
1. Введение
Document AI — это решение для понимания документов, которое обрабатывает неструктурированные данные, такие как документы, электронные письма и т. д., и делает эти данные более понятными, анализируемыми и пригодными для использования.
Используя функцию повышения точности обработки документов в Document AI Workbench, вы можете добиться более высокой точности обработки документов, предоставив дополнительные размеченные примеры для специализированных типов документов и создав новую версию модели.
В этой лабораторной работе вы создадите процессор для обработки счетов-фактур, настроите его для обучения, разметите примеры документов и обучите процессор.
В данной лабораторной работе используется набор документов, состоящий из случайно сгенерированных счетов-фактур вымышленной компании по производству трубопроводов.
Предварительные требования
Данный практический семинар основан на материалах других практических семинаров по искусственному интеллекту для работы с документами.
Перед продолжением рекомендуется выполнить следующие практические задания (Codelabs).
- Оптическое распознавание символов (OCR) с использованием Document AI (Python)
- Анализ форм с помощью Document AI (Python)
- Специализированные процессоры с поддержкой искусственного интеллекта для обработки документов (Python)
- Управление обработчиками документов с помощью ИИ на Python
- Искусственный интеллект для создания документов: участие человека.
Что вы узнаете
- Настройка процесса повышения квалификации для процессора Invoice Parser.
- Разметьте обучающие данные ИИ для документов с помощью инструмента аннотирования.
- Обучите новую версию модели.
- Оцените точность новой версии модели.
Что вам понадобится
2. Настройка
В этом практическом занятии предполагается, что вы выполнили шаги по настройке Document AI, описанные во вводном практическом занятии .
Перед продолжением выполните следующие шаги:
3. Создайте процессор.
Для выполнения этой лабораторной работы вам сначала необходимо создать процессор Invoice Parser.
- В консоли перейдите на страницу «Обзор Document AI» .

- Нажмите «Создать обработчик» , прокрутите вниз до раздела «Специализированные » (или введите «Invoice Parser» в строку поиска) и выберите «Invoice Parser» .

- Назовите его
codelab-invoice-uptraining(или как-нибудь еще, что вы запомните) и выберите ближайший регион из списка.

- Нажмите «Создать» , чтобы создать свой процессор. После этого вы увидите страницу «Обзор процессора».

4. Создайте набор данных.
Для обучения нашего процессора нам потребуется создать набор данных, включающий обучающие и тестовые данные, которые помогут процессору идентифицировать сущности, которые мы хотим извлечь.
Для хранения набора данных вам потребуется создать новый сегмент в Cloud Storage . Примечание: это не должен быть тот же сегмент, где в настоящее время хранятся ваши документы.
- Откройте Cloud Shell и выполните следующие команды для создания корзины. В качестве альтернативы, создайте новую корзину в Cloud Console. Сохраните это имя корзины, оно понадобится вам позже.
export PROJECT_ID=$(gcloud config get-value project)
gsutil mb -p $PROJECT_ID "gs://${PROJECT_ID}-uptraining-codelab"
- Перейдите на вкладку «Набор данных» и нажмите «Создать набор данных».

- Вставьте имя корзины, созданной на первом шаге, в поле «Путь назначения» . (Не включайте
gs://)
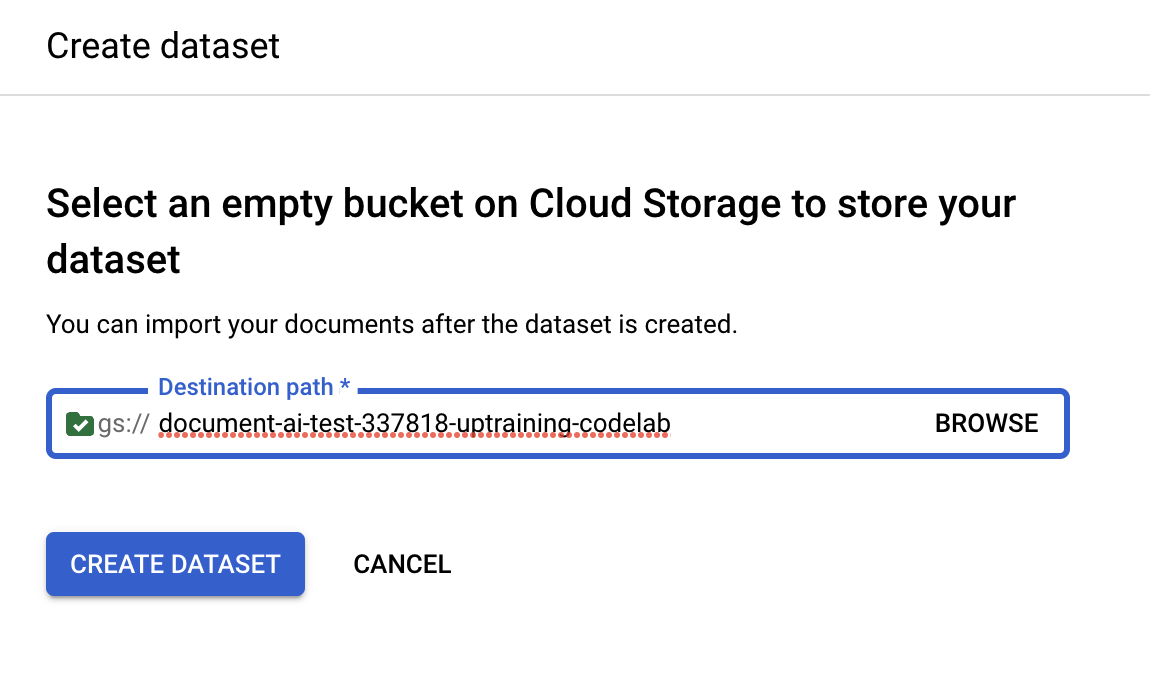
- Дождитесь создания набора данных, после чего вас перенаправит на страницу управления набором данных.

5. Импорт тестового документа
Теперь давайте импортируем образец PDF-файла счета-фактуры в наш набор данных.
- Нажмите на кнопку «Импорт документов» .

- Для выполнения этой лабораторной работы вам будет предоставлен образец PDF-файла. Скопируйте и вставьте следующую ссылку в поле «Путь к источнику» . Пока оставьте поле «Разделение данных» в положении «Не назначено». Нажмите «Импорт» .
cloud-samples-data/documentai/codelabs/uptraining/pdfs

- Дождитесь импорта документа. В моих тестах это заняло менее минуты.

- После завершения импорта вы должны увидеть документ в пользовательском интерфейсе управления наборами данных. Щелкните по нему, чтобы войти в консоль разметки.
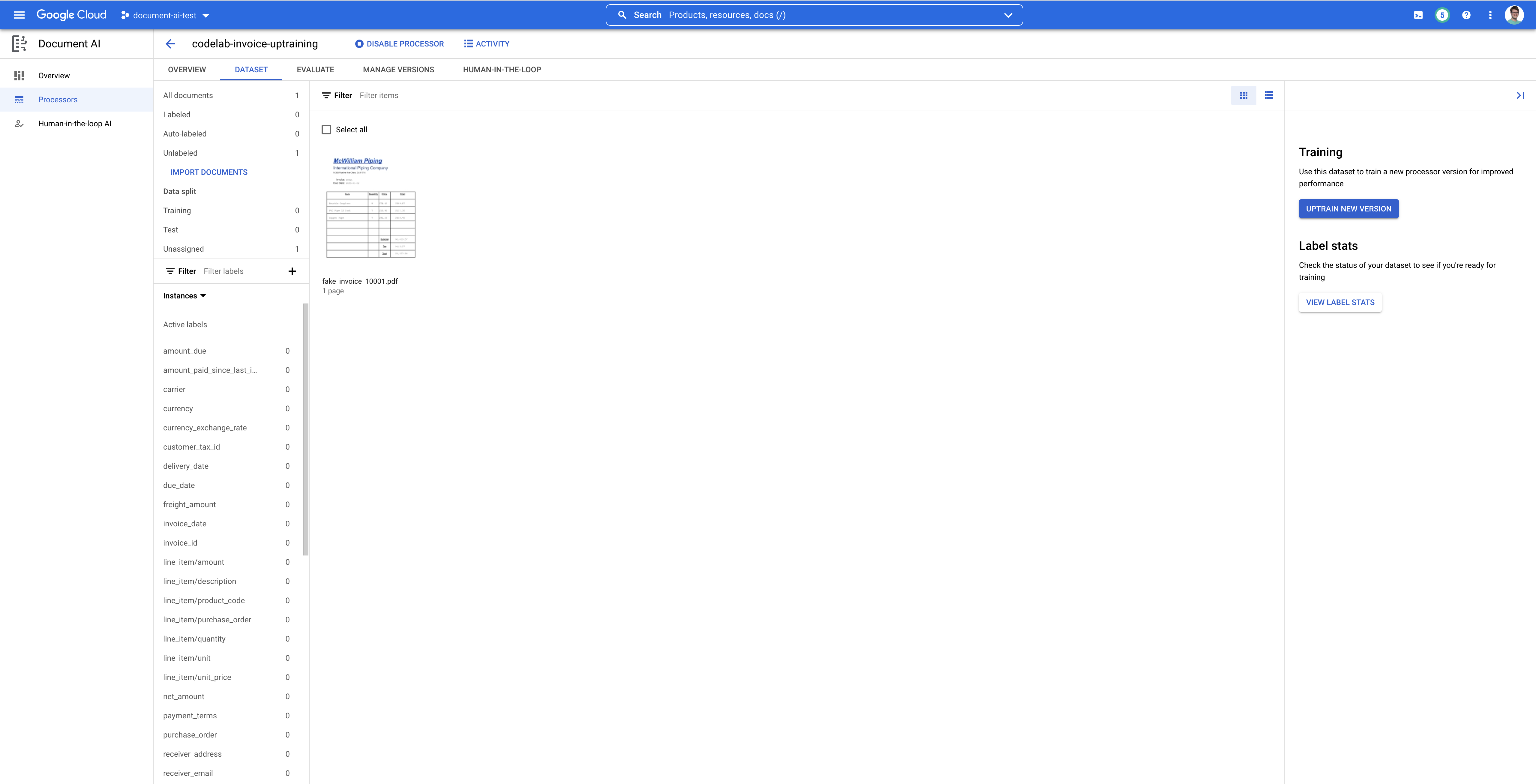
6. Подпишите тестовый документ.
Далее мы определим текстовые элементы и метки для сущностей, которые хотим извлечь. Эти метки будут использованы для обучения нашей модели анализу данной конкретной структуры документа и определению правильных типов.
- Теперь вы должны находиться в консоли маркировки, которая будет выглядеть примерно так.

