
1. Einführung
In diesem Codelab erfahren Sie, wie Sie spezialisierte Document AI-Prozessoren verwenden, um bestimmte Dokumente mit Python zu klassifizieren und zu parsen. Für die Klassifizierung und Aufteilung verwenden wir eine Beispiel-PDF-Datei mit Rechnungen, Belegen und Abrechnungen. Für das Parsen und die Entitätsextraktion verwenden wir eine Rechnung als Beispiel.
Diese Vorgehensweise und der Beispielcode eignen sich für alle von Document AI unterstützten Dokumente.
Voraussetzungen
Dieses Codelab baut auf Inhalten auf, die in anderen Document AI-Codelabs vorgestellt werden.
Wir empfehlen Ihnen, die folgenden Codelabs zu absolvieren, bevor Sie fortfahren:
- Optische Zeichenerkennung (OCR) mit Document AI und Python
- Formulare mit Document AI parsen (Python)
Lerninhalte
- So klassifizieren und identifizieren Sie Aufteilungspunkte für spezielle Dokumente.
- Schematisierte Entitäten mit spezialisierten Prozessoren extrahieren
Voraussetzungen
- Google Cloud-Projekt
- Ein Browser wie Google Chrome oder Mozilla Firefox
- Kenntnisse von Python 3
2. Einrichtung
In diesem Codelab wird davon ausgegangen, dass Sie die im Einführungs-Codelab aufgeführten Einrichtungsschritte für Document AI ausgeführt haben.
Führen Sie die folgenden Schritte aus, bevor Sie fortfahren:
Außerdem sollten Sie Pandas installieren, eine beliebte Bibliothek für Python zur Datenanalyse.
pip3 install --upgrade pandas
3. Spezialisierte Prozessoren erstellen
Sie müssen zuerst Instanzen der Prozessoren erstellen, die Sie für diese Anleitung verwenden.
- Rufen Sie in der Console die Übersicht über die Document AI Platform auf.
- Klicken Sie auf Prozessor erstellen, scrollen Sie nach unten zu Spezialisiert und wählen Sie Splitter für Beschaffungsdokumente aus.
- Geben Sie dem Prozessor den Namen „codelab-procurement-splitter“ (oder einen anderen Namen, den Sie sich merken können) und wählen Sie die nächstgelegene Region aus der Liste aus.
- Klicken Sie auf Erstellen, um den Prozessor zu erstellen.
- Kopieren Sie die Prozessor-ID. Sie müssen sie später in Ihrem Code verwenden.
- Wiederholen Sie die Schritte 2 bis 6 mit dem Invoice Parser (den Sie „codelab-invoice-parser“ nennen können).
Prozessor in der Console testen
Sie können den Rechnungsparser in der Console testen, indem Sie ein Dokument hochladen.
Klicken Sie auf „Dokument hochladen“ und wählen Sie eine Rechnung aus, die analysiert werden soll. Sie können diese Beispielrechnung herunterladen und verwenden, wenn Sie keine eigene Rechnung haben.
