
1. Übersicht

Was ist Document AI?
Document AI ist eine Plattform, mit der Sie Erkenntnisse aus Ihren Dokumenten gewinnen können. Im Grunde bietet es eine wachsende Liste von Dokumentprozessoren (je nach Funktion auch Parser oder Splitter genannt).
Es gibt zwei Möglichkeiten, Document AI-Prozessoren zu verwalten:
- manuell über die Webkonsole
- programmgesteuert über die Document AI API.
Hier sehen Sie ein Beispiel für einen Screenshot Ihrer Prozessorliste, sowohl aus der Webkonsole als auch aus Python-Code:
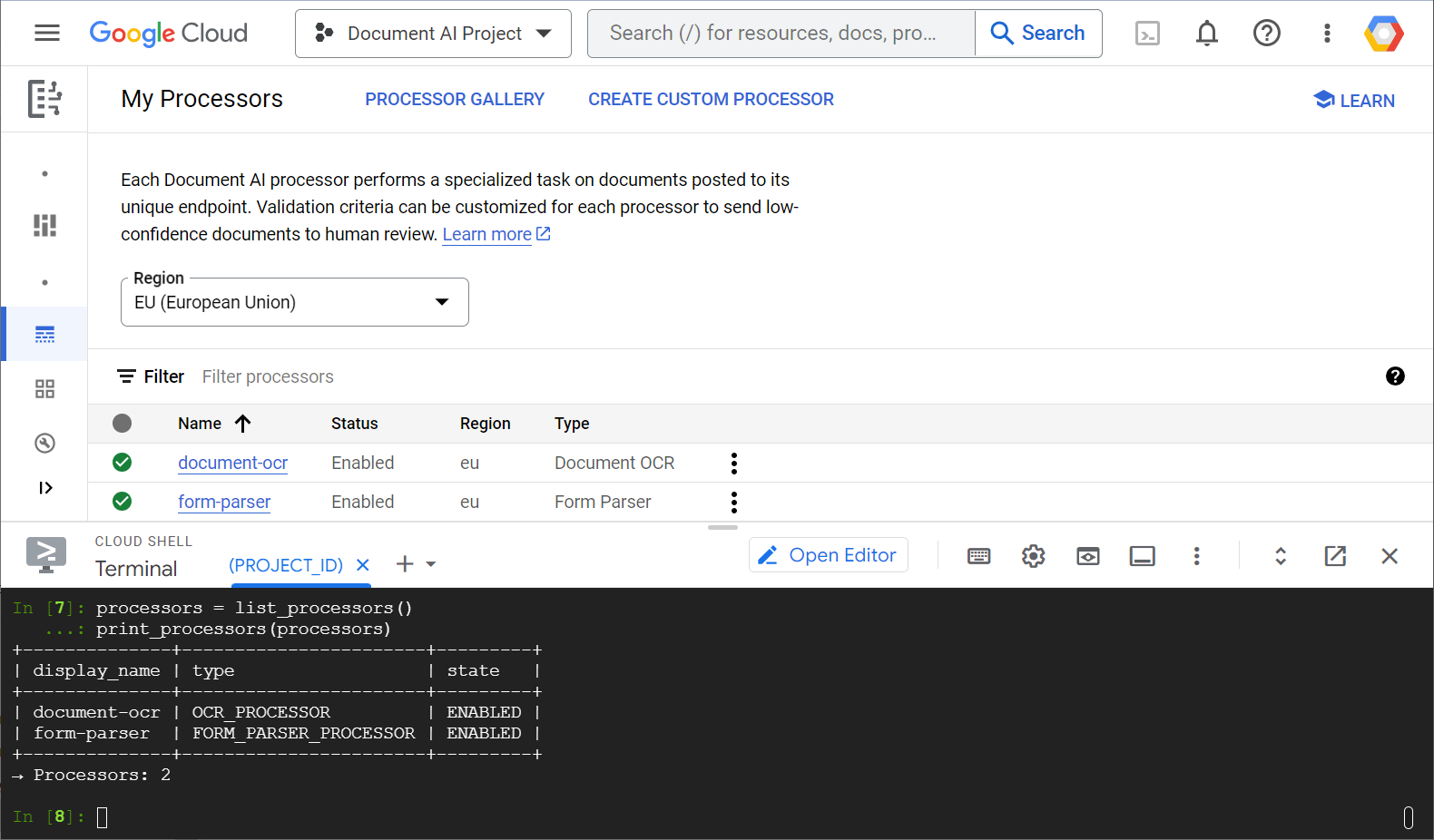
In diesem Lab konzentrieren Sie sich auf die programmatische Verwaltung von Document AI-Prozessoren mit der Python-Clientbibliothek.
