
1. מבוא
ב-Codelab הזה, תשתמשו בכלי המעקב של Cloud Bigtable כדי ליצור יצירות אומנות שונות באמצעות כתיבה וקריאה של נתונים באמצעות Cloud Dataflow ולקוח Java HBase.
כאן מוסבר איך
- טעינת כמויות גדולות של נתונים ל-Bigtable באמצעות Cloud Dataflow
- מעקב אחר טבלאות ומופעים ב-Bigtable בזמן הטמעת הנתונים
- שליחת שאילתה ל-Bigtable באמצעות משימת Dataflow
- היכרות עם כלי הוויזואליזציה העיקרי שבו ניתן להשתמש כדי למצוא נקודות חמות בגלל עיצוב הסכימה
- יצירת אומנות באמצעות כלי הוויזואליזציה העיקרי

איזה דירוג מגיע לדעתך לחוויית השימוש ב-Cloud Bigtable?
איך תשתמשו במדריך הזה?
2. יצירת מסד נתונים ב-Bigtable
Cloud Bigtable הוא שירות מסד הנתונים NoSQL מסוג Big Data של Google. מדובר באותו מסד נתונים שעליה מבוססים שירותי הליבה רבים של Google, כולל חיפוש Google, Analytics, מפות Google ו-Gmail. הוא אידיאלי להרצת עומסי עבודה אנליטיים גדולים ולפיתוח אפליקציות עם זמן אחזור קצר. מומלץ לקרוא מבוא מפורט במאמר מבוא ל-Cloud Bigtable Codelab.
יצירת פרויקט
קודם כול, יוצרים פרויקט חדש. משתמשים ב-Cloud Shell המובנה, שפותחים בלחיצה על "Activate Cloud Shell". בפינה השמאלית העליונה.

כדי שיהיה קל יותר להעתיק ולהדביק את פקודות Codelab, מגדירים את משתני הסביבה הבאים:
BIGTABLE_PROJECT=$GOOGLE_CLOUD_PROJECT INSTANCE_ID="keyviz-art-instance" CLUSTER_ID="keyviz-art-cluster" TABLE_ID="art" CLUSTER_NUM_NODES=1 CLUSTER_ZONE="us-central1-c" # You can choose a zone closer to you
Cloud Shell מגיע עם הכלים שתשתמש בהם ב-Codelab הזה, כלי שורת הפקודה של gcloud, ממשק שורת הפקודה cbt, ו-Maven, שכבר מותקנים.
מריצים את הפקודה הזו כדי להפעיל את ממשקי Cloud Bigtable API.
gcloud services enable bigtable.googleapis.com bigtableadmin.googleapis.com
כדי ליצור מכונה, מריצים את הפקודה הבאה:
gcloud bigtable instances create $INSTANCE_ID \
--cluster=$CLUSTER_ID \
--cluster-zone=$CLUSTER_ZONE \
--cluster-num-nodes=$CLUSTER_NUM_NODES \
--display-name=$INSTANCE_ID
אחרי שיוצרים את המכונה, מריצים את הפקודות הבאות כדי לאכלס את קובץ התצורה cbt ואז ליצור משפחת טבלאות ועמודות:
echo project = $GOOGLE_CLOUD_PROJECT > ~/.cbtrc echo instance = $INSTANCE_ID >> ~/.cbtrc cbt createtable $TABLE_ID cbt createfamily $TABLE_ID cf
3. למידה: כתיבה ב-Bigtable באמצעות Dataflow
עקרונות בסיסיים בכתיבה
כשכותבים ב-Cloud Bigtable, צריך לספק אובייקט של הגדרת CloudBigtableTableConfiguration. האובייקט הזה מציין את מזהה הפרויקט ומזהה המכונה של הטבלה, וגם את שם הטבלה עצמה:
CloudBigtableTableConfiguration bigtableTableConfig =
new CloudBigtableTableConfiguration.Builder()
.withProjectId(PROJECT_ID)
.withInstanceId(INSTANCE_ID)
.withTableId(TABLE_ID)
.build();
לאחר מכן צינור עיבוד הנתונים יכול להעביר אובייקטים מסוג Mutation מסוג HBase, כולל Put ו-Delete.
p.apply(Create.of("hello", "world"))
.apply(
ParDo.of(
new DoFn<String, Mutation>() {
@ProcessElement
public void processElement(@Element String rowkey, OutputReceiver<Mutation> out) {
long timestamp = System.currentTimeMillis();
Put row = new Put(Bytes.toBytes(rowkey));
row.addColumn(...);
out.output(row);
}
}))
.apply(CloudBigtableIO.writeToTable(bigtableTableConfig));
המשימה של LoadData Dataflow
בדף הבא נסביר איך להריץ את המשימה LoadData, אבל כאן אספר על החלקים החשובים בצינור עיבוד הנתונים.