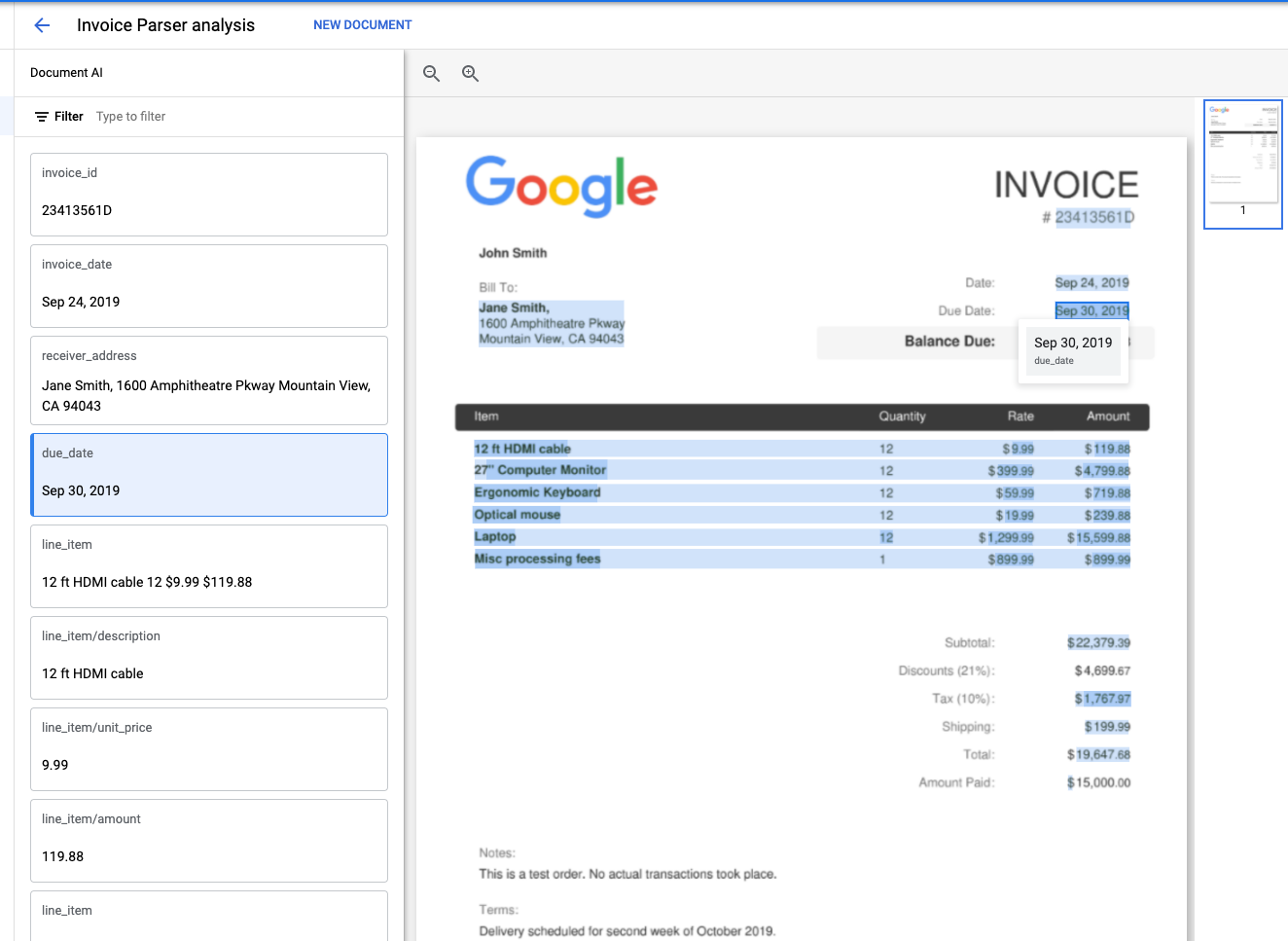
Die Ausgabe sollte so aussehen:
4. Beispieldokumente herunterladen
Wir haben einige Beispieldokumente, die Sie für dieses Lab verwenden können.
Sie können die PDFs über die folgenden Links herunterladen. Laden Sie sie dann in die Cloud Shell-Instanz hoch.
Alternativ können Sie sie mit gsutil aus unserem öffentlichen Cloud Storage-Bucket herunterladen.
gsutil cp gs://cloud-samples-data/documentai/codelabs/specialized-processors/procurement_multi_document.pdf .
gsutil cp gs://cloud-samples-data/documentai/codelabs/specialized-processors/google_invoice.pdf .
5. Dokumente klassifizieren und aufteilen
In diesem Schritt verwenden Sie die Onlineverarbeitungs-API, um ein mehrseitiges Dokument zu klassifizieren und logische Aufteilungspunkte zu erkennen.
Sie können auch die Batchverarbeitungs-API verwenden, wenn Sie mehrere Dateien senden möchten oder die Dateigröße die maximale Seitenzahl für die Onlineverarbeitung überschreitet. Eine Anleitung dazu finden Sie im Document AI OCR-Codelab.
Der Code zum Senden der API-Anfrage ist für einen allgemeinen Prozessor identisch, mit Ausnahme der Prozessor-ID.
Beschaffungs-Splitter/-Klassifikator
Erstellen Sie eine Datei mit dem Namen classification.py und verwenden Sie den folgenden Code.