Was wird angezeigt?
- Umgebung einrichten
- Prozessortypen abrufen
- Prozessoren erstellen
- Projektprozessoren auflisten
- Prozessoren verwenden
- Prozessoren aktivieren/deaktivieren
- Prozessorversionen verwalten
- Prozessoren löschen
Voraussetzungen
Umfrage
Wie werden Sie diese Anleitung verwenden?
Wie würden Sie Ihre Erfahrung mit Python bewerten?
Wie würden Sie Ihre Erfahrungen mit Google Cloud-Diensten bewerten?
2. Einrichtung und Anforderungen
Umgebung zum selbstbestimmten Lernen einrichten
- Melden Sie sich in der Google Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eines erstellen.

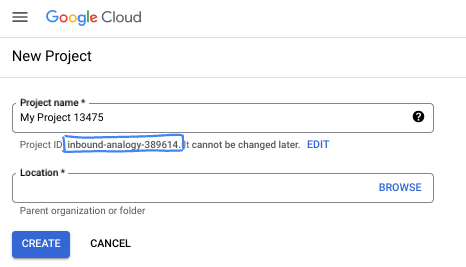
- Der Projektname ist der Anzeigename für die Teilnehmer dieses Projekts. Es handelt sich um einen String, der nicht von Google APIs verwendet wird. Sie können sie jederzeit aktualisieren.
- Die Projekt-ID ist für alle Google Cloud-Projekte eindeutig und unveränderlich (kann nach dem Festlegen nicht mehr geändert werden). In der Cloud Console wird automatisch ein eindeutiger String generiert. Normalerweise ist es nicht wichtig, wie dieser String aussieht. In den meisten Codelabs müssen Sie auf Ihre Projekt-ID verweisen (in der Regel als
PROJECT_IDangegeben). Wenn Ihnen die generierte ID nicht gefällt, können Sie eine andere zufällige ID generieren. Alternativ können Sie es mit einem eigenen Namen versuchen und sehen, ob er verfügbar ist. Sie kann nach diesem Schritt nicht mehr geändert werden und bleibt für die Dauer des Projekts bestehen. - Zur Information: Es gibt einen dritten Wert, die Projektnummer, die von einigen APIs verwendet wird. Weitere Informationen zu diesen drei Werten
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Cloud-Ressourcen/-APIs zu verwenden. Die Durchführung dieses Codelabs kostet wenig oder gar nichts. Wenn Sie Ressourcen herunterfahren möchten, um Kosten zu vermeiden, die über diese Anleitung hinausgehen, können Sie die erstellten Ressourcen oder das Projekt löschen. Neue Google Cloud-Nutzer können am kostenlosen Testzeitraum mit einem Guthaben von 300$ teilnehmen.
Cloud Shell starten
Während Sie Google Cloud von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Lab Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Cloud Shell aktivieren
- Klicken Sie in der Cloud Console auf Cloud Shell aktivieren
 .
.

Wenn Sie die Cloud Shell zum ersten Mal starten, wird ein Fenster mit einer Beschreibung eingeblendet. Klicken Sie in diesem Fall einfach auf Weiter.
Das Herstellen der Verbindung mit der Cloud Shell sollte nur wenige Augenblicke dauern.

Auf dieser virtuellen Maschine sind alle erforderlichen Entwicklungstools installiert. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Die meisten, wenn nicht sogar alle Aufgaben in diesem Codelab können mit einem Browser erledigt werden.
Sobald die Verbindung mit der Cloud Shell hergestellt ist, sehen Sie, dass Sie authentifiziert sind und für das Projekt Ihre Projekt-ID eingestellt ist.
- Führen Sie in der Cloud Shell den folgenden Befehl aus, um zu prüfen, ob Sie authentifiziert sind:
gcloud auth list
Befehlsausgabe
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt:
gcloud config list project
Befehlsausgabe
[core] project = <PROJECT_ID>
Ist dies nicht der Fall, können Sie die Einstellung mit diesem Befehl vornehmen:
gcloud config set project <PROJECT_ID>
Befehlsausgabe
Updated property [core/project].