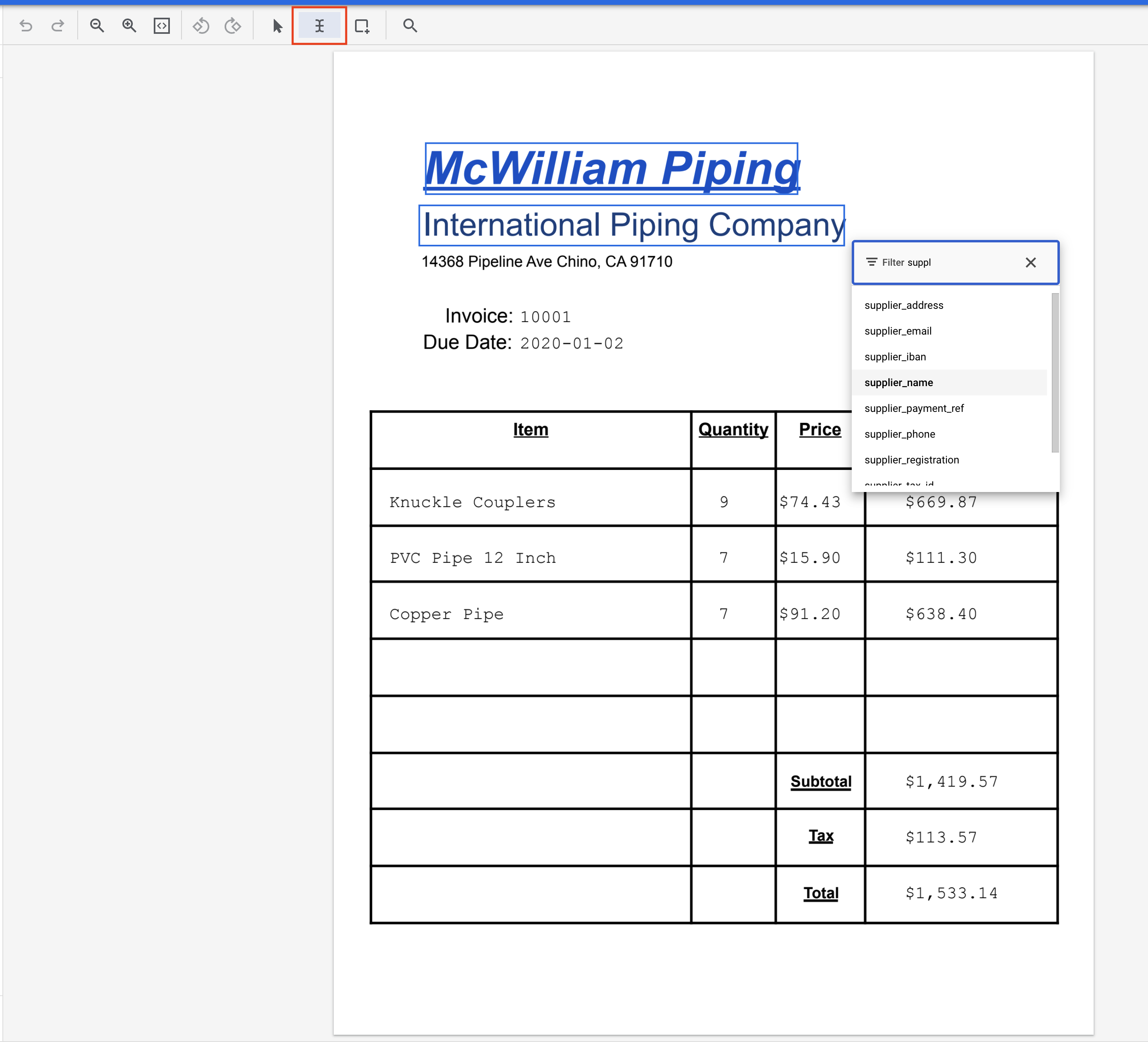
- Щелкните инструмент «Выделить текст», затем выделите текст «McWilliam Piping International Piping Company» и присвойте ему метку
supplier_name. Вы можете использовать текстовый фильтр для поиска названий меток.
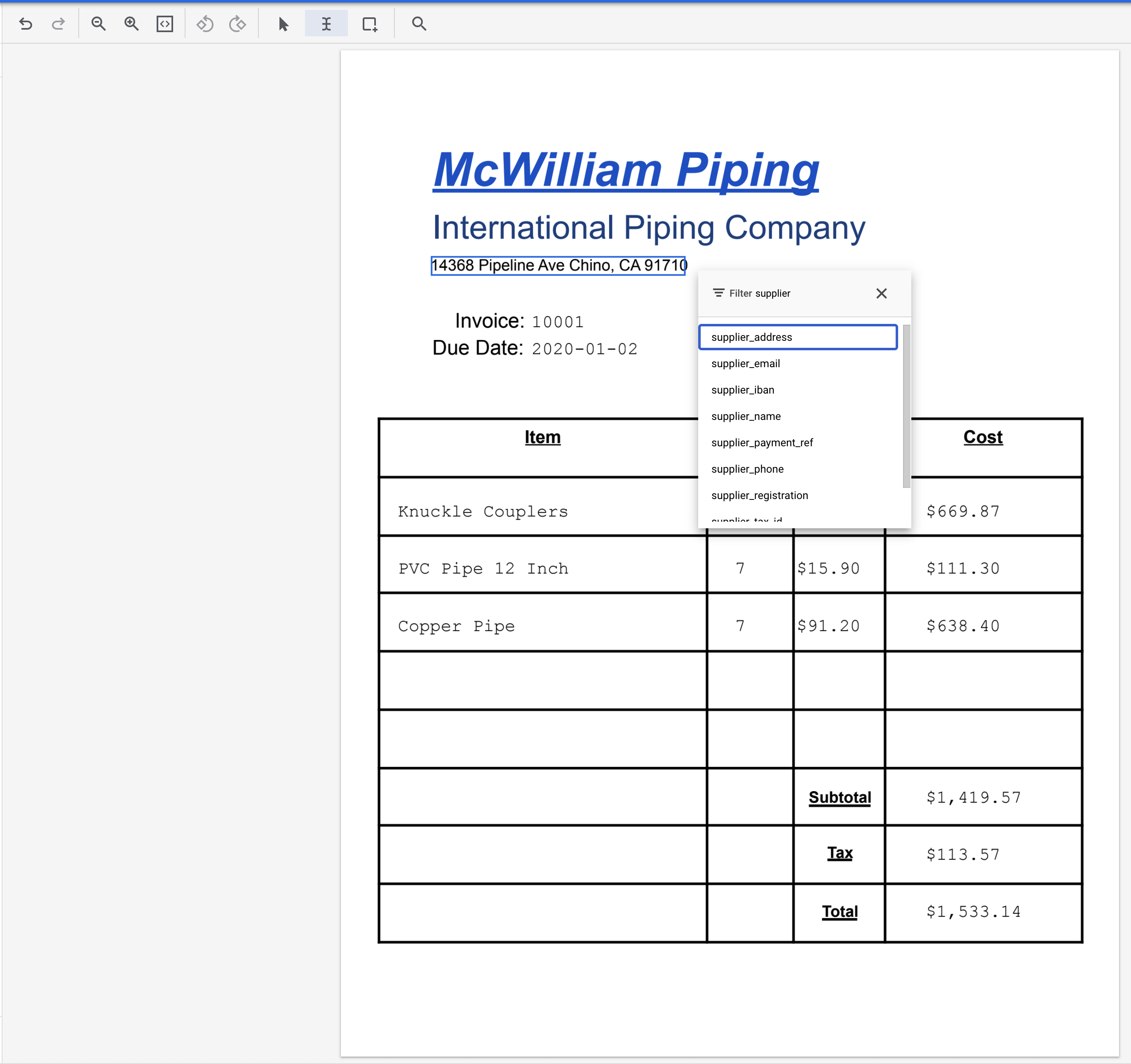
- Выделите текст "14368 Pipeline Ave Chino, CA 91710" и присвойте ему метку
supplier_address.
- Выделите текст "10001" и присвойте ему метку
invoice_id.