כדי ליצור נתונים, צריך ליצור צינור עיבוד נתונים שמשתמש במחלקה GenerateSequence (בדומה ללולאת for) כדי לכתוב מספר שורות עם כמה מגה-בייט של נתונים אקראיים. מקש השורה יהיה המספר הסידורי של הרצף ההפוך, כך שהערך של 250 הופך ל-0000000052.
LoadData.java
String numberFormat = "%0" + maxLength + "d";
p.apply(GenerateSequence.from(0).to(max))
.apply(
ParDo.of(
new DoFn<Long, Mutation>() {
@ProcessElement
public void processElement(@Element Long rowkey, OutputReceiver<Mutation> out) {
String paddedRowkey = String.format(numberFormat, rowkey);
// Reverse the rowkey for more efficient writing
String reversedRowkey = new StringBuilder(paddedRowkey).reverse().toString();
Put row = new Put(Bytes.toBytes(reversedRowkey));
// Generate random bytes
byte[] b = new byte[(int) rowSize];
new Random().nextBytes(b);
long timestamp = System.currentTimeMillis();
row.addColumn(Bytes.toBytes(COLUMN_FAMILY), Bytes.toBytes("C"), timestamp, b);
out.output(row);
}
}))
.apply(CloudBigtableIO.writeToTable(bigtableTableConfig));
4. יצירת נתונים ב-Bigtable ומעקב אחרי הזרימה
הפקודות הבאות יריצו משימה של זרימת נתונים שיוצרת 40GB של נתונים לטבלה שלכם, יותר מהכמות מספיקה כדי להפעיל את Key Visualizer:
הפעלת Cloud Dataflow API
gcloud services enable dataflow.googleapis.com
קבלת הקוד מ-github ושינוי שלו בספרייה
git clone https://github.com/GoogleCloudPlatform/java-docs-samples.git cd java-docs-samples/bigtable/beam/keyviz-art
יצירת הנתונים (הסקריפט נמשך כ-15 דקות)
mvn compile exec:java -Dexec.mainClass=keyviz.LoadData \ "-Dexec.args=--bigtableProjectId=$BIGTABLE_PROJECT \ --bigtableInstanceId=$INSTANCE_ID --runner=dataflow \ --bigtableTableId=$TABLE_ID --project=$GOOGLE_CLOUD_PROJECT"
מעקב אחר הייבוא
אפשר לעקוב אחרי המשימה בממשק המשתמש של Cloud Dataflow. אפשר גם לראות את העומס על המכונה של Cloud Bigtable באמצעות ממשק המשתמש למעקב.
בממשק המשתמש של Dataflow, תוכלו לראות את תרשים המשימות ואת מדדי המשימות השונים, כולל רכיבים שעובדו, יחידות vCPU נוכחיות ותפוקה.


ב-Bigtable יש כלי מעקב סטנדרטיים לפעולות קריאה וכתיבה, נפח אחסון בשימוש, שיעור שגיאות ועוד ברמת המכונה, האשכול והטבלה. בנוסף, ב-Bigtable יש גם את Key Visualizer, שמפרט את השימוש לפי מפתחות השורות שבהם נשתמש כשיצטברו נתונים של 30GB לפחות.

5. למידה: קריאה מ-Bigtable באמצעות Dataflow
מידע בסיסי על קריאה
כשקוראים מ-Cloud Bigtable, צריך לספק אובייקט של הגדרת CloudBigtableTableScanConfiguration. הפעולה הזו דומה לשורה CloudBigtableTableConfiguration, אבל אפשר להגדיר מהן השורות שצריך לסרוק ולקרוא.
