
1. Введение
Document AI — это решение для понимания документов, которое обрабатывает неструктурированные данные, такие как документы, электронные письма и т. д., и делает эти данные более понятными, анализируемыми и пригодными для использования.
С помощью Document AI Workbench вы можете добиться более высокой точности обработки документов, создавая полностью настраиваемые модели на основе собственных обучающих данных.
В этой лабораторной работе вы создадите собственный процессор для извлечения документов, импортируете набор данных, разметите примеры документов и обучите процессор.
В этой лабораторной работе используется набор данных документов из поддельного набора данных W-2 (налоговая форма США) на Kaggle с лицензией CC0: Public Domain.
Предварительные требования
Данный практический семинар основан на материалах других практических семинаров по искусственному интеллекту для работы с документами.
Перед продолжением рекомендуется выполнить следующие практические задания (Codelabs).
- Оптическое распознавание символов (OCR) с использованием Document AI (Python)
- Анализ форм с помощью Document AI (Python)
- Специализированные процессоры с поддержкой искусственного интеллекта для обработки документов (Python)
- Управление обработчиками документов с помощью ИИ на Python
- Искусственный интеллект для создания документов: участие человека.
- Документальный ИИ: переобучение
Что вы узнаете
- Создайте собственный обработчик для извлечения документов.
- Разметьте обучающие данные ИИ для документов с помощью инструмента аннотирования.
- Обучите новую версию модели.
- Оцените точность новой версии модели.
Что вам понадобится
2. Настройка
В этом практическом занятии предполагается, что вы выполнили шаги по настройке Document AI, описанные во вводном практическом занятии .
Перед продолжением выполните следующие шаги:
3. Создайте процессор.
Для выполнения этой лабораторной работы вам сначала необходимо создать пользовательский обработчик извлечения документов.
- В консоли перейдите на страницу «Обзор Document AI» .

- Нажмите «Создать пользовательский обработчик» и выберите «Пользовательский извлекатель документов» .

- Назовите его
codelab-custom-extractor(или как-нибудь еще, что вы запомните) и выберите ближайший регион из списка.
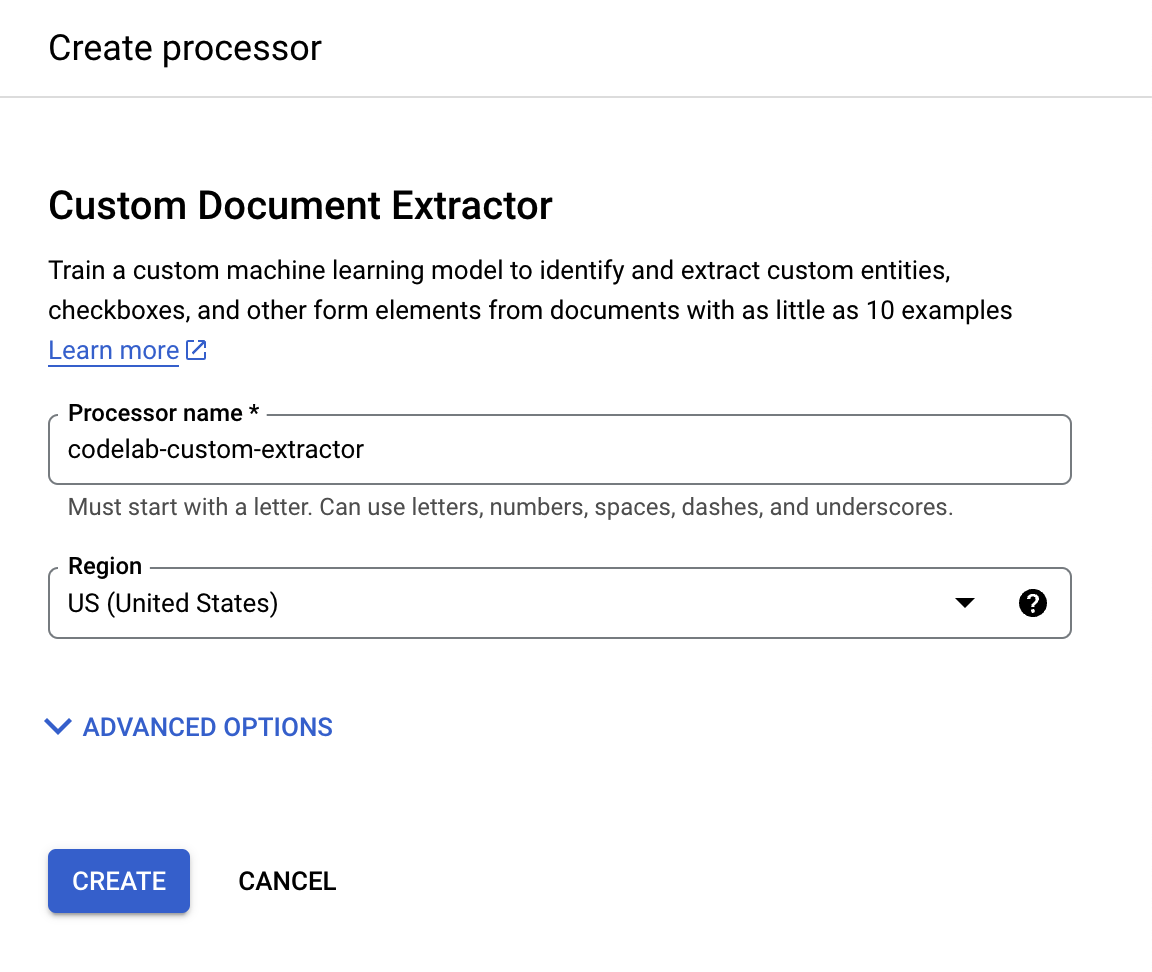
- Нажмите «Создать» , чтобы создать свой процессор. После этого вы увидите страницу «Обзор процессора».