3. Umgebung einrichten
Bevor Sie mit Document AI arbeiten können, müssen Sie die Document AI API aktivieren. Führen Sie dazu den folgenden Befehl in Cloud Shell aus:
gcloud services enable documentai.googleapis.com
Auf dem Bildschirm sollte Folgendes zu sehen sein:
Operation "operations/..." finished successfully.
Jetzt können Sie Document AI verwenden.
Wechseln Sie zu Ihrem Basisverzeichnis:
cd ~
Erstellen Sie eine virtuelle Python-Umgebung, um die Abhängigkeiten zu isolieren:
virtualenv venv-docai
Aktivieren Sie die virtuelle Umgebung:
source venv-docai/bin/activate
Installieren Sie IPython, die Document AI-Clientbibliothek und python-tabulate (mit dem Sie die Anfrageergebnisse formatieren):
pip install ipython google-cloud-documentai tabulate
Auf dem Bildschirm sollte Folgendes zu sehen sein:
... Installing collected packages: ..., tabulate, ipython, google-cloud-documentai Successfully installed ... google-cloud-documentai-2.15.0 ...
Jetzt können Sie die Document AI-Clientbibliothek verwenden.
Legen Sie die folgenden Umgebungsvariablen fest:
export PROJECT_ID=$(gcloud config get-value core/project)
# Choose "us" or "eu"
export API_LOCATION="us"
Ab jetzt sollten alle Schritte in derselben Sitzung ausgeführt werden.
Prüfen Sie, ob Ihre Umgebungsvariablen richtig definiert sind:
echo $PROJECT_ID
echo $API_LOCATION
In den nächsten Schritten verwenden Sie einen interaktiven Python-Interpreter namens IPython, den Sie gerade installiert haben. Starten Sie eine Sitzung, indem Sie ipython in Cloud Shell ausführen:
ipython
Auf dem Bildschirm sollte Folgendes zu sehen sein:
Python 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0] Type 'copyright', 'credits' or 'license' for more information IPython 9.1.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
Kopieren Sie den folgenden Code in Ihre IPython-Sitzung:
import os
from typing import Iterator, MutableSequence, Optional, Sequence, Tuple
import google.cloud.documentai_v1 as docai
from tabulate import tabulate
PROJECT_ID = os.getenv("PROJECT_ID", "")
API_LOCATION = os.getenv("API_LOCATION", "")
assert PROJECT_ID, "PROJECT_ID is undefined"
assert API_LOCATION in ("us", "eu"), "API_LOCATION is incorrect"
# Test processors
document_ocr_display_name = "document-ocr"
form_parser_display_name = "form-parser"
test_processor_display_names_and_types = (
(document_ocr_display_name, "OCR_PROCESSOR"),
(form_parser_display_name, "FORM_PARSER_PROCESSOR"),
)
def get_client() -> docai.DocumentProcessorServiceClient:
client_options = {"api_endpoint": f"{API_LOCATION}-documentai.googleapis.com"}
return docai.DocumentProcessorServiceClient(client_options=client_options)
def get_parent(client: docai.DocumentProcessorServiceClient) -> str:
return client.common_location_path(PROJECT_ID, API_LOCATION)
def get_client_and_parent() -> Tuple[docai.DocumentProcessorServiceClient, str]:
client = get_client()
parent = get_parent(client)
return client, parent
Sie können jetzt Ihre erste Anfrage senden und die Prozessortypen abrufen.
4. Prozessortypen abrufen
Bevor Sie im nächsten Schritt einen Prozessor erstellen, rufen Sie die verfügbaren Prozessortypen ab. Sie können diese Liste mit fetch_processor_types abrufen.
