
১. সংক্ষিপ্ত বিবরণ

ডেটাফ্লো কী?
ডেটাফ্লো হলো বিভিন্ন ধরনের ডেটা প্রসেসিং প্যাটার্ন কার্যকর করার জন্য একটি পরিচালিত পরিষেবা। এই সাইটের ডকুমেন্টেশনে দেখানো হয়েছে কীভাবে ডেটাফ্লো ব্যবহার করে আপনার ব্যাচ এবং স্ট্রিমিং ডেটা প্রসেসিং পাইপলাইনগুলো স্থাপন করবেন, যার মধ্যে পরিষেবার বৈশিষ্ট্যগুলো ব্যবহারের নির্দেশনাও অন্তর্ভুক্ত রয়েছে।
অ্যাপাচি বিম এসডিকে হলো একটি ওপেন সোর্স প্রোগ্রামিং মডেল যা আপনাকে ব্যাচ এবং স্ট্রিমিং উভয় ধরনের পাইপলাইন তৈরি করতে সক্ষম করে। আপনি একটি অ্যাপাচি বিম প্রোগ্রাম দিয়ে আপনার পাইপলাইনগুলো তৈরি করেন এবং তারপর ডেটাফ্লো সার্ভিসে সেগুলো চালান। অ্যাপাচি বিম ডকুমেন্টেশনে অ্যাপাচি বিম প্রোগ্রামিং মডেল, এসডিকে এবং অন্যান্য রানারদের জন্য গভীর ধারণাগত তথ্য ও রেফারেন্স উপাদান সরবরাহ করা হয়।
দ্রুত গতিতে স্ট্রিমিং ডেটা অ্যানালিটিক্স
ডেটাফ্লো কম ডেটা ল্যাটেন্সিতে দ্রুত ও সরলীকৃত স্ট্রিমিং ডেটা পাইপলাইন তৈরি করতে সক্ষম করে।
কার্যক্রম ও ব্যবস্থাপনা সহজ করুন
ডেটাফ্লো-এর সার্ভারবিহীন পদ্ধতি ডেটা ইঞ্জিনিয়ারিংয়ের কাজের অতিরিক্ত পরিচালনগত বোঝা দূর করে, ফলে টিমগুলো সার্ভার ক্লাস্টার পরিচালনার পরিবর্তে প্রোগ্রামিংয়ের ওপর মনোযোগ দিতে পারে।
মালিকানার মোট খরচ কমান
রিসোর্স অটোস্কেলিং এবং ব্যয়-সাশ্রয়ী ব্যাচ প্রসেসিং ক্ষমতার সমন্বয়ে, ডেটাফ্লো অতিরিক্ত খরচ না করেই আপনার মৌসুমী ও আকস্মিক কাজের চাপ সামলানোর জন্য কার্যত সীমাহীন সক্ষমতা প্রদান করে।
মূল বৈশিষ্ট্য
স্বয়ংক্রিয় সম্পদ ব্যবস্থাপনা এবং গতিশীল কাজের ভারসাম্য পুনঃস্থাপন
ডেটাফ্লো প্রসেসিং রিসোর্সের প্রোভিশনিং এবং ম্যানেজমেন্টকে স্বয়ংক্রিয় করে ল্যাটেন্সি কমাতে ও ইউটিলাইজেশন বাড়াতে সাহায্য করে, ফলে আপনাকে ম্যানুয়ালি ইনস্ট্যান্স চালু করতে বা রিজার্ভ করতে হয় না। কাজের বিভাজনও স্বয়ংক্রিয় এবং অপ্টিমাইজ করা থাকে, যা পিছিয়ে থাকা কাজকে গতিশীলভাবে পুনর্বিন্যাস করে। 'হট কী' খুঁজে বের করা বা আপনার ইনপুট ডেটা প্রি-প্রসেস করার কোনো প্রয়োজন নেই।
অনুভূমিক স্বয়ংক্রিয় স্কেলিং
সর্বোত্তম থ্রুপুটের জন্য কর্মী সম্পদের অনুভূমিক স্বয়ংক্রিয় স্কেলিং সামগ্রিকভাবে উন্নততর মূল্য-কর্মক্ষমতা অনুপাত প্রদান করে।
ব্যাচ প্রক্রিয়াকরণের জন্য নমনীয় রিসোর্স সময়সূচী মূল্য নির্ধারণ
কাজের সময়সূচীতে নমনীয়তা রেখে প্রক্রিয়াকরণের জন্য, যেমন রাতের বেলার কাজের ক্ষেত্রে, ফ্লেক্সিবল রিসোর্স শিডিউলিং (FlexRS) ব্যাচ প্রসেসিংয়ের জন্য কম মূল্য প্রদান করে। এই নমনীয় কাজগুলোকে একটি কিউ-তে রাখা হয় এবং এই নিশ্চয়তা দেওয়া হয় যে ছয় ঘণ্টার মধ্যে সেগুলো সম্পাদনের জন্য তুলে নেওয়া হবে।
এই টিউটোরিয়ালটি https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-maven থেকে নেওয়া হয়েছে।
আপনি যা শিখবেন
- জাভা এসডিকে ব্যবহার করে অ্যাপাচি বিম সহ একটি মেভেন প্রজেক্ট কীভাবে তৈরি করবেন
- গুগল ক্লাউড প্ল্যাটফর্ম কনসোল ব্যবহার করে একটি উদাহরণ পাইপলাইন চালান।
- সংশ্লিষ্ট ক্লাউড স্টোরেজ বাকেট এবং এর বিষয়বস্তু কীভাবে মুছে ফেলবেন
আপনার যা যা লাগবে
- একটি ব্রাউজার, যেমন ক্রোম বা ফায়ারফক্স
আপনি এই টিউটোরিয়ালটি কীভাবে ব্যবহার করবেন?
গুগল ক্লাউড প্ল্যাটফর্ম পরিষেবা ব্যবহারের অভিজ্ঞতাকে আপনি কীভাবে মূল্যায়ন করবেন?
২. সেটআপ এবং প্রয়োজনীয়তা
স্ব-গতিতে পরিবেশ সেটআপ
- ক্লাউড কনসোলে সাইন ইন করুন এবং একটি নতুন প্রজেক্ট তৈরি করুন অথবা বিদ্যমান কোনো প্রজেক্ট পুনরায় ব্যবহার করুন। (যদি আপনার আগে থেকে Gmail বা G Suite অ্যাকাউন্ট না থাকে, তবে আপনাকে অবশ্যই একটি তৈরি করতে হবে।)



