
1. खास जानकारी
सर्वरलेस माइग्रेशन स्टेशन की कोडलैब सीरीज़ (अपने हिसाब से सीखने और प्रैक्टिकल करने वाले ट्यूटोरियल) और इससे जुड़े वीडियो का मकसद, Google Cloud सर्वरलेस डेवलपर की मदद करना है. इससे वे एक या उससे ज़्यादा माइग्रेशन करके, अपने ऐप्लिकेशन को बेहतर बना सकते हैं. इनमें मुख्य रूप से लेगसी सेवाओं से माइग्रेट करना शामिल है. ऐसा करने से, आपके ऐप्लिकेशन को एक जगह से दूसरी जगह ले जाना आसान हो जाता है. साथ ही, आपको ज़्यादा विकल्प और सुविधा मिलती है. इससे आपको Cloud प्रॉडक्ट की ज़्यादा रेंज के साथ इंटिग्रेट करने और उन्हें ऐक्सेस करने में मदद मिलती है. साथ ही, भाषा के नए वर्शन पर आसानी से अपग्रेड किया जा सकता है. शुरुआत में, इस सीरीज़ में मुख्य तौर पर App Engine (स्टैंडर्ड एनवायरमेंट) डेवलपर के लिए कॉन्टेंट शामिल किया गया था. हालांकि, अब इसमें अन्य सर्वरलेस प्लैटफ़ॉर्म के लिए भी कॉन्टेंट शामिल किया गया है. जैसे, Cloud Functions और Cloud Run. इसके अलावा, इसमें अन्य प्लैटफ़ॉर्म के लिए भी कॉन्टेंट शामिल किया गया है.
इस कोडलैब में, आपको App Engine Task Queue के पुल टास्क को Module 1 कोडलैब के सैंपल ऐप्लिकेशन में शामिल करने और उनका इस्तेमाल करने का तरीका बताया गया है. हमने इस मॉड्यूल 18 के ट्यूटोरियल में, पुल टास्क के इस्तेमाल के बारे में बताया है. इसके बाद, मॉड्यूल 19 में हमने इस इस्तेमाल को Cloud Pub/Sub पर माइग्रेट करने के बारे में बताया है. पुश टास्क के लिए Task Queues का इस्तेमाल करने वाले लोग, Cloud Tasks पर माइग्रेट करेंगे. उन्हें मॉड्यूल 7 से 9 देखने चाहिए.
आपको इनके बारे में जानकारी मिलेगी
- App Engine Task Queue API/बंडल्ड सेवा का इस्तेमाल करना
- Python 2 Flask App Engine NDB ऐप्लिकेशन में पुल क्यू का इस्तेमाल करना
आपको किन चीज़ों की ज़रूरत होगी
- चालू GCP बिलिंग खाते वाला Google Cloud Platform प्रोजेक्ट
- Python की बुनियादी जानकारी
- Linux की सामान्य कमांड के बारे में जानकारी होना
- App Engine ऐप्लिकेशन डेवलप और डिप्लॉय करने की बुनियादी जानकारी
- App Engine का मॉड्यूल 1 ऐप्लिकेशन (इसका कोडलैब पूरा करें [सुझाया गया] या रिपॉज़िटरी से ऐप्लिकेशन कॉपी करें)
सर्वे
इस ट्यूटोरियल का इस्तेमाल कैसे किया जाएगा?
Python के साथ अपने अनुभव को आप क्या रेटिंग देंगे?
Google Cloud की सेवाओं को इस्तेमाल करने के अपने अनुभव को आप क्या रेटिंग देंगे?
2. बैकग्राउंड
App Engine Task Queue के पुल टास्क से माइग्रेट करने के लिए, Module 1 codelab से मिले मौजूदा Flask और App Engine NDB ऐप्लिकेशन में, इसके इस्तेमाल को जोड़ें. सैंपल ऐप्लिकेशन, असली उपयोगकर्ता को हाल ही की विज़िट दिखाता है. यह ठीक है, लेकिन यह ज़्यादा दिलचस्प होगा कि वेबसाइट पर आने वाले लोगों को भी ट्रैक किया जाए, ताकि यह पता चल सके कि सबसे ज़्यादा लोग कौनसी वेबसाइट पर आते हैं.
हम विज़िटर की संख्या के लिए, पुश टास्क का इस्तेमाल कर सकते हैं. हालांकि, हम ज़िम्मेदारी को दो हिस्सों में बांटना चाहते हैं. पहला हिस्सा, सैंपल ऐप्लिकेशन का है. इसका काम विज़िट रजिस्टर करना और उपयोगकर्ताओं को तुरंत जवाब देना है. दूसरा हिस्सा, "वर्कर" का है. इसका काम, सामान्य अनुरोध-जवाब वर्कफ़्लो के बाहर विज़िटर की संख्या का हिसाब लगाना है.
इस डिज़ाइन को लागू करने के लिए, हम मुख्य ऐप्लिकेशन में पुल क्यू का इस्तेमाल कर रहे हैं. साथ ही, वर्कर फ़ंक्शन की सुविधा भी जोड़ रहे हैं. वर्कर को अलग प्रोसेस के तौर पर चलाया जा सकता है. जैसे, बैकएंड इंस्टेंस या वीएम पर चलने वाला कोड, जो हमेशा चालू रहता है. इसके अलावा, इसे क्रॉन जॉब या curl या wget का इस्तेमाल करके बुनियादी कमांड-लाइन एचटीटीपी अनुरोध के तौर पर भी चलाया जा सकता है. इस इंटिग्रेशन के बाद, अगले (मॉड्यूल 19) कोडलैब में ऐप्लिकेशन को Cloud Pub/Sub पर माइग्रेट किया जा सकता है.