Fügen Sie Ihrer IPython-Sitzung die folgenden Funktionen hinzu:
def fetch_processor_types() -> MutableSequence[docai.ProcessorType]:
client, parent = get_client_and_parent()
response = client.fetch_processor_types(parent=parent)
return response.processor_types
def print_processor_types(processor_types: Sequence[docai.ProcessorType]):
def sort_key(pt):
return (not pt.allow_creation, pt.category, pt.type_)
sorted_processor_types = sorted(processor_types, key=sort_key)
data = processor_type_tabular_data(sorted_processor_types)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor types: {len(sorted_processor_types)}")
def processor_type_tabular_data(
processor_types: Sequence[docai.ProcessorType],
) -> Iterator[Tuple[str, str, str, str]]:
def locations(pt):
return ", ".join(sorted(loc.location_id for loc in pt.available_locations))
yield ("type", "category", "allow_creation", "locations")
yield ("left", "left", "left", "left")
if not processor_types:
yield ("-", "-", "-", "-")
return
for pt in processor_types:
yield (pt.type_, pt.category, f"{pt.allow_creation}", locations(pt))
Prozessortypen auflisten:
processor_types = fetch_processor_types()
print_processor_types(processor_types)
Die Ausgabe sollte in etwa so aussehen:
+--------------------------------------+-------------+----------------+-----------+ | type | category | allow_creation | locations | +--------------------------------------+-------------+----------------+-----------+ | CUSTOM_CLASSIFICATION_PROCESSOR | CUSTOM | True | eu, us | ... | FORM_PARSER_PROCESSOR | GENERAL | True | eu, us | | LAYOUT_PARSER_PROCESSOR | GENERAL | True | eu, us | | OCR_PROCESSOR | GENERAL | True | eu, us | | BANK_STATEMENT_PROCESSOR | SPECIALIZED | True | eu, us | | EXPENSE_PROCESSOR | SPECIALIZED | True | eu, us | ... +--------------------------------------+-------------+----------------+-----------+ → Processor types: 19
Jetzt haben Sie alle Informationen, die Sie zum Erstellen von Prozessoren im nächsten Schritt benötigen.
5. Prozessoren erstellen
Rufen Sie zum Erstellen eines Prozessors create_processor mit einem Anzeigenamen und einem Prozessortyp auf.
Fügen Sie die folgende Funktion hinzu:
def create_processor(display_name: str, type: str) -> docai.Processor:
client, parent = get_client_and_parent()
processor = docai.Processor(display_name=display_name, type_=type)
return client.create_processor(parent=parent, processor=processor)
Testprozessoren erstellen:
separator = "=" * 80
for display_name, type in test_processor_display_names_and_types:
print(separator)
print(f"Creating {display_name} ({type})...")
try:
create_processor(display_name, type)
except Exception as err:
print(err)
print(separator)
print("Done")
Sie sollten Folgendes erhalten:
================================================================================ Creating document-ocr (OCR_PROCESSOR)... ================================================================================ Creating form-parser (FORM_PARSER_PROCESSOR)... ================================================================================ Done
Sie haben neue Prozessoren erstellt.
Als Nächstes erfahren Sie, wie Sie die Prozessoren auflisten.
6. Projektprozessoren auflisten
list_processors gibt die Liste aller Prozessoren zurück, die zu Ihrem Projekt gehören.
Fügen Sie die folgenden Funktionen hinzu:
def list_processors() -> MutableSequence[docai.Processor]:
client, parent = get_client_and_parent()
response = client.list_processors(parent=parent)
return list(response.processors)
def print_processors(processors: Optional[Sequence[docai.Processor]] = None):
def sort_key(processor):
return processor.display_name
if processors is None:
processors = list_processors()
sorted_processors = sorted(processors, key=sort_key)
data = processor_tabular_data(sorted_processors)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processors: {len(sorted_processors)}")
def processor_tabular_data(
processors: Sequence[docai.Processor],
) -> Iterator[Tuple[str, str, str]]:
yield ("display_name", "type", "state")
yield ("left", "left", "left")
if not processors:
yield ("-", "-", "-")
return
for processor in processors:
yield (processor.display_name, processor.type_, processor.state.name)
Funktionen aufrufen:
processors = list_processors()
print_processors(processors)
Sie sollten Folgendes erhalten:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Wenn Sie einen Prozessor anhand seines Anzeigenamens abrufen möchten, fügen Sie die folgende Funktion hinzu:
def get_processor(
display_name: str,
processors: Optional[Sequence[docai.Processor]] = None,
) -> Optional[docai.Processor]:
if processors is None:
processors = list_processors()
for processor in processors:
if processor.display_name == display_name:
return processor
return None
Die Funktion testen:
processor = get_processor(document_ocr_display_name, processors)
assert processor is not None
print(processor)
Auf dem Bildschirm sollte Folgendes zu sehen sein:
name: "projects/PROJECT_NUM/locations/LOCATION/processors/PROCESSOR_ID" type_: "OCR_PROCESSOR" display_name: "document-ocr" state: ENABLED ...