প্রজেক্ট আইডিটি মনে রাখবেন, যা সমস্ত গুগল ক্লাউড প্রজেক্ট জুড়ে একটি অনন্য নাম (উপরের নামটি ইতিমধ্যে ব্যবহৃত হয়েছে এবং আপনার জন্য কাজ করবে না, দুঃখিত!)। এই কোডল্যাবে এটিকে পরবর্তীতে PROJECT_ID হিসাবে উল্লেখ করা হবে।
- এরপরে, গুগল ক্লাউড রিসোর্স ব্যবহার করার জন্য আপনাকে ক্লাউড কনসোলে বিলিং চালু করতে হবে।
এই কোডল্যাবটি চালাতে খুব বেশি খরচ হওয়ার কথা নয়, এমনকি আদৌ কোনো খরচ নাও হতে পারে। "পরিষ্কার-পরিচ্ছন্নতা" (Cleaning up) বিভাগে দেওয়া নির্দেশাবলী অবশ্যই অনুসরণ করবেন, যেখানে রিসোর্স বন্ধ করার পরামর্শ দেওয়া হয়েছে, যাতে এই টিউটোরিয়ালের বাইরে আপনার কোনো বিল না আসে। গুগল ক্লাউডের নতুন ব্যবহারকারীরা ৩০০ মার্কিন ডলারের ফ্রি ট্রায়াল প্রোগ্রামের জন্য যোগ্য।
এপিআইগুলি সক্রিয় করুন
স্ক্রিনের উপরের বাম দিকের মেনু আইকনটিতে ক্লিক করুন।

ড্রপ ডাউন থেকে এপিআই ও পরিষেবা > ড্যাশবোর্ড নির্বাচন করুন।

এপিআই এবং সার্ভিসগুলো নির্বাচন করে সক্রিয় করুন।

সার্চ বক্সে "Compute Engine" লিখে সার্চ করুন। প্রদর্শিত ফলাফলের তালিকা থেকে "Compute Engine API"-তে ক্লিক করুন।

