New principals field, enter the service account ID that you copied earlier.
- In the Select a role field, enter Vertex AI, and then select Vertex AI User role.
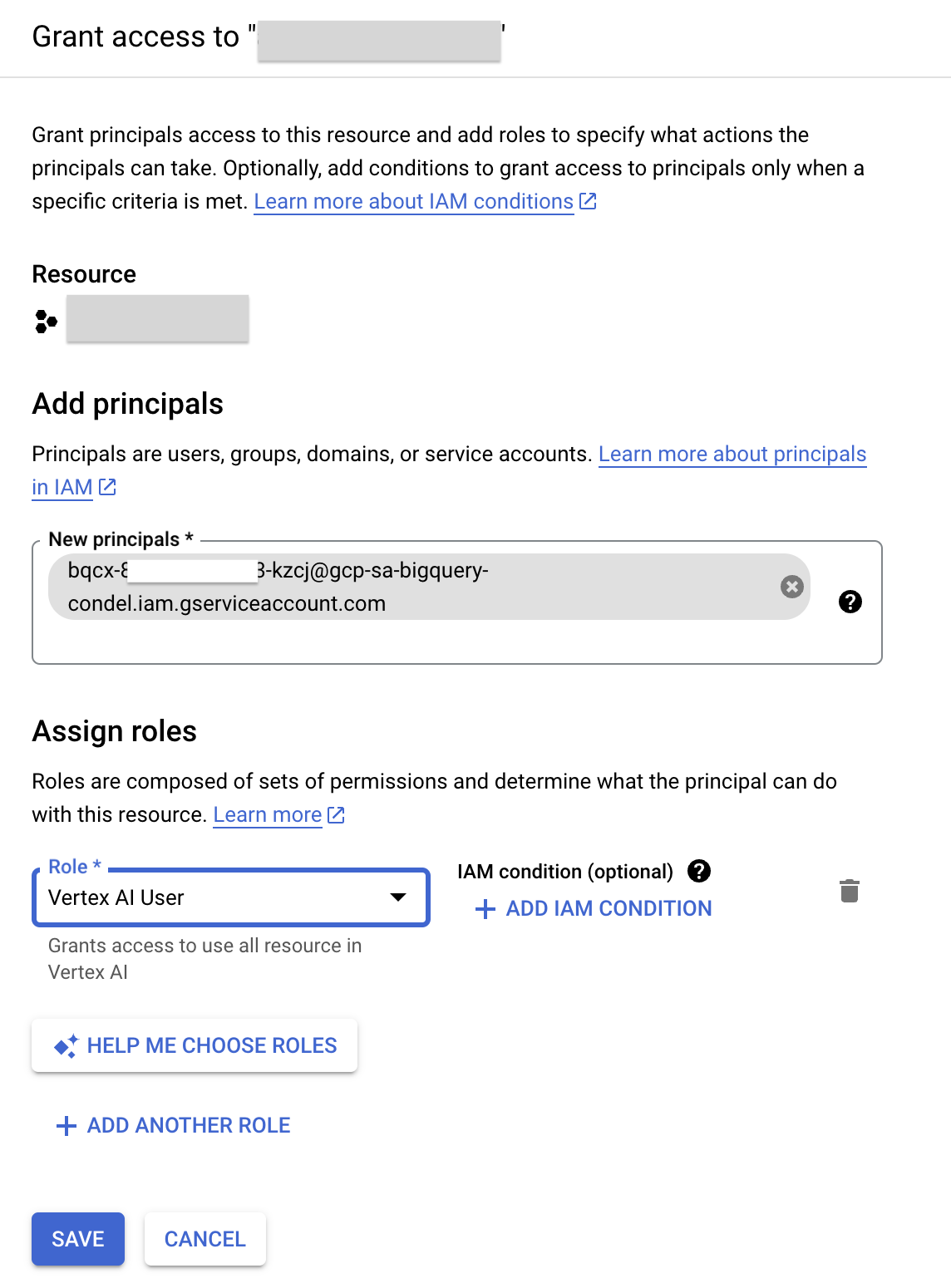
- Click Save. The result is the service account ID now includes the Vertex AI User role.
6. Create the dataset and object table in BigQuery for movie poster images
In this task, you will create a dataset for the project and an object table within it to store the poster images.
The dataset of movie poster images used in this tutorial are stored in a public Google Cloud Storage bucket: gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters
Create a dataset
You will create a dataset to store database objects, including tables and models, used in this tutorial.
- In the Google Cloud console, select the Navigation menu ( ), and then select BigQuery.
- In the Explorer panel, next to your project name, select View actions (
 ), and then select Create dataset.
), and then select Create dataset. - In the Create dataset pane, enter the following information:
- Dataset ID: gemini_demo
- Location type: select Multi-region
- Multi-region: select US
- Leave the other fields at their defaults.