- Выделите текст "2020-01-02" и присвойте ему метку
due_date.

- Переключитесь на инструмент «Ограничивающая рамка». Выделите текст «Шарнирные муфты» и присвойте ему метку
line_item/description.
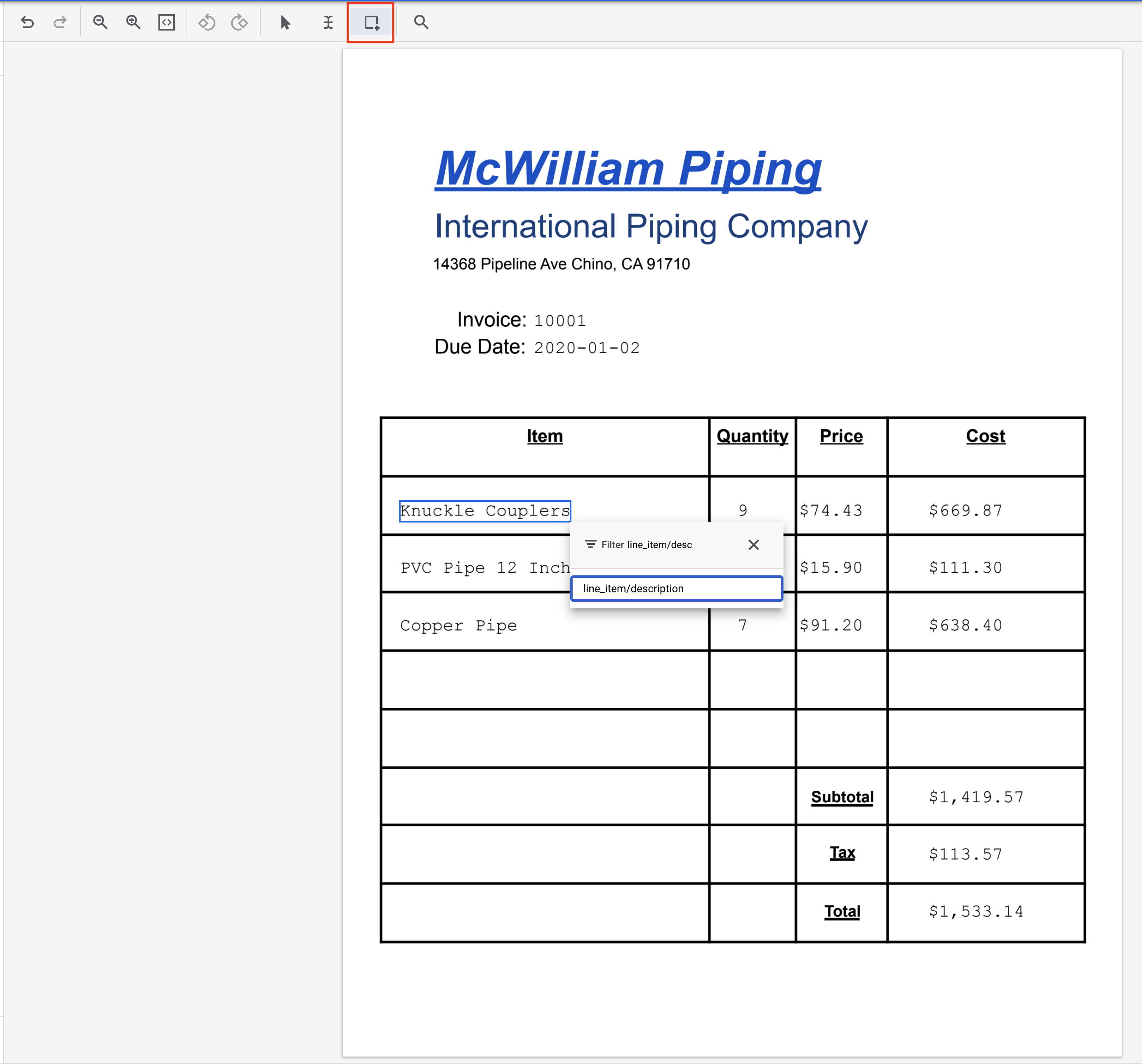
- Выделите текст "9" и присвойте ему метку
line_item/quantity.
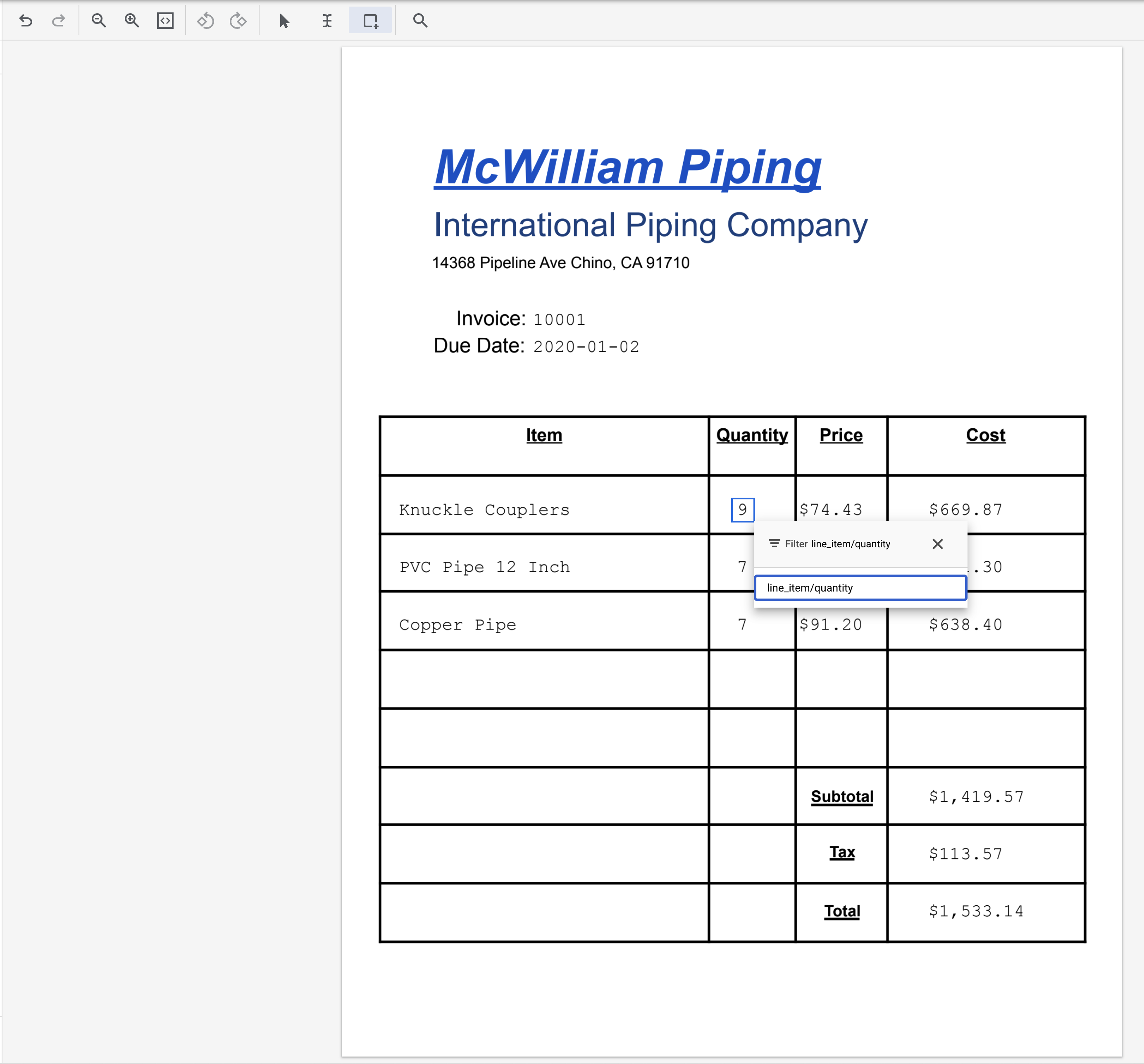
- Выделите текст "74.43" и присвойте ему метку
