
1. مقدمة

Workflows هي خدمة تنسيق مُدارة بالكامل تنفّذ خدمات Google Cloud أو الخدمات الخارجية بالترتيب الذي تحدّده.
BigQuery هو مستودع مُدار بالكامل لبيانات المؤسسات يساعدك في إدارة وتحليل تيرابايت من البيانات باستخدام ميزات مدمجة مثل تعلُّم الآلة والتحليل المكاني الجغرافي وذكاء الأعمال.
في هذا الدرس العملي، ستنفّذ بعض طلبات البحث في BigQuery على مجموعة بيانات Wikipedia العامة. بعد ذلك، ستتعرّف على كيفية تنفيذ طلبات بحث متعدّدة في BigQuery واحدًا تلو الآخر بطريقة تسلسلية، كجزء من عملية تنسيق في Workflows. أخيرًا، ستنفّذ طلبات البحث بالتوازي باستخدام ميزة التكرار المتوازي في Workflows لتحسين السرعة بمقدار 5 أضعاف.
أهداف الدورة التعليمية
- كيفية تنفيذ طلبات بحث BigQuery على مجموعة بيانات Wikipedia
- كيفية تنفيذ طلبات بحث متعددة كجزء من عملية تنظيم مهام سير العمل بشكل تسلسلي
- كيفية موازاة طلبات البحث باستخدام التكرار المتوازي في Workflows لتحسين السرعة بمقدار 5 أضعاف
2. الإعداد والمتطلبات
إعداد البيئة بوتيرة ذاتية
- سجِّل الدخول إلى Google Cloud Console وأنشِئ مشروعًا جديدًا أو أعِد استخدام مشروع حالي. إذا لم يكن لديك حساب على Gmail أو Google Workspace، عليك إنشاء حساب.

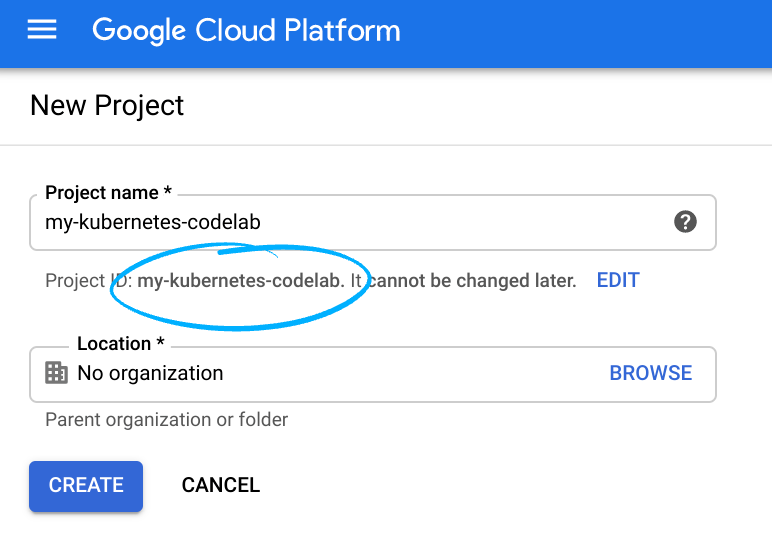
- اسم المشروع هو الاسم المعروض للمشاركين في هذا المشروع. وهي سلسلة أحرف لا تستخدمها Google APIs. ويمكنك تعديله في أي وقت.
- يجب أن يكون رقم تعريف المشروع فريدًا في جميع مشاريع Google Cloud، كما أنّه غير قابل للتغيير (لا يمكن تغييره بعد ضبطه). تنشئ Cloud Console تلقائيًا سلسلة فريدة، ولا يهمّك عادةً ما هي. في معظم دروس البرمجة، عليك الرجوع إلى رقم تعريف المشروع (يتم تحديده عادةً على أنّه
PROJECT_ID). إذا لم يعجبك رقم التعريف الذي تم إنشاؤه، يمكنك إنشاء رقم تعريف عشوائي آخر. يمكنك بدلاً من ذلك تجربة اسم مستخدم من اختيارك لمعرفة ما إذا كان متاحًا. لا يمكن تغيير هذا الخيار بعد هذه الخطوة وسيظل ساريًا طوال مدة المشروع. - للعلم، هناك قيمة ثالثة، وهي رقم المشروع الذي تستخدمه بعض واجهات برمجة التطبيقات. يمكنك الاطّلاع على مزيد من المعلومات عن كل هذه القيم الثلاث في المستندات.