इस ट्यूटोरियल में ये चरण शामिल हैं:
- सेटअप/प्रीवर्क
- कॉन्फ़िगरेशन अपडेट करना
- ऐप्लिकेशन कोड में बदलाव करना
3. सेटअप/प्रीवर्क
इस सेक्शन में, यह बताया गया है कि:
- अपना Cloud प्रोजेक्ट सेट अप करना
- बेसलाइन सैंपल ऐप्लिकेशन पाना
- बेसलाइन ऐप्लिकेशन को (फिर से) डिप्लॉय करें और उसकी पुष्टि करें
इन चरणों से यह पक्का किया जाता है कि आप काम करने वाले कोड से शुरुआत कर रहे हैं.
1. प्रोजेक्ट सेट अप करना
अगर आपने Module 1 codelab पूरा कर लिया है, तो उसी प्रोजेक्ट और कोड का फिर से इस्तेमाल करें. इसके अलावा, एक नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. पक्का करें कि प्रोजेक्ट में चालू बिलिंग खाता हो और App Engine ऐप्लिकेशन चालू हो. अपना प्रोजेक्ट आईडी ढूंढें, क्योंकि आपको इस कोडलैब में कई बार इसकी ज़रूरत होगी. साथ ही, जब भी आपको PROJECT_ID वैरिएबल दिखे, तब इसका इस्तेमाल करें.
2. बेसलाइन सैंपल ऐप्लिकेशन पाना
इस कोडलैब के लिए, यह ज़रूरी है कि आपके पास Module 1 का App Engine ऐप्लिकेशन हो. Module 1 का कोडलैब पूरा करें (सुझाया गया) या repo से Module 1 का ऐप्लिकेशन कॉपी करें. चाहे आपने बनाया हो या हमने, मॉड्यूल 1 का कोड वह जगह है जहां से हम "शुरू करेंगे." इस कोडलैब में, आपको हर चरण के बारे में बताया गया है. साथ ही, इसमें ऐसा कोड भी दिया गया है जो मॉड्यूल 18 के "FINISH" फ़ोल्डर में मौजूद कोड से मिलता-जुलता है.
- शुरू करें: मॉड्यूल 1 फ़ोल्डर (Python 2)
- पूरा करें: Module 18 folder (Python 2)
- पूरी रिपो (क्लोन करने या ZIP फ़ाइल डाउनलोड करने के लिए)
Module 1 के किसी भी ऐप्लिकेशन का इस्तेमाल करने पर, फ़ोल्डर का आउटपुट ऐसा दिखना चाहिए. इसमें lib फ़ोल्डर भी हो सकता है:
$ ls README.md appengine_config.py requirements.txt app.yaml main.py templates
3. बेसलाइन ऐप्लिकेशन को (फिर से) डिप्लॉय करना
Module 1 ऐप्लिकेशन को डिप्लॉय करने के लिए, यह तरीका अपनाएं:
- अगर
libफ़ोल्डर मौजूद है, तो उसे मिटाएं. इसके बाद,pip install -t lib -r requirements.txtचलाकरlibको फिर से भरें. अगर आपके पास Python 2 और 3, दोनों इंस्टॉल हैं, तो आपकोpip2कमांड का इस्तेमाल करना पड़ सकता है. - पक्का करें कि आपने
gcloudकमांड-लाइन टूल को इंस्टॉल और शुरू कर लिया हो. साथ ही, आपने इसके इस्तेमाल की समीक्षा कर ली हो. - अगर आपको हर
gcloudकमांड के साथPROJECT_IDनहीं डालना है, तो अपने Cloud प्रोजेक्ट कोgcloud config set projectPROJECT_IDके साथ सेट करें. gcloud app deployकी मदद से, सैंपल ऐप्लिकेशन को डिप्लॉय करना- पुष्टि करें कि मॉड्यूल 1 ऐप्लिकेशन, उम्मीद के मुताबिक काम कर रहा है और इसमें हाल ही की विज़िट दिख रही हैं (नीचे दिखाया गया है)
4. कॉन्फ़िगरेशन अपडेट करना
App Engine की स्टैंडर्ड कॉन्फ़िगरेशन फ़ाइलों (app.yaml, requirements.txt, appengine_config.py) में कोई बदलाव करने की ज़रूरत नहीं है. इसके बजाय, queue.yaml नाम की एक नई कॉन्फ़िगरेशन फ़ाइल जोड़ें. इसमें यह कॉन्टेंट शामिल करें और इसे टॉप-लेवल की उसी डायरेक्ट्री में रखें:
queue:
- name: pullq
mode: pull
queue.yaml फ़ाइल में, आपके ऐप्लिकेशन के लिए मौजूद सभी टास्क कतारों के बारे में बताया जाता है. हालांकि, इसमें default [पुश] कतार के बारे में नहीं बताया जाता है, क्योंकि इसे App Engine अपने-आप बनाता है. इस मामले में, सिर्फ़ एक पुल क्यू है, जिसका नाम pullq है. App Engine के लिए, mode डायरेक्टिव को pull के तौर पर सेट करना ज़रूरी है. ऐसा न करने पर, यह डिफ़ॉल्ट रूप से पुश क्यू बना देता है. दस्तावेज़ में, पुल कतारें बनाने के बारे में ज़्यादा जानें. अन्य विकल्पों के लिए, queue.yaml रेफ़रंस पेज भी देखें.