4. Создайте набор данных.
Для обучения нашего процессора нам потребуется создать набор данных, включающий обучающие и тестовые данные, которые помогут процессору идентифицировать сущности, которые мы хотим извлечь.
- На странице «Обзор процессора» нажмите «Настроить набор данных» .
- Теперь вы должны находиться на странице «Настройка набора данных» . Если вы хотите указать собственный сегмент для хранения обучающих документов и меток, нажмите « Показать дополнительные параметры» . В противном случае просто нажмите «Продолжить» .

- Дождитесь создания набора данных, после чего вас перенаправит на страницу обучения .

5. Импорт тестового документа
Теперь давайте импортируем образец PDF-файла формы W2 в наш набор данных.
- Нажмите на кнопку «Импорт документов» .

- Для выполнения этой лабораторной работы вам будет предоставлен образец PDF-файла. Скопируйте и вставьте следующую ссылку в поле «Путь к источнику ». Пока оставьте поле «Разделение данных» в положении «Не назначено». Все остальные поля оставьте неотмеченными. Нажмите «Импорт» .
cloud-samples-data/documentai/codelabs/custom/extractor/pdfs

- Дождитесь импорта документа. Это займет менее 1 минуты.
- После завершения импорта вы должны увидеть документ на странице «Обучение» .

6. Создайте этикетки.
Поскольку мы создаём новый тип процессора, нам потребуется создать пользовательские метки, чтобы указать Document AI, какие поля мы хотим извлечь.
- Нажмите кнопку «Редактировать схему» в левом нижнем углу.

- Теперь вы должны находиться в консоли управления схемой.