- بعد ذلك، عليك تفعيل الفوترة في Cloud Console لاستخدام موارد/واجهات برمجة تطبيقات Cloud. لن تكلفك تجربة هذا الدرس التطبيقي حول الترميز الكثير من المال، إن لم تكلفك شيئًا على الإطلاق. لإيقاف الموارد كي لا يتم تحصيل رسوم منك بعد هذا البرنامج التعليمي، يمكنك حذف الموارد التي أنشأتها أو حذف المشروع بأكمله. يمكن لمستخدمي Google Cloud الجدد الاستفادة من برنامج الفترة التجريبية المجانية بقيمة 300 دولار أمريكي.
بدء Cloud Shell
على الرغم من إمكانية تشغيل Google Cloud عن بُعد من الكمبيوتر المحمول، ستستخدم في هذا الدرس العملي Google Cloud Shell، وهي بيئة سطر أوامر تعمل في السحابة الإلكترونية.
من Google Cloud Console، انقر على رمز Cloud Shell في شريط الأدوات أعلى يسار الصفحة:

لن يستغرق توفير البيئة والاتصال بها سوى بضع لحظات. عند الانتهاء، من المفترض أن يظهر لك ما يلي:

يتم تحميل هذه الآلة الافتراضية مزوّدة بكل أدوات التطوير التي ستحتاج إليها. توفّر هذه الخدمة دليلًا منزليًا ثابتًا بسعة 5 غيغابايت، وتعمل على Google Cloud، ما يؤدي إلى تحسين أداء الشبكة والمصادقة بشكل كبير. يمكن إكمال جميع المهام في هذا الدرس العملي ضمن المتصفّح. لست بحاجة إلى تثبيت أي تطبيق.
3- استكشاف مجموعة بيانات Wikipedia
في البداية، استكشِف مجموعة بيانات Wikipedia في BigQuery.
انتقِل إلى قسم BigQuery في "وحدة تحكّم Google Cloud":
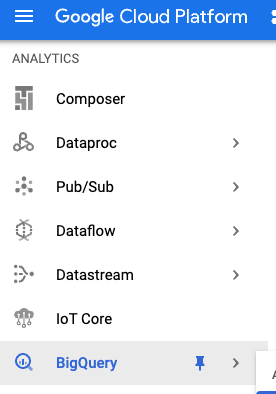
ضمن bigquery-samples، من المفترض أن تظهر لك مجموعات بيانات عامة مختلفة، بما في ذلك بعض مجموعات البيانات ذات الصلة بموقع Wikipedia:
ضمن مجموعة بيانات wikipedia_pageviews، يمكنك الاطّلاع على جداول مختلفة لعدد مشاهدات الصفحة من سنوات مختلفة:
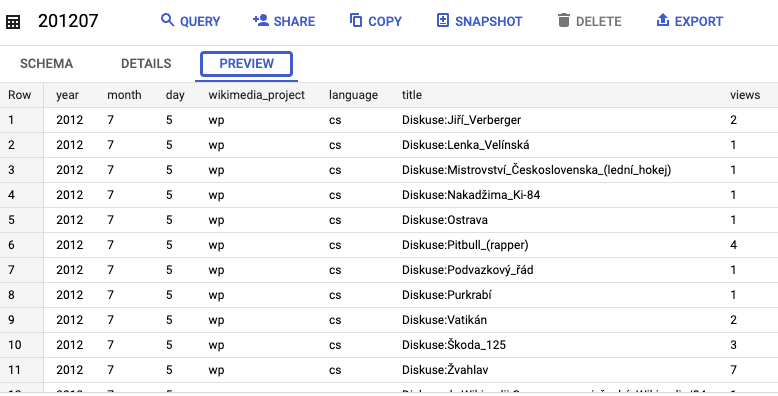
يمكنك اختيار أحد الجداول (مثل 201207) ومعاينة البيانات:
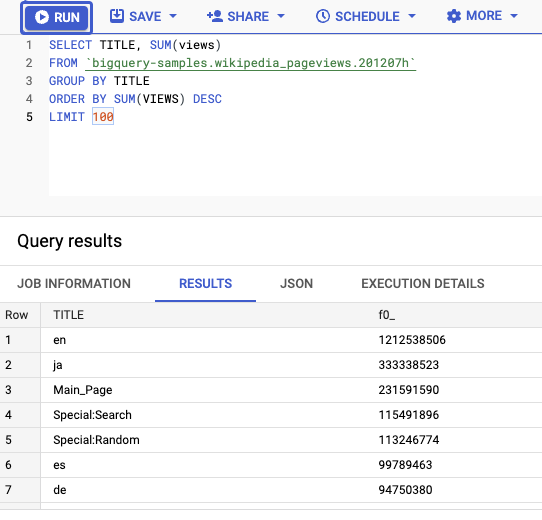
يمكنك أيضًا تنفيذ طلبات بحث في الجدول. على سبيل المثال، يختار هذا الطلب أهم 100 عنوان مع أكبر عدد من المشاهدات:
SELECT TITLE, SUM(views) FROM bigquery-samples.wikipedia_pageviews.201207h GROUP BY TITLE ORDER BY SUM(VIEWS) DESC LIMIT 100
بعد تنفيذ طلب البحث، يستغرق تحميل البيانات حوالي 20 ثانية:
4. تحديد سير عمل لتنفيذ طلبات بحث متعددة
من السهل تنفيذ طلب بحث في جدول واحد. ومع ذلك، قد يصبح تنفيذ طلبات بحث متعددة في جداول متعددة وتجميع النتائج أمرًا شاقًا. للمساعدة في ذلك، يمكن أن تساعدك "سير العمل" في استخدام صيغة التكرار.
داخل Cloud Shell، أنشئ ملف workflow-serial.yaml لإنشاء سير عمل لتشغيل طلبات بحث متعددة مقابل جداول متعددة:
touch workflow-serial.yaml
