
۱. مقدمه

گردشهای کاری یک سرویس هماهنگسازی کاملاً مدیریتشده است که گوگل کلود یا سرویسهای خارجی را به ترتیبی که شما تعریف میکنید، اجرا میکند.
بیگکوئری (BigQuery) یک انبار داده سازمانی کاملاً مدیریتشده است که به شما کمک میکند ترابایتها داده را با ویژگیهای داخلی مانند یادگیری ماشین، تحلیل مکانی و هوش تجاری مدیریت و تجزیه و تحلیل کنید.
در این آزمایشگاه کد، شما تعدادی کوئری BigQuery را روی مجموعه دادههای عمومی ویکیپدیا اجرا خواهید کرد. سپس خواهید دید که چگونه میتوان چندین کوئری BigQuery را یکی پس از دیگری به صورت سریالی، به عنوان بخشی از هماهنگی Workflows، اجرا کرد. در نهایت، با استفاده از ویژگی تکرار موازی Workflows، کوئریها را موازیسازی خواهید کرد تا سرعت تا 5 برابر بهبود یابد.
آنچه یاد خواهید گرفت
- نحوه اجرای کوئریهای BigQuery روی مجموعه دادههای ویکیپدیا.
- نحوه اجرای چندین کوئری به عنوان بخشی از هماهنگی گردشهای کاری به صورت سریالی.
- نحوه موازیسازی کوئریها با استفاده از تکرار موازی گردشهای کاری برای بهبود سرعت تا ۵ برابر.
۲. تنظیمات و الزامات
تنظیم محیط خودتنظیم
- وارد کنسول گوگل کلود شوید و یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید. اگر از قبل حساب جیمیل یا گوگل ورک اسپیس ندارید، باید یکی ایجاد کنید .

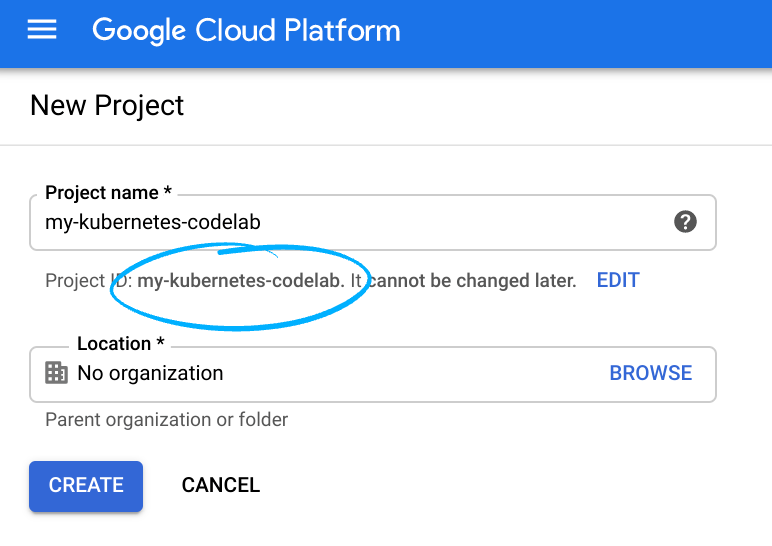
- نام پروژه ، نام نمایشی برای شرکتکنندگان این پروژه است. این یک رشته کاراکتری است که توسط APIهای گوگل استفاده نمیشود. میتوانید آن را در هر زمانی بهروزرسانی کنید.
- شناسه پروژه باید در تمام پروژههای گوگل کلود منحصر به فرد باشد و تغییرناپذیر است (پس از تنظیم، قابل تغییر نیست). کنسول کلود به طور خودکار یک رشته منحصر به فرد تولید میکند؛ معمولاً برای شما مهم نیست که چیست. در اکثر آزمایشگاههای کد، باید شناسه پروژه را ارجاع دهید (که معمولاً با عنوان
PROJECT_IDشناخته میشود). اگر شناسه تولید شده را دوست ندارید، میتوانید یک شناسه تصادفی دیگر ایجاد کنید. به عنوان یک جایگزین، میتوانید شناسه خودتان را امتحان کنید و ببینید که آیا در دسترس است یا خیر. پس از این مرحله قابل تغییر نیست و در طول پروژه باقی خواهد ماند. - برای اطلاع شما، یک مقدار سوم هم وجود دارد، شماره پروژه که برخی از APIها از آن استفاده میکنند. برای کسب اطلاعات بیشتر در مورد هر سه این مقادیر، به مستندات مراجعه کنید.