line_item/unit_price.
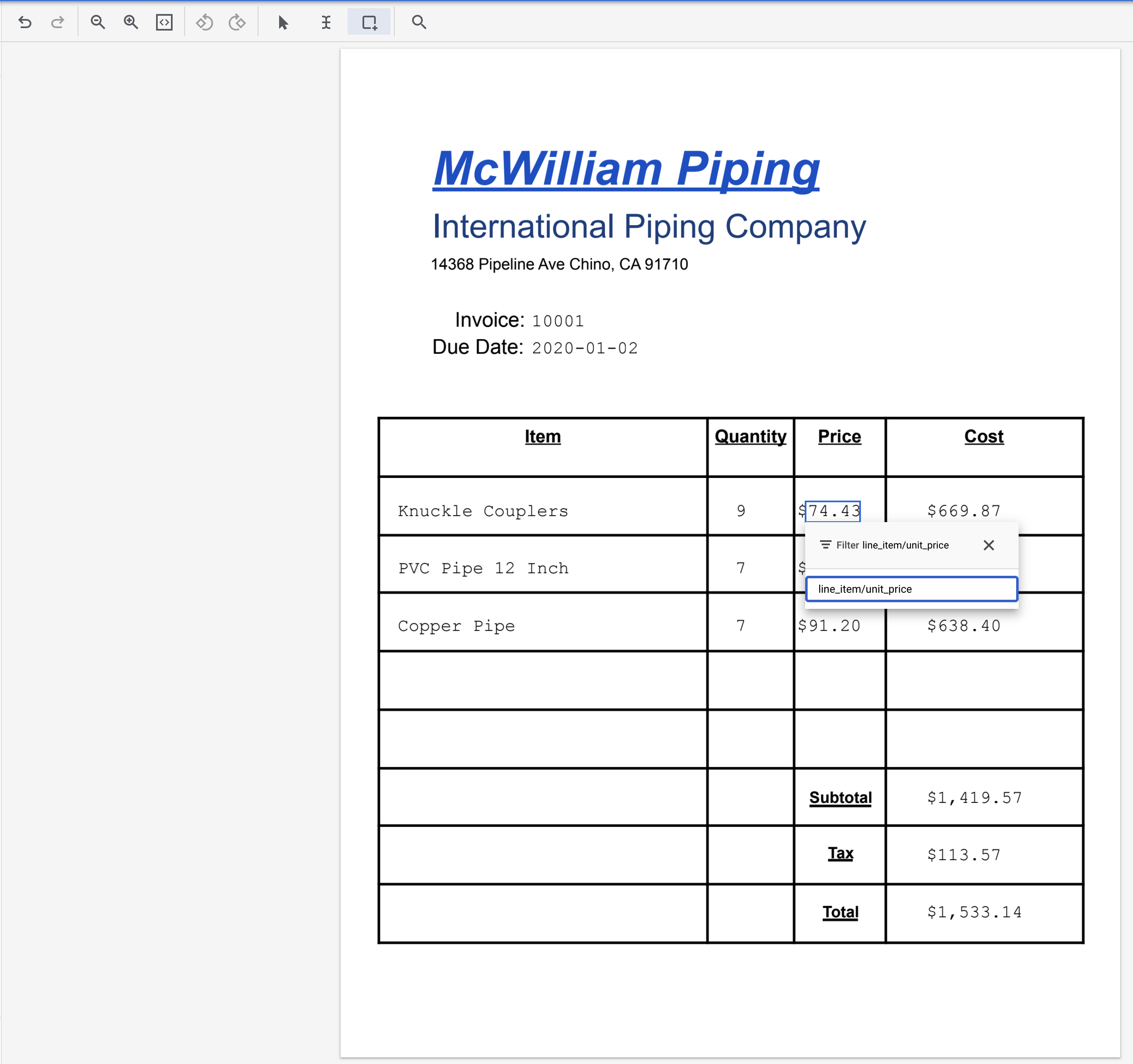
- Выделите текст "669.87" и присвойте ему метку
line_item/amount.
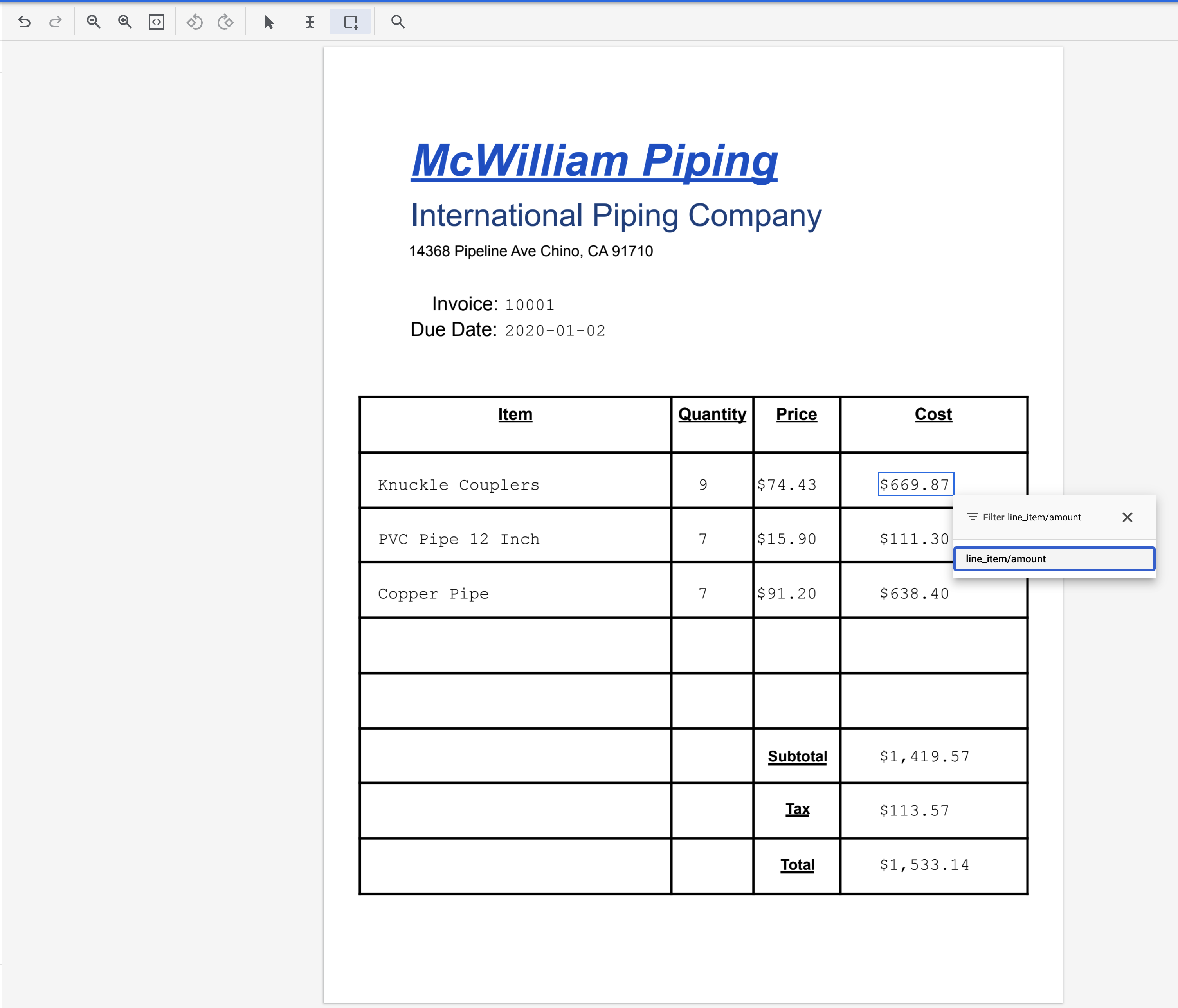
- Повторите предыдущие 4 шага для следующих двух пунктов. В итоге должно получиться вот так.
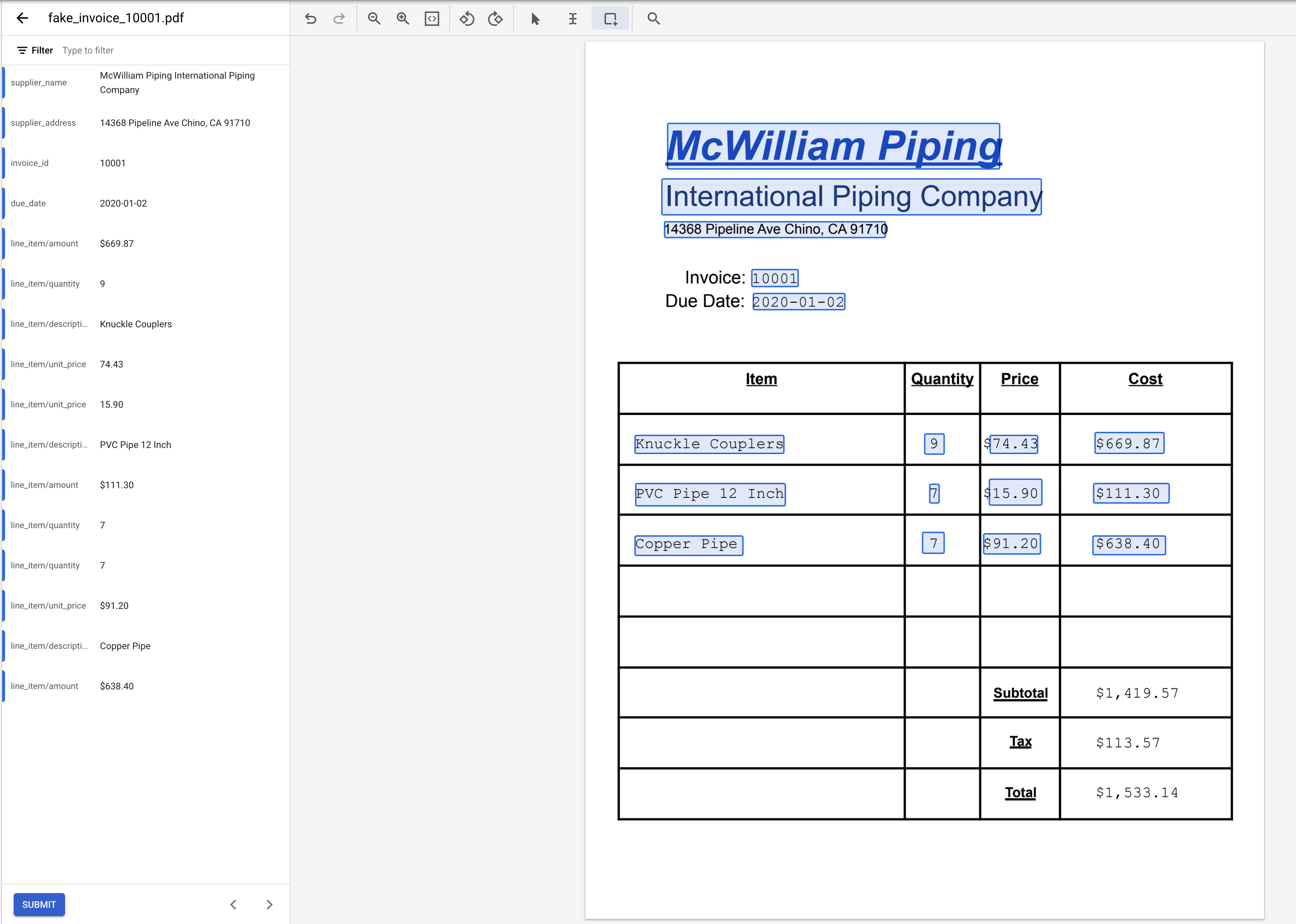
- Выделите текст "1,419.57" (рядом с "Итого") и присвойте ему метку
net_amount.