Scan scan = new Scan();
scan.setCacheBlocks(false);
scan.setFilter(new FirstKeyOnlyFilter());
CloudBigtableScanConfiguration config =
new CloudBigtableScanConfiguration.Builder()
.withProjectId(options.getBigtableProjectId())
.withInstanceId(options.getBigtableInstanceId())
.withTableId(options.getBigtableTableId())
.withScan(scan)
.build();
לאחר מכן משתמשים בו כדי להתחיל את צינור עיבוד הנתונים:
p.apply(Read.from(CloudBigtableIO.read(config)))
.apply(...
עם זאת, אם רוצים לבצע קריאה כחלק מצינור עיבוד הנתונים, אפשר להעביר CloudBigtableTableConfiguration ל-doFn שמרחיבים את AbstractCloudBigtableTableDoFn.
p.apply(GenerateSequence.from(0).to(10))
.apply(ParDo.of(new ReadFromTableFn(bigtableTableConfig, options)));
לאחר מכן צריך לקרוא ל-super() עם ההגדרות האישיות ול-getConnection() כדי לקבל חיבור מבוזר.
public static class ReadFromTableFn extends AbstractCloudBigtableTableDoFn<Long, Void> {
public ReadFromTableFn(CloudBigtableConfiguration config, ReadDataOptions readDataOptions) {
super(config);
}
@ProcessElement
public void processElement(PipelineOptions po) {
Table table = getConnection().getTable(TableName.valueOf(options.getBigtableTableId()));
ResultScanner imageData = table.getScanner(scan);
}
}
המשימה של ReadData Dataflow
ב-Codelab הזה צריך לקרוא מהטבלה כל שנייה, כדי להתחיל את צינור עיבוד הנתונים עם רצף שנוצר שמפעיל מספר טווחי קריאה לפי השעה שבה הוזן קובץ CSV.
יש קצת מתמטיקה כדי לקבוע אילו טווחי שורות לסרוק לפי הזמן, אבל אתם יכולים ללחוץ על שם הקובץ כדי להציג את קוד המקור אם אתם רוצים לקבל מידע נוסף.
ReadData.java
p.apply(GenerateSequence.from(0).withRate(1, new Duration(1000)))
.apply(ParDo.of(new ReadFromTableFn(bigtableTableConfig, options)));
ReadData.java
public static class ReadFromTableFn extends AbstractCloudBigtableTableDoFn<Long, Void> {
List<List<Float>> imageData = new ArrayList<>();
String[] keys;
public ReadFromTableFn(CloudBigtableConfiguration config, ReadDataOptions readDataOptions) {
super(config);
keys = new String[Math.toIntExact(getNumRows(readDataOptions))];
downloadImageData(readDataOptions.getFilePath());
generateRowkeys(getNumRows(readDataOptions));
}
@ProcessElement
public void processElement(PipelineOptions po) {
// Determine which column will be drawn based on runtime of job.
long timestampDiff = System.currentTimeMillis() - START_TIME;
long minutes = (timestampDiff / 1000) / 60;
int timeOffsetIndex = Math.toIntExact(minutes / KEY_VIZ_WINDOW_MINUTES);
ReadDataOptions options = po.as(ReadDataOptions.class);
long count = 0;
List<RowRange> ranges = getRangesForTimeIndex(timeOffsetIndex, getNumRows(options));
if (ranges.size() == 0) {
return;
}
try {
// Scan with a filter that will only return the first key from each row. This filter is used
// to more efficiently perform row count operations.
Filter rangeFilters = new MultiRowRangeFilter(ranges);
FilterList firstKeyFilterWithRanges = new FilterList(
rangeFilters,
new FirstKeyOnlyFilter(),
new KeyOnlyFilter());
Scan scan =
new Scan()
.addFamily(Bytes.toBytes(COLUMN_FAMILY))
.setFilter(firstKeyFilterWithRanges);
Table table = getConnection().getTable(TableName.valueOf(options.getBigtableTableId()));
ResultScanner imageData = table.getScanner(scan);
} catch (Exception e) {
System.out.println("Error reading.");
e.printStackTrace();
}
}
/**
* Download the image data as a grid of weights and store them in a 2D array.
*/
private void downloadImageData(String artUrl) {
...