- Создайте следующие метки, используя кнопку «Создать метку» .
Имя | Тип данных | Событие |
| Число | Требуется несколько |
| Простой текст | Требуется несколько |
| Простой текст | Требуется несколько |
| Адрес | Требуется несколько |
| Деньги | Требуется несколько |
| Деньги | Требуется несколько |
| Деньги | Требуется несколько |
| Деньги | Требуется несколько |
- После завершения консоль должна выглядеть примерно так. Нажмите «Сохранить» .
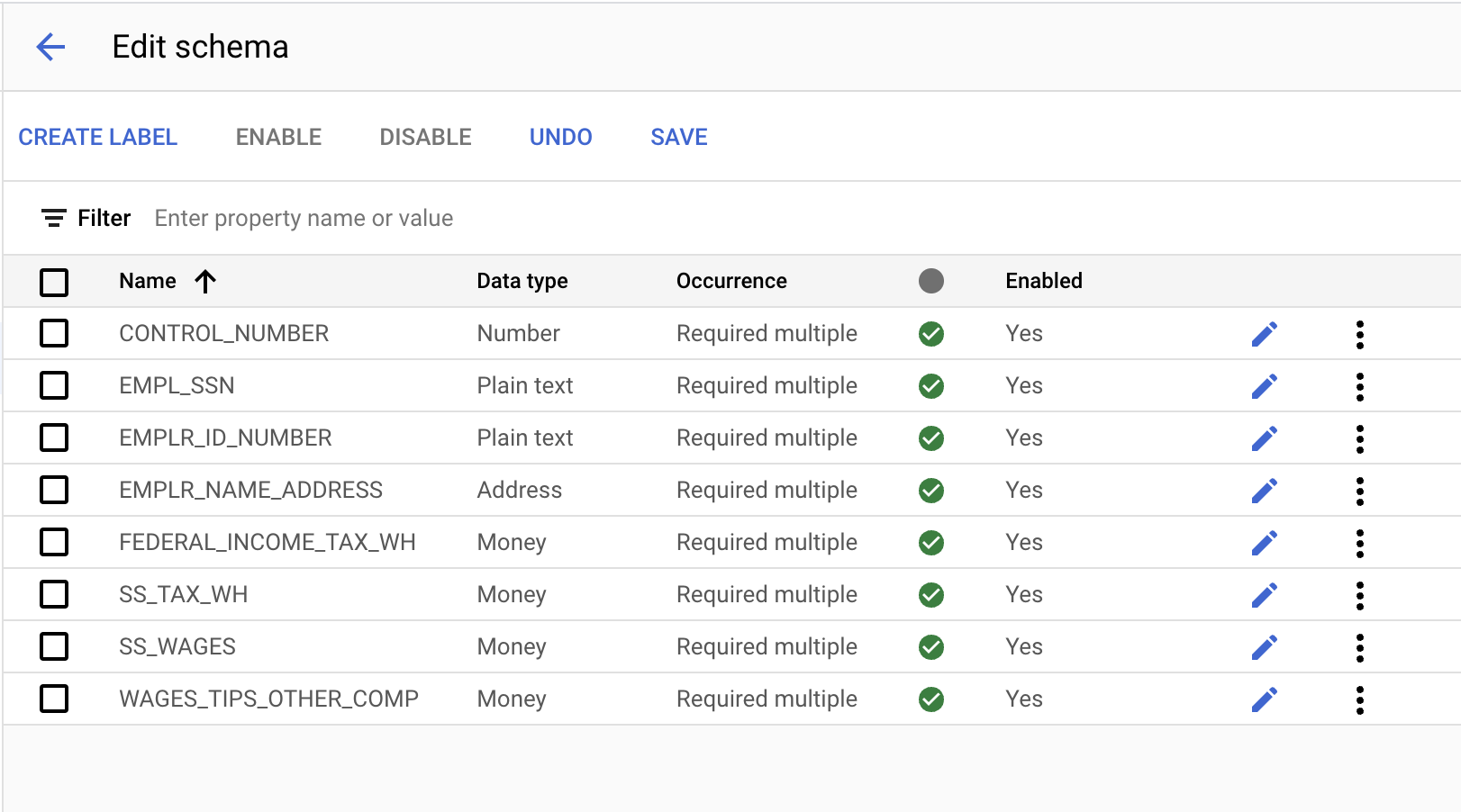