يمكنك بعد ذلك تعديل الملف باستخدام المحرِّر في Cloud Shell:

داخل ملف workflow-serial.yaml، في الخطوة الأولى init، أنشئ خريطة results لتتبُّع كل تكرار مفتاح حسب أسماء الجداول. حدِّد أيضًا مصفوفة tables تتضمّن قائمة بالجداول التي تريد تنفيذ طلبات البحث عليها. في هذه الحالة، نختار 5 جداول:
main:
steps:
- init:
assign:
- results : {}
- tables:
- 201201h
- 201202h
- 201203h
- 201204h
- 201205h
بعد ذلك، حدِّد خطوة runQueries. تكرّر هذه الخطوة كل جدول وتستخدم أداة ربط BigQuery في Workflows لتنفيذ طلب بحث للعثور على أفضل 100 عنوان مع أكبر عدد من مشاهدات الصفحة في كل جدول. بعد ذلك، يتم حفظ العنوان وعدد المشاهدات الأعلى من كل جدول في خريطة النتائج:
- runQueries:
for:
value: table
in: ${tables}
steps:
- runQuery:
call: googleapis.bigquery.v2.jobs.query
args:
projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
body:
useLegacySql: false
useQueryCache: false
timeoutMs: 30000
# Find the top 100 titles with most views on Wikipedia
query: ${
"SELECT TITLE, SUM(views)
FROM `bigquery-samples.wikipedia_pageviews." + table + "`
WHERE LENGTH(TITLE) > 10
GROUP BY TITLE
ORDER BY SUM(VIEWS) DESC
LIMIT 100"
}
result: queryResult
- returnResult:
assign:
# Return the top title from each table
- results[table]: {}
- results[table].title: ${queryResult.rows[0].f[0].v}
- results[table].views: ${queryResult.rows[0].f[1].v}
في الخطوة الأخيرة، أعِد خريطة results:
- returnResults:
return: ${results}
5- تنفيذ طلبات بحث متعددة باستخدام Workflows
قبل أن تتمكّن من نشر سير العمل وتشغيله، عليك التأكّد من تفعيل Workflows API. يمكنك تفعيلها من Google Cloud Console أو باستخدام gcloud في Cloud Shell:
gcloud services enable workflows.googleapis.com
إنشاء حساب خدمة لـ "مهام سير العمل":
SERVICE_ACCOUNT=workflows-bigquery-sa gcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name="Workflows BigQuery service account"
تأكَّد من أنّ حساب الخدمة لديه الأدوار اللازمة لتسجيل وظائف BigQuery وتشغيلها:
PROJECT_ID=your-project-id gcloud projects add-iam-policy-binding $PROJECT_ID \ --role roles/logging.logWriter \ --role roles/bigquery.jobUser \ --member serviceAccount:$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
نفِّذ سير العمل باستخدام حساب الخدمة:
gcloud workflows deploy bigquery-serial \
--source=workflow-serial.yaml \
--service-account=$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
أخيرًا، ستكون جاهزًا لتشغيل سير العمل.
