
1. परिचय

Workflows, पूरी तरह से मैनेज की जाने वाली ऑर्केस्ट्रेशन सेवा है. यह Google Cloud या बाहरी सेवाओं को आपके तय किए गए क्रम में लागू करती है.
BigQuery, एंटरप्राइज़ डेटा वेयरहाउस है, जिसे पूरी तरह से मैनेज किया जाता है. इसकी मदद से, टेराबाइट में मौजूद डेटा को मैनेज और उसका विश्लेषण किया जा सकता है. इसमें मशीन लर्निंग, जियोस्पेशल विश्लेषण, और कारोबार से जुड़ी अहम जानकारी जैसी सुविधाएं पहले से मौजूद होती हैं.
इस कोडलैब में, आपको Wikipedia के सार्वजनिक डेटासेट के ख़िलाफ़ कुछ BigQuery क्वेरी चलाने का तरीका बताया जाएगा. इसके बाद, आपको यह दिखेगा कि Workflows ऑर्केस्ट्रेशन के तहत, BigQuery की कई क्वेरी को एक के बाद एक क्रम से कैसे चलाया जाता है. आखिर में, Workflows की पैरलल इटरेशन सुविधा का इस्तेमाल करके, क्वेरी को पैरलल किया जाएगा. इससे क्वेरी की स्पीड पांच गुना तक बढ़ जाएगी.
आपको क्या सीखने को मिलेगा
- Wikipedia डेटासेट के ख़िलाफ़ BigQuery क्वेरी चलाने का तरीका.
- Workflows orchestration के तहत, एक के बाद एक कई क्वेरी कैसे चलाई जाती हैं.
- वर्कफ़्लो के पैरलल इटरेशन का इस्तेमाल करके, क्वेरी को पैरलल करने का तरीका. इससे क्वेरी की स्पीड पांच गुना तक बढ़ जाती है.
2. सेटअप और ज़रूरी शर्तें
अपनी स्पीड से एनवायरमेंट सेट अप करना
- Google Cloud Console में साइन इन करें और नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. अगर आपके पास पहले से कोई Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.

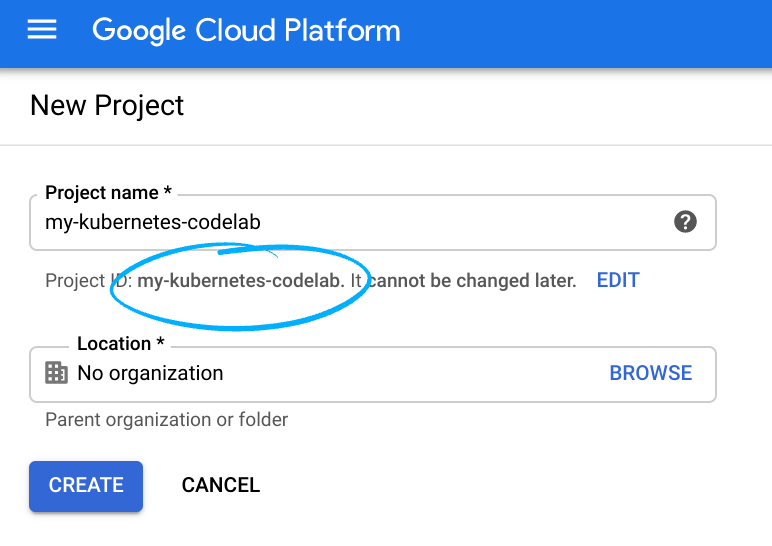
- प्रोजेक्ट का नाम, इस प्रोजेक्ट में हिस्सा लेने वाले लोगों के लिए डिसप्ले नेम होता है. यह एक वर्ण स्ट्रिंग है, जिसका इस्तेमाल Google API नहीं करते. इसे कभी भी अपडेट किया जा सकता है.