- Нажмите на стрелку «Назад», чтобы вернуться на страницу «Обучение» . Обратите внимание, что созданные нами метки отображаются в левом нижнем углу.
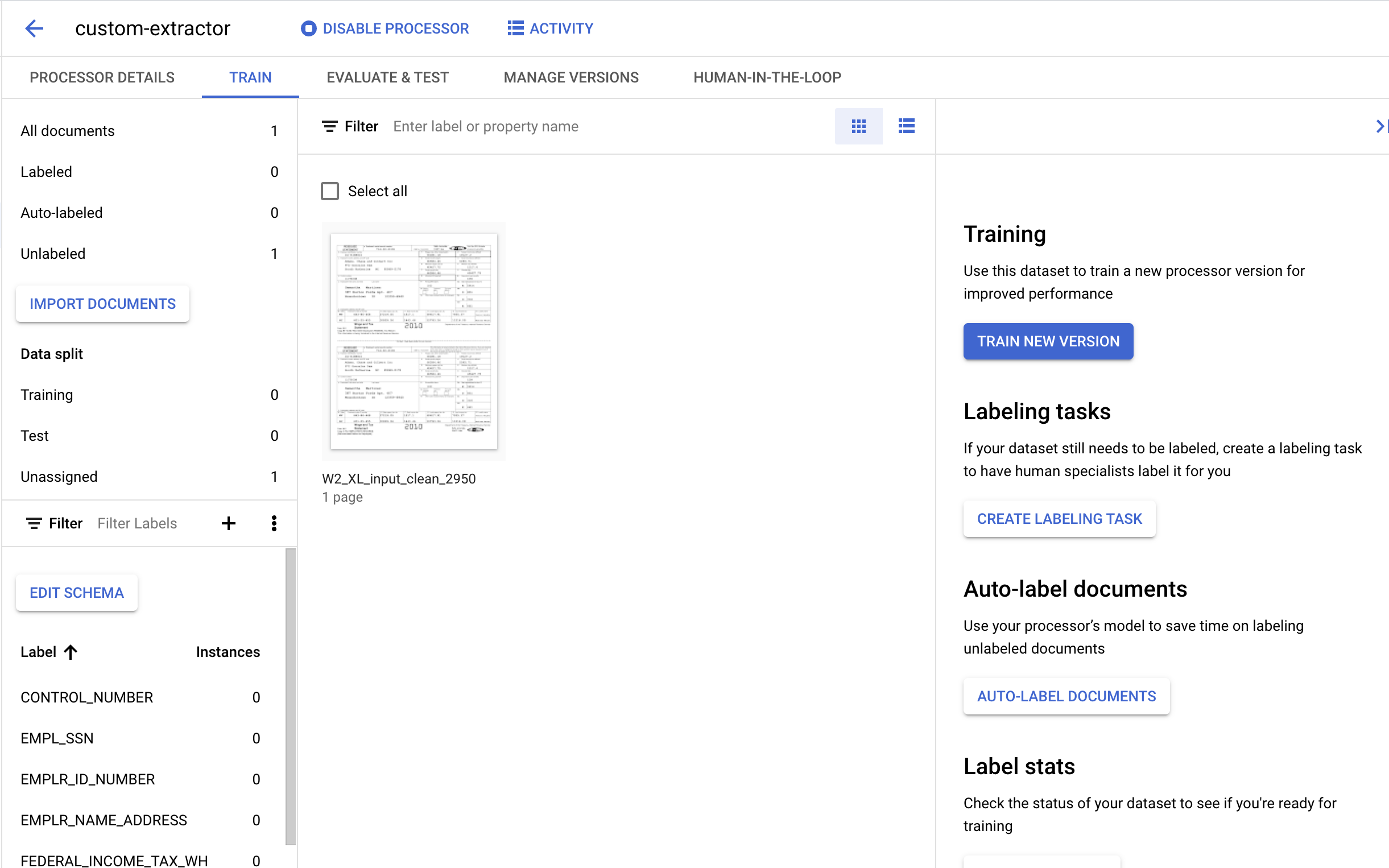
7. Подпишите тестовый документ.
Далее мы определим текстовые элементы и метки для сущностей, которые хотим извлечь. Эти метки будут использованы для обучения нашей модели анализу данной конкретной структуры документа и определению правильных типов.
- Чтобы открыть консоль для добавления меток, дважды щелкните по импортированному ранее документу. Она должна выглядеть примерно так.

