
1. Введение
В этом практическом занятии вы научитесь использовать специализированные процессоры Document AI для классификации и анализа специализированных документов с помощью Python. Для классификации и разделения мы будем использовать пример PDF-файла, содержащего счета-фактуры, квитанции и выписки по коммунальным услугам. Затем, для анализа и извлечения сущностей, мы будем использовать в качестве примера счет-фактуру.
Данная процедура и пример кода будут работать с любым специализированным документом, поддерживаемым Document AI.
Предварительные требования
Данный практический семинар основан на материалах других практических семинаров по искусственному интеллекту для работы с документами.
Перед продолжением рекомендуется выполнить следующие практические задания:
- Оптическое распознавание символов (OCR) с использованием Document AI и Python.
- Анализ форм с помощью Document AI (Python)
Что вы узнаете
- Как классифицировать и выявлять точки разделения для специализированных документов.
- Как извлекать схематизированные сущности с помощью специализированных процессоров.
Что вам понадобится
2. Настройка
В этом практическом занятии предполагается, что вы выполнили шаги по настройке Document AI, описанные во вводном практическом занятии .
Перед продолжением выполните следующие шаги:
Вам также потребуется установить Pandas , популярную библиотеку для анализа данных в Python.
pip3 install --upgrade pandas
3. Создание специализированных процессоров
Для начала необходимо создать экземпляры процессоров, которые вы будете использовать в этом руководстве.
- В консоли перейдите к разделу «Обзор платформы Document AI».
- Нажмите «Создать обработчик» , прокрутите вниз до раздела «Специализированные» и выберите «Разделитель закупочных документов» .
- Присвойте ему имя "codelab-procurement-splitter" (или что-нибудь другое, что вы запомните) и выберите ближайший регион из списка.
- Нажмите «Создать» , чтобы создать свой процессор.
- Скопируйте идентификатор процессора. Он понадобится вам в дальнейшем при работе с кодом.
- Повторите шаги 2-6 с парсером счетов (который можно назвать "codelab-invoice-parser")
Тестовый процессор в консоли
Вы можете протестировать парсер счетов в консоли, загрузив документ.
Нажмите «Загрузить документ» и выберите счет-фактуру для анализа. Вы можете скачать и использовать этот образец счета-фактуры, если у вас нет подходящего варианта.
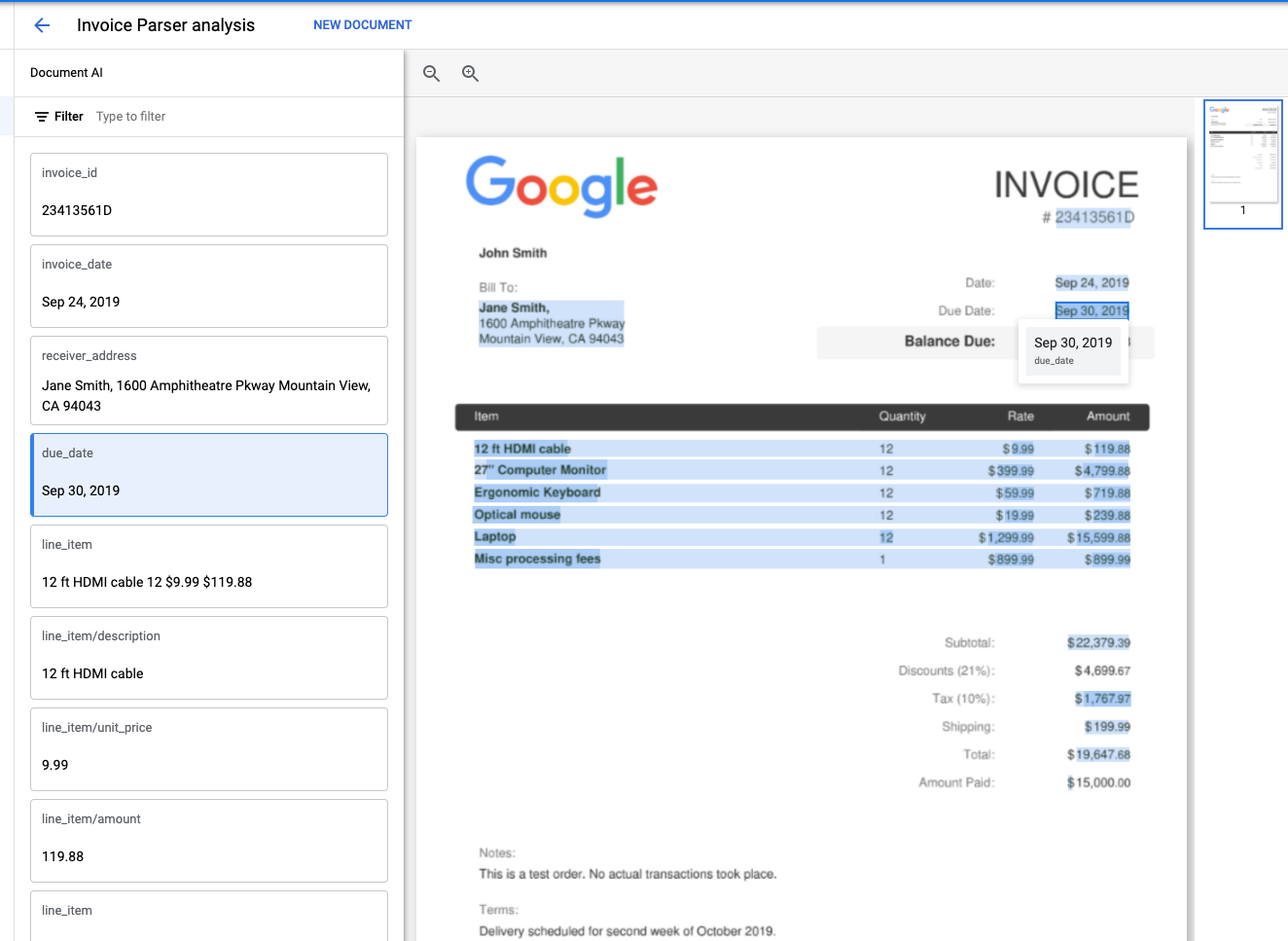
Результат должен выглядеть примерно так:
4. Скачать образцы документов
У нас есть несколько образцов документов, которые можно использовать для этой лабораторной работы.