इस फ़ाइल को अपने ऐप्लिकेशन से अलग तौर पर डिप्लॉय करें. आपको अब भी gcloud app deploy का इस्तेमाल करना होगा. हालांकि, कमांड लाइन पर queue.yaml भी उपलब्ध कराना होगा:
$ gcloud app deploy queue.yaml Configurations to update: descriptor: [/tmp/mod18-gaepull/queue.yaml] type: [task queues] target project: [my-project] WARNING: Caution: You are updating queue configuration. This will override any changes performed using 'gcloud tasks'. More details at https://cloud.google.com/tasks/docs/queue-yaml Do you want to continue (Y/n)? Updating config [queue]...⠹WARNING: We are using the App Engine app location (us-central1) as the default location. Please use the "--location" flag if you want to use a different location. Updating config [queue]...done. Task queues have been updated. Visit the Cloud Platform Console Task Queues page to view your queues and cron jobs. $
5. ऐप्लिकेशन कोड में बदलाव करना
इस सेक्शन में, इन फ़ाइलों के अपडेट के बारे में जानकारी दी गई है:
main.py— मुख्य ऐप्लिकेशन में पुल क्यू का इस्तेमाल करने की सुविधा जोड़नाtemplates/index.html— नया डेटा दिखाने के लिए, वेब टेंप्लेट अपडेट करें
इंपोर्ट और कॉन्स्टेंट
पहला चरण, पुल क्यू के लिए एक नया इंपोर्ट और कई कॉन्स्टेंट जोड़ना है:
- टास्क क्यू लाइब्रेरी,
google.appengine.api.taskqueueका इंपोर्ट जोड़ें. - पुल टास्क (
TASKS) की ज़्यादा से ज़्यादा संख्या को एक घंटे (HOUR) के लिए लीज़ करने की सुविधा देने के लिए, हमारे पुल क्यू (QUEUE) में तीन कॉन्स्टेंट जोड़ें. - सबसे हाल की विज़िट और सबसे ज़्यादा विज़िट करने वाले लोगों (
LIMIT) को दिखाने के लिए, एक कॉन्स्टेंट जोड़ें.
यहां ओरिजनल कोड और अपडेट करने के बाद कोड कैसा दिखता है, यह बताया गया है:
BEFORE:
from flask import Flask, render_template, request
from google.appengine.ext import ndb
app = Flask(__name__)
AFTER:
from flask import Flask, render_template, request
from google.appengine.api import taskqueue
from google.appengine.ext import ndb
HOUR = 3600
LIMIT = 10
TASKS = 1000
QNAME = 'pullq'
QUEUE = taskqueue.Queue(QNAME)
app = Flask(__name__)
पुल टास्क जोड़ना (टास्क के लिए डेटा इकट्ठा करना और पुल क्यू में टास्क बनाना)
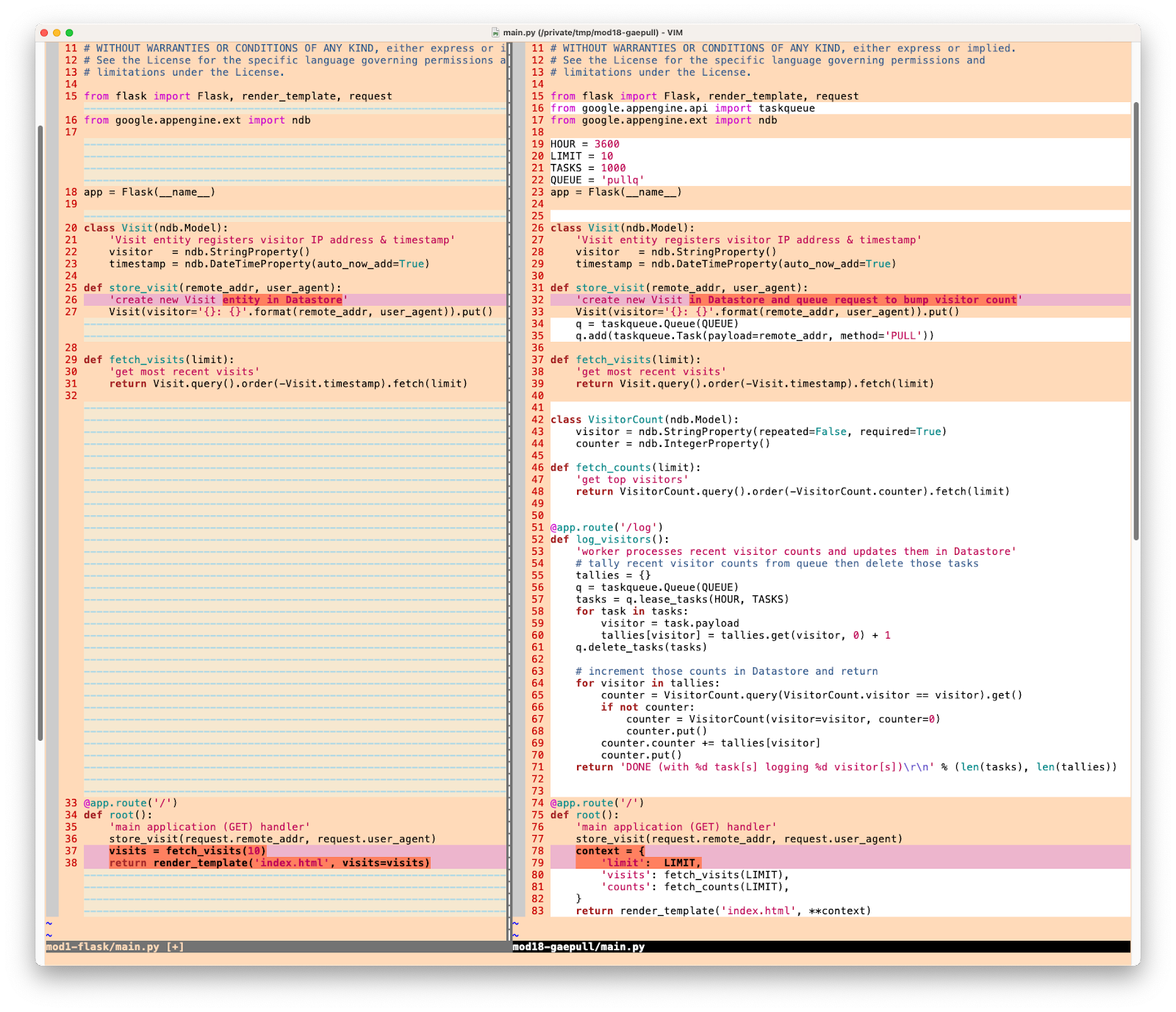
डेटा मॉडल Visit पहले जैसा ही रहता है. साथ ही, Visit में दिखने वाली विज़िट के लिए क्वेरी करने का तरीका भी पहले जैसा ही रहता है.fetch_visits() कोड के इस हिस्से में सिर्फ़ store_visit() में बदलाव करना ज़रूरी है. विज़िट रजिस्टर करने के साथ-साथ, विज़िटर के आईपी पते के साथ पुल क्यू में एक टास्क जोड़ें, ताकि वर्कर विज़िटर काउंटर को बढ़ा सके.
BEFORE:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit entity in Datastore'
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
def fetch_visits(limit):
'get most recent visits'
return Visit.query().order(-Visit.timestamp).fetch(limit)
AFTER:
class Visit(ndb.Model):
'Visit entity registers visitor IP address & timestamp'
visitor = ndb.StringProperty()