- Щелкните инструмент «Ограничивающая рамка», затем выделите текст «1173038» и присвойте ему метку
CONTROL_NUMBER. Вы можете использовать текстовый фильтр для поиска названий меток.

- Завершите настройку для другого экземпляра
CONTROL_NUMBERПосле добавления метки должно получиться вот так.

- Выделите все вхождения следующих текстовых значений и присвойте им соответствующие метки.
Название этикетки | Текст |
| 24-3188810 |
| 19127.2 |
| 5093.71 |
| 66584.46 |
| 56081.18 |
| 714-32-2105 |
| Adams, Chase and Gilbert Inc. 972 Gonzalez Dam South Katherine NC 95869-5178 |
- В результате работы документ с метками должен выглядеть следующим образом. Обратите внимание, что вы можете вносить изменения в эти метки, щелкая по ограничивающей рамке в документе или по имени/значению метки в меню слева. После завершения добавления меток нажмите «Пометить как помеченный» , затем вернитесь в консоль управления набором данных.

8. Присвойте документ обучающему набору.
Теперь вы должны вернуться в консоль управления наборами данных. Обратите внимание, что количество помеченных и непомеченных документов, а также количество экземпляров для каждой метки изменилось.

- Нам нужно присвоить этот документ либо набору «Обучение», либо набору «Тестирование». Щелкните по документу, затем нажмите «Присвоить набору» , а затем нажмите «Обучение» .

- Обратите внимание, что показатели разделения данных изменились.

9. Импорт предварительно размеченных данных
Для работы с пользовательскими обработчиками Document AI требуется как минимум 10 документов в обучающем и тестовом наборах данных, а также 10 экземпляров каждой метки в каждом наборе.
Для достижения наилучших результатов рекомендуется иметь в каждом наборе не менее 50 документов, по 50 экземпляров каждой метки. Большее количество обучающих данных, как правило, приводит к более высокой точности.
Ручная маркировка всех документов займет много времени, поэтому у нас есть несколько предварительно размеченных документов, которые вы можете импортировать для этой лабораторной работы.
Вы можете импортировать предварительно размеченные файлы документов в формате Document.json . Это могут быть результаты вызова обработчика и проверки точности с использованием механизма "человек в цикле" (Human in the Loop, HITL) .
в сторону отрицательный
ПРИМЕЧАНИЕ: При импорте предварительно размеченных данных настоятельно рекомендуется вручную проверить аннотации перед обучением модели.
- Нажмите на кнопку «Импорт документов» .

- Скопируйте и вставьте следующий путь к облачному хранилищу и назначьте его обучающему набору данных.
cloud-samples-data/documentai/codelabs/custom/extractor/training
- Нажмите «Добавить другую папку» . Затем скопируйте и вставьте следующий путь к облачному хранилищу и назначьте его тестовому набору.
cloud-samples-data/documentai/codelabs/custom/extractor/test

- Нажмите «Импорт» и дождитесь завершения импорта документов. Это займет больше времени, чем в прошлый раз, поскольку документов для обработки больше. В итоге это займет около 6 минут. Вы можете покинуть эту страницу и вернуться позже.

- После завершения вы увидите документы на странице «Обучение» .

10. Обучение модели
Теперь мы готовы начать обучение нашего пользовательского инструмента для извлечения документов.
- Click Train New Version

- Дайте вашей версии запоминающееся имя, например,
codelab-custom-1. В поле «Метод обучения» выберите «Обучить с нуля».

- (Необязательно) Вы также можете выбрать «Просмотреть статистику меток» , чтобы увидеть показатели меток в вашем наборе данных.

- Нажмите «Начать обучение» , чтобы начать процесс обучения. Вы будете перенаправлены на страницу управления набором данных. Статус обучения можно посмотреть справа. Обучение займет несколько часов. Вы можете покинуть эту страницу и вернуться позже.

- При нажатии на название версии вы перейдете на страницу «Управление версиями» , где отображается идентификатор версии и текущий статус задания на обучение.

11. Протестируйте новую версию модели.
После завершения процесса обучения (в моих тестах это заняло около часа) вы можете протестировать новую версию модели и начать использовать ее для прогнозирования.
- Перейдите на страницу «Управление версиями» . Здесь вы можете увидеть текущий статус и оценку F1.