Google Compute Engine পেজে Enable-এ ক্লিক করুন।

একবার চালু হয়ে গেলে ফিরে যেতে তীরচিহ্নে ক্লিক করুন।
এখন নিম্নলিখিত API-গুলো অনুসন্ধান করুন এবং সেগুলোও সক্রিয় করুন:
- ক্লাউড ডেটাফ্লো
- স্ট্যাকড্রাইভার
- ক্লাউড স্টোরেজ
- ক্লাউড স্টোরেজ JSON
- বিগকোয়েরি
- ক্লাউড পাব/সাব
- ক্লাউড ডেটাস্টোর
- ক্লাউড রিসোর্স ম্যানেজার এপিআই
৩. একটি নতুন ক্লাউড স্টোরেজ বাকেট তৈরি করুন
গুগল ক্লাউড প্ল্যাটফর্ম কনসোলে , স্ক্রিনের উপরের বাম দিকে থাকা মেনু আইকনে ক্লিক করুন:
নিচে স্ক্রোল করুন এবং স্টোরেজ উপবিভাগে ক্লাউড স্টোরেজ > ব্রাউজার নির্বাচন করুন:

এখন আপনি ক্লাউড স্টোরেজ ব্রাউজারটি দেখতে পাবেন, এবং যদি আপনি এমন একটি প্রজেক্ট ব্যবহার করেন যেখানে বর্তমানে কোনো ক্লাউড স্টোরেজ বাকেট নেই, তাহলে আপনি একটি নতুন বাকেট তৈরি করার জন্য একটি আমন্ত্রণ দেখতে পাবেন। একটি তৈরি করতে 'Create bucket' বোতামটি চাপুন:

আপনার বাকেটের জন্য একটি নাম লিখুন। ডায়ালগ বক্সে যেমন উল্লেখ করা আছে, ক্লাউড স্টোরেজের সব বাকেটের মধ্যে নাম অবশ্যই অনন্য হতে হবে। তাই আপনি যদি "টেস্ট"-এর মতো একটি সহজবোধ্য নাম বেছে নেন, তাহলে সম্ভবত দেখবেন যে অন্য কেউ ইতিমধ্যেই সেই নামে একটি বাকেট তৈরি করে ফেলেছে এবং আপনি একটি ত্রুটি বার্তা পাবেন।
বাকেটের নামে কোন অক্ষর ব্যবহার করা যাবে, সে বিষয়েও কিছু নিয়ম রয়েছে। যদি আপনি আপনার বাকেটের নাম অক্ষর বা সংখ্যা দিয়ে শুরু ও শেষ করেন এবং মাঝখানে শুধু ড্যাশ ব্যবহার করেন, তাহলে কোনো সমস্যা হবে না। যদি আপনি বিশেষ অক্ষর ব্যবহার করার চেষ্টা করেন, অথবা অক্ষর বা সংখ্যা ছাড়া অন্য কিছু দিয়ে আপনার বাকেটের নাম শুরু বা শেষ করার চেষ্টা করেন, তাহলে ডায়ালগ বক্সটি আপনাকে নিয়মগুলো মনে করিয়ে দেবে।

আপনার বাকেটের জন্য একটি অনন্য নাম লিখুন এবং 'Create' চাপুন। আপনি যদি এমন কোনো নাম বেছে নেন যা ইতিমধ্যেই ব্যবহৃত হচ্ছে, তাহলে আপনি উপরে দেখানো ত্রুটির বার্তাটি দেখতে পাবেন। যখন আপনি সফলভাবে একটি বাকেট তৈরি করে ফেলবেন, তখন আপনাকে ব্রাউজারে আপনার নতুন, খালি বাকেটটিতে নিয়ে যাওয়া হবে।

আপনি যে বাকেটের নামটি দেখবেন, তা অবশ্যই ভিন্ন হবে, কারণ সমস্ত প্রোজেক্ট জুড়ে সেগুলোকে অনন্য হতে হবে।
৪. ক্লাউড শেল চালু করুন
ক্লাউড শেল সক্রিয় করুন
- ক্লাউড কনসোল থেকে, Activate Cloud Shell-এ ক্লিক করুন।
.

আপনি যদি আগে কখনো ক্লাউড শেল চালু না করে থাকেন, তাহলে এটি কী তা বর্ণনা করে একটি মধ্যবর্তী স্ক্রিন (নিচে দেওয়া আছে) আপনার সামনে আসবে। যদি তাই হয়, তাহলে 'Continue'-তে ক্লিক করুন (এবং আপনি এটি আর কখনো দেখতে পাবেন না)। একবারের জন্য আসা সেই স্ক্রিনটি দেখতে এইরকম:

ক্লাউড শেল প্রস্তুত করতে এবং এর সাথে সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগা উচিত।