- Выделите текст "113.57" (рядом с "Налог") и присвойте ему метку
total_tax_amount.
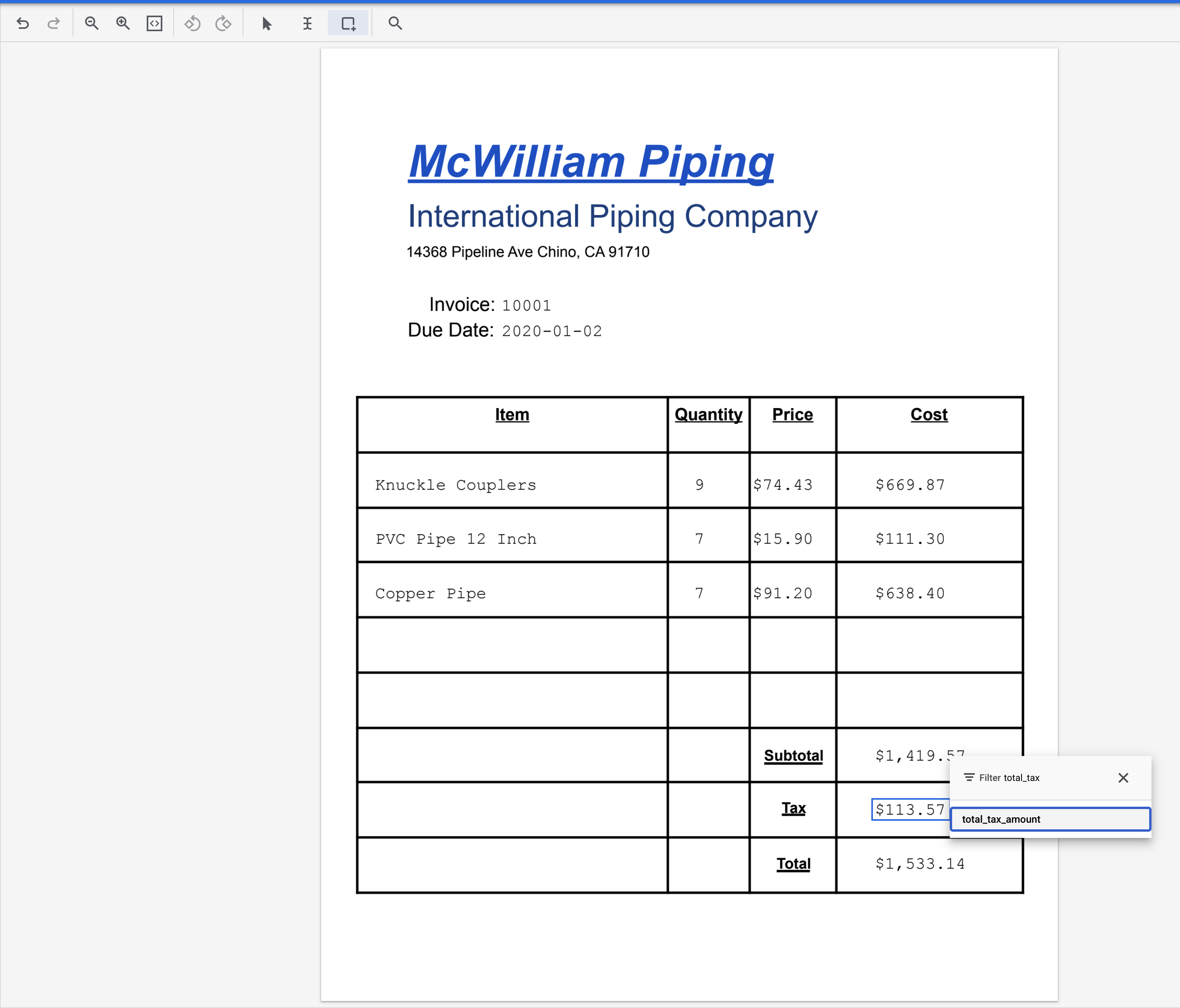
- Выделите текст "1,533.14" (рядом с "Итого") и присвойте ему метку
total_amount.
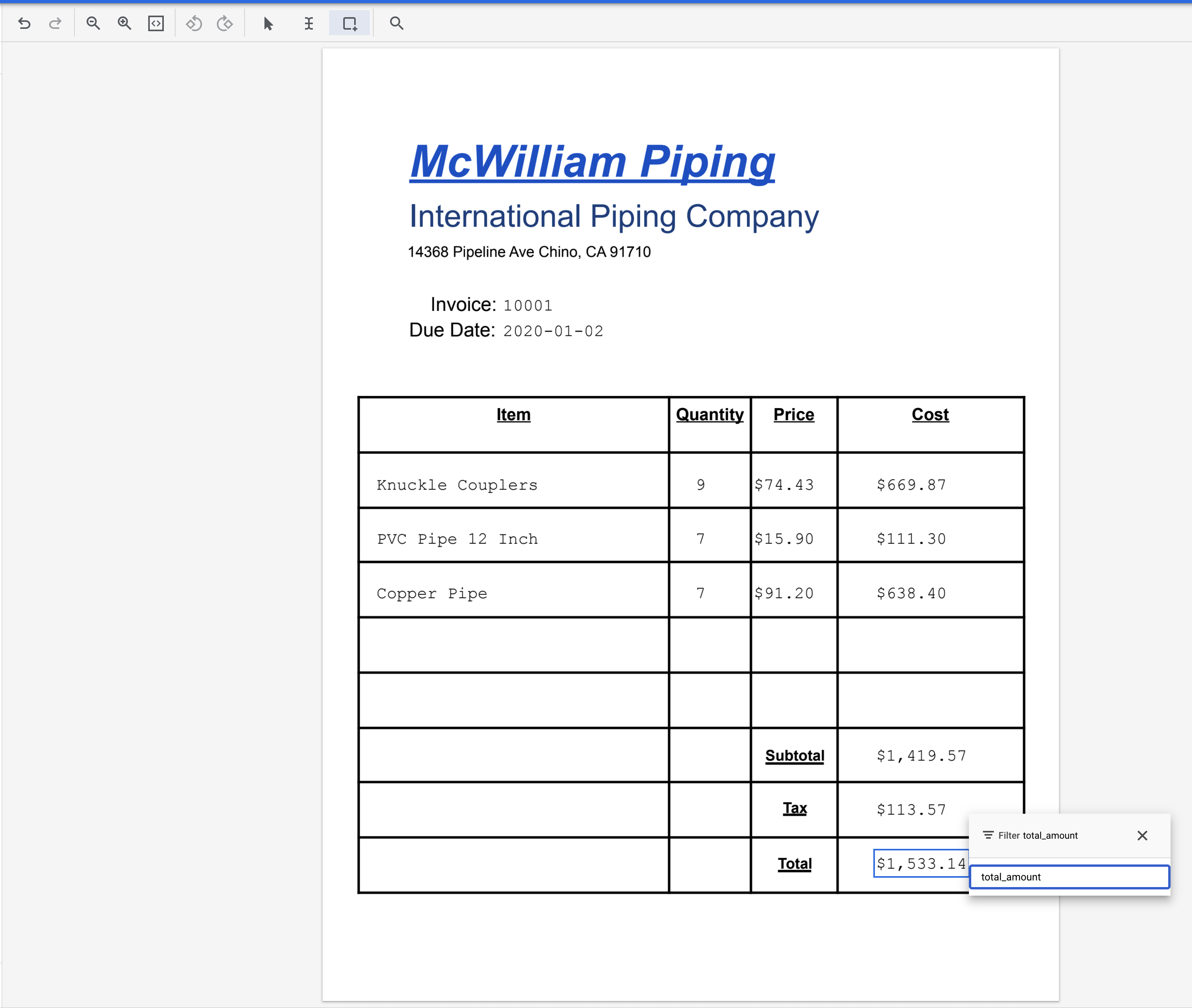
- Выделите один из символов "$" и присвойте ему метку
currency.