- Перед использованием этой версии модели необходимо её развернуть. Щёлкните по вертикальным точкам справа и выберите «Развернуть версию» .
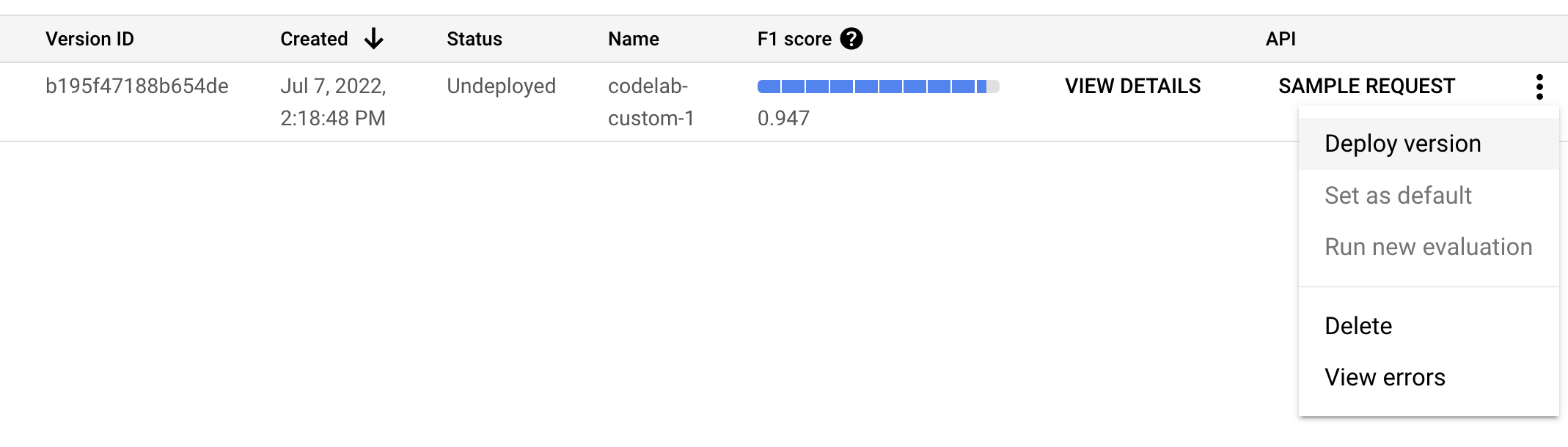
- Выберите «Развернуть» во всплывающем окне и дождитесь завершения развертывания версии. Это займет несколько минут. После развертывания вы также можете установить эту версию в качестве версии по умолчанию.

- После завершения развертывания перейдите на вкладку «Оценка» . На этой странице вы можете просмотреть метрики оценки, включая F1-меру, точность и полноту для всего документа, а также для отдельных меток. Подробнее об этих метриках можно прочитать в документации AutoML .

- Скачайте PDF-файл по ссылке ниже. Это образец формы W2, который не был включен в обучающий или тестовый комплект.
- Нажмите «Загрузить тестовый документ» и выберите PDF-файл.
- Извлеченные объекты должны выглядеть примерно так.

12. Дополнительно: Автоматическая маркировка новых импортированных документов.
После развертывания обученной версии процессора вы можете использовать автоматическую разметку , чтобы сэкономить время на разметке при импорте новых документов.
- На странице «Поезда» нажмите «Импорт документов» .
- Скопируйте и вставьте следующий путь . В этой директории находятся 5 PDF-файлов W2 без меток. В раскрывающемся списке «Разделение данных» выберите «Обучение» .
cloud-samples-data/documentai/Custom/W2/AutoLabel - В разделе «Автоматическая маркировка» установите флажок «Импорт с автоматической маркировкой» .
- Выберите существующую версию процессора для присвоения меток документам.
- Например:
2af620b2fd4d1fcf
- Нажмите «Импорт» и дождитесь завершения импорта документов. Вы можете покинуть эту страницу и вернуться позже.
- После завершения работы документы появятся на странице «Поезд» в разделе «Автоматически помеченные» .
- Вы не можете использовать документы с автоматической разметкой для обучения или тестирования, не пометив их как размеченные. Перейдите в раздел «Автоматическая разметка» , чтобы просмотреть документы с автоматической разметкой.
- Выберите первый документ, чтобы войти в консоль маркировки.
- Проверьте правильность подписей, ограничивающих рамок и значений. Укажите все пропущенные значения.
- После завершения выберите «Отметить как помеченное» .
- Повторите проверку меток для каждого автоматически размеченного документа, затем вернитесь на страницу «Обучение» , чтобы использовать данные для обучения.
13. Заключение
Поздравляем, вы успешно использовали Document AI для обучения пользовательского процессора извлечения документов. Теперь вы можете использовать этот процессор для анализа документов в этом формате так же, как и любой специализированный процессор.
Для повторного ознакомления с порядком обработки ответа на запрос вы можете обратиться к руководству по специализированным процессорам (Specialized Processors Codelab) .
Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этом руководстве:
- В консоли Cloud перейдите на страницу «Управление ресурсами» .
- В списке проектов выберите свой проект и нажмите «Удалить».
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить», чтобы удалить проект.
Ресурсы
- Документация по среде разработки ИИ
- Будущее документов — плейлист на YouTube
- Документация по искусственному интеллекту
- Библиотека клиента Document AI Python
- Примеры документов, созданных с помощью ИИ.
Лицензия
Данная работа распространяется под лицензией Creative Commons Attribution 2.0 Generic.