Ersetzen Sie PROCUREMENT_SPLITTER_ID durch die ID des Procurement Splitter-Prozessors, den Sie zuvor erstellt haben. Ersetzen Sie YOUR_PROJECT_ID und YOUR_PROJECT_LOCATION durch Ihre Cloud-Projekt-ID bzw. den Speicherort des Prozessors.
classification.py
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as file:
file_content = file.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=file_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(name=resource_name, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "PROCUREMENT_SPLITTER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "procurement_multi_document.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
print("Document processing complete.")
types = []
confidence = []
pages = []
# Each Document.entity is a classification
for entity in document.entities:
classification = entity.type_
types.append(classification)
confidence.append(f"{entity.confidence:.0%}")
# entity.page_ref contains the pages that match the classification
pages_list = []
for page_ref in entity.page_anchor.page_refs:
pages_list.append(page_ref.page)
pages.append(pages_list)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame({"Classification": types, "Confidence": confidence, "Pages": pages})
print(df)
Die Ausgabe sollte in etwa so aussehen:
$ python3 classification.py
Document processing complete.
Classification Confidence Pages
0 invoice_statement 100% [0]
1 receipt_statement 98% [1]
2 other 81% [2]
3 utility_statement 100% [3]
4 restaurant_statement 100% [4]
Der Procurement Splitter/Classifier hat die Dokumenttypen auf den Seiten 0–1 und 3–4 korrekt identifiziert.
Seite 2 enthält ein allgemeines Formular für die medizinische Aufnahme, daher wurde es vom Klassifikator korrekt als other identifiziert.
6. Entitäten extrahieren
Sie können jetzt die schematisierten Entitäten aus den Dateien extrahieren, wie Konfidenzwerte, Attribute und normalisierte Werte.
Der Code für die API-Anfrage entspricht dem Code aus dem vorherigen Schritt und eignet sich für Online- oder Batchanfragen.
Wir greifen auf die folgenden Informationen zu den Entitäten zu:
- Entitätstyp
- (z.B.
invoice_date,receiver_name,total_amount)
- (z.B.
- Rohwerte
- Datenwerte, wie sie in der Originaldokumentdatei dargestellt werden.
- Normalisierte Werte
- Datenwerte in einem normalisierten und standardisierten Format, sofern zutreffend.
- Ggf. mit Anreicherung aus dem Enterprise Knowledge Graph
- Konfidenzwerte
- Wie „sicher“ das Modell ist, dass die Werte korrekt sind.
Einige Entitätstypen wie line_item können auch verschachtelte Entitäten als Attribute enthalten, beispielsweise line_item/unit_price und line_item/description.
In diesem Beispiel ist die verschachtelte Struktur zur besseren Übersicht vereinfacht.
Rechnungsparser
Erstellen Sie eine Datei mit dem Namen extraction.py und verwenden Sie den folgenden Code.
Ersetzen Sie INVOICE_PARSER_ID durch die ID des zuvor erstellten Rechnungsparser-Prozessors und verwenden Sie die Datei google_invoice.pdf.
extraction.py
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as file:
file_content = file.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=file_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(name=resource_name, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "INVOICE_PARSER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "google_invoice.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
types = []
raw_values = []
normalized_values = []
confidence = []