- В итоге документ с метками должен выглядеть так. Обратите внимание, что вы можете изменить эти метки, щелкнув по ограничивающей рамке в документе или по названию/значению метки в меню слева. Нажмите «Сохранить», когда закончите добавление меток.

- Вот полный список меток и значений.
Название этикетки | Текст |
| Компания McWilliam Piping International Piping |
| 14368 Pipeline Ave, Chino, CA 91710 |
| 10001 |
| 2020-01-02 |
| Шарнирные муфты |
| 9 |
| 74.43 |
| 669.87 |
| ПВХ-труба 12 дюймов |
| 7 |
| 15.90 |
| 111.30 |
| Медная труба |
| 7 |
| 91.20 |
| 638.40 |
| 1419,57 |
| 113.57 |
| 1533,14 |
| $ |
7. Присвойте документ обучающему набору.
Теперь вы должны вернуться в консоль управления наборами данных. Обратите внимание, что количество помеченных и непомеченных документов, а также количество активных меток изменились.

- Необходимо отнести этот документ либо к обучающей, либо к тестовой группе. Щелкните по документу.

- Нажмите «Назначить набору» , затем нажмите «Обучение» .

- Обратите внимание, что показатели разделения данных изменились.

8. Импорт предварительно размеченных данных
Для повышения точности распознавания объектов в Document AI Uptraining требуется как минимум 10 документов в обучающем и тестовом наборах данных, а также 10 экземпляров каждой метки в каждом наборе.
Для достижения наилучших результатов рекомендуется иметь в каждом наборе не менее 50 документов, по 50 экземпляров каждой метки. Большее количество обучающих данных, как правило, приводит к более высокой точности.
Ручная разметка 100 документов займет много времени, поэтому у нас есть несколько предварительно размеченных документов, которые вы можете импортировать для этой лабораторной работы.
Вы можете импортировать предварительно размеченные файлы документов в формате Document.json . Это могут быть результаты вызова обработчика и проверки точности с использованием механизма "человек в цикле" (Human in the Loop, HITL) .
- Нажмите на кнопку «Импорт документов» .
- Скопируйте и вставьте следующий путь к облачному хранилищу и назначьте его обучающему набору данных.
cloud-samples-data/documentai/codelabs/uptraining/training
- Нажмите «Добавить еще один сегмент» . Затем скопируйте и вставьте следующий путь к облачному хранилищу и назначьте его тестовому набору.
cloud-samples-data/documentai/codelabs/uptraining/test
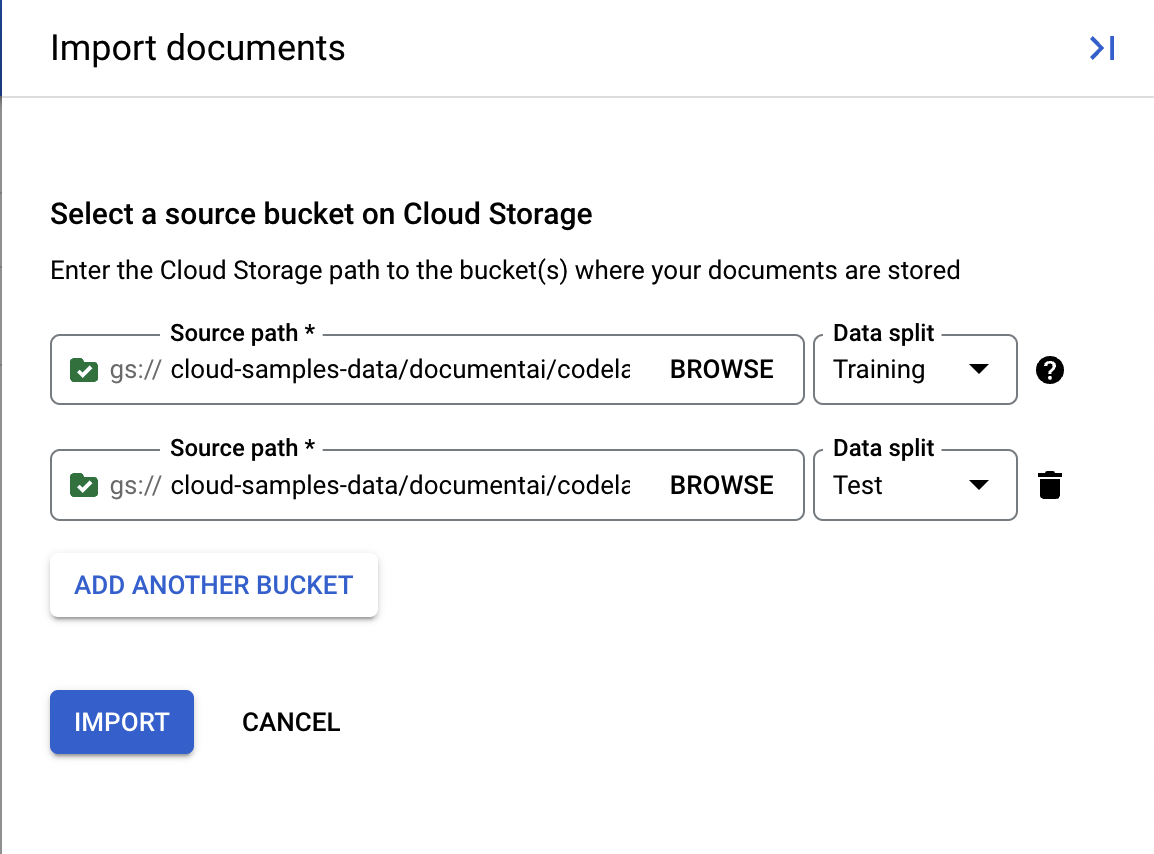
- Нажмите «Импорт» и дождитесь завершения импорта документов. Это займет больше времени, чем в прошлый раз, поскольку документов для обработки больше. В моих тестах это заняло около 6 минут. Вы можете покинуть эту страницу и вернуться позже.