- प्रोजेक्ट आईडी, सभी Google Cloud प्रोजेक्ट के लिए यूनीक होना चाहिए. साथ ही, इसे बदला नहीं जा सकता. Cloud Console, यूनीक स्ट्रिंग अपने-आप जनरेट करता है. आम तौर पर, आपको इससे कोई फ़र्क़ नहीं पड़ता कि यह क्या है. ज़्यादातर कोडलैब में, आपको प्रोजेक्ट आईडी का रेफ़रंस देना होगा. आम तौर पर, इसे
PROJECT_IDके तौर पर पहचाना जाता है. अगर आपको जनरेट किया गया आईडी पसंद नहीं है, तो कोई दूसरा रैंडम आईडी जनरेट किया जा सकता है. इसके अलावा, आपके पास अपना नाम आज़माने का विकल्प भी है. इससे आपको पता चलेगा कि वह नाम उपलब्ध है या नहीं. इस चरण के बाद, इसे बदला नहीं जा सकता. यह प्रोजेक्ट की अवधि तक बना रहेगा. - आपकी जानकारी के लिए बता दें कि एक तीसरी वैल्यू भी होती है, जिसे प्रोजेक्ट नंबर कहते हैं. इसका इस्तेमाल कुछ एपीआई करते हैं. इन तीनों वैल्यू के बारे में ज़्यादा जानने के लिए, दस्तावेज़ देखें.
- इसके बाद, आपको Cloud Console में बिलिंग चालू करनी होगी, ताकि Cloud संसाधनों/एपीआई का इस्तेमाल किया जा सके. इस कोडलैब को पूरा करने में ज़्यादा खर्च नहीं आएगा. इस ट्यूटोरियल के बाद बिलिंग से बचने के लिए, बनाए गए संसाधनों को बंद किया जा सकता है. इसके लिए, बनाए गए संसाधनों को मिटाएं या पूरे प्रोजेक्ट को मिटाएं. Google Cloud के नए उपयोगकर्ताओं को, मुफ़्त में आज़माने के लिए 300 डॉलर का क्रेडिट मिलता है.
Cloud Shell शुरू करना
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:

इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, यह Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
3. Wikipedia डेटासेट एक्सप्लोर करना
सबसे पहले, BigQuery में Wikipedia के डेटासेट को एक्सप्लोर करें.
Google Cloud Console के BigQuery सेक्शन पर जाएं:
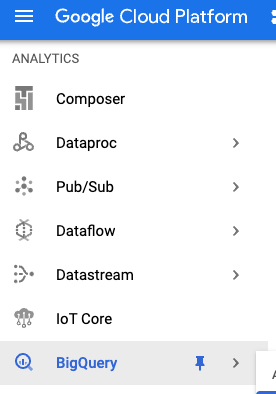
bigquery-samples में, आपको कई सार्वजनिक डेटासेट दिखेंगे. इनमें Wikipedia से जुड़े कुछ डेटासेट भी शामिल हैं:
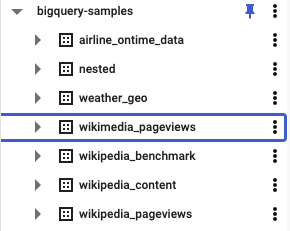
wikipedia_pageviews डेटासेट में, आपको अलग-अलग सालों के पेज व्यू के लिए कई टेबल दिख सकती हैं:
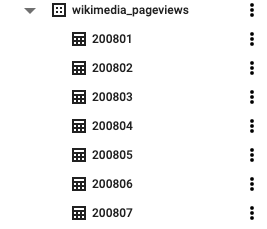
इनमें से कोई एक टेबल चुनी जा सकती है. जैसे, 201207) और डेटा की झलक देखें:
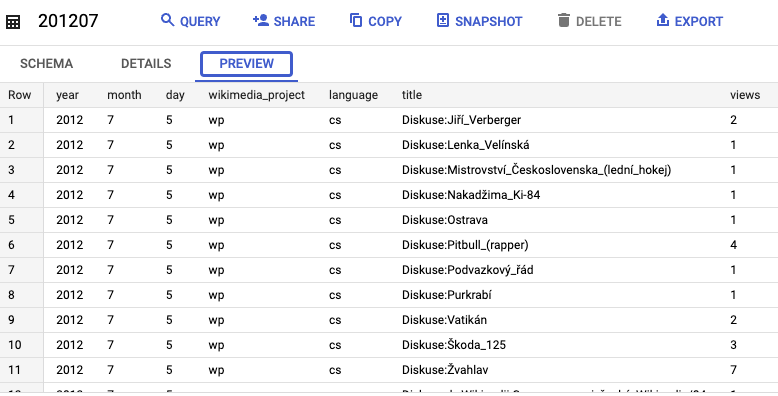
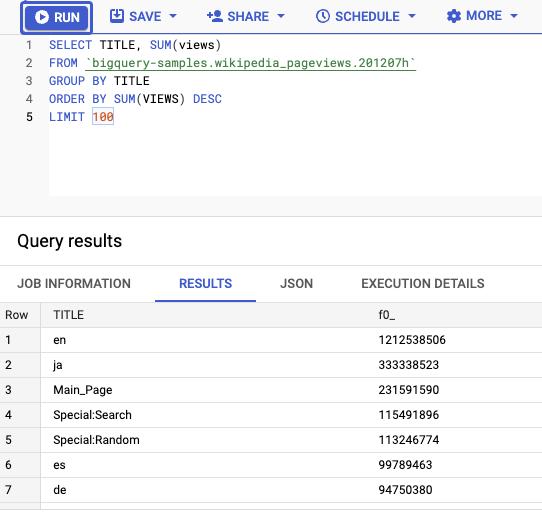
टेबल के ख़िलाफ़ क्वेरी भी चलाई जा सकती हैं. उदाहरण के लिए, यह क्वेरी सबसे ज़्यादा व्यू वाले टॉप 100 टाइटल चुनती है:
SELECT TITLE, SUM(views) FROM bigquery-samples.wikipedia_pageviews.201207h GROUP BY TITLE ORDER BY SUM(VIEWS) DESC LIMIT 100
क्वेरी चलाने के बाद, डेटा लोड होने में करीब 20 सेकंड लगते हैं:
4. एक से ज़्यादा क्वेरी चलाने के लिए, वर्कफ़्लो तय करना
किसी एक टेबल के लिए क्वेरी चलाना आसान है. हालांकि, कई टेबल के लिए एक साथ कई क्वेरी चलाना और नतीजों को इकट्ठा करना काफ़ी मुश्किल हो सकता है. इसमें आपकी मदद करने के लिए, Workflows में iteration सिंटैक्स का इस्तेमाल किया जा सकता है!