timestamp = ndb.DateTimeProperty(auto_now_add=True)
def store_visit(remote_addr, user_agent):
'create new Visit in Datastore and queue request to bump visitor count'
Visit(visitor='{}: {}'.format(remote_addr, user_agent)).put()
QUEUE.add(taskqueue.Task(payload=remote_addr, method='PULL'))
def fetch_visits(limit):
'get most recent visits'
return Visit.query().order(-Visit.timestamp).fetch(limit)
विज़िटर को ट्रैक करने के लिए, डेटा मॉडल और क्वेरी फ़ंक्शन बनाएं
विज़िटर को ट्रैक करने के लिए, डेटा मॉडल VisitorCount जोड़ें. इसमें visitor के लिए फ़ील्ड के साथ-साथ, विज़िट की संख्या को ट्रैक करने के लिए पूर्णांक counter भी होना चाहिए. इसके बाद, एक नया फ़ंक्शन जोड़ें. इसके बजाय, Python classmethod भी जोड़ा जा सकता है. इसका नाम fetch_counts() रखें. यह फ़ंक्शन, सबसे ज़्यादा से सबसे कम विज़िटर की क्वेरी करेगा और उन्हें दिखाएगा. क्लास और फ़ंक्शन को fetch_visits() के बॉडी सेक्शन के ठीक नीचे जोड़ें:
class VisitorCount(ndb.Model):
visitor = ndb.StringProperty(repeated=False, required=True)
counter = ndb.IntegerProperty()
def fetch_counts(limit):
'get top visitors'
return VisitCount.query().order(-VisitCount.counter).fetch(limit)
वर्कर कोड जोड़ना
/log पर GET अनुरोध के ज़रिए, वेबसाइट पर आने वाले लोगों की जानकारी लॉग करने के लिए, नया फ़ंक्शन log_visitors() जोड़ें. यह कुकी, डिक्शनरी/हैश का इस्तेमाल करके, वेबसाइट पर आने वाले लोगों की हाल ही की संख्या को ट्रैक करती है. साथ ही, एक घंटे के लिए ज़्यादा से ज़्यादा टास्क लीज़ करती है. यह हर टास्क के लिए, एक ही व्यक्ति की सभी विज़िट का हिसाब रखता है. इसके बाद, ऐप्लिकेशन इन टैली के आधार पर, Datastore में मौजूद सभी VisitorCount इकाइयों को अपडेट करता है. अगर ज़रूरत होती है, तो नई इकाइयां बनाता है. आखिरी चरण में, एक सामान्य टेक्स्ट मैसेज दिखता है. इससे पता चलता है कि प्रोसेस किए गए कितने टास्क से, कितने लोगों ने रजिस्टर किया. इस फ़ंक्शन को main.py के ठीक नीचे fetch_counts() में जोड़ें:
@app.route('/log')
def log_visitors():
'worker processes recent visitor counts and updates them in Datastore'
# tally recent visitor counts from queue then delete those tasks
tallies = {}
tasks = QUEUE.lease_tasks(HOUR, TASKS)
for task in tasks:
visitor = task.payload
tallies[visitor] = tallies.get(visitor, 0) + 1
if tasks:
QUEUE.delete_tasks(tasks)
# increment those counts in Datastore and return
for visitor in tallies:
counter = VisitorCount.query(VisitorCount.visitor == visitor).get()
if not counter:
counter = VisitorCount(visitor=visitor, counter=0)
counter.put()
counter.counter += tallies[visitor]
counter.put()
return 'DONE (with %d task[s] logging %d visitor[s])\r\n' % (
len(tasks), len(tallies))
डिसप्ले के नए डेटा के साथ मुख्य हैंडलर को अपडेट करना