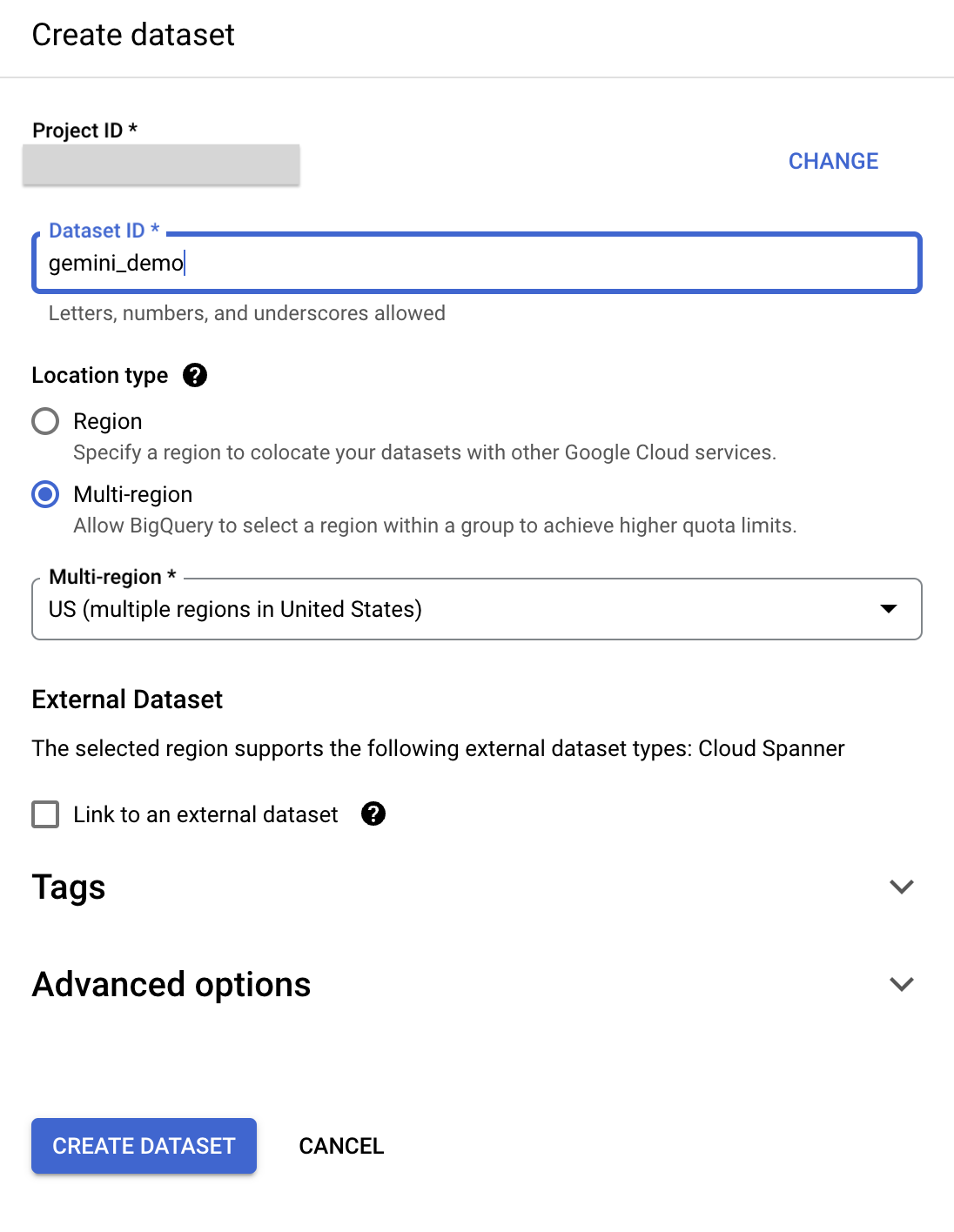
- Click Create Dataset.
The result is the gemini_demo dataset is created and listed underneath your project in the BigQuery Explorer.
Create the object table
BigQuery holds not only structured data, but it can also access unstructured data (like the poster images) through object tables.
You create an object table by pointing to a Cloud Storage bucket, and the resulting object table has a row for each object from the bucket with its storage path and metadata.
To create the object table you will use a SQL query.
- Click the + to Create new SQL query.
- In the query editor, paste the query below.
CREATE OR REPLACE EXTERNAL TABLE
`gemini_demo.movie_posters`
WITH CONNECTION `us.gemini_conn`
OPTIONS (
object_metadata = 'SIMPLE',
uris = ['gs://cloud-samples-data/vertex-ai/dataset-management/datasets/classic-movie-posters/*']
);
- Run the query. The result is a
movie_postersobject table added to thegemini_demodataset and loaded with theURI(the Cloud Storage location) of each movie poster image. - In the Explorer, click on the
movie_postersand review the schema and details. Feel free to query the table to review specific records.