এই ভার্চুয়াল মেশিনটিতে আপনার প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলস লোড করা আছে। এটি একটি স্থায়ী ৫ জিবি হোম ডিরেক্টরি প্রদান করে এবং গুগল ক্লাউডে চলে, যা নেটওয়ার্ক পারফরম্যান্স ও অথেনটিকেশনকে ব্যাপকভাবে উন্নত করে। এই কোডল্যাবে আপনার প্রায় সমস্ত কাজই শুধুমাত্র একটি ব্রাউজার বা আপনার ক্রোমবুক দিয়ে করা সম্ভব।
ক্লাউড শেলে সংযুক্ত হওয়ার পর আপনি দেখতে পাবেন যে, আপনাকে ইতিমধ্যেই প্রমাণীকৃত করা হয়েছে এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে।
- আপনি প্রমাণীকৃত কিনা তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান:
gcloud auth list
কমান্ড আউটপুট
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
gcloud config list project
কমান্ড আউটপুট
[core] project = <PROJECT_ID>
যদি তা না থাকে, তবে আপনি এই কমান্ডটি দিয়ে এটি সেট করতে পারেন:
gcloud config set project <PROJECT_ID>
কমান্ড আউটপুট
Updated property [core/project].
৫. একটি মেভেন প্রজেক্ট তৈরি করুন।
ক্লাউড শেল চালু হওয়ার পর, চলুন অ্যাপাচি বিম-এর জাভা এসডিকে ব্যবহার করে একটি মেভেন প্রজেক্ট তৈরি করে কাজ শুরু করা যাক।
অ্যাপাচি বিম হলো ডেটা পাইপলাইনের জন্য একটি ওপেন সোর্স প্রোগ্রামিং মডেল। আপনি একটি অ্যাপাচি বিম প্রোগ্রামের মাধ্যমে এই পাইপলাইনগুলো সংজ্ঞায়িত করেন এবং আপনার পাইপলাইনটি কার্যকর করার জন্য ডেটাফ্লো-এর মতো একটি রানার বেছে নিতে পারেন।
আপনার শেল-এ নিম্নলিখিতভাবে mvn archetype:generate কমান্ডটি চালান:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.beam \
-DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \
-DarchetypeVersion=2.46.0 \
-DgroupId=org.example \
-DartifactId=first-dataflow \
-Dversion="0.1" \
-Dpackage=org.apache.beam.examples \
-DinteractiveMode=false
কমান্ডটি চালানোর পর, আপনি আপনার বর্তমান ডিরেক্টরির অধীনে first-dataflow নামে একটি নতুন ডিরেক্টরি দেখতে পাবেন। first-dataflow মধ্যে একটি Maven প্রজেক্ট রয়েছে, যাতে Cloud Dataflow SDK for Java এবং উদাহরণ পাইপলাইন অন্তর্ভুক্ত আছে।
৬. ক্লাউড ডেটাফ্লোতে একটি টেক্সট প্রসেসিং পাইপলাইন চালান।
প্রথমে আমাদের প্রজেক্ট আইডি এবং ক্লাউড স্টোরেজ বাকেটের নামগুলো এনভায়রনমেন্ট ভেরিয়েবল হিসেবে সেভ করে নিই। আপনি এটি ক্লাউড শেল-এ করতে পারেন। <your_project_id> জায়গায় অবশ্যই আপনার নিজের প্রজেক্ট আইডি বসিয়ে নেবেন।
export PROJECT_ID=<your_project_id>
এখন আমরা ক্লাউড স্টোরেজ বাকেটের জন্যও একই কাজ করব। মনে রাখবেন, <your_bucket_name> জায়গায় আগের ধাপে বাকেট তৈরি করার জন্য ব্যবহৃত অনন্য নামটি বসাতে হবে।
export BUCKET_NAME=<your_bucket_name>
first-dataflow/ ডিরেক্টরিতে যান।
cd first-dataflow
আমরা WordCount নামের একটি পাইপলাইন চালাব, যেটি টেক্সট পড়ে, টেক্সট লাইনগুলোকে আলাদা আলাদা শব্দে টোকেনাইজ করে এবং সেই শব্দগুলোর প্রতিটির ফ্রিকোয়েন্সি গণনা করে। প্রথমে আমরা পাইপলাইনটি চালাব, এবং এটি চলার সময় প্রতিটি ধাপে কী ঘটছে তা দেখে নেব।
আপনার শেল বা টার্মিনাল উইন্ডোতে mvn compile exec:java কমান্ডটি চালিয়ে পাইপলাইনটি চালু করুন। --project, --stagingLocation, এবং --output আর্গুমেন্টগুলোর জন্য, নিচের কমান্ডটি এই ধাপের শুরুতে আপনার সেট করা এনভায়রনমেন্ট ভেরিয়েবলগুলোকে নির্দেশ করে।
mvn compile exec:java \
-Pdataflow-runner compile exec:java \
-Dexec.mainClass=org.apache.beam.examples.WordCount \
-Dexec.args="--project=${PROJECT_ID} \
--stagingLocation=gs://${BUCKET_NAME}/staging/ \
--output=gs://${BUCKET_NAME}/output \
--runner=DataflowRunner \
--region=us-central1 \
--gcpTempLocation=gs://${BUCKET_NAME}/temp"
কাজটি চলার সময়, চলুন কাজের তালিকা থেকে কাজটি খুঁজে বের করি।
Google Cloud Platform Console- এ Cloud Dataflow Web UI খুলুন। আপনি আপনার wordcount জবটি Running স্ট্যাটাস সহ দেখতে পাবেন।