Cloud Shell में, एक workflow-serial.yaml फ़ाइल बनाएं. इससे एक ऐसा वर्कफ़्लो बनाया जा सकेगा जो कई टेबल के ख़िलाफ़ कई क्वेरी चला सके:
touch workflow-serial.yaml
इसके बाद, Cloud Shell में मौजूद एडिटर की मदद से फ़ाइल में बदलाव किया जा सकता है:

workflow-serial.yaml फ़ाइल में, पहले init चरण में, टेबल के नामों के हिसाब से हर इटरेशन को ट्रैक करने के लिए, एक results मैप बनाएं. इसके अलावा, tables कैटगरी को उन टेबल की सूची के साथ भी तय करें जिनके लिए आपको क्वेरी चलानी हैं. इस मामले में, हम पांच टेबल चुन रहे हैं:
main:
steps:
- init:
assign:
- results : {}
- tables:
- 201201h
- 201202h
- 201203h
- 201204h
- 201205h
इसके बाद, runQueries चरण तय करें. इस चरण में, हर टेबल को दोहराया जाता है. साथ ही, Workflows के BigQuery कनेक्टर का इस्तेमाल करके, क्वेरी चलाई जाती है. इससे हर टेबल में, सबसे ज़्यादा पेज व्यू वाले टॉप 100 टाइटल का पता चलता है. इसके बाद, यह नतीजों के मैप में मौजूद हर टेबल से सबसे ज़्यादा बार देखे गए टाइटल और व्यू सेव करता है:
- runQueries:
for:
value: table
in: ${tables}
steps:
- runQuery:
call: googleapis.bigquery.v2.jobs.query
args:
projectId: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
body:
useLegacySql: false
useQueryCache: false
timeoutMs: 30000
# Find the top 100 titles with most views on Wikipedia
query: ${
"SELECT TITLE, SUM(views)
FROM `bigquery-samples.wikipedia_pageviews." + table + "`
WHERE LENGTH(TITLE) > 10
GROUP BY TITLE
ORDER BY SUM(VIEWS) DESC
LIMIT 100"
}
result: queryResult
- returnResult:
assign:
# Return the top title from each table
- results[table]: {}
- results[table].title: ${queryResult.rows[0].f[0].v}
- results[table].views: ${queryResult.rows[0].f[1].v}
आखिरी चरण में, results मैप को वापस लाएं:
- returnResults:
return: ${results}
5. Workflows की मदद से एक साथ कई क्वेरी चलाना
वर्कफ़्लो को डिप्लॉय और चलाने से पहले, आपको यह पक्का करना होगा कि Workflows API चालू हो. इसे Google Cloud Console से या Cloud Shell में gcloud का इस्तेमाल करके चालू किया जा सकता है:
gcloud services enable workflows.googleapis.com
Workflows के लिए सेवा खाता बनाएं:
SERVICE_ACCOUNT=workflows-bigquery-sa gcloud iam service-accounts create $SERVICE_ACCOUNT \ --display-name="Workflows BigQuery service account"
पक्का करें कि सेवा खाते के पास, BigQuery जॉब को लॉग करने और चलाने की भूमिकाएं हों:
PROJECT_ID=your-project-id gcloud projects add-iam-policy-binding $PROJECT_ID \ --role roles/logging.logWriter \ --role roles/bigquery.jobUser \ --member serviceAccount:$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
सेवा खाते के साथ वर्कफ़्लो डिप्लॉय करें:
gcloud workflows deploy bigquery-serial \
--source=workflow-serial.yaml \
--service-account=$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
अब वर्कफ़्लो चलाने के लिए तैयार हैं.