}
/**
* Generates an array with the rowkeys that were loaded into the specified Bigtable. This is
* used to create the correct intervals for scanning equal sections of rowkeys. Since Bigtable
* sorts keys lexicographically if we just used standard intervals, each section would have
* different sizes.
*/
private void generateRowkeys(long maxInput) {
...
}
/**
* Get the ranges to scan for the given time index.
*/
private List<RowRange> getRangesForTimeIndex(@Element Integer timeOffsetIndex, long maxInput) {
...
}
}
6. יצירת יצירת מופת

עכשיו, אחרי שהבנתם איך לטעון נתונים ב-Bigtable ולקרוא מהם באמצעות Dataflow, אתם יכולים להריץ את הפקודה הסופית שתיצור תמונה של המונה ליסה למשך יותר מ-8 שעות.
mvn compile exec:java -Dexec.mainClass=keyviz.ReadData \ "-Dexec.args=--bigtableProjectId=$BIGTABLE_PROJECT \ --bigtableInstanceId=$INSTANCE_ID --runner=dataflow \ --bigtableTableId=$TABLE_ID --project=$GOOGLE_CLOUD_PROJECT"
יש קטגוריה עם תמונות קיימות שאפשר להשתמש בה. באמצעות הכלי הזה תוכלו גם ליצור קובץ קלט מכל אחת מהתמונות שלכם, ואז להעלות אותם לקטגוריה ציבורית של GCS.
שמות הקבצים נוצרו מדוגמה אחת (gs://keyviz-art/[painting]_[hours]h.txt): gs://keyviz-art/american_gothic_4h.txt
אפשרויות ציור:
- american_gothic
- mona_lisa
- pearl_earring
- persistence_of_memory
- starry_night
- sunday_afternoon
- the_scream
אפשרויות של שעות: 1, 4, 8, 12, 24, 48, 72, 96, 120, 144
כדי להגדיר את הקטגוריה או הקובץ ב-GCS כציבוריים, מקצים ל-allUsers את התפקיד Storage Object Viewer.

לאחר בחירת התמונה, פשוט משנים את הפרמטר --file-path בפקודה הזו:
mvn compile exec:java -Dexec.mainClass=keyviz.ReadData \ "-Dexec.args=--bigtableProjectId=$BIGTABLE_PROJECT \ --bigtableInstanceId=$INSTANCE_ID --runner=dataflow \ --bigtableTableId=$TABLE_ID --project=$GOOGLE_CLOUD_PROJECT \ --filePath=gs://keyviz-art/american_gothic_4h.txt"
7. אבדוק זאת מאוחר יותר
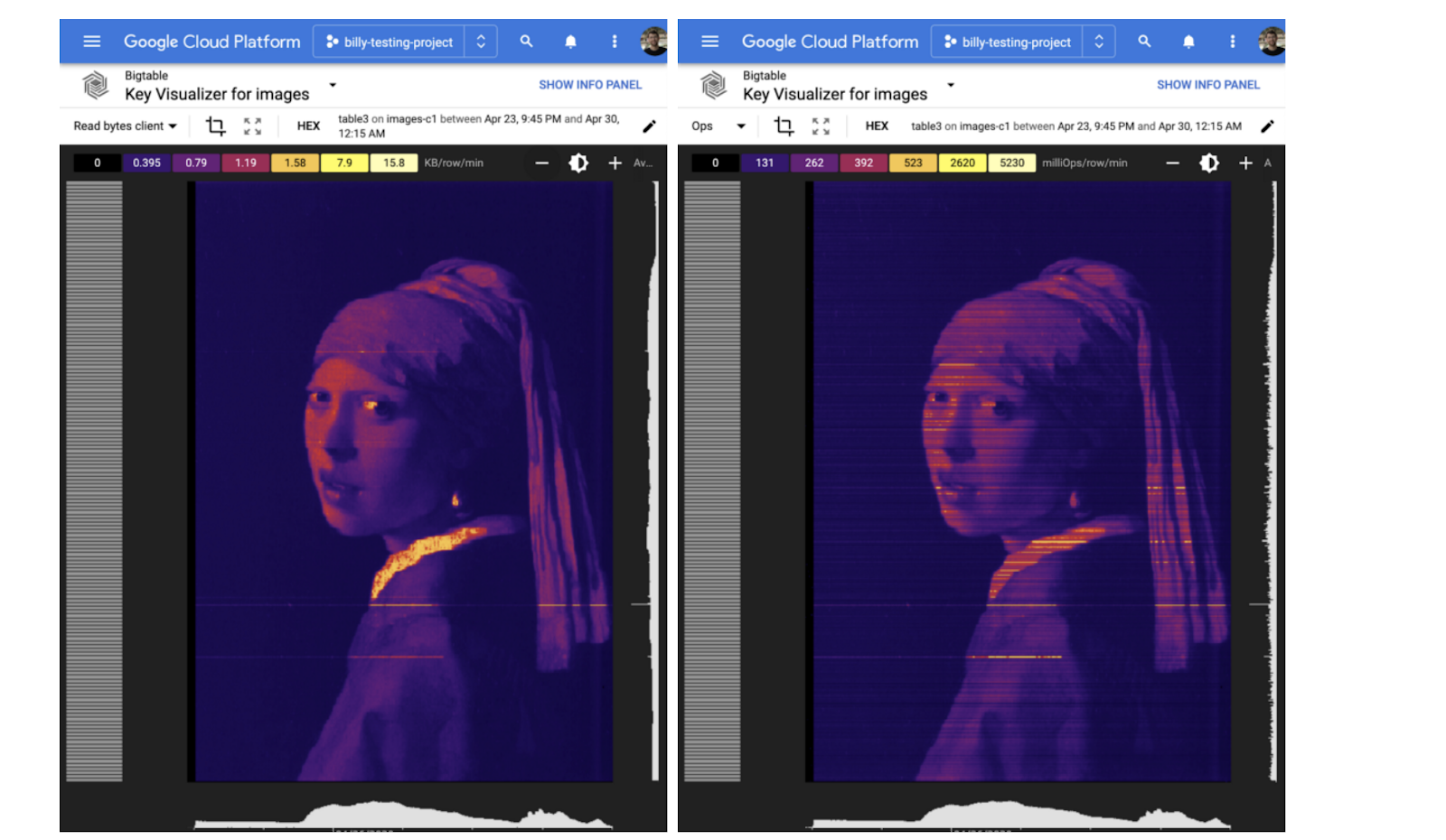
עשויות לחלוף כמה שעות עד שהתמונה המלאה תתעורר לחיים, אבל לאחר 30 דקות אתם אמורים לראות פעילות בכלי הוויזואליזציה של המפתח. יש כמה פרמטרים שאפשר לשחק איתם: שינוי מרחק התצוגה, בהירות ומדד. אפשר לשנות את מרחק התצוגה, להשתמש בגלגל הגלילה שבעכבר או לגרור מלבן ברשת של כלי הוויזואליזציה של המקשים.
הבהירות משנה את קנה המידה של התמונה, וכך היא שימושית אם אתם רוצים לבחון לעומק אזור חם מאוד.

אפשר גם לקבוע איזה מדד יוצג. יש גם גרסאות OP – לקוח Read bytes, כותב לקוח בייטים, "קריאת לקוח בייטים" יוצר תמונות חלקות בזמן ש-"Ops" יוצרת תמונות עם יותר קווים, שיכולות להיראות ממש מגניבות בחלק מהתמונות.
8. סיום
פינוי נפח אחסון כדי להימנע מחיובים
כדי להימנע מצבירת חיובים בחשבון Google Cloud Platform עבור המשאבים ששימשו ב-Codelab הזה, צריך למחוק את המכונה.
gcloud bigtable instances delete $INSTANCE_ID
אילו נושאים דיברנו?
- כתיבה ב-Bigtable באמצעות Dataflow
- קריאה מ-Bigtable באמצעות Dataflow (בתחילת צינור עיבוד הנתונים, באמצע צינור עיבוד הנתונים)
- שימוש בכלי המעקב של Dataflow
- שימוש בכלי המעקב של Bigtable, כולל Key Visualizer
השלבים הבאים
- אפשר לקרוא מידע נוסף על אופן היצירה של אומנות Key Visualizer.
- מידע נוסף על Cloud Bigtable זמין במסמכי התיעוד.
- התנסות בתכונות אחרות של Google Cloud Platform. כדאי לעיין במדריכים שלנו.