এবার, চলুন পাইপলাইন প্যারামিটারগুলো দেখে নেওয়া যাক। আপনার জবের নামে ক্লিক করে শুরু করুন:

যখন আপনি কোনো জব নির্বাচন করেন, তখন আপনি এক্সিকিউশন গ্রাফটি দেখতে পারেন। একটি পাইপলাইনের এক্সিকিউশন গ্রাফ, পাইপলাইনের প্রতিটি ট্রান্সফর্মকে একটি বক্স হিসাবে উপস্থাপন করে, যেটিতে ট্রান্সফর্মের নাম এবং কিছু স্ট্যাটাস তথ্য থাকে। আরও বিস্তারিত দেখতে, আপনি প্রতিটি স্টেপের উপরের ডান কোণায় থাকা ক্যারেট চিহ্নে ক্লিক করতে পারেন।

চলুন দেখি পাইপলাইনটি প্রতিটি ধাপে কীভাবে ডেটা রূপান্তর করে:
- পড়া : এই ধাপে, পাইপলাইনটি একটি ইনপুট উৎস থেকে ডেটা পড়ে। এক্ষেত্রে, এটি ক্লাউড স্টোরেজের একটি টেক্সট ফাইল, যেখানে শেক্সপিয়রের নাটক ‘কিং লিয়ার’ -এর সম্পূর্ণ পাঠ্য রয়েছে। আমাদের পাইপলাইন ফাইলটি লাইন বাই লাইন পড়ে এবং প্রতিটি লাইনকে একটি
PCollectionহিসেবে আউটপুট দেয়, যেখানে আমাদের টেক্সট ফাইলের প্রতিটি লাইন হলো কালেকশনটির একটি উপাদান। - CountWords :
CountWordsধাপটির দুটি অংশ রয়েছে। প্রথমত, এটিExtractWordsনামক একটি প্যারালাল ডু ফাংশন (ParDo) ব্যবহার করে প্রতিটি লাইনকে স্বতন্ত্র শব্দে টোকেনাইজ করে। ExtractWords-এর আউটপুট হলো একটি নতুন PCollection, যেখানে প্রতিটি উপাদান একটি শব্দ। পরবর্তী ধাপ,Count, জাভা SDK দ্বারা প্রদত্ত একটি ট্রান্সফর্ম ব্যবহার করে যা কী, ভ্যালু পেয়ার রিটার্ন করে, যেখানে কী হলো একটি অনন্য শব্দ এবং ভ্যালু হলো শব্দটি কতবার এসেছে তার সংখ্যা। এখানেCountWordsবাস্তবায়নকারী মেথডটি দেওয়া হলো, এবং আপনি GitHub- এ সম্পূর্ণ WordCount.java ফাইলটি দেখতে পারেন:
/**