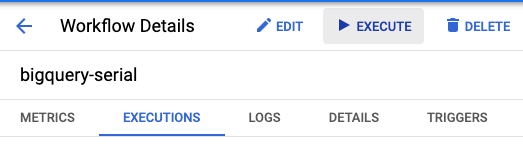
Cloud Console के Workflows सेक्शन में जाकर, bigquery-serial वर्कफ़्लो ढूंढें और Execute बटन पर क्लिक करें:
इसके अलावा, Cloud Shell में gcloud का इस्तेमाल करके भी वर्कफ़्लो चलाया जा सकता है:
gcloud workflows run bigquery-serial
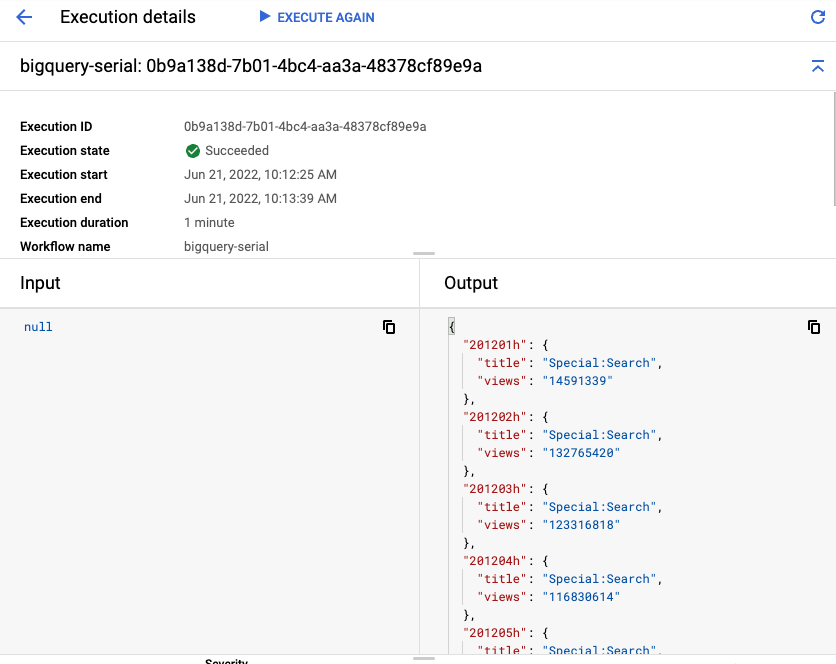
आपको वर्कफ़्लो के पूरा होने में करीब एक मिनट लगेगा. हर टेबल के लिए 20 सेकंड लगेंगे.
आखिर में, आपको सबसे ज़्यादा देखे गए टाइटल और व्यू के साथ हर टेबल का आउटपुट दिखेगा:
6. एक साथ कई चरणों वाली क्वेरी को पैरलल तरीके से प्रोसेस करना
पिछले चरण में, वर्कफ़्लो को पूरा होने में करीब एक मिनट लगा. ऐसा इसलिए हुआ, क्योंकि इसमें पांच क्वेरी चलाई गई थीं और हर क्वेरी को पूरा होने में 20 सेकंड लगे. ये अलग-अलग क्वेरी हैं. इसलिए, Workflows की पैरलल इटरेशन सुविधा का इस्तेमाल करके, इन्हें एक साथ चलाया जा सकता है.
workflow-serial.yaml फ़ाइल को नई workflow-parallel.yaml फ़ाइल में कॉपी करें. नई फ़ाइल में, आपको कुछ बदलाव करने होंगे, ताकि सीरियल चरणों को पैरलल चरणों में बदला जा सके.
workflow-parallel.yaml फ़ाइल में, runQueries चरण बदलें. सबसे पहले, parallel कीवर्ड जोड़ें. इससे, for लूप के हर इटरेशन को पैरलल में चलाया जा सकता है. इसके बाद, results वैरिएबल को shared वैरिएबल के तौर पर एलान करें. इससे वैरिएबल को किसी ब्रांच से लिखा जा सकता है. हम हर नतीजे को इस वैरिएबल में जोड़ देंगे.