Jetzt wissen Sie, wie Sie die Projektprozessoren auflisten und anhand ihrer Anzeigenamen abrufen. Als Nächstes erfahren Sie, wie Sie einen Prozessor verwenden.
7. Prozessoren verwenden
Dokumente können auf zwei Arten verarbeitet werden:
- Synchron: Rufen Sie
process_documentauf, um ein einzelnes Dokument zu analysieren und die Ergebnisse direkt zu verwenden. - Asynchron: Rufen Sie
batch_process_documentsauf, um eine Batchverarbeitung für mehrere oder große Dokumente zu starten.
Ihr Testdokument ( PDF) ist ein gescannter Fragebogen mit handschriftlichen Antworten. Laden Sie die Datei direkt aus Ihrer IPython-Sitzung in Ihr Arbeitsverzeichnis herunter:
!gsutil cp gs://cloud-samples-data/documentai/form.pdf .
Prüfen Sie den Inhalt Ihres Arbeitsverzeichnisses:
!ls
Sie sollten Folgendes haben:
... form.pdf ... venv-docai ...
Sie können die synchrone Methode process_document verwenden, um eine lokale Datei zu analysieren. Fügen Sie die folgende Funktion hinzu:
def process_file(
processor: docai.Processor,
file_path: str,
mime_type: str,
) -> docai.Document:
client = get_client()
with open(file_path, "rb") as document_file:
document_content = document_file.read()
document = docai.RawDocument(content=document_content, mime_type=mime_type)
request = docai.ProcessRequest(raw_document=document, name=processor.name)
response = client.process_document(request)
return response.document
Da es sich bei Ihrem Dokument um einen Fragebogen handelt, wählen Sie den Formularparser aus. Zusätzlich zum Extrahieren des Texts (gedruckt und handschriftlich), was alle Prozessoren tun, erkennt dieser allgemeine Prozessor Formularfelder.
Dokument analysieren:
processor = get_processor(form_parser_display_name)
assert processor is not None
file_path = "./form.pdf"
mime_type = "application/pdf"
document = process_file(processor, file_path, mime_type)
Alle Prozessoren führen einen ersten Durchlauf der optischen Zeichenerkennung (Optical Character Recognition, OCR) für das Dokument aus. Überprüfen Sie den durch den OCR-Vorgang erkannten Text:
document.text.split("\n")
Die Ausgabe sollte etwa so aussehen:
['FakeDoc M.D.', 'HEALTH INTAKE FORM', 'Please fill out the questionnaire carefully. The information you provide will be used to complete', 'your health profile and will be kept confidential.', 'Date:', '9/14/19', 'Name:', 'Sally Walker', 'DOB: 09/04/1986', 'Address: 24 Barney Lane', 'City: Towaco', 'State: NJ Zip: 07082', 'Email: Sally, walker@cmail.com', '_Phone #: (906) 917-3486', 'Gender: F', 'Marital Status:', ... ]
Fügen Sie die folgenden Funktionen hinzu, um die erkannten Formularfelder auszugeben:
def print_form_fields(document: docai.Document):
sorted_form_fields = form_fields_sorted_by_ocr_order(document)
data = form_field_tabular_data(sorted_form_fields, document)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Form fields: {len(sorted_form_fields)}")
def form_field_tabular_data(
form_fields: Sequence[docai.Document.Page.FormField],
document: docai.Document,
) -> Iterator[Tuple[str, str, str]]:
yield ("name", "value", "confidence")
yield ("right", "left", "right")
if not form_fields:
yield ("-", "-", "-")
return
for form_field in form_fields:
name_layout = form_field.field_name
value_layout = form_field.field_value
name = text_from_layout(name_layout, document)
value = text_from_layout(value_layout, document)
confidence = value_layout.confidence
yield (name, value, f"{confidence:.1%}")
Fügen Sie auch diese Hilfsfunktionen hinzu:
def form_fields_sorted_by_ocr_order(
document: docai.Document,
) -> MutableSequence[docai.Document.Page.FormField]:
def sort_key(form_field):