7. Create the Gemini remote model in BigQuery
Now that the object table is created, you can begin to work with it. In this task, you will create a remote model for Gemini 1.5 Flash to make it available in BigQuery.
Create the Gemini 1.5 Flash remote model
- Click the + to Create new SQL query.
- In the query editor, paste the query below and run it.
CREATE OR REPLACE MODEL `gemini_demo.gemini_1_5_flash`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'gemini-1.5-flash')
The result is the gemini_1_5_flash model is created and you see it added to the gemini_demo dataset, in the models section.
- In the Explorer, click on the
gemini_1_5_flashmodel and review the details.
8. Prompt Gemini model to provide movie summaries for each poster
In this task, you will use the Gemini remote model you just created to analyze the movie poster images and generate summaries for each movie.
You can send requests to the model by using the ML.GENERATE_TEXT function, referencing the model in the parameters.
Analyze the images with Gemini 1.5 Flash model
- Create and run a new query with the following SQL statement:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results` AS (
SELECT
uri,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
TABLE `gemini_demo.movie_posters`,
STRUCT( 0.2 AS temperature,
'For the movie represented by this poster, what is the movie title and year of release? Answer in JSON format with two keys: title, year. title should be string, year should be integer. Do not use JSON decorators.' AS PROMPT,
TRUE AS FLATTEN_JSON_OUTPUT)));
When the query runs, BigQuery prompts the Gemini model for each row of the object table, combining the image with the specified static prompt. The result is the movie_posters_results table is created.
- Now let's view the results. Create and run a new query with the following SQL statement:
SELECT * FROM `gemini_demo.movie_posters_results`
The result is rows for each movie poster with the URI (the Cloud Storage location of the movie poster image) and a JSON result including the movie title and the year the movie was released from the Gemini 1.5 Flash model.
You can retrieve these results in a more human readable way by using the next query. This query uses SQL to pull out the movie title and release year from these responses into new columns.
- Create and run a new query with the following SQL statement:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_formatted` AS (
SELECT
uri,
JSON_VALUE(ml_generate_text_llm_result, "$.title") AS title,
JSON_VALUE(ml_generate_text_llm_result, "$.year") AS year
FROM
`gemini_demo.movie_posters_results` results )
The result is the movie_posters_result_formatted table is created.
- You can query the table with the query below, to see the rows created.
SELECT * FROM `gemini_demo.movie_posters_results_formatted`
Notice how the URI column results remain the same, but the JSON is now converted to the title and year columns for each row.
Prompt Gemini 1.5 Flash model to provide movie summaries
What if you wanted a bit more information about each of these movies, say a text summary of each of the movies? This content generation use case is perfect for an LLM model such as the Gemini 1.5 Flash model.
- You can use Gemini 1.5 Flash to provide movie summaries for each poster by running the query below:
SELECT
uri,
title,
year,
prompt,
ml_generate_text_llm_result
FROM
ML.GENERATE_TEXT( MODEL `gemini_demo.gemini_1_5_flash`,
(
SELECT
CONCAT('Provide a short summary of movie titled ',title, ' from the year ',year,'.') AS prompt,
uri,
title,
year
FROM
`gemini_demo.movie_posters_results_formatted`
LIMIT
20 ),
STRUCT(0.2 AS temperature,
TRUE AS FLATTEN_JSON_OUTPUT));
Notice the ml_generate_text_llm_result field of the results; this includes a short summary of the movie.
9. Generate text embeddings using a remote model
Now you can join the structured data you have built with other structured data in your warehouse. The IMDB public dataset available in BigQuery contains a rich amount of information about movies, including ratings by viewers and some sample freeform user reviews as well. This data can help you deepen your analysis of the movie posters and understand how these movies were perceived.
In order to join data, you will need a key. In this case, the movie titles generated by the Gemini model may not match perfectly to the titles in the IMDB dataset.
In this task, you will generate text embeddings of the movie titles and years from both datasets, and then use the distance between these embeddings to join the closest IMDB title with the movie poster titles from your newly created dataset.
Create the remote model
To generate the text embeddings, you will need to create a new remote model pointing to the text-multilingual-embedding-002 endpoint.
- Create and run a new query with the following SQL statement:
CREATE OR REPLACE MODEL `gemini_demo.text_embedding`
REMOTE WITH CONNECTION `us.gemini_conn`
OPTIONS (endpoint = 'text-multilingual-embedding-002')
The result is the text_embedding model is created and appears in the explorer underneath the gemini_demo dataset.
Generate text embeddings for the title and year associated with the posters
You will now use this remote model with the ML.GENERATE_EMBEDDING function to create an embedding for each movie poster title and year.