* A PTransform that converts a PCollection containing lines of text into a PCollection of
* formatted word counts.
*
* <p>Concept #3: This is a custom composite transform that bundles two transforms (ParDo and
* Count) as a reusable PTransform subclass. Using composite transforms allows for easy reuse,
* modular testing, and an improved monitoring experience.
*/
public static class CountWords
extends PTransform<PCollection<String>, PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> expand(PCollection<String> lines) {
// Convert lines of text into individual words.
PCollection<String> words = lines.apply(ParDo.of(new ExtractWordsFn()));
// Count the number of times each word occurs.
PCollection<KV<String, Long>> wordCounts = words.apply(Count.perElement());
return wordCounts;
}
}
- MapElements : এটি নিচে দেওয়া
FormatAsTextFnকল করে, যা প্রতিটি কী ও ভ্যালু জোড়াকে একটি মুদ্রণযোগ্য স্ট্রিং-এ ফরম্যাট করে।
/** A SimpleFunction that converts a Word and Count into a printable string. */
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}
- WriteCounts : এই ধাপে আমরা মুদ্রণযোগ্য স্ট্রিংগুলোকে একাধিক শার্ডেড টেক্সট ফাইলে লিখি।
আমরা কিছুক্ষণের মধ্যেই পাইপলাইন থেকে প্রাপ্ত আউটপুটটি দেখে নেব।
এখন গ্রাফের ডানদিকে থাকা জব ইনফো পেজটি দেখুন, যেখানে সেই পাইপলাইন প্যারামিটারগুলো রয়েছে যেগুলো আমরা mvn compile exec:java কমান্ডে অন্তর্ভুক্ত করেছিলাম।
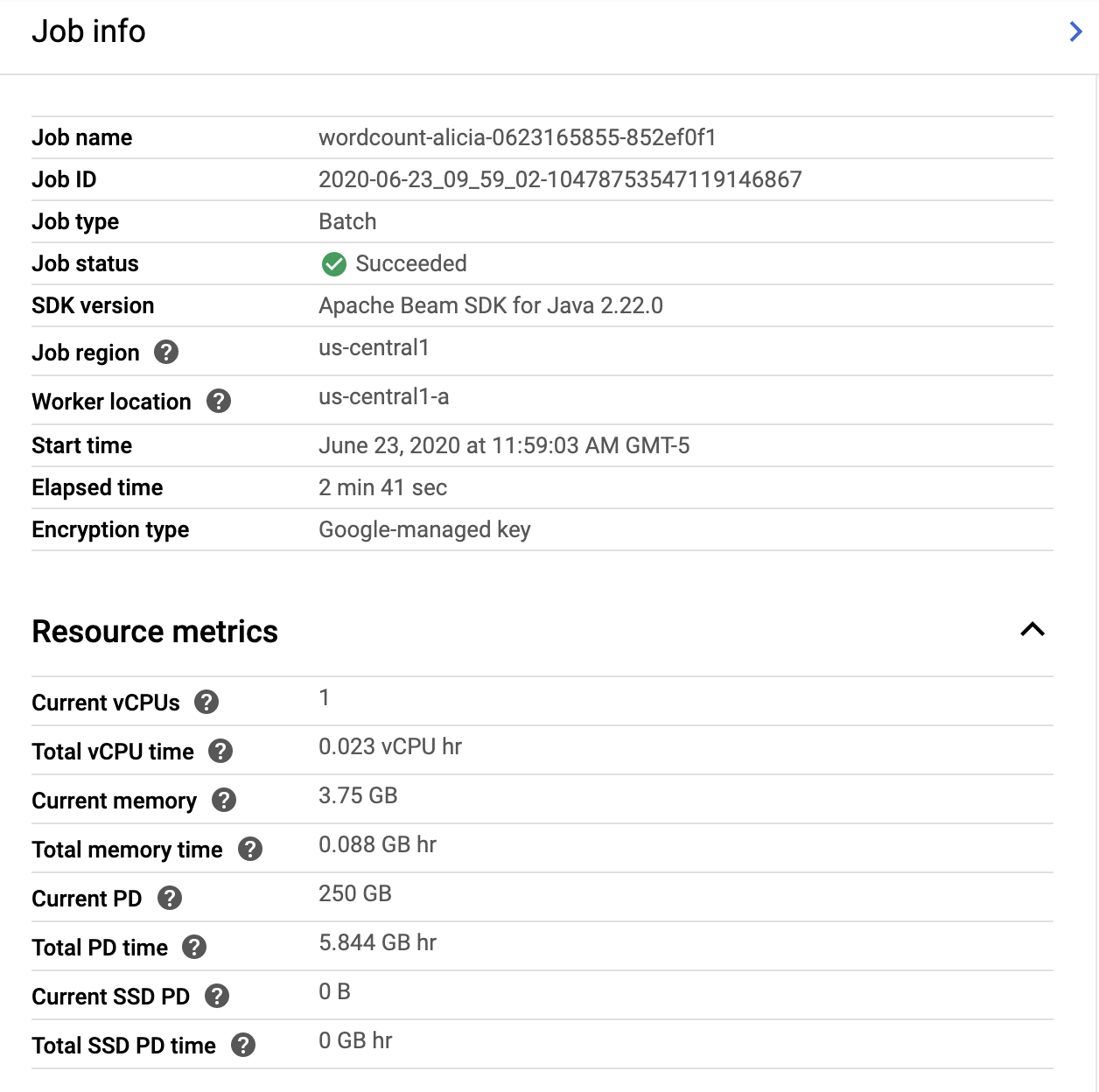