- در مرحله بعد، برای استفاده از منابع/API های ابری، باید پرداخت صورتحساب را در کنسول ابری فعال کنید . اجرای این آزمایشگاه کد، اگر اصلاً هزینهای نداشته باشد، هزینه زیادی نخواهد داشت. برای خاموش کردن منابع به طوری که پس از این آموزش متحمل پرداخت صورتحساب نشوید، میتوانید منابعی را که ایجاد کردهاید یا کل پروژه را حذف کنید. کاربران جدید Google Cloud واجد شرایط برنامه آزمایشی رایگان ۳۰۰ دلاری هستند.
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:

آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
۳. مجموعه دادههای ویکیپدیا را بررسی کنید
ابتدا، مجموعه دادههای ویکیپدیا را در BigQuery بررسی کنید.
به بخش BigQuery در کنسول ابری گوگل بروید:
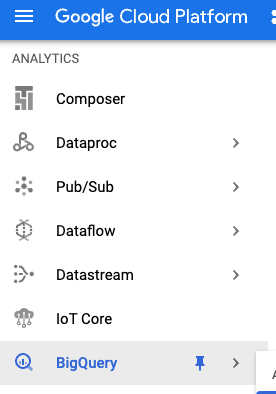
در زیر bigquery-samples ، باید مجموعه دادههای عمومی مختلفی، از جمله برخی از مجموعه دادههای مرتبط با ویکیپدیا را ببینید:
در زیر مجموعه داده wikipedia_pageviews ، میتوانید جداول مختلفی برای تعداد بازدید صفحات از سالهای مختلف مشاهده کنید:
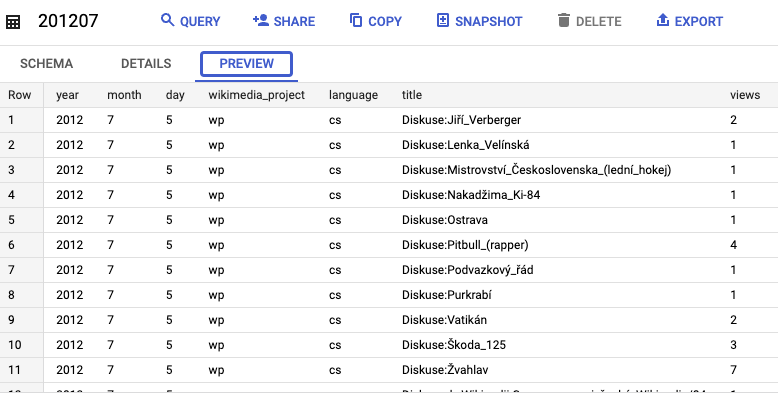
میتوانید یکی از جداول (مثلاً 201207 ) را انتخاب کنید و دادهها را پیشنمایش دهید:
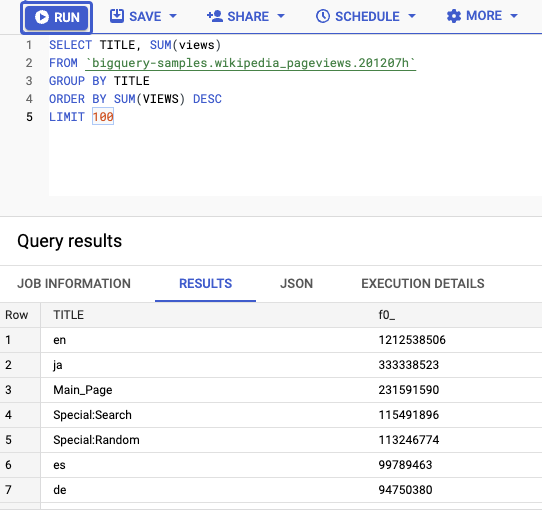
همچنین میتوانید کوئریهایی را روی جدول اجرا کنید. برای مثال، این کوئری ۱۰۰ عنوان برتر با بیشترین بازدید را انتخاب میکند:
SELECT TITLE, SUM(views) FROM bigquery-samples.wikipedia_pageviews.201207h GROUP BY TITLE ORDER BY SUM(VIEWS) DESC LIMIT 100
پس از اجرای کوئری، بارگذاری دادهها حدود ۲۰ ثانیه طول میکشد:
۴. تعریف یک گردش کار برای اجرای چندین پرسوجو
اجرای یک پرسوجو روی یک جدول واحد آسان است. با این حال، اجرای چندین پرسوجو روی چندین جدول و مقایسه نتایج میتواند بسیار خستهکننده باشد. برای کمک به این امر، Workflows میتواند با سینتکس تکرار خود به شما کمک کند!