ابحث عن سير عمل bigquery-serial ضمن قسم "سير العمل" في Cloud Console وانقر على الزر Execute:
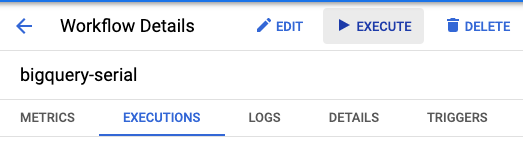
بدلاً من ذلك، يمكنك أيضًا تشغيل سير العمل باستخدام gcloud في Cloud Shell:
gcloud workflows run bigquery-serial
من المفترض أن يستغرق تنفيذ سير العمل دقيقة واحدة تقريبًا (20 ثانية لكل جدول من الجداول الخمسة).
في النهاية، ستظهر لك النتائج من كل جدول مع أهم العناوين وعدد المشاهدات:
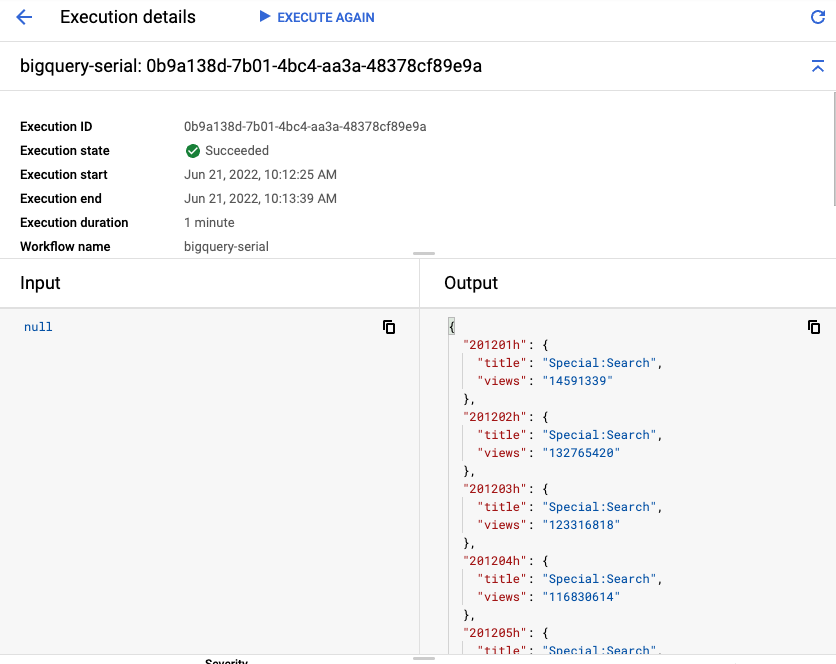
6. موازاة طلبات بحث متعددة باستخدام خطوات متوازية
استغرقت سير العمل في الخطوة السابقة حوالي دقيقة واحدة لأنّها نفّذت 5 طلبات بحث استغرقت 20 ثانية لكل منها. بما أنّ هذه الاستعلامات مستقلة، يمكنك تنفيذها بالتوازي باستخدام ميزة التكرار المتوازي في Workflows.