- После завершения вы увидите документы на странице управления наборами данных.

9. Редактирование меток
В используемых нами примерах документов отсутствуют все метки, поддерживаемые парсером счетов. Перед обучением нам потребуется пометить неиспользуемые метки как неактивные. Аналогичные шаги можно выполнить и для добавления пользовательской метки перед обновлением данных.
- Нажмите на кнопку «Управление метками» в левом нижнем углу.
- Теперь вы должны находиться в консоли управления этикетками.
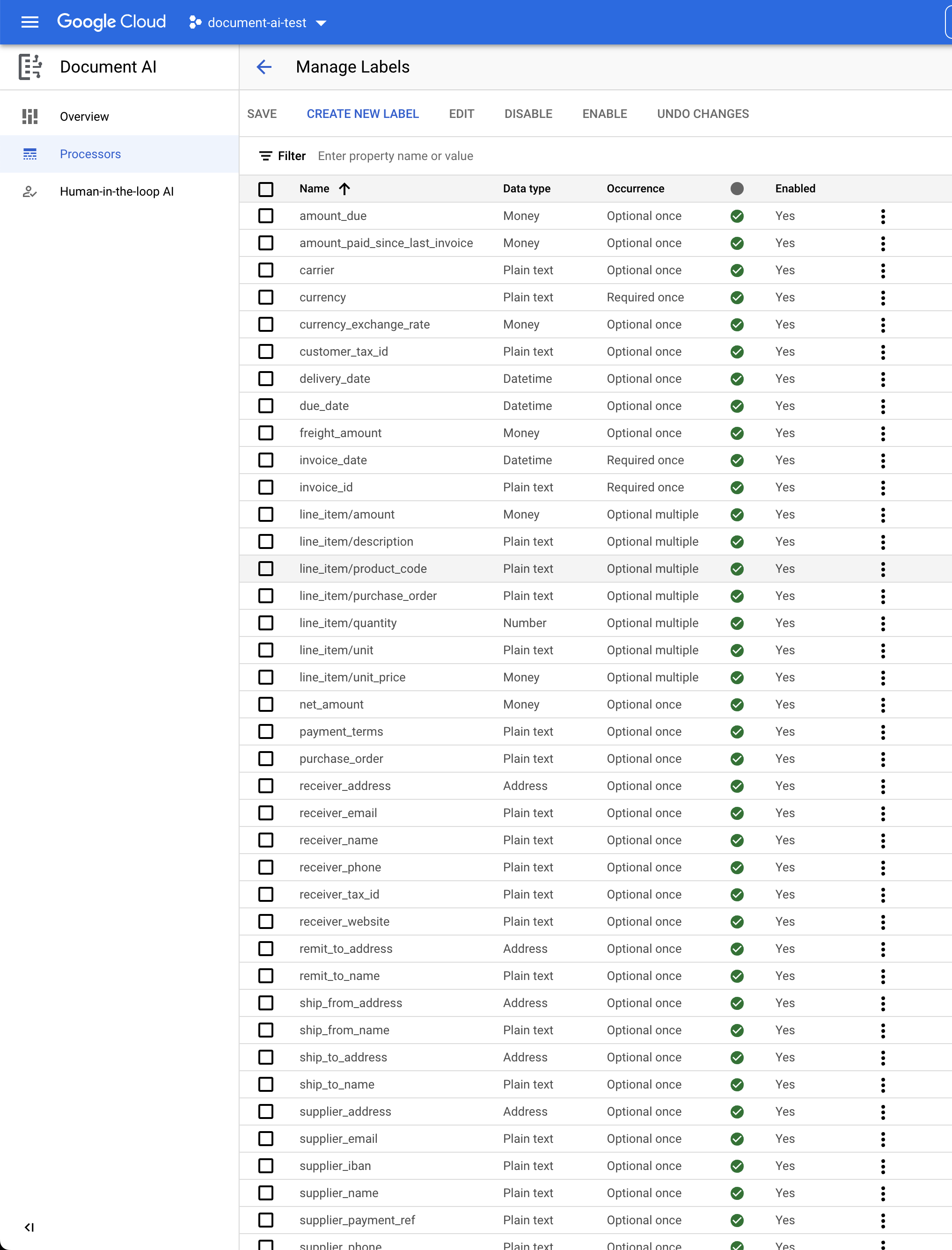
- Используйте флажки и кнопки «Включить / Выключить» , чтобы отметить как включенные ТОЛЬКО следующие элементы.
-
currency -
due_date -
invoice_id -
line_item/amount -
line_item/description -
line_item/quantity -
line_item/unit_price -
net_amount -
supplier_address -
supplier_name -
total_amount -
total_tax_amount
-
- После завершения консоль должна выглядеть примерно так. Нажмите «Сохранить» .

- Нажмите стрелку «Назад», чтобы вернуться в консоль управления наборами данных. Обратите внимание, что метки с 0 экземплярами помечены как «Неактивные».

10. Дополнительно: Автоматическая маркировка новых импортированных документов.
При импорте документов без меток для процессора с уже развернутой версией процессора можно использовать автоматическую разметку , чтобы сэкономить время на разметке.
- На странице «Поезда» нажмите «Импорт документов» .
- Скопируйте и вставьте следующий путь . В этой директории находятся 5 PDF-файлов счетов-фактур без меток. В раскрывающемся списке « Разделение данных» выберите «Обучение» .
cloud-samples-data/documentai/Custom/Invoices/PDF_Unlabeled - В разделе «Автоматическая маркировка» установите флажок «Импорт с автоматической маркировкой» .
- Выберите существующую версию процессора для присвоения меток документам.
- Например:
pretrained-invoice-v1.3-2022-07-15
- Нажмите «Импорт» и дождитесь завершения импорта документов. Вы можете покинуть эту страницу и вернуться позже.
- После завершения работы документы появятся на странице «Поезд» в разделе «Автоматически помеченные» .
- Вы не можете использовать документы с автоматической разметкой для обучения или тестирования, не пометив их как размеченные. Перейдите в раздел «Автоматическая разметка» , чтобы просмотреть документы с автоматической разметкой.
- Выберите первый документ, чтобы войти в консоль маркировки.
- Проверьте правильность подписей, ограничивающих рамок и значений. Укажите все пропущенные значения.
- После завершения выберите «Отметить как помеченное» .
- Повторите проверку меток для каждого автоматически размеченного документа, затем вернитесь на страницу «Обучение» , чтобы использовать данные для обучения.
11. Повышение квалификации модели.
Теперь мы готовы начать обучение нашего анализатора счетов-фактур.
- Click Train New Version
- Дайте вашей версии запоминающееся имя, например,
codelab-uptraining-test-1. Базовая версия — это версия модели, на основе которой будет создана новая версия. Если вы используете новый процессор, единственным вариантом должен быть Google Pretrained Next with Uptraining.
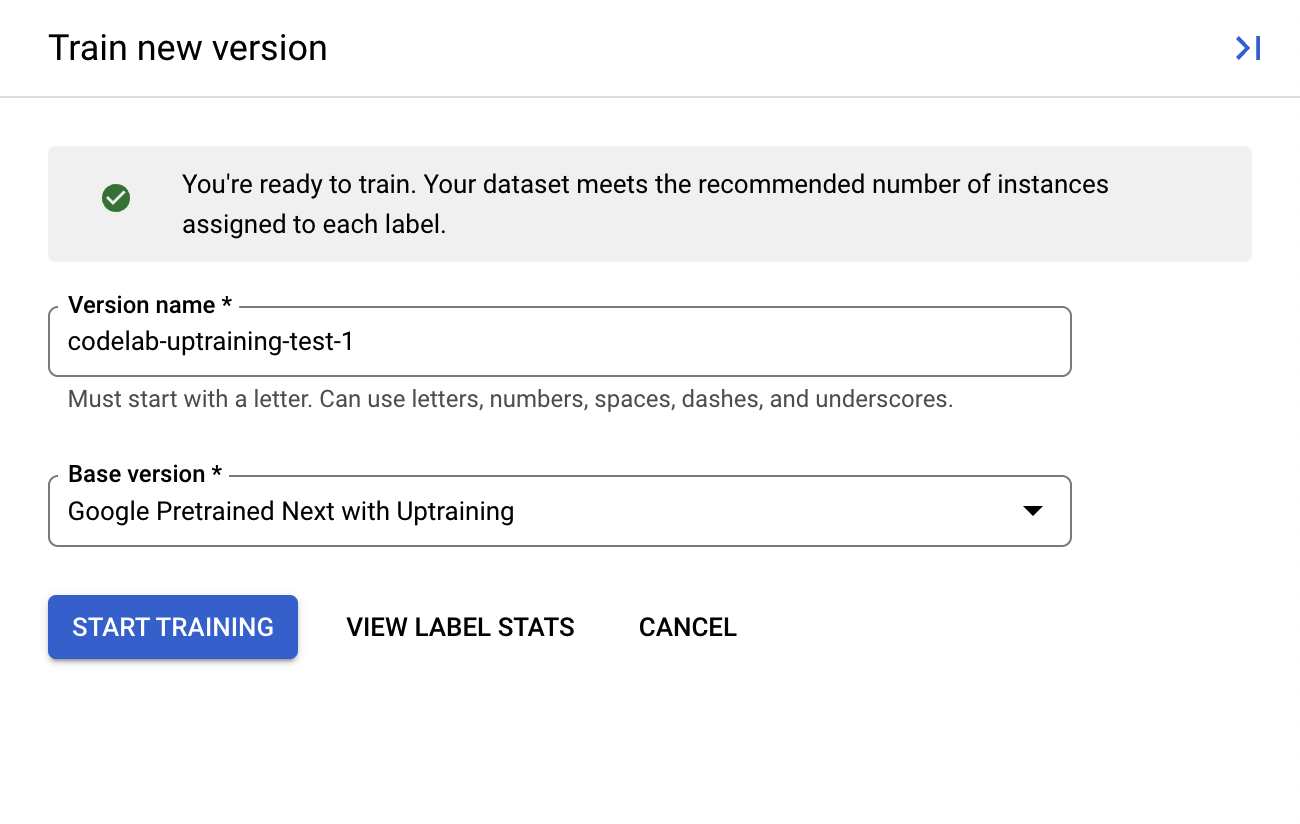
- (Необязательно) Вы также можете выбрать «Просмотреть статистику меток» , чтобы увидеть показатели меток в вашем наборе данных.