- runQueries:
parallel:
shared: [results]
for:
value: table
in: ${tables}
पैरलल वर्कफ़्लो को डिप्लॉय करें:
gcloud workflows deploy bigquery-parallel \
--source=workflow-parallel.yaml \
--service-account=$SERVICE_ACCOUNT@$PROJECT_ID.iam.gserviceaccount.com
वर्कफ़्लो चलाएं:
gcloud workflows run bigquery-parallel
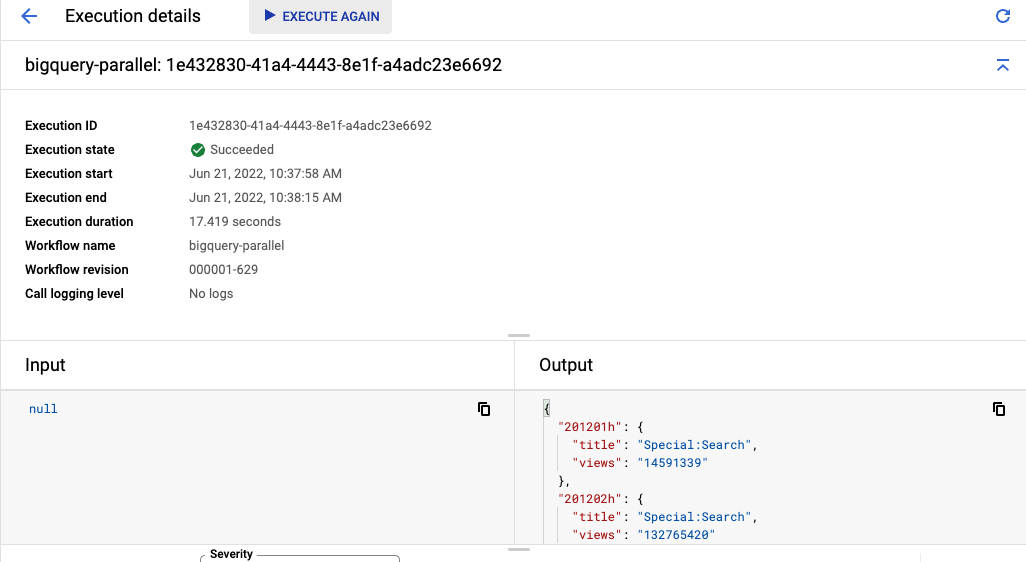
आपको वर्कफ़्लो के एक्ज़ीक्यूट होने में करीब 20 सेकंड लगेंगे. ऐसा इसलिए होता है, क्योंकि सभी पांच क्वेरी एक साथ चल रही हैं. कोड की सिर्फ़ कुछ लाइनों में बदलाव करके, पांच गुना तक स्पीड बढ़ाई जा सकती है!
आखिर में, आपको हर टेबल से एक जैसा आउटपुट दिखेगा. इसमें सबसे ज़्यादा व्यू पाने वाले टाइटल और व्यू की जानकारी होगी. हालांकि, इसे पूरा होने में कम समय लगेगा:
7. बधाई हो
बधाई हो, आपने कोडलैब पूरा कर लिया है! ज़्यादा जानने के लिए, पैरलल चरणों के बारे में वर्कफ़्लो का दस्तावेज़ पढ़ें.
हमने क्या-क्या कवर किया है
- Wikipedia डेटासेट के ख़िलाफ़ BigQuery क्वेरी चलाने का तरीका.
- Workflows orchestration के तहत, एक के बाद एक कई क्वेरी कैसे चलाई जाती हैं.
- वर्कफ़्लो में पैरलल इटरेशन का इस्तेमाल करके, क्वेरी को पैरलल करने का तरीका. इससे क्वेरी की स्पीड पांच गुना तक बढ़ जाती है.