درون پوسته ابری، یک فایل workflow-serial.yaml ایجاد کنید تا یک workflow برای اجرای چندین query روی چندین جدول ایجاد شود:
touch workflow-serial.yaml
سپس میتوانید فایل را با ویرایشگر موجود در Cloud Shell ویرایش کنید:

درون فایل workflow-serial.yaml ، در اولین مرحله init ، یک نقشه results ایجاد کنید تا هر تکرار را که با نام جداول کلیدگذاری شده است، پیگیری کند. همچنین یک آرایه tables با لیست جداولی که میخواهید پرسوجوها را روی آنها اجرا کنید، تعریف کنید. در این مورد، ما 5 جدول را انتخاب میکنیم:
main:
steps:
- init:
assign:
- results : {}
- tables:
- 201201h
- 201202h
- 201203h
- 201204h
- 201205h
در مرحله بعد، یک مرحله runQueries تعریف کنید. این مرحله روی هر جدول تکرار میشود و از رابط BigQuery در Workflows برای اجرای یک پرسوجو جهت یافتن ۱۰۰ عنوان برتر با بیشترین بازدید صفحه در هر جدول استفاده میکند. سپس عنوان و بازدیدهای برتر از هر جدول را در نقشه نتایج ذخیره میکند:
- runQueries:
for:
value: table
in: ${tables}
steps:
- runQuery:
call: googleapis.bigquery.v2.jobs.query
args:
projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
body:
useLegacySql: false
useQueryCache: false
timeoutMs: 30000
# Find the top 100 titles with most views on Wikipedia
query: ${
"SELECT TITLE, SUM(views)
FROM `bigquery-samples.wikipedia_pageviews." + table + "`
WHERE LENGTH(TITLE) > 10
GROUP BY TITLE
ORDER BY SUM(VIEWS) DESC
LIMIT 100"
}
result: queryResult
- returnResult:
assign:
# Return the top title from each table
- results[table]: {}
- results[table].title: ${queryResult.rows[0].f[0].v}
- results[table].views: ${queryResult.rows[0].f[1].v}
در مرحله آخر، نقشه results را برگردانید:
- returnResults:
return: ${results}
۵. اجرای چندین کوئری با Workflowها
قبل از اینکه بتوانید گردش کار را مستقر و اجرا کنید، باید مطمئن شوید که API گردش کار فعال است. میتوانید آن را از کنسول ابری گوگل یا با استفاده از gcloud در Cloud Shell فعال کنید:
gcloud services enable workflows.googleapis.com
یک حساب کاربری سرویس برای Workflows ایجاد کنید:
SERVICE_ACCOUNT=workflows-bigquery-sa gcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name="Workflows BigQuery service account"
مطمئن شوید که حساب کاربری سرویس، نقشهای لازم برای ثبت و اجرای کارهای BigQuery را دارد:
PROJECT_ID=your-project-id gcloud projects add-iam-policy-binding $PROJECT_ID \ --role roles/logging.logWriter \ --role roles/bigquery.jobUser \ --member serviceAccount:$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
گردش کار را با حساب سرویس مستقر کنید:
gcloud workflows deploy bigquery-serial \
--source=workflow-serial.yaml \
--service-account=$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
در نهایت، شما آماده اجرای گردش کار هستید.
گردش کار bigquery-serial را در بخش Workflows کنسول ابری پیدا کنید و دکمه Execute بزنید:
همچنین میتوانید گردش کار را با gcloud در Cloud Shell اجرا کنید:
gcloud workflows run bigquery-serial
باید ببینید که اجرای گردش کار حدود ۱ دقیقه طول میکشد (۲۰ ثانیه برای هر یک از ۵ جدول).
در نهایت، خروجی هر جدول را به همراه عناوین و نماهای برتر مشاهده خواهید کرد:
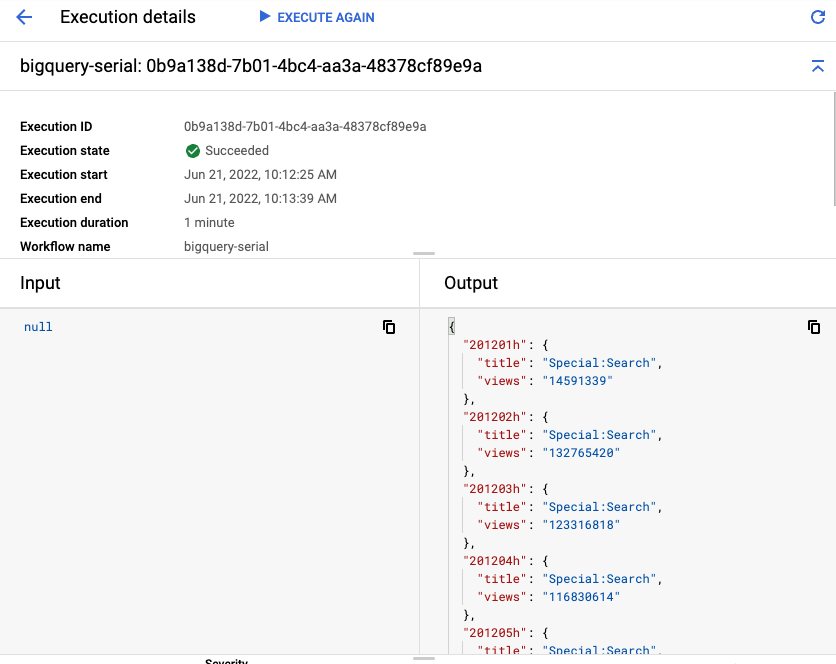
۶. چندین کوئری را با مراحل موازی موازی کنید
گردش کار در مرحله قبل حدود ۱ دقیقه طول کشید زیرا ۵ پرسوجو را اجرا کرد که هر کدام ۲۰ ثانیه طول میکشید. از آنجایی که اینها پرسوجوهای مستقلی هستند، میتوانید آنها را به صورت موازی با استفاده از ویژگی تکرار موازی Workflows اجرا کنید.