# Sort according to the field name detected position
text_anchor = form_field.field_name.text_anchor
return text_anchor.text_segments[0].start_index if text_anchor else 0
fields = (field for page in document.pages for field in page.form_fields)
return sorted(fields, key=sort_key)
def text_from_layout(
layout: docai.Document.Page.Layout,
document: docai.Document,
) -> str:
full_text = document.text
segs = layout.text_anchor.text_segments
text = "".join(full_text[seg.start_index : seg.end_index] for seg in segs)
if text.endswith("\n"):
text = text[:-1]
return text
Geben Sie die erkannten Formularfelder aus:
print_form_fields(document)
Sie sollten eine Ausgabe wie die folgende erhalten:
+-----------------+-------------------------+------------+ | name | value | confidence | +-----------------+-------------------------+------------+ | Date: | 9/14/19 | 83.0% | | Name: | Sally Walker | 87.3% | | DOB: | 09/04/1986 | 88.5% | | Address: | 24 Barney Lane | 82.4% | | City: | Towaco | 90.0% | | State: | NJ | 89.4% | | Zip: | 07082 | 91.4% | | Email: | Sally, walker@cmail.com | 79.7% | | _Phone #: | walker@cmail.com | 93.2% | | | (906 | | | Gender: | F | 88.2% | | Marital Status: | Single | 85.2% | | Occupation: | Software Engineer | 81.5% | | Referred By: | None | 76.9% | ... +-----------------+-------------------------+------------+ → Form fields: 17
Prüfen Sie die erkannten Feldnamen und ‑werte ( PDF). Hier ist die obere Hälfte des Fragebogens:

Sie haben ein Formular analysiert, das sowohl gedruckten als auch handschriftlichen Text enthält. Außerdem haben Sie die Felder mit hoher Zuverlässigkeit erkannt. Das Ergebnis ist, dass Ihre Pixel in strukturierte Daten umgewandelt wurden.
8. Prozessoren aktivieren und deaktivieren
Mit disable_processor und enable_processor können Sie steuern, ob ein Prozessor verwendet werden kann.
Fügen Sie die folgenden Funktionen hinzu:
def update_processor_state(processor: docai.Processor, enable_processor: bool):
client = get_client()
if enable_processor:
request = docai.EnableProcessorRequest(name=processor.name)
operation = client.enable_processor(request)
else:
request = docai.DisableProcessorRequest(name=processor.name)
operation = client.disable_processor(request)
operation.result() # Wait for operation to complete
def enable_processor(processor: docai.Processor):
update_processor_state(processor, True)
def disable_processor(processor: docai.Processor):
update_processor_state(processor, False)
Deaktivieren Sie den Formularparser-Prozessor und prüfen Sie den Status Ihrer Prozessoren:
processor = get_processor(form_parser_display_name)
assert processor is not None
disable_processor(processor)
print_processors()
Sie sollten Folgendes erhalten:
+--------------+-----------------------+----------+ | display_name | type | state | +--------------+-----------------------+----------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | DISABLED | +--------------+-----------------------+----------+ → Processors: 2
Aktivieren Sie den Formularparser-Prozessor wieder:
enable_processor(processor)
print_processors()
Sie sollten Folgendes erhalten:
+--------------+-----------------------+---------+ | display_name | type | state | +--------------+-----------------------+---------+ | document-ocr | OCR_PROCESSOR | ENABLED | | form-parser | FORM_PARSER_PROCESSOR | ENABLED | +--------------+-----------------------+---------+ → Processors: 2
Als Nächstes erfahren Sie, wie Sie Prozessorversionen verwalten.
9. Prozessorversionen verwalten
Prozessoren können in mehreren Versionen verfügbar sein. Hier erfahren Sie, wie Sie die Methoden list_processor_versions und set_default_processor_version verwenden.