सबसे ज़्यादा बार आने वाले लोगों की जानकारी दिखाने के लिए, मुख्य हैंडलर root() को अपडेट करें, ताकि fetch_counts() को शुरू किया जा सके. इसके अलावा, टेम्प्लेट को अपडेट किया जाएगा, ताकि सबसे ज़्यादा विज़िट करने वाले लोगों की संख्या और हाल ही की विज़िट की जानकारी दिखाई जा सके. कॉल से fetch_visits() तक विज़िटर की संख्या और सबसे हाल ही की विज़िट को एक साथ पैकेज करें. इसके बाद, उसे एक context में डालें, ताकि उसे वेब टेंप्लेट में भेजा जा सके. यहां इस बदलाव से पहले और बाद का कोड दिया गया है:
BEFORE:
@app.route('/')
def root():
'main application (GET) handler'
store_visit(request.remote_addr, request.user_agent)
visits = fetch_visits(10)
return render_template('index.html', visits=visits)
AFTER:
@app.route('/')
def root():
'main application (GET) handler'
store_visit(request.remote_addr, request.user_agent)
context = {
'limit': LIMIT,
'visits': fetch_visits(LIMIT),
'counts': fetch_counts(LIMIT),
}
return render_template('index.html', **context)
main.py में ये सभी बदलाव ज़रूरी हैं. यहां उन अपडेट की इमेज दी गई है. इनका मकसद, आपको यह बताना है कि main.py में कौन-कौनसे बदलाव किए जा रहे हैं:
नए डिसप्ले डेटा की मदद से वेब टेंप्लेट अपडेट करना
वेब टेंप्लेट templates/index.html को अपडेट करने की ज़रूरत होती है, ताकि हाल ही में आने वाले लोगों के सामान्य पेलोड के साथ-साथ, सबसे ज़्यादा बार आने वाले लोगों को भी दिखाया जा सके. पेज के सबसे ऊपर मौजूद टेबल में, सबसे ज़्यादा विज़िटर और उनकी संख्या दिखाएं. साथ ही, हाल ही की विज़िट को पहले की तरह रेंडर करना जारी रखें. इसके अलावा, एक और बदलाव यह है कि नंबर को हार्डकोड करने के बजाय, limit वैरिएबल के ज़रिए दिखाया गया है. आपको अपने वेब टेंप्लेट में ये अपडेट करने चाहिए:
BEFORE:
<!doctype html>
<html>
<head>
<title>VisitMe Example</title>
<body>
<h1>VisitMe example</h1>
<h3>Last 10 visits</h3>
<ul>
{% for visit in visits %}
<li>{{ visit.timestamp.ctime() }} from {{ visit.visitor }}</li>
{% endfor %}
</ul>
AFTER:
<!doctype html>
<html>
<head>
<title>VisitMe Example</title>
<body>
<h1>VisitMe example</h1>
<h3>Top {{ limit }} visitors</h3>
<table border=1 cellspacing=0 cellpadding=2>
<tr><th>Visitor</th><th>Visits</th></tr>
{% for count in counts %}
<tr><td>{{ count.visitor|e }}</td><td align="center">{{ count.counter }}</td></tr>
{% endfor %}
</table>
<h3>Last {{ limit }} visits</h3>
<ul>
{% for visit in visits %}
<li>{{ visit.timestamp.ctime() }} from {{ visit.visitor }}</li>
{% endfor %}
</ul>
Module 1 के सैंपल ऐप्लिकेशन में, App Engine की टास्क क्यू में मौजूद पुल टास्क का इस्तेमाल करने के लिए ज़रूरी बदलाव कर दिए गए हैं. आपकी डायरेक्ट्री अब Module 18 के सैंपल ऐप्लिकेशन को दिखाती है. इसमें ये फ़ाइलें होनी चाहिए:
$ ls README.md appengine_config.py queue.yaml templates app.yaml main.py requirements.txt
6. खास जानकारी/सफ़ाई
इस सेक्शन में, ऐप्लिकेशन को डिप्लॉय करके इस कोडलैब को पूरा किया गया है. साथ ही, यह पुष्टि की गई है कि ऐप्लिकेशन ठीक से काम कर रहा है और आउटपुट में कोई गड़बड़ी नहीं है. विज़िटर की संख्या को प्रोसेस करने के लिए, वर्कर को अलग से चलाएं. ऐप्लिकेशन की पुष्टि होने के बाद, क्लीन-अप से जुड़े सभी चरण पूरे करें और आगे की कार्रवाई करें.