انسخ ملف workflow-serial.yaml إلى ملف workflow-parallel.yaml جديد. في الملف الجديد، ستجري بعض التغييرات لتحويل الخطوات التسلسلية إلى خطوات متوازية.
في ملف workflow-parallel.yaml، غيِّر الخطوة runQueries. أولاً، أضِف الكلمة الرئيسية parallel. يتيح ذلك تشغيل كل تكرار من حلقة for بشكل متوازٍ. ثانيًا، عرِّف المتغيّر results كمتغيّر shared. يسمح ذلك للفرع بكتابة المتغيّر. سنضيف كل نتيجة إلى هذا المتغيّر.
- runQueries:
parallel:
shared: [results]
for:
value: table
in: ${tables}
نشر سير العمل المتوازي:
gcloud workflows deploy bigquery-parallel \
--source=workflow-parallel.yaml \
--service-account=$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
تشغيل سير العمل:
gcloud workflows run bigquery-parallel
من المفترض أن ترى تنفيذ سير العمل يستغرق حوالي 20 ثانية. ويرجع ذلك إلى تنفيذ جميع طلبات البحث الخمسة بشكلٍ متزامن. تحسين السرعة بمقدار 5 أضعاف من خلال تغيير بضعة أسطر فقط من الرموز البرمجية
في النهاية، ستظهر لك النتيجة نفسها من كل جدول مع أهم العناوين وعدد المشاهدات، ولكن مع وقت تنفيذ أقصر بكثير:
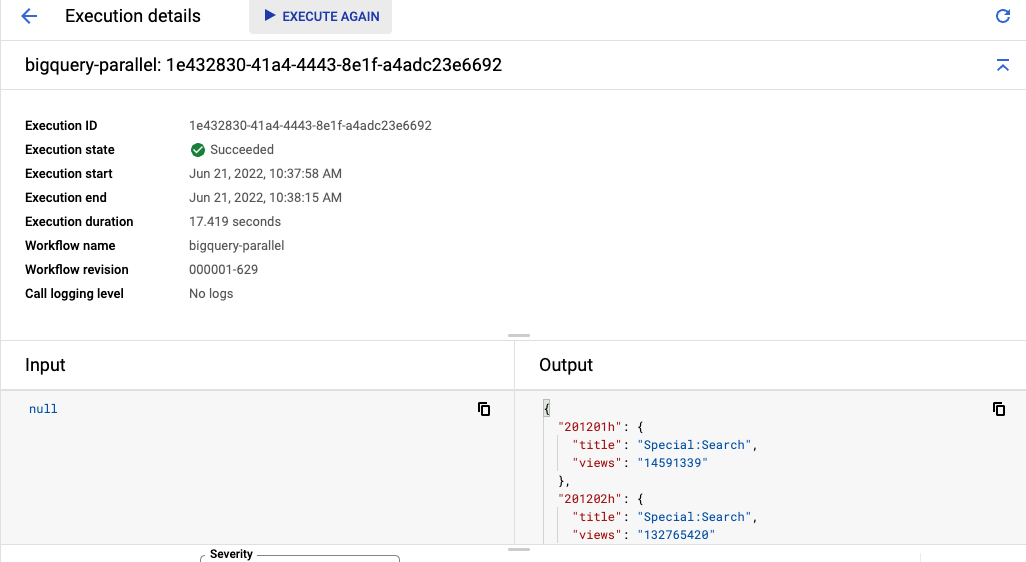
7. تهانينا
تهانينا، لقد أكملت درس البرمجة. لمزيد من المعلومات، يُرجى الاطّلاع على مستندات "سير العمل" حول الخطوات المتوازية.
المواضيع التي تناولناها
- كيفية تنفيذ طلبات بحث BigQuery على مجموعة بيانات Wikipedia
- كيفية تنفيذ طلبات بحث متعددة كجزء من عملية تنظيم مهام سير العمل بشكل تسلسلي
- كيفية موازاة طلبات البحث باستخدام التكرار المتوازي في Workflows لتحسين السرعة بمقدار 5 أضعاف كحد أقصى