আপনি পাইপলাইনের জন্য কাস্টম কাউন্টারও দেখতে পারেন, যা এক্ষেত্রে দেখায় যে এক্সিকিউশনের সময় এখন পর্যন্ত কতগুলো খালি লাইন পাওয়া গেছে। অ্যাপ্লিকেশন-নির্দিষ্ট মেট্রিক ট্র্যাক করার জন্য আপনি আপনার পাইপলাইনে নতুন কাউন্টার যোগ করতে পারেন।

নির্দিষ্ট ত্রুটির বার্তাগুলো দেখতে আপনি কনসোলের নিচের লগস আইকনে ক্লিক করতে পারেন।

প্যানেলটি ডিফল্টরূপে জব লগ মেসেজগুলো দেখায়, যা পুরো জবটির অবস্থা রিপোর্ট করে। আপনি জবের অগ্রগতি এবং স্ট্যাটাস মেসেজ ফিল্টার করতে মিনিমাম সেভিয়ারিটি সিলেক্টরটি ব্যবহার করতে পারেন।

গ্রাফে একটি পাইপলাইন ধাপ নির্বাচন করলে আপনার কোড দ্বারা তৈরি লগ এবং সেই পাইপলাইন ধাপে চলমান তৈরি হওয়া কোড দেখার ভিউ পরিবর্তিত হয়।
জব লগ-এ ফিরে যেতে, গ্রাফের বাইরে ক্লিক করে অথবা ডান পাশের প্যানেলে থাকা ক্লোজ বাটনটি ব্যবহার করে ধাপটি অনির্বাচিত করুন।
আপনার পাইপলাইন চালনাকারী Compute Engine ইনস্ট্যান্সগুলোর ওয়ার্কার লগ দেখতে, আপনি লগস ট্যাবে থাকা ওয়ার্কার লগস বাটনটি ব্যবহার করতে পারেন। ওয়ার্কার লগস-এ আপনার কোড এবং এটিকে চালনাকারী Dataflow দ্বারা তৈরি কোডের লগ লাইনগুলো থাকে।
আপনি যদি পাইপলাইনের কোনো ব্যর্থতা ডিবাগ করার চেষ্টা করেন, তাহলে প্রায়শই ওয়ার্কার লগ- এ অতিরিক্ত লগিং পাওয়া যায় যা সমস্যা সমাধানে সাহায্য করে। মনে রাখবেন যে এই লগগুলি সমস্ত ওয়ার্কারের ডেটা একত্রিত করে দেখানো হয় এবং এগুলি ফিল্টার ও সার্চ করা যায়।

ডেটাফ্লো মনিটরিং ইন্টারফেস শুধুমাত্র সবচেয়ে সাম্প্রতিক লগ বার্তাগুলো দেখায়। লগ প্যানেলের ডানদিকে থাকা Google Cloud Observability লিঙ্কে ক্লিক করে আপনি সমস্ত লগ দেখতে পারেন।