ऐप्लिकेशन डिप्लॉय करना और उसकी पुष्टि करना
पक्का करें कि आपने पुल क्यू पहले ही सेट अप कर लिया हो. हमने इस कोडलैब में सबसे ऊपर gcloud app deploy queue.yaml के साथ ऐसा किया था. अगर आपने यह प्रोसेस पूरी कर ली है और आपका सैंपल ऐप्लिकेशन इस्तेमाल के लिए तैयार है, तो gcloud app deploy की मदद से अपना ऐप्लिकेशन डिप्लॉय करें. आउटपुट, मॉड्यूल 1 के ऐप्लिकेशन जैसा ही होना चाहिए. हालांकि, इसमें सबसे ऊपर "सबसे ज़्यादा विज़िटर" टेबल दिखनी चाहिए:
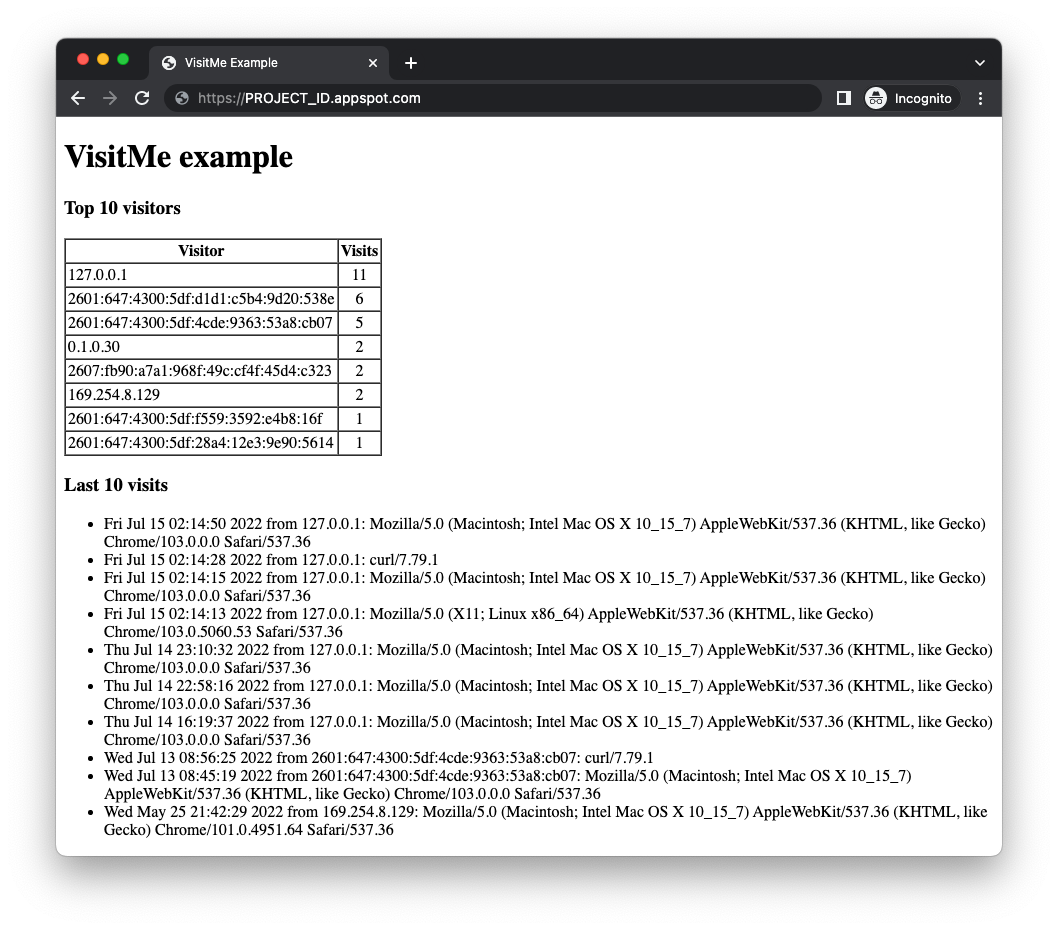
अपडेट किए गए वेब फ़्रंटएंड में, सबसे ज़्यादा विज़िट करने वाले लोगों और हाल ही की विज़िट की जानकारी दिखती है. हालांकि, विज़िटर की संख्या में यह विज़िट शामिल नहीं होती. ऐप्लिकेशन, पिछली बार आने वाले लोगों की संख्या दिखाता है. साथ ही, यह पुल क्यू में इस व्यक्ति की संख्या को बढ़ाने वाला एक नया टास्क जोड़ता है. यह एक ऐसा टास्क है जिसे प्रोसेस किया जाना बाकी है.
/log को कई तरीकों से कॉल करके, टास्क पूरा किया जा सकता है:
- App Engine की बैकएंड सेवा
cronनौकरी- वेब ब्राउज़र
- कमांड-लाइन एचटीटीपी अनुरोध (
curl,wgetवगैरह)
उदाहरण के लिए, अगर आपने /log को GET अनुरोध भेजने के लिए curl का इस्तेमाल किया है, तो PROJECT_ID देने पर, आपको यह आउटपुट दिखेगा:
$ curl https://PROJECT_ID.appspot.com/log DONE (with 1 task[s] logging 1 visitor[s])
इसके बाद, अपडेट की गई संख्या वेबसाइट पर अगली बार आने पर दिखेगी. हो गया!
सैंपल ऐप्लिकेशन में App Engine की टास्क क्यू पुल क्यू सेवा को जोड़ने के लिए, इस कोडलैब को पूरा करने के लिए बधाई. अब इसे Module 19 में Cloud Pub/Sub, Cloud NDB, और Python 3 पर माइग्रेट किया जा सकता है.