- Create and run a new query with the following SQL statement:
CREATE OR REPLACE TABLE
`gemini_demo.movie_posters_results_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING(
MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
uri
FROM
`gemini_demo.movie_posters_results_formatted` ),
STRUCT(TRUE AS flatten_json_output)));
The result is the movie_poster_results_embeddings table is created containing the embeddings for the text content concatenated for each row of the gemini_demo.movie_posters_results_formatted table.
- You can view the results of the query using the new query below:
SELECT * FROM `gemini_demo.movie_posters_results_embeddings`
Here you see the embeddings (vectors represented by numbers) for each movie generated by the model.
Generate text embeddings for a subset of the IMDB dataset
You will create a new view of data from a public IMDB dataset which contains only the movies that were released prior to 1935 (the known time period of the movies from the poster images).
- Create and run a new query with the following SQL statement:
CREATE OR REPLACE VIEW
`gemini_demo.imdb_movies` AS (
WITH
reviews AS (
SELECT
reviews.movie_id AS movie_id,
title.primary_title AS title,
title.start_year AS year,
reviews.review AS review
FROM
`bigquery-public-data.imdb.reviews` reviews
LEFT JOIN
`bigquery-public-data.imdb.title_basics` title
ON
reviews.movie_id = title.tconst)
SELECT
DISTINCT(movie_id),
title,
year
FROM
reviews
WHERE
year < 1935)
The result is a new view containing a list of distinct movie IDs, titles, and year of release from the bigquery-public-data.imdb.reviews table for all movies in the dataset released before 1935.
- You will now create embeddings for the subset of movies from IMDB using a similar process to the previous section. Create and run a new query with the following SQL statement:
CREATE OR REPLACE TABLE
`gemini_demo.imdb_movies_embeddings` AS (
SELECT
*
FROM
ML.GENERATE_EMBEDDING( MODEL `gemini_demo.text_embedding`,
(
SELECT
CONCAT('The movie titled ', title, ' from the year ', year,'.') AS content,
title,
year,
movie_id
FROM
`gemini_demo.imdb_movies` ),
STRUCT(TRUE AS flatten_json_output) )
WHERE
ml_generate_embedding_status = '' );
The result of the query is a table that contains the embeddings for the text content of the gemini_demo.imdb_movies table.
Match the movie poster images to IMDB movie_id using BigQuery VECTOR_SEARCH
Now, you can join the two tables using the VECTOR_SEARCH function.
- Create and run a new query with the following SQL statement:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE');
The query uses the VECTOR_SEARCH function to find the nearest neighbor in the gemini_demo.imdb_movies_embeddings table for each row in the gemini_demo.movie_posters_results_embeddings table. The nearest neighbor is found using the cosine distance metric, which determines how similar two embeddings are.
This query can be used to find the most similar movie in the IMDB dataset for each of the movies identified by Gemini 1.5 Flash in the movie posters. For example, you could use this query to find the closest match for the movie "Au Secours!" in the IMDB public dataset, which references this movie by its English-language title, "Help!".
- Create and run a new query to join some additional information on movie ratings provided in the IMDB public dataset:
SELECT
query.uri AS poster_uri,
query.title AS poster_title,
query.year AS poster_year,
base.title AS imdb_title,
base.year AS imdb_year,
base.movie_id AS imdb_movie_id,
distance,
imdb.average_rating,
imdb.num_votes
FROM
VECTOR_SEARCH( TABLE `gemini_demo.imdb_movies_embeddings`,
'ml_generate_embedding_result',
TABLE `gemini_demo.movie_posters_results_embeddings`,
'ml_generate_embedding_result',
top_k => 1,
distance_type => 'COSINE') DATA
LEFT JOIN
`bigquery-public-data.imdb.title_ratings` imdb
ON
base.movie_id = imdb.tconst
ORDER BY
imdb.average_rating DESC
This query is similar to the previous query. It still uses special numerical representations called vector embeddings to find similar movies to a given movie poster. However, it also joins the average rating and number of votes for each nearest neighbor movie from a separate table from the IMDB public dataset.
10. Congratulations
Congratulations for completing the codelab. You successfully created an object table for your poster images in BigQuery, created a remote Gemini model, used the model to prompt the Gemini model to analyze images and provided movie summaries, generated text embeddings for movie titles, and used those embeddings to match movie poster images to the related movie title in the IMDB dataset.
What we've covered
- How to configure your environment and account to use APIs
- How to create a Cloud Resource connection in BigQuery
- How to create a dataset and object table in BigQuery for movie poster images
- How to create the Gemini remote models in BigQuery
- How to prompt the Gemini model to provide movie summaries for each poster
- How to generate text embeddings for the movie represented in each poster
- How to use BigQuery
VECTOR_SEARCHto match movie poster images with closely related movies in the dataset
Next steps / learn more