- Нажмите «Начать обучение» , чтобы запустить процесс повышения квалификации. Вы будете перенаправлены на страницу управления набором данных. Статус обучения можно посмотреть справа. Обучение займет несколько часов. Вы можете покинуть эту страницу и вернуться позже.

- При нажатии на название версии вы перейдете на страницу «Управление версиями» , где отображается идентификатор версии и текущий статус задания на обучение.

12. Протестируйте новую версию модели.
После завершения процесса обучения (в моих тестах это заняло около часа) вы можете протестировать новую версию модели и начать использовать ее для прогнозирования.
- Перейдите на страницу «Управление версиями» . Здесь вы можете увидеть текущий статус и оценку F1.

- Перед использованием этой версии модели необходимо её развернуть. Щёлкните по вертикальным точкам справа и выберите «Развернуть версию» .

- Выберите «Развернуть» во всплывающем окне и дождитесь завершения развертывания версии. Это займет несколько минут. После развертывания вы также можете установить эту версию в качестве версии по умолчанию.

- После завершения развертывания перейдите на вкладку «Оценка» . Затем щелкните раскрывающийся список «Версия» и выберите нашу недавно созданную версию.
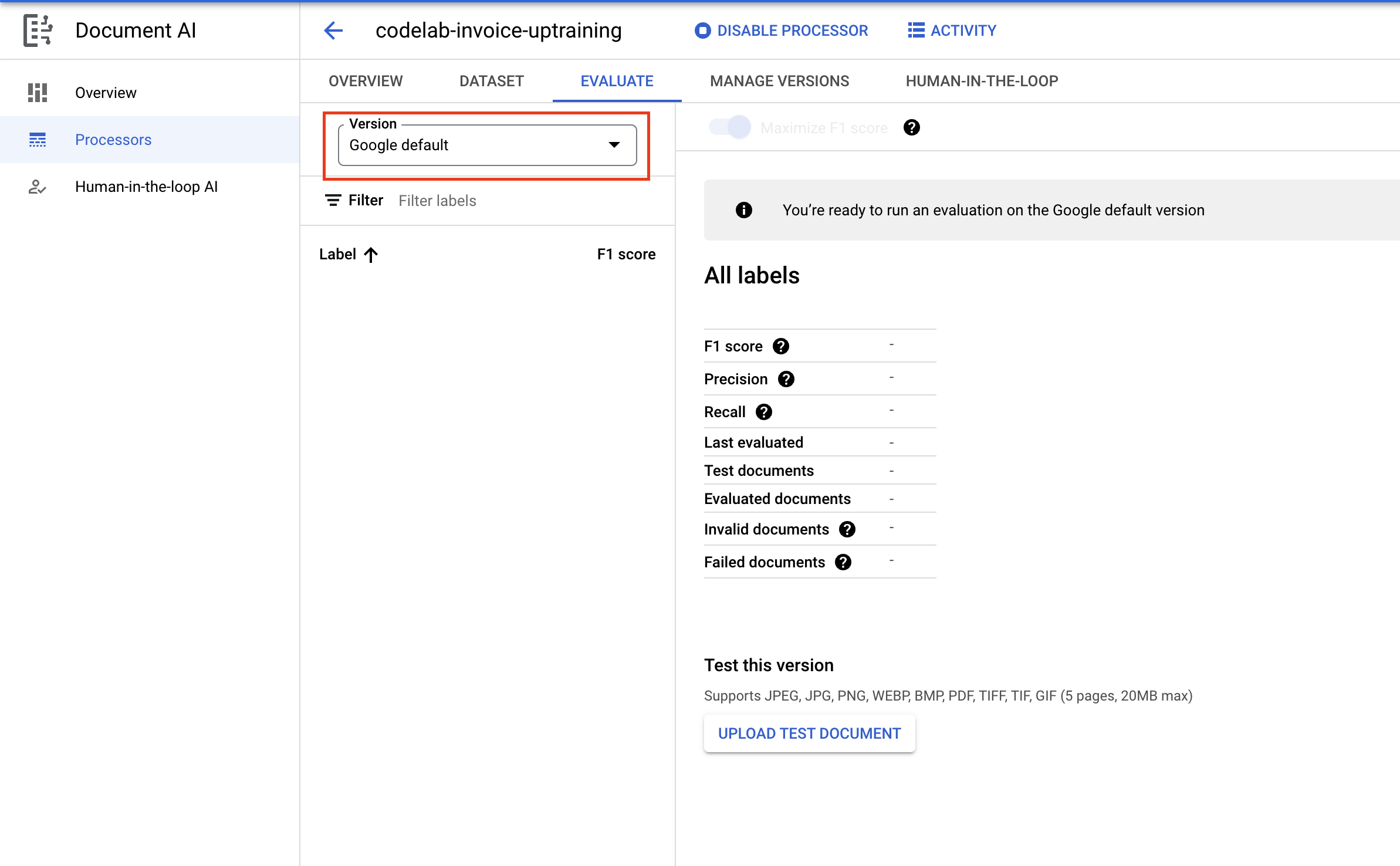
- На этой странице вы можете просмотреть метрики оценки, включая F1-меру, точность и полноту для всего документа, а также для отдельных меток. Более подробную информацию об этих метриках можно найти в документации AutoML .
- Скачайте PDF-файл по ссылке ниже. Это образец документа, который не был включен в обучающий или тестовый комплект.
- Нажмите «Загрузить тестовый документ» и выберите PDF-файл.

- Извлеченные объекты должны выглядеть примерно так.

13. Заключение
Поздравляем, вы успешно использовали Document AI для обучения парсера счетов-фактур. Теперь вы можете использовать этот процессор для анализа счетов-фактур так же, как и любой специализированный процессор.
Для повторного ознакомления с порядком обработки ответа на запрос вы можете обратиться к руководству по специализированным процессорам (Specialized Processors Codelab) .
Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этом руководстве:
- В консоли Cloud перейдите на страницу «Управление ресурсами» .
- В списке проектов выберите свой проект и нажмите «Удалить».
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить», чтобы удалить проект.
Ресурсы
- Документация по среде разработки ИИ
- Будущее документов — плейлист на YouTube
- Документация по искусственному интеллекту
- Библиотека клиента Document AI Python
- Примеры документов, созданных с помощью ИИ.
Лицензия
Данная работа распространяется под лицензией Creative Commons Attribution 2.0 Generic.