व्यवस्थित करें
सामान्य
अगर आपको अभी और काम नहीं करना है, तो हमारा सुझाव है कि आप अपने App Engine ऐप्लिकेशन को बंद कर दें, ताकि आपसे शुल्क न लिया जाए. हालांकि, अगर आपको कुछ और टेस्ट या एक्सपेरिमेंट करने हैं, तो App Engine प्लैटफ़ॉर्म पर मुफ़्त कोटा उपलब्ध है. इसलिए, जब तक आप इस्तेमाल की उस सीमा से ज़्यादा नहीं होते हैं, तब तक आपसे कोई शुल्क नहीं लिया जाएगा. यह शुल्क कंप्यूट के लिए है. हालांकि, App Engine की सेवाओं के लिए भी शुल्क लिया जा सकता है. इसलिए, ज़्यादा जानकारी के लिए कीमत वाला पेज देखें. अगर इस माइग्रेशन में अन्य क्लाउड सेवाएं शामिल हैं, तो उनके लिए अलग से बिल भेजा जाता है. अगर लागू हो, तो दोनों ही मामलों में, नीचे दिया गया "इस कोडलैब के लिए खास जानकारी" सेक्शन देखें.
पूरी जानकारी के लिए बता दें कि App Engine जैसे Google Cloud के सर्वरलेस कंप्यूट प्लैटफ़ॉर्म पर डिप्लॉय करने से, बिल्ड और स्टोरेज के लिए मामूली शुल्क लगता है. Cloud Build का अपना मुफ़्त कोटा होता है. साथ ही, Cloud Storage का भी अपना मुफ़्त कोटा होता है. उस इमेज को सेव करने के लिए, स्टोरेज कोटा का कुछ हिस्सा इस्तेमाल किया जाता है. हालांकि, ऐसा हो सकता है कि आपके देश/इलाके में बिना किसी शुल्क के स्टोरेज इस्तेमाल करने की सुविधा उपलब्ध न हो. इसलिए, स्टोरेज के इस्तेमाल पर नज़र रखें, ताकि संभावित लागत को कम किया जा सके. Cloud Storage के कुछ "फ़ोल्डर" की समीक्षा करनी चाहिए. इनमें ये शामिल हैं:
console.cloud.google.com/storage/browser/LOC.artifacts.PROJECT_ID.appspot.com/containers/imagesconsole.cloud.google.com/storage/browser/staging.PROJECT_ID.appspot.com- ऊपर दिए गए स्टोरेज लिंक, आपके
PROJECT_IDऔर *LOC*ation पर निर्भर करते हैं. उदाहरण के लिए, अगर आपका ऐप्लिकेशन अमेरिका में होस्ट किया गया है, तो "us" दिखेगा.
दूसरी ओर, अगर आपको इस ऐप्लिकेशन या माइग्रेशन से जुड़े अन्य कोडलैब का इस्तेमाल नहीं करना है और आपको सब कुछ पूरी तरह से मिटाना है, तो अपना प्रोजेक्ट बंद करें.
इस कोडलैब के लिए खास तौर पर
यहां दी गई सेवाएं, इस कोड सीखने की लैब के लिए खास तौर पर बनाई गई हैं. ज़्यादा जानकारी के लिए, हर प्रॉडक्ट का दस्तावेज़ देखें:
- App Engine की Task Queue सेवा के लिए, लेगसी बंडल की गई सेवाओं के लिए कीमत वाले पेज के मुताबिक कोई अतिरिक्त बिलिंग नहीं होती. जैसे, Task Queue.
- App Engine Datastore सेवा, Cloud Datastore (Cloud Firestore in Datastore mode) से मिलती है. इसमें भी बिना शुल्क वाली सेवा उपलब्ध है. ज़्यादा जानकारी के लिए, इसका कीमत वाला पेज देखें.
अगले चरण
इस "माइग्रेशन" में, आपने Module 1 के सैंपल ऐप्लिकेशन में Task Queue की पुश क्यू सुविधा का इस्तेमाल किया है. इसके लिए, आपने वेबसाइट पर आने वाले लोगों को ट्रैक करने की सुविधा जोड़ी है. इससे Module 18 का सैंपल ऐप्लिकेशन लागू हो गया है. अगले माइग्रेशन में, App Engine के पुल टास्क को Cloud Pub/Sub पर अपग्रेड किया जाएगा. साल 2021 के आखिर से, Python 3 पर अपग्रेड करने के दौरान उपयोगकर्ताओं को Cloud Pub/Sub पर माइग्रेट करने की ज़रूरत नहीं है. इस बारे में ज़्यादा जानने के लिए, अगला सेक्शन पढ़ें.
Cloud Pub/Sub पर माइग्रेट करने के लिए, मॉड्यूल 19 का कोडलैब देखें. इसके अलावा, माइग्रेट करने के लिए अन्य सेवाएं भी उपलब्ध हैं. जैसे, Cloud Datastore, Cloud Memorystore, Cloud Storage या Cloud Tasks (पुश कतारें). Cloud Run और Cloud Functions पर, अलग-अलग प्रॉडक्ट के माइग्रेशन भी किए जा सकते हैं. Serverless Migration Station का सारा कॉन्टेंट (कोड लैब, वीडियो, सोर्स कोड [उपलब्ध होने पर]) इसके ओपन सोर्स रेपो पर ऐक्सेस किया जा सकता है.