# Grab each key/value pair and their corresponding confidence scores.
for entity in document.entities:
types.append(entity.type_)
raw_values.append(entity.mention_text)
normalized_values.append(entity.normalized_value.text)
confidence.append(f"{entity.confidence:.0%}")
# Get Properties (Sub-Entities) with confidence scores
for prop in entity.properties:
types.append(prop.type_)
raw_values.append(prop.mention_text)
normalized_values.append(prop.normalized_value.text)
confidence.append(f"{prop.confidence:.0%}")
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame(
{
"Type": types,
"Raw Value": raw_values,
"Normalized Value": normalized_values,
"Confidence": confidence,
}
)
print(df)
Die Ausgabe sollte in etwa so aussehen:
$ python3 extraction.py
Type Raw Value Normalized Value Confidence
0 vat $1,767.97 100%
1 vat/tax_amount $1,767.97 1767.97 USD 0%
2 invoice_date Sep 24, 2019 2019-09-24 99%
3 due_date Sep 30, 2019 2019-09-30 99%
4 total_amount 19,647.68 19647.68 97%
5 total_tax_amount $1,767.97 1767.97 USD 92%
6 net_amount 22,379.39 22379.39 91%
7 receiver_name Jane Smith, 83%
8 invoice_id 23413561D 67%
9 receiver_address 1600 Amphitheatre Pkway\nMountain View, CA 94043 66%
10 freight_amount $199.99 199.99 USD 56%
11 currency $ USD 53%
12 supplier_name John Smith 19%
13 purchase_order 23413561D 1%
14 receiver_tax_id 23413561D 0%
15 supplier_iban 23413561D 0%
16 line_item 9.99 12 12 ft HDMI cable 119.88 100%
17 line_item/unit_price 9.99 9.99 90%
18 line_item/quantity 12 12 77%
19 line_item/description 12 ft HDMI cable 39%
20 line_item/amount 119.88 119.88 92%
21 line_item 12 399.99 27" Computer Monitor 4,799.88 100%
22 line_item/quantity 12 12 80%
23 line_item/unit_price 399.99 399.99 91%
24 line_item/description 27" Computer Monitor 15%
25 line_item/amount 4,799.88 4799.88 94%
26 line_item Ergonomic Keyboard 12 59.99 719.88 100%
27 line_item/description Ergonomic Keyboard 32%
28 line_item/quantity 12 12 76%
29 line_item/unit_price 59.99 59.99 92%
30 line_item/amount 719.88 719.88 94%
31 line_item Optical mouse 12 19.99 239.88 100%
32 line_item/description Optical mouse 26%
33 line_item/quantity 12 12 78%
34 line_item/unit_price 19.99 19.99 91%
35 line_item/amount 239.88 239.88 94%
36 line_item Laptop 12 1,299.99 15,599.88 100%
37 line_item/description Laptop 83%
38 line_item/quantity 12 12 76%
39 line_item/unit_price 1,299.99 1299.99 90%
40 line_item/amount 15,599.88 15599.88 94%
41 line_item Misc processing fees 899.99 899.99 1 100%
42 line_item/description Misc processing fees 22%
43 line_item/unit_price 899.99 899.99 91%
44 line_item/amount 899.99 899.99 94%
45 line_item/quantity 1 1 63%
7. Optional: Andere Spezialprozessoren ausprobieren
Sie haben mit Document AI für das Beschaffungswesen Dokumente klassifiziert und eine Rechnung geparst. Document AI unterstützt auch die folgenden Speziallösungen:
Mit dieser Vorgehensweise und diesem Code können Sie jeden spezialisierten Prozessor nutzen.
Wenn Sie die anderen Speziallösungen ausprobieren möchten, können Sie das Lab mit anderen Prozessortypen und anderen Beispieldokumenten noch einmal ausführen.
Beispieldokumente
Hier finden Sie einige Beispieldokumente, mit denen Sie die anderen spezialisierten Prozessoren ausprobieren können.
Lösung | Prozessortyp | Dokument |
Identität | ||
Kreditwesen | ||
Kreditwesen | ||
Verträge |
Weitere Beispieldokumente und Prozessorausgaben finden Sie in der Dokumentation.
8. Glückwunsch
Gute Arbeit. Sie haben mit Document AI erfolgreich Daten aus bestimmten Dokumenten klassifiziert und extrahiert. Wir empfehlen Ihnen, auch andere spezialisierte Dokumenttypen auszuprobieren.
Clean-up
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste Ihr Projekt aus und klicken Sie auf „Löschen“.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf „Beenden“, um das Projekt zu löschen.
Weitere Informationen
In diesen Codelabs erfahren Sie mehr über Document AI.
- Document AI-Prozessoren mit Python verwalten
- Document AI: Human-in-the-Loop
- Document AI Workbench: Uptraining
- Document AI Workbench: Benutzerdefinierte Prozessoren
Ressourcen
- The Future of Documents – YouTube-Playlist
- Document AI-Dokumentation
- Python-Clientbibliothek für Document AI
- Document AI-Beispiele
Lizenz
Dieser Text ist mit einer Creative Commons Attribution 2.0 Generic License lizenziert.