Вы можете скачать PDF-файлы, используя следующие ссылки. Затем загрузите их в экземпляр Cloud Shell .
В качестве альтернативы вы можете загрузить их из нашего общедоступного облачного хранилища с помощью команды gsutil .
gsutil cp gs://cloud-samples-data/documentai/codelabs/specialized-processors/procurement_multi_document.pdf .
gsutil cp gs://cloud-samples-data/documentai/codelabs/specialized-processors/google_invoice.pdf .
5. Классифицируйте и разделите документы.
На этом этапе вы будете использовать API онлайн-обработки для классификации и обнаружения логических точек разделения в многостраничном документе.
Вы также можете использовать API пакетной обработки, если хотите отправить несколько файлов или если размер файла превышает максимальное количество страниц, разрешенное для онлайн-обработки . Инструкции по этому поводу можно найти в руководстве Document AI OCR Codelab .
Код для выполнения запроса к API идентичен для обычного процессора, за исключением идентификатора процессора.
Разделитель/классификатор закупок
Создайте файл с именем classification.py и используйте приведенный ниже код.
Замените PROCUREMENT_SPLITTER_ID на идентификатор созданного вами ранее процессора разделения закупок. Замените YOUR_PROJECT_ID и YOUR_PROJECT_LOCATION на идентификатор вашего облачного проекта и местоположение процессора соответственно.
classification.py
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as file:
file_content = file.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=file_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(name=resource_name, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "PROCUREMENT_SPLITTER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "procurement_multi_document.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
print("Document processing complete.")
types = []
confidence = []
pages = []
# Each Document.entity is a classification
for entity in document.entities:
classification = entity.type_
types.append(classification)
confidence.append(f"{entity.confidence:.0%}")
# entity.page_ref contains the pages that match the classification
pages_list = []
for page_ref in entity.page_anchor.page_refs:
pages_list.append(page_ref.page)
pages.append(pages_list)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame({"Classification": types, "Confidence": confidence, "Pages": pages})
print(df)
Результат должен выглядеть примерно так:
$ python3 classification.py
Document processing complete.
Classification Confidence Pages
0 invoice_statement 100% [0]
1 receipt_statement 98% [1]
2 other 81% [2]
3 utility_statement 100% [3]
4 restaurant_statement 100% [4]
Обратите внимание, что инструмент разделения/классификации закупок правильно определил типы документов на страницах 0-1 и 3-4.
На странице 2 находится типовая медицинская анкета, поэтому классификатор правильно определил ее как other .
6. Извлеките сущности.
Теперь вы можете извлечь из файлов схематизированные сущности, включая оценки достоверности, свойства и нормализованные значения.
Код для выполнения запроса к API идентичен предыдущему шагу, и его можно выполнить как с помощью онлайн-запросов, так и пакетных запросов.
Мы получим следующую информацию от этих организаций:
- Тип сущности
- (например,
invoice_date,receiver_name,total_amount)
- (например,
- Исходные значения
- Значения данных представлены в исходном файле документа.
- Нормализованные значения
- Значения данных представлены в нормализованном и стандартном формате, если применимо.
- Также может включать обогащение данных из корпоративного графа знаний.
- Значения уверенности
- Насколько "уверена" модель в точности полученных значений.
Некоторые типы сущностей, такие как line_item могут также включать свойства, являющиеся вложенными сущностями, например line_item/unit_price и line_item/description .
В этом примере вложенная структура сведена к одному уровню для удобства просмотра.
Парсер счетов-фактур
Создайте файл с именем extraction.py и используйте приведенный ниже код.