Fügen Sie die folgenden Funktionen hinzu:
def list_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
client = get_client()
response = client.list_processor_versions(parent=processor.name)
return list(response)
def get_sorted_processor_versions(
processor: docai.Processor,
) -> MutableSequence[docai.ProcessorVersion]:
def sort_key(processor_version: docai.ProcessorVersion):
return processor_version.name
versions = list_processor_versions(processor)
return sorted(versions, key=sort_key)
def print_processor_versions(processor: docai.Processor):
versions = get_sorted_processor_versions(processor)
default_version_name = processor.default_processor_version
data = processor_versions_tabular_data(versions, default_version_name)
headers = next(data)
colalign = next(data)
print(tabulate(data, headers, tablefmt="pretty", colalign=colalign))
print(f"→ Processor versions: {len(versions)}")
def processor_versions_tabular_data(
versions: Sequence[docai.ProcessorVersion],
default_version_name: str,
) -> Iterator[Tuple[str, str, str]]:
yield ("version", "display name", "default")
yield ("left", "left", "left")
if not versions:
yield ("-", "-", "-")
return
for version in versions:
mapping = docai.DocumentProcessorServiceClient.parse_processor_version_path(
version.name
)
processor_version = mapping["processor_version"]
is_default = "Y" if version.name == default_version_name else ""
yield (processor_version, version.display_name, is_default)
Listen Sie die verfügbaren Versionen für den OCR-Prozessor auf:
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Sie erhalten die Prozessorversionen:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | Y | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Fügen Sie nun eine Funktion hinzu, um die Standardprozessorversion zu ändern:
def set_default_processor_version(processor: docai.Processor, version_name: str):
client = get_client()
request = docai.SetDefaultProcessorVersionRequest(
processor=processor.name,
default_processor_version=version_name,
)
operation = client.set_default_processor_version(request)
operation.result() # Wait for operation to complete
Zur neuesten Prozessorversion wechseln:
processor = get_processor(document_ocr_display_name)
assert processor is not None
versions = get_sorted_processor_versions(processor)
new_version = versions[-1] # Latest version
set_default_processor_version(processor, new_version.name)
# Update the processor info
processor = get_processor(document_ocr_display_name)
assert processor is not None
print_processor_versions(processor)
Sie erhalten die Konfiguration der neuen Version:
+--------------------------------+--------------------------+---------+ | version | display name | default | +--------------------------------+--------------------------+---------+ | pretrained-ocr-v1.0-2020-09-23 | Google Stable | | | pretrained-ocr-v1.1-2022-09-12 | Google Release Candidate | | | pretrained-ocr-v1.2-2022-11-10 | Google Release Candidate | | | pretrained-ocr-v2.0-2023-06-02 | Google Stable | | | pretrained-ocr-v2.1-2024-08-07 | Google Release Candidate | Y | +--------------------------------+--------------------------+---------+ → Processor versions: 5
Als Nächstes die ultimative Methode zur Verwaltung von Prozessoren: das Löschen.
10. Prozessoren löschen
Sehen Sie sich zum Schluss an, wie Sie die Methode delete_processor verwenden.
Fügen Sie die folgende Funktion hinzu:
def delete_processor(processor: docai.Processor):
client = get_client()
operation = client.delete_processor(name=processor.name)
operation.result() # Wait for operation to complete
Testprozessoren löschen:
processors_to_delete = [dn for dn, _ in test_processor_display_names_and_types]
print("Deleting processors...")
for processor in list_processors():
if processor.display_name not in processors_to_delete:
continue
print(f" Deleting {processor.display_name}...")
delete_processor(processor)
print("Done\n")
print_processors()
Sie sollten Folgendes erhalten:
Deleting processors... Deleting form-parser... Deleting document-ocr... Done +--------------+------+-------+ | display_name | type | state | +--------------+------+-------+ | - | - | - | +--------------+------+-------+ → Processors: 0
Sie haben alle Methoden zur Prozessorverwaltung kennengelernt. Fast geschafft…
11. Glückwunsch!
Sie haben gelernt, wie Sie Document AI-Prozessoren mit Python verwalten.
Bereinigen
So bereinigen Sie Ihre Entwicklungsumgebung über Cloud Shell:
- Wenn Sie sich noch in Ihrer IPython-Sitzung befinden, kehren Sie zur Shell zurück:
exit - Beenden Sie die Verwendung der virtuellen Python-Umgebung:
deactivate - Löschen Sie den Ordner für die virtuelle Umgebung:
cd ~ ; rm -rf ./venv-docai
So löschen Sie Ihr Google Cloud-Projekt über Cloud Shell:
- Rufen Sie Ihre aktuelle Projekt-ID ab:
PROJECT_ID=$(gcloud config get-value core/project) - Prüfen Sie, ob dies das Projekt ist, das Sie löschen möchten:
echo $PROJECT_ID - Projekt löschen:
gcloud projects delete $PROJECT_ID
Weitere Informationen
- Document AI in Ihrem Browser ausprobieren: https://cloud.google.com/document-ai/docs/drag-and-drop
- Details zu Document AI-Prozessoren: https://cloud.google.com/document-ai/docs/processors-list
- Python in Google Cloud: https://cloud.google.com/python
- Cloud-Clientbibliotheken für Python: https://github.com/googleapis/google-cloud-python
Lizenz
Dieser Text ist mit einer Creative Commons Attribution 2.0 Generic License lizenziert.