মনিটরিং→লগস পৃষ্ঠা থেকে যে বিভিন্ন ধরণের লগ দেখা যায়, তার একটি সারসংক্ষেপ নিচে দেওয়া হলো:
- জব-মেসেজ লগগুলিতে ডেটাফ্লো-এর বিভিন্ন কম্পোনেন্ট দ্বারা তৈরি জব-লেভেলের মেসেজ থাকে। এর উদাহরণগুলির মধ্যে রয়েছে অটোস্কেলিং কনফিগারেশন, যখন ওয়ার্কার চালু বা বন্ধ হয়, জব স্টেপের অগ্রগতি এবং জবের ত্রুটি। ইউজার কোড ক্র্যাশ করার ফলে সৃষ্ট ওয়ার্কার-লেভেলের ত্রুটি, যা ওয়ার্কার লগগুলিতে উপস্থিত থাকে, সেগুলিও জব-মেসেজ লগ পর্যন্ত চলে আসে।
- ডেটাফ্লো ওয়ার্কারদের দ্বারা ওয়ার্কার লগ তৈরি হয়। ওয়ার্কাররা পাইপলাইনের বেশিরভাগ কাজ করে থাকে (উদাহরণস্বরূপ, ডেটার উপর আপনার ParDos প্রয়োগ করা)। ওয়ার্কার লগে আপনার কোড এবং ডেটাফ্লো দ্বারা লগ করা বার্তাগুলো থাকে।
- বেশিরভাগ ডেটাফ্লো জবে ওয়ার্কার-স্টার্টআপ লগ থাকে এবং এতে স্টার্টআপ প্রক্রিয়া সম্পর্কিত বার্তাগুলো ধারণ করা যায়। স্টার্টআপ প্রক্রিয়ার মধ্যে রয়েছে ক্লাউড স্টোরেজ থেকে জবের জার ফাইলগুলো ডাউনলোড করা এবং তারপর ওয়ার্কারগুলো চালু করা। ওয়ার্কার চালু করতে কোনো সমস্যা হলে, এই লগগুলো খতিয়ে দেখা একটি ভালো উপায়।
- শাফলার লগগুলিতে ওয়ার্কারদের কাছ থেকে আসা বার্তা থাকে, যা সমান্তরাল পাইপলাইন অপারেশনগুলির ফলাফল একত্রিত করে।
- ডকার এবং কিউবলেট লগগুলিতে এই পাবলিক প্রযুক্তিগুলি সম্পর্কিত বার্তা থাকে, যেগুলি ডেটাফ্লো ওয়ার্কারগুলিতে ব্যবহৃত হয়।
পরবর্তী ধাপে, আমরা যাচাই করব যে আপনার কাজটি সফল হয়েছে কিনা।
৭. আপনার কাজটি সফল হয়েছে কিনা তা যাচাই করুন।
Google Cloud Platform Console- এ Cloud Dataflow Web UI খুলুন।
আপনার ওয়ার্ডকাউন্ট জবটির স্ট্যাটাস প্রথমে ' Running' এবং তারপর 'Succeeded' দেখতে পাবেন।

কাজটি সম্পন্ন হতে আনুমানিক ৩-৪ মিনিট সময় লাগবে।
আপনার কি মনে আছে যখন আপনি পাইপলাইনটি চালিয়েছিলেন এবং একটি আউটপুট বাকেট নির্দিষ্ট করেছিলেন? চলুন ফলাফলটি দেখে নেওয়া যাক (কারণ আপনি কি দেখতে চান না যে কিং লিয়ারের প্রতিটি শব্দ কতবার এসেছে?!)। গুগল ক্লাউড প্ল্যাটফর্ম কনসোলের ক্লাউড স্টোরেজ ব্রাউজারে ফিরে যান। আপনার বাকেটে, আপনার জব দ্বারা তৈরি আউটপুট ফাইল এবং স্টেজিং ফাইলগুলি দেখতে পাবেন:

৮. আপনার রিসোর্সগুলো বন্ধ করে দিন।
আপনি গুগল ক্লাউড প্ল্যাটফর্ম কনসোল থেকে আপনার রিসোর্সগুলো বন্ধ করতে পারেন।
গুগল ক্লাউড প্ল্যাটফর্ম কনসোলে ক্লাউড স্টোরেজ ব্রাউজারটি খুলুন।
আপনার তৈরি করা বাকেটটির পাশের চেকবক্সটি সিলেক্ট করুন এবং বাকেট ও এর ভেতরের সবকিছু স্থায়ীভাবে মুছে ফেলতে DELETE বাটনে ক্লিক করুন।


৯. অভিনন্দন!
আপনি শিখেছেন কীভাবে ক্লাউড ডেটাফ্লো এসডিকে ব্যবহার করে একটি মেভেন প্রজেক্ট তৈরি করতে হয়, গুগল ক্লাউড প্ল্যাটফর্ম কনসোল ব্যবহার করে একটি উদাহরণ পাইপলাইন চালাতে হয় এবং সংশ্লিষ্ট ক্লাউড স্টোরেজ বাকেট ও তার ভেতরের সবকিছু মুছে ফেলতে হয়।
আরও জানুন
- ডেটাফ্লো ডকুমেন্টেশন: https://cloud.google.com/dataflow/docs/
লাইসেন্স
এই কাজটি ক্রিয়েটিভ কমন্স অ্যাট্রিবিউশন ৩.০ জেনেরিক লাইসেন্স এবং অ্যাপাচি ২.০ লাইসেন্সের অধীনে লাইসেন্সকৃত।