Замените INVOICE_PARSER_ID на идентификатор созданного вами ранее процессора парсинга счетов и используйте файл google_invoice.pdf
extraction.py
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as file:
file_content = file.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(content=file_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(name=resource_name, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "INVOICE_PARSER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "google_invoice.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
types = []
raw_values = []
normalized_values = []
confidence = []
# Grab each key/value pair and their corresponding confidence scores.
for entity in document.entities:
types.append(entity.type_)
raw_values.append(entity.mention_text)
normalized_values.append(entity.normalized_value.text)
confidence.append(f"{entity.confidence:.0%}")
# Get Properties (Sub-Entities) with confidence scores
for prop in entity.properties:
types.append(prop.type_)
raw_values.append(prop.mention_text)
normalized_values.append(prop.normalized_value.text)
confidence.append(f"{prop.confidence:.0%}")
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame(
{
"Type": types,
"Raw Value": raw_values,
"Normalized Value": normalized_values,
"Confidence": confidence,
}
)
print(df)
Результат должен выглядеть примерно так:
$ python3 extraction.py
Type Raw Value Normalized Value Confidence
0 vat $1,767.97 100%
1 vat/tax_amount $1,767.97 1767.97 USD 0%
2 invoice_date Sep 24, 2019 2019-09-24 99%
3 due_date Sep 30, 2019 2019-09-30 99%
4 total_amount 19,647.68 19647.68 97%
5 total_tax_amount $1,767.97 1767.97 USD 92%
6 net_amount 22,379.39 22379.39 91%
7 receiver_name Jane Smith, 83%
8 invoice_id 23413561D 67%
9 receiver_address 1600 Amphitheatre Pkway\nMountain View, CA 94043 66%
10 freight_amount $199.99 199.99 USD 56%
11 currency $ USD 53%
12 supplier_name John Smith 19%
13 purchase_order 23413561D 1%
14 receiver_tax_id 23413561D 0%
15 supplier_iban 23413561D 0%
16 line_item 9.99 12 12 ft HDMI cable 119.88 100%
17 line_item/unit_price 9.99 9.99 90%
18 line_item/quantity 12 12 77%
19 line_item/description 12 ft HDMI cable 39%
20 line_item/amount 119.88 119.88 92%
21 line_item 12 399.99 27" Computer Monitor 4,799.88 100%
22 line_item/quantity 12 12 80%
23 line_item/unit_price 399.99 399.99 91%
24 line_item/description 27" Computer Monitor 15%
25 line_item/amount 4,799.88 4799.88 94%
26 line_item Ergonomic Keyboard 12 59.99 719.88 100%
27 line_item/description Ergonomic Keyboard 32%
28 line_item/quantity 12 12 76%
29 line_item/unit_price 59.99 59.99 92%
30 line_item/amount 719.88 719.88 94%
31 line_item Optical mouse 12 19.99 239.88 100%
32 line_item/description Optical mouse 26%
33 line_item/quantity 12 12 78%
34 line_item/unit_price 19.99 19.99 91%
35 line_item/amount 239.88 239.88 94%
36 line_item Laptop 12 1,299.99 15,599.88 100%
37 line_item/description Laptop 83%
38 line_item/quantity 12 12 76%
39 line_item/unit_price 1,299.99 1299.99 90%
40 line_item/amount 15,599.88 15599.88 94%
41 line_item Misc processing fees 899.99 899.99 1 100%
42 line_item/description Misc processing fees 22%
43 line_item/unit_price 899.99 899.99 91%
44 line_item/amount 899.99 899.99 94%
45 line_item/quantity 1 1 63%
7. Дополнительно: Попробуйте другие специализированные процессоры.
Вы успешно использовали Document AI для управления закупками, чтобы классифицировать документы и проанализировать счет-фактуру. Document AI также поддерживает другие специализированные решения, перечисленные здесь:
Вы можете следовать той же процедуре и использовать тот же код для обработки любого специализированного процессора.
Если вы хотите опробовать другие специализированные решения, вы можете повторно запустить лабораторную работу с другими типами процессоров и специализированными примерами документов.
Образцы документов
Вот несколько примеров документов, которые вы можете использовать, чтобы опробовать другие специализированные процессоры.
Решение | Тип процессора | Документ |
Личность | ||
Кредитование | ||
Кредитование | ||
Контракты |
Другие примеры документов и результаты работы процессора можно найти в документации .
8. Поздравляем!
Поздравляем, вы успешно использовали Document AI для классификации и извлечения данных из специализированных документов. Мы рекомендуем вам поэкспериментировать с другими специализированными типами документов.
Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этом руководстве:
- В консоли Cloud перейдите на страницу «Управление ресурсами» .
- В списке проектов выберите свой проект и нажмите «Удалить».
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить», чтобы удалить проект.
Узнать больше
Продолжите изучение Document AI с помощью этих дополнительных практических занятий.
- Управление обработчиками документов с помощью ИИ на Python
- Искусственный интеллект для создания документов: участие человека.
- Document AI Workbench: Uptraining
- Document AI Workbench: Пользовательские процессоры
Ресурсы
- Будущее документов — плейлист на YouTube
- Документация по искусственному интеллекту
- Библиотека клиента Document AI Python
- Примеры документов, созданных с помощью ИИ.
Лицензия
Данная работа распространяется под лицензией Creative Commons Attribution 2.0 Generic.