فایل workflow-serial.yaml را در یک فایل جدید workflow-parallel.yaml کپی کنید. در فایل جدید، چند تغییر ایجاد خواهید کرد تا مراحل سریالی به مراحل موازی تبدیل شوند.
در فایل workflow-parallel.yaml ، مرحله runQueries را تغییر دهید. ابتدا، کلمه کلیدی parallel را اضافه کنید. این کار به هر تکرار حلقه for اجازه میدهد تا به صورت موازی اجرا شود. دوم، متغیر results را به عنوان یک متغیر shared تعریف کنید. این کار به متغیر اجازه میدهد تا توسط یک شاخه قابل نوشتن باشد. ما هر نتیجه را به این متغیر اضافه خواهیم کرد.
- runQueries:
parallel:
shared: [results]
for:
value: table
in: ${tables}
گردش کار موازی را مستقر کنید:
gcloud workflows deploy bigquery-parallel \
--source=workflow-parallel.yaml \
--service-account=$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
گردش کار را اجرا کنید:
gcloud workflows run bigquery-parallel
باید ببینید که اجرای گردش کار حدود ۲۰ ثانیه طول میکشد. این به دلیل اجرای موازی هر ۵ کوئری است. بهبود سرعت تا ۵ برابر تنها با تغییر چند خط کد!
در نهایت، خروجی یکسانی از هر جدول با عناوین و نماهای برتر اما با زمان اجرای بسیار کوتاهتر مشاهده خواهید کرد:
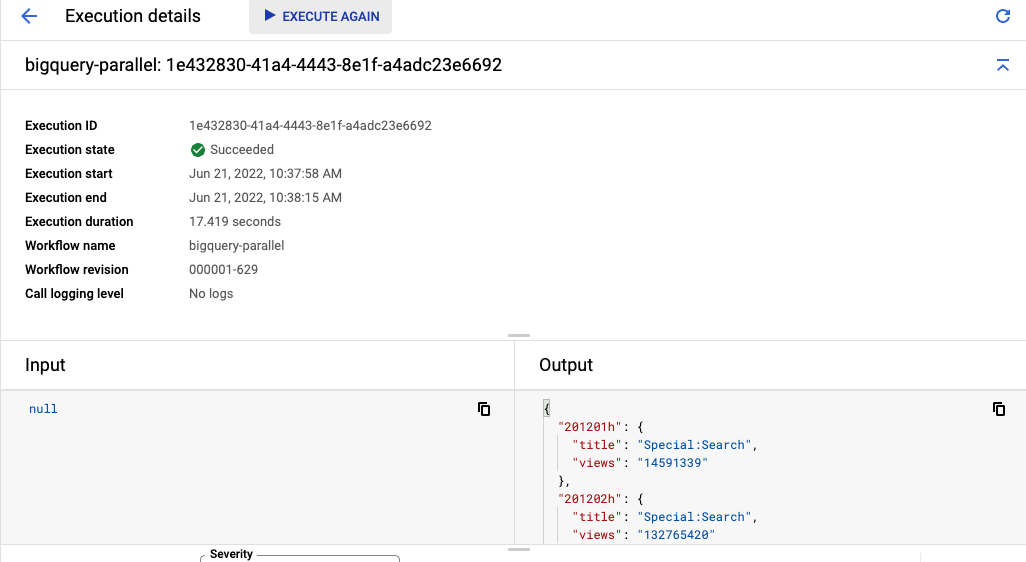
۷. تبریک
تبریک میگویم، شما کار کدنویسی را تمام کردید! برای کسب اطلاعات بیشتر، مستندات گردش کار در مورد مراحل موازی را بررسی کنید.
آنچه ما پوشش دادهایم
- نحوه اجرای کوئریهای BigQuery روی مجموعه دادههای ویکیپدیا.
- نحوه اجرای چندین کوئری به عنوان بخشی از هماهنگی گردشهای کاری به صورت سریالی.
- نحوه موازیسازی کوئریها با استفاده از تکرار موازی گردشهای کاری برای بهبود سرعت تا ۵ برابر.