7. Python 3 पर माइग्रेट करना
साल 2021 के पतझड़ के सीज़न में, App Engine की टीम ने बंडल की गई कई सेवाओं के लिए, सहायता की अवधि बढ़ा दी थी. ये सेवाएं, दूसरी जनरेशन के रनटाइम (जिनमें पहली जनरेशन का रनटाइम होता है) के लिए उपलब्ध कराई गई थीं. इसलिए, अब आपको अपने ऐप्लिकेशन को Python 3 पर पोर्ट करते समय, App Engine Task Queue जैसी बंडल की गई सेवाओं से Cloud Pub/Sub जैसी स्टैंडअलोन Cloud या तीसरे पक्ष की सेवाओं पर माइग्रेट करने की ज़रूरत नहीं है. दूसरे शब्दों में कहें, तो Python 3 App Engine ऐप्लिकेशन में Task Queue का इस्तेमाल तब तक किया जा सकता है, जब तक कोड को अगली जनरेशन के रनटाइम से बंडल की गई सेवाओं को ऐक्सेस करने के लिए फिर से तैयार नहीं किया जाता.
बंडल की गई सेवाओं के इस्तेमाल को Python 3 में माइग्रेट करने के तरीके के बारे में ज़्यादा जानने के लिए, मॉड्यूल 17 का कोडलैब और उससे जुड़ा वीडियो देखें. हालांकि, यह विषय मॉड्यूल 18 के दायरे से बाहर है. यहां मॉड्यूल 1 के Python 3 वर्शन दिए गए हैं. इन्हें Python 3 पर पोर्ट किया गया है और ये अब भी App Engine NDB का इस्तेमाल करते हैं. (कुछ समय बाद, Module 18 ऐप्लिकेशन का Python 3 वर्शन भी उपलब्ध कराया जाएगा.)
8. अन्य संसाधन
यहां डेवलपर के लिए कुछ और संसाधन दिए गए हैं. इनकी मदद से, डेवलपर इस या इससे मिलते-जुलते माइग्रेशन मॉड्यूल के साथ-साथ इससे जुड़े प्रॉडक्ट के बारे में ज़्यादा जान सकते हैं. इसमें इस कॉन्टेंट पर सुझाव/राय देने या शिकायत करने की जगह, कोड के लिंक, और कई तरह के दस्तावेज़ शामिल हैं, जो आपके काम आ सकते हैं.
कोडलैब से जुड़ी समस्याएं/सुझाव/राय
अगर आपको इस कोडलैब में कोई समस्या मिलती है, तो कृपया शिकायत दर्ज करने से पहले अपनी समस्या खोजें. नई समस्याएं खोजने और बनाने के लिए लिंक:
माइग्रेशन के लिए उपलब्ध संसाधन
मॉड्यूल 1 (START) और मॉड्यूल 18 (FINISH) के लिए, रेपो फ़ोल्डर के लिंक यहां दी गई टेबल में देखे जा सकते हैं. इन्हें App Engine के सभी कोडलैब माइग्रेशन के लिए repo से भी ऐक्सेस किया जा सकता है. इसे क्लोन करें या ZIP फ़ाइल डाउनलोड करें.
कोडलैब | Python 2 | Python 3 |
कोड (इस ट्यूटोरियल में शामिल नहीं है) | ||
मॉड्यूल 18 (यह कोडलैब) | लागू नहीं |
ऑनलाइन रेफ़रंस
इस ट्यूटोरियल के लिए काम के संसाधन यहां दिए गए हैं:
App Engine टास्क क्यू
- App Engine की टास्क क्यू सेवा के बारे में खास जानकारी
- App Engine की टास्क क्यू में मौजूद पुल क्यू के बारे में खास जानकारी
- App Engine टास्क क्यू की पुल क्यू का पूरा सैंपल ऐप्लिकेशन
- Task Queue की पुल कतारें बनाना
- Google I/O 2011 में लॉन्च किए गए पुल क्यू का वीडियो ( Votelator का सैंपल ऐप्लिकेशन)
queue.yamlरेफ़रंसqueue.yamlबनाम Cloud Tasks- पुल क्यू से Pub/Sub पर माइग्रेट करने से जुड़ी गाइड
- App Engine की टास्क क्यू की पुल क्यू से Cloud Pub/Sub के दस्तावेज़ के सैंपल पर माइग्रेट करने का तरीका
App Engine प्लैटफ़ॉर्म
App Engine के दस्तावेज़
Python 2 App Engine (स्टैंडर्ड एनवायरमेंट) रनटाइम
Python 3 App Engine (स्टैंडर्ड एनवायरमेंट) रनटाइम
App Engine के स्टैंडर्ड एनवायरमेंट के Python 2 और Python 3 रनटाइम के बीच अंतर
Python 2 से 3 App Engine (स्टैंडर्ड एनवायरमेंट) में माइग्रेट करने से जुड़ी गाइड
App Engine की कीमत और कोटे की जानकारी
App Engine प्लैटफ़ॉर्म की दूसरी जनरेशन लॉन्च की गई (2018)
लेगसी रनटाइम के लिए लंबे समय तक सहायता
दस्तावेज़ माइग्रेट करने के उदाहरण
क्लाउड से जुड़ी अन्य जानकारी
- Google Cloud Platform पर Python
- Google Cloud की Python क्लाइंट लाइब्रेरी
- Google Cloud का "हमेशा के लिए बिना शुल्क" वाला टियर
- Google Cloud SDK (
gcloudकमांड-लाइन टूल) - Google Cloud के सभी दस्तावेज़
वीडियो
- Serverless Migration Station
- Serverless Expeditions
- Google Cloud Tech की सदस्यता लें
- Google Developers की सदस्यता लें
लाइसेंस
इस काम के लिए, Creative Commons एट्रिब्यूशन 2.0 जेनेरिक लाइसेंस के तहत लाइसेंस मिला है.